





ABSTRACT
We present an updated version of the hmcode augmented halo model that can be used to make accurate predictions of the non-linear matter power spectrum over a wide range of cosmologies. Major improvements include modelling of baryon-acoustic oscillation (BAO) damping in the power spectrum and an updated treatment of massive neutrinos. We fit our model to simulated power spectra and show that we can match the results with an root mean square (RMS) error of 2.5 per cent across a range of cosmologies, scales |$k \lt 10\, h\, \mathrm{Mpc}^{-1}$|, and redshifts z < 2. The error rarely exceeds 5 per cent and never exceeds 16 per cent. The worst-case errors occur at z ≃ 2, or for cosmologies with unusual dark energy equations of state. This represents a significant improvement over previous versions of hmcode, and over other popular fitting functions, particularly for massive-neutrino cosmologies with high neutrino mass. We also present a simple halo model that can be used to model the impact of baryonic feedback on the power spectrum. This six-parameter physical model includes gas expulsion by active galactic nuclei (AGN) feedback and encapsulates star formation. By comparing this model to data from hydrodynamical simulations, we demonstrate that the power spectrum response to feedback is matched at the <1 per cent level for z < 1 and |$k\lt 20\, h\, \mathrm{Mpc}^{-1}$|. We also present a single-parameter variant of this model, parametrized in terms of feedback strength, which is only slightly less accurate. We make code available for our non-linear and baryon models at https://github.com/alexander-mead/HMcode and it is also available within camb and soon within class.
1 INTRODUCTION
The non-linear power spectrum of matter fluctuations is a quantity of central importance in modern cosmology. This is primarily because weak-gravitational lensing (e.g. Kilbinger 2015) measures a projected version of the matter spectrum and therefore to extract accurate cosmological constraints from weak lensing observations requires accurate theoretical models of the power spectrum. When fluctuations are small, linear theory allows the power spectrum and its evolution to be calculated analytically – an inflationary power-law spectrum of fluctuations is processed by linear electromagnetic and gravitational evolution (e.g. using camb of Lewis & Challinor 2011). However, matter fluctuations inevitably become large as gravitational collapse generally amplifies inhomogeneity, and eventually linear perturbation theory (e.g. Lewis, Challinor & Lasenby 2000; Blas, Lesgourgues & Tram 2011), and even non-linear perturbation theory (e.g. Bernardeau et al. 2002), fail to accurately track the details of the evolution of the power spectrum. Numerical simulations are currently the only known method for accurately calculating the deeply non-linear evolution of structure. However, simulations are expensive to run and it is therefore useful to have physically motivated semi-analytical models of the non-linear regime of clustering as these can provide insight into an otherwise complex process. A second advantage of semi-analytical models is that they allow predictions to be made for cosmologies that have yet to be simulated.
The halo model (Ma & Fry 2000; Peacock & Smith 2000; Seljak 2000) is just such a semi-analytical model of clustering. All matter is considered to be contained within haloes and the clustering problem is then decomposed into two problems: first, the clustering that arises between haloes (two-halo) and second, the clustering that arises within individual haloes (one-halo). A halo-mass distribution function is required for the calculation, as well as a bias recipe for how haloes cluster with respect to matter, and a choice needs to be made for the halo profile. In its simplest form, the halo model makes a series of assumptions, all of which contribute to inaccuracies: haloes are assumed to be linearly biased tracers of an underlying linear matter density field with exactly spherical profiles the properties of which depend only on the halo mass. With reasonable choices, the model has been shown to be accurate for the matter–matter power spectrum at only the ∼30 per cent level compared to accurate spectra measured from simulations (e.g. Tinker et al. 2005; Valageas & Nishimichi 2011; Mead et al. 2015). In addition, van Daalen & Schaye (2015) showed that the underlying assumptions of the halo model cannot be correct in detail, as the non-linear power spectrum measured in simulations was shown not to be all accounted for by the matter within haloes. Despite this, the halo model is very widely used and has many uses beyond calculating the matter power spectrum, for example it can be used to calculate the power spectrum of galaxies (e.g. Peacock & Smith 2000), the Sunyaev–Zel‘dovich auto spectrum (e.g. Komatsu & Seljak 2002), the cross spectrum between galaxies and matter (e.g. Cacciato et al. 2012; van den Bosch et al. 2013), the cross spectrum between matter and electron pressure (e.g. Ma et al. 2015; Mead et al. 2020), intrinsic alignments (e.g. Fortuna et al. 2020) and higher order statistics (e.g. Cooray & Sheth 2002). The halo model will be more or less accurate depending on the scenario to which it is applied.
To counter the inaccuracy of the halo model for the matter spectrum Smith et al. (2003) developed the popular halofit fitting function. A functional form was chosen, based on the halo model, with similar two- and one-halo terms, but called ‘quasi-linear’ and ‘halo’ terms. Parameters were fitted to simulated data over a wide range of cosmologies, specifically over the parameters h, σ8, ns, Ωm, and |$\Omega _\Lambda$| (curvature included). The model was also fitted to numerical data from pure power-law simulations (in contrast to standard simulations, where the inflationary power law is modified by physical processes in the later universe to create a linear power spectrum with rich features) for theoretical consistency. Takahashi et al. (2012) updated the fitting function to account for inaccuracies that arose because of the limited resolution of simulations available when the original model was fitted, and also to provide a more accurate model for dark energy cosmologies with a fixed equation of state, governed by parameter w. Around the same time, Bird, Viel & Haehnelt (2012) provided a tweak to make the original Smith et al. (2003) model work for massive-neutrino cosmologies. These latter two approaches have never been officially combined; however, the popular camb software contains an unpublished version of the Bird et al. (2012) neutrino model that works in tandem with the Takahashi et al. (2012) update. Recently, Smith & Angulo (2019) have provided an updated halofit that combines perturbation theory at large scales with a small-scale prediction from a smoothing-spline-fit that characterizes the differences between the Takahashi et al. (2012) fitting function and high-resolution simulations.
In Mead et al. (2015) the original hmcode1 was presented, in which the standard halo-model calculation was augmented with fitted parameters so as to provide a better match to simulated matter power spectra data. hmcode differs from halofit in that the halo model calculation is the starting point for hmcode, rather than a fitting function based on the halo model. The physical basis for these additional hmcode fitted parameters is debatable, but it was shown that the hmcode approach is more accurate than the halofit approach, and that this accuracy can be achieved with fewer fitted parameters. hmcode can be thought of as pertaining to an effective population of haloes whose power spectrum provides a better match to data. The hybrid nature of the model is an advantage because the grounding of the model in physical reality allows extensions to the standard cosmological paradigm to be easily considered (Mead et al. 2016). In this paper, we develop hmcode to improve the accuracy so as to provide a tool that is appropriate for use with near-future cosmological data sets.
A comparison of some of the models for the matter power spectrum discussed in this introduction is shown in Figs 1 and 2 where we show linear theory, halofit of Smith et al. (2003), Takahashi et al. (2012), and the version of Takahashi et al. (2012) with the Bird et al. (2012) massive neutrino model, which we call ‘halofit in camb’. We also show hmcode of Mead et al. (2015, 2016) as well as a preview of the model described in this paper. Each different curve shows the model compared to an N-body simulated power spectrum2 for a different cosmology. The date of publication and accuracy of model increases from the bottom to the top of the figure. These results will be discussed in detail in Section 5.
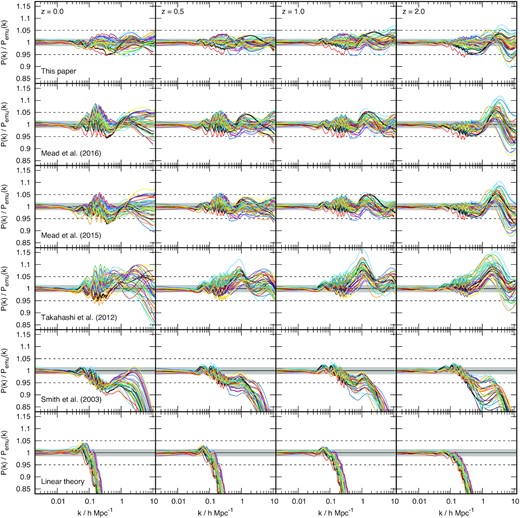
Comparison of different matter power spectrum prediction schemes to the node cosmologies of the franken emu version of the cosmic emulator (Heitmann et al. 2014). These cosmologies span a range of values of ωm, ωb, h, ns, σ8, and w. Each coloured line shows a different cosmology and the columns show z = 0 (left) 0.5, 1, and 2 (right). The different rows show different prediction: hmcode-2020 presented in this paper (top), followed by Mead et al. (2016, 2015), halofit from Takahashi et al. (2012) followed by Smith et al. (2003) and linear theory (bottom). Dashed horizontal lines show 5 per cent errors, and accuracy (and publication date) increases from the bottom to the top. All the hmcode models were fitted to data from these emulator nodes. The grey band, most obvious in the bottom two rows, indicates the 2σ region of the noise floor in the emulator predictions which we calculate from the scatter in the linear predictions are large scales. No prediction scheme can do better than this for these data.
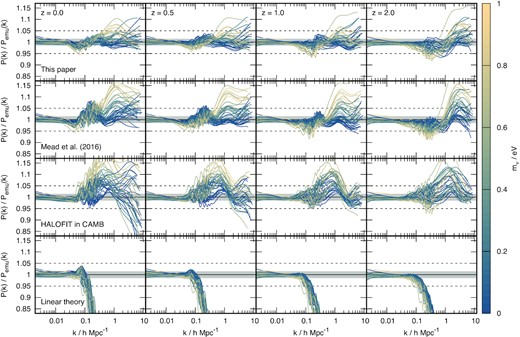
As Fig. 1 but for the nodes of the mira titan version of the cosmic emulator. Compared to franken emu the emulator here additionally covers the extra parameters: time-varying dark energy equation of state, wa; neutrino density, ων. None of the models presented here were fitted to cosmologies from the nodes of this emulator, so this provides a fair comparison. Power spectra here are coloured by the value of neutrino mass so that the correlation of error with neutrino mass is clearly visible. Note that the minimal |$m_\nu \simeq 0.06\, \mathrm{eV}$| corresponds almost to the bluest colour here and that the upper range probed by the emulator is quite high |$\sim \! 1\, \mathrm{eV}$| compared to current constraints on the neutrino mass: |$m_\nu \lt 0.12\, \mathrm{eV}$| (Planck Collaboration VI 2018). Once again, the grey band indicates the 2σ region of the noise floor of the emulator node predictions.
The technique of ‘emulation’ has been used to generate alternative theoretical models for the non-linear matter power spectrum by interpolating between the outputs of measurements from simulations. The original cosmic emu was developed by Heitmann et al. (2010, 2009) and Lawrence et al. (2010) and report per cent level accuracy for |$k\lt 1\, h\, \mathrm{Mpc}^{-1}$| over the parameter space of ωm, ωb, ns, σ8, and w. cosmic emu was extended by Heitmann et al. (2014) who used a combination of perturbation theory and extra simulations to extend the parameter space by including h and to extend the range of scales covered to |$k\lt 10\, h\, \mathrm{Mpc}^{-1}$|, at the expense of some accuracy, which was quoted at 4 per cent after the Frankenstein-esque modifications: this approach was called franken emu. More recently Heitmann et al. (2016) and Lawrence et al. (2017) have created a new emulator, mira titan, based on a new set of simulations and an improved emulation technique. They added the parameters ων and wa to the franken emu parameter space and quote an accuracy of 4 per cent for |$k\lt 7\, h\, \mathrm{Mpc}^{-1}$|, but plan to improve this in the future as more simulations are added to the hypercube. The ranges of franken emu and mira titan are given in Table 1. As discussed by Harnois-Déraps, Giblin & Joachimi (2019), the current range of the emulators is too tight to encompass the parameter space that is constrainable by current weak-lensing surveys such as KiDS (e.g. Asgari et al. 2020; Heymans et al. 2020; Hildebrandt et al. 2020), DES (e.g. Abbott et al. 2018), or HSC (e.g. Hikage et al. 2019; Hamana et al. 2020), although they do contain the Planck Collaboration VI (2018) space. Other emulators of note include: an artificial-neural network, trained by Agarwal et al. (2012, 2014), which includes gas dynamics and massive neutrinos; the euclid emulator of Knabenhans et al. (2019, 2020); and that of Angulo et al. (2020), which is based on a rescaling technique. Giblin et al. (2019) have proposed an emulator that would interpolate over linear power spectrum shape and evolution parameters, rather than cosmological parameters, as these have been demonstrated to be the primary drivers of structure formation.
