





Abstract
The Covid-19 pandemic has required most countries to implement complex sequences of non-pharmaceutical interventions, with the aim of controlling the transmission of the virus in the population. To be able to take rapid decisions, a detailed understanding of the current situation is necessary. Estimates of time-varying, instantaneous reproduction numbers represent a way to quantify the viral transmission in real time. They are often defined through a mathematical compartmental model of the epidemic, like a stochastic SEIR model, whose parameters must be estimated from multiple time series of epidemiological data. Because of very high dimensional parameter spaces (partly due to the stochasticity in the spread models) and incomplete and delayed data, inference is very challenging. We propose a state-space formalization of the model and a sequential Monte Carlo approach which allow to estimate a daily-varying reproduction number for the Covid-19 epidemic in Norway with sufficient precision, on the basis of daily hospitalization and positive test incidences. The method was in regular use in Norway during the pandemics and appears to be a powerful instrument for epidemic monitoring and management.
1 Introduction
We propose a dynamic approach for the estimation of a time-varying or instantaneous reproduction number for a mathematical infectious disease spread model. We apply our method to the Covid-19 pandemic in Norway. Like in most other countries, the pandemic has been tackled with a combination of non-pharmaceutical interventions, from social distancing to partial lock-down, imposed or advised at various time points. Various viral variants with different characteristics have been competing in the population. Vaccination has also been gradually introduced. As a consequence of these changes, and of varying human behaviour, which can emerge both abruptly and smoothly, the reproduction number varies. Instantaneous estimates of reproduction numbers are useful for situational awareness. Being able to estimate such changes rapidly is important in guiding decision makers in future policy planning.
A reproduction number is precisely defined within a mathematical model of transmission. A large class of models, which has been shown to be very appropriate, is the so-called Susceptible-Exposed-Infectious-Removed (SEIR) model (S susceptible, E exposed, I infected, R recovered). In particular, stochastic compartmental models are preferable when there are relatively low number of infections (Keeling & Rohani, 2011, chapter 6). SEIR models are parametrized so that a meaningful estimate of the reproduction number (basic and effective) can be derived. Such compartmental models are based on many latent variables, in particular the number of individuals in each compartment within each region at every time point, and depend on many epidemiological parameters, including the transmission strengths which are key components of reproduction numbers. All unknowns must be estimated from data, which in a realistic situation are scarce and incomplete. For this reason, inference is in general very difficult, because of a high dimensional parameter space, rather flat likelihoods or posterior distributions and, often, weak identifiability (De Angelis et al., 2015).
Moreover, data which carry information about the transmissibility of the virus appear with an inevitable delay. In this paper, we use two data sources, the daily number of patients hospitalized because of Covid-19 and the daily number of positive laboratory-confirmed RNA test cases. Both these data sources carry information about the transmission of the virus in the society, but with a random time delay from transmission. Therefore, the uncertainty of the estimates of a daily reproduction number increases in the last period of data. All this is particularly challenging during an emerging epidemic. For these reasons, instantaneous reproduction numbers are rarely assumed in SEIR models. In this paper, we propose and test a sequential Monte Carlo (SMC) approach to inference which allows the efficient estimation of instantaneous reproduction numbers for the Covid-19 pandemic from real data.
While our SMC approach is generic, we implement it on top of a stochastic SEIR model which we developed for the Covid-19 epidemic (Engebretsen et al., 2021) and which was in regular use by the Norwegian health authorities. This model assumes a spatial scale resolved on county level, and uses mobile phone mobility data for the geographical spread of the virus in temporal steps of 6 hr. In Engebretsen et al. (2021), the transmissibility parameter, which represents the probability of transmission upon a contact times the contact rate in the population, is assumed to be constant in time, and is only changed at designed change-points. Inference in Engebretsen et al. (2021) is performed by a version of approximate Bayesian computation (ABC). Markov chain Monte Carlo (MCMC) convergence was essentially impossible to reach, because of the difficulty to design parameter perturbations which would lead, through the stochastic SEIR, to minor and controlled changes of the posterior distribution. It is very difficult to use ABC when the number of parameters is large, as is the case when including daily-varying reproduction numbers.
In this paper, we propose to perform Bayesian inference in combination with SMC. Static parameters related to the dynamic process for the reproduction number are estimated sequentially through SMC using sufficient statistics (Fearnhead, 2002; Storvik, 2002). Application of SMC methods is challenging because the latent processes are of high dimensions, the SEIR model is only available as a computer algorithm, and data are very limited. A further very important practical aspect when working in real time during a pandemic comes from the continuous need to improve the model, to change epidemiological assumptions, to use different data registries, and to improve the computational efficiency of algorithms. For these reasons, it has been very important to develop an SMC which is very flexible, so that changes in model specifications are easy to implement. This paper shows how a careful design of combination of model and algorithm reaches these aims and leads to a good fit to both data sources. We produce an analysis of the Norwegian pandemic, quantifying how interventions impacted the transmissibility and showing how our estimated instantaneous reproduction numbers were capturing changes rapidly enough. Based on the dynamic model, we perform future predictions of the situation for the next three weeks. We discuss the quantification of uncertainty in forecasts, which is of paramount importance for decision making.
