





ABSTRACT
IMGT/3Dstructure-DB is the three-dimensional (3D) structure database of IMGT®, the international ImMunoGenetics information system® that is acknowledged as the global reference in immunogenetics and immunoinformatics. IMGT/3Dstructure-DB contains 3D structures of immunoglobulins (IG) or antibodies, T cell receptors (TR), major histocompatibility complex (MHC) proteins, antigen receptor/antigen complexes (IG/Ag, TR/peptide/MHC) of vertebrates; 3D structures of related proteins of the immune system (RPI) of vertebrates and invertebrates, belonging to the immunoglobulin and MHC superfamilies (IgSF and MhcSF, respectively) and found in complexes with IG, TR or MHC. IMGT/3Dstructure-DB data are annotated according to the IMGT criteria, using IMGT/DomainGapAlign, and based on the IMGT-ONTOLOGY concepts and axioms. IMGT/3Dstructure-DB provides IMGT gene and allele identification (CLASSIFICATION), region and domain delimitations (DESCRIPTION), amino acid positions according to the IMGT unique numbering (NUMEROTATION) that are used in IMGT/3Dstructure-DB cards, results of contact analysis and renumbered flat files. In its Web version, the IMGT/DomainGapAlign tool analyses amino acid sequences, per domain. Coupled to the IMGT/Collier-de-Perles tool, it provides an invaluable help for antibody engineering and humanization design based on complementarity determining region (CDR) grafting as it precisely defines the standardized framework regions (FR-IMGT) and CDR-IMGT. IMGT/3Dstructure-DB and IMGT/DomainGapAlign are freely available at http://www.imgt.org.
INTRODUCTION
IMGT/3Dstructure-DB (1) is the three-dimensional (3D) structure database of IMGT®, the international ImMunoGenetics information system® (http://www.imgt.org) (2) that is acknowledged as the global reference in immunogenetics and immunoinformatics (3). IMGT/3Dstructure-DB contains 3D structures of (i) antigen receptors that comprise immunoglobulins (IG) or antibodies and T cell receptors (TR), (ii) major histocompatibility complex (MHC) proteins of class I (MHC-I) and class II (MHC-II), (iii) peptide/MHC (pMHC) complexes (pMHC-I, pMHC-II), (iv) antigen receptor/antigen complexes (IG/Ag, TR/pMHC) and (v) related proteins of the immune system (RPI) belonging to the immunoglobulin and MHC superfamilies (IgSF and MhcSF, respectively) and found in complexes with IG, TR or MHC. Major breakthroughs characterize IMGT® and, therefore, IMGT/3Dstructure-DB: a standardized identification (IMGT keywords), a standardized nomenclature (IMGT gene and allele names), a standardized description (IMGT labels) and a standardized numerotation (IMGT unique numbering). These rules are described in the IMGT Scientific chart and are derived from the concepts of identification, classification, description and numerotation, themselves generated from the IDENTIFICATION, CLASSIFICATION, DESCRIPTION and NUMEROTATION axioms of the Formal IMGT-ONTOLOGY, the first ontology in immunogenetics and immunoinformatics (4,5).
The IMGT/3Dstructure-DB structural data are extracted from the Protein Data Bank (PDB) (6,7) and annotated according to the IMGT-ONTOLOGY concepts of classification, using internal tools and IMGT/DomainGapAlign. Thus, IMGT/3Dstructure-DB provides the closest genes and alleles that are expressed in the amino acid sequences of the 3D structures, by aligning these sequences with the IMGT domain reference directory. This directory contains, for the antigen receptors, amino acid sequences of the domains encoded by the constant (C) genes and the translation of the germline variable (V) and joining (J) genes. The identified genes are classified based on the IMGT nomenclature of IG and TR genes and alleles (8,9) that was approved in 1999 by the Human Genome Organisation (HUGO) Nomenclature Committee (HGNC) (10), entered in IMGT/GENE-DB (11) and endorsed by the World Health Organization (WHO)-International Union of Immunological Societies (IUIS) Nomenclature Committee (12,13). Entrez Gene (14) at the National Center for Biotechnology Information (NCBI), Vertebrate Genome Annotation (Vega) (15) at the Wellcome Trust Sanger Institute and Ensembl at the European Bioinformatics Institute (EBI) currently use IMGT nomenclature.
