





Abstract
Phenotyping consists in applying algorithms to identify individuals associated with a specific, potentially complex, trait or condition, typically out of a collection of Electronic Health Records (EHRs). Because a lot of the clinical information of EHRs are lying in texts, phenotyping from text takes an important role in studies that rely on the secondary use of EHRs. However, the heterogeneity and highly specialized aspect of both the content and form of clinical texts makes this task particularly tedious, and is the source of time and cost constraints in observational studies.
To facilitate the development, evaluation and reproducibility of phenotyping pipelines, we developed an open-source Python library named medkit. It enables composing data processing pipelines made of easy-to-reuse software bricks, named medkit operations. In addition to the core of the library, we share the operations and pipelines we already developed and invite the phenotyping community for their reuse and enrichment.
medkit is available at https://github.com/medkit-lib/medkit.
1 Introduction
The collection at large scale of Electronic Health Records (EHRs) and the constitution of Clinical Data Warehouses (CDW) enable the design of clinical studies relying on a secondary use of healthcare data (Madigan et al. 2014). A substantial part of the necessary information to conduct these studies is available in texts, such as clinical notes, hospitalization, or exam reports (Kharrazi et al. 2018). For instance, tasks such as the inclusion/exclusion of patients, and the extraction of outcome variables or covariates often require the consideration of clinical texts.
In biomedical data sciences, the two complementary tasks of either identifying individuals associated with a specific, potentially complex, trait or condition, or listing the traits of an individual are generally named phenotyping. And the specific case of phenotyping from clinical text is a continuous challenge for several reasons (Banda et al. 2018). First clinical text is highly specialized as it includes various factors of complexity such as medical entities absent from the general domain, hypotheses, negations, abbreviations, personal information; what motivates the development of dedicated phenotyping tools (Kreimeyer et al. 2017). Besides, many powerful Natural Language Processing (NLP) tools and models are developed and shared for both the general and biomedical texts, making reuse, adaptation, and chaining rational approaches in biomedicine. But the highly heterogeneous aspect of clinical texts (e.g. physician versus nurse notes, hospital A versus hospital B notes, French versus English notes) makes the performance of a tool hardly predictable on a new corpus. In addition, clinical texts can barely be shared because of their personal and sensitive aspects. This implies the need for tools that ease the evaluation and adaptation of phenotyping approaches to the various types of texts generated in the large variety of existing clinical settings.
We present here medkit, an open-source Python library, that aims primarily at facilitating the reuse, evaluation, adaptation, and chaining of NLP tools for the development of reproducible phenotyping pipelines. By extension, medkit enables the extraction of information related to patient care, such as treatments or procedures, which are not phenotype per se. The rest of this manuscript presents the core elements of the library, develops on its easiness of use and details example pipelines developed with medkit for the extraction of drug treatments from clinical texts. It lists other pipelines already developed and ready for reuse and ends on two particularity added values of the library, which are the support of nondestructive processing and provenance tracing.
2 Related work and positioning
The PheKB initiative proposes a collaborative web portal to share phenotyping algorithms in the form of semi-formal flow charts, documenting their steps and chaining (Kirby et al. 2016). In this manner, PheKB helps exchanging and standardizing phenotyping algorithms. However, provided representations are not shared with their computational implementations, which limits their reproducibility and comparison. In addition, algorithmic steps that rely on clinical texts are underspecified, as they usually require an adaptation to the peculiarities of local texts. The OHDSI community offers software tools such as Atlas, which proposes standard and reusable tools for the data analysis of observational studies from EHRs (Schuemie and DeFalco 2019). Those are developed for steps coming next to the information extraction, once features are structured and normalized. medkit fills this exact step, extracting and normalizing features from unstructured parts of EHRs. The MedCAT library targets this step as well but only focuses on entity recognition and normalization with the UMLS (Kraljevic et al. 2021). The Gate suite provides a graphical user interface which facilitates sequential application of various preprocessing and NLP tools on texts (Cunningham 2002). But Gate is mostly adapted to educational or exploratory purposes, because of its limited ability to analyze large corpora and to adapt to novel tools. NLTK (Bird et al. 2009), spaCy (Honnibal and Montani 2017) and FLAIR (Akbik et al. 2019) are Python libraries dedicated to advanced NLP development, designed for NLP engineers and researchers. Following a different way, medkit aims at being easier to start with, facilitating the reuse and chaining of simple-to-complex NLP tools, such as those developed with the previously cited libraries.
One of the main particularity of medkit is to place a strong emphasis on nondestructive operations, i.e. no information is lost when passing data from one step to another; and on a flexible tracing of data provenance. In this matter, medkit is original and found inspiration in bioinformatic workflow management systems, such as Galaxy and Snakemake (Mölder et al. 2021, Community 2022), which facilitate the reproducibility of bioinformatic pipelines.
