





ABSTRACT
Current and future Type Ia Supernova (SN Ia) surveys will need to adopt new approaches to classifying SNe and obtaining their redshifts without spectra if they wish to reach their full potential. We present here a novel approach that uses only photometry to identify SNe Ia in the 5-yr Dark Energy Survey (DES) data set using the SuperNNova classifier. Our approach, which does not rely on any information from the SN host-galaxy, recovers SNe Ia that might otherwise be lost due to a lack of an identifiable host. We select |$2{,}298$| high-quality SNe Ia from the DES 5-yr data set an almost complete sample of detected SNe Ia. More than 700 of these have no spectroscopic host redshift and are potentially new SNIa compared to the DES-SN5YR cosmology analysis. To analyse these SNe Ia, we derive their redshifts and properties using only their light curves with a modified version of the SALT2 light-curve fitter. Compared to other DES SN Ia samples with spectroscopic redshifts, our new sample has in average higher redshift, bluer and broader light curves, and fainter host-galaxies. Future surveys such as LSST will also face an additional challenge, the scarcity of spectroscopic resources for follow-up. When applying our novel method to DES data, we reduce the need for follow-up by a factor of four and three for host-galaxy and live SN, respectively, compared to earlier approaches. Our novel method thus leads to better optimization of spectroscopic resources for follow-up.
1 INTRODUCTION
Type Ia supernovae (SNe Ia) are crucial tools to directly measure the cosmic expansion and constrain Dark Energy models. Surveys such as the Dark Energy Survey (DES) and Zwicky Transient Facility (ZTF) have already discovered thousands of SNe Ia and other optical transients (Bernstein et al. 2012; Bellm et al. 2018). The upcoming Vera C. Rubin Observatory will provide up to 10 million transient and variable detections every night (Rubin, LSST Science Collaboration 2009). During its 10-yr Legacy Survey of Space and Time (LSST), it will detect more than a million SNe, which can be used to make precise measurements of the equation-of-state parameter of Dark Energy. To constrain cosmological parameters, SNe Ia first need to be accurately classified and redshifts need to be determined.
Traditionally, classification of SNe for cosmology is done using real-time spectroscopy as in the DES 3-yr analysis and Pantheon + (Hicken et al. 2009; Contreras et al. 2010; Doi et al. 2010; Betoule et al. 2014; Scolnic et al. 2018; Abbott et al. 2019; Brout et al. 2022). However, spectroscopic resources are limited and thus, a large fraction of detected SNe have not been classified in these data sets. To fully exploit the power of these current and future time-domain surveys, it has become necessary to classify astrophysical objects using photometry instead of the resource-limited spectroscopy. In recent years, many methods have been developed to classify transients using photometry, with an emphasis on supernovae (PSNID, SNLSPC, SuperNNova (SNN), RAPID, SuperRAENN, and SCONE; Sako et al. 2011; Möller et al. 2016; Möller & de Boissière 2019; Muthukrishna et al. 2019; Villar et al. 2019, 2020; Qu et al. 2021).
The DES 5-yr cosmology analysis (DES Collaboration 2024) uses photometric instead of spectroscopic classification to obtain the largest high-redshift SNe Ia sample from a single survey (Möller et al. 2022; Vincenzi et al. 2024). Around 1499 SNe Ia were classified using their light curves and spectroscopic host-galaxy redshift information. In contrast to most previous cosmological samples, SN Ia classification probabilities were incorporated in the cosmology analysis (Hlozek et al. 2012; Möller & de Boissière 2019; Qu et al. 2021; Vincenzi et al. 2022). This analysis provides the tightest cosmological constraints by any supernova data set to date. It also overcomes contamination uncertainties from previous photometrically classified cosmology analyses (Jones et al. 2018).
To obtain even larger samples and reduce selection biases, methods have been extended to ignore all spectroscopic information. Most of these methods use complete light curves and either photometric host-galaxy redshifts or photometric SN-derived redshifts (Bazin et al. 2011; Lochner et al. 2016; Möller et al. 2016; Boone 2021; Carrick et al. 2021; Gagliano et al. 2023). Some of these methods have been used for obtaining cosmological constraints (Chen et al. 2022; Ruhlmann-Kleider, Lidman & Möller 2022). However, precise classification without the use of any redshift information remains a challenge in particular when using early light curves (Möller et al. 2021; Leoni et al. 2022; Möller & Main de Boissiìre 2022).
In this work, we classify SNe Ia using only the information from the 5-yr DES light curves using an extension of the machine learning framework snn (Möller & de Boissière 2019). We aim to fully harness the power of the DES data by identifying most of the detected SNe Ia in this survey, regardless of whether or not a host redshift has been acquired. We exploit the improved statistics that come from larger, more complete, and more representative samples.
To use these SNe Ia for cosmology, rates, and other astrophysical analyses, we require both accurate classification and redshifts. Traditionally, redshifts are obtained from spectra from the SN or host-galaxies using spectroscopic follow-up (Smith et al. 2018; Lidman et al. 2020). An alternative is to use host-galaxy photometric redshifts but these are biased and have not been widely used in cosmological analyses (Ruhlmann-Kleider et al. 2022). A promising avenue is to use a subsample of host-galaxies that have highly accurate photometric redshifts such as Luminous Red Galaxies (Chen et al. 2022). However, for these methods, host-galaxies need to be identified and high-SNR photometry acquired or produced with stacked images. An alternative, which does not require host identification, is to infer redshifts from the SN light curves directly. These methods have been explored with data from previous surveys obtaining promising results (Kessler et al. 2010; Palanque-Delabrouille et al. 2010; Sako et al. 2011). In this work, we derive redshifts from SN light curves using the SNphoto-z method (Kessler et al. 2010), assess biases and the impact these biases have on astrophysical analyses.
Future surveys will continue to detect more SNe than it is possible to follow-up spectroscopically both for classification and host-galaxy redshift acquisition. In the case of Rubin, the 4-metre Multi-Object Spectroscopic Telescope (4MOST) Time-Domain Extragalactic Survey (TiDES; Swann et al. 2019) will aim to classify live SNe and obtain host-galaxy redshifts for cosmology up to a limiting magnitude of 22.5. 4MOST still won’t be able to follow up all SNe and transients from Rubin.
With a focus towards future surveys and their spectroscopic follow-up programmes, here we use DES data as a test bench to explore the optimization of follow-up resources for both host-galaxy redshift acquisition and live supernovae follow-up. The main spectroscopic follow-up provider for DES was the Australian Dark Energy Survey (OzDES) on the 3.9-m Anglo-Australian Telescope (Yuan et al. 2015; Childress et al. 2017; Lidman et al. 2020). OzDES targets were prioritized using a template-fitting method called Photometric Supernova IDentification software (Sako et al. 2011, PSNID) and selecting hosts mostly with |${r}\lt 24$|. However, this method is time intensive and it will be difficult to scale it for future surveys. To address this, machine learning algorithms have been developed for this challenging task (Möller & de Boissière 2019; Muthukrishna et al. 2019; Leoni et al. 2022). In this work, we use snn (Möller & de Boissière 2019), a photometric classification framework, for spectroscopic follow-up optimization using DES data.
This paper is organized as follows. We introduce the DES in Section 2. For light-curve classification, we use the algorithm snn introduced in Section 3. This algorithm is trained on realistic DES simulations on both complete and partial light curves with performances on complete and partial shown in Sections 3.2 and 3.3, respectively. In Section 4, we use the simulations described in Section 3 to examine the SNphoto-z estimation and its biases which will be used for sample analysis but not for classification. In Section 5, we select a SN Ia sample without the use of any redshift information, study its properties, and compare it to previous DES SN Ia samples. We then explore how machine learning classification can improve follow-up optimization for host-galaxies in Section 6.1 and for early SN identification using partial light curves in Section 6.2. We conclude with prospects for future surveys such as Rubin LSST and 4MOST in Section 7.
2 DARK ENERGY SURVEY (DES)
In this work, we select SNe Ia using only light-curve information from the Dark Energy Survey. DES was a photometric survey that used the Dark Energy Camera (DECam; Flaugher et al. 2015) at the Victor M. Blanco Telescope in Chile. It consisted of a wide-area survey (DES-wide) and a supernova survey (DES-SN). DES-SN, which is used in this work, imaged ten |$2.7~{\rm deg}^2$| fields with an average cadence of 7 d in the |$griz$| filters during 5 yr (Abbott et al. 2018). Eight of these 10 fields (X1, X2, E1, E2, C1, C2, S1, and S2) were observed to a single-visit depth of |$m\approx 23.5$| mag (‘shallow fields’), and the other two (X3,C3) were observed to a depth of |$m\approx 24.5$| mag (‘deep fields’). Detailed information on the SN survey can be found in Smith et al. (2020).
Transients were identified using the DES Difference Imaging Pipeline diffimg (Kessler et al. 2015) coupled with a machine learning algorithm (Goldstein et al. 2015) to reduce difference imaging artefacts. A candidate SN was defined from the difference images by requiring at least two detections with effective S/N threshold about 5 in each band. These criteria were designed to remove artefacts and asteroids. This yielded a sample containing 31 636 light curves with 5-yr photometry. An example of a light curve is shown in Fig. 1.
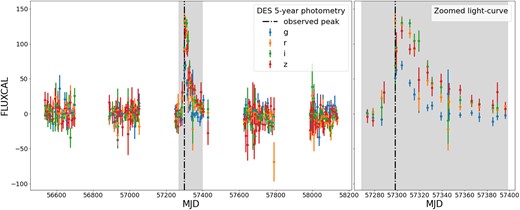
Light curve of DES15X2kvt. The measured calibrated flux (FLUXCAL, defined in Section 3.1) in |$g, r, i$| and z bands is plotted against Modified Julien Date (MJD). In the left-hand panel, we show the full 5-yr light curve. In the right-hand panel, we show the light curve of 30 d before to 100 d after the observed peak flux.
