





ABSTRACT
We employ the eXtreme Gradient Boosting (XGBoost) machine learning (ML) method for the morphological classification of galaxies into two (early-type, late-type) and five (E, S0–S0a, Sa–Sb, Sbc–Scd, Sd–Irr) classes, using a combination of non-parametric (|$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, c_{5090}$|), parametric (Sérsic index, n), geometric (axial ratio, |$BA$|), global colour (|$g-i,\, u-r,\, u-i$|), colour gradient [|$\Delta (g - i)$|], and asymmetry gradient (|$\Delta A_{9050}$|) information, all estimated for a local galaxy sample (|$z\lt 0.15$|) compiled from the Sloan Digital Sky Survey imaging data. We train the XGBoost model and evaluate its performance through multiple standard metrics. Our findings reveal better performance when utilizing all 14 parameters, achieving accuracies of 88 per cent and 65 per cent for the two-class and five-class classification tasks, respectively. In addition, we investigate a hierarchical classification approach for the five-class scenario, combining three XGBoost classifiers. We observe comparable performance to the ‘direct’ five-class classification, with discrepancies of only up to 3 per cent. Using Shapley Additive Explanations (an advanced interpretation tool), we analyse how galaxy parameters impact the model’s classifications, providing valuable insights into the influence of these features on classification outcomes. Finally, we compare our results with previous studies and find them consistently aligned.
1 INTRODUCTION
According to the standard Lambda cold dark matter (|$\Lambda$|CDM) paradigm, galaxies originate in dark matter haloes undergoing a process of continuous mergers in a first stage. However, as the universe expands and redshift decreases, these mergers become less frequent and galaxy evolution becomes internally driven by the so-called secular processes. All these processes collectively shape what we observe today as galaxy morphology.
Since Hubble’s morphological classification scheme (Hubble 1926, 1936), galaxies have been systematically categorized, revealing that morphology is strongly correlated with star formation activity (Strateva et al. 2001; Blanton et al. 2005; Blanton & Moustakas 2009; Kormendy et al. 2009; Conselice 2014). For instance, the bimodal distribution of galaxies in optical colours, characterized by a blue cloud, a red sequence, and an intermediate green valley, is highly linked to morphological types (e.g. Strateva et al. 2001; Blanton et al. 2003; Baldry et al. 2006; Pearson et al. 2021). Furthermore, morphology correlates with various physical properties, such as stellar distribution, colour, environment, gas content, size, and kinematics (e.g. Blanton et al. 2005; Zehavi et al. 2005; Cappellari et al. 2011; Pérez-Millán et al. 2023; Ghosh et al. 2024). Therefore, the classification of galaxies in the nearby universe, based on their physical attributes, is fundamental to understanding their formation and evolution.
For years, many authors have tried to classify galaxies through a traditional visual classification, where they manually assign morphological types directly from images (e.g. Fukugita et al. 2007; Nair & Abraham 2010; Vázquez-Mata et al. 2022). However, this method becomes inefficient as the number of galaxies to classify increases. This challenge is amplified by the current and next generation of large-scale surveys, like the Dark Energy Spectroscopic Instrument (DESI; DESI Collaboration 2016), Euclid (Laureijs et al. 2011), The Legacy Survey of Space and Time (LSST; Ivezić et al. 2008, 2019; Robertson et al. 2019), and The Square Kilometre Array (SKA; Braun et al. 2019), which will generate unprecedented amounts of high-resolution data (images and spectra for billions of objects in the Universe), making it essential to develop new sophisticated and efficient tools to process and analyse such a vast information.
In recent years, several approaches have emerged for the large-scale morphological analysis and automatic classification of galaxies. Visually based methods, such as the Galaxy Zoo (GZ) project (Lintott et al. 2008; Willett et al. 2013; Walmsley et al. 2022), have exploited human pattern recognition capabilities through crowdsourcing to successfully classify thousands of galaxies over a few years. However, even at that rate, classifying the amount of galaxies expected from upcoming surveys would be impossible. Other authors have instead utilized the structural information provided by high-resolution imaging in the form of parametric and non-parametric properties of the observed light distribution of galaxies (e.g. Lotz, Primack & Madau 2004; Cheng et al. 2011; Conselice 2014, and references therein). More recently, machine learning (ML) techniques have shown significant success in predicting galaxy morphology purely from images (e.g. Dieleman, Willett & Dambre 2015; Ghosh et al. 2020; Domínguez Sánchez et al. 2022, and references therein). Among the ML methods employed are Random Forests (de la Calleja & Fuentes 2004a), Locally Weighted Regression (de la Calleja & Fuentes 2004b), and Convolutional Neural Networks (e.g. Dieleman et al. 2015; Huertas-Company et al. 2015; Pérez-Carrasco et al. 2019; Walmsley et al. 2020; Cavanagh, Bekki & Groves 2021; Domínguez Sánchez et al. 2022), all based on supervised ML. More recently, other authors like Martin et al. (2019, 2020), Cheng et al. (2021), Hayat et al. (2021), Zhou et al. (2022), Wei et al. (2022), and Dai et al. (2023) have explored state-of-the-art techniques based on unsupervised or self-supervised ML methods. Parker et al. (2024) presented AstroCLIP, a sophisticated approach that utilizes a pretrained Vision Transformer model capable of embedding both galaxy images and spectra into a shared, physically meaningful latent space. AstroCLIP has different applications, including the morphological classification of galaxies, where it was tested on the GZ questions, achieving accuracies ranging from 0.44 to 0.97, depending on the specific question.
While Deep Learning models have been very successful, particularly for image-based predictions, they require a large amount of data for training and powerful computational resources, including GPUs, for effective implementation. Moreover, they are generally harder to interpret compared to simpler ML techniques. In recent years, various authors have investigated an alternative approach that incorporates physical information, utilizing structural properties to predict galaxy morphology through various ML techniques. For instance, Sreejith et al. (2018) employed multiple ML models to classify galaxies into five distinct categories within the Galaxy and Mass Assembly survey (Driver et al. 2011; Liske et al. 2015), using photometric structural parameters (e.g. Sérsic index, ellipticity) and achieving an average accuracy of 75 per cent. Similarly, Barchi et al. (2020) applied ML techniques using a modified version of the |$CAS$| (Concentration, Asymmetry, Smoothness) parameters, along with entropy (Bishop 2006; Ferrari, de Carvalho & Trevisan 2015) and the new Gradient Pattern Analysis (GPA; Rosa et al. 2018) parameter, to separate late- from early-type galaxies with a 98 per cent accuracy. However, this accuracy decreases to |$\sim$|65 per cent when attempts are made to distinguish morphological types into finer-grained sub-classes. Tarsitano et al. (2022) proposed constructing a 1D sequence from the elliptical isophotes of the galaxies’ light distribution to automatically classify them as early- or late-type. Using the eXtreme Gradient Boosting (XGBoost) ML model, they achieved class accuracies of 86 per cent and 93 per cent, respectively. Mukundan et al. (2024) considered a set of only structural parameters to classify the 11 morphological types reported by Nair & Abraham (2010), utilizing the k-nearest neighbours algorithm. Their classification achieved an average accuracy of approximately 80–90 per cent for each morphological type. However, it should be noted that this level of accuracy was only achieved when a prediction is deemed successful if it falls within |$\pm$|2 T-Types of the original classification.
In this paper, we take advantage of previous results and employ not only a set of structural parameters, as used in previous works, but also integrate a set of colour parameters that capture the star formation properties of galaxies. We have compiled a sample of |$\sim$|18 000 local galaxies, each with detailed visual morphological classifications and a comprehensive set of 14 galaxy parameters. These include well-known structural parameters such as |$CAS$|, Gini (Lotz et al. 2004), |$M_{20}$| (Lotz et al. 2004), shape asymmetry (|$A_\mathrm{ S}$|), Sérsic index (n; Sérsic 1963), and axial ratio (|$BA$|), as well as newer parameters like asymmetry gradient (|$\Delta A_{9050}$|; Hernández-Toledo et al., in preparation), along with star-formation indicators like three colour indices (|$g-i$|, |$u-r$|, and |$u-i$|) and a new colour gradient (|$\Delta (g-i)$|). All parameters were homogeneously estimated from the Sloan Digital Sky Survey (SDSS) images and used to train XGBoost (Chen & Guestrin 2016) models for automatic galaxy classification. We explore various classification tasks, including binary and five-class classifications, experimenting with different parameter configurations to enhance the performance of the models. Additionally, we assess the effectiveness of both direct and hierarchical classification approaches. To further understand the results of the automated classification, we employ interpretation tools to analyse the influence of different galaxy parameters on the model’s predictions. Finally, we discuss possible error sources that could affect model performance, providing a comprehensive evaluation of our methodology and results.
This paper is organized as follows. In Section 2, we describe the data compilation and provide a brief description of the structural and star formation parameters selected for the classification. Section 3 details XGBoost, including the hyperparameter settings used in our experiments, as well as the classification tasks and parameter configurations explored. Section 4 presents the performance results of the trained models, covering both direct and hierarchical approaches. In Section 5, we discuss the obtained results, including model interpretation (Section 5.1), possible error sources (Section 5.2), and comparison with existing works (Section 5.3). Finally, the concluding remarks and a brief summary are presented in Section 6.
2 DATA SET
2.1 Galaxy sample
To carry out an automatic classification using supervised ML methods, it is essential to have a robust training sample with a detailed and trustworthy morphological classification. In this sense, direct visual classification is the most reliable method, as expert classifiers visually examine each object and assign a morphological type following a standard classification scheme. In this work, we considered two existing catalogues with detailed visual classifications: (1) the Nair & Abraham (2010, hereafter NA10) catalogue, which contains |$\sim$|14 000 classified galaxies based on SDSS |$gri$| colour composited images and (2) the Visual Morphology Catalogue for the Mapping Nearby Galaxies (MANGA; Vázquez-Mata et al. 2022, hereafter VM22), which includes |$\sim$|10 500 galaxies classified using digitally post-processed images from the DESI Legacy Imaging r-band Survey (Dey et al. 2019). Both catalogues followed a similar classification scheme using the Hubble T-Type number codes as described in Table 1. We have merged the morphological results from both catalogues, obtaining a total sample of |$\sim$|24 500 galaxies, with |$\sim$|3000 galaxies in common. Notice that, although the morphological classifications in these catalogues are based on different image surveys, VM22 have shown that the morphological classification for the galaxies in common differs by |$\Delta T_{\mathrm{ Type}} =|T_{\mathrm{ VM22}}-T_{\mathrm{ NA10}}|$| = 1.3, in agreement with the expected differences between classifiers found in other works (e.g. in Naim et al. 1995). Therefore, for those galaxies in common we adopt the classification reported by VM22.
Aside from 3000 galaxies in common, the merged sample was also refined by eliminating galaxies coded in both NA10 and VM22 as showing evidence of advanced mergers and strongly perturbed galaxies, both lacking a clear and well-identifiable Hubble morphology, which is a main requisite for this study. We note that the correct identification of mergers and their morphological analysis is highly relevant due to their role in galaxy evolution; however, this is beyond the scope of this work. Our final sample consists of 19 012 galaxies with detailed morphological classification. The redshift (z) limit is 0.15 with an apparent r-band magnitude limit of 17.2, and an absolute |$M_{r}$| magnitude in the range (−24, −16). The overall distributions of the combined sample are presented in Fig. 1, where the z and magnitudes information is coming from the SDSS data base (NASA-Sloan Atlas, NSA catalogue; Blanton et al.2011).
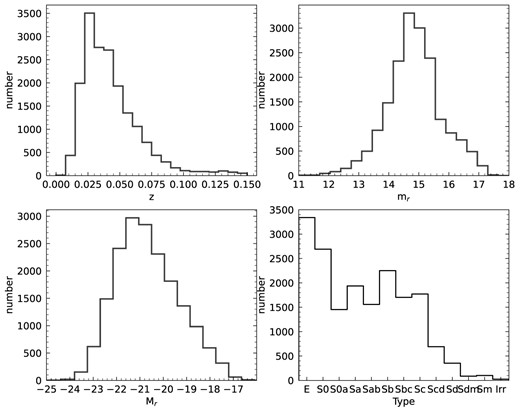
Histograms of some general properties for the final sample in this work. This includes redshift (upper left), apparent (upper right), and absolute r-band magnitude (lower left) adopted from the NSA catalogue, Blanton et al. 2011, and the corresponding morphology (lower right) adopted from the NA10 and VM22 catalogues.
In the following section, we briefly summarize the definitions and corrections adopted for the structural, gradient, and colour parameters used in this paper.
2.2 Structural and star formation parameters
Our approach to predict (parametric and non-parametric) structural parameters requires the analysis of the surface brightness distribution of galaxies on the images. The r-band structural parameters were adopted from an homogeneous estimate by Nevin et al. (2023) for a massive set of galaxies from the SDSS-DR16 photometric catalogue. Since the reliability of these parameters as classification tools is cl osely tied to the properties of the intervening images (namely their resolution and average signal-to-noise ratio per pixel, |$\langle \mathrm{ S/N}\rangle $|; e. g. Lotz et al. 2004), we implemented a minimum cut-off of |$\langle \mathrm{ S/N}\rangle \gt 2.5$|. Most of the SDSS galaxies in our final sample have |$\langle \mathrm{ S/N}\rangle $| values between 5 and 10, corresponding roughly to r-band magnitudes brighter than 16 mag, which is well below the r-band flux limit of the SDSS images (17.7 mag), guaranteeing reliable estimates for this study. Note that Tarsitano et al. (2018) have generated one of the largest samples of structural and morphological parameters for galaxies based on deeper images from the DES survey; unfortunately the overlap with our sample is minimal.
We also estimated a complementary set of parameters related to the star formation activity, specifically the colour gradient and asymmetry gradient parameters. For that purpose, we retrieved 800 pixel |$\times$| 800 pixel g, r, and i-band cut-outs from the SDSS-DR13 data base, centred on the right ascension and declination of each galaxy in our sample. We segmented each cut-out using SExtractor (Bertin & Arnouts 1996) to characterize the background and identify the sources at a given threshold. Once the background is subtracted and the nearby sources were identified and masked, we proceeded to estimate the colour gradient |$\Delta (g-i)$| parameter at two different radii (50 per cent and 90 per cent of a Petrosian radius, |$R_\mathrm{Pet}$|, for each galaxy), following Park & Choi (2005). In a similar way, we estimated a new asymmetry gradient parameter (|$\Delta A_{9050}$|), which measures the asymmetry of the surface brightness distribution of a galaxy at two different radii (50 per cent and 90 per cent of |$R_\mathrm{Pet}$|), following Hernández-Toledo et al. (in preparation, see description below).
Once all structural and star formation parameters were estimated, we further proceeded to a final refinement of the sample by excluding the galaxies with incomplete parameter information. We also excluded galaxies considered as outliers in the colour–colour gradient and colour–asymmetry gradient diagrams, comprising a final sample of 17 966 galaxies.
In the following, we summarize the definitions of the gradient and colour index parameters.
Colour gradient (|$\Delta (g-i)$|): Radial colour gradients arise from underlying age and metallicity gradients. Late-type galaxies exhibit a more pronounced stellar colour and age gradients, giving rise to, for example, negative colour gradients (redder cores and bluer outskirts), expected in galaxy mass assembly scenarios. Park & Choi (2005) found that the colour–colour gradient diagram is a good morphology classification tool. They calculated the colour gradient, |$\Delta (g-i)$| by comparing the |$g-i$| colour in two regions of a galaxy. Specifically, they proposed to adopt the difference in |$(g-i)$| colour between the region with |$R \lt 0.5 R_\mathrm{Pet}$| and that of the annulus with |$0.5 R_\mathrm{Pet} \lt R \lt R_\mathrm{Pet}$|, where |$(g-i)$| is rest frame K-corrected. Hence, a negative colour difference means the galaxy becomes bluer towards the outside.