There is an important literature on time-varying reproduction numbers applied in various epidemics, see for example Cauchemez et al. (2006) and Viboud et al. (2018). A Bayesian framework for estimating time-varying reproduction numbers was proposed by Cauchemez et al. (2006), and applied to the SARS epidemic. In Cori et al. (2013), a time-varying reproduction number is defined as the ratio of the number of infected in day t over , where is the distribution of the generation time of Covid-19, which is often set to be distributed with a mean and a standard deviation estimated from specific studies (Ferretti et al., 2020). There is a very successful R-package implementing this Bayesian method, called EpiEstim (Cori et al., 2021). We include a comparison between EpiEstim and our approach based on only one of the two data sources.
A series of interesting papers has been recently presented in the Royal Statistical Society Special Topic Meeting on Covid-19 transmission (RSS, 2021). Pellis et al. (2022) give a thorough discussion of the reproduction number, its model-dependent definition, its estimation and the challenges in communicating it to the public. A model-agnostic alternative to the reproduction number is the instantaneous epidemic growth rate, and the two measures are compared in Parag et al. (2022). Mishra et al. (2022) extend in various ways the renewal model in Flaxman et al. (2020) and assume a random walk model for a weekly constant reproduction number. In order to study the effect of school closures, Bekker-Nielsen Dunbar et al. (2022) fit a multivariate time-series model to case incidence data and perform an interesting counterfactual analysis. Although in the present paper we concentrate inference about the reproduction numbers, we emphasize that several other measures can be extracted from our model, as shown in the weekly reports published by the Norwegian Institute of Public Health during the pandemic (NIPH, 2022).
Several papers have applied MCMC algorithms to estimate parameters in compartmental models (e.g Gibson & Renshaw, 1998; O’Neill et al., 2000; O’Neill & Roberts, 1999) as well as alternative models (Teh et al., 2021). The recent paper (Birrell et al., 2020) studies various SMC approaches in a SEIR model for influenza. It demonstrates the superiority of the SMC methodology compared to MCMC for such dynamical models. The paper is also useful as a general reference to SMC in epidemic modelling. Our work shares many similarities to this approach, including the use of several sources of data. A difference is our use of a dynamic model for the reproduction numbers. Also, a stochastic delay between infection and observation time is included in our setting. Another general inference framework is implemented in the R-package pomp (King et al., 2016). The package contains multiple different implementations of estimation procedures, including SMC, for inference for partially observed Markov process models. There are several examples of applications of the package to epidemic inference, see for example King et al. (2016) Stocks et al. (2020), and Blackwood et al. (2013).
The outline of the rest of the paper is as follows. In Section 2, the context and the data are described. In Section 3, we specify the full model, formulated as a state space model. In Section 4, we discuss how SMC algorithms can be applied in inference, including estimation of several static parameters. A simulation study and experimental results are reported in Section 5 specifically for the Norwegian Covid-19 pandemic. Additional results, including sensitivity analyses, are collected in the supplementary material. We conclude the paper with a summary and discussion. In the supplementary material details about experimental settings and algorithmic specifications are given. Data and codes are available on our GitHub repository.
2 Context and data
We start by setting the scene of the inferential task. The core is an existing model of the epidemic which has as input a set of parameters and variables, including daily reproduction numbers, and as output a series of time series of infection incidence. In our case, the model is a stochastic compartmental SEIR-type model that produces numbers of susceptible, exposed, pre-symptomatic, symptomatic and asymptomatic infectious and recovered at every time point. We also keep track of the disease incidence. We use two data time series to inform the SEIR model: the daily number of new hospital admissions of Covid-19 patients, and the daily number of laboratory-confirmed positive Polymerase chain reaction (PCR) tested cases. In order to exploit these data, we furthermore model the process of hospitalization and testing of the SEIR output, in particular of the daily incidence of infected. The inferential task is to estimate the input parameters.
The hospitalization data contain admission to all hospitals in Norway of all patients who are admitted with Covid-19 as the main cause. Admission on a certain day informs us of a transmission event that has occurred some days before. This time gap can differ between individuals. We make several assumptions on various time lags, as specified in supplementary material. For example, the number of days between symptom onset and admission to hospital is estimated to be negative binomial distributed with parameters estimated in a separate study of the Norwegian Covid-19 registry (Whittaker et al., 2021). On average, for a patient being hospitalized, the time gap between infection and hospitalization is estimated to be approximately 14 days. For concreteness, in this paper we assumed the distributions of the various time lags to be given.
The second data set is the time series of daily number of positive PCR tests. Again, there is a time gap between onset of symptoms and testing, which we estimate to be randomly distributed with mean about 4 days. It is important for inference that the two data sets are as coherent as possible.
We use two additional data sets, which enter the SEIR model as input variables: the daily number of positive cases who have been tested in Norway but infected outside of Norway, so-called imported cases; and the total number of PCR tests made in Norway, as a surrogate of the effort made to detect positive cases.
We start with the population of Norway, distributed according to the national census in the 11 counties (see www.ssb.no/en/statbank/table/12871/). Like in Engebretsen et al. (2021), we seed our model continuously with positive cases imported from abroad on the day of recorded symptom onset or, if not available, when detected by testing. Imported cases that are hospitalized are not counted in the time series of hospitalizations, because they do not inform the model about the transmissibility of the virus in Norway. Because not all imported cases are likely to be discovered, we assume that each imported case stands for an unknown number of further undetected imported cases. We model this latent import with an additional Poisson distributed number of cases per observed imported case, with Poisson mean estimated from the data during calibration. We call this mean the amplification factor.