From this DES SN candidate sample, SNe Ia were selected for the DES 5-yr cosmological analysis (DES Collaboration 2024). Instead of spectroscopic selection (Smith et al. 2020), SNe Ia were weighted by their probability of being SNe Ia from the classification framework snn (Möller & de Boissière 2019) using light curves and host-galaxy spectroscopic redshifts (Möller et al. 2022, hereafter M22). This SNe Ia sample is the largest and deepest SN cosmological sample acquired from a single survey. Photometric misclassification was shown not to be a limiting uncertainty in the cosmological analysis (Vincenzi et al. 2022, 2024). Part of this analysis tested other photometric classifiers such as SCONE (Qu et al. 2021) to evaluate the systematic uncertainty.
A subsample of DES SNe Ia were classified using spectroscopic follow-up. For this, potential SNe were identified early (before or around maximum brightness). A trigger is defined as a sequence of detections that results in tracking the light curve with forced-photometry and consideration for spectroscopic follow-up. SDSS required two detections on two separate nights; DES required one (or more) detection on two separate nights (Sako et al. 2011), and Rubin LSST will require just one detection. In Section 6.2, we explore early classification with different triggers.
In this work, we use the DES SN candidate sample to select SNe Ia without any spectroscopic information from either host or the SN. We only use the SN candidates 5-yr photometric light curves.
3 CLASSIFICATION PERFORMANCE ON SIMULATIONS
We make use of snn to select SN Ia candidates (Möller & de Boissière 2019). snn is an open-source light-curve classification framework that was used for the classification of Type Ia SNe in the DES 5-yr cosmological analysis using light curves and host-galaxy redshifts (Möller et al. 2022; DES Collaboration 2024) and is part of the Rubin broker Fink (Möller et al. 2021; Fraga et al. 2024).
snn is a non-parametric method that uses as input fluxes and their measurement uncertainties over time for light-curve classification. Additional information such as host-galaxy redshifts can be included to improve performance such as in DES Collaboration (2024). snn includes different classification algorithms, such as long short-term memory (LSTM),1 Recurrent Neural Networks (RNNs), and two approximations for Bayesian Neural Networks. These algorithms can be trained for binary or multiclass classification and then applied to independent data sets to obtain probabilities of a light curve being of a certain class. The classification probabilities can be used to select a sample by performing a threshold cut or by weighting the contribution of candidates by their classification score as in the BEAMS and BBC methods (Möller et al. 2022; DES Collaboration 2024; Vincenzi et al. 2024). In this work, we use an SN Ia probability threshold that we will denote as SNN>threshold.
In this work, we train snn for classification of SNe Ia versus non-Ia using only photometric measurements. To avoid luminosity biases, we use the cosmo_quantile normalization as in M22 which, for a given light curve, normalizes fluxes and uncertainties by the 99th quantile of the flux distribution (to avoid using an outlier). This normalizes the fluxes for each light curve to 1 or near 1, thus making the classification model agnostic to the relative differences in apparent brightness between SNe and retains colour and signal-to-noise information for the classification. A thorough study of the cosmological biases from snn classification can be found in Vincenzi et al. (2022).
The classifier was trained using DES-like simulations described in Section 3.1 and the snn configuration in M22. The performance obtained for complete light curves (using all SN photometry) is discussed in Section 3.2 and for partial light curves (using photometry before maximum brightness) in Section 3.3.
3.1 Simulations
DES-like simulations are used to train and test our photometric classifier using only light curves. Simulations contain light curves of different SNe types generated with realistic observing conditions. These simulations also include a host redshift; however, we withhold this information from the snn classifier. Details on the simulations, which were generated using SNANA (Kessler et al. 2009) within the PIPPIN framework (Hinton & Brout 2020), can be found in M22 and Kessler et al. (2019b). Throughout this work, we use SNANA calibrated flux (FLUXCAL) defined from the magnitude with a fixed zero point given by: |$mag = 27.5 - 2.5*log_{10}$|(FLUXCAL).
As in M22, we first create a training sample with the same number of Type Ia and core-collapse SNe after trigger and selection requirements (equivalent to 50 per cent type Ia and 50 per cent core-collapse SNe). This balanced training sample contains |$3.6\times 10^6$| SNe and covers the redshift range from 0.05 to 1.3. As in Vincenzi et al. (2022), it contains Type Ia based on models in Guy et al. (2007) and the optical + NIR extension from Pierel et al. (2018), peculiar Ia (SN1991bg- like SNe and SN2002cx-like SNe; Kessler et al. 2019a) and core-collapse SNe from Vincenzi et al. (2019) using volumetric rates from Frohmaier et al. (2019).
We generate a smaller data-sized simulation to estimate the expected number of SNe Ia in the DES survey as well to test our photometric classifiers. We simulate 30 realizations of the DES survey using the expected rates of type Ia and non Ia SNe. This simulation contains |$\approx 60~{{\ \rm per\ cent}}$| type Ia and 40 per cent core-collapse SNe, and was generated using the expected abundances of different types of supernovae through cosmic time.
3.2 Performance on complete light curves
We evaluate the classification of complete light curves: up to 100 d beyond the time of peak brightness. We use accuracy, efficiency, and purity as metrics to assess the performance of the classifier.
Accuracy is measured as the number of correct predictions against the total number of predictions. More explicitly, it is calculated as follows:
where TP (resp. TN) are true positives (resp. true negatives) and FP (resp. FN) are false positives (resp. false negatives). TP is the number of correctly classified SNe Ia, while TN is the number of correctly classified non SNe Ia.
The purity of the SN Ia sample and the classification efficiency are defined as:
In Table 1, we list the accuracies, purities, and efficiencies obtained for the balanced data set (same number of Type Ia and core-collapse SNe) and the more realistic DES test set. The balanced data set is useful as an evaluation of the machine learning algorithm while the test data set can be used to assess the reliability of the selected sample as it is physically more representative. We find high-accuracies, purities, and efficiencies for both data sets.
Type Ia versus non-Ia classification metrics for complete light curves with no redshift information. The model was trained and evaluated using two data sets: balanced and test. The metrics indicate the performance of the ML classifier. The metrics for the test data set indicate the expected performance in a real survey. We show the single model and the ensemble method metrics. Uncertainties for the single model are computed from the variance of five models with different seeds and uncertainties for the ensemble methods are computed using three ensembles of fives seeds.
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$97.15\pm 0.03$| | |$97.94\pm 0.06$| | |$96.42\pm 0.07$| |
| Ensemble | |$\mathbf {97.34\pm 0.01}$| | |$\mathbf {98.17\pm 0.02}$| | |$\mathbf {96.57\pm 0.01}$| |
| test dataset (realistic rates) | |||
| Single model | |$97.04 \pm 0.02$| | |$98.12 \pm 0.06$| | |$97.20 \pm 0.05$| |
| Ensemble | |$\mathbf {97.22 \pm 0.01}$| | |$\mathbf {98.36 \pm 0.01}$| | |$\mathbf {97.30 \pm 0.01}$| |
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$97.15\pm 0.03$| | |$97.94\pm 0.06$| | |$96.42\pm 0.07$| |
| Ensemble | |$\mathbf {97.34\pm 0.01}$| | |$\mathbf {98.17\pm 0.02}$| | |$\mathbf {96.57\pm 0.01}$| |
| test dataset (realistic rates) | |||
| Single model | |$97.04 \pm 0.02$| | |$98.12 \pm 0.06$| | |$97.20 \pm 0.05$| |
| Ensemble | |$\mathbf {97.22 \pm 0.01}$| | |$\mathbf {98.36 \pm 0.01}$| | |$\mathbf {97.30 \pm 0.01}$| |
Type Ia versus non-Ia classification metrics for complete light curves with no redshift information. The model was trained and evaluated using two data sets: balanced and test. The metrics indicate the performance of the ML classifier. The metrics for the test data set indicate the expected performance in a real survey. We show the single model and the ensemble method metrics. Uncertainties for the single model are computed from the variance of five models with different seeds and uncertainties for the ensemble methods are computed using three ensembles of fives seeds.
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$97.15\pm 0.03$| | |$97.94\pm 0.06$| | |$96.42\pm 0.07$| |
| Ensemble | |$\mathbf {97.34\pm 0.01}$| | |$\mathbf {98.17\pm 0.02}$| | |$\mathbf {96.57\pm 0.01}$| |
| test dataset (realistic rates) | |||
| Single model | |$97.04 \pm 0.02$| | |$98.12 \pm 0.06$| | |$97.20 \pm 0.05$| |
| Ensemble | |$\mathbf {97.22 \pm 0.01}$| | |$\mathbf {98.36 \pm 0.01}$| | |$\mathbf {97.30 \pm 0.01}$| |
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$97.15\pm 0.03$| | |$97.94\pm 0.06$| | |$96.42\pm 0.07$| |
| Ensemble | |$\mathbf {97.34\pm 0.01}$| | |$\mathbf {98.17\pm 0.02}$| | |$\mathbf {96.57\pm 0.01}$| |
| test dataset (realistic rates) | |||
| Single model | |$97.04 \pm 0.02$| | |$98.12 \pm 0.06$| | |$97.20 \pm 0.05$| |
| Ensemble | |$\mathbf {97.22 \pm 0.01}$| | |$\mathbf {98.36 \pm 0.01}$| | |$\mathbf {97.30 \pm 0.01}$| |
As in M22, we use ensemble predictions to select our sample. In Table 1, we obtain predictions with different snn models trained with different initiation parameters (random seed) and average them to obtain an ‘ensemble probability’. Here we use five models, also called an ‘ensemble set’, trained with different seeds. To report the performance of the methods, we quote the mean and standard deviation of a given metric using three ensemble sets.
3.3 Performance for partial light curves
We now evaluate the performance of our trained classifier when using simulated partial light curves. When training snn, we crop light curves to random time-ranges in the data set, this produces a classification model robust for both complete and partial light-curve classification.
We evaluate the performance on light curves that were cropped to only contain photometric measurements until peak brightness in Table 2. As we use fewer photometric measurements per event, the performance is poorer. However, this type of classification can be used for scheduling spectroscopic follow-up before SNe fade away.
Type Ia versus non-Ia classification metrics for partial light curves with no redshift information. These light curves contain only photometric measurements up to their peak brightness.
