





Abstract
Horizontal and vertical scalability have been widely studied in the context of computational resources. However, with the exponential growth in the number of connected objects, functional scalability (in terms of the size of software systems) is rapidly becoming a central challenge for building efficient service-oriented Internet of Things (IoT) systems that generate huge volumes of data continuously. As systems scale up, a centralized approach for moving data between services becomes infeasible because it leads to a single performance bottleneck. A distributed approach avoids such a bottleneck, but it incurs additional network traffic as data streams pass through multiple mediators. Decentralized data exchange is the only solution for realizing totally efficient IoT systems, since it avoids a single performance bottleneck and dramatically minimizes network traffic. In this paper, we present a functionally scalable approach that separates data and control for the realization of decentralized data flows in service-oriented IoT systems. Our approach is evaluated empirically, and the results show that it scales well with the size of IoT systems by substantially reducing both the number of data flows and network traffic in comparison with distributed data flows.
1. INTRODUCTION
The Internet of Things (IoT) is penetrating essential domains of our daily life such as healthcare, security or city management. This emerging paradigm promises the seamless interconnection of any physical object (i.e. thing) through innovative distributed services, leading to service-oriented IoT systems.1 A proper service composition mechanism is thus required for the integration of IoT services into workflows that consist of both control flow and data flow [1]. Control flow refers to the order in which services are executed, whilst data flow defines how services move data over the network.
As of early 2021, there are over 20 billion connected things and it is predicted that this number will exponentially grow in the next few years [2–4]. Hence, as IoT systems may potentially consist of an overwhelmingly large number of services, functional scalability becomes a challenging concern. Unlike vertical and horizontal scalability, functional scalability accommodates growth in terms of the number of services composed in an IoT system [1]. To tackle the functional scalability challenge, a service composition mechanism must provide the means to compose loosely coupled services that exchange data as efficiently as possible over the network.
IoT services can exchange data in three different ways: (i) with a centralized coordinator, (ii) with multiple distributed coordinators or (iii) in a purely decentralized manner. A centralized approach [5] relies on a single coordinator to mediate data streams between services. Although this is viable for enterprise scenarios where small amounts of data are involved, the coordinator would easily become a bottleneck in IoT systems that generate data in the order of Petabytes. To avoid the central bottleneck, a distributed approach [6] can be used for balancing loads over multiple coordinators. However, this would cause network performance degradation as data passes through multiple mediators before reaching the actual data consumers.
A decentralized approach is the most efficient way to exchange data as it enables direct data exchanges from producers to consumers, thereby decreasing latency and maximising throughput [7–14]. However, exchanging data among loosely coupled IoT services is not trivial, especially in resource-constrained environments where things have poor network connection and low-disk space [7]. Furthermore, building data dependency graphs is hard when control flow and data flow are tightly coupled (i.e. when data follows control). To overcome such issues, recent research [1, 8, 15–18] shows that the separation of control and data can be useful since it allows independent reasoning, monitoring, maintenance and evolution of control flow and data flow. Consequently, an efficient data exchange approach can be defined without considering control, so a reduced number of messages can be transmitted over the network.
1.1. Related work
This section presents and analyses related work on decentralized data flows in service-oriented systems. We classify the existing approaches into three major categories, depending on the composition mechanism they are built on: (i) orchestration (with coordinated data exchanges), (ii) P2P dataflows and (iii) P2P choreography.
In orchestration-based approaches [11, 19–21], a central orchestrator coordinates system execution by passing data references alongside control. Although data values do not follow control like in traditional orchestration [22, 23], additional network traffic is introduced since references and acknowledgement messages are routed via the network. This additional network traffic arises from the fact that orchestration-based approaches do not separate data and control.
Dataflows is a composition mechanism that builds a graph of data transformations, where vertices receive data, perform some computation and pass the result(s) to other vertices via data flow edges [24, 25]. Such data exchanges can be done with or without mediators. In P2P dataflows [14, 26–29], services exchange data with no mediators between them [1]. As control flow is implicit in the collaborative exchange of data, P2P dataflows do not separate data and control.
Service choreography describes decentralized interactions among participants using a well-defined public protocol. In P2P choreography, atomic services are participants that exchange data via direct message passing [30]. Some approaches [13, 31] introduce proxies to coordinate the invocation of services and the exchange of data alongside control. In any case, P2P choreography does not separate data and control.
Table 1 summarizes our analysis of related work, where it is clear that there is no approach supporting the separation of control and data for realizing decentralized data flows between atomic services, in order to efficiently support environments that generate huge volumes of data continuously. Furthermore, existing approaches only consider vertical and horizontal scalability. It is important to mention that the separation of concerns does not imply decentralization but provides a number of benefits. Particularly, the separation is necessary to avoid passing references alongside control during system execution, thus reducing the number of messages transmitted over the network. Also, the orthogonality of data and control enables separate reasoning, monitoring, maintenance, reuse and evolution of those concerns, as discussed in other studies [1, 8].
Analysis of related work.
| Approach | Separation of data and control | Functional scalability | Decentralized dataflows |
|---|---|---|---|
| Orchestration with coordinated data exchanges | |||
| P2P dataflows | |||
| P2P choreography | |||
| Our approach |
| Approach | Separation of data and control | Functional scalability | Decentralized dataflows |
|---|---|---|---|
| Orchestration with coordinated data exchanges | |||
| P2P dataflows | |||
| P2P choreography | |||
| Our approach |
Analysis of related work.
| Approach | Separation of data and control | Functional scalability | Decentralized dataflows |
|---|---|---|---|
| Orchestration with coordinated data exchanges | |||
| P2P dataflows | |||
| P2P choreography | |||
| Our approach |
| Approach | Separation of data and control | Functional scalability | Decentralized dataflows |
|---|---|---|---|
| Orchestration with coordinated data exchanges | |||
| P2P dataflows | |||
| P2P choreography | |||
| Our approach |
In the analysis above, we did not consider decentralized orchestration, coordinated dataflows and choreographed orchestration, since those approaches do not support decentralized data flows between atomic services. Nevertheless, for completeness, we analyse those categories below.
In approaches built on top of decentralized orchestration, multiple composite services coordinate system execution [9, 10, 12, 32]. In particular, approaches like [32] persist data on distributed data spaces, which may become a bottleneck in IoT environments where services exchange huge volumes of data continuously. Although some works (e.g. [12]) solve the bottleneck issue by persisting references instead of values, they require the maintenance of tuple spaces and databases for moving references and storing data, respectively. Moving references is necessary because decentralized orchestration does not separate data and control. Paradoxically, decentralized orchestration does not support decentralized dataflows between atomic services.
In coordinated dataflows [33], a master composite coordinates data flows between slave composites. As data pass through multiple mediators, this approach introduces unnecessary network hops (like decentralized orchestration). This problem is also present in [34], which introduces the notion of abstract data types for moving data outside services. Discovery Net [35] and Kepler [36] are workflow systems that implement the semantics of coordinated dataflows, which provide mechanisms to coordinate the execution of (disjoint) data flow graphs. Discovery Net allows the definition of a control flow graph where nodes exchange control tokens instead of data values. Nodes can be data flow graphs per se. In Kepler, a director is a semantic entity that controls data exchanges from outside a data flow graph. These systems do not support decentralized data flows because their workflow execution mechanisms are centralized [9].
In choreographed orchestration, data pass through multiple orchestrator participants leading to network degradation [37]. To separate control and data, [8] proposes a choreographed orchestration approach that allows the manual modelling of cross-partner data dependencies. However, there are no decentralized data flows between atomic services, but only between partners.
1.2. Paper contributions
This paper proposes a functionally scalable approach that semantically separates data and control, in order to decentralize data flows between atomic services in IoT systems. Accordingly, this paper makes the following contributions:
We propose an (implementation-independent) service composition model that semantically separates data and control by so-called data forests. The semantics allows the encapsulation of explicit control flow graphs and explicit data dependency graphs. As graphs are orthogonal, the semantics enables a separate reasoning and analysis of data and control.
We propose an efficient algorithm that leverages the model semantics for a compositional analysis of data forests. The algorithm analyses a data dependency graph, without considering control flow, for the automatic construction of a decentralized mapping between data consumers and data producers. The algorithm reduces both the number of data flows and network traffic of an IoT system.
Unlike the state-of-the-art on decentralized data flows, we evaluate the proposed approach in terms of functional scalability. The evaluation is implementation-independent and shows that the approach scales well with the number of services by reducing the number of data flows linearly and network traffic logarithmically.
1.3. Paper organisation
The rest of the paper is organized as follows. Section 2 presents a motivating scenario to explain why decentralized data flows are a crucial desideratum in the IoT domain. Section 3 presents an overview of the model semantics and a detailed description of the proposed approach. Section 4 presents the implementation of the proposed solution. Section 5 presents a case study. Section 6 presents a comparative evaluation of decentralized data flows versus distributed data flows in the case study. Section 7 outlines an evaluation of the proposed approach in terms of functional scalability. Section 8 outlines the conclusions. Appendices A and B formalise our motivating scenario. Appendix C describes an example of the deployment-time process. Appendix D presents a source code fragment of our implementation. Appendix E presents the notation used throughout the paper.
