





Abstract
There is a growing interest in longitudinal omics data paired with some longitudinal clinical outcome. Given a large set of continuous omics variables and some continuous clinical outcome, each measured for a few subjects at only a few time points, we seek to identify those variables that co-vary over time with the outcome. To motivate this problem we study a dataset with hundreds of urinary metabolites along with Tuberculosis mycobacterial load as our clinical outcome, with the objective of identifying potential biomarkers for disease progression. For such data clinicians usually apply simple linear mixed effects models which often lack power given the low number of replicates and time points. We propose a penalized regression approach on the first differences of the data that extends the lasso + Laplacian method [Li and Li (Network-constrained regularization and variable selection for analysis of genomic data. Bioinformatics 2008;24:1175–82.)] to a longitudinal group lasso + Laplacian approach. Our method, PROLONG, leverages the first differences of the data to increase power by pairing the consecutive time points. The Laplacian penalty incorporates the dependence structure of the variables, and the group lasso penalty induces sparsity while grouping together all contemporaneous and lag terms for each omic variable in the model.
With an automated selection of model hyper-parameters, PROLONG correctly selects target metabolites with high specificity and sensitivity across a wide range of scenarios. PROLONG selects a set of metabolites from the real data that includes interesting targets identified during EDA.
An R package implementing described methods called “prolong” is available at https://github.com/stevebroll/prolong. Code snapshot available at 10.5281/zenodo.14804245.
1 Introduction
An emerging problem in omics research in the clinical domain is the discovery of useful biomarkers for repeated-measure data where both the clinical outcome and a large number of omics predictors are measured at a few times on a small number of individuals. In many clinical studies of disease progression, prognosis, and effectiveness of new treatments, we track clinical outcomes of a small group of patients over a handful of times (a few weeks, ). Recently it is also more feasible to collect data on a large number of omics features such as metabolite abundance or gene expressions. Clinicians with access to this large pool of omics features are interested in identifying biomarkers associated with the clinical outcome.
Our work is motivated by a pulmonary tuberculosis study consisting of 4 time point observations for 15 subjects each with measured sputum mycobacterial load, quantified by the time to positivity (TTP) in a Mycobacterium tuberculosis (Mtb) culture, and abundances of 352 urinary metabolites. These metabolites are of interest for their potential use as non-invasive markers of the disease process and for insight into biological pathways (Cliff et al. 2013, Dutta et al. 2020, Li et al. 2021). Previous work has been performed on the identification of urinary metabolite-based biomarkers for patients with pulmonary tuberculosis (Isa et al. 2018, Xia et al. 2020) and the creation of a general methodology for metabolite-based biomarker discovery in settings with longitudinal continuous outcomes. Figure 1 shows trajectories over time for the Mtb TTP and for two metabolites. The TTP (top left) shows a consistent upward mean shift, but the individual subject trajectories often show dips. Despite a small number of time points and subjects, we can clearly see associations between the outcome and the metabolite trajectories.
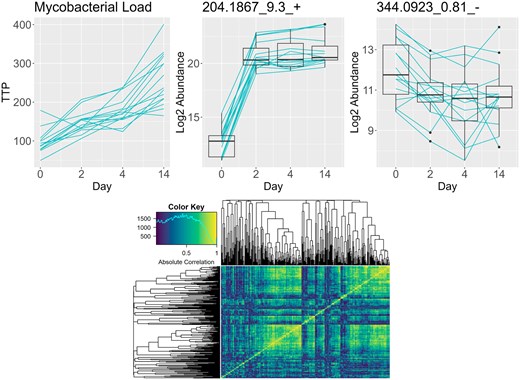
Trajectories for time to positivity which is inversely related to mycobacterial load (top left), an interesting metabolite (top center), and a more stationary but still potentially interesting metabolite (top right). Absolute correlation heatmap for all metabolites for difference of the first two time points (bottom).
Existing works in the short panel clinical omics literature often use univariate longitudinal linear mixed effects (LMEs) regression models (Walsh et al. 2020, Wipperman et al. 2021) for the clinical outcome of interest. Typically, variable selection is conducted by comparing the P-values of the univariate models. Beyond the usual multiplicity adjustment limitations of one-at-a-time modeling and testing, we argue that, by failing to incorporate the underlying omic feature and time correlation structures, this approach is susceptible to low sensitivity and statistical power. For our data, LME does not select a single metabolite.