Asymmetry gradient (|$\Delta A_{9050}$|): Following the ideas in Park & Choi (2005), we estimate a new gradient parameter involving the difference of asymmetries in two regions of a galaxy, |$A_{50}$|: |$0 \lt R \lt 0.5 R_\mathrm{Pet}$| and |$A_{90}$|: |$0.5R_\mathrm{Pet} \lt R \lt R_\mathrm{Pet}$|, such that |$\Delta A_{9050} = A_{90}-A_{50}$|. After background subtraction and masking of the galaxy up to an external |$r_\mathrm{max} \sim 2 R_\mathrm{Pet}$|, we follow Conselice (2003) to estimate what we name as the asymmetry gradient within that region. This metric takes advantage of the fact that as spiral galaxies go from early to late types, they gradually open their spiral arms while increasing the presence and resolution of clumpy regions. This results in a more pronounced asymmetry in the outer regions compared to the inner/bulge regions, leading to more negative asymmetry gradients (more symmetric inner regions and more asymmetric outskirts) compared to early-type spirals. In this paper, we test the ability of |$\Delta A_{9050}$| as a morphological segregator. Similar to the concentration index (see comments below), in a forthcoming paper (Hernández-Toledo et al. in preparation) we will be exploring the robustness and stability of |$\Delta A_{9050}$|. This feature study will examine whether factors like radial extent and other observational errors introduce biases related to image properties such as exposure depth, signal-to-noise ratio, image pre-processing methods, etc.
Colour index parameters: The colours of galaxies reflect their dominant stellar populations. Strateva et al. (2001) proposed the |$u-r$| colour to distinguish between early-type and late-type galaxies. In this work, we considered three colour index parameters after correcting for galactic extinction and K-correction: |$g-i$|, |$u-r,$| and |$u-i$|, all obtained from the NSA catalogue.
We also present a brief summary of the definitions behind the non-parametric structural parameters used in this work:
- Concentration (C): This parameter measures the distribution of light within a galaxy and how centrally concentrated this is. Specifically, the definition adopted in this work is:(1)$$\begin{eqnarray} C=5 \log \left(R_{80}/R_{20}\right), \end{eqnarray}$$
where |$R_{80}$| and |$R_{20}$| are the circular radius that contains 80 per cent and 20 per cent, respectively, of the total flux of the galaxy (Lotz et al. 2004). The total flux is defined as the flux contained within 1.5 |$R_\mathrm{Pet}$| of the galaxy centre (Conselice 2003).
- Inverse concentration index (|$c_{5090}$|): It offers an alternative view of light concentration, and it is defined as(2)$$\begin{eqnarray} c_{5090} = R_{50}/R_{90}, \end{eqnarray}$$
where |$R_{50}$| and |$R_{90}$| are the radii from the centre of the galaxy containing 50 per cent and 90 per cent of the Petrosian flux, respectively. With this definition, higher values of |$c_{5090}$| indicate more light contained in the central regions of the galaxy. |$R_{50}$| and |$R_{90}$| were obtained from the NSA catalogue. In this paper, we adopt these standard definitions of concentration, however, at this point the reader may notice that other definitions showing a robust behaviour against changes of external radius (related to exposure depth and other observational errors; cf. Graham, Trujillo & Caon 2001) could be used and will be explored in future works.
- Asymmetry (A): This parameter quantifies the degree of rotational symmetry in the galaxy light distribution. In particular, A is measured by subtracting the galaxy image rotated by 180 deg about the centre, |$I_{180}$|, from the original image, I (e.g. Conselice, Bershady & Jangren 2000; Lotz et al. 2004):(3)$$\begin{eqnarray} A = \frac{\Sigma _{i,j} \left| I(i,j)-I_{180}(i,j) \right|}{\Sigma _{i,j} \left| I(i,j) \right|}-B_{180}, \end{eqnarray}$$
where |$B_{180}$| is the average asymmetry of the background, which is a correction for background noise. A is summed over all pixels |$(i,j)$| within 1.5 |$R_\mathrm{Pet}$|. The galaxy centre is determined by minimizing A as in Lotz et al. (2004). Galaxies with higher A values tend to have more irregular or disturbed structures.
- Clumpiness (S): By quantifying the fraction of light in a galaxy contained in clumpy distributions, S indicates the degree of small-scale structure in a galaxy. From Conselice (2003) and Lotz et al. (2004), S is calculated as(4)$$\begin{eqnarray} S = \frac{\Sigma _{i,j} \left| I(i,j)-I_S(i,j) \right|}{\Sigma _{i,j} \left| I(i,j) \right|}-B_\mathrm{ S}, \end{eqnarray}$$
where |$I(i,j)$| is the original image and |$I_\mathrm{ S}(i,j)$| is its smoothed counterpart, which is smoothed by a boxcar of width 0.25 |$R_\mathrm{Pet}$|. |$B_\mathrm{ S}$| is the average smoothness of the background. S is summed over all pixels |$(i,j)$| within 1.5 |$R_\mathrm{Pet}$| of the galaxy centre. Since the centres of galaxies often are highly concentrated, the central pixels within the smoothing length of 0.25 |$R_\mathrm{Pet}$| are excluded from the calculation.
Shape Asymmetry (|$A_\mathrm{ S}$|): It is similar to A, but it is calculated using a binary detection mask instead of the image itself (for more details, see Pawlik et al. 2016; Rodriguez-Gomez et al. 2019). |$A_\mathrm{ S}$| is more sensitive to low-surface brightness tidal features than A.
- Gini: This parameter measures the inequality in the distribution of pixel intensities within a galaxy image. Gini correlates with C, however, it does not assume that the brightest pixels are in the central region of the galaxy. Gini is defined by Lotz et al. (2004) as(5)$$\begin{eqnarray} \mathrm{ Gini} = \frac{1}{\left| \overline{f} \right| N(N-1)} \sum _i^N (2i-N-1) \left| f_i \right|, \end{eqnarray}$$
where N is the number of pixels assigned to the galaxy, |$\overline{f}$| is the average flux value, and |$f_i$| is the flux value for each pixel. The pixels are previously ordered by increasing flux value. If Gini is 0, the light is evenly distributed over all galaxy pixels, while if Gini is 1, all the flux is concentrated in just one pixel.
- |$M_{20}$|: It describes the second-order moment of the brightest 20 per cent of the spatial distribution of the galaxy flux (Lotz et al. 2004) and does not assume a central concentration. Mathematically, the total second-order moment, |$M_\mathrm{tot}$|, is(6)$$\begin{eqnarray} M_\mathrm{tot} = \sum _i^N M_i = \sum _i^N f_i \left[\left(x_i-x_\mathrm{ c} \right)^2 + \left(y_i-y_\mathrm{ c} \right)^2 \right], \end{eqnarray}$$where |$f_i$| is the flux in pixel (|$x_i,y_i$|) and (|$x_\mathrm{ c},y_\mathrm{ c}$|) is the galaxy centre which is determined by minimizing |$M_\mathrm{tot}$|. Then, to compute |$M_{20}$|, the galaxy pixels are ranked by flux in descending order and |$M_i$| is summed over the brightest pixels until that sum equals 20 per cent of the total galaxy flux, |$f_\mathrm{tot}$|, and then normalized by |$M_\mathrm{tot}$|:(7)$$\begin{eqnarray} M_{20} = \log _{10} \left(\frac{\Sigma _i M_i}{M_\mathrm{tot}} \right),\, \mathrm{while}\, \sum _i f_i \lt 0.2 f_\mathrm{tot}, \end{eqnarray}$$
|$M_{20}$| is similar to C, however, a |$M_{20}$| value denoting a high concentration (a very negative value) does not imply a central concentration, as the centre of the galaxy is a free parameter. Hence, it provides information about the presence of multiple components, such as bright knots or companion galaxies.
We also describe the definition of the parametric structural Sérsic index:
- Sérsic index (n): This parameter describes the shape of the light profile of a galaxy. It is derived from fitting a Sérsic profile (Sérsic 1963) to the galaxy brightness distribution:(8)$$\begin{eqnarray} I(R) = I_\mathrm{ e} \exp \left(-b_n \left[\left(\frac{R}{R_\mathrm{ e}} \right)^{1/n}-1 \right] \right), \end{eqnarray}$$
where |$I(R)$| is the intensity within a circular radius, R, and |$I_\mathrm{ e}$| is the intensity at the effective radius (|$R_\mathrm{ e}$|), which is the radius that contains half of the total light. |$b_n$| is a constant that depends on the Sérsic index, n. The Sérsic index, n, can indicate whether a galaxy has a steep (high n) or shallow (low n) central brightness profile, providing insights into its bulge or disc dominance.
Finally, we adopt a geometric parameter as a measure of the shape of galaxies:
|$BA$|: We adopt the axial ratio |$b/a$|, from a two-dimensional, single component Sérsic fit in the r band, as reported in the NSA catalogue up to |$R_\mathrm{Pet}$|. In this case, the definition of the |$R_\mathrm{Pet}$| is based on the SDSS r band using elliptical instead of circular apertures.
3 METHODOLOGY
In this section, we introduce the experimental setup to explore the effectiveness of various classification strategies, including different parameter configurations. Additionally, we briefly describe XGBoost and provide the hyperparameter values adopted in this work.
3.1 Experimental setup
To assess the model’s ability to distinguish between various morphological types, we explore different re-categorizations of the sample galaxies. Table 2 outlines our proposed re-categorizations and details the galaxy distribution for each class. The first re-categorization, referred to as 2cats (first row), involves a broad classification between early-type (T-Types: −5 to 0) and late-type (T-Types: 1 to 10) galaxies, providing a baseline for model performance. The 5cats re-categorization (second row) introduces a finer classification, grouping the galaxies into five morphological classes: (−5), (−3, −2, 0), (1, 2, 3), (4, 5, 6), and (7, 8, 9, 10), to evaluate the model’s ability to handle a more complex classification (T-Types are presented in Table 1). In the Early re-categorization (third row), we focus only on early-type galaxies, sub-classifying them into ellipticals (T-Type −5) and lenticulars (T-Types: −3, −2, and 0) to test the model’s performance in distinguishing between these closely related morphological classes. Finally, the late re-categorization (fourth row) concentrates exclusively on late-type galaxies, classifying them into three groups: (1, 2, 3), (4, 5, 6), and (7, 8, 9, 10), which helps us to assess the model’s capability to differentiate among various types of spirals galaxies.
| Category | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 2cats | –5, –3, –2, 0 | 1–10 | – | – | – |
| (E–S0a) | (Sa–Irr) | – | – | – | |
| 7485 | 10 481 | – | – | – | |
| 5cats | –5 | –3, –2, 0 | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 |
| (E) | (S0|$^-$|–S0a) | (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | |
| 3340 | 4145 | 5749 | 4167 | 565 | |
| Early | –5 | –3, –2, 0 | – | – | – |
| (E) | (S0|$^-$|–S0a) | – | – | – | |
| 3340 | 4145 | – | – | – | |
| Late | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 | – | – |
| (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | – | – | |
| 5749 | 4167 | 565 | – | – |
| Category | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 2cats | –5, –3, –2, 0 | 1–10 | – | – | – |
| (E–S0a) | (Sa–Irr) | – | – | – | |
| 7485 | 10 481 | – | – | – | |
| 5cats | –5 | –3, –2, 0 | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 |
| (E) | (S0|$^-$|–S0a) | (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | |
| 3340 | 4145 | 5749 | 4167 | 565 | |
| Early | –5 | –3, –2, 0 | – | – | – |
| (E) | (S0|$^-$|–S0a) | – | – | – | |
| 3340 | 4145 | – | – | – | |
| Late | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 | – | – |
| (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | – | – | |
| 5749 | 4167 | 565 | – | – |
| Category | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 2cats | –5, –3, –2, 0 | 1–10 | – | – | – |
| (E–S0a) | (Sa–Irr) | – | – | – | |
| 7485 | 10 481 | – | – | – | |
| 5cats | –5 | –3, –2, 0 | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 |
| (E) | (S0|$^-$|–S0a) | (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | |
| 3340 | 4145 | 5749 | 4167 | 565 | |
| Early | –5 | –3, –2, 0 | – | – | – |
| (E) | (S0|$^-$|–S0a) | – | – | – | |
| 3340 | 4145 | – | – | – | |
| Late | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 | – | – |
| (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | – | – | |
| 5749 | 4167 | 565 | – | – |
| Category | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 2cats | –5, –3, –2, 0 | 1–10 | – | – | – |
| (E–S0a) | (Sa–Irr) | – | – | – | |
| 7485 | 10 481 | – | – | – | |
| 5cats | –5 | –3, –2, 0 | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 |
| (E) | (S0|$^-$|–S0a) | (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | |
| 3340 | 4145 | 5749 | 4167 | 565 | |
| Early | –5 | –3, –2, 0 | – | – | – |
| (E) | (S0|$^-$|–S0a) | – | – | – | |
| 3340 | 4145 | – | – | – | |
| Late | 1, 2, 3 | 4, 5, 6 | 7, 8, 9, 10 | – | – |
| (Sa–Sb) | (Sbc–Scd) | (Sd–Irr) | – | – | |
| 5749 | 4167 | 565 | – | – |
In addition to these re-categorizations, we investigate the influence of different galaxy parameters on classification performance by combining them into four distinct groups (detailed in Table 3), each representing a different aspect of the galaxy’s physical characteristics. The first configuration, termed ‘Colour’, encompasses the parameters related to colour and colour gradients, namely |$g-i,\, u-r,\, u-i$|, and |$\Delta \left(g-i \right)$|. The ‘Structural1’ configuration comprises eight classical structural parameters: |$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, n,$| and |$c_{5090}$|. Expanding upon Structural1, the ‘Structural2’ configuration adds further structural parameters, including the semiminor to semimajor axial ratio (|$BA$|) and the asymmetry gradient (|$\Delta A_{9050}$|). Finally, the ‘S2+C’ configuration combines the Structural2 and Colour parameter sets, encompassing all 14 parameters. These four configurations allow us to assess the contribution of each parameter set to the model’s overall performance.
Different galaxy parameter configurations adopted in this work.
| Configuration | Set of parameters |
|---|---|
| Colour | |$g-i,\, u-r,\, u-i,\, \Delta (g-i)$| |
| Structural1 | |$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, n,\, c_{5090}$| |
| Structural2 | Structural1 + |$BA,\, \Delta A_{9050}$| |
| S2+C | Structural2 + Colour |
| Configuration | Set of parameters |
|---|---|
| Colour | |$g-i,\, u-r,\, u-i,\, \Delta (g-i)$| |
| Structural1 | |$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, n,\, c_{5090}$| |
| Structural2 | Structural1 + |$BA,\, \Delta A_{9050}$| |
| S2+C | Structural2 + Colour |
Different galaxy parameter configurations adopted in this work.
| Configuration | Set of parameters |
|---|---|
| Colour | |$g-i,\, u-r,\, u-i,\, \Delta (g-i)$| |
| Structural1 | |$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, n,\, c_{5090}$| |
| Structural2 | Structural1 + |$BA,\, \Delta A_{9050}$| |
| S2+C | Structural2 + Colour |
| Configuration | Set of parameters |
|---|---|
| Colour | |$g-i,\, u-r,\, u-i,\, \Delta (g-i)$| |
| Structural1 | |$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, n,\, c_{5090}$| |
| Structural2 | Structural1 + |$BA,\, \Delta A_{9050}$| |
| S2+C | Structural2 + Colour |
Furthermore, seeking to optimize the model’s performance, we also explore two classification approaches for distinguishing between galaxy types using ML models: direct classification and hierarchical classification. In the direct classification approach, a single XGBoost model is trained to perform the entire classification task in one step, distinguishing between all galaxy classes directly according to the chosen re-categorization. This straightforward method serves as a baseline, providing initial insights into the model’s capacity to handle different levels of classification tasks.
In contrast, the hierarchical classification approach breaks down the classification process into a series of steps, each focusing on a specific classification task. As a first step, we train an XGBoost model for a binary classification to distinguish between early-type and late-type galaxies (i.e. the 2cats classification). Once the galaxies are separated into these two broad groups, two additional XGBoost models are trained: one to only sub-classify the early-type galaxies into ellipticals and lenticulars (based on the Early re-categorization, see Table 2) and another to just differentiate the late-type galaxies into three spiral classes (according to the Late re-categorization). Note that this hierarchical approach is only implemented to differentiate between the five galaxy groups outlined for the 5cats re-categorization by training three separate models. The performance of the hierarchical approach is evaluated by combining the results of the individually trained models and comparing them to the direct 5cats classification results.
