





Abstract
To automatically construct a drug indication taxonomy from drug labels using generative Artificial Intelligence (AI) represented by the Large Language Model (LLM) GPT-4 and real-world evidence (RWE).
We extracted indication terms from 46 421 free-text drug labels using GPT-4, iteratively and recursively generated indication concepts and inferred indication concept-to-concept and concept-to-term subsumption relations by integrating GPT-4 with RWE, and created a drug indication taxonomy. Quantitative and qualitative evaluations involving domain experts were performed for cardiovascular (CVD), Endocrine, and Genitourinary system diseases.
2909 drug indication terms were extracted and assigned into 24 high-level indication categories (ie, initially generated concepts), each of which was expanded into a sub-taxonomy. For example, the CVD sub-taxonomy contains 242 concepts, spanning a depth of 11, with 170 being leaf nodes. It collectively covers a total of 234 indication terms associated with 189 distinct drugs. The accuracies of GPT-4 on determining the drug indication hierarchy exceeded 0.7 with “good to very good” inter-rater reliability. However, the accuracies of the concept-to-term subsumption relation checking varied greatly, with “fair to moderate” reliability.
We successfully used generative AI and RWE to create a taxonomy, with drug indications adequately consistent with domain expert expectations. We show that LLMs are good at deriving their own concept hierarchies but still fall short in determining the subsumption relations between concepts and terms in unregulated language from free-text drug labels, which is the same hard task for human experts.
Introduction
Acquisition, normalization, and formalization of medical knowledge is fundamental to medical informatics. Knowledge acquisition from massive clinical text followed by knowledge representation as taxonomies and ontologies is indispensable for consistent interpretation of clinical data and for achieving semantic interoperability desired in clinical research. Despite research advances in automated clinical knowledge acquisition,1,2 normalization and formal knowledge representation still remain largely a laborious manual endeavor by domain experts, who do not necessarily agree with one another.
One notable challenge is to curate the drug indications approved by the Food and Drug Administration (FDA) as published in drug product labeling. Per the DrugBank, a drug indication refers to “the approved conditions, diseases, or states for which a drug can be safely and effectively used.” Drug indication knowledge is essential for various clinical decision support such as monitoring off-label uses or post-marketing pharmacovigilance.3 Formal representation of drug indication knowledge can further facilitate clinical knowledge management and support the secondary use of electronic health records (EHRs) data.4
Existing methods are mainly focused on indication extraction from drug labels. Fung et al.5 and Khare et al.6 leveraged MetaMap to accomplish this task. Ursu et al.7 developed DrugCentral where drug indications were extracted from the Observational Medical Outcomes Partnership Common Data Model and drug labels. Shi et al.8 utilized the pre-trained Bidirectional Encoder Representations from Transformers (BERT) model to extract drug product information from labels.
To normalize indication concepts, a common practice is to map them to existing ontologies manually or automatically using tools such as MetaMap9 and Usagi.10 For example, in DrugCentral, indications were mapped onto SNOMED-CT (a comprehensive clinical ontology) and Unified Medical Language System (UMLS) disease concepts.7 However, indication terms in text may not have an exact mapping (incomplete coverage) or may have different granularities from indication concepts (mismatched granularity) in existing ontologies or terminologies. Incomplete coverage refers to cases where an ontology includes a concept for the sibling term of the target indication but lacks a semantic equivalent concept to the target indication. For example, “metastatic castration-resistant prostate cancer,” an indication for abiraterone acetate, has a semantically equivalent concept in SNOMED-CT, which is “Metastatic castration-resistant prostate cancer.” Conversely, no such semantic equivalence exists in any ontologies for “metastatic castration-sensitive prostate cancer,” an indication for enzalutamide. Mismatched granularity describes the scenario in which the concept in the ontology optimally aligned with the identified indication is broader or narrower in scope. For instance, “moderate to severe rheumatoid arthritis” is an indication for indomethacin. Nonetheless, the best-matched concept in SNOMED-CT is “Rheumatoid arthritis.”
The extant ontologies, while facilitating a broad range of concept mapping applications, exhibit limitations in accurately and comprehensively normalizing indication concepts. This research aims to bridge this gap by automating drug indication taxonomy learning directly from drug labels. Our group has previously developed an automated method for learning domain-specific taxonomies from text using natural language processing.11 This research extends the prior work in 2 innovative aspects: (1) focusing on investigating the subsumption relations between indications, and (2) leveraging the latest generative artificial intelligence (AI) technology represented by large language models (LLMs) and real-world evidence (RWE) for automated taxonomy learning.
The capabilities of LLMs have been explored in the field of clinical informatics.12 Agrawal et al.13 demonstrated the good performance of LLMs at information extraction from clinical texts. Hu et al.14 proposed a generative drug-drug interaction triplet extraction framework based on LLMs. Kartchner et al.15 investigated zero-shot information extraction from clinical trial articles using LLMs, with case studies on drug repurposing and pharmacovigilance. Wang et al.16 explored their in-context learning (ICL) capabilities for biomedical concept linking and achieved high accuracy on disease entity normalization.
Several researchers have employed a crawling procedure to the internal knowledge base of LLMs to construct a concept hierarchy or knowledge graph for a seed concept in general domains.17,18 Despite this, there is a noticeable gap in research related to the use of LLMs for taxonomy construction within the clinical domain. Nonetheless, the demonstrated success of LLMs instills confidence in their potential utility for learning drug indication taxonomy.
In drug indication taxonomy construction, there are 2 properties to consider: indication concepts (ie, nodes in the taxonomy) and indication terms (ie, mentions extracted from free-text drug labels). Terms are to be linked to concepts representing their closest ancestors within the taxonomy. For an ideal drug indication taxonomy, the objective is to differentiate between distinct indication terms, while ensuring semantic equivalent terms are linked to the same concept, with no further distinction made using child nodes. To achieve this, we incorporated RWE to steer the construction process.
This study aims to create an automatic crawling process that harnesses the power of both LLM and RWE to (1) extract indication terms from free-text drug product labels, (2) derive drug indication concept-to-concept and concept-to-term subsumption relations, and (3) create a Drug Indication Standardized Taxonomy Induced by Large Language models (DISTILL) as a basis for organizing drugs. GPT-419 was selected as the foundation language model for this study.
Methods
The general workflow of deriving DISTILL by integrating GPT-4 and RWE, alongside a demonstration example, is described in Figure 1. The detailed flowchart is presented in Figure S1. The whole process is decomposed into multiple subtasks, each of which is either handled with a distinct prompt or computed based on RWE. The full list of prompt designs is presented in Figure 2.