The literature on high-dimensional omics in molecular biology and genomics is vast. However, many of these methods are not designed around using a time-varying clinical outcome, often focusing on differential expression for two or more groups, including DESeq2 (Love et al. 2014), limma (Ritchie et al. 2015), OmicsLonDA (Metwally et al. 2022). Generalized Estimating Equations (GEEs) (Xu et al. 2014), have been applied to modeling outcomes with longitudinal omics data, but this approach requires more samples than are present in our data.
We propose the PROLONG method, Penalized Regression for Outcome guided Longitudinal Omics analysis with Network and Group constraints, which can jointly select longitudinal features that co-vary with a time-varying outcome on the first-difference scale, either contemporaneously or with lags. PROLONG combines the group lasso and Laplacian penalties as an extension of the network-constrained regularization model introduced by Li and Li (2008). The group lasso penalty induces sparsity while grouping all of the contemporaneous and lag terms of each variable, and the network penalty incorporates the correlation structure of the data.
The first-differencing of the outcome and omics variables provides multiple benefits over the levels scale for this problem. Most importantly, it increases power over level scale analysis in the same way a paired t-test offers more power than an unpaired t-test when the two groups are positively correlated. We can view its effect in metabolite 344.0923_0.81_- shown in Fig. 1. The metabolite abundance levels decrease from day 0 to day 2, but the boxplots have substantial overlap. However, tracking the changes in levels for every subject using the blue lines, we see that all except one subject’s metabolite level decreased, increasing our confidence that this change is real. First-differencing also helps us cancel out any time-invariant terms like the intercept and subject-level effects, reducing the number of parameters to estimate and simplifying the model.
The primary innovation of this paper is the use of first-differencing for both the omics predictors and the clinical outcome to gain power in high-dimensional analysis. To our knowledge, first-differencing has not been used in the omics literature despite its ubiquitous use in low-dimensional problems under the so-called change score framework (Oldham 1962, Tu and Gilthorpe 2007, Tennant et al. 2022). Additionally, our inclusion of lag effects allows for the selection of omics variables with more complex relationships with the clinical outcome.
We test PROLONG in simulations with both uncorrelated and correlated data, comparing univariate and multivariate versions of PROLONG with LME. LME performs the worst in all scenarios, especially struggling in the first-difference scale simulations. Both versions of PROLONG have near-perfect sensitivity in all scenarios, with the multivariate PROLONG having better specificity as dimension and sparsity increase.
PROLONG is also tested on the motivating TB clinical trials data, shown in Fig. 1. For this data, PROLONG, which itself does not apply FDR control, selects a set of target metabolites identified in exploratory data analysis and by clinicians, while the univariate longitudinal model picks out no metabolites at reasonable FDR thresholds. Some metabolites selected by PROLONG were identified as targets from the exploratory analysis phase due to their sharp change from the baseline to the second measurement, like 204.1867_9.3+. whose trajectories are shown in Fig. 1. However, many trajectories are not cleanly separated between baseline and post-treatment, such as 344.0923_0.81_- shown in Fig. 1. These metabolites have different levels of variation across time points but do not show a sustained long-term effect after treatment, highlighting the flexibility of PROLONG.
2 Materials and methods
To provide motivation for PROLONG, we first describe the univariate mixed effects model often used for longitudinal omics regression (Walsh et al. 2020). Then we provide our proposed univariate alternative model and a natural hypothesis testing technique. We end this section with our proposed multivariate extension, which includes constraints to induce sparsity in the high-dimension scenario and to incorporate the dependence structure of the omics predictors.
2.1 Background
Longitudinal mixed effects models account for potential temporal dependence in the data as well as subject-level variation. Still, they may have insufficient power to select true metabolites with short-term changes and trends over time in our data setting with such small n and T. This is particularly relevant when the time course data is primarily focused on short-term dynamics, and controlling for time-invariant unobservable factors is crucial (Wooldridge 2010).
To eliminate time-invariant effects and to pair our observations over time to increase power, we move to the first-difference, or delta, scale for both and . When we regress the first-differences of the outcome on our first differences of the metabolites, we seek to identify short-term changes in our outcome that are associated with short-term changes in our feature abundances. This first-difference approach addresses the unobserved time-invariant heterogeneity as well as potential endogeneity concerns related to time-invariant unobserved factors.