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$90.4 \pm 0.1$| | |$91.5 \pm 0.2$| | |$89.4 \pm 0.2$| |
| Ensemble | |$90.73 \pm 0.01$| | |$91.9 \pm 0.1$| | |$89.7 \pm 0.1$| |
| Test data set (realistic rates) | |||
| Single model | |$90.6 \pm 0.1$| | |$92.1 \pm 0.2$| | |$91.7 \pm 0.2$| |
| Ensemble | |$90.46 \pm 0.03$| | |$92.49 \pm 0.03$| | |$91.93 \pm 0.03$| |
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$90.4 \pm 0.1$| | |$91.5 \pm 0.2$| | |$89.4 \pm 0.2$| |
| Ensemble | |$90.73 \pm 0.01$| | |$91.9 \pm 0.1$| | |$89.7 \pm 0.1$| |
| Test data set (realistic rates) | |||
| Single model | |$90.6 \pm 0.1$| | |$92.1 \pm 0.2$| | |$91.7 \pm 0.2$| |
| Ensemble | |$90.46 \pm 0.03$| | |$92.49 \pm 0.03$| | |$91.93 \pm 0.03$| |
Type Ia versus non-Ia classification metrics for partial light curves with no redshift information. These light curves contain only photometric measurements up to their peak brightness.
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$90.4 \pm 0.1$| | |$91.5 \pm 0.2$| | |$89.4 \pm 0.2$| |
| Ensemble | |$90.73 \pm 0.01$| | |$91.9 \pm 0.1$| | |$89.7 \pm 0.1$| |
| Test data set (realistic rates) | |||
| Single model | |$90.6 \pm 0.1$| | |$92.1 \pm 0.2$| | |$91.7 \pm 0.2$| |
| Ensemble | |$90.46 \pm 0.03$| | |$92.49 \pm 0.03$| | |$91.93 \pm 0.03$| |
| Method | Accuracy | Efficiency | Purity |
|---|---|---|---|
| Balanced data set | |||
| Single model | |$90.4 \pm 0.1$| | |$91.5 \pm 0.2$| | |$89.4 \pm 0.2$| |
| Ensemble | |$90.73 \pm 0.01$| | |$91.9 \pm 0.1$| | |$89.7 \pm 0.1$| |
| Test data set (realistic rates) | |||
| Single model | |$90.6 \pm 0.1$| | |$92.1 \pm 0.2$| | |$91.7 \pm 0.2$| |
| Ensemble | |$90.46 \pm 0.03$| | |$92.49 \pm 0.03$| | |$91.93 \pm 0.03$| |
In the following, we use the single model classifier as the performance gain for the ensemble classifier is small and current early classification mechanisms use a single model. However, the extension to ensembles can provide a gain if resources are available to deploy multiple models as they are not very computationally expensive.
4 ESTIMATING REDSHIFTS AND LIGHT-CURVE PARAMETERS SIMULTANEOUSLY
In this work, we will select a photometric SN Ia sample from DES data without the use of redshift information. After classification, we will determine the redshifts and SALT2 light-curve parameters simultaneously on light curves using the SNphoto-z code described in Kessler et al. (2010).
In this section, using simulations, we examine biases arising from this fit and evaluate how these biases affect the efficacy of sample cuts in improving the classification efficiency and limiting contamination.
We start by assuming that all the photometrically classified SNe are SNe Ia and fit them with the SALT2 supernova light-curve model based on (Guy et al. 2007) and extended to the optical + NIR (Pierel et al. 2018). We use the SNANA light-curve fitting program (Kessler et al. 2009) to simultaneously fit for z, |$t_0$|, |$x1$|, c and |$x_0$|, respectively, redshift, time of maximum brightness, stretch, colour, and amplitude, as described in Kessler et al. (2010). To obtain better estimates of redshifts for SNe Ia, a weak distance-modulus prior is applied (Appendix B), assuming a |$\Lambda$|CDM cosmology, and we use when available inferred photometric redshifts of the host-galaxies as a Gaussian prior. When no photometric redshift is available, we use a flat prior. We highlight that this SNphoto-z fit uses a cosmological model.
Detailed analysis of biases on the light-curve parameters and redshift is presented in Section 4.1 and their effect on the cuts to improve the classification by limiting contamination in Section 4.2.
None of the derived redshifts (SNphoto-z) or SALT2 parameters are used for photometric classification. They are only used in Section 5.5 to study the sample properties after classification is done without this information.
4.1 SNphoto-z and light-curve parameters biases
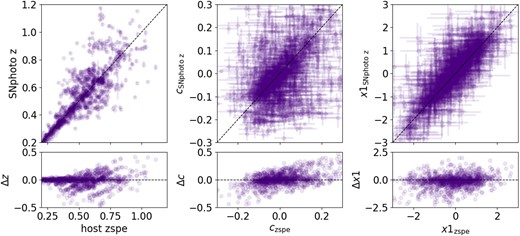
We use the test simulations to evaluate the fitted light-curve parameters and SNphoto-z. In Fig. 2, we compare the fitted light-curve parameters and SNphoto-z against their true values.
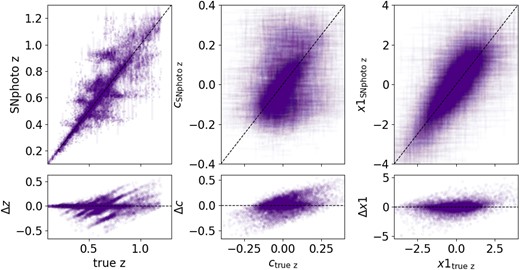
A comparison between the fitted and true parameter values for simulated SNe Ia. Left: a comparison of the SNphoto-z versus true redshifts. Centre and right: comparisons between light-curve parameters colour (c) and stretch (|$x1$|). The dashed line shows the diagonal, where the values should lie if they were equivalent. While the simultaneous fits are only slightly biased on average, there is considerable structure, especially in redshift and colour.
The fitted parameters are slightly biased on average, with median shift of |$-0.003^{+0.035}_{-0.065}$|, |$0.008^{+0.086}_{-0.058}$|, and |$-0.0042^{0.315}_{-0.42}$| for redshift, colour, and stretch, respectively (errors are indicated by the 25th and 75th quantiles). For redshift, colour, and stretch, we compute an outlier fraction of 0.1, 0.06, and 0.07 using the interquartile range (IQR) method.
A complex structure can be found in particular for the redshift estimation. Chen et al. (2022) finds a similar structure, in particular for redshifts around 0.4 when comparing galaxy photometric redshifts obtained in redMaGiC galaxies and their spectroscopic ones. These luminous red galaxies are expected to have highly accurate photometric redshifts and were shown to provide constraints with equivalent Hubble scatter that when using spectroscopic redshifts (Chen et al. 2022).
In Fig. 3, we plot the average behaviour of the SNphoto-z and colour/stretch for simulated SNe Ia. We find a pattern of offsets resulting from degeneracies between colour/stretch and redshift. Interestingly, around redshift 0.7 where noise starts dominating the r because the rest-frame UV regions has low flux, only |$i,z$| are sampling the light curve and the offset reverses. Similarly, at redshift around 0.9, the noise dominates the i band thus light curves are only well sampled in the z band. These effective band drop-outs due to low rest-frame UV flux highlight the importance of multiband light curves. These shifts introduce structured systematics. If these simultaneous fits are to be used in further analyses these offsets must be taken into account potentially by the use of bias corrections, a hierarchical model or grouping events in less bias affected bins. An alternative is to use stronger priors for redshift using host-galaxy photometric redshifts to reduce biases. A detailed study in DES of the cosmological biases using photometric redshifts, including SNphoto-z with or without priors, can be found in Chen et al. (2024).
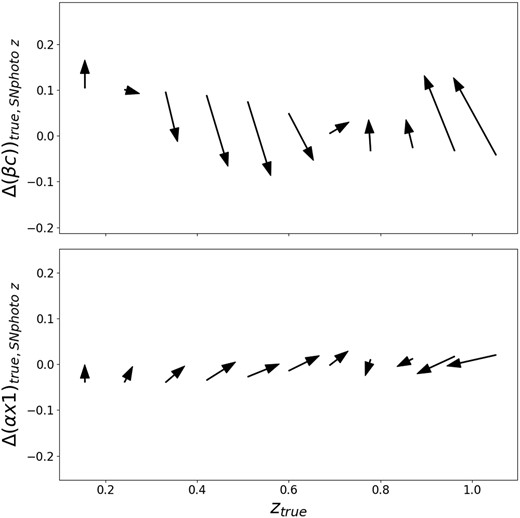
Average offset in SALT2 colour and stretch as a function of redshift. Each arrow represents the average offset in both colour (stretch in the lower plot) and redshift between a fit that fits redshift and SALT light-curve parameters simultaneously and a SALT2 fit that uses as input the true redshift. We show these offsets in magnitudes space as |$\beta c$| and |$\alpha x1$| where |$\alpha = 0.144$| and |$\beta = 3.1$|. High redshift events are fitted towards lower redshifts, redder colours, and lower stretch while intermediate redshift events are offset to higher redshifts, bluer colours, and higher stretch.
4.2 The effect of SNphoto-z fit on SNe Ia samples
In this section, we study how cuts on light-curve parameters affect efficiency and contamination. We study two cuts: the baseline sample selected using only light curves with a threshold of SNN>0.5 using the model in Section 3.2, and a high-quality (HQ) sample with additional cuts on the light-curve parameters. The latter aims to mimic samples for cosmology that apply extra cuts to reduce peculiar SNe Ia (Vincenzi et al. 2021). The HQ cuts are: |$-3.0\lt x1\lt 3.0$|, |$-0.3\lt c\lt 0.3$|, and |$\sigma _{x1}\lt 1$| and |$\sigma _{t_0}\lt 2$|, where c, |$x1$|, |$\sigma _{t_0}$| are estimated using SALT2 light-curve fit and represent colour, stretch, and the error on the time of maximum light, respectively. We also require that the SALT2 chi-square fit probability is larger than 0.001 cut as in M22.
In Fig. 4, we show the true and measured efficiency as defined in equation (3.2) for three cases: the SNN>0.5 sample using its true redshift, the SNN>0.5 sample using SNphoto-z, and a HQ sample using SNphoto-z. In general, we find classification efficiencies above 98 per cent for most of the parameter space. The samples show higher measured efficiency for SNphoto-z due to the migration of true bluer events to redder ones. Conversely, the measured efficiency is lower at higher redshifts.

