





Abstract
Understanding causal relationships is one of the most important goals of modern science. So far, the causal inference literature has focused almost exclusively on outcomes coming from the Euclidean space . However, it is increasingly common that complex datasets are best summarized as data points in nonlinear spaces. In this paper, we present a novel framework of causal effects for outcomes from the Wasserstein space of cumulative distribution functions, which in contrast to the Euclidean space, is nonlinear. We develop doubly robust estimators and associated asymptotic theory for these causal effects. As an illustration, we use our framework to quantify the causal effect of marriage on physical activity patterns using wearable device data collected through the National Health and Nutrition Examination Survey.
1 Introduction
Causal inference has received increasing attention in contemporary data analysis. So far, researchers in causal inference have engaged almost exclusively in studying causal effects on objects from a linear space, most commonly the Euclidean space On the other hand, in many modern applications, the observed data either naturally emerge or may be summarized as distribution functions. Often in these applications, the interest lies in the causal effect on the distributions themselves, rather than a summary measure such as the mean or the quantiles. Here, we detail an example from the study of physical activities; see the Supplementary Material for additional examples on cellular differentiation and metagenomics.
Physical activities
Behavioural scientists are often interested in evaluating the effects of potential risk factors, such as marriage, on physical activity patterns (e.g., King et al., 1998). The physical activity patterns are often recorded over a certain monitoring period. For example, in the National Health and Nutrition Examination Survey 2005–2006, physical activity intensity, ranging from 0 to 32,767 counts per minute, was recorded consecutively for 7 days by a wearable device for subjects at least 6 years old. The trajectory of activity intensity is not directly comparable across different subjects as different individuals might have different circadian rhythms. Instead, the distribution of activity intensity is invariant to circadian rhythms and hence can be compared between groups of individuals (Chang & McKeague, 2020).
On the surface, since the distribution functions belong to L2, a linear space endowed with a Euclidean distance, one may directly extend the classical potential outcome framework (Neyman, 1923; Rubin, 1974) in causal inference using Euclidean averages. For example, the mean potential distribution functions may be defined as the expectation of the random potential distribution function, and the causal contrast among different interventions may be defined as the Euclidean distance among the mean potential distribution functions. However, there has been a growing recognition among the statistics and data science community that in many applications, the structure of data summarized by distribution functions may be best captured by the use of nonEuclidean distances (e.g., Arjovsky et al., 2017; Bernton et al., 2019; Courty et al., 2016; del Barrio et al., 1999; Ho et al., 2017; Panaretos & Zemel, 2019; Verdinelli and Wasserman, 2019). One of the most common choices of distance is the so-called Wasserstein distance based on the geometry of optimal transport. When equipped with such a distance, the space of probability measures on a real interval is referred to as the Wasserstein space, and the average of distribution functions under the Wasserstein distance is known as the Wasserstein barycentre of these distributions.
Significant advances have been made by the emerging field of statistical optimal transport studying the Wasserstein space. For instance, Agueh and Carlier (2011), Bigot et al. (2012), and Kim and Pass (2017) introduced the notion of Wasserstein barycentre of a random distribution and studied its existence, uniqueness, and characteristics. The concept of Wasserstein barycentre, defined in (6), is a generalization of the mean of random variables/vectors to random distributions. Moreover, Bigot et al. (2017) generalized the technique of principal component analysis to data sampled from a Wasserstein space, while Petersen and Müller (2016) and Chen et al. (2021) focused on regression models for such data. Recently, Zhang et al. (2020) and Zhu and Müller (2021) investigated distribution-valued time series and generalized the concept of autoregressive models to Wasserstein spaces, while Zhou et al. (2021) developed a framework for canonical correlation analysis of random distributions. For more related works on statistical data analysis in a Wasserstein space, we refer readers to the survey paper by Bigot (2020) and references therein.
The Wasserstein barycentre and distance have several features that make them particularly appealing for defining causal effects on distribution functions. First, the Wasserstein barycentre reduces to the usual Euclidean mean in the degenerate case where the distribution functions take point mass at real values. Specifically, if δt denotes the Dirac delta function with point mass at t, then the Wasserstein barycentre of is with In contrast, the Euclidean average, defined as the average of the cumulative distribution functions of , corresponds to a uniform distribution on ti, …, tn. Consequently, in the degenerate case where the random distribution function takes point mass at a random real value, their expectation does not correspond to the point mass function at the expectation of the random real value.
Second, compared with the Euclidean distance and other distances such as the Hellinger distance, the Wasserstein barycentre performs exceptionally well in capturing the structure of random distributions (e.g., Cuturi & Doucet, 2014). In Figure 1, we provide a graphical illustration. The distributions in Figure 1a are unimodal distributions; typical distributions of this kind are adult age-at-death distributions (Chen et al., 2021). One can see from Figure 1b and c that the Wasserstein barycentre preserves unimodality while the Euclidean average does not.
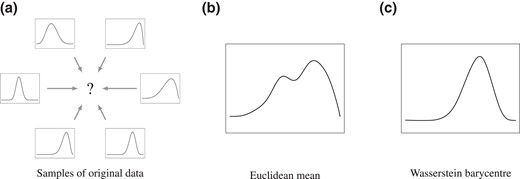
Comparison of Wasserstein barycentre vs. Euclidean average for capturing structural information in random distributions. The barycentre and Euclidean average are based on six unimodal distributions. The Euclidean average has two modes while the Wasserstein barycentre preserves unimodality.
Third, the Wasserstein distance has an intuitive interpretation of the amount of ‘work’ required to transform one distribution to another (Sommerfeld & Munk, 2018). Moreover, it comes with a map that shows how to move from one random object to another, and allows one to create a path of distributions that interpolates between Wasserstein barycentres, while preserving the structural information in the random objects. This is particularly useful when comparing two Wasserstein barycentres each representing potential distribution functions under a particular intervention, as it not only contains information on how much they differ, but also on how one of these barycentres can be moved to the other; see Interpretation 2 in Section 3 for more details. In fact, as the path implied by the Wasserstein distance to move distributions involves the ‘least effort’, it is the natural path taken by biological systems to move from one state to another (e.g., Schiebinger et al., 2019).
Lastly, in the Wasserstein space of distributions on an interval of the real line, which is the focus of this paper, the optimal way to transfer one distribution to another is to move between their corresponding quantiles. In this case, the causal effect map defined using optimal transport (see Definition 1) can be directly interpreted as the difference in quantiles of the Wasserstein barycentres of different potential outcome distributions; see Interpretation 1 in Section 3 for more details.
For these advantages and motivated by the applications in Example 1 and Examples S1, S2 in the Supplementary Material, we propose to define causal effects for distribution functions using the optimal transport between the Wasserstein barycentres of different potential outcome distributions. Our definitions of causal effect, called the average causal effect map, can be identified under straightforward generalizations of standard assumptions in the causal inference literature. We develop doubly robust and cross-fitting procedures for estimating the average causal effect map, and establish asymptotic properties for these estimators. In contrast to the setting for the classical doubly robust estimators (Chernozhukov et al., 2018; Robins et al., 1994), typically even for a fixed unit, the outcome may not be fully observed and needs to be estimated from data. For instance, in our real data application, the data consists of empirical distribution functions of physical activity patterns for individuals rather than their underlying distribution functions. To establish the asymptotic properties with distribution-valued outcomes, our analyses rely on several geometric properties of the Wasserstein space, most notably the isometry between the Wasserstein space and the space of quantile functions. To the best of our knowledge, this is the first systematic study on causal inference for distribution-valued outcomes.