Ranges of cosmological parameters of the franken emu and mira titan emulators that we use in this work. Ωm, Ωb, and Ων are the matter, baryon, and neutrinos cosmological densities, respectively; ωi = Ωih2, ns is the spectral index of the inflationary spectrum, σ8 is the RMS amplitude of linear fluctuations at z = 0 in spheres of radius |$8\, h^{-1}\, \mathrm{Mpc}$|, h is the dimensionless Hubble parameter, w(a) = w0 + (1 − a)wa is the dark energy equation of state. All cosmologies are flat. The node cosmologies of these emulators span the parameter ranges below using a Latin Hypercube design. Only mira titan spans wa and ων.
| Parameter | franken emu | mira titan | ||
|---|---|---|---|---|
| Min | Max | Min | Max | |
| ωm | 0.120 | 0.155 | 0.120 | 0.155 |
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 |
| ns | 0.85 | 1.05 | 0.85 | 1.05 |
| σ8 | 0.616 | 0.9 | 0.7 | 0.9 |
| h | 0.55 | 0.85 | 0.55 | 0.85 |
| w0 | −1.3 | −0.7 | −1.3 | −0.7 |
| wa | – | −1.73 | 1.28 | |
| ων | – | 0 | 0.01 | |
| Parameter | franken emu | mira titan | ||
|---|---|---|---|---|
| Min | Max | Min | Max | |
| ωm | 0.120 | 0.155 | 0.120 | 0.155 |
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 |
| ns | 0.85 | 1.05 | 0.85 | 1.05 |
| σ8 | 0.616 | 0.9 | 0.7 | 0.9 |
| h | 0.55 | 0.85 | 0.55 | 0.85 |
| w0 | −1.3 | −0.7 | −1.3 | −0.7 |
| wa | – | −1.73 | 1.28 | |
| ων | – | 0 | 0.01 | |
Ranges of cosmological parameters of the franken emu and mira titan emulators that we use in this work. Ωm, Ωb, and Ων are the matter, baryon, and neutrinos cosmological densities, respectively; ωi = Ωih2, ns is the spectral index of the inflationary spectrum, σ8 is the RMS amplitude of linear fluctuations at z = 0 in spheres of radius |$8\, h^{-1}\, \mathrm{Mpc}$|, h is the dimensionless Hubble parameter, w(a) = w0 + (1 − a)wa is the dark energy equation of state. All cosmologies are flat. The node cosmologies of these emulators span the parameter ranges below using a Latin Hypercube design. Only mira titan spans wa and ων.
| Parameter | franken emu | mira titan | ||
|---|---|---|---|---|
| Min | Max | Min | Max | |
| ωm | 0.120 | 0.155 | 0.120 | 0.155 |
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 |
| ns | 0.85 | 1.05 | 0.85 | 1.05 |
| σ8 | 0.616 | 0.9 | 0.7 | 0.9 |
| h | 0.55 | 0.85 | 0.55 | 0.85 |
| w0 | −1.3 | −0.7 | −1.3 | −0.7 |
| wa | – | −1.73 | 1.28 | |
| ων | – | 0 | 0.01 | |
| Parameter | franken emu | mira titan | ||
|---|---|---|---|---|
| Min | Max | Min | Max | |
| ωm | 0.120 | 0.155 | 0.120 | 0.155 |
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 |
| ns | 0.85 | 1.05 | 0.85 | 1.05 |
| σ8 | 0.616 | 0.9 | 0.7 | 0.9 |
| h | 0.55 | 0.85 | 0.55 | 0.85 |
| w0 | −1.3 | −0.7 | −1.3 | −0.7 |
| wa | – | −1.73 | 1.28 | |
| ων | – | 0 | 0.01 | |
A confounding issue in the field of modelling the non-linear matter power spectrum is that of ‘baryonic feedback’ (e.g. Semboloni et al. 2011; Chisari et al. 2019): The models and emulators discussed previously were fitted or trained on data from ‘gravity-only’ simulations, in which the effect of gas physics is ignored. In reality, non-gravitational processes such as gas heating as a byproduct of black hole accretion, can inject large amounts of energy in galaxies and from there in to the surrounding halo. Hydrodynamical simulations (e.g. Schaye et al. 2010; Le Brun et al. 2014; McCarthy et al. 2017) are needed, in conjunction with sub-grid recipes, to model these baryonic feedback processes. The physics of these processes are less well understood and more difficult to model compared to standard gravitational collapse. However, it is generally thought that gas expulsion from haloes lowers the amplitude of the power spectrum on scales that are relevant to weak-gravitational lensing observations. The details of this have been investigated via simulations (e.g. Jing et al. 2006; van Daalen et al. 2011, 2014) and via the halo model (e.g. White 2004; Zhan & Knox 2004; Jing et al. 2006; Fedeli 2014; Fedeli et al. 2014; van Daalen et al. 2014; Debackere, Schaye & Hoekstra 2020; Mead et al. 2020). In this paper, we also provide a novel, physically motivated model for how baryons affect the non-linear matter power.
This paper is organized as follows: In Section 2, we provide a short overview of the standard halo-model calculation for the matter power spectrum. In Section 3, we detail some tests that lead us to an optimal set of halo-model ingredients for our new version of hmcode. In Section 4, we present the updated functional forms of hmcode-2020 and in Section 5 we present the updated parameters for the matter power spectrum. In Section 6, we provide a model for how baryonic feedback affects the power. Finally, we summarize in Section 7. In Appendix A, we provide a fitting formula for spherical-collapse parameters that is valid for dark energy and massive neutrino cosmologies. In Appendix B, we discuss the error that different versions of halofit make depending on the neutrino mass. In Appendix C, we discuss the hmcode error for cosmologies that have significant dark energy at early times. Appendix D shows comparisons between the non-linear power from hmcode-2020 and that from some popular emulators.
2 HALO MODEL
3 INGREDIENT CHOICES
In Section 4, we add non-standard terms to the vanilla halo-model calculation and in Section 5 we fit parameters in these in order to accurately match simulated data. However, before we do this we should determine a best-possible set of ingredients for our standard halo model, on which we base our modifications. We must choose ingredients for: the halo profiles (equation 4), the halo definition (equation 5), and the halo mass function (equation 6). For each, there exist a myriad of possible choices in the literature, and often no clear metric for deciding on a best choice. In this section, we show how we decided on a ‘best’ choice of halo-model ingredients for hmcode. This analysis is for the matter–matter power spectrum only, and it is possible that other ingredient choices are better for different power spectra (e.g. Mead et al. 2020).
At the largest physical scales there is a non-zero variance of ∼0.5 per cent. This is the limiting intrinsic accuracy of the emulator, even at the node cosmologies. Assuming that this is not a function of scale gives us a limiting RMS error with σ ≃ 0.007, beyond which we cannot push any model based on these data.
There is a systematic positive bias in the mean at the largest scales, |$k\simeq 0.02\, h\, \mathrm{Mpc}^{-1}$|, of magnitude ∼2 per cent that is not improved by any choice of ingredient. This is caused by the unphysical contribution of the one-halo term at large scales. This problem diminishes at higher z. We address this issue in Section 4.3.
There is a small (∼3 per cent on top of the previous 2 per cent) over prediction of mean power at |$k\simeq 0.07\, h\, \mathrm{Mpc}^{-1}$|, which is a consequence of linear theory not containing the initial ‘pre-virialization’ dip in power, which is the first non-linear (one-loop) effect determined by perturbation theory (Suto & Sasaki 1991). We address this issue in Section 4.2.
There is a general and significant underprediction of mean power (∼20 per cent) which peaks at |$k\simeq 0.7\, h\, \mathrm{Mpc}^{-1}$|. This is the notorious transition region between the two- and the one-halo terms. No choice of ingredients dramatically ameliorates the lack of power in this region, which strongly suggests that a defect in the simplistic halo model is responsible for this error. On scales |$k\sim 0.3\, h\, \mathrm{Mpc}^{-1}$|, slightly larger than the peak of the transition region, no choice of ingredient has an impact on the variance, which suggests that the missing part of the modelling has a significant cosmology dependence. We address these issues with a number of tweaks that are described in the next Section.
On smaller scales, |$k\gt 1\, h\, \mathrm{Mpc}^{-1}$|, the situation is improved, both in mean and variance, which suggests that a description of the power in the Universe originating from virialized haloes is more valid at these scales. It is for these scales that the mean and variance can be significantly improved by making a careful choice of ingredients.

Halo-model predictions for the matter–matter power for different choices of model ingredients. The top 5 rows show comparison to the 37 node cosmologies of franken emu. In the left-hand column, we show the mean prediction across the different node cosmologies, while in the right-hand column we show the standard deviation of the prediction between the different cosmologies. In each panel, the purple curve shows the baseline model, from which all others deviate. The coloured curves in the rows show different choices for the two-halo term (top), halo mass function, halo definition, spherical-collapse calculation, and concentration–mass relation. The bottom row compares to the 26 massive-neutrino node cosmologies of mira titan, because massive neutrinos are not included in the cosmologies of franken emu. In this row ingredients that effect only the massive-neutrino implementation in the halo model are varied. In this figure, we show results at z = 0, but the results are broadly similar for other redshifts, although some of the trends are less extreme.
We now inspect the different rows of Fig. 3 in detail, and use this information to decide on an optimal set of ingredients upon which we base our augmented halo model.
3.1 Two-halo term
The top row of Fig. 3 shows the effect on the power spectrum of different choices for the two-halo term: either simple linear theory, de-wiggled linear theory (discussed in Section 4.1), or the full two-halo term (equation 2). We see that the difference between using linear theory or the standard two-halo term is tiny for the matter–matter power spectrum. This is because these only differ on scales where the one-halo term dominates the total power spectrum. This implies that the choice of halo bias has an insignificant effect on the calculation for the matter–matter power. One the other hand, we see a slight improvement when we use de-wiggled linear theory, but only in the variance of the predictions at |$k\sim 0.1\, h\, \mathrm{Mpc}^{-1}$|. This improvement arises because some of the scatter in predictions that occurs when using linear theory primarily originates through the BAO not being damped, but this only contributes to the scatter since the mean of the wiggle is zero and the location of the wiggles are roughly uncorrelated between the different cosmologies. In previous versions of hmcode we used linear theory for the two-halo term, but the results here lead us to choose de-wiggled linear theory for the hmcode-2020 two-halo term, and therefore to ignore the integral term that usually appears in equation (2), which is equivalent taking the k → 0 limit. Ignoring this integral has the advantage of approximately halving the computational time.
3.2 Halo mass function
In the second row of Fig. 3, we show the differences that arise from choice of mass function, but all with a virial halo definition. We compare Sheth & Tormen (1999), Press & Schechter (1974), Tinker et al. (2008, 2010), and Despali et al. (2016). We note that the Tinker et al. (2008) and Despali et al. (2016) mass functions do not satisfy the required normalization condition for the mass function, but violating this condition does not present a problem for the one-halo term in practice because the integral (equation 3) only depends on the properties of haloes in a tight mass range.6 We see that the Despali et al. (2016) mass function provides the best mean for |$k\lt 1\, h\, \mathrm{Mpc}^{-1}$| but that it becomes considerably worse than the other choices at smaller scales. Unsurprisingly, Press & Schechter (1974) produce a poor mean and large variance while both the Tinker et al. (2008, 2010) mass functions perform very similarly. Somewhat surprisingly, the Sheth & Tormen (1999) mass function slightly outperforms those of Tinker et al. (2008, 2010) both in the mean prediction and in the variance at |$k\sim 1\, h\, \mathrm{Mpc}^{-1}$|. This is despite the fact that Tinker et al. (2008, 2010) has been demonstrated to be a better fit to the mass function data measured from simulations. The improvement in variance is presumably because Sheth & Tormen (1999) was calibrated to a wider range of cosmologies than Tinker et al. (2008, 2010). Based on this, we continue to use the Sheth & Tormen (1999) as the hmcode-2020 halo mass function, as in previous versions of hmcode.
3.3 Halo overdensity
In the third row of Fig. 3 we also show how the power spectrum predictions change when using the Tinker et al. (2010) mass function, but for different definitions of the halo boundary, either 200 times the mean matter density, the virial definition, or 200 times the critical density. This is possible for the Tinker et al. (2010) function because mass-function parameters are provided for a range of halo-mass definitions that can be interpolated between. We also change the halo concentration relation to that appropriate for the new definition using results from Duffy et al. (2008). Using M200, c is far less accurate, both in terms of mean and variance, compared to either M200 or Mvir. For Tinker et al. (2010), using M200 is slightly preferable to Mvir, but the performance is still poorer for |$k\lt 3\, h\, \mathrm{Mpc}^{-1}$| than the model that adopts Mvir with the Sheth & Tormen (1999) mass function and it also only provides marginal benefits for the variance at smaller scales. This supports claims in Courtin et al. (2011), Despali et al. (2016), and Mead (2017) that a virial definition for haloes is preferable and is able to capture some of the complicated cosmology dependence of non-linear quantities.
In the fourth row we compare different choices for the calculation of the virial halo definition Δv and the critical-collapse threshold δc. For Δv, we compare using either the Bryan & Norman (1998) or the Mead (2017) fitting formulae, whereas for δc we compare fixing 1.686, the Nakamura & Suto (1997) fitting formula and the Mead (2017) fitting formula. The Mead (2017) fitting formulae for δc and Δv are similar in scope to their predecessors, but were fitted to spherical-collapse calculations for a wider range of cosmologies and are more accurate for dark energy models – they are detailed in Appendix A. We see that choices of δc make very little difference to the overall mean prediction or to the standard deviation of predictions. However, there is an improvement in the mean and variance when we use Mead (2017) for Δv. For this reason we decide to use the virial definition and the Mead (2017) fitting formulae for hmcode-2020 for both δc and Δv.
3.4 Halo concentration
In the fifth row of Fig. 3, we show the impact of different concentration–mass relations for the NFW halo profile. We see that these only impact upon predictions at the comparatively small scale of |$k\gt 1\, h\, \mathrm{Mpc}^{-1}$|, which makes sense since these changes only affect the innermost portions of the halo. Using either of the two concentration–mass relations presented in Bullock et al. (2001) provide similarly good mean predictions, however, using the more complicated model minimizes the variance at the smallest scales. Either model suppresses the variance dramatically compared to using concentration–mass relations from Duffy et al. (2008), which makes sense because the Bullock et al. (2001) relations are expressed as in terms of cosmology-dependent quantities, such as σ(M, z) or M*(z), defined via σ(M*, z) = δc(z), whereas the relations of Duffy et al. (2008) are expressed as simplistic power laws as functions of halo mass. It is clear that the concentration–mass relation has cosmology dependence, and so a relation that includes this is to be preferred. We also see an improvement in the variance when we apply the Dolag et al. (2004) correction (present in our baseline model) for dark energy cosmologies. We therefore choose to use the full Bullock et al. (2001) relation with a Dolag et al. (2004) correction in hmcode-2020, exactly as in previous versions of hmcode.
3.5 Massive neutrino choices
Finally, in the bottom row of Fig. 3 we show the impact of different choices regarding the implementation of massive neutrinos in our halo model. The baseline case is that the variance that appears in the mass function (equation 7) is calculated using the cold–cold spectrum, neutrino mass is removed from the one-halo term (discussed below equation 5), and that neutrino mass is counted as matter in spherical-collapse calculations of Δv(z) and δc(z) (equations 5 and 7). We show this baseline case as well as what happens when each of this assumptions is modified in turn: calculating the variance using the matter–matter spectrum; ignoring the (1 − fν) correction to halo mass, therefore assuming that neutrinos cluster along with cold matter; accounting for massive neutrinos in the calculation of δc and Δv via the Mead (2017) fitting functions (see Appendix A). We see that the mean deviation and variance are minimized when we take σcc(M) and keep the factors of (1 − fν) both of these choices are in agreement with results presented in Massara et al. (2014). We also see an improvement when we use the Mead (2017) relations for δc and Δv that have a massive-neutrino dependence, thus we choose this for hmcode-2020.
4 HMCODE 2020
Following Mead et al. (2015, 2016), in this section we detail some non-standard features that we are forced to add to the halo model power spectrum calculation in order to return a good match to the simulation data across a wide-range of cosmologies. While these tweaks are not from first principles, we find that they are essential in order to get a good match to power spectra measured in simulations. These parameters make up for inherent deficiencies in the standard halo-model calculation, some of which have been addressed by other authors: beyond-linear perturbation theory (Smith, Scoccimarro & Sheth 2007; Valageas & Nishimichi 2011; Schmidt 2016; Philcox, Spergel & Villaescusa-Navarro 2020); non-linear halo bias (Smith et al. 2007; Mead & Verde 2020); halo exclusion (Takada & Jain 2004; Smith, Desjacques & Marian 2011; Cacciato et al. 2012; van den Bosch et al. 2013); profile compensation (Cooray & Sheth 2002; Chen & Afshordi 2019); aspherical haloes (Smith & Watts 2005); scatter in halo properties at fixed mass (e.g. Giocoli et al. 2010); matter not contained in haloes (Smith & Markovic 2011; Voivodic, Rubira & Lima 2020); halo substructure (Sheth & Jain 2003; Giocoli et al. 2010). We do not include any of these advanced strategies in this work because they can considerably increase the computation time of a numerical halo-model implementation; one of the prime advantages of hmcode is that the calculation is fast. In Section 5, we fit our model to the node cosmologies of the franken emu and mira titan emulators.