The percentage efficiency per bin of fitted SALT2 peak i-band magnitude (|$i_{\rm peak}$|), redshift, colour (c), and stretch (|$x1$|) for the simulated data set. We show the efficiency for a SALT2 fit with a fixed true redshift and that obtained using the SNphoto-z obtained simultaneously with SALT2 light-curve parameters. We also study a sample selected with additional HQ cuts.
We also study contamination as a function of light-curve properties in Fig. 5. Contamination is measured |$1-purity$| as defined in equation (3.2). The overall contamination is less than 6 per cent in any parameter bin while the true contamination is higher for redder events. However, when measuring it using the SNphoto-z, this contamination migrates to other colour bins and can also be absorbed by the lack of convergence of the fit. Higher contamination for redder events has also been observed for samples selected using host-galaxy redshifts such as in Möller et al. (2022); Vincenzi et al. (2022). When using SNphoto-z, we find that more distant and hence fainter supernovae have a higher contamination.
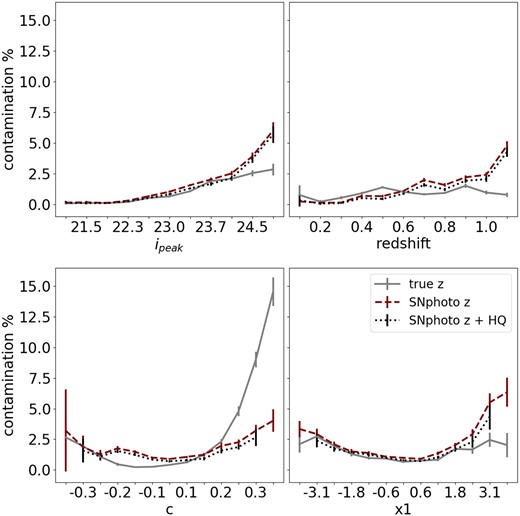
The percentage contamination per bin of fitted SALT2 peak i-band magnitude (|$i_{\rm peak}$|), redshift, colour (c), and stretch (|$x1$|) for the simulated data set. We show the contamination for a SALT2 fit with a fixed true redshift and that obtained with SNphoto-z fitted simultaneously with SALT2 parameters. We also study a sample selected with the simultaneous fit and HQ cuts. Contamination is distributed differently when using a fixed or SNphoto-z.
For the purpose of using this sample for astrophysical analyses, it is promising that the contamination of a sample using SNphoto-zs remains low and below 6 per cent for any given parameter bin. Applying HQ cuts reduces this contamination for the complete parameter space. This causes only a small reduction in efficiency for higher stretch events and events at higher redshifts.
5 CLASSIFICATION OF SNE IA WITHOUT REDSHIFT INFORMATION
In this section, we classify light curves without redshift information to obtain a large, HQ sample of photometrically selected SNe Ia. First, we use simulations to estimate the expected number of SNe Ia in DES in Section 5.1. Next, we pre-process DES data in Section 5.2. We define a sample using a threshold similar to M22 in Section 5.3. Using the SNphoto-z method introduced in Section 4, we obtain a HQ sample in Section 5.4 and study its properties in Section 5.5. We conclude by comparing this sample to other DES SN Ia samples in Section 5.6.
5.1 Expected number of HQ DES SNe Ia
We use the DES realistic simulation introduced in Section 3.1 to estimate the number of SNe Ia the DES survey. This simulation consists of 30 realistic simulations of the full DES 5-yr SN survey up to redshift 1.2.
From these simulations, we expect to detect |$4{,}961\pm 69$| SNe Ia (median and standard deviation of 30 realizations). No selection cuts other than detection are applied at this stage.
From these, we expect |$2{,}360\pm 43$| HQ SNe Ia using the cuts introduced in Section 4.2. For this estimate, we use the simulated redshift when fitting the light curve with SALT2. We then apply the cuts.
This simulation also includes other types that are not normal type Ia SNe with realistic rates. We estimate that DES detected |$3{,}466 \pm 64$| SNe of other types. Importantly, we estimate up to |$231\pm 13$| non-normal type Ia SNe that would pass the HQ cuts if a SALT2 fit using their redshift was done. These SNe are contaminants for cosmology analyses that are reduced by using photometric classifiers. For a thorough discussion on biases, refer to Vincenzi et al. (2022, 2024).
5.2 SN candidates pre-processing
In this section, we use the DES SN candidate sample introduced in Section 2. We make use of light curves from 31 636 candidates, using both the fluxes and their uncertainties.
We use the pre-processing introduced by M22 to prepare light curves for photometric classification with snn:
We select a subset of 5-yr photometry within a time-window in the observer frame of 30 d before to 100 d after maximum brightness of the detected event, as shown in Fig. 1.
We eliminate photometry that has been flagged as flawed using bitmap flags from Source Extractor (Bertin & Arnouts 1996). Around 6 per cent of measurements are discarded here.
We filter multiseason events, which include AGN, by requiring a large ratio of good detections with respect to all detections using a Real/Bogus classifier. We require a ratio between the number of epochs with detections that pass the Real/Bogus classifier (autoScan; Goldstein et al.2015) and the total number of epochs with detections to be larger than 0.2 as inSmith et al. (2020).
With these cuts, the sample is reduced from |$31{,}636$| to |$14{,}070$| SN candidates. While these cuts reduce the contamination, some residual AGN remain. The number of candidates that remain after each cut is listed in Table 3. We highlight that from the original 415 spectroscopic SNe Ia, 10 are eliminated due to the multiseason cut as they may be in galaxies with AGN.
The number of candidates selected after each cut is applied. We show results for the shallow and deep fields, as well as the total number. Note that a couple of per cent events belong to both shallow and deep fields due to field overlap. Columns show the selection cut, the number of selected candidates, the number of spectroscopic SN Ia in the sample, and the number of the DES 5-yr photometrically classified SNe Ia (photo Ia M22).
| Selection cut | Shallow | Deep | Total DES 5-yr | ||||
|---|---|---|---|---|---|---|---|
| selected | spec Ia | selected | spec Ia | selected | spec Ia | photo Ia M22 | |
| DES-SN 5-yr candidate sample | 23 795 | 322 | 7863 | 93 | 31 636 | 415 | 1484 |
| Filtering multiseason | 9607 | 317 | 4464 | 88 | 14 070 | 405 | 1484 |
| Photometric sampling | 8969 | 314 | 4150 | 86 | 13 118 | 400 | 1484 |
| SNN>0.001 | 3680 | 303 | 1996 | 83 | 5676 | 386 | 1481 |
| SNN>0.5 (high purity) | 2199 | 291 | 1348 | 77 | 3547 | 368 | 1376 |
| Converging SALT2 and SNphoto-z fit | 1630 | 250 | 909 | 60 | 2539 | 310 | 1261 |
| HQ | 1559 | 249 | 739 | 60 | 2298 | 309 | 1236 |
| Selection cut | Shallow | Deep | Total DES 5-yr | ||||
|---|---|---|---|---|---|---|---|
| selected | spec Ia | selected | spec Ia | selected | spec Ia | photo Ia M22 | |
| DES-SN 5-yr candidate sample | 23 795 | 322 | 7863 | 93 | 31 636 | 415 | 1484 |
| Filtering multiseason | 9607 | 317 | 4464 | 88 | 14 070 | 405 | 1484 |
| Photometric sampling | 8969 | 314 | 4150 | 86 | 13 118 | 400 | 1484 |
| SNN>0.001 | 3680 | 303 | 1996 | 83 | 5676 | 386 | 1481 |
| SNN>0.5 (high purity) | 2199 | 291 | 1348 | 77 | 3547 | 368 | 1376 |
| Converging SALT2 and SNphoto-z fit | 1630 | 250 | 909 | 60 | 2539 | 310 | 1261 |
| HQ | 1559 | 249 | 739 | 60 | 2298 | 309 | 1236 |
The number of candidates selected after each cut is applied. We show results for the shallow and deep fields, as well as the total number. Note that a couple of per cent events belong to both shallow and deep fields due to field overlap. Columns show the selection cut, the number of selected candidates, the number of spectroscopic SN Ia in the sample, and the number of the DES 5-yr photometrically classified SNe Ia (photo Ia M22).
| Selection cut | Shallow | Deep | Total DES 5-yr | ||||
|---|---|---|---|---|---|---|---|
| selected | spec Ia | selected | spec Ia | selected | spec Ia | photo Ia M22 | |
| DES-SN 5-yr candidate sample | 23 795 | 322 | 7863 | 93 | 31 636 | 415 | 1484 |
| Filtering multiseason | 9607 | 317 | 4464 | 88 | 14 070 | 405 | 1484 |
| Photometric sampling | 8969 | 314 | 4150 | 86 | 13 118 | 400 | 1484 |
| SNN>0.001 | 3680 | 303 | 1996 | 83 | 5676 | 386 | 1481 |
| SNN>0.5 (high purity) | 2199 | 291 | 1348 | 77 | 3547 | 368 | 1376 |
| Converging SALT2 and SNphoto-z fit | 1630 | 250 | 909 | 60 | 2539 | 310 | 1261 |
| HQ | 1559 | 249 | 739 | 60 | 2298 | 309 | 1236 |
| Selection cut | Shallow | Deep | Total DES 5-yr | ||||
|---|---|---|---|---|---|---|---|
| selected | spec Ia | selected | spec Ia | selected | spec Ia | photo Ia M22 | |
| DES-SN 5-yr candidate sample | 23 795 | 322 | 7863 | 93 | 31 636 | 415 | 1484 |
| Filtering multiseason | 9607 | 317 | 4464 | 88 | 14 070 | 405 | 1484 |
| Photometric sampling | 8969 | 314 | 4150 | 86 | 13 118 | 400 | 1484 |
| SNN>0.001 | 3680 | 303 | 1996 | 83 | 5676 | 386 | 1481 |
| SNN>0.5 (high purity) | 2199 | 291 | 1348 | 77 | 3547 | 368 | 1376 |
| Converging SALT2 and SNphoto-z fit | 1630 | 250 | 909 | 60 | 2539 | 310 | 1261 |
| HQ | 1559 | 249 | 739 | 60 | 2298 | 309 | 1236 |
Additionally, we require at least one photometric detection before 10 d after peak, and at least one after 10 d after peak. We highlight that the peak brightness is an observed peak brightness, and it does not necessarily correspond to the peak SN flux. Five events do not pass these criteria.
