




Abstract
Natural language processing (NLP) is widely applied in biological domains to retrieve information from publications. Systems to address numerous applications exist, such as biomedical named entity recognition (BNER), named entity normalization (NEN) and protein–protein interaction extraction (PPIE). High-quality datasets can assist the development of robust and reliable systems; however, due to the endless applications and evolving techniques, the annotations of benchmark datasets may become outdated and inappropriate. In this study, we first review commonlyused BNER datasets and their potential annotation problems such as inconsistency and low portability. Then, we introduce a revised version of the JNLPBA dataset that solves potential problems in the original and use state-of-the-art named entity recognition systems to evaluate its portability to different kinds of biomedical literature, including protein–protein interaction and biology events. Lastly, we introduce an ensembled biomedical entity dataset (EBED) by extending the revised JNLPBA dataset with PubMed Central full-text paragraphs, figure captions and patent abstracts. This EBED is a multi-task dataset that covers annotations including gene, disease and chemical entities. In total, it contains 85000 entity mentions, 25000 entity mentions with database identifiers and 5000 attribute tags. To demonstrate the usage of the EBED, we review the BNER track from the AI CUP Biomedical Paper Analysis challenge. Availability: The revised JNLPBA dataset is available at https://iasl-btm.iis.sinica.edu.tw/BNER/Content/Re vised_JNLPBA.zip. The EBED dataset is available at https://iasl-btm.iis.sinica.edu.tw/BNER/Content/AICUP _EBED_dataset.rar. Contact: Email: [email protected], Tel. 886-3-4227151 ext. 35203, Fax: 886-3-422-2681 Email: [email protected], Tel. 886-2-2788-3799 ext. 2211, Fax: 886-2-2782-4814 Supplementary information: Supplementary data are available at Briefings in Bioinformatics online.
1 Introduction
An accelerating growth of scientific literature has been reported for more than 10 years [1, 2]. This rapid accumulation of scientific publications has made it difficult for biologists to remain abreast of cutting-edge research. Natural language processing (NLP) is a literature mining technique that is crucial for assisting in biological information retrieval [3]. NLP-based methods serve as important bridges between computers and human languages. Different NLP systems are designed to target applications such as named entity recognition (NER), named entity normalization (NEN) [4], relation extraction (RE) [5] and question answering (QA) [6].
To promote the establishment of reliable systems, many task-specific datasets or corpora have been developed and made publicly available. However, the definitions and annotations of some early datasets have been gradually found to be insufficient and inconsistent; consequently, the applications of these datasets are restricted. Many studies require additional human effort to process original datasets before their systems can utilize the information [7, 8]. For instance, automatically extracting protein–protein interaction (PPI) from text is an important literature mining task [5, 9, 10], but some NLP systems have shown low performance on PPI datasets, like AImed [11] and BioInfer [12]. The major reason for low performance is that their biomedical named entity recognition (BNER) models are usually trained on commonly used BNER datasets such as GENETAG [13] or JNLPBA [17], in which the biomedical named entity definitions are too broad to focus on the real protein entities in relationships.
Although the annotation criteria of biomedical datasets have been improved over time, some problems remain unaddressed. One such problem is whether entity annotations in a dataset are compatible with downstream applications, such as entity linking, RE, information retrieval, QA and knowledge graph generation [14]. Moreover, since annotation requires a lot of human effort and is time-consuming, most datasets are task-specific. This results in a low usage of each dataset and makes challenging the integration of different task-specific systems into a pipeline system. To broaden the usage of a given single dataset, a high-quality multi-task oriented dataset is indispensable.
In this work, we review current BNER datasets, including different semantic types and commonly used BNER systems. Next, we take the JNLPBA dataset as a case study to illustrate the potential problems of early annotations. A revision process is further conducted on the JNLPBA dataset to show the influence of higher annotation consistency on system performance. The portability of the revised JNLPBA dataset is validated simultaneously on several PPI datasets for which the spans of gene mentions are annotated. The demonstration of such downstream potential by the revised JNLPBA dataset supports similar revision of other high-quality BNER datasets in future studies.
Furthermore, we revise and extend the JNLPBA dataset into a new, multi-task oriented dataset called the ensembled biomedical entity dataset (EBED). The NER, NEN and attribute linking (AL) tasks are integrated into this new dataset, as shown in Figure 1; these are regarded as the foundation of RE. Furthermore, the EBED collects additional documents from multiple sources, including full-text paragraphs, figure captions and patent abstracts. The completion of this dataset can serve as a paradigm for elevating the generality of current datasets. To show the usage of the EBED dataset, we introduce the AI CUP Biomedical Paper Analysis (BPA) Competition-BNER Track for computer science and bioinformatics college students, which included a total of 435 participants.
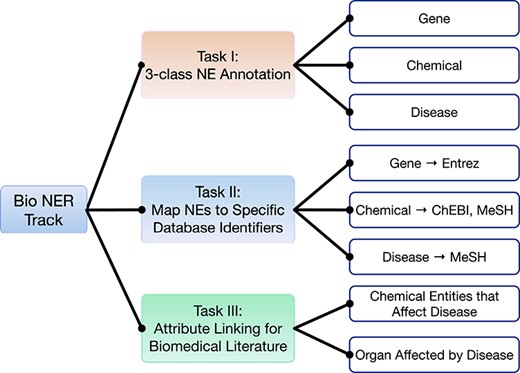
BNER track overview.
2 Overview of biomedical-related named entity datasets
In the biomedical field, the scope of research topics can range from the functional identification of an arbitrary sequence to the conceptual integration of system biology. It is often the case that one biomedical research question spans multiple major domains such as biology, chemistry, psychology and statistics. Between biomedical datasets, semantic types and annotation criteria are usually quite different depending on the target task of each dataset [15].
In general, many named entities appear commonly in biomedical topics; these include gene/protein, disease, variant/mutation, chemical/drug, species, cell/anatomy and clinical information from electronic medical records (EMRs). Many useful tools have been developed based on the fundamental NER datasets, and this diversity of tools can benefit downstream applications. For example, since a gene entity may link to numerous synonyms, sometimes the identified NEs have to be mapped to official databases such as Entrez, Uniprot, MeSH and PubChem in order to construct information retrieval and QA systems like SemBioNLQA [16]. Moreover, the interactions between different entities are also hot downstream topics in the literature. Relationships such as that of glucose and insulin in metabolism or vaccines and influenza in public health can produce hundreds of publications every year. Besides, NER systems such as CTD database, Pubtator Central and miRtarbase are commonly used to assist biocuration.
Therefore, we first introduce fundamental NER datasets including the entities mentioned above. Then, we review datasets for realizing the further applications of NER studies. Table 1 summarizes all the reviewed gold datasets including the annotation scopes and the task applications.
The annotation scope of gold standard datasets
| Dataset | Text genre | Text type | Text size | Entity type | Task type | Reference |
|---|---|---|---|---|---|---|
| IEPA | MEDLINE | Abstract | |$\sim $|300 | Biochemical mentions | NER RE information retrieval (IR) | [22] |
| GENIA | MEDLINE | Abstract | 2000 | 36 selected classes of the GENIA ontology | NER | [17] |
| JNLPBA | MEDLINE | Abstract | 2404 | Protein, DNA, RNA, cell line and cell type | NER | [7] |
| Biocreative I GN task | MEDLINE | Abstract | 16218 | Gene/protein from fly, mouse, and yeast (document-level) | NEN | [23] |
| GENETAG (Biocreative II GM task) | MEDLINE | Sentence | 20000 | Gene/protein | NER | [13] |
| AIMed | MEDLINE | Abstract | 980 | Gene/protein | protein-protein interaction (PPI) | [11] |
| LLL | MEDLINE | Sentence | 167 | Gene/protein in Bacillus subtilis | PPI | [24] |
| HPRD50 | HPRD | Abstract | 50 | Gene/protein | PPI | [25] |
| Bioinfer | PubMed | Sentence | 1100 | Gene/protein and RNA | PPI | [12] |
| Corbett’s | PubMed | Abstract | 500 | Chemical | NER | [26] |
| SCAI | MEDLINE | Abstract | 100 | Chemical | NER | [27] |
| Biocreative II GN task | PubMed MEDLINE | Abstract | 543 | Gene/protein | NEN | [28] |
| OSIRIS | PubMed | Abstract | 105 | Gene/protein and variation | NEN | [29] |
| Arizona Disease | PubMed | Abstract | 793 | Disease | NER | [30] |
| IBD corpus | VA Health Care System | EMR | 316 | Eight IBD associated mentions (document-level) | document classification information extraction (IE) | [31] |
| BioCreative II.5 Interactor Normalization task | PMC | Full-text | 595 | Gene/protein (document-level) | NEN to Uniprot IDs | [32] |
| LINNAEUS | PMC | Full-text | 100 | Species | NER | [33] |
| SNPCorpus | MEDLINE | Abstract | 296 | protein sequence mutations nucleotide sequence mutations | NER NEN | [34] |
| BioCreative III GN task | PMC | Full-text | 1309 | Gene/protein (document-level) | NEN | [35] |
| CellFinder | PMC | Full-text | 10 | Anatomy, cell component, cell line, cell type, gene/protein and species | NER | [36] |
| AnEM | PubMed PMC | Abstract Full-text | 500 | Ten anatomical mentions and pathological formation mention | NER | [37] |
| CRAFT | PMC | Full-text | 97 | Nine biomedical ontologies and terminologies | NER NEN IE | [38] |
| EU-ADR | PubMed | Abstract | 300 | Gene/protein, variation, disease and drug | NER RE | [39] |
| Drug-DDI (DDIExtraction 2013) | MEDLINE DrugBank | Abstract | 1025 | Four pharmacological mentions | NER drug-drug interaction | [40] |
| Species-800 (S800) | MEDLINE | Abstract | 800 | Species | NER | [41] |
| IGN | PubMed MEDLINE | Abstract Full-text | 627 | Gene/protein | NEN | [8] |
| NCBI Disease | PubMed | Abstract | 793 | Disease | NER | [42] |
| BioCreative IV GO task | FlyBase MaizeGDB RatGenome Database TAIR WormBase | Full-text | 200 | GO terms (document level) | GO curation IR | [43] |
| CHEMDNER (Biocreative IV) | PubMed | Abstract | 10000 | Chemical | document classification NER | [44] |
| 2014 i2b2/UT Health NLP-ST | Partners Healthcare | EMR | 1304 | Diagnosis information of CAD (document-level) | de-identification document classification | [45] |
| Cancer Genetics (BioNLP-ST 2013 CG task) | PubMed | Abstract | 600 | 17 cancer-related mentions | event extraction NER | [46] |
| Pathway Curation (BioNLP-ST 2013 PC task) | PubMed | Abstract | 525 | Gene/protein, chemical, complex, and cellular component | event extraction NER | [46] |
| CDR (Biocreative V CDR task) | PubMed | Abstract | 1500 | Chemical, disease | NER chemical-disease relation | [47] |
| Biocreative V.5 GPRO | Patent | Abstract | 30000 | Eight gene related GPRO mentions | NER | [48] |
| Cho’s | PubMed | Abstract | 208 | Plant mentions | NER NEN | [49] |
| CER | Hospitals Specialty clinics | EMR | 5160 | 11 clinical mentions | NER RE | [50] |
| MedMention | PubMed | Abstract | 4392 | 18 ontologies in UMLS | NER NEN IR | [51] |
| Dataset | Text genre | Text type | Text size | Entity type | Task type | Reference |
|---|---|---|---|---|---|---|
| IEPA | MEDLINE | Abstract | |$\sim $|300 | Biochemical mentions | NER RE information retrieval (IR) | [22] |
| GENIA | MEDLINE | Abstract | 2000 | 36 selected classes of the GENIA ontology | NER | [17] |
| JNLPBA | MEDLINE | Abstract | 2404 | Protein, DNA, RNA, cell line and cell type | NER | [7] |
| Biocreative I GN task | MEDLINE | Abstract | 16218 | Gene/protein from fly, mouse, and yeast (document-level) | NEN | [23] |
| GENETAG (Biocreative II GM task) | MEDLINE | Sentence | 20000 | Gene/protein | NER | [13] |
| AIMed | MEDLINE | Abstract | 980 | Gene/protein | protein-protein interaction (PPI) | [11] |
| LLL | MEDLINE | Sentence | 167 | Gene/protein in Bacillus subtilis | PPI | [24] |
| HPRD50 | HPRD | Abstract | 50 | Gene/protein | PPI | [25] |
| Bioinfer | PubMed | Sentence | 1100 | Gene/protein and RNA | PPI | [12] |
| Corbett’s | PubMed | Abstract | 500 | Chemical | NER | [26] |
| SCAI | MEDLINE | Abstract | 100 | Chemical | NER | [27] |
| Biocreative II GN task | PubMed MEDLINE | Abstract | 543 | Gene/protein | NEN | [28] |
| OSIRIS | PubMed | Abstract | 105 | Gene/protein and variation | NEN | [29] |
| Arizona Disease | PubMed | Abstract | 793 | Disease | NER | [30] |
| IBD corpus | VA Health Care System | EMR | 316 | Eight IBD associated mentions (document-level) | document classification information extraction (IE) | [31] |
