





ABSTRACT
We present the joint tomographic analysis of galaxy-galaxy lensing and galaxy clustering in harmonic space (HS), using galaxy catalogues from the first three years of observations by the Dark Energy Survey (DES Y3). We utilize the redMaGiC and MagLim catalogues as lens galaxies and the metacalibration catalogue as source galaxies. The measurements of angular power spectra are performed using the pseudo-|$C_\ell$| method, and our theoretical modelling follows the fiducial analyses performed by DES Y3 in configuration space, accounting for galaxy bias, intrinsic alignments, magnification bias, shear magnification bias and photometric redshift uncertainties. We explore different approaches for scale cuts based on non-linear galaxy bias and baryonic effects contamination. Our fiducial covariance matrix is computed analytically, accounting for mask geometry in the Gaussian term, and including non-Gaussian contributions and super-sample covariance terms. To validate our HS pipelines and covariance matrix, we used a suite of 1800 log-normal simulations. We also perform a series of stress tests to gauge the robustness of our HS analysis. In the |$\Lambda$|CDM model, the clustering amplitude |$S_8 =\sigma _8(\Omega _m/0.3)^{0.5}$| is constrained to |$S_8 = 0.704\pm 0.029$| and |$S_8 = 0.753\pm 0.024$| (68 per cent C.L.) for the redMaGiC and MagLim catalogues, respectively. For the wCDM, the dark energy equation of state is constrained to |$w = -1.28 \pm 0.29$| and |$w = -1.26^{+0.34}_{-0.27}$|, for redMaGiC and MagLim catalogues, respectively. These results are compatible with the corresponding DES Y3 results in configuration space and pave the way for HS analyses using the DES Y6 data.
1 INTRODUCTION
The accelerating expansion of the Universe, first discovered through the analysis of supernova light curves (Perlmutter et al. 1997, 1999; Riess et al. 1998), has received significant further evidence from a variety of complementary observations. These include measurements of properties of the cosmic microwave background (CMB; Hinshaw et al. 2013; Planck Collaboration et al. 2020; Qu et al. 2024) and the large-scale structure (LSS) of the universe (see Weinberg et al. 2013 for a recent review). Analysis from these different observations have statistically converged during the recent decades upon a concordance cosmological model, the |$\Lambda$|CDM model. This model describes a spatially flat Universe composed of roughly 30 per cent of visible and cold dark matter (CDM), and 70 per cent dark energy. This dark energy is responsible for the accelerated expansion and is consistent with a cosmological constant (|$\Lambda$|), but its physical nature remains as an open problem.
Recent progress has been significant in enhancing the data quality and quantity, along with improved techniques, for extracting cosmological information from various LSS probes of cosmic acceleration. Notably, the distribution of matter traced by galaxy positions (galaxy clustering) and the weak gravitational lensing distortion it induces on the shapes of distant galaxies (cosmic shear) have proven to be powerful tools for constraining cosmological models (DES Collaboration 2018, 2022; Alam et al. 2021; Asgari et al. 2021; Dalal et al. 2023; Li et al. 2023). These techniques are considered to be amongst the key scientific drivers of current Stage-III observational programmes and will continue to be for the next generation of experiments (Laureijs et al. 2011; Ivezić et al. 2019). The Dark Energy Survey [DES1; The Dark Energy Survey (2005)] is the largest stage-III imaging survey today, covering almost 5000 deg|$^2$| of the southern sky. One of the key cosmological results obtained from the large-scale structure and weak lensing data from the first three years of observations (DES Y3) consisted of the analysis of three two-point angular correlation functions (3|$\times$|2pt) arising from the clustering and gravitational shear of galaxies (DES Collaboration 2022). The final analyses using the full 6 yr of data (DES Y6) are well under way.
In addition to these main results obtained from the configuration/real space angular correlation functions, complementary analyses using their Fourier/Harmonic counterpart, the two-point angular power spectra, were also conducted within DES. The angular power spectra of the data collected in the first year (DES Y1) were studied for galaxy clustering (Andrade-Oliveira et al. 2021) and cosmic shear (Camacho et al. 2022) whereas Doux et al. (2022) obtained cosmological constraints from the analysis of cosmic shear in harmonic space (HS) for DES Y3. These results add up to the ongoing generation of observations from Stage-III dark energy experiments, having as a main scientific goal a better understanding of the nature of cosmic acceleration. In the context of combined multiprobe analysis from weak gravitational lensing and galaxy clustering, the Kilo-Degree Survey (KiDS2) has released results combining its cosmic shear observations with galaxy clustering from the overlapping Baryon Oscillation Spectroscopic Survey (BOSS3) and the 2-degree Field Lensing Survey (2dFLenS4) in configuration space (CS; Heymans et al. 2021; Joachimi et al. 2021). Analogously, the Hyper Suprime-Cam (HSC5) has also cross-correlated its weak lensing signal measurements with clustering from BOSS (More et al. 2023), but based in configuration space. In a complementary way, the cosmic shear angular power spectrum was also recently measured from the three-year galaxy shear catalogue from the HSC imaging survey (Dalal et al. 2023; Li et al. 2023). A reanalysis of HSC data only, which combines the galaxy clustering and weak lensing signals in HS, is currently in development (Sanchez-Cid et al. LSST-DESC, in preparation).
In this paper we present, for the first time within the DES, results from a combination of two angular power spectra in HS, namely the two-point correlation of galaxy positions, |$\langle \delta _g \delta _g \rangle$|, and the cross-correlation of galaxy positions and shapes, |$\langle \delta _g \gamma \rangle$|, which we refer to as 2|$\times$|2pt. The proposed methodology is tested for internal consistency and robustness and the results are compared to the ones obtained from the CS analyses on the same data set (Pandey et al. 2022; Porredon et al. 2022). For the maglim sample, we present results that utilize the first four tomographic bins (employed in the fiducial results of Porredon et al. 2022), and with all six tomographic bins, and discuss the consistency of the results across these different redshift ranges. This work represents an important milestone probing the robustness of the different analyses of DES data, being a completely independent data reduction to a different set of summary statistics. The presented methodology has its own estimators, covariances, and modelling, constraining the survey information in a unique way. This paves the way for a full 3|$\times$|2pt analysis in HS using the final DES Y6 data set, as well as for future analyses of next-generation cosmological surveys.
This paper is organized as follows. In Section 2, we review the data used, namely the two catalogues for the lens galaxies, redMaGiC (Pandey et al. 2022) and MagLim (Porredon et al. 2021), and the metacalibration catalogue for the source galaxies (Gatti et al. 2021). In this section, we also describe the generation of log-normal simulations used to validate the estimated covariance matrix and assess the accuracy of our cosmological analysis pipeline. Section 3 describes the theoretical modelling of the angular power spectra, accounting for galaxy bias, intrinsic alignments, magnification bias, shear magnification bias, and photometric redshift uncertainties. Scale cuts are devised to mitigate small-scale uncertainties, and a likelihood analysis is presented and tested against simulated data vectors. Our results for |$\Lambda$|CDM and wCDM models are presented in Section 4 along with internal consistency and robustness tests, and our conclusions are summarized in Section 5.
2 DATA
The DES is a photometric galaxy survey that imaged about one-fourth of the southern sky in five optical filters: |$g, r, i, z$|, and Y, collecting data from more than 500 million galaxies. Using the Dark Energy Camera (DECam) on the Blanco telescope at the Cerro Tololo Inter-American Observatory (CTIO) in Chile, DES completed its observations in January 2019 after 6 yr of operations. In this paper, we utilize data from the initial three-year observation period (Y3), spanning August 2013–February 2016.
2.1 DES Y3 catalogues
The DES Y3 photometric data set resulted in a catalogue encompassing nearly 390 million objects over an area of 4946 deg|$^2$| of the sky, with a depth reaching a signal-to-noise ratio of approximately 10 for extended objects up to an AB system magnitude in the i band of approximately 23. Its detailed selection is referred to as the Gold catalogue, and is described in detail in Sevilla-Noarbe et al. (2021). To mitigate the influence of astrophysical foregrounds and known data processing artefacts on subsequent cosmological analyses, additional masking was implemented. This process resulted in a final catalogue encompassing a reduced area of 4143 deg|$^2$|. This data set was used to further select two distinct lens samples and one source sample of galaxies. The source sample serves as the background population for weak lensing analysis, while the lens samples are employed for both weak lensing, as foreground population, and galaxy clustering analyses.
The first lens sample used in the DES Y3 analyses was constructed using the redMaGiC algorithm (outlined in Rozo et al. 2016). This algorithm is specifically designed to identify luminous red galaxies (LRGs) with minimal uncertainties in their photometric redshifts. It achieves this by leveraging the well-established magnitude–colour–redshift relationship exhibited by red-sequence galaxies. The resulting selection on the DES Y3 data, the so-called redMaGiC sample, consists of 2.6 million galaxies, which are divided into five tomographic bins described in Table 1. The full redMaGiC catalogue’s angular density is depicted in the upper-central panel of Fig. 1. The redshift distribution of each bin is shown in Fig. 2. For more details about the redMaGiC algorithm, the redMaGiC sample, and its comparison with other samples we refer the reader to Rozo et al. (2016) and Pandey et al. (2022), respectively.
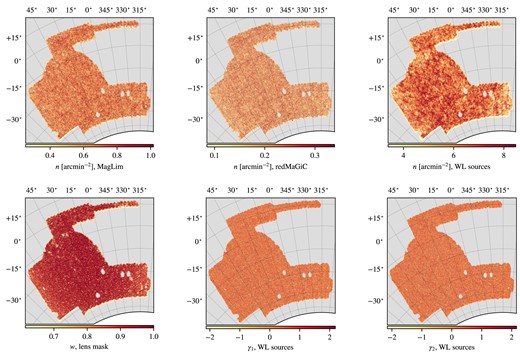
The maps of the different DES Y3 catalogues used in this work. Top: the number densities of the full redMaGiC, MagLim, and metacalibration samples, without tomographic selection. Bottom left: The covered fraction of the sky common to all samples, used as the mask for the lens samples. Bottom middle and right: the two components of shear ellipticities in the metacalibration sample.
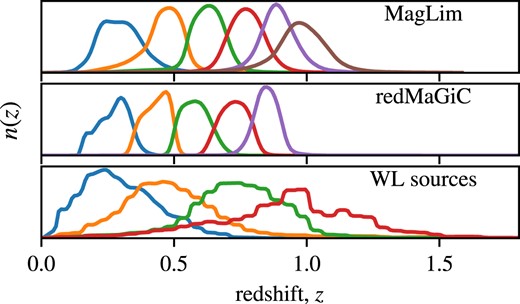
Normalized redshift distributions for the DES Y3 lens and source catalogues. Each panel corresponds to a sample and each curve corresponds to a tomographic bin selection.
The DES Y3 lens samples specifications used in this work. This table shows the photometric redshift selection, total number of galaxies selected, (|$N_{\rm gal}$|), effective angular number density of galaxies in |${\rm arcmin}^{-2}$|, (|$n_{\rm eff}$|), and magnification bias, (|$C_{\rm g}$|), as measured in Elvin-Poole, MacCrann et al. (2023). The survey property systematic weights have been accounted for in the effective angular number density following equation (5).
| Redshift bin | |$N_{\mathrm{gal}}$| | |$n_\mathrm{eff}$| | |$C_{\rm g}$| |
|---|---|---|---|
| redMaGiC lens sample | |||
| |$0.15 \lt z_\mathrm{ph} \lt 0.35$| | 330 243 | 0.022 | 1.3134 |
| |$0.35 \lt z_\mathrm{ph} \lt 0.50$| | 571 551 | 0.038 | –0.5179 |
| |$0.50 \lt z_\mathrm{ph} \lt 0.65$| | 872 611 | 0.058 | 0.3372 |
| |$0.65 \lt z_\mathrm{ph} \lt 0.80$| | 442 302 | 0.029 | 2.2515 |
| |$0.80 \lt z_\mathrm{ph} \lt 0.90$| | 377 329 | 0.025 | 1.9667 |
| MagLim lens sample | |||
| |$0.20 \lt z_\mathrm{ph} \lt 0.40$| | 2 236 473 | 0.150 | 1.2143 |
| |$0.40 \lt z_\mathrm{ph} \lt 0.55$| | 1 599 500 | 0.107 | 1.1486 |
| |$0.55 \lt z_\mathrm{ph} \lt 0.70$| | 1 627 413 | 0.109 | 1.8759 |
| |$0.70 \lt z_\mathrm{ph} \lt 0.85$| | 2 175 184 | 0.146 | 1.9694 |
| |$0.85 \lt z_\mathrm{ph} \lt 0.95$| | 1 583 686 | 0.106 | 1.7805 |
| |$0.95 \lt z_\mathrm{ph} \lt 1.05$| | 1 494 250 | 0.100 | 2.4789 |
| Redshift bin | |$N_{\mathrm{gal}}$| | |$n_\mathrm{eff}$| | |$C_{\rm g}$| |
|---|---|---|---|
| redMaGiC lens sample | |||
| |$0.15 \lt z_\mathrm{ph} \lt 0.35$| | 330 243 | 0.022 | 1.3134 |
| |$0.35 \lt z_\mathrm{ph} \lt 0.50$| | 571 551 | 0.038 | –0.5179 |
| |$0.50 \lt z_\mathrm{ph} \lt 0.65$| | 872 611 | 0.058 | 0.3372 |
| |$0.65 \lt z_\mathrm{ph} \lt 0.80$| | 442 302 | 0.029 | 2.2515 |
| |$0.80 \lt z_\mathrm{ph} \lt 0.90$| | 377 329 | 0.025 | 1.9667 |
| MagLim lens sample | |||
| |$0.20 \lt z_\mathrm{ph} \lt 0.40$| | 2 236 473 | 0.150 | 1.2143 |
| |$0.40 \lt z_\mathrm{ph} \lt 0.55$| | 1 599 500 | 0.107 | 1.1486 |
| |$0.55 \lt z_\mathrm{ph} \lt 0.70$| | 1 627 413 | 0.109 | 1.8759 |
| |$0.70 \lt z_\mathrm{ph} \lt 0.85$| | 2 175 184 | 0.146 | 1.9694 |
| |$0.85 \lt z_\mathrm{ph} \lt 0.95$| | 1 583 686 | 0.106 | 1.7805 |
| |$0.95 \lt z_\mathrm{ph} \lt 1.05$| | 1 494 250 | 0.100 | 2.4789 |
The DES Y3 lens samples specifications used in this work. This table shows the photometric redshift selection, total number of galaxies selected, (|$N_{\rm gal}$|), effective angular number density of galaxies in |${\rm arcmin}^{-2}$|, (|$n_{\rm eff}$|), and magnification bias, (|$C_{\rm g}$|), as measured in Elvin-Poole, MacCrann et al. (2023). The survey property systematic weights have been accounted for in the effective angular number density following equation (5).
| Redshift bin | |$N_{\mathrm{gal}}$| | |$n_\mathrm{eff}$| | |$C_{\rm g}$| |
|---|---|---|---|
| redMaGiC lens sample | |||
| |$0.15 \lt z_\mathrm{ph} \lt 0.35$| | 330 243 | 0.022 | 1.3134 |
| |$0.35 \lt z_\mathrm{ph} \lt 0.50$| | 571 551 | 0.038 | –0.5179 |
| |$0.50 \lt z_\mathrm{ph} \lt 0.65$| | 872 611 | 0.058 | 0.3372 |
| |$0.65 \lt z_\mathrm{ph} \lt 0.80$| | 442 302 | 0.029 | 2.2515 |
| |$0.80 \lt z_\mathrm{ph} \lt 0.90$| | 377 329 | 0.025 | 1.9667 |
| MagLim lens sample | |||
| |$0.20 \lt z_\mathrm{ph} \lt 0.40$| | 2 236 473 | 0.150 | 1.2143 |
| |$0.40 \lt z_\mathrm{ph} \lt 0.55$| | 1 599 500 | 0.107 | 1.1486 |
| |$0.55 \lt z_\mathrm{ph} \lt 0.70$| | 1 627 413 | 0.109 | 1.8759 |
| |$0.70 \lt z_\mathrm{ph} \lt 0.85$| | 2 175 184 | 0.146 | 1.9694 |
| |$0.85 \lt z_\mathrm{ph} \lt 0.95$| | 1 583 686 | 0.106 | 1.7805 |
| |$0.95 \lt z_\mathrm{ph} \lt 1.05$| | 1 494 250 | 0.100 | 2.4789 |
| Redshift bin | |$N_{\mathrm{gal}}$| | |$n_\mathrm{eff}$| | |$C_{\rm g}$| |
|---|---|---|---|
| redMaGiC lens sample | |||
| |$0.15 \lt z_\mathrm{ph} \lt 0.35$| | 330 243 | 0.022 | 1.3134 |
| |$0.35 \lt z_\mathrm{ph} \lt 0.50$| | 571 551 | 0.038 | –0.5179 |
| |$0.50 \lt z_\mathrm{ph} \lt 0.65$| | 872 611 | 0.058 | 0.3372 |
| |$0.65 \lt z_\mathrm{ph} \lt 0.80$| | 442 302 | 0.029 | 2.2515 |
| |$0.80 \lt z_\mathrm{ph} \lt 0.90$| | 377 329 | 0.025 | 1.9667 |
| MagLim lens sample | |||
| |$0.20 \lt z_\mathrm{ph} \lt 0.40$| | 2 236 473 | 0.150 | 1.2143 |
| |$0.40 \lt z_\mathrm{ph} \lt 0.55$| | 1 599 500 | 0.107 | 1.1486 |
| |$0.55 \lt z_\mathrm{ph} \lt 0.70$| | 1 627 413 | 0.109 | 1.8759 |
| |$0.70 \lt z_\mathrm{ph} \lt 0.85$| | 2 175 184 | 0.146 | 1.9694 |
| |$0.85 \lt z_\mathrm{ph} \lt 0.95$| | 1 583 686 | 0.106 | 1.7805 |
| |$0.95 \lt z_\mathrm{ph} \lt 1.05$| | 1 494 250 | 0.100 | 2.4789 |
The second, and fiducial, lens sample used for the DES Y3 analyses, the so-called MagLim sample, was optimized in Porredon et al. (2021) to maximize its constraining power for combined galaxy clustering and galaxy–galaxy lensing. MagLim is a magnitude-limited sample defined by a magnitude cut in the i band that is linearly dependent on the photometric redshift, which allows including more galaxies at higher redshift. The photometric redshift estimation for the MagLim sample used the Directional Neighbourhood Fitting (dnf) algorithm (De Vicente, Sánchez & Sevilla-Noarbe 2016). In order to remove stellar contamination from binary stars and other bright objects, the MagLim selection applies a further lower magnitude cut of |$i \gt 17.5$|. The resultant sample, comprising 10.7 million galaxies, is divided into the six tomographic bins detailed in Table 16 and comprises a wider redshift distribution and 3.5 times more galaxies compared to the redMaGiC sample, resulting in tighter cosmological parameter constraints (Porredon et al. 2022). The angular density of the full MagLim catalogue is shown on the top-left panel of Fig. 1.