The rest of the paper is structured as follows. In Section 2, we present background on causal inference and Wasserstein space. In Section 3, we introduce the notion of average causal effect map for outcomes from a Wasserstein space, and develop identifiability results and doubly robust estimators for the average causal effect map. We then study their asymptotic properties in Section 4. We provide numerical studies in Section 5 and a real data illustration in Section 6. We end with a brief discussion in Section 7.
2 Background
2.1 The potential outcomes framework
We shall define causal effects using the potential outcomes framework. Suppose that the treatment is A ∈ {0, 1}, with 0 and 1 being the labels for control and active treatments, respectively. We use X to denote baseline covariates taking values in . For each level of treatment a, we assume there exists a potential outcome Y(a), representing the outcome had the subject, possibly contrary to the fact, been given treatment a. Here, Y(a) is a random object that resides in a possibly nonlinear space. We make the stable unit treatment value assumption (SUTVA, Rubin, 1980) so that the potential outcomes for any unit do not vary with the treatments assigned to other units, and, for each unit, there are no different versions of treatments that lead to different potential outcomes. Under this assumption, the observed outcome Y = Y(A), where Y(A) = Y(1) if A = 1 and Y(A) = Y(0) if A = 0. We assume we observe n independent samples from an infinite super-population of (A, X, Y), denoted by (Ai, Xi, Yi), i = 1, …, n.
When Y(a) resides in , the causal effect is commonly defined as the contrast between a summary measure of the potential outcome distributions. For example, the average causal effect is defined as the difference between the means of the potential outcome distributions:
the quantile treatment effect is defined as the difference between the quantiles of the potential outcome distributions
where FZ(z) = P(Z ≤ z) is the cumulative distribution function (CDF) of the random variable Z, and
is the corresponding quantile function. Causal effects defined in this manner can be interpreted on the population level, as they concern contrasts between potential outcomes in two hypothetical populations. These population-level interpretations concern the effect of introducing a particular treatment to a population and are most relevant to policy makers.
There is, however, a subtle but important distinction between the individual-level interpretations of ACE and QTE(α). Let CEi = Yi(1) − Yi(0) be the individual causal effect for unit i. Individual causal effects provide useful information for individualized treatment decision-making and are most relevant to individual subjects. Since , it can be interpreted as averages of individual causal effects; here the expectation is taken over units in the super-population. The individual-level interpretation of ACE extends to the conditional average treatment effect, where L is a subset of observed baseline covariates. In contrast, generally, QTE(α) cannot be interpreted as the α−quantile of individual causal effects. This distinction connects to desideratum (d) in Section 3.1.
2.2 Causal effect identification and estimation
The following assumptions are standard in the causal inference literature (e.g., Hernán & Robins, 2020; Rosenbaum & Rubin, 1983).
Ignorability
A⫫Y(a) | X, a = 0, 1.
Positivity
The propensity score π(X) := P(A = 1 | X) is bounded away from 0: There exists , such that
Under Assumptions 1 and 2, when Y(a) resides in , the mean potential outcome is given by
Similarly, the potential outcome distributions FY(a)(y) can be identified by replacing Y in the last term of equation (4) with I(Y ≤ y). Based on (4), the average causal effect can be identified as , and the quantile treatment effect can be identified as .
Given the identification formula (4), one may use plug-in estimators to estimate the mean potential outcomes. Let and f(A | X) = Aπ(X) + (1 − A)(1 − π(X)). Also denote as estimates of their corresponding population quantities obtained using standard parametric or nonparametric/machine-learning techniques. Some leading estimators of μa include the outcome regression estimator , the inverse probability weighting (IPW) estimator and the so-called doubly robust estimator ; here refers to the empirical average operator: .
2.3 Wasserstein space
Let be an interval of , V1 and V2 be random variables taking values in with finite second moments, and λ1, λ2 be their (cumulative) distribution functions, respectively. To define the Wasserstein distance between λ1 and λ2, we let Λ(λ1, λ2) denote all joint distributions λ12 of (V1, V2) that have marginal distributions λ1 and λ2. The (2-)Wasserstein distance between λ1 and λ2 is defined as
The Wasserstein space of order 2 on is then defined as the space of distribution functions on with finite second moments
endowed with the 2-Wasserstein distance.
The Wasserstein distance can be motivated by the problem of optimal transport. Consider a pile of mass on space with a distribution λ1. We wish to transport the mass in such a way that the new mass distribution is λ2. Assume also that the cost of transporting a unit mass from point s to point t is (s − t)2. A transport plan to move λ1 to λ2 can be described by the function λ12 such that dλ12(s, t) denotes the amount of mass to move from s to t. Since the amount of mass to be moved out of s must match dλ1(s), and the amount of mass to be moved into t must match dλ2(t), we have . In other words, λ12 ∈ Λ(λ1, λ2). The Wasserstein distance then corresponds to the minimum effort that is required in order to transport the mass of λ1 to produce the mass distribution of λ2. The minimizer to the problem in (5) always exists (Santambrogio, 2015, Theorems 1.7 and 1.22) and is known as the optimal transport plan.
If λ1 is continuous, then there exists a unique function such that (Santambrogio, 2015, Theorems 1.7 & 1.22). Intuitively, in this case, the optimal transport plan moves all the mass at s to T(s). The function T(·) is known as the optimal transport map. Let λ−1 be the quantile function of the distribution λ. It can be shown that (Ambrosio et al., 2005, Theorem 6.0.2) the optimal transport map , so that it moves mass between corresponding quantiles of λ1 and λ2. The following proposition, summarizing the above discussion, shows that given a fixed continuous distribution λ1, the distribution λ2 can be defined via the optimal transport map from λ1 to λ2. The proof of Proposition 1 is straightforward and hence omitted.
Given a continuous distribution function λ1, there is a one-to-one correspondence between a distribution function λ2 and the optimal transport map from λ1 to λ2.
Based on the notion of Wasserstein distance W2, we can define the mean of a set of distributions λ1, …, λn in the Wasserstein space by the so-called Wasserstein barycentre , defined as the distribution λ that minimizes . In Lemma S2 in the Supplementary Material, it is shown that so that the quantile function corresponding to the Wasserstein barycentre equals the (Euclidean) averages of the individual quantile functions. The mean of distributions can also be defined in various other ways, such as the mean under the Euclidean distance . Compared with alternative centre measures, the Wasserstein barycentre typically provides a better summary that captures the structure of the random objects represented by distribution functions, such as shapes, curves, and images; see for example, Figure 1 and Cuturi and Doucet (2014, Figure 1) for illustrations.
3 Causal inference on distribution functions
3.1 Definition of causal effects
We now introduce a definition of average causal effect for outcomes taking value in the Wasserstein space . In parallel to the definition of causal effects introduced in Section 2.1, we first define the mean potential outcomes. As both Yi(1) and Yi(0) take value in the Wasserstein space, we define their means using their Wasserstein barycentres:
Intuitively, μa is a ‘typical’ potential distribution under treatment A = a. Let δt denote the Dirac delta function with point mass at t. Ideally, a causal effect definition in the Wasserstein space should satisfy the following desiderata:
When Y(0), the causal effect equals zero;
In the degenerate case where , corresponding to the classical scenario where the outcome resides in , the causal effect corresponds to the usual average causal effect ACE defined in (1);
The average causal effect is a contrast between the averages of potential outcomes in two hypothetical populations, Y(1) and Y(0), and thus can be interpreted on the population level;
The average causal effect equals the average of individual causal effects, thus maintaining the individual-level interpretation of the ACE for real-valued outcomes discussed at the end of Section 2.1.