IMGT/3Dstructure-DB provides the IMGT Colliers de Perles (16,17) that are 2D graphical representations based on the IMGT unique numbering, the key IMGT-ONTOLOGY concept of numerotation. IMGT Colliers de Perles are currently available for three domain types: V type (that includes the V-DOMAIN of IG and TR, and V-LIKE-DOMAIN of the IgSF other than IG and TR) (18), C type (that includes the C-DOMAIN of IG and TR, and C-LIKE-DOMAIN of the IgSF other than IG and TR) (19) and G type (that includes the G-DOMAIN of MHC, and G-LIKE-DOMAIN of the MhcSF other than MHC) (20).
IMGT-ONTOLOGY concepts have been crucial in bridging the gap between sequences and 3D structures in IMGT/3Dstructure-DB (21,22). Since 2008, amino acid sequences of monoclonal antibodies (mAb, suffix -mab) and of fusion proteins for immune applications (FPIA, suffix -cept) from the World Health Organization/International Nonproprietary Name (WHO/INN) have been entered in IMGT®. Being able to analyse sequences and 3D structures with the same concepts of classification (nomenclature), description (labels) and numerotation (IMGT unique numbering) facilitates comparative studies of antigen receptors and FPIA, and of their constitutive chains, even if 3D structures are not yet available. Results from IMGT/DomainGapAlign and the associated IMGT/Collier-de-Perles tool are widely used by researchers, particularly for antibody engineering and humanization design.
IMGT/3DStructure-DB DATABASE
Besides an increase in the number of IMGT/3Dstructure-DB coordinate files (634 in 2004, 1649 in 2009), the database itself was enhanced with (i) new data types (IgSF other than IG and TR, MhcSF other than MHC), (ii) novel functionalities that include chain sequences in IMGT format, contact analysis of paratope/epitope, ‘IMGT pMHC contact sites’ (23,34) and ‘IMGT numbering comparison’ and (iii) improvement of the IMGT/DomainGapAlign tool that allows the identification of the closest gene(s) and allele(s) expressed in IMGT/3Dstructure-DB protein sequences and IG and TR variable domains, by comparison with the IMGT domain directory, and the display of amino acid differences.
IMGT/3Dstructure-DB is queried through a user-friendly interface and different displays for the results can be chosen from the database home page, as previously described (1). Each entry in the database is detailed in an IMGT/3Dstructure-DB card. Eight tabs are available at the top of each card: ‘Chain details’, ‘Contact analysis’, ‘Paratope and epitope’, ‘3D visualization Jmol or QuickPDB’, ‘Renumbered IMGT file’, ‘IMGT numbering comparison’, ‘References and links’ and ‘Printable card’. First, we will describe ‘Chain details’, and then a selection of three features related to ‘Contact analysis’ (IMGT Collier de Perles on two layers with hydrogen bonds, IMGT pMHC contact sites, IMGT/3Dstructure-DB Domain pair contacts) and the IMGT/DomainGapAlign results in its Web version (Figure 1).
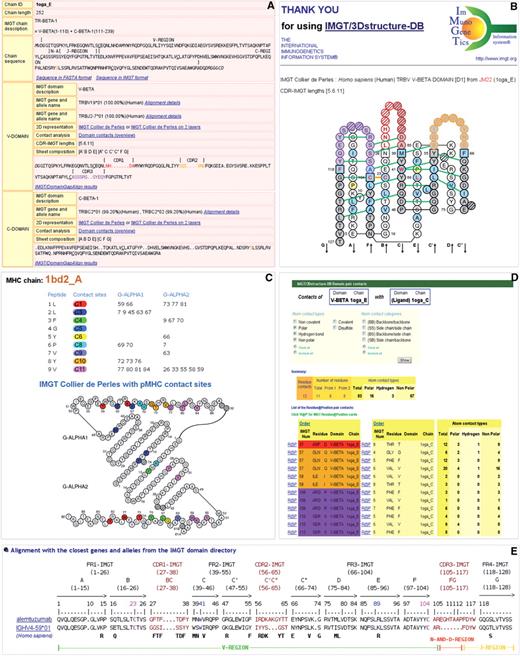
(A) IMGT/3Dstructure-DB ‘Chain details’. (B) IMGT Collier de Perles on two layers with hydrogen bonds. (C) IMGT pMHC contact sites of human HLA-A∗0201 MHC-I and a 9-amino acid peptide (1bd2). (D) IMGT/3Dstructure-DB Domain pair contacts between a V-BETA domain and a ligand (1oga). (E) IMGT/DomainGapAlign Web results of alemtuzumab.
