





Abstract
WormBase (Author Webpage), a model organism database for Caenorhabditis elegans and other related nematodes, continues to evolve and expand. Over the past year WormBase has added new data on C.elegans, including data on classical genetics, cell biology and functional genomics; expanded the annotation of closely related nematodes with a new genome browser for Caenorhabditis remanei; and deployed new hardware for stronger performance. Several existing datasets including phenotype descriptions and RNAi experiments have seen a large increase in new content. New datasets such as the C.remanei draft assembly and annotations, the Vancouver Fosmid library and TEC-RED 5′ end sites are now available as well. Access to and searching WormBase has become more dependable and flexible via multiple mirror sites and indexing through Google.
DESCRIPTION
Much of our understanding of biological processes and human biology comes from a vast amount of data generated in the study of a few model organisms. The National Human Genome Research Institute (NHGRI; Author Webpage) in the United States and the British Medical Research Council have funded model organism databases (MODs) to store and integrate information for individual model organisms. WormBase is one of these MODs for the small, soil nematode, Caenorhabditis elegans. WormBase originated in 2001 and initially was simply a web-based interface for its predecessor, ACeDB (1,2) (Author Webpage), which contained primarily the genetic and physical maps, and the genome sequence of C.elegans. Over the years, WormBase has evolved and expanded through developing and utilizing better software, and providing richer content (3) by bringing in data from classical genetics, cell biology and functional genomics (4,5), and the genomic sequences of other closely related nematodes (6,7).
WormBase is maintained by the International WormBase Consortium, a group of ∼30 scientists located at four sites (Author Webpage). The data are organized into a single database that is available for downloading (Author Webpage) and web browsing. Access to, and use of, the database and resources are freely available, subject to an Acceptable Use Policy (Author Webpage) and copyrights (Author Webpage). There is also a User's Guide (Author Webpage), an evolving Wiki site (Author Webpage) and an email-based Help Desk ([email protected])
WormBase is not a static database. It is constantly growing with new data continually being added and made available to users through new builds and releases of the database every three weeks. Every 10th release is maintained as a permanently available, stable data source for reference. This review is an overview of major new content, software and performance improvements, and how the user community helps to focus efforts of WormBase.
NEW CONTENT
WormBase's content has doubled in the last three years as measured by the size of its underlying database (Figure 1). This growth is expected to increase as research using C.elegans expands and more nematode genome sequencing projects are completed.
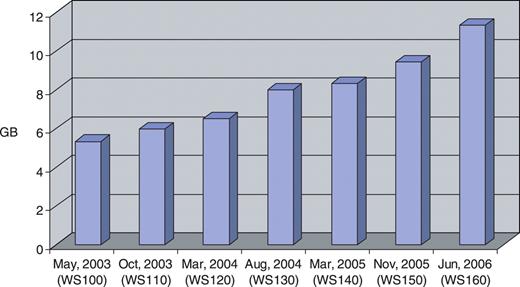
The increase in content of WormBase as measured by the size of the underlying database. Plotted are the sizes in gigabytes of the archived releases of the WormBase database.
Additions to existing data types
Phenotypes
Over the past year one of the largest percentage increases in an existing data type has been for phenotype objects. There have been major changes in phenotype curation, including a new and expanded Phenotype Ontology, the evaluation and consolidation of preexisting phenotype classes, and improvements in phenotype curation methods. All of these allow more accurate and detailed phenotype information to be stored in WormBase, and make querying for phenotype-related information more efficient. Consequently, the number of phenotype objects in WormBase has increased dramatically over the past year from 119 to 1282.
Gene Ontology
Gene products annotated with Gene Ontology (GO) terms are another existing data type to see a large percentage increase. WormBase is a member of the Gene Ontology Consortium (8), and is developing GO content and annotating C.elegans' genes in GO terms. Currently there are over 50 000 GO annotations for over 10 000 genes in WormBase. Most of these are automated mappings, although there are curator-performed, manual annotations for ∼700 genes with over 800 unique papers cited as references. The automatic GO annotations are of two types. The first is the automated assignment of GO terms to genes based on the RNAi-knockdown phenotype. For example, an RNAi phenotype of Egl (egg-laying defective) is automatically assigned the GO biological process term ‘oviposition’. These are based on manual mapping of phenotypes to GO terms from large-scale RNAi screens. The second type of automated GO annotation uses the InterPro2GO mappings (Author Webpage) provided by the European Bioinformatics Institute (Author Webpage). WormBase has recently begun determining InterPro domains with each build to ensure that they are completely up to date. These are GO term assignments based on protein family, domain, repeat, etc. In WormBase the GO annotations can now be found in a Gene Ontology section on the Gene page, which is the most common entry point for users (Supplementary Figure 1a). A summary of all the GO annotations (Supplementary Figure 1b) is reached through the GO summary link in the ‘Gene Ontology’ section. Details for individual annotations (Supplementary Figure 1c) can also be obtained through links in the section.