A final aspect, which is not central in this paper but that we mention for completeness, is that we use a geographical SEIR model on county (regional) level, so that the various compartments are geographically defined. Individuals are moved at random between the 11 counties of Norway using a mobility matrix, which is obtained every 6 hr from the movements of mobile phones in Norway, as explained in Engebretsen et al. (2021). In the present paper, all parameters in the model are however shared between counties. Even if hospitalization and test data are available at county level, in this paper we use only nationally aggregated data, because of the heterogeneity in the population size among the regions. A very important further aspect is the need to obtain inferential results as rapidly as possible, in at most a few hours, so to be able to publish results quickly just after release of the data update.
3 Model
Let be the vector of hospitalization and test data on day t. Let be the output vector of compartmental variables in the SEIR model at time t, for example the number of individuals in each county who are infected and symptomatic. Here, we consider the model generically as an algorithm which outputs the compartmental variables at each time point t. is the unknown reproduction number at time t. We consider the following state-space model:
To simplify notation, we do not include the dependence of the models on the set of static parameters . The distribution needs to be available analytically and easy to sample from. The distribution is assumed to be only available through a computer algorithm and we are only able to simulate from this distribution. In certain situations, this distribution can be available as a huge and complex Markov process. However, this is not often the case, for example because of the complexity of the code or because of the lack of availability of sensitive data, like the mobility matrices in our case. The dimension of is large, while is low-dimensional. In this work, we consider a common scalar for all counties. Note that the data depend on the whole history making only weakly informative about . This is due to the fact that there is a random delay from transmission to being tested and possibly hospitalized. A graphical representation of the model is given in the left panel of Figure 1. Our aim is to construct an efficient SMC method for the computation of and we are interested in estimating the current status , in smoothing (), and in forecasting .
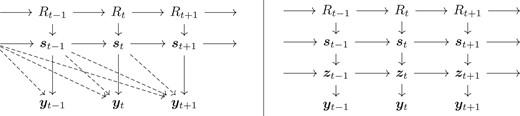
Graphical representation of model (1) (left) and its reformulation (right). The hyper-parameters are not included and can influence all conditional distributions. The dashed arrows illustrate the dependence due to the random delays between infections and testing and possibly hospitalization.
The stochastic process is assumed to be Markov. We suggest three alternative prior models for . Let be independent from all other variables. The first model is a random walk (RW) on log scale, the second model extends this to an AR(1) structure. In the third model, is assumed to be piece-wise constant, with jumps occurring at random.
For all models, we assume a constant start: Until a given time point D, is constant and equal to . The date D is set to the day when the social distancing implementation started. Before D, the reproduction number was not likely to change significantly. In this paper, we set D equal to 8 March 2020, when teleworking started in many companies and universities in Norway. The Norwegian government announced the first package of interventions on 12 March 2020. The models above describe the dynamics after D. All the static parameters in the three models must be estimated.
The proposed method is not dependent on a specific model (1b), and would work with any epidemic model. In this work, we use the particular SEIR model described in Engebretsen et al. (2020, 2019), and whose algorithm is available though the spread package (Engebretsen et al., 2020).
In particular, this SEIR model has six compartments in each region (county) i: susceptible (S), exposed and not infectious (), pre-symptomatic and infectious (), infectious symptomatic (I), infectious asymptomatic (), and recovered (R). The dynamics is described by the following equations:
where is 6 hr. We assume random mixing in each county in each 6 hr period, and move individuals between counties at the end of each such period according to a mobility matrix. In Engebretsen et al. (2021), mobile phone data are used to estimate such mobility matrices. These matrices report the number of individuals moving from county A to county B during each period, which we pick at random among those currently present in A, but favour the residents of B to return to B, to capture commuting. This rule makes the computational complexity of the SEIR model quadratic in the number of counties, due to the need for storage of both current visited location and residence of individuals. The reproduction number is related to through the equation
Finally, we describe the likelihood model for the data (1c). A main difficulty is the link between the latent process and the observation process because of the unknown stochastic delays between infection and observation time, making the computation of hard. We introduce an auxiliary process with two components, one dedicated to the hospitalization and the other to the test data. The auxiliary variable is defined as the number of individuals who are infected at time t and hospitalized v days later. The time lag v is assumed to vary in , for some appropriate . Similarly is the number of individuals who are infected at time t and tested positive v days later. We rewrite (1c) as
where is a Markov transition distribution assumed to be easy to simulate from. Now is easy to compute. In more details, define to be the number of daily Covid-19 admissions to hospital. An individual who is infected at time t is hospitalized with probability at time . The time lag u from infection until hospitalization is assumed to follow a discrete distribution on the integers . Let be the probability of delay u. To structure the model further, we attach to each infected individual its potential time lag until hospitalization. So is the number of individuals infected at time t and who could possibly be hospitalized u time-units later. Let be the total number of infected individuals at time t, which is available through the SEIR model as a component of . We can formulate the model as
where we here consider a Beta-Binomial distribution for a patient being hospitalized to take into account variability in hospitalization between regions. The parameter is specified indirectly through a time-varying probability such that where is predefined using the age–structure of the individuals having tested positive. By storing and sequentially updating the quantities as well, we obtain a first-order Markovian state-space structure as illustrated in the right panel of Figure 1.