Statistics
In September 2009, the IMGT/3Dstructure-DB database manages 1649 coordinate files that correspond to 1773 receptors (Table 1).
Number of receptors and complexes in IMGT/3Dstructure-DB
| Number per species | ||||
| Homo sapiens | Mus musculus | Other species | Total | |
| Receptor type | ||||
| IG | 293 | 655 | 144 | 1092 |
| TR | 48 | 40 | 1 | 89 |
| MHC | 251 | 133 | 3 | 387 |
| RPI | 168 | 23 | 14 | 205 |
| Total | 760 | 851 | 162 | 1773 |
| Complex typea | ||||
| Antigen receptor/antigen | ||||
| IG/Ag | 141 | 393 | 54 | 588 |
| TR/pMHC | ||||
| TR/pMHC-I | 17 | 10 | 0 | 27 |
| TR/pMHC-II | 5 | 6 | 0 | 11 |
| peptide/MHC | ||||
| pMHC-I | 155 | 90 | 3 | 248 |
| pMHC-II | 37 | 9 | 0 | 46 |
| Total | 355 | 508 | 57 | 920 |
| Number per species | ||||
| Homo sapiens | Mus musculus | Other species | Total | |
| Receptor type | ||||
| IG | 293 | 655 | 144 | 1092 |
| TR | 48 | 40 | 1 | 89 |
| MHC | 251 | 133 | 3 | 387 |
| RPI | 168 | 23 | 14 | 205 |
| Total | 760 | 851 | 162 | 1773 |
| Complex typea | ||||
| Antigen receptor/antigen | ||||
| IG/Ag | 141 | 393 | 54 | 588 |
| TR/pMHC | ||||
| TR/pMHC-I | 17 | 10 | 0 | 27 |
| TR/pMHC-II | 5 | 6 | 0 | 11 |
| peptide/MHC | ||||
| pMHC-I | 155 | 90 | 3 | 248 |
| pMHC-II | 37 | 9 | 0 | 46 |
| Total | 355 | 508 | 57 | 920 |
Complexes involving RPI are not shown.
Number of receptors and complexes in IMGT/3Dstructure-DB
| Number per species | ||||
| Homo sapiens | Mus musculus | Other species | Total | |
| Receptor type | ||||
| IG | 293 | 655 | 144 | 1092 |
| TR | 48 | 40 | 1 | 89 |
| MHC | 251 | 133 | 3 | 387 |
| RPI | 168 | 23 | 14 | 205 |
| Total | 760 | 851 | 162 | 1773 |
| Complex typea | ||||
| Antigen receptor/antigen | ||||
| IG/Ag | 141 | 393 | 54 | 588 |
| TR/pMHC | ||||
| TR/pMHC-I | 17 | 10 | 0 | 27 |
| TR/pMHC-II | 5 | 6 | 0 | 11 |
| peptide/MHC | ||||
| pMHC-I | 155 | 90 | 3 | 248 |
| pMHC-II | 37 | 9 | 0 | 46 |
| Total | 355 | 508 | 57 | 920 |
| Number per species | ||||
| Homo sapiens | Mus musculus | Other species | Total | |
| Receptor type | ||||
| IG | 293 | 655 | 144 | 1092 |
| TR | 48 | 40 | 1 | 89 |
| MHC | 251 | 133 | 3 | 387 |
| RPI | 168 | 23 | 14 | 205 |
| Total | 760 | 851 | 162 | 1773 |
| Complex typea | ||||
| Antigen receptor/antigen | ||||
| IG/Ag | 141 | 393 | 54 | 588 |
| TR/pMHC | ||||
| TR/pMHC-I | 17 | 10 | 0 | 27 |
| TR/pMHC-II | 5 | 6 | 0 | 11 |
| peptide/MHC | ||||
| pMHC-I | 155 | 90 | 3 | 248 |
| pMHC-II | 37 | 9 | 0 | 46 |
| Total | 355 | 508 | 57 | 920 |
Complexes involving RPI are not shown.