The first-difference approach is appropriate for our motivating example, as the subjects all receive the same treatment but show time heterogeneous TTP and metabolite abundances. We view our independent variables not as a treatment themselves but as potential mediators for the treatment effect on the clinical outcome. Identifying significant linear relationships on the delta scale can inform clinicians of biomarkers for early disease progression.
2.2 PROLONG: univariate case
In this subsection we give the sequence of step to deduce a matrix representation of the differenced regression model from Equation (1). For each subject, we first matricize the data to incorporate all time points into a single model. Once in the form of matrices, the difference between subsequent time points can be represented in terms of other matrices.
For the test parameters we use the coefficients from the models for each component of Y, and for the covariance matrix we use a block diagonal with blocks containing the covariance matrix for the coefficients of the respective models. This univariate test encapsulates the model structure we are proposing and could be used for small sets of variables that are not heavily correlated. For larger or correlated variable sets we will need a joint model with appropriate constraints.
2.3 PROLONG: multivariate case
Using the matrix representations of the difference based dependent and independent variables in Equations (3) and (8) the longitudinal regression model takes the form where u is the mean-zero error vector and with for .
Here, we scale the columns of X, but this is a zero intercept model and we do not center the columns of .
The basic regression model does not contain a known underlying graph connecting the dependence among the independent variables (metabolites), so we now develop a graph-based penalization via the design matrix X dependence structure. Since each of the T−1 separate time components of Y are jointly modeled the block diagonal dependence matrix will mirror our design matrix.
Each block is a dependence matrix for the columns of , that is, the block of dependencies among the independent variables.
PROLONG uses a regular group lasso penalty along with a network constraint via the Laplacian matrix of the graph associated with R. First, estimate R via . We define this graph G as having edges between columns u, v of X whose edge-weights are The degree of each vertex is
The penalization criterion used by Li and Li (2008) contains terms for the network constraint and for the lasso penalty, and for our data would be .
Operationally, we estimate via lasso on the augmented data then rescale by to debias.
After minimizing over both λ2 and λR, we add to L before computing via decomposition. Then λ1 is selected via group lasso cross-validation on the augmented model generated using λ2 and λR. Upon solving for , we rescale by .
PROLONG inherits characteristics of both network-constrained regularization and group-lasso. The group lasso penalty ensures that all coefficients associated with a given omics feature are either zero or non-zero, but not necessarily identical. The network constraint guarantees that if xi = xj then , and omics features that are highly correlated but not identical will be grouped together. This grouping effect as well as asymptotic results for the group lasso + Laplacian model are described in the following theorems and the proofs are provided in the Supplementary.
3 Results
First, we will compare the performance of PROLONG to that of our benchmark univariate mixed effects models for simulated uncorrelated data with Y generated on the first-difference scale. Uncorrelated data is a good first comparison as the network constraint portion of PROLONG will not have any real signal to work with, so it could be thought of as more challenging than data with correlated predictors. Then we will compare PROLONG and benchmarks on correlated data with Y generated on the first-difference scale. Finally we will compare PROLONG and benchmarks on correlated data with Y generated on the levels scale, both with and without a time-varying intercept αt.
We are not so much interested in recovering the exact generating coefficients as we are in correctly distinguishing between targets and noise. To assess the performance of PROLONG and the univariate method we will compare the selection rates for each variable, target and noise, across 100 simulations for each scenario.
3.1 Simulated differenced-scale data with uncorrelated predictors
3.1.1 Small scale results
As seen in Fig. 2a, with and , we find that the univariate mixed effects models struggled to distinguish between targets and noise. This pattern holds across FDR thresholds, as the rate of acceptance increased flatly across targets and noise. PROLONG picked up 99.2% of the targets and 3.75% of the noise across simulations. At an FDR of 0.05, the Wald test selected every target and 11.15% of the noise across simulations.