3 The core components of medkit
For internal data management, medkit represents data with three simple core classes: Documents, Annotations, and Attributes. Each of these classes is associated with properties and methods to represent data and metadata of various modalities such as audio or images, even though medkit is primarily designed for text. A Document is the minimal data structure of medkit, which associates an identifier with a set of Annotations; in turn an Annotation associates an identifier, a label, and a set of Attributes; lastly Attributes associate an identifier, a label, and a value.
For data processing, medkit defines two main classes: Operations and Pipelines. Typically, an operation is taking data as an input, runs a function over these data and returns output data. For instance, an Operation can input a Document, perform Named Entity Recognition (NER) and output a set of Annotations associated with the Document. Accordingly, an operation can be the encapsulation of a previously developed tool, or a new piece of software developed in Python using medkit classes. Converters are particular operations for input and output management, which enable the transformation from standard formats such as CSV, JSON, Brat, Docanno annotations, into medkit Documents, Annotations and Attributes, or inversely. Lastly, Pipelines enable to chain Operations within processing workflows.
We refer readers to the medkit documentation for more details on its core components (see Availability for a web link).
4 Encapsulate, chain, and reuse operations
Numerous data processing tools exist, in particular in NLP, where pretrained models are routinely shared within libraries or platforms such as spaCy or Hugging Face (Honnibal and Montani 2017, Wolf et al. 2019). The goal of medkit is to facilitate their reuse, evaluation, and chaining. Following are examples of available medkit operations that reuse third-party tools: the Microsoft library named Presidio for text de-identification (Mendels et al. 2018); a date and time matcher from the EDS-NLP lib (Wajsburt et al.); text translator using transformers from the Hugging Face platform. Similarly, medkit operations enable the encapsulation of spaCy modules in particular by input, output and annotation conversion functions.
In addition, we internally developed original operations for: NER; relation extraction; preprocessing; deidentification; evaluation; the pre-annotation of clinical texts to speed-up manual annotation; the detection of negation, hypothesis, and antecedents within the context of entities; the fine-tuning of preexisting models; the classification of sentence and documents; the loading of audio patient-caregiver conversations, their diarisation and transcription to text (Nun et al.); and others. We aim at progressively enriching the catalogue of shared tools, thanks to the continuous growth of the community of medkit users and contributors.
The development of medkit pipelines is facilitated by three main elements. First, medkit data format asks for an initial conversion, but avoids further formatting in subsequent treatments. Second, sharing ready-to-use operations and open-source example pipelines speeds up the prototyping of new ones. Third, good practices in software development such as continuous integration, rich documentation facilitate start-off.
5 Example pipelines
As an illustration, we describe two medkit pipelines in Fig. 1 for the extraction of drug treatment from clinical texts. The first, in black, aims at comparing the performances of two NER tools named Drug NER 1 and 2, which are dictionary-based and Transformer-based methods respectively. Considering that Drug NER 2 obtained the best performances, the second pipeline is designed to use only the latter to extract the mentions of drug treatments from new texts. Both pipelines share three steps of preprocessing: conversion of raw texts into medkit Documents, sentence splitting and de-identification. The first pipeline evaluates the two tools on the basis of reference annotations saved as Brat format, whereas the second pipeline annotates new documents with drugs and produces output annotations in Brat format. A snippet of code for the medkit implementation of the second pipeline is shown in Fig. 2. The full implementation of the two pipelines is available at https://medkit-lib.org/cookbook/drug_ner_eval/.
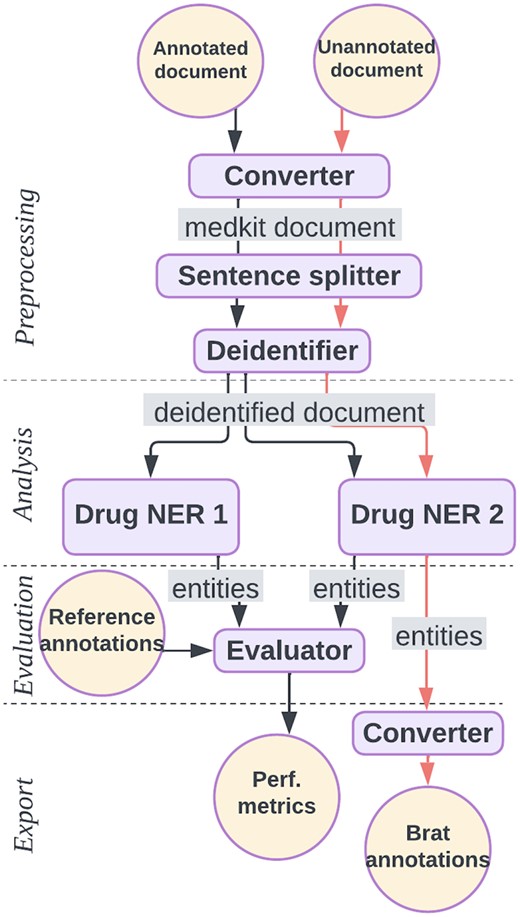
Example medkit pipelines. The black pipeline converts raw texts to the medkit format, deidentifies them, recognizes drug entities with two distinct tools and compute performances for comparison. The orange pipeline, performs the same preprocessing tasks, recognizes drugs with only Drug NER 2 and outputs annotations in the Brat format.

