




Summary
Basket trials have emerged as a new class of efficient approaches in oncology to evaluate a new treatment in several patient subgroups simultaneously. In this article, we extend the key ideas to disease areas outside of oncology, developing a robust Bayesian methodology for randomized, placebo-controlled basket trials with a continuous endpoint to enable borrowing of information across subtrials with similar treatment effects. After adjusting for covariates, information from a complementary subtrial can be represented into a commensurate prior for the parameter that underpins the subtrial under consideration. We propose using distributional discrepancy to characterize the commensurability between subtrials for appropriate borrowing of information through a spike-and-slab prior, which is placed on the prior precision factor. When the basket trial has at least three subtrials, commensurate priors for point-to-point borrowing are combined into a marginal predictive prior, according to the weights transformed from the pairwise discrepancy measures. In this way, only information from subtrial(s) with the most commensurate treatment effect is leveraged. The marginal predictive prior is updated to a robust posterior by the contemporary subtrial data to inform decision making. Operating characteristics of the proposed methodology are evaluated through simulations motivated by a real basket trial in chronic diseases. The proposed methodology has advantages compared to other selected Bayesian analysis models, for (i) identifying the most commensurate source of information and (ii) gauging the degree of borrowing from specific subtrials. Numerical results also suggest that our methodology can improve the precision of estimates and, potentially, the statistical power for hypothesis testing.
1. Introduction
There has been an increasing interest in precision medicine (Mirnezami and others, 2012; Schork, 2015) over the past few decades. Rapid advances in genomics and biomarkers allow stratification of patients into subgroups that may have different benefit from new treatments. Unlike the one-size-fits-all concept in conventional paradigms of clinical drug development, the aim of precision medicine is to target the right treatments to the right patients at the right time. In the era of precision medicine, new trial designs have been developed, several of which are examples of master protocols (Woodcock and LaVange, 2017; Renfro and Mandrekar, 2018) to study multiple diseases or multiple agents, or sometimes both. One well-known class of master protocols is basket trials (Renfro and Sargent, 2017). In the simplest formulation, basket trials evaluate a single-targeted agent to patients that share a common feature, such as similar genetic mutation, but may present various disease subtypes. It is administratively more efficient to plan a basket trial than a number of separate trials for the small subgroups, respectively. With one subtrial performed in each patient subgroup, basket trials are advantageous also for addressing multiple research questions simultaneously, for example, which subgroup(s) of patients may benefit and to what extent. To date, sophisticated approaches to the design and analysis of basket trials have predominantly been proposed for early phase oncology drug development, where the “standard” approach is a single-arm design with binary RECIST endpoint (Eisenhauer and others, 2009; Schwartz and others, 2016). This manuscript extends the key ideas of basket trials to disease areas outside of oncology, for example, in cases where patients have distinct clinical conditions but share similar symptoms. For this, we develop efficient approaches for analyzing randomized, placebo-controlled basket trials which collect data on a continuous endpoint.
When analyzing early phase basket trials, one major concern is the potential heterogeneity of the treatment effect in various patient subgroups. Investigators are faced with the dilemma of discarding or incorporating data from other subgroups to reach a decisive conclusion about the treatment effect for a specific subgroup. The option of using complementary data from subtrials that run concurrently is intriguing, as it may lead to considerable increase in the statistical power of the study to detect drug activity in one or more subgroups. This should be balanced with the risk that treatment effect in an important patient subgroup may be overlooked or missed. Conventional analysis strategies such as stand-alone analyses (also known as the approach of no borrowing) and complete pooling irrespective of subgroup labels have been criticized. Some authors have proposed using hierarchical random-effects models, as a compromise between the two limiting opinions, to enable borrowing of information across subgroups (Thall and others, 2003; Thall and Wathen, 2008; Berry and others, 2013). Such well-established approaches for information borrowing are justified, under the assumption of the exchangeability (Bernardo, 1996) of subgroup-specific treatment effects. More specifically, exchangeability means that the magnitude of clinical benefit may differ, but nothing is known a priori to suppose patients of some subgroups benefit better than others. Neuenschwander and others (2016) discuss a robust extension to the standard hierarchical models by including the possibility of non-exchangeability for each parameter (vector) that underpins a subgroup. Their approach permits an extreme subgroup not to be overly influenced by other subgroups in situations of data inconsistency.