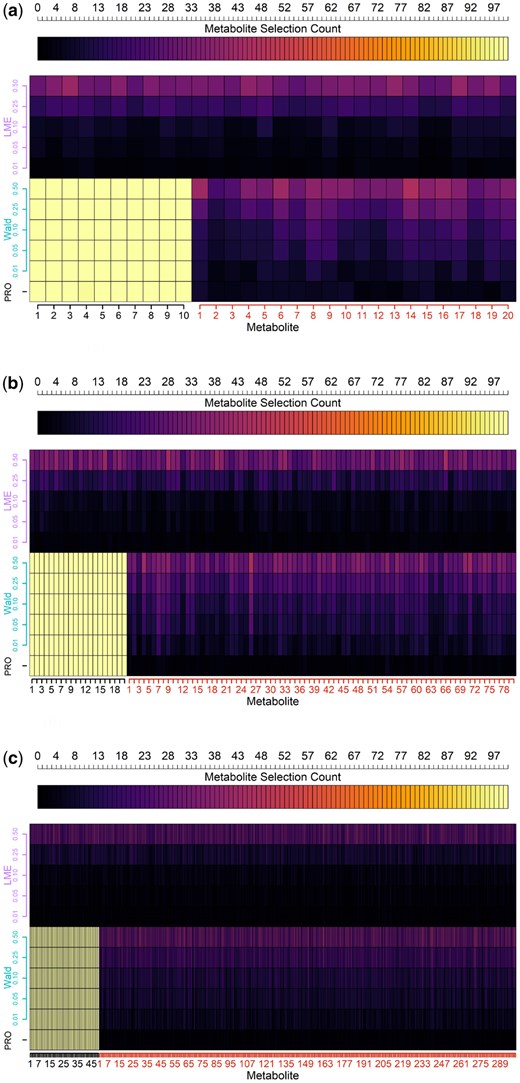
Comparison of selection counts (top axis) across simulations for target and noise metabolites (x-axis) using PROLONG, univariate Wald tests, and univariate Linear Mixed Effects (LME) models at Various FDR Thresholds (y-axis). PROLONG and its Wald analog both have perfect or near-perfect sensitivity across scenarios and FDR thresholds, PROLONG has higher specificity across the scenarios than Wald FDR 0.05, and the linear mixed effects models struggle everywhere. (a) Simulated uncorrelated data, 10 targets and 20 noise. (b) Simulated uncorrelated data, with 20 target and 80 noise variables. (c) Simulated uncorrelated data, 50 targets and 300 noise.
Figure S6 in the Supplementary File shows the coefficient paths and group lasso CV loss for a simulation run from each of the correlated and uncorrelated small-scale simulations. The blue lines show the coefficient paths for the target variables, red show the paths for the noise variables. The higher blue paths indicate coefficients for the time points that are used to generate the changes in Y, while those closer to zero represent time points not used to generate Y but that are kept from being shrunk to zero by the group penalty. In this example of the uncorrelated data, we see a wide gap in the log lambda scale for the selection of noise and targets. We can observe a steady decline in the noise coefficients, while the non-significant time points for the target variables are relatively flat across the lambda scale.
3.1.2 Large scale results
Figure 2b shows that when and PROLONG selected every target metabolite and 0.43% of the noise. The Wald tests also selected the targets perfectly at an FDR of 0.05 along with 9.9% of the noise. With this larger variable set we see a much stronger performance for PROLONG compared to the Wald test. Again, the univariate mixed effects models struggled as expected with flat selection across noise and target variables.
3.1.3 Full data scale results
Figure 2c shows results for the full data-scale results where and . The univariate mixed effects models again showed no difference across target and noise. PROLONG and Wald at an FDR of 0.05 both select all targets once again, with 0.18% and 8.8% of noise picked up, respectively.
3.2 Simulated differenced-scale data with correlated predictors
Next, we will compare PROLONG and the univariate tests for performance on simulated correlated data. The univariate mixed effects models cannot make use of any correlation between variables, so we do not expect the results to vary meaningfully between uncorrelated and correlated simulations.
This simulation setup only differs from the previous by the definition of ΣX. Here we have where for our covariance matrix associated with our target variables is constructed so that the variances on the diagonal are in the same range as those of the noise variables, while the off-diagonal elements correspond to off-diagonal elements of correlation matrix C drawn uniformly from .
Constructing ΣX in this way ensures we have some (random) correlation between the target variables that generate Y that can be leveraged by the correlation network penalty.