Statistically significant correlations were found between the galaxy number density of both the redMaGiC and MagLim lens samples and various observational survey properties. Such correlation imprints a non-cosmological bias into the galaxy clustering signal for the lens samples. We account for those biases by applying weights to each galaxy corresponding to the inverse of the estimated angular selection function. The computation and validation of these weights, for both lens samples, is described in Rodríguez-Monroy et al. (2022).
Finally, we used as source sample the DES Y3 weak lensing shape catalogue (Gatti et al. 2021). The source shapes are measured using the metacalibration method (Sheldon 2014; Huff & Mandelbaum 2017; Sheldon & Huff 2017). This method offers a self-calibrating approach to correct for biases in the galaxy shear estimation. This is achieved by applying an iterative process where a single elliptical Gaussian model is fitted to artificially sheared replicas of each galaxy. This procedure results in the construction of a shear response matrix, denoted as |$R = R_\gamma + R_S$|, which encapsulates two distinct components: |$R_\gamma$| representing the response of the shape estimator and |$R_S$| representing the response of object selection. The calibrated shear measurements are then obtained by multiplying the estimated galaxy ellipticities by the inverse of this matrix (Gatti et al. 2021).
For the DES Y3 shape catalogue, the metacalibration method improves the accuracy of galaxy shape measurements over its DES Y1 counterpart (Zuntz et al. 2018) by incorporating per galaxy inverse variance weights based on signal-to-noise ratio and size (Gatti et al. 2021), better astrometric methods (Sevilla-Noarbe et al. 2021), and better point-spread function (PSF) estimation (Jarvis et al. 2021). On top of that, shear biases sourced by object blending, not taken into account by metacalibration, were calibrated using image simulations in MacCrann et al. (2022). The resultant shape catalogue comprises 100.2 million galaxies covering the same area as the lens catalogues. This translates to an effective angular galaxy density of 5.59 arcmin|$^{-2}$|, as defined by Heymans et al. (2013). Furthermore, the catalogue exhibits an effective shape noise |$\sigma _e = 0.261$| per ellipticity component. The catalogue is further subdivided into four tomographic bins, selecting in photometric redshift estimates that rely on the Self-Organizing Map Photometric Redshift (SOMPZ) method as described by Myles, Alarcon et al. (2021), each possessing a normalizer redshift distribution as illustrated in Fig. 2 and properties detailed in Table 2.
The DES Y3 source sample properties. Similar to Table 1, this table shows the photometric redshift selection, the effective galaxy number density, (|$n_{\rm eff}$|) in arcmin|$^{-2}$|, the shape-noise per-component, (|$\sigma _e$|) and the mean shear response, (|$\langle R_\gamma \rangle$|), and the mean selection response, (|$\langle R_S \rangle$|).
| Redshift bin | |$n_\mathrm{eff}$| | |$\sigma _e$| | |$\langle R_\gamma \rangle$| | |$\langle R_S \rangle$| |
|---|---|---|---|---|
| |$0.0 \lt z_\mathrm{ph} \lt 0.36$| | 1.476 | 0.243 | 0.7636 | 0.0046 |
| |$0.36 \lt z_\mathrm{ph} \lt 0.63$| | 1.479 | 0.262 | 0.7182 | 0.0083 |
| |$0.63 \lt z_\mathrm{ph} \lt 0.87$| | 1.484 | 0.259 | 0.6887 | 0.0126 |
| |$0.87 \lt z_\mathrm{ph} \lt 2.0$| | 1.461 | 0.301 | 0.6154 | 0.0145 |
| Redshift bin | |$n_\mathrm{eff}$| | |$\sigma _e$| | |$\langle R_\gamma \rangle$| | |$\langle R_S \rangle$| |
|---|---|---|---|---|
| |$0.0 \lt z_\mathrm{ph} \lt 0.36$| | 1.476 | 0.243 | 0.7636 | 0.0046 |
| |$0.36 \lt z_\mathrm{ph} \lt 0.63$| | 1.479 | 0.262 | 0.7182 | 0.0083 |
| |$0.63 \lt z_\mathrm{ph} \lt 0.87$| | 1.484 | 0.259 | 0.6887 | 0.0126 |
| |$0.87 \lt z_\mathrm{ph} \lt 2.0$| | 1.461 | 0.301 | 0.6154 | 0.0145 |
The DES Y3 source sample properties. Similar to Table 1, this table shows the photometric redshift selection, the effective galaxy number density, (|$n_{\rm eff}$|) in arcmin|$^{-2}$|, the shape-noise per-component, (|$\sigma _e$|) and the mean shear response, (|$\langle R_\gamma \rangle$|), and the mean selection response, (|$\langle R_S \rangle$|).
| Redshift bin | |$n_\mathrm{eff}$| | |$\sigma _e$| | |$\langle R_\gamma \rangle$| | |$\langle R_S \rangle$| |
|---|---|---|---|---|
| |$0.0 \lt z_\mathrm{ph} \lt 0.36$| | 1.476 | 0.243 | 0.7636 | 0.0046 |
| |$0.36 \lt z_\mathrm{ph} \lt 0.63$| | 1.479 | 0.262 | 0.7182 | 0.0083 |
| |$0.63 \lt z_\mathrm{ph} \lt 0.87$| | 1.484 | 0.259 | 0.6887 | 0.0126 |
| |$0.87 \lt z_\mathrm{ph} \lt 2.0$| | 1.461 | 0.301 | 0.6154 | 0.0145 |
| Redshift bin | |$n_\mathrm{eff}$| | |$\sigma _e$| | |$\langle R_\gamma \rangle$| | |$\langle R_S \rangle$| |
|---|---|---|---|---|
| |$0.0 \lt z_\mathrm{ph} \lt 0.36$| | 1.476 | 0.243 | 0.7636 | 0.0046 |
| |$0.36 \lt z_\mathrm{ph} \lt 0.63$| | 1.479 | 0.262 | 0.7182 | 0.0083 |
| |$0.63 \lt z_\mathrm{ph} \lt 0.87$| | 1.484 | 0.259 | 0.6887 | 0.0126 |
| |$0.87 \lt z_\mathrm{ph} \lt 2.0$| | 1.461 | 0.301 | 0.6154 | 0.0145 |
2.2 Log-normal realizations
In order to validate our covariance matrix and parameter inference pipeline, we rely on the simulation of a large ensemble of log-normal random fields. The log-normal distribution has been used in a broad range of applications for modelling cosmic fields (Coles & Jones 1991). Their efficacy has been demonstrated in approximating the 1-point probability density function (PDF) of weak lensing convergence/shear (Hilbert, Hartlap & Schneider 2011; Xavier, Abdalla & Joachimi 2016) and the distribution of late-time matter density contrast fields (Friedrich et al. 2018; Gruen et al. 2018). In the context of DES, Clerkin et al. (2017) further validated the log-normal distribution assumption using Science Verification data for the convergence field. More recently, Friedrich et al. (2021) employed it to compute and validate covariance matrices for the full combination of weak lensing and galaxy clustering correlation functions, the 3|$\times$|2pt data vector in the CS of DES Y3.
In this work we use the implementation of the Full-sky log-normal Astro-fields Simulation Kit (flask; Xavier et al. 2016) to generate a suite of 1800 log-normal realizations of our data vector.
The flask requires a set of angular power spectra as its primary input. These spectra must include the auto- and cross-correlations of all the desired cosmic fields, simulated as healpix maps. We generate them using the theoretical framework presented in Section 3.1 at the fiducial redMaGiC + metacalibration cosmology of Table 3. A more detailed description of the parameters of Table 3 is found in Section 3.1 and the power spectra measurements in the suite of log-normal realizations are presented in Appendix B.
The parameters used in the present analyses. We show the fiducial values used for the construction of the log-normal realizations and the prior probability distributions used for the Bayesian parameter inference. Priors for the redMaGiC + metacalibration analysis follow the ones described in Pandey et al. (2022) while the priors for the MagLim + metacalibration are the same as in Porredon et al. (2022). Uniform priors are described by |$\mathcal {U}(x,y)$|, with x and y denoting the prior edges, and Gaussian priors are represented by |$\mathcal {N}(\mu ,\sigma)$|, with |$\mu$| and |$\sigma$| being the mean and standard deviation. The dark energy equation of state w is fixed at |$-1$| for |$\Lambda$|CDM chains, while for wCDM it varies following the indicated uniform prior. The main analyses were performed only with linear galaxy bias in their modelling; the non-linear galaxy bias parameters were used in some additional runs (see Sections 3.2 and 4.3).
| Cosmology | Intrinsic alignments | ||||
|---|---|---|---|---|---|
| Parameters | Fiducial values | Priors | Parameters | Fiducial values | Priors |
| |$\Omega _m$| | 0.3 | |$\mathcal {U}(0.1, 0.9)$| | |$a_1$| | 0.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$h_0$| | 0.69 | |$\mathcal {U}(0.55, 0.91)$| | |$a_2$| | –1.36 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$\Omega _b$| | 0.048 | |$\mathcal {U}(0.03, 0.07)$| | |$\alpha _1$| | –1.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$n_s$| | 0.97 | |$\mathcal {U}(0.87, 1.07)$| | |$\alpha _2$| | –2.5 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$A_s 10^{9}$| | 2.19 | |$\mathcal {U}(0.5, 5.0)$| | |$b_{\text{TA}}$| | 1.0 | |$\mathcal {U}(0.0, 2.0)$| |
| |$\Omega _\nu h^2$| | 0.00083 | |$\mathcal {U}(0.0006, 0.00644)$| | |$z_0$| | 0.62 | Fixed |
| w | |$-1$| | |$\Lambda$|CDM: fixed| wCDM: |$\mathcal {U}(-2, -0.33)$| | |||
| redMaGiC + metacalibration | MagLim + metacalibration | ||||
| Linear galaxy bias | Linear galaxy bias | ||||
| |$b_i$| | 1.7, 1.7, 1.7, 2.0, 2.0 | |$\mathcal {U}(0.8, 3.0)$| | |$b_i$| | 1.5, 1.8, 1.8, 1.9, 2.3, 2.3 | |$\mathcal {U}(0.8, 3.0)$| |
| Non-linear galaxy bias | Non-linear galaxy bias | ||||
| |$b^i_1 \sigma _8$| | 1.42, 1.42, 1.42, 1.68, 1.68 | |$\mathcal {U}(0.67, 2.52)$| | |$b_1^i \sigma _8$| | 1.43, 1.43, 1.43, 1.69, 1.69, 1.69 | |$\mathcal {U}(0.67, 3.0)$| |
| |$b^i_2 \sigma _8$| | 0.16, 0.16, 0.16, 0.35, 0.35 | |$\mathcal {U}(-3.5, 3.5)$| | |$b_2^i \sigma _8$| | 0.16, 0.16, 0.16, 0.36, 0.36, 0.36 | |$\mathcal {U}(-4.2, 4.2)$| |
| Shear calibration | Shear calibration | ||||
| |$m^1$| | |$-0.0063$| | |$\mathcal {N}(-0.0063, 0.0091)$| | |$m^1$| | |$-0.006$| | |$\mathcal {N}(-0.006, 0.008)$| |
| |$m^2$| | |$-0.0198$| | |$\mathcal {N}(-0.0198, 0.0078)$| | |$m^2$| | |$-0.010$| | |$\mathcal {N}(-0.010, 0.013)$| |
| |$m^3$| | |$-0.0241$| | |$\mathcal {N}(-0.0241, 0.0076)$| | |$m^3$| | |$-0.026$| | |$\mathcal {N}(-0.026, 0.009)$| |
| |$m^4$| | |$-0.0369$| | |$\mathcal {N}(-0.0369, 0.0076)$| | |$m^4$| | |$-0.032$| | |$\mathcal {N}(-0.032, 0.012)$| |
| Source photo-z | Source photo-z | ||||
| |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| | |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| |
| |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.015)$| | |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.011)$| | |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.006)$| |
| |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.017)$| | |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| Lens photo-z | Lens photo-z shift | ||||
| |$\Delta z^1_l$| | |$0.006$| | |$\mathcal {N}(0.006, 0.004)$| | |$\Delta z^1_l$| | |$-0.009$| | |$\mathcal {N}(-0.009, 0.007)$| |
| |$\Delta z^2_l$| | 0.001 | |$\mathcal {N}(0.001, 0.003)$| | |$\Delta z^2_l$| | |$-0.035$| | |$\mathcal {N}(-0.035, 0.011)$| |
| |$\Delta z^3_l$| | 0.004 | |$\mathcal {N}(0.004, 0.003)$| | |$\Delta z^3_l$| | |$-0.005$| | |$\mathcal {N}(-0.005, 0.006)$| |
| |$\Delta z^4_l$| | |$-0.002$| | |$\mathcal {N}(-0.002, 0.005)$| | |$\Delta z^4_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.006)$| |
| |$\Delta z^5_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.01)$| | |$\Delta z^5_l$| | 0.002 | |$\mathcal {N}(0.002, 0.007)$| |
| – | – | – | |$\Delta z^6_l$| | 0.002 | |$\mathcal {N}(0.002, 0.008)$| |
| Lens photo-z stretch | Lens photo-z stretch | ||||
| |$\sigma z^1_l$| | 1.0 | Fixed | |$\sigma z^1_l$| | 0.975 | |$\mathcal {N}(0.975, 0.062)$| |
| |$\sigma z^2_l$| | 1.0 | Fixed | |$\sigma z^2_l$| | 1.306 | |$\mathcal {N}(1.306, 0.093)$| |
| |$\sigma z^3_l$| | 1.0 | Fixed | |$\sigma z^3_l$| | 0.870 | |$\mathcal {N}(0.870, 0.054)$| |
| |$\sigma z^4_l$| | 1.0 | Fixed | |$\sigma z^4_l$| | 0.918 | |$\mathcal {N}(0.918, 0.051)$| |
| |$\sigma z^5_l$| | 1.23 | |$\mathcal {N}(1.23, 0.054)$| | |$\sigma z^5_l$| | 1.080 | |$\mathcal {N}(1.080, 0.067)$| |
| – | – | – | |$\sigma z^6_l$| | 0.845 | |$\mathcal {N}(0.845, 0.073)$| |
| Cosmology | Intrinsic alignments | ||||
|---|---|---|---|---|---|
| Parameters | Fiducial values | Priors | Parameters | Fiducial values | Priors |
| |$\Omega _m$| | 0.3 | |$\mathcal {U}(0.1, 0.9)$| | |$a_1$| | 0.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$h_0$| | 0.69 | |$\mathcal {U}(0.55, 0.91)$| | |$a_2$| | –1.36 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$\Omega _b$| | 0.048 | |$\mathcal {U}(0.03, 0.07)$| | |$\alpha _1$| | –1.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$n_s$| | 0.97 | |$\mathcal {U}(0.87, 1.07)$| | |$\alpha _2$| | –2.5 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$A_s 10^{9}$| | 2.19 | |$\mathcal {U}(0.5, 5.0)$| | |$b_{\text{TA}}$| | 1.0 | |$\mathcal {U}(0.0, 2.0)$| |
| |$\Omega _\nu h^2$| | 0.00083 | |$\mathcal {U}(0.0006, 0.00644)$| | |$z_0$| | 0.62 | Fixed |
| w | |$-1$| | |$\Lambda$|CDM: fixed| wCDM: |$\mathcal {U}(-2, -0.33)$| | |||
| redMaGiC + metacalibration | MagLim + metacalibration | ||||
| Linear galaxy bias | Linear galaxy bias | ||||
| |$b_i$| | 1.7, 1.7, 1.7, 2.0, 2.0 | |$\mathcal {U}(0.8, 3.0)$| | |$b_i$| | 1.5, 1.8, 1.8, 1.9, 2.3, 2.3 | |$\mathcal {U}(0.8, 3.0)$| |
| Non-linear galaxy bias | Non-linear galaxy bias | ||||
| |$b^i_1 \sigma _8$| | 1.42, 1.42, 1.42, 1.68, 1.68 | |$\mathcal {U}(0.67, 2.52)$| | |$b_1^i \sigma _8$| | 1.43, 1.43, 1.43, 1.69, 1.69, 1.69 | |$\mathcal {U}(0.67, 3.0)$| |
| |$b^i_2 \sigma _8$| | 0.16, 0.16, 0.16, 0.35, 0.35 | |$\mathcal {U}(-3.5, 3.5)$| | |$b_2^i \sigma _8$| | 0.16, 0.16, 0.16, 0.36, 0.36, 0.36 | |$\mathcal {U}(-4.2, 4.2)$| |
| Shear calibration | Shear calibration | ||||
| |$m^1$| | |$-0.0063$| | |$\mathcal {N}(-0.0063, 0.0091)$| | |$m^1$| | |$-0.006$| | |$\mathcal {N}(-0.006, 0.008)$| |
| |$m^2$| | |$-0.0198$| | |$\mathcal {N}(-0.0198, 0.0078)$| | |$m^2$| | |$-0.010$| | |$\mathcal {N}(-0.010, 0.013)$| |
| |$m^3$| | |$-0.0241$| | |$\mathcal {N}(-0.0241, 0.0076)$| | |$m^3$| | |$-0.026$| | |$\mathcal {N}(-0.026, 0.009)$| |
| |$m^4$| | |$-0.0369$| | |$\mathcal {N}(-0.0369, 0.0076)$| | |$m^4$| | |$-0.032$| | |$\mathcal {N}(-0.032, 0.012)$| |
| Source photo-z | Source photo-z | ||||
| |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| | |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| |
| |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.015)$| | |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.011)$| | |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.006)$| |
| |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.017)$| | |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| Lens photo-z | Lens photo-z shift | ||||
| |$\Delta z^1_l$| | |$0.006$| | |$\mathcal {N}(0.006, 0.004)$| | |$\Delta z^1_l$| | |$-0.009$| | |$\mathcal {N}(-0.009, 0.007)$| |
| |$\Delta z^2_l$| | 0.001 | |$\mathcal {N}(0.001, 0.003)$| | |$\Delta z^2_l$| | |$-0.035$| | |$\mathcal {N}(-0.035, 0.011)$| |
| |$\Delta z^3_l$| | 0.004 | |$\mathcal {N}(0.004, 0.003)$| | |$\Delta z^3_l$| | |$-0.005$| | |$\mathcal {N}(-0.005, 0.006)$| |
| |$\Delta z^4_l$| | |$-0.002$| | |$\mathcal {N}(-0.002, 0.005)$| | |$\Delta z^4_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.006)$| |
| |$\Delta z^5_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.01)$| | |$\Delta z^5_l$| | 0.002 | |$\mathcal {N}(0.002, 0.007)$| |
| – | – | – | |$\Delta z^6_l$| | 0.002 | |$\mathcal {N}(0.002, 0.008)$| |
| Lens photo-z stretch | Lens photo-z stretch | ||||
| |$\sigma z^1_l$| | 1.0 | Fixed | |$\sigma z^1_l$| | 0.975 | |$\mathcal {N}(0.975, 0.062)$| |
| |$\sigma z^2_l$| | 1.0 | Fixed | |$\sigma z^2_l$| | 1.306 | |$\mathcal {N}(1.306, 0.093)$| |
| |$\sigma z^3_l$| | 1.0 | Fixed | |$\sigma z^3_l$| | 0.870 | |$\mathcal {N}(0.870, 0.054)$| |
| |$\sigma z^4_l$| | 1.0 | Fixed | |$\sigma z^4_l$| | 0.918 | |$\mathcal {N}(0.918, 0.051)$| |
| |$\sigma z^5_l$| | 1.23 | |$\mathcal {N}(1.23, 0.054)$| | |$\sigma z^5_l$| | 1.080 | |$\mathcal {N}(1.080, 0.067)$| |
| – | – | – | |$\sigma z^6_l$| | 0.845 | |$\mathcal {N}(0.845, 0.073)$| |
The parameters used in the present analyses. We show the fiducial values used for the construction of the log-normal realizations and the prior probability distributions used for the Bayesian parameter inference. Priors for the redMaGiC + metacalibration analysis follow the ones described in Pandey et al. (2022) while the priors for the MagLim + metacalibration are the same as in Porredon et al. (2022). Uniform priors are described by |$\mathcal {U}(x,y)$|, with x and y denoting the prior edges, and Gaussian priors are represented by |$\mathcal {N}(\mu ,\sigma)$|, with |$\mu$| and |$\sigma$| being the mean and standard deviation. The dark energy equation of state w is fixed at |$-1$| for |$\Lambda$|CDM chains, while for wCDM it varies following the indicated uniform prior. The main analyses were performed only with linear galaxy bias in their modelling; the non-linear galaxy bias parameters were used in some additional runs (see Sections 3.2 and 4.3).