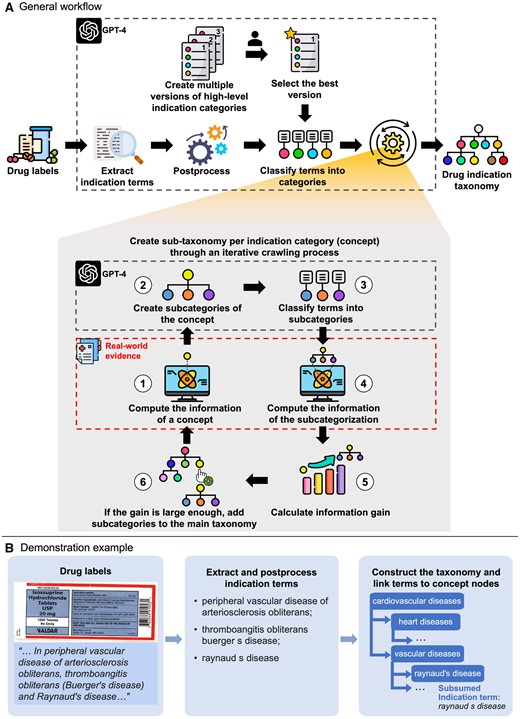
Overview of the development of the drug indication standardized taxonomy induced by large language models (DISTILL) and real-world evidence (RWE). Panel (A) displays the general workflow of the drug indication taxonomy development. Subtasks highlighted within the large black dotted boxes are supported by LLM, and subtasks within the red dotted box are supported by RWE. Panel (B) presents a demonstration example from drug labels to established drug indication taxonomy. Some icons were made by Freepik, Muhammad Ali, Becris, Uniconlabs, Pixel perfect, and xnimrodx from www.flaticon.com.
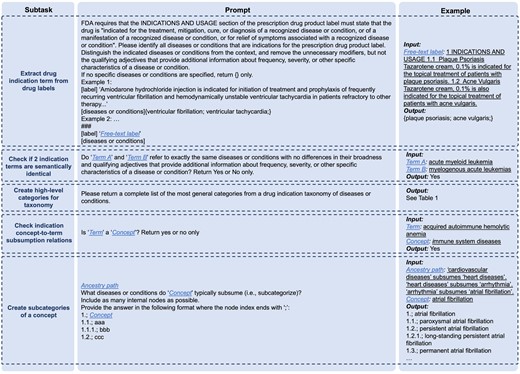
Prompts for 5 subtasks with an example input and output.
Drug indication extraction
DailyMed (https://dailymed.nlm.nih.gov/dailymed/) stores FDA-approved product labels, where the Indications and Usage section provides information on the approved indications.3 We first retrieved all human prescription drug labels and identified the active moieties of drugs. For each active moiety, we identified the drug label with the longest Indication and Usage section by token length, from which we extracted the drug indications using GPT-4 with few-shot prompting. To account for the inherent stochasticity in GPT-4 and obtain a comprehensive list of indications from a label, we executed the prompt five times and subsequently formed the union set of the identified indication terms, defined as the indications of the drug.
We normalized and de-duplicated the resulting set of indication terms from all labels by converting terms to lowercase, removing punctuations and unnecessary spaces through regular expressions, and substituting the suffixes (eg, “infection,” “disease,” “disorder,” “syndrome,” and their plural forms) with the longest suffix found among the terms sharing the same base.
We further sought to eliminate terms that have the same meaning as the others. This was achieved by embedding terms into vectors using the OpenAI “text-embedding-ada-002” model and calculating their cosine similarities. Any term pairs demonstrating a similarity score exceeding 0.9 were further evaluated using GPT-4 to determine whether they corresponded to the same disease or condition. Within each semantically equivalent group, terms with the maximum string length were retained for subsequent analysis.
Drug indication taxonomy learning
We generated various interpretations of high-level categories within a drug indication taxonomy by GPT-4, and the best one was selected by the domain expert. Each category is an indication concept. We assigned the extracted indication terms to these concepts using GPT-4 by checking subsumption relations (“is-a” relationship) between each concept-term pair. We then created a sub-taxonomy for each concept through an iterative crawling process.
After calculating the information of the concept of interest, we created its subcategories using GPT-4 with its whole ancestry provided. We specifically allowed it to generate up to 3 levels of hierarchy, with the first being the concept itself. This aims to include as many true child concepts as possible while avoiding the undesirable outcome of collapsing a multi-layered hierarchy into a flattened structure, where all descendant concepts are reduced into child concepts. All its child concepts were considered subcategories. We classified indication terms into these subcategories by GPT-4 and removed those without an indication term.
We then computed the information of the subcategorization , defined as the average of the information of subcategories, each of which was calculated using Formula (1). We calculated the information gain () from the inclusion of those subcategories. It indicates how well the subcategorization increases the similarity among indication terms falling under the same concept. If the gain was larger than the threshold (eg, 1e-5), we added the subcategories into the main taxonomy representing the subsumption relations between indication concepts. We iteratively and recursively searched for the subcategories of leaf nodes in the updated taxonomy which subsume more than 1 indication term.
We defined and applied multiple intra-procedural rules. First, we prevented terminal drug indication concepts from subcategorization. This type of concept was identified by assessing whether the output from GPT-4 aligned with the regex pattern “not(?:\typically)?\(further\)? (subcat|subsume).” Second, we removed subcategories verbatim identical to their ancestors in the overall hierarchical structure (ie, main taxonomy) to prevent cyclic hierarchies. Third, miscellaneous subcategories (ie, subcategories with keywords such as “miscellaneous,” “unknown,” and “unspecified”) were excluded, while the specified subcategories nested under them were retained and incorporated. Additionally, before creating the subcategories of the concept of interest , we first checked if there was a verbatim identical concept that had been explored. If existed, we directly set the sub-taxonomy of as that of and classified indications terms under into those subcategories. The purpose of this checking was both to optimize computational efficiency and to ensure consistent sub-taxonomy of verbatim identical concepts throughout the entire taxonomy.
After constructing the whole sub-taxonomy for a high-level category, we applied 2 post-procedural rules to further ensure taxonomy consistency. First, we constructed a union set of indication terms subsumed by the nodes that are verbatim identical in the taxonomy. This union set was subsequently assigned to each node within the aforementioned node group. Besides, from the bottom (ie, leaf nodes) to the top (ie, the root node) of the taxonomy, if node is verbatim identical to a sibling (defined as node ) of its ancestor, node and its descendants were removed.
Evaluation
We selected 3 high-level indication categories and constructed their sub-taxonomies. For each sub-taxonomy, we conducted a quantitative topological analysis and a qualitative assessment by comparing DISTILL to SNOMED-CT. We assessed the accuracy of DISTILL by evaluating indication concept-to-concept and concept-to-term relations, respectively. For concept-to-concept relations, we randomly sampled 5% of leaf nodes and retrieved their paths to the root node in DISTILL. We assessed the validity of the subsumption relation for each distinct parent-child concept pair in the paths. For concept-to-term relations, we randomly sampled 10% of distinct concept-term pairs and evaluated the correctness of these subsumption relations. Three experts (ie, G.R., D.D., and P.R.), participated in the evaluation. Inter-rater reliability was assessed through Gwet’s AC1 agreement coefficient.21 The temperature was fixed at 0 in all queries submitted to GPT-4 to decrease variability in output.
Results
Statistics on extracted drug indication terms
We extracted 4190 verbatim distinct indication terms from 46 421 human prescription product labels from DailyMed as of February 2023. After post-processing, we had 2909 terms left. The median number of terms per active moiety is 2. We linked indication terms to RxNorm through product labels. 2219 terms were with corresponding drugs (1177 distinct drugs in total). Additional details on the term extraction results are available in the Supplemental Results.
