





ABSTRACT
We present fitcov an approach for accurate estimation of the covariance of two-point correlation functions that requires fewer mocks than the standard mock-based covariance. This can be achieved by dividing a set of mocks into jackknife regions and fitting the correction term first introduced in Mohammad & Percival (2022), such that the mean of the jackknife covariances corresponds to the one from the mocks. This extends the model beyond the shot-noise limited regime, allowing it to be used for denser samples of galaxies. We test the performance of our fitted jackknife approach, both in terms of accuracy and precision, using lognormal mocks with varying densities and approximate EZmocks mimicking the Dark Energy Spectroscopic Instrument LRG and ELG samples in the redshift range of z = [0.8, 1.1]. We find that the Mohammad–Percival correction produces a bias in the two-point correlation function covariance matrix that grows with number density and that our fitted jackknife approach does not. We also study the effect of the covariance on the uncertainty of cosmological parameters by performing a full-shape analysis. We demonstrate that our fitted jackknife approach based on 25 mocks can recover unbiased and as precise cosmological parameters as the ones obtained from a covariance matrix based on 1000 or 1500 mocks, while the Mohammad–Percival correction produces uncertainties that are twice as large. The number of mocks required to obtain an accurate estimation of the covariance for the two-point correlation function is therefore reduced by a factor of 40–60. The fitcov code that accompanies this paper is available at this GitHub repository.
1 INTRODUCTION
A new generation of cosmological surveys such as Dark Energy Spectroscopic Instrument (DESI Collaboration 2016, 2022); have started taking data and even more will in the coming years with e.g. the start of operations of Euclid (Laureijs et al. 2011) and the Vera Rubin Observatory (Ivezić et al. 2019). Therefore, it is becoming vital to develop methods for deriving covariance matrices in order to estimate the uncertainties on the cosmological parameters of interest.
Existing methods of evaluating the covariance matrix that quantifies the errors on the galaxy two-point correlation function of galaxy redshift surveys can be separated into three different categories: mock-based, analytic, and internal, each best suited to different scenarios. Mock-based covariance matrices are built from a large suite of numerical simulations, ‘mock’ catalogues, that mimic the properties of the cosmological surveys with high fidelity. These mocks need to be (i) accurate in the sense that they have to reproduce the two- and higher-point statistics with limited biases and (ii) numerous in order to avoid sample variance, which introduces noise in the covariance matrices that could bias the inferred parameter uncertainties (e.g. Dawson et al. 2013; Percival et al. 2014).
Analytic approaches provide expectation values of the large-scale structure statistics directly and are much less computationally expensive. However, that requires a description of the non-Gaussian terms that enter the four-point correlation function, which is needed to compute the covariance of the two-point correlation function. Accurate modelling of the non-linear gravitational evolution, galaxy bias, redshift-space distortions, and shot noise is thus a challenge to compute analytic covariance matrices. The modelling usually relies on Perturbation Theory (PT) which limits the domain of accuracy to the quasi-linear regime when the density perturbations remain small compared to unity. Moreover, one also needs to account for survey geometry and window function effects. Recent progress in this direction has been made to develop codes for the power spectrum (CovaPT, Wadekar, Ivanov & Scoccimarro 2020). Additionally, we can mention semi-analytic approaches, which use the data to calibrate themselves, for example, rascalc code (Philcox et al. 2019; O’Connell et al. 2016).
Finally, data-based or internal methods, such as jackknife and bootstrap, are often used especially when large sets of mocks are not available. They consist in resampling the survey data by slicing the original data into subsamples and weighting these subsamples following specific prescriptions. In the standard jackknife approach, for a given jackknife realization i, the subsamples have unit weight except the subsample indexed i that is weighted 0, hence this approach is also called ‘delete-one’ jackknife resampling. Internal resampling methods do not rely on any assumption about the underlying gravity model and are thus less sensitive to unknown physics. However, they can lack precision and suffer from biases, as discussed in Norberg et al. (2009), