





Abstract
Motivation: Target characterization for a biochemical network is a heuristic evaluation process that produces a characterization model that may aid in predicting the suitability of each molecule for drug targeting. These approaches are typically used in drug research to identify novel potential targets using insights from known targets. Traditional approaches that characterize targets based on their molecular characteristics and biological function require extensive experimental study of each protein and are infeasible for evaluating larger networks with poorly understood proteins. Moreover, they fail to exploit network connectivity information which is now available from systems biology methods. Adopting a network-based approach by characterizing targets using network features provides greater insights that complement these traditional techniques. To this end, we present Tenet (Target charactErization using NEtwork Topology), a network-based approach that characterizes known targets in signalling networks using topological features.
Results: Tenet first computes a set of topological features and then leverages a support vector machine-based approach to identify predictive topological features that characterizes known targets. A characterization model is generated and it specifies which topological features are important for discriminating the targets and how these features should be combined to quantify the likelihood of a node being a target. We empirically study the performance of Tenet from a wide variety of aspects, using several signalling networks from BioModels with real-world curated outcomes. Results demonstrate its effectiveness and superiority in comparison to state-of-the-art approaches.
Availability and implementation: Our software is available freely for non-commercial purposes from: https://sites.google.com/site/cosbyntu/softwares/tenet
Contact: [email protected] or [email protected]
Supplementary information: Supplementary data are available at Bioinformatics online.
1 Introduction
Complex intra- and inter-cellular signalling drives various biological processes, such as growth, proliferation and apoptosis within systems. In systems biology, these molecular interactions are typically modelled as signalling networks (Klamt et al., 2009) that provide a holistic view of the various interactions between different molecular players in the system. As signalling networks become an increasingly acceptable way for representing biological systems, various network-based computational techniques have been developed to analyze these networks with the goal of answering biological needs, such as target characterization (Chua et al., 2014) and target discovery (Yang et al., 2008). In this article, we focus on the target characterization problem for signalling networks.
Target characterization identifies characteristics (e.g. topological features) that distinguishes targets (i.e. nodes) from other nodes in the network. These characteristics can be summarized as models which we refer to as characterization models. Traditionally, targets are characterized based on their molecular characteristics [e.g. structure and binding sites of targets (Maira et al., 2008)] and biological function [e.g. regulation of apoptosis (Yan et al., 2013)]. These traditional approaches focus primarily on the target alone and are oblivious to the presence of other interacting molecules in the system. However, understanding how a target interacts with other molecules in a biological system may provide valuable and holistic insights for superior target characterization. For example, the degree centrality of a target may be leveraged to assess potential toxicity of targets as high degree nodes tend to be involved in essential protein–protein interactions (He et al., 2006) and are potentially toxic as a result. In particular, network-based target characterization techniques can exploit such topological features for superior characterization of targets.
Recently, there have been increasing efforts toward devising network-based target characterization techniques (Hwang et al., 2008; Zhang et al., 2010; McDermott et al., 2012). These methods focus on using topological features to characterize targets of protein–protein interaction (ppi) networks. Specifically, McDermott et al. (2012) performed characterization of targets in protein co-abundancenetworks [The protein co-abundance networks are essentially protein–protein interaction (ppi) networks constructed by identifying highly differentially regulated proteins from proteomics data using specific filters.] using several topological features such as degree centrality. Although this study suggests that multiple topological features can be combined for superior target characterization, it did not explore how these topological features should be combined towards this goal. In contrast, Hwang et al. (2008) concluded that bridging centrality is useful in identifying targets in ppi networks. However, the complexity and diversity of biological networks make target characterization using a single feature challenging as in some networks the chosen feature may perform poorly. Indeed, Chua et al. (2014) showed that bridging centrality performs well in the mapk-pi3k network, but not in the glucose metabolism network. Zhang et al. (2010) proposed the use of machine learning techniques such as support vector machines (svm) and logistic regression for characterizing known targets in a manually curated human ppi network using 15 topological features. In contrast to McDermott et al. (2012), their goal was to identify topological characteristics of drug targets in general, instead of for specific diseases. However, characterizing targets in general assumes that targets of different diseases share similar target characteristics, which may not always be true. Indeed, as we shall see in Section 3, known targets in signalling networks tend to be characterized by different sets of topological features. Consequently, target characterization based on individual disease-specific networks may yield better characterization that is specific to the disease.
A common thread running through the aforementioned target characterization techniques is their focus on ppi networks. Surprisingly, similar systematic study in curated signalling networks has been lacking in the literature. Compared to signalling networks, ppi networks may contain many false-positive ppi in the sense that although these proteins can truly physically bind they may never do so inside cells due to different localization or they are not simultaneously expressed. Furthermore, ppi networks are static. That is, the edges in ppi networks are undirected; there is neither flow of information nor mass between nodes. Hence, they lack of knowledge of the underlying mechanism (i.e. actual signal flow) causing the disease. As network quality directly affects the results of network-based target characterization, the aforementioned limitations of ppi networks may adversely impact the search for superior characteristics of targets. Signalling networks, however, model the dynamic interaction of the biological systems and present an attractive alternative to ppi networks.
In our recent work (Chua et al., 2014), we took the first step to demonstrate how signalling networks can be effectively leveraged to identify topological features that are discriminative of targets using the Wilcoxon test. However, similar to McDermott et al. (2012), this work does not shed any insight on a predictive model to combine these features for identifying potential targets. In this article, we address this limitation by presenting Tenet (Target charactErization using NEtwork Topology), a network-based approach that characterizes known targets in signalling networks using topological features. Specifically, we use an svm-based approach to identify the set of topological features (referred to as predictive topological features) that characterizes known targets and to generate a characterization model using these features. The model specifies which topological features are important for discriminating the targets and how these features should be combined to produce a quantitative score that identifies the likelihood of a node being a target. In particular, Tenet uses feature selection to select predictive topological features and weighted misclassification cost (wmc) to handle svm training issues such as noisy labels and imbalanced data. Our empirical study on four real-world curated signalling networks demonstrates the effectiveness and superiority of Tenet.
