




Abstract
Protein remote homology detection is a fundamental and important task for protein structure and function analysis. Several search methods have been proposed to improve the detection performance of the remote homologues and the accuracy of ranking lists. The position-specific scoring matrix (PSSM) profile and hidden Markov model (HMM) profile can contribute to improving the performance of the state-of-the-art search methods. In this paper, we improved the profile-link (PL) information for constructing PSSM or HMM profiles, and proposed a PL-based search method (PL-search). In PL-search, more robust PLs are constructed through the double-link and iterative extending strategies, and an accurate similarity score of sequence pairs is calculated from the two-level Jaccard distance for remote homologues. We tested our method on two widely used benchmark datasets. Our results show that whether HHblits, JackHMMER or position-specific iterated-BLAST is used, PL-search obviously improves the search performance in terms of ranking quality as well as the number of detected remote homologues. For ease of use of PL-search, both its stand-alone tool and the web server are constructed, which can be accessed at http://bliulab.net/PL-search/.
Introduction
Protein remote homology detection is a key element of protein structure and function analysis. The available protein sequences are increasing rapidly; however, the high costs of experimental protein structure determination are driving the development of computational prediction methods based on sequence information for protein remote homology detection [1, 2].
Sequence-based alignment methods such as Smith–Waterman [3], basic local alignment search tool (BLAST) [4], HAlign [5] and FASTA [6] can distinguish close homology unambiguously. However, these techniques cannot be applied for protein remote homology detection. To enhance the possibility of detecting remote homology sequences, many position-specific scoring matrix (PSSM)-based alignment methods such as position-specific iterated-BLAST (PSI-BLAST) [4] and comparison of multiple protein sequence alignments [7] have been proposed. Considering the emission and state transition probabilities for each position of a protein sequence, the Hidden Markov Model (HMM) profile-based alignment methods HMMER [8] and HHsearch [9] achieve better performance than PSSM-based alignment methods. The state-of-the-art performance of these profile-based methods is based on the useful evolution information of the query’s family contained in the PSSM or HMM profile. Regardless of the PSSM- or HMM-based alignment methods, these approaches can detect more remote homology protein sequences by incorporating an iterative strategy, such as HHblits [10], PSI-BLAST [4] or JackHMMER [11].
Alignment methods form the foundations of many methods of protein remote homology detection, and some predictors are further improved by incorporating the search results from original alignment methods. For example, SCOOP [12] compares common sequences between two outputs of HMM-based search methods to increase the accuracy of protein remote homology detection, RankProp [13, 14] proposes a network-based ranking algorithm with edge weights constructed by PSI-BLAST. HITS-PR-HHblits [15] constructs a protein similarity network based on the true labels of proteins from the Structural Classification of Proteins (SCOP) database [16]. Given the complementarity of different alignment methods, some state-of-the-art fusion algorithms such as CHASE [17] and ProtDec-LTR3.0 [18] re-rank the search results to create an accurate ranking list. Although the above-mentioned methods contribute to the development of protein remote homology detection, there are still some shortcomings: (i) re-ranking methods can effectively improve the ranking quality of original search results, but the number of detected homology sequences are still limited by the original search methods; (ii) the accuracy of improved methods can be effected by the search results of the original alignment methods without filtering the non-homologous sequences, many studies [19, 20] have shown that input of non-homologous sequences into PSSM has disastrous effects on later iterations in iterative search methods; (iii) null search results from the original alignment methods are inevitable, and can lead to null results in the improved methods because they cannot provide any useful information.
In light of the above information, we propose the profile-link-based search method (PL-search) to achieve improved performance for protein remote homology detection. The framework of PL-search has two major parts (Figure 1): PL construction and similarity calculation. For more useful link information, the PL is constructed by using a double-link strategy and iterative extending-link strategy; for more accurate search results and increased detection of homologous protein sequences, the two-level Jaccard distance is used to calculate the similarity score of sequence pairs. The two parts complete the retrieval process relying on PL information rather than constructing a profile. To summarize, the main contributions of this paper are: (i) presentation of the PL-search based on HHblits (PL-HHblits) approach that outperforms other state-of-the-art original search methods in terms of ranking quality and the ability of detecting remote homology protein sequences; (ii) the demonstration that PL-search is a general search method, which can incorporate the search results of HHblits [10], PSI-BLAST [4] or JackHMMER [11] to construct PL information, which are widely used by biologists [21]; (iii) the identification of a solution for null results in HHblits and JackHMMER through use of PL-HHblits and PL-HMMER, respectively.
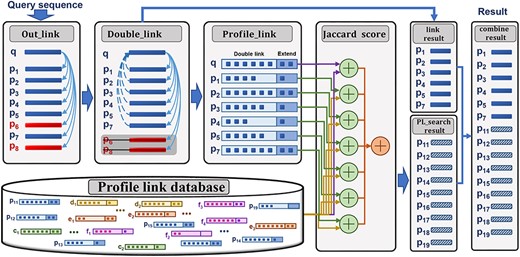
Flowchart of PL-based search. First, the out-link of the query sequence is obtained from an original search method with E-value of 0.001. Second, for a more robust PL, the out-link is updated to double-link and extended double-link. All sequences in the database are represented with extended double-link in the same strategy. Third, the two-level Jaccard distance is used to calculate the similarity of sequence pairs. The final ranking list is then constructed based on the double-link list and ranking list calculated by using the two-level Jaccard distance.
Materials and method
Benchmark datasets
To evaluate the performance of PL-search, we use two widely used benchmark datasets based on SCOP databases [16] with less than 95% identity to evaluate the performance of a predictor, including SCOP1.59 benchmark dataset and SCOPe2.06 benchmark dataset. The SCOP1.59 benchmark dataset contains 7329 sequences, and the SCOPe2.06 benchmark dataset contains 28 010 sequences, which is an updated version with some new hierarchy and classification of new protein structures from the Protein Data Bank (PDB) [22].
PL construction
In iterative search methods, profile construction selects homology sequences according to E-value score from search results in order to construct a profile. Previous studies [23, 24] have shown that true homology sequences in PSSM can provide true evolution information, leading to increased detection of homologous sequences and more accurate ranking. However, when non-homologous sequences occur in the profile, more non-homologous sequences are searched in later iterations. In the present study, non-homologous sequences in the profile provide incorrect link information, therefore eliminating these sequences and providing enough homology information in the PL are important. We propose two strategies to address this: (i) the double-link strategy to filter non-homologous sequences and (ii) the iterative extending-link strategy for more robust PLs.
Double-link strategy
During information retrieval, in-link is used to provide important search information as out-link. Link-based search methods, such as the PageRank algorithm [25] and Hypertext Induced Topic Selection algorithm [26], utilize the relationship of in-link and out-link to improve search results. In the present study, we construct a double-link strategy based on the relationship of in-link and out-link.
Iterative extending strategy
The double-link strategy improves the quality of PL, but it is inevitable that the number will be reduced. To overcome this problem, we propose an iterative extending-link strategy. A related study [27] has demonstrated that extending the link set by common links between two link sets can improve the robustness of the link set.
The iteration extending process of PL.
| 1: Parameters: |${\beta}_1$| adjusts extending link in first situation,|${\beta}_2$| |
| adjusts extending link in second situation |
| 2: Input: double-link set of query sequence, double-link sets of |
| database |
| 3: Output: Extended PL |$\mathit{\operatorname{Re}}(q)$| |
| 4: |$\mathit{\operatorname{Re}}(q)$| = |${R}_{doule}(q)$| |
| 5: For|${p}_i$| in ||${R}_{double}(q)$|| do |
| 1: Parameters: |${\beta}_1$| adjusts extending link in first situation,|${\beta}_2$| |
| adjusts extending link in second situation |
| 2: Input: double-link set of query sequence, double-link sets of |
| database |
| 3: Output: Extended PL |$\mathit{\operatorname{Re}}(q)$| |
| 4: |$\mathit{\operatorname{Re}}(q)$| = |${R}_{doule}(q)$| |
| 5: For|${p}_i$| in ||${R}_{double}(q)$|| do |
The iteration extending process of PL.
