





Abstract
Recent developments in optimization theory have extended some traditional algorithms for least-squares optimization of real-valued functions (Gauss–Newton, Levenberg–Marquardt, etc.) into the domain of complex functions of a complex variable. This employs a formalism called the Wirtinger derivative, and derives a full-complex Jacobian counterpart to the conventional real Jacobian. We apply these developments to the problem of radio interferometric gain calibration, and show how the general complex Jacobian formalism, when combined with conventional optimization approaches, yields a whole new family of calibration algorithms, including those for the polarized and direction-dependent gain regime. We further extend the Wirtinger calculus to an operator-based matrix calculus for describing the polarized calibration regime. Using approximate matrix inversion results in computationally efficient implementations; we show that some recently proposed calibration algorithms such as StefCal and peeling can be understood as special cases of this, and place them in the context of the general formalism. Finally, we present an implementation and some applied results of CohJones, another specialized direction-dependent calibration algorithm derived from the formalism.
1 INTRODUCTION
In radio interferometry, gain calibration consists of solving for the unknown complex antenna gains, using a known (prior, or iteratively constructed) model of the sky. Traditional (second generation, or 2GC) calibration employs an instrumental model with a single direction-independent (DI) gain term (which can be a scalar complex gain, or 2 × 2 complex-valued Jones matrix) per antenna, per some time/frequency interval. Third-generation (3GC) calibration also addresses direction-dependent (DD) effects, which can be represented by independently solvable DD gain terms, or by some parametrized instrumental model (e.g. primary beams, pointing offsets, ionospheric screens). Different approaches to this have been proposed and implemented, mostly in the framework of the radio interferometry measurement equation (RIME; see Hamaker, Bregman & Sault 1996); Smirnov (2011a,b,c) provides a recent overview. In this work we will restrict ourselves specifically to calibration of the DI and DD gains terms (the latter in the sense of being solved independently per direction).
Gain calibration is a non-linear least squares (NLLS) problem, since the noise on observed visibilities is almost always Gaussian (though other treatments have been proposed by Kazemi & Yatawatta 2013). Traditional approaches to NLLS problems involve various gradient-based techniques (for an overview, see Madsen, Nielsen & Tingleff 2004), such as Gauss–Newton (GN) and Levenberg–Marquardt (LM). These have been restricted to functions of real variables, since complex differentiation can be defined in only a very restricted sense (in particular, |$\mathrm{\partial} \bar{z}/\mathrm{\partial} z$| does not exist in the usual definition). Gains in radio interferometry are complex variables: the traditional way out of this conundrum has been to recast the complex NLLS problem as a real problem by treating the real and imaginary parts of the gains as independent real variables.
Recent developments in optimization theory (Kreutz-Delgado 2009; Laurent, van Barel & de Lathauwer 2012) have shown that using a formalism called the Wirtinger complex derivative (Wirtinger 1927) allows for a mathematically robust definition of a complex gradient operator. This leads to the construction of a complex Jacobian|${\bf J}$|, which in turn allows for traditional NLLS algorithms to be directly applied to the complex variable case. We summarize these developments and introduce basic notation in Section 2. In Section 3, we follow on from Tasse (2014b) to apply this theory to the RIME, and derive complex Jacobians for (unpolarized) DI and DD gain calibration.
In principle, the use of Wirtinger calculus and complex Jacobians ultimately results in the same system of LS equations as the real/imaginary approach. It does offer two important advantages: (i) equations with complex variables are more compact, and are more natural to derive and analyse than their real/imaginary counterparts, and (ii) the structure of the complex Jacobian can yield new and valuable insights into the problem. This is graphically illustrated in Fig. 1 (in fact, this figure may be considered the central insight of this paper). Methods such as GN and LM hinge around a large matrix – |${\bf J}$|H|${\bf J}$| – with dimensions corresponding to the number of free parameters; construction and/or inversion of this matrix is often the dominant algorithmic cost. If |${\bf J}$|H|${\bf J}$| can be treated as (perhaps approximately) sparse, these costs can be reduced, often drastically. Fig. 1 shows the structure of an example |${\bf J}$|H|${\bf J}$| matrix for a DD gain calibration problem. The left-hand column shows versions of |${\bf J}$|H|${\bf J}$| constructed via the real/imaginary approach, for four different orderings of the solvable parameters. None of the orderings yields a matrix that is particularly sparse or easily invertible. The right-hand column shows a complex |${\bf J}$|H|${\bf J}$| for the same orderings. Panel (f) reveals sparsity that is not apparent in the real/imaginary approach. This sparsity forms the basis of a new fast DD calibration algorithm discussed later in the paper.
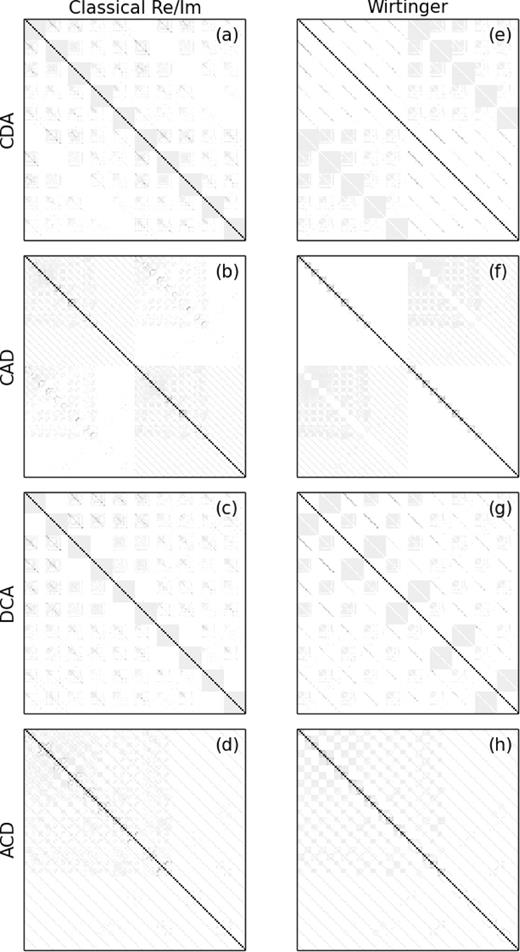
A graphical representation of |${\bf J}$|H|${\bf J}$| for a case of 40 antennas and five directions. Each pixel represents the amplitude of a single matrix element. The left-hand column (a)–(d) shows conventional real-only Jacobians constructed by taking the partial derivatives with respect to the real and imaginary parts of the gains. The ordering of the parameters is (a) real/imaginary major, direction, antenna minor (i.e. antenna changes fastest); (b) real/imaginary, antenna, direction; (c) direction, real/imaginary, antenna; (d) antenna, real/imaginary, direction. The right-hand column (e)–(h) shows full complex Jacobians with similar parameter ordering (direct/conjugate instead of real/imaginary). Note that panel (f) can also be taken to represent the DI case, if we imagine each 5 × 5 block as 1 pixel.