| BioCreative II.5 Interactor Normalization task | PMC | Full-text | 595 | Gene/protein (document-level) | NEN to Uniprot IDs | [32] |
| LINNAEUS | PMC | Full-text | 100 | Species | NER | [33] |
| SNPCorpus | MEDLINE | Abstract | 296 | protein sequence mutations nucleotide sequence mutations | NER NEN | [34] |
| BioCreative III GN task | PMC | Full-text | 1309 | Gene/protein (document-level) | NEN | [35] |
| CellFinder | PMC | Full-text | 10 | Anatomy, cell component, cell line, cell type, gene/protein and species | NER | [36] |
| AnEM | PubMed PMC | Abstract Full-text | 500 | Ten anatomical mentions and pathological formation mention | NER | [37] |
| CRAFT | PMC | Full-text | 97 | Nine biomedical ontologies and terminologies | NER NEN IE | [38] |
| EU-ADR | PubMed | Abstract | 300 | Gene/protein, variation, disease and drug | NER RE | [39] |
| Drug-DDI (DDIExtraction 2013) | MEDLINE DrugBank | Abstract | 1025 | Four pharmacological mentions | NER drug-drug interaction | [40] |
| Species-800 (S800) | MEDLINE | Abstract | 800 | Species | NER | [41] |
| IGN | PubMed MEDLINE | Abstract Full-text | 627 | Gene/protein | NEN | [8] |
| NCBI Disease | PubMed | Abstract | 793 | Disease | NER | [42] |
| BioCreative IV GO task | FlyBase MaizeGDB RatGenome Database TAIR WormBase | Full-text | 200 | GO terms (document level) | GO curation IR | [43] |
| CHEMDNER (Biocreative IV) | PubMed | Abstract | 10000 | Chemical | document classification NER | [44] |
| 2014 i2b2/UT Health NLP-ST | Partners Healthcare | EMR | 1304 | Diagnosis information of CAD (document-level) | de-identification document classification | [45] |
| Cancer Genetics (BioNLP-ST 2013 CG task) | PubMed | Abstract | 600 | 17 cancer-related mentions | event extraction NER | [46] |
| Pathway Curation (BioNLP-ST 2013 PC task) | PubMed | Abstract | 525 | Gene/protein, chemical, complex, and cellular component | event extraction NER | [46] |
| CDR (Biocreative V CDR task) | PubMed | Abstract | 1500 | Chemical, disease | NER chemical-disease relation | [47] |
| Biocreative V.5 GPRO | Patent | Abstract | 30000 | Eight gene related GPRO mentions | NER | [48] |
| Cho’s | PubMed | Abstract | 208 | Plant mentions | NER NEN | [49] |
| CER | Hospitals Specialty clinics | EMR | 5160 | 11 clinical mentions | NER RE | [50] |
| MedMention | PubMed | Abstract | 4392 | 18 ontologies in UMLS | NER NEN IR | [51] |
The annotation scope of gold standard datasets
| Dataset | Text genre | Text type | Text size | Entity type | Task type | Reference |
|---|---|---|---|---|---|---|
| IEPA | MEDLINE | Abstract | |$\sim $|300 | Biochemical mentions | NER RE information retrieval (IR) | [22] |
| GENIA | MEDLINE | Abstract | 2000 | 36 selected classes of the GENIA ontology | NER | [17] |
| JNLPBA | MEDLINE | Abstract | 2404 | Protein, DNA, RNA, cell line and cell type | NER | [7] |
| Biocreative I GN task | MEDLINE | Abstract | 16218 | Gene/protein from fly, mouse, and yeast (document-level) | NEN | [23] |
| GENETAG (Biocreative II GM task) | MEDLINE | Sentence | 20000 | Gene/protein | NER | [13] |
| AIMed | MEDLINE | Abstract | 980 | Gene/protein | protein-protein interaction (PPI) | [11] |
| LLL | MEDLINE | Sentence | 167 | Gene/protein in Bacillus subtilis | PPI | [24] |
| HPRD50 | HPRD | Abstract | 50 | Gene/protein | PPI | [25] |
| Bioinfer | PubMed | Sentence | 1100 | Gene/protein and RNA | PPI | [12] |
| Corbett’s | PubMed | Abstract | 500 | Chemical | NER | [26] |
| SCAI | MEDLINE | Abstract | 100 | Chemical | NER | [27] |
| Biocreative II GN task | PubMed MEDLINE | Abstract | 543 | Gene/protein | NEN | [28] |
| OSIRIS | PubMed | Abstract | 105 | Gene/protein and variation | NEN | [29] |
| Arizona Disease | PubMed | Abstract | 793 | Disease | NER | [30] |
| IBD corpus | VA Health Care System | EMR | 316 | Eight IBD associated mentions (document-level) | document classification information extraction (IE) | [31] |
| BioCreative II.5 Interactor Normalization task | PMC | Full-text | 595 | Gene/protein (document-level) | NEN to Uniprot IDs | [32] |
| LINNAEUS | PMC | Full-text | 100 | Species | NER | [33] |
| SNPCorpus | MEDLINE | Abstract | 296 | protein sequence mutations nucleotide sequence mutations | NER NEN | [34] |
| BioCreative III GN task | PMC | Full-text | 1309 | Gene/protein (document-level) | NEN | [35] |
| CellFinder | PMC | Full-text | 10 | Anatomy, cell component, cell line, cell type, gene/protein and species | NER | [36] |
| AnEM | PubMed PMC | Abstract Full-text | 500 | Ten anatomical mentions and pathological formation mention | NER | [37] |
| CRAFT | PMC | Full-text | 97 | Nine biomedical ontologies and terminologies | NER NEN IE | [38] |
| EU-ADR | PubMed | Abstract | 300 | Gene/protein, variation, disease and drug | NER RE | [39] |
| Drug-DDI (DDIExtraction 2013) | MEDLINE DrugBank | Abstract | 1025 | Four pharmacological mentions | NER drug-drug interaction | [40] |
| Species-800 (S800) | MEDLINE | Abstract | 800 | Species | NER | [41] |
| IGN | PubMed MEDLINE | Abstract Full-text | 627 | Gene/protein | NEN | [8] |
| NCBI Disease | PubMed | Abstract | 793 | Disease | NER | [42] |
| BioCreative IV GO task | FlyBase MaizeGDB RatGenome Database TAIR WormBase | Full-text | 200 | GO terms (document level) | GO curation IR | [43] |
| CHEMDNER (Biocreative IV) | PubMed | Abstract | 10000 | Chemical | document classification NER | [44] |
| 2014 i2b2/UT Health NLP-ST | Partners Healthcare | EMR | 1304 | Diagnosis information of CAD (document-level) | de-identification document classification | [45] |
| Cancer Genetics (BioNLP-ST 2013 CG task) | PubMed | Abstract | 600 | 17 cancer-related mentions | event extraction NER | [46] |
| Pathway Curation (BioNLP-ST 2013 PC task) | PubMed | Abstract | 525 | Gene/protein, chemical, complex, and cellular component | event extraction NER | [46] |
| CDR (Biocreative V CDR task) | PubMed | Abstract | 1500 | Chemical, disease | NER chemical-disease relation | [47] |
| Biocreative V.5 GPRO | Patent | Abstract | 30000 | Eight gene related GPRO mentions | NER | [48] |
| Cho’s | PubMed | Abstract | 208 | Plant mentions | NER NEN | [49] |
| CER | Hospitals Specialty clinics | EMR | 5160 | 11 clinical mentions | NER RE | [50] |
| MedMention | PubMed | Abstract | 4392 | 18 ontologies in UMLS | NER NEN IR | [51] |
| Dataset | Text genre | Text type | Text size | Entity type | Task type | Reference |
|---|---|---|---|---|---|---|
| IEPA | MEDLINE | Abstract | |$\sim $|300 | Biochemical mentions | NER RE information retrieval (IR) | [22] |
| GENIA | MEDLINE | Abstract | 2000 | 36 selected classes of the GENIA ontology | NER | [17] |
| JNLPBA | MEDLINE | Abstract | 2404 | Protein, DNA, RNA, cell line and cell type | NER | [7] |
| Biocreative I GN task | MEDLINE | Abstract | 16218 | Gene/protein from fly, mouse, and yeast (document-level) | NEN | [23] |
| GENETAG (Biocreative II GM task) | MEDLINE | Sentence | 20000 | Gene/protein | NER | [13] |
| AIMed | MEDLINE | Abstract | 980 | Gene/protein | protein-protein interaction (PPI) | [11] |
| LLL | MEDLINE | Sentence | 167 | Gene/protein in Bacillus subtilis | PPI | [24] |
| HPRD50 | HPRD | Abstract | 50 | Gene/protein | PPI | [25] |
| Bioinfer | PubMed | Sentence | 1100 | Gene/protein and RNA | PPI | [12] |
| Corbett’s | PubMed | Abstract | 500 | Chemical | NER | [26] |
| SCAI | MEDLINE | Abstract | 100 | Chemical | NER | [27] |
| Biocreative II GN task | PubMed MEDLINE | Abstract | 543 | Gene/protein | NEN | [28] |
| OSIRIS | PubMed | Abstract | 105 | Gene/protein and variation | NEN | [29] |
| Arizona Disease | PubMed | Abstract | 793 | Disease | NER | [30] |
| IBD corpus | VA Health Care System | EMR | 316 | Eight IBD associated mentions (document-level) | document classification information extraction (IE) | [31] |
| BioCreative II.5 Interactor Normalization task | PMC | Full-text | 595 | Gene/protein (document-level) | NEN to Uniprot IDs | [32] |
| LINNAEUS | PMC | Full-text | 100 | Species | NER | [33] |
| SNPCorpus | MEDLINE | Abstract | 296 | protein sequence mutations nucleotide sequence mutations | NER NEN | [34] |
| BioCreative III GN task | PMC | Full-text | 1309 | Gene/protein (document-level) | NEN | [35] |
| CellFinder | PMC | Full-text | 10 | Anatomy, cell component, cell line, cell type, gene/protein and species | NER | [36] |
| AnEM | PubMed PMC | Abstract Full-text | 500 | Ten anatomical mentions and pathological formation mention | NER | [37] |
| CRAFT | PMC | Full-text | 97 | Nine biomedical ontologies and terminologies | NER NEN IE | [38] |
| EU-ADR | PubMed | Abstract | 300 | Gene/protein, variation, disease and drug | NER RE | [39] |
| Drug-DDI (DDIExtraction 2013) | MEDLINE DrugBank | Abstract | 1025 | Four pharmacological mentions | NER drug-drug interaction | [40] |
| Species-800 (S800) | MEDLINE | Abstract | 800 | Species | NER | [41] |
| IGN | PubMed MEDLINE | Abstract Full-text | 627 | Gene/protein | NEN | [8] |
| NCBI Disease | PubMed | Abstract | 793 | Disease | NER | [42] |
| BioCreative IV GO task | FlyBase MaizeGDB RatGenome Database TAIR WormBase | Full-text | 200 | GO terms (document level) | GO curation IR | [43] |
| CHEMDNER (Biocreative IV) | PubMed | Abstract | 10000 | Chemical | document classification NER | [44] |
| 2014 i2b2/UT Health NLP-ST | Partners Healthcare | EMR | 1304 | Diagnosis information of CAD (document-level) | de-identification document classification | [45] |
| Cancer Genetics (BioNLP-ST 2013 CG task) | PubMed | Abstract | 600 | 17 cancer-related mentions | event extraction NER | [46] |
| Pathway Curation (BioNLP-ST 2013 PC task) | PubMed | Abstract | 525 | Gene/protein, chemical, complex, and cellular component | event extraction NER | [46] |
| CDR (Biocreative V CDR task) | PubMed | Abstract | 1500 | Chemical, disease | NER chemical-disease relation | [47] |
| Biocreative V.5 GPRO | Patent | Abstract | 30000 | Eight gene related GPRO mentions | NER | [48] |
| Cho’s | PubMed | Abstract | 208 | Plant mentions | NER NEN | [49] |
| CER | Hospitals Specialty clinics | EMR | 5160 | 11 clinical mentions | NER RE | [50] |
| MedMention | PubMed | Abstract | 4392 | 18 ontologies in UMLS | NER NEN IR | [51] |
2.1 General NER datasets
The GENIA corpus [17] is an earlier BNER dataset that has affected many later BNER datasets and applications. It consists of 2000 abstracts retrieved from MEDLINE with specific query terms such as ‘human’, ‘blood cells’ and ‘transcription factors’ and was annotated according to the GENIA ontology [18], which defined a fine-grained tree for biological entities. The GENIA corpus contains 47 biomedical classes and subclasses, such as ‘DNA’, ‘cell line’, ‘lipid’ and ‘organic compound’; all of these have a common root ‘Entity’.
Since the scale of the GENIA corpus is suitable for the construction of machine learning (ML) models, it has been used in several shared tasks [7, 9, 10] to establish training and test sets. However, not all classes are equally important in the biomedical domain, and some are more interesting for domain experts. Therefore, the later BioNLP/JNLPBA shared task, which extended the GENIA dataset by adding 400 new annotated abstracts, only uses five super-classes: ‘DNA’, ‘RNA’, ‘protein’, ‘cell line’ and ‘cell type’. We refer to this as the JNLPBA [7] dataset. As its top performance, the BioNLP/JNLPBA shared task achieved an |$F_1$|-measure of 72.6% [19]. Combining fine-grained classes allowed the simplification of the task and reduced potential annotation inconsistency. However, there is concern that low annotation consistency in JNLPBA makes it difficult to improve performance [20]. Even recent deep learning (DL) approaches, like GRAM-CNN, have only achieved an |$F_1$|-measure of 72.57% [21].
Due to the coherent and tight relationships among DNA, RNA and proteins [52, 53], sometimes it is only necessary to be concerned with the higher gene level. Therefore, the BioCreative II gene mention recognition (GMR) [13] task built the GENETAG dataset, which excludes general sequence mentions from annotations and treats protein, DNA and RNA as belonging to the same entity type in order to reduce the complexity of GMR. Similar to the JNLPBA and GENIA datasets, the GENETAG dataset also faces problems with inconsistency. However, by allowing participants’ predictions to match alternative gold NE boundaries, its top performance achieved an |$F_1$|-measure of 87.21% [54].
To capture the difference between specific and general mentions, BioCreative V.5 organized the Gene and Protein Related Object (GPRO) task [55]. This task compiled a dataset with two entity types, GPRO Type 1 and Type 2. Entities belonging to Type 1 can be normalized, while those in Type 2 cannot. In other words, a GPRO Type 2 entity can represent a gene family term or multiple genes rather than just a single name. At its best, the GPRO task achieved a 79.19% |$F_1$|-measure on GPRO type 1; its performance dropped slightly to 78.66% when given the combination of GPRO type 1 and type 2 [48].
