





Abstract
The increasing demands for curated, high-quality research data are driving the emergence of a novel registry type. The need to assemble, curate, and export this data grows, and the conventional simplicity of registry models is driving the need for advanced, multimodal data registries—the dawn of the next-generation registry.
The article provides an outline of the technology roles and responsibilities needed for successful implementations of next-generation registries.
We propose a framework for the planning, construction, maintenance, and sustainability of this new registry type.
A rubric of organizational, computational, and human resource needs is discussed in detail, backed by over 40 years of combined in-the-field experiences by the authors.
A novel field, registry science, within the clinical research informatics domain, has arisen to offer its insights into conceiving, structuring, and sustaining this new breed of tools.
Introduction
One of medicine's thorniest challenges is understanding how populations react to diseases, medications, devices, or other exposures or therapies. Developing innovative methodologies to garner insights about disease progression by tracking cohorts of patients over time can be a difficult, daunting task, doubly so for rare diseases. Understanding compliance with government mandates and guidelines is likewise complex, though the questions here may be more administrative, but no less important.
One shortcut has been to leverage data produced by the healthcare process: the medical records, medical & pharmacy claims, and other routinely collected data—what has come to be known as “secondary data use” in informatics and as “real-world evidence” (RWE) in clinical research.1,2 But this shortcut is rife with bumps. Using routinely collected data for research requires intensive curation to deal with inconsistency, missingness, and a lack of interoperability between base systems.3,4
The authors have collectively spent over 40 years as informaticians, delivering registry projects and data. The observations and conclusions we present help to explain several concepts that are not well-understood in the industry. However, the need for clarity has become more acute in response to the growing variety and complexity of registry programs.
Background
Registries are specialized observational research methods that collect and curate healthcare data for focused needs to very high levels of quality. The earliest registries were built for epidemiological studies and typically revolved around a handful of variables.5 These first-generation registries typically collected and curated similar types of data using a standardized case report form. One such successful registry is the Cystic Fibrosis Registry. The Cystic Fibrosis (CF) Registry started in 1966 when the Cystic Fibrosis Foundation (CFF) established a patient registry to track the health status of CF patients. The registry was created to collect and maintain data on diagnosis, treatment, and outcomes to improve care and advance research.6 Importantly, the CF Registry has also grown and evolved, allowing for new data types, fields, and other capabilities to become part of this well-over 50-year-old system.
Today, genomic sequences, wearable sensors, and other “big data” forms are becoming routine. Linking heterogeneous data types to a single patient over time is feasible and desirable, as is the capacity to run numerous studies on a single platform. Still, both demand greater complexity from supporting systems and processes. Below, we will look more closely at what has changed and what the changes imply.
We use the term “next-generation” to describe an emerging class of registries that already exist; we do not mean to imply that these have not yet come into being. Rather, we mean to point out that, currently, there is a wide spectrum of registry programs that range from traditional to next-generation, with many falling into a transitional zone somewhere in between. Our objective is to highlight the important distinction as a hidden driver of complexity and to identify factors that make building, managing, and sustaining next-generation registries substantially more challenging.
What has changed, and what do the changes imply?
Domain growth
The scope of “registry” has diffused from the original uses for basic epidemiology to cover several related applications. The diffusion makes it challenging to discuss “registries” as a unified whole. The 7 application areas below summarize the bulk of the use cases:
Safety and Surveillance (closest to the earliest epidemiologic use cases)
Medical device or treatment
Clinical research
Care delivery for chronic disease management
Quality improvement
Health Economics and Outcomes Research (HEOR)
Natural history of disease7
These represent broad classes of use cases that may motivate the creation of a registry. Once accrued, registry data may be put to a wide variety of additional analytic and utility uses, such as computational phenotyping, which identifies and/or describes cohorts across single or multiple data types, or cross-linking of patients across registries, which may today is likely to involve sophisticated tokenization approaches. The number of possible uses for collected registry data is unconstraint, and we will not attempt to enumerate them in this article.
Additional users
Many uses imply different types of users from organizations that fund, steward, and own these programs. Today, stakeholders may include academic researchers, regulators, providers, payers, life sciences organizations, patient organizations, and professional societies.