In Section 4, we show that different algorithms may be derived by combining different sparse approximations to |${\bf J}$|H|${\bf J}$| with conventional GN and LM methods. In particular, we show that StefCal, a fast DI calibration algorithm recently proposed by Salvini & Wijnholds (2014a), can be straightforwardly derived from a diagonal approximation to a complex |${\bf J}$|H|${\bf J}$|. We show that the complex Jacobian approach naturally extends to the DD case, and that other sparse approximations yield a whole family of DD calibration algorithms with different scaling properties. One such algorithm, CohJones (Tasse 2014b), has been implemented and successfully applied to simulated Low Frequency Array (LOFAR) data: this is discussed in Section 7.
In Section 5, we extend this approach to the fully polarized case, by developing a Wirtinger-like operator calculus in which the polarization problem can be formulated succinctly. This naturally yields fully polarized counterparts to the calibration algorithms defined previously. In Section 6, we discuss other algorithmic variations, and make connections to older DD calibration techniques such as peeling (Noordam 2004).
While the scope of this work is restricted to LS solutions to the DI and DD gain calibration problem, the potential applicability of complex optimization to radio interferometry is perhaps broader. We will return to this in the conclusions.
2 WIRTINGER CALCULUS AND COMPLEX LEAST SQUARES
The traditional approach to optimizing a function of n complex variables |$f(\boldsymbol {z}),$||$\boldsymbol {z}\in \mathbb {C}^n$| is to treat the real and imaginary parts |$\boldsymbol {z}=\boldsymbol {x}+{\rm i}\boldsymbol {y}$| independently, turning f into a function of 2n real variables |$f(\boldsymbol {x},\boldsymbol {y})$|, and the problem into an optimization over |$\mathbb {R}^{2n}$|.
Note that while |$\delta \boldsymbol {z}$| and |$\delta \bar{\boldsymbol {z}}$| are formally computed independently, the structure of the equations is symmetric (since the function being minimized – the Frobenius norm – is real and symmetric with respect to |$\boldsymbol {z}$| and |$\bar{\boldsymbol {z}}$|), which ensures that |$\overline{\delta \boldsymbol {z}} = \delta \bar{\boldsymbol {z}}$|. In practice this redundancy usually means that only half the calculations need to be performed.
Laurent et al. (2012) show that equations (2.8) and (2.9) yield exactly the same system of LS equations as would have been produced had we treated |$\boldsymbol {r}(\boldsymbol {z})$| as a function of real and imaginary parts |$\boldsymbol {r}(\boldsymbol {x},\boldsymbol {y})$|, and taken ordinary derivatives in |$\mathbb {R}^{2n}$|. However, the complex Jacobian may be easier and more elegant to derive analytically, as we will see below in the case of radio interferometric calibration.
3 SCALAR (UNPOLARIZED) CALIBRATION
In this section we will apply the formalism above to the scalar case, i.e. that of unpolarized calibration. This will then be extended to the fully polarized case in Section 5.
3.1 Direction-independent calibration
3.2 Computing the parameter update
We will see examples of both conditions below, so it is worth stressing the difference: equation (3.18) allows us to compute updated solutions directly from the data vector, bypassing the residuals. This is a substantial computational shortcut, however, when an approximate inverse for |${\bf H}$| is in use, it does not necessarily apply (or at least is not exact). Under the condition of equation (3.20), however, such a shortcut is exact.
3.3 Time/frequency solution intervals
3.4 Weighting
3.5 Direction-dependent calibration
4 INVERTING |$\boldsymbol {{{\bf J}}^{\rm H}{{\bf J}}}$| AND SEPARABILITY
In principle, implementing one of the flavours of calibration above is ‘just’ a matter of plugging equations (3.12)+(3.14), (3.22)+(3.23), (3.26)+(3.27), or (3.30)+3.31 into one the algorithms defined in Appendix C. Note, however, that both the GN and LM algorithms hinge around inverting a large matrix. This will have a size of 2Nant or 2NantNdir squared for the DI or DD case, respectively. With a naive implementation of matrix inversion, which scales cubically, algorithmic costs become dominated by the |$O(N_\mathrm{ant}^3)$| or |$O(N_\mathrm{ant}^3N_\mathrm{dir}^3)$| cost of inversion.
In this section we investigate approaches to simplifying the inversion problem by approximating |${\bf H}$| = |${\bf J}$|H|${\bf J}$| by some form of (block-) diagonal matrix |$\tilde{{{\bf H}}}$|. Such approximation is equivalent to separating the optimization problem into subsets of parameters that are treated as independent. We will show that some of these approximations are similar to or even fully equivalent to previously proposed algorithms, while others produce new algorithmic variations.
4.1 Diagonal approximation and StefCal
Equation (4.3) is identical to the update step proposed by Hamaker (2000), and later adopted by Mitchell et al. (2008) for Murchison Widefield Array (MWA) calibration, and independently derived by Salvini & Wijnholds (2014a) for the StefCal algorithm. Note that these authors arrive at the result from a different direction, by treating equation (3.2) as a function of |$\boldsymbol {g}$| only, and completely ignoring the conjugate term. The resulting complex Jacobian (equation 3.6) then has null off-diagonal blocks, and |${\bf J}$|H|${\bf J}$| becomes diagonal.
Establishing this equivalence is very useful for our purposes, since the convergence properties of StefCal have been thoroughly explored by Salvini & Wijnholds (2014a), and we can therefore hope to apply these lessons here. In particular, these authors have shown that a direct application of GN produces very slow (oscillating) convergence, whereas combining GN and LM leads to faster convergence. They also propose a number of variations of the algorithm, all of which are directly applicable to the above.
Finally, let us note in passing that the update step of equation (4.3) is embarrassingly parallel, in the sense that the update for each antenna is computed entirely independently.
4.2 Separability of the direction-dependent case
Now consider the problem of inverting |${\bf J}$|H|${\bf J}$| in the DD case. This is a massive matrix, and a brute force approach would scale as |$O(N_\mathrm{dir}^3N_\mathrm{ant}^3)$|. We can, however, adopt a few approximations. Note again that we are free to reorder our augmented parameter vector (which contains both |$\boldsymbol {g}$| and |$\boldsymbol {\bar{g}}$|), as long as we reorder the rows and columns of |${\bf J}$|H|${\bf J}$| accordingly.
Let us consider a number of orderings for |$\boldsymbol {\breve{g}}$|:
- conjugate major, direction, antenna minor (CDA):(4.5)\begin{eqnarray} \left[g^{(1)}_1 \dots g^{(1)}_{N_\mathrm{ant}}, g^{(2)}_1 \dots g^{(2)}_{N_\mathrm{ant}}, g^{(3)}_1 \dots g^{(N_\mathrm{dir})}_{N_\mathrm{ant}}, \bar{g}^{(1)}_1 \dots \bar{g}^{(1)}_{N_\mathrm{ant}} \dots \right]^{\rm T}; \end{eqnarray}
- conjugate, antenna, direction (CAD):(4.6)\begin{equation} \left[g^{(1)}_1 \dots g^{(N_\mathrm{dir})}_1, g^{(1)}_2 \dots g^{(N_\mathrm{dir})}_2, g^{(1)}_3 \dots g^{(N_\mathrm{dir})}_{N_\mathrm{ant}}, \bar{g}^{(1)}_1 \dots \right]^{\rm T}; \end{equation}
- direction, conjugate, antenna (DCA):(4.7)\begin{equation} \left[g^{(1)}_1 \dots g^{(1)}_{N_\mathrm{ant}},\bar{g}^{(1)}_1 \dots \bar{g}^{(1)}_{N_\mathrm{ant}}, g^{(2)}_1 \dots g^{(2)}_{N_\mathrm{ant}}, \bar{g}^{(2)}_1 \dots \right]^{\rm T}; \end{equation}
- antenna, conjugate, direction (ACD):(4.8)\begin{equation} \left[g^{(1)}_1 \dots g^{(N_\mathrm{dir})}_1,\bar{g}^{(1)}_1 \dots \bar{g}^{(N_\mathrm{dir})}_1, g^{(1)}_2 \dots g^{(N_\mathrm{dir})}_2, \bar{g}^{(1)}_2 \dots \right]^{\rm T}. \end{equation}
Figs 1(e)–(h) graphically illustrates the structure of the Jacobian under these orderings.
