





Abstract
Factor analysis is often used to assess whether a single univariate latent variable is sufficient to explain most of the covariance among a set of indicators for some underlying construct. When evidence suggests that a single factor is adequate, research often proceeds by using a univariate summary of the indicators in subsequent research. Implicit in such practices is the assumption that it is the underlying latent, rather than the indicators, that is causally efficacious. The assumption that the indicators do not have effects on anything subsequent, and that they are themselves only affected by antecedents through the underlying latent is a strong assumption, effectively imposing a structural interpretation on the latent factor model. In this paper, we show that this structural assumption has empirically testable implications, even though the latent variable itself is unobserved. We develop a statistical test to potentially reject the structural interpretation of a latent factor model. We apply this test to data concerning associations between the Satisfaction with Life Scale and subsequent all-cause mortality, which provides strong evidence against a structural interpretation for a univariate latent underlying the scale. Discussion is given to the implications of this result for the development, evaluation and use of measures, and for the use of factor analysis itself.
1 INTRODUCTION
The model underlying classical test theory and much of measure construction often assumes an underlying univariate latent variable which itself gives rise to, or causes, various observed indicators (DeVellis, 2016; Price, 2016). These indicators themselves form the empirical bases of the measures that are constructed. Various psychometric tests are available to evaluate the adequacy of this measurement model and to assess whether a single univariate latent adequately captures the covariance structure among the set of observed item responses or indicators (Brown, 2015; Comrey & Lee, 2013; Kline, 2014; Thompson, 2004). When the evidence seems to indicate that a unidimensional factor is sufficient, the indicators are then typically combined, often simply as a mean of their values, to form a measure that is then used in subsequent research. The measure is thought to be an adequate assessment of the underlying latent variable that corresponds to the relevant construct that is of theoretical interest and worthy of empirical investigation. The measure will then typically be used in subsequent research to study the causes that might give rise to the phenomenon relevant to the construct under consideration, and also causal relations with other outcomes.
However, when used in this way, a subtle implicit supposition is made which is often overlooked. From the univariate latent model fitting reasonably well, it is often subsequently assumed by empirical researchers that it is in fact the supposed underlying latent variable that is causally efficacious, as often represented in a structural equation model (Bollen, 1989; Sánchez et al., 2005). The individual indicators are assumed to be effectively causally inert, and it is thus the measure, imperfectly but appropriately representing the latent, that is sufficient for use in causal research. In such reasoning, however, an unwarranted leap in logic is in fact made. From the covariance of the individual indicators fitting a univariate latent covariance structure well, it does not follow that it is the supposed underlying univariate latent that is causally efficacious and that the indicators are not. The univariate latent measurement model fitting well is in fact entirely consistent with each indicator having separate distinct causal effects on subsequent outcomes, and with these effects being considerably different from each other across indicators. In this paper, we show that these questions are in fact subject to empirical investigation. It is demonstrated that the structural interpretation of the latent factor model—that it is the supposed univariate latent rather than its indicators that are causally efficacious—imposes assumptions that are sufficiently strong so as to give rise to empirical implications that can be tested, and rejected. We make use of these empirical implications to develop statistical tests that can lead to the rejection of the structural interpretation of a latent factor model. We illustrate this test with empirical data concerning associations between the Satisfaction with Life Scale (SWLS; Diener et al., 1985) and subsequent all-cause mortality to examine whether an underlying univariate ‘life satisfaction’ latent variable with a structural interpretation is reasonable.
It should of course be noted that not all measure construction or latent variable modelling proceeds with an assumption of univariate latent variable. A large methodological literature exists concerning model selection, and on identification procedures for using observable model implications of latent variable models for model selection and causal discovery (Bollen, 1989; Gignac, 2016; Glymour & Spirtes, 1988; Kummerfeld et al., 2014; Kummerfeld & Ramsey, 2016; Mansolf & Reise, 2017; Silva et al., 2006; Spirtes et al., 2000; Sullivant et al., 2010). Our intent here is not a general critique of the latent variable and structural equation modelling literature. Rather, our critique is focused on the relatively common practice of simply examining a basic factor model for evidence of uni-dimensionality, and then thereafter presuming the latent factor model is structural. The empirical implications and the tests we develop in the sections that follow focus on this case. However, if a structural interpretation of a univariate latent factor model is rejected, then additional model selection and identification literature of course becomes yet further relevant. With regard to the present paper, after laying out the empirical constraints implied by a univariate structural latent factor model and the corresponding statistical tests, we then further discuss the implications of this result, and of the often inappropriate assumption of a structural interpretation, for the development, evaluation and use of measures and for the use factor analysis itself.
2 LATENT FACTORS MODELS AND EMPIRICAL IMPLICATIONS
The classical model used in much measurement theory and scale development, sometimes also referred to as a ‘reflective model’, presupposes an underlying continuous latent variable η that gives rise to continuous indicators or measurements as in Figure 1.
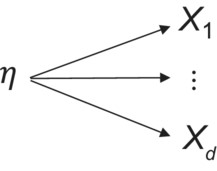
Basic latent factor model with latent η and indicators
In practice, the indicators are often not strictly continuous but may arise from subject responses from a Likert scale and are assumed approximately continuous. After standardisation so that each indicator Xi has mean 0 and variance 1, which is often done for comparability and ease of interpretation, it is then often assumed that each indicator Xi is given by a linear function of the latent variable η plus a mean-zero random error εi independent of η:
where λi are generally assumed unknown and where random errors εi are often, but not always, assumed normally distributed and independent of one another. Throughout, as is common, we will assume that the coefficients λi are non-zero for all of the indicators, , since, otherwise, any indicator for which λi = 0 would be irrelevant for the latent variable η supposedly corresponding to the construct of interest and would thus be omitted. The model above forms the basis of much psychometric measure evaluation (DeVellis, 2016; Price, 2016). However, after this evaluation is complete, the measures that are used in practice are generally just some univariate function of the indicators, . Let denote the measure that is eventually employed. When the indicators are on the same scale, often the mean of the indicators is used. The function of the indicators is meant to be an imprecise measure, subject to error, of the underlying latent variable η that corresponds to the psycho-social construct of interest. It will then often be of interest to assess the relationship of this measure with various other important outcomes. This is what is typically done in structural equation models (Bollen, 1989; Sánchez et al., 2005).