4.1 BAO damping
4.2 Perturbative damping of the two-halo term
4.3 Large-scale damping of the one-halo term
4.4 One-halo ingredients
4.5 Total power
5 NON-LINEAR MODEL
5.1 Parameter fitting
The free parameters in our model are constrained using the 37 node cosmologies of the franken emu emulator, which reports to be accurate at the 4 per cent level. However, this is the quoted accuracy for the emulation scheme, and evaluating at the node cosmologies is considerably more accurate given that this involves no interpolation. From Fig. 1, we estimate the accuracy to be ≲1 per cent at the nodes. The set of node cosmologies spans a Latin Hypercube, with parameter ranges given in Table 1. Working with the nodes has the additional advantage of allowing us to exploit the Hypercube design. The parameter space of franken emu encompasses ωm, ωb, ns, σ8, w, and h.
Our best-fitting parameters are given in Table 2. To perform the fitting we used the Nelder & Mead (1965) simplex algorithm with a large number of initial starting points. We constrain the parameters using all node cosmologies, with an equal logarithmic weight in k between 0.01 and |$10\, h\, \mathrm{Mpc}^{-1}$| and using data from z = 0, 0.5, 1, and 2 with equal weight. Initially cosmologies and redshifts were fitted independently, taking constant values for parameters, to determine if the model worked well for the cosmologies on a case-by-case basis. We then fitted the cosmologies and redshifts simultaneously, and plot the residuals to determine reasonable functional forms to encompass cosmology and redshift dependence. We parametrize this via quantities that depend on the power spectrum shape and amplitude, rather than the classic cosmological parameters. This is sensible because the Universe does not really know the value of cosmological parameters like h, Ωm, w etc., instead structure formation is driven by the spectral shape and amplitude, and evolution (Peacock & Dodds 1994; Smith et al. 2003). Our functional forms thus depend on σ8, cc(z) and |$n^\mathrm{eff}_\mathrm{cc}(z)$| (equations 8 and 11). It is important to note that all the cosmology dependence of parameters in our model depend on the cold spectrum, as this is the quantity that drives structure formation in massive-neutrino cosmologies. Recall that the cold power spectrum is equal to the matter power spectrum in the absence of massive neutrinos.
hmcode-2020 parameters. We list the parameter, with a short explanation of the meaning of the parameter, the equation where the parameter is defined in the text and the default value. We then show the best-fitting value, which in most cases is a functional form, and then an example of this function evaluated (to 3 significant figures) at z = 0 for a standard ΛCDM (Ωm = 0.3, σ8 = 0.8) cosmology. There are a total of 12 fitted parameters.
| Parameter | Explanation | Equation | Default value | Fitted functional form or value | Example z = 0 value (3 s.f.) |
|---|---|---|---|---|---|
| kd | Two-halo term damping wavenumber | 16 | – | |$0.05699\times \sigma _{8,\mathrm{cc}}^{-1.089}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.073\, h\, \mathrm{Mpc}^{-1}$| |
| f | Two-halo term fractional damping | 16 | 0 | |$0.2696\times \sigma _{8,\mathrm{cc}}^{0.9403}(z)$| | 0.219 |
| nd | Two-halo term damping power | 16 | – | 2.853 | 2.85 |
| k* | One-halo term damping wavenumber | 17 | 0 | |$0.05618\times \sigma _{8,\mathrm{cc}}^{-1.013}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.070\, h\, \mathrm{Mpc}^{-1}$| |
| η | Halo bloating | 19 | 0 | |$0.1281\times \sigma _{8,\mathrm{cc}}^{-0.3644}(z)$| | 0.139 |
| B | Minimum halo concentration | 20 | 4 | 5.196 | 5.20 |
| α | Transition smoothing | 23 | 1 | |$1.875\times (1.603)^{n^\mathrm{eff}_\mathrm{cc}}$| | 0.719 |
| Parameter | Explanation | Equation | Default value | Fitted functional form or value | Example z = 0 value (3 s.f.) |
|---|---|---|---|---|---|
| kd | Two-halo term damping wavenumber | 16 | – | |$0.05699\times \sigma _{8,\mathrm{cc}}^{-1.089}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.073\, h\, \mathrm{Mpc}^{-1}$| |
| f | Two-halo term fractional damping | 16 | 0 | |$0.2696\times \sigma _{8,\mathrm{cc}}^{0.9403}(z)$| | 0.219 |
| nd | Two-halo term damping power | 16 | – | 2.853 | 2.85 |
| k* | One-halo term damping wavenumber | 17 | 0 | |$0.05618\times \sigma _{8,\mathrm{cc}}^{-1.013}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.070\, h\, \mathrm{Mpc}^{-1}$| |
| η | Halo bloating | 19 | 0 | |$0.1281\times \sigma _{8,\mathrm{cc}}^{-0.3644}(z)$| | 0.139 |
| B | Minimum halo concentration | 20 | 4 | 5.196 | 5.20 |
| α | Transition smoothing | 23 | 1 | |$1.875\times (1.603)^{n^\mathrm{eff}_\mathrm{cc}}$| | 0.719 |
hmcode-2020 parameters. We list the parameter, with a short explanation of the meaning of the parameter, the equation where the parameter is defined in the text and the default value. We then show the best-fitting value, which in most cases is a functional form, and then an example of this function evaluated (to 3 significant figures) at z = 0 for a standard ΛCDM (Ωm = 0.3, σ8 = 0.8) cosmology. There are a total of 12 fitted parameters.
| Parameter | Explanation | Equation | Default value | Fitted functional form or value | Example z = 0 value (3 s.f.) |
|---|---|---|---|---|---|
| kd | Two-halo term damping wavenumber | 16 | – | |$0.05699\times \sigma _{8,\mathrm{cc}}^{-1.089}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.073\, h\, \mathrm{Mpc}^{-1}$| |
| f | Two-halo term fractional damping | 16 | 0 | |$0.2696\times \sigma _{8,\mathrm{cc}}^{0.9403}(z)$| | 0.219 |
| nd | Two-halo term damping power | 16 | – | 2.853 | 2.85 |
| k* | One-halo term damping wavenumber | 17 | 0 | |$0.05618\times \sigma _{8,\mathrm{cc}}^{-1.013}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.070\, h\, \mathrm{Mpc}^{-1}$| |
| η | Halo bloating | 19 | 0 | |$0.1281\times \sigma _{8,\mathrm{cc}}^{-0.3644}(z)$| | 0.139 |
| B | Minimum halo concentration | 20 | 4 | 5.196 | 5.20 |
| α | Transition smoothing | 23 | 1 | |$1.875\times (1.603)^{n^\mathrm{eff}_\mathrm{cc}}$| | 0.719 |
| Parameter | Explanation | Equation | Default value | Fitted functional form or value | Example z = 0 value (3 s.f.) |
|---|---|---|---|---|---|
| kd | Two-halo term damping wavenumber | 16 | – | |$0.05699\times \sigma _{8,\mathrm{cc}}^{-1.089}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.073\, h\, \mathrm{Mpc}^{-1}$| |
| f | Two-halo term fractional damping | 16 | 0 | |$0.2696\times \sigma _{8,\mathrm{cc}}^{0.9403}(z)$| | 0.219 |
| nd | Two-halo term damping power | 16 | – | 2.853 | 2.85 |
| k* | One-halo term damping wavenumber | 17 | 0 | |$0.05618\times \sigma _{8,\mathrm{cc}}^{-1.013}(z)\, h\, \mathrm{Mpc}^{-1}$| | |$0.070\, h\, \mathrm{Mpc}^{-1}$| |
| η | Halo bloating | 19 | 0 | |$0.1281\times \sigma _{8,\mathrm{cc}}^{-0.3644}(z)$| | 0.139 |
| B | Minimum halo concentration | 20 | 4 | 5.196 | 5.20 |
| α | Transition smoothing | 23 | 1 | |$1.875\times (1.603)^{n^\mathrm{eff}_\mathrm{cc}}$| | 0.719 |
5.2 Model comparison
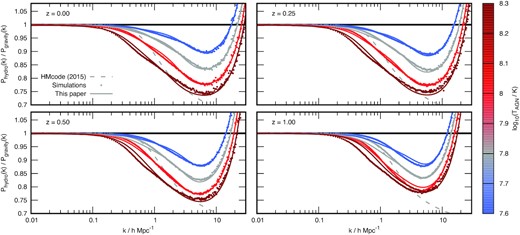
Our model is shown compared to the 37 node cosmologies of franken emu in Fig. 1 and then compared to the 36 node cosmologies of mira titan in Fig. 2, alongside comparisons with other popular fitting functions. In the franken emu comparison we show linear theory, halofit from Smith et al. (2003) and Takahashi et al. (2012), and hmcode from Mead et al. (2015, 2016). In the mira titan figure we omit comparisons with Smith et al. (2003) and Mead et al. (2015) since these models were not fitted to cosmologies that included massive neutrinos. In Fig. 2, we colour the cosmologies according to the neutrino mass in order to show the correlation with the error. The accuracy of all hmcode and halofit versions is summarized in Table 3. In Appendix D, we show additional comparisons between hmcode-2020, some other emulators, and the recent version of halofit from Smith & Angulo (2019).
Accuracy of different predictions schemes for the non-linear matter power spectrum compared to the node cosmologies of franken emu and mira titan. The number of fitted parameters is given, along with the additional number of fitted parameters for massive-neutrino models. The first number in the accuracy columns show the RMS residual of the model with respect to the emulator averaged logarithmically over k (between 0.01 and |$10\, h\, \mathrm{Mpc}^{-1}$| for franken emu and between 0.01 and |$7\, h\, \mathrm{Mpc}^{-1}$| for Mira Titan) and over z = 0, 0.5, 1, and 2. The second number in the accuracy column shown the maximum error over the same range over all node cosmologies.
| Prediction scheme | Reference | # Fitted parameters | franken emu error [per cent] | mira titan error [per cent] | ||
|---|---|---|---|---|---|---|
| RMS | Max | RMS | Max | |||
| hmcode-2020 | This paper | 12 | 1.7 | 10.6 | 2.5 | 15.9 |
| hmcode | Mead et al. (2016) | 12 (+2) | 2.3 | 12.9 | 4.2 | 22.9 |
| hmcode | Mead et al. (2015) | 12 | 2.2 | 12.5 | – | |
| halofit | Takahashi et al. (2012), Bird et al. (2012) | 34 (+6) | 3.6 | 16.5 | 5.0 | 24.7 |
| halofit | Smith et al. (2003) | 30 | 9.5 | 43.5 | – | |
| Prediction scheme | Reference | # Fitted parameters | franken emu error [per cent] | mira titan error [per cent] | ||
|---|---|---|---|---|---|---|
| RMS | Max | RMS | Max | |||
| hmcode-2020 | This paper | 12 | 1.7 | 10.6 | 2.5 | 15.9 |
| hmcode | Mead et al. (2016) | 12 (+2) | 2.3 | 12.9 | 4.2 | 22.9 |
| hmcode | Mead et al. (2015) | 12 | 2.2 | 12.5 | – | |
| halofit | Takahashi et al. (2012), Bird et al. (2012) | 34 (+6) | 3.6 | 16.5 | 5.0 | 24.7 |
| halofit | Smith et al. (2003) | 30 | 9.5 | 43.5 | – | |
Accuracy of different predictions schemes for the non-linear matter power spectrum compared to the node cosmologies of franken emu and mira titan. The number of fitted parameters is given, along with the additional number of fitted parameters for massive-neutrino models. The first number in the accuracy columns show the RMS residual of the model with respect to the emulator averaged logarithmically over k (between 0.01 and |$10\, h\, \mathrm{Mpc}^{-1}$| for franken emu and between 0.01 and |$7\, h\, \mathrm{Mpc}^{-1}$| for Mira Titan) and over z = 0, 0.5, 1, and 2. The second number in the accuracy column shown the maximum error over the same range over all node cosmologies.
| Prediction scheme | Reference | # Fitted parameters | franken emu error [per cent] | mira titan error [per cent] | ||
|---|---|---|---|---|---|---|
| RMS | Max | RMS | Max | |||
| hmcode-2020 | This paper | 12 | 1.7 | 10.6 | 2.5 | 15.9 |
| hmcode | Mead et al. (2016) | 12 (+2) | 2.3 | 12.9 | 4.2 | 22.9 |
| hmcode | Mead et al. (2015) | 12 | 2.2 | 12.5 | – | |
| halofit | Takahashi et al. (2012), Bird et al. (2012) | 34 (+6) | 3.6 | 16.5 | 5.0 | 24.7 |
| halofit | Smith et al. (2003) | 30 | 9.5 | 43.5 | – | |
| Prediction scheme | Reference | # Fitted parameters | franken emu error [per cent] | mira titan error [per cent] | ||
|---|---|---|---|---|---|---|
| RMS | Max | RMS | Max | |||
| hmcode-2020 | This paper | 12 | 1.7 | 10.6 | 2.5 | 15.9 |
| hmcode | Mead et al. (2016) | 12 (+2) | 2.3 | 12.9 | 4.2 | 22.9 |
| hmcode | Mead et al. (2015) | 12 | 2.2 | 12.5 | – | |
| halofit | Takahashi et al. (2012), Bird et al. (2012) | 34 (+6) | 3.6 | 16.5 | 5.0 | 24.7 |
| halofit | Smith et al. (2003) | 30 | 9.5 | 43.5 | – | |
In the bottom row of Figs 1 and 2 we see a comparison of linear theory (from camb, which we also use in hmcode-2020) against the emulators. We see that linear theory provides a good description of the data at large scales, but we see that it starts to underestimate the true power spectrum at smaller scales. How well linear theory matches the non-linear result is a function of both z and cosmology, as would be expected, with linear theory providing a better match to smaller scales at higher z. It is perhaps surprising that we see a small, per cent level, scatter even at the largest scales shown, when we know that linear theory should be a near-perfect (Lesgourgues 2011) description of the power spectrum. This scatter arises due to the emulation scheme not perfectly reproducing the results at the node cosmologies, and so this gives an indication of how accurately the emulators work in the best-case scenario. If we take the error to be scale independent, then the emulator predicts the true power for the node cosmologies with an accuracy better than 1 per cent.