At this point we may derive a whole family of DD calibration algorithms – there are many ways to skin a cat. Each algorithm is defined by picking an ordering for |$\boldsymbol {\breve{g}}$|, then examining the corresponding |${\bf J}$|H|${\bf J}$| structure and specifying an approximate matrix inversion mechanism, then applying GN or LM optimization. Let us now work through a couple of examples.
4.2.1 DCA: separating by direction
The sum over samples s is essentially just an integral over a complex fringe. We may expect this to be small (i.e. the sky model components to be more orthogonal) if the directions are well separated, and also if the sum is taken over longer time and frequency intervals.
4.2.2 COHJONES: separating by antenna
By analogy with the StefCal approach, we may assume |${\bf B}^i_j \approx 0$|, i.e. treat the problem as separable by antenna. The |$\tilde{{{\bf H}}}$| matrix then becomes block diagonal, and we only need to compute the true matrix inverse of each |${\bf A}^i_i$|. The inversion problem then reduces to |$O(N_\mathrm{dir}^3N_\mathrm{ant})$| in complexity, and either LM or GN optimization may be applied.
This approach has been implemented as the CohJones (complex half-Jacobian optimization for n-directional estimation) algorithm,4 the results of which applied to simulated data are presented below.
4.2.3 ALLJONES: separating all
4.3 Convergence and algorithmic cost
Evaluating the gain update (e.g. as given by equation 3.18) involves a number of computational steps:
computing |$\tilde{{{\bf H}}}\approx {{\bf J}}^{\rm H}{{\bf J}}$|;
inverting |$\tilde{{{\bf H}}}$|;
computing the |${{\bf J}}^{\rm H}\boldsymbol {\breve{d}}$| vector;
multiplying the result of (ii) and (iii).
Since each of the algorithms discussed above uses a different sparse approximation for |${\bf J}$|H|${\bf J}$|, each of these steps will scale differently [except (iii), which is |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| for all algorithms]. Table 2 summarizes the scaling behaviour. An additional scaling factor is given by the number of iterations required to converge. This is harder to quantify. For example, in our experience (Smirnov 2013), an ‘exact’ (LM) implementation of DI calibration problem converges in much fewer iterations than StefCal (on the order of a few versus a few tens), but is much slower in terms of ‘wall time’ due to the more expensive iterations (|$N_\mathrm{ant}^3$| versus Nant scaling). This trade-off between ‘cheap–approximate’ and ‘expensive–accurate’ is typical for iterative algorithms.
Notation and frequently used symbols.
| x | Scalar value x |
| |$\bar{x}$| | Complex conjugate |
| |$\boldsymbol {x}$| | Vector |$\boldsymbol {x}$| |
| |${\bf X}$| | Matrix |${\bf X}$| |
| |$\boldsymbol {X}$| | Vector of 2 × 2 matrices |$\boldsymbol {X}=[{\bf X}_i]$| (Section 5) |
| |$\mathbb {R}$| | Space of real numbers |
| |$\mathbb {C}$| | Space of complex numbers |
| |$\mathbb {I}$| | Identity matrix |
| |$\mathrm{diag}\,\boldsymbol {x}$| | Diagonal matrix formed from |$\boldsymbol {x}$| |
| || · ||F | Frobenius norm |
| ( · )T | Transpose |
| ( · )H | Hermitian transpose |
| ⊗ | Outer product also known as Kronecker product |
| |$\boldsymbol {\bar{x}},\boldsymbol {\bar{X}}$| | Element-by-element complex conjugate of |$\boldsymbol {x}$|, |$\boldsymbol {X}$| |
| |$\boldsymbol {\breve{x}}, \boldsymbol {\breve{X}}$| | Augmented vectors $\boldsymbol {\breve{x}} = \left[\begin{array}{@{}c@{}}\boldsymbol {x} \\
\boldsymbol {\bar{x}}\end{array} \right],\ \ \boldsymbol {\breve{X}}=\left[\begin{array}{@{}c@{}}\boldsymbol {X}_i \\
\boldsymbol {X}^{\rm H}_i\end{array} \right]$ |
| |${\bf X}_\mathrm{U}$| | Upper half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{L}, {\bf X}_\mathrm{R}$| | Left, right half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{UL}$| | Upper left quadrant of matrix |${\bf X}$| |
| order of operations is |${\bf X}^Y_\mathrm{U}= {\bf X}^{\ \ Y}_\mathrm{U}= ({\bf X}_\mathrm{U})^Y$|, | |
| or |${\bf X}^Y_{\ \mathrm{U}} = ({\bf X}^Y)_\mathrm{U}$| | |
| |$\boldsymbol {d},\boldsymbol {v},\boldsymbol {r}, \boldsymbol {g}, \boldsymbol {m}$| | Data, model, residuals, gains, sky coherency |
| ( · )k | Value associated with iteration k |
| ( · )p, k | Value associated with antenna p, iteration k |
| ( · )(d) | Value associated with direction d |
| |${\bf W}$| | Matrix of weights |
| |${{\bf J}}_k, {{\bf J}}_{k^*}$| | Partial, conjugate partial Jacobian at iteration k |
| |${\bf J}$| | Full complex Jacobian |
| |$\boldsymbol {H}, \boldsymbol {\tilde{H}}$| | |${\bf J}$|H|${\bf J}$| and its approximation |
| |$\mathrm{vec}\,\boldsymbol {X}$| | Vectorization operator |
| |$\mathcal {R}_{{A}}$| | Right-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\mathcal {L}_{{A}}$| | Left-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\delta ^i_j$| | Kronecker delta symbol |
$\left[\begin{array}{@{}c@{\ }c@{\ }c@{}}
{\bf A} \quad |\quad {\bf B} \\
{\cdots\cdots\cdots} \\
{\bf C} \quad |\quad {\bf D}
\end{array} \right]$ | Matrix blocks |
| ↘, ↗, ↓ | Repeated matrix block |
| x | Scalar value x |
| |$\bar{x}$| | Complex conjugate |
| |$\boldsymbol {x}$| | Vector |$\boldsymbol {x}$| |
| |${\bf X}$| | Matrix |${\bf X}$| |
| |$\boldsymbol {X}$| | Vector of 2 × 2 matrices |$\boldsymbol {X}=[{\bf X}_i]$| (Section 5) |
| |$\mathbb {R}$| | Space of real numbers |
| |$\mathbb {C}$| | Space of complex numbers |
| |$\mathbb {I}$| | Identity matrix |
| |$\mathrm{diag}\,\boldsymbol {x}$| | Diagonal matrix formed from |$\boldsymbol {x}$| |
| || · ||F | Frobenius norm |
| ( · )T | Transpose |
| ( · )H | Hermitian transpose |
| ⊗ | Outer product also known as Kronecker product |
| |$\boldsymbol {\bar{x}},\boldsymbol {\bar{X}}$| | Element-by-element complex conjugate of |$\boldsymbol {x}$|, |$\boldsymbol {X}$| |