This sample of |$13{,}118$| candidates includes the following spectroscopically classified events: 400 SNe Ia (241 of these were in the DES 3-yr analysis), 83 core-collapse SNe, 2 peculiar SNe Ia, 16 Super Luminous SNe, 1 Tidal Disruption Event, 1 M Star, and 36 AGN.
5.3 High purity sample (SNN>0.5)
We select a higher purity sample with the same threshold as M22 but without the use of redshift information. We select |$3{,}545$|2 light curves that have an ensemble probability of being SNe Ia larger than 0.5 as shown in Table 3. As shown in Table 3, this stricter cut reduces the number of events while maintaining most of the DES 5-yr SNe in M22. In Section 4.2, we estimated the core-collapse contamination of such a photometrically identified sample to be around 6 per cent.
This photometric SNe Ia sample is a factor of two larger than the DES 5-yr SN Ia sample from M22 which used redshift information. Our new sample, classified without redshifts, contains 93 per cent of the SNe Ia in M22, thus providing reasonably good overlap with less information. Events in M22 that were not selected when classifying them without redshifts are evenly distributed at all redshifts, with a slight peak around 0.5, and they have slightly narrower light curves. While the simultaneous fit is not used for the selection, it provides an indication of the SNIa-likeness of these events. When fitting the light curves of the lost M22 SNe, we find systematic offsets in colour, stretch, and redshift.
Approximately 4 per cent of the SNN>0.5 sample have no associated host-galaxy detected with deep photometry in Wiseman et al. (2020b). In Section 6.1, we discuss further how our selection probes events with fainter hosts than other DES samples that were mostly limited to hosts with |$m^{\rm host}_r \le 24$|.
5.4 High-quality (HQ) sample
We select a high-quality sample from the |$3{,}547$| candidates described in Section 5.3 by applying cuts on the SNphoto-z and SALT2 parameters fit described in Section 4. We find that only |$2{,}539$| obtain a successful fit. This is due to convergence issues resulting from difficulties to obtain a simultaneous SNphoto-z and SALT2 fit.
We select a HQ SN Ia sample shown in Table 3 by applying SALT2 cuts introduced in Section 4.1. As the estimation of the SNphoto-z was restricted up to redshift 1.2, we add a cut where SNphoto-z must be below 1.2. We identify |$2{,}298$| photometric SNe Ia. This sample is slightly smaller to the expected number of HQ SNe Ia within this redshift range. This small reduction may be due to some issues obtaining SNphoto-z for the SNe Ia consistent with the efficiency estimated in Fig. 4. Using simulations, in Section 4.2, we estimate the contamination of a HQ selected sample to be less than 1 per cent.
Around 83 per cent of the DES 5-yr SNIa sample in M22 is also selected in our HQ sample. M22 SN Ia that were not selected in the HQ sample have differences of up to 0.3 in the SNphoto-zs. We study in more detail the effect of SNphoto-z and the overlap between the samples in Appendix A. Due to this simultaneous fit that offsets significantly the redshift of the event, these SNe Ia have SALT2 parameters that are not compatible with a HQ sample.
We do not find any spectroscopically classified non-Type Ia SN in this HQ sample. We find seven events in galaxies that have AGN, five of them have a separation from the centre of the galaxy |$\gt 1^{\prime \prime }$| and thus are kept. We eliminate two events that are in the centre of the galaxy with an AGN (SNIDs 1303165, 1257010).
5.5 Sample properties
In Fig. 6, we show the redshift and SALT2 measured light-curve parameters for our sample and for simulations as a function of redshift. In the following, true redshift will be the host-galaxy spectroscopic redshift for data and simulated one for simulations; while SNphoto-z will come from the method introduced in Section 4.
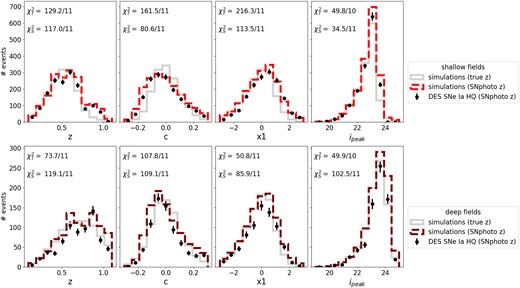
Distributions of redshift, SALT2 |$x1$|, SALT2 c and i-band peak magnitude |$i_{\rm peak}$| for the HQ, photometrically classified sample. We show distributions for both the SNphoto-z and SALT2 light-curve parameters (in red for shallow fields and maroon for deep fields) and the distributions if simulated redshift was used (in grey). Poisson uncertainties are assumed. Both the simulation and data pass HQ cuts. The goodness-of-fit for each histogram is shown as the |$\chi ^2$|/number of bins on each plot for both the SNphoto-z (|$\chi ^2_S$|) and fixed true redshift (|$\chi ^2_T$|). The simulations replicate the data better when the SNphoto-z is used for the shallow fields only.
Our photometric sample in the shallow fields agrees better in colour and stretch with simulations using the SNphoto-z, and less with the distribution using parameters derived with the true redshift as shown in the second and third panel in Fig. 6. This reinforces the results from Section 4.1 and Fig. 2 showing that we can simulate and reproduce the biases introduced by the SNphoto-z method. However, for the deep fields, we find a better agreement with simulations using the true redshift. This may be due to a reduction of selection effects at high redshift that dominates the shallow fields. We note that for some parameters, such as colour, the distributions with true, and SNphoto redshifts are comparable.
We study the redshift evolution of SN Ia light-curve parameters colour and stretch in Fig. 7. As the classifier does neither use the SNphoto-z nor light-curve parameters, the selected sample is not influenced by the step that estimates these parameters. The differences between simulations in this plot are only due to the values obtained during the SNphoto-z fit.
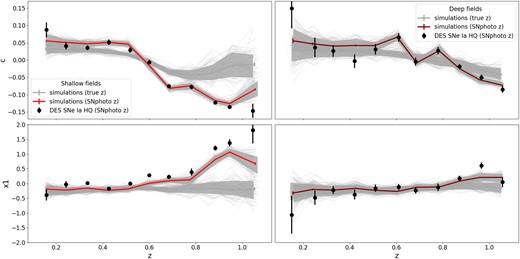
Redshift dependence of SALT2 c and |$x1$| for the photometric sample (black markers) and simulated SNe Ia (piecewise curves). We plot SALT2 parameters and SNphoto-z that are simultaneously fit for the shallow (red lines in the left-hand panels) and the deep (maroon lines in the right-hand panels) fields. The curves using the simulated (true) redshift are shown in grey. For the simulation, lines are binned averages of the measured parameters. The individual light grey lines represent 150 realizations of the DES-SN 5-yr survey and the solid grey filled area covers 68 per cent of these realizations. The mean and the standard deviation of the DES-SN 5-yr data are shown using black markers.
We find that the data follow the simulation when using SNphoto-z. This suggests that these biases can be reproduced in the simulations. For the deep fields, we observe that the offset from the true z values is coincident with the redshifts were noise starts dominating a band.
5.6 Comparing DES SN Ia samples
In this section, we compare differently selected SNe Ia samples from DES: spectroscopically classified, photometrically classified using host-galaxy redshifts M22; DES Collaboration (2024); Vincenzi et al. (2024), and – our current work- a z-free photometrically classified sample. We study SALT2 SN Ia parameters, as well as host-galaxy properties derived in Wiseman et al. (2020a).
Host redshifts are only available for a subset of events. We show in Fig. 8 that a sample selected without host or SN redshifts information includes SNe Ia probing a wider range of parameters (e.g. redshift coverage), in greater numbers and in fainter hosts. Our z-free sample also contains SNe Ia that are on average bluer, fainter and with broader light curves when comparing to spectroscopically classified and photometrically classified with host-galaxy redshift samples.

Distributions of redshift, SALT2 |$x1$|, SALT2 c, i-band peak magnitude |$i_{\rm peak}$|, and host-galaxy r-band magnitude for the HQ sample classified without host information in this work, the photometrically selected SN Ia sample with spectroscopic host-galaxy redshifts M22, and the spectroscopically classified SNe Ia.
We check the power of our new sample in the context of host-galaxies. For those SNe Ia that have an identified host, we compute their host stellar masses using different sources of redshift. Using SNphoto-z, in Fig. 9, we find that the z-free classification includes fainter hosts at all redshifts and with lower masses from z>0.4. We highlight that the z-free sample includes most of M22 plus lower mass galaxies at higher redshifts. We find that the distribution of host-galaxy masses from this sample remains the same at all redshifts below 1 when using masses derived with host-galaxy spectroscopic redshifts or SNphoto-z.

SALT2 stretch and colour, host-galaxy mass, and r magnitude as a function of the redshift for the HQ sample classified without host information (green), the photometrically selected SN Ia sample with spectroscopic host-galaxy redshifts (in M22 in orange) and the spectroscopically classified SNe Ia (in blue). For the sample classified without host information (green) we show two versions: one using SNphoto-z (solid line) computed simultaneously with colour and stretch; and the other using the host-galaxy spectroscopic redshift when available (dotted line). The error bars show the standard error for a given redshift bin. The HQ sample probes SNe Ia in fainter hosts than the M22 sample at all redshifts as well as lower mass hosts from z>0.4.
We further investigate correlations between stretch and host-galaxy mass in Fig. 10. We find that the DES SNe Ia HQ using SNphoto-z have higher stretch at higher masses than other DES samples (first row). This is also seen even if we restrict to events with host-galaxy spectroscopic redshift in this sample (second row) or if we create a ‘mixed sample’ that uses spectroscopic host-galaxy spectroscopic redshifts if available and then SNphoto-z for those without it (third row). A detailed study of these correlations is left for future work.