2 Materials and methods
2.1 Terminology
A biological signalling network can be modelled as a directed hypergraph (Klamt et al., 2009) where the nodes V represent molecules (e.g. proteins) and the hyperedges E represent biochemical reactions and processes. A hyperedge connects one node set U to another W, where . For instance, in the activation of erk, the set U in the hyperedge consists of erk and its kinase, phosphorylated mek whereas W contains the phosphorylated erk (erkpp). Analysis of directed hypergraphs is generally more complex than graphs and many graph algorithms cannot be used directly on hypergraphs. Hence, they are often transformed into graphs containing simple edges for analysis. Methods (e.g. bipartite and substrate graph representation) exist for such transformation (Klamt et al., 2009). In this article, we use the bipartite graph representation as it retains the original information of the hypergraph (Klamt et al., 2009). Signalling networks generally contain characteristics such as feedback and feedforward loops, which are common in complex regulatory control (Kwon et al., 2008). These loops in turn give rise to graph characteristics, such as strongly connected components (scc).
The activity of nodes in the signalling network is generally governed by complex interconnectivity of various nodes in the same network. We refer to a node as a candidate target if when perturbed, it modulates the activity of a specific node (referred to as output node). An output node is a protein that is either involved in some biological processes which may be deregulated, resulting in manifestation of a disease, or be of interest due to its potential role in the disease. For instance, in the mapk-pi3k network (Hatakeyama et al., 2003) that is often implicated in cancer, erkpp can be considered as an output node due to its role in proliferation. Given a signalling network and an output node , let the set of nodes having a path leading to x be denoted as . Then, the set of candidate target nodes in G relevant to x is denoted as .
Network-based analysis can be applied to signalling networks to study the characteristics and properties of these networks. In this article, we examine a total of 16 topological features that are summarized in Table 1. These features are selected based on their role in measuring relative importance of a node in a signalling network. The formal definitions as well as motivation for selecting these features are given in Chua et al. (2014) (also detailed in Supplementary Material S1.1).
Topological features
| Symbol | Description |
|---|---|
| θu | Degree centrality of node u. The in, out and total degree centralities are denoted as and , respectively |
| αu | Eigenvector centrality of node u |
| βu | Closeness centrality of node u |
| γu | Eccentricity centrality of node u |
| δu | Betweenness centrality of node u |
| πu | Bridging coefficient of node u |
| ζu | Bridging centrality of node u |
| κu | Clustering coefficient of node u. The undirected, in, out, cycle and middleman clustering coefficients are denoted as and , respectively |
| μu | Proximity prestige of node u |
| ωu | Target downstream effect of node u |
| Symbol | Description |
|---|---|
| θu | Degree centrality of node u. The in, out and total degree centralities are denoted as and , respectively |
| αu | Eigenvector centrality of node u |
| βu | Closeness centrality of node u |
| γu | Eccentricity centrality of node u |
| δu | Betweenness centrality of node u |
| πu | Bridging coefficient of node u |
| ζu | Bridging centrality of node u |
| κu | Clustering coefficient of node u. The undirected, in, out, cycle and middleman clustering coefficients are denoted as and , respectively |
| μu | Proximity prestige of node u |
| ωu | Target downstream effect of node u |
Topological features
| Symbol | Description |
|---|---|
| θu | Degree centrality of node u. The in, out and total degree centralities are denoted as and , respectively |
| αu | Eigenvector centrality of node u |
| βu | Closeness centrality of node u |
| γu | Eccentricity centrality of node u |
| δu | Betweenness centrality of node u |
| πu | Bridging coefficient of node u |
| ζu | Bridging centrality of node u |
| κu | Clustering coefficient of node u. The undirected, in, out, cycle and middleman clustering coefficients are denoted as and , respectively |
| μu | Proximity prestige of node u |
| ωu | Target downstream effect of node u |
| Symbol | Description |
|---|---|
| θu | Degree centrality of node u. The in, out and total degree centralities are denoted as and , respectively |
| αu | Eigenvector centrality of node u |
| βu | Closeness centrality of node u |
| γu | Eccentricity centrality of node u |
| δu | Betweenness centrality of node u |
| πu | Bridging coefficient of node u |
| ζu | Bridging centrality of node u |
| κu | Clustering coefficient of node u. The undirected, in, out, cycle and middleman clustering coefficients are denoted as and , respectively |
| μu | Proximity prestige of node u |
| ωu | Target downstream effect of node u |
2.2 Topological feature-based target characterization
Intuitively, the goal of topological feature-based target characterization is to use a set of predictive topological features to characterize known targets in a network. Hence, the topological feature-based target characterization problem can be formulated as a supervised learning problem. In a supervised learning problem, a training set is given where is the predictor of xi and the goal is to learn some target function which can be applied to predict unseen data w. The problem can be subdivided into two categories: regression when the predictor yields a continuous outcome and classification when the outcome is discrete. A regression problem can be converted into a binary classification problem by specifying a threshold h and assigning xi with f greater than h to one class and the remaining to the other class. We advocate that the topological feature-based target characterization problem is best represented as a regression problem. In this problem, we are interested in finding out how likely one node is a target relative to another node based on a set of predictive topological features. This is different from the target classification problem where we want to find out the class membership of a node. Note that the regression problem can be converted into a classification problem by specifying a threshold h and assigning nodes having target function greater than h to the target class and the rest to the non-target class.
Although we examine 16 topological features, as we shall see later, not all features are relevant to a given signalling network. In fact, incorporating irrelevant features may adversely impact the performance of the prediction model. Hence, it is important to learn a set of predictive topological features that best characterizes targets (referred to as topological feature selection) for a given network. Formally, it is defined as follows.
Then the topological feature-based target characterization problem is formally defined as follows.
Figure 1 depicts a pictorial overview of the topological feature-based target characterization problem. For example, given the mapk-pi3k signalling network, its associated output node erkpp, the set of known targets in this network and the topological features in Table 1, the goal of this problem is to produce the followings: (i) identify the set of predictive topological features and (ii) learn a characterization model g(ξ(erkpp, . Note that in Definition 2, there is no need to explicitly specify a threshold h if we are only interested in obtaining the relative rankings of the nodes. The threshold is required if we want to assign class labels (e.g. target class) to the nodes.
