





One of the most powerful tools in plant genetics is generation of transgenic organisms using Agrobacterium-mediated transformation. Agrobacterium tumefaciens can deliver plasmids into plant cells, where part of the plasmid (transfer DNA, T-DNA) is integrated into the plant genome through nonhomologous recombination. Through this process, Agrobacteria have been used by scientists to generate vast collections of T-DNA insertion mutants, deliver genome editing components, and overexpress genes of interest.
In an ideal scenario, a single copy T-DNA is inserted in the plant genome between the left border and right border repeat sequences with few to no sequence changes. However, T-DNA insertion is often “messy:” small pieces of DNA can be inserted between the T-DNA and plant genomic DNA (Kleinboelting et al., 2015), and a single Agrobacterium-mediated transformation often leads to T-DNA insertions in several discrete locations and/or multiple copies of T-DNA inserted in a single locus (Grevelding et al., 1993; Jeon et al., 2000). Moreover, chromosomal DNA from A. tumefaciens can also be inserted into plant DNA (Ulker et al., 2008). Agrobacterium-mediated transformation can also cause deletions, duplications, and chromosomal rearrangements in the plant genome (Pucker et al., 2021). These complications can thus make the identification of loci with T-DNA insertions difficult for researchers. While certainly nontrivial, it is considered good scientific practice for plant geneticists to identify T-DNA insertion sites.
The two most common approaches for identifying T-DNA insertion sites are thermal asymmetric interlaced PCR (TAIL-PCR) and adapter-ligated PCR (reviewed in O’Malley and Ecker, 2010). PCR methods work based on prior knowledge of the left border and right border T-DNA sequences. PCR-based approaches are not very effective when T-DNA insertions concomitantly cause deletions, insertions, or chromosomal rearrangements.
Because the cost of whole genome sequencing has become affordable, paired-end sequencing reads from transgenic plants can be used to identify T-DNA insertion sites. When using a whole genome sequencing-based method, a researcher needs to look for discordant read pairs and/or split reads. A discordant read pair is a scenario where two reads in a read pair align uniquely to the reference sequence but are located further apart than expected based on sequencing fragment size (e.g. the reads within the pair are aligned to the plant reference sequence and the T-DNA vector). Discordant reads can easily be found by simply looking at the alignment classifications of reads of interest in a given standard alignment file (e.g. SAM formatted alignment files). Split reads describe a situation where, within a single read, one portion aligns to one genomic locus and the rest of the read aligns to a different genomic position. In T-DNA insertion mapping, a researcher would search for split reads that contain one portion aligning uniquely to the plant reference genome or T-DNA vector but also contain appreciable amounts of unmapped bases that could be further searched for matches either to the plant reference or the T-DNA vector. The previously reported program TDNAscan is designed to identify informative cases of split reads, but the program fails to resolve situations where a small random DNA piece is inserted between the plant genomic DNA and the T-DNA fragment (Sun et al., 2019). Long-read next-generation sequencing can also help resolve these difficulties, but such methods are often too expensive for many researchers.
In this issue of Plant Physiology, Li and colleagues have developed an analysis pipeline, T-LOC, to accurately identify T-DNA insertion events in plant genomes (Li et al., 2022). The authors have demonstrated that T-LOC outperforms previous methods of identifying T-DNA insertion sites.
T-LOC takes advantage of a property of short read mapping called “soft-clipping.” During typical alignment, unmapped bases in 5′ and 3′ ends of reads are cut from the mapped portions, otherwise known as “hard-clipping.” In contrast, “soft-clipped” aligned reads retain the unmapped bases. By using the soft-clipped alignment method, T-LOC obtains cases of split reads where one portion maps to the plant reference genome (referred to as REF) and other to the T-DNA vector (referred to as TDNA). Next, T-LOC then looks within unmapped portions of reads for the following: (1) presence with perfect matches to the plant genome or T-DNA vector; (2) presence but with mismatches to the plant genome or T-DNA vector; (3) presence with insertions allowed between the plant genome or T-DNA vector (Figure 1A). T-LOC then outputs ordered REF-TDNA alignments in their original orientation if mapped to the plant reference Watson strand or outputs the reverse-complement if aligned to the Crick strand. T-LOC also supplies additional information to users, such as detailed sequences that define the T-DNA insertion site, as well as 1-kb of the plant reference genome surrounding the T-DNA insertion event. T-LOC also gives users the sequencing coverage of the plant reference genome encompassing the T-DNA insertion site (Figure 1B).
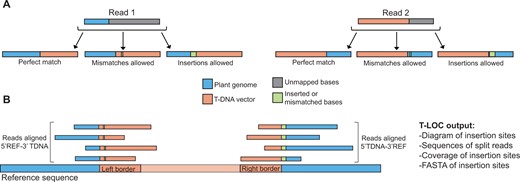
Schematic describing split read alignment for identification of T-DNA insertion sites. A, Schematic describing “soft-clipped” read alignment for identification of split reads that can be used to find T-DNA insertion sites. A split read describes a scenario where one portion of the read aligns to one genomic locus and the rest of the read aligns to a different genomic position. In this schematic, the second locus in the split read aligns to a T-DNA vector. T-LOC looks for three cases of split reads: (1) Perfect match between the plant reference genome and T-DNA vector; (2) Mismatched bases allowed in the reference and/or T-DNA vector; (3) Inserted bases allowed between the reference and T-DNA vector. B, Schematic showing split reads aligned to a T-DNA insertion site, as well as a list of outputs from T-LOC. REF, reference genome sequence; TDNA, T-DNA vector sequence. Adapted from Li et al. (2022).
To verify T-LOC as a robust pipeline for identification of T-DNA insertion sites, Li and colleagues used T-LOC to characterize T-DNA insertion events in 48 transgenic rice (Oryza sativa) lines. They also compared their results to outputs obtained from TDNAscan (Sun et al., 2019). From these 48 rice plants, T-LOC identified 75 T-DNA insertion sites along with their left and right borders. Twenty-three events were randomly selected for PCR verification, and all were confirmed. When comparing the performance of T-LOC to TDNAscan, Li and colleagues found that in complete cases of T-DNA insertion events, the two methods were comparable. However, T-LOC was better at accurately identifying loci where complex insertion events had occurred, such as chromosomal rearrangements or insertion of bases between the plant reference genome and T-DNA borders.
In sum, Li and colleagues have provided plant geneticists a useful and robust tool that enables accurate and fast identification of T-DNA insertion sites. The only data required are whole genome sequencing reads from a transgenic plant of interest. It would be interesting to test whether small amounts of reads (e.g. less than 5× coverage of a given genome) would be enough information for T-LOC to identify insertion events. Furthermore, it would also be useful to extend T-LOC to Agrobacterium rhizogenes-based insertion events.
Conflict of interest statement. None declared.

{kind=link}