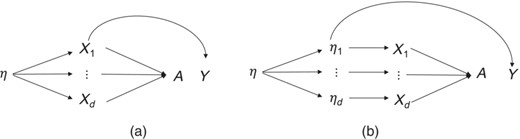
However, the model in Equation (1) is entirely consistent with different sets of causal relationships with some outcome of interest Y. Contrast the relationships in Figure 2. On the one hand it is possible that it is the supposed underlying variable η that has a causal effect on the outcome Y and that the indicators are causally inert as in Figure 2. On the other hand, it is possible that it is the individual indicators that each exert causal effects on the outcome Y as in Figure 2. Importantly, both of these causal structures are entirely consistent with the measurement model in Equation (1) and Figure 1, as are other structures as well such as if both the latent variable η and the indicators affected Y.
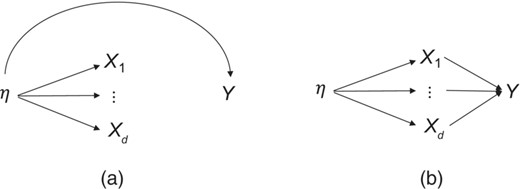
(a) Structural latent factor model with latent η causally efficacious for outcome Y; (b) basic latent factor model with indicators causally efficacious for outcome Y
Similarly, consider a randomised trial of some treatment T in which we are interested in whether the treatment T might have causal effects relevant to the construct or phenomenon under study. In practice, we would often compare the average value of our measure A, across arms of the randomised treatment T and assess causal effects as . Suppose we found some effect of treatment T on our measure A. Once again at least two possibilities might arise. It might be that T exerts an effect on the underlying latent η which affects the indicators and thus also our measure A as in Figure 3. Alternatively, however, it may be the case that T in fact directly affects the indicators and thus also our measure A as in Figure 3. Once again, both of these causal structures are entirely consistent with the measurement model in Equation (1) and Figure 1, as indeed are many others, such as if T affected both the latent variable η and the indicators .
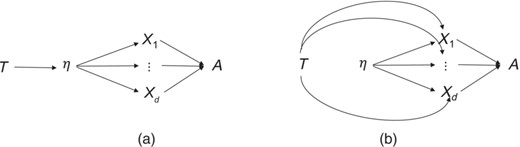
(a) Structural latent factor model with latent η causally affected by treatment T; (b) basic latent factor model with indicators directly causally affected by treatment T
In practice, once a measure is formed, with some evidence that the covariance structure among the items is unidimensional, it is then subsequently presumed that the underlying latent is causally efficacious and thus that the measure is reasonably suitable for empirical research intended to examine causal relationships and that the indicators themselves can effectively be ignored once they are used to form the measure A. This is what is implicitly assumed when the measure A is used in regression analyses or sometimes in forming a typical structural equation model (Bollen, 1989; Sánchez et al., 2005). But this is presumption. There is nothing in the measurement model in Equation (1) fitting well that implies that Figure 2, rather than Figure 2 or some other model, represent causal relationships with outcome Y, or that Figure 3, rather than Figure 3 or some other, represent causal relationships with treatment T.
The assumption that it is the latent variable, rather than the indicators, that is causally efficacious, is precisely that—an assumption. It is an assumption that might be made about the latent variable and the indicators that fit model (1), but it is not one that necessarily holds. To acknowledge that the assumption is not implied by the measurement model in Equation (1) and Figure 1, it might be preferable to refer to the models with, and without, the assumption differently. We might refer to the measurement model represented in Equation (1) and Figure 1 as the basic univariate latent factor model. In contrast, we will refer to the univariate latent factor model as structural, if it is further assumed that the indicators, , do not have causal effects on anything subsequent, and if moreover they are themselves only affected by antecedents through the latent variable η. Thus, on a causal diagram (Pearl, 2009), for a structural latent factor model, the indicators would have no children, and also no parents except η (and possibly arrows from correlated error terms of in models that allowed these). On a causal diagram, this would in turn imply that for any other variable Z on the diagram we would have that Z is independent of conditional on η. This assumption that a latent factor model is structural is thus strong. However, it is an assumption that is often effectively implicitly made.
In practice, on the basis of Equation (1) fitting the data well, it is often simply assumed that the basic latent factor model is also structural, but this is, once again, an assumption. Moreover, it is a strong assumption and one that has empirically testable implications, even though the latent η is itself unobserved. Specifically, we show in the Appendix that if the structural latent factor model holds, then the empirical conditions stated in the theorem below must hold between the indicators and any other variable Z.
Theorem 1Suppose that Z is independent ofconditional on η and that the basic latent factor model in Equation (1) holds, then for any i and j, and any values z and z*, we must have
Theorem 1 has empirical implications provided both λi and λj are non-zero. As noted above, when latent factor models are used in practice, it is generally assumed that all λi are non-zero since any indicator with λi = 0 would typically be discarded. Although in practice it is typically assumed that the causal structure for the latent factor model corresponds to Figure 1, all that is needed to derive the result in Theorem 1 is that Equation (1) holds along with the conditional independence of Z and given η. The result is thus applicable even if the indicators potentially causally affect one another. The result also holds even if εi in Equation (1) is degenerate for one or more indicators so that . As discussed in the Appendix, generalisations are also possible to settings with a multi-dimensional latent variable η. However, the assumption of a univariate latent variable η covers a large number of proposed scales in the psychosocial empirical literature and will be the focus here.
It is easiest to see the implications of this result when the variable Z corresponds to some randomised treatment T and the indicators have been centred. If we apply the result with Z = z corresponding to T = 1 and Z = z* corresponding to T = 0 we obtain:
or
Essentially what we have is that the effect of the randomised treatment T on Xj, scaled by its reliability λj in model (1) must be the same as the effect of treatment T on Xi, scaled by its reliability λi. Intuitively, this must be the case, because under the structural interpretation, T can only act on Xi and Xj through its effects on the latent variable η. The structural latent factor model itself thus has empirical implications in a randomised trial of some treatment T. As an extreme example, if in a randomised trial of treatment T, it were known that T had an effect on Xi but no effect on Xj, then we would know that the structural latent factor model was false, even if the basic latent factor model in (1) would otherwise fit the data well. In other words, if a randomised treatment had an effect on Xi but not on Xj then this would imply that Figure 3 or some other model, rather than Figure 3, was the correct representation of the causal relations.