While the number of registry applications has added complexity to registry work, 3 other factors are responsible for the complexity growing exponentially in the last decade.
Factor 1: Agility—the demand for multiple use cases from a single system. Somewhat confusingly, the last application on our list, “natural history of the disease” (marked with an asterisk), has become a shorthand for “registries that serve multiple purposes, including characterizing the natural history of disease.” Further, because new applications often emerge in response to new opportunities, registry programs that need to adapt to additional applications and outputs are often called “agile.” We will refer to this first factor as the “demand for agility.”
Factor 2: Demand for extreme longitudinality refers to tracking over more extended periods and with greater frequency. Some changes in disease are only observable over a span of years. Long-term outcomes from newer therapies, such as genetic and cellular therapies, may even require monitoring of health outcomes over decades to establish safety and efficacy. The long view can reveal patterns invisible at shorter intervals, provided the data are meticulously collected and well-curated. Modern natural history registries track patients for long periods over many observation waves.
Thus, the overall trend with registries is to track the unit of analysis (usually the patient, sometimes the provider) over longer durations and via more frequent waves of data collection. We will refer to this second factor—the desire for longer intervals and more waves of longitudinal follow-up, all connected to the object of study—as the “demand for extreme longitudinality.”
Factor 3: Demand for multi-modality refers to ingesting multiple data types. This is driven by more ambitious research designs and the growing advancement of precision medicine.8 For example, targeted therapies in rare diseases and oncology promote the need for genomics, transcriptomics, imaging, and patient-reported outcomes data. We propose the term “multi-modal,” which already has some informal currency in practice, to describe methods combining many different data types for a more multifaceted view of the patient, disease, or treatment. We will refer to this third factor—the desire to ingest multiple data types for a richer perspective on the object of study—as the “demand for multi-modality.”
Multi-modality adds complexity and cost to data generation. With the rise in artificial intelligence and the ability to leverage machine learning techniques, the demands for this type of data are growing at a similar pace to the advancements in AI.
Next-generation registries
The cumulative impact of the 3 drivers has been multiplicative, pushing complexity to grow geometrically or, in some cases, exponentially. The resulting increase in complexity requires a new approach to registry programs, research models, and platforms. We borrow from emerging industry practice to call this approach “next-generation registries.” Next-generation registries include sophisticated techniques for addressing multi-modality, extreme longitudinality, and agility, but they are more challenging to plan, execute, and sustain.
The next-generation registry must support data collection, ingestion, storage, and emission. Furthermore, it must integrate, harmonize, and curate data to produce fit-for-purpose, high-quality data products. Achieving this—despite the additional challenges of multi-modality, extreme longitudinality, and agility—requires a dramatically expanded menu of capabilities. We next turn to the capabilities necessary to plan, deliver, and sustain a next-generation registry. Please see Figure 1 for an illustration of the differences between traditional and next-generation registries.
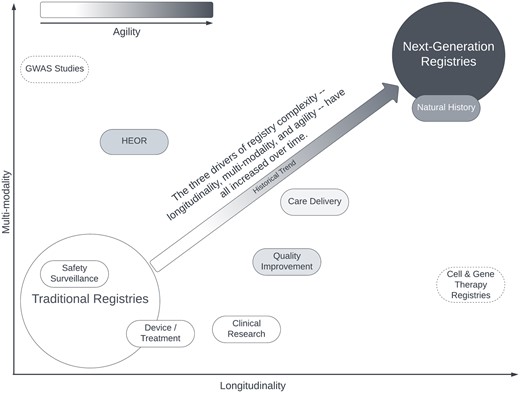
Approximate relative positioning of traditional registry applications and next-generation registries along the 3 dimensions of registry complexity: Longitudinality, multi-modality, and agility. Image used with permission of the authors.9
Application of proposed factors to illustrative examples with existing registries
Table 1 demonstrates how the proposed factors apply to a range of registry programs. The eleven registries were selected to illustrate the variability in modern registry projects. We chose registries that are either well-known in the industry (SEER, Antiretroviral Pregnancy Registry, N3C, All of Us) or those that the authors have direct experience with (IPSO, REN, CFR, ABC-CT, ASH, MMRF, Komen). Note that some of the more sophisticated projects may not call themselves “registries” however, they do fit the conventional definition.10 The factor model holds up well. While the boundary between traditional and next-generation registries is subject to debate, it is clear that the programs low on all 3 factors are much lower in complexity than those that are high on all 3, with the transitional programs falling in between. In practice, complexity maps onto cost. While exact cost numbers are not publically available for most projects, we can informally share from our experience that programs on the traditional end tend to cost in the hundreds of thousands, the transitional in the millions, and the next-generation registries are in the tens of millions.