Throughout this work, we evaluate and compare each classification task (galaxy re-categorization), parameter configuration, and classification approach, aiming to explore the model’s performance across different levels of classification complexity and input data information. The results of these experiments will provide insights into the relative importance of different types of galaxy parameters in morphological classification, the model’s ability to handle diverse classification tasks, and the efficacy of direct versus hierarchical classification approaches.
For all experiments, we adopt a stratified split of the data set (17 966 galaxies), with 70 per cent (12 576 galaxies) allocated for training and 30 per cent (5390 galaxies) for testing. This stratified split ensures that the distribution of galaxies across different classes remains consistent between the training and testing subsets, preserving the relative proportions for each re-categorization.
Additionally, we apply a stratified three-fold cross-validation, where the training subset is randomly split into three stratified folds. Two of the three folds are used to train the model, and the remaining fold is used as validation subset to evaluate the model’s performance. The above process is repeated for all three permutations, ensuring each fold is used once as the validation subset. To obtain a more robust estimation of the model’s performance, we repeated the three-fold cross-validation process 10 times, where each repetition involves a different stratified random split of the training subset into folds. The resulting performance metrics (e.g. accuracy, precision, etc., see Section 4.1) are averaged across the complete process to estimate the model performance. Finally, to assess the model’s performance on unseen data, we further evaluate it on the test subset (30 per cent of the data set).
3.2 XGBoost model
XGBoost, short for eXtreme Gradient Boosting (Chen & Guestrin 2016), is a powerful and widely used ML method known for its high performance and effectiveness in a variety of tasks (e.g. regression, classification, ranking, and recommendation systems). It belongs to the family of gradient boosting methods, which are ensemble learning methods that combine multiple weak predictive models, typically decision trees, to create a strong predictive model.
The idea behind XGBoost is to iteratively train a series of decision trees and combine their predictions to produce a final ensemble model. Each tree is built sequentially, with each subsequent tree attempting to correct the mistakes made by the previous tree. Decision trees are simple models that make predictions based on a series of hierarchical decisions. Additionally, XGBoost incorporates regularization techniques such as L1 and L2 weight penalty terms1 to mitigate overfitting, as well as tree pruning, which prevents the model from becoming overly complex.
In this work, we employ XGBoost to perform the galaxy morphlogical classification due to its effectiveness for handling structured data, its robustness against overfitting, and its capability to model complex non-linear relationships. Specifically, we use the XBGClassifier class from the XGBoost library.2 The input data of the XGBoost model comprises any of the different parameter combinations in Table 3. Given an input, the model generates a probability vector, with each element representing the probability of belonging to a specific class. Subsequently, the model’s prediction is determined by selecting the class with the highest probability value.
3.3 Selection of hyperparameters
The parameters that determine the design of a ML method and those that specify its learning process are known as hyperparameters. For the XBGClassifier, we perform an empirical hyperparameter search considering the 5cats classification with the S2+C input data. In particular, we tuned the following hyperparameters: learning_rate (step size shrinkage to prevent overfitting), alpha (L1 regularization term on weights), reg_lambda (L2 regularization term on weights), max_depth (maximum depth of a tree), colsample_bytree (subsample ratio of columns when constructing each tree), max_delta_step (maximum delta step allowed for the weight estimation of each tree), min_child_weight (minimum sum of instance weight needed in a child), gamma (minimum loss reduction required to make a further partition on a leaf node of the tree), and subsample (subsample ratio of the training instances).
For each of the 20 hyperparameter configurations investigated, we conduct a stratified three-fold cross-validation, repeating the process 10 times to obtain a more robust evaluation of performance. This cross-validation process follow the procedure detailed in Section 3.1, and the performance metrics are averaged across all repetitions to obtain reliable performance estimates. After evaluating all hyperparameter configurations, we select the hyperparameters that obtained the top performance, namely: learning_rate = 0.1, alpha = 2, reg_lambda = 0.5, max_depth = 5, colsample_bytree = 0.7, max_delta_step = 2, min_child_weight = 3, gamma = 0.3, and subsample = 0.9. These hyperparameter values will be used for all the experiments in this work.
4 RESULTS
In this section, we present the performance results of the classification experiments outlined in Section 3.1 using the XGBoost model. To evaluate and compare the outcomes of the experiments, we compute various performance metrics, including accuracy, precision, recall, F1-score, and the Area Under the ROC Curve (AUC-ROC; Bradley 1997; Fawcett 2005), which are described in Appendix A. In addition, we provide the confusion matrices (CMs) of the highest performing experiments.
4.1 Direct classification approach
As introduced in Section 3.1, the direct classification approach involves training a single XGBoost model to carry out the given classification task. Here, we adopt such an approach and evaluate the model performance for each classification task (see Table 2) using different parameter configurations (Table 3). For each of these experiments, we perform 10 repetitions of a three-fold cross-validation (on the training subset), as described in Section 3.1. Table 4 presents the mean accuracy, precision, recall, and AUC-ROC metrics, along with their standard deviations across the cross-validation procedure for each parameter configuration in both the 2cats and 5cats direct classification tasks. For metrics other than accuracy, the reported values represent the averages across all classes. Specifically, they represent the macro average, where the metric is calculated for each class independently, and then the unweighted average of these class-wise scores is taken. As a reference, a random classifier with a uniform class distribution would achieve an accuracy, precision, recall, and AUC-ROC of 50 per cent for the 2cats task, and 20 per cent accuracy, precision, and recall with a 50 per cent AUC-ROC for the 5cats task.
Mean and standard deviation of different performance metrics across 10 repetitions of a three-fold cross-validation for different parameter configurations in the 2cats and 5cats direct classifications. Precision, recall, and AUC-ROC values correspond to the macro average. Note that for a random classification with a uniform class distribution the accuracy, precision, and recall are all at 50 per cent for 2cats and 20 per cent for 5cats, while AUC-ROC is at 50 per cent in both tasks.
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| 2cats | Colour | |$0.821\pm 0.006$| | |$0.852\pm 0.009$| | |$0.853\pm 0.009$| | |$0.893\pm 0.005$| |
| Structural1 | |$0.825\pm 0.006$| | |$0.855\pm 0.011$| | |$0.858\pm 0.007$| | |$0.904\pm 0.005$| | |
| Structural2 | |$0.850\pm 0.006$| | |$0.875\pm 0.009$| | |$0.880\pm 0.009$| | |$0.923\pm 0.004$| | |
| S2+C | |$0.869\pm 0.007$| | |$0.892\pm 0.008$| | |$0.893\pm 0.009$| | |$0.943\pm 0.004$| | |
| 5cats | Colour | |$0.520\pm 0.008$| | |$0.490\pm 0.014$| | |$0.455\pm 0.009$| | |$0.829\pm 0.004$| |
| Structural1 | |$0.541\pm 0.009$| | |$0.489\pm 0.035$| | |$0.454\pm 0.008$| | |$0.831\pm 0.004$| | |
| Structural2 | |$0.589\pm 0.008$| | |$0.534\pm 0.026$| | |$0.502\pm 0.007$| | |$0.860\pm 0.004$| | |
| S2+C | |$0.634\pm 0.007$| | |$0.608\pm 0.012$| | |$0.580\pm 0.011$| | |$0.897\pm 0.003$| | |
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| 2cats | Colour | |$0.821\pm 0.006$| | |$0.852\pm 0.009$| | |$0.853\pm 0.009$| | |$0.893\pm 0.005$| |
| Structural1 | |$0.825\pm 0.006$| | |$0.855\pm 0.011$| | |$0.858\pm 0.007$| | |$0.904\pm 0.005$| | |
| Structural2 | |$0.850\pm 0.006$| | |$0.875\pm 0.009$| | |$0.880\pm 0.009$| | |$0.923\pm 0.004$| | |
| S2+C | |$0.869\pm 0.007$| | |$0.892\pm 0.008$| | |$0.893\pm 0.009$| | |$0.943\pm 0.004$| | |
| 5cats | Colour | |$0.520\pm 0.008$| | |$0.490\pm 0.014$| | |$0.455\pm 0.009$| | |$0.829\pm 0.004$| |
| Structural1 | |$0.541\pm 0.009$| | |$0.489\pm 0.035$| | |$0.454\pm 0.008$| | |$0.831\pm 0.004$| | |
| Structural2 | |$0.589\pm 0.008$| | |$0.534\pm 0.026$| | |$0.502\pm 0.007$| | |$0.860\pm 0.004$| | |
| S2+C | |$0.634\pm 0.007$| | |$0.608\pm 0.012$| | |$0.580\pm 0.011$| | |$0.897\pm 0.003$| | |
Mean and standard deviation of different performance metrics across 10 repetitions of a three-fold cross-validation for different parameter configurations in the 2cats and 5cats direct classifications. Precision, recall, and AUC-ROC values correspond to the macro average. Note that for a random classification with a uniform class distribution the accuracy, precision, and recall are all at 50 per cent for 2cats and 20 per cent for 5cats, while AUC-ROC is at 50 per cent in both tasks.
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| 2cats | Colour | |$0.821\pm 0.006$| | |$0.852\pm 0.009$| | |$0.853\pm 0.009$| | |$0.893\pm 0.005$| |
| Structural1 | |$0.825\pm 0.006$| | |$0.855\pm 0.011$| | |$0.858\pm 0.007$| | |$0.904\pm 0.005$| | |
| Structural2 | |$0.850\pm 0.006$| | |$0.875\pm 0.009$| | |$0.880\pm 0.009$| | |$0.923\pm 0.004$| | |
| S2+C | |$0.869\pm 0.007$| | |$0.892\pm 0.008$| | |$0.893\pm 0.009$| | |$0.943\pm 0.004$| | |
| 5cats | Colour | |$0.520\pm 0.008$| | |$0.490\pm 0.014$| | |$0.455\pm 0.009$| | |$0.829\pm 0.004$| |
| Structural1 | |$0.541\pm 0.009$| | |$0.489\pm 0.035$| | |$0.454\pm 0.008$| | |$0.831\pm 0.004$| | |
| Structural2 | |$0.589\pm 0.008$| | |$0.534\pm 0.026$| | |$0.502\pm 0.007$| | |$0.860\pm 0.004$| | |
| S2+C | |$0.634\pm 0.007$| | |$0.608\pm 0.012$| | |$0.580\pm 0.011$| | |$0.897\pm 0.003$| | |
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| 2cats | Colour | |$0.821\pm 0.006$| | |$0.852\pm 0.009$| | |$0.853\pm 0.009$| | |$0.893\pm 0.005$| |
| Structural1 | |$0.825\pm 0.006$| | |$0.855\pm 0.011$| | |$0.858\pm 0.007$| | |$0.904\pm 0.005$| | |
| Structural2 | |$0.850\pm 0.006$| | |$0.875\pm 0.009$| | |$0.880\pm 0.009$| | |$0.923\pm 0.004$| | |
| S2+C | |$0.869\pm 0.007$| | |$0.892\pm 0.008$| | |$0.893\pm 0.009$| | |$0.943\pm 0.004$| | |
| 5cats | Colour | |$0.520\pm 0.008$| | |$0.490\pm 0.014$| | |$0.455\pm 0.009$| | |$0.829\pm 0.004$| |
| Structural1 | |$0.541\pm 0.009$| | |$0.489\pm 0.035$| | |$0.454\pm 0.008$| | |$0.831\pm 0.004$| | |
| Structural2 | |$0.589\pm 0.008$| | |$0.534\pm 0.026$| | |$0.502\pm 0.007$| | |$0.860\pm 0.004$| | |
| S2+C | |$0.634\pm 0.007$| | |$0.608\pm 0.012$| | |$0.580\pm 0.011$| | |$0.897\pm 0.003$| | |
Notably, the precision and recall scores in each experiment of Table 4 are similar to each other, indicating a balanced performance of the models. For example, in the 2cats classification, the difference between these two metrics is within the standard deviation, while in the 5cats classification, the difference is up to 1.2 per cent. This balance implies that the models are equally effective at identifying true positive instances (recall) and ensuring that the identified positive instances are indeed correct (precision), highlighting the reliability of the classification models. Additionally, the consistency of this balance across the different experiments indicates a robust model performance.
Regarding the different parameter configurations, in the 2cats classification, the model performance is quite similar across the configurations, with differences up to 4.1 per cent. The S2+C configuration yields the best performance, while the Colour configuration yields the worst. However, the differences in performance between Colour and Structural1 are within their standard deviation. For the 5cats classification, the performance differences among the parameter configurations are more pronounced, with variations up to 10.7 per cent. Similar to the 2cats classification, the S2+C configuration achieves the best performance, and the Colour configuration performs the worst. Again, the differences in performance metrics for Colour and Structural1 are within their standard deviation, except for accuracy where the difference is only 0.4 per cent.
Hence, across both 2cats and 5cats classification tasks, the Colour parameters provide a baseline performance that is adequate for the 2cats classification but less effective for the more complex 5cats classification. The Structural1 configuration offers a baseline performance which is almost identical to the Colour configuration, regardless of the classification task. This suggests that neither set of parameters is significantly more informative than the other when used in isolation, and both have similar limitations. For instance, Colour parameters lack information about structural properties of galaxies, whereas Structural1 parameters lack information about star-formation history.
The Structural2 configuration improves model performance, especially in the 5cats classification, indicating the importance of shape axial ratio (|$BA$|) and gradient asymmetry (|$\Delta A_{9050}$|) in galaxy classification. Finally, the S2+C configuration consistently delivers the best performance, highlighting the advantage of integrating both photometric and structural data. This performance improvement (up to 4.1 per cent for 2cats and up to 10.7 per cent for 5cats) indicates that both parameter types (photometric and structural) capture complementary information of the galaxies, leading to a more comprehensive and effective model.
To assess the model’s performance on unseen data, we first evaluate the overall metrics (accuracy, precision, recall, F1-socre, and AUC-ROC) on the test subset (unseen by the model during the training process) using the S2+C parameter configuration for both the 2cats and 5cats classification tasks (see Table B1 in Appendix B). For the 2cats classification, the model achieves 88 per cent across accuracy, precision, recall, and F1-score, with an AUC-ROC of 95 per cent, reflecting the strong performance in binary classification. For the more complex 5cats classification, the model achieves 65 per cent in both accuracy and recall, 64 per cent in precision and F1-score, and 90 per cent in AUC-ROC. The difference in performance between the two tasks reflects their inherent complexity, making them not directly comparable. The 2cats classification is a simpler task, involving only two broad galaxy types, while the 5cats task requires finer differentiation among multiple galaxy morphologies. Therefore, a poorer performance for the 5cats classification is expected since it is more challenging, even for human visual inspection, than the 2cats task.
In addition, comparing the achieved performance with a random classifier, we observe a clear improvement of the XGBoost model over random guessing highlights its ability to capture meaningful patterns in the data and reliably distinguish between galaxy classes.
Next, we analysed the per-class performance (precision, recall, and F1-score) on the test subset for both tasks (see Table B1). In the 2cats classification, the model shows balanced performance across both classes, without favouring one class over the other. In the 5cats classification, performance varies among the classes, with Class 0 (elliptical) and Class 3 (Sbc–Scd) obtaining the highest scores (e.g. |$\sim$|71 per cent in F1-score), while Class 4 (Sd–Irr) records the lowest (e.g. 39 per cent in F1-score). However, it should be noted that Class 4 has |$\sim$|85 per cent fewer galaxies than the other classes, making it more challenging for the model to learn sufficient distinguishing features for this class. In addition, there is a balance between precision and recall metrics within each class for both classification tasks, except for Class 4, which shows a 17 per cent gap. This underscores the model’s difficulty in handling this under-represented class. Despite challenges with specific classes in the 5cats task, the high AUC-ROC value (90 per cent) demonstrates the model’s strong overall ability to differentiate between galaxy types, providing a solid foundation for further improvements.
Fig. 2 shows the CMs of the 2cats (upper panel) and 5cats (bottom panel) classifications using the S2+C parameter configuration, obtained using the test subset. The x-axis displays the predicted classes by the model and the y-axis the true classes from the catalogue. Therefore, the diagonal of the CM indicates the success rates of the model’s predictions, while off-diagonal values indicate misclassifications. In the 2cats classification, the model performs well in distinguishing between Class 0 (early-type) and Class 1 (late-type) galaxies, with success prediction rates of 86 per cent and 89 per cent, respectively. This indicates that the model makes relatively lower misclassification rates (14 per cent for Class 0 and 11 per cent for Class 1) for galaxies between these two broad groups.