Additional concerns about the subgroup effect are essential in precision medicine. Often, the targeted therapy is effective only in some subgroups, and certain subgroups illustrate more similar clinical benefit between themselves than with others. Several variations of standard hierarchical modeling have been considered suitably for the context of basket trials to implement borrowing of information (Liu and others, 2017; Chu and Yuan, 2018). Modifications are motivated mainly by (i) justification about plausible clustering of similar subgroups and (ii) quantification about the magnitude, to which a subgroup-specific parameter should be shrunk towards the mean effect across subgroups. Most recently, more sophisticated methods in the framework of Bayesian model averaging (Madigan and Raftery, 1994; Draper, 1995) have been applied to analyzing basket trials. Psioda and others (2019) average over the complete model space, which is constituted by all models for possible configurations of the subgroups that may demonstrate the same or disparate efficacy. In a model that assumes identical treatment effect among specific subgroups, information is pooled across the corresponding subgroups under the assumption of inter-patient exchangeability. The number of models to be included in the complete model space for averaging increases exponentially with the number of subgroups involved in the basket trial. Hobbs and Landin (2018) enumerate all possible subgroup pairs, wherein the parameters are considered to be either exchangeable or non-exchangeable. Using the product of, rather than the individual, prior probabilities for any two subgroups being exchangeable or not, their method offers considerable computational efficiency with respect to conventional Bayesian model averaging.
In this article, we propose methodology motivated by a randomized, placebo-controlled phase II basket trial, which is being undertaken in patients with chronic diseases. Patients who share a common disease symptom that the new treatment can potentially improve, will be stratified into subgroups according to their clinical conditions. Efficacy will be recorded on a continuous endpoint. Adjustment for baseline covariate(s) is desirable to allow for a more precise estimate of treatment effect. We develop a Bayesian methodology for borrowing of information across consistent subgroups based on commensurate priors (Hobbs and others, 2011, 2012), which lead to a type of hierarchical model for robust estimation in circumstances of just a small number of complementary studies. Using it can facilitate inferences with respect to all possible pairwise borrowing of information between |$K$| subgroups in a basket trial, which accounts for the level of data commensurability across subtrials. More explicitly, given any complementary subtrial data, a commensurate prior can be specified for the treatment effect in the subtrial of contemporary analysis interest. It is basically a normal predictive prior centered at the complementary subtrial data parameter, with a precision factor to capture the commensurability of the parameters that underpin the complementary and contemparory subtrials.
We explore placing an empirical spike-and-slab prior (Mitchell and Beauchamp, 1988) on the precision factor, which determines the degree of point-to-point borrowing. For overcoming a prior-data conflict, we propose using a distributional discrepancy measure to characterize the commensurability of information between any two subtrials. It could quantify the probability mass to be placed on the “spike” prior for strong borrowing, and that on the “slab” prior for discounting inconsistent information from a complementary subtrial, respectively. This discrepancy measure meanwhile discerns the complementary subtrials (when at least three subgroups are involved) according to their relative commensurability, and can therefore encourage differential borrowing of information to estimate the model parameter specific to a subtrial. The proposed methodology for basket trials is fundamentally different from the existing approaches to information sharing. It avoids the limiting assumption about exchangeability for parameters of certain or all subtrials but features the use of a distributional discrepancy measure to inform the borrowing only from the most commensurate subtrial(s).
The remainder of this article is structured as follows. We describe the motivating example and decision criteria in Section 2. In Section 3, we present our analysis methodology and discuss how a discrepancy measure may help make appropriate use of complementary data in a basket trial. In Section 4, we perform a simulation study to evaluate the operating characteristics of phase II basket trials that would have been analyzed using the proposed methodology, and compare our Bayesian model with some alternative analysis models. We close with a discussion of our findings and future research that arises in Section 5.
2. Motivating example and notation
We use a randomized, placebo-controlled phase II basket trial, as a motivating example, which evaluates a new treatment for cognitive dysfunction in patients of primary biliary cholangitis (PBC) and Parkinson’s disease (PD). This clinical trial is led by Newcastle University; at the time of writing, it has been funded but not yet opened to participants. By stages and types of the chronic diseases, patients are to be recruited and stratified into three disjoint subgroups, that is, early-stage PBC, late-stage PBC, and PD. The PBC and PD basket trial thus comprises three subtrials. A continuous outcome measuring cognitive performance will be used as the clinical endpoint in each subtrial. Once the trial begins, patients within each subtrial will be randomized to receive either the new treatment or a placebo.