While the intuition may be clearest in a randomised trial, in fact similar results apply also if we examine the relationships between the indicators and outcomes, rather than between the indicators and treatments. Suppose we have some binary outcome Y (say, death during follow-up) and that instead of considering treatment values T = 1 and T = 0 we consider outcome values Y = 1 and Y = 0. By the same logic we would have . If we compare the prior retrospective values of indicator Xj among those who die during follow-up (Y = 1) versus survive (Y = 0) and scale this difference by dividing by the reliability then we should obtain the same quantity as we obtain if we do this with a different indicator Xi. The intuition here is that if the structural latent factor model holds so that it is the latent η, rather than the indicators, that have effects on the outcome Y, then the latent factor model constrains the relationships between Y and each indicator Xi. If these constraints do not hold, then the structural latent factor model cannot be correct, and causal relationships represented by Figure 2, rather than by Figure 2, may be more plausible, or it may be the case that both the latent η and the indicators have causal effects on the outcome.
While the intuition here corresponds to the causal effect of the latent η, versus the indicators on the outcome Y, the observed associations between and Y in fact need not be causal with respect to either η or for Theorem 1 to hold, or for the logic to be applicable. For example, even if, as in Figure 4, the effect of η on Y was confounded by covariates C, and C was not controlled for in the analysis it is still nevertheless the case that the empirical relations in Theorem 1, with Z = Y, must still hold if the structural latent factor model is true. One need not adjust for C to render the empirical relations of Theorem 1 to be necessary under the structural interpretation. Essentially, a structural latent factor model implies not only that causal associations will respect the factor model structure, but also that confounded associations will likewise respect the factor model structure. It is, however, also the case that, under the structural latent factor model, a conditional analogue to Theorem 1 (see the Appendix) likewise applies, wherein every expression in Theorem 1 is conditional on C, so that one could alternatively examine equalities conditional on C, such as if one were specifically interested in assessing constraints concerning causal effects. However, again, controlling for a sufficient set of confounding variables for the effect of η on Y is not necessary for the empirical equalities to be required to hold under the structural factor model.
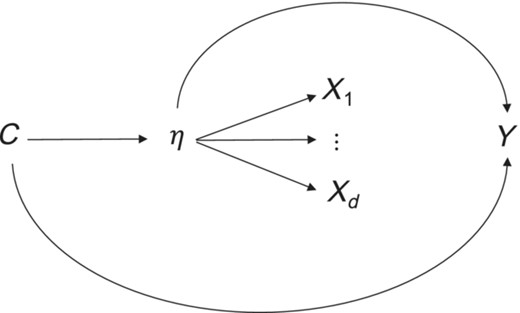
Causal effect of latent η on outcome Y confounded by covariates C, but the structural interpretation still requiring indicators independent of Y conditional on η
Likewise, while the intuitions given above relate to the ‘effects of randomized treatment on the latent η’ or the ‘effect of the latent η on some other outcome’, in fact, under a structural latent factor model, the empirical relations in Theorem 1 must hold for any other variable Z. Thus, in the causal diagram given in Figure 5, under a structural latent factor model for η, the empirical relations given in Theorem 1 would have to hold between and Z, even though Z has no effect on η, and η has no effect on Z. Again, under a structural latent factor model, the empirical relations in Theorem 1 must hold between and any other variable Z.
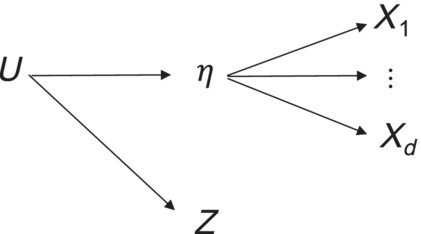
Structural latent factor model with Z neither affecting, nor affected, by latent η, but the structural interpretation still requiring indicators independent of Z conditional on η
We can see then that the assumption that the latent factor model is structural is a very strong assumption. That only the supposedly underlying latent variable η, and not the indicators, are causally efficacious has numerous testable empirical implications, even though the latent variable η itself is unobserved. As noted above, it should be remembered that if the empirical constraints implied by a univariate structural latent factor model do not hold, this does not necessarily imply that the causal models in Figure 2 or 3 are applicable. The model may be more complex still, potentially involving effects from, or to, the latent variable and the indicators, and possibly involving multiple potentially related latent variables or none at all (Gignac, 2016; Kummerfeld et al., 2014; Mansolf & Reise, 2017; Silva et al., 2006). Rejection of the univariate structural latent factor model does not settle the question of the appropriate underlying causal structure and further methodology on model selection and identification may be useful in these settings (Bollen, 1989; Kummerfeld & Ramsey, 2016; Silva et al., 2006; Spirtes et al., 2000).
3 STATISTICAL TESTS TO REJECT THE STRUCTURAL LATENT FACTOR MODEL
In developing formal statistical tests of the empirical implications of a structural interpretation of the latent factor model, as expressed by Theorem 1, we will consider two distinct tests. The first test relies on estimates of the reliabilities λi of the different indicators, which we discuss in Section 3.1 and the test will then be proposed in Section 3.2. This test requires data on at least three indicators (in order to identify the reliabilities), but imposes no restrictions on the variable Z in Theorem 1. Reliance on estimates of the reliabilities, however, renders this test dependent on the specific distributional assumptions that are made in fitting model (1), such as assumptions about the mutual independence of the error terms. We view this as potentially undesirable when assessing the supposed structural interpretation of the latent factor model. Thus, in Section 3.3, we introduce an alternative test which does not rely on estimates of the reliabilities. It evaluates exclusively the constraints imposed by the structural interpretation of the latent factor model, as expressed in terms of its implications given in Theorem 1, making no use of the additional distributional assumptions contained in model (1).