Regarding the test data, as in Engebretsen et al. (2021) we consider the probability that an infected case is tested by means of a PCR test. We ignore that tests can lead to false positive responses. The logit of this probability is assumed to be linear in the total number of daily tests in day t in addition to a time independent intercept. We write the detection probability at time t as
The time lag between infection and testing is assumed to follow a discrete distribution on for an appropriate . The approach for handling this delay is exactly as for the hospital incidence, with now playing the role of . We introduce a new set of auxiliary variables for the test data , similarly to the ones introduced for the hospitalization data. Defining , we are within the model formulation (3).
4 Sequential Monte Carlo
Let . Our aim is to perform inference on the whole set of latent variables as well as on static hyper-parameters at each time point t, by means of the posterior distribution . A description of the SMC algorithm with resampling at each step is given in Algorithm 1. See also Chopin and Papaspiliopoulos (2020), which contains more general algorithms. Although in this paper we focus on inference for , also will be of interest. In our setting, the main computational burden is the sampling from which has been parallelized in our implementation. For resampling, residual resampling (Liu & Chen, 1998) has been applied. However, the resampling step is both hard to parallelize and requires message passing, resulting in that a too high number of cores can decrease performance.
Auxiliary SMC with resampling at each time step. Operations involving index b must be performed for . Here, denotes the transition distribution for , while is the proposal distribution for . The indices defines the ancestral particles at time t after resampling.
| 1: | ⊳ Proposal at time 0 |
| 2: , | ⊳ Calculating weights |
| 3: | ⊳ Estimate of |
| 4: for to T do | |
| 5: | ⊳ Resampling |
| 6: | ⊳ Proposal at time t |
| 7: , | ⊳ Calculating weights |
| 8: | ⊳ Estimate of |
| 9: end for |
| 1: | ⊳ Proposal at time 0 |
| 2: , | ⊳ Calculating weights |
| 3: | ⊳ Estimate of |
| 4: for to T do | |
| 5: | ⊳ Resampling |
| 6: | ⊳ Proposal at time t |
| 7: , | ⊳ Calculating weights |
| 8: | ⊳ Estimate of |
| 9: end for |
Auxiliary SMC with resampling at each time step. Operations involving index b must be performed for . Here, denotes the transition distribution for , while is the proposal distribution for . The indices defines the ancestral particles at time t after resampling.
| 1: | ⊳ Proposal at time 0 |
| 2: , | ⊳ Calculating weights |
| 3: | ⊳ Estimate of |
| 4: for to T do | |
| 5: | ⊳ Resampling |
| 6: | ⊳ Proposal at time t |
| 7: , | ⊳ Calculating weights |
| 8: | ⊳ Estimate of |
| 9: end for |
| 1: | ⊳ Proposal at time 0 |
| 2: , | ⊳ Calculating weights |
| 3: | ⊳ Estimate of |
| 4: for to T do | |
| 5: | ⊳ Resampling |
| 6: | ⊳ Proposal at time t |
| 7: , | ⊳ Calculating weights |
| 8: | ⊳ Estimate of |
| 9: end for |
The SMC algorithm is by design sequential so that by storing values of obtained at the previous day, updates can easily be performed as new data arrive. A main challenge here is that the state at time t heavily depends on future observations because of the delay in hospitalization. Although the reformulated model reduces immediate dependence, there are still strong correlations backwards, as illustrated in Figure 1. There are clearly possibilities to develop more efficient proposal distributions, despite the availability of the SEIR model only as a computer algorithm. Because the main purpose of this paper is to investigate the utility of SMC methods for the estimation of daily-varying reproduction numbers, we use only simple bootstrapping proposals. We do however take into account the delay aspect by using fixed lag smoothing, using data ahead of current time, that is
where are simulations of based on data up to time point . Fixed lag smoothing with a lag of days has been used in the Covid-19 runs in this paper. At the end of the time series, is used. The estimates on the last days will be more uncertain.
4.1 Parameter estimation
Algorithm 1 assumes that the parameters are known. Now we describe Bayesian inference for some of the static parameters. We denote by the set of parameters in the model for , the ones in the process, and the parameters appearing in the data model. As mentioned, some of these parameters are fixed based on other data sources, and here for simplicity we do not propagate their uncertainty. For other parameters, sequential updates of their estimates are desirable. In principle, all parameters could be included as part of the state vector where the propagation of these static components just keeps them fixed. However, repeated resampling will quickly give degenerate samples for these parameters.
A review of parameter estimation in SMC is given in Kantas et al. (2015). Off-line methods such as particle MCMC (PMCMC, Andrieu et al., 2010) have proven to be very effective in many applications, but require repeated runs of the SMC routine. Although much smaller number of particles can be applied in such settings, some experiments with our models indicate that at least 250 particles are necessary, in which case one run uses about 10 min using 4 cores on Linux server and more cores did not help much in this case. Some experiments with an implementation of the Particle Metropolis-Hastings algorithm, based on the pseudo-marginal method by Andrieu and Roberts (2009), is reported in the online supplementary Section D. We will however focus on online methods for parameter estimation here.