| 1: Parameters: |${\beta}_1$| adjusts extending link in first situation,|${\beta}_2$| |
| adjusts extending link in second situation |
| 2: Input: double-link set of query sequence, double-link sets of |
| database |
| 3: Output: Extended PL |$\mathit{\operatorname{Re}}(q)$| |
| 4: |$\mathit{\operatorname{Re}}(q)$| = |${R}_{doule}(q)$| |
| 5: For|${p}_i$| in ||${R}_{double}(q)$|| do |
| 1: Parameters: |${\beta}_1$| adjusts extending link in first situation,|${\beta}_2$| |
| adjusts extending link in second situation |
| 2: Input: double-link set of query sequence, double-link sets of |
| database |
| 3: Output: Extended PL |$\mathit{\operatorname{Re}}(q)$| |
| 4: |$\mathit{\operatorname{Re}}(q)$| = |${R}_{doule}(q)$| |
| 5: For|${p}_i$| in ||${R}_{double}(q)$|| do |
| 6: if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|\ge{\beta}_1\mid{R}_{double}\Big({p}_i\Big)\mid$|then |
| 7: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup{R}_{double}\Big({p}_i\Big)$| |
| 8: else if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|=\Big|{R}_{double}(q)\Big|$|then |
| 9: if|${\beta}_2\Big|{R}_{double}(q)\Big|<\Big|{R}_{double}\Big({p}_i\Big)\Big|$|then |
| 10: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:{\beta}_2\Big|{R}_{double}(q)\Big|\Big]\Big)$| |
| 11: else|$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:|{R}_{double}\Big({p}_i\Big)|\Big]\Big)$| |
| 12: End for |
| 13: Return|$\mathit{\operatorname{Re}}(q)$| |
| 6: if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|\ge{\beta}_1\mid{R}_{double}\Big({p}_i\Big)\mid$|then |
| 7: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup{R}_{double}\Big({p}_i\Big)$| |
| 8: else if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|=\Big|{R}_{double}(q)\Big|$|then |
| 9: if|${\beta}_2\Big|{R}_{double}(q)\Big|<\Big|{R}_{double}\Big({p}_i\Big)\Big|$|then |
| 10: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:{\beta}_2\Big|{R}_{double}(q)\Big|\Big]\Big)$| |
| 11: else|$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:|{R}_{double}\Big({p}_i\Big)|\Big]\Big)$| |
| 12: End for |
| 13: Return|$\mathit{\operatorname{Re}}(q)$| |
| 6: if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|\ge{\beta}_1\mid{R}_{double}\Big({p}_i\Big)\mid$|then |
| 7: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup{R}_{double}\Big({p}_i\Big)$| |
| 8: else if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|=\Big|{R}_{double}(q)\Big|$|then |
| 9: if|${\beta}_2\Big|{R}_{double}(q)\Big|<\Big|{R}_{double}\Big({p}_i\Big)\Big|$|then |
| 10: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:{\beta}_2\Big|{R}_{double}(q)\Big|\Big]\Big)$| |
| 11: else|$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:|{R}_{double}\Big({p}_i\Big)|\Big]\Big)$| |
| 12: End for |
| 13: Return|$\mathit{\operatorname{Re}}(q)$| |
| 6: if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|\ge{\beta}_1\mid{R}_{double}\Big({p}_i\Big)\mid$|then |
| 7: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup{R}_{double}\Big({p}_i\Big)$| |
| 8: else if|$\Big|{R}_{double}(q)\cap{R}_{double}\Big({p}_i\Big)\Big|=\Big|{R}_{double}(q)\Big|$|then |
| 9: if|${\beta}_2\Big|{R}_{double}(q)\Big|<\Big|{R}_{double}\Big({p}_i\Big)\Big|$|then |
| 10: |$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:{\beta}_2\Big|{R}_{double}(q)\Big|\Big]\Big)$| |
| 11: else|$\mathit{\operatorname{Re}}(q)={R}_{double}(q)\cup \Big({R}_{double}\Big({p}_i\Big)\Big[0:|{R}_{double}\Big({p}_i\Big)|\Big]\Big)$| |
| 12: End for |
| 13: Return|$\mathit{\operatorname{Re}}(q)$| |
A more robust PL set is constructed according to the common links between two double-link sets. Two main situations were considered: first, all double links of |${p}_i$| were included in the query’s double-link set when most double links of |${p}_i$| existed in the query’s double-link set. Second, some high quality double-links of |${p}_i$| were included in the query’s double-link set when all double links of query were contained by the double-link set of |${p}_i$| and out of the first situation, which is complementary to the first situation. The double-link set of the query sequence was extended with all feedback sequences in the double-link set, and the iteration process initiated from the lower E-value feedback sequence with a higher probability of being homologous with the query sequence. The pseudo codes of this iterative extending-link strategy are shown in Algorithm 1.
Comparison of the performance of three search methods and their corresponding PL-based search methods on two benchmark datasets
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | |
| HHblits | 0.8429 | 0.8834 | 0.7142 | 48.9877 | 32.4237 | 16.5641 | 0.8918 | 0.9284 | 0.6817 | 95.9875 | 42.1521 | 53.8355 |
| PSI-BLAST | 0.7674 | 0.8016 | 0.4986 | 37.7994 | 29.9679 | 7.8315 | 0.8513 | 0.8941 | 0.5134 | 74.8642 | 38.3208 | 36.5434 |
| JackHMMER | 0.8029 | 0.8071 | 0.4981 | 36.1603 | 30.1036 | 6.0568 | 0.8919 | 0.9059 | 0.5288 | 139.4054 | 64.8227 | 74.5828 |
| PL-HHblitsa | 0.8690 | 0.8976 | 0.7290 | 55.7637 | 32.3890 | 23.3747 | 0.9207 | 0.9426 | 0.7184 | 106.1307 | 44.5174 | 61.6133 |
| PL-BLASTb | 0.8158 | 0.8268 | 0.5093 | 46.2541 | 30.0705 | 16.1835 | 0.9047 | 0.9155 | 0.5327 | 76.8930 | 39.2832 | 37.6097 |
| PL-HMMERc | 0.8119 | 0.8182 | 0.5311 | 50.8473 | 30.8277 | 19.9914 | 0.9043 | 0.9188 | 0.5642 | 174.4203 | 70.4275 | 103.9928 |
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | |
| HHblits | 0.8429 | 0.8834 | 0.7142 | 48.9877 | 32.4237 | 16.5641 | 0.8918 | 0.9284 | 0.6817 | 95.9875 | 42.1521 | 53.8355 |
| PSI-BLAST | 0.7674 | 0.8016 | 0.4986 | 37.7994 | 29.9679 | 7.8315 | 0.8513 | 0.8941 | 0.5134 | 74.8642 | 38.3208 | 36.5434 |
| JackHMMER | 0.8029 | 0.8071 | 0.4981 | 36.1603 | 30.1036 | 6.0568 | 0.8919 | 0.9059 | 0.5288 | 139.4054 | 64.8227 | 74.5828 |
| PL-HHblitsa | 0.8690 | 0.8976 | 0.7290 | 55.7637 | 32.3890 | 23.3747 | 0.9207 | 0.9426 | 0.7184 | 106.1307 | 44.5174 | 61.6133 |
| PL-BLASTb | 0.8158 | 0.8268 | 0.5093 | 46.2541 | 30.0705 | 16.1835 | 0.9047 | 0.9155 | 0.5327 | 76.8930 | 39.2832 | 37.6097 |
| PL-HMMERc | 0.8119 | 0.8182 | 0.5311 | 50.8473 | 30.8277 | 19.9914 | 0.9043 | 0.9188 | 0.5642 | 174.4203 | 70.4275 | 103.9928 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
ePercentage of homology sequence (belonging to the same SCOP superfamily) searched.
fTP number at close homology level (belonging to the same SCOP family).
gTP number at remote homology level (belonging to the same SCOP superfamily, but not belong to the same family).
Comparison of the performance of three search methods and their corresponding PL-based search methods on two benchmark datasets
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | |
| HHblits | 0.8429 | 0.8834 | 0.7142 | 48.9877 | 32.4237 | 16.5641 | 0.8918 | 0.9284 | 0.6817 | 95.9875 | 42.1521 | 53.8355 |
| PSI-BLAST | 0.7674 | 0.8016 | 0.4986 | 37.7994 | 29.9679 | 7.8315 | 0.8513 | 0.8941 | 0.5134 | 74.8642 | 38.3208 | 36.5434 |
| JackHMMER | 0.8029 | 0.8071 | 0.4981 | 36.1603 | 30.1036 | 6.0568 | 0.8919 | 0.9059 | 0.5288 | 139.4054 | 64.8227 | 74.5828 |
| PL-HHblitsa | 0.8690 | 0.8976 | 0.7290 | 55.7637 | 32.3890 | 23.3747 | 0.9207 | 0.9426 | 0.7184 | 106.1307 | 44.5174 | 61.6133 |
| PL-BLASTb | 0.8158 | 0.8268 | 0.5093 | 46.2541 | 30.0705 | 16.1835 | 0.9047 | 0.9155 | 0.5327 | 76.8930 | 39.2832 | 37.6097 |
| PL-HMMERc | 0.8119 | 0.8182 | 0.5311 | 50.8473 | 30.8277 | 19.9914 | 0.9043 | 0.9188 | 0.5642 | 174.4203 | 70.4275 | 103.9928 |
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | ROC1d | ROC50d | Coveragee | TPd | TPf | TPg | |
| HHblits | 0.8429 | 0.8834 | 0.7142 | 48.9877 | 32.4237 | 16.5641 | 0.8918 | 0.9284 | 0.6817 | 95.9875 | 42.1521 | 53.8355 |
| PSI-BLAST | 0.7674 | 0.8016 | 0.4986 | 37.7994 | 29.9679 | 7.8315 | 0.8513 | 0.8941 | 0.5134 | 74.8642 | 38.3208 | 36.5434 |
| JackHMMER | 0.8029 | 0.8071 | 0.4981 | 36.1603 | 30.1036 | 6.0568 | 0.8919 | 0.9059 | 0.5288 | 139.4054 | 64.8227 | 74.5828 |
| PL-HHblitsa | 0.8690 | 0.8976 | 0.7290 | 55.7637 | 32.3890 | 23.3747 | 0.9207 | 0.9426 | 0.7184 | 106.1307 | 44.5174 | 61.6133 |
| PL-BLASTb | 0.8158 | 0.8268 | 0.5093 | 46.2541 | 30.0705 | 16.1835 | 0.9047 | 0.9155 | 0.5327 | 76.8930 | 39.2832 | 37.6097 |
| PL-HMMERc | 0.8119 | 0.8182 | 0.5311 | 50.8473 | 30.8277 | 19.9914 | 0.9043 | 0.9188 | 0.5642 | 174.4203 | 70.4275 | 103.9928 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
ePercentage of homology sequence (belonging to the same SCOP superfamily) searched.
fTP number at close homology level (belonging to the same SCOP family).
gTP number at remote homology level (belonging to the same SCOP superfamily, but not belong to the same family).