Statistical and topological characteristics of DISTLL
24 high-level categories of DISTILL are presented in Table 1. For instance, there are 234 indication terms falling under the category of “Cardiovascular disease” with 189 distinct RxNorm drugs associated.
24 high-level categories of the drug indication taxonomy (DISTILL) and related summary statistics.
| Index | Category | Number of indication terms | Number of drugsa |
|---|---|---|---|
| 0 | Cardiovascular diseases | 234 | 189 |
| 1 | Respiratory diseases | 209 | 219 |
| 2 | Digestive system diseases | 311 | 267 |
| 3 | Nervous system diseases | 368 | 303 |
| 4 | Musculoskeletal diseases | 135 | 137 |
| 5 | Endocrine system diseases | 269 | 175 |
| 6 | Immune system diseases | 353 | 296 |
| 7 | Infectious diseases | 521 | 312 |
| 8 | Mental disorders | 85 | 101 |
| 9 | Neoplasms (cancer) | 532 | 192 |
| 10 | Skin diseases | 265 | 257 |
| 11 | Eye diseases | 101 | 80 |
| 12 | Ear, nose, and throat diseases | 107 | 150 |
| 13 | Genitourinary system diseases | 314 | 260 |
| 14 | Blood diseases | 311 | 225 |
| 15 | Congenital, hereditary, and neonatal diseases | 267 | 142 |
| 16 | Nutritional and metabolic diseases | 206 | 156 |
| 17 | Pregnancy complications | 154 | 221 |
| 18 | Substance-related disorders | 42 | 36 |
| 19 | Injuries, wounds, and traumas | 82 | 101 |
| 20 | Poisoning, toxicity, and environmental exposure | 56 | 26 |
| 21 | Rare diseases | 880 | 350 |
| 22 | Aging-related diseases | 228 | 355 |
| 23 | Others | 250 | 252 |
| Index | Category | Number of indication terms | Number of drugsa |
|---|---|---|---|
| 0 | Cardiovascular diseases | 234 | 189 |
| 1 | Respiratory diseases | 209 | 219 |
| 2 | Digestive system diseases | 311 | 267 |
| 3 | Nervous system diseases | 368 | 303 |
| 4 | Musculoskeletal diseases | 135 | 137 |
| 5 | Endocrine system diseases | 269 | 175 |
| 6 | Immune system diseases | 353 | 296 |
| 7 | Infectious diseases | 521 | 312 |
| 8 | Mental disorders | 85 | 101 |
| 9 | Neoplasms (cancer) | 532 | 192 |
| 10 | Skin diseases | 265 | 257 |
| 11 | Eye diseases | 101 | 80 |
| 12 | Ear, nose, and throat diseases | 107 | 150 |
| 13 | Genitourinary system diseases | 314 | 260 |
| 14 | Blood diseases | 311 | 225 |
| 15 | Congenital, hereditary, and neonatal diseases | 267 | 142 |
| 16 | Nutritional and metabolic diseases | 206 | 156 |
| 17 | Pregnancy complications | 154 | 221 |
| 18 | Substance-related disorders | 42 | 36 |
| 19 | Injuries, wounds, and traumas | 82 | 101 |
| 20 | Poisoning, toxicity, and environmental exposure | 56 | 26 |
| 21 | Rare diseases | 880 | 350 |
| 22 | Aging-related diseases | 228 | 355 |
| 23 | Others | 250 | 252 |
Statistics on drugs are based on the available 1177 distinct RxNorm terms that are linked to the indications in the high-level category of interest.
24 high-level categories of the drug indication taxonomy (DISTILL) and related summary statistics.
| Index | Category | Number of indication terms | Number of drugsa |
|---|---|---|---|
| 0 | Cardiovascular diseases | 234 | 189 |
| 1 | Respiratory diseases | 209 | 219 |
| 2 | Digestive system diseases | 311 | 267 |
| 3 | Nervous system diseases | 368 | 303 |
| 4 | Musculoskeletal diseases | 135 | 137 |
| 5 | Endocrine system diseases | 269 | 175 |
| 6 | Immune system diseases | 353 | 296 |
| 7 | Infectious diseases | 521 | 312 |
| 8 | Mental disorders | 85 | 101 |
| 9 | Neoplasms (cancer) | 532 | 192 |
| 10 | Skin diseases | 265 | 257 |
| 11 | Eye diseases | 101 | 80 |
| 12 | Ear, nose, and throat diseases | 107 | 150 |
| 13 | Genitourinary system diseases | 314 | 260 |
| 14 | Blood diseases | 311 | 225 |
| 15 | Congenital, hereditary, and neonatal diseases | 267 | 142 |
| 16 | Nutritional and metabolic diseases | 206 | 156 |
| 17 | Pregnancy complications | 154 | 221 |
| 18 | Substance-related disorders | 42 | 36 |
| 19 | Injuries, wounds, and traumas | 82 | 101 |
| 20 | Poisoning, toxicity, and environmental exposure | 56 | 26 |
| 21 | Rare diseases | 880 | 350 |
| 22 | Aging-related diseases | 228 | 355 |
| 23 | Others | 250 | 252 |
| Index | Category | Number of indication terms | Number of drugsa |
|---|---|---|---|
| 0 | Cardiovascular diseases | 234 | 189 |
| 1 | Respiratory diseases | 209 | 219 |
| 2 | Digestive system diseases | 311 | 267 |
| 3 | Nervous system diseases | 368 | 303 |
| 4 | Musculoskeletal diseases | 135 | 137 |
| 5 | Endocrine system diseases | 269 | 175 |
| 6 | Immune system diseases | 353 | 296 |
| 7 | Infectious diseases | 521 | 312 |
| 8 | Mental disorders | 85 | 101 |
| 9 | Neoplasms (cancer) | 532 | 192 |
| 10 | Skin diseases | 265 | 257 |
| 11 | Eye diseases | 101 | 80 |
| 12 | Ear, nose, and throat diseases | 107 | 150 |
| 13 | Genitourinary system diseases | 314 | 260 |
| 14 | Blood diseases | 311 | 225 |
| 15 | Congenital, hereditary, and neonatal diseases | 267 | 142 |
| 16 | Nutritional and metabolic diseases | 206 | 156 |
| 17 | Pregnancy complications | 154 | 221 |
| 18 | Substance-related disorders | 42 | 36 |
| 19 | Injuries, wounds, and traumas | 82 | 101 |
| 20 | Poisoning, toxicity, and environmental exposure | 56 | 26 |
| 21 | Rare diseases | 880 | 350 |
| 22 | Aging-related diseases | 228 | 355 |
| 23 | Others | 250 | 252 |
Statistics on drugs are based on the available 1177 distinct RxNorm terms that are linked to the indications in the high-level category of interest.