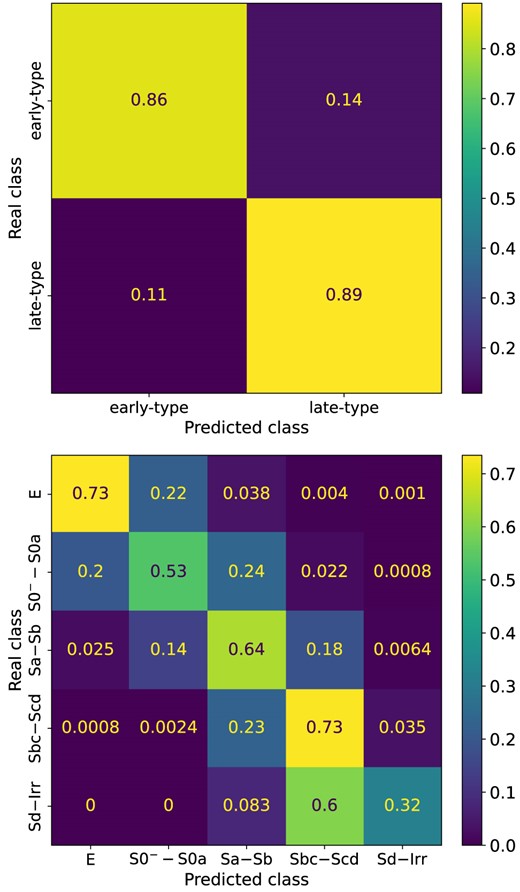
CMs for 2cats (upper) and 5cats (bottom) direct classifications (see Table 2) using the S2+C parameter configuration, calculated with the test subset. Colour contrasts are according to the performance of the classification. 2cats shows a balanced performance, whereas in 5cats, performance varies across the classes, with most misclassifications occurring between adjacent classes.
The CM for the 5cats classification (bottom panel of Fig. 2) shows a varying performance across the classes. For Class 0 (elliptical), the model achieves 73 per cent success in predictions but has a noticeable misclassification rate of 22 per cent into Class 1 (lenticular: S0|$^-$|–S0a). This is explained, in part, since a fraction of lenticulars share structural and colour similarities with elliptical galaxies. In the case of Class 1, the model has moderate performance with a 53 per cent success rate, but has misclassifications of 24 per cent and 20 per cent in the adjacent Class 2 (Sa–Sb) and Class 0, respectively. This is also related to the nature of lenticular galaxies, showing a wide variety of structural properties, some resembling those of ellipticals, but another fraction resembling those of spiral discs (e.g. Laurikainen et al. 2007; Cappellari et al. 2011; Graham 2019).
Furthermore, the model correctly classifies 64 per cent of Class 2 instances, with misclassifcation rates of 18 per cent into Class 3 (Sbc–Scd) and 14 per cent into Class 1, expected this time due to structural and colour similarities among the adjacent (1 and 3) classes. Similar to Class 0, the model performs well for Class 3 with 73 per cent correct classifications, however it misclassifies 23 per cent as Class 2, also suggesting some overlapping features between these classes. Finally, for Class 4 (Sd–Irr), the model has the lowest performance with only 32 per cent of successful predictions and a high misclassification rate of 60 per cent into Class 3. It is important to highlight that although a fraction of missclassifications, typically 10–20 per cent, are expected due to both structural and colour similarities with the adjacent Class 3, a higher missclasification rate is probably due to a significant under-representation of Class 4 in our data set, providing to the model a poor training set for this class.
The CMs, clearly illustrate that an important part of the model misclassifications occur between adjacent galaxy classes, highlighting the difficulty in distinguishing galaxies with similar features with a combination of parametric and non-parametric approaches but also even after a visual inspection. Therefore, although the model performs well overall, particularly in binary classification, there is room for improvement in accurately distinguishing between galaxy classes, especially in the more complex multiclass classification task. In Section 5, we will discuss these aspects further.
4.2 Hierarchical classification approach
Aiming to improve the performance of the 5cats direct classification, we also explored a hierarchical classification approach, as described in Section 3.1. In this approach, the classification process is divided into a sequence of steps, each handled by a separate XGBoost model. The first step classifies galaxies according to the 2cats re-categorization (early-type versus late-type galaxies). Subsequently, two additional models are trained: one to further classify early-type galaxies following the Early re-categorization (elliptical versus lenticular), and the other to only sub-classify late-type galaxies according to the Late re-categorization (see Table 2). The predictions from these three models are then combined to achieve the final five-class classification as follows: if a galaxy is classified as early-type by the top classifier, it is further subclassified as elliptical (E) or lenticular (S0|$^-$|–S0a) by the bottom left classifier; else if it is classified as late-type, it is further subclassified as one either Sa–Sb, Sbc–Scd, or Sd–Irr by the bottom right classifier.
As with the direct classification, we evaluated this hierarchical approach by employing different parameter configurations (Table 3), and for each configuration we carry out 10 repetitions of a three-fold cross-validation (on the training subset). For these hierarchical experiments, we explored two scenarios: one where the same parameter configuration is applied across all three models and another one where different parameter configurations are allowed for each model. This second scenario is motivated by the structural diversity and varying characteristics of galaxies at different steps of the classification process. For instance, previous studies have shown that combining distinct galaxy parameters, such as concentration (|$C_{9050}$|), bulge-to-total light ratio (|$B/T$|), and axial ratio (|$b/a$|), can help in segregating early-type galaxies into ellipticals and lenticulars more effectively (Cheng et al. 2011; VM22). Meanwhile, both colour–colour gradient (Park & Choi 2005) and colour–asymmetry gradient (Hernández-Toledo et al. in preparation) diagrams offer a more refined segregation of spiral galaxies into subclasses. Given these findings, it is plausible that different parameter configurations may be better suited for specific classification tasks within the hierarchical process. Therefore, this flexible scenario may improve the classification performance by adapting the feature configuration to the specific morphological distinctions being made.
We investigated all possible combinations of the four parameter configurations for each step in the hierarchical process. Table 5 presents the mean values of the performance metrics and their standard deviations, from the cross-validation procedure, for the best-performing experiments in the hierarchical approach. Specifically, it shows two experiments: the first (Hier1) uses the same parameter configuration (S2+C) across all three classifiers, while the second (Hier2) uses different configurations, with S2+C being applied to the 2cats (early-type versus late-type) and Late (Sa–Sb, Sbc–Scd, Sd–Irr) steps, and Structural2 to the Early (ellipticals versus lenticulars) step. Additionally, we include the individual performance results for the Late classification step using the S2+C configuration and for the Early step using both the Structural2 and S2+C configurations. Note that the results for the 2cats classification step are provided in Table 4.
Mean and standard deviation of different performance metrics across 10 repetitions of a three-fold cross-validation, for the best hierarchical classification experiments (Hier1 and Hier2). Precision, Recall, and AUC-ROC correspond to the Macro average. Note that Late classification correspond to the hierarchical step that subclassifies late-type galaxies into Sa–Sb, Sbc–Scd, and Sd–Irr, whereas Early to the step that only subclassifies early-type galaxies into E and S0|$^-$|–S0a.
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| Late | S2+C | |$0.759\pm 0.009$| | |$0.678\pm 0.024$| | |$0.623\pm 0.015$| | |$0.890\pm 0.005$| |
| Early | Structural2 | |$0.757\pm 0.011$| | |$0.786\pm 0.018$| | |$0.772\pm 0.016$| | |$0.833\pm 0.009$| |
| S2+C | |$0.762\pm 0.010$| | |$0.787\pm 0.016$| | |$0.781\pm 0.018$| | |$0.846\pm 0.010$| | |
| Hier1 | All three models: S2+C | |$0.637\pm 0.007$| | |$0.613\pm 0.014$| | |$0.583\pm 0.011$| | |$0.864\pm 0.005$| |
| Hier2 | 2cats: S2+C, Early: Structural2, Late: S2+C | |$0.636\pm 0.007$| | |$0.611\pm 0.014$| | |$0.583\pm 0.011$| | |$0.863\pm 0.005$| |
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| Late | S2+C | |$0.759\pm 0.009$| | |$0.678\pm 0.024$| | |$0.623\pm 0.015$| | |$0.890\pm 0.005$| |
| Early | Structural2 | |$0.757\pm 0.011$| | |$0.786\pm 0.018$| | |$0.772\pm 0.016$| | |$0.833\pm 0.009$| |
| S2+C | |$0.762\pm 0.010$| | |$0.787\pm 0.016$| | |$0.781\pm 0.018$| | |$0.846\pm 0.010$| | |
| Hier1 | All three models: S2+C | |$0.637\pm 0.007$| | |$0.613\pm 0.014$| | |$0.583\pm 0.011$| | |$0.864\pm 0.005$| |
| Hier2 | 2cats: S2+C, Early: Structural2, Late: S2+C | |$0.636\pm 0.007$| | |$0.611\pm 0.014$| | |$0.583\pm 0.011$| | |$0.863\pm 0.005$| |
Mean and standard deviation of different performance metrics across 10 repetitions of a three-fold cross-validation, for the best hierarchical classification experiments (Hier1 and Hier2). Precision, Recall, and AUC-ROC correspond to the Macro average. Note that Late classification correspond to the hierarchical step that subclassifies late-type galaxies into Sa–Sb, Sbc–Scd, and Sd–Irr, whereas Early to the step that only subclassifies early-type galaxies into E and S0|$^-$|–S0a.
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| Late | S2+C | |$0.759\pm 0.009$| | |$0.678\pm 0.024$| | |$0.623\pm 0.015$| | |$0.890\pm 0.005$| |
| Early | Structural2 | |$0.757\pm 0.011$| | |$0.786\pm 0.018$| | |$0.772\pm 0.016$| | |$0.833\pm 0.009$| |
| S2+C | |$0.762\pm 0.010$| | |$0.787\pm 0.016$| | |$0.781\pm 0.018$| | |$0.846\pm 0.010$| | |
| Hier1 | All three models: S2+C | |$0.637\pm 0.007$| | |$0.613\pm 0.014$| | |$0.583\pm 0.011$| | |$0.864\pm 0.005$| |
| Hier2 | 2cats: S2+C, Early: Structural2, Late: S2+C | |$0.636\pm 0.007$| | |$0.611\pm 0.014$| | |$0.583\pm 0.011$| | |$0.863\pm 0.005$| |
| Experiment | Performance metrics | ||||
|---|---|---|---|---|---|
| Classification | Input data | Accuracy | Precision | Recall | AUC-ROC |
| Late | S2+C | |$0.759\pm 0.009$| | |$0.678\pm 0.024$| | |$0.623\pm 0.015$| | |$0.890\pm 0.005$| |
| Early | Structural2 | |$0.757\pm 0.011$| | |$0.786\pm 0.018$| | |$0.772\pm 0.016$| | |$0.833\pm 0.009$| |
| S2+C | |$0.762\pm 0.010$| | |$0.787\pm 0.016$| | |$0.781\pm 0.018$| | |$0.846\pm 0.010$| | |
| Hier1 | All three models: S2+C | |$0.637\pm 0.007$| | |$0.613\pm 0.014$| | |$0.583\pm 0.011$| | |$0.864\pm 0.005$| |
| Hier2 | 2cats: S2+C, Early: Structural2, Late: S2+C | |$0.636\pm 0.007$| | |$0.611\pm 0.014$| | |$0.583\pm 0.011$| | |$0.863\pm 0.005$| |
From Table 5, we observe that the performance metrics for Hier1 and Hier2 are quite similar, with Hier1 showing only up to a 0.2 per cent improvement over Hier2. However, accounting for the standard deviation values, both Hier1 and Hier2 metrics fall within the same range. This similar performance can be explained since, for the Early classification, both the Structural2 and S2+C configurations have similar performance. This indicates that for a sub-classification between elliptical and lenticular galaxies, the Structural2 configuration (which includes |$BA$| and |$c_{5090}$|) is highly informative and effective. Hence, the addition of photometric parameters in the S2+C configuration does not significantly improve performance, suggesting that the Colour configuration may not provide substantial complementary information that is already captured by the structural parameters.
Furthermore, the precision and recall metrics are similar within each experiment (considering the standard deviation). In particular, for Hier1, the gap between these two metrics is 0.5 per cent, and for Hier2, it is 0.3 per cent, indicating a balanced performance.
Evaluating the Hier1 and Hier2 on unseen data (test subset), they achieved an accuracy of 65 per cent and 64 per cent, respectively. In a per-class performance context, on the test subset, we also observe a similar performance between the Hier1 and Hier2 classifications (see Fig. B2 in Appendix B), with differences not higher than 2 per cent in the metrics (precision, recall, and F1-score).
In Fig. 3, we provide the CM’s of the Hier1 (upper panel) and Hier2 (bottom panel) hierarchical classifications, calculated using the test subset. Again, both classifications yield similar results, with only a 1 per cent difference in the successful prediction of Class 0 (elliptical) and a 2 per cent difference for Class 1 (lenticular). We also observe that the majority of the model’s misclassifications are between adjacent classes. For instance, a 22 per cent of Class 1 instances are misclassified as Class 2 (Sa–Sb), and |$\sim$|20 per cent as Class 0. This underscores the morphological similarities between adjacent galaxy types.
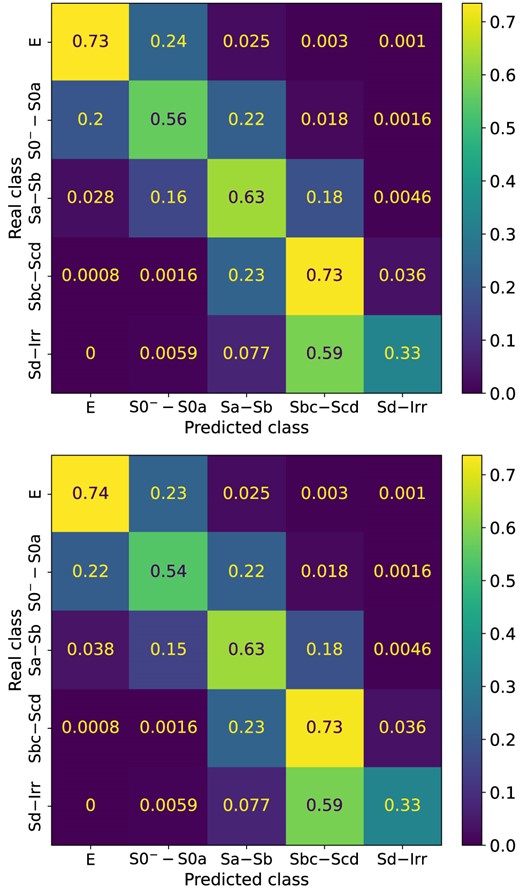
CMs for the Hier1 (upper) and Hier2 (bottom) classifications, calculated with the test subset. Colour constrasts are according to the accuracy of the classification. Hier1, Hier2, and 5cats (Fig. 2) classifications yield similar performance.
Comparing the Hier1 and Hier2 performance results with those obtained from the 5cats direct classification using the S2+C parameter configuration (see Table 4 and Fig. 2), we observe that they are closely aligned, with differences of 0.2 per cent-0.5 per cent in mean performance metrics and up to 3 per cent in CM and AUC-ROC. This indicates that hierarchical and direct classification approaches are equally effective for galaxy classification. Given these findings, along with the increased complexity (in both implementation and evaluation) and computational cost of the hierarchical approach, we will continue our discussion adopting the simpler and more efficient 5cats direct classification.
5 DISCUSSION
5.1 Model interpretation
In the following, we present the interpretative analysis of the trained XGBoost model. For illustrative purposes, we focused on the 5cats direct classification for this analysis, as its greater complexity provides a more comprehensive exploration of feature contributions across a broader range of galaxy types than the 2cats classification. Understanding the relationships between input features and model predictions is important for the model interpretation. For this purpose, we use the SHapley Additive exPlanations (SHAP; Lundberg & Lee 2017) library3, a powerful visualization tool designed to elucidate the decision-making processes of complex models. SHAP is based on the concept of Shapley values, a game-theoretic approach that offers a unified measure to explain each feature’s contribution to a prediction. SHAP values specify both the direction of a feature’s impact (whether it increases or decreases the prediction probability) and the magnitude of its contribution. In particular, we use the SHAP functions shap.summary_plot and shap.plots.waterfall to visualize these contributions.