Fig. 1 shows the performance of the two different versions of halofit, the original of Smith et al. (2003) and the update of Takahashi et al. (2012), compared to the franken emu node cosmologies. We see that the original Smith et al. (2003) model systematically underpredicts the power spectrum for |$k \gt 0.1\, h\, \mathrm{Mpc}^{-1}$| to a level that reaches tens of per cent by |$k=10\, h\, \mathrm{Mpc}^{-1}$|. The halofit of Takahashi et al. (2012) performs much better, with errors around the 10 per cent level for the range of scales and redshifts we show. The general underprediction of power at small scales of the original halofit was one of the issues addressed by Takahashi et al. (2012) by using simulations with higher resolution. In Fig. 2, we show the comparison with mira titan, which contains cosmologies with time-varying dark energy equations of state, w(a) = w0 + (1 − a)wa, so we have to make a choice if we interpret the Takahashi et al. (2012) ‘w’ as w0 or w(a). We chose the latter based on the fact that this produces better results. The same choice is made in the implementation of Takahashi et al. (2012) within camb. We show results with an unpublished version of the Bird et al. (2012) neutrino model applied to the Takahashi et al. (2012) halofit, as this is the default halofit prediction given by camb, this is discussed in Appendix B. In Fig. 2, we can see that the halofit error degrades when massive neutrinos and time-varying dark energy are added. There is a noticeable correlation of the error with neutrino mass at z > 0. In both figures there is a significant scatter around the BAO scale and a further scatter for |$k\sim 10\, h\, \mathrm{Mpc}^{-1}$| at z = 0. At higher redshifts there is a systematic ‘kink’ feature in the residuals at |$k\sim 1\, h\, \mathrm{Mpc}^{-1}$|. We find that the RMS accuracy of the Takahashi et al. (2012) version of halofit is 4.2 per cent over both sets of emulator nodes, but that errors can be as much as 24.7 per cent for some cosmologies.
Fig. 1 also shows the performance of the Mead et al. (2015, 2016) versions of hmcode compared to the node cosmologies of franken emu. Both hmcode versions were fitted to the node cosmologies of franken emu, so these results present a best-case scenario for the models. We see that the performance of the two versions are almost identical, with an RMS error of 2.3 per cent and the error rarely exceeding 5 per cent. The performance degrades at |$k\simeq 10\, h\, \mathrm{Mpc}^{-1}$| at z = 2 compared to the other scales and redshifts. Fig. 2 shows the performance of hmcode to the mira titan nodes. The Mead et al. (2015) version is omitted from this figure as it was not designed to work with cosmologies that include massive neutrinos. We see that for low neutrino mass, the performance is similar to the case of franken emu, which is reassuring given that this version of hmcode was not fitted to mira titan data. However, we see a significant error for higher neutrino masses which manifests as a systematic underprediction of power for |$k\simeq 0.1\, h\, \mathrm{Mpc}^{-1}$| followed by a significant and systematic overprediction of power for |$k\simeq 1\, h\, \mathrm{Mpc}^{-1}$|. For mira titan the RMS error of this version of hmcode is 4.2 per cent with errors as large as 22.9 per cent for the most extreme neutrino masses. The neutrino model of hmcode was only fitted to data for |$m_\nu \lt 0.6\, \mathrm{eV}$|, so it is perhaps not surprising that it fails more significantly for higher neutrino masses. These results are in accordance with those presented in Lawrence et al. (2017).
hmcode-2020 can be seen in the top rows of Figs 1 (franken emu) and 2 (mira titan). The model was fitted franken emu, but not to mira titan. The mean error between our new model from the data is 1.7 per cent for franken emu and we can see that the error rarely exceeds 5 per cent, with it being around 10 per cent in the worst-case scenario (z = 2, |$k\simeq 10\, h\, \mathrm{Mpc}^{-1}$|). This represents a significant improvement over all previous fitting functions for the non-linear matter–matter power spectrum. For mira titan, which is not used in our fitting, the results are degraded, but we still have an RMS error of 2.5 per cent and a worst-case error of 15.9 per cent, both of which are significantly better than the other models. As for the other versions of hmcode, the performance degrades slightly at z = 2 compared to the other redshifts. This is perhaps surprising given that one may assume non-linear structure formation to be simpler at higher redshift given that structure is less developed. However, this may be because the assumptions in the halo model of virialized spherical haloes may be less valid at higher redshift, when structure is forming more rapidly due to the shape of standard linear power spectra.8 We also see that there is some correlation of the error with neutrino mass, with the model systematically overpredicting power for |$k\simeq 1\, h\, \mathrm{Mpc}^{-1}$| at z = 0 and systematically underpredicting power for |$k\simeq 0.2\, h\, \mathrm{Mpc}^{-1}$| at z = 2 for the highest neutrino masses. We also note that for a few cosmologies the model fails more severely for |$k\gt 1\, h\, \mathrm{Mpc}^{-1}$|. As shown in Appendix C, these specific cosmologies all have early-time dark energy equations of state that are close to zero, and therefore qualify as ‘early dark energy’ cosmologies. These equations of state means that the dark energy density decays very slowly with redshift compared to other models; for example Ωw(z = 100) ∼ 0.1. We suspect that cosmologies like these may have significantly different structure formation pathways, and that our prescription for calculating the halo concentration may not be correct for these exotic cosmologies.
5.3 Comments on hmcode parameters
We now comment on the values of some of the hmcode fitted parameters shown in Table 2:
The value of f at z = 0 in a standard ΛCDM cosmology is 0.22 with |$k_\mathrm{d}=0.073\, h\, \mathrm{Mpc}^{-1}$|. Referring to equation (16), this is perhaps surprising since we anticipated that this parameter would account for few per cent (not 20 per cent) effects at |$\simeq 0.03\, h\, \mathrm{Mpc}^{-1}$|, which would cover perturbative effects at these scales. However, this damping does have per cent level effects on the power at |$k=0.04\, h\, \mathrm{Mpc}^{-1}$| so it feasibly does account for this damping, but it has a much larger effect at smaller scales than we anticipated (≃10 per cent at |$k=0.1\, h\, \mathrm{Mpc}^{-1}$|). From Fig. 1 we can see that linear theory already underpredicts the power by around 10 per cent at this scale so adding another 10 per cent deficit at this scale without any compensation would be catastrophic. The required compensation arises from the α parameter (equation 23) that is smoothing the transition between the two- and one-halo term, such that part of the one-halo term adds power back at these scales.
The wavenumbers for the two-halo damping and one-halo damping are very similar, both |$\simeq 0.07\, h\, \mathrm{Mpc}^{-1}$|. Given the very different roles that these damping terms play we can only assume this to be coincidental.
As in previous versions of hmcode, we find it necessary to include the halo bloating parameter η, which deforms haloes in a mass-dependent way. The z = 0 value for a standard ΛCDM cosmology is 0.139, the fact that this is positive makes νη in equation (19) greater than unity for ν > 1 haloes and visa versa. This means that high-mass haloes are larger than they would otherwise be; ≃16 per cent larger for a ν = 3 (|$\sim \! 10^{15}\, h^{-1}\, \mathrm{M_\odot }$| at z = 0 for standard ΛCDM) halo. A combination of this halo bloating, the concentration modification, and the transition region smoothing seem to be necessary to get a good match to the non-linear power spectrum by creating a one-halo term that is more curved than the standard.
The value of η is closer to the default than it was in previous versions of hmcode (where η ≃ 0.4). This is probably because our default halo model (Section 3), on which hmcode is based, is a better description of the data prior to any parameter fitting.
Finally, in Fig. 4 we show a comparison between the power from the standard halo-model calculation described in Section 3, and the fitted hmcode as described in this section. We see: the one-halo term at the largest scales falling off more steeply than standard (equation 17); the small-scale suppression in the two-halo term, for |$k\sim 0.1\, h\, \mathrm{Mpc}^{-1}$| (equation 16); the boost in power in the transition region (|$k\sim 0.5\, h\, \mathrm{Mpc}^{-1}$|), we can infer that this is predominantly due to the α parameter (equation 23) because this boost is not present in either the two- or the one-halo terms; and a boost of power at |$k\sim 10\, h\, \mathrm{Mpc}^{-1}$| due to the modified concentration–mass relation.

Comparison of the ratio of power spectra for hmcode-2020 compared to that from the regular halo-model calculation with the same basic ingredients. The models are shown for a standard ΛCDM cosmology at z = 0. The two-halo term (long dashed), the one-halo term (short-dashed), and the total (solid) are shown for each model to illustrate the main differences between them.
6 BARYONIC FEEDBACK
In the previous section, we developed a model for the matter power spectrum assuming that gravity is the only important force for structure formation. This assumption is built in to our model given that we use ingredients for the halo model, such as the mass function and halo profiles, that are calibrated on simulations that only consider the gravitational interaction, and also because we have fitted our model to power spectra from such simulations. However, in reality we know that electromagnetic processes, particularly those associated with star formation and black hole accretion, can have a significant impact on the distribution of matter. In this section, we develop a simple model to account for the effect of these baryonic feedback processes on the matter power spectrum. This is possible with the halo model since we have physical information such as the masses, distribution, and structural properties of haloes that we expect to be altered by feedback.
6.1 Baryonic feedback model
We parametrize an effective model for baryonic physics by including three physically motivated changes to the standard halo model (nothmcode-2020) discussed in Section 3:
We allow feedback to deform haloes via a change in halo concentration (Rudd, Zentner & Kravtsov 2008) via the parameter B in equation (20). This is similar to the approach taken in Mead et al. (2015, 2020). Physically, we expect that gas expulsion from haloes removes mass from the halo centre, thus lowering the effective concentration from the default B = 4.
We include a central delta-function term, of magnitude f*, in the halo density profile to account for the presence of stars within haloes. As shown in Fedeli (2014), Debackere et al. (2020), and Mead et al. (2020), a term like this is necessary to model the power spectra of stellar matter as seen in hydrodynamic simulations. Stars that have an appreciable effect on the matter power spectrum predominantly cluster in the centres of haloes and this creates a shot-noise term in the power spectrum, as well a cross term between this and the NFW profile, both of which contribute to additional small-scale power. The parameter 0 < f* < Ωb/Ωm can be thought of as an effective halo stellar mass fraction.
- We account for gas expulsion by lowering the gas content of haloes viawhere fg is the halo gas fraction, the pre-factor in parenthesis is the available gas reservoir, while Mb > 0 and β > 0 are fitted parameters. Haloes of M ≫ Mb are unaffected while those of M < Mb have lost more than half of their gas.(24)$$\begin{eqnarray*} f_\mathrm{g}(M)=\left(\frac{\Omega _\mathrm{b}}{\Omega _\mathrm{m}}-f_*\right)\frac{(M/M_\mathrm{b})^\beta }{1+(M/M_\mathrm{b})^\beta }, \end{eqnarray*}$$
In previous versions of hmcode the feedback model was more basic. The parameters B from equation (20) and η from equation (19) were fitted to data from the original owls simulations (Schaye et al. 2010; van Daalen et al. 2011) to provide a model that approximately matched the suppression due to AGN feedback. Both this change in halo concentration and this ‘halo bloating’ were found to be necessary to provide a good match. However, there was no term to account for star formation, so the model would only ever predict a suppression in power.
6.2 Baryonic feedback parameters
The best-fitting baryon feedback parameters for all the simulations we considered are listed in Table 4. All fitted models have an RMS error of less than one per cent. We mainly focused on simulations that include realistic AGN feedback, but we also constrained our model using the cosmo-owls ref and no-cool simulations, which are not considered to be realistic. However, the fact that the model is still able to fit these simulations demonstrates some level of robustness. We see some obvious trends in our best-fitting parameters, particularly with the AGN ‘strength’, which is governed in the simulations by the sub-grid heating parameter TAGN – this is not a physical parameter that could be measured in the Universe. As feedback strength is increased Mb increases, which makes physical sense as more violent feedback expels more gas from the haloes. We also see a decrease in the star fraction, f*, as TAGN increases, which indicates that star formation is being suppressed by AGN feedback. Surprisingly, we see a preference for f* to increase with z in all AGN feedback models, which taken literally would suggest that halo star fractions were higher in the past. This might be possible, if star formation peaked at higher redshifts and then shut off. However, this trend was not seen in Mead et al. (2020), which suggests that the relatively simplicity of the modelling presented here means that f* is capturing physics not associated directly with stars. In all simulations with AGN we see a preference for a decrease in the concentration–mass parameter B away from the standard value of 4. However, in bahamas, B decreases with feedback strength while in cosmo-owlsB increases. This difference may be due to the different hydrodynamical implementations between the two simulation suites, or it may point to a more complicated relationship between feedback strength and the backreaction effect on the halo concentration. It may also be due to our model being overly simplistic since we take B and f* to be independent of halo mass or because we do not attempt to explicitly model the bound or ejected gas profiles. In general, the feedback in cosmo-owls has a stronger impact on the power spectrum than that in bahamas, and it is possible that there is a non-monotonic relationship between the feedback strength and the effect on B. As shown in McCarthy et al. (2018), the power spectrum response to feedback when the neutrino mass is varied is quite minimal. This is reflected in the relatively similar best-fitting model parameters, particularly for the Planck 2015 case where the other cosmological parameters are all adjusted to be best fitting for the Planck data, which preserves the linear spectrum shape and therefore the feedback response.