Desideratum (a) is natural, given the causal effect is defined as a comparison between two (hypothetical) populations. Desideratum (b) ensures that the definition is a generalization of the standard definition of the ACE (1) in the Euclidean space. Desiderata (c) and (d) are in place to ensure that the definition can be interpreted at both population and individual levels.
From an optimal transport point of view, it may be tempting to define the causal effect as the Wasserstein distance between μ1 and μ0; see Section S2 in the Supplementary Material for more discussions on causal effect defined in this way. Although causal effect defined in this way satisfies desiderata (a)–(c), in general, it fails to satisfy desideratum (d). Instead, we introduce a novel definition of average causal effect, called the causal effect map. In Section 3.2, we shall see that the causal effect map satisfies all the desiderata, and contains richer information than the single summary measure W2(μ1, μ0); in particular, one can compute W2(μ1, μ0) based on the causal effect map.
Let λ be a continuous distribution function. The individual causal effect map of A on Y is defined as
where we say λ is a reference distribution; for a = 0, 1, Yi(a)−1 is the quantile function of the distribution Yi(a) as defined in (3). The (average) causal effect map of A on Y is defined as
A crucial component in Definition 1 is the choice of reference distribution λ, that is allowed to have a domain different from that of Y. In general, a different reference distribution leads to a different interpretation of the causal effect maps. Hence, one should choose the reference distribution based on the desired interpretation. We now illustrate some common choices of λ with their interpretations.
Difference in quantiles
If the reference distribution λ is the uniform distribution on [0, 1] so that λ(t) = t, t ∈ [0, 1], then the causal effect map Δ(·) can be interpreted as difference in quantiles.
The interpretation in terms of difference in quantiles is not to be confused with the quantile treatment effect defined in (2). In our setting, the potential outcomes are random distribution functions, and is the α−quantile of the mean potential outcome under treatment. In contrast, in the quantile treatment effect setting, the realizations of potential outcomes are real numbers, and is the α−quantile of the distribution of potential outcomes under treatment.
To discuss the second interpretation, analogous to the concepts of optimal transport map, we define the individual causal transport map as Ti(·) = Yi(1)−1Yi(0)(·) and the (population) causal transport map as The causal transport maps are of natural interest in some applications. For example, biological experiments (Schiebinger et al., 2019) have found that cellular differentiation follows the shortest path under the Wasserstein geometry. So in Online Supplementary Material, Example S1, the causal transport map T describes how a group of cells would differentiate after being exposed to an intervention, measured using gene expression levels.
When the potential outcomes Y(1), Y(0), and hence the barycentres μ1 and μ0 (e.g., Bigot et al., 2017, Proposition 4.1), are continuous distributions, with certain choices of the reference distribution, the causal effect maps can be interpreted as the (inverse of) causal transport maps up to an identity function.
Causal transport maps
Consider the case where the potential outcomes are random continuous distribution functions. If the reference distribution is chosen to be the barycentres μ0 or μ1, then
If the reference distribution is chosen to be Yi, then
3.2 Properties of causal effect maps
We now describe several desirable properties of the causal effect maps. First, it is easy to verify that for any choice of reference distribution λ, the causal effect map satisfies desiderata (a)–(c). The following theorem, which is crucial for identification of the average causal effect map as we shall see later in Section 3.3, shows that the causal effect map also satisfies desideratum (d). This theorem can be proved using Lemma S2 in the Supplementary Material.
The average causal effect map corresponds to the average of individual causal effect maps with respect to the same reference distribution λ:
In contrast to Theorem 1, the population causal transport map is generally different from the average of individual causal transport maps: . To see this, note that as shown in Interpretation 2, while Although as we show in Theorem 1, under the same reference distribution λ, in general, Instead, as we illustrate later in Section 6, to estimate the (expectation of) causal transport map for a particular individual i, one first estimates the average causal effect map with reference distribution Yi, and then applies (7).
In some scenarios, practitioners may also want a scalar quantity that measures the magnitude of the causal effect. The Wasserstein distance is a natural choice from an optimal transport point of view. The following proposition shows that one may compute the Wasserstein distance W2(μ1, μ0) from the causal effect map . In particular, for any U that follows the reference distribution λ, W2(μ1, μ0) equals the ℓ2-norm of . It can be proved using Lemma S2 in the Supplementary Material.
The Wasserstein distance W2(μ1, μ0) is determined by the causal effect map via
3.3 Identification and estimation
Under the ignorability and positivity assumptions, similar to (4), we can identify the causal effect map
To see the above, note that
In general, when Y(a) is a random distribution function,
So μa, a = 0, 1 may not be directly identified using the identification formula (4) for real-valued Y. Instead, following Theorem 2, the mean potential outcomes μa, a = 0, 1 may be identified as the inverse of
When the outcome is a distribution function, Assumption 1 is stronger than the same assumption applied to a summary measure of the outcome.
Similar to Section 2.2, we let so that We consider a regression model , where β may be finite or infinite dimensional. In practice, the outcome Yi, which is a distribution function itself, might not be fully observed. Instead, we typically only observe ki samples from Yi. We hence propose to construct a doubly robust estimator for in the following steps: (i) Use standard nonparametric methods such as the nonparametric maximum-likelihood estimation, or local polynomial smoothing to obtain the estimates ; (ii) If λ is unknown, obtain an estimate of λ, denoted as ; for notational convenience, we let if λ is a fixed or fully observed reference distribution; (iii) Regress on X and A to obtain an estimate of for each individual in the sample, denoted as this may be done using a standard functional regression model (see e.g., Ramsay & Silverman, 2005, Chapter 13); (iv) Construct an estimate for f(A | X), denoted as ; (v) Construct a doubly robust estimator via
This estimator, motivated by the doubly robust estimator discussed in Section 2.2, combines an outcome regression estimator with an IPW estimator. We establish its asymptotic properties in Section 4.
In the doubly robust estimating procedure described above, the data are used twice: once for estimating , and , and once for estimating the causal effect . Theoretical analysis of such estimators is rather challenging and requires some complex conditions that may fail in settings involving machine learning methods; see Assumption 7 and Remark 5. To overcome this difficulty, following Chernozhukov et al. (2018), we propose the following cross-fitting estimators. The entire data are randomly partitioned into K parts of roughly equal sizes, denoted by For k = 1, …, K, we use to obtain estimates , , and (if λ is chosen to be an unknown distribution), and use to estimate the causal effect by , where
where nk is the sample size of the kth partition. Finally, we combine the effects from different partitions via
where is estimated using the entire dataset. In the above, if each reference distribution is fixed to a common distribution , then (9) is reduced to . Otherwise, the objects reside in distinct spaces for k = 1, …, K, where is the domain of λ. In this case, to combine , in (9) we apply the optimal transport between the measures and to move it from the space into the space .
To reduce the sensitivity of the cross-fitting estimator to partitioning, as suggested by Chernozhukov et al. (2018), one may repeat the estimator for R times over independent partitioning. This results in estimates for r = 1, …, R. We then estimate by
4 Asymptotic properties
We study the asymptotic properties of the proposed estimators, including and , in this section. Let , that potentially coincides with , be the domain of the reference distribution λ. For simplicity, we assume and to be a bounded interval of . This condition may be replaced by some moment conditions on Yi and other relevant quantities; see Remarks S1 and S2 in the Supplementary Material for details.
In the following, we shall first introduce assumptions on the variability from estimating Yi, i = 1, …, n and λ.