In cases where sufficient statistics for the parameters are available, the SMC algorithm can be easily updated to target instead (Fearnhead, 2002; Storvik, 2002). This is the case for the parameters. Simulations of at each time point can then be obtained from which then again can be used to obtain new samples of (step 6 in Algorithm 1). A crucial step is that can be recursively updated. The online supplementary Section A gives details on how can be updated by this approach. Note that these methods can suffer from the degeneracy problem (Andrieu et al., 2005). In the online supplementary Section D, we validate the parameter estimates obtained by this procedure both through comparisons between different runs and by using the samples obtained by the Particle Metropolis-Hastings algorithm.
5 Results
5.1 Norwegian Covid-19 data
For the analysis of the Norwegian Covid-19 case, we used the 11 counties as our spatial scale. Mobility data and imported cases were used at regional scale, while hospital incidence data and test data were used at national scale. Also the prior process was assumed to be common for all regions. The hospital incidence data are from the Norwegian national Beredt-C19 registry and the Norwegian Intensive Care and Pandemic Registry, and the test data are from the Norwegian Surveillance System for Communicable Diseases (MSIS registry). The reproduction number is assumed constant until 7 March 2020. The results are based on data up to 1 July 2021 with test data included only from 1 August 2020, when testing capacity in Norway was scaled as needed, and after which testing criteria had become rather stable. The number of parameters is large: the dimension of is 3,157. In addition, we have the reproduction numbers and the auxiliary variables s. The prior distributions assumed for the parameters involved in the dynamics of are given in the first column of Table 1.
Posterior medians and 95% credibility intervals (in parentheses) for hyper-parameters of the three models of the dynamics
| Model | |||
|---|---|---|---|
| Prior | RW | AR | CP |
| 0.563 (0.430,0.659) | |||
| 0.176 (0.157,0.202) | 0.340 (0.300,0.477) | 0.574 (0.485,0.678) | |
| 0.158 (0.119, 0.198) | |||
| MLIK | 3028.20 | 3008.68 | 3020.69 |
| MLIK-no test | 1252.15 | 1221.09 | 1230.71 |
| Model | |||
|---|---|---|---|
| Prior | RW | AR | CP |
| 0.563 (0.430,0.659) | |||
| 0.176 (0.157,0.202) | 0.340 (0.300,0.477) | 0.574 (0.485,0.678) | |
| 0.158 (0.119, 0.198) | |||
| MLIK | 3028.20 | 3008.68 | 3020.69 |
| MLIK-no test | 1252.15 | 1221.09 | 1230.71 |
Note. Although the prior for σ is defined through the precision, the numbers are for σ itself. The two last rows of the table give the value of the marginal log-likelihoods based on both data sources (MLIK) and on hospitalization data only (MLIK-no test).
Posterior medians and 95% credibility intervals (in parentheses) for hyper-parameters of the three models of the dynamics
| Model | |||
|---|---|---|---|
| Prior | RW | AR | CP |
| 0.563 (0.430,0.659) | |||
| 0.176 (0.157,0.202) | 0.340 (0.300,0.477) | 0.574 (0.485,0.678) | |
| 0.158 (0.119, 0.198) | |||
| MLIK | 3028.20 | 3008.68 | 3020.69 |
| MLIK-no test | 1252.15 | 1221.09 | 1230.71 |
| Model | |||
|---|---|---|---|
| Prior | RW | AR | CP |
| 0.563 (0.430,0.659) | |||
| 0.176 (0.157,0.202) | 0.340 (0.300,0.477) | 0.574 (0.485,0.678) | |
| 0.158 (0.119, 0.198) | |||
| MLIK | 3028.20 | 3008.68 | 3020.69 |
| MLIK-no test | 1252.15 | 1221.09 | 1230.71 |
Note. Although the prior for σ is defined through the precision, the numbers are for σ itself. The two last rows of the table give the value of the marginal log-likelihoods based on both data sources (MLIK) and on hospitalization data only (MLIK-no test).
When running the model, we did not estimate the SEIR parameters in equation (2), nor the parameters and in equation (5), because they were estimated separately as described in Engebretsen et al. (2021). Also the parameters in equation (4) were pre-estimated through other data sources. All further details on the model are given in the online supplementary Section B. Each run is based on particles. One run of the 500 days considered here, using a linux server with 128 cores, took approximately 5 hr, which is appropriate for practical real-time purposes. Figure 2 shows our estimates of , with a 7-precedent-days moving-average smoothing (daily estimates are given in the online supplementary Figure S3), using the three considered models for the reproduction number. Posterior medians and symmetric 95% credibility intervals of the estimated parameters are reported in the second column of Table 1. The autoregressive (AR) model for was simplified by fixing : when we estimated μ, we obtained an estimate very close to zero, but we also experienced some difficulties in the estimation of . In addition, the marginal log-likelihood (MLIK) was slightly higher. We therefore opted for the simpler AR model.

Estimates of the weekly averaged instantaneous reproduction number based on the random walk (RW, upper), autoregressive (AR, middle) and piece-wise constant model (PC, lower). We used hospital data from 8 March 2020 to 1 July 2021, test data from 1 August 2020 to 1 July 2021. We used particles. Corresponding not-averaged daily estimates are given in the online supplementary Figure C.2. The first vertical stippled green line corresponds to the date at which test data are included in the analysis, the second stippled green vertical line corresponds to the last date with observations, after that Bayesian prediction is performed. Blue shadow bands indicate posterior uncertainty quantiles. The red curves correspond to 50% median-centred credibility intervals only based on hospitalization data.
