





Abstract
To identify a cohort of COVID-19 cases, including when evidence of virus positivity was only mentioned in the clinical text, not in structured laboratory data in the electronic health record (EHR).
Statistical classifiers were trained on feature representations derived from unstructured text in patient EHRs. We used a proxy dataset of patients with COVID-19 polymerase chain reaction (PCR) tests for training. We selected a model based on performance on our proxy dataset and applied it to instances without COVID-19 PCR tests. A physician reviewed a sample of these instances to validate the classifier.
On the test split of the proxy dataset, our best classifier obtained 0.56 F1, 0.6 precision, and 0.52 recall scores for SARS-CoV2 positive cases. In an expert validation, the classifier correctly identified 97.6% (81/84) as COVID-19 positive and 97.8% (91/93) as not SARS-CoV2 positive. The classifier labeled an additional 960 cases as not having SARS-CoV2 lab tests in hospital, and only 177 of those cases had the ICD-10 code for COVID-19.
Proxy dataset performance may be worse because these instances sometimes include discussion of pending lab tests. The most predictive features are meaningful and interpretable. The type of external test that was performed is rarely mentioned.
COVID-19 cases that had testing done outside of the hospital can be reliably detected from the text in EHRs. Training on a proxy dataset was a suitable method for developing a highly performant classifier without labor-intensive labeling efforts.
Lay Summary
For a significant period at the start of the COVID-19 pandemic, some hospitals routinely tested every patient who came to the emergency room or was admitted for COVID-19 with a polymerase chain reaction (PCR) test. However, they may have skipped this test if the patient reported a recent positive test outside the hospital, and these patients would be treated as if they had tested positive at the hospital. These patients are hard to detect for later study, because hospitals will not have an electronic record of a positive test. In this work, we hypothesized that we could detect these patients by teaching machine learning methods to read the text in electronic health records, where positive tests would be mentioned by clinicians. We found that we could detect these patients with high accuracy, as validated by a clinician, that there are many additional cases that we can find this way, and that many of these cases would be hard to detect with other methods.
INTRODUCTION AND BACKGROUND
One approach to identifying a hospital cohort of patients with COVID-19 is to search for positive polymerase chain reaction (PCR) diagnostics within an electronic health record (EHR) laboratory results database. Using this approach, though, a patient who already carries a test-positive COVID-19 diagnosis prior to arrival would be missed, because they may not be retested. This is a problem for downstream use cases, both because more data will make our analyses more robust (and COVID-19 is less frequent in pediatric populations), and because patients with missing tests may be different in important ways (i.e., leaving them out may lead to biased results in downstream analyses). “Computable phenotypes” leveraging structured and/or unstructured EHR data are increasingly used to identify patient cohorts.1–3
OBJECTIVE
We sought to augment structured EHR data with natural language processing (NLP)-derived information to identify a cohort of patient visits at a children’s hospital, where the patient had COVID-19 within the last 90 days, but who do not have a PCR test result in the EHR. Our computable case definition uses machine learning classifiers over unstructured clinical text in the EHR. Further, to avoid time-consuming and expensive manual chart review, we designed this classifier under the constraint of minimizing the need for labeled data.
METHODS
Setting and subjects
This is a retrospective study applying machine learning methods to EHR data from patients of all ages seen at a large academic pediatric teaching hospital. We queried the research data warehouse for patient visits after March 1, 2020 with an emergency department (ED) note or an admission note and requested all notes of either type for each such visit, as well as any associated SARS-CoV2 PCR tests. The study was approved by the Boston Children’s Hospital Institutional Review Board.
Each classifier instance consisted of all associated ED or admission notes for a patient visit with at least one of either type. Since our goal was to capture patient visits with a positive SARS-CoV2 test prior to presenting to the hospital, we limited the text data we considered to ED and admission notes generated from the first day of a visit. To account for slight variations in note timestamps (year, month, day, time), we used a simple procedure to add a 1-day buffer: for each visit, we defined the start date (year, month, day) as the earliest recorded day associated with any of its notes. We derived an end date (year, month, day) for the classification by adding 1 calendar day to the identified start date. Then we identified all ED notes and admission notes with timestamps on either the start date or the end date. This set of notes was concatenated into a single string that served as the input text for a single instance for the classifier.