Examples of traditional, transitional, and next-generation registries.
| Program | Agility | Longitudinality | Multi-Modality | Assessment: Type / Complexity |
|---|---|---|---|---|
| SEER New York Cancer Registry11 | Low | Low | Low | Traditional/Low—example of a epidemilogic use-case registry |
| The Antiretroviral Pregnancy Registry12 | Low | Low | Low | Traditional/Low—example of a pregnancy/safety registry |
| Children’s Hospital Association Improving Pediatric Sepsis Outcomes (IPSO) Collaborative13 | Low | Low | Low | Traditional/Low—example of site-based QI registry example measuring frequency of infections; site is the unit of analysis, not the patient |
| Rare Epilepsy Network (REN)14 | Low | Low | Low | Traditional/Low—example of a rare-disease patient-powered registry collecting patient-generated health data |
| Cystic Fibrosis Registry (CFR)15 | High | High | Medium* | Transitional/Intermediate (*majority of data is eCRF-based, with subsets supplemented with patient surveys) |
| Autism Biomarker Consortium for Clinical Trials (ABC-CT)16 | Medium* | Medium^ | High | Transitional/Intermediate (*data, although highly multi-modal, was collected primarily to create an analytic data set to support planned analyzes for a single study; ∧3 tightly scheduled waves within a 24-month period) |
| NCATS National COVID Cohort Collaborative (N3C)17 | High | High | High* | Next-gen/High (*all data pulled automatically from EHRs but includes a broad swath of clinical, laboratory, medication, and demographic data) |
| ASH Research Collaborative Data Hub18 | High | High | High* | Next-gen/High (*variety of diseases, with some data collection happening across multiple modalities, eg, COVID-19) |
| MMRF CureCloud19 | High | High | High | Next-gen/High |
| Susan G. Komen ShareForCures Breast Cancer Registry20 | High | High | High | Next-gen/High |
| All of Us21 | High | High | High | Next-gen/High |
| Program | Agility | Longitudinality | Multi-Modality | Assessment: Type / Complexity |
|---|---|---|---|---|
| SEER New York Cancer Registry11 | Low | Low | Low | Traditional/Low—example of a epidemilogic use-case registry |
| The Antiretroviral Pregnancy Registry12 | Low | Low | Low | Traditional/Low—example of a pregnancy/safety registry |
| Children’s Hospital Association Improving Pediatric Sepsis Outcomes (IPSO) Collaborative13 | Low | Low | Low | Traditional/Low—example of site-based QI registry example measuring frequency of infections; site is the unit of analysis, not the patient |
| Rare Epilepsy Network (REN)14 | Low | Low | Low | Traditional/Low—example of a rare-disease patient-powered registry collecting patient-generated health data |
| Cystic Fibrosis Registry (CFR)15 | High | High | Medium* | Transitional/Intermediate (*majority of data is eCRF-based, with subsets supplemented with patient surveys) |
| Autism Biomarker Consortium for Clinical Trials (ABC-CT)16 | Medium* | Medium^ | High | Transitional/Intermediate (*data, although highly multi-modal, was collected primarily to create an analytic data set to support planned analyzes for a single study; ∧3 tightly scheduled waves within a 24-month period) |
| NCATS National COVID Cohort Collaborative (N3C)17 | High | High | High* | Next-gen/High (*all data pulled automatically from EHRs but includes a broad swath of clinical, laboratory, medication, and demographic data) |
| ASH Research Collaborative Data Hub18 | High | High | High* | Next-gen/High (*variety of diseases, with some data collection happening across multiple modalities, eg, COVID-19) |
| MMRF CureCloud19 | High | High | High | Next-gen/High |
| Susan G. Komen ShareForCures Breast Cancer Registry20 | High | High | High | Next-gen/High |
| All of Us21 | High | High | High | Next-gen/High |
Examples of traditional, transitional, and next-generation registries.