3.2.1 Small scale results
Figure S1a in the Supplementary File displays our results when and . The univariate mixed effects model struggled as in the uncorrelated case, while PROLONG picked up 95% of targets and Wald tests picked up every target. PROLONG selected only 5.75% of the noise, lower than Wald tests at an FDR of 0.05 with 11.05%.
3.2.2 Large scale results
Figure S1b in the Supplementary File shows results for and . PROLONG and Wald tests at an FDR of 0.05 selected all of the targets along with 0.62% and 9.8%, respectively.
3.2.3 Full data scale results
Figure S1c in the Supplementary File shows results for the full data-scale results where and . The univariate mixed effects models again showed no difference across target and noise. PROLONG and Wald tests at an FDR of 0.05 both select all targets once again along with 0.18% and 8.74% of the noise, respectively.
3.3 Simulated levels-scale data with correlated predictors
3.3.1 No time-varying intercept
Figure S2a in the Supplementary File shows the results with αt = 0. PROLONG selects all targets and 5.7% of the noise across simulations. At an FDR of 0.05, the Wald tests and LMEs models selected 100% and 90.7% of the targets, respectively, along with 9.075% and 4.2% of the noise.
3.3.2 With time-varying intercept
Figure S2b in the Supplementary File shows the results with αt = t. PROLONG again selects all targets and slightly more noise at 6%. The Wald tests select all targets and 8.5% of the noise, and the LMEs models pick 89.4% of the targets and, as with , 4.2% of the noise.
3.3.3 With large time-varying intercept
Figure S2c in the Supplementary File shows the results with αt = 5t. PROLONG still selects all targets, along with a higher 16% of the noise. The Wald tests select all targets with 7.6% of the noise, and the LMEs models match the scenario with 89% of targets and 4.2% of noise.
3.4 Summary of simulation results
For the first difference-scale simulations we can observe that PROLONG had near-perfect sensitivity in both correlated and uncorrelated simulated data and improved as we increased our variable size and sparsity. The univariate mixed effects models struggled in all scenarios. The Wald tests at an FDR threshold of 0.05 picked up every target, but also much more noise than PROLONG and improved more slowly as dimension increased. The correlation did not provide a significant advantage here. Even uncorrelated variables with a lower signal were picked up nearly always across all scenarios, so there was little room for improvement with the incorporation of a correlation structure within the target variables.
The levels-scale simulations show much better success for the LMEs models, while still preserving a strong performance for PROLONG and the Wald tests. The LME models miss about 10% of the targets but have a flat noise rate of 4.2%. The Wald tests pick up every target but have higher noise across αt. In the large αt scenario PROLONG selects more noise than either univariate model, but in the other scenarios it is slightly above the LME models and below Wald tests. PROLONG also selects every target across scenarios. It should be noted that in this final scenario . Even in the presence of this very large time intercept PROLONG preserves its sensitivity, only picking up additional noise to fill in the αt signal.
Additional results are shown in the Supplementary File. Figure S3 shows various scenarios as before (delta- and levels-scale) with an additional levels-scale version of the PROLONG model (denoted LEV) included. This levels-scale version of PROLONG has much less power than the delta-scale PROLONG across all simulations. Figure S4 shows the same scenarios and models as Fig. S3 but with X generated from cubic splines. Levels-scale PROLONG struggles even more in these scenarios, while PROLONG only slightly loses power. Figure S5 shows scenarios comparing PROLONG, its levels-scale version, and PGEE (Wang et al. 2012). PGEE fails to distinguish between targets and noise, with low overall power as well.
3.5 Data
3.5.1 Clinical significance
TB remains a major global health issue, with an estimated 10 million new cases and 1.4 million deaths annually, despite being preventable and treatable (WHO et al. 2021). Challenges include long treatment durations, rising drug resistance, and a lack of reliable biomarkers for diagnosis and for monitoring treatment efficacy (Das et al. 2016, Dartois and Rubin 2022, Salari et al. 2023, Gillespie et al. 2024). We are investigating the potential of urinary metabolomic data from TB trials as biomarkers for early bactericidal activity.
While immediate motivation for the proposed method stems from the TB study, the development of statistical models for short-panel omics data may enhance our ability to handle similar data structures in diverse medical research. In fact, this data is reflective of an increasingly common collection of biomarkers across a few time points with some continuous outcome of interest. There is extensive work on differential expression methods, but here we have monotonically increasing but variable improvement in TTP across subjects, as well as potentially interesting biomarkers that are not significantly different from the first and last time points of measurement. While some metabolites do show a strong spike and plateau pattern, others primarily show variability between subjects at the first few time points while having a relatively stable mean. This data is representative of other new datasets while also providing a challenge that existing methods are not intended to address.