RNAi
RNAi data have also increased significantly over the past year, specifically from papers that describe individual RNAi experiments. Curation of these experiments is slow and labor intensive compared with papers containing large-scale datasets. Nonetheless, there has been a 150% increase in the individual RNAi experiments in WormBase. There are currently 2754 such experiments. Including curation of large-scale datasets, there are 63 740 total, curated RNAi experiments in WormBase, compared with 59 882 a year ago. There is still more to do, however. Approximately 45% of 871 C.elegans papers that contain RNAi data have been curated, compared with just over 20% a year ago. RNAi results are summarized in the Function section of the Gene page (Supplementary Figure 2a). A link to view all RNAi experiments that target the gene takes the user to a table (Supplementary Figure 2b) containing the details and results of each RNAi experiment.
Microarray data
The June 2006 database release (WS160) has microarray data from 33 papers describing 417 experiments, which represents almost a doubling in the number of curated, microarray papers and a 78% increase in the number of curated experiments in WormBase over the past year.
To support microarray research in the worm community, the probe sets for two new microarray platforms available from Agilent (Author Webpage) and Washington University's Genome Sequencing Center (Author Webpage) are now in WormBase. These are in addition to the Affymetrix chip data previously available in WormBase. All of these data can be downloaded using the WormBase data-mining tool, WormMart (Author Webpage). The probes are mapped to the genome sequence and displayed as a track on the Genome Browser (9) (Supplementary Figure 3a). They are also mapped to corresponding gene models (Supplementary Figure 3b) with detailed reports (Supplementary Figure 3c) linked to the Gene page.
Intellectual lineage
The Intellectual Lineage was conceived as a way to indicate the heritage of the C.elegans research community. The types of connections a person can have are as follows: Supervised, Supervised by and Collaborated with. There are 1461 people that have connections to other people with 3729 person-to-person connections. This is up from 1030 people and 2626 person-to-person connections from a year ago. The lineage for an individual can be found on their Person page (Supplementary Figure 4), while the global view of the entire worm community lineage is available at WormBase (Author Webpage).
New datasets
Caenorhabditis remanei annotations
A preliminary, draft assembly and automated annotations of the C.remanei genome are now available on a Genome Browser (Author Webpage) and can be download from the WormBase ftp site (Author Webpage). Annotations include gene predictions from several ab initio and alignment-based algorithms. Sequence improvement is ongoing at the Washington University Genome Sequencing Center with a final draft assembly and new annotations anticipated early in 2007. A summary of the best BLASTP match to C.remanei is now displayed on C.elegans and Caenorhabditis briggsae Gene pages (Supplementary Figure 5).
Vancouver fosmids
The fosmid library constructed and mapped to the genome by Don Moerman and colleagues at the C.elegans Reverse Genetics Core Facility located at the University of British Columbia is now available on the Genome Browser in the YAC, Fosmids and Cosmids track (Supplementary Figure 6) and searchable in WormBase. This library was made to supplement the aging cosmid and YAC libraries used in the original mapping and sequencing of the genome, some of which are now over 20 years old, and are more difficult to work with than fosmids.
TEC-RED
This relatively new technique involves trans-spliced exon coupled 5′ RNA end determination, which identifies 5′ ends of expressed genes in nematodes [details of the procedure can be found in reference (10)]. The TEC-RED data of Hwang et al. (10) is now in WormBase and can be viewed in the Genome Browser (Supplementary Figure 7). These data have been used extensively to update numerous gene structures.
IMPROVED ACCESS AND USABILITY
Fast and robust access
Community use of WormBase continues to grow. There are now over 2 million page hits per month, a 40% increase over the past year, with the Gene page being the most frequently accessed page. This increase prompted the deployment of a multiply-redundant, load-balancing server system, which now distributes requests across three back-end servers, each capable of serving the complete WormBase site. Two additional servers handle specialized tasks such as BLAST requests and query pages. There is also robust caching that delivers the most frequently requested pages from a high-speed, in-memory and on-disk cache. These improvements have resulted in dramatic increases in reliability and performance. Inserting low-cost machines into the existing infrastructure can easily accommodate increased demand in the future.