‘Other species’ refers to receptors from species other than Homo sapiens (human) and Mus musculus (mouse), and also to engineered proteins (humanized, chimeric or synthetic). Thus, ‘Other species’ refers, for IG, to Camelus dromedarius (36), Lama glama (10), Rattus norvegicus (14), Ginglymostoma cirratum (6), Orectolobus maculatus (5), Cricetinae gen. sp. (1), Oryctolagus cuniculus (1), Cavia porcellus (1), humanized (23), chimeric (29) and synthetic (18); for TR, to R. rattus (1); for MHC, to R. norvegicus (3); and for RPI, to R. norvegicus (9), Hyalophora cecropia (1), Branchiostoma floridae (2) and chimeric (2). A total of 318 different genes (corresponding to 415 alleles) were identified in V-DOMAIN: 266 for IG (155 IGHV, 93 IGKV and 18 IGLV) and 52 for TR (29 TRAV, 18 TRBV, 3 TRDV and 2 TRGV). IMGT/3Dstructure-DB contains 920 antigen receptor/antigen complexes that comprise 588 IG/Ag (141 human, 393 mouse and 54 ‘other species’) and 38 TR/pMHC (22 human, 16 mouse). There are 294 pMHC complexes (192 human, 99 mouse and 3 other species) (Table 1).
IMGT/3Dstructure-DB ‘Chain details’
The ‘Chain details’ (Figure 1A) comprises information, first on the chain itself, and then on each domain, starting from the N-terminal end.
IMGT chain annotation includes:
Chain ID;
Chain length;
IMGT chain description, with IMGT labels indicating the constitutive domains and their delimitations [for example, in Figure 1A: TR-BETA-1 = V-BETA (1–110) + C-BETA (111–239)]; and
Chain sequence, with delimited regions (for example, V-REGION, N-AND-REGION and J-REGION for a V-BETA domain) and links to Sequence in FASTA format and Sequence in IMGT format.
IMGT domain annotation includes:
IMGT domain description;
IMGT gene and allele name, with percentage of identity and species, and a link to Alignment details (V and J genes and alleles are given, in the case of a V domain, as in Figure 1A);
2D representation, with links to IMGT Collier de Perles (on one layer) and, for V and C type domains, to IMGT Collier de Perles on two layers;
Contact analysis, with a link to Domain contacts (overview);
CDR-IMGT lengths: lengths of the three CDR, CDR1-IMGT, CDR2-IMGT and CDR3-IMGT, shown between brackets and separated by dots, for example [5.6.11], this information being determined by IMGT/DomainGapAlign;
Sheet composition: strands of each layer being indicated between brackets, for example [A′BDE] [A″CC′C″FG], this information being deduced from the PDB file; and
Domain amino acid sequence with gaps according to the IMGT numbering and region delimitations (for example, CDR1, CDR2, CDR3 for a V-DOMAIN, as in Figure 1A) and a link to IMGT/DomainGapAlign results.
IMGT Collier de Perles on two layers with hydrogen bonds
IMGT Colliers de Perles on two layers, available for the V and C type domains (18,19), are displayed with hydrogen bonds (green lines in Figure 1B), this information being determined from structural data extracted from the PDB files. The V type domain is made of nine antiparallel beta strands (A, B, C, C′, C″, D, E, F and G) linked by beta turns (AB, CC′, C″D, DE and EF) or loops (BC, C′C″ and FG), forming a sandwich of two sheets (18). The sheets are closely packed against each other through hydrophobic interactions giving a hydrophobic core and joined together by a disulfide bridge between the B-STRAND in the first sheet and the F-STRAND in the second sheet. In the IMGT unique numbering, the conserved amino acids always have the same position, for instance cysteine 23 (1st-CYS), tryptophan 41 (CONSERVED-TRP), conserved hydrophobic amino acid 89 and cysteine 104 (2nd-CYS) (18). The C type domain has similar topology and 3D structure than the V type domain, but it differs by the number of strands: it is made of seven beta strands linked by beta turns or loops, and arranged so that four strands form one sheet and three strands form a second sheet (19). In September 2009, there are about 22 000 IMGT Colliers de Perles on two layers with hydrogen bonds that correspond to 7300 V and C domains (Table 2).