Other gene-related NER datasets, like SNPCorpus [34], serve as a bridge between gene and variation entities. SNPCorpus gathers about 300 abstracts involving protein and nucleotide sequence statements to discriminate distinct gene status, such as variants and mutations. It classifies SNP mentions into protein sequence mutations and nucleotide sequence mutations. The associations between these variations and genes are highly challenging, and even biologists must take time to link them correctly.
In addition to the above-mentioned entities, variation in the identification of disease is too important to be ignored. An earlier disease mention recognition dataset, the Arizona Disease Corpus (AZDC) [30], annotated the disease mentions of 793 PubMed abstracts. The semantic annotations of AZDC can be linked to the unique concepts of the Unified Medical Language System (UMLS), which integrates key terminology of biomedical domains such as NCBI taxonomy, Gene Ontology, MeSH and OMIM. The AZDC only contains disease identifiers from a subset of MeSH and is not sufficient for disease researchers. Therefore, [42] refined the AZDC dataset by generating specific identifiers for disease entities from the MeSH and OMIM databases. This derived dataset is named the NCBI disease corpus [42] and is separated into training, development and test sets for broader applicability.
The recognition of chemical and extended drug entities is also a complicated endeavor since varied chemical mentions appear in all corners of texts. There are many earlier datasets that can be used to access the chemical NER. For instance, International Union of Pure and Applied Chemistry (IUPAC) training/test datasets provide the chemical annotations of IUPAC entities [56]. The DrugDDI dataset annotates drug compounds with drug–drug interactions (DDIs) and is also used in part of the DDIExtraction 2013 dataset [57]. Corbett’s and SCAI datasets annotate general chemicals [26, 27]; however, Corbett’s dataset is not publicly available. The SCAI dataset annotates 100 MEDLINE abstracts and categorizes chemical entities into six classes: ‘IUPAC’, ‘PART’, ‘ABB’ (abbreviations), ‘TRIVIAL’ (trivial names), ‘SUM’ (sum formula) and ‘FAMILY’. On this dataset, the hybrid conditional random fields (CRF)-dictionary system ChemSpot [58] achieved an |$F_1$|-measure of 68.1%. In the later BioCreative IV challenge, the CHEMDNER task was raised to identify chemical compounds and drugs [59]; it defined eight chemical types: ‘abbreviation’, ‘identifier’, ‘family’, ‘trivial’, ‘formula’, ‘systematic’, ‘multiple’ and ‘no class’ [44]. The construction of the CHEMDNER dataset (BC4CHEMD) depended on this classification; it contains 85 000 chemical mentions from 10 000 PubMed abstracts that were split into three sections for the CHEMDNER task. At its best performance, BC4CHEMD obtained an |$F_1$|-measure of 87.39%. In the CHEMDNER-patent task of BioCreative V, a CHEMDNER-patent dataset was newly annotated to support the text mining of patent abstracts [60]. It contains 21 000 annotated abstracts and 99 634 chemical mentions, making it significantly larger than the CHEMDNER dataset.
Another concern in text mining is taxonomic entity recognition, driven by the diverse species mentions in biomedical literature. LINNAEUS is an open-source species NER system [33] whose development is supported by the full text of 100 PubMed Central (PMC) articles with species annotations. LINNAEUS obtained a recall of 94% and a precision of 97% at the instancelevel and a recall of 98% and a precision of 90% at the document level. Meanwhile, the Species-800 (S800) taxonomy dataset contains 800 abstracts rather than full-text documents [41]. To expand the diversity of included species names, the S800 dataset covers articles from eight different categories: protistology, entomology, virology, bacteriology, zoology, mycology, botany and medicine.
Being the main environments of many biological events, cell/anatomy mentions usually co-occur with other common entities such as genes, drugs and diseases. CellFinder is a stem cell domain dataset that consists of 10 topic-related full-text documents. The dataset aims to fetch information for six entity types: ‘anatomical part’, ‘cell component’, ‘cell line’, ‘cell type’, ‘gene/protein’ and ‘species’ [36]. For more general study, AnEM is a domain-independent dataset that collects 500 documents from PubMed abstracts and the subsections of PMC publications [37] and whose annotation scope covers 11 cell/anatomy mention types. The size of the AnEM dataset and its annotation scope probably make it a considerable resource in related research.
Last but far from least, the clinical data in EMRs are another obstacle that in recent years has become urgent to conquer. An ideal medical NER system for EMRs would be able to retrieve key information to support the decision-making of doctors. Considering the potential risk of privacy leakage, EMR datasets are hard to construct and less commonly released. The CER dataset contains 5160 clinical records from 40 different clinical domains [50]; 11 clinical entity mentions are selected and annotated in this dataset. The quality of CER was evaluated with a CRF-based model, which achieved an |$F_1$|-measure of 91.58%.
2.2 Coherent datasets for NER downstream applications
Unlike the above-mentioned datasets, which only contain NE annotations, some datasets have been further developed to train and evaluate NEN methods. Through establishing correct linkages between the entity mentions and identifiers in a database, NEN systems provide valuable information. Unfortunately, most normalization datasets provide document-level rather than instance-level annotations. For example, the BioCreative II gene normalization (GN) task [28] provides 543 MEDLINE abstracts with 1157 unique human Entrez gene IDs, but the exact boundaries of each gene are not given in the corresponding abstracts. In contrast, the BioCreative II.5 interactor protein and GN tasks provide not only cross-species protein/gene IDs but also document-level gene IDs from the collected PMC full-texts [32]. However, without instance-level annotations, it is difficult to use these to train an ML model. Hence, most of these systems achieve low performances.
Annotating IDs at the instance level is time-consuming, and thus not all annotators of datasets are willing to do it. Nevertheless, instance-level IDs are more suitable for ML approaches and the finding of optimization solutions. For example, [8] manually revise the BioCreative II GN dataset into instance-level annotations, termed the instance-level gene normalization (IGN) corpus. Their Markov logic networks-based approach is then trained on the IGN corpus and receives an improvement of 15% |$F_1$|-measure over the previous system that was only implemented on document-level annotations. In addition to gene-only datasets, the OSIRIS dataset [29] curates genetic variation and genes with the corresponding dbSNP and EntrezGene identifiers [61, 62]. The associations of potential variants and their associated genes can be clearly captured during normalization.
The NCBI disease dataset is well known for correlated studies involving both disease named entity recognition (DNER) and normalization tasks. In this NCBI, labeled concepts are assigned to the MeSH or OMIM databases [63, 64]. Many disease normalization tools have been developed on this dataset, such as the DNorm system [65], TaggerOne [66] and jointRN [67]. Chao et al. 2017 [49] also proposes a NEN method for the NCBI disease dataset. Moreover, they manually construct a plant dataset containing 208 abstracts and 3985 mentions to evaluate the ability of their model to map concepts in the NCBI taxonomy database. Some datasets additionally present more than one normalization category. Among the benchmark datasets related to normalization, the Colorado Richly Annotated Full-Text (CRAFT) corpus is a comprehensive dataset that collected 97 full-text documents annotated with mentions of nearly all concepts from nine ontologies and terminologies including gene/protein, cell attribute, chemical, species, sequence mention and the three gene ontology sub-classes [38]. Meanwhile, MedMentions [51] is a recently published biomedical corpus that incorporates over 4000 abstracts and over 350 000 linked mentions. This dataset is designed for applications including BNER and linking researches. The considerable size and broad scope of MedMention make it a beneficial resource for NER and NEN research.
For more advanced purposes, using a group of datasets provides the annotations for biological interactions between various entities, allowing NER systems to recognize the potential relationships connecting the entities. Depending on the entity types involved, numerous relationships can be incorporated such as PPI, chemical-disease relation (CDR), DDI and miRNA–target gene interaction. To the best of our knowledge, five conventional PPI datasets are available for the development of information extraction methods: AIMed [11], Bioinfer [12], IEPA [22], HPRD50 [25] and LLL [24]. A comparative study [68] was conducted to evaluate the characteristics of these five datasets. In general, AImed and Bioinfer are larger, containing over 1000 sentences. Moreover, both AImed and Bioinfer include all occurring entities, while the other datasets have restricted entity scopes in particular lists. A pipeline system using the other three datasets may demonstrate lower performance, as limited entity scope contributes to false-positive predictions.
Beyond the relationships among proteins/genes, other biological interactions are also important to investigate, such as signaling transduction and gene regulation pathways. For instance, the Cancer Genetics (CG) and Pathway Curation (PC) tasks, which are part of BioNLP Shared Task 2013 [5], concentrate on relations other than PPI. The CG dataset concerns 18 cancer-related entity types and the 40 kinds of corresponding events that occur in 600 PubMed abstracts, while the PC dataset contains 525 documents and focuses on the relations/reactions among ‘chemical’, ‘gene’, ‘complex’ and ‘cellular component’ entities [46].
Understanding the effects of chemicals/drugs on a target disease is regarded as another critical obstacle in biomedical domains. The datasets derived for this purpose include DDI [40], CDR [47] and EU-ADR [39]. The DDI dataset, comprising more than 700 documents, mainly attends to drug entities and binary relationships between them [40]. The documents are gathered from Drugbank and Medline, and the entity scope includes ‘drug’, ‘brand’, ‘group’ and ‘drug_n’. In terms of overall inter-annotator agreement (IAA), the dataset presents very high agreement in the DDI-Drugbank section (91.04%) while the DDI-Medline section obtains moderate agreement (79.62%). Meanwhile, the CDR dataset (BC5CDR) [47] is built for the challenge of DNER and the chemical-induced disease task in BioCreative V. BC5CDR consists of 1500 PubMed abstracts, and the entity annotation covers both text mentions and normalized identifiers. For disease and chemical entities, it achieves average IAA results of 87.49% and 96.05%, respectively. Similar to BC5CDR, the EU-ADR dataset aims to assist systems in retrieving drug–disorder, drug–target and target–disorder relationships [39]. The target entity is represented as a collection of gene, protein, RNA and associated variants. IAA measurement is conducted across all 300 PubMed abstracts, and the overall agreement is 75.3%.
2.3 Document-level annotation for NER
NER is a crucial component of an NLP application. However, when it comes to developing a new application, it is commonly found that there is a lack of a high-quality dataset that can be used to build NER components even though NLP has been promoted for decades in the biomedical domains. Fortunately, there is a fine-grained biomedical taxonomy mechanism that provides the official index for different kinds of biomedical concepts. For example, the Human Phenotype Ontology provides the index for human disease symptoms [69]. Furthermore, these databases usually supplement the index of each record with supporting evidence. For instance, in the Entrez dataset, we can find the gene together with its GO Terms and the evidence of PMIDs for the GO Terms [43]. The document-level datasets are summarized in Table 1, and some of them are used in NLP challenges [23, 28, 32, 35].
The document-level annotations are commonly used in clinical records to identify and retrieve valuable indications of the studied disease. For example, a clinical dataset is developed by the US Veterans Administration Health Care System to develop information extraction systems [31]. There are 316 clinical records in the dataset, and physicians worked as annotators and defined eight attributes for the phenotypic information of inflammatory bowel disease (IBD). Additionally, 2014 i2b2/UT Health NLP-ST proposed a longitudinal clinical dataset to investigate risk factors of diabetic patients developing coronary artery disease (CAD) [45]. There are a total of 1304 medical records from 296 patients in the dataset, with document-level labels specifying the diagnosis of CAD for each case. These clinical resources contribute to promote the developments of both NLP and the medical research communities.
3 Overview of NER systems
For different biomedical research problems, different biomedical entity types (e.g. gene, variation, chemical, disease, species) need to be identified. Through automatically highlighting target entities, biomedical researchers can efficiently obtain interesting information from the biomedical literature. However, complicated nomenclatures [70–72] cause greater challenges for entity recognition. Many strategies have been developed to overcome this issue; briefly, these can be classified into five categories: dictionary-based, rule-based, traditional ML-based, DL-based and hybrid approaches. Dictionary-based methods are characterized by intrinsic higher precision but a weakness of lower recall rate due to the potential of new bioentities. To improve on this defect, [73] proposes a dictionary-based system that contains three modules: construction and expansion of the dictionary, approximate string matching and post-processing. The system performance is validated via the JNLPBA dataset. With the relatively flexible processing step, the recall rate improves remarkably, achieving a |$F_1$|-score of 68.80%. As a well-known dictionary-based system proposed by the National Library of Medicine (NLM), MetaMap recognizes the biomedical candidates and normalizes them to the concepts in the UMLS [74, 75]. Several studies have compared their performances with MetaMap or implemented MetaMap into their system architectures [76, 77]. In the recognition of disease concepts, MetaMap obtained an |$F_1$|-score of 60.9% on the AZDC test set [78].
Rule-based methods identify potential entities through constructed rule patterns, of which the context around the entity can become a part. For instance, the study of [79] proposed a rule-based system called PROPER. They observed that protein names mainly consisting of core terms, like ‘p53’, and concatenated terms, like ‘receptor’. Therefore, their protein name patterns used entity features such as protein name nomenclature, variation in entity expression styles and distinct prefixes/suffixes. The target entities are extracted with precision and recall values both greater than 90%. Although PROPER is only verified in two small datasets of 30 and 50 abstracts, respectively, it still reveals the merits of rule-based models. Text Detective [80], another rule-based system, participated in the BioCreAtIvE challenge [81]. Since it widely tags the compositions of biological entities as different categories, it is possible to annotate potential new terms with combinations of categories. It achieved final values of 84% precision and 71% recall for the Gene Mention (GM) task [82].