| Cosmology | Intrinsic alignments | ||||
|---|---|---|---|---|---|
| Parameters | Fiducial values | Priors | Parameters | Fiducial values | Priors |
| |$\Omega _m$| | 0.3 | |$\mathcal {U}(0.1, 0.9)$| | |$a_1$| | 0.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$h_0$| | 0.69 | |$\mathcal {U}(0.55, 0.91)$| | |$a_2$| | –1.36 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$\Omega _b$| | 0.048 | |$\mathcal {U}(0.03, 0.07)$| | |$\alpha _1$| | –1.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$n_s$| | 0.97 | |$\mathcal {U}(0.87, 1.07)$| | |$\alpha _2$| | –2.5 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$A_s 10^{9}$| | 2.19 | |$\mathcal {U}(0.5, 5.0)$| | |$b_{\text{TA}}$| | 1.0 | |$\mathcal {U}(0.0, 2.0)$| |
| |$\Omega _\nu h^2$| | 0.00083 | |$\mathcal {U}(0.0006, 0.00644)$| | |$z_0$| | 0.62 | Fixed |
| w | |$-1$| | |$\Lambda$|CDM: fixed| wCDM: |$\mathcal {U}(-2, -0.33)$| | |||
| redMaGiC + metacalibration | MagLim + metacalibration | ||||
| Linear galaxy bias | Linear galaxy bias | ||||
| |$b_i$| | 1.7, 1.7, 1.7, 2.0, 2.0 | |$\mathcal {U}(0.8, 3.0)$| | |$b_i$| | 1.5, 1.8, 1.8, 1.9, 2.3, 2.3 | |$\mathcal {U}(0.8, 3.0)$| |
| Non-linear galaxy bias | Non-linear galaxy bias | ||||
| |$b^i_1 \sigma _8$| | 1.42, 1.42, 1.42, 1.68, 1.68 | |$\mathcal {U}(0.67, 2.52)$| | |$b_1^i \sigma _8$| | 1.43, 1.43, 1.43, 1.69, 1.69, 1.69 | |$\mathcal {U}(0.67, 3.0)$| |
| |$b^i_2 \sigma _8$| | 0.16, 0.16, 0.16, 0.35, 0.35 | |$\mathcal {U}(-3.5, 3.5)$| | |$b_2^i \sigma _8$| | 0.16, 0.16, 0.16, 0.36, 0.36, 0.36 | |$\mathcal {U}(-4.2, 4.2)$| |
| Shear calibration | Shear calibration | ||||
| |$m^1$| | |$-0.0063$| | |$\mathcal {N}(-0.0063, 0.0091)$| | |$m^1$| | |$-0.006$| | |$\mathcal {N}(-0.006, 0.008)$| |
| |$m^2$| | |$-0.0198$| | |$\mathcal {N}(-0.0198, 0.0078)$| | |$m^2$| | |$-0.010$| | |$\mathcal {N}(-0.010, 0.013)$| |
| |$m^3$| | |$-0.0241$| | |$\mathcal {N}(-0.0241, 0.0076)$| | |$m^3$| | |$-0.026$| | |$\mathcal {N}(-0.026, 0.009)$| |
| |$m^4$| | |$-0.0369$| | |$\mathcal {N}(-0.0369, 0.0076)$| | |$m^4$| | |$-0.032$| | |$\mathcal {N}(-0.032, 0.012)$| |
| Source photo-z | Source photo-z | ||||
| |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| | |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| |
| |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.015)$| | |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.011)$| | |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.006)$| |
| |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.017)$| | |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| Lens photo-z | Lens photo-z shift | ||||
| |$\Delta z^1_l$| | |$0.006$| | |$\mathcal {N}(0.006, 0.004)$| | |$\Delta z^1_l$| | |$-0.009$| | |$\mathcal {N}(-0.009, 0.007)$| |
| |$\Delta z^2_l$| | 0.001 | |$\mathcal {N}(0.001, 0.003)$| | |$\Delta z^2_l$| | |$-0.035$| | |$\mathcal {N}(-0.035, 0.011)$| |
| |$\Delta z^3_l$| | 0.004 | |$\mathcal {N}(0.004, 0.003)$| | |$\Delta z^3_l$| | |$-0.005$| | |$\mathcal {N}(-0.005, 0.006)$| |
| |$\Delta z^4_l$| | |$-0.002$| | |$\mathcal {N}(-0.002, 0.005)$| | |$\Delta z^4_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.006)$| |
| |$\Delta z^5_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.01)$| | |$\Delta z^5_l$| | 0.002 | |$\mathcal {N}(0.002, 0.007)$| |
| – | – | – | |$\Delta z^6_l$| | 0.002 | |$\mathcal {N}(0.002, 0.008)$| |
| Lens photo-z stretch | Lens photo-z stretch | ||||
| |$\sigma z^1_l$| | 1.0 | Fixed | |$\sigma z^1_l$| | 0.975 | |$\mathcal {N}(0.975, 0.062)$| |
| |$\sigma z^2_l$| | 1.0 | Fixed | |$\sigma z^2_l$| | 1.306 | |$\mathcal {N}(1.306, 0.093)$| |
| |$\sigma z^3_l$| | 1.0 | Fixed | |$\sigma z^3_l$| | 0.870 | |$\mathcal {N}(0.870, 0.054)$| |
| |$\sigma z^4_l$| | 1.0 | Fixed | |$\sigma z^4_l$| | 0.918 | |$\mathcal {N}(0.918, 0.051)$| |
| |$\sigma z^5_l$| | 1.23 | |$\mathcal {N}(1.23, 0.054)$| | |$\sigma z^5_l$| | 1.080 | |$\mathcal {N}(1.080, 0.067)$| |
| – | – | – | |$\sigma z^6_l$| | 0.845 | |$\mathcal {N}(0.845, 0.073)$| |
| Cosmology | Intrinsic alignments | ||||
|---|---|---|---|---|---|
| Parameters | Fiducial values | Priors | Parameters | Fiducial values | Priors |
| |$\Omega _m$| | 0.3 | |$\mathcal {U}(0.1, 0.9)$| | |$a_1$| | 0.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$h_0$| | 0.69 | |$\mathcal {U}(0.55, 0.91)$| | |$a_2$| | –1.36 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$\Omega _b$| | 0.048 | |$\mathcal {U}(0.03, 0.07)$| | |$\alpha _1$| | –1.7 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$n_s$| | 0.97 | |$\mathcal {U}(0.87, 1.07)$| | |$\alpha _2$| | –2.5 | |$\mathcal {U}(-5.0, 5.0)$| |
| |$A_s 10^{9}$| | 2.19 | |$\mathcal {U}(0.5, 5.0)$| | |$b_{\text{TA}}$| | 1.0 | |$\mathcal {U}(0.0, 2.0)$| |
| |$\Omega _\nu h^2$| | 0.00083 | |$\mathcal {U}(0.0006, 0.00644)$| | |$z_0$| | 0.62 | Fixed |
| w | |$-1$| | |$\Lambda$|CDM: fixed| wCDM: |$\mathcal {U}(-2, -0.33)$| | |||
| redMaGiC + metacalibration | MagLim + metacalibration | ||||
| Linear galaxy bias | Linear galaxy bias | ||||
| |$b_i$| | 1.7, 1.7, 1.7, 2.0, 2.0 | |$\mathcal {U}(0.8, 3.0)$| | |$b_i$| | 1.5, 1.8, 1.8, 1.9, 2.3, 2.3 | |$\mathcal {U}(0.8, 3.0)$| |
| Non-linear galaxy bias | Non-linear galaxy bias | ||||
| |$b^i_1 \sigma _8$| | 1.42, 1.42, 1.42, 1.68, 1.68 | |$\mathcal {U}(0.67, 2.52)$| | |$b_1^i \sigma _8$| | 1.43, 1.43, 1.43, 1.69, 1.69, 1.69 | |$\mathcal {U}(0.67, 3.0)$| |
| |$b^i_2 \sigma _8$| | 0.16, 0.16, 0.16, 0.35, 0.35 | |$\mathcal {U}(-3.5, 3.5)$| | |$b_2^i \sigma _8$| | 0.16, 0.16, 0.16, 0.36, 0.36, 0.36 | |$\mathcal {U}(-4.2, 4.2)$| |
| Shear calibration | Shear calibration | ||||
| |$m^1$| | |$-0.0063$| | |$\mathcal {N}(-0.0063, 0.0091)$| | |$m^1$| | |$-0.006$| | |$\mathcal {N}(-0.006, 0.008)$| |
| |$m^2$| | |$-0.0198$| | |$\mathcal {N}(-0.0198, 0.0078)$| | |$m^2$| | |$-0.010$| | |$\mathcal {N}(-0.010, 0.013)$| |
| |$m^3$| | |$-0.0241$| | |$\mathcal {N}(-0.0241, 0.0076)$| | |$m^3$| | |$-0.026$| | |$\mathcal {N}(-0.026, 0.009)$| |
| |$m^4$| | |$-0.0369$| | |$\mathcal {N}(-0.0369, 0.0076)$| | |$m^4$| | |$-0.032$| | |$\mathcal {N}(-0.032, 0.012)$| |
| Source photo-z | Source photo-z | ||||
| |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| | |$\Delta z^1_s$| | 0.0 | |$\mathcal {N}(0.0, 0.018)$| |
| |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.015)$| | |$\Delta z^2_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.011)$| | |$\Delta z^3_s$| | 0.0 | |$\mathcal {N}(0.0, 0.006)$| |
| |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.017)$| | |$\Delta z^4_s$| | 0.0 | |$\mathcal {N}(0.0, 0.013)$| |
| Lens photo-z | Lens photo-z shift | ||||
| |$\Delta z^1_l$| | |$0.006$| | |$\mathcal {N}(0.006, 0.004)$| | |$\Delta z^1_l$| | |$-0.009$| | |$\mathcal {N}(-0.009, 0.007)$| |
| |$\Delta z^2_l$| | 0.001 | |$\mathcal {N}(0.001, 0.003)$| | |$\Delta z^2_l$| | |$-0.035$| | |$\mathcal {N}(-0.035, 0.011)$| |
| |$\Delta z^3_l$| | 0.004 | |$\mathcal {N}(0.004, 0.003)$| | |$\Delta z^3_l$| | |$-0.005$| | |$\mathcal {N}(-0.005, 0.006)$| |
| |$\Delta z^4_l$| | |$-0.002$| | |$\mathcal {N}(-0.002, 0.005)$| | |$\Delta z^4_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.006)$| |
| |$\Delta z^5_l$| | |$-0.007$| | |$\mathcal {N}(-0.007, 0.01)$| | |$\Delta z^5_l$| | 0.002 | |$\mathcal {N}(0.002, 0.007)$| |
| – | – | – | |$\Delta z^6_l$| | 0.002 | |$\mathcal {N}(0.002, 0.008)$| |
| Lens photo-z stretch | Lens photo-z stretch | ||||
| |$\sigma z^1_l$| | 1.0 | Fixed | |$\sigma z^1_l$| | 0.975 | |$\mathcal {N}(0.975, 0.062)$| |
| |$\sigma z^2_l$| | 1.0 | Fixed | |$\sigma z^2_l$| | 1.306 | |$\mathcal {N}(1.306, 0.093)$| |
| |$\sigma z^3_l$| | 1.0 | Fixed | |$\sigma z^3_l$| | 0.870 | |$\mathcal {N}(0.870, 0.054)$| |
| |$\sigma z^4_l$| | 1.0 | Fixed | |$\sigma z^4_l$| | 0.918 | |$\mathcal {N}(0.918, 0.051)$| |
| |$\sigma z^5_l$| | 1.23 | |$\mathcal {N}(1.23, 0.054)$| | |$\sigma z^5_l$| | 1.080 | |$\mathcal {N}(1.080, 0.067)$| |
| – | – | – | |$\sigma z^6_l$| | 0.845 | |$\mathcal {N}(0.845, 0.073)$| |
2.3 Angular power spectra measurements
We estimate angular power spectra of galaxy clustering (GCL) and galaxy–galaxy lensing (GGL) using the so-called pseudo-|$C_\ell$| (PCL) or MASTER method (Peebles 1973; Hivon et al. 2002; Brown, Castro & Taylor 2005), as implemented in the NaMASTER code7 (Alonso et al. 2019).
We commence by constructing weighted tomographic cosmic shear maps as
where the index i runs over galaxies in the catalogue, index p runs over pixels in map, |$\hat{\vec{\gamma }}_i=(\hat{\gamma }_{1,i}, \hat{\gamma }_{2,i})$| is the calibrated galaxy shear and |$v^{(\gamma)}_i$| its associated weight.
Analogously, tomographic galaxy over-density maps are given by
where |$N_p = \sum _{i\in p} v^{(\delta)}_i$| gives the number of galaxies at a given pixel p, with |$v_i$| the weight associated with the ith galaxy as given by the systematics weights (see Section 2). When working with simulated log-normal realizations, we assume |$v_i = 1$|. Whereas, |$w^{(\delta)}_p$| gives the effective fraction of the area covered by the survey at pixel p.
In addition to the cosmic shear and galaxy clustering signal maps, the pseudo-|$C_\ell$| method relies on the use of an angular window function, also known as the mask. Such a mask encodes the information of the partial-sky coverage of the observed signal and is used to deconvolve this effect on the estimated bandpowers. For the cosmic shear maps, we use the inverse-variance weighting scheme as presented in Nicola et al. (2021), and construct tomographic mask maps as
We note this approach assigns the weighted number of galaxies map as mask, thus there are different masks for each source tomographic bin.
The discrete nature of galaxies introduces a shot-noise contribution to the autocorrelation spectra. We estimate this noise analytically, as specified below, and subsequently, we subtract it from our power spectrum estimates. For the case of galaxy clustering we assume this noise to be Poissonian, and estimate it analytically for the pseudo-spectra following Alonso et al. (2019), Nicola et al. (2020), and García-García et al. (2021) as
where |$N_{\rm pix}$| is the total number of pixels in our maps. We note that this noise is constant over all multipoles. For healpix-based pixelization, this is given in terms of the healpix resolution parameter (Górski et al. 2005), |$N_{\rm side}$| as |$N_{\rm pix} = 12 N_{\rm side}^2$|. Note the first term in parentheses is the mean of the mask on the sphere. The second term is the Poissonian noise in terms of the effective mean angular number density, |$n_{\rm eff}$|, when accounting for the galaxy weights, |$v^{\delta }_i$|, as
where |$\Omega _{\rm pix}$| is the area of each healpix pixel at the given resolution.
For the case of cosmic shear, the pseudo-spectra noise is computed following Nicola et al. (2020) as
where |$\sigma _{e, i}^2 = \left(\hat{\gamma }_{1,i}^2 + \hat{\gamma }_{2,i}^2 \right)/2$| is the RMS noise per galaxy for a given shape estimator.
Finally, the different pseudo-spectra are binned into bandpowers. The chosen bandpowers are a set of 32 square-root-spaced bins within the multipole interval |$\ell = [8, 2048]$|. The angular power spectra measurements for C |$C^{\text{gg}}_\ell$| and GGC |$C^{\text{gE}}_\ell$| using the redMaGiC and MagLim lens samples are shown in Figs 3 and 4, along with the theory prediction calculated at the |$\Lambda$|CDM best-fitting values. For MagLim, we use one prediction considering only the first four tomographic bins (green) and another using all six bins (purple). The residual plots comparing the measurements to these predictions are shown below for each redshift combination. The measurements of the 1800 log-normal realizations can be found in Appendix B.
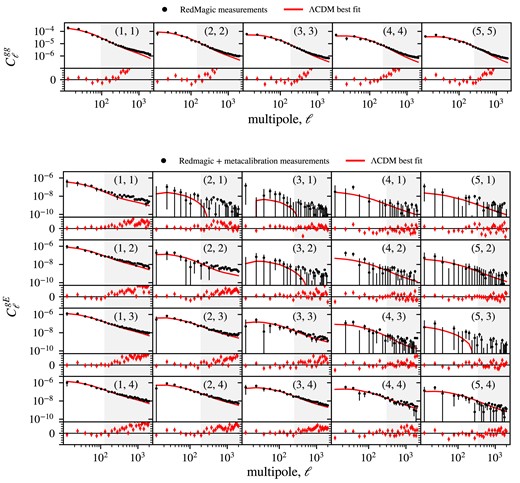
Angular power spectrum measurements of GC (|$C_\ell ^{\text{gg}}$|) and galaxy–galaxy lensing (|$C_\ell ^{\text{gE}}$|) from the DES Y3 redMaGiC and metacalibration catalogues, along side with theoretical prediction calculated at the |$\Lambda$|CDM best-fitting values. Residual plots compare measurements with the theoretical prediction.