3.1 Estimation of reliability
In order to attain a relatively simple testing procedure in Section 3.2, we will make use of reliability estimates that have a simple asymptotic distribution and are easy to obtain with standard software, while being reasonably efficient. We will assume model (1) holds, along with the default assumption that η is a mean zero variable with unit variance, independent of the residual errors εi, and that the residual errors εi are independent of one another. This then implies that
for i, j = 1, …, d. Let denote the value of the indicator across subjects k = 1, …, N. Consistent estimators of for i = 1, …, d are thus readily obtained by solving d unbiased estimating equations
for , where is the sample average of indicator across subjects k = 1,…, N, and denotes the sample covariance between and . When the reliabilities are positive—which is generally plausible, possibly pending reversal of the coding of some indicators so as to render the sample covariances between all pairs of indicators positive—these solutions are readily obtained using off-the-shelf software as the exponentiated estimated coefficients from a quasi-Poisson model with log link, with outcome given by the d(d − 1)-dimensional vector of sample covariances, without intercept, and with d covariates given by the dichotomous indicators that the considered covariance involves item i = 1, …, d. In particular, the solutions for to the above equations can be calculated as , with the maximum pseudo-likelihood estimator of under working model
assuming mutually independent and homoscedastic errors, where I(.) denotes an indicator function, which is 1 if the argument is true and 0 otherwise.
3.2 A statistical test dependent on reliability estimates
Consider a discrete Z with categories {1, …,p}. If the reliabilities λi of the different indicators were known and non-zero, then a statistical test of the identities in Theorem 1 would be equivalent to a test of the null hypothesis that for z = 2, …, p, and i, j = 1, …, d. To test this hypothesis, we will first derive estimators of the conditional expectations , which obey this null hypothesis. If we define and then under the null hypothesis we can parameterise as:
for i = 1, …, d, where and are unknown. Let be a (p × d)-dimensional vector with elements for z = 1, …, p, and i = 1, …, d. With known fixed λi, i = 1, …, d, consistent generalised methods of moments estimators (Newey & McFadden, 1994) for and under model (2) are readily obtained by minimising
with respect to these parameters, where is the empirical covariance matrix of , k = 1, …, N, and is the transpose of . It follows from general results on distance metric statistics in theorem 9.2 of Newey and McFadden (1994) that the resulting minimum serves as a test statistic of the above null hypothesis, which converges to a χ2 distribution with (d − 1)(p − 1) degrees of freedom under that hypothesis as the sample size N goes to infinity, provided that the vectors of indicators (X1k, …, Xdk) measured for different subjects are independent and identically distributed and that is non-zero. We refer to the Appendix for justification of the degrees of freedom. Optionally, numerical minimisation of can be initiated at inefficient consistent estimators for and which can be obtained by fitting model (2) at the given , using independence generalised estimating equations.
In practice, , are unknown and must be substituted by estimates , as given in Section 3.1. To accommodate the uncertainty in these estimated reliabilities in the above test statistic, it suffices to re-define in the expression for as the empirical covariance matrix of
(see the Appendix), where is the vector of reliabilities and is a d-dimensional vector with elements
for i = 1,…, d, as defined in Section 3.1; in this expression, can be substituted by . As before, consistent generalised methods of moments estimators for and under model (2) are then obtained by minimising , now using the revised choice of , and the minimised value of can be used as a test statistic of the null hypothesis that the structural interpretation of the latent factor model holds. It converges to a χ2 distribution with (d − 1)(p − 1) degrees of freedom under that null hypothesis as the sample size N goes to infinity, provided that the vectors of indicators (X1k, …, Xdk) measured for different subjects are independent and identically distributed and that is non-zero.
3.3 A statistical test independent of reliability estimates
That the proposed statistical test relies on reliability estimates may be viewed as not entirely satisfactory, because the test may be biased when the covariance structure between the residual error terms in model (1) is mis-specified. This could in turn lead to an inflated risk of falsely rejecting the structural interpretation of the latent factor model due solely to the mis-specified covariance. In this section, we will therefore propose an alternative test, which does not rely on reliability estimates and can therefore be used even when only two indicators are available, but does then require that Z have at least three levels. The proposed test is based on the following, equivalent formulation of the identity in Theorem 1.
Theorem 2Under the basic latent factor model in equation (1), for any discrete Z, the following two conditions are equivalent:
- 1.
for any i and j, and any values z and z*,
- 2.
for any i and any values z, and for an arbitrary fixed value z*, for some parameters.
Provided at least two of the indicators have non-zero λi and Z has at least three levels, we can use this result to construct a test of the empirical implications of the structural latent factor model. Consider again a discrete Z with categories {1, …, p}. Theorem 2 then suggests that under the null hypothesis that the structural latent factor model holds, we can parameterise as:
for all i and all values z. This model has (2d + p − 2) unknown parameters (since the product is invariant to rescaling of the form and for any non-zero ). A test statistic of the null hypothesis can next be constructed by redefining Uk to be the (dp)-dimensional column vector with elements for i = 1, …, d and w = 1, …, p, where we define . Consistent generalised methods of moments estimators (Newey & McFadden, 1994) for and under model (3) are readily obtained by minimising
where is the empirical covariance matrix of Uk, k = 1, …, N. It then follows from general results on distance metric statistics in theorem 9.2 of Newey and McFadden (1994) that the resulting minimum is a test statistic of the null hypothesis that the structural latent factor model holds, which converges to a χ2 distribution with (d − 1)(p − 2) degrees of freedom under the null hypothesis as the sample size N goes to infinity, provided that the vectors of indicators (X1k, …, Xdk) measured for different subjects are independent and identically distributed and that E(Xi|Z = z) is non-zero for at least one i and z; we refer to the Appendix for justification of the degrees of freedom and for inefficient consistent estimators that can optionally be used as initial values in this minimisation.
The developments in Sections 3.2 and 3.3 consider tests for the null hypothesis that the structural latent factor model holds without making use of covariates C. As noted in Section 2, conditioning on C can be done in employing Theorem 1, but such conditioning is optional since the empirical restrictions imposed by the structural latent factor model hold irrespective of such conditioning. With a set of discrete covariates C, one could, however, consider conducting tests within strata defined by C. In some settings, this may increase power as a result of testing more conditions. However, in other settings this may decrease power due to the reduced sample size in each stratum and the need for multiple testing corrections. Future work will consider extensions to high-dimensional and continuous C and Z.