2. WHY DO WE NEED DECENTRALIZED DATA FLOWS IN IOT?
This section discusses the rationale for enabling decentralized data flows in IoT, with the help of a scenario based on the smart parking system presented in [1] and real-world occupancy data from car parks in Birmingham, UK (Appendix A). The system is used by drivers who want to find the nearest parking space while they drive around a smart city. The workflow for this scenario is a combination of the reduce and the sequential data patterns and involves the services shown in Figure 1. Although data pass through operations, we consider that it is routed between services as there is a one-to-one relationship between services and operations. For simplicity, we assume that services are deployed on different things, e.g. the Availability Checking Service is deployed on an infostation while the Space Finding Service is deployed on an edge router. An infostation is an urban infrastructure device that collects up-to-date status from all occupancy sensors in range. We assume that all parking spaces are equipped with occupancy sensors whose functionality is abstracted by a Sensor Service.

Workflow of the smart parking system.
The workflow of our scenario is triggered by a driver’s request, and it starts with two parallel tasks. In the first one, the Data Reducer 2 receives the driver’s coordinates from the GPS Service. In the second one, the Data Reducer 1 pulls the states from multiple Sensor services to create a list that shows the status of parking spaces. Then, the Availability Checking Service uses the list to determine which parking spaces are free. As some spaces can be reserved in advance, the Reservation Service determines which free parking spaces are unreserved and passes its resulting list to the Data Reducer 2. Once the Data Reducer 2 receives all its inputs, it forwards them to the Mapping Service. The Mapping Service then computes the distance between each (free and unreserved) space and the driver’s location and appends the distances to the list. Finally, the Space Finding Service determines the nearest parking space for the driver, using the calculations from the Mapping Service. The coordinates of the nearest parking space are the final result of the workflow and are passed to the car control application.
As the number of occupancy sensors could be huge, especially in large cities, the services of the smart parking system may potentially exchange vast amounts of data continuously. This is because there is a one-to-one mapping between sensors and services, and occupancy sensors are frequently producing data. Thus, functional scalability becomes a challenging concern. To understand how we can address this problem, we analyse the three existing approaches for passing data between the services of our scenario (Fig. 2). For simplicity, we do not show control flow and we assume that there are no data required for both pulling sensor data and starting the execution of the system (from the car control application).
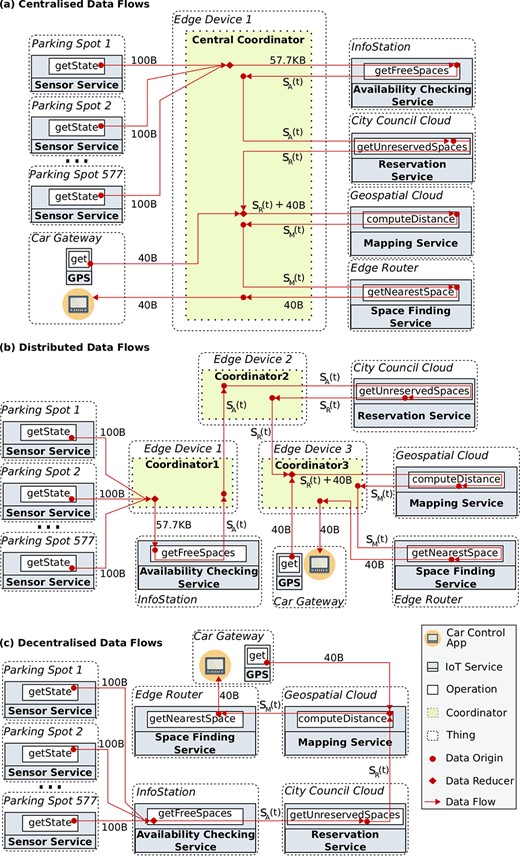
Data flow approaches for the smart parking system.
In our scenario, there are 373 drivers arriving to the car park BHMBCCMKT01 between 07:59:45 and 16:26:47 on a given day (Appendix A). This car park has 577 occupancy sensors each producing 100 bytes, so there are
We refer the reader to Appendix A for details about the data set and the formalisms used in our scenario. Appendix B presents the calculations for the total data transmitted over the network, considering that there are
A centralized approach [5, 38, 39] depends on a single coordinator for passing data between services. Figure 2(a) shows how a central coordinator mediates data streams for the smart parking system. The main drawback of this approach is that such a coordinator is a potential bottleneck (as huge amounts of data are exchanged) and introduces an extra network hop for passing data. This approach is therefore a threat for scalability as pointed out by many researchers [7, 8, 11, 14]. Furthermore, IoT may potentially require the deployment of coordinators on resource-constrained things (e.g. edge devices), which can lead to bottlenecks due to the presence of low computing power and poor network resources [7]. For instance, the central coordinator of our scenario is deployed on an edge device, which manages
Although a distributed approach [33, 40, 41] removes the central coordinator, it introduces unnecessary network traffic as data passes through multiple mediators, even if data is unimportant for them. For example, in Figure 2(b) the data generated by the Availability Checking Service goes through Coordinator1 and then through Coordinator2, before reaching the service that really needs the data (i.e. the Reservation Service). These additional network hops negatively impact the overall performance of the system.
For our scenario, the distribution of data load among three coordinators avoids a single bottleneck. However, as coordinators mediate interactions,
The decentralized data exchange approach [7, 8, 11, 13] is the most efficient one, since data are passed directly to the services that actually need it. Particularly, it requires only one network hop to pass data from a data producer to a data consumer, as depicted in Figure 2(c). The decentralized version of our scenario requires a total data transfer of
3. THE DX-MAN MODEL
To realize decentralized data flows, we propose to extend the semantics of DX-MAN [42–44], which is an algebraic model for building IoT systems, where services and exogenous composition operators are first-class semantic entities (Fig. 3).
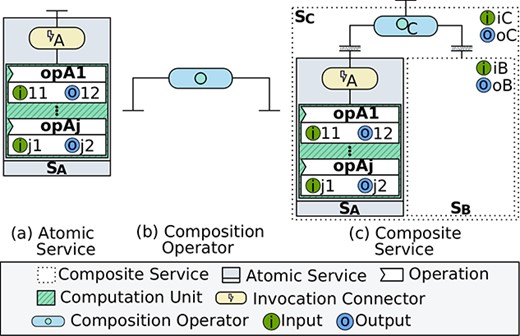
DX-MAN Model.
A service
where
An atomic service is syntactically formed by connecting an invocation connector with a computation unit which encapsulates the implementation of multiple operations and it is not allowed to invoke other units (Fig. 3(a)). Semantically, this is equivalent to constructing an atomic workflow space whose variants invoke different operations in the computation unit via the invocation connector. An operation performs some computation and has an input parameter and an output parameter.
The DX-MAN model relies on algebraic composition for defining complex services. Algebraic composition is the process by which a composition operator hierarchically composes multiple services of type
A composite service is syntactically formed by connecting a composition operator with multiple (atomic and/or composite) services, which has an input parameter and an output parameter (Fig. 3(c)). Semantically, it is a composite workflow space produced by a composition operator taking sub-workflow spaces as operands. There are composition operators for sequencing (i.e. sequencer), branching (i.e. inclusive selector and exclusive selector) and parallelism (i.e. parallelizer). A sequencer or a parallelizer defines an infinite workflow space, whilst a branching operator defines a finite one.
The control flow structure of a composite service is represented by an abstract workflow tree whose leaves are operations in atomic sub-services, whole composite sub-services or any combination thereof (Fig. 4). An abstract workflow tree allows the definition of a particular variant from a composite workflow space. To do so, a concrete workflow tree must be created, which is a selection function over a set of workflow variants, and it is therefore isomorphic to an abstract workflow tree. The edges of a concrete workflow tree are labelled according to the composition operator used. In particular, the label of a sequencer edge is an ordered list of natural numbers and the label of a parallelizer edge is a natural number (representing the amount of parallel tasks). For the edges of an inclusive selector and an exclusive selector, the labels are conditions and boolean values, respectively. An exclusive selector also has an associated global condition. For further details on workflow selection, see [42, 43].
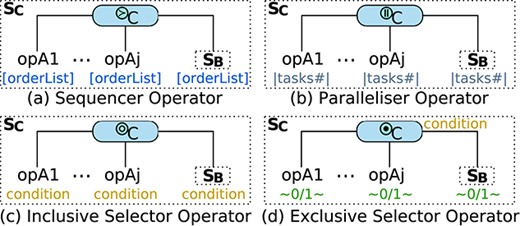
Abstract workflow trees for the composite service shown in Figure 3, when
3.1. Separation of control flows and data flows
IoT service composition can be endogenous or exogenous, depending on control flow origin [45]. Endogenous composition is used by P2P choreographies, which mix service computation (i.e. operations) with control flow constructs (Fig. 5(a)). By contrast, exogenous composition relies on coordinators that define control flow outside the computation of composed services (Fig. 5(b)). This composition approach is used by orchestration and by DX-MAN. Unlike its counterpart, exogenous composition avoids control flow dependencies between services and facilitates reuse at scale [29, 36, 44, 46, 47]. It also avoids application logic being embedded in the computation of multiple atomic services, thereby facilitating tracking and monitoring, which are crucial desiderata of functional scalability [1, 48].
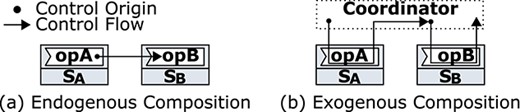
Endogenous composition versus exogenous composition.