Best-fitting parameter values for our 6-parameter feedback model that match the data from bahamas and cosmo-owls hydrodynamical simulations. The exact cosmological parameters of each simulation can be found in table 2 of van Daalen et al. (2020). For the WMAP 9 simulations with neutrinos the value of σ8 decreases as the neutrino mass increases. For the Planck 2015 simulations with neutrinos all cosmological parameters change as the neutrino mass changes such that the Planck CMB data remain well fitted.
| Simulation suite | Feedback | |$\log _{10}(T_\mathrm{AGN}/\, \mathrm{K})$| | Cosmology | |$M_\nu /\, \mathrm{eV}$| | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z |
|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | agn | 7.6 | WMAP 9 | 0 | 3.55 | −0.060 | 2.06 | 0.40 | 13.52 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0 | 3.41 | −0.066 | 2.03 | 0.41 | 13.84 | −0.14 |
| bahamas | agn | 8.0 | WMAP 9 | 0 | 3.37 | −0.075 | 1.94 | 0.41 | 14.24 | −0.05 |
| bahamas | agn | 7.8 | Planck 2013 | 0 | 3.55 | −0.066 | 1.85 | 0.42 | 13.78 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.06 | 3.41 | −0.065 | 2.09 | 0.41 | 13.84 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0.12 | 3.42 | −0.071 | 2.09 | 0.42 | 13.88 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.24 | 3.36 | −0.069 | 2.30 | 0.40 | 13.86 | −0.14 |
| bahamas | agn | 7.8 | WMAP 9 | 0.48 | 3.28 | −0.071 | 2.65 | 0.39 | 13.86 | −0.10 |
| bahamas | agn | 7.8 | Planck 2015 | 0.06 | 3.45 | −0.057 | 2.03 | 0.40 | 13.82 | −0.13 |
| bahamas | agn | 7.8 | Planck 2015 | 0.12 | 3.44 | −0.058 | 2.07 | 0.40 | 13.83 | −0.14 |
| bahamas | agn | 7.8 | Planck 2015 | 0.24 | 3.41 | −0.058 | 2.20 | 0.40 | 13.84 | −0.12 |
| bahamas | agn | 7.8 | Planck 2015 | 0.48 | 3.37 | −0.065 | 2.54 | 0.40 | 13.84 | −0.10 |
| cosmo-owls | agn | 8.0 | WMAP 7 | 0 | 3.13 | −0.046 | 2.26 | 0.40 | 13.56 | −0.09 |
| cosmo-owls | agn | 8.5 | WMAP 7 | 0 | 3.19 | −0.055 | 2.03 | 0.40 | 14.28 | −0.11 |
| cosmo-owls | agn | 8.7 | WMAP 7 | 0 | 3.22 | −0.057 | 1.77 | 0.40 | 14.83 | 0.57 |
| cosmo-owls | agn | 8.0 | Planck 2013 | 0 | 3.23 | −0.039 | 2.07 | 0.40 | 13.53 | −0.09 |
| cosmo-owls | agn | 8.5 | Planck 2013 | 0 | 3.30 | −0.046 | 1.88 | 0.40 | 14.26 | −0.13 |
| cosmo-owls | agn | 8.7 | Planck 2013 | 0 | 3.38 | −0.056 | 1.58 | 0.42 | 14.79 | 0.29 |
| cosmo-owls | no-cool | – | WMAP 7 | 0 | 4.22 | 0.015 | 0.00 | 0.00 | 12.39 | −0.15 |
| cosmo-owls | ref | – | WMAP 7 | 0 | 3.79 | −0.007 | 3.92 | 0.27 | 13.20 | −0.41 |
| Simulation suite | Feedback | |$\log _{10}(T_\mathrm{AGN}/\, \mathrm{K})$| | Cosmology | |$M_\nu /\, \mathrm{eV}$| | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z |
|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | agn | 7.6 | WMAP 9 | 0 | 3.55 | −0.060 | 2.06 | 0.40 | 13.52 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0 | 3.41 | −0.066 | 2.03 | 0.41 | 13.84 | −0.14 |
| bahamas | agn | 8.0 | WMAP 9 | 0 | 3.37 | −0.075 | 1.94 | 0.41 | 14.24 | −0.05 |
| bahamas | agn | 7.8 | Planck 2013 | 0 | 3.55 | −0.066 | 1.85 | 0.42 | 13.78 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.06 | 3.41 | −0.065 | 2.09 | 0.41 | 13.84 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0.12 | 3.42 | −0.071 | 2.09 | 0.42 | 13.88 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.24 | 3.36 | −0.069 | 2.30 | 0.40 | 13.86 | −0.14 |
| bahamas | agn | 7.8 | WMAP 9 | 0.48 | 3.28 | −0.071 | 2.65 | 0.39 | 13.86 | −0.10 |
| bahamas | agn | 7.8 | Planck 2015 | 0.06 | 3.45 | −0.057 | 2.03 | 0.40 | 13.82 | −0.13 |
| bahamas | agn | 7.8 | Planck 2015 | 0.12 | 3.44 | −0.058 | 2.07 | 0.40 | 13.83 | −0.14 |
| bahamas | agn | 7.8 | Planck 2015 | 0.24 | 3.41 | −0.058 | 2.20 | 0.40 | 13.84 | −0.12 |
| bahamas | agn | 7.8 | Planck 2015 | 0.48 | 3.37 | −0.065 | 2.54 | 0.40 | 13.84 | −0.10 |
| cosmo-owls | agn | 8.0 | WMAP 7 | 0 | 3.13 | −0.046 | 2.26 | 0.40 | 13.56 | −0.09 |
| cosmo-owls | agn | 8.5 | WMAP 7 | 0 | 3.19 | −0.055 | 2.03 | 0.40 | 14.28 | −0.11 |
| cosmo-owls | agn | 8.7 | WMAP 7 | 0 | 3.22 | −0.057 | 1.77 | 0.40 | 14.83 | 0.57 |
| cosmo-owls | agn | 8.0 | Planck 2013 | 0 | 3.23 | −0.039 | 2.07 | 0.40 | 13.53 | −0.09 |
| cosmo-owls | agn | 8.5 | Planck 2013 | 0 | 3.30 | −0.046 | 1.88 | 0.40 | 14.26 | −0.13 |
| cosmo-owls | agn | 8.7 | Planck 2013 | 0 | 3.38 | −0.056 | 1.58 | 0.42 | 14.79 | 0.29 |
| cosmo-owls | no-cool | – | WMAP 7 | 0 | 4.22 | 0.015 | 0.00 | 0.00 | 12.39 | −0.15 |
| cosmo-owls | ref | – | WMAP 7 | 0 | 3.79 | −0.007 | 3.92 | 0.27 | 13.20 | −0.41 |
Best-fitting parameter values for our 6-parameter feedback model that match the data from bahamas and cosmo-owls hydrodynamical simulations. The exact cosmological parameters of each simulation can be found in table 2 of van Daalen et al. (2020). For the WMAP 9 simulations with neutrinos the value of σ8 decreases as the neutrino mass increases. For the Planck 2015 simulations with neutrinos all cosmological parameters change as the neutrino mass changes such that the Planck CMB data remain well fitted.
| Simulation suite | Feedback | |$\log _{10}(T_\mathrm{AGN}/\, \mathrm{K})$| | Cosmology | |$M_\nu /\, \mathrm{eV}$| | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z |
|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | agn | 7.6 | WMAP 9 | 0 | 3.55 | −0.060 | 2.06 | 0.40 | 13.52 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0 | 3.41 | −0.066 | 2.03 | 0.41 | 13.84 | −0.14 |
| bahamas | agn | 8.0 | WMAP 9 | 0 | 3.37 | −0.075 | 1.94 | 0.41 | 14.24 | −0.05 |
| bahamas | agn | 7.8 | Planck 2013 | 0 | 3.55 | −0.066 | 1.85 | 0.42 | 13.78 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.06 | 3.41 | −0.065 | 2.09 | 0.41 | 13.84 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0.12 | 3.42 | −0.071 | 2.09 | 0.42 | 13.88 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.24 | 3.36 | −0.069 | 2.30 | 0.40 | 13.86 | −0.14 |
| bahamas | agn | 7.8 | WMAP 9 | 0.48 | 3.28 | −0.071 | 2.65 | 0.39 | 13.86 | −0.10 |
| bahamas | agn | 7.8 | Planck 2015 | 0.06 | 3.45 | −0.057 | 2.03 | 0.40 | 13.82 | −0.13 |
| bahamas | agn | 7.8 | Planck 2015 | 0.12 | 3.44 | −0.058 | 2.07 | 0.40 | 13.83 | −0.14 |
| bahamas | agn | 7.8 | Planck 2015 | 0.24 | 3.41 | −0.058 | 2.20 | 0.40 | 13.84 | −0.12 |
| bahamas | agn | 7.8 | Planck 2015 | 0.48 | 3.37 | −0.065 | 2.54 | 0.40 | 13.84 | −0.10 |
| cosmo-owls | agn | 8.0 | WMAP 7 | 0 | 3.13 | −0.046 | 2.26 | 0.40 | 13.56 | −0.09 |
| cosmo-owls | agn | 8.5 | WMAP 7 | 0 | 3.19 | −0.055 | 2.03 | 0.40 | 14.28 | −0.11 |
| cosmo-owls | agn | 8.7 | WMAP 7 | 0 | 3.22 | −0.057 | 1.77 | 0.40 | 14.83 | 0.57 |
| cosmo-owls | agn | 8.0 | Planck 2013 | 0 | 3.23 | −0.039 | 2.07 | 0.40 | 13.53 | −0.09 |
| cosmo-owls | agn | 8.5 | Planck 2013 | 0 | 3.30 | −0.046 | 1.88 | 0.40 | 14.26 | −0.13 |
| cosmo-owls | agn | 8.7 | Planck 2013 | 0 | 3.38 | −0.056 | 1.58 | 0.42 | 14.79 | 0.29 |
| cosmo-owls | no-cool | – | WMAP 7 | 0 | 4.22 | 0.015 | 0.00 | 0.00 | 12.39 | −0.15 |
| cosmo-owls | ref | – | WMAP 7 | 0 | 3.79 | −0.007 | 3.92 | 0.27 | 13.20 | −0.41 |
| Simulation suite | Feedback | |$\log _{10}(T_\mathrm{AGN}/\, \mathrm{K})$| | Cosmology | |$M_\nu /\, \mathrm{eV}$| | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z |
|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | agn | 7.6 | WMAP 9 | 0 | 3.55 | −0.060 | 2.06 | 0.40 | 13.52 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0 | 3.41 | −0.066 | 2.03 | 0.41 | 13.84 | −0.14 |
| bahamas | agn | 8.0 | WMAP 9 | 0 | 3.37 | −0.075 | 1.94 | 0.41 | 14.24 | −0.05 |
| bahamas | agn | 7.8 | Planck 2013 | 0 | 3.55 | −0.066 | 1.85 | 0.42 | 13.78 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.06 | 3.41 | −0.065 | 2.09 | 0.41 | 13.84 | −0.13 |
| bahamas | agn | 7.8 | WMAP 9 | 0.12 | 3.42 | −0.071 | 2.09 | 0.42 | 13.88 | −0.16 |
| bahamas | agn | 7.8 | WMAP 9 | 0.24 | 3.36 | −0.069 | 2.30 | 0.40 | 13.86 | −0.14 |
| bahamas | agn | 7.8 | WMAP 9 | 0.48 | 3.28 | −0.071 | 2.65 | 0.39 | 13.86 | −0.10 |
| bahamas | agn | 7.8 | Planck 2015 | 0.06 | 3.45 | −0.057 | 2.03 | 0.40 | 13.82 | −0.13 |
| bahamas | agn | 7.8 | Planck 2015 | 0.12 | 3.44 | −0.058 | 2.07 | 0.40 | 13.83 | −0.14 |
| bahamas | agn | 7.8 | Planck 2015 | 0.24 | 3.41 | −0.058 | 2.20 | 0.40 | 13.84 | −0.12 |
| bahamas | agn | 7.8 | Planck 2015 | 0.48 | 3.37 | −0.065 | 2.54 | 0.40 | 13.84 | −0.10 |
| cosmo-owls | agn | 8.0 | WMAP 7 | 0 | 3.13 | −0.046 | 2.26 | 0.40 | 13.56 | −0.09 |
| cosmo-owls | agn | 8.5 | WMAP 7 | 0 | 3.19 | −0.055 | 2.03 | 0.40 | 14.28 | −0.11 |
| cosmo-owls | agn | 8.7 | WMAP 7 | 0 | 3.22 | −0.057 | 1.77 | 0.40 | 14.83 | 0.57 |
| cosmo-owls | agn | 8.0 | Planck 2013 | 0 | 3.23 | −0.039 | 2.07 | 0.40 | 13.53 | −0.09 |
| cosmo-owls | agn | 8.5 | Planck 2013 | 0 | 3.30 | −0.046 | 1.88 | 0.40 | 14.26 | −0.13 |
| cosmo-owls | agn | 8.7 | Planck 2013 | 0 | 3.38 | −0.056 | 1.58 | 0.42 | 14.79 | 0.29 |
| cosmo-owls | no-cool | – | WMAP 7 | 0 | 4.22 | 0.015 | 0.00 | 0.00 | 12.39 | −0.15 |
| cosmo-owls | ref | – | WMAP 7 | 0 | 3.79 | −0.007 | 3.92 | 0.27 | 13.20 | −0.41 |
6.3 Single-parameter model
It may be preferable to have a less general, but single-parameter, model for baryonic feedback. Since degeneracies may exist between the 6 parameters of our model, top-hat priors may not represent the true uncertainty, while also slowing down MCMC analyses. Based on the bahamas best-fitting parameters in Table 4 we see roughly linear trends between parameters and the feedback temperature. We therefore propose the model detailed in Table 5, where all 6 feedback parameters have been linearly fitted as functions of log10(TAGN/K) for the bahamas simulations. Given our modelling it is not possible to have a single-parameter model that works for both cosmo-owls and bahamas since we observe the opposite trend in the mass–concentration parameter B with TAGN in each case. We therefore present a model only for bahamas, although it would be straightforward to develop a similar model for cosmo-owls. In Fig. 5, we show the performance of our single-parameter model against the three different TAGNbahamas simulations to which it was fitted. We see that the single-parameter model response follows the simulation response to within a couple of per cent across the entire range of scales shown. The largest errors are at the largest scales at z = 1, where the scale dependence of the departure of the response from unity in the model does not follow the simulations particularly well. However, the amplitude of the maximum dip in power and the smaller-scale increase in power are both well recovered. It should be noted that this one-parameter model has no limit in which the ‘gravity only’ result is recovered. For comparison, in Fig. 5 we also show the feedback model from the previous versions of hmcode. The suppression in the previous model activates at smaller scales compared to the new model, predicts more suppression than all scenarios discussed in this paper for |$k\gt 5\, h\, \mathrm{Mpc}^{-1}$|, and has no upturn because there was no attempt to model star formation in Mead et al. (2015).
Comparison of our single-parameter baryonic feedback response model against three different versions of bahamas AGN feedback simulations with the WMAP 9 cosmology that differ only by their values of the ‘sub-grid heating’ temperature (blue, grey, and light-red for log10(TAGN/K) = 7.6, 7.8, and 8.0). The dots show the simulation measurements while the lines show the hmcode model. In all cases we see that baryonic feedback suppresses power, starting at |$k\sim 0.1\, h\, \mathrm{Mpc}^{-1}$| with a maximum suppression effect of tens of per cent at |$k\sim 7\, h\, \mathrm{Mpc}^{-1}$|, which is followed by a sharp rise in power. The suppression is caused by AGN feedback expelling gas from haloes while the rise in power is caused by galaxy formation in halo centres. The dark-red curve shows the cosmo-owls extreme AGN simulation with the Planck 2013 cosmology. This feedback scenario is quite well matched with the same single-parameter feedback model with an increased effective AGN temperature of log10(TAGN/K) = 8.3. The dashed-grey line shows the AGN feedback model from the previous versions of hmcode, which suppresses the power more than any of the scenarios shown here for |$k\gt 5\, h\, \mathrm{Mpc}^{-1}$| and the onset of the suppression is at slightly smaller scales compared to the bahamas and cosmo-owls simulations.