5.1.1 SHAP global analysis
The shap.summary_plot visualization function provides a global view of feature importance by aggregating the SHAP values across the entire data set. It displays how much each feature contributes to the prediction classes, identifying the most influential features for the process of distinguishing between different types of galaxies.
Fig. 4 presents the SHAP summary plots for the 5cats direct classification task using the S2+C parameter configuration. This figure consists of six panels: the upper-left panel shows the combined feature importance for all classes, while the remaining five panels represent the feature importance for each class separately, going from Class 0 up to Class 4. Each panel shows a horizontal bar chart with the morphological parameters ranked by importance on the y-axis and the mean absolute SHAP values on the x-axis. Parameters with larger bars have more impact on the model’s predictions. Moreover, the different colours in the horizontal bars of the upper-left panel correspond to each class. Hence, the extent of the colour within that bar corresponds to the importance of that parameter for the corresponding class.
Overall, we can observe that a combination of colour and structural parameters, namely the |$u-r$| colour, a shape parameter (the axial ratio |$BA$|), the surface brightness distribution (the |$c_{5090}$| inverse concentration index), and a gradient parameter [|$\Delta (g-i)$|] are playing a significant role in the model’s galaxy classification across all classes (upper-left panel of Fig. 4). This is consistent with the results reported in other works (e.g. Strateva et al. 2001; Graham 2019).
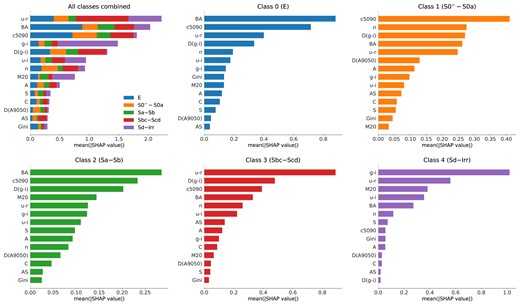
Feature importance in the XGBoost model for the 5cats direct classification using the S2+C parameter configuration. The upper-left panel shows the SHAP summary plot for all classes combined, and the other panels the SHAP summary plot for each individual class, where the upper-middle panel corresponds to Class 0 and the bottom-right panel to Class 4. In each plot, the features are ranked vertically by importance, with the mean absolute SHAP value displayed horizontally. |$u-r$|, |$BA$|, |$c5090$|, |$g-i$|, and |$\Delta (g-i)$|, are, overall, the parameters with more impact on the model. Additionally, the structural parameters are more important for early-type galaxies whereas the photometric parameters are more important for late-type galaxies.
The subsequent panels of Fig. 4 also illustrate the relative importance of the features, now split into different galaxy classes. Specifically, for Class 0 (elliptical, upper-middle panel) the most influential feature is |$BA$|, followed by |$c_{5090}$| and |$u-r$|. Elliptical galaxies tend to have a smoother spheroidal shape, with a centrally concentrated light distribution due to a dominant bulge and older stellar populations. Consequently, |$BA$| and |$c_{5090}$| capture essential morphological and structural characteristics, while |$u-r$|, third in importance, correlates with the stellar population ages, helping differentiate Class 0 from other classes.
For lenticular galaxies (S0|$^-$|–S0a) in Class 1 (upper right-most panel of Fig. 4), the |$c_{5090}$|, n (Sérsic index), |$\Delta \left(g-i \right)$|, |$BA$|, and |$u-r$| features are the most relevant. These last four parameters show consistently similar mean SHAP values, suggesting a wide diversity of structural properties in this class. While S0 galaxies show a diversity of bulge components within a definite disc structure, S0a galaxies show, in addition, hints of a very tight spiral structure in the outer disc along with mixed stellar populations with older stars in the bulge and some intermediate-age stars in the disc, supporting the relevance of the colour and colour gradient parameters.
For Class 2 (bottom-left panel of Fig. 4), |$BA$|, |$c_{5090}$|, and a colour gradient |$\Delta \left(g-i \right)$| parameter appear as the more relevant, followed by |$M_{20}$|. This class includes Sa, Sab, and Sb galaxies, which show a diversity of bulges in a disc, hence the relevance of |$BA$| and |$c_{5090}$| to capture those structural characteristics. This class also exhibit a variety of spiral arms, mixed stellar populations, increasing gas and dust content from Sa to Sb, and higher star formation rates compared to Classes 0 and 1, underscoring the relevance of |$M_{20}$| and |$\Delta \left(g-i \right)$| in capturing the concentration of the brightest regions in the disc and arms.
In contrast to early-types, in Class 3 (bottom-middle panel of Fig. 4) the |$u-r$| colour and |$\Delta \left(g-i \right)$| colour gradient parameters play the most relevant role in the model’s prediction, followed this time by the structural features (|$c_{5090}$|, |$BA$|, and n). Sbc, Sc, and Scd galaxies compose this class, which are characterized by a central bulge of decreasing prominence but prominent, loosely wound spiral arms in the disc. These arms are traced by abundant star-forming regions and contain higher amounts of gas and dust, supporting the relevance of the colour and colour gradient parameters as first-order predictors.
Finally, for Class 4 (bottom-right panel of Fig. 4), the different combinations of colour parameters, represented by the |$g-i$|, |$u-r$|, and |$u-i$| colour indices, and the |$M_{20}$| parameter are the most important for the model prediction. This class is composed by very late Sd, Sdm, Sm, and Irr galaxies, where the bulge component goes from being almost absent to being completely absent, and the spiral structure goes from being very loosely wound and almost absent to completely absent, with very prominent and widespread star-forming regions. Hence, the importance of the colour parameters, capturing the wide range of star formation activity and the youngest stellar populations in these galaxies. |$M_{20}$| and |$BA$|, although with less impact than colour parameters, help to capture localized structures along the disc.
In summary, we note that for Classes 0, 1, and 2, the structural shape (|$BA$|) and surface brightness distribution (|$c_{5090}$|) parameters appear among the most relevant for the model predictions, followed by the colour (|$u-r$|) and/or colour-gradient [|$\Delta \left(g-i \right)$|] parameters. These results are consistent with the morphological results by Cheng et al. (2011) and VM22 who argue that |$BA$| and |$c_{5090}$| are among the most influential parameters for a light-based morphological classification of early-type galaxies (Classes 0 and 1). In contrast, for Classes 3 and 4, colour and colour gradient parameters are among the most influential for the model’s predictions (consistent with, e.g. Park & Choi 2005), reflecting the star formation and younger stellar populations properties along the disc in these galaxies. It is also noticeable the presence of the |$M_{20}$| parameter reflecting the degree of locality of the light distribution in star-forming regions when going from Sbc up to irregular types.
Overall, the XGBoost model was trained to classify galaxies using a combination of structural and colour parameters associated to their light distribution and star formation properties, rendering results consistent with the known properties of the different galaxy classes. These results, analysed with the SHAP tool, capture the importance of the structural and colour features, aligning with the morphological properties of galaxies, and reinforcing the reliability and interpretability of the XGBoost model’s predictions.
It is important to mention that these feature importance scores are specific to the trained XGBoost model and the data set it was trained on.
5.1.2 SHAP individual analysis
To understand in more detail the model’s predictions, we perform, this time on an individual basis, a SHAP analysis looking at the contribution of each feature to individual predictions and trying to recognize cases where the model either correctly or incorrectly predicts a galaxy class. To that purpose, we use the shap.plots.waterfall visualization function of the SHAP tool. The SHAP waterfall plot decomposes the prediction of a particular instance into the contributions of each feature to the final classification outcome. In the context of a multiclass classification, the waterfall plot would display the contributions of each feature towards assigning the instance to one of the multiple classes. Hence, in a five-class problem, for each instance there will be five waterfall plots, one per class.
Fig. 5 presents the waterfall plots of three different cases: (i) a case where the model correctly predicts the galaxy class with high confidence (left column), (ii) a case where the model makes an incorrect prediction (with high probability), misclassifying the galaxy by one class (middle column), and (iii) an extreme (and rare) case where the model misclassifies the galaxy by three classes away from the expected class (right column). These cases correspond to the 5cats direct classification task using the S2+C parameter configuration. The first row shows the galaxy images indicating their ‘real’ class (as given in the catalogue), the XGBoost predicted class, and the prediction probability. Each column displays the waterfall plots for each of the five classes, from Class 0 (top) to Class 4 (bottom). Notice that the ‘real’ (catalogued) class in the three examples corresponds to Class 0 (elliptical), and that the red frames (boxes in red colour) indicate the waterfall plot of the model’s predicted class.
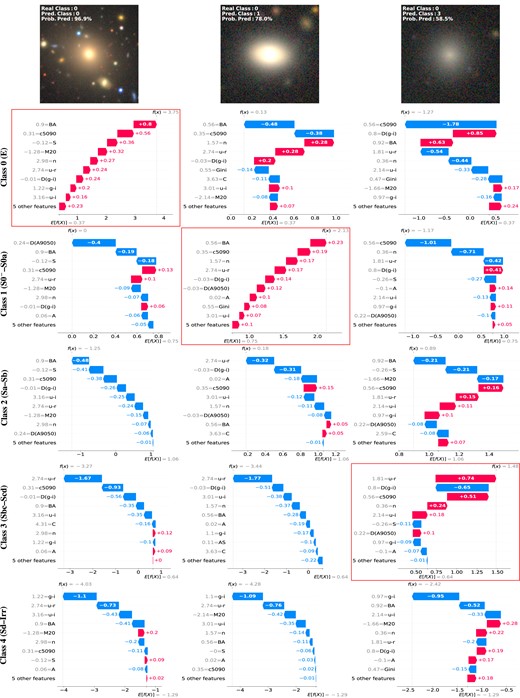
SHAP waterfall plots depicting three scenarios: a correct prediction with high confidence (left), an incorrect prediction with high confidence (middle), and an error prediction three classes away (right). In all cases, the catalogued Class is 0. The rows show, from top to bottom, the galaxy image, and the plots for Classes 0 to 4. The framed plots represent the model’s predicted classes. See the main text for discussion.
In these plots, the x-axis represents the contribution of each input parameter to the difference between the model’s output, |$f(x)$| (vertical line), and the baseline prediction, |$E[f(x)]$| (mean predicted probabilities of the corresponding class; e.g. Lundberg et al. 2020). The y-axis lists the input parameters and their respective values (in grey) for the specific instance, ordered by the magnitude of their SHAP values in descending order. The bars in the plots indicate the SHAP values of each feature, where the length corresponds to the magnitude of the feature’s contribution to the model’s output, and their direction and colour indicates whether its contribution increases (red) or decreases (blue) the model’s output compared to the baseline prediction.
The left column in Fig. 5 presents an example where the XGBoost model correctly predicts the catalogued class (Class 0). The red box (second row) shows that all input parameter values for this galaxy increase the probability of it being classified as Class 0. This indicates that all feature values for this galaxy are typical of Class 0 (elliptical galaxies), with |$BA=0.90$| and |$c_{5090}=0.31$| contributing the most. For this class, |$E[f(x)]=0.37$| and |$f(x)=3.75$|, resulting in a net contribution of |$+3.38$| from all parameters. The subsequent plots in the first column (rows 3 to 6) display the Classes 1 to 4. It is noticeable how the net contribution of the galaxy parameters decreases the probability of this galaxy being classified by the model as any of those classes.
The middle column of Fig. 5 illustrates an example where the catalogued class of the galaxy is Class 0, but the XGBoost model predicts it as Class 1 (S0|$^-$|–S0a). In this case, the waterfall plot for Class 0 (middle column, second row) indicates that the net contribution of the galaxy parameters results in a low probability of this galaxy being Class 0, with |$BA=0.56$| and |$c_{5090}=0.35$| having a more negative impact on the model’s prediction. In contrast, the waterfall plot for Class 1 (red box, third row) shows that all input parameters augment the probability of this galaxy being Class 1, this time with |$BA=0.56$| and |$c_{5090}=0.35$| having the most positive impact, followed by the Sérsic index and a colour parameter. In this case, |$E[f(x)]=0.75$| and |$f(x)=2.13$|, suggesting that the galaxy’s parameter values align more with Class 1. After closer inspection, we agree with the model’s prediction that this galaxy belongs to Class 1, thus allowing us to identify a case of visual misclassification. However, even though the model classified this galaxy correctly as Class 1, it was considered a prediction error because, for the evaluation of the model, we assume that the provided catalogued classification is the ground truth.
We also present an example where the catalogued class is Class 0, but the XGBoost model predicts it as Class 3 (right column of Fig. 5). The waterfall plot for Class 0 (right column, second row) reveals that the net contribution of all galaxy parameters diminishes the probability of this galaxy being Class 0, with |$c_{5090}=0.56$| having the most negative impact. In contrast, the waterfall plot for Class 3 (right column, fifth row) shows that |$\Delta \left(g-i \right)=0.80$|, |$S=-0.26$|, |$g-i=0.97$|, and |$A=-0.10$| decrease the probability of being a Class 3 (Sbc–Scd) galaxy. Even so, |$u-r=1.81$|, |$c_{5090}=0.56$|, |$n=0.36$|, |$u-i=2.14$|, and |$\Delta A_{9050}=0.22$| greatly increase the probability in favour of Class 3. The contribution of the remaining parameters is lower. Consequently, the model misclassified this galaxy as Class 3.
Although this galaxy has a visual appearance of an elliptical (Class 0), a more careful inspection to the parameter values show that the light distribution, as indicated by |$c_{5090}=0.56$| and |$n=0.36$|, is not consistent with an early-type galaxy. Instead, it shows a flatter light distribution, resembling fainter galaxies where the structural properties and the colour properties depart from the average values of more massive galaxies. For instance, the colour parameter |$u-r=1.81$| suggests a bluer colour, which is atypical for early-type galaxies (Classes 0 and 1) and thus consistent with a discordant-morphology galaxy. This is a rare case. As shown in the CM (bottom panel of Fig. 2), there are very few such instances, with around four for the catalogued Class 0, and one each for the catalogued Classes 1 and 3 in the test subset.
5.2 Identification of possible error sources and their impact on the results
An evaluation of our trained models achieved overall performance metrics (accuracy, precision, recall, and F1-score) of up to 60–65 per cent for a five-group classification, with the best results obtained when using a combination of both structural and star formation parameters (see Table 4). To better understand these performance levels, we carried out a model interpretation study to elucidate the role of different parameters on the model’s classification and examined the model’s prediction for specific galaxies (see Section 5.1). From this analysis, we have identified the following possible error sources that could be affecting the model’s performance:
inaccuracies in the visual classification of galaxies,
the presence of galaxies with discordant morphology, and
geometric and projection effects influencing the colours of galaxies.
A first important error source impacting the performance of our ML models is the accuracy of the visual classification. The galaxy sample used in this work (see Section 2.1) is the result of combining two independent visual classifications of galaxies in the local universe: the MaNGA (VM22) sample and the NA10 sample. As a measure of the morphological variability in our sample introduced by different classifiers, Fig. 6 compares the morphological classifications reported for the subset of galaxies common to both samples. The green line in the upper panel shows the one-to-one correspondence between the classifications. The 2D density isocontours are displayed in linear scale, with the outermost contour enclosing at least 10 galaxies in the bin, while the error bars indicate the standard deviation around the average for each morphological type in the NA10 classification. The lower panels provide a measure of the scatter and offset between individual classifications for a given morphological type. The blue-dotted line indicates the median, and the red-dotted line is placed at zero as reference.

The observed median scatter indicates that the consistency of the classification between the NA10 and MaNGA samples lies within |$\pm$|1.3 T-Type, with a larger scatter in the S0 morphological type. Therefore, our merged sample inherits this |$\pm$|1.3 T-Type scatter in the visual morphological classification, hence impacting at that level the model predictions. Since this level of scatter is consistent with findings in other studies comparing different classifiers (e.g. Naim et al. 1995), we do not attempt to make any correction for this source of inaccuracy. It should be noted that this scatter is considered intrinsic to our sample, and all the prediction scores reported in our experiments always include that error source.