Next, we divided the instances into 2 datasets based on whether they had associated SARS-CoV2 PCR test results from the hospital laboratory. The labeled dataset consisted of instances in which a PCR test was performed by the laboratory, and where we had gold standard COVID-19+ or COVID-19− labels. We filtered SARS-CoV2 PCR tests to retain only those with timestamps occurring during a period starting 90 days before the start date and ending on the end date (BCH policy is to not retest if there is a positive PCR test recorded in the last 90 days). The unlabeled dataset consisted of instances in which no PCR test was performed at the hospital.
Classification, model development, and evaluation
We defined 2 categories that we wanted to identify within the unlabeled dataset: those with mentions of positive tests (Test) and those without mentions of positive tests (NoTest). Because there was a low prevalence of Test cases, it would be prohibitively expensive to manually label enough data to learn from. To address this problem, we used a proxy training data approach, using the labeled dataset. We trained the classifier on the labeled dataset (subjects that did have PCR tests completed at the hospital) and treated instances labeled COVID-19+ as equivalent to Test, and instances labeled COVID-19− as equivalent to NoTest. This approach essentially hypothesizes that positive tests would be discussed in the notes using similar language in the unlabeled and labeled datasets. We divided the labeled dataset into Proxy-Train, Proxy-Dev, and Proxy-Test for training the model, doing model selection/hyperparameter tuning, and final testing, respectively. This split was stratified so that the training and development data had the same prevalence.
We explored several models and features for classifying the notes. These included a support vector machine (SVM) classifier with bag of words features, 4 a convolutional neural network (CNN) over randomly initialized word embeddings, 5 bag of vectors with pre-trained static word embeddings, 6 and pre-trained transformers.7 We used open-source libraries for implementation: sci-kit learn8 for the SVM implementation, Fasttext6 for the bag of vectors implementation, and cnlp_transformers9 for the CNN and transformer implementations. Each model used the notes of an instance as the input and produced an output in the form of a class label. We chose the best model configuration for each classifier type by finding the best F1 score in a grid search over hyperparameters on the Proxy-Dev data. We then evaluated each classifier type on the Proxy-Test data set. For the unlabeled cohort, we used the best model on the Proxy-Text data to make predictions.
To validate the classifier, a clinician expert (AZ) reviewed 100 instances in the unlabeled cohort that our classifier identified as COVID-19 positive and 100 instances that our classifier identified as not COVID-19 positive. The clinician examined the notes for mention of the patient having COVID-19 in the last 90 days and mention of whether the patient had a SARS-CoV2 test completed. If a positive test was mentioned, the clinician identified whether the test type was specified in the note (PCR test, antigen test, or no test type specified). Based on this information, the clinician determined whether the instance was correctly classified. We then applied the validated classifier to the remaining cases in our cohort without PCR tests performed, to estimate the number of missing cases, and tracked the counts of these cases over time. We also queried for ICD-10 codes associated with these instances, in order to quantify the number of COVID-19 positive cases identified by the classifier that could not have been captured by either PCR tests or ICD-10 codes.
Evaluation metrics include true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN), which were used to compute recall (i.e., sensitivity), precision (i.e., positive predictive value), and F1 score in the usual way.
We chose F1 as our primary metric, as we were focused on identifying positive cases with a minimum number of FP. Since these data have a highly imbalanced distribution between positive and negative cases, obtaining high scores on negative cases is not difficult, and variations in performance are not particularly meaningful.
RESULTS
There were 455 032 ED and admission notes and 104 986 COVID-19 PCR test results from 166 659 patients aged 0–78 and seen from December 31, 2015 to June 3, 2022. (While our population is primarily pediatric, there are some adults in our patient population as is typical of most children’s hospitals and we did not explicitly attempt to filter them at this stage.)