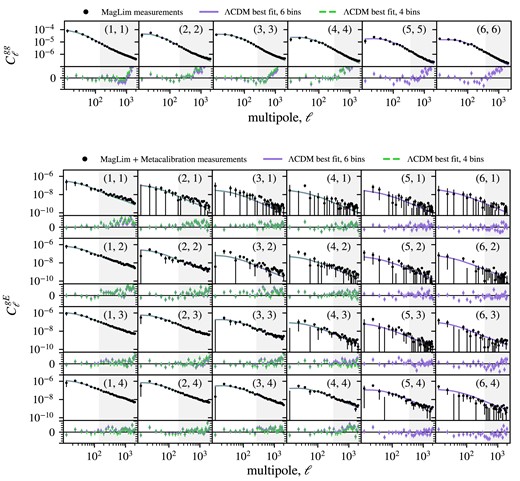
Angular power spectrum measurements of galaxy clustering (|$C_\ell ^{\text{gg}}$|) and galaxy–galaxy lensing (|$C_\ell ^{\text{gE}}$|) from the DES Y3 MagLim and metacalibration catalogues, alongside with theoretical prediction calculated at the |$\Lambda$|CDM best-fitting values from the analysis using all six tomographic lenses (solid, purple line) and only the first four bins (dashed, green line). Residual plots compare measurements with the theoretical prediction from the six-bin (purple markers) and four-bin (green points) analysis. The indexes |$(z_i, z_j)$| in each subplot indicate the redshift bin combination. For GGL, |$z_i$| and |$z_j$| refer to the bin of the lens and source, respectively.
3 METHODOLOGY
3.1 Theoretical modelling
Our theoretical framework for modelling the angular power spectra draws upon the formalism presented in Krause et al. (2021).
We calculated the galaxy clustering angular power spectra using the full non-Limber approach detailed in section III.B of Krause et al. (2021),
where the kernel accounts for linear density growth (D), redshift-space distortions (RSD), and lensing magnification (|$\mu$|), |$\Delta ^i_{\delta _{\rm g}}(k,\ell)=\Delta ^i_{\rm D}(k,\ell)+\Delta ^i_{\rm {RSD}}(k,\ell)+\Delta ^i_{\mu }(k,\ell)$|. The specific form of each term is provided by Krause et al. (2021) and Fang et al. (2020b). Numerical integrations were performed using the FFTLog algorithm (Hamilton 2000) as implemented by Fang et al. (2020b).
The galaxy–galaxy lensing spectra, on the other hand, were evaluated under the Limber approximation,
In both equations (7) and (8), we refer to |$\delta _{\rm g}$| as the lens galaxy sample overdensity field and |$\gamma$| as the source galaxy sample shear field and |$i, j$| run over tomographic redshift bins for the corresponding galaxy sample.
Furthermore, equations (7) and (8) can be understood as projections of the non-linear total matter power spectrum, |$P_{\rm NL}(k, z)$|, computed using CAMB (Lewis, Challinor & Lasenby 2000) and halofit (Takahashi et al. 2012), by specific radial kernels per tomographic bin along the comoving distance |$\chi$| or redshift z. These kernels encode the response to the large-scale structure of the different probes at different scales and are given by
where |$H_0$| is the Hubble’s constant, |$\Omega _{\rm m}$| the matter density, |$a(\chi)$| the scale factor corresponding to the comoving distance |$\chi$|, |$b(k,z)$| the scale-dependent galaxy bias, and |$n^i_{{\delta _{g}}/\gamma }(z)$| the normalizer redshift distributions of the lens/source galaxies in the tomographic bin i.
We consider two models for the galaxy bias |$b(k,z)$|. The first, and fiducial choice, is a linear bias model where |$b(k,z)=b^{i}$| is a constant free parameter for each tomographic bin i. The second one is a non-linear biasing model presented by Saito et al. (2014) and Pandey et al. (2022), consisting of a perturbative galaxy bias model to third order in the density field with four parameters: |$b^{i}_1$| (linear bias), |$b^{i}_2$| (local quadratic bias), |$b^{i}_{s^2}$| (tidal quadratic bias), and |$b^{i}_{\rm 3nl}$| (third-order non-local bias). Following Pandey et al. (2022) and Porredon et al. (2022), we fix the bias parameters |$b_{s^2}^i$| and |$b_{\rm 3nl}^i$| to their co-evolution value of |$b_{s^2}^i=-4(b^i-1)/7$| and |$b_{\rm 3nl}^i=b^i-1$| (Saito et al. 2014), making the total number of free parameters for this bias model two per tomographic bin i. We further note that for this second model, the power spectra from halofit is not used. Instead, different kernels for each bias term are computed from the linear power spectrum, following Saito et al. (2014) and Pandey et al. (2022).
To account for the contribution to the observed galaxy shapes caused by the gravitational tidal field, the so-called intrinsic alignment (IA) effect, we adopt the tidal alignment tidal torquing (TATT) model of Blazek et al. (2019). The TATT model has five parameters: |$a_1$| and |$\alpha _1$| characterize the amplitude and redshift dependence of the tidal alignment; |$a_2$| and |$\alpha _2$| characterize the amplitude and redshift dependence of the tidal torquing effect and |$b_{\rm TA}$| accounts for the fact that our measurement is weighted by the observed galaxy counts. Following Pandey et al. (2022) and Porredon et al. (2022), we will also compare our results using a simpler IA model, the nonlinear alignment (NLA) model of Bridle & King (2007). The NLA model is equivalent to the TATT model in the limit where |$a_2,\alpha _2,b_{\rm TA}\rightarrow 0$|, thus having two free parameters.
Foreground structure can distort the observed lens galaxy properties due to gravitational lensing magnification effects. Such distortions are commonly known as lens magnification, and impact both the apparent position and the distribution of light received from individual galaxy images. We model the effect of lens magnification following Krause et al. (2021) and Elvin-Poole et al. (2023) by modifying the lens galaxy overdensity kernel, equation (9), as
where |$\kappa _{\rm g}^i$| is the tomographic convergence field, as defined in Krause et al. (2021) and Elvin-Poole et al. (2023), and |$C_{\rm g}^i$| are the magnification bias coefficients. We fix the values of |$C_{\rm g}^i$| to the ones estimated by Elvin-Poole et al. (2023) as listed in Table 1.
To account for possible residual uncertainty in both lens and source galaxies redshift distributions, we introduce shift parameters, |$\Delta z^i$|, when modelling the redshift distributions
For the lens sample, motivated by Cawthon et al. (2022) and Porredon et al. (2022) we additionally introduce stretch parameters (|$\sigma ^i_{z}$|), as
where |$\langle z \rangle$| is the mean redshift of the ith tomographic bin.
To account for possible residual uncertainty in the shear calibration, we introduce multiplicative factors to the shear kernel, equation (10), as
where |$m^{i}$| is the shear calibration bias for source bin i.
Finally, the theoretical angular power spectrum is binned into bandpowers. This is done by filtering the predictions with a set of bandpower windows, |$\mathcal {F}_{q\ell }^{ab}$|, consistent with the pseudo-|$C_\ell$| approach we follow for the data estimates (see Section 2.3). Thus the final model for a bandpower, |$\ell \in q$|, is computed as
where |$(i, j)$| represents the tomographic redshift bin pair, and a vector notation, |$\mathbf {C} = \left(C^{gg}, C^{gE}, C^{gB} \right)$|, is required to account for the |$E/B$|-mode decomposition of the shear field. We refer the reader to Alonso et al. (2019) for the detailed expressions for the bandpower windows and details about the |$E/B$|-mode decomposition.
All the different pieces for the modelling presented above are integrated as modules in the CosmoSiS8 framework (Zuntz et al. 2015) in an analogous way to what was done for the configuration-space analysis presented in Porredon et al. (2022) and Pandey et al. (2022).
The complete set of parameters of the theoretical modelling is summarized in Table 3, including their fiducial values and priors. For |$\Lambda$|CDM analyses, we sample over the matter density |$\Omega _m$|, the Hubble parameter |$h_0$|, the amplitude of primordial scalar density fluctuations |$A_s$|, the spectral index |$n_s$|, the baryonic density |$\Omega _b$|, and the massive neutrino density |$\Omega _\nu$|. The equation of state of dark energy w is set as a free parameter in the wCDM analyses. Following the DES standard, we quote our results in terms of the clustering amplitude, defined as
where |$\sigma _8$| is the amplitude of mass fluctuations on 8 Mpc|$\,h^{-1}$| scale in linear theory.
3.2 Scale cuts
Due to the fact that the chosen theoretical modelling is not a complete astrophysical modelling – lacking known effects that appear in smaller, non-linear scales such as baryonic dynamics and higher order non-linear galaxy bias – using the full range of scales in this analysis would result in inaccurate results. For that reason, finding the scales for which our modelling correctly predicts the physics involved is a crucial part of this work.
In order to find this range of scales, we test our pipeline with two simulated data vectors. One represents our fiducial modelling, while the other includes additional modelling for non-linear galaxy bias and baryons, the dominant non-linear effects of galaxy clustering and GGL. From now on, they will be referred to as baseline and contaminated data vectors, respectively. The non-linear galaxy bias were modelled by including contributions from the local quadratic bias |$b_2^i$| for every photo-z bin of lenses i (see Section 3.1). Their fiducial values are the same ones from (Pandey et al. 2022) and (Porredon et al. 2022), and can be found in Table 3. The impact of the baryonic physics were modelled using hydrodynamic simulations with strong AGN feedback. In particular, we use the AGN simulation (van Daalen et al. 2011) from the OverWhelmingly Large Simulations project (OWLS) suite (Schaye et al. 2010). Following the approach of the DES Y3 methods paper (Krause et al. 2021), we expect a valid scale cut to satisfy the criteria of |$0.3\sigma _{\text{2D}}$| of compatibility in the |$S_8 \times \Omega _m$| plane of posteriors, calculated at the best-fitting values from both data vectors.
The galaxy–galaxy lensing signal in CSis inherently non-local. This means the predicted signal at a given source–lens separation depends on the modelling of all scales within that separation, including non-linear small scales. Several approaches have emerged to address the non-locality of the CSgalaxy–galaxy lensing signal (Baldauf et al. 2010; MacCrann et al. 2020; Park, Rozo & Krause 2021), see Prat et al. (2023) for a recent comparison of different approaches. In this work, we do not implement any additional methodology to circumvent non-localities in GGL. In HS, the modelling of a given scale does not exhibit explicit dependence on smaller scales. Nevertheless, we try to be extra careful about the scales we are including in the analysis. We present two approaches: the conservative and extended scale cuts. For both, we made sure that the baseline and contaminated data vectors have a compatibility well under the |$0.3\sigma _{\text{2D}}$| criterion. We evaluated compatibility using our standard pipeline with the priors of Table 3. To remain conservative and apply more stringent tests to the models considered, we did not perform nuisance parameter marginalization, following the prescription in Krause et al. (2021). The results are summarized in Fig. 5. The ellipses represent the marginalized |$0.3\sigma _{\text{2D}}$| contours of the baseline and contaminated data vectors under the extended scale cut, and the difference between the peaks of these posteriors are denoted by the arrows.
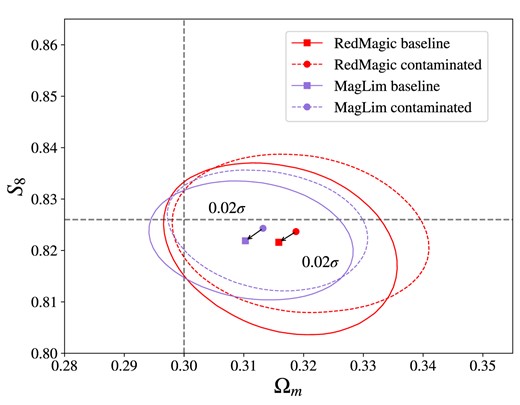
2D posterior of |$S_8$| and |$\Omega _m$| for redMaGiC and MagLim baseline and contaminated data vectors under the extended (8, 6) Mpc h−1 scale cut, both analysed with linear bias and halofit model. The ellipses represent |$0.3\sigma _{\text{2D}}$| contours around their best-fitting values marked in the centre. The arrows and numbers show the distance between the best fit of baseline and contaminated chains.
To select these scale cuts, we first defined a minimum physical distance |$R_{\text{min}}$| that is associated with a maximum comoving Fourier mode |$k_{\text{max}} = 1/R_{\text{min}}$|. The maximum multipole |$\ell _{\text{max}}$| can then be extracted for every redshift bin of lenses by the following relation:
where |$\langle z_i \rangle = \left(\int z \, n_i(z) \, dz \right)/\left(\int n_i(z) \, dz \right)$| is the mean redshift for the ith tomographic set of lenses and |$\chi$| is the comoving distance assuming the fiducial cosmology of the analysis (see Table 3). This means that GGL combinations sharing the same lenses also share the same |$\ell _{\text{max}}$|.
From this relation come our two sets of scale cuts: the conservative approach using |$R_{\text{min}}^{\text{gcl}} = 8 \text{ Mpc}\,h^{-1}$| and |$R_{\text{min}}^{\text{ggl}} = 12 \text{ Mpc}\,h^{-1}$| for clustering and GGL, respectively; and the extended approach, that goes to lower scales in GGL with |$R_{\text{min}}^{\text{ggl}} = 6 \text{ Mpc}\,h^{-1}$|. Both methodologies follow the criteria from DES CSanalyses. The |$R_{\text{min}}^{\text{ggl}}$| reference in the conservative approach is the same as the one in DES Collaboration (2018), when the GGL data also did not receive special modelling for its non-localities. On the other hand, the minimum physical scale of |$R_{\text{min}}^{\text{ggl}} = 6 \text{ Mpc}\,h^{-1}$| was chosen in (DES Collaboration et al. 2022; Pandey et al. 2022; Prat et al. 2022), when those non-localities were modelled using the point-mass marginalization technique. Appendix E summarizes the maximum multipoles associated with each one of these minimum distances for clustering and GGL.
3.3 Likelihood
We assume our power spectra measurements follow a multivariate Gaussian likelihood distribution with a fixed covariance matrix,
where |$\mathbf {d}(\Theta)$| is the theoretical prediction for our data vector, constructed by stacking the power spectra bandpowers for both probes, GCL and GGL, given the parameters |$\Theta$| as described in Section 3, and assuming a model M.
The corresponding measured data vector, |$\mathbf {D}$|, is also constructed by stacking the measured power spectra bandpowers for both probes over the different pair combinations of tomographic bins considered, accounting for scale cuts (see Sections 2.3 and 3.2). We note that including shear ratios (SR) measurements is out of the scope of this work. The SR methodology, as described by Sánchez et al. (2022), consists in taking the ratios of two GGL measurements that share the same lens tomographic bin. Under the limit that the lens distribution is sufficiently thin, this ratio loses its dependency on the power spectra and, thus, results in a geometrical measurement of the lensing system. One can then use the SR from the small scales measurements of GGL, which would be discarded after the scale cut, to increase the constraining power of the analysis by improving the constraints of the systematics and nuisance parameters of the model. These measurements were incorporated at the likelihood level in other DES Y3 works (DES Collaboration 2022; Doux et al. 2022; Pandey et al. 2022; Porredon et al. 2022). The methods to measure and apply shear ratios to HS analyses are currently under development and will be implemented in future projects using DES Y6 data.
Finally, |$\mathbf {C}$| is the joint covariance of galaxy clustering and GGL power spectra. It is analytically decomposed into Gaussian and non-Gaussian components arising from the cosmic shear and galaxy overdensity fields. The Gaussian contribution is computed using NaMASTER to account for binning and mode coupling coming from partial sky coverage with the improved narrow-kernel approximation (iNKA) developed by García-García et al. (2021), as optimized by Nicola et al. (2021). We also account for the noise contribution to the covariance in the Gaussian term, using the analytical estimate from equations (4) and (6) as described in Nicola et al. (2021). For this, we rely on the iNKA implementation of the general covariance calculator interface to be used for the Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST9) Dark Energy Science Collaboration (DESC) LSST Dark Energy Science Collaboration (2012), TJPCov.10
The non-Gaussian contribution comprises two components: (i) the connected four-point covariance (cNG), arising from the joint cosmic shear and galaxy clustering trispectra; and (ii) the super-sample covariance (SSC), which accounts for correlations between Fourier modes used in the analysis and super-survey modes (Takada & Hu 2013). The computation of both components utilizes the implementation provided by CosmoLike (Krause & Eifler 2017; Fang, Eifler & Krause 2020a). This follows the methodology outlined in Krause et al. (2021), which in turn draws upon formulae established in the works of Takada & Jain (2009) and Schaan, Takada & Spergel (2014). We simplify the treatment of partial sky coverage and binning for the non-Gaussian contribution by scaling it with the observed fraction of the sky, |$f_{\rm sky}$| and computing it on the grid of points defined by the effective multipole of each bandpower considered.
A sample covariance was also computed from a set of 1800 log-normal simulations, and its comparison with our theoretical covariance is discussed in Section 3.4. The right-hand panel of Fig. 6 shows both covariances side by side, while the left-hand panel shows the ratio of their diagonal. The compatibility between them is discussed in Section 3.4.
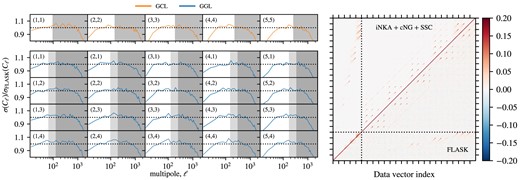
The analytical covariance matrix used in this work is computed using TJPCov, NaMASTER, and CosmoLike. Left: Comparison of the error bars estimated from log-normal realizations with the fiducial ones. We show the GCL and GGL separately and the indexes |$(z_i, z_j)$| in each subplot indicate the redshift bin combination. For GGL, |$z_i$| and |$z_j$| refer to the bin of the lens and source, respectively. Right: The full correlation matrix, from the log-normal realizations in the lower triangle, and the full analytical model including Gaussian (iNKA) and non-Gaussian (nNG + SSC) contributions in the upper triangle (note the normalization in the range -0.2 to 0.2).
As discussed in Friedrich et al. (2021), calculating covariance matrices at a set of values considerably different from the best-fitting values of the analysis can have a meaningful impact on the likelihood contours. For that reason, the results on data shown in Section 4 were run twice, where in the second run the covariance was recalculated at the best-fit values of the first iteration. Appendix A discusses the impact of updating the covariance in our main analyses.