Calculation of the similarity of sequence pairs by Jaccard distance
In previous studies involving PSI-BLAST [4] or JackHMMER [28], the similarity of sequence pairs was calculated by using profile alignment algorithms. In the present study, we measured the similarity between two PLs by using the Jaccard distance [29, 30]. The Jaccard distance is a useful similarity algorithm for calculating similarity scores between two sets. It has been successfully used in studies on genotyping data/next-generation sequencing data analysis [31], drug-drug interactions [32], gene interaction [33] and influenza vaccination responses [34].
Final ranking list
The maximum score of |$Jscore(q,{p}_i)$| is set to 0.99 to reject low-quality search results. The final ranking list is equal to the double-link set when the Jscore is set to zero.
Evaluation of the method
We assessed the ranking quality and detected homology number to evaluate the performance of PL-search and original search methods. For ranking quality, the receiver operating characteristic scores receiver operating characteristic1 (ROC1) and ROC50 [35–37] were used. ROC1 and ROC50 are the area under the ROC curve when the first and fiftieth false non-homologous sequence appears, respectively. A higher ROC score indicates a more accurate ranking of search results. The statistical significance differences between the original search methods and their corresponding PL-based search methods in terms of ROC are calculated by t-test [38]. For detected homology number, the true positive (TP) number [9, 11, 39] and coverage [40] were evaluated. TP number is the number of detected homology protein sequences. Coverage or true positive rate is the percentage of detected homology protein sequences for a given Jscore threshold [41, 42]. Increased TP numbers and higher coverage indicate that more homologous protein sequences exist in the search results. In order to more objectively and comprehensively evaluate the coverage and TP number, errors per query (EPQ) is used as a threshold score. EPQ is the number of non-homologous sequences divided by the number of non-homologous sequences plus the number of homologous sequences.
Results and discussion
PL-search improves the performance of search methods
To explore the search ability of PL-search, its PL is constructed based on three search methods: PSI-BLAST [4], JackHMMER [28] and HHblits [10]. The performance of PL-search was tested on the two SCOP benchmark datasets based on three original search methods. This revealed that PL-search significantly improves the ranking quality as well as the number of remote homology protein sequences identified (Table 1 and 2).
Statistical significance differences between three search methods and their corresponding PL-based search methods on the two benchmark datasets
| Method | Scop1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| P-value of ROC1d | P-value of ROC50d | P-value of ROC1d | P-value of ROC50d | |
| PL-HHblitsa versus HHblits | 6.5606e-07 | 0.0021 | 2.0240e-44 | 8.1488e-17 |
| PL-BLASTb versus PSI-BLAST | 2.0208e-14 | 3.5188e-05 | 4.5773e-108 | 3.4125e-22 |
| PL-HMMERc versus JackHMMER | 0.1597 | 0.0810 | 1.4187e-07 | 8.1410e-09 |
| Method | Scop1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| P-value of ROC1d | P-value of ROC50d | P-value of ROC1d | P-value of ROC50d | |
| PL-HHblitsa versus HHblits | 6.5606e-07 | 0.0021 | 2.0240e-44 | 8.1488e-17 |
| PL-BLASTb versus PSI-BLAST | 2.0208e-14 | 3.5188e-05 | 4.5773e-108 | 3.4125e-22 |
| PL-HMMERc versus JackHMMER | 0.1597 | 0.0810 | 1.4187e-07 | 8.1410e-09 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dP-value was calculated by t-test [44].
Statistical significance differences between three search methods and their corresponding PL-based search methods on the two benchmark datasets
| Method | Scop1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| P-value of ROC1d | P-value of ROC50d | P-value of ROC1d | P-value of ROC50d | |
| PL-HHblitsa versus HHblits | 6.5606e-07 | 0.0021 | 2.0240e-44 | 8.1488e-17 |
| PL-BLASTb versus PSI-BLAST | 2.0208e-14 | 3.5188e-05 | 4.5773e-108 | 3.4125e-22 |
| PL-HMMERc versus JackHMMER | 0.1597 | 0.0810 | 1.4187e-07 | 8.1410e-09 |
| Method | Scop1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| P-value of ROC1d | P-value of ROC50d | P-value of ROC1d | P-value of ROC50d | |
| PL-HHblitsa versus HHblits | 6.5606e-07 | 0.0021 | 2.0240e-44 | 8.1488e-17 |
| PL-BLASTb versus PSI-BLAST | 2.0208e-14 | 3.5188e-05 | 4.5773e-108 | 3.4125e-22 |
| PL-HMMERc versus JackHMMER | 0.1597 | 0.0810 | 1.4187e-07 | 8.1410e-09 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dP-value was calculated by t-test [44].
In terms of ranking quality, the best performance of PL-search was achieved when its PL was constructed based on the results from HHblits (Table 1, Figure 2A–D), indicating that improved performance of the original search methods can improve the performance of PL-search. It is worth noting that when the ROC score is at its maximum, the ranking qualities of PL-search and original search methods show the largest discrepancy (Figure 2A–B, E–F and I–G). This big difference indicates that search results can be improved to the best ranking by using PL-search in many cases.
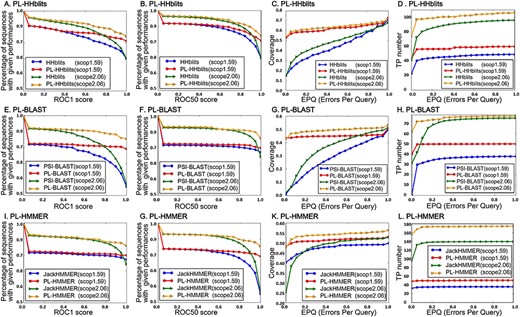
PL-based search improves the performance of three original search methods on two benchmark datasets. PL-HHblits, PL-BLAST and PL-HMMER represent PL-based search methods based on HHblits, PSI-BLAST and JackHMMER, respectively. (A), (B), (E), (F), (I) and (G) plot the percentage of sequences for which those methods exceed a given ROC1 and ROC50 scores. (C), (D), (G), (H), (K) and (I) plot the coverage and TP number for which those methods exceed a given EPQ score. Higher curves mean better performance for (A)–(L).
The highest detected number of remote homology protein sequences by PL-search was achieved with HHblits (Table 1, Figure 2A–D). From Figure 2C–D, G–H and K–L and Table 1, we can see that, compared with most search results of original search methods, the number of detected homology protein sequences increases with PL-search. The most significant improvement was observed for remote homology protein sequences, suggesting that PL-search is appropriate for protein remote homology detection. Because the number of search results of PL-search without non-homologous sequences was obviously higher than that of original search methods, which can be seen when EPQ score equals zero, the PL-search can be concluded to provide highly accurate search results. Furthermore, the gap of coverage between original search methods and their corresponding PL-search methods was lower than that of the TP number, indicating that the larger superfamilies tend to have more TP number increase.
Owing to PL construction, many null results of original search methods can be resolved by PL-search when JackHMMER and HHblits (Table 3) are employed. A high-quality ranking list can then be achieved by PL-search for the resolved sequences (Table 4).
Comparison of null results of three search methods and their corresponding PL-search methods on the two benchmark datasets
| Method | Number of NULL result | |
|---|---|---|
| SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | |
| HHblits | 7 | 135 |
| PL-HHblitsa | 2 | 25 |
| PSI-BLAST | 15 | 28 |
| PL-BLASTb | 15 | 28 |
| JackHMMER | 1207 | 1365 |
| PL-HMMERc | 1141 | 1261 |
| Method | Number of NULL result | |
|---|---|---|
| SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | |
| HHblits | 7 | 135 |
| PL-HHblitsa | 2 | 25 |
| PSI-BLAST | 15 | 28 |
| PL-BLASTb | 15 | 28 |
| JackHMMER | 1207 | 1365 |
| PL-HMMERc | 1141 | 1261 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
Comparison of null results of three search methods and their corresponding PL-search methods on the two benchmark datasets
| Method | Number of NULL result | |
|---|---|---|
| SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | |
| HHblits | 7 | 135 |
| PL-HHblitsa | 2 | 25 |
| PSI-BLAST | 15 | 28 |
| PL-BLASTb | 15 | 28 |
| JackHMMER | 1207 | 1365 |
| PL-HMMERc | 1141 | 1261 |
| Method | Number of NULL result | |
|---|---|---|
| SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | |
| HHblits | 7 | 135 |
| PL-HHblitsa | 2 | 25 |
| PSI-BLAST | 15 | 28 |
| PL-BLASTb | 15 | 28 |
| JackHMMER | 1207 | 1365 |
| PL-HMMERc | 1141 | 1261 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
Performance of the PL-search methods after solving the search results of null on the two benchmark datasets
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| ROC1c | ROC50c | ROC1c | ROC50c | |
| PL-HHblitsa | 1.0000 | 1.0000 | 0.9736 | 0.9745 |
| PL-HMMERb | 0.8086 | 0.8405 | 0.8702 | 0.9100 |
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| ROC1c | ROC50c | ROC1c | ROC50c | |
| PL-HHblitsa | 1.0000 | 1.0000 | 0.9736 | 0.9745 |
| PL-HMMERb | 0.8086 | 0.8405 | 0.8702 | 0.9100 |
aFive and one hundered ten query proteins cannot be detected by HHblits but can be detected by PL-HHblits on SCOP1.59 benchmark dataset and SCOPe2.06 benchmark dataset, respectively.