Tests to reject a structural interpretation of a latent factor model could in principle also be carried out using goodness-of-fit tests for structural equation models (Bollen, 1989) comparing, for example, models with arrows from η to Z, versus models with arrows from to Z. This has not, however, typically been employed in practice. Moreover, we believe the statistical test that is developed here is advantageous over the potential structural equation model approach because (i) the goodness-of-fit test for the structural equation model may also depend on other features of the structural equation model that are not directly relevant to whether it is η or that has effects on Z; (ii) the statistical test here is applicable under weaker distributional assumptions and (iii) the test here is applicable for testing the structural interpretation even if both η and affect Z, or even if neither η nor affect, or are affected by, Z, as in Figure 5. The test developed here is thus more versatile and is applicable under weaker assumptions. However, as noted above, the test we have developed is targeted to evidence for rejecting the structural interpretation of a univariate latent factor model. Other model selection and identification approaches are important in trying to discern a model that may in fact approximately correspond to the underlying causal structures (Bollen, 1989; Kummerfeld & Ramsey, 2016; Silva et al., 2006; Spirtes et al., 2000; Sullivant et al., 2010).
4 EXAMPLE: THE POTENTIAL EFFECT OF LIFE SATISFACTION ON ALL-CAUSE MORTALITY
Kim et al. (2021) consider the effect of life satisfaction (η), as assessed by Diener et al.'s (1985) Satisfaction with Life Scale (SWLS) , on subsequent all-cause mortality 4 years later (Y). The SWLS (Diener et al., 1985) has d = 5 items, , each rated 1–7. These items are: ‘In most ways my life is close to my ideal’; ‘The conditions of my life are excellent’; ‘I am satisfied with my life’; ‘So far I have gotten the important things I want in life’; and ‘If I could live my life over, I would change almost nothing’. The specific items were chosen and the scale was developed using factor analytic methods. The scale has been documented to have very good psychometric properties: Cronbach's alpha is high and a single underlying factor seems to explain a considerable proportion of the variance across item responses (Diener et al., 1985; Pavot & Diener, 1993). According to Google Scholar the paper that presents the scale (Diener et al., 1985) has now been cited over 34,000 times. In light of the psychometric evidence, the responses to the individual items are thus typically summed for an overall measure, , between 5 and 35.
The primary analyses of Kim et al. (2021) compared tertiles of this satisfaction of life score in 2010 or 2012 and examined associations with all-cause mortality 4 years later using data on N = 12,998 participants in the Health and Retirement Study, controlling for numerous potentially confounding variables. These included sociodemographic characteristics (age, sex, race/ethnicity, marital status, annual household income, total wealth, level of education, employment status, health insurance, geographic region), childhood abuse, religious service attendance, health conditions and behaviours (diabetes, hypertension, stroke, cancer, heart disease, lung disease, arthritis, overweight/obesity, chronic pain, binge drinking, current smoking status, physical activity, sleep problems), various other aspects of psychological well-being (positive affect, optimism, purpose in life, mastery, depressive symptoms, hopelessness, negative affect, loneliness, social integration), and personality factors (openness, conscientiousness, extraversion, agreeableness, neuroticism). In the primary analysis, those in the top tertile of life-satisfaction were 0.74 (95% CI: 0.64, 0.87) times less likely to die during the 4 years of follow-up than those in the bottom tertile.
In supplementary analyses, Kim et al. also examined similar associations using each item of Diener et al.'s (1985) SWLS separately. Relatively similar risk ratios pertained to four of the items: ‘In most ways my life is close to my ideal’ (RR = 0.75; 95% CI: 0.61, 0.91); ‘The conditions of my life are excellent’ (RR = 0.79; 95% CI: 0.66, 0.95); ‘I am satisfied with my life’ (RR = 0.72; 95% CI: 0.62, 0.84) and ‘So far I have gotten the important things I want in life’ (RR = 0.85; 95% CI: 0.73, 0.99). However, for the fifth item ‘If I could live my life over, I would change almost nothing’ the association with all-cause mortality in the 4 years following was effectively null (RR = 0.98; 95% CI: 0.83, 1.16). It thus appears that there may be some evidence that the indicators of the SWLS are differentially associated with all-cause mortality. Here we formally examine whether these data are in fact sufficient to reject the structural interpretation of the latent factor model for the SWLS. The Health and Retirement Study data are publicly available online at http://hrsonline.isr.umich.edu/index.php?p=avail&_ga=2.50444521.1751399216.1593436952-1257117760.1593436952 and code for the analysis is available in the Online Supplement and at https://github.com/svsteela/StructuralRejection.
To investigate the plausibility of the structural interpretation of a latent factor model underlying the scale, we first used the test statistic in Section 3.2 with Z taken to be all-cause mortality at the end of the 4-year follow-up. This test statistic requires estimating the reliabilities λi and the test assumes independence of the residual errors εi, an assumption which we will later relax. With d = 5 indicators and the variable Z taking p = 2 levels, under the null hypothesis that the factor model is structural, the test statistic T0 in section 3.2 follows a χ2 distribution with (d − 1)(p − 1) = 4 degrees of freedom. The analysis here again used the Health and Retirement Study data with responses from 12,135 individuals, after removal of incomplete records. After estimating the reliabilities λi and fitting the restricted model (2), the test statistic T0 was 57.25 after adjusting for the uncertainty in the estimated reliabilities. Comparing this with a χ2 distribution with 4 degrees of freedom suggests very strong evidence (p = 1.1 10−11) against the null hypothesis of a structural interpretation of the latent factor model.
To add more robust support to this result, we next evaluated the test statistic of Section 3.3, which does not rely on the distributional assumptions behind model (1), but only on the implications of the structural interpretation of the model. As per Section 3.3, to avoid estimating reliabilities requires a variable Z with at least p = 3 levels. For this, we let Z be a four-level variable defined by all-cause mortality and pre-baseline physical activity (measured in 2006 or 2008), coded as 1 (alive and < 1×/week of prior vigorous or moderate exercise), 2 (dead and < 1×/week of prior vigorous or moderate exercise), 3 (alive and ≥1×/week of prior vigorous or moderate exercise) and 4 (dead and ≥1×/week of prior vigorous or moderate exercise). With d = 5 indicators and the variable Z taking p = 4 levels, under the null hypothesis that the factor model is structural, the test statistic T1 in Section 3.3 follows a χ2 distribution with (d − 1)(p − 2) = (5 − 1)(4 − 2) = 8 degrees of freedom. The analysis here once again used the Health and Retirement Study data with responses from 10,362 individuals, after removal of incomplete records. This resulted in a test statistic T1 of 141.73. Comparing this with a χ2 distribution with 8 degrees of freedom suggests very strong evidence (p < 1 10−10) against the null hypothesis of a structural interpretation of the latent factor model.