Despite the above advantages, exogenous composition suffers from performance issues when data follow control [11, 14, 49]. This is because coordinators mediate data streams even for data that are unimportant for them (Figs 2(a) and (b)).2 To address this problem, we propose to define control flow and data flow as orthogonal dimensions (Fig. 6). The idea is that coordinators (i.e. composition operators) never exchange data during workflow execution, but only control.

Possible DX-MAN dimensions. This paper proposes an approach for realizing (b).
In DX-MAN, a workflow is defined by a concrete workflow tree (Fig. 7(b)). It has an input parameter and an output parameter and describes a series of steps for the invocation of operations in atomic services, sub-workflows or any combination thereof.3 Figure 7(c) shows an example of a sequential workflow for the invocation of the operation opA (provided by the atomic service
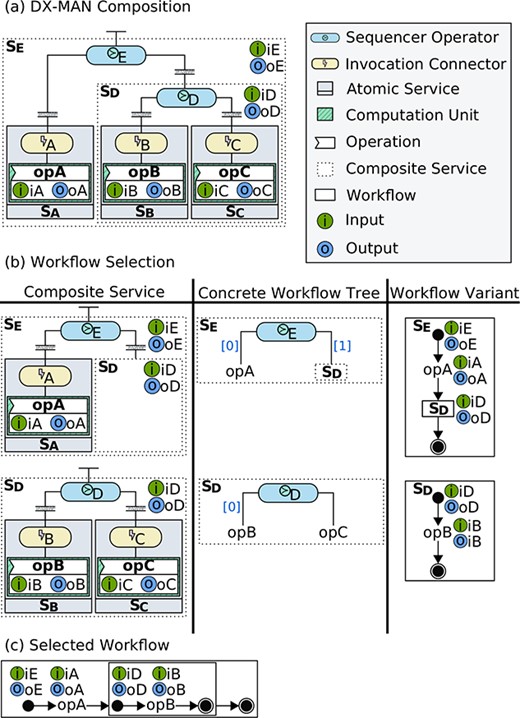
Relationship between DX-MAN compositions and IoT workflows.
A workflow execution traverses a control flow tree from top to bottom and then returns backwards (Fig. 8). Thus, the execution of the workflow depicted in Figure 7(c) starts with the activation of
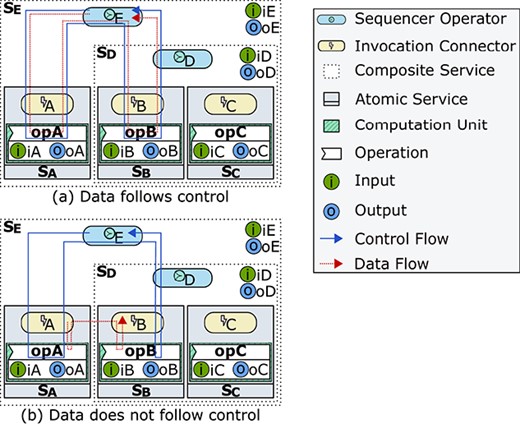
Possible executions of the workflow shown in Figure 7(c) when control flows and data flows are (a) mixed or (b) orthogonal. In (a), composition operators (i.e. coordinators) mediate data streams, even if data are unimportant for them. In (b), data are passed directly between atomic services. This paper proposes an approach to realize (b).
If data follow control, it passes through the composition connectors
3.2. Design-time: (semantic) data forest definition
A DX-MAN system is a workflow control flow variant with an orthogonal data forest. The latter is a graph of directed data dependency trees defined on service composition at design-time, whose edges define an explicit relationship between parameters. Formally, a data forest is a graph
For a parallelizer, the workflow input is connected to the inputs of all the invoked elements (i.e. operations or sub-workflows) whose outputs are, in turn, connected to the workflow output. In this paper, we only describe how parallel and sequential data forests are formed, since decentralized data flows are only meaningful for parallelism and sequencing. For a sequencer, the connection of vertices forms a data pipeline, so the output of an invoked element is connected to the input of the next invoked element. Additionally, the workflow input is connected to the input of the first invoked element, and the output of the last invoked element is connected to the workflow output.
Figure 9 analyses thoroughly the composition depicted in Figure 7. It shows the sequential workflow variants and the data forests for the composites
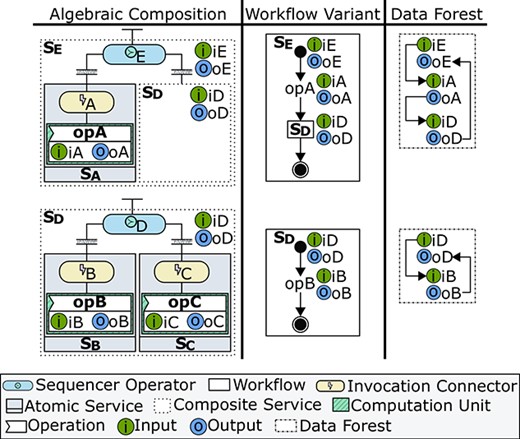
Separation of control and data in sequential composites. Control constructs and data dependencies are explicitly defined by exogenous composition operators and data forests, respectively.
Reusability is also present in the composite depicted in Figure 10(a), which shows an example where the parallelizer
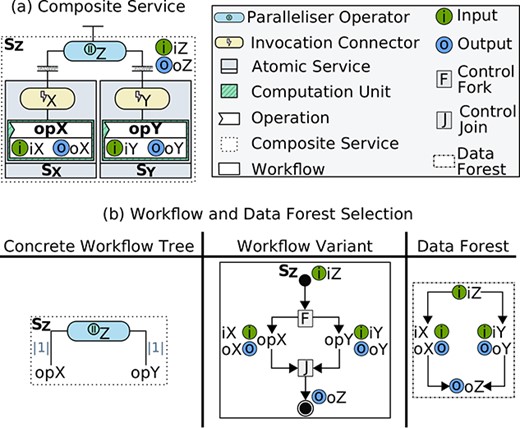
Separation of control and data in a parallel composite. Parallel constructs (i.e. fork and join) and data dependencies are explicitly defined by exogenous composition operators and data forests, respectively.
Although decentralized data flows are only meaningful for parallelism and sequencing, for completeness we describe how branchial data forests are formed. For both exclusive and inclusive selectors, the corresponding connection scheme is isomorphic to the one defined for a parallelizer in which the workflow input is connected to the inputs of all the invoked elements, and the outputs of the elements are connected to the workflow output (Fig. 10(b)). This connection is done to ensure that there is an output value no matter the execution branch taken.
3.3. Deployment-time: data forest refinement
At deployment-time, a data forest can be (manually) refined in three different ways: (i) by adding or removing edges, (ii) by adding input data into exogenous operators or (iii) by introducing data processors. These refinements are entirely optional with the overall aim of providing extra flexibility for system modellers. To understand them, we consider the data forest of the composite
where
For all the scenarios, we show how edges and vertices change with respect to the original data forest (Fig. 11(a)).
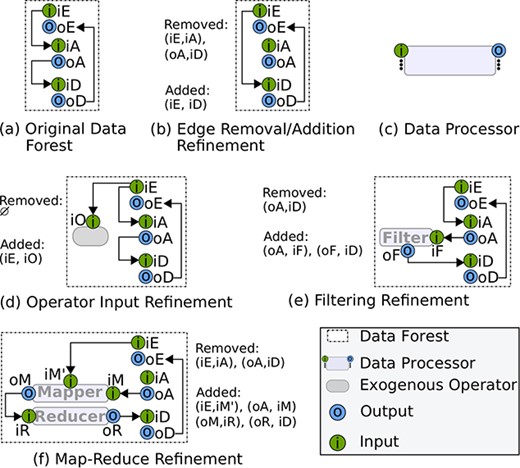
Data forest refinement.
3.3.1. Edges refinement
Refining edges is useful for changing data relationships and optimizing data flows. For instance, the edge
3.3.2. Exogenous operator refinement
Although they do not perform any computation, exogenous operators might require input values to evaluate boolean conditions at run-time. By default, exogenous operators do not have any parameters, but parameters can be added for a specific workflow. To do so, new vertices are added into the respective data forest and connected manually at the discretion of the modeller. Edge connections must conform to the rules described in [49]. Figure 11(d) shows an example of this kind of refinement, where
3.3.3. Data processor refinement
Data processors can be introduced in a data forest to perform intermediate processing. A data processor is a function that receives at least one input data, performs some custom computation and stores result(s) in at least one output (Fig. 11(c)). By introducing data processors, we avoid tangling with the original workflow control flow of an IoT system. Although the DX-MAN model currently supports the most common data patterns (i.e. map-reduce and filtering), other data processors can be defined using the same semantics. For instance, a replicator could be introduced to copy data to multiple parameters.
Figure 11(e) customises
3.4. Deployment-time: data forest analysis
Once data forests have been defined and refined (if needed), a direct mapping between consumer parameters and producer parameters is created. To describe our approach, some formal notations are provided.