| Program | Agility | Longitudinality | Multi-Modality | Assessment: Type / Complexity |
|---|---|---|---|---|
| SEER New York Cancer Registry11 | Low | Low | Low | Traditional/Low—example of a epidemilogic use-case registry |
| The Antiretroviral Pregnancy Registry12 | Low | Low | Low | Traditional/Low—example of a pregnancy/safety registry |
| Children’s Hospital Association Improving Pediatric Sepsis Outcomes (IPSO) Collaborative13 | Low | Low | Low | Traditional/Low—example of site-based QI registry example measuring frequency of infections; site is the unit of analysis, not the patient |
| Rare Epilepsy Network (REN)14 | Low | Low | Low | Traditional/Low—example of a rare-disease patient-powered registry collecting patient-generated health data |
| Cystic Fibrosis Registry (CFR)15 | High | High | Medium* | Transitional/Intermediate (*majority of data is eCRF-based, with subsets supplemented with patient surveys) |
| Autism Biomarker Consortium for Clinical Trials (ABC-CT)16 | Medium* | Medium^ | High | Transitional/Intermediate (*data, although highly multi-modal, was collected primarily to create an analytic data set to support planned analyzes for a single study; ∧3 tightly scheduled waves within a 24-month period) |
| NCATS National COVID Cohort Collaborative (N3C)17 | High | High | High* | Next-gen/High (*all data pulled automatically from EHRs but includes a broad swath of clinical, laboratory, medication, and demographic data) |
| ASH Research Collaborative Data Hub18 | High | High | High* | Next-gen/High (*variety of diseases, with some data collection happening across multiple modalities, eg, COVID-19) |
| MMRF CureCloud19 | High | High | High | Next-gen/High |
| Susan G. Komen ShareForCures Breast Cancer Registry20 | High | High | High | Next-gen/High |
| All of Us21 | High | High | High | Next-gen/High |
| Program | Agility | Longitudinality | Multi-Modality | Assessment: Type / Complexity |
|---|---|---|---|---|
| SEER New York Cancer Registry11 | Low | Low | Low | Traditional/Low—example of a epidemilogic use-case registry |
| The Antiretroviral Pregnancy Registry12 | Low | Low | Low | Traditional/Low—example of a pregnancy/safety registry |
| Children’s Hospital Association Improving Pediatric Sepsis Outcomes (IPSO) Collaborative13 | Low | Low | Low | Traditional/Low—example of site-based QI registry example measuring frequency of infections; site is the unit of analysis, not the patient |
| Rare Epilepsy Network (REN)14 | Low | Low | Low | Traditional/Low—example of a rare-disease patient-powered registry collecting patient-generated health data |
| Cystic Fibrosis Registry (CFR)15 | High | High | Medium* | Transitional/Intermediate (*majority of data is eCRF-based, with subsets supplemented with patient surveys) |
| Autism Biomarker Consortium for Clinical Trials (ABC-CT)16 | Medium* | Medium^ | High | Transitional/Intermediate (*data, although highly multi-modal, was collected primarily to create an analytic data set to support planned analyzes for a single study; ∧3 tightly scheduled waves within a 24-month period) |
| NCATS National COVID Cohort Collaborative (N3C)17 | High | High | High* | Next-gen/High (*all data pulled automatically from EHRs but includes a broad swath of clinical, laboratory, medication, and demographic data) |
| ASH Research Collaborative Data Hub18 | High | High | High* | Next-gen/High (*variety of diseases, with some data collection happening across multiple modalities, eg, COVID-19) |
| MMRF CureCloud19 | High | High | High | Next-gen/High |
| Susan G. Komen ShareForCures Breast Cancer Registry20 | High | High | High | Next-gen/High |
| All of Us21 | High | High | High | Next-gen/High |
Capabilities required to create next-generation registries: the dawn of registry science
The required skills and capabilities intersect with observational and outcomes research, epidemiology, population health, statistics, data science, medical informatics, genomics, transcriptomics, real-world data/real-world evidence (RWD/RWE), and information technology. Less obviously, they may include areas like social science and behavioral economics to maximize stakeholder engagement, as well as skills for managing long-term sustainability and operations that ensure complex programs can thrive over time, such as Human Resources and Finance/Fund Raising. Whereas in the past, a single scientist/informatician might be able to build and run a registry, that is no longer the case today. A program leader, such as a Chief Data Officer, should understand the contribution of the varied skills and capabilities to the success of a next-generation registry program. Part of their leadership is to ensure that the correct skills are brought to bear at the right time in the program’s life cycle to ensure overall success.