bSixty-six and one hundered four query proteins cannot be detected by JackHMMER but can be detected by PL-HMMER on SCOP1.59 benchmark dataset and SCOPe2.06, respectively.
cPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Performance of the PL-search methods after solving the search results of null on the two benchmark datasets
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| ROC1c | ROC50c | ROC1c | ROC50c | |
| PL-HHblitsa | 1.0000 | 1.0000 | 0.9736 | 0.9745 |
| PL-HMMERb | 0.8086 | 0.8405 | 0.8702 | 0.9100 |
| Method | SCOP 1.59 benchmark dataset | SCOPe 2.06 benchmark dataset | ||
|---|---|---|---|---|
| ROC1c | ROC50c | ROC1c | ROC50c | |
| PL-HHblitsa | 1.0000 | 1.0000 | 0.9736 | 0.9745 |
| PL-HMMERb | 0.8086 | 0.8405 | 0.8702 | 0.9100 |
aFive and one hundered ten query proteins cannot be detected by HHblits but can be detected by PL-HHblits on SCOP1.59 benchmark dataset and SCOPe2.06 benchmark dataset, respectively.
bSixty-six and one hundered four query proteins cannot be detected by JackHMMER but can be detected by PL-HMMER on SCOP1.59 benchmark dataset and SCOPe2.06, respectively.
cPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Impact of Jscore threshold for PL-based search
Because a lower E-value threshold can improve the ranking quality of many search methods with losing homologous sequences in the search result, this leads us to question whether the Jscore (cf. Equation (5)) threshold of PL-search affects the search results?
To address this, we studied the effect of Jscore on the performance of PL-search in terms of ranking quality and TP number. From Figure 3 and Tables 5 and 6. we can see that the coverage decreases with decreasing Jscore threshold. An obvious decrease in coverage is observed when the Jscore decreases from 0.99 to 0.8 for all PL-search methods, indicating that many homologous sequences have lower common PLs. Higher ROC1 scores were obtained with lower Jscores, although the relation is not liner. Furthermore, the accuracy of the ranking list and number of homologous sequences can be improved by adjusting Jscore threshold.
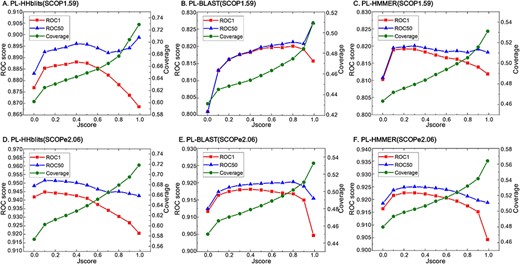
Lower Jscore threshold (cf. Equation (5)) reduces the number of detected homology sequence (●, right y-axis) and leads to more accurate ranking lists (■ and ▲, left y-axis) in most situations for PL-based search. PL-HHblits ((A) and (D)), PL-BLAST(B and E) and PL-HMMER ((C) and (F)) represent PL-based search methods based on HHblits, PSI-BLAST and JackHMMER, respectively. The results on the SCOP1.59 benchmark dataset are plotted in subfigures (A)–(C), and the results on the SCOPe2.06 benchmark dataset are plotted in subfigures (D)–(F).
Impact of the Jscore threshold (cf. Equation (6)) on the three PL-based search methods on the SCOP 1.59 benchmark dataset
| Jscore | SCOP 1.59 benchmark dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.8690 | 0.8976 | 0.7290 | 0.8158 | 0.8268 | 0.5093 | 0.8119 | 0.8182 | 0.5311 |
| 0.9 | 0.8736 | 0.8942 | 0.7041 | 0.8192 | 0.8208 | 0.4845 | 0.8139 | 0.8191 | 0.5157 |
| 0.8 | 0.8782 | 0.8929 | 0.6770 | 0.8201 | 0.8213 | 0.4748 | 0.8151 | 0.8182 | 0.5054 |
| 0.7 | 0.8824 | 0.8921 | 0.6649 | 0.8197 | 0.8207 | 0.4690 | 0.8162 | 0.8186 | 0.4996 |
| 0.6 | 0.8854 | 0.8942 | 0.6555 | 0.8197 | 0.8203 | 0.4634 | 0.8166 | 0.8184 | 0.4940 |
| 0.5 | 0.8876 | 0.8958 | 0.6493 | 0.8194 | 0.8198 | 0.4585 | 0.8174 | 0.8189 | 0.4891 |
| 0.4 | 0.8881 | 0.8961 | 0.6429 | 0.8183 | 0.8185 | 0.4540 | 0.8183 | 0.8195 | 0.4837 |
| 0.3 | 0.8871 | 0.8946 | 0.6376 | 0.8176 | 0.8177 | 0.4512 | 0.8191 | 0.8201 | 0.4795 |
| 0.2 | 0.8865 | 0.8936 | 0.6310 | 0.8162 | 0.8163 | 0.4483 | 0.8192 | 0.8198 | 0.4757 |
| 0.1 | 0.8854 | 0.8925 | 0.6251 | 0.8130 | 0.8131 | 0.4451 | 0.8189 | 0.8195 | 0.4718 |
| 0.0 | 0.8769 | 0.8831 | 0.6022 | 0.8011 | 0.8011 | 0.4313 | 0.8103 | 0.8108 | 0.4633 |
| Jscore | SCOP 1.59 benchmark dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.8690 | 0.8976 | 0.7290 | 0.8158 | 0.8268 | 0.5093 | 0.8119 | 0.8182 | 0.5311 |
| 0.9 | 0.8736 | 0.8942 | 0.7041 | 0.8192 | 0.8208 | 0.4845 | 0.8139 | 0.8191 | 0.5157 |
| 0.8 | 0.8782 | 0.8929 | 0.6770 | 0.8201 | 0.8213 | 0.4748 | 0.8151 | 0.8182 | 0.5054 |
| 0.7 | 0.8824 | 0.8921 | 0.6649 | 0.8197 | 0.8207 | 0.4690 | 0.8162 | 0.8186 | 0.4996 |
| 0.6 | 0.8854 | 0.8942 | 0.6555 | 0.8197 | 0.8203 | 0.4634 | 0.8166 | 0.8184 | 0.4940 |
| 0.5 | 0.8876 | 0.8958 | 0.6493 | 0.8194 | 0.8198 | 0.4585 | 0.8174 | 0.8189 | 0.4891 |
| 0.4 | 0.8881 | 0.8961 | 0.6429 | 0.8183 | 0.8185 | 0.4540 | 0.8183 | 0.8195 | 0.4837 |
| 0.3 | 0.8871 | 0.8946 | 0.6376 | 0.8176 | 0.8177 | 0.4512 | 0.8191 | 0.8201 | 0.4795 |
| 0.2 | 0.8865 | 0.8936 | 0.6310 | 0.8162 | 0.8163 | 0.4483 | 0.8192 | 0.8198 | 0.4757 |
| 0.1 | 0.8854 | 0.8925 | 0.6251 | 0.8130 | 0.8131 | 0.4451 | 0.8189 | 0.8195 | 0.4718 |
| 0.0 | 0.8769 | 0.8831 | 0.6022 | 0.8011 | 0.8011 | 0.4313 | 0.8103 | 0.8108 | 0.4633 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Impact of the Jscore threshold (cf. Equation (6)) on the three PL-based search methods on the SCOP 1.59 benchmark dataset
| Jscore | SCOP 1.59 benchmark dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.8690 | 0.8976 | 0.7290 | 0.8158 | 0.8268 | 0.5093 | 0.8119 | 0.8182 | 0.5311 |
| 0.9 | 0.8736 | 0.8942 | 0.7041 | 0.8192 | 0.8208 | 0.4845 | 0.8139 | 0.8191 | 0.5157 |
| 0.8 | 0.8782 | 0.8929 | 0.6770 | 0.8201 | 0.8213 | 0.4748 | 0.8151 | 0.8182 | 0.5054 |
| 0.7 | 0.8824 | 0.8921 | 0.6649 | 0.8197 | 0.8207 | 0.4690 | 0.8162 | 0.8186 | 0.4996 |
| 0.6 | 0.8854 | 0.8942 | 0.6555 | 0.8197 | 0.8203 | 0.4634 | 0.8166 | 0.8184 | 0.4940 |
| 0.5 | 0.8876 | 0.8958 | 0.6493 | 0.8194 | 0.8198 | 0.4585 | 0.8174 | 0.8189 | 0.4891 |
| 0.4 | 0.8881 | 0.8961 | 0.6429 | 0.8183 | 0.8185 | 0.4540 | 0.8183 | 0.8195 | 0.4837 |
| 0.3 | 0.8871 | 0.8946 | 0.6376 | 0.8176 | 0.8177 | 0.4512 | 0.8191 | 0.8201 | 0.4795 |
| 0.2 | 0.8865 | 0.8936 | 0.6310 | 0.8162 | 0.8163 | 0.4483 | 0.8192 | 0.8198 | 0.4757 |
| 0.1 | 0.8854 | 0.8925 | 0.6251 | 0.8130 | 0.8131 | 0.4451 | 0.8189 | 0.8195 | 0.4718 |
| 0.0 | 0.8769 | 0.8831 | 0.6022 | 0.8011 | 0.8011 | 0.4313 | 0.8103 | 0.8108 | 0.4633 |