Let
Let
Let
Let
Let
Let
Let
Our approach analyses the edges of all the data forests of an IoT system, from bottom to top with a complexity of
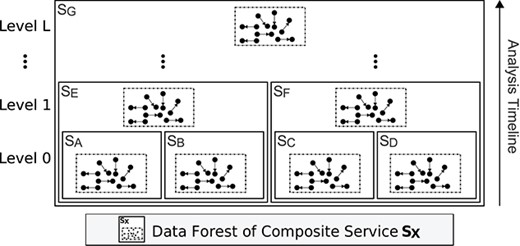
Bottom-up analysis of data forests: from level 0 to level
We have designed Algorithm 1 to analyse individual data forest edges. The algorithm uses the sets

4. IMPLEMENTATION
The DX-MAN platform [50] implements the semantics of the DX-MAN model and provides Java APIs to algebraically compose, deploy and execute IoT systems. Our approach is implemented on top of that platform and uses the Blockchain as the underlying decentralized data space. Please note that a Blockchain platform is just a possible implementation of a decentralized data space. Other possible implementations include OpenLink Data Spaces (ODS), ZeroMQ messaging, a shared memory for IoT or even Apache Storm.4 We chose a Blockchain implementation to ensure data ownership for every service and data provenance for discovering data flow histories. Furthermore, we guarantee an extra layer of performance, security and auditability. It is important to note that we do not claim any contributions in terms of implementation. Our implementation is just for validation purposes.
Our approach uses Hyperledger Fabric 1.2 as the underlying Blockchain infrastructure and Hyperledger Composer 0.20.0 to define a Blockchain model based on three smart contracts (Fig. 13). CreateParameters initialises the consumer parameters of an IoT system, whereas UpdateParameters and ReadParameters change and retrieve a list of parameter values from the data space, respectively. The implementation logic of the contracts is written in JavaScript and it is shown in Appendix D.

Blockchain model.
The DX-MAN platform provides the programming abstractions for composing IoT services (at design-time) and selecting IoT workflows (at deployment-time). When a workflow is selected, a data forest is automatically created for the respective control flow. Workflow selection is out of the scope of this paper; on this matter, we refer the reader to [42]. Also, to guarantee openness and replicability, the source code of the DX-MAN platform is available at https://github.com/damianarellanes/dxman.
Once workflows have been selected, Algorithm 1 analyses the edges of all the data forests involved to build a Java Hashmap (i.e. a binary relation
At run-time, exogenous operators coordinate an IoT system execution by passing control only via CoAP messages.5 When an exogenous operator receives control, it performs one of the processes shown in Figure 14(b and c) only if input data are needed; otherwise, steps 1–2 are omitted. When control triggers an invocation connector, the latter performs the process shown in Figure 14(a). Firstly, the connector executes the transaction ReadParameters to retrieve the necessary inputs from the data space. For each input, the Blockchain directly consumes values from the producer list.
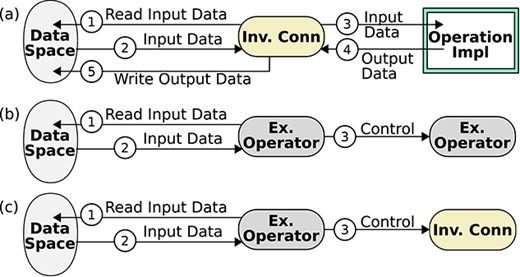
Steps performed by (a) an invocation connector and (b–c) an exogenous operator after receiving control. (b–c) are only applicable for exogenous operators that require input data. Other operators ignore the steps 1 and 2.
Producer data are stored in the Blockchain as soon as it is available, even before control reaches consumer services. To avoid run-time synchronisation problems, control flow blocks in an invocation connector until all needed input values are retrieved. Next, the connector executes the computation of an operation by passing it the respective data. The result is stored in the Blockchain via the transaction UpdateParameters.
UpdateParameters raises an UpdateParameterEvent after changing a parameter value. This is useful for data processor instances that subscribe to events notified by producer parameters. Thus, a data processor instance performs a user-defined computation after receiving all the events for its inputs. Currently, our implementation supports mappers, reducers and filters, but further processors (e.g. a replicator) can be implemented conforming to the semantics presented in Section 3.3.
Consumer parameters are unaware of data producers, and vice versa, since data references are stored in the Blockchain. Furthermore, the mapping generated by Algorithm 1 avoids the inefficient approach of passing data values through exogenous operators at run-time. Therefore, as consumer parameters read data directly from producers and they are unaware of each other, our approach enables a (transparent) decentralized data exchange.
5. CASE STUDY
This section describes how to enable decentralized data flows in the smart parking scenario presented in Section 2, by covering the three phases of a DX-MAN system life-cycle.
5.1. Design-time
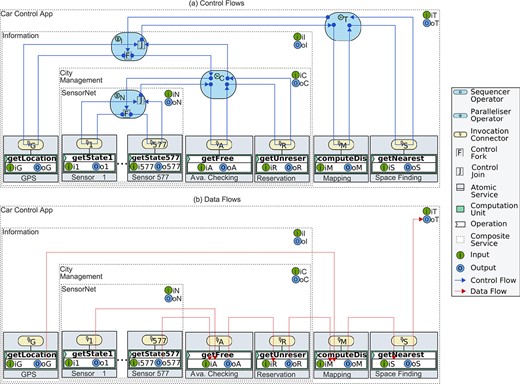
At design-time, we use the syntactic constructs presented in Section 3 to define a multi-level composition structure for our smart parking application (Fig. 15). This process is done in a hierarchical bottom-up manner, starting with the composition of Sensor Services into SensorNet, via the parallelizer operator
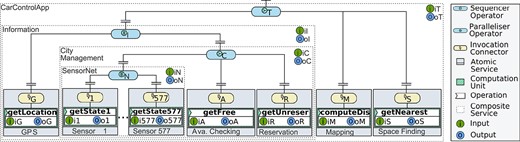
DX-MAN composition for the smart parking scenario.
5.2. Deployment-time
For each composite, we define a concrete workflow tree to explicitly choose a workflow and a data forest from the respective space (Section 3). In particular, for SensorNet there is a workflow that executes all sensor operations in parallel. For CityManagement, there is a workflow that sequentially invokes the SensorNet sub-workflow, the getFree operation and the getUnreser operation, in that order. For Information, there is a workflow that synchronises the execution of the getLocation operation and the CityManagement sub-workflow. Finally, in the top-level composite, the Information sub-workflow, the computeDis operation and the getNearest operation are triggered sequentially. The concrete workflow trees for each composite are shown in Figure 16 and the whole workflow of our scenario is depicted in Figure 17(a). The latter is just a concatenation of individual workflows.
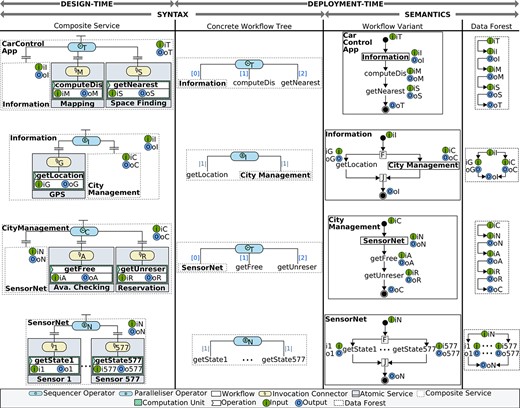
Selecting workflows explicitly and data forests implicitly for the smart parking scenario.
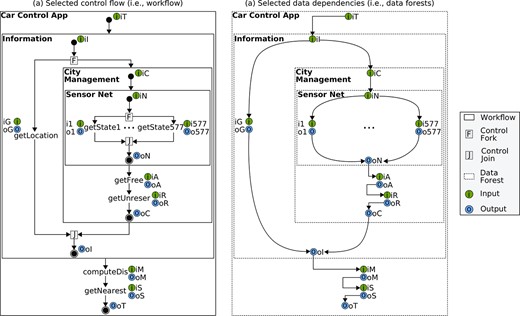
Orthogonality between control flow (i.e. workflow) and data dependencies (i.e. data forests) in the smart parking scenario.
In Section 3, we mentioned that data forests are implicitly selected when workflows are chosen. On that basis, the resulting data forests for each composite service are shown in Figure 16 and the complete concatenation of data forests is illustrated in Figure 17(b). Note that both workflows and data forests are not manually created, but just selected using the syntactic representation of concrete workflow trees.
Once data dependencies are in place, some data forests are refined (Fig. 18(a)). In particular, we remove the edges between the inputs of the parallel composites (i.e. SensorNet and Information) and the inputs of their respective sub-services. Similarly, we remove the edges connecting the inputs of the sequential composites (i.e. CarControlApp and CityManagement) and the inputs of the parallel composites. Note that this does not mean that edges are always refined. In some scenarios, refinement never takes place.
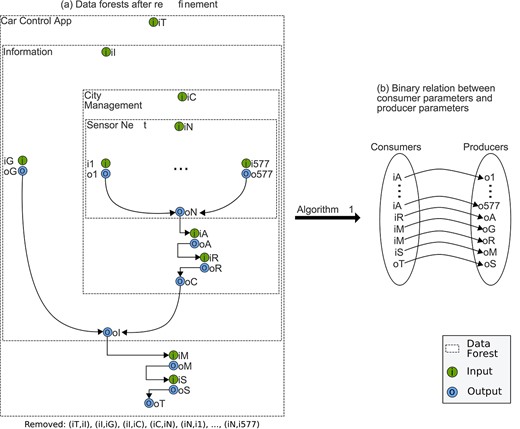
Transforming data forests into a binary relation between consumer parameters and producer parameters.