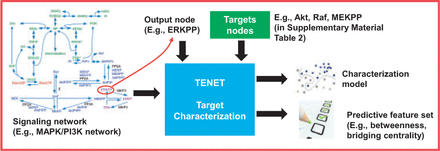
Target characterization problem
2.3 svm-based target characterization
We employ support vector classification (svc) to select predictive topological features and support vector regression (svr) to generate the characterization model. The svc and svr are typically formulated as constrained optimization problems and solved using the Lagrangian multiplier method. In general, svm models contain multiple parameters, such as the cost parameter C and parameters related to the kernel function, that affect the learning and performance of the models (Chapelle et al., 2002). We follow the method in Hsu et al. (2003) for training the svm. The feature values are scaled linearly to the range of [0, 1] for each signalling network to avoid features with larger ranges dominating those with smaller ranges. We use stratified (The training data were sampled from the original data such that the ratio of the targets to non-targets is similar to that of the original data.) cross-validation (Supplementary Material S1.3) and grid-search (Hsu et al., 2003) on the training data to identify the best values of the model parameters. Note that cross-validation helps us to avoid the issue of overfitting the data whereas stratification enables us to keep the percentage of targets in the different folds similar to the original dataset. The best parameter is the one that yields the best average prediction accuracy for the cross-validation process. Wherever possible (In our study, we set a lower bound of one target in all our test sets.), we use a 10-fold stratified cross-validation as larger fold numbers reduce pessimistic bias and 10-folds generally give good performances (Kohavi et al., 1995).
2.4 The Tenet algorithm
Given a signalling network , an output node , a known target set , a set of topological features and a step-size of the misclassification cost s, Tenet identifies the set of predictive structural features and a characterization model that best characterizes these known targets. Note that and s are optional inputs and are set to default values ( is set to the 16 topological features given in Table 1 whereas s is set to 0.1.) if they are not given. The known targets Tx can be extracted by following the curation process described in Chua et al. (2014) (Supplementary Material S1.2). The Tenet algorithm comprised three phases, namely, the pruning phase, the feature extraction phase and the model training phase. First, the pruning phase identifies relevant nodes (denoted as Vcandidate) that shall be used for training the svm. Then, the feature extraction phase extracts all the topological features (denoted as ) of each candidate node and stores them in a matrix H. Finally, in the model training phase, Tenet learns the optimal set of predictive topological features and the best model parameters of the characterization model . We shall now describe these phases in turn. The formal algorithm is given in Supplementary Material S1.4.
2.4.1 Phase 1: Pruning
In this phase, Tenet prunes nodes that do not have paths leading to the output node x. This phase yields a set of potential candidate nodes and is used to reduce the subsequent computation. In the pruning process, the given network G is first preprocessed into a bipartite graph and then converted into a directed acyclic graph (dag), a graph with consistent topological ordering, to facilitate indexing of nodes. Note that the node indices shall be used subsequently to perform reachability check to identify the nodes to be pruned. We adopt the method in Engelfiet et al. (1990) for bipartite graph conversion. In order to convert the bipartite graph into its dag representation, we adopt the approach in Tarjan et al. (1972) to identify sccs and replace each scc with a representative node (referred to as meta node). Then, we adopt the indexing approach of Chen et al. (2005) to index the dag. This indexing approach performs depth-first traversal to assign each node v a preorder index (when v is first visited) and a postorder index (when all descendent nodes of v are visited). Finally, an index-based reachability algorithm is used to determine whether there exists a path from each node v to the output node x (denoted as ). Given a node v and x, let w be the descendent of v that is not in the spanning tree (referred to as non-spanning tree node) and v.preorder and v.postorder denote the preorder and postorder indexes of v, respectively. A path exists if any of the following conditions are satisfied (Chen et al., 2005):
and .
and .
Note that the pruning step is beneficial in improving execution time for larger sparsely connected networks and for output node that are positioned further upstream. For instance, in the mapk-pi3k network, no nodes are pruned when we select erkpp (downstream) as the output node whereas 17 nodes (47.2%) are pruned when activated Ras (Rasgtp) (upstream) is selected.
2.4.2 Phase 2: Feature extraction
In this phase, for all nodes in Vcandidate, Tenet extracts all the topological features in Table 1 for characterizing the known targets.
2.4.3 Phase 3: Model training
Given a matrix of topological feature values H, a target set Tx and a step-size of the misclassification cost s, this phase identifies a set of predictive topological features and the best parameters for configuring the characterization model . First, the misclassification cost of the target class C+ is initialized to a default value of 0.5. Then, feature selection is used to obtain the predictive topological feature set . We iterate over three different feature selection approaches (bse, wre and wre-bse). Next, the step-size s is used to step through the range of misclassification cost (0–1). In each iteration, the misclassification cost of the target class C+ is incremented according to the number of iterations completed, before the svm training is performed to obtain the parameter settings of the characterization model with the best accuracy.
The bse approach is a well-known greedy approach that progressively removes features from the naïve svm model (built using all topological features) and trains a new best model after each feature removal. The elimination process stops when removal of additional features results in a worse average accuracy of the validation set prediction. In contrast, the wre approach performs two statistical tests, namely, one-tailed Wilcoxon Rank-Sum (referred to as Wilcoxon) and receiver operating characteristics (referred to as roc). The results are used to eliminate features that do not discriminate between targets and non-targets in a significant manner (based on Wilcoxon) and that do not classify targets well (based on roc). Note that we perform two 1-tailed Wilcoxon tests and for each test; P-values smaller than 0.05 are considered significant. Hence, we take the difference of the P-values for both test hypotheses (referred to as P-value difference) and remove features with P-value difference less than 0.9. For the roc analysis, features with auc less than 0.7 (Hosmer Jr et al., 2004) are considered poor performers and are removed. The best characterization model is found by training the svm using the remaining features. The wre-bse approach first performs wre followed by bse.
The worst-case time complexity of Tenet is where is the worst-case time complexity for extracting the features and is the worst-case time complexity of the feature selection method used. Note that in this article, whereas (for bse) where k is the number of iterations required for the grid-search. Proofs are given in Supplementary Material S1.5.