Another error source arises from the presence of galaxies within our sample that deviate from the typical relationship between colour and morphology, which defines the red and blue sequences in the colour–magnitude diagram (see Fig. 7). A careful inspection of the structural and colour distributions within each morphological type revealed a fraction of late-type discs unexpectedly showing red colours (Yamauchi & Goto 2004; Ishigaki, Goto & Matsuhara 2007), as well as early-type galaxies exhibiting unusual blue colours (Ferreras et al. 2005; Lee, Lee & Hwang 2006). These morphologically discordant galaxies could be contributing to the model’s classification errors, particularly when colour is a relevant parameter for the model.
Colour–magnitude diagrams illustrating morphologically discordant E–S0a early-types (left; dots below the division line), Sbc–Irr late-types (middle; dots above the division line), and Sa–Irr galaxies with inclination values Inc > 65 degrees (right; dots above the division line).
The Galaxy Zoo (GZ; Lintott et al. 2008, 2011) project reported that about 6 per cent of the low-redshift early-type galaxy population is blue (Schawinski et al. 2009), with the fraction of blue ellipticals increasing to about 12 per cent towards lower mass galaxies situated in lower density regions (Park et al. 2007; Bamford et al. 2009; Park & Choi 2009). The GZ project also revealed a significant population of red spirals (Bamford et al. 2009; Skibba et al. 2009), suggesting that around 20 per cent of spiral galaxies lie on the red sequence, with an increasing fraction in intermediate-density environments.
Furthermore, late-type spirals may appear in the red sequence due to effects unrelated to stellar population, such as inclination-dependent dust reddening (Maller et al. 2009; Masters et al. 2010), which may also be impacting the model predictions when the colour information is relevant for the classification.
Fig. 7 shows the loci of discordant blue ellipticals in our sample, identified as those with |$g-r$| colours below the division line between the red and blue regions as described in Appendix C. Similarly, the middle panel illustrates the loci of discordant red late-type spirals (Sbc–Irr) with inclinations <65|$^{\circ }$| (above the division line), while the right panel displays the loci of S0a–Irr galaxies reddened by inclination effects (inclinations >65|$^{\circ }$|, above the division line). As a reference, the vertical line at |$M_\mathrm{ r}$| = −17.5 indicates the transition into the sub-dwarf galaxy regime, which could be another source of error. However, as the number of galaxies in this regime is very low, we did not attempt to make any correction.
From this analysis we identified 238 blue elliptical galaxies, 532 red late-type galaxies (Sbc–Irr), and 2605 reddened spiral galaxies due to strong inclination effects (inc > 65|$^{\circ }$|), amounting to 3375 galaxies or |$\sim$|19 per cent of the original data sample. To better understand the impact of these discordant and highly inclined galaxies on the model performance, we excluded them from our sample and re-trained the 5cats direct model with the S2+C parameter configuration. This exclusion lead to a 1–2 per cent improvement in overall performance metrics, including accuracy, precision, recall, AUC-ROC, and F1-score.
For per-class performance metrics (see Table D1 in Appendix D), we found some trends of improvement. Specifically, Class 0 maintains its performance, Class 1 improves by 2–6 per cent, Class 2 has a 5 per cent gain in precision, Class 3 improves up to 7 per cent, and Class 4 has an enhanced precision of 4 per cent. The CM (see Fig. 8) also shows improvements, with a 6 per cent and 7 per cent increase in the success prediction rate for Classes 1 and 3, respectively. Additionally, although misclassification rates remain generally similar across classes, there is a noticeable 5 per cent reduction in Class 1 being misclassified as Class 2, and a 7 per cent reduction in Class 3 being misclassified as Class 2.
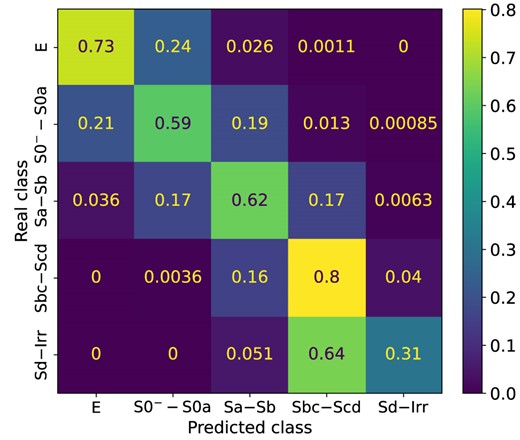
CM for the experiment excluding discordant and highly inclined galaxies, calculated with the test subset. Colour contrasts are according to the accuracy of the classification. There is an improvement for Classes 1 and 3.
Figs 2, 3, and 8 present the CMs summarizing the results of the different tests carried out in this work. For elliptical galaxies (Class 0), the trained models show a reasonable good success prediction rate of 73 per cent. However, the adjacent off-diagonal values consistently remain at 22–24 per cent, suggesting that a proportion of lenticular galaxies (S0|$^-$|, S0) are overlapping their structural properties. Cheng et al. (2011) proposed to combine the concentration (|$C_{9050}$|), the geometric axial ratio (|$b/a$|), and the bulge-to-total light fraction (|$B/T$|) as an optimum parameter space to segregate early-type (E, S0, and Sa) galaxies, achieving a completeness (recall) and reliability (precision) consistent with our results. More recently, VM22 applied the classification scheme proposed by Cheng et al. (2011) to the MaNGA sample, further suggesting an alternative segregation region in the |$C-B/T-b/a$| parameter space, consistent with the results of the SHAP analysis in this work and with other detailed studies using 2D image decomposition analysis of lenticular galaxies (Laurikainen et al. 2011).
For the combination of lenticular (S0|$^-$|, S0) and transition S0a galaxies (Class 1), the true prediction rate after various experiments accounts for 53 per cent, increasing to |$\sim$|60 per cent after excluding discordant and highly inclined galaxies from the training and test samples. This performance is explained by the structural similarities that a fraction of S0 galaxies share with Class 0 (left off-diagonal value), but also to similarities that another fraction of S0 share with early-type spirals (right off-diagonal rate) and intermediate- or late-type spirals. S0 galaxies exhibit not only a disc-like structure similar to spirals but also a wide variety of bulge-to-disc (|$B/D$|) ratios, comparable to those seen along the spiral sequence (cf. Laurikainen et al. 2011). It is worth mentioning that our ML-based conclusions on the diverse nature of S0 galaxies may fit, in a broader sense, with the findings of Graham & Sahu (2023); Graham, Jarrett & Cluver (2024). They argue that S0 galaxies can be divided into two distinct types: low mass, primordial S0s, and high mass, dust-rich S0s formed through major wet mergers. This differentiation is based on the relationship between spheroids and their central massive black holes.
Fig. 6 shows that the scatter in the visual classification for these galaxies is |$\pm$|2 T-Types, the highest among all types, reflecting the difficulty of capturing the wide variety of structural and colour properties through a visual classification, which impacts the success rates of the models.
The galaxies of types Sa, Sab, and Sb (Class 2) have a success rate roughly constant at a level of 64 per cent across all our experiments. This can be attributed to the structural similarities shared with Class 1 (left off-diagonal element) as well as the overlap in structural and colour properties with galaxies of types Sbc, Sc, and Scd (Class 3; right off-diagonal element). For Class 3 galaxies (Sbc–Scd), the correct prediction rate increases from 73 per cent to 80 per cent after removing discordant and highly inclined galaxies from our sample. Notably, the misclassification rate in the left off-diagonal element also decreases, indicating that the colour properties of Classes 2 and 3 can be better separated when discordant galaxies and inclination effects are properly corrected.
For the under-represented Class 4 galaxies (Sd–Irr), the true prediction rate (|$\sim$|32 per cent) is the lowest among all classes and across the different experiments. This class also presents the highest misclassification rate (|$\sim$|60 per cent) in the left off-diagonal element, suggesting the trained models lack enough representative examples to accurately characterize the morphological features of these galaxies. It is thus important to further work and improve the under-representation of galaxies in this class. However, the methods to address such imbalance in the galaxy sample are out of the scope of this paper.
Finally, given that the model that excludes discordant and highly inclined galaxies yields improved performance across the evaluated metrics compared to the original models (with all galaxies; see Section 4), we recommend applying this model only when discordant galaxies can be omitted from the data set.
5.3 Comparison to other works
To provide context for the performance of our trained models, we compare our results with other studies. Although they are not directly comparable due to variations in data set characteristics and/or classification tasks, examining the trends and insights from various works can offer valuable perspectives on the efficacy of different approaches.
Table 6 presents this comparison, in different columns (from left to right) including the authors of different works from the literature, data sets used, input data (galaxy features used for training), the number of adopted classes, the ML methods employed, and their corresponding classification accuracies. Note that we focus our comparison with works that employed galaxy parameters as input data, since they are more closely related to our methodology.
Accuracy comparison with other works. Note the difference in data sets employed and the classification task across the studies.
| Author | Data set | Input data | Classification | ML method | Top accuracy (per cent) |
|---|---|---|---|---|---|
| This work | NA10 + VM22 (17 966 galaxies) | S2+C parameters | 2cats | XGBoost | 88.0 |
| 5cats | 65.0 | ||||
| Hier1 | 65.0 | ||||
| Hier2 | 64.0 | ||||
| Vavilova et al. (2021) | SDSS-DR9 (6163 galaxies) | |$[u, g, r, i, z, u-r, g-i, r-z, c_{5090}]$| | ET, LT | SVM | 96.4 |
| GZ2 (|$\sim$|8500 galaxies) | 76.0 | ||||
| Barchi et al. (2020) | GZ1 (58 030 galaxies) | |$[C_{7535}, A_3, S_3, H, \mathrm{GPA}]$| | E, Sp | MLP | 98.6 |
| NA10 (14 034 galaxies) | 87.0 | ||||
| GZ2 (67 637 galaxies) | E, Sp, SB | 78.8 | |||
| E, Sa, Sb, Sc, SBa, SBb, SBc | 66.0 | ||||
| E, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 66.2 | ||||
| Er, Ei, Ec, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 57.7 | ||||
| de Diego et al. (2020) | OTELO catalogue (1834 galaxies) | |$[u-r,g-r,r-i,r-z,r-J,r-H_\mathrm{ b},r-K_\mathrm{ s},r,n]$| | ET, LT | MLP | 98.5 |
| COSMOS (34 688 galaxies) | 96.7 | ||||
| Ferrari et al. (2015) | EFIGI (4458 galaxies) | |$[C, A_3, S_3, H, \sigma _\psi ]$| | E, Sp | LDA | 93.8 |
| NA10 (14 034 galaxies) | 90.2 | ||||
| LEGACY (804 974 galaxies) | 87.7 | ||||
| LEGACY-|$zr$| (337 097 galaxies) | 93.8 |
| Author | Data set | Input data | Classification | ML method | Top accuracy (per cent) |
|---|---|---|---|---|---|
| This work | NA10 + VM22 (17 966 galaxies) | S2+C parameters | 2cats | XGBoost | 88.0 |
| 5cats | 65.0 | ||||
| Hier1 | 65.0 | ||||
| Hier2 | 64.0 | ||||
| Vavilova et al. (2021) | SDSS-DR9 (6163 galaxies) | |$[u, g, r, i, z, u-r, g-i, r-z, c_{5090}]$| | ET, LT | SVM | 96.4 |
| GZ2 (|$\sim$|8500 galaxies) | 76.0 | ||||
| Barchi et al. (2020) | GZ1 (58 030 galaxies) | |$[C_{7535}, A_3, S_3, H, \mathrm{GPA}]$| | E, Sp | MLP | 98.6 |
| NA10 (14 034 galaxies) | 87.0 | ||||
| GZ2 (67 637 galaxies) | E, Sp, SB | 78.8 | |||
| E, Sa, Sb, Sc, SBa, SBb, SBc | 66.0 | ||||
| E, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 66.2 | ||||
| Er, Ei, Ec, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 57.7 | ||||
| de Diego et al. (2020) | OTELO catalogue (1834 galaxies) | |$[u-r,g-r,r-i,r-z,r-J,r-H_\mathrm{ b},r-K_\mathrm{ s},r,n]$| | ET, LT | MLP | 98.5 |
| COSMOS (34 688 galaxies) | 96.7 | ||||
| Ferrari et al. (2015) | EFIGI (4458 galaxies) | |$[C, A_3, S_3, H, \sigma _\psi ]$| | E, Sp | LDA | 93.8 |
| NA10 (14 034 galaxies) | 90.2 | ||||
| LEGACY (804 974 galaxies) | 87.7 | ||||
| LEGACY-|$zr$| (337 097 galaxies) | 93.8 |
Accuracy comparison with other works. Note the difference in data sets employed and the classification task across the studies.
| Author | Data set | Input data | Classification | ML method | Top accuracy (per cent) |
|---|---|---|---|---|---|
| This work | NA10 + VM22 (17 966 galaxies) | S2+C parameters | 2cats | XGBoost | 88.0 |
| 5cats | 65.0 | ||||
| Hier1 | 65.0 | ||||
| Hier2 | 64.0 | ||||
| Vavilova et al. (2021) | SDSS-DR9 (6163 galaxies) | |$[u, g, r, i, z, u-r, g-i, r-z, c_{5090}]$| | ET, LT | SVM | 96.4 |
| GZ2 (|$\sim$|8500 galaxies) | 76.0 | ||||
| Barchi et al. (2020) | GZ1 (58 030 galaxies) | |$[C_{7535}, A_3, S_3, H, \mathrm{GPA}]$| | E, Sp | MLP | 98.6 |
| NA10 (14 034 galaxies) | 87.0 | ||||
| GZ2 (67 637 galaxies) | E, Sp, SB | 78.8 | |||
| E, Sa, Sb, Sc, SBa, SBb, SBc | 66.0 | ||||
| E, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 66.2 | ||||
| Er, Ei, Ec, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 57.7 | ||||
| de Diego et al. (2020) | OTELO catalogue (1834 galaxies) | |$[u-r,g-r,r-i,r-z,r-J,r-H_\mathrm{ b},r-K_\mathrm{ s},r,n]$| | ET, LT | MLP | 98.5 |
| COSMOS (34 688 galaxies) | 96.7 | ||||
| Ferrari et al. (2015) | EFIGI (4458 galaxies) | |$[C, A_3, S_3, H, \sigma _\psi ]$| | E, Sp | LDA | 93.8 |
| NA10 (14 034 galaxies) | 90.2 | ||||
| LEGACY (804 974 galaxies) | 87.7 | ||||
| LEGACY-|$zr$| (337 097 galaxies) | 93.8 |
| Author | Data set | Input data | Classification | ML method | Top accuracy (per cent) |
|---|---|---|---|---|---|
| This work | NA10 + VM22 (17 966 galaxies) | S2+C parameters | 2cats | XGBoost | 88.0 |
| 5cats | 65.0 | ||||
| Hier1 | 65.0 | ||||
| Hier2 | 64.0 | ||||
| Vavilova et al. (2021) | SDSS-DR9 (6163 galaxies) | |$[u, g, r, i, z, u-r, g-i, r-z, c_{5090}]$| | ET, LT | SVM | 96.4 |
| GZ2 (|$\sim$|8500 galaxies) | 76.0 | ||||
| Barchi et al. (2020) | GZ1 (58 030 galaxies) | |$[C_{7535}, A_3, S_3, H, \mathrm{GPA}]$| | E, Sp | MLP | 98.6 |
| NA10 (14 034 galaxies) | 87.0 | ||||
| GZ2 (67 637 galaxies) | E, Sp, SB | 78.8 | |||
| E, Sa, Sb, Sc, SBa, SBb, SBc | 66.0 | ||||
| E, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 66.2 | ||||
| Er, Ei, Ec, Sa, Sb, Sc, Sd, SBa, SBb, SBc, SBd | 57.7 | ||||
| de Diego et al. (2020) | OTELO catalogue (1834 galaxies) | |$[u-r,g-r,r-i,r-z,r-J,r-H_\mathrm{ b},r-K_\mathrm{ s},r,n]$| | ET, LT | MLP | 98.5 |
| COSMOS (34 688 galaxies) | 96.7 | ||||
| Ferrari et al. (2015) | EFIGI (4458 galaxies) | |$[C, A_3, S_3, H, \sigma _\psi ]$| | E, Sp | LDA | 93.8 |
| NA10 (14 034 galaxies) | 90.2 | ||||
| LEGACY (804 974 galaxies) | 87.7 | ||||
| LEGACY-|$zr$| (337 097 galaxies) | 93.8 |
From Table 6, we see that most of the works studied binary classification tasks, such as distinguishing between elliptical (E) versus spiral (Sp) galaxies (Ferrari et al. 2015; Barchi et al. 2020) or early-type (ET) versus late-type (LT) galaxies (de Diego et al. 2020; Vavilova et al. 2021). Our 2cats classification task closely aligns with the ET versus LT classification, where we attained an accuracy of 88.0 per cent using the S2+C parameter configuration. In comparison, de Diego et al. (2020) reached accuracies of 96.7 per cent and 98.5 per cent for the COSMOS (Scoville et al. 2007) and OTELO (Bongiovanni et al. 2019) data sets, respectively, utilizing photometric parameters (optical and near-infrared photometry) and Sérsic index (n) as input data with a Multilayer Perceptron (MLP; Rosenblatt 1958; Fukushima 1975; Fukushima, Miyake & Ito 1983). Similarly, Vavilova et al. (2021) used photometric data and a Support Vector Machine (SVM; Cortes & Vapnik 1995; Vapnik 1995; Hearst et al. 1998) for ET versus LT classification, achieving an accuracy of 96.4 per cent in a sample of 6163 galaxies from SDSS-DR9 visually classified by them. However, the accuracy drops to 76.0 per cent when their model is applied to a sample of |$\sim$|8500 galaxies from the Galaxy Zoo 2 (GZ2; Willett et al. 2013) catalogue.