After refinement, Algorithm 1 analyses the edges of each data forest from the bottom-level composite (i.e. SensorNet) to the top-level one (i.e. CarControlApp). The resulting binary relation between consumer parameters and producer parameters is illustrated in Figure 18(b).
5.3. Run-time
At run-time, composition operators coordinate the execution of the selected workflow by passing control only (Fig. 19(a)), while atomic services exchange data directly (Fig. 19(b)). In particular, when a driver requests a nearest parking space,
Orthogonal control flows and data flows in the smart parking scenario.
Figure 19 illustrates the execution of the smart parking scenario, where it is clear that data never passes alongside control, but it flows in a decentralized manner according to the binary relation shown in Figure 18(b). It is important to note that control blocks in an invocation connector until all producer values become available (Section 4). For instance,
6. DISTRIBUTED DATA FLOWS VERSUS DECENTRALIZED DATA FLOWS IN THE SMART PARKING SCENARIO
This section presents a quantitative comparison between the proposed approach (when data are separated from control) and distributed data flows (when data follow control), in terms of network traffic generated and response time perceived. Our evaluation is based on two OMNET++ simulations in which composition operators and invocation connectors are OMNET++ modules, whereas control flow and data flow are channels between modules.6 For fairness, we assume ideal wireless channels communicating over IEEE 802.11a links at a rate of
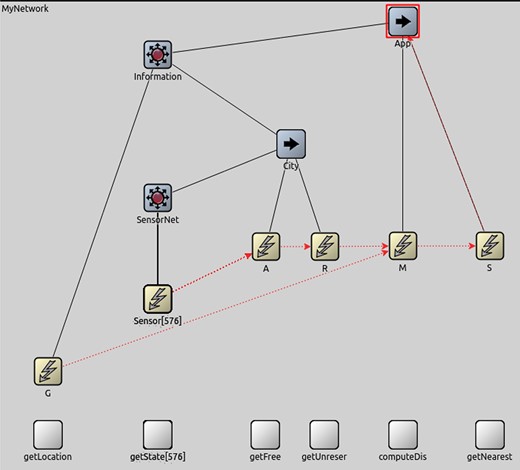
OMNET++ configuration for the smart parking system. The simulation on distributed data flows do not use the channels between invocation connectors, whereas the simulation on decentralized data flows use all visible channels.
An OMNET++ experiment simulates drivers using the smart parking application between 07:59:45 and 16:26:47 (Appendix A). In all the experiments, we assume that there is no network traffic for invoking operations, since invocation connectors reside in the same device as their connected operations. Also, composition operators and invocation connectors do not incur any processing time since they only forward data or control. The latter is just a 1-byte signal that activates an operator or a connector.
For simplicity and clarity, we also assume that IoT devices hosting atomic services have a fixed data processing time of
Considering the above assumptions, the first experiment simulates decentralized data flows in the smart parking system. Here, control is exchanged among composition operators and invocation connectors, while data are passed between producer connectors and consumer connectors via ideal OMNET++ channels (Fig. 20). These channels simulate read-write operations on a decentralized space (regardless its implementation). These actions are performed by invocation connectors on behalf of their connected operations. In this experiment, the total network traffic from 07:59:45 to 16:26:47 is
Network traffic in the smart parking scenario (from 07:59:45 to 16:26:47).
| Data traffic (MB) | Control traffic (MB) | Total (MB) | |
|---|---|---|---|
| Decentralized | 51.49 | 0.44 | 51.93 |
| Distributed | 140.41 | 0.22 | 140.63 |
| Data traffic (MB) | Control traffic (MB) | Total (MB) | |
|---|---|---|---|
| Decentralized | 51.49 | 0.44 | 51.93 |
| Distributed | 140.41 | 0.22 | 140.63 |
Network traffic in the smart parking scenario (from 07:59:45 to 16:26:47).
| Data traffic (MB) | Control traffic (MB) | Total (MB) | |
|---|---|---|---|
| Decentralized | 51.49 | 0.44 | 51.93 |
| Distributed | 140.41 | 0.22 | 140.63 |
| Data traffic (MB) | Control traffic (MB) | Total (MB) | |
|---|---|---|---|
| Decentralized | 51.49 | 0.44 | 51.93 |
| Distributed | 140.41 | 0.22 | 140.63 |
The second simulation considers a distributed version of the smart parking scenario, in which data pass alongside control through invocation connectors and composition operators. The only exception is when control traverses from
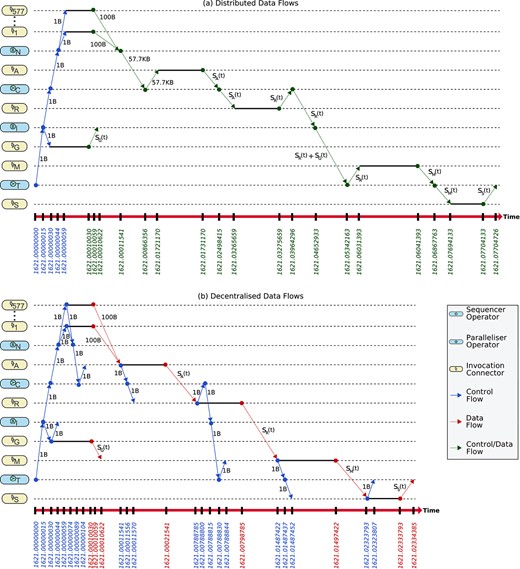
Decentralized data flows versus distributed data flows in the smart parking scenario.
Although our approach requires 50% more control messages than its counterpart, the network traffic is dramatically minimized by a rate of
Reducing network traffic improves the overall response time of the smart parking system by an average factor of
where
As an example, Figure 21 shows the time window for the driver’s request at 08:26 (i.e. 1621 seconds after 07:59:45), where it is clear that the system is executed in 0.08 seconds using the distributed approach and in
Table 2 presents the results of a quantitative evaluation that considers a few services. However, the benefit of our approach becomes more evident as the number of services increases. To evaluate this property, known as functional scalability, we conducted an experiment in which we gradually increase the data being processed by the smart parking application through the continuous addition of sensor services (up to 100 000). The aim of this experiment is to analyse network traffic in the order of Gigabytes. The results are shown in Figure 22.
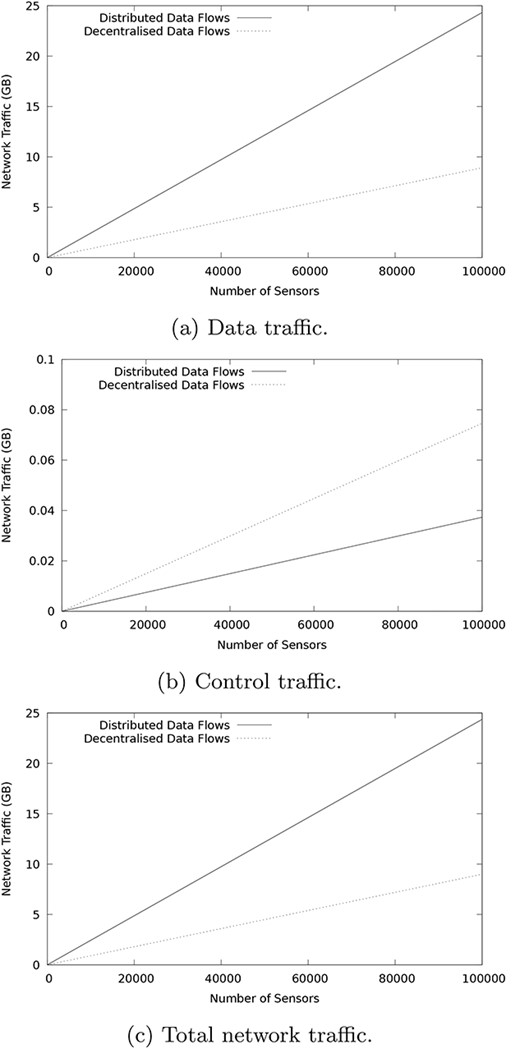
Impact of increasing the number of sensor services in the smart parking scenario.
Figure 22 shows that our approach outperforms distributed data flows in terms of data traffic, whereas the distributed version outperforms our approach in terms of control traffic. Despite this, the total network traffic is linearly improved by our approach since control messages are minimal (i.e. they always oscillate below
The next section presents a generic evaluation of functional scalability that is independent of any implementation or specific case studies. In this evaluation, we do not only increase services horizontally (for the same composite) but also vertically (by increasing the number of composition levels).
7. EVALUATION OF FUNCTIONAL SCALABILITY
This section presents a comparative evaluation between decentralized data flows (when control flow and data flow are separated—Fig. 8(b)) and distributed data flows (when data follows control—Fig. 8(a)), in terms of functional scalability. To do so, two major research questions are studied: (RQ1) Does the proposed approach scale with the number of services? and (RQ2) Under which conditions are decentralized data flows beneficial?
To answer the above questions, we conducted a series of experiments based on the following statements.
Let
Let
The functions
We assume that
7.1. Initial experimental setting
The worst performance of a distributed approach occurs when all composite services are sequential. So, for our evaluation we consider the DX-MAN composition shown in Figure 23, which has four hierarchy levels, four atomic services and three composites. The sequential workflow variants selected for each composite and their respective data forests are also presented in the figure.