We also raise a question: is the complexity of the next-generation registries such that we need a sub-discipline called “Registry Science” within Informatics? In addition to connecting with Clinical Research Informatics, which has traditionally concerned itself with registry programs, “Registry Science” would cover managing the emerging complexity born of interactions between agility, extreme longitudinality, and multi-modality.
Needed capabilities are organized in layers
Next-generation registries require extensive capabilities, but the menu is organized into sections. We propose considering the sections as “layers” since the layering metaphor correctly implies that higher levels depend on the lower. From lowest to highest, they are the program layer, the technology platform layer, and the research initiative layer.
The program layer: The lowest foundational level is the programmatic infrastructure. This level includes capabilities necessary for long-range planning and management of the registry program as a whole, including aligning the research, technology, and business considerations.
The technology platform layer: The second layer includes the information technology tooling and staffing necessary to launch and execute the registry. It is especially critical where multi-modal data are being collected (data of different modalities such as genomic or imaging) and integrated using the technology stack and where the needs for longitudinality and agility are high.
The research initiative layer: The topmost layer includes the capabilities for long-range and day-to-day research activities that must be performed to collect and prepare data for use. It is usually performed by research staff under the supervision of a PI or some analogous model.
In our model, shown in Figure 2, each of the 3 layers includes 7 capabilities needed to ensure a registry's construction, launch, and long-term viability.
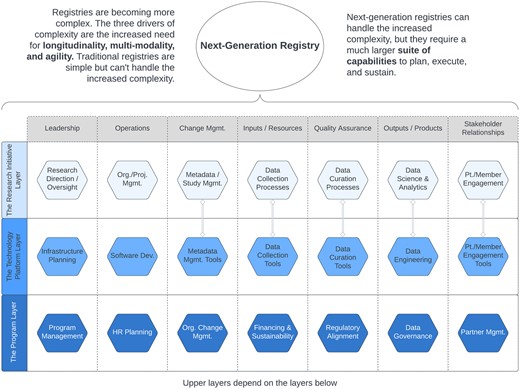
Capabilities need to plan, execute, and sustain next-generation registries. Double-line links between pairs of items show close direct dependencies. Used with permission of the authors.22
Capabilities: Expanded definitions
The sections below will provide expanded descriptions of the capabilities listed in Figure 2, which are needed to support each of the 3 layers of a next-generation registry program.
Program-level infrastructure capabilities
Program management: This is a critical infrastructure capability required to establish leadership and vision, and align participants towards common objectives, and is often overlooked. Program managers, often certified in project management (such as PMP certification),23 excel at maintaining order in potentially chaotic environments.
Human resources: A large multi-modal registry requires different skill sets at different stages of its life cycle. HR professionals are crucial in ensuring the right hires are made at the appropriate times. For instance, early on, engineering skills may be crucial, while patient engagement specialists become vital for long-term success as the system matures.
Partner management. While basic registries may involve only a few partners, natural history or multi-modal registries require an array of collaborators, from vendors to customers, to ensure success. Skilled partner managers are vital in smoothly coordinating and overseeing these external organizations, enhancing the registry's overall efficiency.
Regulatory & legal alignment—Regulatory and legal considerations are significant for research-oriented registries, although the specifics will depend on jurisdiction and scope. For example, US registries that use healthcare-generated data must navigate HIPAA, while those in the EU must tackle GDPR. Registries seeking to acquire data from US provider systems may need to understand the 21st Century Cures Act interoperability anti-data-blocking rules.24 Any activity that may fits the US definition of Human Subjects Research must comply with the Common Rule25 (eg, obtain informed consent). Special attention needs to be paid to national, regional, and local laws that govern consent26 and data sharing.27
Organizational change management—Many organizations planning an ambitious registry program need to prepare for substantial organizational change required for long-term success. These changes can be especially difficult to manage when they generate friction between managers who control different overlapping domains.