In ML-based NER systems, NER is formulated as either a word classification problem or a sequence labeling problem. In both cases, the labels are a set of tags [83], each consisting of a NE type and a prefix that indicates the boundary of the NE. For example, the tags ‘B-Gene’ and ‘I-Gene’ respectively denote words that are beginning and inner gene mentions. The major factors influencing performance are the ML models and features. ML-based NER approaches perform well on task-specific datasets. In BNER, several ML models are regularly adopted, such as support vector machines (SVMs), hidden Markov models (HMMs) and CRFs. For instance, [84] established an SVM model along with a number of designed features (i.e. ‘word feature’, ‘part-of-speech’, ‘prefix’, ‘suffix’, ‘substring’ and ‘preceding class’). Using the GENIA corpus, their system achieved |$F_1$|-measures of 56.5% and 51.5% for protein mention recognition and all type mention recognition. Later, [85] built an HMM-based bio-entity recognizer that achieved |$F_1$|-measures of 75.8% and 66.6% in the protein type and all type. Ryan et al. proposed a CRF-based model to identify gene and protein mentions in texts [86] using a feature induction system to determine the most helpful feature candidates. After training on 7500 MEDLINE sentences with a development set of 2500 sentences, their system achieved an |$F_1$|-measure of 82.4% in the BioCreative I Gene Mention Identification task. CRF uses the Viterbi algorithm to find the optimal NER solution of a whole sentence, and it has been found to be useful in many NER tasks [87]. Therefore, this approach is commonly employed, and even recent recurrent neural networks also incorporate CRF to find an optimal sequence. Moreover, many architectures use hybrid approaches that concatenate CRF-based systems with other models. For example, the interpretable ML method named SPBA and used in the GPRO task of BioCreatvie V.5 generates predictions as the features supplied to a CRF model [88]. The SPBA-CRF system obtained |$F_1$|-measures of 73.73% and 78.66% when evaluating GPRO type 1 and the combination of GPRO types 1 and 2, respectively.
DL-based methods use different neuron network architectures to model classification problems. Outstanding models, such as convolution neural networks (CNNs), recurrent neural networks (RNNs) and long short-term memory models (LSTMs), have been widely applied in multiple applications, including automatic speech recognition [89], image recognition [90] and NLP [91–93]. DL-based methods formulate NER as a sequence-to-sequence architecture for which the input is the sentence, where the words are presented in embeddings. There are many pre-trained word embeddings available, which can be used to map word into word embeddings such as in [94], BioWordVec [95] and BioBERT [96]. The output is an n |$\times $| m matrix, where n is the length of the sequence and m is the number of NE tags. One end-to-end DL model is GRAM-CNN, developed for biomedical NER tasks [21], which concatenated pre-trained word embeddings, part-of-speech (POS) tags and character embeddings. In GRAM-CNN, three CNN kernels are responsible for extracting context information, and the results are processed by CRF to generate the model output. GRAM-CNN demonstrates competitive performance on all three biomedical NER datasets, including achieving |$F_1$|-scores of 87.26% in the BC2 GM task [54], 87.26% for the NCBI disease dataset, and 72.57% for the JNLPBA dataset. These results demonstrate that the DL approach is a potent means to solve different bioNER problems using a single architecture and without adding additional text pre- and post-processing. Furthermore, the report of BioBERT [96] that is established on the architecture of BERT [97], sparked considerable discussions because of its excellent performance on different topics with only a few task-specific modifications. According to the study, BioBERT achieves an average |$F_1$|-measure of 86.04% across eight BNER corpora: NCBI disease [42], 2010 i2b2/VA [98], BC5CDR [47], BC4CHEMD [55], BC2GM [54], JNLPBA [7], LINNAEUS [33] and Species-800 [41]. Furthermore, BioBERT performs at an average of 81.28% on three relation datasets: GAD [99], EU-ADR [39] and CHEMPROT [100]. In general, BioBERT outperforms most of the previous state-of-the-art models, even though it presents some minor performance issues with some datasets. Furthermore, all of the mentioned models can undoubtedly contribute to promoting the development of bio-literature mining.
To illustrate the progress of NER systems clearly, the publications mentioned above are summarized in Figure 2. Dictionary-based and rule-based approaches are referred to as knowledge-based systems. Traditional ML systems, which are distinguished from DL systems, denote the statistical-based methods including SVM, HMM and CRF. Since the task-dependent applications are quite different, there is no biomedical NER dataset that can serve as the gold standard for system comparison. Despite this, the progress of traditional ML methods and the stability of DL systems are intuitively observed throughout the research developments.
4 Potential shortcomings of JNLPBA
JNLPBA is a commonly-used BNER benchmark dataset; however, it is difficult to use for advancing NER system improvement due to some problems with its annotation. Hence, we revised the annotations of JNLPBA, mainly by addressing the vulnerabilities of JNLPBA and without changing the original semantic annotation types of the dataset.
To conduct the necessary dataset revision, we first summarize the imperfections of the current JNLPBA dataset and raise explanations for why we consider those types of annotations inappropriate. We categorize the problems into five classes: ‘problem of general terms’, ‘redundant preceding’, ‘entity type confusion’, ‘neglected adjacent clues’ and ‘missing annotations’. The overall annotation process is implemented using the web-based annotation tool brat, which is suitable for task-specific configuration [101]. Below, we describe each problem and how we revised it. Table 2 gives descriptive statistics of the JNLPBA and its revised version.
Descriptive statistics of JNLPBA corpora
| Entity type | Training set | Test set | ||
|---|---|---|---|---|
| JNLPBA | Revised JNLPBA | JNLPBA | Revised JNLPBA | |
| cell line | 3830 | 2779 | 500 | 404 |
| cell type | 6718 | 8312 | 1921 | 2070 |
| DNA | 9534 | 6648 | 1056 | 808 |
| protein | 30269 | 25379 | 5067 | 5256 |
| RNA | 951 | 970 | 118 | 161 |
| Entity type | Training set | Test set | ||
|---|---|---|---|---|
| JNLPBA | Revised JNLPBA | JNLPBA | Revised JNLPBA | |
| cell line | 3830 | 2779 | 500 | 404 |
| cell type | 6718 | 8312 | 1921 | 2070 |
| DNA | 9534 | 6648 | 1056 | 808 |
| protein | 30269 | 25379 | 5067 | 5256 |
| RNA | 951 | 970 | 118 | 161 |
Descriptive statistics of JNLPBA corpora
| Entity type | Training set | Test set | ||
|---|---|---|---|---|
| JNLPBA | Revised JNLPBA | JNLPBA | Revised JNLPBA | |
| cell line | 3830 | 2779 | 500 | 404 |
| cell type | 6718 | 8312 | 1921 | 2070 |
| DNA | 9534 | 6648 | 1056 | 808 |
| protein | 30269 | 25379 | 5067 | 5256 |
| RNA | 951 | 970 | 118 | 161 |
| Entity type | Training set | Test set | ||
|---|---|---|---|---|
| JNLPBA | Revised JNLPBA | JNLPBA | Revised JNLPBA | |
| cell line | 3830 | 2779 | 500 | 404 |
| cell type | 6718 | 8312 | 1921 | 2070 |
| DNA | 9534 | 6648 | 1056 | 808 |
| protein | 30269 | 25379 | 5067 | 5256 |
| RNA | 951 | 970 | 118 | 161 |
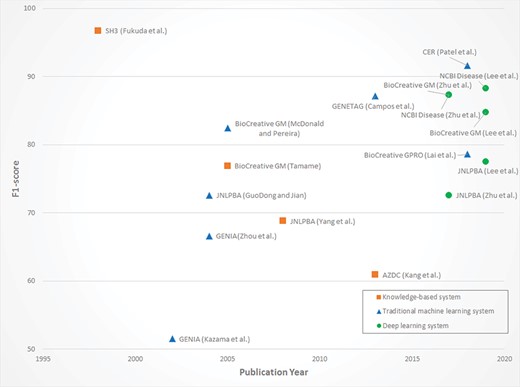
Performance distribution of NER systems.
Problem of general terms
If the word/phrase of an entity contains a unique name, then the entity can be clearly recognized in either the database or a specific family/group. In contrast, if an entity consists of only the words of general properties, it is not appropriate to assign the same label for the general-only entity as for the entity with a unique name. In such a situation, it is better to remove the so-called general terms or assign other tags to them. The following examples in the JNLPBA illustrate the differences between specific and general entities:
‘Treatment of SKW 6.4 cells with IL 6 induced a transient and early stimulation of c-fos sense mRNA expression.’
PMID: 1537389
‘Substitution mutations in this consensus sequence eliminate binding of the inducible factor.’
PMID: 8985415
In the first sentence, the bold entities comprise specific names, such as ‘SKW 6.4,’ ‘IL 6,’ and ‘c-fos’, which can respectively be found in the American Type Culture Collection, UniProt and Entrez databases. It is appropriate to classify all of these into cell line, protein and RNA types. However, in the second sentence, the bold terms are respectively labeled as DNA and protein in the JNLPBA dataset, but lack the major features to become specific entities.
Even though these general terms should not limit BNER performance, their presence still causes obstacles because of inconsistent annotations in the general terms. To solve this problem, we removed general terms, thereby improving consistency; the remained entities were also more meaningful for biologists.
Redundant preceding
The words surrounding entities often provide intrinsic properties or external status information to make the entities more intact; such properties are critical in assisting assignment of correct identities and are therefore suitable to be recruited as part of entities. For example, ‘human’ and ‘murine’ can serve as evidence to separate instances of the same entity ‘IL-2’ into different gene IDs. However, extrinsic information can sometimes depict additional properties that are not helpful when distinguishing these entities. The following instance serves to illustrate this scenario:
‘Expression of dominant negative MAPKK-1 prevents NFAT induction.’
PMID: 8670897
‘MAPKK-1’ is the core of the bold entity, while ‘dominant negative’ is regarded as a mutant form of protein. If one intends to determine the real source of ‘MAPKK-1’, the mutation description carries no useful message; in such situations, we remove the preceding words.
Entity type confusion
Some entity types in the JNLPBA share similar features, and this association may sometimes cause misclassification. An example is illustrated by comparison of the following two sentences:
‘Here we report that the type II IL-1R does not mediate gene activation in Jurkat cells.’
PMID: 8387521
‘Functionally, galectin-3 was shown to activate interleukin-2 production in Jurkat T cells.’
PMID: 8623933
In this instance, the two similar bold entities are labeled as cell line and cell type, respectively. However, the core term ‘Jurkat’ is a powerful attribution for annotating both as cell lines. This phenomenon also occurs in gene mentions, and we address the problem depending on the practical text attributes of a given case.
Neglected adjacent clues
In some sentences, gene mention entities are concatenated with strong type keywords, making it easy to clarify the real types of entities. However, several observations indicate that a few keywords are neglected in the JNLPBA, such as in the example below:
‘The 5’ sequences up to nucleotide -120 of the human and murine IL-16 genes share > 84% sequence homology and...’
PMID: 9990060
When not considering proximal keywords such as ‘genes’ and ‘nucleotide’, ‘IL-16’ was wrongly classified into the protein type. In the revision process, these keywords are taken into account so that entity types are classified correctly.
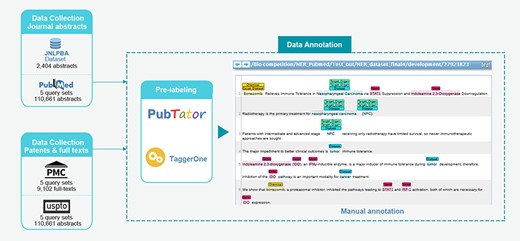
Flowchart describing EBED construction.
Missing annotations
When a dataset is huge, annotations missed during manual curation is an inevitable problem. The JNLPBA dataset also suffered from this problem. The following sentence provides an example missing annotations:
‘Three additional smaller regions show homology to the ELK-1 and SAP-1 genes, a subgroup of the ets gene family...’
PMID: 7909357
According to the GENIA ontology, ‘ELK-1’ should be referred to as a DNA entity, but it is missing from the JNLPBA dataset. To solve the problem of missing annotations, we went through the whole dataset and newly added these entities into the revised JNLPBA.
In summary, the problems of JNLPBA are mainly caused by the forced combination of heterogeneous ontologies. The ambiguity in general entities makes it difficult for other applications to apply our findings in JNLPBA. To overcome this dilemma, several tricks are incorporated in the construction of the EBED dataset. First of all, the entity type ‘Gene’ accommodates the terms of proteins, DNAs and RNAs to reduce the complexity. Second, we take context-dependent features into consideration when determining the entity type in order to resolve some ambiguities. For instance, the token ‘AML’ can be considered as a type of leukemia (disease) or the protein causing AML. The incorporation of context information speeds up the manual curation process. Third, an ambiguous case (case where there are multiple options for its annotation) will be annotated with the domain of higher specificity. For example,the term ‘insulin’, which has the potential of being either a chemical or a gene, is eventually annotated as a gene entity. Finally, hybrid cases that originated from multiple sources are classified into larger domains to ensure the overall coverage. For instance, the protein-chemical complex HAMLET, which is a molecule containing protein and chemical components, is annotated as a chemical entity. Please refer to the Supplementary materials for more details on the annotation guidelines.
5 Compilation of the EBED
In the AI CUP BPA Competition-BNER Track, we design a three-stage task. The first stage requires identifying the target named entities in biomedical literature. Entity normalization is carried out for each entity in the second stage, and AL is the last stage. A dataset construction pipeline that satisfies the task requirements is shown in Figure 3, and the biomedical NER track is defined in detail in section 5.1 Task definition.
5.1 Task definition
The first task is NER of three entity types (gene, disease and chemical).
The second task is entity normalization. Gene entities are required to map to Entrez database IDs, while disease entities must be assigned to MeSH IDs. Lastly, the ChEBI and MeSH databases serve as primary and secondary sources of chemical normalization.
The third task is AL. To build a positive or negative causal connection, a disease identifier is linked to the corresponding chemical entity in its containing sentence with a Cause_Disease tag. The disease entities are also required to connect with affected organ tissues using the Target_Organ label. A list of organ MeSH IDs is provided as the linking source.
Figure 4 illustrates corresponding instances for each task. It is worth noting that participants must identify the potential entity types of abbreviation terms even without the full-name attributes. For example, ‘TETs’ in Figure 4A is denoted as ‘thymic epithelial tumors’, for which mapping the relevant information is provided only in the first sentence of the introduction. In the NEN task, alternative predictions are allowed in certain circumstances. For instance, chemical entities can be normalized to either primary or secondary ChEBI IDs, as shown in Figure 4B. Additional methods of task simplification are presented in section 6.3 Evaluation metric. The last AL task is designed to encourage our participants to establish prior RE systems. In the left of Figure 4C, participants have to create a simple linkage between MCS-18 and atherosclerosis through analyzing a sentence or phrase. To construct connections between disease entities and organ IDs, participants are required to parse the structure of a MeSH tree since indirect relationships are not always expressed in the entities or their surrounding context.