The estimates are independent, and there are two sequences of constants αn = o(1) and νn = o(1) such that
The conditional expectation in Assumption 3 is a real-valued measurable function defined on , the precise definition of which is given in Section S3 of the Supplementary Material. Assumption 3 requires that , converge to their population counterparts at certain rates. Suppose that the number of observations for unit i, for some constant ζ > 0. If is obtained using the corresponding empirical distribution function, then under some additional moment assumptions, condition (11) holds with . This can be shown via a combination of Fournier and Guillin (2015, Theorem 1) and Santambrogio (2015, Proposition 2.17). Assumption 3 also holds with many other standard nonparametric estimators for Yi. For example, under some regularity conditions on the distribution of Y, the estimator by Petersen and Müller (2016) satisfies condition (11) with a faster rate: and .
The following Assumption 4 imposes a condition on the rate of convergence for . It is satisfied, for example, when λ is a fixed and known distribution so that . Under Assumption 3, it holds for λ = Yi. It also holds when λ is the Fréchet mean of Yi and is the sample Fréchet mean; see Lemma S7 in the Supplementary Material.
.
Let be an estimate of by using the outcome Yi, i = 1, …, n and λ. To study the asymptotic properties of the causal effect map estimator , we introduce Assumption 5 that is standard in causal effect estimation (e.g., Hernán & Robins, 2020). Part (a) of Assumption 5 assumes positivity of the estimated propensity scores, while part (b) assumes that and converge to their limits uniformly.
The estimated propensity scores are bounded away from zero: for some , .
The outcome regression and propensity score estimates converge: and for some functions and π*.
The following Assumption 6 assumes that the outcome regression estimates obtained using and are not too far away from the quantities . It holds for estimators that are Lipschitz continuous functions of a weighted average of . Examples include local polynomial estimators and parametric estimators satisfying certain regularity conditions. Note that the optimal transport in the assumption is needed to transport , which resides in the space , into the space where resides.
for a = 0, 1.
To state the last condition, we first define the concept of Donsker class. Consider a fixed a ∈ {0, 1}. For a real number , a function and a function , we view the element as a real-valued function defined on (A, X, Y) by
and for a family of functions in the form of , we view as a real-valued random process indexed by functions in . Let denote the collection of real-valued functions H defined on and satisfying . We say is a Donsker class if converges to a tight Gaussian measure on .
Let be a class of functions containing . For , define and . Conditional on , η defines a pseudo-distance function on . Let be a ball in with radius r, and Na(δ, r, η) denote the smallest number of δ-balls in the pseudo-metric space that are required to cover Ba(r; ma). Without loss of generality, we assume Na(δ, r, η) is continuous in δ and r. Otherwise, we just redefine it with its continuous upper bound.
The following Assumption 7 imposes some technical conditions on the estimators and . Part (a) assumes that each data point has an asymptotically equal contribution to the estimators, i.e., there is no outlier in the sense that as the sample size grows, the influence of a single data point on the estimates and is negligible. Part (b) restricts to be a Donsker class, and part (c) limits the complexity of via a bound on the metric entropy, which enables us to employ empirical process theory to provide an upper bound on the convergence rate of . These conditions are satisfied, for example, by a logistic model for π and a simple linear regression model for .
Stability of the estimators: For a constant C4 > 0, and , where and are the estimates of π and without using the ith subject, respectively.
For a = 0, 1, the class is a Donsker class containing for all t, and with probability tending to one, for all t.
For a = 0, 1, for some fixed K > 0, , , and log Na(δ, r, η) ≤ Krδ−1 for all r, δ > 0 almost surely.
Assumption 7 may fail in settings invoking machine learning methods, in which case the dimension of covariates X is modelled as an increasing function of the sample size (Chernozhukov et al., 2018). Notably Theorem 4 for the cross-fitting estimator does not require this assumption and thus can accommodate machine learning methods for modelling π and .
Let , the integrated squared error of for estimating , where FX denotes the probability measure induced by X. Similarly, the integrated squared error of for estimating π is denoted by . Define and . Let be endowed with the inner product and the induced norm . Finally, let
The following Theorem 3 shows that the estimator enjoys the double robustness property whether is a fixed and known distribution or is estimated from data, so that the convergence rate is n−1/2 when either of and is of the order n−1/2 and the other one is bounded. Moreover, one may use flexible nonparametric methods for estimating and π, provided that the nonparametric convergence rates satisfy . Theorem 3 also shows that is an asymptotically linear estimator with influence function .
Suppose that both and are continuous distribution functions. If Assumptions 1–7 hold with αn = o(n−1/2) and νn = o(n−1/2), then
;
if , then , and consequently converges weakly to a centred Gaussian process in the space with the same asymptotic distribution as .
The covariance function of the limit distribution of can be estimated from data, as follows. Let and . Then G and its limit distribution share the same covariance function of V. Letting , we can use the sample covariance as an estimate of the covariance function of V, where and .
The above asymptotic result enables inference on . Take the case that λ is fixed and known so that , for example. An approximate simultaneous confidence band (SCB) in the form of with a constant qα/2 for all , i.e., for a significance level α, can be derived for , by estimating qα/2 via a resampling strategy. Specifically, we draw B realizations G1, …, GB, for example, B = 1,000, from the centred Gaussian process with the covariance , and for each realization Gj we compute . Then qα/2 is estimated by the 1 − α/2 empirical quantile of g1, …, gB, and the approximate SCB is given by . With the derived SCB, one can also test the null hypothesis , for example, by rejecting the null at the significance level α if for some . Note that the same procedure applies to the estimator and the cross-fitting estimators in light of the theorems in the sequel.
Next, we turn to the cross-fitting estimator (9) and show that it enjoys double robustness and asymptotic normality properties without the technical Assumption 7 (e.g., Chernozhukov et al., 2018). For this, we require that the sizes of the partitions are of the same order, quantified by Assumption 9, and we tailor Assumption 6 to the cross-fitting estimator by Assumption 8. Let , the counterpart of , be estimated by using the outcomes Yi (instead of ) and the reference distribution λ (instead of ).
for a = 0, 1 and k = 1, …, K.
There exist constants c1 and c2 such that 0 < c1 ≤ nk/n ≤ c2 < 1 for all n and k = 1, …, K.
Suppose that both and λ are continuous distribution functions. If Assumptions 1–3 and 8–9 hold with αn = o(n−1/2) and νn = o(n−1/2), and additionally, Assumptions 4–5 hold for , , and for k = 1, …, K, then for the estimator defined in (9), we have
;
if , then , and consequently converges weakly to a centred Gaussian process in the space with the same asymptotic distribution as .
The above results show that the cross-fitting estimator also enjoys double robustness. A SCB for can be constructed using the method described in Remark 7. For the estimator in (10), as in Chernozhukov et al. (2018), the covariance function C(·, ·) of the process may be estimated as follows. For r = 1, 2, …, R, let , where is given at the end of Section 3.3, and is the estimated covariance for as per Remark 6. Let be the index of whose operator norm is a median among . Then we use as the estimate of the covariance function of .
5 Simulation studies
Our simulation data consist of n independent samples from the joint distribution of (X, A, Y). The confounder X follows a uniform distribution on [−1, 1]. Conditional on X, the treatment A follows a Bernoulli distribution with mean , where . The outcome Y, which is a random distribution function, is generated through the corresponding quantile function , where is independently generated from a uniform distribution on [−0.5, 0.5]. Note that for any realization of X and A, Y−1(0) = 0, Y−1(1) = 1, and Y−1(α) is a continuous and strictly increasing function of α, so that Y−1 is a quantile function for a continuous random variable taking values in It follows that We are interested in estimating the causal effect at the reference distribution μ0, whose true value is
The sample sizes are n = 50, 200, 1,000. For each subject i = 1, …, n, we assume that we have access to 1,001 independent and identically distributed observations sampled from the distribution function Yi(t), t ∈ [0, 1]. We estimated the outcomes Yi(t) by the empirical cumulative distribution function based on these observations.