| Jscore | SCOP 1.59 benchmark dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.8690 | 0.8976 | 0.7290 | 0.8158 | 0.8268 | 0.5093 | 0.8119 | 0.8182 | 0.5311 |
| 0.9 | 0.8736 | 0.8942 | 0.7041 | 0.8192 | 0.8208 | 0.4845 | 0.8139 | 0.8191 | 0.5157 |
| 0.8 | 0.8782 | 0.8929 | 0.6770 | 0.8201 | 0.8213 | 0.4748 | 0.8151 | 0.8182 | 0.5054 |
| 0.7 | 0.8824 | 0.8921 | 0.6649 | 0.8197 | 0.8207 | 0.4690 | 0.8162 | 0.8186 | 0.4996 |
| 0.6 | 0.8854 | 0.8942 | 0.6555 | 0.8197 | 0.8203 | 0.4634 | 0.8166 | 0.8184 | 0.4940 |
| 0.5 | 0.8876 | 0.8958 | 0.6493 | 0.8194 | 0.8198 | 0.4585 | 0.8174 | 0.8189 | 0.4891 |
| 0.4 | 0.8881 | 0.8961 | 0.6429 | 0.8183 | 0.8185 | 0.4540 | 0.8183 | 0.8195 | 0.4837 |
| 0.3 | 0.8871 | 0.8946 | 0.6376 | 0.8176 | 0.8177 | 0.4512 | 0.8191 | 0.8201 | 0.4795 |
| 0.2 | 0.8865 | 0.8936 | 0.6310 | 0.8162 | 0.8163 | 0.4483 | 0.8192 | 0.8198 | 0.4757 |
| 0.1 | 0.8854 | 0.8925 | 0.6251 | 0.8130 | 0.8131 | 0.4451 | 0.8189 | 0.8195 | 0.4718 |
| 0.0 | 0.8769 | 0.8831 | 0.6022 | 0.8011 | 0.8011 | 0.4313 | 0.8103 | 0.8108 | 0.4633 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Impact of the Jscore threshold (cf. Equation (6)) on the three PL-based search methods on the SCOPe 2.06 benchmark dataset
| Jscore threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.9207 | 0.9426 | 0.7184 | 0.9047 | 0.9155 | 0.5327 | 0.9043 | 0.9188 | 0.5642 |
| 0.9 | 0.9268 | 0.9438 | 0.6952 | 0.9150 | 0.9190 | 0.5107 | 0.9152 | 0.9197 | 0.5416 |
| 0.8 | 0.9305 | 0.9451 | 0.6795 | 0.9168 | 0.9203 | 0.5017 | 0.9175 | 0.9213 | 0.5321 |
| 0.7 | 0.9341 | 0.9446 | 0.6651 | 0.9170 | 0.9200 | 0.4947 | 0.9194 | 0.9229 | 0.5240 |
| 0.6 | 0.9375 | 0.9464 | 0.6517 | 0.9175 | 0.9200 | 0.4889 | 0.9206 | 0.9239 | 0.5176 |
| 0.5 | 0.9411 | 0.9488 | 0.6393 | 0.9179 | 0.9198 | 0.4834 | 0.9214 | 0.9245 | 0.5128 |
| 0.4 | 0.9426 | 0.9502 | 0.6288 | 0.9181 | 0.9196 | 0.4789 | 0.9222 | 0.9248 | 0.5068 |
| 0.3 | 0.9436 | 0.9509 | 0.6201 | 0.9180 | 0.9193 | 0.4741 | 0.9226 | 0.9250 | 0.5026 |
| 0.2 | 0.9442 | 0.9514 | 0.6122 | 0.9175 | 0.9187 | 0.4703 | 0.9226 | 0.9248 | 0.4987 |
| 0.1 | 0.9448 | 0.9516 | 0.6026 | 0.9164 | 0.9174 | 0.4658 | 0.9216 | 0.9237 | 0.4935 |
| 0.0 | 0.9419 | 0.9484 | 0.5738 | 0.9117 | 0.9125 | 0.4504 | 0.9164 | 0.9185 | 0.4800 |
| Jscore threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.9207 | 0.9426 | 0.7184 | 0.9047 | 0.9155 | 0.5327 | 0.9043 | 0.9188 | 0.5642 |
| 0.9 | 0.9268 | 0.9438 | 0.6952 | 0.9150 | 0.9190 | 0.5107 | 0.9152 | 0.9197 | 0.5416 |
| 0.8 | 0.9305 | 0.9451 | 0.6795 | 0.9168 | 0.9203 | 0.5017 | 0.9175 | 0.9213 | 0.5321 |
| 0.7 | 0.9341 | 0.9446 | 0.6651 | 0.9170 | 0.9200 | 0.4947 | 0.9194 | 0.9229 | 0.5240 |
| 0.6 | 0.9375 | 0.9464 | 0.6517 | 0.9175 | 0.9200 | 0.4889 | 0.9206 | 0.9239 | 0.5176 |
| 0.5 | 0.9411 | 0.9488 | 0.6393 | 0.9179 | 0.9198 | 0.4834 | 0.9214 | 0.9245 | 0.5128 |
| 0.4 | 0.9426 | 0.9502 | 0.6288 | 0.9181 | 0.9196 | 0.4789 | 0.9222 | 0.9248 | 0.5068 |
| 0.3 | 0.9436 | 0.9509 | 0.6201 | 0.9180 | 0.9193 | 0.4741 | 0.9226 | 0.9250 | 0.5026 |
| 0.2 | 0.9442 | 0.9514 | 0.6122 | 0.9175 | 0.9187 | 0.4703 | 0.9226 | 0.9248 | 0.4987 |
| 0.1 | 0.9448 | 0.9516 | 0.6026 | 0.9164 | 0.9174 | 0.4658 | 0.9216 | 0.9237 | 0.4935 |
| 0.0 | 0.9419 | 0.9484 | 0.5738 | 0.9117 | 0.9125 | 0.4504 | 0.9164 | 0.9185 | 0.4800 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Impact of the Jscore threshold (cf. Equation (6)) on the three PL-based search methods on the SCOPe 2.06 benchmark dataset
| Jscore threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.9207 | 0.9426 | 0.7184 | 0.9047 | 0.9155 | 0.5327 | 0.9043 | 0.9188 | 0.5642 |
| 0.9 | 0.9268 | 0.9438 | 0.6952 | 0.9150 | 0.9190 | 0.5107 | 0.9152 | 0.9197 | 0.5416 |
| 0.8 | 0.9305 | 0.9451 | 0.6795 | 0.9168 | 0.9203 | 0.5017 | 0.9175 | 0.9213 | 0.5321 |
| 0.7 | 0.9341 | 0.9446 | 0.6651 | 0.9170 | 0.9200 | 0.4947 | 0.9194 | 0.9229 | 0.5240 |
| 0.6 | 0.9375 | 0.9464 | 0.6517 | 0.9175 | 0.9200 | 0.4889 | 0.9206 | 0.9239 | 0.5176 |
| 0.5 | 0.9411 | 0.9488 | 0.6393 | 0.9179 | 0.9198 | 0.4834 | 0.9214 | 0.9245 | 0.5128 |
| 0.4 | 0.9426 | 0.9502 | 0.6288 | 0.9181 | 0.9196 | 0.4789 | 0.9222 | 0.9248 | 0.5068 |
| 0.3 | 0.9436 | 0.9509 | 0.6201 | 0.9180 | 0.9193 | 0.4741 | 0.9226 | 0.9250 | 0.5026 |
| 0.2 | 0.9442 | 0.9514 | 0.6122 | 0.9175 | 0.9187 | 0.4703 | 0.9226 | 0.9248 | 0.4987 |
| 0.1 | 0.9448 | 0.9516 | 0.6026 | 0.9164 | 0.9174 | 0.4658 | 0.9216 | 0.9237 | 0.4935 |
| 0.0 | 0.9419 | 0.9484 | 0.5738 | 0.9117 | 0.9125 | 0.4504 | 0.9164 | 0.9185 | 0.4800 |
| Jscore threshold | PL-HHblitsa | PL-BLASTb | PL-HMMERc | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | ROC1d | ROC50d | Coveraged | |
| 0.99 | 0.9207 | 0.9426 | 0.7184 | 0.9047 | 0.9155 | 0.5327 | 0.9043 | 0.9188 | 0.5642 |
| 0.9 | 0.9268 | 0.9438 | 0.6952 | 0.9150 | 0.9190 | 0.5107 | 0.9152 | 0.9197 | 0.5416 |
| 0.8 | 0.9305 | 0.9451 | 0.6795 | 0.9168 | 0.9203 | 0.5017 | 0.9175 | 0.9213 | 0.5321 |
| 0.7 | 0.9341 | 0.9446 | 0.6651 | 0.9170 | 0.9200 | 0.4947 | 0.9194 | 0.9229 | 0.5240 |
| 0.6 | 0.9375 | 0.9464 | 0.6517 | 0.9175 | 0.9200 | 0.4889 | 0.9206 | 0.9239 | 0.5176 |
| 0.5 | 0.9411 | 0.9488 | 0.6393 | 0.9179 | 0.9198 | 0.4834 | 0.9214 | 0.9245 | 0.5128 |
| 0.4 | 0.9426 | 0.9502 | 0.6288 | 0.9181 | 0.9196 | 0.4789 | 0.9222 | 0.9248 | 0.5068 |
| 0.3 | 0.9436 | 0.9509 | 0.6201 | 0.9180 | 0.9193 | 0.4741 | 0.9226 | 0.9250 | 0.5026 |
| 0.2 | 0.9442 | 0.9514 | 0.6122 | 0.9175 | 0.9187 | 0.4703 | 0.9226 | 0.9248 | 0.4987 |
| 0.1 | 0.9448 | 0.9516 | 0.6026 | 0.9164 | 0.9174 | 0.4658 | 0.9216 | 0.9237 | 0.4935 |
| 0.0 | 0.9419 | 0.9484 | 0.5738 | 0.9117 | 0.9125 | 0.4504 | 0.9164 | 0.9185 | 0.4800 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Impact of parameters for PL-based search
To investigate the effects of parameters of PL-search on the search performance, we analysed the performance of PL-search based on different original search methods with different parameters on the SCOP1.59 benchmark dataset. There are two parameters (cf. Algorithm 1) in our method, which contribute to better performance by adjusting the quality of the PL. The accuracy of ranking is less sensitive to these parameters, but parameter |${\beta}_1$| significantly impacts the TP number for PL-search (Tables 7 and 8).