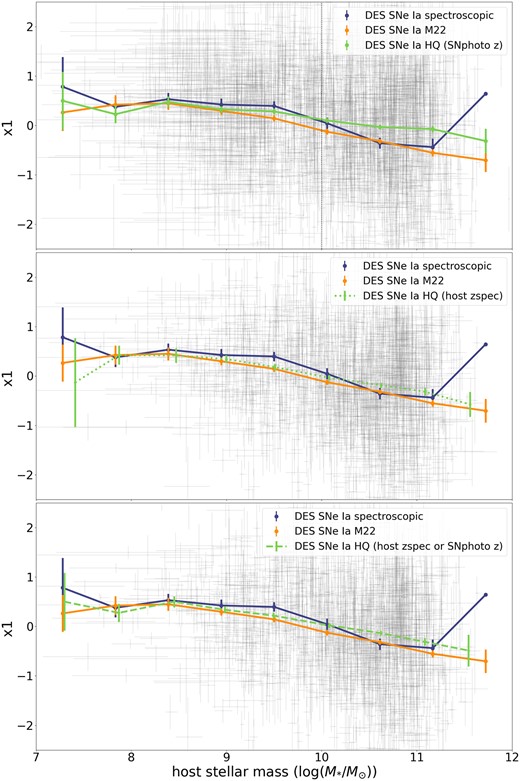
SNIa stretch as a function of host-galaxy mass. In coloured lines we show the median values for the HQ sample classified without host information (green), the photometrically selected SN Ia sample with spectroscopic host-galaxy redshifts (in M22 in orange) and the spectroscopically classified SNe Ia (in blue). The error bars show the standard error for a given redshift bin. In grey, we show each of the measurements for a given SNe Ia in the z-free sample. Each row uses a different redshift for the DES SNe Ia HQ sample and thus its x1 measurement, first row SNphoto-z, second row host-galaxy spectroscopic redshifts if available, and third row a mixture of host-galaxy spectroscopic redshift and when not available SNphoto-z. The z-free sample shows for any choice of redshift, a higher stretch at higher mass than the M22 sample.
This z-free classified sample will be of value for studying rates, Delay Time Distributions (DTDs), intrinsic populations, and understanding selection biases in our current analyses. However, redshifts are still needed for understanding how these quantities vary through cosmic time. Using the light curve to estimate redshifts along with light-curve parameters was shown to produce biased estimates. These biases can be reduced by using large redshift bins or by using simulations to correct for the biases. This has been shown in a preliminary analysis with a subset of the DES SN-candidate sample for rates (Lasker 2020). For cosmology, another alternative could be to select only candidates in certain types of galaxies such as redMaGiC that can provide accurate host photometric redshifts (Chen et al. 2022) to use for the light-curve fitting or apply SN Ia light-curve redshift driven methods such as the method described in Qu & Sako (2023).
6 PHOTOMETRIC CLASSIFICATION FOR FOLLOW-UP OPTIMIZATION
In this section, we explore how to use photometric classification to optimize spectroscopic follow-up of host-galaxies (Section 6.1) and SNe while still bright enough to observe and preferably before maximum light (Section 6.2).
6.1 Follow-up of host-galaxies
Host-galaxy follow-up provides accurate redshifts, which are needed for the Hubble diagram and thus cosmology. As spectroscopic resources are scarce, prioritization of potential SN Ia host-galaxies is necessary for spectroscopic follow-up programmes.
The Australian Dark Energy Survey (OzDES) provided multi-object fibre spectroscopy for the DES using the 2dF fibre positioner and AAOmega spectrograph on the 3.9-m Anglo-Australian Telescope (Yuan et al. 2015; Childress et al. 2017; Lidman et al. 2020). OzDES targeted a wide range of sources over the 6 yr, with active transients, AGNs, and host-galaxies with |$r\lt 24$| having the highest priority and occupying most of the fibres.
For DES, OzDES targeted |$8{,}666$| candidate SN hosts and obtained redshifts for |$6{,}391$| of these galaxies (Lidman et al. 2020). OzDES targets were selected from |$31{,}636$| DES SN candidates by prioritizing those with a high probability of being SNe Ia from fits with the Photometric Supernova IDentification software (Sako et al. 2011, psnid) and selecting hosts mostly with |${r}\lt 24$|.
In this section, we explore using snn probabilities for host-galaxy spectroscopic follow-up prioritization. This will be crucial for future surveys such as Rubin LSST and its follow-up programme the Time-Domain Extragalactic Survey (TiDES; Swann et al. 2019) on the 4-metre Multi-Object Spectrograph Telescope (4MOST).
SNN>0.001
We explore the use of a loose cut in SN Ia probability for identifying potential host-galaxies. We apply an SNN>0.001 cut after pre-processing cuts in Section 5.2. From the pre-processed |$13{,}118$| candidates, this cut reduces significantly the sample to |$5{,}676$| as shown in the fourth row of Table 3 and in the third bar of Fig. 11 while keeping all events in the M22 sample except 3 (shown in orange in Fig. 11).
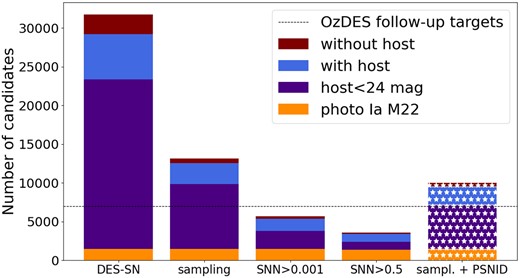
Number of events as a function of cuts applied. The size of the bar includes all events and they are split according to the subsamples (e.g. M22 photometric SNe Ia in yellow, events with hosts brighter than 24 mag in purple, without host in maroon). From left to right the first four bars represent an additional cut being applied. The right starred bar represents the DES survey follow-up prioritization strategy: sampling cuts plus a loose cut in PSNID probabilities. We show the number of OzDES follow-up targets as a dashed line.
To estimate the performance of this selection method we apply the same SNN>0.001 cut to DES SN simulations. We recover almost all of the simulated SNe Ia, obtaining an efficiency of |$99.996 \pm 0.001~{{\ \rm per\ cent}}$|. As this is a loose cut, we find that the purity of the sample is only |$88.68 \pm 0.06~{{\ \rm per\ cent}}$|. For one realization of the DES survey, with |$4{,}962$| type Ia and |$3{,}466$| core-collapse SNe, this cut selects all the type Ia and 613 core-collapse SNe. We highlight, that this simulation does not include other types of transients and spurious detections which may contaminate the candidates.
We now compare this loose snncut with respect to the method used during the DES survey to prioritize potential SNe host-galaxies. During the DES survey, a loose PSNID probability cut was used to select candidates. In Fig. 11, we find that a loose SNN probability cut (third bar) reduces the follow-up sample from PSNID by a factor of two while maintaining the number of DES 5-yr SNe Ia M22 (yellow bar).
Future surveys, such as Rubin LSST, will not only require accurate selection of candidates, but also scalable methods to address the big data volumes. snn has been shown to be scalable, classifying thousands of light curves per second.
SNN>0.5
We now explore whether a tighter probability cut provides a good sample for host-galaxy follow-up.
Using simulations, we estimate that such a cut would recover |$4{,}883$| from |$4{,}962$| type Ia and select 128 from |$3{,}466$| non Ia SNe. This represents an efficiency of |$98.36 \pm 0.01~{{\ \rm per\ cent}}$| and purity of |$97.297 \pm 0.004~{{\ \rm per\ cent}}$|. As in the previous Section, these simulations only indicate the performance on SN light curves while the data may include other transients and spurious detections.
We apply a SNN>0.5 threshold as in Section 5.3 to the DES SN-candidates, finding that there is a significant reduction on the number of follow-up candidates, while maintaining the number SNe Ia. From these |$3{,}547$| host-galaxy follow-up candidates, |$1{,}441$| have no spectroscopic redshift from DES follow-up programmes.
As shown in Fig. 12, most of the host-galaxies without redshift are faint. In the context of DES, if we select those events in host-galaxies with a limiting magnitude similar to that for spectroscopic follow-up at the OzDES programme, |$m^{\rm host}_r \le 24$|, we obtain |$2{,}394$| potential follow-up host-galaxies. Most of these galaxies were followed-up and a redshift was acquired. The majority of hosts without redshifts come from SN candidates in the last 2 yr of the survey, which had less time to be followed-up and thus resulted in shorter integration times. These selection effects were modelled by Vincenzi et al. (2022).
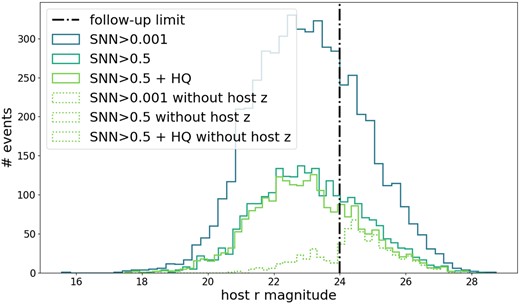
Number of events in the photometrically selected SN Ia sample as a function of host-galaxy r band magnitude. We show samples with different snn classification scores and a DES cosmology-like cut (solid lines) and those events that had no redshift in the DES data base (dotted). The host-galaxy magnitude limit used in OzDES is shown as a vertical line.
This method provides potential prioritization for follow-up galaxies to extend the DES 5-yr sample with 447 new events with hosts within the magnitude limits of the AAT and the OzDES programme.
6.2 Early classification for live SN follow-up
In this Section, we explore the early identification of candidates for SN spectroscopic follow-up optimization. This identification is done with partial light curves, preferably before maximum brightness.
DES light curves are preprocessed using the following cuts:
Artifacts are rejected using the transient_status flag as in Smith et al. (2018).
We eliminate photometry that has been flagged as flawed using bitmap flags from Source Extractor (Bertin & Arnouts 1996).
To trigger follow-up, a sequence of detections must be identified. The DES trigger required at least one detection on two separate nights. To verify its performance, we select photometric measurements (i) within a time-window of 7 d before to 20 d after the DES-like trigger and (ii) within a time-window of 30 d before the observed peak and the observed peak. We apply |$SNN\gt 0.5$| classification threshold to select candidates for follow-up as shown in Table 4.