The likelihood (equation 18) is related to the posterior distributions of the parameters via the Bayes’ theorem:
where |$\Pi (\Theta |M)$| is the prior probability distribution given a model M. The parameters constraints are reported by the mean of their marginalized posterior distributions and the 68 per cent confidence limits (C.L.) relative to this mean as error bars. The constraining power of different analyses are compared through the 2D figure of merit, defined as |$\text{FoM}_{\Theta _1, \Theta _2} = (\text{det Cov}(\Theta _1, \Theta _2))^{-1/2}$|, while the distance between their constraints is calculated as the difference between their best-fitting values in terms of |$\sigma _\text{2D}$|, the marginalized 68 per cent C.L. on the |$S_8 \times \Omega _m$| plane. The parameter inference was performed with the PolyChord sampler (Handley, Hobson & Lasenby 2015a, b).
3.4 Validations on simulated data
Before any work on data was done, all the aspects of the pipeline were extensively tested using simulated data vectors and covariances, to make sure that the developed methodology would not rely on biased expectations for the real measurements. A set of 1800 independent log-normal realizations generated by the code flask (Xavier et al. 2016) were produced for this purpose (Section 2.2). The measurements of the angular power spectra of this set are discussed in Appendix B.
The simulated covariance is a sample covariance matrix calculated out of this set of log-normal realizations. The right-hand panel of Fig. 6 shows the analytical and sample covariance side by side. In the left-hand panel, we compare the diagonal terms of both covariances, finding a good agreement in the valid range of scales after performing the scale cuts (non-shaded areas). The largest deviations occur at large scales – more specifically, at the first and second bandpowers – where the sample covariance has error bars around |$\sim 10~{{\ \rm per\ cent}}$| larger than the analytical for most combinations. We assessed the compatibility between our analytical and sample covariance by verifying their impact on cosmological constraints. Running the pipeline on our baseline data vector with the sample covariance and the final, analytical covariance for the redMaGiC analysis showed an excellent agreement, resulting in a difference lower than |$0.01\sigma _{\text{2D}}$|. The marginalized constraints are shown in the first (sample cov.) and second (theoretical cov.) rows of Fig. 7.
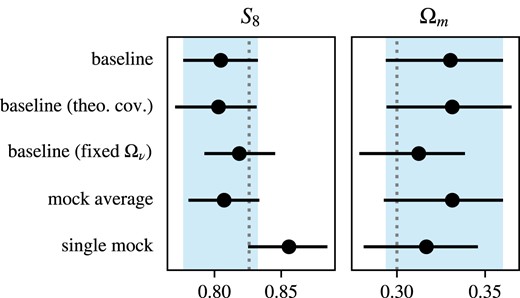
Comparison of marginalized constraints of redMaGiC-like analyses between a fiducial, noiseless data vector (baseline), and data vectors constructed from the mean over the 1800 log-normal realizations (mock average) and a single realization (single mock). First two rows: constraints of the baseline data vector with the sample covariance and the final theoretical covariance used in the redMaGiC analysis. Third row: constraint of the baseline data vector with the sample covariance, but fixing the value of |$\Omega _\nu$|. Forth and fifth rows: constraints of the mock average and single mock data vectors with the sample covariance. The vertical dotted lines represent the fiducial values used to construct both the noiseless data vector and the log-normal realizations. Shaded vertical regions are the 68 per cent C.L. marginalized regions from the constraints in the first row.
One can notice that, despite the baseline angular power spectra being a noiseless, simulated data vector, the constraints found are not centred at their fiducial values – although they are still consistent within |$1\sigma$|. This deviation can be attributed to the so-called prior projection effects. In this particular analysis, the projection of the |$\Omega _{\nu }$| prior is the main source of this effect (see Krause et al. 2021 for more discussions on that). This statement is illustrated by the constraints shown in the third row of Fig. 7, where we run the pipeline on the same baseline data vector but with this parameter fixed, resulting in a much smaller deviation. This happens because |$\Omega _{\nu }$| is prior dominated and its true value is set close to the boundary of the flat prior, which allows the peak of the likelihood to shift in the direction of its degeneracies.
For the remaining two rows of Fig. 7, we perform some more pipeline tests with the sample covariance but using the average of all 1800 log-normal realizations (mock average) and a single, arbitrary realization (single mock) as data vectors. As expected, we see that the constraints obtained by the mock average case are consistent with the baseline ones, and that the single mock constraints are compatible with the true values within |$1\sigma$|.
Finally, taking advantage of the single mock data vector, we also check the goodness-of-fit compatibility between our analytical and sample covariance. After running the pipeline on the single mock with the sample covariance matrix, we obtained |$\chi ^2_F = 182$| at the best-fitting parameters for the extended scale cut, with |$227-30 = 197$| degrees of freedom (DoF; reduced |$\chi ^2_F = 0.92$|), while the same test using our theoretical matrix resulted in |$\chi ^2_T = 208$| (reduced |$\chi ^2_T = 1.05$|).
This |$\chi ^2$| difference, |$\Delta \chi ^2_{T-F} = 11$|, can be compared with analytical approximations for its expected value and variance (see section 7 in Andrade-Oliveira et al. 2021 and Fang et al. 2020a):
where Tr represents the trace operator, |${\bf C}_T$| and |${\bf C}_F$| are the theoretical and the sample covariance from flask, respectively, and |$N_D$| is the number of degrees of freedom. These give us the estimation |$\text{E}[\Delta \chi ^2_{T-F}] = 9.11 \pm 9.00$|, within a |$1\sigma$| agreement with what was previously calculated for the particular realization.
4 RESULTS
After all the processes described in Section 3 to validate our methodology with simulated data vectors and covariance, the analysis pipeline was applied to the real data. Due to the fact that the DES Y3 catalogues are public already, no specific blinding method was applied. That being said, as described in Section 3, every step of the pipeline had been previously tested and validated using simulations so that measurements of the catalogues and the main cosmological chains had to be run only once.
The main results of this work are presented in this Section. First, the constraints for |$\Lambda$|CDM (Section 4.1) and wCDM (Section 4.2) modelling are shown and discussed alongside the main results from Pandey et al. (2022) and Porredon et al. (2022). Table 4 summarizes the constraints obtained, as well as the gain in constraining power in the 1D marginalized posteriors of |$\Omega _m$|, |$S_8$|, and w, and the agreement between harmonic and CSchains in the |$S_8 \times \Omega _m$| 2D plane. In Appendix C, we discuss the goodness-of-fit of these results. Subsequently, a series of internal consistency and robustness tests are discussed (Section 4.3).
68 per cent C.L. marginalized cosmological constraints in |$\Lambda$|CDM and wCDM using the combination of DES Y3 galaxy clustering and galaxy–galaxy lensing measurements (2|$\times$|2pt) in HS. In parenthesis after the constraints are the improvements of the error bars when compared to the CS results from Pandey et al. (2022) and Porredon et al. (2022). Last column shows the agreement, calculated as described in Section 3.3.
| redMaGiC model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | (8,6) Mpc h−1 | |$0.325\pm 0.040$| (|$-19~\%$|) | |$0.704\pm 0.029$| (|$+2~\%$|) | |$0.681^{+0.045}_{-0.072}$| | – | |$1.03 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM | (8,12) Mpc h−1 | |$0.328\pm 0.041$| (|$-22~\%$|) | |$0.690\pm 0.034$| (|$-15~\%$|) | |$0.665^{+0.041}_{-0.071}$| | – | |$0.29 \sigma _{\text{2D}}$| |
| wCDM | (8,6) Mpc h−1 | |$0.301^{+0.037}_{-0.048}$| (|$+7~\%$|) | |$0.682^{+0.025}_{-0.039}$| (0 %) | |$0.685^{+0.042}_{-0.052}$| | |$-1.28\pm 0.29$| (|$+8~\%$|) | |$0.95 \sigma _{\text{2D}}$| |
| MagLim model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
| |$\Lambda$|CDM, 6 bins | (8,6) Mpc h−1 | |$0.307^{+0.027}_{-0.037}$| (|$+14~\%$|) | |$0.753\pm 0.024$| (|$+29~\%$|) | |$0.748\pm 0.054$| | – | |$0.9 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 6 bins | (8,12) Mpc h−1 | |$0.315^{+0.028}_{-0.042}$| (|$+9~\%$|) | |$0.739\pm 0.033$| (|$+3~\%$|) | |$0.726\pm 0.061$| | – | |$1.27 \sigma _{\text{2D}}$| |
| wCDM, 6 bins | (8,6) Mpc h−1 | |$0.302\pm 0.036$| (|$+17~\%$|) | |$0.759\pm 0.032$| (|$+20~\%$|) | |$0.760\pm 0.051$| | |$-1.01^{+0.24}_{-0.18}$| (|$+2~\%$|) | |$0.35 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,6) Mpc h−1 | |$0.324^{+0.032}_{-0.047}$| (|$-7~\%$|) | |$0.779\pm 0.028$| (|$+18~\%$|) | |$0.754\pm 0.064$| | – | |$0.02 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,12) Mpc h−1 | |$0.330^{+0.038}_{-0.043}$| (|$-9~\%$|) | |$0.761\pm 0.035$| (|$-3~\%$|) | |$0.731^{+0.058}_{-0.076}$| | – | |$0.14 \sigma _{\text{2D}}$| |
| wCDM, 4 bins | (8,6) Mpc h−1 | |$0.321^{+0.040}_{-0.047}$| (|$+17~\%$|) | |$0.745\pm 0.039$| (|$+24~\%$|) | |$0.726^{+0.057}_{-0.067}$| | |$-1.26^{+0.34}_{-0.27}$| (|$+7~\%$|) | 0.42 |$\sigma _{\text{2D}}$| |
| redMaGiC model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | (8,6) Mpc h−1 | |$0.325\pm 0.040$| (|$-19~\%$|) | |$0.704\pm 0.029$| (|$+2~\%$|) | |$0.681^{+0.045}_{-0.072}$| | – | |$1.03 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM | (8,12) Mpc h−1 | |$0.328\pm 0.041$| (|$-22~\%$|) | |$0.690\pm 0.034$| (|$-15~\%$|) | |$0.665^{+0.041}_{-0.071}$| | – | |$0.29 \sigma _{\text{2D}}$| |
| wCDM | (8,6) Mpc h−1 | |$0.301^{+0.037}_{-0.048}$| (|$+7~\%$|) | |$0.682^{+0.025}_{-0.039}$| (0 %) | |$0.685^{+0.042}_{-0.052}$| | |$-1.28\pm 0.29$| (|$+8~\%$|) | |$0.95 \sigma _{\text{2D}}$| |
| MagLim model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
| |$\Lambda$|CDM, 6 bins | (8,6) Mpc h−1 | |$0.307^{+0.027}_{-0.037}$| (|$+14~\%$|) | |$0.753\pm 0.024$| (|$+29~\%$|) | |$0.748\pm 0.054$| | – | |$0.9 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 6 bins | (8,12) Mpc h−1 | |$0.315^{+0.028}_{-0.042}$| (|$+9~\%$|) | |$0.739\pm 0.033$| (|$+3~\%$|) | |$0.726\pm 0.061$| | – | |$1.27 \sigma _{\text{2D}}$| |
| wCDM, 6 bins | (8,6) Mpc h−1 | |$0.302\pm 0.036$| (|$+17~\%$|) | |$0.759\pm 0.032$| (|$+20~\%$|) | |$0.760\pm 0.051$| | |$-1.01^{+0.24}_{-0.18}$| (|$+2~\%$|) | |$0.35 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,6) Mpc h−1 | |$0.324^{+0.032}_{-0.047}$| (|$-7~\%$|) | |$0.779\pm 0.028$| (|$+18~\%$|) | |$0.754\pm 0.064$| | – | |$0.02 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,12) Mpc h−1 | |$0.330^{+0.038}_{-0.043}$| (|$-9~\%$|) | |$0.761\pm 0.035$| (|$-3~\%$|) | |$0.731^{+0.058}_{-0.076}$| | – | |$0.14 \sigma _{\text{2D}}$| |
| wCDM, 4 bins | (8,6) Mpc h−1 | |$0.321^{+0.040}_{-0.047}$| (|$+17~\%$|) | |$0.745\pm 0.039$| (|$+24~\%$|) | |$0.726^{+0.057}_{-0.067}$| | |$-1.26^{+0.34}_{-0.27}$| (|$+7~\%$|) | 0.42 |$\sigma _{\text{2D}}$| |
68 per cent C.L. marginalized cosmological constraints in |$\Lambda$|CDM and wCDM using the combination of DES Y3 galaxy clustering and galaxy–galaxy lensing measurements (2|$\times$|2pt) in HS. In parenthesis after the constraints are the improvements of the error bars when compared to the CS results from Pandey et al. (2022) and Porredon et al. (2022). Last column shows the agreement, calculated as described in Section 3.3.
| redMaGiC model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | (8,6) Mpc h−1 | |$0.325\pm 0.040$| (|$-19~\%$|) | |$0.704\pm 0.029$| (|$+2~\%$|) | |$0.681^{+0.045}_{-0.072}$| | – | |$1.03 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM | (8,12) Mpc h−1 | |$0.328\pm 0.041$| (|$-22~\%$|) | |$0.690\pm 0.034$| (|$-15~\%$|) | |$0.665^{+0.041}_{-0.071}$| | – | |$0.29 \sigma _{\text{2D}}$| |
| wCDM | (8,6) Mpc h−1 | |$0.301^{+0.037}_{-0.048}$| (|$+7~\%$|) | |$0.682^{+0.025}_{-0.039}$| (0 %) | |$0.685^{+0.042}_{-0.052}$| | |$-1.28\pm 0.29$| (|$+8~\%$|) | |$0.95 \sigma _{\text{2D}}$| |
| MagLim model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
| |$\Lambda$|CDM, 6 bins | (8,6) Mpc h−1 | |$0.307^{+0.027}_{-0.037}$| (|$+14~\%$|) | |$0.753\pm 0.024$| (|$+29~\%$|) | |$0.748\pm 0.054$| | – | |$0.9 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 6 bins | (8,12) Mpc h−1 | |$0.315^{+0.028}_{-0.042}$| (|$+9~\%$|) | |$0.739\pm 0.033$| (|$+3~\%$|) | |$0.726\pm 0.061$| | – | |$1.27 \sigma _{\text{2D}}$| |
| wCDM, 6 bins | (8,6) Mpc h−1 | |$0.302\pm 0.036$| (|$+17~\%$|) | |$0.759\pm 0.032$| (|$+20~\%$|) | |$0.760\pm 0.051$| | |$-1.01^{+0.24}_{-0.18}$| (|$+2~\%$|) | |$0.35 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,6) Mpc h−1 | |$0.324^{+0.032}_{-0.047}$| (|$-7~\%$|) | |$0.779\pm 0.028$| (|$+18~\%$|) | |$0.754\pm 0.064$| | – | |$0.02 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,12) Mpc h−1 | |$0.330^{+0.038}_{-0.043}$| (|$-9~\%$|) | |$0.761\pm 0.035$| (|$-3~\%$|) | |$0.731^{+0.058}_{-0.076}$| | – | |$0.14 \sigma _{\text{2D}}$| |
| wCDM, 4 bins | (8,6) Mpc h−1 | |$0.321^{+0.040}_{-0.047}$| (|$+17~\%$|) | |$0.745\pm 0.039$| (|$+24~\%$|) | |$0.726^{+0.057}_{-0.067}$| | |$-1.26^{+0.34}_{-0.27}$| (|$+7~\%$|) | 0.42 |$\sigma _{\text{2D}}$| |
| redMaGiC model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | (8,6) Mpc h−1 | |$0.325\pm 0.040$| (|$-19~\%$|) | |$0.704\pm 0.029$| (|$+2~\%$|) | |$0.681^{+0.045}_{-0.072}$| | – | |$1.03 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM | (8,12) Mpc h−1 | |$0.328\pm 0.041$| (|$-22~\%$|) | |$0.690\pm 0.034$| (|$-15~\%$|) | |$0.665^{+0.041}_{-0.071}$| | – | |$0.29 \sigma _{\text{2D}}$| |
| wCDM | (8,6) Mpc h−1 | |$0.301^{+0.037}_{-0.048}$| (|$+7~\%$|) | |$0.682^{+0.025}_{-0.039}$| (0 %) | |$0.685^{+0.042}_{-0.052}$| | |$-1.28\pm 0.29$| (|$+8~\%$|) | |$0.95 \sigma _{\text{2D}}$| |
| MagLim model | Scale cut | |$\Omega _m$| | |$S_8$| | |$\sigma _8$| | w | HS–CS agreement |
| |$\Lambda$|CDM, 6 bins | (8,6) Mpc h−1 | |$0.307^{+0.027}_{-0.037}$| (|$+14~\%$|) | |$0.753\pm 0.024$| (|$+29~\%$|) | |$0.748\pm 0.054$| | – | |$0.9 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 6 bins | (8,12) Mpc h−1 | |$0.315^{+0.028}_{-0.042}$| (|$+9~\%$|) | |$0.739\pm 0.033$| (|$+3~\%$|) | |$0.726\pm 0.061$| | – | |$1.27 \sigma _{\text{2D}}$| |
| wCDM, 6 bins | (8,6) Mpc h−1 | |$0.302\pm 0.036$| (|$+17~\%$|) | |$0.759\pm 0.032$| (|$+20~\%$|) | |$0.760\pm 0.051$| | |$-1.01^{+0.24}_{-0.18}$| (|$+2~\%$|) | |$0.35 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,6) Mpc h−1 | |$0.324^{+0.032}_{-0.047}$| (|$-7~\%$|) | |$0.779\pm 0.028$| (|$+18~\%$|) | |$0.754\pm 0.064$| | – | |$0.02 \sigma _{\text{2D}}$| |
| |$\Lambda$|CDM, 4 bins | (8,12) Mpc h−1 | |$0.330^{+0.038}_{-0.043}$| (|$-9~\%$|) | |$0.761\pm 0.035$| (|$-3~\%$|) | |$0.731^{+0.058}_{-0.076}$| | – | |$0.14 \sigma _{\text{2D}}$| |
| wCDM, 4 bins | (8,6) Mpc h−1 | |$0.321^{+0.040}_{-0.047}$| (|$+17~\%$|) | |$0.745\pm 0.039$| (|$+24~\%$|) | |$0.726^{+0.057}_{-0.067}$| | |$-1.26^{+0.34}_{-0.27}$| (|$+7~\%$|) | 0.42 |$\sigma _{\text{2D}}$| |
As discussed in Section 3.3, after running the pipeline on data once, we recalculated the theoretical covariance at its best-fitting values and ran the pipeline again with the updated covariance. Although the results of all these first iteration chains had a satisfactory goodness-of-fit, the runs for MagLim using all six photometric bins of lenses resulted in a p-value very close to the 0.01 requirement on goodness-of-fit used in the DES Y3 unblinding process (see Table C1). This worst fit for the six-bin case after updating the covariance also happened in Porredon et al. (2022), where they localized the problem to be related to the last two redshift bins. Combining this with the fact that the best-fitting values found for the six-bin case are considerably more sensitive to the covariance update, as discussed in Appendix A, we decided to quote the four-bin MagLim results as the fiducial ones for this work. For completeness, however, the results found using all six bins of MagLim are still shown in this Section.