3.5.2 Collection and preprocessing
Missingness is a common issue in mass-spectometry based metabolomics data (Wei et al. 2018), and so for the purpose of model development we limited the following analysis to metabolites with less than 20% observations missing across subjects and time points. We have 352 metabolites that meet this criterion, of which 79 have no missing values. We split the mostly complete 352 metabolites into 4 matrices, one for each time point, and used softImpute (Mazumder et al. 2010, Hastie and Mazumder 2021) to fill in missing values for each time point’s matrix of metabolite abundances by subject. Imputation was done in this way to avoid introducing any new dependence across time points.
3.5.3 Benchmark method
As in the simulations we are interested in the model results as classifying targets versus noise. We investigate the selected metabolites for PROLONG, our Wald tests, and the univariate longitudinal mixed effects models, checking for target metabolites identified in our exploratory analysis and previous literature.
3.5.4 Data results
No metabolites are selected by the univariate mixed effects models. This approach likely struggles with the apparent differential nature of the data. The data result mirror the first difference-scale simulations where Wald and PROLONG select many but the mixed effects models select very few amongst targets or noise.
Figure 3 shows 5 of the 29 metabolites selected by the PROLONG model, sorted by average coefficient magnitude but excluding 204.1867_9.3_+ shown in the introduction. PROLONG also picks up 344.0923_0.01_- shown in Fig. 1. 100.1019_11.01_+ shows a pattern similar to 204.1867_9.3_+, but among the rest we don’t always have the same clear spike and plateau. There are still easily observable differential effects in at least a few subjects that were picked up by the model. We can also observe that PROLONG does not only pick up metabolites that are differentially expressed between the first and last time points.
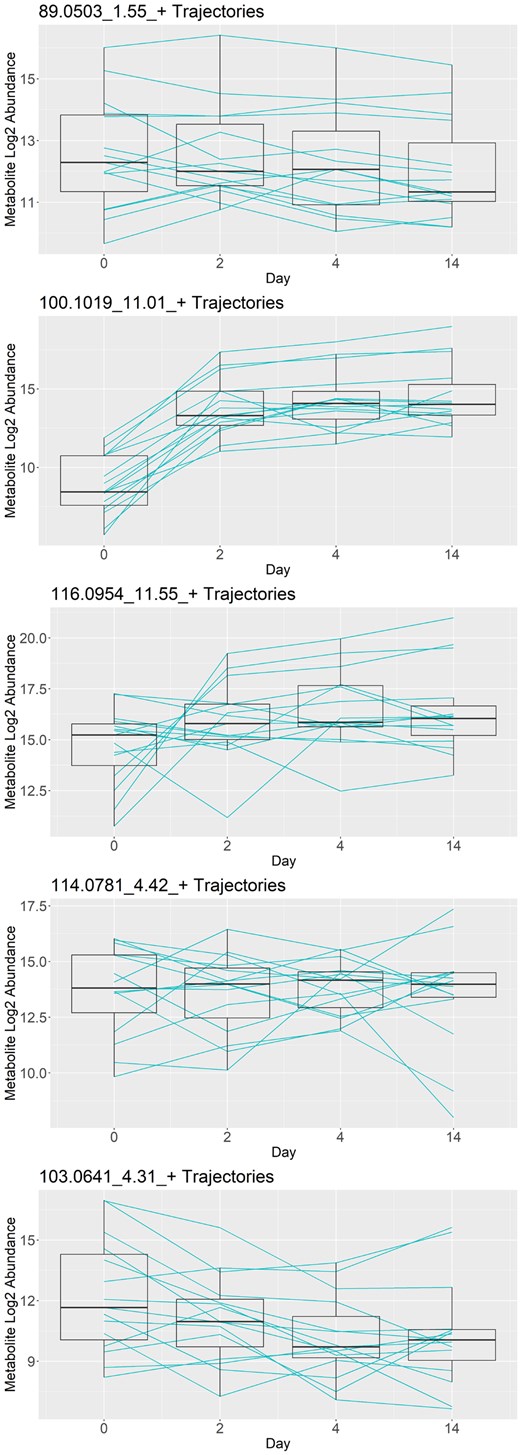
Trajectories for the five metabolites selected by PROLONG with the highest coefficients, excluding 204.1867_9.3_+ shown in the introduction. These metabolites show a variety in trend and variance over time and demonstrate the versatility of PROLONG.