In Figure 2, we see that the different models lead to rather similar estimates for the time dynamics of . The AR model (central panel) seems to have more uncertainty. On the other hand, this model is to be the preferred in terms of MLIK (Table 1, last rows). Note that all models capture quickly the dramatic reduction in transmission in mid-March 2020 when Norway had the first lockdown, which was implemented between 9 and 14 March 2020. In the second half of April 2020, society was re-opened, including schools and kindergarten, and the 2-m distance rule was reduced to 1 m: appears to increase to around 1. A new peak appears in the end of July and beginning of August 2020, in correspondence with the end of the Norwegian vacations, the returning of Norwegians from abroad and the arrival in Norway of tourists. In particular, there have been several isolated clusters, for example in two cruise ships and the return of students to university campuses. These clusters were well controlled by contract tracing, and the reproduction number dropped rapidly below 1. The autumn 2020 was also characterized by a series of larger local outbreaks, which were rapidly controlled. The growth of starting in October 2020 was also due to local outbreaks, and the incoming winter season which affects the viral transmission. The number of cases was so large that contact tracing became less effective. The Norwegian government imposed a second national intervention, first in the end of October 2020 and then again in early November 2020. This reduced the reproduction number again to below 1, in two pushes, where we can see that the second strengthening of the intervention was in fact needed for this purpose. We can see that the autumn 2020 interventions allowed the reproduction number to fall from approximately 1.5 to below 1 in about three weeks. Interestingly, we see a peak of just around Christmas 2020, in connection with vacation travel and intensive shopping. January 2021 marks the arrival of the alpha variant of the virus, which was more transmissible and which increased the risk of hospitalization. The alpha variant was predominant in Norway at the end of March 2021, and we see just below 1.5 again. This increase happened despite at the end of January 2021 Norway introduced the strictest lockdown rules during the whole pandemic so far, including essential closure of all borders, and vaccination of the elderly started. During March and April 2021, started to decrease again, to remain below or around 1 until the middle of May 2021. Governmental interventions were reduced from May 2021, and the reproduction number stabilized around 1. At the end June 2021, approximately 50% of the adult Norwegian population had been vaccinated at least once, and approximately 30% twice. The effective reproduction number reflects the effect of vaccination which is included in the SEIR model. It is remarkable how the estimated reproduction number quantify the history of the epidemic so precisely. Another feature is the cyclic behaviour of , with a drop following an increase. The AR prior model on log scale also attracts towards 1. In Norway, this is expected because of the rapid intervention strategy of the government (named ‘control’) whenever was growing rapidly above 1, and the rapid reopening when the epidemic appeared under control. Local outbreaks were frequent, also visible in the raw data, but they were rapidly controlled by appropriate contact tracing and other successful local interventions.
The red lines in Figure 2 give 50% centred credibility intervals based only on hospitalization data. We investigate in this way the value of the test data as a second source of information. Because we used test data only from August 1 2020, the estimates are essentially identical until then. After 1 August 2020, the estimates based only on hospital data are smoother, indicating that the test data contain information about transmission (and its change) that is not transferred to the hospitalization. One reason for this is that the younger generations have been infected in the autumn more than the elderly ones, who are most at risk for hospitalization. The test data also contribute to a more precise estimate of the daily prevalence of infected in Norway. We also observe some misalignment in time between the two estimates, probably because the time delays were not stationary, while we assumed them constant during the whole epidemic.
The last green horizontal line in Figure 2 corresponds to the last day with data, 1 July 2021, after which we perform a three weeks prediction, by simply running the model forward in time. The predictions for the three models have similar means but differ in uncertainty. Both the RW and the piece-wise constant model are non-stationary, which explains the high increase in uncertainty after the last observation point. On the other hand, the AR model shows a more stable prediction performance, as expected. Figure 3 gives predicted number of new daily infected cases. Before the last green dashed line, these credibility intervals give predictions based on the observed data, after this line, the predictions are obtained by running the SEIR model forward three weeks in time using the predicted reproduction numbers. When predicting forward in time, mobility matrices, imported cases and total number of tests are needed as input. We here re-use the values in the previous 21 days in the forecasts. We see the three waves which hit Norway in March/April 2020, from November 2020 to January 2021 and in March 2021. The number of cases is estimated around 1,000 per day in the peaks (1,300 in the third wave). The number of cases would in fact grow during July 2021, as here correctly predicted.
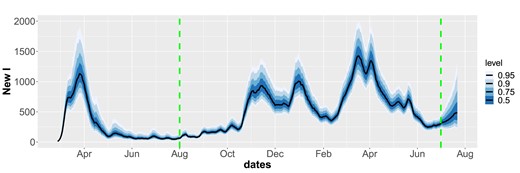
Predicted number of newly infected based on the autoregressive model in Figure 2. The estimates after the last dashed green line are predictions 3 weeks ahead.
Table 1 provides the estimates of the parameters in the three dynamic models of . How these estimates are learned over time is shown in the online supplementary Figures C.3–C.5. The plots also allow a comparison of the prior (which is the first time point to the left) and the final posterior estimate (last time point on the right). The estimates stabilize nicely. We report about some limited validation of the parameter estimates in the online supplementary Section D. Note that the variance of the RW dynamics is estimated to be smaller than the one of the AR model, as is also clear in Figure 2. On the other hand, the variance related to the piece-wise constant model is considerably smaller even if the variability seems to be smaller in Figure 2. This is due the fact that for most time points there are no discontinuities, while when changes occur there may be large discontinuities.