The impact of the parameter |${\beta}_1$| on the three PL-search methods with parameter |${\beta}_2$| value of 0 (cf. Algorithm 1) on the SCOP 1.59 benchmark dataset
| |${\beta}_1$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0.5 | 0.8665 | 0.8979 | 59.8753 | 0.1622 | 0.8144 | 0.8266 | 49.8214 | 0.1937 | 0.8090 | 0.8175 | 50.9113 | 0.1940 |
| 0.55 | 0.8660 | 0.8977 | 59.8083 | 0.1620 | 0.8144 | 0.8265 | 49.8127 | 0.1937 | 0.8101 | 0.8179 | 50.8361 | 0.1936 |
| 0.6 | 0.8661 | 0.8975 | 59.8041 | 0.1619 | 0.8144 | 0.8265 | 49.8094 | 0.1936 | 0.8106 | 0.8181 | 50.7664 | 0.1937 |
| 0.65 | 0.8681 | 0.8981 | 59.6346 | 0.1616 | 0.8139 | 0.8260 | 49.6661 | 0.1936 | 0.8104 | 0.8180 | 50.7631 | 0.1937 |
| 0.7 | 0.8680 | 0.8974 | 59.5931 | 0.1611 | 0.8138 | 0.8260 | 49.6592 | 0.1936 | 0.8096 | 0.8176 | 50.7622 | 0.1935 |
| 0.75 | 0.8680 | 0.8980 | 59.5616 | 0.1607 | 0.8138 | 0.8259 | 49.6050 | 0.1936 | 0.8107 | 0.8179 | 50.7414 | 0.1931 |
| 0.8 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8138 | 0.8258 | 49.5833 | 0.1936 | 0.8106 | 0.8183 | 50.7027 | 0.1928 |
| 0.85 | 0.8682 | 0.8969 | 59.3253 | 0.1587 | 0.8148 | 0.8258 | 49.4494 | 0.1939 | 0.8106 | 0.8181 | 50.6633 | 0.1917 |
| 0.9 | 0.8676 | 0.8966 | 59.1802 | 0.1569 | 0.8151 | 0.8258 | 49.3557 | 0.1939 | 0.8109 | 0.8180 | 50.6579 | 0.1903 |
| 0.95 | 0.8679 | 0.8985 | 58.9995 | 0.1532 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8111 | 0.8179 | 50.6132 | 0.1886 |
| 1.0 | 0.8679 | 0.8976 | 48.2747 | 0.1491 | 0.8158 | 0.8262 | 40.8559 | 0.1930 | 0.8125 | 0.8184 | 46.3268 | 0.1880 |
| |${\beta}_1$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0.5 | 0.8665 | 0.8979 | 59.8753 | 0.1622 | 0.8144 | 0.8266 | 49.8214 | 0.1937 | 0.8090 | 0.8175 | 50.9113 | 0.1940 |
| 0.55 | 0.8660 | 0.8977 | 59.8083 | 0.1620 | 0.8144 | 0.8265 | 49.8127 | 0.1937 | 0.8101 | 0.8179 | 50.8361 | 0.1936 |
| 0.6 | 0.8661 | 0.8975 | 59.8041 | 0.1619 | 0.8144 | 0.8265 | 49.8094 | 0.1936 | 0.8106 | 0.8181 | 50.7664 | 0.1937 |
| 0.65 | 0.8681 | 0.8981 | 59.6346 | 0.1616 | 0.8139 | 0.8260 | 49.6661 | 0.1936 | 0.8104 | 0.8180 | 50.7631 | 0.1937 |
| 0.7 | 0.8680 | 0.8974 | 59.5931 | 0.1611 | 0.8138 | 0.8260 | 49.6592 | 0.1936 | 0.8096 | 0.8176 | 50.7622 | 0.1935 |
| 0.75 | 0.8680 | 0.8980 | 59.5616 | 0.1607 | 0.8138 | 0.8259 | 49.6050 | 0.1936 | 0.8107 | 0.8179 | 50.7414 | 0.1931 |
| 0.8 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8138 | 0.8258 | 49.5833 | 0.1936 | 0.8106 | 0.8183 | 50.7027 | 0.1928 |
| 0.85 | 0.8682 | 0.8969 | 59.3253 | 0.1587 | 0.8148 | 0.8258 | 49.4494 | 0.1939 | 0.8106 | 0.8181 | 50.6633 | 0.1917 |
| 0.9 | 0.8676 | 0.8966 | 59.1802 | 0.1569 | 0.8151 | 0.8258 | 49.3557 | 0.1939 | 0.8109 | 0.8180 | 50.6579 | 0.1903 |
| 0.95 | 0.8679 | 0.8985 | 58.9995 | 0.1532 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8111 | 0.8179 | 50.6132 | 0.1886 |
| 1.0 | 0.8679 | 0.8976 | 48.2747 | 0.1491 | 0.8158 | 0.8262 | 40.8559 | 0.1930 | 0.8125 | 0.8184 | 46.3268 | 0.1880 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
The impact of the parameter |${\beta}_1$| on the three PL-search methods with parameter |${\beta}_2$| value of 0 (cf. Algorithm 1) on the SCOP 1.59 benchmark dataset
| |${\beta}_1$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0.5 | 0.8665 | 0.8979 | 59.8753 | 0.1622 | 0.8144 | 0.8266 | 49.8214 | 0.1937 | 0.8090 | 0.8175 | 50.9113 | 0.1940 |
| 0.55 | 0.8660 | 0.8977 | 59.8083 | 0.1620 | 0.8144 | 0.8265 | 49.8127 | 0.1937 | 0.8101 | 0.8179 | 50.8361 | 0.1936 |
| 0.6 | 0.8661 | 0.8975 | 59.8041 | 0.1619 | 0.8144 | 0.8265 | 49.8094 | 0.1936 | 0.8106 | 0.8181 | 50.7664 | 0.1937 |
| 0.65 | 0.8681 | 0.8981 | 59.6346 | 0.1616 | 0.8139 | 0.8260 | 49.6661 | 0.1936 | 0.8104 | 0.8180 | 50.7631 | 0.1937 |
| 0.7 | 0.8680 | 0.8974 | 59.5931 | 0.1611 | 0.8138 | 0.8260 | 49.6592 | 0.1936 | 0.8096 | 0.8176 | 50.7622 | 0.1935 |
| 0.75 | 0.8680 | 0.8980 | 59.5616 | 0.1607 | 0.8138 | 0.8259 | 49.6050 | 0.1936 | 0.8107 | 0.8179 | 50.7414 | 0.1931 |
| 0.8 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8138 | 0.8258 | 49.5833 | 0.1936 | 0.8106 | 0.8183 | 50.7027 | 0.1928 |
| 0.85 | 0.8682 | 0.8969 | 59.3253 | 0.1587 | 0.8148 | 0.8258 | 49.4494 | 0.1939 | 0.8106 | 0.8181 | 50.6633 | 0.1917 |
| 0.9 | 0.8676 | 0.8966 | 59.1802 | 0.1569 | 0.8151 | 0.8258 | 49.3557 | 0.1939 | 0.8109 | 0.8180 | 50.6579 | 0.1903 |
| 0.95 | 0.8679 | 0.8985 | 58.9995 | 0.1532 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8111 | 0.8179 | 50.6132 | 0.1886 |
| 1.0 | 0.8679 | 0.8976 | 48.2747 | 0.1491 | 0.8158 | 0.8262 | 40.8559 | 0.1930 | 0.8125 | 0.8184 | 46.3268 | 0.1880 |
| |${\beta}_1$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0.5 | 0.8665 | 0.8979 | 59.8753 | 0.1622 | 0.8144 | 0.8266 | 49.8214 | 0.1937 | 0.8090 | 0.8175 | 50.9113 | 0.1940 |
| 0.55 | 0.8660 | 0.8977 | 59.8083 | 0.1620 | 0.8144 | 0.8265 | 49.8127 | 0.1937 | 0.8101 | 0.8179 | 50.8361 | 0.1936 |
| 0.6 | 0.8661 | 0.8975 | 59.8041 | 0.1619 | 0.8144 | 0.8265 | 49.8094 | 0.1936 | 0.8106 | 0.8181 | 50.7664 | 0.1937 |
| 0.65 | 0.8681 | 0.8981 | 59.6346 | 0.1616 | 0.8139 | 0.8260 | 49.6661 | 0.1936 | 0.8104 | 0.8180 | 50.7631 | 0.1937 |
| 0.7 | 0.8680 | 0.8974 | 59.5931 | 0.1611 | 0.8138 | 0.8260 | 49.6592 | 0.1936 | 0.8096 | 0.8176 | 50.7622 | 0.1935 |
| 0.75 | 0.8680 | 0.8980 | 59.5616 | 0.1607 | 0.8138 | 0.8259 | 49.6050 | 0.1936 | 0.8107 | 0.8179 | 50.7414 | 0.1931 |
| 0.8 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8138 | 0.8258 | 49.5833 | 0.1936 | 0.8106 | 0.8183 | 50.7027 | 0.1928 |
| 0.85 | 0.8682 | 0.8969 | 59.3253 | 0.1587 | 0.8148 | 0.8258 | 49.4494 | 0.1939 | 0.8106 | 0.8181 | 50.6633 | 0.1917 |
| 0.9 | 0.8676 | 0.8966 | 59.1802 | 0.1569 | 0.8151 | 0.8258 | 49.3557 | 0.1939 | 0.8109 | 0.8180 | 50.6579 | 0.1903 |
| 0.95 | 0.8679 | 0.8985 | 58.9995 | 0.1532 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8111 | 0.8179 | 50.6132 | 0.1886 |
| 1.0 | 0.8679 | 0.8976 | 48.2747 | 0.1491 | 0.8158 | 0.8262 | 40.8559 | 0.1930 | 0.8125 | 0.8184 | 46.3268 | 0.1880 |
aPL-based search based on HHblits with the default parameters.