3 Results and discussion
Tenet is implemented using Java. We shall now present the experiments conducted to study the performance of Tenet and report some of the results here (additional results are given in Supplementary Material). The experiments are performed on a computer system using a 64-bit operating system with 8 gbram and a dual core processor running at 3.60 GHz. We characterize four signalling networks (referred to as individual networks) in BioModels (I1–I4 in Table 2) and a combined network that is generated by iteratively performing a union of the nodes and edges in individual networks. The resulting combined network is a graph consisting of four disconnected (The node and edge sets of the individual networks are disjoint.) subgraphs, each representing one individual network. For the combined network, we use each of the signalling network as the test set in turn (C1–C4 in Table 2) and examine the effects of generating characterization models from individual networks and from the combined network. Pruning in Tenet is performed on each individual network within the combined network. Supplementary Material S1.3 describes the generation of the training and test data. Note that in all our experiments, we use the linear kernel as it yielded the same accuracy as other kernels but is faster to train (Supplementary Material S1.7.1). We study different variants of Tenet (Table 3) by varying the svm training approach.
Dataset
| Network notation | I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|---|---|---|
| Dataset (BioModel ID) | mapk-pi3k (0000000146) | g lucose-stimulated insulin secretion (0000000239) | endomesoderm gene regulatory (0000000235) | glucose metabolism (0000000244) | All networks | |||
| Output node(s) | erkpp | atp mitochondrial | Protein_E_Endo16 | acetate | {erkpp, atpmitochondrial, Protein_E_Endo16, acetate} | |||
| No. of nodes in dataset | 36 | 59 | 622 | 47 | 764 | 764 | 764 | 764 |
| No. of hyperedges in dataset | 34 | 45 | 778 | 109 | 966 | 966 | 966 | 966 |
| No. (%) of targets in dataset | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) | 237 (31%) | 237 (31%) | 237 (31%) | 237 (31%) |
| Cross validation | 8-fold | 5-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold |
| Test set | Supplementary Material and Table 5 | mapk-pi3k | glucose-stimulated insulin secretion | endomesoderm gene regulatory | glucose metabolism | |||
| No. (%) of targets in test set | 1 (25%) | 1 (10%) | 21 (34.4%) | 2 (40%) | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) |
| Network notation | I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|---|---|---|
| Dataset (BioModel ID) | mapk-pi3k (0000000146) | g lucose-stimulated insulin secretion (0000000239) | endomesoderm gene regulatory (0000000235) | glucose metabolism (0000000244) | All networks | |||
| Output node(s) | erkpp | atp mitochondrial | Protein_E_Endo16 | acetate | {erkpp, atpmitochondrial, Protein_E_Endo16, acetate} | |||
| No. of nodes in dataset | 36 | 59 | 622 | 47 | 764 | 764 | 764 | 764 |
| No. of hyperedges in dataset | 34 | 45 | 778 | 109 | 966 | 966 | 966 | 966 |
| No. (%) of targets in dataset | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) | 237 (31%) | 237 (31%) | 237 (31%) | 237 (31%) |
| Cross validation | 8-fold | 5-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold |
| Test set | Supplementary Material and Table 5 | mapk-pi3k | glucose-stimulated insulin secretion | endomesoderm gene regulatory | glucose metabolism | |||
| No. (%) of targets in test set | 1 (25%) | 1 (10%) | 21 (34.4%) | 2 (40%) | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) |
Dataset
| Network notation | I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|---|---|---|
| Dataset (BioModel ID) | mapk-pi3k (0000000146) | g lucose-stimulated insulin secretion (0000000239) | endomesoderm gene regulatory (0000000235) | glucose metabolism (0000000244) | All networks | |||
| Output node(s) | erkpp | atp mitochondrial | Protein_E_Endo16 | acetate | {erkpp, atpmitochondrial, Protein_E_Endo16, acetate} | |||
| No. of nodes in dataset | 36 | 59 | 622 | 47 | 764 | 764 | 764 | 764 |
| No. of hyperedges in dataset | 34 | 45 | 778 | 109 | 966 | 966 | 966 | 966 |
| No. (%) of targets in dataset | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) | 237 (31%) | 237 (31%) | 237 (31%) | 237 (31%) |
| Cross validation | 8-fold | 5-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold |
| Test set | Supplementary Material and Table 5 | mapk-pi3k | glucose-stimulated insulin secretion | endomesoderm gene regulatory | glucose metabolism | |||
| No. (%) of targets in test set | 1 (25%) | 1 (10%) | 21 (34.4%) | 2 (40%) | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) |
| Network notation | I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|---|---|---|
| Dataset (BioModel ID) | mapk-pi3k (0000000146) | g lucose-stimulated insulin secretion (0000000239) | endomesoderm gene regulatory (0000000235) | glucose metabolism (0000000244) | All networks | |||
| Output node(s) | erkpp | atp mitochondrial | Protein_E_Endo16 | acetate | {erkpp, atpmitochondrial, Protein_E_Endo16, acetate} | |||
| No. of nodes in dataset | 36 | 59 | 622 | 47 | 764 | 764 | 764 | 764 |
| No. of hyperedges in dataset | 34 | 45 | 778 | 109 | 966 | 966 | 966 | 966 |
| No. (%) of targets in dataset | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) | 237 (31%) | 237 (31%) | 237 (31%) | 237 (31%) |
| Cross validation | 8-fold | 5-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold | 10-fold |
| Test set | Supplementary Material and Table 5 | mapk-pi3k | glucose-stimulated insulin secretion | endomesoderm gene regulatory | glucose metabolism | |||
| No. (%) of targets in test set | 1 (25%) | 1 (10%) | 21 (34.4%) | 2 (40%) | 9 (25%) | 6 (10.2%) | 206 (33.1%) | 16 (34%) |
Tenet variant and wmc weight ratios used in experiment
 |
|
indicates the approach(es) used in the variant.
Tenet variant and wmc weight ratios used in experiment
|
|
indicates the approach(es) used in the variant.
3.1 Performance metrics
We evaluate the performance of Tenet based on prediction accuracy [The accuracy for the validation and test sets are denoted as and , respectively, where X indicates the method used for training the svm model. Average prediction accuracy is denoted as ] (), sensitivity (tpr), specificity (tnr) and precision (ppv) of the generated characterization models using the same training and test set. The definitions are as follows: =, tpr=, tnr= and ppv= where and denote true positive, true negative, false positive and false negative prediction, respectively. Note that ppv is set to 0 when the classifier did not make any positive prediction. We include an additional metric feature reduction factor (frf) to compare the performance of the feature selection methods. Formally, frf = 1− where is the entire set of features considered in the study. The performance of different characterization models is compared using an integrated performance score (This score can be modified according to the needs of the application.) where TPR, TNR, PPV} and valm is the value of metric m. Note that a larger score indicates better performance.