In Figure 4, we use the estimated parameters, including the instantaneous reproduction numbers, to simulate the daily hospitalization incidence and the daily number of positive tests. We propagate uncertainty and produce probabilistic estimates, which we compare with the actual data. These plots show that we are able to fit both data sources well. We note the weekly structure in the test data. These plots also show three weeks ahead forecasts. The super-imposition of the actual data of these three weeks, which were not used in the analysis, show that predictions were good.

Predicted (blue shadows representing the quantiles of the posterior predictive distribution) and observed daily hospitalization incidence and laboratory-confirmed positive tests incidence (red dots) based on the autoregressive model.
5.2 Sensitivity analysis
There are several parameters that are fixed in the current implementation:
Hyper-parameters in the prior model for , see Table 1.
Parameters related to the observations: the age-dependent probabilities of being hospitalized and detected positive by testing, and the parameters describing the distribution for delay from infection to testing or hospitalization.
Several parameters inside the SEIR model.
The number of particles used in the SMC runs.
We did not perform a systematic sensitivity analysis, but focus on the SMC design parameters. The online supplementary Figure C.1 shows posterior median estimates of the instantaneous reproduction numbers for several different prior settings for the AR model. The figure indicates that the estimates of are not sensitive to the tested prior settings (credibility intervals also show similar results).
Next, we studied the importance of the number of particles. The online supplementary Figure C.7 compares results for the AR model based on vs. particles. The difference in the estimated marginal likelihoods is small compared to the differences between models (about 5.0). This figure (and other similar ones, not included) shows that the results are quite stable and that might have been sufficient for estimation of . However, if interest is also in the latent structure or marginal likelihood values, more particles have shown to be necessary.
5.3 Comparison with EpiEstim
EpiEstim (Cori et al., 2013) is a popular method for estimation of the reproduction number based on case incidence as well as imported cases. It does however not allow for the incorporation of multiple data, so that hospital data are not taken into account, nor mobility. In Figure 5, we compare estimates of obtained by our SMC approach, though only using test data and this time from the start of the epidemic, with the results obtained by using the EpiEstim package in R (Cori et al., 2021, version 2.2.4). For EpiEstim we assumed a serial interval (the time between the onset of symptoms of a primary case and the onset of symptoms of secondary cases) with mean 7.5 days and a standard deviation of 3 days. We see a very good agreement between the two estimated curves in general. However, the 95% confidence bands are unrealistically narrower for EpiEstim. There are some differences between the estimates during March 2020 and during the summer 2020 and November 2020. There are also some small lag differences between the estimates obtained by our approach compared to the results obtained by EpiEstim. This is probably because the assumed models for the delay between infection and testing times are quite different. Furthermore, the effect of the importations of cases, which is not accounted for by EpiEstim, may be very relevant to explain the disagreement between the models in certain periods such as in January 2021 (Christmas) and in the end of March 2021.

Estimates of using the SEIR model combined with the autoregressive model for using SMC based only on test data (blue band, 95% confidence bands) and estimates obtained from EpiEstim (red lines, also 95% confidence bands).
5.4 Simulated data
Based on an estimate obtained by the AR model from the real data, we simulated from the model for all t. Twenty independent data sets were generated and for each case the simulated set was used for estimating . Figure 6 shows the results from one of these simulated data sets, demonstrating that the method is able to capture the main structure quite well, although in periods where the true is considerably unstable (July/August 2020) estimates are worse. The online supplementary Figure C.6 shows results based on all 20 data sets, demonstrating the strong information content in such type of data about the process.

Simulation experiment. Estimates of using (blue) based on one simulated data set. Same set-up as Figure 2, hospitalization data from 12 March 2020 to 1 July 2021, test data from 1 August 2020 to 1 July 2021. The red curve corresponds to the assumed true process.
6 Discussion
A time-varying transmissibility allows to quantify the effects of interventions and changes in the behaviour of people, in real-time. This is of key importance to policy makers, as the interventions often have immense societal and health costs. Understanding, while an epidemic develops, whether the implemented interventions are sufficient or not, or if interventions could be lifted, is essential. The Norwegian government’s strategy was to control the epidemic, and this was achieved by multiple national and local non-pharmaceutical interventions, which are reflected in the temporal variations of the reproduction number. To our knowledge, our approach is the first which allows to monitor a daily-varying reproduction number when using a complex compartmental model informed by multiple streams of data. The fact that our estimates of react rapidly to changes in the test data, means that the situation is captured only with a delay given by the generation time of the disease under study and the time gap between transmission and testing. For Covid-19, this amounts to about a week, because of a generation time of about 5 days and a delay between transmission and test of about 2 days. Picking up an exponential growth () before the epidemic grows out of control is essential for surveillance. The possibility of our method to validate the efficacy of contact tracing, to lead back to below 1, or not, is also very important.
We have shown how daily reproduction numbers and the latent compartment-wise populations in an SEIR model can be put into a state space model, so that an SMC technique for inference can be used. Obtaining unbiased estimates of the marginal likelihoods also makes it possible to do parameter estimation within a PMCMC framework, although more work is needed here to make this computationally efficient. Compared to a parallel effort using ABC (Engebretsen et al., 2021), the SMC approach is much faster and also easier to modify with respect to model changes, confirming the findings in Birrell et al. (2020). Our implementation is modular, does not depend on the specific epidemic model (here SEIR), so that alternatives can easily be tested.