bPL-based search based on PSI-BLAST with default parameters except that the iterations was set as five.
cPL-based search based on JackHMMER with the default parameters.
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
The impact of parameter |${\beta}_2$| on the three PL-search methods on the SCOP 1.59 benchmark dataset
| |${\beta}_2$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TP | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8109 | 0.8180 | 50.6132 | 0.1903 |
| 0.5 | 0.8685 | 0.8968 | 59.4602 | 0.1596 | 0.8153 | 0.8260 | 49.4026 | 0.1940 | 0.8111 | 0.8178 | 50.6957 | 0.1886 |
| 0.6 | 0.8685 | 0.8969 | 59.4658 | 0.1596 | 0.8153 | 0.8260 | 49.4271 | 0.1940 | 0.8111 | 0.8178 | 50.7016 | 0.1886 |
| 0.7 | 0.8688 | 0.8970 | 59.4765 | 0.1600 | 0.8153 | 0.8260 | 49.5291 | 0.1940 | 0.8111 | 0.8179 | 50.7594 | 0.1886 |
| 0.8 | 0.8690 | 0.8973 | 59.6349 | 0.1601 | 0.8153 | 0.8263 | 49.5385 | 0.1941 | 0.8112 | 0.8181 | 50.7648 | 0.1888 |
| 0.9 | 0.8689 | 0.8973 | 59.6375 | 0.1602 | 0.8154 | 0.8262 | 49.5561 | 0.1936 | 0.8112 | 0.8182 | 50.7772 | 0.1890 |
| 1.0 | 0.8689 | 0.8972 | 59.8296 | 0.1607 | 0.8158 | 0.8268 | 49.8555 | 0.1942 | 0.8112 | 0.8182 | 50.8469 | 0.1901 |
| 1.1 | 0.8690 | 0.8976 | 59.8305 | 0.1608 | 0.8158 | 0.8268 | 49.8559 | 0.1942 | 0.8114 | 0.8181 | 50.8510 | 0.1899 |
| 1.2 | 0.8688 | 0.8982 | 59.8465 | 0.1611 | 0.8157 | 0.8269 | 49.8670 | 0.1943 | 0.8114 | 0.8181 | 50.8533 | 0.1903 |
| 1.3 | 0.8688 | 0.8987 | 59.8570 | 0.1612 | 0.8158 | 0.8269 | 49.8679 | 0.1942 | 0.8114 | 0.8181 | 50.8436 | 0.1905 |
| 1.4 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
| 1.5 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
| |${\beta}_2$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TP | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8109 | 0.8180 | 50.6132 | 0.1903 |
| 0.5 | 0.8685 | 0.8968 | 59.4602 | 0.1596 | 0.8153 | 0.8260 | 49.4026 | 0.1940 | 0.8111 | 0.8178 | 50.6957 | 0.1886 |
| 0.6 | 0.8685 | 0.8969 | 59.4658 | 0.1596 | 0.8153 | 0.8260 | 49.4271 | 0.1940 | 0.8111 | 0.8178 | 50.7016 | 0.1886 |
| 0.7 | 0.8688 | 0.8970 | 59.4765 | 0.1600 | 0.8153 | 0.8260 | 49.5291 | 0.1940 | 0.8111 | 0.8179 | 50.7594 | 0.1886 |
| 0.8 | 0.8690 | 0.8973 | 59.6349 | 0.1601 | 0.8153 | 0.8263 | 49.5385 | 0.1941 | 0.8112 | 0.8181 | 50.7648 | 0.1888 |
| 0.9 | 0.8689 | 0.8973 | 59.6375 | 0.1602 | 0.8154 | 0.8262 | 49.5561 | 0.1936 | 0.8112 | 0.8182 | 50.7772 | 0.1890 |
| 1.0 | 0.8689 | 0.8972 | 59.8296 | 0.1607 | 0.8158 | 0.8268 | 49.8555 | 0.1942 | 0.8112 | 0.8182 | 50.8469 | 0.1901 |
| 1.1 | 0.8690 | 0.8976 | 59.8305 | 0.1608 | 0.8158 | 0.8268 | 49.8559 | 0.1942 | 0.8114 | 0.8181 | 50.8510 | 0.1899 |
| 1.2 | 0.8688 | 0.8982 | 59.8465 | 0.1611 | 0.8157 | 0.8269 | 49.8670 | 0.1943 | 0.8114 | 0.8181 | 50.8533 | 0.1903 |
| 1.3 | 0.8688 | 0.8987 | 59.8570 | 0.1612 | 0.8158 | 0.8269 | 49.8679 | 0.1942 | 0.8114 | 0.8181 | 50.8436 | 0.1905 |
| 1.4 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
| 1.5 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
aRepresents PL-HHblits with β1 value of 0.8 (cf. Algorithm 1).
bRepresents PL-BLAST with β1 value of 0.95 (cf. Algorithm 1).
cRepresents PL-HMMER with β1 value of 0.95 (cf. Algorithm 1).
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
The impact of parameter |${\beta}_2$| on the three PL-search methods on the SCOP 1.59 benchmark dataset
| |${\beta}_2$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TP | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8109 | 0.8180 | 50.6132 | 0.1903 |
| 0.5 | 0.8685 | 0.8968 | 59.4602 | 0.1596 | 0.8153 | 0.8260 | 49.4026 | 0.1940 | 0.8111 | 0.8178 | 50.6957 | 0.1886 |
| 0.6 | 0.8685 | 0.8969 | 59.4658 | 0.1596 | 0.8153 | 0.8260 | 49.4271 | 0.1940 | 0.8111 | 0.8178 | 50.7016 | 0.1886 |
| 0.7 | 0.8688 | 0.8970 | 59.4765 | 0.1600 | 0.8153 | 0.8260 | 49.5291 | 0.1940 | 0.8111 | 0.8179 | 50.7594 | 0.1886 |
| 0.8 | 0.8690 | 0.8973 | 59.6349 | 0.1601 | 0.8153 | 0.8263 | 49.5385 | 0.1941 | 0.8112 | 0.8181 | 50.7648 | 0.1888 |
| 0.9 | 0.8689 | 0.8973 | 59.6375 | 0.1602 | 0.8154 | 0.8262 | 49.5561 | 0.1936 | 0.8112 | 0.8182 | 50.7772 | 0.1890 |
| 1.0 | 0.8689 | 0.8972 | 59.8296 | 0.1607 | 0.8158 | 0.8268 | 49.8555 | 0.1942 | 0.8112 | 0.8182 | 50.8469 | 0.1901 |
| 1.1 | 0.8690 | 0.8976 | 59.8305 | 0.1608 | 0.8158 | 0.8268 | 49.8559 | 0.1942 | 0.8114 | 0.8181 | 50.8510 | 0.1899 |
| 1.2 | 0.8688 | 0.8982 | 59.8465 | 0.1611 | 0.8157 | 0.8269 | 49.8670 | 0.1943 | 0.8114 | 0.8181 | 50.8533 | 0.1903 |
| 1.3 | 0.8688 | 0.8987 | 59.8570 | 0.1612 | 0.8158 | 0.8269 | 49.8679 | 0.1942 | 0.8114 | 0.8181 | 50.8436 | 0.1905 |
| 1.4 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
| 1.5 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
| |${\beta}_2$| | PL-HHblitsa | PL-BLASTb | PL-HMMERc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROC1d | ROC50d | TP | EPQd | ROC1d | ROC50d | TPd | EPQd | ROC1d | ROC50d | TPd | EPQd | |
| 0 | 0.8684 | 0.8966 | 59.4196 | 0.1593 | 0.8157 | 0.8261 | 49.2459 | 0.1932 | 0.8109 | 0.8180 | 50.6132 | 0.1903 |
| 0.5 | 0.8685 | 0.8968 | 59.4602 | 0.1596 | 0.8153 | 0.8260 | 49.4026 | 0.1940 | 0.8111 | 0.8178 | 50.6957 | 0.1886 |
| 0.6 | 0.8685 | 0.8969 | 59.4658 | 0.1596 | 0.8153 | 0.8260 | 49.4271 | 0.1940 | 0.8111 | 0.8178 | 50.7016 | 0.1886 |
| 0.7 | 0.8688 | 0.8970 | 59.4765 | 0.1600 | 0.8153 | 0.8260 | 49.5291 | 0.1940 | 0.8111 | 0.8179 | 50.7594 | 0.1886 |
| 0.8 | 0.8690 | 0.8973 | 59.6349 | 0.1601 | 0.8153 | 0.8263 | 49.5385 | 0.1941 | 0.8112 | 0.8181 | 50.7648 | 0.1888 |
| 0.9 | 0.8689 | 0.8973 | 59.6375 | 0.1602 | 0.8154 | 0.8262 | 49.5561 | 0.1936 | 0.8112 | 0.8182 | 50.7772 | 0.1890 |
| 1.0 | 0.8689 | 0.8972 | 59.8296 | 0.1607 | 0.8158 | 0.8268 | 49.8555 | 0.1942 | 0.8112 | 0.8182 | 50.8469 | 0.1901 |
| 1.1 | 0.8690 | 0.8976 | 59.8305 | 0.1608 | 0.8158 | 0.8268 | 49.8559 | 0.1942 | 0.8114 | 0.8181 | 50.8510 | 0.1899 |
| 1.2 | 0.8688 | 0.8982 | 59.8465 | 0.1611 | 0.8157 | 0.8269 | 49.8670 | 0.1943 | 0.8114 | 0.8181 | 50.8533 | 0.1903 |
| 1.3 | 0.8688 | 0.8987 | 59.8570 | 0.1612 | 0.8158 | 0.8269 | 49.8679 | 0.1942 | 0.8114 | 0.8181 | 50.8436 | 0.1905 |
| 1.4 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
| 1.5 | 0.8687 | 0.8988 | 59.9074 | 0.1613 | 0.8158 | 0.8268 | 49.8742 | 0.1942 | 0.8119 | 0.8182 | 50.8473 | 0.1904 |
aRepresents PL-HHblits with β1 value of 0.8 (cf. Algorithm 1).