3.2 Feature selection
First, we examine the performance of different feature selection approaches (Tenet-b, Tenet-r and Tenet-h) and compare it with Tenet-naïve for different signalling networks. Note that in this set of experiments, we study the effect of the feature selection approaches in isolation. The effect of incorporating wmc into the svm shall be investigated later. Table 4 reports the predictive feature sets for each network using different approaches. In total, 24 experiments were conducted as there are three feature selection methods and eight networks (I1–I4 and C1–C4). Amongst these 24 experiments, 25% of the predictive feature sets consist of only one feature whereas the remaining had multiple features (ranging from 4 to 15 features). This supports our previous observation (Chua et al., 2014) that multiple features result in better prediction of known targets. Observe that in Table 4, bridging centrality is not always in the predictive feature set (e.g. I2). Figure 2 plots the performances of different feature selection approaches. We can make several observations. First, no single approach performs consistently well on all performance metrics. In fact, network topology plays an important role in feature selection. For instance, I4 has extremely high density of edges (ratio of edges to nodes) compared to other networks. The connectivity features of such networks become less informative and other features such as target downstream effect become more important. Hence, the most appropriate feature selection approach is dependent on the signalling network. However, we note that for larger sized networks, a larger number of features are informative (regardless of feature selection approach). This is perhaps because larger networks provide greater richness of context and diversity of structure in the sub-networks. As network sizes are growing and network analysis demands applicability to larger networks, future methods might benefit particularly from the use of multiple features. Second, feature selection generally led to an improvement in prediction accuracy (87.5% for validation dataset and 50% in test dataset) over the naïve approach. An exception is C4 in which feature selection resulted in poorer performance. In C4, the characterization model is generated using I1, I2 and I3 as training data whereas I4 is used as the test data. The characteristics of the known targets in the training data may be quite different from that of the test data. Indeed, from Table 4, we observe that bridging coefficient π is included in the predictive topological feature set of C4, but not in I4. Including redundant features may lead to poorer performance. Third, the models generally have high specificity due to imbalanced dataset. Fourth, Tenet-r has the best runtime performance, followed by Tenet-h and Tenet-b. The poorer performance of Tenet-b is due to the interaction of the feature selection approach with the classifier (classifier-aware approach) which is different from Tenet-r where the feature selection approach is a wrapper layer that sits on top of the classifier. Finally, the size of the networks used for training affects the runtime performance. In general, larger size networks require longer runtime. In the Supplementary Material S1.7.6, we report Tenet’s performance on the human cancer signalling network containing more than 2500 nodes.
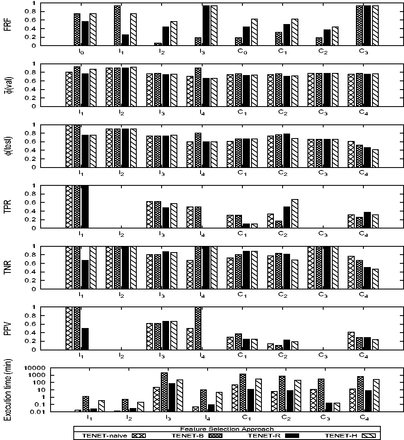
Performance of different feature selection approaches
Features selected by various feature selection approaches
| Data | Tenet-b | Tenet-r | Tenet-h |
|---|---|---|---|
| I1 | δ, π, θin, θout | δ, ζ, β, ϑ, θout, μ, κundir | δ, ζ, β, ϑ |
| I2 | θin | δ, π, β, κundir, κcyc, α, θin, κin, μ, κmid, θout, θtotal | π, β, κcyc, κundir |
| I3 | δ, ζ, π, β, κcyc, ϑ, α, κin, κmid, μ, κout, θout, ω, θtotal, κundir | δ, ζ, ϑ, α, κmid, θout, θtotal, ω, κundir | δ, ζ, ϑ, α, θout, θtotal, κundir |
| I4 | ζ, β, κcyc, ϑ, α, κin, κmid, μ, ω, κout, θout, θtotal, κundir | ω | ω |
| C1 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, μ, ω, κundir | δ, ζ, π, β, ϑ, α, κmid, κundir, θout | ζ, π, ϑ, α, θout, κundir |
| C2 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, κundir | δ, ζ, α, κmid, θout, ω, θtotal, κundir | δ, ζ, α, κmid, ω, κundir |
| C3 | θin | ζ | ζ |
| C4 | ζ, π, β, κcyc, ϑ, α, κin, θin, ω, κout, θout, θtotal, κundir | δ, ζ, π, ϑ, α, κmid, θout, ω, θtotal, κundir | ζ, π, ϑ, α, κundir, ω, θout, θtotal, κmid |
| Data | Tenet-b | Tenet-r | Tenet-h |
|---|---|---|---|
| I1 | δ, π, θin, θout | δ, ζ, β, ϑ, θout, μ, κundir | δ, ζ, β, ϑ |
| I2 | θin | δ, π, β, κundir, κcyc, α, θin, κin, μ, κmid, θout, θtotal | π, β, κcyc, κundir |
| I3 | δ, ζ, π, β, κcyc, ϑ, α, κin, κmid, μ, κout, θout, ω, θtotal, κundir | δ, ζ, ϑ, α, κmid, θout, θtotal, ω, κundir | δ, ζ, ϑ, α, θout, θtotal, κundir |
| I4 | ζ, β, κcyc, ϑ, α, κin, κmid, μ, ω, κout, θout, θtotal, κundir | ω | ω |
| C1 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, μ, ω, κundir | δ, ζ, π, β, ϑ, α, κmid, κundir, θout | ζ, π, ϑ, α, θout, κundir |
| C2 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, κundir | δ, ζ, α, κmid, θout, ω, θtotal, κundir | δ, ζ, α, κmid, ω, κundir |
| C3 | θin | ζ | ζ |
| C4 | ζ, π, β, κcyc, ϑ, α, κin, θin, ω, κout, θout, θtotal, κundir | δ, ζ, π, ϑ, α, κmid, θout, ω, θtotal, κundir | ζ, π, ϑ, α, κundir, ω, θout, θtotal, κmid |
Features selected by various feature selection approaches
| Data | Tenet-b | Tenet-r | Tenet-h |
|---|---|---|---|