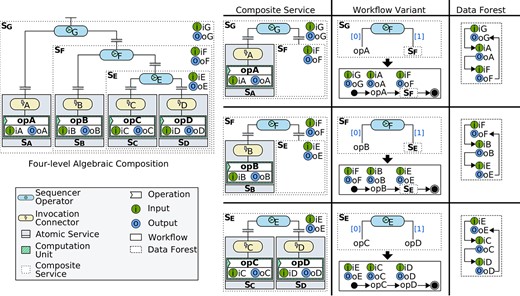
Initial experimental setting.
Figure 24 shows the resulting workflow control flow and the data exchange approaches that we use in our experiments. For the distributed approach (Fig. 24(b)), we consider the graph
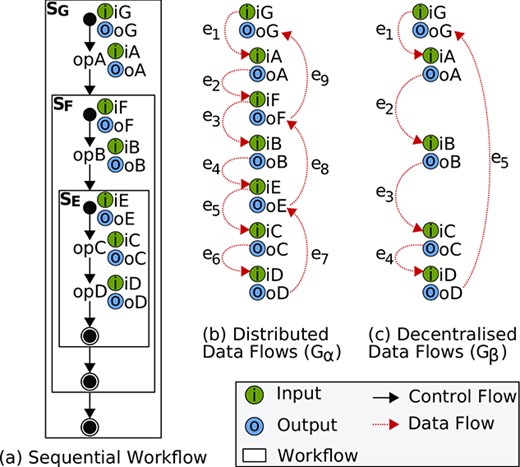
Distributed data flows versus decentralized data flows.
For the decentralized approach (Fig. 24(c)), we consider the graph
7.2. RQ1: does the proposed approach scale with the number of services?
We conducted an experiment to dynamically increase the number of composites in the (four-level) composition shown in Figure 23. The experiment is carried out in
At each step of the experiment, we compose a replica of
As they capture the growth pattern of data flows, we use the functions
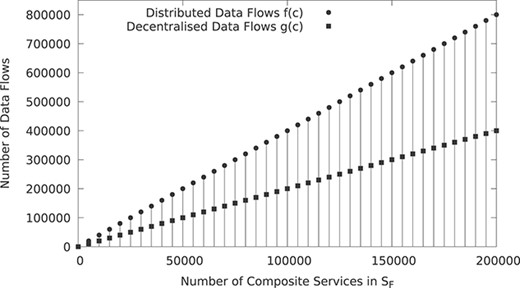
Impact of data flows when increasing the number of composite services in
7.3. RQ2: under which conditions are decentralized data flows beneficial?
We conducted two experiments to determine if there is a benefit of decentralized data flows as the number of levels increases in a DX-MAN composition. To do so, we consider the total network costs of passing the output oD (of the atomic service
For each experiment, we compute ten samples over 100 levels each. At each sample, we increase the number of composition levels by
Figure 26 shows the result of our experiments, where it is clear that the benefit of decentralized data flows is logarithmic and, as such, it becomes more evident as the number of levels of a DX-MAN composition increases. This is because
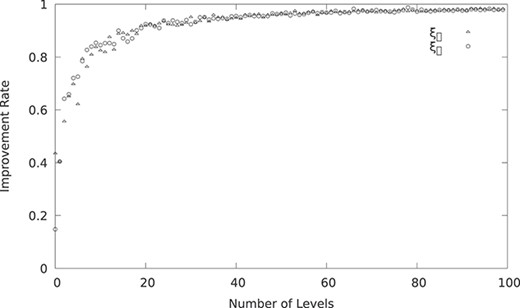
Improvement rate of decentralized data flows when increasing the number of levels in a DX-MAN composition:
8. CONCLUSIONS
In this paper, we presented a functionally scalable approach that semantically separates control and data in DX-MAN compositions for the realization of decentralized data flows in service-oriented IoT systems. At design-time, the algebraic semantics of the model allows the definition of data forests that denote data dependencies between service operation parameters. At deployment-time, data forests are (manually) refined and (automatically) analysed by an algorithm that leverages the separation of control and data. The algorithm works for any workflow in a composite workflow space and produces a direct mapping from consumer parameters to producer parameters. Thus, preventing coordinators (i.e. exogenous operators) from passing data at run-time. In fact, exogenous operators coordinate an IoT system execution by passing control only. To realize our approach, we implemented it on top of the DX-MAN platform, which uses the Blockchain as the underlying data space for persisting direct mappings and managing data at run-time. It is important to mention that our approach is not exclusive to a specific data space implementation (e.g. Blockchain or ODS). For that reason, we evaluated the benefits of the proposed approach rather than the benefits of a particular implementation.
Unfortunately, as other composition models have their own constructs and do not define composition operators like DX-MAN, it is not possible to extend other composition model semantics using our proposed approach. Instead, a custom extension per model would be required to enable the semantic separation of data and control. Another interesting future direction is to explore the possibility of incorporating stateful services into the semantics of DX-MAN.
DX-MAN is a service composition model that semantically separates data, control and computation for separate reasoning, monitoring, maintenance and evolution of such dimensions. More concretely, this separation allows passing data from producer parameters to consumer parameters directly and enables the use of distinct technologies to manage control flows and data flows separately. For example, in our implementation we use CoAP to pass control between exogenous operators and the Blockchain for handling data flows.
Our experimental results confirm that our approach scales well with the number of services, by reducing the number of data flows by an average factor of two with respect to a distributed approach (where data follows control). They also show that our approach scales well with the number of levels of a DX-MAN composition. From our results, we found that the proposed approach provides the best performance when the cost of performing operations on a data space is less than the cost of exchanging data over the network. Thus, our solution is potentially beneficial for large-scale IoT systems in which loosely coupled services exchange huge amounts of data continuously.
DATA AVAILABILITY
The data underlying this article are available in UCI Machine Learning Repository at https://archive.ics.uci.edu/ml/datasets/Parking+Birmingham#.
FUNDING
This work was partially supported by the I-BiDaaS project, funded by the European Union's Horizon 2020 Research and Innovation programme under grant agreement No. 780787.
CONFLICT OF INTEREST
The authors declare that they have no known conflict of interest.
Footnotes
For the rest of the paper, the terms IoT system and service-oriented IoT system are used interchangeably.
Section 2 provides a running example to describe the problem of coordinated data exchanges when using exogenous composition.
As a DX-MAN workflow is semantically equivalent to an orchestration, a DX-MAN composite is equivalent to a (potentially) infinite number of orchestrations.
A pipeline of different technologies can be used to efficiently implement data exchanges between services [51].
Appendix A presents the computation for the number of drivers.
REFERENCES
A. APPENDIX
This appendix presents the notation required for the analysis of the IoT scenario described in Section 2. This scenario considers a real-world data set publicly available at https://archive.ics.uci.edu/ml/datasets/Parking+Birmingham#, which collects occupancy status in car parks operated by the Birmingham City Council, from 07:59:45 to 16:26:47 on October 22, 2016 [52]. Table A3 presents the data obtained for the car park BHMBCCMKT01 whose total capacity is
Occupancy in the car park BHMBCCMKT01.
| Measurement time | Availability rate | ||
|---|---|---|---|
| 07:59:45 | 0 | 57 | 0.90 |
| 08:26:46 | 1621 | 59 | 0.90 |
| 08:59:44 | 3599 | 72 | 0.88 |
| 09:26:47 | 5222 | 93 | 0.84 |
| 09:59:44 | 7199 | 130 | 0.77 |
| 10:26:47 | 8822 | 156 | 0.73 |
| 10:59:47 | 10802 | 198 | 0.66 |
| 11:32:43 | 12778 | 239 | 0.59 |
| 11:59:46 | 14401 | 261 | 0.55 |
| 12:32:47 | 16382 | 324 | 0.44 |
| 12:59:47 | 18002 | 359 | 0.38 |
| 13:32:43 | 19978 | 380 | 0.34 |
| 13:59:48 | 21603 | 408 | 0.29 |
| 14:39:47 | 24002 | 430 | 0.25 |
| 14:59:48 | 25203 | 424 | 0.27 |
| 15:26:49 | 26824 | 403 | 0.30 |
| 15:59:47 | 28802 | 384 | 0.33 |
| 16:26:47 | 30422 | 340 | 0.41 |
| Measurement time | Availability rate | ||
|---|---|---|---|
| 07:59:45 | 0 | 57 | 0.90 |
| 08:26:46 | 1621 | 59 | 0.90 |
| 08:59:44 | 3599 | 72 | 0.88 |
| 09:26:47 | 5222 | 93 | 0.84 |
| 09:59:44 | 7199 | 130 | 0.77 |
| 10:26:47 | 8822 | 156 | 0.73 |
| 10:59:47 | 10802 | 198 | 0.66 |
| 11:32:43 | 12778 | 239 | 0.59 |
| 11:59:46 | 14401 | 261 | 0.55 |
| 12:32:47 | 16382 | 324 | 0.44 |
| 12:59:47 | 18002 | 359 | 0.38 |
| 13:32:43 | 19978 | 380 | 0.34 |
| 13:59:48 | 21603 | 408 | 0.29 |
| 14:39:47 | 24002 | 430 | 0.25 |
| 14:59:48 | 25203 | 424 | 0.27 |
| 15:26:49 | 26824 | 403 | 0.30 |
| 15:59:47 | 28802 | 384 | 0.33 |
| 16:26:47 | 30422 | 340 | 0.41 |
Occupancy in the car park BHMBCCMKT01.