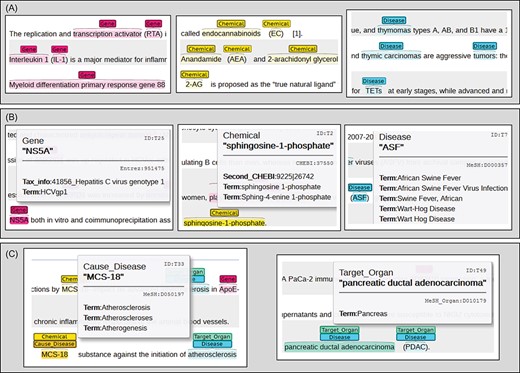
Annotation schematic diagram for defined tasks.
5.2 Data collection
Data collection for EBED recruited four article types: abstracts, paragraphs in full-text, figure legends and patent texts. The abstracts are extracted from PubMed (https://www.ncbi.nlm.nih.gov/pubmed), while the associated full-text article is sourced from PMC [102] (https://www.ncbi.nlm.nih.gov/pmc/). Publications are independently retrieved by using the following five query sets: ‘cancer’, ‘virus’, ‘immune’, ‘metabolism’, ‘microbiology’ and concatenated with their corresponding synonyms by ‘OR’. We exclude review-type articles from the search results and only consider candidate texts published between 2016 and 2018. To increase the reliability of the retrieved data, at this stage we only preserve results with an impact factor greater than three. Additionally, the JNLPBA dataset is also considered as part of EBED. Since the prospective entity types in the EBED are quite different from the inherent semantic labels of JNLPBA, the inclusion of this dataset reduces the effort needed for our dataset collection. Finally, patent texts are collected from the United States Patent and Trademark Office website (http://patft.uspto.gov/netahtml/PTO/index.html). Because patent texts present more practical applications, other seven keywords ( ‘Keytruda’, ‘PD-1’, ‘immunotherapy’, ‘apoptosis’, ‘FGFR’, ‘CD24’ and ‘CD27’) are incorporated in the patent query. The filtered patents were included as a component of EBED.
5.3 Data annotation
Automatic entity pre-labeling and manual curation are two major stages in preparing the subsequent data annotation. PubTator [103, 104], which is a web-based tool for PubMed literature curation, is utilized to tag the abstracts gathered from PubMed and JNLPBA dataset, and all cell attribute entities are removed from the JNLPBA. Meanwhile, TaggerOne [66] is used for the full-text documents and patent abstracts due to having better tagging efficacy than a self-constructed LSTM-CRF model. After that pre-labeling, the curators comprehensively revise the entity levels of the processed documents to make sure the annotations are in accordance with the demands of the guideline. For normalization, chemical entity identifiers are provided by ChEBI [105] and MeSH [63], while gene and disease entities are mapped to Entrez and MeSH, respectively. Furthermore, chemical and disease entities are objects of the AL subtask, in which curators add the Cause_Disease tag with disease identifier to a chemical compound to encapsulate a connection between entities based on the information in the source sentence. With regard to AL of disease, a MeSH ID list of Target_Organ tags is provided in the Supplementary Information. Organ IDs are assigned to diseases based on the entity classification in the MeSH tree. It is worth mentioning that each entity may link to multiple identifiers at once. Notably, the annotations from identifier normalization and the AL are only applied in the newly collected abstracts as limited resources present difficulties for covering the entire dataset. A profile of EBED annotations is given in Table 3. Pairwise comparisons of annotators are evaluated via IAA analysis as mentioned in section 6.2 to ensure the acceptable agreement of annotations.
Descriptive statistics of EBED annotations
| Annotation Stage | Training | Development | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Gene | Disease | Chemical | Gene | Disease | Chemical | Gene | Disease | Chemical | |
| Entity | 36265 | 3777 | 8876 | 8983 | 4445 | 3832 | 10811 | 4373 | 4007 |
| Normalization | - | - | - | 6519 | 2970 | 2280 | 6044 | 4367 | 2881 |
| Linking | - | - | - | - | 2217 | 225 | - | 2253 | 265 |
| Annotation Stage | Training | Development | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Gene | Disease | Chemical | Gene | Disease | Chemical | Gene | Disease | Chemical | |
| Entity | 36265 | 3777 | 8876 | 8983 | 4445 | 3832 | 10811 | 4373 | 4007 |
| Normalization | - | - | - | 6519 | 2970 | 2280 | 6044 | 4367 | 2881 |
| Linking | - | - | - | - | 2217 | 225 | - | 2253 | 265 |
Descriptive statistics of EBED annotations
| Annotation Stage | Training | Development | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Gene | Disease | Chemical | Gene | Disease | Chemical | Gene | Disease | Chemical | |
| Entity | 36265 | 3777 | 8876 | 8983 | 4445 | 3832 | 10811 | 4373 | 4007 |
| Normalization | - | - | - | 6519 | 2970 | 2280 | 6044 | 4367 | 2881 |
| Linking | - | - | - | - | 2217 | 225 | - | 2253 | 265 |
| Annotation Stage | Training | Development | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Gene | Disease | Chemical | Gene | Disease | Chemical | Gene | Disease | Chemical | |
| Entity | 36265 | 3777 | 8876 | 8983 | 4445 | 3832 | 10811 | 4373 | 4007 |
| Normalization | - | - | - | 6519 | 2970 | 2280 | 6044 | 4367 | 2881 |
| Linking | - | - | - | - | 2217 | 225 | - | 2253 | 265 |
5.4 Dataset statistics
The EBED dataset is divided into three sections: training, development and test sets. Table 4 delineates the statistics of documents in the EBED dataset categorized by their type, which includes four different sources and training/development/test sets. The training set consists of only 2200 abstracts randomly selected from the JNLPBA dataset. Moreover, the document proportions in development and test sets are designed to avoid model defects due to data bias. To prevent the submission of manual annotations, the announced test set is 50-fold larger than the practical one used for scoring.
Summary of document distribution among EBED subsets.
| Abstracts | Paragraphs | Figure legends | Patents | Total | |
|---|---|---|---|---|---|
| Training | 2200 | - | - | - | 2200 |
| Development | 500 | 200 | 150 | 150 | 1000 |
| Test (scoring) | 500 | 200 | 150 | 150 | 1000 |
| Test (announcement) | 25000 | 10000 | 7500 | 7500 | 50000 |
| Abstracts | Paragraphs | Figure legends | Patents | Total | |
|---|---|---|---|---|---|
| Training | 2200 | - | - | - | 2200 |
| Development | 500 | 200 | 150 | 150 | 1000 |
| Test (scoring) | 500 | 200 | 150 | 150 | 1000 |
| Test (announcement) | 25000 | 10000 | 7500 | 7500 | 50000 |
Summary of document distribution among EBED subsets.
| Abstracts | Paragraphs | Figure legends | Patents | Total | |
|---|---|---|---|---|---|
| Training | 2200 | - | - | - | 2200 |
| Development | 500 | 200 | 150 | 150 | 1000 |
| Test (scoring) | 500 | 200 | 150 | 150 | 1000 |
| Test (announcement) | 25000 | 10000 | 7500 | 7500 | 50000 |
| Abstracts | Paragraphs | Figure legends | Patents | Total | |
|---|---|---|---|---|---|
| Training | 2200 | - | - | - | 2200 |
| Development | 500 | 200 | 150 | 150 | 1000 |
| Test (scoring) | 500 | 200 | 150 | 150 | 1000 |
| Test (announcement) | 25000 | 10000 | 7500 | 7500 | 50000 |
6 Evaluation results
6.1 Evaluation setup
The evaluation process is organized into 2-folds. In the first fold, the improvement and portability of the revised JNLPBA are evaluated relative to the original JNLPBA. In the second fold, we illustrate the results obtained by AI CUP participants.
To evaluate the effects of revising the JNLPBA dataset, we conduct two experiments. Five NER systems are included in the evaluation in order to prevent inappropriate judgments due to bias from using a single-model evaluation. In the first experiment, BANNER [106], Gimli [107], NERsuite [108], GRAM-CNN [21] and BioBERT [96] are trained and tested using the same dataset. This procedure is repeated for JNLPBA and revised JNLPBA separately. The second experiment measures the portability of the dataset. In this experiment, NER systems are trained on the two versions of the JNLPBA and then assessed on protein–protein interaction extraction (PPIE) and biomedical event extraction (BEE) corpora. The PPIE datasets include AImed [11], BioInfer [12] and HPRD50 [25], while the BEE datasets consist of BioNLP 2013 ST GE, CG and PC datasets [5]. All non-gene and cell-related entities are excluded from these datasets.
Finally, the AI CUP BPA Competition-BNER Track is conducted to demonstrate the overall performance of participants working with the EBED. In the first NER subtask, 327 teams join the topic and 75 teams submit their final predictions for the test set. The second normalization and third AL subtasks seem more difficult than the NER subtask, so in these issues we only have 82 and 80 teams involved and 8 and 10 with final submissions, respectively. According to the official statistics, the participants generally come from three fields: computer science, biomedical and electrical engineering. We list details for the teams whose models outperform baseline in section 6.6.
6.2 IAA analysis
Two annotators participated in IAA analysis of the JNLPBA dataset revision. We measure the kappa values twice during the revision; the initial value is presented for agreements after reading the annotation guideline. Annotators would discuss the disagreement labeling, generally before the second evaluation. The first and second kappa values are 79.5% and 91.4%, respectively, which suggest the achievement of higher consensus after discussing the disagreement labeling. In the EBED corpus, the data are curated by three annotators following similar pipelines. Since there are multiple tasks in the dataset, the annotations and discussions are iteratively advanced throughout the entire progress. The IAAs are averagely greater than 60% at all levels (Table 5). Furthermore, according to the kappa interpretation of Altman, annotation of the EBED achieves a good agreement result.
IAA scores (%) of the EBED dataset
| Entity level | Normalization level (by document level) | Linking level (by document level) | |
|---|---|---|---|
| Annotator A-B | 95.03 | 70.02 (75.36) | 65.69 (71.32) |
| Annotator B-C | 97.09 | 73.67 (83.02) | 70.08 (78.53) |
| Annotator C-A | 93.78 | 62.18 (69.40) | 58.54 (65.11) |
| Average value | 95.30 | 68.62 (75.93) | 64.77 (71.65) |
| Entity level | Normalization level (by document level) | Linking level (by document level) | |
|---|---|---|---|
| Annotator A-B | 95.03 | 70.02 (75.36) | 65.69 (71.32) |
| Annotator B-C | 97.09 | 73.67 (83.02) | 70.08 (78.53) |
| Annotator C-A | 93.78 | 62.18 (69.40) | 58.54 (65.11) |
| Average value | 95.30 | 68.62 (75.93) | 64.77 (71.65) |
IAA scores (%) of the EBED dataset
| Entity level | Normalization level (by document level) | Linking level (by document level) | |
|---|---|---|---|
| Annotator A-B | 95.03 | 70.02 (75.36) | 65.69 (71.32) |
| Annotator B-C | 97.09 | 73.67 (83.02) | 70.08 (78.53) |
| Annotator C-A | 93.78 | 62.18 (69.40) | 58.54 (65.11) |
| Average value | 95.30 | 68.62 (75.93) | 64.77 (71.65) |
| Entity level | Normalization level (by document level) | Linking level (by document level) | |
|---|---|---|---|
| Annotator A-B | 95.03 | 70.02 (75.36) | 65.69 (71.32) |
| Annotator B-C | 97.09 | 73.67 (83.02) | 70.08 (78.53) |
| Annotator C-A | 93.78 | 62.18 (69.40) | 58.54 (65.11) |
| Average value | 95.30 | 68.62 (75.93) | 64.77 (71.65) |
6.3 Evaluation metric
To evaluate performance on original/revised JNLPBA, we use the evaluation script provided by the BioNLP/JNLPBA 2004 task (http://www.nactem.ac.uk/tsujii/GENIA/ERtask/report.html). In addition, we used three different |$F_1$|-measure metrics to evaluate submissions for AI CUP, as follows:
This metric is the same as the one from the BioNLP/JNLPBA 2004 task. However, we re-implement it in Python to fit our leaderboard.
In the AI CUP NEN task, we also use the |$F_1$|-measure for evaluation. However, we found that it was too challenging for participants to map all NEs into their database identifiers. Therefore, the task is simplified with three strategies, as follows:
Instead of returning the instance-level ID of each NE, participants only have to return document-level IDs. In other words, participants are required to submit the Entrez/MeSH/ChEBI IDs of a given document rather than to provide their offsets in the document.
The Entrez database contains many homologous genes. We employ a homologous dictionary to allow participants’ submitted Entrez IDs to be homologs of the gold IDs.
Even for our curators, it is sometimes hard to determine the specific ChEBI layer ID of a chemical. Therefore, we allow a submitted ChEBI ID to be a parental or child ID of the corresponding gold ChEBI ID.
For the AI CUP AL task, the evaluation is derived from that of the NEN task by adding attribute IDs. However, two special situations may occur:
One disease entity can have more than one target organs assigned. In our evaluation, we consider these as multiple diseases, each linking to a distinct target organ ID.
Similarly, the same disease/chemical entity may in different sentences refer to different Target_Organ/Cause_Disease relationships. We again treat them as different disease/chemical entities.
6.4 Intrinsic comparison of original/revised JNLPBA datasets
The inconsistencies in the JNLPBA, which are likely due to annotators having different annotation criteria, create a bottleneck for BNER performance. To alleviate any negative effects of this problem, we revised the dataset based on the annotation guideline. The efficacy of this revision is assessed by five methods: BANNER, Gimli, NERsuite, GRAM-CNN and BioBERT. The first three of these methods are derived from traditional CRF models, while the last two are newly published language models that achieve excellent performance in numerous NLP tasks. All five systems are firstly trained on the original/revised JNLPBA training set, and then evaluated on the corresponding test set; Table 6 gives the performances from these evaluations. All systems demonstrate overall higher performance (at least 12% increase in |$F_1$|-measure) with the revised JNLPBA test set than with the original JNLPBA. On the original JNLPBA, GRAM-CNN achieves the best performance, with an |$F_1$|-measure of 72.57%. With the revised JNLPBA, BioBERT is the most robust system, improving by 15.64% to achieve an |$F_1$|-measure of 88.18%.