We considered two specifications for the outcome regression model: a linear regression model with predictor X in mA(X) (correct) and one with predictor X2 (incorrect), and two specifications for the propensity score model: a logistic regression model with predictor X (correct) and one with predictor X2 (incorrect). The estimation error is quantified using two measures: (1) bias of difference in medians, i.e., ; (2) root mean integrated squared error under the reference distribution μ0, i.e., .
To illustrate double robustness of the estimators and , we compare them with the IPW and outcome regression (OR) estimators, defined by and . The cross-fitting estimator is based on the median of cross-fitting estimators from 100 random splits, where for each random split, we consider the fivefold cross-fitting.
Table 1 summarizes the simulation results based on 1,000 Monte Carlo replicates. The bias of difference in medians of the doubly robust estimator becomes closer to zero as the sample size increases when either the outcome regression or propensity score model is correct, thus confirming ‘double robustness’. In comparison, neither the OR nor IPW estimator has the double robustness property: When the corresponding model is misspecified, their bias of difference in medians can be large even with a sample size of 1,000. Similar results hold for root mean integrated squared error. We further note that when the outcome resides in a Euclidean space, it is well known that when both models are correct, the standard error of the OR estimator is no larger than that of the DR estimator, which is in turn no larger than that of the IPW estimator. One can see a similar phenomenon from Table 1, where the outcome is a random distribution function residing in . Although the cross-fitting estimator is more appealing theoretically, for the setting we consider here, has better finite sample performance, especially when the sample size is small.
Bias of difference in medians ×100 (standard error ×100) and root mean integrated squared error ×100 (standard error ×100) of four proposed estimators: the outcome regression estimator , the inverse probability weighting estimator , the doubly robust estimator , and the cross-fitting estimator
| Estimator | Model | Sample size | |||
|---|---|---|---|---|---|
| PS | OR | n = 50 | n = 200 | n = 1,000 | |
| Bias of difference in medians ×100 | |||||
| – | ✓ | 0.010(0.037) | −0.036(0.018) | 0.008(0.008) | |
| – | × | 3.898(0.075) | 3.787(0.037) | 3.819(0.017) | |
| ✓ | – | 0.433(0.157) | 0.008(0.045) | 0.021(0.018) | |
| × | – | 3.975(0.084) | 3.706(0.036) | 3.738(0.016) | |
| ✓ | ✓ | 0.005(0.04) | −0.033(0.019) | 0.013(0.008) | |
| ✓ | × | 0.194(0.057) | −0.001(0.022) | 0.020(0.010) | |
| × | ✓ | 0.015(0.038) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 3.881(0.074) | 3.704(0.036) | 3.737(0.016) | |
| ✓ | ✓ | −0.066(0.091) | −0.032(0.019) | 0.013(0.008) | |
| ✓ | × | −2.151(0.141) | −0.383(0.025) | −0.051(0.010) | |
| × | ✓ | 0.014(0.047) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 4.193(0.108) | 3.726(0.036) | 3.741(0.016) | |
| Root mean integrated squared error ×100 | |||||
| – | ✓ | 0.695(0.016) | 0.339(0.008) | 0.150(0.003) | |
| – | × | 2.941(0.05) | 2.773(0.027) | 2.796(0.012) | |
| ✓ | – | 2.912(0.108) | 0.981(0.029) | 0.425(0.009) | |
| × | – | 3.176(0.057) | 2.715(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.740(0.017) | 0.348(0.008) | 0.156(0.004) | |
| ✓ | × | 0.991(0.028) | 0.409(0.010) | 0.183(0.004) | |
| × | ✓ | 0.709(0.016) | 0.342(0.008) | 0.150(0.003) | |
| × | × | 2.942(0.048) | 2.712(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.981(0.054) | 0.352(0.008) | 0.156(0.004) | |
| ✓ | × | 2.163(0.107) | 0.495(0.013) | 0.188(0.004) | |
| × | ✓ | 0.834(0.047) | 0.343(0.008) | 0.150(0.003) | |
| × | × | 3.289(0.070) | 2.728(0.026) | 2.738(0.012) | |
| Estimator | Model | Sample size | |||
|---|---|---|---|---|---|
| PS | OR | n = 50 | n = 200 | n = 1,000 | |
| Bias of difference in medians ×100 | |||||
| – | ✓ | 0.010(0.037) | −0.036(0.018) | 0.008(0.008) | |
| – | × | 3.898(0.075) | 3.787(0.037) | 3.819(0.017) | |
| ✓ | – | 0.433(0.157) | 0.008(0.045) | 0.021(0.018) | |
| × | – | 3.975(0.084) | 3.706(0.036) | 3.738(0.016) | |
| ✓ | ✓ | 0.005(0.04) | −0.033(0.019) | 0.013(0.008) | |
| ✓ | × | 0.194(0.057) | −0.001(0.022) | 0.020(0.010) | |
| × | ✓ | 0.015(0.038) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 3.881(0.074) | 3.704(0.036) | 3.737(0.016) | |
| ✓ | ✓ | −0.066(0.091) | −0.032(0.019) | 0.013(0.008) | |
| ✓ | × | −2.151(0.141) | −0.383(0.025) | −0.051(0.010) | |
| × | ✓ | 0.014(0.047) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 4.193(0.108) | 3.726(0.036) | 3.741(0.016) | |
| Root mean integrated squared error ×100 | |||||
| – | ✓ | 0.695(0.016) | 0.339(0.008) | 0.150(0.003) | |
| – | × | 2.941(0.05) | 2.773(0.027) | 2.796(0.012) | |
| ✓ | – | 2.912(0.108) | 0.981(0.029) | 0.425(0.009) | |
| × | – | 3.176(0.057) | 2.715(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.740(0.017) | 0.348(0.008) | 0.156(0.004) | |
| ✓ | × | 0.991(0.028) | 0.409(0.010) | 0.183(0.004) | |
| × | ✓ | 0.709(0.016) | 0.342(0.008) | 0.150(0.003) | |
| × | × | 2.942(0.048) | 2.712(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.981(0.054) | 0.352(0.008) | 0.156(0.004) | |
| ✓ | × | 2.163(0.107) | 0.495(0.013) | 0.188(0.004) | |
| × | ✓ | 0.834(0.047) | 0.343(0.008) | 0.150(0.003) | |
| × | × | 3.289(0.070) | 2.728(0.026) | 2.738(0.012) | |