| Measurement time | Availability rate | ||
|---|---|---|---|
| 07:59:45 | 0 | 57 | 0.90 |
| 08:26:46 | 1621 | 59 | 0.90 |
| 08:59:44 | 3599 | 72 | 0.88 |
| 09:26:47 | 5222 | 93 | 0.84 |
| 09:59:44 | 7199 | 130 | 0.77 |
| 10:26:47 | 8822 | 156 | 0.73 |
| 10:59:47 | 10802 | 198 | 0.66 |
| 11:32:43 | 12778 | 239 | 0.59 |
| 11:59:46 | 14401 | 261 | 0.55 |
| 12:32:47 | 16382 | 324 | 0.44 |
| 12:59:47 | 18002 | 359 | 0.38 |
| 13:32:43 | 19978 | 380 | 0.34 |
| 13:59:48 | 21603 | 408 | 0.29 |
| 14:39:47 | 24002 | 430 | 0.25 |
| 14:59:48 | 25203 | 424 | 0.27 |
| 15:26:49 | 26824 | 403 | 0.30 |
| 15:59:47 | 28802 | 384 | 0.33 |
| 16:26:47 | 30422 | 340 | 0.41 |
| Measurement time | Availability rate | ||
|---|---|---|---|
| 07:59:45 | 0 | 57 | 0.90 |
| 08:26:46 | 1621 | 59 | 0.90 |
| 08:59:44 | 3599 | 72 | 0.88 |
| 09:26:47 | 5222 | 93 | 0.84 |
| 09:59:44 | 7199 | 130 | 0.77 |
| 10:26:47 | 8822 | 156 | 0.73 |
| 10:59:47 | 10802 | 198 | 0.66 |
| 11:32:43 | 12778 | 239 | 0.59 |
| 11:59:46 | 14401 | 261 | 0.55 |
| 12:32:47 | 16382 | 324 | 0.44 |
| 12:59:47 | 18002 | 359 | 0.38 |
| 13:32:43 | 19978 | 380 | 0.34 |
| 13:59:48 | 21603 | 408 | 0.29 |
| 14:39:47 | 24002 | 430 | 0.25 |
| 14:59:48 | 25203 | 424 | 0.27 |
| 15:26:49 | 26824 | 403 | 0.30 |
| 15:59:47 | 28802 | 384 | 0.33 |
| 16:26:47 | 30422 | 340 | 0.41 |
Considering the columns 2 and 4 from our data set, we performed a cubic regression to approximate a function
where
The probability of a parking space being unreserved at
where
B. APPENDIX
This appendix presents the result of the calculations for the total data transmitted over the network in our IoT scenario (Section 2 and Appendix A). The calculations are presented for each data exchange approach, i.e. centralized data flows, distributed data flows and decentralized data flows. For all of them, we assume that:
There are 577 occupancy sensors near a driver, corresponding to each space in the car park BHMBCCMKT01.
Each Sensor Service is hosted in an occupancy sensor and produces 100 bytes.
Once all sensor data are collected by a reducer, it is processed by the Availability Checking Service.
The Mapping Service appends 20 bytes to each parking space that is both free and unreserved. These extra bytes correspond to the distance between the driver’s location and each occupancy sensor.
The Space Finding Service produces 40 bytes for the coordinates of the nearest parking space.
There is a driver requesting a nearest parking space every
The GPS service produces 40 bytes for the coordinates of the driver.
The driver always finds a nearest parking space, since the car park is never full (see
Considering assumptions (1) and (2), let
For the sake of clarity and conciseness, we use the functions below to compute the number of bytes returned by the Availability Checking Service, the Reservation Service, the Mapping Service and the Space Finding Service, respectively.
Let
Let
Considering assumptions (1) and (4), let
Considering the assumption (5), let
Considering the assumption (7), let
A centralized approach for exchanging data requires two data flows for moving data from a service producer to a service consumer. Therefore,
For the distributed approach, each coordinator requires two data flows for passing data between a service producer and a service consumer. In addition, Coordinator1 requires a data flow for moving data to the Coordinator2 which, in turn, requires another data flow for passing data to the Coordinator3. Thus, the exchanges between the Availability Checking Service and the Reservation Service are done with three data flows. Likewise, there are three data flows for passing data from the Reservation Service to the Mapping Service. The symbol
A decentralized approach is the most efficient since it requires only one data flow for moving data from a service producer to a service consumer. Based on this premise,
Taking into account the above calculations, the distributed approach leads to
C. APPENDIX
This appendix presents an example of how data forests are analysed in a bottom-up fashion using the Algorithm 1 at deployment-time. Our example considers the three-level data forest depicted in Figure C.2, which obeys the connection rules described in Section 3.2. Here, G is the forest of a parallel workflow that simultaneously executes the corresponding workflow for F and an atomic operation (with input iD and output oD). The workflow for F sequentially executes the workflow for E and then an atomic operation (with input iC and output oC). To pre-process data, F has a filter that takes the data produced by E before sending it to the corresponding operation. In our example, E is the lowest-level data forest defined by a branchial workflow that uses the input parameter iS to choose an operation to execute (out of two possible ones).
Deployment of the data forest shown in Figure C.2.
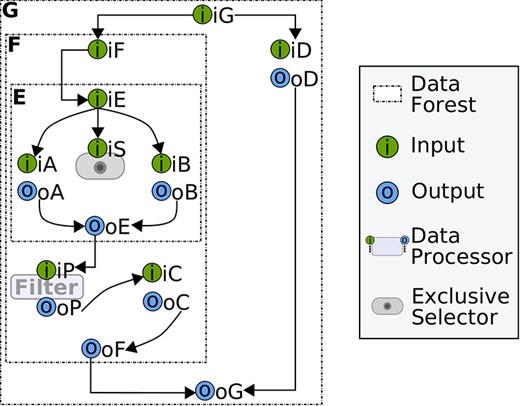
Three-level data forest.
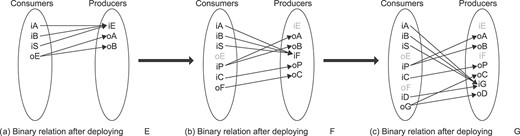
As described in Section 3.4, the deployment process begins at the bottom-level. So, we first analyse the edges of the branchial data forest E via the Algorithm 1. The resulting binary relation is shown in Figure B.1.(a).
In the next step, we analyse the edges of the sequential data forest F to yield the binary relation described in Figure B.1.(b). Here, we can notice that the relations from the output oE are now the relations from iP. This is because the filter input does not require to read from oE. Instead, the filter reads data directly from any of the actual producers, viz. the operation output oA or the operation output oB. Likewise, the input parameters iA, iB and iS do not read data from iE since a new (intermediate) top-level data producer has been found (i.e. iF). Complementarily, the operation input iC reads data directly from the filter output, whereas the (intermediate) top-level output oF reads data from oC.
Finally, in the last deployment step, the edges of the data forest G are analysed to yield the binary relation depicted in Figure B.1.(c). As iG is the new top-level data producer, the relations from consumers iA, iB and iS are updated accordingly. Similarly, as G is a parallel forest, the top-level output oG takes both the data source from oF (i.e. oC) and the output oD. At the end of the deployment process, we have a mapping scheme that discards unnecessary relations to allow data consumers read values directly from data producers.
D. APPENDIX
Figure D.3. presents the JavaScript source code of the three smart contracts used in our implementation. The source code follows the contract model definition described in Section 4.
Smart contracts logic.
E. APPENDIX
This appendix presents the notation used throughout the paper.