3. Methods
Derivable from the Cauchy–Schwarz inequality, the computed Hellinger distance |$d_{\phi_H}(\pi_{\theta_k}, \pi_{\theta_{k^\star}}\!)$| will strictly fall into the interval of [0, 1], which is convenient for characterizing the probability that treatment effects of any two subtrials are regarded as dissimilar. We may then relate the “slab” prior probability |$w_{kk^\star}$| with the computed Hellinger distance, simply by stipulating |$w_{kk^\star} = d_{H}(\pi_{\theta_k}, \pi_{\theta_{k^\star}}\!)$|. In an extreme case that two subtrials are perfectly consistent, i.e., |$d_{H}(\pi_{\theta_k}, \pi_{\theta_{k^\star}}\!) \to 0$|, the whole probability mass will be concentrated at the “spike,” |$\mathcal{S}$|. In turn, this will result in a notably small normal variance |$1/\nu_{kk^\star}^2$| of the CPP in (3.3) such that the complementary subtrial data |$\boldsymbol{x}_k$| can be fully incorporated. In addition, knowing the upper and lower bounds, which are 0 and 1 for the Hellinger distance, makes it easier to standardize a collection of pairwise discrepancy measurements. This can help quantify the relative importance of all other subtrials |$k \neq k^\star$| to form a prior for |$\theta_{k^\star}$| in circumstances of |$K\geq 3$|. More importantly, the Hellinger distance is preferred over other distributional discrepancy measures, because of its desirable properties of symmetry and invariance to any transformation, for example, logarithmic, exponential, or inverse of square root, of both densities (Jeffreys, 1961). As a symmetric measure of discrepancy, |$d_{H}(\pi_{\theta_k}, \pi_{\theta_{k^\star}}\!) = d_{H}(\pi_{\theta_k^\star}, \pi_{\theta_{k}})$|. In a basket trial with |$K=2$| and no a priori assumption about which subtrial has stronger treatment effect, using the Hellinger distance to define the spike-and-slab prior will result in the same magnitude of down-weighting or leveraging subtrial data |$\boldsymbol{x}_1$| to subtrial 2 and |$\boldsymbol{x}_2$| to subtrial 1. Whilst the invariance property ensures that the computed Hellinger distance |$d_{H}(\pi_{\theta_k}, \pi_{\theta_{k^\star}}\!)$| truly reflects the discrepancy between the treatment effect distributions in different patient subtrials, when the linear regression model (2.1) may be parameterized in a different way, for example, with the treatment effect represented by the exponential of |$\theta_k$|. Given the invariance, we know that |$d_{H}(\pi_{\theta_k}, \pi_{\theta_{k^\star}}\!) = d_{H}(\pi_{\exp(\theta_k)}, \pi_{\exp(\theta_{k^\star})})$|.
We would like to add one more note here. The stipulation of weights |$p_{kk^\star}$| summing to 1 does not restrict the potential of full borrowing of information in situations, where all the |$(K-1)$| complementary subtrials are perfectly consistent with subtrial |$k^\star$|. In such a scenario, the Hellinger distance |$d_{kk^\star} = 0$|, suggesting that the CPPs marginally on |$\theta_{k^\star}$|, represented by |$N(\lambda_k, \xi_k^2)$|, have identical mean and variance to those of |$\pi_{k^\star} (\theta_{k^\star} | \boldsymbol{x}_{k^\star})$|. Moreover, equal weights, i.e., |$p_{kk^\star} = \frac{1}{K-1}$|, will be allocated to the complementary subtrials, |$k \neq k^\star$|. Following (3.8), a predictive prior |$\pi^\text{MPP}(\theta_{k^\star} | \boldsymbol{x}_{(-k^\star)})$| would be obtained with its mean as |$\lambda_k$| and variance as |$\frac{1}{K-1} \xi_k^2$|. With the inclusion of |$\boldsymbol{x}_{k^\star}$|, the posterior mean and variance become |$\lambda_k$| and |$\frac{1}{K} \xi_k^2$|, respectively. This indicates all the complementary subtrial data |$\boldsymbol{x}_{(-k^\star)}$| have been fully incorporated, and our methodology converges to the approach of complete pooling in the case of perfect information consistency.
4. Simulation study
In this section, we illustrate applications of the proposed analysis methodology, and compare it with alternative Bayesian models that may be used for analyzing basket trials through a simulation study. Our trial examples are hypothetical, but can represent the situation of a phase II basket trial, for which the analyses are performed to enable sharing of information. The main characteristics of the basket trials we simulate are based on the motivating PBC and PD trial described in Section 2. For illustrative purposes, we assume six subtrials instead of three, as typically a fairly large number of patient subgroups would be examined; for example, Hyman and others (2015, 2018 report the results from basket trials with six and nine subtrials, respectively.
4.1. Basic settings
Simulation scenarios with specification of the “true” treatment effect |$\theta_k$| to compare the Bayesian analysis models. The figure in bold indicates a 0 or low treatment effect.