So far only simple bootstrap filters have been applied. This can be improved by utilizing more efficient proposals, alternative algorithms such as the resample-move algorithm (Gilks & Berzuini, 2001) which was used in Birrell et al. (2020) or the recent promising ideas of iterated auxiliary filters and twisted models (Guarniero et al., 2017; Heng et al., 2020). We expect these approaches to be very useful when we expand the SEIR model to have different reproduction numbers in each of the 11 Norwegian counties.
We compared three simple dynamics for and found that the AR model was slightly better than the others. More work needs to be done here to compare the models in terms of prediction. In our approach, it is easy to predict the future hospitalization incidence and the number of positive cases tested. Note however that such simple dynamic models for are mostly suitable for now-casting and for short term forecasting, because of the lack of stationary that interventions and feedbacks imply. There are then interesting questions on how to use our probabilistic prediction of the time-varying transmission strength to propagate uncertainty, in the context of variable planned interventions.
Estimation of (static) parameters is a challenging task in SMC. Several parameters related to the SEIR model, as well as parameters related to the observation processes, were pre-estimated based on external data sources. In Engebretsen et al. (2021), we used a version of ABC. Parameters in the dynamic process were estimated online based on the procedure of sufficient statistics, a method that can lead to degeneracy. We have also tested out the particle Metropolis-Hastings algorithm by Andrieu et al. (2010). However, convergence was slow and challenging, because of the computational cost of running the SMC algorithm even for a small number of particles. We validated our estimates in the supplementary material, and find that our online estimation procedure worked reasonably well for the given models and data. However, some experiments with the AR model when also including estimation of the parameter μ, did cause degeneracy problems as have been reported in in Andrieu et al. (2005). A more efficient SMC algorithm might be better in utilizing the potential of such algorithms to estimate static parameters. However, our estimates of appear to be relatively robust with respect to changes in these parameters. Other parameters related to the SEIR model and the observation processes can be more important.
Communicating uncertainty of estimates and the effect of stochastic and uncertain time lags from data back to infections, is a major challenge. Our current strategy has been to report estimates of the reproduction numbers one week back in time as the most reliable estimates, and this needs to be studied further.
As pointed out by one of the our reviewers, it is quite easy to extend the modelling approach (and the algorithm) to include dummy variables describing interventions made by the government. In this case, one would need to estimate a time delay between the time point in which the interventions are decided and when they effect viral transmission. This delay might change in time and be intervention specific. In our model, interventions appear in the data after a delay, and are then reflected in a change of the reproduction number. It is possible to interpret changes in the estimated reproduction numbers in the light of the interventions set in place.
Finally, it is interesting to compare the estimates of the instantaneous reproduction number produced by this SMC model, with the estimates obtained by models which keep the reproduction number constant over longer time intervals, for example over four weeks. The SMC-based is able to capture changes at shorter time scales significantly better, but possibly with larger uncertainty than estimates of reproduction numbers assumed to be constant over longer time periods, if the transmission has been stable during such periods. Comparing prediction power is a further aspects that can be examined. Results from our SMC model were used in the weekly reports of the Norwegian Institute of Public Health at least until April 2022, see www.fhi.no/en/publ/2020/weekly-reports-for-coronavirus-og-covid-19/.
Acknowledgments
We acknowledge the work of many colleagues at the Norwegian Institute of Public Health for the collection and preparation of the data. We thank the editor, the associate editor, and two anonymous reviewers for many valuable comments which have greatly improved the paper.
Funding
Funding for this project was provided by the centre BigInsight (NFR project 237718), the project ‘A real-time analytical pipeline for preparedness, planning and response during the Covid-19 pandemic in Norway’ (NFR project 312721), and the Nordic project ‘Data streams and mathematical modelling pipelines to support preparedness and decision making for Covid-19 and future pandemics’ (Nordforsk NordicMathCovid project).
Data availability
The data sets analysed in this paper come from the national emergency preparedness registry for Covid-19, owned by the Norwegian Institute of Public Health. The preparedness registry is temporary and comprises data from a variety of central health registries, national clinical registries, and other national administrative registries. Further information on the registry, including access to data, is available at www.fhi.no/en/id/infectious-diseases/coronavirus/emergency-preparedness-register-for-covid-19/. See also https://nordicmathcovid.cs.aalto.fi/data/. An R-package called smc.covid is available at github.com/geirstorvik/smc.covid. It contain scripts for running the SMC algorithm on some data examples. Because data are sensitive, not all data sets are public. The number of individuals in hospital and the number of positive cases per day are available, but the number of imported cases and the mobility matrices are confidential. For the two latter data sets we have therefore provided some simulated synthetic data sets which resemble the true ones.
Supplementary material
Supplementary material is available online at Journal of the Royal Statistical Society: Series A.
References
Author notes
Read before The Royal Statistical Society in London at the second meeting on ‘Statistical aspects of the Covid-19 Pandemic’ organized by the Discussion Meetings Committee on Thursday, 16 June 2022, Dr Shirley Coleman in the Chair.
Conflict of interest None declared.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}