Data governance—Because next-generation registries cannot foresee all the future use cases, sound data governance is essential throughout the registry's life. Effective registry data governance considers how the data can be or should be used, who gets to use it, and for what purpose.
Financing and sustainability—Financial sustainability is not an issue for every registry, but the trend is greater attention to funding. For example, if a patient advocacy organization is launching a registry to study a rare disease and does not have a grant or other sustainable funding source, finding a way to generate revenue will constrain long-term sustainability.
One relatively new approach to funding and sustainability is to monetize the data produced by a registry. While promising, it can introduce additional complexities and conflicts of interest among the owners and their partners/customers.
Technology platform-level infrastructure capabilities
Infrastructure planning—Even a registry that starts simply may grow more complex. Because these systems are meant to run for decades and often need to evolve over time, an infrastructure that can adapt to anticipated changes is critical. Adaptability requires early planning.
Data collection tools—User interfaces must address the main data entry challenges of the study participants, data entry staff, and data managers.
Data curation tools—High levels of data curation differentiate registries from other systems. Including the right tools to help automate data cleansing and cleanup is critical. There are suites of curation tools that can be used for these tasks. These include everything from EHR metadata tagging to natural language processing tools for free text. Knowing which tools are best for which task and how to include them in the overall platform can make a big difference in the manual effort required for high data usability downstream.
Data engineering—Ensuring that data flows effortlessly through the data collection steps onward to the curation and storage steps requires that sound engineering and architecture principles are applied at each step of the program. Comprehensive requirements gathering by the data engineering team is a step that should be considered.
Metadata management tools—New metadata terms, ontologies, and vocabulary may be needed for next-generation registries. This could occur during the formative stage of the registry, or it could occur during the registry’s run mode as new medicines and therapies may be invented. Having tools that enforce sound metadata management practices can become essential to the value of the resulting data as well as its ease of use in the analytics phase.
Software development—A registry solution needs software development that follows best industry practices (eg, collaborative revision control; agile programming teams; release staging; unit and regression testing). These needs often arise in customizing and integrating front-end components.
Patient/member engagement tools—Patient/member engagement and retention is critically important, especially as these systems may have a long-life expectancy. Keeping patients or participants interested in continued participation will not only provide the long-term longitudinal data required for a registry but will also ensure a better chance of data completeness. Techniques borrowed from the domain of Behavioral Economics and Psychology can play a major role in keeping patients engaged.28
Research initiative-level infrastructure capabilities
Research direction/oversight—Providing overall project vision and direction for the program's research agenda is essential to success. Without strong leadership and oversight, these complex projects can stall. In addition to clinical experts, early planning should include epidemiologists and statisticians who can shape research methods toward desired analytic results.
Data collection processes—Data collection processes may be simple or complex. Although retrospective (and retrolective) data collection is somewhat more common than prospective, the latter becomes central to natural history studies, especially of rare diseases, increasing collection complexity further. The Technology Platform layer defines the tools to be used; the Research Initiative layer defines the processes. Sound planning for how you are going to collect data into your registry is only part of this capability. Piloting all processes, including how the data are collected, can dramatically help with a smooth execution phase.
Data curation processes—Effort invested in data curation pays off during the program's data analytics and visualization phases. Curation processes might entail activities such as metadata tagging, ensuring the appropriate use of data standards for clinical elements,29 or conformance with an overall standard data model (eg, FHIR or OMOP). The Technology Platform layer can provide tools that automate some of the data curation functions, but the unavoidable human effort required to use the tools belongs in the Research Initiative layer.
Metadata study management—In many cases, metadata study management is coupled with data curation. As with data collection and curation, the tooling to automate metadata study management must be delivered in the Technology Platform layer, but the human activities implementing the processes are included in the Research Initiative layer. Early in the construction of a registry, having experts involved in selecting metadata standards will ensure that the overall quality of the resulting data will be of the highest quality.
Data science and analytics—The ultimate value of a registry program will be judged by its ability to produce analytic data sets that can address questions of interest. Involving analysis experts early can pay dividends as they can anticipate data collection and curation features that will enable more powerful analytics.