The size of the unlabeled and labeled cohorts, as well as the train and test splits, are shown in Table 1. Classifier results on the proxy dataset are shown in Table 2. The best-performing classifier on our proxy dataset was the SVM with bag of words features, with an F1 score of 0.56 on the class we are most interested in. All classifiers had similarly high performance on the COVID-19 negative class. Neural methods (CNN, Fasttext, and Transformer) that used the full text without any feature selection had worse performance, despite extensive hyperparameter tuning. During iterative evaluation loops, we periodically applied our best-performing classifier on small samples of unlabeled instances to manually check if it was performing as expected. We also performed manual error analysis on the outputs of the classifier applied to the held-out proxy data, discovering that many of the errors it made were due to notes that described pending PCR tests. These errors reflect a limitation of the query strategy rather than the model training. Given these analyses, we were confident that the F1 scores we were obtaining on the proxy dataset were under-estimates of how well the classifier was performing and chose the classifier with the highest F1 score to apply to the entire unlabeled dataset and validate manually.
Counts of instances in the labeled and unlabeled cohorts, broken down by negative and positive labels
| Labeled | Proxy-Train | Proxy-Test | Unlabeled | |
|---|---|---|---|---|
| Negative | 35 030 | 28 023 | 7007 | — |
| Positive | 1891 | 1513 | 378 | — |
| Total | 36 921 | 29 536 | 7385 | 53 640 |
| Labeled | Proxy-Train | Proxy-Test | Unlabeled | |
|---|---|---|---|---|
| Negative | 35 030 | 28 023 | 7007 | — |
| Positive | 1891 | 1513 | 378 | — |
| Total | 36 921 | 29 536 | 7385 | 53 640 |
Note: Proxy-Train and Proxy-Test counts are derived from the labeled cohort. Proxy-Train is further divided into Proxy-Train and Proxy-Dev using different strategies in different classifiers.
Counts of instances in the labeled and unlabeled cohorts, broken down by negative and positive labels
| Labeled | Proxy-Train | Proxy-Test | Unlabeled | |
|---|---|---|---|---|
| Negative | 35 030 | 28 023 | 7007 | — |
| Positive | 1891 | 1513 | 378 | — |
| Total | 36 921 | 29 536 | 7385 | 53 640 |
| Labeled | Proxy-Train | Proxy-Test | Unlabeled | |
|---|---|---|---|---|
| Negative | 35 030 | 28 023 | 7007 | — |
| Positive | 1891 | 1513 | 378 | — |
| Total | 36 921 | 29 536 | 7385 | 53 640 |
Note: Proxy-Train and Proxy-Test counts are derived from the labeled cohort. Proxy-Train is further divided into Proxy-Train and Proxy-Dev using different strategies in different classifiers.
Experimental results of the different classifier types on the proxy dataset
| Positive | Negative | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| SVM | 0.55 | 0.56 | 0.56 | 0.98 | 0.98 | 0.98 | 0.76 | 0.77 | 0.77 |
| CNN | 0.73 | 0.39 | 0.51 | 0.97 | 0.99 | 0.98 | 0.85 | 0.69 | 0.76 |
| Fasttext | 0.62 | 0.39 | 0.48 | 0.97 | 0.99 | 0.98 | 0.80 | 0.69 | 0.73 |
| Transformer | 0.53 | 0.21 | 0.30 | 0.96 | 0.99 | 0.97 | 0.74 | 0.60 | 0.64 |
| Positive | Negative | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| SVM | 0.55 | 0.56 | 0.56 | 0.98 | 0.98 | 0.98 | 0.76 | 0.77 | 0.77 |
| CNN | 0.73 | 0.39 | 0.51 | 0.97 | 0.99 | 0.98 | 0.85 | 0.69 | 0.76 |
| Fasttext | 0.62 | 0.39 | 0.48 | 0.97 | 0.99 | 0.98 | 0.80 | 0.69 | 0.73 |
| Transformer | 0.53 | 0.21 | 0.30 | 0.96 | 0.99 | 0.97 | 0.74 | 0.60 | 0.64 |
Note: We include precision (P), recall (R), and F1 score for positive (COVID-19+) and negative (COVID-19−) classes, as well as the overall P, R, and F1 score of all predictions.