That we were able to reject the structural interpretation of the latent factor model for the SWLS does not imply that it is a bad scale. It arguably does capture well a number of important aspects of a person's satisfaction with the life that he or she has lived, and this is arguably an important outcome to study; the scale is indeed useful for that purpose. Whether absence of regret (‘If I could live my life over, I would change almost nothing’) ought to be included in that outcome is arguably a conceptual question, concerning the intended coverage of the construct, not an empirical question.
Nevertheless, the rejection here of the structural interpretation of the scale does imply that there is no underlying univariate latent variable ‘life satisfaction’ measured by the SWLS, such that it is the underlying latent, rather than what is constituted by its indicators, that is causally efficacious. Indeed, different aspects of satisfaction with life appear to be associated with subsequent all-cause mortality in different ways. It may be important to better understand these distinctions and nuances.
One could potentially attempt the formation of a measure that may more closely correspond to an underlying univariate latent with a structural interpretation by dropping the item, ‘If I could live my life over, I would change almost nothing’. This might then render the remaining four items more similarly associated with all-cause mortality. However, this would not necessarily guarantee that comparable associations would still hold with other outcomes (or with the effects on the indicators of various treatments). That would of course require further empirical investigation. However, as noted above and discussed further below, the rejection of the structural interpretation of the latent factor model for the SWLS does not mean that the scale ought to be abandoned. It does mean, though, that prior psychometric evidence does not justify such a structural interpretation. Life satisfaction, as assessed by the scale, is not a unidimensional construct with some underlying factor with uniform effects on outcomes.
5 IMPLICATIONS AND CONCLUSIONS
The possibility that the structural interpretation of the latent factor model may be wrong—even when the basic univariate latent factor model seems to fit the indicators well—has a number of potentially far-reaching implications.
First, the evidence for the structural latent factor model should be established through empirical testing; it should not be presumed. Common practice seems to be to use factor analysis to examine evidence for the uni-dimensionality of a scale. If certain standards and criteria are met, and this is considered established, the scale or measure is then considered ‘validated’ for use in empirical research (DeVellis, 2016; Price, 2016). The scale is employed in other, ideally longitudinal or randomised studies, to examine evidence for causes and effects. However, as this paper has made clear, even if the basic univariate latent factor model holds, this does not imply that the interpretation of that model is necessarily structural, that is, that it is the supposedly underlying latent factor, rather than the indicators (or whatever phenomena are related to them), that is causally efficacious. It is a big leap to assume that this is so. It is a leap that is often made with no evidence, but such practices could change.
As shown in this paper it is possible to empirically test for, and reject, the implications of a structural interpretation of the univariate latent factor model. It is conceivable that over many outcomes, or in examining the effects of numerous treatments or interventions, these tests generally do not reject the empirical implications of the structural latent factor model given in Theorem 1. It is possible that the implications of structural latent factor model described in Theorem 1 do closely hold with all outcomes examined, and with all treatments examined. This is not a proof that the structural interpretation holds, but it would constitute evidence. The implications of the structural interpretation of the univariate latent factor model are not fully empirically verifiable, but if numerous tests across numerous different outcomes and treatments did not reject, one might have reason to believe that the structural latent factor model held to a reasonable approximation. One might also use other model selection and identification approaches to compare the univariate structural latent factor model to other more complex models (Bollen, 1989; Kummerfeld et al., 2014; Kummerfeld & Ramsey, 2016; Silva et al., 2006; Spirtes et al., 2000). After carrying out this work, one might eventually be more justified in assuming that the construct under consideration was reasonably well represented by a univariate causally efficacious latent variable. One might thus also be more justified in subsequently using the corresponding univariate scale, with other treatments and outcomes in precisely the way that these scales are used at present (but arguably, currently, without adequate justification).
It is entirely possible that in some cases the structural univariate latent factor model will be a reasonably good approximation, while in other cases it will not. But until we examine the evidence, we do not know. Simply showing conformity to the basic univariate latent factor model is not sufficient. Again, this tells us nothing about the potential causal efficacy, or not, of the supposed univariate latent variable versus the indicators. Conformity to the basic univariate latent factor model does not help us distinguish between the causal structures in Figure 2 versus Figure 2 or in Figure 3 versus Figure 3 or between other more complex structures. In this regard, not only exploratory factor analysis, but also in fact confirmatory factor analysis are effectively hypothesis-generating with respect to whether we have identified a univariate factor with a structural causal interpretation. Evidence from exploratory and confirmatory factor analysis that leads to the identification of factors fitting the basic latent factor model in Equation (1) are a good place to begin with respect to assessing whether that supposed univariate factor is in fact structural. But this should be considered the beginning of that process, rather than its conclusion. If the search for factors is ultimately to uncover constructs that can be effectively represented by a univariate and causally efficacious latent variable in the structural sense, then it will subsequently be desirable to evaluate whether the empirical relations given in Theorem 1 hold with respect to a range of treatments and outcomes. Evidence for so-called measurement invariance (Cheung & Rensvold, 2002; Meredith, 1993; Meredith & Teresi, 2006; Putnick & Bornstein, 2016) might help partially mitigate the possibility of differential treatment effect across the indicators, but does nothing to ensure comparable associations of the indicators with other subsequent outcomes. In any case, the implications of the structural univariate factor model should be examined to justify current practices of using univariate scales in ensuing subsequent empirical research.
A second related implication also follows from this: until there is substantial evidence already in place, from multiple outcomes and multiple treatments, that the structural factor model holds, we should, until that evidence is established, continue to examine the potential casual relationships between individual indicators and outcomes, and between treatments and individual indicators, one indicator at a time. The current practice is that once it is shown that the basic latent factor model fits a set of indicators well, and the items and scale meet other criteria (DeVellis, 2016), then, it is typically assumed that this is adequate justification for using the scale, and not the individual indicators, in all subsequent research. Indeed, investigators are not infrequently criticised for the practice of examining associations between outcomes and individual indicators. However, if the structural interpretation of the univariate latent factor model has not been established, then such criticisms are inappropriate. Indeed item-by-item examination may be important for uncovering the nuances of the constructs being considered and their differing relations to outcomes of interest (VanderWeele, 2022).