Number of IMGT/3Dstructure-DB data for IMGT Collier de Perles, Contact analysis and IMGT/DomainGapAlign
| Numbera | IG, TR, IgSF RPIb | MHC, MhcSF RPIc | |
| IMGT Collier de Perles | |||
| On one layer | 9000 | V, C | G, C |
| On two layers with hydrogen bonds | 22 000 | V, C | nr |
| Contact analysis | |||
| IMGT pMHC contact sites | 15 000 | nr | Peptide – G |
| IMGT/3Dstructure-DB Domain pair contacts | 45 000 | (V or C) – (V or C) | (G or C) – (G or C) |
| (V or C) – (Ligand) | (G or C) – (Ligand) | ||
| IMGT Residue@Position cards | 1500 000 | V, C | G, C |
| IMGT/DomainGapAlign | |||
| IMGT/DomainGapAlign results | 9000 | V, C | G, C |
| Numbera | IG, TR, IgSF RPIb | MHC, MhcSF RPIc | |
| IMGT Collier de Perles | |||
| On one layer | 9000 | V, C | G, C |
| On two layers with hydrogen bonds | 22 000 | V, C | nr |
| Contact analysis | |||
| IMGT pMHC contact sites | 15 000 | nr | Peptide – G |
| IMGT/3Dstructure-DB Domain pair contacts | 45 000 | (V or C) – (V or C) | (G or C) – (G or C) |
| (V or C) – (Ligand) | (G or C) – (Ligand) | ||
| IMGT Residue@Position cards | 1500 000 | V, C | G, C |
| IMGT/DomainGapAlign | |||
| IMGT/DomainGapAlign results | 9000 | V, C | G, C |
Numbers (September 2009) have been rounded off.
IgSF RPI: IgSF proteins other than IG and TR.
MhcSF RPI: MhcSF proteins other than MHC. MHC and MhcSF RPI also belong to IgSF RPI, by their C-like domain, if present.
V, V type; C, C type; G, G type; nr, not relevant.
Number of IMGT/3Dstructure-DB data for IMGT Collier de Perles, Contact analysis and IMGT/DomainGapAlign
| Numbera | IG, TR, IgSF RPIb | MHC, MhcSF RPIc | |
| IMGT Collier de Perles | |||
| On one layer | 9000 | V, C | G, C |
| On two layers with hydrogen bonds | 22 000 | V, C | nr |
| Contact analysis | |||
| IMGT pMHC contact sites | 15 000 | nr | Peptide – G |
| IMGT/3Dstructure-DB Domain pair contacts | 45 000 | (V or C) – (V or C) | (G or C) – (G or C) |
| (V or C) – (Ligand) | (G or C) – (Ligand) | ||
| IMGT Residue@Position cards | 1500 000 | V, C | G, C |
| IMGT/DomainGapAlign | |||
| IMGT/DomainGapAlign results | 9000 | V, C | G, C |
| Numbera | IG, TR, IgSF RPIb | MHC, MhcSF RPIc | |
| IMGT Collier de Perles | |||
| On one layer | 9000 | V, C | G, C |
| On two layers with hydrogen bonds | 22 000 | V, C | nr |
| Contact analysis | |||
| IMGT pMHC contact sites | 15 000 | nr | Peptide – G |
| IMGT/3Dstructure-DB Domain pair contacts | 45 000 | (V or C) – (V or C) | (G or C) – (G or C) |
| (V or C) – (Ligand) | (G or C) – (Ligand) | ||
| IMGT Residue@Position cards | 1500 000 | V, C | G, C |
| IMGT/DomainGapAlign | |||
| IMGT/DomainGapAlign results | 9000 | V, C | G, C |
Numbers (September 2009) have been rounded off.
IgSF RPI: IgSF proteins other than IG and TR.
MhcSF RPI: MhcSF proteins other than MHC. MHC and MhcSF RPI also belong to IgSF RPI, by their C-like domain, if present.
V, V type; C, C type; G, G type; nr, not relevant.