| Subtrial |$k$| (Sample size, |$n_k$|)} | ||||||
|---|---|---|---|---|---|---|
| Scenario | 1 (|$n_1 = 10$|) | 2 (|$n_3 = 10$|) | 3 (|$n_2 = 14$|) | 4 (|$n_5 = 16$|) | 5 (|$n_4 = 20$|) | 6 (|$n_6 = 20$|) |
| 1 | 0.49 | 0.67 | 0.54 | 0.43 | 0.79 | 0.35 |
| 2 | 0.35 | 0.37 | 0.80 | 1.30 | 1.38 | 0.40 |
| 3 | 0.29 | 0.77 | 0.68 | 0.75 | 0.33 | 0.30 |
| 4 | 0.59 | 1.17 | 1.02 | 0.95 | 0.13 | 0.75 |
| 5 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 |
| 6 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 |
| 7 | 0 | 0 | 0 | 0 | 0.37 | 0.37 |
| 8 | 0.33 | 0 | 0.82 | 0.90 | 0 | 0.83 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 |
| Subtrial |$k$| (Sample size, |$n_k$|)} | ||||||
|---|---|---|---|---|---|---|
| Scenario | 1 (|$n_1 = 10$|) | 2 (|$n_3 = 10$|) | 3 (|$n_2 = 14$|) | 4 (|$n_5 = 16$|) | 5 (|$n_4 = 20$|) | 6 (|$n_6 = 20$|) |
| 1 | 0.49 | 0.67 | 0.54 | 0.43 | 0.79 | 0.35 |
| 2 | 0.35 | 0.37 | 0.80 | 1.30 | 1.38 | 0.40 |
| 3 | 0.29 | 0.77 | 0.68 | 0.75 | 0.33 | 0.30 |
| 4 | 0.59 | 1.17 | 1.02 | 0.95 | 0.13 | 0.75 |
| 5 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 |
| 6 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 |
| 7 | 0 | 0 | 0 | 0 | 0.37 | 0.37 |
| 8 | 0.33 | 0 | 0.82 | 0.90 | 0 | 0.83 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 |
Simulation scenarios with specification of the “true” treatment effect |$\theta_k$| to compare the Bayesian analysis models. The figure in bold indicates a 0 or low treatment effect.
| Subtrial |$k$| (Sample size, |$n_k$|)} | ||||||
|---|---|---|---|---|---|---|
| Scenario | 1 (|$n_1 = 10$|) | 2 (|$n_3 = 10$|) | 3 (|$n_2 = 14$|) | 4 (|$n_5 = 16$|) | 5 (|$n_4 = 20$|) | 6 (|$n_6 = 20$|) |
| 1 | 0.49 | 0.67 | 0.54 | 0.43 | 0.79 | 0.35 |
| 2 | 0.35 | 0.37 | 0.80 | 1.30 | 1.38 | 0.40 |
| 3 | 0.29 | 0.77 | 0.68 | 0.75 | 0.33 | 0.30 |
| 4 | 0.59 | 1.17 | 1.02 | 0.95 | 0.13 | 0.75 |
| 5 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 |
| 6 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 |
| 7 | 0 | 0 | 0 | 0 | 0.37 | 0.37 |
| 8 | 0.33 | 0 | 0.82 | 0.90 | 0 | 0.83 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 |
| Subtrial |$k$| (Sample size, |$n_k$|)} | ||||||
|---|---|---|---|---|---|---|
| Scenario | 1 (|$n_1 = 10$|) | 2 (|$n_3 = 10$|) | 3 (|$n_2 = 14$|) | 4 (|$n_5 = 16$|) | 5 (|$n_4 = 20$|) | 6 (|$n_6 = 20$|) |
| 1 | 0.49 | 0.67 | 0.54 | 0.43 | 0.79 | 0.35 |
| 2 | 0.35 | 0.37 | 0.80 | 1.30 | 1.38 | 0.40 |
| 3 | 0.29 | 0.77 | 0.68 | 0.75 | 0.33 | 0.30 |
| 4 | 0.59 | 1.17 | 1.02 | 0.95 | 0.13 | 0.75 |
| 5 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 | 0.45 |
| 6 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 | 0.30 |
| 7 | 0 | 0 | 0 | 0 | 0.37 | 0.37 |
| 8 | 0.33 | 0 | 0.82 | 0.90 | 0 | 0.83 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 |
To implement our methodology for estimating |$\theta_k$|, we choose setting |$\mathcal{B}_1 = 0.01, \, \mathcal{B}_2 = 1,$| and |$\mathcal{S} = 100$| for the spike-and-slab prior on each |$\nu_{kk^\star}$|. The “slab” prior is very uninformative and is sufficient to fully discard the entire information from an external subtrial |$k$|; the “spike” prior is specified so that the proposed methodology can be reduced to complete pooling in situations of perfect information commensurability. Justification of choosing this spike-and-slab prior is provided in Section B of the supplementary material available at Biostatistics online. An initial vague prior |$\pi_{0k}(\theta_k)$| is used for |$\theta_k, \, k = 1, \dots, 6$|; we use |$N(0, 10^2)$| such that the 95% prior credible interval is (|$-$|19.560, 19.560), covering a wide range of possible |$\theta_k$|. To yield a large (small) weight |$p_{kk^\star}$| corresponding to a small (large) Hellinger distance, we let |$s_0 = 0.15$| for the transformation. Nevertheless, we study how different stipulations of |$s_0$| may impact on the identification of the most consistent subtrial(s) in Section C of the supplementary material available at Biostatistics online, exploring |$s_0 = 0.25, 0.35, 0.45$| in addition. We are interested in comparing the proposed methodology with
(1) Standard hierarchical model (HM) that assumes fully exchangeable parameters: |$\theta_k | \mu_, \tau \sim N(\mu, \tau^2)$| with |$\mu \sim N(0, 10^2)$| and |$\tau\sim HN(0.125)$|. The median and 95% credible interval of |$HN$|(0.125) are 0.084 and (0.004, 0.280), respectively.