The topological characteristics of the DISTILL sub-taxonomies for 3 high-level categories (ie, “Cardiovascular diseases,” “Endocrine system diseases,” and “Genitourinary system diseases”) are presented in Table 2. The depth of a sub-taxonomy refers to the number of levels from the root node to the deepest node. All 3 categories have a depth of greater than or equal to 10. The width of a sub-taxonomy refers to the number of child nodes of a node in the structure. All 3 categories had a median width of 3 and the maximum widths were all greater than 10. Our primary goal was to create a taxonomy specifically for drug indication, not a comprehensive condition taxonomy. Therefore, nodes lacking associated indication terms were removed from the taxonomy. Out of the 3 categories, “Genitourinary system diseases” has the most complex hierarchical structure with the largest number of nodes (n = 516) and leaf nodes (n = 349), followed by “Endocrine system diseases.” The median number of indication terms per node was consistently 1 across the 3 categories. Figure 3 displays the sub-taxonomy for “Cardiovascular diseases.” The entire sub-taxonomies for the 3 categories are in Table S1.
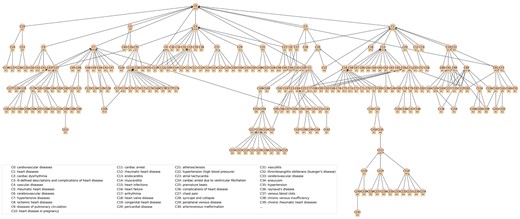
DISTILL sub-taxonomy for the high-level category: Cardiovascular diseases. Identifiers beginning with the letter “C” represent the concept IDs. Names of the first 40 concepts are displayed in the upper right corner of the figure. Numerical values prefixed with the symbol “#” denote the number of indication terms that are linked to the concept nodes. A concept may have multiple parent concepts in the taxonomy. For example, C144 hypertensive heart disease has 2 parent concepts C7 hypertensive diseases and C77 non-ischemic heart failure.
Topological characteristics of the structure of the drug indication taxonomy (DISTILL).
| Index | 0 | 5 | 13 | ||
|---|---|---|---|---|---|
| High-level category name | Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
| Depth | 11 | 14 | 10 | ||
| Width | Median [Q1, Q3] | 3 [2, 5] | 3 [2, 5] | 3 [2, 5] | |
| Min | 2 | 2 | 2 | ||
| Max | 12 | 14 | 16 | ||
| Statistics of all unique nodes | Count | 242 | 339 | 516 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 0 | 0 | 0 | ||
| Max | 23 | 78 | 36 | ||
| Number of nodes with 1+ RxNorm drugs | 199 | 218 | 411 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 7] | 2 [1, 4] | 3 [1, 7] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
| Statistics of unique leaf nodes | Count | 170 | 235 | 349 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 1 | 1 | 1 | ||
| Max | 17 | 78 | 33 | ||
| Number of nodes with 1+ RxNorm drugs | 154 | 169 | 325 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 6.75] | 2 [1, 4] | 2 [1, 5] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
| Index | 0 | 5 | 13 | ||
|---|---|---|---|---|---|
| High-level category name | Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
| Depth | 11 | 14 | 10 | ||
| Width | Median [Q1, Q3] | 3 [2, 5] | 3 [2, 5] | 3 [2, 5] | |
| Min | 2 | 2 | 2 | ||
| Max | 12 | 14 | 16 | ||
| Statistics of all unique nodes | Count | 242 | 339 | 516 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 0 | 0 | 0 | ||
| Max | 23 | 78 | 36 | ||
| Number of nodes with 1+ RxNorm drugs | 199 | 218 | 411 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 7] | 2 [1, 4] | 3 [1, 7] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
| Statistics of unique leaf nodes | Count | 170 | 235 | 349 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 1 | 1 | 1 | ||
| Max | 17 | 78 | 33 | ||
| Number of nodes with 1+ RxNorm drugs | 154 | 169 | 325 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 6.75] | 2 [1, 4] | 2 [1, 5] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
Topological characteristics of the structure of the drug indication taxonomy (DISTILL).
| Index | 0 | 5 | 13 | ||
|---|---|---|---|---|---|
| High-level category name | Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
| Depth | 11 | 14 | 10 | ||
| Width | Median [Q1, Q3] | 3 [2, 5] | 3 [2, 5] | 3 [2, 5] | |
| Min | 2 | 2 | 2 | ||
| Max | 12 | 14 | 16 | ||
| Statistics of all unique nodes | Count | 242 | 339 | 516 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 0 | 0 | 0 | ||
| Max | 23 | 78 | 36 | ||
| Number of nodes with 1+ RxNorm drugs | 199 | 218 | 411 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 7] | 2 [1, 4] | 3 [1, 7] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
| Statistics of unique leaf nodes | Count | 170 | 235 | 349 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 1 | 1 | 1 | ||
| Max | 17 | 78 | 33 | ||
| Number of nodes with 1+ RxNorm drugs | 154 | 169 | 325 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 6.75] | 2 [1, 4] | 2 [1, 5] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
| Index | 0 | 5 | 13 | ||
|---|---|---|---|---|---|
| High-level category name | Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
| Depth | 11 | 14 | 10 | ||
| Width | Median [Q1, Q3] | 3 [2, 5] | 3 [2, 5] | 3 [2, 5] | |
| Min | 2 | 2 | 2 | ||
| Max | 12 | 14 | 16 | ||
| Statistics of all unique nodes | Count | 242 | 339 | 516 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 0 | 0 | 0 | ||
| Max | 23 | 78 | 36 | ||
| Number of nodes with 1+ RxNorm drugs | 199 | 218 | 411 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 7] | 2 [1, 4] | 3 [1, 7] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
| Statistics of unique leaf nodes | Count | 170 | 235 | 349 | |
| Indication terms per node | Median [Q1, Q3] | 1 [1, 3] | 1 [1, 2] | 1 [1, 2] | |
| Min | 1 | 1 | 1 | ||
| Max | 17 | 78 | 33 | ||
| Number of nodes with 1+ RxNorm drugs | 154 | 169 | 325 | ||
| RxNorm drug per node | Median [Q1, Q3] | 2 [1, 6.75] | 2 [1, 4] | 2 [1, 5] | |
| Min | 1 | 1 | 1 | ||
| Max | 62 | 94 | 50 | ||
Comparison between DISTLL and SNOMED-CT
Cardiovascular diseases
In SNOMED-CT, “Disorder of cardiovascular system” has 7585 SNOMED-CT standard descendant concepts, 5917 of which had at least 1 record observed (direct or mapped via source vocabulary) in a network of 15 real-world databases. This includes 53 direct children, among which the most prevalently occurring conditions in real-world data are (with number of descendants and highlighted concepts in descendants): heart disease (n = 2292, heart failure, atrial fibrillation, myocardial infarction), hypertensive disorder (n = 133, essential hypertension, pregnancy-induced hypertension), vascular disorder (n = 3404, including atherosclerosis, migraine, embolism), acute disease of cardiovascular system (n = 347, acute myocardial infarction, paroxysmal atrial fibrillation, transient cerebral ischemia), chronic disease of cardiovascular system (n = 248, chronic heart failure, rheumatic heart disease, chronic atrial fibrillation), cardiovascular injury (n = 791, myocardial infarction, angina pectoris, cerebrovascular accident), peripheral vascular disease (n = 211, peripheral arterial disease, arteriosclerosis of artery of extremity), cerebrovascular disease (n = 556, transient cerebral ischemia, carotid artery obstruction, thrombotic stroke), thrombosis (n = 498, deep venous thrombosis), and low blood pressure (n = 28, orthostatic hypotension). The sub-taxonomy of “Disorder of cardiovascular system” is large, with some concepts having 9 levels of separation, but most concepts (3753/5917) are within 4 levels.