It is entirely possible for the basic factor model to hold with a multi-item scale and yet, for example, to have only one of the indicators have any causal efficacy. Such would be the case in Figure 6 with only the item X1 having causal efficacy or in Figure 6 in which each indicator Xi corresponds to some underlying latent ηi but only η1 has causal efficacy for the outcome Y.
Basic latent factor model for η with only (a) one single indicator X1, or (b) one single subsequent latent η1, causally efficacious for outcome Y
Both of these models in Figure 6 are entirely consistent with the basic factor model perfectly fitting the data for the set of indicators . If we do not examine the indicators' relationships one at a time with the outcome we would miss this critical nuance. If the indicators are strongly correlated with one another, then we will still see substantial association between the measure A (constructed by e.g. an average of the indicators) and the outcome Y, but we will not see that this is attributable solely to, for example, X1 in Figure 6 (or that which underlies it, η1, in Figure 6). To see this, we would need to regress Y on all of the indicators simultaneously, and under the structure in Figure 6, for example, we would then see that only X1 is relevant for the outcome.
In many cases, we may find that the structural interpretation of the univariate latent factor model does not hold, as was the case for the SWLS. This does not mean the scale should be abandoned. It may be an appropriate or desired summary of a set of indicators or items, interpreted simply as an average of these. It may be useful as an outcome. The scale may also potentially be used as an exposure or independent variable of interest, even if the structural interpretation does not hold, as it is still possible to give the estimates using the scale a causal interpretation, albeit one that is more nuanced using causal inference theory for multiple versions of treatment (VanderWeele, 2022; VanderWeele & Hernan, 2013). However, while we can still use a scale, even as a single univariate exposure without having established the structural interpretation of the underlying factor model, we should keep in mind that we may be obscuring important distinctions and differential relationships across indicators. If we do not already have considerable evidence for the structural interpretation then we certainly should not criticise item-by-item analyses. Indeed, these may be precisely what is helpful in gaining more nuanced insight.
Third, if the latent factor model is not in fact structural, then an intervention itself can alter the observed factor structure across items. Suppose that for a set of indicators a univariate latent factor model as in Equation (1) fits the data well. Suppose that a new treatment T is introduced that affects indicators X1 and X2 but none of the other indicators as in Figure 7. This situation may in fact be relatively ubiquitous, with specific treatments effectively altering certain indicators but not others, again challenging the plausibility of structural factor models.
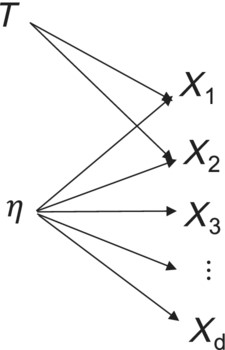
Basic latent factor model for η with treatment T directly affecting indicators X1 and X2, and thereby altering the factor structure
Suppose further, however, that over time the use of treatment T becomes more widespread so that it would be present among many individuals in most samples. While a univariate latent factor model might have originally fit the data well, once T is introduced, the factor structure has been changed. A new treatment may alter the factor structure. This cannot happen if the latent factor model is structural so that any and all effects on operate through η, but if the latent factor model is basic but not structural, then treatments can change the properties of the basic factor model.
Fourth, taking these various possibilities into account, there is a potentially dangerous process of feedback that has occurred between (i) numerous statistical analyses often suggesting that, in many settings, a basic univariate latent factor explains reasonably well the covariance across item responses; (ii) the supposition that this then entails a structural interpretation of the latent factor model; (iii) the fact that causal relationships between latent factors can suggest a basic univariate latent factor model, even when the true underlying structures are multivariate (VanderWeele & Batty, 2020) and (iv) the lack of consideration of causal relations between underlying structural latent factors, or between prior causes and indicators leading to an overreliance on factor analysis with one wave of data (VanderWeele & Batty, 2020). That the covariance structures across indicators does, in scale development, often seem to fit well a one-factor model reinforces the supposition that this is nothing unusual and then further reinforces the fundamental error of concluding that the univariate latent factor model is structural. In light of the considerations above, current practices of factor analysis do not constitute an adequate approach for model selection or for scale development.
These mutually reinforcing experiences and suppositions need to be revisited. Differential associations of the indicators in well-established scales with specific outcomes (or specific treatments, or other variables) and the tests in this paper will challenge the structural interpretation of latent factor models. The recognition that these latent factor models may not be structural, even if the basic univariate latent factor model fits the data well, might lead to a better appreciation that there may be important aspects of the constructs under consideration that are multi-dimensional in nature, and that these various dimensions may be very differently related to outcomes of interest. This may in fact be the reality for many, most, or even nearly all, psychosocial constructs. It may then also become apparent that there has been an overreliance on factor analysis itself for model selection and for scale development and other approaches may be considered (Kummerfeld & Ramsey, 2016; Silva et al., 2006; Spirtes et al., 2000; Sullivant et al., 2010). It is time that this process of re-examination begins. We may need to return to well-established scales and consider the items one-by-one, and utilise the tests described in this paper and employ further tests and methods for more complex settings, to evaluate the evidence pertaining to whether well-fitting univariate latent factor models are indeed structural, or whether the presumption that they are, has obscured important distinctions.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are openly available in: https://hrsdata.isr.umich.edu/data-products/public-survey-data?_ga=2.63854507.549649331.1622319543-1459317861.1622319543
ACKNOWLEDGEMENTS
This research was funded by the National Institutes of Health, USA.
REFERENCES
APPENDIX A
A.1. Proofs of Theorems 1 and 2
We begin by discussing generalisations of Theorem 1 that allow for conditioning on a set of covariates C and that may involve a multi-dimensional latent variable η.
Generalization of Theorem 1Suppose that Z is independent of conditional on univariate η and covariates C, and that the basic latent factor model in Equation (1) holds such that with independent of η conditional on C, then for any i and j, and any values z and z*, we must have
Proof of Generalisation of Theorem 1For any variable such that Z is independent of conditional on (η, C) we have that
It likewise follows that
from which
Let us first assume that differs from 0. Then . Now applying this result again to we similarly obtain provided that also differs from 0, and thus we must have When then it follows from the earlier derivation that so that the identity continues to hold. When the set of covariates C is empty we obtain the result given in the text. This completes the proof.