(2) Bayesian model with no borrowing of information. Trial data are stratified by subtrials for stand-alone analyses, setting each |$\theta_k \sim N(0, 10^2)$|. Random effects for |$\gamma_{0k}$|, |$\gamma_{1k}$|, and |$\gamma_{2k}$| therefore cannot be estimated; we then place a |$N(0, 5^2)$| prior on each.
(3) EXNEX model by Neuenschwander and others (2016), with equal prior probabilities of exchangeability (EX) and non-exchangeability (NEX). The EX distribution has the same parameter configuration as what was stipulated for the standard HM above, and the six NEX distributions are all set to be |$N(0, 10^2)$|.
an erroneous Go decision in a subtrial where the “true” |$\theta_k =0$|, and
a correct Go decision in a subtrial where the “true” |$\theta_k > 0$|,
Results are summarized by averaging across 10 000 replicates of the basket trial. The Bayesian analysis models are fitted in R version 3.4.4 using the R2OpenBUGS package based on two parallel chains, with each running the Gibbs sampler for 10 000 iterations that follow a burn-in of 3000 iterations. OpenBUGS code, together with R functions, to implement each of the Bayesian analysis models is available at https://github.com/BasketTrials/Bayesian-analysis-models.
4.2. Results
Figure 1 compares the performance of the posterior estimators yielded by the Bayesian models. It shows that the proposed methodology produces smaller bias and MSE compared with the standard HM and EXNEX, across nearly all scenarios. Point estimators based on the standard HM and EXNEX work well in scenarios 5, 6, and 9 as the small-to-moderate variability between |$\theta_k$|s can be addressed by setting |$\tau \sim HN(0.125)$|. The proposed analysis methodology, in contrast, distinguishes the heterogeneity more sensitively. Much smaller bias and MSE are yielded when estimating |$\theta_k$| for basket trials with divergent treatment effects across subtrials; see, for example, scenario 2. In situations where information from other subtrials should be largely discounted, referring to scenarios 7 and 8, our methodology generates comparatively similar bias to the no borrowing approach but with a smaller MSE. This is because information from subtrials with a non-zero treatment effect, can be largely discounted to formulate the marginal predictive prior for e.g., |$\theta_2$| in scenario 8.
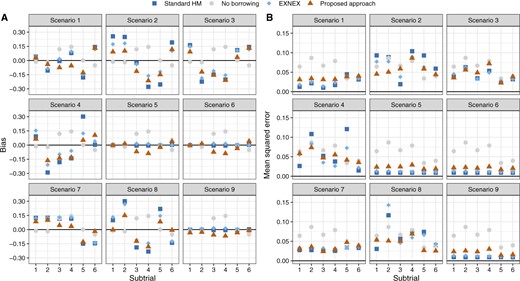
Bias and mean squared error of the posterior estimators for |$\theta_k$| based on the Bayesian models.
We have also compared the Bayesian analysis models in terms of the average width of the posterior credible intervals for |$\theta_k$|. In contrast to the alternative Bayesian models, the proposed methodology yields posterior estimates with narrower credible intervals when there is at least one consistent complementary subtrial; see Figure S1 of the supplementary material available at Biostatistics online. When using the proposed analysis methodology for borrowing of information, investigators may be interested in the weight eventually allocated to each external subtrial for obtaining the marginal predictive prior. In Figures S3 and S4 of the supplementary material available at Biostatistics online, we comment with regards to scenarios 4 (divergent |$\theta_k$|) and 5 (consistent |$\theta_k$|) on the weight allocation based on the assessed pairwise commensurability, and illustrate how the pre-specified value of |$s_0$| would impact the sensitivity of the proposed methodology to identify the most commensurate subtrial(s).