Multi-modality and longitudinality increase the importance of Data Science and Data Engineering during planning, execution, and use. Integrating data sets of different types and/or collected during different waves is complex, and the ability to generate a harmonized data set for analytics is far from given. Advanced involvement from skilled data scientists and data engineers is essential.
Organizational management—Frequently, it takes many skills and people to ensure that the system will work. Organizing the many roles and skills to work together requires organizational management. Managing internal teams with things like RACI models (responsible, accountable, consulted, informed) helps manage the construction and execution of many registries, as does having an appropriate organizational management and leadership structure for the various departments involved.
Engagement planning—Regardless of whether the study unit is a medical practice or an individual patient, well-thought-through plans are needed to ensure that the subject of study remains engaged for the duration. Losing subjects to attrition devalues the overall data set. A good subject engagement plan will entice sites, patients, and other participants to stay with the research for as long as possible.
Discussion
Next-generation registries are rapidly emerging as important methods in Informatics. They can deliver highly curated, temporally relevant longitudinal data supporting precision care and the training data needs of AI/ML applications. To construct, implement, and sustain these sophisticated programs, organizations need capabilities from the program, technology, and research layers. We recommend naming this expanded perspective on capabilities “Registry Science.” The capabilities model we presented above should help data leaders anticipate the complexities and plan for the success of these promising methods and may form a starting point for further developments in Registry Science.
Several observations arise from the model:
Curation is critical to success: Data curation capabilities are required for all registry types. Curation may remain manual with traditional registries. However, next-generation registries may require (and benefit from) significant automation to achieve the curation of integrated data sets.
Data science and analytics capabilities must be considered at the program's outset: The value of the registry is judged by its output data products. With traditional registries, the outputs look like the inputs: the analytic data set is often a direct mapping from the data collection tool(s). Next-generation registries may have many data products, none of which look much like the inputs. Involving data engineers, data scientists, and visualization experts early in registry design ensures the outputs can meet analytic goals.
Attention to confidentiality and privacy: Once multiple data types are brought together, risks of reidentification may grow unpredictably. Additional care must be taken to protect privacy and confidentiality, especially with rare diseases or treatments.
The value of a registry depends on data quality, diversity, and completeness: The value of traditional and next-generation registries is predicated on how much quality data in each domain is matched to a single patient.
There is also a need for improved standards and interoperability:
Adherence to Standards is Key for Interoperability and Data Integration. As complexity increases across next-generation registries, the ability to consolidate, exchange, and collectively analyze similar data elements across systems will require strict adherence to common data, clinical terminology, security, privacy, and ethical standards. Formalizing “Registry Science” as a discipline could promote defining, disseminating, and gaining adoption of such operational standards.
Cross-Registry Data Linkage and Federated Analytics Demand Increased Interoperability. The factors driving registry complexity also create opportunities for innovative analytics by linking patient data across independent registries. Realizing techniques like federated analysis on distributed data or token-based record linkage requires compatible data environments, standardized APIs, strictly aligned metadata, and unified policy frameworks. A consolidated Registry Science community could lead the development of models and specifications to enhance interoperability.
Shared Metadata Standards, Data Models, and Exchange Formats are Needed as Complexity Increases. As registries evolve to support more use cases using more modalities while operating over longer time horizons, the consistency and compatibility of data structures become more critical. A discipline of Registry Science should seek to define, extend, and govern common specifications, schemas, and exchange formats tailored to registry requirements as they become more sophisticated.
Traditional registries are analogous to a time-lapse movie: that is: If you take images of a flower opening once an hour at an identical interval, you can see the subtle changes as the flower opens its petals. Registries provide the temporal lag needed for that “time-lapse” view of data to ensure researchers can detect subtle changes over time. They are, in a sense, a method for amplifying subtle, temporally extended signals by using a repeated-measures, within-subjects design to increase the power to detect small changes over time.
Multimodal datasets expand registries from a single time-lapse movie to many such films from different perspectives focused on the same subject, with some modalities adding the equivalent of audio (or other) tracks. To push the analogy further, by integrating these multiple perspectives, we may be able to construct a 4D (3D + time) model of the flower and thus generate views that were not collected initially or anticipated. Replace the flower with the patient, and we see why next-generation registries must support agile outputs by creating representations integrating multi-modality and longitudinality.