bRepresents PL-BLAST with β1 value of 0.95 (cf. Algorithm 1).
cRepresents PL-HMMER with β1 value of 0.95 (cf. Algorithm 1).
dPerformance at homology level that contains close homology and remote homology (belonging to the same SCOP superfamily).
Parameter |${\beta}_1$| is the most important parameter for increasing the detection of homologous protein sequences. In terms of reliability of the search results in this study, it is worth noting that the ROC1 score has higher priority than TP number for selecting |${\beta}_1$|. Therefore, |${\beta}_1$| was set to 0.8, 0.95 and 0.95 for PL-HHblits, PL-BLAST and PL-HMMER, respectively. From Table 7, we can see that is an obvious increase in the number of homologous protein sequences when |${\beta}_1$| is set to 0.95 for all original search methods, indicating that constructing the PL with the iterative extending-link strategy significantly improves the search for homologous protein sequences. Further reduction of |${\beta}_1$| resulted in lower TP number and erratic fluctuation of the ROC score, while higher ranking quality can be obtained by fixing parameters |${\beta}_1=1$| and |${\beta}_2=0$|, when there is no requirement to obtain more homologous sequences.
Parameter |${\beta}_2$| can further improve TP number with stable ranking quality (Table 8). Compared with |${\beta}_1$|, the improvement for PL-search is reduced because |${\beta}_2$| is complementary to |${\beta}_1$|; |${\beta}_2$| was set to 1.10, 1.50 and 1.50 for PL-HHblits, PL-BLAST and PL-HMMER, respectively, to achieve an improved ranking list.
An example to show how PL-HHblits works
An example can help the users to deeply understand the process of PL-search [43]. Therefore, an example of how the PL-HHblit predictor improves the predictive performance of HHblits is shown in Figure 4. Compared with the search results obtained from HHblits (Figure 4A), PL-HHblits (Figure 4D) detects more homology protein sequences, and fewer non-homology protein sequences. There are three reasons for the improved performance of PL-HHblits: (i) double-link strategy filters some non-homology protein sequences (Figure 4B and Equations (2) and (3)), and the sequences in double-link provide high quality feedback protein sequences for PL-search (see Figure 4D and Equation (6)); (ii) there are some common links between the PL of query protein (Figure 4C) and the PLs of the homology proteins (Figure 4F), contributing to detect more homology protein sequence; (iii) there are no common links between the PL of query protein (Figure 4C) and the PLs of the non-homology proteins (Figure 4E), resulting in a more accurate ranking list.
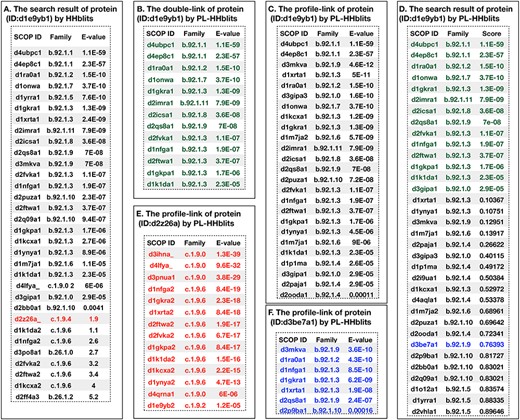
The search results of query protein (SCOP ID: d1e9yb1 and Family: b.92.1.1) generated by HHblits and PL-HHblits, and the link information of PL-HHblits. (A) and (B) show the search results outputted by HHblits and PL-HHblits, respectively. Subfigure C represents the double-link list of query protein (cf. Equation (3)). (D) represents the PLs of query protein (cf. Algorithm 1). (E) shows the PLs of a non-homology protein SCOP ID:d2z26a of the query protein, which is in the ranking list of HHblits but not in the ranking list of PL-HHblits. (F) represents the PLs of a homology protein SCOP ID: d3be7a1 of the query protein detected by PL-HHblits.
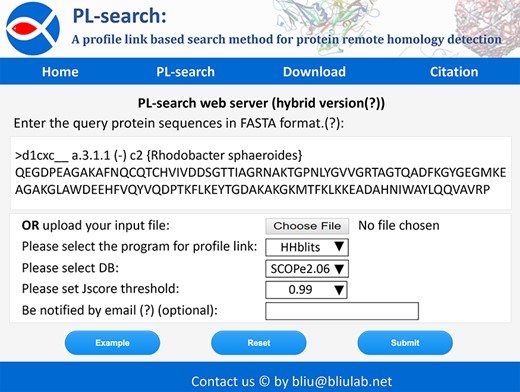
Screenshot of the web server of PL-search.
Stand-alone tool and web server for PL-based search
Because user-friendly web servers and stand-alone tools are useful for biologists, we construct the web server of the PL-search and its stand-alone tool, which can be accessed at http://bliulab.net/PL-search/. For the web server, three PL databases are provided. Furthermore, parallel speed-up is implemented in the web server and stand-alone tool. The steps for using the web server are shown below.
Step 1. Access the web server at http://bliulab.net/PL-search/server. The interface of PL-search is shown in Figure 5.
Step 2. First, query protein sequences in FASTA format should be written/copied or uploaded into the input box of the server interface. An example can be displayed by clicking the Example button. Second, one of the three search methods can be selected to construct the profile-link for PL-search. Third, the database version should be set. Fourth, the Jscore threshold can be set to filter the search results.
Step 3. Click the Submit button. Search results will be shown on the screen with three-dimensional structure information.
Step 4. The related data can be freely downloaded from http://bliulab.net/PL-search/download/.
Conclusion
In this study, we propose the PL-search method that extracts PL information from search methods to recalculate the similarity scores of sequence pairs and solves the problems associated with protein remote homology detection. Experimental results show that PL-search obviously improves the accuracy of ranking lists, and returns more homologous protein sequences than the corresponding original search method. The strong generality of PL-search is provided by three versions of PL-search methods based on three different search methods: including PSI-BLAST [4], JackHMMER [28] and HHblits [10]. Because PL-search can more accurately measure the similarity between proteins, it is able to improve the performance of these three search methods. Furthermore, PL-search can detect remote homologous proteins when the original search methods fail to detect any homologues.
Because protein remote homology detection is an important task for protein structure and function analysis, it is imperative to develop more accurate computational methods for this task.
A new search method called PL-search is proposed, which constructs more robust PLs by double link strategy and iterative extending strategy, and uses a two-level Jaccard distance to get more accurate similarity scores.
Experimental results on two benchmark datasets show that PL-search based on HHblits, JackHMMER and PSI-BLAST can obviously improve the search performance in terms of ranking quality and the number of detected remote homologues.
Acknowledgements
The authors are very much indebted to the three anonymous reviewers, whose constructive comments are very helpful in strengthening the presentation of this article.
Funding
This work was supported by the National Key R&D Program of China (No. 2018AAA0100100), the National Natural Science Foundation of China (No. 61822306, 61672184 and 61732012, 61861146002), Beijing Natural Science Foundation (No. JQ19019), Fok Ying-Tung Education Foundation for Young Teachers in the Higher Education Institutions of China (161063) and Scientific Research Foundation in Shenzhen (JCYJ20180306172207178).
Xiaopeng Jin is a PhD candidate at the School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen, Guangdong, China. His research areas include bioinformatics and machine learning.
Qing Liao (PhD) is an Associate Professor at the School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen, Guangdong, China. Her research areas include bioinformatics and machine learning.
Bin Liu (PhD) is a Professor at the School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen, China, and School of Computer Science and Technology, Beijing Institute of Technology, Beijing, China. His expertise is in bioinformatics, nature language processing and machine learning.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}