The differences in performance between these works and this study can be attributed in part to the data set characteristics, such as data quality and distribution of the classes. For example, Vavilova et al. (2021) attributed the performance difference between the SDSS-DR9 and GZ2 samples to inconsistencies in human labelling, as well as the GZ2 sample containing more discordant galaxies than their own visually classified sample. Additionally, the method for galaxy classification before training differs across the works. In de Diego et al. (2020), galaxies were classified based on the best fit between observed fluxes and spectral index distribution templates. By contrast, both Vavilova et al. (2021) and our data set (NA10 + VM22) relied on human visual classification, which is influenced by human biases but can capture subtle morphological features that SED-based classification might miss.
Furthermore, the data set employed by de Diego et al. (2020) was highly imbalanced, with only 5.4 per cent ET and 94.6 per cent LT galaxies, whereas our data set has a more balanced distribution of 42 per cent ET and 58 per cent LT galaxies (see Table 2). Class imbalance can affect model performance toward the dominant class, potentially increasing the accuracy. Nevertheless, from Table 5 of de Diego et al. (2020), they achieved an F1-score (macro average) of 93 per cent, reflecting good performance across both classes. In comparison, we achieved an F1-score of 87 per cent, which still remains consistent.
Beyond data set characteristics, differences in input parameters also influence model performance. While de Diego et al. (2020) employed both optical and near-infrared photometry, Vavilova et al. (2021) used optical photometry, and we combined structural parameters with optical photometric data. The inclusion of structural features in our work provides additional morphological information that purely photometric models may miss. On the other hand, the near-infrared photometry can capture a wider range of galaxy properties than optical photometry alone. However, given the differences on data set characteristics across these works, a direct comparison of the performance of each input parameter configuration is not feasible.
The studies conducted by Barchi et al. (2020) and Ferrari et al. (2015) reported accuracies ranging from 87.7 per cent to 98.6 per cent for an E versus Sp classification task. Specifically, Barchi et al. (2020) used the Galaxy Zoo 1 (GZ1; Lintott et al. 2008, 2011) catalogue and a five-parameter configuration, incorporating features such as concentration (|$C_{7535}$| = |$\log (R_{75}/R_{35})$|), asymmetry (|$A_3=1-s(I, I_{180})$|, with |$s()$| being the Spearman’s rank correlation coefficient; Press 2005), clumpiness (|$S_3=1-s(I, I_{\mathrm{ S}})$|), entropy (H; Bishop 2006), and GPA (Rosa et al. 2018), alongside an MLP. They also evaluated their model using the NA10 data set. Ferrari et al. (2015) employed parameters like C, |$A_3$|, |$S_3$|, H, and spirality (|$\sigma _\Psi$|; Shamir 2011), using a Linear Discriminant Analysis (LDA; Murtagh & Heck 1987; Duda, Hart & Stork 2000; Bishop 2006) to assess their model across four catalogues: EFIGI (Baillard et al. 2011), NA10, SDSS-DR7 (Abazajian et al. 2009) complete LEGACY data base, and a volume-limited subsample (LEGACY-zr).
A key difference between these works and our study is the classification task. While both Barchi et al. (2020) and Ferrari et al. (2015) focused on distinguishing between elliptical and spiral galaxies, our task differentiates between ET (elliptical + lenticular) and LT (spiral) galaxies. Additionally, the GZ1 sample used by Barchi et al. (2020) is class-imbalanced, with 13 per cent E and 87 per cent Sp, which, as discussed earlier, can affect model performance. Although data set characteristics also play a role, the NA10 data set is more closely related to our work. When comparing our 2cats results (88 per cent accuracy) with Barchi et al. (2020) and Ferrari et al. (2015) using the NA10 catalogue (87.0 per cent and 90.2 per cent accuracy, respectively), they are on a par, though it is worth noting that their studies excluded lenticular galaxies.
Table 6 further illustrates that only two studies, Barchi et al. (2020) and this work, have undertaken classification tasks involving more than two classes. As the number of classes increases, the accuracy tends to decline, which is unsurprising given the increased complexity of classification tasks, even for visual (human) classification. For instance, Barchi et al. (2020), employing an MLP and galaxy parameters, reported an accuracy of 98.6 per cent for E versus Sp classification, which dropped to 78.8 per cent for their three-class classification involving the classes E, Sp, and SB (barred galaxies). Furthermore, they obtained accuracies of 66.0 per cent, 66.2 per cent, and 57.7 per cent for seven-, nine-, and eleven-class tasks, respectively. In comparison, we achieved 65.0 per cent accuracy for our 5cats direct classification using the S2+C parameter configuration and XGBoost. Although our accuracy is lower than the seven- and nine-class tasks of Barchi et al. (2020), it is important to highlight that the classification tasks are different. Our classification takes into account lenticular and irregular galaxies, whereas Barchi et al. (2020) incorporate barred galaxies. Additionally, the data sets differ, with Barchi et al. (2020) using GZ2 and our work utilizing NA10.
Finally, it is important to highlight that variations in accuracy across the listed works may arise from differences in data sets, input features, classification tasks, and the ML methods used. For example, de Diego et al. (2020) observed a 1.4 per cent difference in accuracy when changing data sets, while Vavilova et al. (2021) found a |$\sim$|20 per cent variation, and Ferrari et al. (2015) obtained a 6.1 per cent variance across data sets. In our study, we found accuracy differences ranging from 0.6 per cent to 3.5 per cent for the 2cats classification and from 3.0 per cent to 9.9 per cent for the 5cats direct classification, depending on the parameter configuration used for training (see Table 4). In addition, Vavilova et al. (2021) evaluated five different ML methods for binary galaxy classification (ET versus LT), with accuracy variations ranging from 0.9 per cent to 7.0 per cent across models. Barchi et al. (2020) also explored three traditional ML methods and found |$\sim$|0.2 per cent accuracy differences across methods for the E versus Sp classification, with this difference reaching up to 3.0 per cent for finer classification tasks. Therefore, our findings are overall consistent with other studies.
Beyond this consistency, our work offers two key contributions. First, we provide a detailed evaluation of various combinations of structural and star formation parameters, offering a more nuanced understanding of their roles in automated classification. Second, through the application of interpretation tools, we gained valuable insights into how these parameters influence model predictions, revealing patterns that correspond to physically expected behaviours of galaxies. These contributions not only reinforce existing research but also offer new perspectives on the interplay between ML models and astrophysical parameters in galaxy classification.
6 CONCLUSIONS
In this paper, we have used a sample of local galaxies assembled by merging two independent samples, the NA10 and VM22 catalogues, both of which include detailed visual morphological classifications. We also incorporated a comprehensive set of structural and star formation parameters, uniformly estimated from SDSS images, to train XGBoost models for automatic morphological classification. Specifically, the structural parameters used included |$C,\, A,\, S,\, A_\mathrm{ S},\, \mathrm{Gini},\, M_{20},\, n,\, c_{5090},\, BA$|, and |$\Delta A_{9050}$|, while the star formation parameters included |$g-i,\, u-r,$||$u-i$|, and |$\Delta (g-i)$|.
We conducted a series of experiments with the goal of analysing classification performance. These experiments explored different combinations of the structural and star formation parameters (as detailed in Table 3) and diverse morphological type groupings (see Table 2). Additionally, we investigated two classification approaches: (1) a direct approach, where a single model was trained to directly classify galaxies into the specified classes, and (2) a hierarchical approach, which decomposed the five-class task into three steps: first, distinguishing early- from late-type galaxies; second, further classifying early-type galaxies; and third, sub-classifying only late-type galaxies. We evaluated the performance of both direct and hierarchical models in galaxy classification using a range of standard metrics, including the CM, accuracy, precision, recall, F1-score, and AUC-ROC.
One of the main contributions of this paper is the comprehensive evaluation of different combinations of structural and star formation parameters for automated galaxy classification. This analysis provides a deeper understanding of how these parameters affect model performance, allowing us to identify the configurations that yield the best classification results across multiple metrics. Another important contribution is the use of advanced interpretation tools, such as SHAP, to analyse the impact of galaxy parameters on model predictions. By linking the model’s decision-making process to the physical properties of galaxies, we gained valuable insights into how these features influence the classification results. This analysis not only highlighted the relative importance of different parameters but also allowed us to connect the model’s outputs with the physically expected behaviour of galaxies. Through this approach, we identified the key features driving the model’s decisions across different galaxy classes, revealing how they align with the distinct physical characteristics of each morphological type.
In the following, we summarize our findings:
Among all the parameter configurations tested, we found that the S2+C configuration (using all 14 parameters) led to better performance. Specifically, for the 2cats classification, S2+C improved performance by up to 3.5 per cent, 2.3 per cent, 2.2 per cent, and 4.1 per cent for accuracy, precision, recall, and AUC-ROC, respectively. Similarly, in the 5cats direct classification, the S2+C configuration yielded improvements ranging from 3.0–9.9 per cent, 3.6–9.2 per cent, 6.0–10.7 per cent, and 3.0–6.1 per cent for accuracy, precision, recall, and AUC-ROC metrics, respectively.
The 2cats classification task achieved an accuracy of 88 per cent, with precision, recall, and F1-score all at 88 per cent, and an AUC-ROC at 95 per cent. This indicates the model’s ability to distinguish between early-type and late-type galaxies. In contrast, the more challenging 5cats direct classification resulted in an accuracy of 65 per cent, with precision, recall, and F1-score at 64–65 per cent, and an AUC-ROC of 90 per cent. The drop in performance is expected due to the increased granularity and overlap between certain morphological types, which presents a more challenging task for the classifier.
The experiments with hierarchical classification for the five-class task yielded a performance comparable to the 5cats direct classification, using the S2+C parameter configuration. Performance differences across metrics were minimal, with variations of less than 3.0 per cent. Given these similar outcomes, both approaches can be equally effective for the five-class galaxy classification. However, the hierarchical approach is more complex to implement and evaluate, and it also leads to a higher computational cost.
Our model interpretation analysis, using SHAP for the 5cats direct classification with the S2+C parameter configuration, revealed that, overall, the |$u-r$| colour parameter emerged as the most significant contributor to the classification task, followed by |$BA$|, |$c_{5090}$|, |$g-i$|, and |$\Delta \left(g-i \right)$|. Furthermore, on a per-class basis, we found that the structural parameters |$BA$|, |$c_{5090}$|, and n had more impact on the model’s prediction for Classes 0 (E), 1 (S0|$^-$|–S0a), and 2 (Sa–Sb). In contrast, the photometric parameters |$u-r$|, |$g-i$|, and |$\Delta \left(g-i \right)$| were more relevant for Classes 3 (Sbc–Scd) and 4 (Sd–Irr).
After the model interpretation analysis of individual galaxies, we identified possible error sources that could have an impact on the automated classification performance: (1) inaccuracies in the visual classification on the data set, (2) discordant-morphology galaxies (i.e. blue early-type or red late-type galaxies), and (3) dust reddening due to inclination effects. Although we found consistency in visual classifications between the NA10 and VM22 catalogues within |$\pm$|1.3 T-Type, we did not attempt to make any correction for this source of inaccuracy and considered it intrinsic to our sample. After excluding |$\sim$|19 per cent of the sample to remove discordant and highly inclined galaxies, we observed a 1–2 per cent improvement in overall performance metrics and significant gains in true prediction rates for Classes 1 and 3, with increases of 6 per cent and 7 per cent, respectively. These findings suggest that addressing intrinsic data set issues can enhance model performance.
Finally, upon comparing our findings with those of other studies, we observed that our results exhibit consistency with existing research. However, there are still areas of improvement that can be addressed in future work. For example, tackling the class imbalance in the 5cats task by applying techniques like class-weight adjustments, oversampling, or undersampling, among others, could lead to better performance, especially for the highly under-represented Class 4 (Sd–Irr). Moreover, the error sources we identified (see Section 5.2) indicate the importance of refining the input data and addressing these issues, as the quality of the data set and accuracy of the labels are crucial for model training. By mitigating these errors, we can improve classification performance. Another possible area for improvement is the incorporation of additional parameters that capture not only global galaxy properties but also more localized features (e.g. bulge-to-total light fraction) or spatially resolved properties within galaxies, like those inferred from integral-field spectroscopic surveys (cf. MaNGA, Bundy et al. 2015; Cano-Díaz et al. 2016, 2019; SAMI, Croom et al. 2012; Brough et al. 2017; van de Sande et al. 2021). This would allow an exploration of the connection between internal physical properties and their relation to the global morphology of galaxies.
Looking ahead to the application of our model in the context of the next generation surveys like Euclid and LSST, it is important to emphasize that although higher quality and deeper imaging will be available, that is not enough to either guarantee for a correct estimate of any structural parameter nor for any model performance. Previous works in this direction (Nevin et al. 2019 for SDSS, Tarsitano et al. (2018) for the Dark Energy Survey, and Martin et al. 2022 for the upcoming LSST data) clearly suggest that a more detailed identification of biases and uncertainties present in imaging data is necessary to fully exploit the capabilities of the surveys (see also Walmsley et al. 2024). Future work could involve training models on simulated data with varying |$\langle S/N\rangle $| levels, hence helping models to perform better with noisier observations, or to mimic the |$\langle S/N\rangle $| level of a particular survey.
ACKNOWLEDGEMENTS
GAA and JAVM thank support from the CONAHCYT Postdoctoral program Estancias Postdoctorales por Mexico. HMHT acknowledges CONAHCYT project CF-G-543 entitled ‘Arqueología y filogenética de dinosaurios galácticos: formación y evolución de galaxias masivas apagadas’. GAA, GFP, HMHT, and JAVM acknowledge support from CONAHCYT project CF-2023-G-1052 entitle ‘Sinergia y Retos del Censo LSST del Observatorio Vera Rubin para la Astrofísica, la Ciencia de datos, la Química y otras disciplinas’. RD gratefully acknowledges support by the ANIDBASAL project FB210003. YJT acknowledges financial support from the Spanish MINECO grant PID2022-136598NB-C32 and from the State Agency for Research of the Spanish MCIU through the Center of Excellence Severo Ochoa award to the Instituto de Astrofísica de Andalucía (SEV-2017-0709) and grant CEX2021-001131-S funded by MCIN/AEI/10.13039/501100011033. GM acknowledges support from the UK STFC under grant ST/X000982/1. WJP has been supported by the Polish National Science Center project UMO-2023/51/D/ST9/00147. CS acknowledges support from the Agencia Nacional de Investigación y Desarrollo(ANID) through Basal project FB210003. We thank Dr Alister Graham for his valuable comments and suggestions on this work. The authors thank the computing credits provided through ‘Proyectos de investigación en la Nube UNAM-AWS’. The authors acknowledge the LSST-MX Consortium for the management to facilitate their participation in the Rubin Observatory (www.fisica.ugto.mx/~lsstmx/).