| |$\boldsymbol {\breve{x}}, \boldsymbol {\breve{X}}$| | Augmented vectors $\boldsymbol {\breve{x}} = \left[\begin{array}{@{}c@{}}\boldsymbol {x} \\
\boldsymbol {\bar{x}}\end{array} \right],\ \ \boldsymbol {\breve{X}}=\left[\begin{array}{@{}c@{}}\boldsymbol {X}_i \\
\boldsymbol {X}^{\rm H}_i\end{array} \right]$ |
| |${\bf X}_\mathrm{U}$| | Upper half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{L}, {\bf X}_\mathrm{R}$| | Left, right half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{UL}$| | Upper left quadrant of matrix |${\bf X}$| |
| order of operations is |${\bf X}^Y_\mathrm{U}= {\bf X}^{\ \ Y}_\mathrm{U}= ({\bf X}_\mathrm{U})^Y$|, | |
| or |${\bf X}^Y_{\ \mathrm{U}} = ({\bf X}^Y)_\mathrm{U}$| | |
| |$\boldsymbol {d},\boldsymbol {v},\boldsymbol {r}, \boldsymbol {g}, \boldsymbol {m}$| | Data, model, residuals, gains, sky coherency |
| ( · )k | Value associated with iteration k |
| ( · )p, k | Value associated with antenna p, iteration k |
| ( · )(d) | Value associated with direction d |
| |${\bf W}$| | Matrix of weights |
| |${{\bf J}}_k, {{\bf J}}_{k^*}$| | Partial, conjugate partial Jacobian at iteration k |
| |${\bf J}$| | Full complex Jacobian |
| |$\boldsymbol {H}, \boldsymbol {\tilde{H}}$| | |${\bf J}$|H|${\bf J}$| and its approximation |
| |$\mathrm{vec}\,\boldsymbol {X}$| | Vectorization operator |
| |$\mathcal {R}_{{A}}$| | Right-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\mathcal {L}_{{A}}$| | Left-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\delta ^i_j$| | Kronecker delta symbol |
$\left[\begin{array}{@{}c@{\ }c@{\ }c@{}}
{\bf A} \quad |\quad {\bf B} \\
{\cdots\cdots\cdots} \\
{\bf C} \quad |\quad {\bf D}
\end{array} \right]$ | Matrix blocks |
| ↘, ↗, ↓ | Repeated matrix block |
Notation and frequently used symbols.
| x | Scalar value x |
| |$\bar{x}$| | Complex conjugate |
| |$\boldsymbol {x}$| | Vector |$\boldsymbol {x}$| |
| |${\bf X}$| | Matrix |${\bf X}$| |
| |$\boldsymbol {X}$| | Vector of 2 × 2 matrices |$\boldsymbol {X}=[{\bf X}_i]$| (Section 5) |
| |$\mathbb {R}$| | Space of real numbers |
| |$\mathbb {C}$| | Space of complex numbers |
| |$\mathbb {I}$| | Identity matrix |
| |$\mathrm{diag}\,\boldsymbol {x}$| | Diagonal matrix formed from |$\boldsymbol {x}$| |
| || · ||F | Frobenius norm |
| ( · )T | Transpose |
| ( · )H | Hermitian transpose |
| ⊗ | Outer product also known as Kronecker product |
| |$\boldsymbol {\bar{x}},\boldsymbol {\bar{X}}$| | Element-by-element complex conjugate of |$\boldsymbol {x}$|, |$\boldsymbol {X}$| |
| |$\boldsymbol {\breve{x}}, \boldsymbol {\breve{X}}$| | Augmented vectors $\boldsymbol {\breve{x}} = \left[\begin{array}{@{}c@{}}\boldsymbol {x} \\
\boldsymbol {\bar{x}}\end{array} \right],\ \ \boldsymbol {\breve{X}}=\left[\begin{array}{@{}c@{}}\boldsymbol {X}_i \\
\boldsymbol {X}^{\rm H}_i\end{array} \right]$ |
| |${\bf X}_\mathrm{U}$| | Upper half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{L}, {\bf X}_\mathrm{R}$| | Left, right half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{UL}$| | Upper left quadrant of matrix |${\bf X}$| |
| order of operations is |${\bf X}^Y_\mathrm{U}= {\bf X}^{\ \ Y}_\mathrm{U}= ({\bf X}_\mathrm{U})^Y$|, | |
| or |${\bf X}^Y_{\ \mathrm{U}} = ({\bf X}^Y)_\mathrm{U}$| | |
| |$\boldsymbol {d},\boldsymbol {v},\boldsymbol {r}, \boldsymbol {g}, \boldsymbol {m}$| | Data, model, residuals, gains, sky coherency |
| ( · )k | Value associated with iteration k |
| ( · )p, k | Value associated with antenna p, iteration k |
| ( · )(d) | Value associated with direction d |
| |${\bf W}$| | Matrix of weights |
| |${{\bf J}}_k, {{\bf J}}_{k^*}$| | Partial, conjugate partial Jacobian at iteration k |
| |${\bf J}$| | Full complex Jacobian |
| |$\boldsymbol {H}, \boldsymbol {\tilde{H}}$| | |${\bf J}$|H|${\bf J}$| and its approximation |
| |$\mathrm{vec}\,\boldsymbol {X}$| | Vectorization operator |
| |$\mathcal {R}_{{A}}$| | Right-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\mathcal {L}_{{A}}$| | Left-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\delta ^i_j$| | Kronecker delta symbol |
$\left[\begin{array}{@{}c@{\ }c@{\ }c@{}}
{\bf A} \quad |\quad {\bf B} \\
{\cdots\cdots\cdots} \\
{\bf C} \quad |\quad {\bf D}
\end{array} \right]$ | Matrix blocks |
| ↘, ↗, ↓ | Repeated matrix block |
| x | Scalar value x |
| |$\bar{x}$| | Complex conjugate |
| |$\boldsymbol {x}$| | Vector |$\boldsymbol {x}$| |
| |${\bf X}$| | Matrix |${\bf X}$| |
| |$\boldsymbol {X}$| | Vector of 2 × 2 matrices |$\boldsymbol {X}=[{\bf X}_i]$| (Section 5) |
| |$\mathbb {R}$| | Space of real numbers |
| |$\mathbb {C}$| | Space of complex numbers |
| |$\mathbb {I}$| | Identity matrix |
| |$\mathrm{diag}\,\boldsymbol {x}$| | Diagonal matrix formed from |$\boldsymbol {x}$| |
| || · ||F | Frobenius norm |
| ( · )T | Transpose |
| ( · )H | Hermitian transpose |
| ⊗ | Outer product also known as Kronecker product |
| |$\boldsymbol {\bar{x}},\boldsymbol {\bar{X}}$| | Element-by-element complex conjugate of |$\boldsymbol {x}$|, |$\boldsymbol {X}$| |
| |$\boldsymbol {\breve{x}}, \boldsymbol {\breve{X}}$| | Augmented vectors $\boldsymbol {\breve{x}} = \left[\begin{array}{@{}c@{}}\boldsymbol {x} \\
\boldsymbol {\bar{x}}\end{array} \right],\ \ \boldsymbol {\breve{X}}=\left[\begin{array}{@{}c@{}}\boldsymbol {X}_i \\
\boldsymbol {X}^{\rm H}_i\end{array} \right]$ |
| |${\bf X}_\mathrm{U}$| | Upper half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{L}, {\bf X}_\mathrm{R}$| | Left, right half of matrix |${\bf X}$| |
| |${\bf X}_\mathrm{UL}$| | Upper left quadrant of matrix |${\bf X}$| |
| order of operations is |${\bf X}^Y_\mathrm{U}= {\bf X}^{\ \ Y}_\mathrm{U}= ({\bf X}_\mathrm{U})^Y$|, | |
| or |${\bf X}^Y_{\ \mathrm{U}} = ({\bf X}^Y)_\mathrm{U}$| | |
| |$\boldsymbol {d},\boldsymbol {v},\boldsymbol {r}, \boldsymbol {g}, \boldsymbol {m}$| | Data, model, residuals, gains, sky coherency |
| ( · )k | Value associated with iteration k |