We note that there are other DES works that performed cosmological analyses using all six bins of MagLim in configuration space. In Giannini et al. (2023) an alternative calibration for the MagLim redshift distributions was presented, and in Elvin-Poole et al. (2023) the impact of the magnification bias was studied. We further note the results shown in these analyses are consistent with both the fiducial CSanalysis (Porredon et al. 2022) and the present work.
4.1 |$\Lambda$|CDM
The constraints derived from the HS pipeline developed for this study, using galaxy clustering and galaxy–galaxy lensing measurements in |$\Lambda$|CDM analyses, are presented in Fig. 8 for redMaGiC (left-hand panel) and MagLim (right-hand panel; HS contours in the lower triangle include all six tomographic bins, while only the first four are included in the upper triangle) samples. The results for the DES Y3 2|$\times$|2pt CSanalyses (Pandey et al. 2022; Porredon et al. 2022) are also shown for comparison. It is important to emphasize that even though the HS scale cuts were based on the same physical scale threshold as the real space ones, that does not mean both analyses were performed using the exact same information. Furthermore, these CScurves use their fiducial analysis choice, which includes shear ratios measurements. As mentioned in Section 3.3, the HS curves do not include shear ratios. The marginalized posterior probability distributions for |$\Omega _m$|, |$S_8$|, and |$\sigma _8$| are summarized in Table 4.
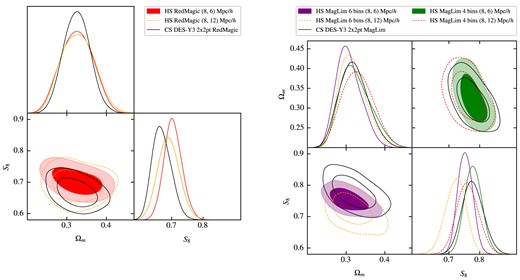
marginalized constraints on |$S_8$| and |$\Omega _m$| in |$\Lambda$|CDM from galaxy clustering and galaxy–galaxy lensing joint analyses. Left: HS and CS redMaGiC constraints. Right: HS and CS MagLim constraints. CS curves are the main results from Pandey et al. (2022) and Porredon et al. (2022), which includes shear ratio measurements in their analysis and four tomographic bins of lenses for MagLim.
From Fig. 8, one can immediately notice that the redMaGiC constraints point to lower values of |$S_8$|, both in harmonic and configuration space. This is properly discussed in (Pandey et al. 2022), where they found a bias in the galaxy selection of the fiducial sample of redMaGiC. This issue was responsible for the best-fit values of the galaxy bias |$b_i$| from the clustering part of the data vector to be systematically higher than the GGL part, thus implying that the phenomenological parameter |$X_\text{lens}^i = b^i_{\text{GGL}}/b^i_{\text{GCL}}$|, often referenced as ‘de-correlation’, would not be equal to 1 as predicted from local biasing models. In fact, they found |$X_\text{lens} = 0.9\pm 0.03$| for the fiducial redMaGiC catalogue when using a single de-correlation parameter for all redshift bins – a |$3.5\sigma$| deviation from 1. They were able to trace back the source of this de-correlation to be associated with the goodness-of-fit threshold |$\chi ^2_{\text{RM}}$| for a galaxy to be classified as part of the redMaGiC sample in the procedure described in (Rozo et al. 2016). Creating a new redMaGiC sample with a broader |$\chi ^2_{\text{RM}}$| was enough to recover |$X_\text{lens}$| compatible with 1.
In this work we only perform analyses using the fiducial redMaGiC sample. Although the HS constraints of this sample also point to lower values of |$S_8$| when compared to MagLim results, we notice that these constraints are not as low as the one found in configuration space, resulting in a tension of |$3.01\sigma _{\text{2D}}$| and |$2.01\sigma _{\text{2D}}$| between redMaGiC and MagLim four and six bins in HS, respectively, under the extended scale cut. The de-correlation parameter |$X_{\text{lens}}$| for the redMaGiC fiducial sample in HS is consistent with what was found in configuration space, although slightly more compatible with 1 due to the higher |$S_8$|, as indicates Fig. 9. In order to compare the |$X_{\text{lens}}$| constraints from HS and CS, we followed the prescription in Pandey et al. (2022), where the cosmological parameters were fixed at the DES Y1 best-fitting values (DES Collaboration 2018).
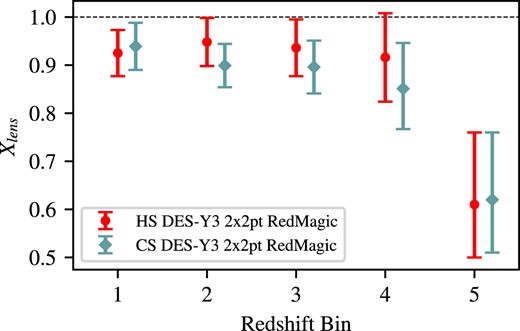
Constraints on the de-correlation parameter |$X_{\text{lens}}$| for each tomographic redshift bin of the fiducial redMaGiC sample. HS results are represented by the red, circle markers, while the green, diamond markers represents CS from Pandey et al. (2022).
From Fig. 8 and Table 4 we can see that the HS results using the extended scale cut (shaded curves) have tighter constraints for the clustering amplitude |$S_8$| in all three analyses (redMaGiC and MagLim four and six bins) when compared to the CSones (black lines). On the other hand, while we do find tighter constraints for matter energy density |$\Omega _m$| in the four and six bins analyses of MagLim, the constraining power of redMaGiC for this parameter is weaker in HS. The |$\Lambda$|CDM four and six bins analyses of MagLim had an improvement in FoM of 64 and 14 per cent for our extended scale cut, while redMaGiC had a decrease of |$-15~\%$|.
The level of agreement between the harmonic and CSresults can be quantified on the |$S_8 \times \Omega _m$| plane, as shown in the last column of Table 4. For all |$\Lambda$|CDM cases we see deviations lower than |$1\sigma$|, except for the |$1.03\sigma$| and |$1.27\sigma$| found for redMaGiC with the extended and MagLim six bins with the conservative scale cut, which are still statistically compatible with the CSresults. In particular, the MagLim results with four redshift bins shows a strong agreement with CS results (|$0.02\sigma _{\text{2D}}$| and |$0.14\sigma _{\text{2D}}$|).
The marginalized posteriors of the galaxy bias under the extended scale cut are shown in Figs 10 and 11. We find an overall good compatibility between the harmonic and CS constraints. The redMaGiC HS results systematically show a small tail towards lower values of |$b_i$|, making the constraints slightly looser than in CS. For MagLim, on the other hand, the results for the four bins analysis reproduce well what was found in CS, while the six bins run shows an expected increase in the constraining power. Appendix D shows the 1D marginalized posteriors of all parameters, along with their priors and their CS counterparts. A discussion about the goodness-of-fit of all these runs can be found in Appendix C.
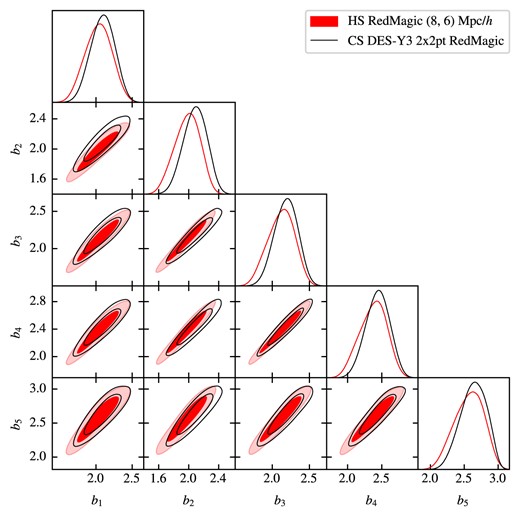
Marginalized posteriors of the linear galaxy bias found in the redMaGiC analysis. The red, shaded contours are the HS results under the extended scale cut, and the black contours are the CS results from Pandey et al. (2022).
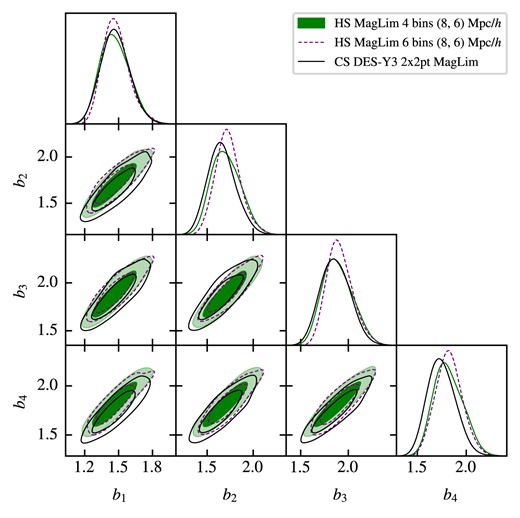
Marginalized posteriors of the linear galaxy bias found in the MagLim analysis. The green, shaded contours are the HS results under the extended scale cut and using the first four bins of the sample, while the purple, dashed curves are the constraints from using all six bins of MagLim. The black contours are the CS results from Porredon et al. (2022).
4.2 wCDM
Similarly to what was presented in Section 4.1, the HS results of the analogous chains but considering the wCDM cosmological model and our extended scale cut are shown in Fig. 12 (again, bottom triangle includes all six tomographic bins of MagLim, while the upper triangle includes only the first four bins). The HS constraints are represented by the shaded contours, and we also included their respective counterpart results in CS following the fiducial choices of Pandey et al. (2022) and Porredon et al. (2022) (black and grey lines).
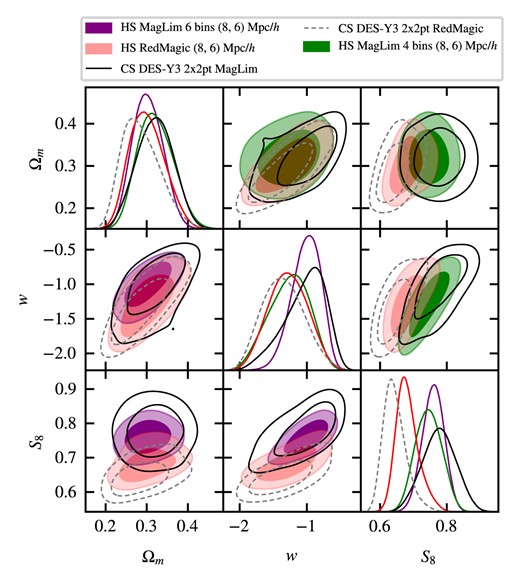
Marginalized constraints on w, |$S_8$|, and |$\Omega _m$| in wCDM from galaxy clustering and galaxy–galaxy lensing joint analyses. Purple and red shaded contours represent the HS chains under the (8,6) Mpc/h scale cut respectively. Solid and dashed contours represent the CS wCDM results from Pandey et al. (2022) and Porredon et al. (2022), which includes shear ratio measurements in their analysis and four tomographic bins of lenses for MagLim.
The constraints derived for |$\Omega _m$|, |$S_8$|, |$\sigma _8$|, and w can be seen in Table 4, which also shows the agreement between harmonic and CS results in the |$S_8 \times \Omega _m$| plane. All wCDM results in HS are compatible with CS under |$1\sigma _{\text{2D}}$|. However, we note that the redMaGiC and MagLim four bins constraints are very consistent with each other and are compatible with |$w = -1$| within |$1\sigma$|.
4.3 Internal consistency and robustness tests
A series of additional tests on data were performed to investigate the internal consistency of the data vectors and the robustness of our modelling. The results of those tests are summarized in Fig. 13 for redMaGiC (left) and MagLim (right).
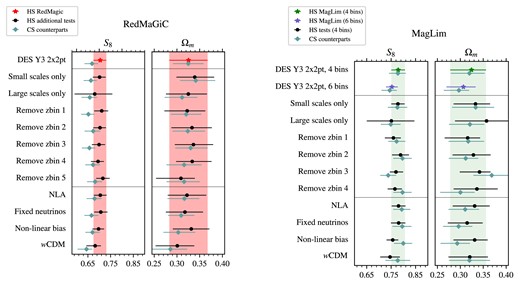
Internal consistency and robustness tests for the galaxy clustering and galaxy–galaxy lensing joint analyses for the extended scale cut. Left: redMaGiC DES Y3 2|$\times$|2pt (red star) in HS, additional tests in HS (black circles) and their CS counterparts (green diamonds) from Pandey et al. (2022). Right: MagLim DES Y3 2|$\times$|2pt (purple star) in HS, additional tests in HS (black circles) and their CS counterparts (green diamonds) from Porredon et al. (2022). All CS tests include shear ratio measurements and use four tomographic bins of lenses for MagLim, except where otherwise is mentioned. From top to bottom of both figures: first quadrant demarcates main results; second quadrant, internal consistency tests; and third quadrant, tests for the model robustness.
The first set of tests (second quadrant in Fig. 13) consists in additional runs changing the structure of the data vectors. The small scales only test restricts the analysis to physical scales smaller than the threshold of 30 Mpc h−1 (same threshold used in Pandey et al. (2022) and Porredon et al. (2022)), while large scales only restricts the analysis to scales larger than this limit. The other consistency tests are chains removing the information from one tomographic bin of lenses at a time.
The second set of tests (third quadrant in Fig. 13) corresponds to the following changes in the theoretical modelling:
NLA: variation of the intrinsic alignment model, setting parameters |$a_2$|, |$\eta _2$|, and |$b_{\text{TA}}$| to zero.
Fixed neutrinos: the mass range of neutrinos modelling is fixed at its lower boundary.
Non-linear bias: the modelling also includes the non-linear galaxy bias effect, following the parameters in Table 3.
wCDM: changes the dark energy parametrization.
The respective results in CS for each internal consistency and robustness test are also shown in Fig. 13, all following their main analyses choices of including shear ratios and four bins of lenses for MagLim (green diamond marker).
Overall, these series of tests show that HS analyses respond well to changes in the data vector and in the theoretical modelling. One can see that the large scales only results have much bigger error bars for |$S_8$| than its CS counterpart. This is probably due to the fact that the |$S_8$| information comes mainly from large multipoles |$\ell$|, which is also the reason why the extended scale cut gives tighter constraints for |$S_8$| over the conservative, but does not improve |$\Omega _m$| (see Fig. 8). Moreover, the limit of 30 Mpc|$\,h^{-1}$| used to define small and large scales did not separate evenly the number of points in each group. Because of that, the large scales test had |$1-4$| less points than the small scales test for each combination.
5 CONCLUSIONS
This work presents the HS joint analysis of galaxy clustering and galaxy–galaxy lensing using the DES Y3 data. We performed two independent analyses using the redMaGiC and MagLim catalogues for lens galaxies. In both, the source galaxies came from the metacalibration catalogue.
In order to compare these analyses with their counterparts in configuration space, the theoretical modelling and prior choice followed the ones described in Pandey et al. (2022) and Porredon et al. (2022), although the overall methodology was designed around the harmonic case. In particular, our main results have an optimized scale cut for HS and include two versions of the MagLim analysis: using only the first four tomographic bins of lenses and using all six bins.
We describe our data and measurements in Section 2. The estimators used to measure the angular power spectra followed the PCL/MASTER method (Hivon et al. 2002), implemented via the NaMASTER code (Alonso et al. 2019). The entire measurement and analysis pipelines were first rigorously tested using a large set of log-normal realizations. The same set of realizations and contaminated versions of the baseline data vector with non-linear galaxy bias and baryonic effects were used to select and validate our scale cuts and theoretical covariance. We presented two sets of scale cuts: the conservative (|$R_{\text{min}}^{\text{gcl}} = 8 \text{ Mpc}\,h^{-1}$| and |$R_{\text{min}}^{\text{ggl}} = 12 \text{ Mpc}\,h^{-1}$|) and extended (|$R_{\text{min}}^{\text{gcl}} = 8 \text{ Mpc}\,h^{-1}$| and |$R_{\text{min}}^{\text{ggl}} = 6 \text{ Mpc}\,h^{-1}$|) approaches.
For our fiducial MagLim analysis (first four tomographic bins of lenses and the extended scale cut) in the |$\Lambda$|CDM modelling, we found a clustering amplitude of |$S_8 = 0.779\pm 0.028$| and a matter energy density of |$\Omega _m = 0.324^{+0.032}_{-0.047}$|, corresponding to a constraining power increase of 14 per cent in the |$S_8 \times \Omega _m$| plane compared to the main results in Porredon et al. (2022). The same analysis but using all six tomographic bins resulted in |$S_8 = 0.753\pm 0.024$| and |$\Omega _m = 0.307^{+0.027}_{-0.037}$|, representing 64 per cent increase in constraining power. It is worth noting, however, that the six-bin analysis exhibited the poorest goodness-of-fit and the greatest impact on the cosmological constraints following the update of the covariance, as detailed in Appendices A and C. Their respective results for a wCDM modelling was |$S_8 = 0.745\pm 0.039$|, |$\Omega _m = 0.321^{+0.040}_{-0.047}$|, and |$w = -1.26^{+0.34}_{-0.27}$| for the four-bin analysis, and |$S_8 = 0.759\pm 0.032$|, |$\Omega _m = 0.302\pm 0.036$|, and |$w = -1.01^{+0.24}_{-0.18}$| for the six-bin.
For redMaGiC with the (8,6) Mpc h−1 scale cut, on the other hand, our |$\Lambda$|CDM results were |$S_8 = 0.704\pm 0.029$| and |$\Omega _m = 0.325 \pm 0.040$|, representing a 15 per cent decrease in the constraining power when compared to the main results in Pandey et al. (2022). Interestingly, however, the harmonic chains for redMaGiC prefer slightly higher values of |$S_8$|.
The goodness-of-fit of all analyses are discussed in Appendix C and the 1D marginalized posteriors of each parameter are shown along side with their priors and CS counterparts in Appendix D.
Additional tests were made and presented in Section 4.3 to check the internal consistency of our data vectors and the robustness of the theoretical modelling. The tests had a very consistent agreement with our DES Y3 2|$\times$|2pt results for redMaGiC and MagLim, as Fig. 13 summarizes.