The increasing complexity of registry programs demands a dedicated focus on developing a knowledge base and skills that do not exist. A formalized “Registry Science” discipline could produce standardized best practices, reference data and vocabulary models, metadata schemas, architectural frameworks, and financial models tailored specifically for registries. For example, documentation on ideal technical architectures, validated approaches to collecting multi-modal data, gold-standard methods for computational phenotyping from registry data, common policies for ethics and privacy protection, and sustainable business models. By bringing together cross-disciplinary experts into a consolidated registry science community to produce such knowledge assets and training programs, operational excellence and continuous improvement of registry implementations could be greatly enhanced.
Conclusions
The increasing complexity of next-generation registries requires dedicated focus and science behind conceiving, planning, executing, curating, analyzing, and sustaining them. Formalizing “Registry Science” as a discipline will produce the knowledge base and skills to successfully manage modern demands for sophisticated registry systems and their resulting data. We have presented a perspective on why registries are valuable, how they have developed, and why they are changing. We have explained how increased demand for longitudinal and, multi-modal registries. We have described agile approaches that have pushed the field from traditional to next-generation registry methods. We have then described a model of capabilities needed to implement these sophisticated methods and briefly discussed that achieving these capabilities requires multi-disciplinary teams and leaders.
The proposed model structures the wide range of capabilities needed for overall success. We hope it serves as a helpful guide to those considering next-generation registries. It should also provide managers, stakeholders, and participants involved in such registries with a clear understanding of what is expected during a registry’s planning, construction, and lifespan.
We also hope the informatics community begins formalizing the emerging practice as the new discipline: Registry Science.
Acknowledgments
The authors gratefully acknowledge the assistance of Natasha Dudek, PhD, Qunatori, and Rachel Richesson, PhD, University of Michigan, for their generous contributions in editing and reviewing early drafts of this work. The authors would also like to acknowledge the work of the Multiple Myeloma Research Foundation’s CureCloud Team, without which the impetus for this article might not have happened.
Author contributions
The initial conceptualization of the article was done by L.R. and S.L.; and L.R., S.L., and Y.Q. agreed to the outline of the article. S.L. and L.R. together wrote the first draft of the manuscript. All authors contributed to the writing and revision. All authors revised and approved the final manuscript.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors. The views expressed in this publication are those of the authors and not necessarily those of their employers. The only funding provided was in the form of the salaries for the authors from their home institutions.
Conflicts of interest
The authors have no competing interests to declare.
Data availability
There were no experimental data created nor analyzed for this article. Therefore, there is none to disclose or make available.
References
Larsen GY, Brilli R, Macias CG, et al. Development of a quality improvement learning collaborative to improve pediatric sepsis outcomes. Pediatrics. 2021;
Rare Epilepsy Network (REN). About REN. Accessed January 12, 2024. https://www.rareepilepsynetwork.org/about
Cystic Fibrosis Foundation. Patient Registry. Accessed January 6, 2024. https://www.cff.org/medical-professionals/patient-registry
McPartland JC, Bernier RA, Jeste SS, et al. The Autism Biomarkers Consortium for Clinical Trials (ABC-CT): scientific context, study design, and progress toward biomarker qualification. Front Integr Neurosci. 2020;14:16. https://doi.org/10.3389/fnint.2020.00016
ASH Research Collaborative. The Date Hub. Accessed January 12, 2024. https://www.ashresearchcollaborative.org/s/about-the-data-hub
National Institute of Health. The Future of Health Begins with You. Accessed January 6, 2024. https://allofus.nih.gov/
The Knowledge Refinery. The Evolution of Healthcare Registries from Traditional to Next-Generation. Accessed January 16, 2024. https://knowledgerefinery.substack.com/p/the-evolution-of-healthcare-registries
PMP® Certification Requirements. The Project Management Academy. Accessed July 25, 2022. https://projectmanagementacademy.net/pmp-certification- requirements
HealthiT.gov. Information Blocking. Accessed July 19, 2023. https://www.healthit.gov/topic/information-blocking.
U.S. Department of Health and Human Services. Federal Policy for the Protection of Human Subjects ('Common Rule'). Accessed August 21, 2023. https://www.hhs.gov/ohrp/regulations-and-policy/regulations/common-rule/index.html

{kind=link}
{kind=link}