Bias of difference in medians ×100 (standard error ×100) and root mean integrated squared error ×100 (standard error ×100) of four proposed estimators: the outcome regression estimator , the inverse probability weighting estimator , the doubly robust estimator , and the cross-fitting estimator
| Estimator | Model | Sample size | |||
|---|---|---|---|---|---|
| PS | OR | n = 50 | n = 200 | n = 1,000 | |
| Bias of difference in medians ×100 | |||||
| – | ✓ | 0.010(0.037) | −0.036(0.018) | 0.008(0.008) | |
| – | × | 3.898(0.075) | 3.787(0.037) | 3.819(0.017) | |
| ✓ | – | 0.433(0.157) | 0.008(0.045) | 0.021(0.018) | |
| × | – | 3.975(0.084) | 3.706(0.036) | 3.738(0.016) | |
| ✓ | ✓ | 0.005(0.04) | −0.033(0.019) | 0.013(0.008) | |
| ✓ | × | 0.194(0.057) | −0.001(0.022) | 0.020(0.010) | |
| × | ✓ | 0.015(0.038) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 3.881(0.074) | 3.704(0.036) | 3.737(0.016) | |
| ✓ | ✓ | −0.066(0.091) | −0.032(0.019) | 0.013(0.008) | |
| ✓ | × | −2.151(0.141) | −0.383(0.025) | −0.051(0.010) | |
| × | ✓ | 0.014(0.047) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 4.193(0.108) | 3.726(0.036) | 3.741(0.016) | |
| Root mean integrated squared error ×100 | |||||
| – | ✓ | 0.695(0.016) | 0.339(0.008) | 0.150(0.003) | |
| – | × | 2.941(0.05) | 2.773(0.027) | 2.796(0.012) | |
| ✓ | – | 2.912(0.108) | 0.981(0.029) | 0.425(0.009) | |
| × | – | 3.176(0.057) | 2.715(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.740(0.017) | 0.348(0.008) | 0.156(0.004) | |
| ✓ | × | 0.991(0.028) | 0.409(0.010) | 0.183(0.004) | |
| × | ✓ | 0.709(0.016) | 0.342(0.008) | 0.150(0.003) | |
| × | × | 2.942(0.048) | 2.712(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.981(0.054) | 0.352(0.008) | 0.156(0.004) | |
| ✓ | × | 2.163(0.107) | 0.495(0.013) | 0.188(0.004) | |
| × | ✓ | 0.834(0.047) | 0.343(0.008) | 0.150(0.003) | |
| × | × | 3.289(0.070) | 2.728(0.026) | 2.738(0.012) | |
| Estimator | Model | Sample size | |||
|---|---|---|---|---|---|
| PS | OR | n = 50 | n = 200 | n = 1,000 | |
| Bias of difference in medians ×100 | |||||
| – | ✓ | 0.010(0.037) | −0.036(0.018) | 0.008(0.008) | |
| – | × | 3.898(0.075) | 3.787(0.037) | 3.819(0.017) | |
| ✓ | – | 0.433(0.157) | 0.008(0.045) | 0.021(0.018) | |
| × | – | 3.975(0.084) | 3.706(0.036) | 3.738(0.016) | |
| ✓ | ✓ | 0.005(0.04) | −0.033(0.019) | 0.013(0.008) | |
| ✓ | × | 0.194(0.057) | −0.001(0.022) | 0.020(0.010) | |
| × | ✓ | 0.015(0.038) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 3.881(0.074) | 3.704(0.036) | 3.737(0.016) | |
| ✓ | ✓ | −0.066(0.091) | −0.032(0.019) | 0.013(0.008) | |
| ✓ | × | −2.151(0.141) | −0.383(0.025) | −0.051(0.010) | |
| × | ✓ | 0.014(0.047) | −0.038(0.018) | 0.009(0.008) | |
| × | × | 4.193(0.108) | 3.726(0.036) | 3.741(0.016) | |
| Root mean integrated squared error ×100 | |||||
| – | ✓ | 0.695(0.016) | 0.339(0.008) | 0.150(0.003) | |
| – | × | 2.941(0.05) | 2.773(0.027) | 2.796(0.012) | |
| ✓ | – | 2.912(0.108) | 0.981(0.029) | 0.425(0.009) | |
| × | – | 3.176(0.057) | 2.715(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.740(0.017) | 0.348(0.008) | 0.156(0.004) | |
| ✓ | × | 0.991(0.028) | 0.409(0.010) | 0.183(0.004) | |
| × | ✓ | 0.709(0.016) | 0.342(0.008) | 0.150(0.003) | |
| × | × | 2.942(0.048) | 2.712(0.026) | 2.736(0.012) | |
| ✓ | ✓ | 0.981(0.054) | 0.352(0.008) | 0.156(0.004) | |
| ✓ | × | 2.163(0.107) | 0.495(0.013) | 0.188(0.004) | |
| × | ✓ | 0.834(0.047) | 0.343(0.008) | 0.150(0.003) | |
| × | × | 3.289(0.070) | 2.728(0.026) | 2.738(0.012) | |
We assess the finite-sample coverage of the proposed confidence bands in Remark 7 when both models are correctly specified. For the DR method, the coverage probabilities of the SCB are , , and , respectively for n = 50, 200, 1,000, based on 1,000 Monte Carlo replicates. For the CF method, the coverage probabilities are , , and , respectively, for n = 50, 200, 1,000. These coverage probabilities are reasonably close to the nominal level considering the difficulty to derive effective confidence bands for functional objects.
We further consider the data-adaptive DR and CF estimators for two scenarios. Scenario 1 is exactly the same as the previous simulation. In Scenario 2, both the propensity score model and the outcome regression model are nonlinear functions of X. In particular, we set and , i.e., we replace the term X in these two models by sin (πX). The remaining settings are the same as those in Scenario 1. In both scenarios, we fit the outcome regression model using smoothing spline, implemented by the R function smooth.spline, while for the propensity score model, we consider the logistic smoothing spline fit, implemented by the R function gssanova in package gss. The default tuning methods of these R functions are adopted, namely, generalized cross-validation for smooth.spline and cross-validation for gssanova; see the corresponding R packages for more details. The results based on 1,000 Monte Carlo replicates are summarized in Table 2. From the results, one can see that for Scenario 1, the data-adaptive methods work reasonably well, although not as good as the method where we correctly specify both the outcome and propensity score models parametrically. When both the underlying true outcome and propensity score models are nonlinear, the root mean integrated squared errors of the data-adaptive methods decay as the sample size increases, suggesting consistency of these methods for estimating the average treatment effect.