Experimental results of the different classifier types on the proxy dataset
| Positive | Negative | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| SVM | 0.55 | 0.56 | 0.56 | 0.98 | 0.98 | 0.98 | 0.76 | 0.77 | 0.77 |
| CNN | 0.73 | 0.39 | 0.51 | 0.97 | 0.99 | 0.98 | 0.85 | 0.69 | 0.76 |
| Fasttext | 0.62 | 0.39 | 0.48 | 0.97 | 0.99 | 0.98 | 0.80 | 0.69 | 0.73 |
| Transformer | 0.53 | 0.21 | 0.30 | 0.96 | 0.99 | 0.97 | 0.74 | 0.60 | 0.64 |
| Positive | Negative | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| SVM | 0.55 | 0.56 | 0.56 | 0.98 | 0.98 | 0.98 | 0.76 | 0.77 | 0.77 |
| CNN | 0.73 | 0.39 | 0.51 | 0.97 | 0.99 | 0.98 | 0.85 | 0.69 | 0.76 |
| Fasttext | 0.62 | 0.39 | 0.48 | 0.97 | 0.99 | 0.98 | 0.80 | 0.69 | 0.73 |
| Transformer | 0.53 | 0.21 | 0.30 | 0.96 | 0.99 | 0.97 | 0.74 | 0.60 | 0.64 |
Note: We include precision (P), recall (R), and F1 score for positive (COVID-19+) and negative (COVID-19−) classes, as well as the overall P, R, and F1 score of all predictions.
Validation of classifier on unlabeled cohort
Of the notes reviewed for the validation, 84 of the 100 randomly selected COVID-19 classifier positive notes and 93 of the 100 randomly selected COVID-19 classifier negative notes were included. The majority of excluded notes were because they were found on manual review to actually have reference to a pending or completed COVID-19 PCR test at the hospital and were thus not appropriately in the unlabeled cohort. 81/84 COVID-19 classifier positive notes were correctly identified as having COVID-19 based on the content in the clinical text. Of the 81 TP, 7 instances specifically mentioned that an antigen test was done and 5 that a PCR test was done. The rest of the instances did not specifically mention a test or did not specify what type of test was performed. 91/93 COVID-19 classifier negative notes were correctly identified as not having COVID-19 based on the content in the clinical text. Based on this validation, the classifier had a sensitivity of 97.6%, specificity of 96.8%, positive predictive value of 96.4% and negative predictive value of 97.8% in detecting cases of COVID-19 without a PCR test performed in hospital, but where one performed outside the hospital was detected in the clinical notes.
Feature analysis
The highest-scored bag of words features are shown in Table 3. The most significant feature of the COVID-19 classifier positive notes was “positive,” followed by “COVID.” We observed that the top 10 positive features were COVID-19-related unigrams and bigrams. The most significant feature of COVID-19 classifier negative notes was “negative,” followed by “COVID negative.”
Top 10 features for both positive and negative cases
| Positive | Negative |
|---|---|
| Positive | Negative |
| COVID | COVID negative |
| covidpunctminusnum | rsv |
| COVID positive | Daycare |
| covidpunctminusnum confirmed | Temperature num |
| covidpunctplus | Negative |
| COVID punctplus | COVID negative |
| Confirmed follow | Elevated |
| Coronavirus | Amoxicillin |
| remdesivir | Wheezing |
| Positive | Negative |
|---|---|
| Positive | Negative |
| COVID | COVID negative |
| covidpunctminusnum | rsv |
| COVID positive | Daycare |
| covidpunctminusnum confirmed | Temperature num |
| covidpunctplus | Negative |
| COVID punctplus | COVID negative |
| Confirmed follow | Elevated |
| Coronavirus | Amoxicillin |
| remdesivir | Wheezing |
Note: Features include single tokens (i.e., unigrams) and 2-word token sequences (i.e., bigrams). Our token preprocessing step mapped some punctuation symbols to text tokens, for example, the “−” symbol to the token “punctminus.” We also mapped numbers to the token “num,” so that, for example, the string “COVID-19” would be mapped to the feature covidpunctminusnum.