| ( · )p, k | Value associated with antenna p, iteration k |
| ( · )(d) | Value associated with direction d |
| |${\bf W}$| | Matrix of weights |
| |${{\bf J}}_k, {{\bf J}}_{k^*}$| | Partial, conjugate partial Jacobian at iteration k |
| |${\bf J}$| | Full complex Jacobian |
| |$\boldsymbol {H}, \boldsymbol {\tilde{H}}$| | |${\bf J}$|H|${\bf J}$| and its approximation |
| |$\mathrm{vec}\,\boldsymbol {X}$| | Vectorization operator |
| |$\mathcal {R}_{{A}}$| | Right-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\mathcal {L}_{{A}}$| | Left-multiply by |$\boldsymbol {A}$| operator (Section 5) |
| |$\delta ^i_j$| | Kronecker delta symbol |
$\left[\begin{array}{@{}c@{\ }c@{\ }c@{}}
{\bf A} \quad |\quad {\bf B} \\
{\cdots\cdots\cdots} \\
{\bf C} \quad |\quad {\bf D}
\end{array} \right]$ | Matrix blocks |
| ↘, ↗, ↓ | Repeated matrix block |
The scaling of computational costs for a single iteration of the four DD calibration algorithms discussed in the text, broken down by computational step. The dominant term(s) in each case are marked by ‘†’. Not shown is the cost of computing the |${{\bf J}}^{\rm H}\boldsymbol {\breve{d}}$| vector, which is |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| for all algorithms. ‘Exact’ refers to a naive implementation of GN or LM with exact inversion of the |${\bf J}$|H|${\bf J}$| term. Scaling laws for DI calibration algorithms may be obtained by assuming Ndir = 1, in which case CohJones or AllJones become equivalent to StefCal.
| Algorithm | |$\tilde{{{\bf H}}}$| | |$\tilde{{{\bf H}}}^{-1}$| | Multiply |
|---|---|---|---|
| Exact | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| |
| AllJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir})^\dagger$| | O(NantNdir) | O(NantNdir) |
| CohJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^2)$| |
| DCA | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir})^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| |
| Algorithm | |$\tilde{{{\bf H}}}$| | |$\tilde{{{\bf H}}}^{-1}$| | Multiply |
|---|---|---|---|
| Exact | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| |
| AllJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir})^\dagger$| | O(NantNdir) | O(NantNdir) |
| CohJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^2)$| |
| DCA | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir})^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| |
The scaling of computational costs for a single iteration of the four DD calibration algorithms discussed in the text, broken down by computational step. The dominant term(s) in each case are marked by ‘†’. Not shown is the cost of computing the |${{\bf J}}^{\rm H}\boldsymbol {\breve{d}}$| vector, which is |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| for all algorithms. ‘Exact’ refers to a naive implementation of GN or LM with exact inversion of the |${\bf J}$|H|${\bf J}$| term. Scaling laws for DI calibration algorithms may be obtained by assuming Ndir = 1, in which case CohJones or AllJones become equivalent to StefCal.
| Algorithm | |$\tilde{{{\bf H}}}$| | |$\tilde{{{\bf H}}}^{-1}$| | Multiply |
|---|---|---|---|
| Exact | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| |
| AllJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir})^\dagger$| | O(NantNdir) | O(NantNdir) |
| CohJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^2)$| |
| DCA | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir})^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| |
| Algorithm | |$\tilde{{{\bf H}}}$| | |$\tilde{{{\bf H}}}^{-1}$| | Multiply |
|---|---|---|---|
| Exact | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)$| |
| AllJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir})^\dagger$| | O(NantNdir) | O(NantNdir) |
| CohJones | |$O(N_\mathrm{ant}^2N_\mathrm{dir}^2)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^3)^\dagger$| | |$O(N_\mathrm{ant}N_\mathrm{dir}^2)$| |
| DCA | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| | |$O(N_\mathrm{ant}^3N_\mathrm{dir})^\dagger$| | |$O(N_\mathrm{ant}^2N_\mathrm{dir})$| |
CohJones accounts for interactions between directions, but ignores interactions between antennas. Early experience indicates that it converges in a few tens of iterations. AllJones uses the most approximative step of all, ignoring all interactions between parameters. Its convergence behaviour is untested at this time.
It is clear that depending on Nant and Ndir, and also on the structure of the problem, there will be regimes where one or the other algorithm has a computational advantage. This should be investigated in a future work.
4.4 Smoothing in time and frequency
From physical considerations, we know that gains do not vary arbitrarily in frequency and time. It can therefore be desirable to impose some sort of smoothness constraint on the solutions, which can improve conditioning, especially in low-SNR situations. A simple but crude way to do this is use solution intervals (Section 3.3), which gives a constant gain solution per interval, but produces non-physical jumps at the edge of each interval. Other approaches include a posteriori smoothing of solutions done on smaller intervals, as well as various filter-based algorithms (Tasse 2014a).
There is a very efficient way of implementing this in practice. Let us assume that dpq and ypq are loaded into memory and computed for a large chunk of t, ν values simultaneously (any practical implementation will probably need to do this anyway, if only to take advantage of vectorized math operations on modern CPUs and GPUs). The parameter update step is then also evaluated for a large chunk of t, ν, as are the αp and βp terms. We can then take advantage of highly optimized implementations of convolution [e.g. via fast Fourier transforms (FFTs)] that are available on most computing architectures.