In comparison, the DISTILL sub-taxonomy of “Cardiovascular diseases” is much smaller, having 242 descendant concepts, including 11 direct children (Figure 2): heart diseases (n = 139, endocarditis, heart failure, atrial fibrillation, coronary artery disease, myocardial infarction), hypertensive diseases (n = 42, essential hypertension, pulmonary arterial hypertension, hypertensive heart renal disease), vascular diseases (n = 79, peripheral venous disease, cerebrovascular disease, stroke, myocardial infarction, hypertension, deep vein thrombosis, pulmonary embolism), cardiac dysrhythmia (n = 21, atrial fibrillation), rheumatic heart diseases (n = 3), cerebrovascular diseases (n = 7, stroke), ischemic heart diseases (n = 21, angina, myocardial infarction), diseases of pulmonary circulation (n = 17, pulmonary embolism, pulmonary artery hypertension), heart disease in pregnancy (n = 7), cardiac arrest (n = 3), and ill-defined descriptions and complications of heart disease (n = 70, including heart failure, atrial fibrillation, chest pain, myocardial infarction). While SNOMED-CT is more granular, DISTILL has greater maximum depth than SNOMED-CT, with 1 concept “systemic disease-associated cardiomyopathy” having 10 levels of separation; most concepts (155/242) are within 3 levels.
There is high alignment between the categories in the 2 classifications, with strong overlap in clinical concepts in heart disease, hypertensive disorders, vascular disorder, and cerebrovascular disease. SNOMED-CT split peripheral vascular disease, while DISTILL organized related peripheral venous diseases under vascular diseases. SNOMED-CT created an orthogonal classification of acute and chronic conditions, many of which belong to other ancestors within the “Disease of cardiovascular system” hierarchy. One noteworthy clinical example of classification inconsistency is “ischemic stroke”: SNOMED-CT classifies “cerebral infarction” as a “Disorder of nervous system,” while DISTILL mapped the term “cerebral infarction” to the concept “stroke,” which was classified under both “vascular diseases” and “cerebrovascular diseases” within the “Cardiovascular diseases” sub-taxonomy.
Endocrine system diseases
In SNOMED-CT, “Disorder of endocrine system” subsumes “Diabetes mellitus,” “Disorder of thyroid gland,” “Disorder of ovary,” “Disorder of endocrine gland,” “Neoplasm of endocrine system,” “Disease of pancreas,” “Disorder of pituitary gland,” and “Disorder of adrenal gland” amongst its 47 direct children, collectively covering 2121 concepts. While DISTILL has comparable coverage of diabetes, thyroid/pituitary/adrenal gland-related conditions, and endocrine cancers under its sub-taxonomy of “Endocrine system disorders,” it does not cover hypoglycemia or all other pancreatic or ovary-related disorders (such as acute pancreatitis or ovarian cyst) amongst its 339 concepts. It does, however, contain “hyperlipidemia” and “hypercholesterolemia” under both “lipid disorders” and “metabolic disorders,” which in SNOMED-CT gets classified under “Disorder of lipoprotein and/or lipid metabolism” outside of the “Disease of endocrine system.”
Genitourinary system diseases
SNOMED-CT’s “Disorder of the genitourinary system” concept subsumes 5671 concepts, and has 20 direct children, including “Disorder of urinary system,” “Disorder of reproductive system,” “Chronic disease of genitourinary system,” “Infectious disease of genitourinary system,” “Malignant neoplasm of genitourinary system,” “Inflammatory disorder of genitourinary system,” and “Acute genitourinary disorder.” In contrast, DISTILL’s organization beneath its “Genitourinary system diseases” concept was more anatomically aligned, with direct children including “Urinary tract infections,” “Kidney diseases,” “Bladder diseases,” “Prostate diseases,” “Testicular diseases,” “Penile diseases,” “Urethral diseases,” and “Gynecological diseases,” amongst its 516 concepts. Both contain highly prevalent clinical findings, including “End-stage renal disease,” “urinary tract infectious disease”/“urinary tract infections,” “Acute renal failure syndrome”/“acute kidney injury,” “Primary malignant neoplasm of prostate”/“Prostate cancer,” “Chronic kidney disease,” “Kidney stone,” “testicular hypofunction,” “benign prostatic hyperplasia,” “acute cystitis,” and “dysmenorrhea.” Clinical findings in SNOMED-CT not covered in DISTILL included “hematuria syndrome,” “cyst of ovary,” and “Chronic kidney disease due to type 2 diabetes mellitus.”
Performance of DISTLL
Based on Table 3, for concept-to-concept subsumption relations, the accuracies for each of the 3 high-level categories, as assessed by any of the evaluators, are higher than 0.7. The inter-rater reliability scores exceed 0.7, indicating “good to very good” reliability.22 However, for concept-to-term subsumption relations, the accuracies range from 0.329 to 0.819. The inter-rater reliability scores are lower than 0.5, indicating “fair to moderate” reliability.22
Evaluation results of drug indication concept-to-concept and concept-to-term subsumption relations for 3 high-level categories from 3 evaluators and their inter-rater reliability.
| Relationship type | High-level category | Number of test cases | Accuracy | Gwet’s AC1 coefficient (95% CI) | ||
|---|---|---|---|---|---|---|
| Rater 1 | Rater 2 | Rater 3 | ||||
| Concept-to-concept | Cardiovascular diseases | 49 | 0.857 | 1 | 0.898 | 0.84 (0.733, 0.947) |
| Endocrine system diseases | 73 | 0.863 | 0.986 | 0.712 | 0.72 (0.596, 0.844) | |
| Genitourinary system diseases | 75 | 0.84 | 0.907 | 0.787 | 0.857 (0.784, 0.93) | |
| Concept-to-term | Cardiovascular diseases | 64 | 0.562 | 0.703 | 0.672 | 0.462 (0.285, 0.64) |
| Endocrine system diseases | 85 | 0.6 | 0.8 | 0.329 | 0.234 (0.086, 0.381) | |
| Genitourinary system diseases | 105 | 0.81 | 0.819 | 0.467 | 0.43 (0.293, 0.566) | |
| Relationship type | High-level category | Number of test cases | Accuracy | Gwet’s AC1 coefficient (95% CI) | ||
|---|---|---|---|---|---|---|
| Rater 1 | Rater 2 | Rater 3 | ||||
| Concept-to-concept | Cardiovascular diseases | 49 | 0.857 | 1 | 0.898 | 0.84 (0.733, 0.947) |
| Endocrine system diseases | 73 | 0.863 | 0.986 | 0.712 | 0.72 (0.596, 0.844) | |
| Genitourinary system diseases | 75 | 0.84 | 0.907 | 0.787 | 0.857 (0.784, 0.93) | |
| Concept-to-term | Cardiovascular diseases | 64 | 0.562 | 0.703 | 0.672 | 0.462 (0.285, 0.64) |
| Endocrine system diseases | 85 | 0.6 | 0.8 | 0.329 | 0.234 (0.086, 0.381) | |
| Genitourinary system diseases | 105 | 0.81 | 0.819 | 0.467 | 0.43 (0.293, 0.566) | |
Evaluation results of drug indication concept-to-concept and concept-to-term subsumption relations for 3 high-level categories from 3 evaluators and their inter-rater reliability.