Values for our single-parameter baryonic feedback model as a function of the sub-grid heating temperature in the bahamas feedback models. In the formulae below |$\theta =\log _{10}(T_\mathrm{AGN}/10^{7.8}\, \mathrm{K})$|. In equation (24) β = 2 has been fixed. Parameter X(z) is constructed from X0 and Xz as |$X(z) = X_0\times 10^{z X_z}$|.
Values for our single-parameter baryonic feedback model as a function of the sub-grid heating temperature in the bahamas feedback models. In the formulae below |$\theta =\log _{10}(T_\mathrm{AGN}/10^{7.8}\, \mathrm{K})$|. In equation (24) β = 2 has been fixed. Parameter X(z) is constructed from X0 and Xz as |$X(z) = X_0\times 10^{z X_z}$|.
In Fig. 5, we also show the performance of the same single-parameter model against the extreme agn 8.7 simulation from the cosmo-owls suite. This feedback model was not used in the generation of our feedback model, but is well matched when assigned with an effective bahamas log10(TAGN/K) = 8.3. The other cosmo-owls agn 8.0 and 8.5 models can be similarly well matched with effective log10(TAGN/K) = 7.7 and 8.0, respectively. We should not be surprised that the effective bahamas AGN temperature assigned to these cosmo-owls feedback scenarios is different from their cosmo-owls temperature because the underlying physical feedback model differs between the two simulation suites. However, it is pleasing that the same physical model can be made to work for both suites. Of all the feedback models, the extreme cosmo-owls model shown in the figure is the least well matched, with the largest errors at z = 1 for |$k \lt 3 \, h\, \mathrm{Mpc}^{-1}$|.
Our single-parameter model is calibrated on the bahamasWMAP 9 (Hinshaw et al. 2013) simulations, therefore we should compare it to the alternative bahamas with Planck2013 cosmology simulation. For the same sub-grid heating temperature, the simulations show that the Planck 2013 cosmology has less feedback-induced suppression, with a maximum of ≃13 per cent at |$k\simeq 7\, h\, \mathrm{Mpc}^{-1}$| at z = 0, compared to ≃17 per cent with the WMAP 9 cosmology. If we evaluate our single-parameter feedback model for the Planck cosmology, the model does predict less suppression, but with the maximum reduced from ≃17 to only ≃15, rather than as far as ≃13 per cent. Within our model, this change at fixed TAGN arises due to the different baryon fractions12 in each cosmology as because of differences in the halo mass functions. It is encouraging that this change with cosmology predicted by the model is in the correct direction, but disheartening that it is not quite strong enough. Table 4 tells us that the Planck cosmology prefers a slightly lower value of Mb, 0 compared to WMAP 9 (|$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })=13.78$|, rather than 13.84). We tried to change the parametrization in equation (24) for Mb to be proportional to the non-linear mass, σ(M*, z) = δc(z), but this trends in the wrong direction.13 The simulations demonstrate that cosmologies with higher baryon fractions have a larger feedback-induced suppression in the matter power spectrum, presumably because a larger fraction of the halo mass is expelled. The dependence on the baryon fraction is built into our model via equation (25) but this comparison suggests that the true dependence is slightly different. In any case, we find that the suppression in the Planck cosmology is well fitted, with an RMS error below one per cent, by our single-parameter model but with a slightly reduced log10(TAGN/K) = 7.75.
The van Daalen et al. (2020) library contains cosmologies that combine baryonic feedback with massive neutrinos. There are two cases to consider: WMAP 9, where as the neutrino mass is increased σ8 is decreased and Planck 2015, where as the neutrino mass is increased all other cosmological parameters are changed to maintain a good fit to the Planck data. In the WMAP 9 case there is a weak dependence on the suppression with neutrino mass, with the trend that the suppression slightly increases as the neutrino mass increases. If we evaluate our single-parameter model, we find the correct direction for the trend, but one that is slightly stronger than that seen in the simulations. However, since the change seen in the simulations is very slight, the eventual model error is quite small. In the extreme |$M_\nu =0.48\, \mathrm{eV}$| case, the difference in suppression between this and the Mν = 0 case is predicted to be around twice as large as is seen in the data, but the maximum error is only 2 per cent – an improved match can be made with a slight increase in the corresponding AGN temperature. The same holds for the Planck 2015 massive-neutrino cases, but the trends, and the eventual error in our model, are both smaller.
6.4 Priors
Based on the data in Table 4 reasonable priors could be adopted for our 6 parameter model which would cover the full range of feedback scenarios from van Daalen et al. (2020). These ranges could be tightened if the more extreme, and less physically reasonable, cosmo-owls simulations were discarded. The gravity-only model is recovered in the limit B → 4, Mb → 0, and f* → 0. In Table 6, we explicitly state our recommended prior ranges for each scenario. We also include a prior range for our single-parameter model. In the bahamas case, we recommend varying between the range of TAGN probed by the bahamas simulations: |$7.6\lt \log _{10}(T_\mathrm{AGN}/\, \mathrm{K})\lt 8.0$|. This temperature range was chosen so that the bahamas simulations reproduced the full range of halo-gas fraction observations (McCarthy et al. 2017), which Debackere et al. (2020) and van Daalen et al. (2020) have shown is closely linked to the eventual magnitude of the feedback suppression. If one wanted to consider more extreme feedback scenarios, then in the bahamas + cosmo-owls case we recommend extending the upper bound such that |$7.6\lt \log _{10}(T_\mathrm{AGN}/\, \mathrm{K})\lt 8.3$| is explored, since this encompasses the full range of bahamas and cosmo-owls feedback, as demonstrated in Fig. 5.
Recommended priors for our baryonic feedback model that are able to encompass specific hydrodynamic feedback scenarios. We list parameters that encompass the bahamas suite, those that encompass both bahamas and cosmo-owls, and those that additionally include the gravity-only case, which would be correct if there were no feedback. The first column lists the scenario, the next 6 columns list the 6 parameters of our feedback model, while the two values in each column indicate the lower and upper bound. The final column lists the TAGN values that should be used for our single-parameter model. Note that our single-parameter model does not encompass the gravity only scenario.
| Scenario | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z | log10(TAGN/K) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | 3.28 | 3.55 | −0.075 | −0.057 | 1.85 | 2.65 | 0.39 | 0.42 | 13.52 | 14.24 | −0.16 | −0.05 | 7.6 | 8.0 |
| +cosmo-owls | 3.13 | 3.55 | −0.075 | −0.039 | 1.58 | 2.65 | 0.39 | 0.42 | 13.52 | 14.83 | −0.16 | 0.57 | 7.6 | 8.3 |
| +gravity-only | 3.13 | 4.00 | −0.075 | −0.039 | 0 | 2.65 | 0.39 | 0.42 | 0 | 14.83 | −0.16 | 0.57 | – | |
| Scenario | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z | log10(TAGN/K) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | 3.28 | 3.55 | −0.075 | −0.057 | 1.85 | 2.65 | 0.39 | 0.42 | 13.52 | 14.24 | −0.16 | −0.05 | 7.6 | 8.0 |
| +cosmo-owls | 3.13 | 3.55 | −0.075 | −0.039 | 1.58 | 2.65 | 0.39 | 0.42 | 13.52 | 14.83 | −0.16 | 0.57 | 7.6 | 8.3 |
| +gravity-only | 3.13 | 4.00 | −0.075 | −0.039 | 0 | 2.65 | 0.39 | 0.42 | 0 | 14.83 | −0.16 | 0.57 | – | |
Recommended priors for our baryonic feedback model that are able to encompass specific hydrodynamic feedback scenarios. We list parameters that encompass the bahamas suite, those that encompass both bahamas and cosmo-owls, and those that additionally include the gravity-only case, which would be correct if there were no feedback. The first column lists the scenario, the next 6 columns list the 6 parameters of our feedback model, while the two values in each column indicate the lower and upper bound. The final column lists the TAGN values that should be used for our single-parameter model. Note that our single-parameter model does not encompass the gravity only scenario.
| Scenario | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z | log10(TAGN/K) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | 3.28 | 3.55 | −0.075 | −0.057 | 1.85 | 2.65 | 0.39 | 0.42 | 13.52 | 14.24 | −0.16 | −0.05 | 7.6 | 8.0 |
| +cosmo-owls | 3.13 | 3.55 | −0.075 | −0.039 | 1.58 | 2.65 | 0.39 | 0.42 | 13.52 | 14.83 | −0.16 | 0.57 | 7.6 | 8.3 |
| +gravity-only | 3.13 | 4.00 | −0.075 | −0.039 | 0 | 2.65 | 0.39 | 0.42 | 0 | 14.83 | −0.16 | 0.57 | – | |
| Scenario | B0 | Bz | f*, 0/10−2 | f*, z | |$\log _{10}(M_{\mathrm{b},0}/\, h^{-1}\, \mathrm{M_\odot })$| | Mb, z | log10(TAGN/K) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bahamas | 3.28 | 3.55 | −0.075 | −0.057 | 1.85 | 2.65 | 0.39 | 0.42 | 13.52 | 14.24 | −0.16 | −0.05 | 7.6 | 8.0 |
| +cosmo-owls | 3.13 | 3.55 | −0.075 | −0.039 | 1.58 | 2.65 | 0.39 | 0.42 | 13.52 | 14.83 | −0.16 | 0.57 | 7.6 | 8.3 |
| +gravity-only | 3.13 | 4.00 | −0.075 | −0.039 | 0 | 2.65 | 0.39 | 0.42 | 0 | 14.83 | −0.16 | 0.57 | – | |
7 SUMMARY AND DISCUSSION
We have presented hmcode-2020, an updated and augmented halo model for the non-linear matter–matter power spectrum that has an RMS error compared to simulated data of less than 2.5 per cent across a wide range of cosmologies, scales, and redshifts. This represents a significant improvement over previous halofit and hmcode versions. The span of cosmological parameters also ensures that this encompasses a wide range of linear spectrum shapes, so that we can be confident that our model is capturing many of the non-trivial aspects of non-linear evolution. Our augmented halo model is parametrized in terms of the linear power spectrum, transformed into the mass function and concentration parameters via the halo model, as well as in terms of variables that pertain to the linear spectrum properties such as σ8(z) or neff(z). We believe that parametrizing the model this way is advantageous because there is no specific dependence on the standard cosmological parameters so that the model may be applied to novel cosmological scenarios as and when they are invented. Parameters in hmcode-2020 were fitted to simulated data taken from the node cosmologies of franken emu. hmcode-2020 was also compared to mira titan, to which it was not fitted, and was shown to out perform competing models. It is possible that performance would be further improved if we had additionally fitted to the node cosmologies of mira titan, but we have not done this and instead prefer to leave mira titan as a fair test. hmcode-2020 is also rapid; the non-linear power for 128 k values, at nz = 16 redshifts for a single cosmology can be evaluated in |$160\, \mathrm{ms}$| on a single core of a modern laptop, with the compute time scaling as |$t\simeq (22+5n_z)\, \mathrm{ms}$|. The computation is slower for massive-neutrino cosmologies, scaling as |$t\simeq (1500+9n_z)\, \mathrm{ms}$|. These timings are similar to previous versions of hmcode.
Section 3 provides a comparison of the accuracy of vanilla halo model predictions compared to simulations – both in terms of the mean prediction across a range of cosmologies as well as the variance about this mean. This allowed us to select an optimal set of ingredients for hmcode-2020. We demonstrated that halo-model predictions when using haloes defined using the 200-times critical density definition were particularly poor compared to other halo definitions. We also demonstrated that predictions using the Sheth & Tormen (1999) mass function were better compared to when using Tinker et al. (2010), and we suggest that this because the mass function of Sheth & Tormen (1999) was fitted to a broader range of cosmologies. We are not aware of any similar analyses, and this conclusion may be useful when decisions are taken regarding ingredients to use in other halo model calculations, such as for the galaxy power spectrum or for the tSZ effect.
Perturbative effects are missing from the standard halo model calculation. In hmcode they are included in an approximate way via an ad hoc damping term applied to the linear power in the two-halo term, as well as via the damping of BAO amplitude via a well-known perturbation theory result. We have yet to include actual perturbation theory calculations within hmcode but this would be a fruitful direction for future research, as long as the speed of the calculation could be kept under control. Combing perturbation theory and the halo model has been considered by other authors including Valageas & Nishimichi (2011), Mohammed et al. (2014), Seljak & Vlah (2015), Hand et al. (2017), Cataneo et al. (2019) and Philcox et al. (2020). While these results are promising, the authors do not achieve the same accuracy across the range of scales, redshifts and cosmologies as has been achieved using hmcode, although most achieve better accuracy at larger scales. In these approaches the one-halo term is often thrown away, or treated as a generic series expansion. We suggest that keeping the cosmological information in the one-halo term, which enters via the mass function and halo profile, is preferable since we have seen that the ability of the halo model to track the power in the non-linear regime can be greatly improved with the correct choice of these ingredients.
We use the Bullock et al. (2001) halo concentration–mass relation in hmcode. While this works well for our purposes, as demonstrated in Section 3, it may be preferable to update the relations to those presented in Correa et al. (2015), Ludlow et al. (2016), or Diemer & Joyce (2019), where the concentration is tied to the halo mass-accretion history. However, each of these relations is calibrated for halo mass definitions of 200 times the critical density, whereas we demonstrated that our halo-model predictions were far superior when using the virial halo definition. It is tempting to try to change the halo definition using the well-known method involving a fixed NFW profile and scale radius, but we do not do this here as it is not obvious that this method produces the haloes with the same characteristics as would be observed if a halo finder with a different overdensity threshold were used to identify haloes in the same simulation.
In order to reproduce accurate power spectra we were forced to introduce a number of free-parameters and ad hoc changes to the standard halo model. It is tempting to view these as indicative of some underlying fundamental model, but we caution against this. For example, we were forced to introduce the η parameter, which bloats haloes as a function of mass, reaching an ≃15 per cent size increase for haloes of |$10^{15}\, h^{-1}\, \mathrm{M_\odot }$| at z = 0. The unphysical bloating is necessary to get a good match to simulated spectra, but it is alarming that the haloes to which the model pertains are not the same as haloes in the real Universe. Another cause for concern is the α parameter, which smooths the transition between the two- and one-halo terms, and is absolutely essential in getting good matches to the simulated data. Could the same α work for other halo model calculations that have similar problems in the transition region? Alas, a simple thought experiment proves that this is not possible. Consider a field that is made up of the sum of two constituent fields (for example matter, being made of CDM and baryons). If the auto- and cross-power spectrum of each field separately can be written as a sum of two- and one-halo terms then it can only be that the total field can also be written as a sum of two- and one-halo terms if α = 1. Clearly a less crude technique than our ad hoc smoothing will be required to solve this fundamental issue.