Bias of difference in medians ×100 (standard error ×100) and root mean integrated squared error ×100 (standard error ×100) of data-adaptive doubly robust estimator and the data-adaptive cross-fitting estimator
| Estimator | Scenario | Sample size | ||
|---|---|---|---|---|
| n = 50 | n = 200 | n = 1,000 | ||
| Bias of difference in medians ×100 | ||||
| 1 | −0.047(0.127) | −0.096(0.046) | 0.012(0.008) | |
| 2 | −0.205(0.139) | −0.010(0.042) | 0.030(0.008) | |
| 1 | −2.505(0.534) | −0.469(0.035) | −0.102(0.011) | |
| 2 | −1.206(0.788) | −0.808(0.122) | 0.180(0.021) | |
| Root mean integrated squared error ×100 | ||||
| 1 | 1.604(0.091) | 0.545(0.044) | 0.156(0.004) | |
| 2 | 1.867(0.096) | 0.686(0.153) | 0.161(0.004) | |
| 1 | 3.648(0.355) | 0.767(0.024) | 0.244(0.006) | |
| 2 | 5.111(0.894) | 2.202(0.183) | 0.568(0.012) | |
| Estimator | Scenario | Sample size | ||
|---|---|---|---|---|
| n = 50 | n = 200 | n = 1,000 | ||
| Bias of difference in medians ×100 | ||||
| 1 | −0.047(0.127) | −0.096(0.046) | 0.012(0.008) | |
| 2 | −0.205(0.139) | −0.010(0.042) | 0.030(0.008) | |
| 1 | −2.505(0.534) | −0.469(0.035) | −0.102(0.011) | |
| 2 | −1.206(0.788) | −0.808(0.122) | 0.180(0.021) | |
| Root mean integrated squared error ×100 | ||||
| 1 | 1.604(0.091) | 0.545(0.044) | 0.156(0.004) | |
| 2 | 1.867(0.096) | 0.686(0.153) | 0.161(0.004) | |
| 1 | 3.648(0.355) | 0.767(0.024) | 0.244(0.006) | |
| 2 | 5.111(0.894) | 2.202(0.183) | 0.568(0.012) | |
Bias of difference in medians ×100 (standard error ×100) and root mean integrated squared error ×100 (standard error ×100) of data-adaptive doubly robust estimator and the data-adaptive cross-fitting estimator
| Estimator | Scenario | Sample size | ||
|---|---|---|---|---|
| n = 50 | n = 200 | n = 1,000 | ||
| Bias of difference in medians ×100 | ||||
| 1 | −0.047(0.127) | −0.096(0.046) | 0.012(0.008) | |
| 2 | −0.205(0.139) | −0.010(0.042) | 0.030(0.008) | |
| 1 | −2.505(0.534) | −0.469(0.035) | −0.102(0.011) | |
| 2 | −1.206(0.788) | −0.808(0.122) | 0.180(0.021) | |
| Root mean integrated squared error ×100 | ||||
| 1 | 1.604(0.091) | 0.545(0.044) | 0.156(0.004) | |
| 2 | 1.867(0.096) | 0.686(0.153) | 0.161(0.004) | |
| 1 | 3.648(0.355) | 0.767(0.024) | 0.244(0.006) | |
| 2 | 5.111(0.894) | 2.202(0.183) | 0.568(0.012) | |
| Estimator | Scenario | Sample size | ||
|---|---|---|---|---|
| n = 50 | n = 200 | n = 1,000 | ||
| Bias of difference in medians ×100 | ||||
| 1 | −0.047(0.127) | −0.096(0.046) | 0.012(0.008) | |
| 2 | −0.205(0.139) | −0.010(0.042) | 0.030(0.008) | |
| 1 | −2.505(0.534) | −0.469(0.035) | −0.102(0.011) | |
| 2 | −1.206(0.788) | −0.808(0.122) | 0.180(0.021) | |
| Root mean integrated squared error ×100 | ||||
| 1 | 1.604(0.091) | 0.545(0.044) | 0.156(0.004) | |
| 2 | 1.867(0.096) | 0.686(0.153) | 0.161(0.004) | |
| 1 | 3.648(0.355) | 0.767(0.024) | 0.244(0.006) | |
| 2 | 5.111(0.894) | 2.202(0.183) | 0.568(0.012) | |
6 Data application
Behavioural scientists are often interested in evaluating the effects of potential risk factors, such as marriage, on physical activity patterns (e.g., King et al., 1998). In this section, we apply our proposed method to estimate the causal effect of marriage on physical activity levels, with data obtained from the National Health and Nutrition Examination Survey (NHANES) 2005–20061. The NHANES is a program of studies designed to assess the health and nutritional status of adults and children in the USA. The survey is unique in that it combines interviews and physical examinations. The NHANES interview includes demographic, socioeconomic, dietary, and health-related questions. The examination component consists of medical, dental, and physiological measurements, as well as laboratory tests administered by highly trained medical personnel.
In the 2005–2006 cycle of NHANES, participants of ages 6 years and older were asked to wear an Actigraph 7,164 on a waist belt during all nonsleeping hours for 7 days. The technology and application of current accelerometer-based devices in physical activity research allow the capture and storage or transmission of large volumes of raw acceleration signal data (Troiano et al., 2014). The NHANES accelerometer data have been widely used by researchers to explore relationships among accelerometer measures and a variety of other measures (e.g., Tudor-Locke et al., 2012). The monitors were programmed to begin recording activity information for successive 1-min intervals (epochs) beginning at 12:01 a.m. the day after the health examination. The device was placed on an elasticized fabric belt, custom-fitted for each subject, and worn on the right hip. Subjects were told to keep the device dry (i.e. remove it before swimming or bathing) and to remove the device at bedtime. For each participant, the physical activity intensity, ranging from 0 to 32,767 counts per minute (cpm), was recorded every minute for 24 h, 7 days, where 32,767 is the maximum value that the wearable device can record.
In our analysis, the exposure of interest is marriage, coded as a binary variable, with 1 being married or living with a partner, and 0 being otherwise. To define the outcome variable, we note that the trajectory of activity intensity is not directly comparable across different subjects as different individuals might have different circadian rhythms. Instead, the distribution of activity intensity is invariant to circadian rhythms and hence can be compared between groups of individuals. Specifically, our outcome of interest is Y(s) = Leb({t : Z(t) ≤ s})/7, the distribution of physical activity intensity over 7 days, where Leb denotes the Lebesgue measure.
To obtain robust and reliable results, we applied the following preprocessing steps. Firstly, we excluded all observations that data reliability is questionable following NHANES protocol, after which there were 7,170 subjects left. Secondly, following Chang and McKeague (2020), for each subject, we removed observations with intensity values higher than 1,000 or equal to 0. In the dataset, most intensity values are between 0 and 1,000 cpm. Observations with zero intensity value were removed as they could represent activities with very different intensities, such as sleeping, bathing, and swimming. Thirdly, we removed subjects with no more than 100 observations left, which further reduced the sample size to 7,014. Lastly, for illustrative purposes, we removed 1,490 participants for whom we do not have information on their marital status.
After the preprocessing steps, we are left with 5,524 participants in the dataset, among which 2,682 are in the married group and 2,842 participants are in the unmarried group. The average age was 40.2 years old with a standard deviation of 21.3, and of them were female. As an example of the outcome data, in Figure 2a, we plot the empirical cumulative distribution function for a randomly selected participant (subject ID 31144) who was 21 years old, male, and unmarried. In Figure 2b, we plot the Wasserstein barycentres of the empirical cumulative distribution functions in the married group and unmarried group, respectively. One can see that the Wasserstein barycentres retain the key structural information in the individual empirical CDFs. For example, their derivatives decrease with the intensity level, suggesting that the physical intensity level is low most of the time. The Wasserstein barycentre in the married group is stochastically greater than that in the unmarried group, suggesting a positive association between marriage and physical activity level. However, this crude association may be subject to potential confounders such as age and gender.
![Panel (a) plots the preprocessed data for a randomly selected subject, where we transform the raw trajectory data to a cumulative distribution function in W2([1,1,000]). Panel (b) plots the Wasserstein barycentre of the empirical cumulative distribution functions in the married group (black solid line) and unmarried group (blue dashed line).](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/jrsssb/85/2/10.1093_jrsssb_qkad008/2/m_qkad008f2.jpeg?Expires=1750216632&Signature=SkdxizLgWxXXvSZLPDy~Tvf2fqdv~Or0uA7SfdOWxyO4I9IvqPpim1f16XjXpcLCexla-PlvoWnk~dC0d7LqVnIAXsQ8dRLA1Igq7CgiaZ26QhKtsVKY1Cim~3tDD5pAKA4v-9iq8K3oCOoAgQIyQkj8EGxd7qJK0jE4uAb83bNwdtHN8pkgLTtLeC38MHxaIoDCz8Vm2Vi4SSJ9OZJXrRkI-yUmn49Q3Y940rGB4WLsSAvkgm3JSFUMzKD5rSogQe1bQLM0b2WSo4MC2YRLgaYtZ0qQ~tP9pLSfiIsMSgLx0JbJmAankU~Oo-KnudbvS0PlcylzGC3s9CyHZacqfw__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
Panel (a) plots the preprocessed data for a randomly selected subject, where we transform the raw trajectory data to a cumulative distribution function in . Panel (b) plots the Wasserstein barycentre of the empirical cumulative distribution functions in the married group (black solid line) and unmarried group (blue dashed line).
A simple approach to answering our question of interest is to first summarize the distribution functions with their means and then apply standard approaches such as the doubly robust estimator of Robins et al. (1994) to estimate the causal effect. With a linear outcome regression model and a logistic propensity score model, this simple doubly robust approach suggests that marriage increases the average physical intensity by 21.7 ( CI = [17.1, 26.3]) cpm.