Access to the data at WormBase is becoming more diverse and flexible. In addition to the main WormBase site located at the Cold Spring Harbor Laboratory (Author Webpage), there are now two new mirror sites: one at the Welcome Trust Sanger Institute in England (Author Webpage) and one at the University of Marseille in France (Author Webpage) that provide flexibility and backup if the main server experiences problems. This increases the total number of mirror sites to four with the existing sites at the California Institute of Technology (Author Webpage) and the Institute of Molecular Biology and Biochemistry in Greece (Author Webpage). There are links to all the mirror sites and the main and development site on the WormBase homepage (Supplementary Figure 8).
Another portal to WormBase is through WormBook (Author Webpage). WormBook content is extensively linked to WormBase with Genes, Proteins and Cells linked to the relevant pages in WormBase. Links from WormBase back to WormBook have recently been implemented to provide users easy access to background and in-depth information.
Improved searching
More recently, access to WormBase can be gained through search engines such as Google, which are now able to index the site. Previously their access had been restricted due to load issues on the old, single server infrastructure. Researchers worldwide can now search the vast content of highly curated data without having to actually visit the WormBase site. Google searches can be limited to WormBase results by using the format ‘site: Author Webpage [search terms]’. Google's page caching also provides an additional layer of redundancy during unexpected server interruptions at the WormBase site.
Searching for strains at the Caenorhabditis Genetic Center (CGC) has been improved and is now hosted at WormBase. In addition to searching by strain name, users may now search for strains carrying a specific gene or allele, or other information found in the strain class (i.e. species, mutagen, data received and remarks).
Improved data presentation
Data layout and access has become more intuitive with new or updated web pages. Information from the Protein Data Bank's TargetDB (11) (Author Webpage), which provides status and tracking information on the production and solution of structures, is now displayed on Gene pages. Also on the Gene page, a GO summary (Supplementary Figure 1) has been added as well as three types of evolutionary data: InParanoid clusters of orthologous genes (12) (Author Webpage), Treefam's (13) (Author Webpage) curated ortholog and paralog assignments (Figure 2), and C.elegans/C.briggsae mutual best BLASTP matches (Supplementary Figure 5). The Gene pages also include the phenotype of RNAi experiments, and physical and genetic interactions, which are now displayed in a convenient table (Supplementary Figure 2a).
Screen shot of the Homology section of the mec-14 Gene page showing InParanoid groups, C.briggsae orthologs and a TreeFam tree.
WORMBASE IS COMMUNITY DRIVEN
The focus and direction of WormBase is driven by the user community. Two ways this occurs is through user surveys and the WormBase advisory board. User surveys are commissioned periodically to gauge user concerns and direct future efforts for data curation. The most recent survey was conducted in the fall of 2005 (Author Webpage). The results were discussed at the WormBase advisory board in November 2005 and summarized in the January 2006 WormBase Newsletter (Author Webpage). One of the concerns of many of the respondents was the speed of WormBase. The Advisory Board felt improving response time should be a major priority, and WormBase responded with the new hardware structure, additional servers and page caching described above.
The WormBase Advisory board meets once a year with the entire WormBase staff to review progress and prioritize projects for the upcoming year. The board consists of several members of the C.elegans research community, as well as people with expertise in bioinformatics and databases.
WormBase also reaches out to the user community by having staff members at all the international, regional and topical C.elegans meetings, as well as other meetings, often presenting talks and posters, but mainly to receive input from users regarding problems as well as new features or datasets they would like to see WormBase host. Some requests are for information for which WormBase simply does not have access, such as large-scale studies before publication. WormBase strives to have data available at the time of publication and encourages authors to contact WormBase about upcoming publications.
The WormBase Wiki site (Author Webpage) provides a mechanism for users to easily add content to WormBase. Individuals can post experimental protocols, make posting about meetings and job openings, or add useful information about their favorite gene(s). A long-term goal is for the Wiki site to assume the role of the print version of the Worm Breeder's Gazette.
P.W.S. is an investigator with the Howard Hughes Medical Institute. WormBase is supported by grant P41-HG02223 from the US National Human Genome Research Institute and by the British Medical Research Council. Funding to pay the Open Access publication charges for this article was provided by grant P41-HG02223 from the US National Human Genome Research Institute.
Conflict of interest statement. None declared.

{kind=link}
{kind=link}
Comments