Smoothing may also be trivially incorporated into the AllJones algorithm, since its update step (equation 4.21) has exactly the same structure. A different smoothing kernel may be employed per direction (e.g. directions further from the phase centre can employ a narrower kernel).
Since smoothing involves computing a |$\boldsymbol {g}$| value at every t, ν point, rather than one value per solution interval, its computational costs are correspondingly higher. To put it another way, using solution intervals of size Nt × Nν introduces a savings of Nt × Nν (in terms of the number of invert and multiply steps required, see Table 2) over solving the problem at every t, ν slot; using smoothing foregoes these savings. In real implementations, this extra cost is mitigated by the fact that the computation given by equation (4.21) may be vectorized very efficiently over many t, ν slots. However, this vectorization is only straightforward because the matrix inversion in StefCal or AllJones reduces to simple scalar division. For CohJones or DCA this is no longer the case, so while smoothing may be incorporated into these algorithms in principle, it is not clear if this can be done efficiently in practice.
5 THE FULLY POLARIZED CASE
This is a set of 2 × 2 matrix equations, rather than the vector equations employed in the complex NNLS formalism above (equation 2.4). In principle, there is a straightforward way of recasting matrix equations into a form suitable to equation (2.4): we can vectorize each matrix equation, turning it into an equation on four vectors, and then derive the complex Jacobian in the usual manner (equation 2.7).
In this section we will obtain a more elegant derivation by employing an operator calculus where the ‘atomic’ elements are 2 × 2 matrices rather than scalars. This will allow us to define the Jacobian in a more transparent way, as a matrix of linear operators on 2 × 2 matrices. Mathematically, this is completely equivalent to vectorizing the problem and applying Wirtinger calculus (each matrix then corresponds to four elements of the parameter vector, and each operator in the Jacobian becomes a 4 × 4 matrix block). The casual reader may simply take the postulates of the following section on faith – in particular, that the operator calculus approach is completely equivalent to using 4 × 4 matrices. A rigorous formal footing to this is given in Appendix B.
5.1 Matrix operators and derivatives
5.2 Complex Jacobians for the polarized RIME
5.3 Parameter updates and the diagonal approximation
To actually implement GN or LM optimization, we still need to invert the operator represented by the |${\bf J}$|H|${\bf J}$| matrix in equation (5.22). We have two options here.
The brute-force numerical approach is to substitute the 4 × 4 matrix forms of the |$\mathcal {R}$| and |$\mathcal {L}$| operators (equations B10 and B11) into the equation, thus resulting in conventional matrix, and then do a straightforward matrix inversion.
5.4 Polarized direction-dependent calibration
- if we assume separability by both direction and antenna, as in the AllJones algorithm, then the |$\tilde{{{\bf H}}}$| matrix is fully diagonal in operator form, and the GN update step can be computed asnote that in this case (as in the unpolarized AllJones version) the condition of equation (3.20) is not met, so we must use the residuals and compute δ|${\bf G}$|;(5.29)\begin{equation} \delta {{\bf G}}^{(d)}_{p,k+1} = \left[ \sum \limits _{q\ne p,s} {{\bf Y}}^{(d){\rm H}}_{pqs} {{\bf R}}_{pqs} \right] \left[ \sum \limits _{q\ne p,s} {{\bf Y}}^{(d)}_{pqs} {{\bf Y}}^{(d){\rm H}}_{pqs} \right]^{-1}, \end{equation}
if we only assume separability by antenna, as in the CohJones algorithm, then the |$\tilde{{{\bf H}}}$| matrix becomes 4Ndir × 4Ndir block diagonal, and may be inverted exactly at a cost of |$O(N_\mathrm{dir}^3N_\mathrm{ant})$|. The condition of equation (3.20) is met.
It is also straightforward to add weights and/or sliding window averaging to this formulation, as per Sections 3.4 and 4.4.
Equations (5.27) and (5.28) can be considered the principal result of this work. They provide the necessary ingredients for implementing GN or LM methods for DD calibration, treating it as a fully complex optimization problem. The equations may be combined and approximated in different ways to produce different types of calibration algorithms.
Another interesting note is that equation (5.29) and its ilk are embarrassingly parallel, since the update step is completely separated by direction and antenna. This makes it particularly well suited to implementation on massively parallel architectures such as GPUs.
6 OTHER DD ALGORITHMIC VARIATIONS
The mathematical framework developed above (in particular, equations 5.27 and 5.28) provides a general description of the polarized DD calibration problem. Practical implementations of this hinge around inversion of a very large |${\bf J}$|H|${\bf J}$| matrix. The family of algorithms proposed in Section 4 takes different approaches to approximating this inversion. Their convergence properties are not yet well understood; however, we may note that the StefCal algorithm naturally emerges from this formulation as a specific case, and its convergence has been established by Salvini & Wijnholds (2014a). This is encouraging, but ought not be treated as anything more than a strong pointer for the DD case. It is therefore well worth exploring other approximations to the problem. In this section we map out a few such options.
6.1 Feed-forward
Salvini & Wijnholds (2014b) propose variants of the StefCal algorithm (‘two basic’ and ‘two-relax’) where the results of the update step (equation 5.26, in essence) are computed sequentially per antenna, with updated values for |${\bf G}$|1…|${\bf G}$|k − 1 fed forward into the equations for |${\bf G}$|k (via the appropriate |${\bf Y}$| terms). This is shown to substantially improve convergence, at the cost of sacrificing the embarrassing parallelism by antenna. This technique is directly applicable to both the AllJones and CohJones algorithms.
The CohJones algorithm considers all directions simultaneously, but could still implement feed-forward by antenna. The AllJones algorithm (equation 5.29) could implement feed-forward by both antenna (via |${\bf Y}$|) and by direction – by recomputing the residuals |${\bf R}$| to take into account the updated solutions for |${\bf G}$|(1)…|${\bf G}$|(d − 1) before evaluating the solution for |${\bf G}$|(d). The optimal order for this, as well as whether in practice this actually improves convergence to justify the extra complexity, is an open issue that remains to be investigated.
6.2 Triangular approximation
6.3 Peeling
The peeling procedure was originally suggested by Noordam (2004) as a ‘kludge’, i.e. an implementation of DD calibration using the DI functionality of existing packages. In a nutshell, this procedure solves for DD gains towards one source at a time, from brighter to fainter, by
rephasing the visibilities to place the source at phase centre;
averaging over some time/frequency interval (to suppress the contribution of other sources);
doing a standard solution for DI gains (which approximates the DD gains towards the source);
subtracting the source from the visibilities using the obtained solutions;
repeating the procedure for the next source.
The term ‘peeling’ comes from step (iv), since sources are ‘peeled’ away one at a time.5
Within the framework above, peeling can be considered as the ultimate feed-forward approach. Peeling is essentially feed-forward by direction, except rather than taking one step over each direction in turn, each direction is iterated to full convergence before moving on to the next direction. The procedure can then be repeated beginning with the brightest source again, since a second cycle tends to improve the solutions.