Suppose now that η is multivariate and that a basic latent factor model holds such that with independent of η conditional on C, with λi constituting a vector. Suppose once again that Z is independent of conditional η and covariates C. Let and and so that We then have that
from which it follows
This set of d equations will in general give us empirical implications from the observed data provided d > dim().
Proof of Theorem 2Let us denote E(Xi|Z = 1) = γi. For indicators, i and j, the basic identity in Theorem 1 is that
for all i, j, z. Consider the analogous expression evaluated at some z*. Multiplying the two expressions, with j = 1, shows that
and, under the assumption that λi is non-zero for all i, that
for all i, j, z, z*. Denote
And letting
we conclude that if the identity in Theorem 1 holds, then
If E(X1|Z = z*)- γ1 = 0, then the result continues to hold upon changing the references category z* or j = 1 so that E(X1|Z = z*) − γ1 is no longer zero; if this is not possible, then Z is independent of all indicators and thus the identity holds trivially.
Conversely, given the reference value j for which αj differs from zero, the latter identity implies that
with
thus confirming the identity in Theorem 1. Note that such reference value j for which αj differs from zero can always be found except when E(Xi|Z = z) = E(Xi|Z = z*) for all i and z, in which case the identity in Theorem 1 still holds.
A.2. Asymptotic distribution of the test statistic of Section 3.2
Define
where we suppress dependence on and , as these are substituted by the corresponding minimisers of at the given . For fixed, known , it follows by a direct application of theorem 9.2 in Newey and McFadden (1994) that asymptotically follows a chi-square distribution. For the degrees of freedom, consider the saturated parameterisation
The null hypothesis can be expressed as for all i = 1, …, d and z = 2, …, p. Let and be vectors of d(p−1) elements and , respectively; we choose not to include in as the null hypothesis does not involve , so that the reasoning below would remain unchanged when including it. The vector has p − 1 elements that are guaranteed to equal zero, regardless of the values of , namely those where i = 1. Without loss of generality, we place these elements in the first p − 1 rows of . The first p − 1 rows in the gradient of with respect to thus contain only zeroes. The remaining rows have on the diagonal position, and 0 on all other positions except possibly the first p − 1 columns. We conclude that the rank of this gradient is d(p − 1) − (p − 1) = (d − 1)(p − 1) when differs from zero. It then follows from Newey and McFadden (1994) that the proposed test has (d − 1)(p − 1) degrees of freedom.
We next study the asymptotic behaviour of for the same choice of . We will later deal with the estimation of . It follows by a Taylor expansion that
Here, the middle term on the right is uniformly tight but not generally converging to zero in probability because and are uniformly tight (and not converging to zero in probability), and converges in probability to a non-zero constant. In view of this, we consider
where
and is its covariance matrix. For given, known , this follows the same asymptotic distribution as before (by theorem 9.2 in Newey and McFadden (1994)), provided that and , are substituted by the corresponding minimisers of at the given . By a similar Taylor expansion as before, we then have
where the middle term on the right now converges to zero in probability since converges to zero in probability by the weak law of large numbers and all remaining terms are uniformly tight. We conclude that and follow the same asymptotic distribution. The result in Section 3.2 now follows upon noting that, by Slutsky's theorem, the substitution of by a consistent estimator (which involves a consistent estimator of does not change the asymptotic distribution.
The above Taylor expansion does not explicate the fact that a change from to may also change the values for and , at which the test statistic is minimised. Let be the vector of values and , and be the corresponding minimiser of . Then the righthand side of the above Taylor expansion for in principle must include the additional term
We ignored this term since by virtue of minimising and since all remaining terms are uniformly tight.
RemarkNote that does not merely involve the data for subject k, but depends on other subjects' data through the sample averages . This does not pose additional complications because is the influence function for the covariance between and under the non-parametric model (see e.g. Hines et al. (2022)). Asymptotically equivalent results would therefore be obtained when re-defining .
A.3. Initial values for the parameters in the minimisation of Section 3.3
In this paragraph, we provide easy-to-calculate, but inefficient consistent estimators of and , i = 1, …, d, and , w = 2, …, p, which can optionally be used as starting values in the minimisation procedure. In particular, we will estimate , i = 1, …, d, as the solution to
and , i = 1, …, d, as the solution to
where N is the number of subjects. We will moreover estimate , z = 2, …, p by solving
for . These unbiased estimating equations can be solved by iterating the following procedure until convergence:
- 1.
Estimate as with and set at the current iteration.
- 2.
Estimate as with and set at the current iteration.
- 3.
Estimate as with and set at the current iteration.
As initial estimates of and , i = 1, …, d, in this iterative process, we can use 0 and the sample average of Xi in the subgroup Z = 1, respectively. We can assess convergence by monitoring the sum of squares of the function values to the above 2d + p − 1 estimating equations with , and substituted by , and , respectively; this sum of squares should converge to zero.
A.4. Degrees of freedom of the test statistic of Section 3.3
Consider the saturated parameterisation
Reasoning as in the proof of Theorem 2, the null hypothesis can be expressed as for all i = 1, …, d and z = 2, …, p. Let and be vectors of d(p − 1) elements and , respectively; we choose not to include in as the null hypothesis does not involve , so that the reasoning below would remain unchanged when including it. The vector has d + p − 2 elements that are guaranteed to equal zero, regardless of the values of , namely those where either i = 1 or z = 2. Without loss of generality, we place these elements in the first d + p − 2 rows of . The first d + p − 2 rows in the gradient of with respect to thus contain only zeroes. The remaining rows have on the diagonal position, and 0 on all other positions except possibly the first d + p − 2 columns. We conclude that the rank of this gradient is d(p − 1)-(d + p − 2) = (d − 1)(p − 2) when differs from zero. It then follows from Newey and McFadden (1994) that the proposed test has (d − 1)(p − 2) degrees of freedom. When is zero, one may change the coding of the indices i and z to render it non-zero, except when is independent of all indicators.
Author notes
Funding information Division of Cancer Prevention, National Cancer Institute, Grant/Award Number: R01CA222147; National Institutes of Health, USA

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}