We then present a finer analysis of these data with the proposed approaches. We first plot the estimates of causal Wasserstein barycentres, and by OR, DR, and CF in Figure 3. Here, for a = 0, 1, is the corresponding cumulative distribution function of the estimate for , where for the OR method, for the DR method, is defined in (8), and for the CF method, in the spirit of (10), with being the estimator in (9) for the rth partitioning. With these estimators, the former is stochastically greater than the latter, suggesting that marriage improves the entire distribution of physical intensity level at every quantile.
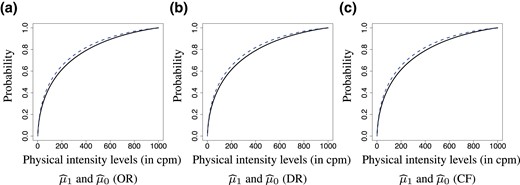
Panel (a), (b), and (c) plots (black solid line) and (blue dashed line) estimated by OR, DR, and CF, respectively.
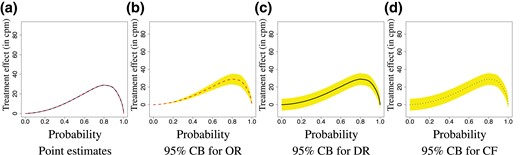
To quantify the size of the treatment effect, we take the difference between and , corresponding to the difference in quantiles of the mean potential outcomes μ1 and μ0. To quantify the uncertainty of these estimates, we plot the corresponding confidence bands in Figure 4b–d, where the confidence bands for the doubly robust and cross-fitting estimators were obtained using our asymptotic results presented in Theorems 3 and 4, and the confidence band for the outcome regression estimator was obtained using the conventional linear regression confidence interval for the slope coefficient corresponding to the exposure A. As expected, the estimation results from the three methods are very close to each other, and the OR method has the tightest confidence band among the three methods.
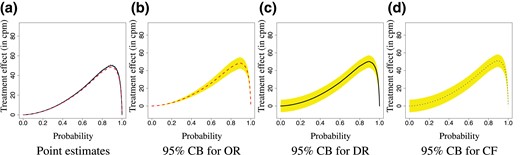
Difference in quantiles estimates with the OR (red dashed), DR (black solid), and CF (blue dotted) estimators: point estimates and 95% confidence bands.
One can see from Figure 4 that the effect of marriage on physical activity level is significant at the 0.05 level. One can also get the causal effect on individual quantiles from these plots. For example, according to the DR estimation results, on average, marriage improves the median physical intensity level by 19.1 (95% CI = [12.1, 26.1]) cpm. Due to Theorem 1, this effect may be interpreted on both the population and individual levels. On the population level, this means that marriage improves the median of ‘average’ (in the sense of Wasserstein barycentre) physical intensity level by 19.1 cpm. On the individual level, this means that the average improvement on the median physical intensity level is 19.1 cpm. We also estimate the Wasserstein distance between , , and the estimate is 27.6 cpm (95% CI: [24.0, 31.2]).
One may also be interested in predicting the unobserved potential outcome for a particular individual. As an illustration, we estimate Yi(1) for Subject 31144, who was unmarried so Y31144 = Y31144(0). Recall that . We first estimate the individual causal effect map for Subject 31144 using the average causal effect map with reference distribution the latter being estimated using the DR method. We then apply the individual causal transport map to his empirical CDF to obtain plotted in Figure 5b. From this, one may obtain, for example, getting married would raise his mean physical activity from 144.5 cpm to 166.3 cpm (95% CI: [159.5, 173.7]).
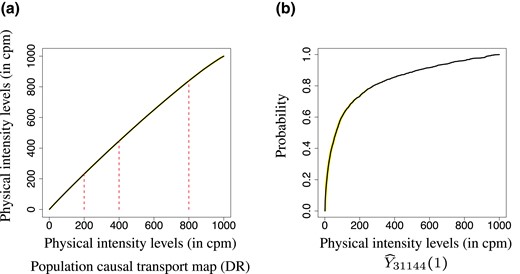
Panel (a) plots the DR estimate of population causal transport map, superimposed with the 95% confidence band; Panel (b) plots the DR estimate of counterfactual outcome Y(1) with 95% confidence band for individual 31144, who was unmarried so that Y31144 = Y31144(0).
We also compare our adjusted estimates with the results where we do not adjust for the observed confounders age and gender. In particular, we apply the OR, DR, and CF estimators for estimating the average treatment effect . We plot these estimates and the corresponding confidence bands in Figure 6. One can see the treatment effect is attenuated without adjusting for age and gender.
Difference in quantiles estimates with the OR (red dashed), DR (black solid), and CF (blue dotted) estimators when we do not adjust for observed confounders age and gender: point estimates and 95% confidence bands.
7 Discussion
In this paper, we study causal inference for distribution functions that reside in a Wasserstein space. We propose novel definitions of causal effects and develop doubly robust estimation procedures for estimating these effects under the assumption of no unmeasured confounding. It would be interesting to extend classical causal inference methods for dealing with unmeasured confounding, such as the instrumental variable methods (e.g., Ogburn et al., 2015; Wang & Tchetgen Tchetgen, 2018) to this setting.
To the best of our knowledge, ours is the first formal study of causal effects for outcomes defined in a nonlinear space. As such, we have only considered a leading special case of nonlinear spaces. There are many other data objects from nonlinear spaces that we do not consider in this paper. For example, the Wasserstein spaces of probability distributions on higher dimensional Euclidean spaces exhibit structures different from and thus pose new challenges for causal inference on such spaces. We also note that although the Wasserstein space is not a Riemannian manifold (Bigot et al., 2017), it can be endowed with a Riemannian structure, including the tangent space and Riemannian logarithmic map. In particular, let cl(S) denote the closure of set S. With a continuous reference distribution λ, the space can be viewed as the tangent space of at λ, and the mapping can be viewed as the Riemannian logarithmic map at λ (Ambrosio et al., 2004). From this perspective, with the notation , the individual causal effect maps can be written as so they may be equivalently defined as the contrasts between the Riemannian logarithmic maps of distribution functions Yi(1) and Yi(0). By Theorem 1, the average causal effect map may then be equivalently defined as These connections allow one to extend the proposed definition of causal effect from random distributions to random elements residing on a Riemannian manifold; see Srivastava and Klassen (2016) for concepts and tools of Riemannian manifolds that are relevant to statistics.
Another interesting venue for future research is the study of efficiency theory with distribution-valued outcomes. It is well known that the classical doubly robust and cross-fitting estimators (Chernozhukov et al., 2018; Robins et al., 1994) are both doubly robust and locally semiparametric efficient. In Theorems 3 and 4, we establish double robustness of our proposed doubly robust and cross-fitting estimators. On the other hand, to establish semiparametric efficiency of these proposed estimators, one needs to extend semiparametric efficiency theory to accommodate distribution-valued outcomes that reside in infinite-dimensional functional spaces. This will be developed in a separate paper.
Supplementary material
Supplementary material are available at Journal of the Royal Statistical Society: Series B online.
Data availability
The supplementary file contains some auxiliary results, technical lemmas, and proofs for all the theorems. R code to reproduce the simulation studies and data analysis can be found in the repository https://github.com/kongdehanstat/causaldistributionfunction. The data analysed in Section 6 is available at https://wwwn.cdc.gov/nchs/nhanes/ContinuousNhanes/Default.aspx?BeginYear=2005.
References
Footnotes
Author notes
Conflict of interest None declared.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}