6.4 Exact matrix inversion
Better approximations to (|${\bf J}$|H|${\bf J}$|)−1 (or a faster exact inverse) may exist. Consider, for example, Fig. 1(f): the matrix consists of four blocks, with the diagonal blocks being trivially invertible, and the off-diagonal blocks having a very specific structure. All the approaches discussed in this paper approximate the off-diagonal blocks by zero, and thus yield algorithms which converge to the solution via many cheap approximative steps. If a fast way to invert matrices of the off-diagonal type (i.e. faster than O(N3)) could be found, this could yield calibration algorithms that converge in fewer more accurate iterations.
7 IMPLEMENTATIONS
7.1 StefCal in MeqTrees
Some of the ideas above have already been implemented in the MeqTrees (Noordam & Smirnov 2010) version of StefCal (Smirnov 2013). In particular, the MeqTrees version uses peeling (Section 6.3) to deal with DD solutions, and implements fully polarized StefCal with support for both solution intervals and time/frequency smoothing with a Gaussian kernel (as per Section 4.4). This has already been applied to JVLA L-band data to obtain what is (at time of writing) a world record dynamic range (3.2 million) image of the field around 3C 147 (Perley 2013).
7.2 CohJones tests with simulated data
The CohJones algorithm, in the unpolarized version, has been implemented as a stand alone Python script that uses the pyrap6 and casacore7 libraries to interface to Measurement Sets. This section reports on tests of our implementation with simulated LOFAR data.
For the tests, we build a data set using a LOFAR layout with 40 antennas. The phase centre is located at δ = +52°, the observing frequency is set to 50 MHz (single channel), and the integrations are 10 s. We simulate 20 min of data.
For the first test, we use constant DD gains. We then run CohJones with a single solution interval corresponding to the entire 20 min. This scenario is essentially just a test of convergence. For the second test, we simulate a physically realistic time-variable ionosphere to derive the simulated DD gains.
7.2.1 Constant DD gains
To generate the visibilities for this test, we use a sky model containing five sources in a ‘+’ shape, separated by 1°. The gains for each antenna p, direction d are constant in time, and are taken at random along a normal distribution |$g^{(d)}_{p}\sim \mathcal {N}\left(0,1\right)+{\rm i}\mathcal {N}\left(0,1\right)$|. The data vector |$\boldsymbol {\breve{d}}$| is then built from all baselines, and the full 20 min of data. The solution interval is set to the full 20 min, so a single solution per direction, per antenna is obtained.
The corresponding matrix (|${\bf J}$|H|${\bf J}$|)UL is shown in Fig. 2. It is block diagonal, each block having size Ndir × Ndir. The convergence of gain solutions as a function of direction is shown in Fig. 3. It is important to note that the problem becomes better conditioned (and CohJones converges faster) as the blocks of (|${\bf J}$|H|${\bf J}$|)UL become more diagonally dominated (equivalently, as the sky model components become more orthogonal). As discussed in Section 4.2.1, this happens (i) when more visibilities are taken into account (larger solution intervals) or (ii) if the directions are further away from each other.
Amplitude (left-hand panel) and phase (right-hand panel) of the block-diagonal matrix (|${\bf J}$|H|${\bf J}$|)UL for the data set described in the text. Each block corresponds to one antenna; the pixels within a block correspond to directions.
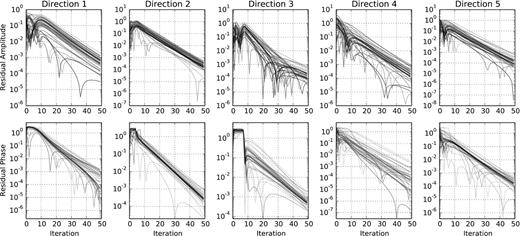
Amplitude (top row) and phase (bottom row) of the difference between the estimated and true gains, as a function of iteration. Columns correspond to directions. Different lines correspond to different antennas.
7.2.2 Time-variable DD gains
To simulate a more realistic data set, we use a sky model composed of 100 point sources of random (uniformly distributed) flux density. We also add noise to the visibilities, at a level of about 1 per cent of the total flux. We simulate (scalar, phase-only) DD gains, using an ionospheric model consisting of a simple phase screen (an infinitesimally thin layer at a height of 100 km). The total electron content (TEC) values at the set of sample points are generated using Karhunen–Loeve decomposition (the spatial correlation is given by Kolmogorov turbulence; see van der Tol 2009). The constructed TEC screen has an amplitude of ∼0.07 TEC-Unit, and the corresponding DD phase terms are plotted in Fig. 4.
For calibration purposes, the sources are clustered in 10 directions using Voronoi tessellation (Fig. 5). The solution time interval is set to 4 min, and a separate gain solution is obtained per each direction. Fig. 6 shows images generated from the residual visibilities, where the best-fitting model is subtracted in the visibility domain. The rms residuals after CohJones has been applied are a factor of ∼4 lower than without DD solutions.
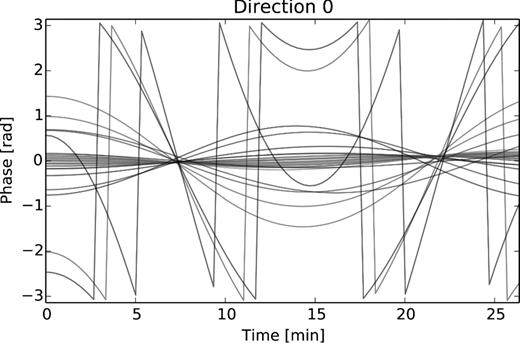
The complex phases of the DD gain terms (for all antennas and a single direction) derived from the time-variable TEC screen used in Section 7.2.2.
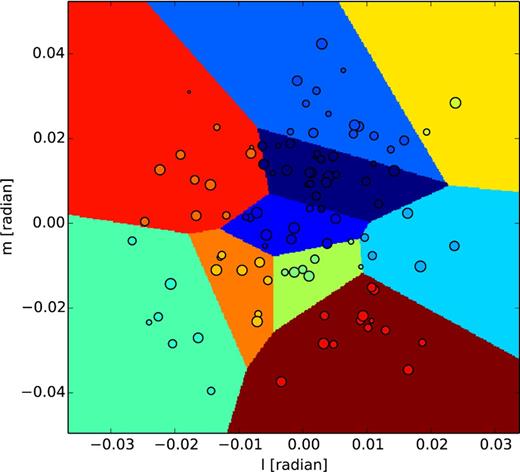
In order to conduct DD calibration, sources are clustered using a Voronoi tessellation algorithm. Each cluster has its own DD gain solution.
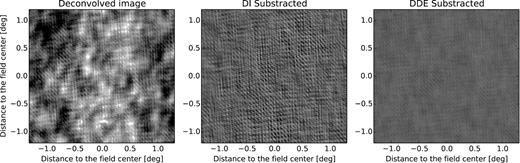
Simulation with time-variable DD gains. We show a deconvolved image (left) where no DD solutions have been applied, a residual image (centre) made by subtracting the sky model (in the visibility plane) without any DD corrections, and a residual image (right) made by subtracting the sky model with CohJones estimated DD gain solutions (right). The colour scale is the same in all panels. In this simulation, applying CohJones for DD calibration reduces the residual rms level by a factor of ∼4.