IOT SCENARIO
| Number of occupied parking spaces at | |
| Set of measurement times (in seconds) | |
| Number of drivers requesting a nearest space between | |
| Rate of free spaces at | |
| Rate of spaces that are both free and unreserved at | |
| Total sensor data (in bytes) produced for a driver’s request | |
| Number of bytes produced by the Availability Checking Service for a driver’s request | |
| Number of bytes produced by the Reservation Service for a driver’s request | |
| Number of bytes produced by the Mapping Service for a driver’s request | |
| Fixed number of bytes produced by the Space Finding Service | |
| Fixed number of bytes produced by the GPS Service | |
| Number of bytes exchanged in our scenario using a centralized approach | |
| Number of bytes exchanged in our scenario using a distributed approach | |
| Number of bytes exchanged in our scenario using a decentralized approach |
| Number of occupied parking spaces at | |
| Set of measurement times (in seconds) | |
| Number of drivers requesting a nearest space between | |
| Rate of free spaces at | |
| Rate of spaces that are both free and unreserved at | |
| Total sensor data (in bytes) produced for a driver’s request | |
| Number of bytes produced by the Availability Checking Service for a driver’s request | |
| Number of bytes produced by the Reservation Service for a driver’s request | |
| Number of bytes produced by the Mapping Service for a driver’s request | |
| Fixed number of bytes produced by the Space Finding Service | |
| Fixed number of bytes produced by the GPS Service | |
| Number of bytes exchanged in our scenario using a centralized approach | |
| Number of bytes exchanged in our scenario using a distributed approach | |
| Number of bytes exchanged in our scenario using a decentralized approach |
IOT SCENARIO
| Number of occupied parking spaces at | |
| Set of measurement times (in seconds) | |
| Number of drivers requesting a nearest space between | |
| Rate of free spaces at | |
| Rate of spaces that are both free and unreserved at | |
| Total sensor data (in bytes) produced for a driver’s request | |
| Number of bytes produced by the Availability Checking Service for a driver’s request | |
| Number of bytes produced by the Reservation Service for a driver’s request | |
| Number of bytes produced by the Mapping Service for a driver’s request | |
| Fixed number of bytes produced by the Space Finding Service | |
| Fixed number of bytes produced by the GPS Service | |
| Number of bytes exchanged in our scenario using a centralized approach | |
| Number of bytes exchanged in our scenario using a distributed approach | |
| Number of bytes exchanged in our scenario using a decentralized approach |
| Number of occupied parking spaces at | |
| Set of measurement times (in seconds) | |
| Number of drivers requesting a nearest space between | |
| Rate of free spaces at | |
| Rate of spaces that are both free and unreserved at | |
| Total sensor data (in bytes) produced for a driver’s request | |
| Number of bytes produced by the Availability Checking Service for a driver’s request | |
| Number of bytes produced by the Reservation Service for a driver’s request | |
| Number of bytes produced by the Mapping Service for a driver’s request | |
| Fixed number of bytes produced by the Space Finding Service | |
| Fixed number of bytes produced by the GPS Service | |
| Number of bytes exchanged in our scenario using a centralized approach | |
| Number of bytes exchanged in our scenario using a distributed approach | |
| Number of bytes exchanged in our scenario using a decentralized approach |
The DX-MAN model
| The type of a service | |
| A service | |
| The type a workflow space | |
| A workflow space | |
| The type of a composition operator | |
| A composition operator defining a composite service | |
| The type of a parameter | |
| A data forest | |
| The set of parameter vertices in a data forest | |
| A parameter | |
| The set of edges in a data forest | |
| An edge |
| The type of a service | |
| A service | |
| The type a workflow space | |
| A workflow space | |
| The type of a composition operator | |
| A composition operator defining a composite service | |
| The type of a parameter | |
| A data forest | |
| The set of parameter vertices in a data forest | |
| A parameter | |
| The set of edges in a data forest | |
| An edge |
The DX-MAN model
| The type of a service | |
| A service | |
| The type a workflow space | |
| A workflow space | |
| The type of a composition operator | |
| A composition operator defining a composite service | |
| The type of a parameter | |
| A data forest | |
| The set of parameter vertices in a data forest | |
| A parameter | |
| The set of edges in a data forest | |
| An edge |
| The type of a service | |
| A service | |
| The type a workflow space | |
| A workflow space | |
| The type of a composition operator | |
| A composition operator defining a composite service | |
| The type of a parameter | |
| A data forest | |
| The set of parameter vertices in a data forest | |
| A parameter | |
| The set of edges in a data forest | |
| An edge |
Algorithm for edge analysis
| The tail of a data forest edge | |
| The head of a data forest edge | |
| The type of a processor input | |
| The type of a processor output | |
| The type of an operation input | |
| The type of an operation output | |
| The type of a (top-level) workflow input | |
| The type of a (top-level) workflow output | |
| The type of an exogenous operator input | |
| The type of a vertex parameter that consumes data during workflow execution | |
| A consumer parameter | |
| The type of a vertex parameter that produces data during workflow execution | |
| A producer parameter | |
| A binary relation between some consumer parameters and some producer parameters | |
| The domain of the relation | |
| A binary relation between some producer parameters and some consumer parameters | |
| The domain of the relation | |
| The sum of the number of edges in all the data forests involved in a multi-level composition | |
| A set of producer parameters | |
| A set of consumer parameters |
| The tail of a data forest edge | |
| The head of a data forest edge | |
| The type of a processor input | |
| The type of a processor output | |
| The type of an operation input | |
| The type of an operation output | |
| The type of a (top-level) workflow input | |
| The type of a (top-level) workflow output | |
| The type of an exogenous operator input | |
| The type of a vertex parameter that consumes data during workflow execution | |
| A consumer parameter | |
| The type of a vertex parameter that produces data during workflow execution | |
| A producer parameter | |
| A binary relation between some consumer parameters and some producer parameters | |
| The domain of the relation | |
| A binary relation between some producer parameters and some consumer parameters | |
| The domain of the relation | |
| The sum of the number of edges in all the data forests involved in a multi-level composition | |
| A set of producer parameters | |
| A set of consumer parameters |
Algorithm for edge analysis
| The tail of a data forest edge | |
| The head of a data forest edge | |
| The type of a processor input | |
| The type of a processor output | |
| The type of an operation input | |
| The type of an operation output | |
| The type of a (top-level) workflow input | |
| The type of a (top-level) workflow output | |
| The type of an exogenous operator input | |
| The type of a vertex parameter that consumes data during workflow execution | |
| A consumer parameter | |
| The type of a vertex parameter that produces data during workflow execution | |
| A producer parameter | |
| A binary relation between some consumer parameters and some producer parameters | |
| The domain of the relation | |
| A binary relation between some producer parameters and some consumer parameters | |
| The domain of the relation | |
| The sum of the number of edges in all the data forests involved in a multi-level composition | |
| A set of producer parameters | |
| A set of consumer parameters |
| The tail of a data forest edge | |
| The head of a data forest edge | |
| The type of a processor input | |
| The type of a processor output | |
| The type of an operation input | |
| The type of an operation output | |
| The type of a (top-level) workflow input | |
| The type of a (top-level) workflow output | |
| The type of an exogenous operator input | |
| The type of a vertex parameter that consumes data during workflow execution | |
| A consumer parameter | |
| The type of a vertex parameter that produces data during workflow execution | |
| A producer parameter | |
| A binary relation between some consumer parameters and some producer parameters | |
| The domain of the relation | |
| A binary relation between some producer parameters and some consumer parameters | |
| The domain of the relation | |
| The sum of the number of edges in all the data forests involved in a multi-level composition | |
| A set of producer parameters | |
| A set of consumer parameters |
Evaluation (preliminaries)
| A weighted graph of distributed data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A distributed data flow | |
| The function that maps a distributed data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a distributed data flow | |
| The type of a finite walk of data flows in | |
| A finite walk of data flows in | |
| The function that maps a finite walk | |
| The network cost of writing a value produced by | |
| The network cost of reading a value for | |
| A weighted graph of decentralized data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A decentralized data flow | |
| The function that maps a decentralized data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a decentralized data flow | |
| The operator for function composition | |
| The tail of a decentralized data flow | |
| The head of a decentralized data flow | |
| The total network cost of routing data from a producer parameter |
| A weighted graph of distributed data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A distributed data flow | |
| The function that maps a distributed data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a distributed data flow | |
| The type of a finite walk of data flows in | |
| A finite walk of data flows in | |
| The function that maps a finite walk | |
| The network cost of writing a value produced by | |
| The network cost of reading a value for | |
| A weighted graph of decentralized data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A decentralized data flow | |
| The function that maps a decentralized data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a decentralized data flow | |
| The operator for function composition | |
| The tail of a decentralized data flow | |
| The head of a decentralized data flow | |
| The total network cost of routing data from a producer parameter |
Evaluation (preliminaries)
| A weighted graph of distributed data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A distributed data flow | |
| The function that maps a distributed data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a distributed data flow | |
| The type of a finite walk of data flows in | |
| A finite walk of data flows in | |
| The function that maps a finite walk | |
| The network cost of writing a value produced by | |
| The network cost of reading a value for | |
| A weighted graph of decentralized data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A decentralized data flow | |
| The function that maps a decentralized data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a decentralized data flow | |
| The operator for function composition | |
| The tail of a decentralized data flow | |
| The head of a decentralized data flow | |
| The total network cost of routing data from a producer parameter |
| A weighted graph of distributed data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A distributed data flow | |
| The function that maps a distributed data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a distributed data flow | |
| The type of a finite walk of data flows in | |
| A finite walk of data flows in | |
| The function that maps a finite walk | |
| The network cost of writing a value produced by | |
| The network cost of reading a value for | |
| A weighted graph of decentralized data flows | |
| The set of parameters in | |
| A producer parameter | |
| A consumer parameter | |
| The set of directed data flows (between parameters) in | |
| A decentralized data flow | |
| The function that maps a decentralized data flow | |
| The network cost of passing the value from the output parameter oA to the input parameter iB, via a decentralized data flow | |
| The operator for function composition | |
| The tail of a decentralized data flow | |
| The head of a decentralized data flow | |
| The total network cost of routing data from a producer parameter |
Evaluation (experiments)
| The number of steps in the RQ1 experiment | |
| The number of distributed data flows when there are | |
| The number of decentralized data flows when there are | |
| The image of the function | |
| The image of the function | |
| The image of the function |
| The number of steps in the RQ1 experiment | |
| The number of distributed data flows when there are | |
| The number of decentralized data flows when there are | |
| The image of the function | |
| The image of the function | |
| The image of the function |
Evaluation (experiments)
| The number of steps in the RQ1 experiment | |
| The number of distributed data flows when there are | |
| The number of decentralized data flows when there are | |
| The image of the function | |
| The image of the function | |
| The image of the function |
| The number of steps in the RQ1 experiment | |
| The number of distributed data flows when there are | |
| The number of decentralized data flows when there are | |
| The image of the function | |
| The image of the function | |
| The image of the function |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}