| I1 | δ, π, θin, θout | δ, ζ, β, ϑ, θout, μ, κundir | δ, ζ, β, ϑ |
| I2 | θin | δ, π, β, κundir, κcyc, α, θin, κin, μ, κmid, θout, θtotal | π, β, κcyc, κundir |
| I3 | δ, ζ, π, β, κcyc, ϑ, α, κin, κmid, μ, κout, θout, ω, θtotal, κundir | δ, ζ, ϑ, α, κmid, θout, θtotal, ω, κundir | δ, ζ, ϑ, α, θout, θtotal, κundir |
| I4 | ζ, β, κcyc, ϑ, α, κin, κmid, μ, ω, κout, θout, θtotal, κundir | ω | ω |
| C1 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, μ, ω, κundir | δ, ζ, π, β, ϑ, α, κmid, κundir, θout | ζ, π, ϑ, α, θout, κundir |
| C2 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, κundir | δ, ζ, α, κmid, θout, ω, θtotal, κundir | δ, ζ, α, κmid, ω, κundir |
| C3 | θin | ζ | ζ |
| C4 | ζ, π, β, κcyc, ϑ, α, κin, θin, ω, κout, θout, θtotal, κundir | δ, ζ, π, ϑ, α, κmid, θout, ω, θtotal, κundir | ζ, π, ϑ, α, κundir, ω, θout, θtotal, κmid |
| Data | Tenet-b | Tenet-r | Tenet-h |
|---|---|---|---|
| I1 | δ, π, θin, θout | δ, ζ, β, ϑ, θout, μ, κundir | δ, ζ, β, ϑ |
| I2 | θin | δ, π, β, κundir, κcyc, α, θin, κin, μ, κmid, θout, θtotal | π, β, κcyc, κundir |
| I3 | δ, ζ, π, β, κcyc, ϑ, α, κin, κmid, μ, κout, θout, ω, θtotal, κundir | δ, ζ, ϑ, α, κmid, θout, θtotal, ω, κundir | δ, ζ, ϑ, α, θout, θtotal, κundir |
| I4 | ζ, β, κcyc, ϑ, α, κin, κmid, μ, ω, κout, θout, θtotal, κundir | ω | ω |
| C1 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, μ, ω, κundir | δ, ζ, π, β, ϑ, α, κmid, κundir, θout | ζ, π, ϑ, α, θout, κundir |
| C2 | δ, ζ, π, β, κcyc, ϑ, α, θin, κmid, θout, κundir | δ, ζ, α, κmid, θout, ω, θtotal, κundir | δ, ζ, α, κmid, ω, κundir |
| C3 | θin | ζ | ζ |
| C4 | ζ, π, β, κcyc, ϑ, α, κin, θin, ω, κout, θout, θtotal, κundir | δ, ζ, π, ϑ, α, κmid, θout, ω, θtotal, κundir | ζ, π, ϑ, α, κundir, ω, θout, θtotal, κmid |
3.3 Effect of varying wmc
Intuitively, when we vary the wmc, we expect that as the target misclassification cost C+ increases, the prediction accuracy, sensitivity, specificity and precision would display a negative skewed, increasing, decreasing and positive skewed distribution, respectively. This is because a large C+ eventually results in a model that is likely biased towards classifying data as targets. We noted the following when the wmc was varied. First, amongst the individual networks, only I3 (Fig. 3) displays the expected trends. This could be due to the extreme small target size (1 or 2) in the test set that resulted in extreme fluctuations in the performance metrics and deviation from the expected trends. Hence, the target size of the test set can have significant impact on the observed results. Second, the performance of the combined networks C1, C2 and C4 (Supplementary Material S1.7.2) resembles that of I3, possibly due to the large size of I3 dominating over other networks used for training. This implies large training networks can have undue influence on the characterization model. Third, sensitivity generally improves whereas specificity generally deteriorates when the target misclassification cost is set higher than the non-target misclassification cost (). The choice of an appropriate model depends on the application. Fourth, the prediction accuracy tends to display a skewed distribution where accuracy initially increases (or remains constant) with increasing C+, and then decreases with increasing C+. Fifth, individual networks and combined networks behave differently. In individual networks, prediction accuracy, sensitivity and precision generally improve when C+ is set larger than C−. However, in combined networks, sensitivity improves whereas other performance criteria deteriorate when C+ is set larger than C−. Hence, there is no single universal best value of C+ and the choice of C+ depends on the network.
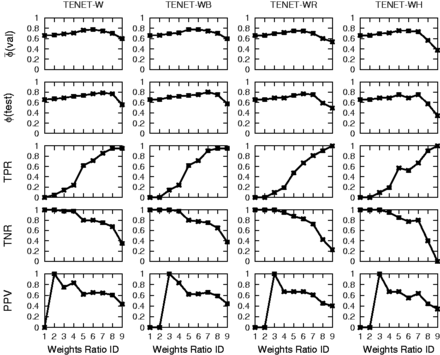
Performance of Tenet variants incorporating feature selection approach and wmc for the endomesoderm gene regulatory network
3.4 Best Tenet variant
We identify the best Tenet variant (Table 5) using the integrated performance score . We note the following. First, the best Tenet variant is network dependent. Second, variants incorporating both wmc and feature selection generally perform well. Specifically, setting C+ greater than C− led to better results. Third, Tenet variants based on individual networks (I1 to I4) outperform that based on combined networks (C1–C4). The poorer performance of the combined networks may be due to insufficient number of training networks, inappropriate or insufficient features used for training or that signalling networks by nature have distinct characteristics and it is just not possible to have a generalized model. Finally, the predictive topological features differ across networks (Tables 4 and 5). Hence, as we mentioned in Section 1, a single set of predictive topological features may not effectively characterize known targets in all signalling networks. When we compare the results with that in our previous work, we note that the set of predictive topological features is different from the discriminative topological features (dtf) identified in Chua et al. (2014) although there was an overlap of at least 50% of the features (We consider only I1 to I3 and exclude I4 from this comparison as no dtf was found at P-value less than 0.05). The difference is due to the different approach used to identify the features. The characterization models (We use svm with wmc and wre to generate the characterization models.) generated by these dtfs also yielded poorer average roc (0.873) than that generated using Tenet (0.913) (Approach Differ in Fig. 4).