Selection of targets for spectroscopic follow-up. The first two rows show the number of events selected from their partial light curves using photometry |$-$|7<DES-like trigger<20 d. The following two rows show the same statistics but for light curves selected within a time-window of |$-$|30<peak<1 and then for |$-$|7<LSST-like trigger<20. For all cases, we only include events with peak magnitudes brighter than 22.7 in any band, which was the OzDES limiting magnitude for live transient follow-up.
| cut | total | specIa | M22 | spec nonIa | multiseason |
|---|---|---|---|---|---|
| |$-$|7<DES-like trigger<20 | |||||
| |$-$|7<DES<20 | 3250 | 336 | 776 | 120 | 230 |
| SNN>0.5 | 1288 | 294 | 687 | 4 | 18 |
| |$-$|30<peak<1 | |||||
| |$-$|30<peak<1 | 5702 | 359 | 810 | 144 | 622 |
| SNN>0.5 | 1428 | 305 | 683 | 4 | 19 |
| |$-$|7<LSST-like trigger<20 | |||||
| |$-$|7<LSST<20 | 3327 | 296 | 689 | 95 | 219 |
| SNN>0.5 | 1305 | 264 | 618 | 4 | 28 |
| cut | total | specIa | M22 | spec nonIa | multiseason |
|---|---|---|---|---|---|
| |$-$|7<DES-like trigger<20 | |||||
| |$-$|7<DES<20 | 3250 | 336 | 776 | 120 | 230 |
| SNN>0.5 | 1288 | 294 | 687 | 4 | 18 |
| |$-$|30<peak<1 | |||||
| |$-$|30<peak<1 | 5702 | 359 | 810 | 144 | 622 |
| SNN>0.5 | 1428 | 305 | 683 | 4 | 19 |
| |$-$|7<LSST-like trigger<20 | |||||
| |$-$|7<LSST<20 | 3327 | 296 | 689 | 95 | 219 |
| SNN>0.5 | 1305 | 264 | 618 | 4 | 28 |
Selection of targets for spectroscopic follow-up. The first two rows show the number of events selected from their partial light curves using photometry |$-$|7<DES-like trigger<20 d. The following two rows show the same statistics but for light curves selected within a time-window of |$-$|30<peak<1 and then for |$-$|7<LSST-like trigger<20. For all cases, we only include events with peak magnitudes brighter than 22.7 in any band, which was the OzDES limiting magnitude for live transient follow-up.
| cut | total | specIa | M22 | spec nonIa | multiseason |
|---|---|---|---|---|---|
| |$-$|7<DES-like trigger<20 | |||||
| |$-$|7<DES<20 | 3250 | 336 | 776 | 120 | 230 |
| SNN>0.5 | 1288 | 294 | 687 | 4 | 18 |
| |$-$|30<peak<1 | |||||
| |$-$|30<peak<1 | 5702 | 359 | 810 | 144 | 622 |
| SNN>0.5 | 1428 | 305 | 683 | 4 | 19 |
| |$-$|7<LSST-like trigger<20 | |||||
| |$-$|7<LSST<20 | 3327 | 296 | 689 | 95 | 219 |
| SNN>0.5 | 1305 | 264 | 618 | 4 | 28 |
| cut | total | specIa | M22 | spec nonIa | multiseason |
|---|---|---|---|---|---|
| |$-$|7<DES-like trigger<20 | |||||
| |$-$|7<DES<20 | 3250 | 336 | 776 | 120 | 230 |
| SNN>0.5 | 1288 | 294 | 687 | 4 | 18 |
| |$-$|30<peak<1 | |||||
| |$-$|30<peak<1 | 5702 | 359 | 810 | 144 | 622 |
| SNN>0.5 | 1428 | 305 | 683 | 4 | 19 |
| |$-$|7<LSST-like trigger<20 | |||||
| |$-$|7<LSST<20 | 3327 | 296 | 689 | 95 | 219 |
| SNN>0.5 | 1305 | 264 | 618 | 4 | 28 |
We find that the median number of detections per SN in all bands for early classification using the DES-like trigger and peak selection methods respectively are: (i) |$7\pm 4$| and (ii) |$6\pm 5$| (errors are given by one standard deviation for all SNe).
We compare our selection for potential live SN follow-up with the OzDES strategy for a magnitude limited sample. OzDES obtained 1460 spectra of live-transients prioritizing events that were brighter than 22.7. As shown in Table 4, for candidates with any band magnitude |$\lt 22.7$| we find that snnreduces the number of potential follow-up candidates by more than a factor of 3, maintaining most of the SNe Ia.
Interestingly, snn is able to eliminate a large fraction of multiseason (e.g. AGN) events. These events were not part of the training set and this indicates that the classification is robust to out-of-distribution events.
7 PROSPECTIVES FOR RUBIN AND 4MOST
The Vera C. Rubin Observatory is expected to obtain up to 10 million detections (alerts) of transients every night during the 10-yr Legacy Survey of Space and Time (LSST; Bellm et al. 2019). There is the potential of discovering hundreds of thousands supernovae for cosmology and astrophysical studies (LSST Science Collaboration 2009; Hambleton et al. 2023). This is several orders of magnitudes larger than DES. Rubin LSST will provide multiband light curves for all these transients. The 4MOST Time-Domain Extragalactic Survey (TiDES; Swann et al. 2019) will provide a large fraction of follow-up for host-galaxies and live transients with spectroscopy.
Given the sheer volume of data from LSST, it will be crucial to optimize resources for the spectroscopic follow-up of hosts-galaxies and live supernovae.
TiDES is expected to obtain host-galaxy redshifts for 50 000 SNe Ia up to redshift of 1. In Section 6.1 we have shown that snn can drastically reduce the number of candidates sent for host-galaxy follow up while maintaining most of the SNe Ia in the sample.
For follow-up of live transients, LSST will emit an alert when a detection occurs with S/N>5. These alerts will be received by Rubin Community brokers (e.g. Fink, Möller et al. 2021). In Table 4, we show the effect of using a single detection for the DES data to select early SNe. In the following, we explore the adequacy of a single LSST-like trigger and then explore a follow-up similar in magnitude depth as TiDES.
7.1 Is a LSST-like trigger a good indicator for a real event?
We now test an LSST-like trigger, where only one detection with S/N>5 is required. Intuitively, the LSST-like trigger time should be within a month of the observed peak for SNe. We check whether the LSST-like trigger is within 30 d of the observed peak finding only 85 per cent for the DES 5-yr photometric SN Ia sample (in M22) and 81 per cent for the spectroscopically classified SNe Ia satisfy this condition.
These results show that a LSST-like trigger is not necessarily a robust indicator of the start of the SN event for large surveys. An example of a SN with a trigger in a different year than the event is shown in Fig. 13.
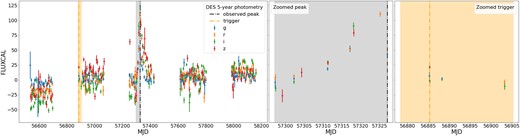
The full 5-yr light curve of DES15C3lvt in the left panel. The measured flux in |$g, r, i, z$| bands, plotted against Modified Julien Date (MJD). In the centre and right-hand panels, we show the photometry used for classification before observed peak (grey) and around trigger (orange). For this event the trigger, or first detection, is far away from the SN and was probably due to noise.
Importantly, using a single detection as a criterion for follow-up will not optimize our scarce follow-up resources. A larger fraction of LSST-like triggers when compared to a DES-like trigger will not correspond to a SN-like event. To reduce the number of spurious detections it will be necessary to increase the number of detections necessary for follow-up and monitor whether the light curve is rising in brightness together with a classifier (e.g. Leoni et al. (2022)) or to implement a requirement for a second detection within 30 d as in DES.
7.2 TiDES-like selection
Simulations predict that TiDES will be able to classify live transients as faint as |$r_{\rm mag}\approx 22.5$| (Swann et al. 2019). In this section, we discuss the early classification of transients in the DES survey as a precursor for the Rubin LSST SN sample.
The main contamination is multiseason events identified a posteriori by their detection over multiple seasons. For Rubin, it could be beneficial to incorporate AGN models into the training set to reduce this contaminant or to filter out these events using pre-existing photometry if this photometry is available. For example, much of the area that LSST will cover has imaging data with DECam.
Importantly, for DES we found that the LSST-like trigger can sometimes occur much earlier than the SN event as a result of noise fluctuation or subtraction artefact. This can be an issue if classification is restricted to a small time window around trigger. Thus, to avoid losing potential SN, a DES-like trigger could be applied or an strategy could be applied where detections are classified regardless of the trigger time with algorithms that can classify SNe at any time step. To increase purity, additional requirements can be included such as a second detection night or rising light curves.
In this work, we use data from DES as a precursor for Rubin LSST. Using LSST simulations, other works have explored: the optimization of the 4MOST follow-up strategy Carrick et al. (2021) and the rate of recovery of SNe Ia using snn (Petreca et al. in prep.).
8 CONCLUSIONS
In this work, we photometrically classified SNe Ia from the 5-yr DES survey data using only light curves and the framework SNN. Our goal was to classify detected SNe Ia regardless of whether their hosts could be identified. In anticipation of future surveys, we also explore the use of snn to optimize follow-up resources for host-galaxies and live SNe.
From the DES 5-yr data, we obtain |$3{,}547$| SNe Ia, photometrically classified without using any redshift information. This sample doubles the DES 5-yr sample classified with host-galaxy redshifts in Möller et al. (2022), DES Collaboration (2024), Vincenzi et al. (2024), and contains SNe Ia in faint galaxies.
To obtain a high-quality SN Ia sample, we first estimate redshifts from the SN light curves using the SNphoto-z method (Kessler et al. 2010). We then use the redshifts and light-curve parameters to restrict our sample to 2298 high-quality SNe Ia. This is consistent with the estimated number of well-measured SNe Ia in DES according to simulations.
We find that this HQ sample contains 83 per cent of the previous SNe Ia sample classified with host-redshifts in M22. Most of the M22 SNe Ia are lost due to lack of convergence of the SNphoto-z. If new host-galaxy photo-z are available, combining the SNphoto-z method with a host-galaxy photo-z prior is expected to significantly improve photo-z estimates and the fitting efficiency (Mitra et al. 2023).