During the final stages of this work, Park et al. (2024) proposed a unified approach to survey geometry and scale cuts for harmonic and CS analyses. Their work was validated for cosmic shear analyses. We believe it is important to extend such efforts to 2×2pt and full 3×2pt analyses for better understanding of future data.
This work is the first publication of the Dark Energy Survey collaboration to describe a methodology for galaxy–galaxy lensing in the HS, paving the path for a |$3\times 2$|pt analysis in HS for DES Y6, a project already under development. To do so, other than combining this work with the one developed for the DES Y3 cosmic shear in HS (Doux et al. 2022) and incorporating the Y6 guidelines being currently developed for the 3|$\times$|2pt in configuration space, there are additional procedures to be worked on.
We expect the methodology presented in this work to pave the way for and incentivise future HS analyses of significantly larger data sets from next generation Stage-IV imaging programmes, such as those anticipated from LSST (Ivezić et al. 2019) and Euclid (Laureijs et al. 2011).
ACKNOWLEDGEMENTS
We acknowledge the invaluable contributions of everyone involved in this work. LF contributed to the development and validation of the measurements, covariances, and analysis pipelines; development of the manuscript, ran the pipeline, and coordinated the HS team. FA-O contributed to the development of the measurements and analysis pipelines and contributed to the supervision of LF and the development of the manuscript. HC contributed to the development of the measurement and analysis pipeline, the development of the manuscript, and coordinated the HS team. CD coordinated the team in early stages of this work, contributing to first versions of pipelines and the construction and validation of the metacalibration catalogue. RR provided helpful feedback that was instrumental in shaping the analysis and contributed to the supervision of LF. ML contributed to the supervision of LF and offered valuable feedback which significantly informed the development of the analysis. XF contributed with the original version of the CosmoLike code for computing the non-Gaussian contributions to the covariance matrix. JP contributed to the construction and validation of the metacalibration catalogue and its photometric redshifts and served as internal reviewer. AP contributed to the construction and validation of the LSS catalogues and photometric redshifts and served as internal reviewer. Construction and validation of the DES Y3 Gold catalogue: KB, MB, MC-K, AC-R, AD-W, RG, ER, IS-N, ES, BYa. Construction and validation of the DES Y3 metacalibration catalogue: AAm, MB, GB, CC, RC, AC, JE-P, AF, MG, DG, IH, MJ, NM, JMc, AN-A, SP, RR, CS, LS, ES, TS, MT, IT. Construction and validation of the DES Y3 LSS catalogues and systematics: MC, AC-R, JE-P, PF, MR-M, NW. Construction and validation of photometric redshifts: AAl, AAm, GB, AC, RC, JC, MC, JD, SD, JE-P, SE, MG, GG, DG, IH, NM, JMc, JMy, MR, AR, ER, CS, MT, BYi. The remaining authors have made contributions to this paper that include, but are not limited to, the construction of DECam and other aspects of collecting the data; data processing and calibration; developing broadly used methods, codes, and simulations; running the pipelines and validation tests; and promoting the science analysis.
This work was partially supported by the Laboratório Interinstitucional de e-Astronomia (LIneA), the Brazilian funding agencies CNPq and CAPES, the Instituto Nacional de Ciência e Tecnologia (INCT) e-Universe (CNPq grant 465376/2014-2) and the São Paulo State Research Agency (FAPESP). LF is supported by CNPq. HC is supported by FAPESP (19/04881-8) and CNPq (151411/2022-0). FA-O acknowledges the support from the Swiss National Science Foundation (SNSF) through grant no. 231766. FA-O would also like to thank FAPESP grant 2016/01343-7 in August 2022 where part of this work was done. ML is supported by FAPESP and CNPq. The authors acknowledge the use of computational resources from LIneA, the Center for Scientific Computing (NCC/GridUNESP) of the São Paulo State University (UNESP), and from the National Laboratory for Scientific Computing (LNCC/MCTI, Brazil), where the SDumont supercomputer ( sdumont.lncc.br ) was used. This research used resources of the National Energy Research Scientific Computing Center (NERSC), a Department of Energy Office of Science User Facility using NERSC award HEP-ERCAP-0027266.
Funding for the DES Projects has been provided by the U.S. Department of Energy, the U.S. National Science Foundation, the Ministry of Science and Education of Spain, the Science and Technology Facilities Council of the United Kingdom, the Higher Education Funding Council for England, the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign, the Kavli Institute of Cosmological Physics at the University of Chicago, the Center for Cosmology and Astro-Particle Physics at the Ohio State University, the Mitchell Institute for Fundamental Physics and Astronomy at Texas A&M University, Financiadora de Estudos e Projetos, Fundação Carlos Chagas Filho de Amparo à Pesquisa do Estado do Rio de Janeiro, Conselho Nacional de Desenvolvimento Científico e Tecnológico and the Ministério da Ciência, Tecnologia e Inovação, the Deutsche Forschungsgemeinschaft and the Collaborating Institutions in the Dark Energy Survey.
The Collaborating Institutions are Argonne National Laboratory, the University of California at Santa Cruz, the University of Cambridge, Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas-Madrid, the University of Chicago, University College London, the DES-Brazil Consortium, the University of Edinburgh, the Eidgenössische Technische Hochschule (ETH) Zürich, Fermi National Accelerator Laboratory, the University of Illinois at Urbana-Champaign, the Institut de Ciències de l’Espai (IEEC/CSIC), the Institut de Física d’Altes Energies, Lawrence Berkeley National Laboratory, the Ludwig-Maximilians Universität München and the associated Excellence Cluster Universe, the University of Michigan, the National Optical Astronomy Observatory, the University of Nottingham, The Ohio State University, the University of Pennsylvania, the University of Portsmouth, SLAC National Accelerator Laboratory, Stanford University, the University of Sussex, Texas A&M University, and the OzDES Membership Consortium.
The DES data management system is supported by the National Science Foundation under Grant Numbers AST-1138766 and AST-1536171. The DES participants from Spanish institutions are partially supported by MINECO under grants AYA2015-71825, ESP2015-88861, FPA2015-68048, SEV-2012-0234, SEV-2016-0597, and MDM-2015-0509, some of which include ERDF funds from the European Union. IFAE is partially funded by the CERCA program of the Generalitat de Catalunya. Research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Program (FP7/2007-2013) including ERC grant agreements 240672, 291329, and 306478. We acknowledge support from the Australian Research Council Centre of Excellence for All-sky Astrophysics (CAASTRO), through project number CE110001020.
This manuscript has been authored by Fermi Research Alliance, LLC under Contract No. DE-AC02-07CH11359 with the U.S. Department of Energy, Office of Science, Office of High Energy Physics. The United States Government retains and the publisher, by accepting the article for publication, acknowledges that the United States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for United States Government purposes.
Based in part on observations at Cerro Tololo Inter-American Observatory, National Optical Astronomy Observatory, which is operated by the Association of Universities for Research in Astronomy (AURA) under a cooperative agreement with the National Science Foundation.
The analysis presented in this work made use of the software tools scipy: Virtanen et al. (2020), numpy: Harris et al. (2020), matplotlib: Hunter (2007), camb: Lewis et al. (2000); Lewis & Bridle (2002); Howlett et al. (2012), getdist: Lewis (2019), multinest: Feroz & Hobson (2008); Feroz, Hobson & Bridges (2009); Feroz et al. (2019), polychord: Handley et al. (2015a), cosmosis: Zuntz et al. (2015), cosmolike: Krause & Eifler (2017), and treecorr Jarvis, Bernstein & Jain (2004).
DATA AVAILABILITY
A general description of the Dark Energy Survey (DES) data releases can be found on the survey’s website https://www.darkenergysurvey.org/the-des-project/data-access/. A partial release of the DES Year 3 (Y3) cosmological data is available on the DES Data Management website, hosted by the National Center for Supercomputing Applications (NCSA) https://des.ncsa.illinois.edu/releases/y3a2. This release includes Gold products, point spread function (PSF) modelling, and the Y3 lens and source galaxy catalogues, which contain the redshift distributions used in this analysis. The CosmoSiS software (Zuntz et al. 2015) is available at https://bitbucket.org/joezuntz/cosmosis/wiki/Home. The measurement code, used in this analysis to interface DES catalogues and namaster is publicly available at https://github.com/hocamachoc/3x2hs_measurements. Synthetic data produced by the analysis presented here, such as flask catalogues, can be shared on request to the corresponding authors.
Footnotes
REFERENCES
APPENDIX A: IMPACT OF COVARIANCE UPDATE
The choice of cosmological parameters employed to calculate the analytical covariance matrix within a Bayesian framework can introduce a bias into the inferred parameter constraints if these parameters deviate significantly from the recovered values (see Friedrich et al. 2021 and references therein). To mitigate bias, the protocol adopted in this and other DES studies involves re-running the analysis with the covariance matrix updated to the best-fitting values obtained from the previous iteration.
Fig. A1 illustrates the effect of covariance updates on the |$\Lambda$|CDM analyses when applying the extended scale cut. The second iteration of the covariance causes a low impact for redmagic (|$0.01\sigma _{\text{2D}}$|) and maglim four bins (|$0.04\sigma _{\text{2D}}$|) in the |$S_8 \times \Omega _m$| plane. For maglim six bins, however, we see a greater impact, although still under |$0.3\sigma _{\text{2D}}$|. We tested updating one more time the covariance for maglim six bins, but it did not result in a convergence as good as the others. As mentioned in Section 4, the better convergence of the covariance and the goodness of fit (detailed in Appendix C) were the reasons to choose the four bins configuration as the fiducial maglim results of the present work.
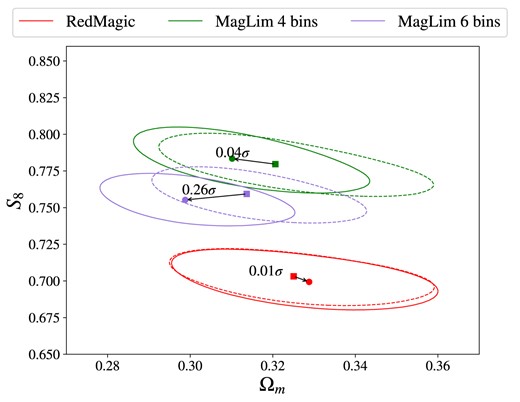
The impact on the |$S_8 \times \Omega _m$| plane of updating the covariance for the different cases considered for the |$2\times 2$|pt analysis in HS. All cases assume the extended scale cut and |$\Lambda$|CDM modelling. The square marker and dashed ellipses represent the best-fitting value and |$0.3\sigma _{\text{2D}}$| contour for the analyses using the original covariances (calculated at fiducial values of Table 3). The circle marker and solid curves represent the analyses using the updated covariance (recalculated at the best-fiting values of the previous run).
APPENDIX B: MEASUREMENTS ON THE LOG-NORMAL SIMULATIONS
The pipeline developed to measure the angular power spectra from the DES catalogues was first validated using a set of 1800 log-normal, redMaGiC-like realizations. These realizations were generated using the flask code (Xavier et al. 2016), as detailed in Section 2.2.
Fig. B1 presents the measurements of galaxy clustering (top panels) and galaxy–galaxy lensing (bottom panels). It displays the mean of all realizations (solid, blue line) and the associated standard deviation (shaded, blue regions). The simulated power spectra, assumed to be noiseless, used as input for generating the realizations are shown as the dashed black lines (see Table 3 for the fiducial parameters). Across all tomographic combinations of power spectra, the simulated signal is faithfully reproduced by the mean of the realizations well within its standard deviation. This demonstrates the internal consistency of the measurement pipeline.
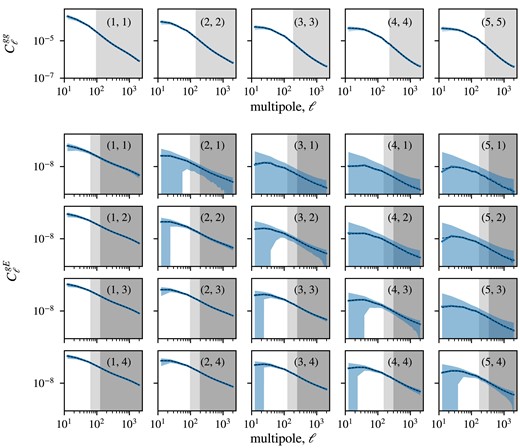
The angular power spectrum measurements for the set of 1800 log-normal realizations. Top panel: average of the galaxy clustering measurements |$C_\ell ^{\text{gg}}$| (solid line) and their standard deviation (blue, shaded area). The grey shaded area represents the scale cut based on the minimum physical scale |$R^{\text{gcl}}_{\text{min}} = 8$| Mpc h−1. Bottom panel: average of the GGL measurements |$C_\ell ^{\text{gE}}$| (solid line) and their standard deviation (blue, shaded area). The grey shaded area represents the scale cuts based on the minimum physical scale |$R^{\text{ggl}}_{\text{min}} = 6$| Mpc h−1 (light grey) and |$R^{\text{ggl}}_{\text{min}} = 12$| Mpc h−1 (dark grey). The indexes |$(z_i, z_j)$| in each subplot indicate the redshift bin combination. For GGL, |$z_i$| and |$z_j$| refer to the bin of the lens and source, respectively. The black dashed curves show the input power spectra used to generate the log-normal realizations.
The same set of measurements on log-normal realizations was further used in the validation of the analytical covariance matrix and the analysis pipeline, as detailed in Section 3.4.
APPENDIX C: GOODNESS-OF-FIT
In this section, we summarize and discuss the goodness-of-fit for all the |$\Lambda$|CDM and wCDM presented in Sections 4.1 and 4.2. As described in Section 3.3 and Appendix A, the pipeline was run twice: the first iteration used the original covariance matrix, calculated at the fiducial values listed in Table 3; and the second, for each case, used an updated covariance matrix calculated at the corresponding first iteration best-fitting values. Table C1 summarizes the goodness-of-fit information for both iterations of each analysis. It is important to consider that the presented reduced |$\chi ^2$| does not incorporate the informative priors. Consequently, its actual value is likely to be lower, particularly for the simulations employing the conservative scale cut with fewer data points. Appendix D presents the marginalized |$\Lambda$|CDM posteriors alongside the priors for each parameter.
The goodness-of-fit for different configurations of the 2|$\times$|2pt analysis in HS. The first column displays the cosmological model and the number of tomographic bins of lenses for the cases using the MagLim sample. The second column shows the scale cut used: either extended (8, 6) Mpc h−1 or conservative (8, 12) Mpc h−1. The covariance iteration column tells which version of the covariance was used: either original (calculated at the fiducial parameters shown in Table 3 or recalculated at best-fitting values). The last five columns are: the number of total free parameters, the number of data points in the data vector after scale cuts, the |$\chi ^2$| at best-fitting values, the reduced |$\chi ^2$| assuming the number of DoF as number data points in the data vector minus the total number of parameters constrained, and the corresponding p-value.
| redMaGiC model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
|---|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | Extended | Updated | 30 | 227 | 187 | 0.95 | 0.68 |
| |$\Lambda$|CDM | Conservative | Updated | 30 | 159 | 128 | 0.99 | 0.51 |
| wCDM | Extended | Updated | 31 | 227 | 190 | 0.96 | 0.63 |
| |$\Lambda$|CDM | Extended | Original | 30 | 227 | 206 | 1.05 | 0.32 |
| |$\Lambda$|CDM | Conservative | Original | 30 | 159 | 137 | 1.07 | 0.28 |
| wCDM | Extended | Original | 31 | 227 | 210 | 1.09 | 0.18 |
| MagLim model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
| |$\Lambda$|CDM, 6 bins | Extended | Updated | 37 | 295 | 314 | 1.22 | 0.01 |
| |$\Lambda$|CDM, 6 bins | Conservative | Updated | 37 | 207 | 230 | 1.35 | 0.001 |
| wCDM, 6 bins | Extended | Updated | 38 | 295 | 304 | 1.17 | 0.03 |
| |$\Lambda$|CDM, 4 bins | Extended | Updated | 31 | 178 | 146 | 0.99 | 0.51 |
| |$\Lambda$|CDM, 4 bins | Conservative | Updated | 31 | 122 | 108 | 1.18 | 0.09 |
| wCDM, 4 bins | Extended | Updated | 32 | 178 | 154 | 1.05 | 0.31 |
| |$\Lambda$|CDM, 6 bins | Extended | Original | 37 | 295 | 242 | 0.94 | 0.75 |
| |$\Lambda$|CDM, 6 bins | Conservative | Original | 37 | 207 | 178 | 1.05 | 0.32 |
| wCDM, 6 bins | Extended | Original | 38 | 295 | 244 | 0.95 | 0.73 |
| |$\Lambda$|CDM, 4 bins | Extended | Original | 31 | 178 | 135 | 0.92 | 0.77 |
| |$\Lambda$|CDM, 4 bins | Conservative | Original | 31 | 122 | 94 | 1.03 | 0.40 |
| wCDM, 4 bins | Extended | Original | 32 | 178 | 143 | 0.98 | 0.56 |
| redMaGiC model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
|---|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | Extended | Updated | 30 | 227 | 187 | 0.95 | 0.68 |
| |$\Lambda$|CDM | Conservative | Updated | 30 | 159 | 128 | 0.99 | 0.51 |
| wCDM | Extended | Updated | 31 | 227 | 190 | 0.96 | 0.63 |
| |$\Lambda$|CDM | Extended | Original | 30 | 227 | 206 | 1.05 | 0.32 |
| |$\Lambda$|CDM | Conservative | Original | 30 | 159 | 137 | 1.07 | 0.28 |
| wCDM | Extended | Original | 31 | 227 | 210 | 1.09 | 0.18 |
| MagLim model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
| |$\Lambda$|CDM, 6 bins | Extended | Updated | 37 | 295 | 314 | 1.22 | 0.01 |
| |$\Lambda$|CDM, 6 bins | Conservative | Updated | 37 | 207 | 230 | 1.35 | 0.001 |
| wCDM, 6 bins | Extended | Updated | 38 | 295 | 304 | 1.17 | 0.03 |
| |$\Lambda$|CDM, 4 bins | Extended | Updated | 31 | 178 | 146 | 0.99 | 0.51 |
| |$\Lambda$|CDM, 4 bins | Conservative | Updated | 31 | 122 | 108 | 1.18 | 0.09 |
| wCDM, 4 bins | Extended | Updated | 32 | 178 | 154 | 1.05 | 0.31 |
| |$\Lambda$|CDM, 6 bins | Extended | Original | 37 | 295 | 242 | 0.94 | 0.75 |
| |$\Lambda$|CDM, 6 bins | Conservative | Original | 37 | 207 | 178 | 1.05 | 0.32 |
| wCDM, 6 bins | Extended | Original | 38 | 295 | 244 | 0.95 | 0.73 |
| |$\Lambda$|CDM, 4 bins | Extended | Original | 31 | 178 | 135 | 0.92 | 0.77 |
| |$\Lambda$|CDM, 4 bins | Conservative | Original | 31 | 122 | 94 | 1.03 | 0.40 |
| wCDM, 4 bins | Extended | Original | 32 | 178 | 143 | 0.98 | 0.56 |
The goodness-of-fit for different configurations of the 2|$\times$|2pt analysis in HS. The first column displays the cosmological model and the number of tomographic bins of lenses for the cases using the MagLim sample. The second column shows the scale cut used: either extended (8, 6) Mpc h−1 or conservative (8, 12) Mpc h−1. The covariance iteration column tells which version of the covariance was used: either original (calculated at the fiducial parameters shown in Table 3 or recalculated at best-fitting values). The last five columns are: the number of total free parameters, the number of data points in the data vector after scale cuts, the |$\chi ^2$| at best-fitting values, the reduced |$\chi ^2$| assuming the number of DoF as number data points in the data vector minus the total number of parameters constrained, and the corresponding p-value.