| Relationship type | High-level category | Number of test cases | Accuracy | Gwet’s AC1 coefficient (95% CI) | ||
|---|---|---|---|---|---|---|
| Rater 1 | Rater 2 | Rater 3 | ||||
| Concept-to-concept | Cardiovascular diseases | 49 | 0.857 | 1 | 0.898 | 0.84 (0.733, 0.947) |
| Endocrine system diseases | 73 | 0.863 | 0.986 | 0.712 | 0.72 (0.596, 0.844) | |
| Genitourinary system diseases | 75 | 0.84 | 0.907 | 0.787 | 0.857 (0.784, 0.93) | |
| Concept-to-term | Cardiovascular diseases | 64 | 0.562 | 0.703 | 0.672 | 0.462 (0.285, 0.64) |
| Endocrine system diseases | 85 | 0.6 | 0.8 | 0.329 | 0.234 (0.086, 0.381) | |
| Genitourinary system diseases | 105 | 0.81 | 0.819 | 0.467 | 0.43 (0.293, 0.566) | |
| Relationship type | High-level category | Number of test cases | Accuracy | Gwet’s AC1 coefficient (95% CI) | ||
|---|---|---|---|---|---|---|
| Rater 1 | Rater 2 | Rater 3 | ||||
| Concept-to-concept | Cardiovascular diseases | 49 | 0.857 | 1 | 0.898 | 0.84 (0.733, 0.947) |
| Endocrine system diseases | 73 | 0.863 | 0.986 | 0.712 | 0.72 (0.596, 0.844) | |
| Genitourinary system diseases | 75 | 0.84 | 0.907 | 0.787 | 0.857 (0.784, 0.93) | |
| Concept-to-term | Cardiovascular diseases | 64 | 0.562 | 0.703 | 0.672 | 0.462 (0.285, 0.64) |
| Endocrine system diseases | 85 | 0.6 | 0.8 | 0.329 | 0.234 (0.086, 0.381) | |
| Genitourinary system diseases | 105 | 0.81 | 0.819 | 0.467 | 0.43 (0.293, 0.566) | |
We further computed the self-checking consistency score for the prompt for investigating the concept-to-term subsumption relation and its question-level consistency score using semantically equivalent questions.23 For the self-checking consistency score, the temperature was set to 1,24 and 10 stochastic samples were generated. For the question-level consistency score, the temperature was set to 0 and the following 3 semantic equivalent questions were included (1) “Is “term” subsumed by “concept”? Return yes or no only”; (2) “Does “term” fall under “concept”? Return yes or no only”; (3) “Is “term” a type of “concept”? Return yes or no only”. According to Table 4, concept-term pairs for which all evaluators concurred that GPT-4 accurately identified the subsumption relation, had greater consistencies. Those on which evaluators did not reach a consensus on GPT-4’s judgment, had relatively lower consistencies. Those for which all evaluators concurred that GPT-4’s judgment was inaccurate, had the lowest consistencies.
Average self-checking consistency score and average question-level consistency score for the 3 high-level categories.
| Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
|---|---|---|---|---|
| All cases | N (%) | 64 (100%) | 85 (100%) | 105 (100%) |
| Avg. self-checking consistency score (SD) | 0.095 (0.254) | 0.167 (0.322) | 0.111 (0.27) | |
| Avg. question-level consistency score (SD) | 0.182 (0.244) | 0.176 (0.255) | 0.137 (0.215) | |
| Fully agreed correct cases | N (%) | 27 (42.2%) | 22 (25.9%) | 43 (41%) |
| Avg. self-checking consistency score (SD) | 0.011 (0.042) | 0.077 (0.243) | 0.035 (0.149) | |
| Avg. question-level consistency score (SD) | 0.099 (0.155) | 0.045 (0.117) | 0.039 (0.108) | |
| Discrepant cases | N (%) | 28 (43.8%) | 50 (58.8%) | 52 (49.5%) |
| Avg. self-checking consistency score (SD) | 0.089 (0.218) | 0.142 (0.294) | 0.179 (0.326) | |
| Avg. question-level consistency score (SD) | 0.19 (0.211) | 0.2 (0.269) | 0.192 (0.25) | |
| Fully agreed incorrect cases | N (%) | 9 (14.1%) | 13 (15.3%) | 10 (9.5%) |
| Avg. self-checking consistency score (SD) | 0.367 (0.485) | 0.415 (0.428) | 0.09 (0.285) | |
| Avg. question-level consistency score (SD) | 0.407 (0.401) | 0.308 (0.287) | 0.267 (0.211) | |
| Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
|---|---|---|---|---|
| All cases | N (%) | 64 (100%) | 85 (100%) | 105 (100%) |
| Avg. self-checking consistency score (SD) | 0.095 (0.254) | 0.167 (0.322) | 0.111 (0.27) | |
| Avg. question-level consistency score (SD) | 0.182 (0.244) | 0.176 (0.255) | 0.137 (0.215) | |
| Fully agreed correct cases | N (%) | 27 (42.2%) | 22 (25.9%) | 43 (41%) |
| Avg. self-checking consistency score (SD) | 0.011 (0.042) | 0.077 (0.243) | 0.035 (0.149) | |
| Avg. question-level consistency score (SD) | 0.099 (0.155) | 0.045 (0.117) | 0.039 (0.108) | |
| Discrepant cases | N (%) | 28 (43.8%) | 50 (58.8%) | 52 (49.5%) |
| Avg. self-checking consistency score (SD) | 0.089 (0.218) | 0.142 (0.294) | 0.179 (0.326) | |
| Avg. question-level consistency score (SD) | 0.19 (0.211) | 0.2 (0.269) | 0.192 (0.25) | |
| Fully agreed incorrect cases | N (%) | 9 (14.1%) | 13 (15.3%) | 10 (9.5%) |
| Avg. self-checking consistency score (SD) | 0.367 (0.485) | 0.415 (0.428) | 0.09 (0.285) | |
| Avg. question-level consistency score (SD) | 0.407 (0.401) | 0.308 (0.287) | 0.267 (0.211) | |
Concept-term pairs within the test set were further categorized into fully agreed correct cases (ie, all 3 evaluators concurred that GPT-4 accurately identified their subsumption relation), discrepant cases (ie, evaluators did not reach a consensus on GPT-4’s judgment), and fully agreed incorrect cases (all evaluators concurred that GPT-4 inaccurately identified their subsumption relation). The closer the score to 0, the greater the consistency of the GPT-4’s output.