DATA AVAILABILITY
The code and data underlying this article can be shared on reasonable request to the corresponding author.
Footnotes
For more information see, e.g. Murphy (2012).
REFERENCES
APPENDIX A: PERFORMANCE METRICS DESCRIPTION
In this appendix, we provide definitions and explanations of the performance metrics used to evaluate the classification tasks presented in this study. These metrics are commonly used in ML and are essential for assessing various aspects of classification performance:
Confusion Matrix (CM): Compares the true or real classes to the predicted classes. By convention in ML, the rows and columns correspond to the real and predicted (by the ML method) classes, respectively. The entry i, j in a CM is the number of observations actually in class i, but predicted to be in class j. Hence, the diagonal of the CM indicates the successful predictions of the ML model, while off-diagonal values indicate the failing predictions. The best performance is a diagonal matrix.
Accuracy: Fraction of correctly predicted objects to the total number of objects. The best performance is 1.
Precision: Fraction of true positive predictions to the total positive predictions, denoting how many of the positive predictions are actually correct. Hence, this is a contamination indicator. The best value is 1.
Recall: Ratio of true positive predictions to the total real positive instances. This is a completeness proxy, since it indicates how well the model recognizes the real positive instances. The best value is 1.
F1-score: Can be interpreted as a harmonic mean of the precision and recall. The best value is 1 and the worst value is 0.
AUC-ROC: Refers to the Area Under the ROC Curve (Bradley 1997; Fawcett 2005). A Receiver Operating Characteristic (ROC) curve represents the true positive rate (TPR) as function of the false positive rate (FPR) for various probability thresholds. AUC-ROC provides a single value that quantifies the overall performance of the classification model across all possible thresholds. This is a separability indicator, since it shows how well a ML model is capable of distinguishing between classes. The higher the AUC-ROC value (best value is 1), the better the classification performance and the discrimination ability of the model. ROC curve and AUC-ROC are most commonly associated with binary classification, where TPR and FPR are unambigously defined. For a multiclass task, these metrics can still be obtained by two supported approaches: the one-versus-one (OvO) algorithm, which compares every unique pairwise combination of classes, and the one-versus-rest (OvR) algorithms, which compares each class against all the others (assumed as one). Then, there will be one ROC curve and one AUC value for each class, which can be averaged (e. g. macro average) to summarize overall model performance. In this work, both OvO and OvR approaches yield the same result.
APPENDIX B: PER-CLASS PERFORMANCE METRICS
B1 Direct classification tasks
Table B1 presents the per-class precision, recall, and F1-score metrics for the 2cats (upper) and 5cats (bottom) direct classifications using the S2+C configuration on the test subset. The table also includes the macro average and the weighted average for each metric, where the weighted average takes into account the presence of each class in the true data sample. Additionally, it shows the accuracy and AUC-ROC (macro average). For the 2cats classification, there is a balanced performance across both classes in the three metrics (precision, recall, and F1-score), similar to the results observed in Section 4.1. This consistency indicates that the model is performing well and is reliable in predicting both galaxy types, without favouring one class over the other.
Precision, recall, F1-score, accuracy, and AUC-ROC evaluated over the test subset for the 2cats (upper) and 5cats (bottom) classifications using the S2+C configuration.
| 2cats with S2+C | |||
|---|---|---|---|
| Class | Precision | Recall | F1-score |
| 0: E–S0a | 0.85 | 0.86 | 0.85 |
| 1: Sa–Irr | 0.90 | 0.89 | 0.89 |
| Macro avg | 0.87 | 0.87 | 0.87 |
| Weighted avg | 0.88 | 0.88 | 0.88 |
| Accuracy: 0.88 | AUC-ROC: 0.95 | ||
| 5cats with S2+C | |||
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.59 | 0.53 | 0.56 |
| 2: Sa–Sb | 0.63 | 0.64 | 0.64 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.49 | 0.32 | 0.39 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.90 | ||
| 2cats with S2+C | |||
|---|---|---|---|
| Class | Precision | Recall | F1-score |
| 0: E–S0a | 0.85 | 0.86 | 0.85 |
| 1: Sa–Irr | 0.90 | 0.89 | 0.89 |
| Macro avg | 0.87 | 0.87 | 0.87 |
| Weighted avg | 0.88 | 0.88 | 0.88 |
| Accuracy: 0.88 | AUC-ROC: 0.95 | ||
| 5cats with S2+C | |||
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.59 | 0.53 | 0.56 |
| 2: Sa–Sb | 0.63 | 0.64 | 0.64 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.49 | 0.32 | 0.39 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.90 | ||
Precision, recall, F1-score, accuracy, and AUC-ROC evaluated over the test subset for the 2cats (upper) and 5cats (bottom) classifications using the S2+C configuration.
| 2cats with S2+C | |||
|---|---|---|---|
| Class | Precision | Recall | F1-score |
| 0: E–S0a | 0.85 | 0.86 | 0.85 |
| 1: Sa–Irr | 0.90 | 0.89 | 0.89 |
| Macro avg | 0.87 | 0.87 | 0.87 |
| Weighted avg | 0.88 | 0.88 | 0.88 |
| Accuracy: 0.88 | AUC-ROC: 0.95 | ||
| 5cats with S2+C | |||
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.59 | 0.53 | 0.56 |
| 2: Sa–Sb | 0.63 | 0.64 | 0.64 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.49 | 0.32 | 0.39 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.90 | ||
| 2cats with S2+C | |||
|---|---|---|---|
| Class | Precision | Recall | F1-score |
| 0: E–S0a | 0.85 | 0.86 | 0.85 |
| 1: Sa–Irr | 0.90 | 0.89 | 0.89 |
| Macro avg | 0.87 | 0.87 | 0.87 |
| Weighted avg | 0.88 | 0.88 | 0.88 |
| Accuracy: 0.88 | AUC-ROC: 0.95 | ||
| 5cats with S2+C | |||
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.59 | 0.53 | 0.56 |
| 2: Sa–Sb | 0.63 | 0.64 | 0.64 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.49 | 0.32 | 0.39 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.90 | ||
In the 5cats direct classification (bottom panel of Table B1), performance varies significantly among the classes, indicating that the model performs better for some galaxy classes than others. Consistent with our findings in the CM (Fig. 2), Class 0 (elliptical) and Class 3 (Sbc–Scd) have the best performance, with F1-scores of 72 per cent and 70 per cent, respectively. Next in performance are the Classes 2 (Sa–Sb), 1 (S0|$^-$|–S0a), and 4 (Sd–Irr), which have lower performance than Class 0 by 8–9 per cent, 12–20 per cent, and 22–41 per cent, respectively. The poor performance of Class 4 (e.g. 39 per cent in F1-score) could be attributed to its significant under-representation in the data set, therefore the model has limited data to learn from.
As observed in Section 4.1, precision and recall are similar for each class, especially for Class 0 and Class 2, where they differ by only 1 per cent, indicating a balanced performance. For Class 1 and Class 3, the difference is slightly larger at 6 per cent, suggesting a low variability in the model’s performance for these two classes. However, Class 4 shows the largest difference with a 17 per cent gap between precision (49 per cent) and recall (32 per cent), highlighting the model’s struggle with this under-represented class. This significant disparity indicates that while the model is conservative and identifies many of the galaxies it labels as Class 4 (better precision), it misses a large portion of true instances (lower recall), leading to inconsistent performance for this class.
On average, the precision and recall differ by 3 per cent for the macro average and by 1 per cent for the weighted average, suggesting a relatively balanced model overall, though individual class performance may vary. The macro averages for the three metrics range from 59 per cent to 62 per cent, and the weighted average goes between 64 per cent and 65 per cent, indicating moderate overall performance across all classes.
B2 Hierarchical classification tasks
Table B2 shows the precision, recall and F1-score per class metrics calculated from the test subset for the Hier1 (upper panel) and Hier2 (bottom panel) classifications. This table also shows the accuracy and AUC-ROC (macro average). The performance metrics of both hierarchical classifications are quite similar, with differences of up to 2 per cent only for Classes 0 and 1. Comparing these results with the 5cats direct classification (bottom panel of Table B1) we observe that the three classifications yield very similar results. The differences among the three classifications are up to 3 per cent in the metrics. Therefore, as discuss in Section 4.2, Hier1, Hier2, and 5cats are comparable, regardless of their different classification approach.
Precision, recall, F1-score, accuracy, and AUC-ROC evaluated over the test subset for the Hier1 (upper) and Hier2 (bottom) hierarchical classifications (Fig. 3).
| Hier1 | |||
|---|---|---|---|
| (2cats: S2+C, Early: S2+C, Late: S2+C) | |||
| Class | Precision | Recall | F1-score |
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.58 | 0.56 | 0.57 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.60 | 0.61 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.87 | ||
| Hier2 | |||
| (2cats: S2+C, Early: Structural2, Late: S2+C) | |||
| 0: E | 0.69 | 0.74 | 0.71 |
| 1: S0|$^-$|–S0a | 0.58 | 0.54 | 0.56 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.64 | 0.64 |
| Accuracy: 0.64 | AUC-ROC: 0.87 | ||
| Hier1 | |||
|---|---|---|---|
| (2cats: S2+C, Early: S2+C, Late: S2+C) | |||
| Class | Precision | Recall | F1-score |
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.58 | 0.56 | 0.57 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.60 | 0.61 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.87 | ||
| Hier2 | |||
| (2cats: S2+C, Early: Structural2, Late: S2+C) | |||
| 0: E | 0.69 | 0.74 | 0.71 |
| 1: S0|$^-$|–S0a | 0.58 | 0.54 | 0.56 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.64 | 0.64 |
| Accuracy: 0.64 | AUC-ROC: 0.87 | ||
Precision, recall, F1-score, accuracy, and AUC-ROC evaluated over the test subset for the Hier1 (upper) and Hier2 (bottom) hierarchical classifications (Fig. 3).
| Hier1 | |||
|---|---|---|---|
| (2cats: S2+C, Early: S2+C, Late: S2+C) | |||
| Class | Precision | Recall | F1-score |
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.58 | 0.56 | 0.57 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.60 | 0.61 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.87 | ||
| Hier2 | |||
| (2cats: S2+C, Early: Structural2, Late: S2+C) | |||
| 0: E | 0.69 | 0.74 | 0.71 |
| 1: S0|$^-$|–S0a | 0.58 | 0.54 | 0.56 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.64 | 0.64 |
| Accuracy: 0.64 | AUC-ROC: 0.87 | ||
| Hier1 | |||
|---|---|---|---|
| (2cats: S2+C, Early: S2+C, Late: S2+C) | |||
| Class | Precision | Recall | F1-score |
| 0: E | 0.71 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.58 | 0.56 | 0.57 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.60 | 0.61 |
| Weighted avg | 0.64 | 0.65 | 0.64 |
| Accuracy: 0.65 | AUC-ROC: 0.87 | ||
| Hier2 | |||
| (2cats: S2+C, Early: Structural2, Late: S2+C) | |||
| 0: E | 0.69 | 0.74 | 0.71 |
| 1: S0|$^-$|–S0a | 0.58 | 0.54 | 0.56 |
| 2: Sa–Sb | 0.64 | 0.63 | 0.63 |
| 3: Sbc–Scd | 0.67 | 0.73 | 0.70 |
| 4: Sd–Irr | 0.50 | 0.33 | 0.40 |
| Macro avg | 0.62 | 0.59 | 0.60 |
| Weighted avg | 0.64 | 0.64 | 0.64 |
| Accuracy: 0.64 | AUC-ROC: 0.87 | ||
APPENDIX C: COLOUR–MAGNITUDE DIAGRAM
Fig. C1 shows the colour–magnitude [|$\left(g-r\right)$| versus |$M_\mathrm{ r}$|] diagram for the entire data sample in this work (grey symbols), where |$M_\mathrm{ r}$| is the absolute magnitude in the r band, emphasizing the red region (overdense region at |$(g-r)$| > 0.6; red line fit), the blue region (overdense region at |$(g-r)$| < 0.6; blue line fit), and the division line (solid black line). Colours and magnitudes were corrected as described in Section 2.2. The fitting to the red and blue regions were estimated by setting a random division between them at |$(g-r)$| = 0.6, and then estimating the |$mean$| in colour given a |$M_\mathrm{ r}$| bin in the red and blue regions, and also estimating the corresponding standard deviation (|$\mathrm{ SD}$|). The mean–SD values for the red sequence, as well as the mean + SD values for the blue sequence were fit. Given the fact that these lines are not perpendicular, we considered the bisector of the angle formed at their intersection. This bisector is then used as the new division line between the red and blue region. We repeat this process until the resulting division line does not varies significantly, and we adopt it to separate the red region from the blue region. As reference, we plot final |$\mathrm{ SD}$| error bars and their corresponding fit in dashed black lines. The division line is adopted in the lower panels in solid black line.
APPENDIX D: PERFORMANCE METRICS EXCLUDING DISCORDANT AND HIGHLY INCLINED GALAXIES
The experiment excluding the discordant galaxies in the data set (|$\sim$|3375 galaxies) for the 5cats direct classification using the S2+C parameter configuration achieves an accuracy of 66 per cent and AUC-ROC of 91 per cent, after retraining the model and evaluating it on the test subset. Table D1 shows the per-class performance metrics for this experiment, in addition to the macro and weighted averages. Comparing these results with Table B1, we observe some improvements, particularly on Classes 1 and 3.
The colour–magnitude diagram for the data sample galaxies in this paper . The lower and upper solid lines show the blue, and red regions, respectively. The region between the dashed lines corresponds to the green valley and the middle solid line corresponds to the division line between the red and blue regions. This line is used to find the discordant galaxies presented in Fig. 7.
Precision, recall, F1-score, accuracy, and AUC-ROC evaluated over the test subset for the experiment excluding discordant and highly inclined galaxies.
| Class | Precision | Recall | F1-score |
|---|---|---|---|
| 0: E | 0.70 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.61 | 0.59 | 0.60 |
| 2: Sa–Sb | 0.68 | 0.62 | 0.65 |
| 3: Sbc–Scd | 0.67 | 0.80 | 0.73 |
| 4: Sd–Irr | 0.53 | 0.31 | 0.39 |
| Macro avg | 0.64 | 0.61 | 0.62 |
| Weighted avg | 0.66 | 0.66 | 0.66 |
| Accuracy: 0.66 | AUC-ROC: 0.91 | ||
| Class | Precision | Recall | F1-score |
|---|---|---|---|
| 0: E | 0.70 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.61 | 0.59 | 0.60 |
| 2: Sa–Sb | 0.68 | 0.62 | 0.65 |
| 3: Sbc–Scd | 0.67 | 0.80 | 0.73 |
| 4: Sd–Irr | 0.53 | 0.31 | 0.39 |
| Macro avg | 0.64 | 0.61 | 0.62 |
| Weighted avg | 0.66 | 0.66 | 0.66 |
| Accuracy: 0.66 | AUC-ROC: 0.91 | ||
Precision, recall, F1-score, accuracy, and AUC-ROC evaluated over the test subset for the experiment excluding discordant and highly inclined galaxies.
| Class | Precision | Recall | F1-score |
|---|---|---|---|
| 0: E | 0.70 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.61 | 0.59 | 0.60 |
| 2: Sa–Sb | 0.68 | 0.62 | 0.65 |
| 3: Sbc–Scd | 0.67 | 0.80 | 0.73 |
| 4: Sd–Irr | 0.53 | 0.31 | 0.39 |
| Macro avg | 0.64 | 0.61 | 0.62 |
| Weighted avg | 0.66 | 0.66 | 0.66 |
| Accuracy: 0.66 | AUC-ROC: 0.91 | ||
| Class | Precision | Recall | F1-score |
|---|---|---|---|
| 0: E | 0.70 | 0.73 | 0.72 |
| 1: S0|$^-$|–S0a | 0.61 | 0.59 | 0.60 |
| 2: Sa–Sb | 0.68 | 0.62 | 0.65 |
| 3: Sbc–Scd | 0.67 | 0.80 | 0.73 |
| 4: Sd–Irr | 0.53 | 0.31 | 0.39 |
| Macro avg | 0.64 | 0.61 | 0.62 |
| Weighted avg | 0.66 | 0.66 | 0.66 |
| Accuracy: 0.66 | AUC-ROC: 0.91 | ||

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}