IMGT pMHC contact sites
‘IMGT pMHC contact sites’ graphically represent, in the IMGT Colliers de Perles for G-DOMAIN (20), the MHC amino acid positions that contact the peptide side chains in pMHC complexes (Figure 1C), and thus allow comparison of pMHC interactions (23,24). Eleven ‘IMGT pMHC contact sites’ were defined (C1–C11). They take into account the length of the peptides and are considered independently of the MHC class and sequence polymorphisms. All direct contacts (defined with a cutoff equal to the sum of the atom van der Waals radii and of the diameter of a water molecule) and water-mediated hydrogen bonds are taken into account for the determination of the peptide/MHC interface. Amino acid positions involved in the binding interface are filtered and then classified in the IMGT pMHC contact sites that combine contact analysis (as detailed in next paragraph) with an interaction scoring function. The score assigned to each contact is a constant value, independent on the distance between atoms [40 for direct hydrogen bond, 20 for water-mediated hydrogen bond, 20 for polar interaction and 1 for nonpolar interaction (23)], which roughly complies with the true mean energy ratio (25). The IMGT pMHC contact sites allow to compare, for the first time in a database, the pMHC contacts whatever the MHC class (I or II), whatever the G domain (G-ALPHA1, G-ALPHA2, G-ALPHA or G-BETA) and whatever the peptide length. This structural information is an important asset in peptide vaccine design, particularly for peptide binding to MHC-II as it allows to clearly identify and to visualize amino acids in the groove.
IMGT/3Dstructure-DB Domain pair contacts
‘IMGT/3Dstructure-DB Domain pair contacts’ (Figure 1D) measure contacts between structural units (domains or ligand). Contacts are obtained in IMGT/3Dstructure-DB by a local program written in C in which atoms are considered to be in contact when no water molecule can take place between them. The cutoff using the diameter of a water molecule allows to identify the van der Waals interactions. For the identification of hydrogen bonds, more stringent criteria are considered: the distance between the donor and acceptor atoms must be below or equal to 3.2 Å; the angle C–A–D, defined by the carbon connected to the acceptor atom (C), the acceptor atom (A) and the donor atom (D), must be above 90°; the angle D–H–A, defined by the donor atom (D), the hydrogen atom given by the donor atom (H) and the acceptor atom (A), must be above 140°. Two cases arise: (i) if the hydrogen coordinates can be directly computed (hydrogen linked to the backbone nitrogen, to the nitrogen of the tryptophan side chain, etc.), the angle is directly measured; (ii) in the case of the donor being linked to a single heavy atom, the position of the hydrogen cannot be directly computed (because of the free rotation around the axis defined by the donor and this heavy atom). In that case the hydrogen atom is supposed to be coplanar with the carbon linked to the donor atom, the donor (D) and the acceptor (A). This allows us to compute the D–H–A angle by a simple geometric equation. The coplanar assumption is acceptable given the free rotation mentioned above. The angles' and distances' values used for the computation are derived from (25). The atom contact types are identified as ‘noncovalent’, ‘polar’, ‘hydrogen bond’, ‘nonpolar’, ‘covalent’ or ‘disulfide’ and the atom contact categories as ‘(BB) Backbone/backbone’, ‘(SS) Side chain/side chain’, ‘(BS) Backbone/side chain’ and ‘(SB) Side chain/backbone’. As an example, Figure 1D shows the ‘IMGT/3Dstructure-DB Domain pair contacts’ between a V-BETA domain and its ligand (a peptide bound to a MHC). Twelve domain pair contacts, involving 11 different residues, 6 from V-BETA and 5 from the peptide, are listed with information on the atom contact types. Positions that belong to the CDR-IMGT are highlighted as they contribute to the specificity of the antigen receptors: red (CDR1-IMGT), orange (CDR2-IMGT) and purple (CDR3-IMGT), according to the IMGT color menu (same colors as in Figure 1B). In September 2009, IMGT/3Dstructure-DB contains ∼45 000 domain pair contacts (Table 2).