Average self-checking consistency score and average question-level consistency score for the 3 high-level categories.
| Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
|---|---|---|---|---|
| All cases | N (%) | 64 (100%) | 85 (100%) | 105 (100%) |
| Avg. self-checking consistency score (SD) | 0.095 (0.254) | 0.167 (0.322) | 0.111 (0.27) | |
| Avg. question-level consistency score (SD) | 0.182 (0.244) | 0.176 (0.255) | 0.137 (0.215) | |
| Fully agreed correct cases | N (%) | 27 (42.2%) | 22 (25.9%) | 43 (41%) |
| Avg. self-checking consistency score (SD) | 0.011 (0.042) | 0.077 (0.243) | 0.035 (0.149) | |
| Avg. question-level consistency score (SD) | 0.099 (0.155) | 0.045 (0.117) | 0.039 (0.108) | |
| Discrepant cases | N (%) | 28 (43.8%) | 50 (58.8%) | 52 (49.5%) |
| Avg. self-checking consistency score (SD) | 0.089 (0.218) | 0.142 (0.294) | 0.179 (0.326) | |
| Avg. question-level consistency score (SD) | 0.19 (0.211) | 0.2 (0.269) | 0.192 (0.25) | |
| Fully agreed incorrect cases | N (%) | 9 (14.1%) | 13 (15.3%) | 10 (9.5%) |
| Avg. self-checking consistency score (SD) | 0.367 (0.485) | 0.415 (0.428) | 0.09 (0.285) | |
| Avg. question-level consistency score (SD) | 0.407 (0.401) | 0.308 (0.287) | 0.267 (0.211) | |
| Cardiovascular diseases | Endocrine system diseases | Genitourinary system diseases | ||
|---|---|---|---|---|
| All cases | N (%) | 64 (100%) | 85 (100%) | 105 (100%) |
| Avg. self-checking consistency score (SD) | 0.095 (0.254) | 0.167 (0.322) | 0.111 (0.27) | |
| Avg. question-level consistency score (SD) | 0.182 (0.244) | 0.176 (0.255) | 0.137 (0.215) | |
| Fully agreed correct cases | N (%) | 27 (42.2%) | 22 (25.9%) | 43 (41%) |
| Avg. self-checking consistency score (SD) | 0.011 (0.042) | 0.077 (0.243) | 0.035 (0.149) | |
| Avg. question-level consistency score (SD) | 0.099 (0.155) | 0.045 (0.117) | 0.039 (0.108) | |
| Discrepant cases | N (%) | 28 (43.8%) | 50 (58.8%) | 52 (49.5%) |
| Avg. self-checking consistency score (SD) | 0.089 (0.218) | 0.142 (0.294) | 0.179 (0.326) | |
| Avg. question-level consistency score (SD) | 0.19 (0.211) | 0.2 (0.269) | 0.192 (0.25) | |
| Fully agreed incorrect cases | N (%) | 9 (14.1%) | 13 (15.3%) | 10 (9.5%) |
| Avg. self-checking consistency score (SD) | 0.367 (0.485) | 0.415 (0.428) | 0.09 (0.285) | |
| Avg. question-level consistency score (SD) | 0.407 (0.401) | 0.308 (0.287) | 0.267 (0.211) | |
Concept-term pairs within the test set were further categorized into fully agreed correct cases (ie, all 3 evaluators concurred that GPT-4 accurately identified their subsumption relation), discrepant cases (ie, evaluators did not reach a consensus on GPT-4’s judgment), and fully agreed incorrect cases (all evaluators concurred that GPT-4 inaccurately identified their subsumption relation). The closer the score to 0, the greater the consistency of the GPT-4’s output.
Discussion
We developed an automatic pipeline using LLM and RWE for drug indication taxonomy learning, from free-text drug labels to a structured hierarchical classification of indication concepts. LLMs perform a variety of critical roles in the pipeline, each contributing to a specific subtask and cumulatively enhancing the pipeline’s overall functionality. It functions as a text parser to extract indication terms and a similarity checker to detect their semantic equivalence. It also serves as a content generator to create a more granular classification of indications and a relation checker to determine subsumption relations between 2 clinical entities. RWE, on the other hand, plays the role of a quality controller, ensuring an appropriate granularity and maintaining the right balance in the taxonomy’s structure—neither too shallow to miss essential details and fail to distinguish distinct drug indication terms, nor too deep to become overly complex and create unnecessary subdivisions for semantically equivalent terms. Additionally, we defined rules to maintain consistency and acyclicity of the taxonomy.
The rationale behind deciding on 3 levels of hierarchy for each creation of sub-categories resulted from our iterative and extensive trial-and-error experimentation. We initially restricted it to 2 levels but observed that GPT-4 tended to collapse the hierarchical structure of concepts, which was not desirable because it leads to a large flat list and is against the ontology design principles listed in “Ontology development 101” by Noy and McGuinness.25 Our later experiments with 4 layers resulted in GPT-4 overly emphasizing the depth of the structure, which also did not yield the desired outcome in terms of generating as many accurate child concepts as possible. Therefore, after careful consideration of the tradeoffs between going deeper or shallower in these experiments, we chose the depth of 3, which provided the most desirable balance for our framework.
Cimino26 proposed the widely adopted desiderata for controlled medical taxonomy. Various levels of granularity are preferred and necessary. The 3 high-level categories in the evaluation have a depth comparable to the counterparts in SNOMED-CT. Prior to the proposed approach, we had attempted to derive a complete taxonomy for a root concept using a single prompt; however, the outputs were not satisfactory. It failed to produce a taxonomy with the necessary level of granularity to differentiate indication terms effectively. In this study, we implemented a crawling procedure, enabling the construction of a taxonomy with a fine-grained granularity.
A key desideratum is facilitating the expansion of content. The continuous emergence of novel products targeting newly identified diseases and subtypes underscores this necessity and our framework inherently accommodates such expansions. Upon the identification of a new drug indication term, our method will systematically determine the most appropriate position within the taxonomy by checking its subsumption relation to the concepts from top to bottom and finding its closest ancestor concepts. Additional potential descendant concepts will be generated by LLMs, and their inclusion will depend on their information gain determined by RWE. Multiple previous studies have also investigated the automatic text-mining-based methods for ontology extension, adding new sibling or child concepts to the existing ones in a biomedical ontology.27,28 Compared to theirs, we are taking advantage of LLMs, including their language generation capability, adaptability, and scalability.
Another desirable characteristic is polyhierarchy, where a concept can have multiple parent concepts. It facilitates a variety of strategies for navigating taxonomy and integrating data.29 Fortunately, our framework fulfills this demand. For example, the concept “acute pyelonephritis” belongs to both “kidney infections” and “urinary tract infections with pyelonephritis” in a parent-child relationship. Additionally, our approach also meets the desideratum of avoiding the use of “not elsewhere classified” concepts, whose definitions can only be determined by the rest of the concepts. Miscellaneous concepts were excluded.
We have conducted evaluations for indication concept-to-concept and concept-to-term subsumption relations. The former achieved higher accuracies and “good to very good” inter-rater reliability, suggesting that LLMs are good at constructing their own hierarchies for drug indications. However, the latter achieved lower accuracies and “fair to moderate” inter-rater reliability, indicating the complexity of the concept-to-term subsumption relation determination.