Performance of tested systems on JNLPBA and revised JNLPBA datasets
| System | JNLPBA | Revised JNLPBA | |$\pm \Delta $||$F_1$|-measures | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| BANNER | |||||||
| [106] | 66.65 | 69.34 | 67.97 | 89.11 | 75.51 | 80.46 | +12.49 |
| Gimli | |||||||
| [107] | 72.85 | 71.62 | 72.23 | 91.33 | 82.84 | 86.88 | +14.65 |
| NERsuite | |||||||
| [108] | 69.95 | 72.41 | 71.16 | 89.13 | 83.41 | 86.17 | +15.01 |
| GRAM-CNN | |||||||
| [21] | 69.73 | 75.64 | 72.57 | 85.50 | 87.50 | 86.49 | +13.92 |
| BioBERT | |||||||
| [96] | 66.99 | 79.08 | 72.54 | 88.12 | 88.25 | 88.18 | +15.64 |
| System | JNLPBA | Revised JNLPBA | |$\pm \Delta $||$F_1$|-measures | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| BANNER | |||||||
| [106] | 66.65 | 69.34 | 67.97 | 89.11 | 75.51 | 80.46 | +12.49 |
| Gimli | |||||||
| [107] | 72.85 | 71.62 | 72.23 | 91.33 | 82.84 | 86.88 | +14.65 |
| NERsuite | |||||||
| [108] | 69.95 | 72.41 | 71.16 | 89.13 | 83.41 | 86.17 | +15.01 |
| GRAM-CNN | |||||||
| [21] | 69.73 | 75.64 | 72.57 | 85.50 | 87.50 | 86.49 | +13.92 |
| BioBERT | |||||||
| [96] | 66.99 | 79.08 | 72.54 | 88.12 | 88.25 | 88.18 | +15.64 |
Symbols: Precision(P); Recall(R); F-score(F)
Performance of tested systems on JNLPBA and revised JNLPBA datasets
| System | JNLPBA | Revised JNLPBA | |$\pm \Delta $||$F_1$|-measures | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| BANNER | |||||||
| [106] | 66.65 | 69.34 | 67.97 | 89.11 | 75.51 | 80.46 | +12.49 |
| Gimli | |||||||
| [107] | 72.85 | 71.62 | 72.23 | 91.33 | 82.84 | 86.88 | +14.65 |
| NERsuite | |||||||
| [108] | 69.95 | 72.41 | 71.16 | 89.13 | 83.41 | 86.17 | +15.01 |
| GRAM-CNN | |||||||
| [21] | 69.73 | 75.64 | 72.57 | 85.50 | 87.50 | 86.49 | +13.92 |
| BioBERT | |||||||
| [96] | 66.99 | 79.08 | 72.54 | 88.12 | 88.25 | 88.18 | +15.64 |
| System | JNLPBA | Revised JNLPBA | |$\pm \Delta $||$F_1$|-measures | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| BANNER | |||||||
| [106] | 66.65 | 69.34 | 67.97 | 89.11 | 75.51 | 80.46 | +12.49 |
| Gimli | |||||||
| [107] | 72.85 | 71.62 | 72.23 | 91.33 | 82.84 | 86.88 | +14.65 |
| NERsuite | |||||||
| [108] | 69.95 | 72.41 | 71.16 | 89.13 | 83.41 | 86.17 | +15.01 |
| GRAM-CNN | |||||||
| [21] | 69.73 | 75.64 | 72.57 | 85.50 | 87.50 | 86.49 | +13.92 |
| BioBERT | |||||||
| [96] | 66.99 | 79.08 | 72.54 | 88.12 | 88.25 | 88.18 | +15.64 |
Symbols: Precision(P); Recall(R); F-score(F)
Among all tested systems, the performance of BANNER is relatively low. We suspect there is a potential causal effect in the feature selection of the BANNER system being based on the BioCreative II GM dataset rather than the JNLPBA dataset. Nevertheless, BANNER still demonstrates a significant improvement when implemented on the revised dataset. The improved performances for all systems indicate that the revision process clearly promotes annotation homogeneity of the dataset.
6.5 Portability evaluation of original/revised JNLPBA datasets
In addition to intrinsic evaluation, we design another experiment to evaluate the portability of the revised dataset. Here, the JNLPBA and revised JNLPBA datasets serve as training sets for NER open-source systems. Subsequently, the performance of those systems is assessed on the PPIE and BEE datasets. Tables 7 and 8 respectively give the results of assessment on the PPIE and BEE datasets. The lower performance obtained for BNER systems stems from the fact that there is no general consensus regarding PPIE and BEE annotations; that is, the definitions of BNE boundaries differ among PPIE, BEE and the JNLPBA/revised JNLPBA datasets. For example, in JNLPBA and revised JNLPBA, ‘human Myt1 kinase’ is designated as an entity. However, in the BioInfer dataset, only the core term ‘Myt1’ is regarded as a target entity. As general entities were removed from the revised JNLPBA, this dataset is able to promote the precision of NER systems. However, the recall rate might slightly drop.
Performance (in %) of model systems on PPIE datasets
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | AImed | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 51.1 | 64.3 | 56.9 | 58.7 | 65.7 | 67.2 | +10.3 |
| GIM | 54.7 | 61.0 | 57.7 | 69.7 | 63.1 | 66.3 | +8.6 |
| NS | 52.6 | 64.8 | 58.1 | 68.0 | 65.8 | 66.9 | +8.8 |
| GCN | 44.2 | 64.8 | 52.5 | 64.5 | 61.2 | 57.7 | +5.2 |
| BBT | 51.0 | 70.8 | 59.3 | 66.6 | 70.4 | 68.5 | +9.2 |
| Bioinfer | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 55.6 | 55.6 | 56.7 | 80.1 | 55.1 | 65.3 | +8.6 |
| GIM | 67.8 | 47.2 | 51.3 | 81.6 | 51.0 | 62.8 | +11.5 |
| NS | 64.9 | 48.7 | 55.6 | 77.9 | 52.2 | 62.5 | +6.9 |
| GCN | 55.4 | 53.7 | 54.5 | 63.4 | 49.3 | 55.5 | +1.0 |
| BBT | 68.1 | 64.2 | 66.1 | 77.1 | 62.7 | 69.1 | +3.0 |
| HPRD50 | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 50.3 | 58.5 | 54.1 | 63.4 | 58.3 | 60.7 | +6.6 |
| GIM | 53.4 | 59.3 | 56.2 | 60.2 | 62.1 | 61.1 | +4.9 |
| NS | 51.7 | 63.8 | 57.1 | 60.9 | 62.3 | 61.6 | +4.5 |
| GCN | 48.6 | 62.6 | 54.7 | 56.4 | 61.3 | 58.8 | +4.1 |
| BBT | 52.1 | 72.9 | 60.7 | 61.0 | 71.9 | 66.0 | +5.3 |
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | AImed | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 51.1 | 64.3 | 56.9 | 58.7 | 65.7 | 67.2 | +10.3 |
| GIM | 54.7 | 61.0 | 57.7 | 69.7 | 63.1 | 66.3 | +8.6 |
| NS | 52.6 | 64.8 | 58.1 | 68.0 | 65.8 | 66.9 | +8.8 |
| GCN | 44.2 | 64.8 | 52.5 | 64.5 | 61.2 | 57.7 | +5.2 |
| BBT | 51.0 | 70.8 | 59.3 | 66.6 | 70.4 | 68.5 | +9.2 |
| Bioinfer | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 55.6 | 55.6 | 56.7 | 80.1 | 55.1 | 65.3 | +8.6 |
| GIM | 67.8 | 47.2 | 51.3 | 81.6 | 51.0 | 62.8 | +11.5 |
| NS | 64.9 | 48.7 | 55.6 | 77.9 | 52.2 | 62.5 | +6.9 |
| GCN | 55.4 | 53.7 | 54.5 | 63.4 | 49.3 | 55.5 | +1.0 |
| BBT | 68.1 | 64.2 | 66.1 | 77.1 | 62.7 | 69.1 | +3.0 |
| HPRD50 | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 50.3 | 58.5 | 54.1 | 63.4 | 58.3 | 60.7 | +6.6 |
| GIM | 53.4 | 59.3 | 56.2 | 60.2 | 62.1 | 61.1 | +4.9 |
| NS | 51.7 | 63.8 | 57.1 | 60.9 | 62.3 | 61.6 | +4.5 |
| GCN | 48.6 | 62.6 | 54.7 | 56.4 | 61.3 | 58.8 | +4.1 |
| BBT | 52.1 | 72.9 | 60.7 | 61.0 | 71.9 | 66.0 | +5.3 |
BNR: BANNER, GIM: Gimli, NS: NERsuite, GCN: GRAM-CNN, BBT: BioBERT
Performance (in %) of model systems on PPIE datasets
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | AImed | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 51.1 | 64.3 | 56.9 | 58.7 | 65.7 | 67.2 | +10.3 |
| GIM | 54.7 | 61.0 | 57.7 | 69.7 | 63.1 | 66.3 | +8.6 |
| NS | 52.6 | 64.8 | 58.1 | 68.0 | 65.8 | 66.9 | +8.8 |
| GCN | 44.2 | 64.8 | 52.5 | 64.5 | 61.2 | 57.7 | +5.2 |
| BBT | 51.0 | 70.8 | 59.3 | 66.6 | 70.4 | 68.5 | +9.2 |
| Bioinfer | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 55.6 | 55.6 | 56.7 | 80.1 | 55.1 | 65.3 | +8.6 |
| GIM | 67.8 | 47.2 | 51.3 | 81.6 | 51.0 | 62.8 | +11.5 |
| NS | 64.9 | 48.7 | 55.6 | 77.9 | 52.2 | 62.5 | +6.9 |
| GCN | 55.4 | 53.7 | 54.5 | 63.4 | 49.3 | 55.5 | +1.0 |
| BBT | 68.1 | 64.2 | 66.1 | 77.1 | 62.7 | 69.1 | +3.0 |
| HPRD50 | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 50.3 | 58.5 | 54.1 | 63.4 | 58.3 | 60.7 | +6.6 |
| GIM | 53.4 | 59.3 | 56.2 | 60.2 | 62.1 | 61.1 | +4.9 |
| NS | 51.7 | 63.8 | 57.1 | 60.9 | 62.3 | 61.6 | +4.5 |
| GCN | 48.6 | 62.6 | 54.7 | 56.4 | 61.3 | 58.8 | +4.1 |
| BBT | 52.1 | 72.9 | 60.7 | 61.0 | 71.9 | 66.0 | +5.3 |
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | AImed | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 51.1 | 64.3 | 56.9 | 58.7 | 65.7 | 67.2 | +10.3 |
| GIM | 54.7 | 61.0 | 57.7 | 69.7 | 63.1 | 66.3 | +8.6 |
| NS | 52.6 | 64.8 | 58.1 | 68.0 | 65.8 | 66.9 | +8.8 |
| GCN | 44.2 | 64.8 | 52.5 | 64.5 | 61.2 | 57.7 | +5.2 |
| BBT | 51.0 | 70.8 | 59.3 | 66.6 | 70.4 | 68.5 | +9.2 |
| Bioinfer | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 55.6 | 55.6 | 56.7 | 80.1 | 55.1 | 65.3 | +8.6 |
| GIM | 67.8 | 47.2 | 51.3 | 81.6 | 51.0 | 62.8 | +11.5 |
| NS | 64.9 | 48.7 | 55.6 | 77.9 | 52.2 | 62.5 | +6.9 |
| GCN | 55.4 | 53.7 | 54.5 | 63.4 | 49.3 | 55.5 | +1.0 |
| BBT | 68.1 | 64.2 | 66.1 | 77.1 | 62.7 | 69.1 | +3.0 |
| HPRD50 | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 50.3 | 58.5 | 54.1 | 63.4 | 58.3 | 60.7 | +6.6 |
| GIM | 53.4 | 59.3 | 56.2 | 60.2 | 62.1 | 61.1 | +4.9 |
| NS | 51.7 | 63.8 | 57.1 | 60.9 | 62.3 | 61.6 | +4.5 |
| GCN | 48.6 | 62.6 | 54.7 | 56.4 | 61.3 | 58.8 | +4.1 |
| BBT | 52.1 | 72.9 | 60.7 | 61.0 | 71.9 | 66.0 | +5.3 |
BNR: BANNER, GIM: Gimli, NS: NERsuite, GCN: GRAM-CNN, BBT: BioBERT
Performance (in %) of model systems on BEE datasets
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | Genia Event Extraction (GE) | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 40.9 | 61.0 | 49.0 | 51.6 | 56.9 | 54.1 | +5.1 |
| GIM | 41.1 | 52.9 | 46.2 | 50.5 | 56.7 | 53.4 | +7.2 |
| NS | 40.1 | 59.0 | 47.7 | 48.4 | 59.1 | 53.2 | +5.5 |
| GCN | 39.1 | 55.6 | 45.9 | 44.3 | 60.3 | 51.1 | +5.2 |
| BBT | 45.0 | 62.3 | 52.3 | 53.0 | 59.9 | 56.2 | +3.9 |
| Cancer Genetics (CG) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 62.4 | 49.6 | 55.2 | 73.5 | 43.7 | 54.8 | -0.4 |
| GIM | 64.4 | 45.4 | 53.3 | 76.5 | 51.4 | 61.5 | +8.2 |
| NS | 64.9 | 49.8 | 56.4 | 73.3 | 50.5 | 59.8 | +3.4 |
| GCN | 47.1 | 60.1 | 52.8 | 66.2 | 50.2 | 57.1 | +4.3 |
| BBT | 52.6 | 51.0 | 51.8 | 59.7 | 50.1 | 54.5 | +2.7 |
| Pathway Curation (PC) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 54.5 | 61.1 | 57.6 | 68.2 | 58.7 | 63.1 | +5.5 |
| GIM | 54.5 | 54.2 | 54.3 | 63.2 | 60.7 | 61.9 | +7.6 |
| NS | 54.5 | 58.7 | 56.5 | 66.4 | 61.2 | 63.7 | +7.2 |
| GCN | 45.0 | 61.1 | 51.9 | 54.3 | 54.7 | 54.5 | +2.6 |
| BBT | 56.7 | 68.3 | 62.0 | 66.9 | 68.2 | 67.6 | +5.6 |