We also find that there are structured offsets between the estimates of SNphoto-z and SALT2 parameters with respect to the true values in simulations. However, we find potential for using this sample with SNphoto-zs for analyses in the deep fields or in analyses that require a binning over redshift or other parameters.
Future surveys such as Rubin LSST will continue to detect more SNe than it is possible to follow-up spectroscopically both for classification and host-galaxy redshift acquisition. In this work, we also show that snn is more effective than previous methods at reducing the number of candidates for host-galaxy (four times) and live SN (three times) follow-up while maintaining the number of SNe Ia. Importantly, it significantly reduces contaminants such as AGN that were not used for training as they are challenging to simulate.
We use our DES results to examine potential challenges and solutions for Rubin LSST and the spectroscopic time domain follow-up programme 4MOST TiDES. In particular for live SN follow-up we find that using an LSST-like trigger (only 1 detection SNR>5) yields a large number of triggers not coincident with real SNe detections. We find that an alternative to improve triggering is to use a DES-like trigger to define the time region for classification.
In this work, we have identified most of the expected SNe Ia in the DES data set. When compared to other DES SN Ia samples both the spectroscopically classified and the photometrically classified using host-galaxy redshifts in M22, we find that we are probing higher redshift, fainter, bluer, and higher stretch SNe Ia populations. For those SNe Ia in this sample with an identified host, we find that we are probing lower host-galaxy masses at high-redshifts and at higher host masses we are obtaining higher stretch SNe Ia.
A purely light curve classified SN Ia sample, such as the one in this work, harnesses the power of large surveys such as DES. These large statistical sample, has the potential to further shed light on questions about SNe Ia diversity and environments.
ACKNOWLEDGEMENTS
AM is supported by the ARC Discovery Early Career Researcher Award (DECRA) project number DE230100055. LG acknowledges financial support from the Spanish Ministerio de Ciencia e Innovación (MCIN) and the Agencia Estatal de Investigación (AEI) 10.13039/501100011033 under the PID2020-115253GA-I00 HOSTFLOWS project, from Centro Superior de Investigaciones Científicas (CSIC) under the PIE project 20215AT016 and the program Unidad de Excelencia María de Maeztu CEX2020-001058-M, and from the Departament de Recerca i Universitats de la Generalitat de Catalunya through the 2021-SGR-01270 grant.
Author contributions. AM performed the analysis and wrote the manuscript. The top-tier authors aided in the interpretation of the analysis and: PW constructed the host-galaxy catalogue; MS, CL and TD were internal reviewers, collected and reduced data; MS computed host-galaxy masses; RK provided advice on SNphoto-z and simulations; MS was internal reviewer. The following authors contributed to the analysis of the DES5YR data set: LG, JL, RN, BS, and BT. The remaining authors have made contributions to this paper that include, but are not limited to, the construction of DECam and other aspects of collecting the data; data processing and calibration; developing broadly used methods, codes, and simulations; running the pipelines and validation tests; and promoting the science analysis.
This paper has gone through internal review by the DES collaboration. Funding for the DES Projects has been provided by the US Department of Energy, the US National Science Foundation, the Ministry of Science and Education of Spain, the Science and Technology Facilities Council of the United Kingdom, the Higher Education Funding Council for England, the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign, the Kavli Institute of Cosmological Physics at the University of Chicago, the Center for Cosmology and Astro-Particle Physics at the Ohio State University, the Mitchell Institute for Fundamental Physics and Astronomy at Texas A&M University, Financiadora de Estudos e Projetos, Fundação Carlos Chagas Filho de Amparo à Pesquisa do Estado do Rio de Janeiro, Conselho Nacional de Desenvolvimento Científico e Tecnológico and the Ministério da Ciíncia, Tecnologia e Inovação, the Deutsche Forschungsgemeinschaft and the Collaborating Institutions in the Dark Energy Survey. The Collaborating Institutions are Argonne National Laboratory, the University of California at Santa Cruz, the University of Cambridge, Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas-Madrid, the University of Chicago, University College London, the DES-Brazil Consortium, the University of Edinburgh, the Eidgenössische Technische Hochschule (ETH) Zürich, Fermi National Accelerator Laboratory, the University of Illinois at Urbana-Champaign, the Institut de Ciències de l’Espai (IEEC/CSIC), the Institut de Física d’Altes Energies, Lawrence Berkeley National Laboratory, the Ludwig-Maximilians Universität München and the associated Excellence Cluster Universe, the University of Michigan, NFS’s NOIRLab, the University of Nottingham, The Ohio State University, the University of Pennsylvania, the University of Portsmouth, SLAC National Accelerator Laboratory, Stanford University, the University of Sussex, Texas A&M University, and the OzDES Membership Consortium.
Based in part on observations at Cerro Tololo Inter-American Observatory at NSF’s NOIRLab (NOIRLab Prop. ID 2012B-0001; PI: J. Frieman), which is managed by the Association of Universities for Research in Astronomy (AURA) under a cooperative agreement with the National Science Foundation.
The DES data management system is supported by the National Science Foundation under Grant Numbers AST-1138766 and AST-1536171. The DES participants from Spanish institutions are partially supported by MICINN under grants ESP2017-89838, PGC2018-094773, PGC2018-102021, SEV-2016-0588, SEV-2016-0597, and MDM-2015-0509, some of which include ERDF funds from the European Union. IFAE is partially funded by the CERCA program of the Generalitat de Catalunya. Research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Program (FP7/2007-2013) including ERC grant agreements 240672, 291329, and 306478. We acknowledge support from the Brazilian Instituto Nacional de Ciência e Tecnologia (INCT) do e-Universo (CNPq grant 465376/2014- 2).
This work was completed in part with Midway resources provided by the University of Chicago’s Research Computing Center.
This work makes use of data acquired at the Anglo-Australian Telescope, under program A/2013B/012. We acknowledge the traditional owners of the land on which the AAT stands, the Gamilaraay people, and pay our respects to elders past and present.
DATA AVAILABILITY
For reproducibility we provide: (i) the SNANA and/or Pippin configurations to reproduce the simulations in this paper and (Möller et al. 2022) at https://github.com/anaismoller/DES5YR_SNeIa_hostz, (ii) analysis code in python to reproduce plots and results at https://github.com/anaismoller/DES5YR_SNeIa_nohost. The DES SN-candidate data will be released by the Collaboration at a later stage.
Footnotes
LSTM; Hochreiter & Schmidhuber 1997)
Two light curves are discarded since they have close-by AGN as discussed in Section 5.4.
REFERENCES
APPENDIX A: DES HQ SAMPLE AND SNPHOTO-Z
In this appendix, we inspect events in the HQ sample introduced in Section 5 and their SNphoto-z and SALT2 light-curve parameter fits.
In Fig. A1, we find that for the common events in DES HQ SNe Ia and the M22 sample, the SNphoto-z estimation agrees mostly with their spectroscopic host redshifts. For the 248 events from M22 that are not selected in our z-free sample, only 116 obtain a SNphoto z estimation. For the latter, in Fig. A2, we find a large dispersion on the fitted vs. spectroscopic redshift parameters. In some cases these parameters are estimated outside the HQ cuts.
DES HQ overlap with M22. Left: a comparison of the SNphoto-z versus host-galaxy spectroscopic redshifts. Centre and right: comparisons between light-curve parameters colour (c) and stretch (|$x1$|) using the SNphoto-zs and the host spectroscopic one. The dashed line shows the diagonal where the values should converge if they were equivalent. The lower row indicated the difference between parameters with host-galaxy spectroscopic redshift and SNphoto-z. Events classified by SNe Ia by both methods are mostly consistent with their estimates.
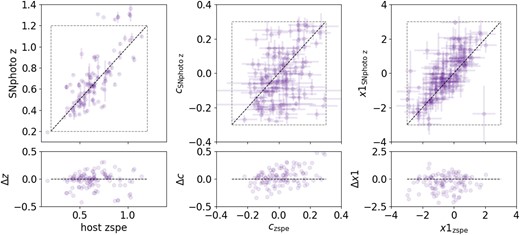
M22 SNe Ia not included in the DES HQ sample (248 SNe Ia). We show only events that have a converging SNphoto z fit (116 events). Left: a comparison of the SNphoto-z versus host-galaxy spectroscopic redshifts. Centre and right: comparisons between light-curve parameters colour (c) and stretch (|$x1$|) using the SNphoto-zs and the host spectroscopic one. The dashed line shows the diagonal where the values should converge if they were equivalent. Lost M22 events include SNe Ia that have SNphoto-z beyond the HQ cuts (shown as a square grey dashed line) and some more scattered fitted events.
APPENDIX B: FITTED LIGHT-CURVE PHOTOMETRIC REDSHIFT
The method used in this work to estimate photometric redshifts by simultaneously fitting redshift with SALT2 light-curve parameters is further described in Kessler et al. (2010) and in the SNANA manual Section 5.12.
In this appendix, we clarify the distance prior mechanism used for this fit. We assume a |$\Lambda CDM$| cosmology with wide priors centred around |$H_0 = 70$|, |$w=-1$|, |$\Omega _{m} = 0.315$|, |$\Omega _\Lambda =0.685$| (Planck Collaboration 2020).
First, the fitted distance modulus, |$\mu _{SALT2}$|, is approximately computed as
where |$x0, x1$| and c are SALT2 light-curve parameters, and we use default parameters |$\alpha = 0.14$| and |$\beta = 3.2$|.
Next, the difference between the fitted and theoretical distance modulus, |$\mu _{DIF}$|, is computed as:
where |$z_{PHOT}$| is the SNphoto-z.
An intentionally large estimate of the distance uncertainty, |$\sigma _{\mu }^2$|, is given by:
where |$\sigma _{\Omega _M}=0.3$| and |$\sigma _w=0.1$| are errors in the cosmological parameters, the factor 4 is an arbitrary number to do an overestimation of the uncertainty, |$\Omega _M$| and w, matter density and equation of state of Dark Energy, respectively.
For the fitting procedure, to the nominal SALT2 |$\chi ^2$|, we add:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}