The atom contact types and categories for each amino acid are provided in ‘IMGT Residue@Position cards’. A Residue@Position is defined by the position numbering (for example 23), according to the IMGT unique numbering, the residue name in the three-letter abbreviation and in the one-letter abbreviation for amino acids [e.g. CYS (C)], the IMGT domain description (e.g. V-BETA) and the IMGT chain ID (e.g. 1oga_E). ‘IMGT Residue@Position card’ can be obtained by clicking on ‘R@P’ in ‘IMGT/3Dstructure-DB Domain pair contacts’ (Figure 1D), or on any residue in the ‘IMGT Collier de Perles on one layer’ or in the amino acid sequence. In September 2009, IMGT/3Dstructure-DB contains about 1500 000 IMGT Residue@Position contacts (Table 2).
IMGT/DomainGapAlign
IMGT/DomainGapAlign, used internally for the analysis of amino acid sequences in IMGT/3Dstructure-DB, is also available on the Web. The tool aligns the user amino acid sequences with the IMGT domain reference directory, identifies the closest V, C and G domains, creates gaps according to the IMGT unique numbering and highlights differences with the closest reference(s). For an antibody V domain sequence, IMGT/DomainGapAlign identifies the closest germline V-REGION and J-REGION, and provides a delimitation of the strands, framework regions (FR-IMGT) and CDR-IMGT (Figure 1E). The IMGT gene and allele name of the closest sequence(s) from the IMGT domain reference directory is provided with a percentage of identity and a Smith–Waterman score. Regions and domains are highlighted using the IMGT Color menu. Several sequences can be analysed simultaneously and users can choose how many alignments to display for each sequence. The IMGT Colliers de Perles are generated from the sequences provided by IMGT/DomainGapAlign tool.
CONCLUSION
The IMGT standardization has allowed to build a unique frame for the comparison of the IG, TR and MHC structural data and interactions with their ligands. That standardization has been extended to the IgSF and MhcSF proteins that involve V, C and/or G type domains (26–29) and used, as an example, to develop a binding prediction method for MhcSF G type domain and beta2-microglobulin (30). IG/Ag and TR/pMHC complexes can be queried from the IMGT/3Dstructure-DB home page. IMGT/3Dstructure-DB data are particularly useful in antibody engineering and humanization design. Indeed they allow to precisely define and to easily compare amino acid sequences of the FR-IMGT and CDR-IMGT, between the nonhuman (mouse, rat, etc.) and the closest human V domains. A recent analysis performed on humanized antibodies used in oncology underlines the importance of a correct delimitation of the CDR to be grafted (31). IMGT3Dstructure-DB facilitates the identification of potential immunogenic residues at given positions in chimeric or humanized antibodies, including those of the constant domains (32,33). Moreover, the low potential immunogenicity of nonhuman primate antibodies and their potential use as therapeutics in humans has been shown by this approach (34,35). This is particularly important for nonhuman primate antibodies neutralizing Bacillus anthracis and the anthrax lethal toxin or the ricin toxin that could be used as therapeutics in ricin intoxication and against bioweapons (36,37). These therapeutic applications emphasize the importance of the IMGT/3Dstructure-DB standardized approach that bridges the gap between sequences and 3D structures whatever the species.
AVAILABILITY AND CITATION
Authors who use the IMGT/3Dstructure-DB database and IMGT/DomainGapAlign are encouraged to cite this article and to quote the IMGT® Home page URL, http://www.imgt.org.
ACKNOWLEDGEMENTS
We thank Véronique Giudicelli, Patrice Duroux and Gérard Lefranc for helpful discussion. We are grateful to all the IMGT® users from academic and industrial laboratories who help promoting standardization.
FUNDING
IMGT® is funded by the Centre National de la Recherche Scientifique (CNRS), the Ministère de l'Enseignement Supérieur et de la Recherche (MESR) (Université Montpellier 2 Plan Pluri-Formation, Institut Universitaire de France), Agence Nationale de la Recherche (ANR-06-BIOSYS-005-01, FLAVORES), Région Languedoc-Roussillon (GPTR, GEPETOS), GIS IBiSA Infrastructures en Biologie Santé et Agronomie (2008-37). Funding for open access charge: CNRS.
Conflict of interest statement. None declared.
REFERENCES
Author notes
Present address: Quentin Kaas, The University of Queensland, Institute for Molecular Bioscience, Brisbane QLD 4072, Australia.

{kind=link}
Comments