4 Discussion
Data and figures shown in this paper illustrate the effectiveness of PROLONG as well as its univariate Wald test analog to a lesser extent. PROLONG can be thought of as a principled classification method where we are not so much interested in the coefficients themselves or least squares error as we are in statistical power. The simulations show that both sensitivity and specificity are very high, particularly in the larger simulated datasets, and the real metabolites selected by PROLONG show the type of biological signal that motivated the model itself. Notably, PROLONG does not only select those metabolites that are strongly differentially expressed before and after treatment but also those that are relatively consistent in mean but show subject variability patterns that correspond to subject variability in improvement in TTP over time.
Using difference-scale time-varying coefficients for our variables does not allow for these coefficients to be identifiable with the inclusion of an intercept term. However, we do not have indication that this should pose a significant problem- the additional noise selected is minimal with reasonable αt’s. The simulations indicate that PROLONG selects significantly less noise than its Wald test analog when αt is zero or reasonably small, and that the LMEs models struggle on the first-differenced scale. If our data had a large αt we would expect more selection from PROLONG than from the Wald test analog, and if the relationship was better explained on the levels-scale than the first-difference scale we would expect some selections from the LMEs models. The use of PROLONG for this data allows for the identification of metabolites that would have been missed with LMEs models.
There is limited preprocessing necessary for PROLONG; all that is necessary is first-differencing the data, scaling the predictors, and computing the incidence matrix. Prior biological knowledge is helpful, and could be incorporated into the network penalty in place of absolute correlation in appropriate scenarios. By default, however, the network penalty uses observed correlations rather than known pathways and can be used as-is for data without a known connective structure or for data where molecule identification is possible but costly.
The extension of PROLONG to multiple types of continuous omics data is immediate. The graph and model assumptions do not require a specific covariance structure, so we could combine the multiple omics types column-wise before proceeding with the same design matrix stacking and model procedure. For the graph edge weights, the correlation between two individual omics of different types is already interpretable, so we don’t expect to need any adjustments for this part of the extension. For a mixture of binary, count, and/or continuous omic data types, caution will need to be exercised in the selection of correlation measure for the graph’s edge weights. This method extension provides a clear path towards effective multi-omic integration, not only allowing for simultaneous feature selection but also incorporating additional knowledge about how the features co-vary.
The standard group lasso penalty used in PROLONG guarantees all non-zero or all zero coefficients within a group. There may be some advantages to inducing sparsity within each of these groups with sparse group lasso. In many datasets we should expect some time points, such as those closest to treatment, will be more important than others. Within-group sparsity may reveal additional information about the temporal relationship between the outcome and selected variables in such data.
The inclusion of continuous demographic or other time-invariant variables can be accomplished by adding an additional Zb term. This term would allow cross-sectional variables to be included outside the network and group lasso constraints.
Author contributions
Steven Broll (Conceptualization [equal], Investigation [equal], Methodology [equal], Software [lead]), Sumanta Basu (Conceptualization [equal], Funding acquisition [equal], Investigation [equal], Methodology [equal]), Myung Hee Lee (Conceptualization [equal], Investigation [equal], Methodology [equal]), and Martin Wells (Conceptualization [equal], Funding acquisition [equal], Investigation [equal], Methodology [equal], Supervision [equal])
Supplementary data
Supplementary data are available at Bioinformatics online.
Conflict of interest: None declared.
Funding
All authors acknowledge partial support from National Institutes of Health award NIH R01GM135926. S.Ba. acknowledges partial support from National Science Foundation awards DMS-1812128, DMS-2210675, CAREER DMS–2239102 and National Institutes of Health award NIH R21NS120227. S.Br. and M.T.W. acknowledge support from NIH 1T32HD113301-01.
Data availability
The data underlying this article cannot be shared publicly to maintain the privacy of the individuals that participated in the study. The data will be shared on reasonable request to the corresponding author.


{kind=link}
{kind=link}
{kind=link}