Table 2 quantifies the impact of using different Bayesian models on the error rate control under the null hypothesis. Here, we report the (analog of) type I error rate for scenarios involving at least one subtrial with |$\theta_k =0$|, setting |$\delta_U=0.25$|. Comparisons where we set |$\delta_U=0.30$| are given in Table S1 of the supplementary material available at Biostatistics online. For scenario 9 (global null), all the four Bayesian analysis models control the error rate well following the decision criterion. Nevertheless, the approaches that enable borrowing of information, i.e., standard HM, EXNEX, and the proposed methodology, have resulted in smaller type I error rates, compared with the approach of no borrowing, since incorporating consistent information from other subtrials reassures that making a Go decision is not justified. Our approach produces slightly higher error rates than standard HM and EXNEX, as for some simulated trials information from subtrials with a similar low treatment effect may be shared (but not with those of a null |$\theta_k$|’s), leading to a higher chance to reject the null hypothesis. In scenario 8 where some subtrials have large treatment effects, we observe a higher error rate when using standard HM and EXNEX approaches, compared with the proposed approach. We note that a difference in the sample sizes of subtrials 2 and 4 or 5 (for all scenarios) leads to disparate {magnitudes of the error rate} using the same approach in the same null scenario: those for subtrial 2 are regularly larger than subtrial 4 or 5. More explicitly, when reacting to a data conflict, a larger sample size of subtrial 4 or 5 provides more evidence to evaluate the plausibility of down-weighting; estimation of |$\theta_4$| or |$\theta_5$| thus has increased chances to avoid being overwhelmed by the complementary information.
Comparison of the Bayesian analysis models with respect to the analogue of type I error rate: null hypothesis is erroneously rejected under scenarios of any |$\theta_k =0$|, setting |$\delta_U=0.25$| and |$\zeta = 0.975$|.
| Subtrial | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | Overall | ||
| Scenario 7 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | — | — | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | — | — | 0.0269 | |
| EXNEX | 0.0001 | 0.0003 | 0.0002 | 0.0000 | — | — | 0.0006 | |
| Proposed approach | 0.0073 | 0.0089 | 0.0002 | 0.0002 | — | — | 0.0166 | |
| Scenario 8 | Standard HM | — | 0.0155 | — | — | 0.0080 | — | 0.0207 |
| No borrowing | — | 0.0077 | — | — | 0.0008 | — | 0.0085 | |
| EXNEX | — | 0.0195 | — | — | 0.0056 | — | 0.0251 | |
| Proposed approach | — | 0.0155 | — | — | 0.0017 | — | 0.0172 | |
| Scenario 9 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | 0.0008 | 0.0006 | 0.0283 | |
| EXNEX | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | |
| Proposed approach | 0.0014 | 0.0028 | 0.0000 | 0.0000 | 0.0002 | 0.0020 | 0.0064 | |
| Subtrial | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | Overall | ||
| Scenario 7 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | — | — | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | — | — | 0.0269 | |
| EXNEX | 0.0001 | 0.0003 | 0.0002 | 0.0000 | — | — | 0.0006 | |
| Proposed approach | 0.0073 | 0.0089 | 0.0002 | 0.0002 | — | — | 0.0166 | |
| Scenario 8 | Standard HM | — | 0.0155 | — | — | 0.0080 | — | 0.0207 |
| No borrowing | — | 0.0077 | — | — | 0.0008 | — | 0.0085 | |
| EXNEX | — | 0.0195 | — | — | 0.0056 | — | 0.0251 | |
| Proposed approach | — | 0.0155 | — | — | 0.0017 | — | 0.0172 | |
| Scenario 9 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | 0.0008 | 0.0006 | 0.0283 | |
| EXNEX | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | |
| Proposed approach | 0.0014 | 0.0028 | 0.0000 | 0.0000 | 0.0002 | 0.0020 | 0.0064 | |
Overall: the proportion of trials with erroneous Go decision for at least one subtrial.
Comparison of the Bayesian analysis models with respect to the analogue of type I error rate: null hypothesis is erroneously rejected under scenarios of any |$\theta_k =0$|, setting |$\delta_U=0.25$| and |$\zeta = 0.975$|.
| Subtrial | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | Overall | ||
| Scenario 7 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | — | — | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | — | — | 0.0269 | |
| EXNEX | 0.0001 | 0.0003 | 0.0002 | 0.0000 | — | — | 0.0006 | |
| Proposed approach | 0.0073 | 0.0089 | 0.0002 | 0.0002 | — | — | 0.0166 | |
| Scenario 8 | Standard HM | — | 0.0155 | — | — | 0.0080 | — | 0.0207 |
| No borrowing | — | 0.0077 | — | — | 0.0008 | — | 0.0085 | |
| EXNEX | — | 0.0195 | — | — | 0.0056 | — | 0.0251 | |
| Proposed approach | — | 0.0155 | — | — | 0.0017 | — | 0.0172 | |
| Scenario 9 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | 0.0008 | 0.0006 | 0.0283 | |
| EXNEX | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | |
| Proposed approach | 0.0014 | 0.0028 | 0.0000 | 0.0000 | 0.0002 | 0.0020 | 0.0064 | |
| Subtrial | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | Overall | ||
| Scenario 7 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | — | — | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | — | — | 0.0269 | |
| EXNEX | 0.0001 | 0.0003 | 0.0002 | 0.0000 | — | — | 0.0006 | |
| Proposed approach | 0.0073 | 0.0089 | 0.0002 | 0.0002 | — | — | 0.0166 | |
| Scenario 8 | Standard HM | — | 0.0155 | — | — | 0.0080 | — | 0.0207 |
| No borrowing | — | 0.0077 | — | — | 0.0008 | — | 0.0085 | |
| EXNEX | — | 0.0195 | — | — | 0.0056 | — | 0.0251 | |
| Proposed approach | — | 0.0155 | — | — | 0.0017 | — | 0.0172 | |
| Scenario 9 | Standard HM | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| No borrowing | 0.0036 | 0.0077 | 0.0056 | 0.0100 | 0.0008 | 0.0006 | 0.0283 | |
| EXNEX | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | |
| Proposed approach | 0.0014 | 0.0028 | 0.0000 | 0.0000 | 0.0002 | 0.0020 | 0.0064 | |
Overall: the proportion of trials with erroneous Go decision for at least one subtrial.