8 CONCLUSIONS
Recent developments in optimization theory have extended traditional NLLS optimization approaches to functions of complex variables. We have applied this to radio interferometric gain calibration, and shown that the use of complex Jacobians allows for new insights into the problem, leading to the formulation of a whole new family of DI and DD calibration algorithms. These algorithms hinge around different sparse approximations of the |${\bf J}$|H|${\bf J}$| matrix; we show that some recent algorithmic developments, notably StefCal, naturally fit into this framework as a particular special case of sparse (specifically, diagonal) approximation.
The proposed algorithms have different scaling properties depending on the selected matrix approximation – in all cases better than the cubic scaling of brute-force GN or LM methods – and may therefore exhibit different computational advantages depending on the dimensionality of the problem (number of antennas, number of directions). We also demonstrate an implementation of one particular algorithm for DD gain calibration, CohJones.
The use of complex Jacobians results in relatively compact and simple equations, and the resulting algorithms tend to be embarrassingly parallel, which makes them particularly amenable to implementation on new massively parallel computing architectures such as GPUs.
Complex optimization is applicable to a broader range of problems. Solving for a large number of independent DD gain parameters is not always desirable, as it potentially makes the problem underconstrained, and can lead to artefacts such as ghosts and source suppression. The alternative is solving for DD effect models that employ (a smaller set of) physical parameters, such as parameters of the primary beam and ionosphere. If these parameters are complex, then the complex Jacobian approach applies. Finally, although this paper only treats the NLLS problem (thus implicitly assuming Gaussian statistics), the approach is valid for the general optimization problem as well.
Other approximations or fast ways of inverting the complex |${\bf J}$|H|${\bf J}$| matrix may exist, and future work can potentially yield new and faster algorithms within the same unifying mathematical framework. This flexibility is particularly important for addressing the computational needs of the new generation of the so-called ‘Square Kilometre Array (SKA) pathfinder’ telescopes, as well as the SKA itself.
We would like to thank the referee, Johan Hamaker, for extremely valuable comments that improved the paper. This work is based upon research supported by the South African Research Chairs Initiative of the Department of Science and Technology and National Research Foundation. Trienko Grobler originally pointed us in the direction of Wirtinger derivatives.
It should be stressed that Wirtinger calculus can be applied to a broader range of optimization problems than just LS.
Laurent et al. (2012) define the Jacobian via |$\mathrm{\partial} \boldsymbol {r}$| rather than |$\mathrm{\partial} \boldsymbol {v}$|. This yields a Jacobian of the opposite sign, and introduces a minus sign into equations (2.8) and (2.9). In this paper we use the |$\mathrm{\partial} \boldsymbol {v}$| convention, as is more common in the context of radio interferometric calibration.
In principle, the autocorrelation terms pp, corresponding to the total power in the field, are also measured, and may be incorporated into the equations here. It is, however, common practice to omit autocorrelations from the interferometric calibration problem due to their much higher noise, as well as technical difficulties in modelling the total intensity contribution. The derivations below are equally valid for p ≤ q; we use p < q for consistency with practice.
In fact it was the initial development of CohJones by Tasse (2014b) that directly led to the present work.
The term ‘peeling’ has occasionally been misappropriated to describe other schemes, e.g. simultaneous independent DD gain solutions. We consider this a misuse: both the original formulation by Noordam (2004) and the word ‘peeling’ itself strongly imply dealing with one direction at a time.
Note that Hamaker (2000) employs a similar formalism, but uses the (non-canonical) stacked rows definition instead.
see below
REFERENCES
APPENDIX A: |${\bf J}$| AND |$\boldsymbol {{{\bf J}}^{\rm H}{{\bf J}}}$| FOR THE THREE-ANTENNA CASE
APPENDIX B: Operator calculus
Note that equation (5.5), which we earlier derived from the operator definitions, can now be verified with the 4 × 4 forms. Note also that equation (5.5) is equally valid whether interpreted in terms of chaining operators, or multiplying the equivalent 4 × 4 matrices.
B1 Derivative operators and Jacobians
APPENDIX C: GRADIENT-BASED OPTIMIZATION ALGORITHMS
This appendix documents the various standard least-squares optimization algorithms that are referenced in this paper.
C1 Algorithm SD (steepest descent)
Start with a best guess for the parameter vector, |$\boldsymbol {z}_0$|;
at each step k, compute the residuals |$\boldsymbol {\breve{r}}_k$|, and the Jacobian |${{\bf J}}={{\bf J}}(\boldsymbol {\breve{z}}_k)$|;
- compute the parameter update as (note that due to redundancy, only the top half of the vector actually needs to be computed):where λ is some small value;(C1)\begin{equation} \delta \boldsymbol {\breve{z}}_k = - \lambda {{\bf J}}^{\rm H} \boldsymbol {\breve{r}}_k, \end{equation}
if not converged,9 set |$\boldsymbol {z}_{k+1}=\boldsymbol {z}_k+\delta \boldsymbol {z}$|, and go back to step (ii).
C2 Algorithm GN
Start with a best guess for the parameter vector, |$\boldsymbol {z}_0$|;
at each step k, compute the residuals |$\boldsymbol {\breve{r}}_k$|, and the Jacobian |${{\bf J}}={{\bf J}}(\boldsymbol {\breve{z}}_k)$|;
compute the parameter update |$\delta \boldsymbol {\breve{z}}$| using equation (2.9) with λ = 0 (note that only the top half of the vector actually needs to be computed);
if not converged, set |$\boldsymbol {z}_{k+1}=\boldsymbol {z}_k+\delta \boldsymbol {z}$|, and go back to step (ii).
C3 Algorithm LM
Several variations of this exist, but a typical one is
start with a best guess for the parameter vector, |$\boldsymbol {z}_0$|, and an initial value for the damping parameter, e.g. λ = 1;
at each step k, compute the residuals |$\boldsymbol {\breve{r}}_k$|, and the cost function |$\chi ^2_k=\Vert \boldsymbol {\breve{r}}_k\Vert _{\rm F}$|;
if |$\chi ^2_k\ge \chi ^2_{k-1}$| (unsuccessful step), reset |$\boldsymbol {z}_k=\boldsymbol {z}_{k-1}$|, and set λ = λK (where typically K = 10);
otherwise (successful step) set λ = λ/K;
compute the Jacobian |${{\bf J}}={{\bf J}}(\boldsymbol {\breve{z}}_k)$|;
compute the parameter update |$\delta \boldsymbol {\breve{z}}_k$| using equation (2.9) (note that only the top half of the vector actually needs to be computed);
if not converged, set |$\boldsymbol {z}_{k+1}=\boldsymbol {z}_k+\delta \boldsymbol {z}$|, and go back to step (ii).
C4 Convergence
All of the above algortihms iterate to ‘convergence’. One or more of the following convergence criteria may be implemented in each case.
Parameter update smaller than some pre-defined threshold: |$\Vert \delta \boldsymbol {z}\Vert _{\rm F}<\delta _0$|.
Improvement to cost function smaller than some pre-defined threshold: |$\chi ^2_{k-1}-\chi ^2_{k}<\epsilon _0$|.
Norm of the gradient smaller than some threshold: |||${\bf J}$|||F < γ0.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}