Top 10 features for both positive and negative cases
| Positive | Negative |
|---|---|
| Positive | Negative |
| COVID | COVID negative |
| covidpunctminusnum | rsv |
| COVID positive | Daycare |
| covidpunctminusnum confirmed | Temperature num |
| covidpunctplus | Negative |
| COVID punctplus | COVID negative |
| Confirmed follow | Elevated |
| Coronavirus | Amoxicillin |
| remdesivir | Wheezing |
| Positive | Negative |
|---|---|
| Positive | Negative |
| COVID | COVID negative |
| covidpunctminusnum | rsv |
| COVID positive | Daycare |
| covidpunctminusnum confirmed | Temperature num |
| covidpunctplus | Negative |
| COVID punctplus | COVID negative |
| Confirmed follow | Elevated |
| Coronavirus | Amoxicillin |
| remdesivir | Wheezing |
Note: Features include single tokens (i.e., unigrams) and 2-word token sequences (i.e., bigrams). Our token preprocessing step mapped some punctuation symbols to text tokens, for example, the “−” symbol to the token “punctminus.” We also mapped numbers to the token “num,” so that, for example, the string “COVID-19” would be mapped to the feature covidpunctminusnum.
Deployment results
After applying the classifier to the 53 640 instances of the unlabeled cohort, the COVID-19 classifier labeled 960 of the instances as positive COVID-19 cases, a potential 50.8% increase in cohort size. Of these 960 potential identified cases, only 177 were labeled with the ICD-10 code for COVID-19, U07.1, meaning the added value of the NLP classifier is 783 potential new COVID-19 cases. This represents a recall of 0.184 of ICD-10 relative to the NLP. Overall, ICD-10 codes for COVID-19 were recorded in 262 of the unlabeled instances. Figure 1 shows the monthly PCR positive and NLP positive case count over the labeled and unlabeled cohorts.
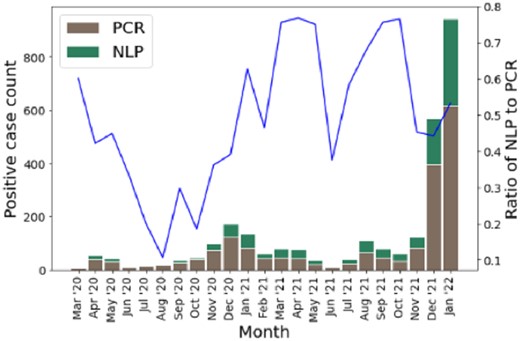
Monthly COVID-19 case count detected by SARS-CoV2 PCR in the structured data or by NLP are represented as bars, with counts corresponding to the left y-axis. The line represents the percent increase in cases afforded by use of the classifier during that month, corresponding to the right y-axis. The spike from October through December 2020 likely represents the Delta variant, while the spike starting in December 2021 likely represents the Omicron variant.
DISCUSSION
A relatively simple text-based classifier can have a large impact on identifying additional COVID-19 cases that did not have a PCR test performed in a tertiary care pediatric hospital context. Overall, the classifier identified an additional 960 likely COVID-19 positive instances without record of COVID-19 PCR tests performed in hospital in the structured data. This is in addition to the 1891 cases found using PCR test results alone. Further, these cases could not be easily obtained by other simple means such as billing codes, as ICD-10 coding only identified 18.4% of these cases. In addition, the ratio of additional COVID-19 cases detected by the classifier seems to show an increasing trend as the pandemic goes on, and therefore an increase in value of our classifier. The trend has a big jump in 2021, which is probably due to increased COVID-19 testing outside of the hospital setting.