After revisiting the wrong concept-term pairs, 2 primary types of errors were identified. The first type of error refers to the shared children issue. Both the indication concept and indication term function as parents. They share children, but at least 1 of them has their own unique offspring. For example, the concept “arrhythmias in pregnancy” and the term “repetitive paroxysmal supraventricular tachycardia” could potentially share the child “repetitive paroxysmal supraventricular tachycardia in pregnancy,” but “arrhythmias in pregnancy” could have unique children such as “atrial fibrillation in pregnancy.” The prompt was designed to determine an “is-a” relationship between a term and a concept. However, lacking knowledge of any of their potential children led to wrong decisions. A possible solution is to implement a 2-step verification process. For a concept and a term , we can first check the possibility for a patient of having without , and then check the possibility of having without . The idea behind this verification process is to identify the existence of unshared children unique to or . If the output is YY (ie, yes-yes), and have both shared and unshared children. If the output is NN (ie, no-no), and are synonyms. If the output is YN, subsumes , and vice versa. The determination of concept-to-concept relations was not subject to the same issue, owing to its purely top-down derivation process.
The second type of error pertains to the inversion of concept-term subsumption relations. Specifically, the term falling under the concept unexpectedly subsumes that concept. For example, the concept “st-segment elevation myocardial infarction (stemi)” is subsumed by, but does not subsume, the term “acute myocardial infarction coronary occlusion.” A follow-up experiment was conducted where we directed queries to LLMs that inverted the concept-term subsumption relation, asking “Is “concept” a “term”? Return yes or no only”. The responses were affirmative in most of the cases with this type of error, suggesting that they were treated as synonyms.
Additionally, concept-term pairs on which evaluators reach no consensus or even completely disagree tend to exhibit low consistency in their prompt outputs for subsumption relation checking. A lower consistency suggests that GPT-4 may find this task challenging leading to increased chances of mistakes. LLMs still struggle to classify indication terms in unregulated language extracted from product labels into a structured vocabulary. Substantial gains can be further achieved regarding using LLMs for concept normalization.
There are several limitations in our study. First, the available RWE for information gain computation is limited where 24% of indication terms were without a linked RxNorm drug. Imprecision might arise in the process of expanding the taxonomy based on information gain, which could affect its granularity. Second, we only selected GPT-4 as the underlying model. It is crucial to acknowledge the diversity of general LLMs (eg, LLaMA,30 PaLM231) and domain-specific LLMs (eg, PMC-LLaMA,32 Med-PaLM 233). No single LLM consistently outperforms all others across every scenario.34 Conducting comparative studies across various LLMs may be valuable. Additionally, the prompt engineering might not be fully optimized for each subtask. Sivarajkumar et al.,35 investigated the optimal prompt types for different clinical NLP tasks, providing guidance in refining prompts. Regarding the generated high-level categories, many indication terms fell under the category of rare diseases as its definition is vague and diverse. It is recommended to provide a specific definition in the prompt for checking the concept-to-term subsumption relation for the concept “rare diseases.”
Following our current study, numerous potential directions for future research arise. First, we can further take advantage of the inherent non-determinism of LLMs. Beyond using RWE to control the depth of the taxonomy, it can also guide us in selecting the optimal stochastic output of the subcategories for a concept of interest. In addition, it would be worthwhile to explore to what extent a domain-specific LLM helps compared to a general LLM. One might be interested in first fine-tuning an LLM on drug labels and extant biomedical ontologies such as SNOMED and Disease Ontology36 and then using it for drug indication taxonomy construction. Furthermore, future work could involve analyzing drug indications in a more detailed manner, being linked not only to an active moiety but also to its dosage. The drug-indication relationships would be further categorized into prevention, diagnosis, treatment, and symptomatic alleviation. It may be interesting to see how our method can be adapted into a pipeline for constructing an ontology with various attributes and relationships included. Additionally, although we endeavored to develop as comprehensive a taxonomy as possible, we acknowledge that it may remain an incomplete representation. This situation arises because, despite employing an iterative and recursive concept searching strategy, as well as designing prompts specifically crafted to encourage GPT-4 to identify all true child concepts of the concept of interest, achieving complete coverage of all child concepts is inherently challenging. As part of our future work, we plan to assess the completeness of the taxonomy and dedicate efforts towards its refinement. We also plan to enrich our taxonomy by incorporating extracted terms that are subsumed by concept C but not by its child concepts and are not synonyms of C. These will be added as additional child concepts of C, thereby constructing a more comprehensive taxonomy.
Having the detailed pipeline we developed for drug indication taxonomy construction, it is crucial to recognize the broader implications of our approach. Our core principles are to break down the task into manageable subtasks and incorporate RWE to steer the process. The methodologies and strategies we have implemented hold great potential for adaptation and application across various tasks involving information acquisition, normalization, and classification of medical knowledge.
Conclusions
Generative AI can be used to support various taxonomy development activities. However, they do not fully support an end-to-end process such as directly mapping terms to concepts in existing vocabularies or directly generating a complete taxonomy for a concept. We proposed an automatic pipeline integrating LLMs and RWE to generate a taxonomy, optimized to distinguish between indications and further organize the drugs. Further evaluation is needed to assess its support for downstream tasks, such as enabling large-scale phenotyping based on drug-indication relationships and indication taxonomy. Overall, we provide a general framework for developing a taxonomy that can be applied beyond the context of drug indications.
Acknowledgments
The authors would like to thank Gowtham Rao and Dmitry Dymshyts for their clinical expertise and independent validation of the concept-to-concept and concept-to-term subsumption relations.
Author contributions
The authors contributed to the study as follows: Yilu Fang: Idea initialization, conceptualization, methodology, data curation, formal analysis, investigation, validation, visualization, and writing—original draft. Patrick Ryan: Idea initialization, project administration, conceptualization, methodology, formal analysis, investigation, validation, research supervision, and writing—reviewing and editing. Chunhua Weng: Project administration, investigation, funding acquisition, research supervision, and writing—reviewing and editing.
Supplementary material
Supplementary material is available at Journal of the American Medical Informatics Association online.
Funding
The research reported in this publication was supported by the National Center for Advancing Translational Sciences grant OT2TR003434, National Library of Medicine grants 1R01LM014344 and R01LM009886. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Conflicts of interest
Y.F. and C.W. declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. P.R. is an employee of Janssen Research and Development and a shareholder of Johnson & Johnson.
Data availability
The data underlying this article are available in the article and in its online supplementary material. The source code is available upon reasonable request from the corresponding author.
References
Indications and Usage Section of Labeling for Human Prescription Drug and Biological Products–Content and Format Guidance for Industry. https://www.fda.gov/files/drugs/published/Indications-and-Usage-Section-of-Labeling-for-Human-Prescription-Drug-and-Biological-Products-%E2%80%94-Content-and-Format-Guidance-for-Industry.pdf
OHDSI. Usagi. Accessed November 1, 2023. https://github.com/OHDSI/Usagi
Author notes
Patrick Ryan and Chunhua Weng contributed equally and are considered senior authors of this work.

{kind=link}
{kind=link}
{kind=link}