What may also be interesting to investigators is the potential increase in statistical power to demonstrate the treatment effect, by incorporating information from complementary subtrials. Figure 2 visualizes the comparison of the Bayesian analysis models in terms of correctly declaring a clinical benefit in subtrial |$k$|, setting |$\delta_U=0.25$|; see Figure S5 of supplementary material available at Biostatistics online that visualizes the comparison setting |$\delta_U=0.30$|. Across nearly all subtrials of the simulated basket trials in scenarios 1–5, the Bayesian approaches of borrowing show substantial advantages over the approach of no borrowing. When comparing between the Bayesian approaches of borrowing, we check how the chance would be for a subtrial with comparatively low treatment effect to be concluded with a correct Go decision, in the presence of consistent subtrials. Looking at scenarios 3, for example, our approach leads to higher statistical power for subtrials 2 and 6 compared with other Bayesian models.
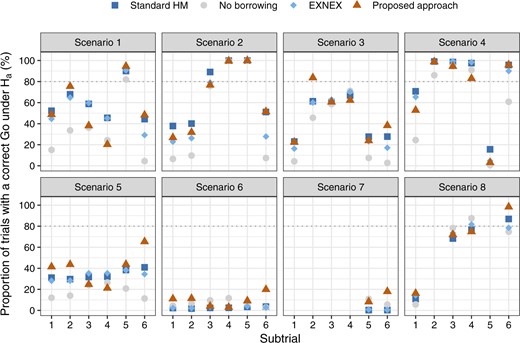
Comparison of the Bayesian analysis models with respect to the analog of statistical power: null hypothesis is correctly rejected in the presence of a treatment effect per subtrial, setting |$\delta_U=0.25$| and |$\zeta = 0.975$|.
Scenarios 5 and 6 represent situations where all subtrials are commensurate, but the former has a larger treatment effect size. Given our criterion that |$\mathbb{P}(\theta_k > 0.25) > 0.975$| for a Go decision, scenario 6 with all |$\theta_k = 0.30$| is particularly a hard scenario to allocate a Go. Compared with the approaches that enable borrowing, using the approach of no borrowing results in subtrials 3 and 4 having a slightly higher probability of correct Go decision. However, this does not mean the no borrowing approach is superior, since standard HM and EXNEX produce estimates of |$\theta_k$| with a similar level of bias, but much smaller posterior variances than the approach of no borrowing. These results are observed from Figure 1 and Figure S2 of the supplementary material available at Biostatistics online. More informative posterior distributions for |$\theta_k$| nevertheless do not necessarily mean a higher interval probability of |$\theta_k>\delta_U$|: it is possible that diffuse posteriors for |$\theta_k$| obtained from the approach of no borrowing has comparable or even higher chances to exceed the level |$\gamma = 0.975$|. When the consistent “true” |$\theta_k$|s increase from 0.30 (scenario 6) to 0.45 (scenario 5), we begin to observe the efficiency gains by using Bayesian models that permit borrowing of information than no borrowing. The proposed methodology appears to present a larger absolute gain in power compared with the alternative models, although we note that the absolute gain in power can be a misleading metric due to the non-linear shape of the power curve.
In scenario 7, due to the prior specification of |$\tau \sim HN(0.125)$| being incapable of accounting for the variability across subtrials, both standard HM and EXNEX shrink |$\theta_5$| and |$\theta_6$| excessively towards the mean effect across subgroups. This in turn dilutes the treatment effect in corresponding subtrials. Consequently, it seems better to implement the approach of no borrowing for possibility of declaring a positive treatment effect. Our approach presents slightly higher power than the no borrowing approach as there is some consistent information to be incorporated from a complementary subtrial. In scenario 8, our approach performs similarly to the alternatives, but slightly better for subtrial 6 due to leveraging consistent information.