One interesting result is that our classifier had trouble exceeding an F1 score of 0.6 during development on the proxy corpus, but when validated it had a much higher performance. During model development, we occasionally did informal validations on very small samples of the unlabeled cohort, and found the classifier performed well on these small samples. This was what motivated us to proceed to validate the model that performed best on the held-out proxy data. This does raise the question of how the classifier could perform so well on our target data. One explanation is that in the proxy data, pending COVID-19 PCR tests are mentioned, so even if the patient eventually tests negative, there will be test-related terms in the text. In contrast, perhaps in the unlabeled cohort, tests are only mentioned in the context where the patient is reporting a positive outside test.
Another interesting result is the relative simplicity of the best-performing model, compared to the more complex neural models which performed slightly worse on the Proxy-Dev set. This led to us selecting the simpler SVM model with bag of words features for deployment. One potential explanation is that the more complex models were overfitting to some of the noise in the labeled training data.
The COVID-19 pandemic presents a rather distinctive scenario, prompting us to contemplate the extent of generalizability of the methodologies we have developed here. Specifically, few other health conditions have mandated hospital-based testing to the universal extent as executed for COVID-19. Additionally, it is uncommon for patients to regularly administer at-home tests for other ailments. Nevertheless, there may exist instances where certain tests are omitted if a patient undergoes testing at external facilities. In such situations, our proposed proxy training approach could emerge as a feasible alternative for training classifiers, especially when manual data labeling proves to be cost-prohibitive.
In most EHR-based COVID-19 work, we found the starting point is typically positive PCR tests, with some studies also using ICD10 codes. For instance, two studies for predicting outcomes of patients admitted for COVID-19 used diagnosis codes and lab tests to define their cohort, 10,11 while another study predicting hospitalization used positive lab tests only.12 A study attempting to disentangle admissions for COVID-19 with those incidentally with COVID-19 used positive lab tests for their cohort.13 For defining a phenotype, one study found that standard tools like positive lab tests and ICD10 codes had limited precision and recall.14 Our work is complementary to that work in showing the value of NLP to improve sensitivity and find additional cases. Other computable phenotyping work is in the context of post-acute sequelae SARS-CoV-2 infection (PASC),15 and therefore must address the heterogeneity and uncertainty of the condition. In all of these studies, if significant numbers of additional cases exist that cannot be found with lab tests or ICD10 codes (as our analysis found), the conclusions may be biased by excluding the kinds of patients who would obtain tests on their own before going to the hospital.
CONCLUSIONS
Our study demonstrated the utility of a text-based classifier in identifying patients with COVID-19 that did not have a PCR test performed during a hospital visit. Additionally, this classifier was able to identify cases that were not captured by ICD-10 codes. By identifying these cases, the classifier has potential to be used to improve public health surveillance and cohort identification for research related to COVID-19.
FUNDING
Research reported in this manuscript was supported by the Centers for Disease Control and Prevention of the U.S. Department of Health and Human Services (HHS) as part of a financial assistance award. This work was also supported by a Training Grant from the National Institute of Child Health and Human Development, T32HD040128; Contracts 90AX0022, 90AX0019, 90AX0031, and 90C30007 from the Office of the National Coordinator of Health Information Technology; a cooperative agreement from the National Center for Advancing Translational Sciences U01TR002623; Grants from the National Library of Medicine (R01LM012973, R01LM012918); and the Boston Children’s Hospital PrecisionLink Initiative. The contents are those of the author(s) and do not necessarily represent the official views of, nor an endorsement, by CDC/HHS, or the US Government.
AUTHOR CONTRIBUTIONS
TM and KM designed the study, LW, AZ, AG, and AM contributed to this effort. AZ performed the validation on the held out dataset. LW implemented the data pipeline and carried out the experiments. TM and LW performed iterative error analysis and model improvement. LW, TM drafted the manuscript. All authors contributed to reviewing and editing the manuscript.
CONFLICT OF INTEREST STATEMENT
None declared.
DATA AVAILABILITY
The raw data underlying this article cannot be shared publicly due to privacy laws around identifiable health data. The classifier outputs used to calculate performance metrics is publicly available at https://doi.org/10.5061/dryad.51c59zwdj.
REFERENCES
Author notes
Kenneth D. Mandl and Timothy A. Miller contributed equally to this work.

{kind=link}