Summary of best Tenet variant for different networks
| I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 | |
|---|---|---|---|---|---|---|---|---|
| Best approaches | Tenet-ba, Tenet-wb (C+ = 0.1, 0.2, 0.3, 0.4) | Tenet-wh (C+ = 0.9a) | Tenet-wb (C+ = 0.7a) | Tenet-wb (C+ = 0.2, 0.3, 0.4, 0.6, 0.8a) | Tenet-wh (C+ = 0.6a) | Tenet-ra | Tenet-wr (C+ = 0.8a), Tenet-wh (C+ = 0.8) | Tenet-naïvea |
| 4.935 | 4.109 | 3.86 | 4.9 | 3.08 | 3.022 | 3.268 | 2.917 | |
| [] | 0.935 [0.16] | 0.82 [−0.087] | 0.747 [−0.02] | 0.9 [0.268] | 0.734 [−0.013] | 0.711 [−0.052] | 0.561 [−0.274] | 0.757 [0] |
| [] | 1 [0] | 0.9 [0] | 0.803 [0.088] | 1 [0.667] | 0.694 [0.136] | 0.78 [0.070] | 0.724 [0.097] | 0.609 [0] |
| tpr [Δtpr] | 1 [0] | 1 [] | 0.905 [0.462] | 1 [1] | 0.4 [0.333] | 0.5 [0.502] | 0.602 [] | 0.313 [0] |
| tnr [Δtnr] | 1 [0] | 0.889 [−0.111] | 0.75 [−0.063] | 1 [0.499] | 0.808 [0.105] | 0.811 [0.048] | 0.788 [−0.212] | 0.767 [0] |
| ppv [Δppv] | 1 [0] | 0.5 [] | 0.655 [0.058] | 1 [1] | 0.444 [0.48] | 0.231 [0.615] | 0.593 [] | 0.471 [0] |
| I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 | |
|---|---|---|---|---|---|---|---|---|
| Best approaches | Tenet-ba, Tenet-wb (C+ = 0.1, 0.2, 0.3, 0.4) | Tenet-wh (C+ = 0.9a) | Tenet-wb (C+ = 0.7a) | Tenet-wb (C+ = 0.2, 0.3, 0.4, 0.6, 0.8a) | Tenet-wh (C+ = 0.6a) | Tenet-ra | Tenet-wr (C+ = 0.8a), Tenet-wh (C+ = 0.8) | Tenet-naïvea |
| 4.935 | 4.109 | 3.86 | 4.9 | 3.08 | 3.022 | 3.268 | 2.917 | |
| [] | 0.935 [0.16] | 0.82 [−0.087] | 0.747 [−0.02] | 0.9 [0.268] | 0.734 [−0.013] | 0.711 [−0.052] | 0.561 [−0.274] | 0.757 [0] |
| [] | 1 [0] | 0.9 [0] | 0.803 [0.088] | 1 [0.667] | 0.694 [0.136] | 0.78 [0.070] | 0.724 [0.097] | 0.609 [0] |
| tpr [Δtpr] | 1 [0] | 1 [] | 0.905 [0.462] | 1 [1] | 0.4 [0.333] | 0.5 [0.502] | 0.602 [] | 0.313 [0] |
| tnr [Δtnr] | 1 [0] | 0.889 [−0.111] | 0.75 [−0.063] | 1 [0.499] | 0.808 [0.105] | 0.811 [0.048] | 0.788 [−0.212] | 0.767 [0] |
| ppv [Δppv] | 1 [0] | 0.5 [] | 0.655 [0.058] | 1 [1] | 0.444 [0.48] | 0.231 [0.615] | 0.593 [] | 0.471 [0] |
Note: C+ values are provided in bracket besides approaches using wmc. where xbest and are the values of performance metric x of the best Tenet variant and Tenet-naïve, respectively.
aBest models selected for generating the characterization model.
bInstances where .
Summary of best Tenet variant for different networks
| I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 | |
|---|---|---|---|---|---|---|---|---|
| Best approaches | Tenet-ba, Tenet-wb (C+ = 0.1, 0.2, 0.3, 0.4) | Tenet-wh (C+ = 0.9a) | Tenet-wb (C+ = 0.7a) | Tenet-wb (C+ = 0.2, 0.3, 0.4, 0.6, 0.8a) | Tenet-wh (C+ = 0.6a) | Tenet-ra | Tenet-wr (C+ = 0.8a), Tenet-wh (C+ = 0.8) | Tenet-naïvea |
| 4.935 | 4.109 | 3.86 | 4.9 | 3.08 | 3.022 | 3.268 | 2.917 | |
| [] | 0.935 [0.16] | 0.82 [−0.087] | 0.747 [−0.02] | 0.9 [0.268] | 0.734 [−0.013] | 0.711 [−0.052] | 0.561 [−0.274] | 0.757 [0] |
| [] | 1 [0] | 0.9 [0] | 0.803 [0.088] | 1 [0.667] | 0.694 [0.136] | 0.78 [0.070] | 0.724 [0.097] | 0.609 [0] |
| tpr [Δtpr] | 1 [0] | 1 [] | 0.905 [0.462] | 1 [1] | 0.4 [0.333] | 0.5 [0.502] | 0.602 [] | 0.313 [0] |
| tnr [Δtnr] | 1 [0] | 0.889 [−0.111] | 0.75 [−0.063] | 1 [0.499] | 0.808 [0.105] | 0.811 [0.048] | 0.788 [−0.212] | 0.767 [0] |
| ppv [Δppv] | 1 [0] | 0.5 [] | 0.655 [0.058] | 1 [1] | 0.444 [0.48] | 0.231 [0.615] | 0.593 [] | 0.471 [0] |
| I1 | I2 | I3 | I4 | C1 | C2 | C3 | C4 | |
|---|---|---|---|---|---|---|---|---|
| Best approaches | Tenet-ba, Tenet-wb (C+ = 0.1, 0.2, 0.3, 0.4) | Tenet-wh (C+ = 0.9a) | Tenet-wb (C+ = 0.7a) | Tenet-wb (C+ = 0.2, 0.3, 0.4, 0.6, 0.8a) | Tenet-wh (C+ = 0.6a) | Tenet-ra | Tenet-wr (C+ = 0.8a), Tenet-wh (C+ = 0.8) | Tenet-naïvea |
| 4.935 | 4.109 | 3.86 | 4.9 | 3.08 | 3.022 | 3.268 | 2.917 | |
| [] | 0.935 [0.16] | 0.82 [−0.087] | 0.747 [−0.02] | 0.9 [0.268] | 0.734 [−0.013] | 0.711 [−0.052] | 0.561 [−0.274] | 0.757 [0] |
| [] | 1 [0] | 0.9 [0] | 0.803 [0.088] | 1 [0.667] | 0.694 [0.136] | 0.78 [0.070] | 0.724 [0.097] | 0.609 [0] |
| tpr [Δtpr] | 1 [0] | 1 [] | 0.905 [0.462] | 1 [1] | 0.4 [0.333] | 0.5 [0.502] | 0.602 [] | 0.313 [0] |
| tnr [Δtnr] | 1 [0] | 0.889 [−0.111] | 0.75 [−0.063] | 1 [0.499] | 0.808 [0.105] | 0.811 [0.048] | 0.788 [−0.212] | 0.767 [0] |
| ppv [Δppv] | 1 [0] | 0.5 [] | 0.655 [0.058] | 1 [1] | 0.444 [0.48] | 0.231 [0.615] | 0.593 [] | 0.471 [0] |
Note: C+ values are provided in bracket besides approaches using wmc. where xbest and are the values of performance metric x of the best Tenet variant and Tenet-naïve, respectively.