Snippet of the implementation of the orange pipeline of Fig. 1.
6 Available pipelines
We implemented and share pipelines for: the phenotyping of chemotherapy toxicities, and their grades (Rogier et al. 2022); the phenotyping of rheumatoid arthritis in French clinical reports (Fabacher et al. 2023b); the phenotyping of COVID-19 and the comparisons of pipelines relying either on the English versus French UMLS (Neuraz et al. 2024); the benchmarking of NER approaches on three clinical case corpora, comparing dictionary-based, transformer, and generative approaches (Hubert et al. 2024); the detection of text duplications in collections of clinical texts (Fabacher et al. 2023a). A last example of pipeline chains the recognition of drug, dates with a sentence classifier to detect treatment start and stop (Pohyer et al. 2024).
We refer the reader to the tutorial and cookbook sections of the medkit documentation for a list of available operations and examples of pipelines (see Availability for a web link).
7 Nondestructive processing and provenance
The medkit library features two noteworthy functionalities: nondestructive processing and flexible provenance tracing. Nondestructive processing ensures that no information is lost when passing from one operation to the next. This is of interest to get back on the raw text, after this one underwent various transformation steps, such as deidentification or character replacements. Nondestructive processing is enabled by the propagation of original spans through successive operations. We note that this functionality might be lost in the case of external and noncompliant tools encapsulated in medkit operations.
Provenance tracing consists in recording provenance data, i.e. meta-data documenting where data come from and how it was transformed. medkit implements this tracing by generating provenance data using the PROV-O standard ontology (Lebo et al. 2013). This tracing is flexible in the sense that users can set the level of verbosity and details they want to trace about the previous operations and states, in order to avoid generating large amounts of provenance data when those are unnecessary.
The unique combination of nondestructive processing and provenance tracing improves the explainability and reproducibility of results of pipelines of various level of complexity. These functionalities, along with its open-source nature and its focus on interoperability with existing libraries, pipelines, and models, make it well aligned with the FAIR principles for research software (Barker et al. 2022).
8 Availability
medkit is hosted at https://github.com/medkit-lib/medkit, and released under an MIT license. Its documentation, with examples and tutorials, is hosted at https://medkit-lib.org/.
9 Conclusion and perspectives
medkit is an open-source library for the composition of data processing pipelines made of easy-to-reuse software bricks, which aim at facilitating phenotyping from clinical texts. In addition to the core of the library, we share many of these bricks and examples of pipelines, and invite the phenotyping community for their reuse and enrichment.
So far, medkit enables linear execution of pipelines over a set of documents. Whereas it is simple to distribute the execution of pipelines by splitting a large corpus in subsets, parallelization within pipelines is not supported yet, but is planned for the future. We would like to grow the community of users of medkit, first by developing a searchable library of available operations, by enriching this library and enabling users to share their own pipelines. Pipelines may be showcased in a gallery of examples to inspire and facilitate reuse. Next developments will concern operations for the generation of features that are compliant with the OMOP Common Data Model, and operations that facilitate the use of large language models and prompting.
Acknowledgements
Authors thank users of medkit, L.-A. Guiottel, M. Hassani, S. Cossin, T. Hubert, and V. Pohyer for their insightful inputs.
Author contributions
C.A., O.B. and K.T.H.: Conceptualization, Software, Writing—review & editing. T.F. and A.R.: Software, Writing—review & editing. G.V., N.G., B.R.: Conceptualization, Project administration, Software, Supervision, Writing—review & editing. I.L.: Conceptualization, Funding acquisition, Software, Writing—review & editing. A.N. and A.C. Conceptualization, Funding acquisition, Project administration, Software, Supervision, Writing—original draft, Writing—review & editing.
Conflict of interest: No competing interest to declare.
Funding
This work was supported by Inria, Inria Paris; and the ANR under the France 2030 program [ANR-22-PESN-0007].


{kind=link}
{kind=link}