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | Genia Event Extraction (GE) | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 40.9 | 61.0 | 49.0 | 51.6 | 56.9 | 54.1 | +5.1 |
| GIM | 41.1 | 52.9 | 46.2 | 50.5 | 56.7 | 53.4 | +7.2 |
| NS | 40.1 | 59.0 | 47.7 | 48.4 | 59.1 | 53.2 | +5.5 |
| GCN | 39.1 | 55.6 | 45.9 | 44.3 | 60.3 | 51.1 | +5.2 |
| BBT | 45.0 | 62.3 | 52.3 | 53.0 | 59.9 | 56.2 | +3.9 |
| Cancer Genetics (CG) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 62.4 | 49.6 | 55.2 | 73.5 | 43.7 | 54.8 | -0.4 |
| GIM | 64.4 | 45.4 | 53.3 | 76.5 | 51.4 | 61.5 | +8.2 |
| NS | 64.9 | 49.8 | 56.4 | 73.3 | 50.5 | 59.8 | +3.4 |
| GCN | 47.1 | 60.1 | 52.8 | 66.2 | 50.2 | 57.1 | +4.3 |
| BBT | 52.6 | 51.0 | 51.8 | 59.7 | 50.1 | 54.5 | +2.7 |
| Pathway Curation (PC) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 54.5 | 61.1 | 57.6 | 68.2 | 58.7 | 63.1 | +5.5 |
| GIM | 54.5 | 54.2 | 54.3 | 63.2 | 60.7 | 61.9 | +7.6 |
| NS | 54.5 | 58.7 | 56.5 | 66.4 | 61.2 | 63.7 | +7.2 |
| GCN | 45.0 | 61.1 | 51.9 | 54.3 | 54.7 | 54.5 | +2.6 |
| BBT | 56.7 | 68.3 | 62.0 | 66.9 | 68.2 | 67.6 | +5.6 |
BNR: BANNER, GIM: Gimli, NS: NERsuite, GCN: GRAM-CNN, BBT: BioBERT
Performance (in %) of model systems on BEE datasets
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | Genia Event Extraction (GE) | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 40.9 | 61.0 | 49.0 | 51.6 | 56.9 | 54.1 | +5.1 |
| GIM | 41.1 | 52.9 | 46.2 | 50.5 | 56.7 | 53.4 | +7.2 |
| NS | 40.1 | 59.0 | 47.7 | 48.4 | 59.1 | 53.2 | +5.5 |
| GCN | 39.1 | 55.6 | 45.9 | 44.3 | 60.3 | 51.1 | +5.2 |
| BBT | 45.0 | 62.3 | 52.3 | 53.0 | 59.9 | 56.2 | +3.9 |
| Cancer Genetics (CG) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 62.4 | 49.6 | 55.2 | 73.5 | 43.7 | 54.8 | -0.4 |
| GIM | 64.4 | 45.4 | 53.3 | 76.5 | 51.4 | 61.5 | +8.2 |
| NS | 64.9 | 49.8 | 56.4 | 73.3 | 50.5 | 59.8 | +3.4 |
| GCN | 47.1 | 60.1 | 52.8 | 66.2 | 50.2 | 57.1 | +4.3 |
| BBT | 52.6 | 51.0 | 51.8 | 59.7 | 50.1 | 54.5 | +2.7 |
| Pathway Curation (PC) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 54.5 | 61.1 | 57.6 | 68.2 | 58.7 | 63.1 | +5.5 |
| GIM | 54.5 | 54.2 | 54.3 | 63.2 | 60.7 | 61.9 | +7.6 |
| NS | 54.5 | 58.7 | 56.5 | 66.4 | 61.2 | 63.7 | +7.2 |
| GCN | 45.0 | 61.1 | 51.9 | 54.3 | 54.7 | 54.5 | +2.6 |
| BBT | 56.7 | 68.3 | 62.0 | 66.9 | 68.2 | 67.6 | +5.6 |
| Trained on JNLPBA | Trained on revised JNLPBA | ||||||
|---|---|---|---|---|---|---|---|
| System | Genia Event Extraction (GE) | |$\Delta $|F | |||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 40.9 | 61.0 | 49.0 | 51.6 | 56.9 | 54.1 | +5.1 |
| GIM | 41.1 | 52.9 | 46.2 | 50.5 | 56.7 | 53.4 | +7.2 |
| NS | 40.1 | 59.0 | 47.7 | 48.4 | 59.1 | 53.2 | +5.5 |
| GCN | 39.1 | 55.6 | 45.9 | 44.3 | 60.3 | 51.1 | +5.2 |
| BBT | 45.0 | 62.3 | 52.3 | 53.0 | 59.9 | 56.2 | +3.9 |
| Cancer Genetics (CG) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 62.4 | 49.6 | 55.2 | 73.5 | 43.7 | 54.8 | -0.4 |
| GIM | 64.4 | 45.4 | 53.3 | 76.5 | 51.4 | 61.5 | +8.2 |
| NS | 64.9 | 49.8 | 56.4 | 73.3 | 50.5 | 59.8 | +3.4 |
| GCN | 47.1 | 60.1 | 52.8 | 66.2 | 50.2 | 57.1 | +4.3 |
| BBT | 52.6 | 51.0 | 51.8 | 59.7 | 50.1 | 54.5 | +2.7 |
| Pathway Curation (PC) | |$\Delta $|F | ||||||
| Precision | Recall | F-score | Precision | Recall | F-score | ||
| BNR | 54.5 | 61.1 | 57.6 | 68.2 | 58.7 | 63.1 | +5.5 |
| GIM | 54.5 | 54.2 | 54.3 | 63.2 | 60.7 | 61.9 | +7.6 |
| NS | 54.5 | 58.7 | 56.5 | 66.4 | 61.2 | 63.7 | +7.2 |
| GCN | 45.0 | 61.1 | 51.9 | 54.3 | 54.7 | 54.5 | +2.6 |
| BBT | 56.7 | 68.3 | 62.0 | 66.9 | 68.2 | 67.6 | +5.6 |
BNR: BANNER, GIM: Gimli, NS: NERsuite, GCN: GRAM-CNN, BBT: BioBERT
As shown in Table 7, models tested on AImed, Bioinfer and HPRD50 (PPIE datasets), which share similar domains with the JNLPBA dataset, demonstrate moderate performance. On the BEE datasets, the tested obtain generally minor performance improvements, as shown in Table 8. However, both cases demonstrated generally positive changes in performance for models developed on the revised JNLPBA dataset, with the sole exception being BANNER applied to the CG dataset. Overall, these results illustrate the benefits of the revision. In conclusion, the revised JNLPBA offers more portability for developed NER systems and can be another option for extending the applications of constructed models.
6.6 Overview of team performance in the AI CUP BNER track
Task baselines are used as references in judging the performance of participant models. For the NER baseline, the combination of training and development sets served as the training source of a CRF model that achieved an |$F_1$|-measure of 57.2%. In the normalization and AL tasks, several mapping dictionaries are provided by this track. Using these dictionaries, both baseline models can be implemented as directly dependent on the outputs of the NER baseline. These models exhibit performances of 35.8% and 30.4% in their respective stages. Systems from participants should have better performance than the baselines to be considered for further evaluation. Among participants in this track, there were fourteen standout teams (Table 9). These teams include members from seven universities with diverse backgrounds such as computer science, bioinformatics and electrical engineering.
Overview of top-performing teams
| Team ID | Team Leader | Institution |
|---|---|---|
| Team_38 | You-Zhi Chang | National Taitung University |
| Team_74 | Shi-Wei Ye | National Central University |
| Team_108 | Yi-Ting Ding | National Cheng Kung University |
| Team_115 | Chang-Yu Shih | National Central University |
| Team_141 | Jun-Wei Wang | Chaoyang University of Technology |
| Team_143 | Jun-Kai Wu | National Tsing Hua University |
| Team_150 | Fattah Azzuhry Rahadian | National Central University |
| Team_210 | Kai-Ru Jeng | National Chung Hsing University |
| Team_254 | Sara Chang | National Central University |
| Team_286 | Wei-Hong Lu | National Taitung University |
| Team_293 | Cheng-Han Wu | Tunghai University |
| Team_294 | Jong-Kang Lee | National Central University |
| Team_297 | Chen-Po Kai | National Central University |
| Team_303 | Yi Lu | National Central University |
| Team ID | Team Leader | Institution |
|---|---|---|
| Team_38 | You-Zhi Chang | National Taitung University |
| Team_74 | Shi-Wei Ye | National Central University |
| Team_108 | Yi-Ting Ding | National Cheng Kung University |
| Team_115 | Chang-Yu Shih | National Central University |
| Team_141 | Jun-Wei Wang | Chaoyang University of Technology |
| Team_143 | Jun-Kai Wu | National Tsing Hua University |
| Team_150 | Fattah Azzuhry Rahadian | National Central University |
| Team_210 | Kai-Ru Jeng | National Chung Hsing University |
| Team_254 | Sara Chang | National Central University |
| Team_286 | Wei-Hong Lu | National Taitung University |
| Team_293 | Cheng-Han Wu | Tunghai University |
| Team_294 | Jong-Kang Lee | National Central University |
| Team_297 | Chen-Po Kai | National Central University |
| Team_303 | Yi Lu | National Central University |
Overview of top-performing teams
| Team ID | Team Leader | Institution |
|---|---|---|
| Team_38 | You-Zhi Chang | National Taitung University |
| Team_74 | Shi-Wei Ye | National Central University |
| Team_108 | Yi-Ting Ding | National Cheng Kung University |
| Team_115 | Chang-Yu Shih | National Central University |
| Team_141 | Jun-Wei Wang | Chaoyang University of Technology |
| Team_143 | Jun-Kai Wu | National Tsing Hua University |
| Team_150 | Fattah Azzuhry Rahadian | National Central University |
| Team_210 | Kai-Ru Jeng | National Chung Hsing University |
| Team_254 | Sara Chang | National Central University |
| Team_286 | Wei-Hong Lu | National Taitung University |
| Team_293 | Cheng-Han Wu | Tunghai University |
| Team_294 | Jong-Kang Lee | National Central University |
| Team_297 | Chen-Po Kai | National Central University |
| Team_303 | Yi Lu | National Central University |
| Team ID | Team Leader | Institution |
|---|---|---|
| Team_38 | You-Zhi Chang | National Taitung University |
| Team_74 | Shi-Wei Ye | National Central University |
| Team_108 | Yi-Ting Ding | National Cheng Kung University |
| Team_115 | Chang-Yu Shih | National Central University |
| Team_141 | Jun-Wei Wang | Chaoyang University of Technology |
| Team_143 | Jun-Kai Wu | National Tsing Hua University |
| Team_150 | Fattah Azzuhry Rahadian | National Central University |
| Team_210 | Kai-Ru Jeng | National Chung Hsing University |
| Team_254 | Sara Chang | National Central University |
| Team_286 | Wei-Hong Lu | National Taitung University |
| Team_293 | Cheng-Han Wu | Tunghai University |
| Team_294 | Jong-Kang Lee | National Central University |
| Team_297 | Chen-Po Kai | National Central University |
| Team_303 | Yi Lu | National Central University |
6.6.1 Team strategy overview in the BNER task
After evaluation of the NER stage, 10 teams are selected out of 60 valid submissions. Table 10 summarizes the performances and strategies of these 10 teams; the best |$F_1$|-score is 77.29%, all have performances exceeding 70.0%. It is evident that CRF is generally joined to the designed architecture, which method is still competitive with DL approaches (teams 297, 143, 293 and 150) if the appropriate features are considered. Moreover, the inclusion of models such as BiLSTM and CNN demonstrate the strength of DL methods in bio-entity identification. Aside from intrinsic architecture, the incorporation of extrinsic sources is another way to promote the systems. For instance, GENIA tagger [110] and NLTK [111] are employed for POS tagging, while Glove [112] serves as the pre-trained embedding for participant models.