We have also presented a halo model for the response in the power spectrum to baryonic feedback. Simple recipes for gas expulsion and star formation are included, as well as the impact of feedback on the halo concentration. The feedback model was fitted to simulation data, taken from the library of van Daalen et al. (2020), with an RMS error of less than one per cent for all feedback models that we considered (|$k\lt 20\, h\, \mathrm{Mpc}^{-1}$|; z < 1). We provide the best-fitting parameters of our model to each simulation and suggest that these can be used to generate an informative prior range that may be sampled over in future weak-lensing data analyses to immunize cosmological constraints against the unknown magnitude of baryonic feedback. Alternatively, we provide a single-parameter feedback model, parametrized in terms of the sub-grid AGN heating temperature of the bahamas simulations, which may be robust to modest extrapolation. We noted that this model did not capture the full cosmology dependence of the feedback correctly, underestimating the shift between the WMAP 9 and Planck 2013 cosmology by half, although still only making a maximum 2 per cent error in the absolute response. However, the Planck 2013 feedback suppression was well matched with a slightly reduced effective AGN temperature (log10(TAGN/K) = 7.75, rather than 7.8). We consider this to be acceptable since TAGN is not a physical parameter and would be marginalized over in future analyses, so that it is only important that physical feedback suppression is captured by some value of the TAGN parameter and that we marginalize over a suitable range. The single-parameter model also slightly overpredicts the change in response as massive neutrinos are introduced, but again only making small absolute errors because the neutrinos have a minimal effect on the suppression. Despite this, in both cases excellent results can still be obtained if one slightly modifies the AGN temperature. In its current form, the single-parameter model maps an AGN temperature to a unique value of Mb, the mass below which a halo has lost half of its initial gas content, and this removes a fixed fraction of the baryons originally in a halo. Clearly this is simplistic, and cosmologies with different baryon fractions may be differently affected for the same AGN temperature. The cosmology dependence of the amplitude of feedback clearly warrants further research, and for this it would be useful to have access to hydrodynamic simulations over a wider range of cosmologies. We found it more difficult to fit our model to z > 1, particularly considering the z dependence we adopted for our feedback model. It is probably sufficient for current lensing studies to concentrate on the feedback only at the lowest redshifts, because it is a small-scale effect, but in the not-too-distant future the increased fidelity of observational data may force this to be revisited.
ACKNOWLEDGEMENTS
AJM and TT have received funding from the Horizon 2020 research and innovation programme of the European Union under Marie Skłodowska-Curie grant agreements No. 702971and797794 respectively. AJM, TT and CH acknowledge support from the European Research Council under grant number 647112. CH acknowledges support from the Max Planck Society and the Alexander von Humboldt Foundation in the framework of the Max Planck-Humboldt Research Award endowed by the Federal Ministry of Education and Research. The authors acknowledge useful conversations with Licia Verde, Simeon Bird, Sarah Brown, and Mijin Yoon.
DATA AVAILABILITY
The code developed and used in this article is available at https://github.com/alexander-mead/HMcode. The data underlying this article will be shared upon request to the corresponding author.
Footnotes
In principle i and j could be different. For example, ij = mc would indicate the cross spectrum between the total matter and the cold matter. However, in this paper we only use autospectra of total matter and cold matter, so ij = mm or ij = cc, but we retain the two index notation for theoretical completeness.
This mass function was fitted to simulated haloes defined using a virial halo definition.
For mass functions that do not satisfy the normalization condition we force the large-scale normalization of the two-halo term to be correct via the procedure described in the appendix of Mead et al. (2020).
To create the smoothed power spectrum we first divide the linear spectrum by the ‘no-wiggle’ approximation from Eisenstein & Hu (1998) and we then smooth the resulting function of |$\ln (k/h\, \mathrm{Mpc}^{-1})$| with a Gaussian with σ = 0.25. The eventual de-wiggled power is quite insensitive to σ, and our results are minimally affected for values between 0.15 and 0.35.
At early times, many scales cross the threshold for collapse simultaneously because Δ2 is roughly constant at the relevant scales. At later times Δ2 is steeper and structure formation is more orderly.
http://www.astro.ljmu.ac.uk/ igm/BAHAMAS.
The baryon-mass fraction, Ωb/Ωm, in the WMAP 9 cosmology is ≃0.166 while it is ≃0.154 in Planck 2013.
At z = 0 in WMAP 9 |$M_*=10^{12.61}\, h^{-1}\, \mathrm{M_\odot }$| whereas in Planck 2013 |$M_*=10^{12.74}\, h^{-1}\, \mathrm{M_\odot }$|.
More correctly |$\delta _\mathrm{c}=(3/20)\times (12\pi)^{2/3}$| and |$\Delta _\mathrm{v}=18\pi ^2$|.
REFERENCES
APPENDIX A: FITTING FUNCTIONS FOR δc AND Δv
In this Appendix, we detail fitting functions for the spherical-collapse parameters δc and Δv that are valid for homogeneous dark energy models that also work for cosmologies with substantial curvature. These fitting functions originally appeared in Mead (2017), but are repeated here with some minor alterations that make them appropriate for massive-neutrino cosmologies. An alternative ΛCDM fitting function for δc can be found in Nakamura & Suto (1997) and for Δv in Bryan & Norman (1998). For matter-dominated open and closed cosmologies exact formulae may be derived (e.g. Coles & Lucchin 2002). The fitting functions presented here are constructed in such a way that they do not depend explicitly on any dark energy parametrization, and are instead parametrized in terms of the matter density, linear growth, and the integrated growth, which are defined below.
| δc | Value | Δv | Value |
|---|---|---|---|
| p1, 0 | −0.0069 | p3, 0 | −0.79 |
| p1, 1 | −0.0208 | p3, 1 | −10.17 |
| p1, 2 | 0.0312 | p3, 2 | 2.51 |
| p1, 3 | 0.0021 | p3, 3 | 6.51 |
| α1 | 1 | α3 | 1 |
| p2, 0 | 0.0001 | p4, 0 | −1.89 |
| p2, 1 | −0.0647 | p4, 1 | 0.38 |
| p2, 2 | −0.0417 | p4, 2 | 18.8 |
| p2, 3 | 0.0646 | p4, 3 | −15.87 |
| α2 | 0 | α4 | 2 |
| δc | Value | Δv | Value |
|---|---|---|---|
| p1, 0 | −0.0069 | p3, 0 | −0.79 |
| p1, 1 | −0.0208 | p3, 1 | −10.17 |
| p1, 2 | 0.0312 | p3, 2 | 2.51 |
| p1, 3 | 0.0021 | p3, 3 | 6.51 |
| α1 | 1 | α3 | 1 |
| p2, 0 | 0.0001 | p4, 0 | −1.89 |
| p2, 1 | −0.0647 | p4, 1 | 0.38 |
| p2, 2 | −0.0417 | p4, 2 | 18.8 |
| p2, 3 | 0.0646 | p4, 3 | −15.87 |
| α2 | 0 | α4 | 2 |
| δc | Value | Δv | Value |
|---|---|---|---|
| p1, 0 | −0.0069 | p3, 0 | −0.79 |
| p1, 1 | −0.0208 | p3, 1 | −10.17 |
| p1, 2 | 0.0312 | p3, 2 | 2.51 |
| p1, 3 | 0.0021 | p3, 3 | 6.51 |
| α1 | 1 | α3 | 1 |
| p2, 0 | 0.0001 | p4, 0 | −1.89 |
| p2, 1 | −0.0647 | p4, 1 | 0.38 |
| p2, 2 | −0.0417 | p4, 2 | 18.8 |
| p2, 3 | 0.0646 | p4, 3 | −15.87 |
| α2 | 0 | α4 | 2 |
| δc | Value | Δv | Value |
|---|---|---|---|
| p1, 0 | −0.0069 | p3, 0 | −0.79 |
| p1, 1 | −0.0208 | p3, 1 | −10.17 |
| p1, 2 | 0.0312 | p3, 2 | 2.51 |
| p1, 3 | 0.0021 | p3, 3 | 6.51 |
| α1 | 1 | α3 | 1 |
| p2, 0 | 0.0001 | p4, 0 | −1.89 |
| p2, 1 | −0.0647 | p4, 1 | 0.38 |
| p2, 2 | −0.0417 | p4, 2 | 18.8 |
| p2, 3 | 0.0646 | p4, 3 | −15.87 |
| α2 | 0 | α4 | 2 |
The spherical-collapse calculations to which our relations were fitted do not include the buoying effect of darkenergy in the calculation of the final virial density of haloes, and so consequently our Δv does not map exactly to that of the Bryan & Norman (1998) formula. For example, for a standard Ωm = 0.3 ΛCDM model the Bryan & Norman (1998) relation gives Δv ≃ 337, whereas the Mead (2017) relation gives Δv ≃ 308. Attempts to include general dark energy in calculations of the virial density can be found in Mota & van de Bruck (2004) or Wintergerst & Pettorino (2010), but are not included here.
As shown in Mead et al. (2016) these spherical-collapse results can be applied to massive neutrino cosmologies by making the multiplicative correction that appears in the denominators in the left-hand side of equations (A1) and (A2) compared to the results presented in Mead (2017). These values were calculated for matter-dominated models, but the same correction also works for massive-neutrino cosmologies with exotic dark energy equations of state. In the massive neutrino case g(a), G(a), and Ωm(a) that appear in the fitting functions are all evaluated in an equivalent massless neutrino cosmology with the mass in neutrinos converted to CDM.
APPENDIX B: HALOFIT AND MASSIVE NEUTRINOS
halofit has three separate versions all published by different groups. The first, Smith et al. (2003), version is inaccurate compared to modern simulations, as can be seen in Fig. 1, a consequence of it having been fitted to low-resolution simulations that systematically underpredict power at small scales. Chronologically, the Bird et al. (2012) and the Takahashi et al. (2012) papers were published at similar times, and both provided updates of the original Smith et al. (2003) halofit fitting function. Takahashi et al. (2012) improved the model to be generally more accurate by fitting to more modern simulations and also introduced an explicit dependence on w, the dark energy equation of state. In doing so, all parameters in the model were refitted to a modern simulation suite. In contrast, the focus of Bird et al. (2012) was on cosmologies with massive neutrinos, which were ignored by Takahashi et al. (2012). In Bird et al. (2012) most parameters of the original Smith et al. (2003) version were left unaltered and terms were added with explicit dependencies on the neutrino mass. Because the base model was left almost unaltered, the overall accuracy of Bird et al. (2012) version for standard cosmologies with no massive neutrinos was worse than that of Takahashi et al. (2012). To rectify this, the Bird et al. (2012) neutrino model was later reconfigured using the more accurate Takahashi et al. (2012) halofit as a base (Bird, private communication). This reconfiguration has not been published, but it is the default halofit version in camb. If the neutrino mass is zero then this ‘camb’ version of halofit is exactly the Takahashi et al. (2012) version because the only new parameters vanish in this limit.
In Fig. B1, we show the performance of different versions of halofit compared to the node cosmologies of mira titan that have massive neutrinos (26 of 36 nodes): We show the original Bird et al. (2012) model; the original version of Takahashi et al. (2012), which has no explicit dependence on neutrino mass; and we show the unpublished version of the Bird et al. (2012) neutrino halofit, which is the default model that appears in camb. It is surprising to see that the camb version, which is explicitly calibrated on cosmologies with massive neutrinos, performs worse than Takahashi et al. (2012) version, despite the latter having no explicit dependence on neutrino mass. This poor performance is especially striking for the highest neutrino masses. While there are some obvious systematic errors in the mean prediction of the Bird et al. (2012) version, it is interesting that the variance between the predictions for the different cosmologies is better than for the other two models around |$k\sim 0.3\, h\, \mathrm{Mpc}^{-1}$| and also that the variance is not significantly worse than for the other models at smaller scales.

Performance of different versions of halofit compared to the massive-neutrino node cosmologies of mira titan. Each line is a different cosmological model and these are colour coded according to the neutrino mass. We show three versions of halofit: the bottom row shows the original Bird et al. (2012) version, which itself is a correction to the original of Smith et al. (2003); the third row shows the original of Takahashi et al. (2012) which has no explicit dependence on neutrino mass; the second row shows an unpublished version of the Bird et al. (2012) neutrino halofit, which is the default in camb; the top row shows hmcode-2020 for comparison. We note that the unpublished halofit that contains explicit neutrino-mass dependence performs worse, especially for high neutrino masses, compared to the Takahashi et al. (2012) version with no explicit neutrino mass dependence.
It is probable that this can be explained by the different techniques used to include massive neutrinos in cosmological simulations. The three main techniques, in order of complexity, are:
Linear neutrinos: are treated entirely via linear theory (e.g. Agarwal & Feldman 2011). Their energy density is included in the evolution of the background, and their contribution to the gravitational potential is included and affects the simulation particles, but there is no backreaction on the neutrinos from the simulation particles.
Semilinear neutrinos: have linear equations of motion for the neutrinos evolved either on a grid (Brandbyge & Hannestad 2009) or by solving the Boltzmann equation linearized with respect to the neutrino overdensity (Ali-Haïmoud & Bird 2013) while the simulation is run. While these equations are linear, they are sourced by the non-linear gravitational potential that arises from the simulation particles so they do not evolve as in linear theory. Simulation particles know about the neutrino grid via their contribution to the gravitational potential.
Particle neutrinos: neutrinos are explicitly included as a separate particle species in the simulation, with different initial conditions compared to CDM and with initial thermal velocities (e.g. Viel, Haehnelt & Springel 2010).
While the final technique seems the most comprehensive there are pitfalls that must be avoided: one must decide on when to inject the neutrino particles in to the simulation, too early and the neutrinos are too hot and make circuits of the simulation volume, too late and non-linear evolution in the neutrino density is missed. More recently hybrid techniques have been developed to address this (e.g. Bird et al. 2018).
It has been shown that simulations using the three different techniques give very similar results for the eventual non-linear matter power spectrum for low neutrino masses (|$m_\nu \lesssim 0.3\, \mathrm{eV}$|). This makes sense, since these neutrinos are the hottest and their evolution closely follows linear theory, even at late times, and they also contribute less to the energy budget of the cosmos due to their low mass (recall that Ων ∝ mν). However, at high masses the results diverge. The mira titan simulations of Lawrence et al. (2017) use the linear neutrinos and the simulations to which the Bird et al. (2012) halofit model was fitted use particle neutrinos. In this paper, we are not in a position to comment on which of these options is better, but we suggest that differences between these simulation techniques are probably responsible for the fact that the Bird et al. (2012) additions seem to degrade the performance of Takahashi et al. (2012) for massive neutrino cosmologies when comparing to mira titan. Note carefully that hmcode-2020 reproduces the results of the mira titan emulator well, even at high neutrino masses. If it turned out that the mira titan neutrino simulation technique was inaccurate at high neutrino masses, then so would be hmcode-2020.