| redMaGiC model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
|---|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | Extended | Updated | 30 | 227 | 187 | 0.95 | 0.68 |
| |$\Lambda$|CDM | Conservative | Updated | 30 | 159 | 128 | 0.99 | 0.51 |
| wCDM | Extended | Updated | 31 | 227 | 190 | 0.96 | 0.63 |
| |$\Lambda$|CDM | Extended | Original | 30 | 227 | 206 | 1.05 | 0.32 |
| |$\Lambda$|CDM | Conservative | Original | 30 | 159 | 137 | 1.07 | 0.28 |
| wCDM | Extended | Original | 31 | 227 | 210 | 1.09 | 0.18 |
| MagLim model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
| |$\Lambda$|CDM, 6 bins | Extended | Updated | 37 | 295 | 314 | 1.22 | 0.01 |
| |$\Lambda$|CDM, 6 bins | Conservative | Updated | 37 | 207 | 230 | 1.35 | 0.001 |
| wCDM, 6 bins | Extended | Updated | 38 | 295 | 304 | 1.17 | 0.03 |
| |$\Lambda$|CDM, 4 bins | Extended | Updated | 31 | 178 | 146 | 0.99 | 0.51 |
| |$\Lambda$|CDM, 4 bins | Conservative | Updated | 31 | 122 | 108 | 1.18 | 0.09 |
| wCDM, 4 bins | Extended | Updated | 32 | 178 | 154 | 1.05 | 0.31 |
| |$\Lambda$|CDM, 6 bins | Extended | Original | 37 | 295 | 242 | 0.94 | 0.75 |
| |$\Lambda$|CDM, 6 bins | Conservative | Original | 37 | 207 | 178 | 1.05 | 0.32 |
| wCDM, 6 bins | Extended | Original | 38 | 295 | 244 | 0.95 | 0.73 |
| |$\Lambda$|CDM, 4 bins | Extended | Original | 31 | 178 | 135 | 0.92 | 0.77 |
| |$\Lambda$|CDM, 4 bins | Conservative | Original | 31 | 122 | 94 | 1.03 | 0.40 |
| wCDM, 4 bins | Extended | Original | 32 | 178 | 143 | 0.98 | 0.56 |
| redMaGiC model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
|---|---|---|---|---|---|---|---|
| |$\Lambda$|CDM | Extended | Updated | 30 | 227 | 187 | 0.95 | 0.68 |
| |$\Lambda$|CDM | Conservative | Updated | 30 | 159 | 128 | 0.99 | 0.51 |
| wCDM | Extended | Updated | 31 | 227 | 190 | 0.96 | 0.63 |
| |$\Lambda$|CDM | Extended | Original | 30 | 227 | 206 | 1.05 | 0.32 |
| |$\Lambda$|CDM | Conservative | Original | 30 | 159 | 137 | 1.07 | 0.28 |
| wCDM | Extended | Original | 31 | 227 | 210 | 1.09 | 0.18 |
| MagLim model | Scale cut | Cov. iteration | Total params. | Data points | |$\chi ^2$| | |$\frac{\chi ^2}{\text{DoF}}$| | p-value |
| |$\Lambda$|CDM, 6 bins | Extended | Updated | 37 | 295 | 314 | 1.22 | 0.01 |
| |$\Lambda$|CDM, 6 bins | Conservative | Updated | 37 | 207 | 230 | 1.35 | 0.001 |
| wCDM, 6 bins | Extended | Updated | 38 | 295 | 304 | 1.17 | 0.03 |
| |$\Lambda$|CDM, 4 bins | Extended | Updated | 31 | 178 | 146 | 0.99 | 0.51 |
| |$\Lambda$|CDM, 4 bins | Conservative | Updated | 31 | 122 | 108 | 1.18 | 0.09 |
| wCDM, 4 bins | Extended | Updated | 32 | 178 | 154 | 1.05 | 0.31 |
| |$\Lambda$|CDM, 6 bins | Extended | Original | 37 | 295 | 242 | 0.94 | 0.75 |
| |$\Lambda$|CDM, 6 bins | Conservative | Original | 37 | 207 | 178 | 1.05 | 0.32 |
| wCDM, 6 bins | Extended | Original | 38 | 295 | 244 | 0.95 | 0.73 |
| |$\Lambda$|CDM, 4 bins | Extended | Original | 31 | 178 | 135 | 0.92 | 0.77 |
| |$\Lambda$|CDM, 4 bins | Conservative | Original | 31 | 122 | 94 | 1.03 | 0.40 |
| wCDM, 4 bins | Extended | Original | 32 | 178 | 143 | 0.98 | 0.56 |
In particular, for the MagLim analyses employing all six bins of the sample, the update in the covariance matrix parameters leads to a significant increase in the |$\chi ^2$|. This effect, while less pronounced, mirrors the one already observed in the corresponding CS analysis, as described in appendix B of Porredon et al. (2022). Fig. 4 displays the residual plots of the |$\Lambda$|CDM best-fitting predictions against the angular power spectra measurements.
APPENDIX D: FULL MARGINALIZED POSTERIORS
We show all the marginalized 1D posteriors for the full parameter space of our fiducial |$\Lambda$|CDM analysis in Figs D1 and D2 for redMaGiC and MagLim, respectively. For comparison, the CS counterparts from Pandey et al. (2022) and Porredon et al. (2022) are also shown as well as their common prior distributions as computed by the apriori sampler11 of CosmoSiS.
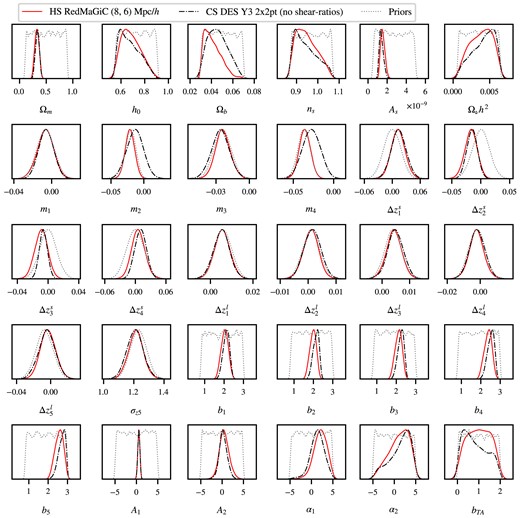
The full marginalized 1D posterior distributions for the fiducial HS analysis of the redMaGiC data set (red). The fiducial DES Y3 CS analysis counterpart is also shown (black) for comparison as well as the input priors common to both analyses (grey). The prior distributions were sampled using the apriori sampler of CosmoSiS.
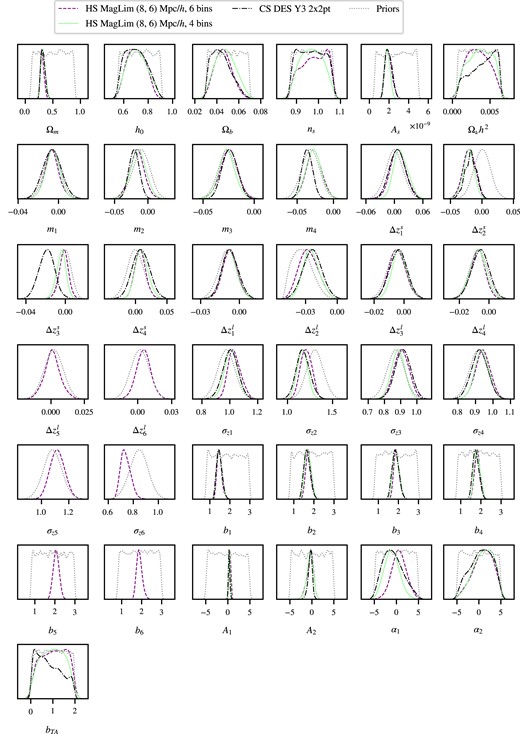
The full marginalized 1D posterior distributions for the fiducial HS analysis of the MagLim data set using 4 (purple) and 6 (green) tomographic bins of lenses. The DES Y3 CS analysis without shear ratios counterpart is also shown (black) for comparison as well as the input priors common to both analyses (grey). The prior distributions were sampled using the apriori sampler of CosmoSiS.
We find no statistically significant constraints on the nuisance parameters, including photometric redshift biases and stretches, and cosmic shear calibration biases, beyond those imposed by the priors.
APPENDIX E: SCALE CUTS IN MULTIPOLE SPACE
In this appendix, we present the effective maximum multipoles, |$\ell _{\rm max}$|, associated with the different scale cut schemes discussed in Section 3.2. Table E1 present summarizes the different values for the different power spectra considered.
Scale cuts used for the analyses. The maximum multipoles included were calculated from a certain minimum physical distance |$R_{\text{min}}$|, which is converted to |$\ell _\text{max}$| via equation (17) for every photo-z bin of lenses. This means that GGL combinations sharing the same lenses also share the same |$\ell _{\text{max}}$|. From this we derived our two sets of scale cuts. The conservative scale cut uses |$R_{\text{min}} = (8, 12)$| Mpc h−1, respectively, for GCL and GGL, following the approach in (DES Collaboration 2018). The extended scale cut, which is our fiducial choice, is derived from |$R_{\text{min}} = (8, 6)$| Mpc h−1.
| redMaGiC + metacalibration | MagLim + metacalibration | |||||
|---|---|---|---|---|---|---|
| GCL | GGL | GGL | GCL | GGL | GGL | |
| |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$| Mpc h−1 | |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$|Mpc h−1 | |
| Lens 1 | |$\ell _{\text{max}} = 94$| | |$\ell _{\text{max}} = 126$| | |$\ell _{\text{max}} = 63$| | |$\ell _{\text{max}} = 105$| | |$\ell _{\text{max}} = 139$| | |$\ell _{\text{max}} = 70$| |
| Lens 2 | |$\ell _{\text{max}} = 144$| | |$\ell _{\text{max}} = 193$| | |$\ell _{\text{max}} = 96$| | |$\ell _{\text{max}} = 154$| | |$\ell _{\text{max}} = 204$| | |$\ell _{\text{max}} = 103$| |
| Lens 3 | |$\ell _{\text{max}} = 187$| | |$\ell _{\text{max}} = 250$| | |$\ell _{\text{max}} = 125$| | |$\ell _{\text{max}} = 199$| | |$\ell _{\text{max}} = 264$| | |$\ell _{\text{max}} = 133$| |
| Lens 4 | |$\ell _{\text{max}} = 226$| | |$\ell _{\text{max}} = 302$| | |$\ell _{\text{max}} = 151$| | |$\ell _{\text{max}} = 237$| | |$\ell _{\text{max}} = 315$| | |$\ell _{\text{max}} = 158$| |
| Lens 5 | |$\ell _{\text{max}} = 255$| | |$\ell _{\text{max}} = 340$| | |$\ell _{\text{max}} = 170$| | |$\ell _{\text{max}} = 265$| | |$\ell _{\text{max}} = 353$| | |$\ell _{\text{max}} = 177$| |
| Lens 6 | – | – | – | |$\ell _{\text{max}} = 283$| | |$\ell _{\text{max}} = 376$| | |$\ell _{\text{max}} = 189$| |
| redMaGiC + metacalibration | MagLim + metacalibration | |||||
|---|---|---|---|---|---|---|
| GCL | GGL | GGL | GCL | GGL | GGL | |
| |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$| Mpc h−1 | |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$|Mpc h−1 | |
| Lens 1 | |$\ell _{\text{max}} = 94$| | |$\ell _{\text{max}} = 126$| | |$\ell _{\text{max}} = 63$| | |$\ell _{\text{max}} = 105$| | |$\ell _{\text{max}} = 139$| | |$\ell _{\text{max}} = 70$| |
| Lens 2 | |$\ell _{\text{max}} = 144$| | |$\ell _{\text{max}} = 193$| | |$\ell _{\text{max}} = 96$| | |$\ell _{\text{max}} = 154$| | |$\ell _{\text{max}} = 204$| | |$\ell _{\text{max}} = 103$| |
| Lens 3 | |$\ell _{\text{max}} = 187$| | |$\ell _{\text{max}} = 250$| | |$\ell _{\text{max}} = 125$| | |$\ell _{\text{max}} = 199$| | |$\ell _{\text{max}} = 264$| | |$\ell _{\text{max}} = 133$| |
| Lens 4 | |$\ell _{\text{max}} = 226$| | |$\ell _{\text{max}} = 302$| | |$\ell _{\text{max}} = 151$| | |$\ell _{\text{max}} = 237$| | |$\ell _{\text{max}} = 315$| | |$\ell _{\text{max}} = 158$| |
| Lens 5 | |$\ell _{\text{max}} = 255$| | |$\ell _{\text{max}} = 340$| | |$\ell _{\text{max}} = 170$| | |$\ell _{\text{max}} = 265$| | |$\ell _{\text{max}} = 353$| | |$\ell _{\text{max}} = 177$| |
| Lens 6 | – | – | – | |$\ell _{\text{max}} = 283$| | |$\ell _{\text{max}} = 376$| | |$\ell _{\text{max}} = 189$| |
Scale cuts used for the analyses. The maximum multipoles included were calculated from a certain minimum physical distance |$R_{\text{min}}$|, which is converted to |$\ell _\text{max}$| via equation (17) for every photo-z bin of lenses. This means that GGL combinations sharing the same lenses also share the same |$\ell _{\text{max}}$|. From this we derived our two sets of scale cuts. The conservative scale cut uses |$R_{\text{min}} = (8, 12)$| Mpc h−1, respectively, for GCL and GGL, following the approach in (DES Collaboration 2018). The extended scale cut, which is our fiducial choice, is derived from |$R_{\text{min}} = (8, 6)$| Mpc h−1.
| redMaGiC + metacalibration | MagLim + metacalibration | |||||
|---|---|---|---|---|---|---|
| GCL | GGL | GGL | GCL | GGL | GGL | |
| |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$| Mpc h−1 | |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$|Mpc h−1 | |
| Lens 1 | |$\ell _{\text{max}} = 94$| | |$\ell _{\text{max}} = 126$| | |$\ell _{\text{max}} = 63$| | |$\ell _{\text{max}} = 105$| | |$\ell _{\text{max}} = 139$| | |$\ell _{\text{max}} = 70$| |
| Lens 2 | |$\ell _{\text{max}} = 144$| | |$\ell _{\text{max}} = 193$| | |$\ell _{\text{max}} = 96$| | |$\ell _{\text{max}} = 154$| | |$\ell _{\text{max}} = 204$| | |$\ell _{\text{max}} = 103$| |
| Lens 3 | |$\ell _{\text{max}} = 187$| | |$\ell _{\text{max}} = 250$| | |$\ell _{\text{max}} = 125$| | |$\ell _{\text{max}} = 199$| | |$\ell _{\text{max}} = 264$| | |$\ell _{\text{max}} = 133$| |
| Lens 4 | |$\ell _{\text{max}} = 226$| | |$\ell _{\text{max}} = 302$| | |$\ell _{\text{max}} = 151$| | |$\ell _{\text{max}} = 237$| | |$\ell _{\text{max}} = 315$| | |$\ell _{\text{max}} = 158$| |
| Lens 5 | |$\ell _{\text{max}} = 255$| | |$\ell _{\text{max}} = 340$| | |$\ell _{\text{max}} = 170$| | |$\ell _{\text{max}} = 265$| | |$\ell _{\text{max}} = 353$| | |$\ell _{\text{max}} = 177$| |
| Lens 6 | – | – | – | |$\ell _{\text{max}} = 283$| | |$\ell _{\text{max}} = 376$| | |$\ell _{\text{max}} = 189$| |
| redMaGiC + metacalibration | MagLim + metacalibration | |||||
|---|---|---|---|---|---|---|
| GCL | GGL | GGL | GCL | GGL | GGL | |
| |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$| Mpc h−1 | |$R_{\text{min}} = 8$| Mpc h−1 | |$R_{\text{min}} = 6$| Mpc h−1 | |$R_{\text{min}} = 12$|Mpc h−1 | |
| Lens 1 | |$\ell _{\text{max}} = 94$| | |$\ell _{\text{max}} = 126$| | |$\ell _{\text{max}} = 63$| | |$\ell _{\text{max}} = 105$| | |$\ell _{\text{max}} = 139$| | |$\ell _{\text{max}} = 70$| |
| Lens 2 | |$\ell _{\text{max}} = 144$| | |$\ell _{\text{max}} = 193$| | |$\ell _{\text{max}} = 96$| | |$\ell _{\text{max}} = 154$| | |$\ell _{\text{max}} = 204$| | |$\ell _{\text{max}} = 103$| |
| Lens 3 | |$\ell _{\text{max}} = 187$| | |$\ell _{\text{max}} = 250$| | |$\ell _{\text{max}} = 125$| | |$\ell _{\text{max}} = 199$| | |$\ell _{\text{max}} = 264$| | |$\ell _{\text{max}} = 133$| |
| Lens 4 | |$\ell _{\text{max}} = 226$| | |$\ell _{\text{max}} = 302$| | |$\ell _{\text{max}} = 151$| | |$\ell _{\text{max}} = 237$| | |$\ell _{\text{max}} = 315$| | |$\ell _{\text{max}} = 158$| |
| Lens 5 | |$\ell _{\text{max}} = 255$| | |$\ell _{\text{max}} = 340$| | |$\ell _{\text{max}} = 170$| | |$\ell _{\text{max}} = 265$| | |$\ell _{\text{max}} = 353$| | |$\ell _{\text{max}} = 177$| |
| Lens 6 | – | – | – | |$\ell _{\text{max}} = 283$| | |$\ell _{\text{max}} = 376$| | |$\ell _{\text{max}} = 189$| |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}