Summary of team participation in the NER task
| Rank | Team ID | |$F_1$|-measure | Approach | External Source |
|---|---|---|---|---|
| 1 | Team_74 | 77.29 | CRF | GENIATagger |
| 2 | Team_210 | 74.82 | CRF | NLTK |
| 3 | Team_297 | 73.84 | BiLSTM-CRF | Glove |
| 4 | Team_143 | 73.75 | BiLSTM-CNN-CRF | - |
| 5 | Team_38 | 73.25 | CRF | word2vec |
| 6 | Team_293 | 72.79 | BiLSTM-CRF | Glove |
| 7 | Team_150 | 72.78 | BiLSTM-CNN-CRF | - |
| 8 | Team_115 | 72.74 | CRF | - |
| 9 | Team_141 | 72.62 | CRF | - |
| 10 | Team_286 | 71.86 | CRF | - |
| Rank | Team ID | |$F_1$|-measure | Approach | External Source |
|---|---|---|---|---|
| 1 | Team_74 | 77.29 | CRF | GENIATagger |
| 2 | Team_210 | 74.82 | CRF | NLTK |
| 3 | Team_297 | 73.84 | BiLSTM-CRF | Glove |
| 4 | Team_143 | 73.75 | BiLSTM-CNN-CRF | - |
| 5 | Team_38 | 73.25 | CRF | word2vec |
| 6 | Team_293 | 72.79 | BiLSTM-CRF | Glove |
| 7 | Team_150 | 72.78 | BiLSTM-CNN-CRF | - |
| 8 | Team_115 | 72.74 | CRF | - |
| 9 | Team_141 | 72.62 | CRF | - |
| 10 | Team_286 | 71.86 | CRF | - |
Summary of team participation in the NER task
| Rank | Team ID | |$F_1$|-measure | Approach | External Source |
|---|---|---|---|---|
| 1 | Team_74 | 77.29 | CRF | GENIATagger |
| 2 | Team_210 | 74.82 | CRF | NLTK |
| 3 | Team_297 | 73.84 | BiLSTM-CRF | Glove |
| 4 | Team_143 | 73.75 | BiLSTM-CNN-CRF | - |
| 5 | Team_38 | 73.25 | CRF | word2vec |
| 6 | Team_293 | 72.79 | BiLSTM-CRF | Glove |
| 7 | Team_150 | 72.78 | BiLSTM-CNN-CRF | - |
| 8 | Team_115 | 72.74 | CRF | - |
| 9 | Team_141 | 72.62 | CRF | - |
| 10 | Team_286 | 71.86 | CRF | - |
| Rank | Team ID | |$F_1$|-measure | Approach | External Source |
|---|---|---|---|---|
| 1 | Team_74 | 77.29 | CRF | GENIATagger |
| 2 | Team_210 | 74.82 | CRF | NLTK |
| 3 | Team_297 | 73.84 | BiLSTM-CRF | Glove |
| 4 | Team_143 | 73.75 | BiLSTM-CNN-CRF | - |
| 5 | Team_38 | 73.25 | CRF | word2vec |
| 6 | Team_293 | 72.79 | BiLSTM-CRF | Glove |
| 7 | Team_150 | 72.78 | BiLSTM-CNN-CRF | - |
| 8 | Team_115 | 72.74 | CRF | - |
| 9 | Team_141 | 72.62 | CRF | - |
| 10 | Team_286 | 71.86 | CRF | - |
Due to the competitive performances of BioBERT in prior experiments, it is therefore applied to the NER task of the EBED dataset. The results for each entity type are displayed in Table 11. Although BioBERT generally achieves a better |$F_1$|-score than the other participating teams, we still observed room for improvement in its predictions. Numerous abbreviation terms appear in the text in the EBED dataset without their full name as they are extracted from different paragraphs of scientific articles, and cases as such often result in prediction errors. For example, ‘GLA’ is tagged as a gene by BioBERT where it stands for ‘glaucocalyxin A’, which is a chemical entity. ‘MHR’, which represents ‘major homology region’, is classified as a gene in the prediction even though it is not a specific type of entity. Moreover, nested names are also hot spots for erroneous recognitions. For instance, we found that the chemical ‘rapamycin’ in the gene ‘mammalian target of rapamycin’ is incorrectly predicted by the BioBERT system.
Performance (in%) of BioBERT on the NER task of EBED dataset
| Precision | Recall | |$F_1$|-measure | |
|---|---|---|---|
| Gene | 87.46 | 82.88 | 85.11 |
| Chemical | 81.43 | 78.35 | 79.86 |
| Disease | 83.36 | 79.71 | 81.50 |
| Total | 84.96 | 81.07 | 82.97 |
| Precision | Recall | |$F_1$|-measure | |
|---|---|---|---|
| Gene | 87.46 | 82.88 | 85.11 |
| Chemical | 81.43 | 78.35 | 79.86 |
| Disease | 83.36 | 79.71 | 81.50 |
| Total | 84.96 | 81.07 | 82.97 |
Performance (in%) of BioBERT on the NER task of EBED dataset
| Precision | Recall | |$F_1$|-measure | |
|---|---|---|---|
| Gene | 87.46 | 82.88 | 85.11 |
| Chemical | 81.43 | 78.35 | 79.86 |
| Disease | 83.36 | 79.71 | 81.50 |
| Total | 84.96 | 81.07 | 82.97 |
| Precision | Recall | |$F_1$|-measure | |
|---|---|---|---|
| Gene | 87.46 | 82.88 | 85.11 |
| Chemical | 81.43 | 78.35 | 79.86 |
| Disease | 83.36 | 79.71 | 81.50 |
| Total | 84.96 | 81.07 | 82.97 |
There is a widely held assumption that the IAA is the upper limit of system performance [113–115]. Indeed, the performances of the participating teams and BioBERT are lower than the IAA of the EBED dataset, which is greater than 90% in the NER subtask. Nevertheless, previous statistical comparisons stand against this assumption [116]. We believe that comprehensive error analyses as well as advanced features and/or model designs are feasible means to further boost the performance of various systems.
6.6.2 Team strategy overview for the NEN task
For the normalization task, results were received from eight teams, five of which outperformed baseline (Table 12). Since the preceding step is NER, most teams develop their systems on the basis of the inherent concepts and track dictionaries. Ingeniously, Team_294, which won second prize in this task, integrates TaggerOne and Pubtator to complete entity identification and normalization simultaneously. Furthermore, a crawler is applied by the top team to retrieve the candidate IDs of gene and disease entities.
Summary of team participation in the normalization task
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach |
|---|---|---|---|---|
| 1 | Team_74 | 65.76 | CRF | Crawler, Dictionary |
| 2 | Team_294 | 64.62 | TaggerOne, Pubtator | |
| 3 | Team_210 | 63.56 | CRF | Dictionary |
| 4 | Team_303 | 58.72 | BiLSTM-CNN-CRF | Dictionary |
| 5 | Team_254 | 49.49 | BiLSTM-CRF+Rule | Pubtator |
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach |
|---|---|---|---|---|
| 1 | Team_74 | 65.76 | CRF | Crawler, Dictionary |
| 2 | Team_294 | 64.62 | TaggerOne, Pubtator | |
| 3 | Team_210 | 63.56 | CRF | Dictionary |
| 4 | Team_303 | 58.72 | BiLSTM-CNN-CRF | Dictionary |
| 5 | Team_254 | 49.49 | BiLSTM-CRF+Rule | Pubtator |
Summary of team participation in the normalization task
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach |
|---|---|---|---|---|
| 1 | Team_74 | 65.76 | CRF | Crawler, Dictionary |
| 2 | Team_294 | 64.62 | TaggerOne, Pubtator | |
| 3 | Team_210 | 63.56 | CRF | Dictionary |
| 4 | Team_303 | 58.72 | BiLSTM-CNN-CRF | Dictionary |
| 5 | Team_254 | 49.49 | BiLSTM-CRF+Rule | Pubtator |
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach |
|---|---|---|---|---|
| 1 | Team_74 | 65.76 | CRF | Crawler, Dictionary |
| 2 | Team_294 | 64.62 | TaggerOne, Pubtator | |
| 3 | Team_210 | 63.56 | CRF | Dictionary |
| 4 | Team_303 | 58.72 | BiLSTM-CNN-CRF | Dictionary |
| 5 | Team_254 | 49.49 | BiLSTM-CRF+Rule | Pubtator |
Summary of team participation in the AL task
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach | Linking Approach |
|---|---|---|---|---|---|
| 1 | Team_74 | 56.61 | CRF | Crawler, Dictionary | Dictionary, MeSH |
| 2 | Team_294 | 56.25 | TaggerOne, Pubtator | MeSH | |
| 3 | Team_210 | 55.11 | CRF | Dictionary | MeSH |
| 4 | Team_108 | 54.63 | BiLSTM-CRF | Pubtator, Dictionary | MeSH |
| 5 | Team_303 | 51.39 | BiLSTM-CNN-CRF | Dictionary | Dictionary, MeSH, Co-occurrence |
| 6 | Team_254 | 42.83 | BiLSTM-CRF+Rule | Pubtator | MeSH |
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach | Linking Approach |
|---|---|---|---|---|---|
| 1 | Team_74 | 56.61 | CRF | Crawler, Dictionary | Dictionary, MeSH |
| 2 | Team_294 | 56.25 | TaggerOne, Pubtator | MeSH | |
| 3 | Team_210 | 55.11 | CRF | Dictionary | MeSH |
| 4 | Team_108 | 54.63 | BiLSTM-CRF | Pubtator, Dictionary | MeSH |
| 5 | Team_303 | 51.39 | BiLSTM-CNN-CRF | Dictionary | Dictionary, MeSH, Co-occurrence |
| 6 | Team_254 | 42.83 | BiLSTM-CRF+Rule | Pubtator | MeSH |
Summary of team participation in the AL task
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach | Linking Approach |
|---|---|---|---|---|---|
| 1 | Team_74 | 56.61 | CRF | Crawler, Dictionary | Dictionary, MeSH |
| 2 | Team_294 | 56.25 | TaggerOne, Pubtator | MeSH | |
| 3 | Team_210 | 55.11 | CRF | Dictionary | MeSH |
| 4 | Team_108 | 54.63 | BiLSTM-CRF | Pubtator, Dictionary | MeSH |
| 5 | Team_303 | 51.39 | BiLSTM-CNN-CRF | Dictionary | Dictionary, MeSH, Co-occurrence |
| 6 | Team_254 | 42.83 | BiLSTM-CRF+Rule | Pubtator | MeSH |
| Rank | Team ID | |$F_1$|-measure | NER Approach | Normalization Approach | Linking Approach |
|---|---|---|---|---|---|
| 1 | Team_74 | 56.61 | CRF | Crawler, Dictionary | Dictionary, MeSH |
| 2 | Team_294 | 56.25 | TaggerOne, Pubtator | MeSH | |
| 3 | Team_210 | 55.11 | CRF | Dictionary | MeSH |
| 4 | Team_108 | 54.63 | BiLSTM-CRF | Pubtator, Dictionary | MeSH |
| 5 | Team_303 | 51.39 | BiLSTM-CNN-CRF | Dictionary | Dictionary, MeSH, Co-occurrence |
| 6 | Team_254 | 42.83 | BiLSTM-CRF+Rule | Pubtator | MeSH |
As with the NER subtask, entity normalization faces a few obstacles. For example, some identifiers cannot be fetched directly because the entities present as various synonyms in the database. Therefore, intermediate mapping to other databases may be required. Also, the boundary difference between NER and normalization stages for certain entities is worthy to note. For instance, the entity ‘Hepatitis B virus-human chimeric transcript HBx-LINE1’ is recognized as an intact gene name in the NER level, while the bold terms are the practical normalization targets. The simple concatenation of NER outputs with the normalization method is insufficient to deal with such exceptions.
6.6.3 Team strategy overview for the AL task
In the final stage, we receive six outstanding teams among 12 valid submissions, described in Table 13. For the AL task, MeSH and dictionaries are generally picked by the participants due to relying on the model established in the prior two stages. Relative to normalization, the AL process is less intuitive; teams should extract attribute identifiers from the MeSH database and map them to the corresponding entities. Consequently, the performances reveal database processing abilities; five teams achieved |$F_1$|-measures greater than 50.0%. Amazingly, Team_303, which achieves an |$F_1$|-score of 51.39%, conducts co-occurrence analysis to trace the associations between chemicals and diseases. Since the causal connections of chemical and disease depend on sentence information, any RE methods are advisable. In addition, the use of an external resource such as the comparative toxicogenomics database (CTD) [117] may also benefit this task because chemical-disease information is wellorganized and continuously updated. Integration of the above knowledge enables advanced models to face further NLP challenges in the biomedical domain.
7 Conclusion
In this work, we review current biomedical NER datasets and potential applications of NER systems. To demonstrate a common dilemma presented by early NER datasets, inconsistent annotations in the JNLPBA are enumerated and classified. The subsequent revision of JNLPBA and construction of the EBED exemplify feasible means of utilizing those original NER datasets. Furthermore, the multi-task EBED dataset is capable of encouraging the development of biomedical pipeline systems. Through feedback in the form of participant results, it is indicated that the EBED dataset is competent to smelt the outstanding systems. We envision that the two datasets described here can contribute substantially to biomedical NLP studies in the future.
The JNLPBA dataset is analyzed and we present the inappropriate circumstances that would likely impede the development of system.
We release the revised JNLPBA dataset that can lead the model progression under the homogeneous annotations.
We propose a brand new biomedical corpus, EBED, which contain gene, disease and chemical entities with their corresponding identifiers.
The EBED dataset can provide the assistance in the researches of biomedical named entity recognition, normalization and preliminary relation extraction.
Acknowledgments
The authors would like to thank the Ministry of Education, Taiwan, Pervasive AI Research Labs, Ministry of Science and Technology, Taiwan, and the Ministry of Science and Technology, Taiwan for financially supporting this research. We are grateful to the National Center for High-performance Computing for computer time and facilities.
Funding
Ministry of Education, Taiwan; Ministry of Science and Technology, Taiwan (108-2319-B-400-001).
Ming-Siang Huang is now a PhD candidate in the Institute of Biomedical Informatics, National Yang Ming University, Taipei, Taiwan, and the Bioinformatics Program, Taiwan International Graduate Program, Institute of Information Science, Academia Sinica, Taipei, Taiwan.
Po-Ting Lai was a PhD student in Department of Computer Science, National Tsing-Hua University, Taiwan and was Research Assistant in Institute of Information Science, Academia Sinica, Taiwan. Dr. Lai participated in this project when he was in NTHU and Academia Sinica. He is now a Visiting Scholar in National Center for Biotechnology Information National Library of Medicine, National Institutes of Health Bethesda, MD, USA
Pei-Yen Lin, MS (National Taiwan University), is a Research Assistant in the Institute of Information Science, Academia Sinica, Taipei, Taiwan.
Yu-Ting You, MS (National Yang Ming University), is a Research Assistant in the Institute of Information Science, Academia Sinica, Taipei, Taiwan.
Richard Tzong-Han Tsai is currently a Professor of Bioinformatics in the Department of Computer Science and Information Engineering, National Central University, Taoyuan, Taiwan. His paper has been published in leading journals such as Bioinformatics and Nucleic Acids Research.
Wen-Lian Hsu is an IEEE Fellow, Distinguished Research Fellow of the Institute of Information Science, Academia Sinica, Taipei, Taiwan, and Pervasive AI Research Labs, Ministry of Science and Technology, Taiwan.
REFERENCES

{kind=link}
{kind=link}
{kind=link}
{kind=link}