aBest models selected for generating the characterization model.
bInstances where .
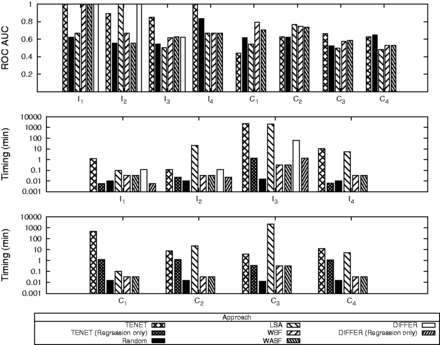
Performance of different prioritization approaches
3.5 Comparison with state-of-the-art approaches
Recall that state-of-the-art techniques such as McDermott et al. (2012), Zhang et al. (2010) and Hwang et al. (2008) focus on ppi networks instead of signalling networks. To the best of our knowledge, there does not exist any target characterization technique for signalling networks. However, one way to investigate the performance of Tenet is to examine how well the characterization model generated by it prioritizes known targets. Intuitively, target prioritization aims to rank the nodes according to their potential of being a target based on some importance measures (e.g. gene expression level; Chen et al., 2011). A more detailed exposure to the target prioritization problem as well as how Tenet is used to prioritize known targets is given in Supplementary Material S1.6.
For our study, we compare Tenet with several network-aware target prioritization approaches, namely, random prioritization, lsa (Gustafson et al., 1996) and NetworkPrioritizer (Kacprowski et al., 2013). Comparison with network-unaware techniques as well as ppi network-based techniques is reported in the Supplementary Material S1.7.3 and Supplementary Data, respectively.
In random prioritization, the nodes were randomly assigned a rank in the range [1–] where is the number of nodes in the network and we assume that no ranking ties are present. lsa was performed using Copasi (Sahle et al., 2006) with the following configuration: {task=sensitivities; subtask=time series; function=all variables of the model; and variable=all parameter values}. We consider both Weighted Borda Fuse (wbf) and Weighted AddScore Fuse (wasf) in NetworkPrioritizer and consider all features provided. Note that uniform weights were used for rank aggregation as we do not have prior knowledge of the best weights or features to consider. For Tenet, we use the characterization model to generate prioritization ranks of known targets. Specifically, we apply the svm models to obtain these ranks. The svm type is set to ϵ-svr [In ϵ-svr, the error function is an ϵ-insensitive loss function and error smaller than ϵ is ignored (Chang et al., 2011).] with default ϵ value (1 × 10−3) and the svm parameters are set according to the best models for each network (Table 5 and Supplementary Material S1.7). Note that the nodes are ranked in decreasing order of the regression score and higher ranked nodes are more likely to be targets.
The experimental results reveal that the normalized ranks (The normalized rank of a node u for a particular approach x is defined as .) of a given node vary widely using different approaches (Supplementary Material S1.7.5). Hence, an approach that performs better for one particular network can perform poorly in another. We further perform roc analysis based on the rankings of the nodes in the test set for each network. From Figure 4, we observe that Tenet outperforms other approaches in terms of the quality of the prioritization results, particularly for individual networks, and is comparable in terms of runtime performance when svm training is performed offline [Tenet (Regression only)].
4 Conclusions
We propose Tenet, an svm-based approach that characterizes known targets in signalling networks using topological features by identifying a set of predictive topological features and using them to generate a characterization model. Tenet uses feature selection to remove redundant features, thereby improving prediction accuracy of the characterization models and wmc to improve other performance criteria (e.g. sensitivity). Our empirical study reveals that the characterization models generated by Tenet outperform state-of-the-art approaches in prioritizing signalling and ppi networks. In summary, the contribution of this work is a machine learning-based framework that affords flexibility in characterizing signalling networks of different sizes and with different number of known targets. Although Tenet is evaluated on a small (Manual target curation, a time-intensive process, is needed to identify known targets of signalling networks for validating our experimental results.) number of signalling networks, it can easily incorporate additional signalling networks without any modification to the framework. As part of future work, we intend to explore how the characterization models learnt by Tenet can be leveraged for target prioritization of signalling networks with unknown targets.
Funding
This work was supported in part by a Singapore MOE AcRF Tier 1 Grant RGC 1/13 to SSB and by a Duke-NUS block grant to LTK.
Conflict of Interest: none declared.
References
Author notes
Associate Editor: Alfonso Valencia


{kind=link}
{kind=link}
{kind=link}
{kind=link}