We note this simulation study does not consider cases of basket trials involving rare disease subgroups, where certain subtrials can have a much smaller sample size than others. We present several hypothetical data examples in Section D of the supplementary material available at Biostatistics online to comment on the sensitivity to the difference in subtrial sample sizes.}
5. Discussion
The paradigm shift towards precision medicine opens new avenues for novel trial designs and analysis methodologies to deliver more tailored healthcare to patients. Basket trials emerge as a new class of efficient approaches to oncology drug development in the era of precision medicine, offering a framework to evaluate the treatment effect together with its heterogeneity in various patient subgroups. In this article, we have extended the key ideas of a basket trial approach to disease areas outside of oncology, and proposed a new Bayesian model to enable borrowing of information from the most commensurate subtrial(s) without requiring a priori clustering of similar subgroups. By including an information discrepancy measure, it can discern the degree of borrowing from complementary subtrials. In particular, the Hellinger distance plays a dual role in our methodology: (i) it gauges the maximum amount of information that could be leveraged from a specific subtrial |$k \neq k^\star$| to estimate |$\theta_{k^\star}$|; (ii) when there are |$K \geq 3$| subtrials, it determines the weight allocation to reflect the relative importance for appropriate borrowing of information.
The Bayesian analysis methodology in Section 3 has been developed assuming the basket trial generates continuous response data. However, it could be easily generalized to analyze other types of data that can be fitted using a generalized linear model for non-Gaussian error distributions. For example, it would be readily applicable to analyzing phase II basket trials that use binary endpoints: after fitting the patient-level data per subtrial with a logistic regression model, our approach may be considered to stipulate commensurate predictive priors, informed by the pairwise Hellinger distance, for the subtrial-specific treatment effect parameters to permit borrowing of information from the most consistent subtrial(s). For down-weighting in cases of a data conflict suggested by the Hellinger distance, we did not delve into calibration of the “slab” prior but simply used a very uninformative uniform distribution, which ensures data from an inconsistent subtrial can be discarded. When using the proposed methodology in practice, we recommend specifying the spike-and-slab prior based on some preliminary knowledge about the magnitude of variances of |$\theta_k$|. Specification of the “slab” prior may particularly deserve future research to exploit the advantage of the proposed methodology. We refer to Mutsvari and others (2016) as a relevant investigation, which focuses on choosing the diffuse component of a mixture prior for robust inferences. We also note that the exploration may be closely linked with the users’ stipulation of the prior probability weight, which is based upon the Hellinger distance, to be attributed to the “slab” prior.
In our simulation study, we have considered imbalance subtrial sizes. Simulation results show that our methodology can down-weight inconsistent information from a subtrial that has larger sample sizes. For illustrative purposes, we have supposed equal randomization ratio between treatment groups within a subtrial. Investigators can pragmatically determine the randomization ratio as well as the subtrial-wise sample size for a basket trial that may base decision making on our analysis methodology. Potentially, more dosage groups of the same treatment in each subtrial can be considered. Also, many have shown a great interest in sequential basket trials (Simon and others, 2016; Cunanan and others, 2017; Hobbs and Landin, 2018) with interim look(s) incorporated for the possibility of, say, terminating enrollment of patients in ineffective subgroups. We note that the proposed Bayesian approach can be implemented with any number of analyses following a flexible timescale for interim decision making. There is no requirement of a minimum sample size per subtrial to carry out an interim look, due to the use of an initial operational prior |$\pi_{0k}(\theta_k)$| for computing the pairwise Hellinger distance. However, an inflation of type I error rate arising from such repeated significance tests would occur.
Throughout, we have restricted our focus onto basket trials, where the subtrials use the same endpoint across patient subgroups. In many disease areas, multiple endpoints (FDA, 2017) may often arise, as it could involve various dimensions to conclude on the clinical benefit. One common situation is to continue monitoring toxicity in addition to the assessment of efficacy (Bryant and Day, 1995; Tournoux and others, 2007). With regards to this, our approach could be extended in several ways. For instance, in cases where the set of multiple endpoints remain the same across subgroups, it would be straightforward to establish a joint probability model and derive the pairwise Hellinger distance between multivariate probability densities (Pardo, 2005). Suitable alternatives include separating the discussion about borrowing of information by endpoint. A unified utility function may then be adopted for trial decision making based on evidence on multiple endpoints. In another more complex setting where the efficacy endpoint, for example, could be distinct but correlated across subgroups, one might need to translate the subtrial data onto a common scale in order to adapt the present approach. Ideas could be drawn from Zheng and others (2020), where incorporation of supplementary data recorded on a different measurement scale has been discussed in the context of phase I clinical trials.
6. Software
Software in the form of OpenBUGS code together with R functions is available on GitHub (https://github.com/BasketTrials/Bayesian-analysis-models).
Acknowledgments
The authors are thankful to the Associate Editor and two anonymous reviewers for carefully reading the manuscript and giving very helpful comments. Conflict of Interest: None declared.
Funding
JW is funded by the UK Medical Research Council (MC_UU_00002/6).
References
Fda. (

{kind=link}
{kind=link}