APPENDIX C: EARLY DARK ENERGY
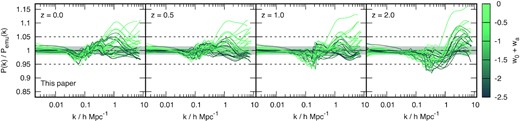
The performance of the new version of hmcode presented in this paper compared against the mira titan node cosmologies, colour coded according to w0 + wa = w(a → 0). The results presented here are the same as in Fig. 2 but with a different colour bar. It is clear that the error in hmcode for |$k\gt 0.5\, h\, \mathrm{Mpc}^{-1}$| is a strong function of the early-time value of the dark energy equation of state. Cosmologies with w0 + wa values close to zero can be considered ‘early dark energy’ models, where the cosmological Ωw(a → 0) can still be considerable.
APPENDIX D: EMULATOR COMPARISON
In Fig. D1, we show a comparison between the non-linear power spectrum predicted by hmcode-2020 and that from emulators at z = 0: cosmic emu (1 per cent accurate; Lawrence et al. 2010), franken emu (5 per cent accurate; Heitmann et al. 2014), mira titan (4 per cent accurate; Lawrence et al. 2017), halofit (1 per cent accurate; Smith & Angulo 2019), euclid (version 2; 1 per cent accurate; Knabenhans et al. 2020), and bacco (3 per cent accurate; Angulo et al. 2020). In the main body of this paper we compared to power from the node cosmologies of franken emu and mira titan, which we took to be essentially perfect, but here we compare to 100 (uniform) random cosmologies drawn from the quoted cosmology range of each emulator (see Table D1). Note that this means that 100 cosmologies are different in each panel, because each emulator covers a different range of cosmological-parameter space. We therefore need to consider the accuracy of each emulator together with our quoted 2.5 per cent for hmcode-2020. We include the new version of halofit in this ‘emulator’ comparison because, within its parameter space, it calculates the non-linear power by interpolating and/or extrapolating N-body data in a similar way to the other emulators (although they all use different techniques). However, for the halofit comparison we set the running of the spectral index to zero; if we do not we see a large scatter between the predictions, presumably because none of the halo-model ingredients have been calibrated for cosmologies with running spectral indices. This indicates that improving the halo model for cosmologies with running spectral indices may be a fruitful direction for further research.
Performance of hmcode-2020 compared to emulator predictions for 100 (different) random cosmological models drawn from the parameter space of each emulator at z = 0. The black line shows the mean prediction across cosmologies, while the coloured bands show percentiles, with the inner-most band containing the central 20 per cent and then stepping out in 20 per cent steps to reach 100 per cent for the outer-most band. Vertical dashed lines show the maximum k emulated, for power beyond this wavenumber we extend the emulator prediction as a power law (we would not expect this to be accurate). Dashed horizontal lines show the expected error if we assume that the 2.5 per cent hmcode-2020 error and that of the emulator can be added in quadrature.
Cosmological parameter ranges covered by those power-spectrum emulators discussed in this Appendix. The table is split into parameters for: standard matter density (top), neutrinos, power spectrum normalization, power spectrum shape, h, and dark energy (bottom). Note that Ωcold = Ωm − Ων = Ωc + Ωb and is different from Ωc, which is the CDM density parameter. Only mira titan, euclid, and bacco consider massive neutrinos. Only halofit considers the running of the spectral index nrun.cosmic emu and franken emu do not consider time-varying dark energy. All emulators assume a flat universe, so Ωw = 1 − Ωm always. With these considerations, the values of the ‘missing’ cosmological parameters, marked with a -, can always be calculated from the given parameters, while those parameters marked with a * are not considered by an emulator (fixed to 0 in all cases except h for cosmic emu, which is fixed via the well-measured angular extent of the CMB acoustic scale).
| Parameter | cosmic emu | franken emu | mira titan | halofit | euclid | bacco | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | |
| Ωm | – | – | – | 0.21 | 0.4 | 0.24 | 0.4 | – | ||||
| ωm | 0.12 | 0.155 | 0.12 | 0.155 | 0.12 | 0.155 | – | – | – | |||
| Ωb | – | – | – | – | 0.04 | 0.06 | 0.04 | 0.06 | ||||
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.02 | 0.024 | – | – | ||
| Ωc | – | – | – | – | – | – | ||||||
| ωc | – | – | – | 0.1 | 0.13 | – | – | |||||
| Ωcold = Ωm − Ων | – | – | – | – | – | 0.23 | 0.4 | |||||
| ων | * | * | 0 | 0.01 | * | – | – | |||||
| |$m_\nu /\, \mathrm{eV}$| | * | * | – | * | 0 | 0.15 | 0 | 0.4 | ||||
| σ8 | 0.61 | 0.9 | 0.616 | 0.9 | 0.7 | 0.9 | – | – | – | |||
| σ8, cold | – | – | – | – | – | 0.73 | 0.90 | |||||
| As/10−9 | – | – | – | 1.72 | 2.58 | 1.7 | 2.5 | – | ||||
| ns | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.92 | 1 | 0.92 | 1.01 |
| nrun | * | * | * | −0.2 | 0.2 | * | * | |||||
| h | * | 0.55 | 0.85 | 0.55 | 0.85 | – | 0.61 | 0.73 | 0.6 | 0.8 | ||
| w0 | −1.3 | −0.7 | −1.3 | −0.7 | −1.3 | −0.7 | −1.05 | −0.95 | −1.3 | −0.7 | −1.15 | −0.85 |
| wa | * | * | −1.73 | 1.28 | −0.4 | 0.4 | −0.7 | 0.5 | −0.3 | 0.3 | ||
| Parameter | cosmic emu | franken emu | mira titan | halofit | euclid | bacco | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | |
| Ωm | – | – | – | 0.21 | 0.4 | 0.24 | 0.4 | – | ||||
| ωm | 0.12 | 0.155 | 0.12 | 0.155 | 0.12 | 0.155 | – | – | – | |||
| Ωb | – | – | – | – | 0.04 | 0.06 | 0.04 | 0.06 | ||||
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.02 | 0.024 | – | – | ||
| Ωc | – | – | – | – | – | – | ||||||
| ωc | – | – | – | 0.1 | 0.13 | – | – | |||||
| Ωcold = Ωm − Ων | – | – | – | – | – | 0.23 | 0.4 | |||||
| ων | * | * | 0 | 0.01 | * | – | – | |||||
| |$m_\nu /\, \mathrm{eV}$| | * | * | – | * | 0 | 0.15 | 0 | 0.4 | ||||
| σ8 | 0.61 | 0.9 | 0.616 | 0.9 | 0.7 | 0.9 | – | – | – | |||
| σ8, cold | – | – | – | – | – | 0.73 | 0.90 | |||||
| As/10−9 | – | – | – | 1.72 | 2.58 | 1.7 | 2.5 | – | ||||
| ns | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.92 | 1 | 0.92 | 1.01 |
| nrun | * | * | * | −0.2 | 0.2 | * | * | |||||
| h | * | 0.55 | 0.85 | 0.55 | 0.85 | – | 0.61 | 0.73 | 0.6 | 0.8 | ||
| w0 | −1.3 | −0.7 | −1.3 | −0.7 | −1.3 | −0.7 | −1.05 | −0.95 | −1.3 | −0.7 | −1.15 | −0.85 |
| wa | * | * | −1.73 | 1.28 | −0.4 | 0.4 | −0.7 | 0.5 | −0.3 | 0.3 | ||
Cosmological parameter ranges covered by those power-spectrum emulators discussed in this Appendix. The table is split into parameters for: standard matter density (top), neutrinos, power spectrum normalization, power spectrum shape, h, and dark energy (bottom). Note that Ωcold = Ωm − Ων = Ωc + Ωb and is different from Ωc, which is the CDM density parameter. Only mira titan, euclid, and bacco consider massive neutrinos. Only halofit considers the running of the spectral index nrun.cosmic emu and franken emu do not consider time-varying dark energy. All emulators assume a flat universe, so Ωw = 1 − Ωm always. With these considerations, the values of the ‘missing’ cosmological parameters, marked with a -, can always be calculated from the given parameters, while those parameters marked with a * are not considered by an emulator (fixed to 0 in all cases except h for cosmic emu, which is fixed via the well-measured angular extent of the CMB acoustic scale).
| Parameter | cosmic emu | franken emu | mira titan | halofit | euclid | bacco | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | |
| Ωm | – | – | – | 0.21 | 0.4 | 0.24 | 0.4 | – | ||||
| ωm | 0.12 | 0.155 | 0.12 | 0.155 | 0.12 | 0.155 | – | – | – | |||
| Ωb | – | – | – | – | 0.04 | 0.06 | 0.04 | 0.06 | ||||
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.02 | 0.024 | – | – | ||
| Ωc | – | – | – | – | – | – | ||||||
| ωc | – | – | – | 0.1 | 0.13 | – | – | |||||
| Ωcold = Ωm − Ων | – | – | – | – | – | 0.23 | 0.4 | |||||
| ων | * | * | 0 | 0.01 | * | – | – | |||||
| |$m_\nu /\, \mathrm{eV}$| | * | * | – | * | 0 | 0.15 | 0 | 0.4 | ||||
| σ8 | 0.61 | 0.9 | 0.616 | 0.9 | 0.7 | 0.9 | – | – | – | |||
| σ8, cold | – | – | – | – | – | 0.73 | 0.90 | |||||
| As/10−9 | – | – | – | 1.72 | 2.58 | 1.7 | 2.5 | – | ||||
| ns | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.92 | 1 | 0.92 | 1.01 |
| nrun | * | * | * | −0.2 | 0.2 | * | * | |||||
| h | * | 0.55 | 0.85 | 0.55 | 0.85 | – | 0.61 | 0.73 | 0.6 | 0.8 | ||
| w0 | −1.3 | −0.7 | −1.3 | −0.7 | −1.3 | −0.7 | −1.05 | −0.95 | −1.3 | −0.7 | −1.15 | −0.85 |
| wa | * | * | −1.73 | 1.28 | −0.4 | 0.4 | −0.7 | 0.5 | −0.3 | 0.3 | ||
| Parameter | cosmic emu | franken emu | mira titan | halofit | euclid | bacco | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | |
| Ωm | – | – | – | 0.21 | 0.4 | 0.24 | 0.4 | – | ||||
| ωm | 0.12 | 0.155 | 0.12 | 0.155 | 0.12 | 0.155 | – | – | – | |||
| Ωb | – | – | – | – | 0.04 | 0.06 | 0.04 | 0.06 | ||||
| ωb | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.0215 | 0.0235 | 0.02 | 0.024 | – | – | ||
| Ωc | – | – | – | – | – | – | ||||||
| ωc | – | – | – | 0.1 | 0.13 | – | – | |||||
| Ωcold = Ωm − Ων | – | – | – | – | – | 0.23 | 0.4 | |||||
| ων | * | * | 0 | 0.01 | * | – | – | |||||
| |$m_\nu /\, \mathrm{eV}$| | * | * | – | * | 0 | 0.15 | 0 | 0.4 | ||||
| σ8 | 0.61 | 0.9 | 0.616 | 0.9 | 0.7 | 0.9 | – | – | – | |||
| σ8, cold | – | – | – | – | – | 0.73 | 0.90 | |||||
| As/10−9 | – | – | – | 1.72 | 2.58 | 1.7 | 2.5 | – | ||||
| ns | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.85 | 1.05 | 0.92 | 1 | 0.92 | 1.01 |
| nrun | * | * | * | −0.2 | 0.2 | * | * | |||||
| h | * | 0.55 | 0.85 | 0.55 | 0.85 | – | 0.61 | 0.73 | 0.6 | 0.8 | ||
| w0 | −1.3 | −0.7 | −1.3 | −0.7 | −1.3 | −0.7 | −1.05 | −0.95 | −1.3 | −0.7 | −1.15 | −0.85 |
| wa | * | * | −1.73 | 1.28 | −0.4 | 0.4 | −0.7 | 0.5 | −0.3 | 0.3 | ||
From the Fig. D1 we see good agreement between hmcode-2020 and the emulators in all cases, and the agreement is within the accuracy range of each emulator if we assume that the errors add with that of hmcode-2020 in quadrature. The exception is with the halofit emulator, where we see that hmcode-2020 systematically overpredicts the power by a few per cent for |$k\sim 5\, h\, \mathrm{Mpc}^{-1}$|; this overprediction is not present in the other comparisons. From the comparisons with mira titan, euclid, and bacco we note a systematic feature of hmcode-2020 to slightly underpredict the power for |$k\sim 0.08\, h\, \mathrm{Mpc}^{-1}$| and then slightly overpredict for |$k\sim 0.2\, h\, \mathrm{Mpc}^{-1}$|. We suspect that this may be due to our relatively schematic treatment of these ‘perturbative’ scales, and we note that this systematic bias vanishes at higher z. The larger deviations seen in the mira titan and bacco panels for |$k\sim 1\, h\, \mathrm{Mpc}^{-1}$| are all cosmologies with high neutrino fractions. The larger deviations seen in the mira titan panel for |$k\sim 10\, h\, \mathrm{Mpc}^{-1}$| are all cosmologies with dark energy equations of state that lead to significant early dark energy. We note that compared to the euclid emulator our power is systematically slightly low for |$k\sim 1\, h\, \mathrm{Mpc}^{-1}$|, but it is systematically slightly high around the same scales when compared to mira titan, which indicates that there may be differences between the power produced by the different simulation techniques at this scale.
Note that Fig. D1 should not necessarily be used to compare the performance of the emulators themselves, as each covers a different sub-space of cosmological parameters (see Table D1). Some parameter combinations make predictions more difficult, and hmcode may be systematically biased in some regions of parameter space. For example, the parameter space of mira titan covers high-mass neutrinos and dark energy models with high-z equations of state that are close to zero. The near-perfect agreement at large scales with halofit arises because this model defaults to a perturbative treatment of power at these scales, and this uses exactly the same linear spectrum as the hmcode calculation. The agreement at large scales with euclid and bacco is a result of these emulators emulating a ‘correction function’ to the linear power spectrum, whereas the other techniques emulate the non-linear power directly. For bacco, this correction factor asymptotes to unity at large scales, so the agreement is perfect with hmcode-2020 because each model is then simply linear theory. The ∼0.5 per cent high bias compared to euclid arises from the correction factor not asymptoting perfectly to unity, even at large scales. In Knabenhans et al. (2020) this difference (which also exists between the different versions of the euclid emulator) is attributed to simulation volume.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}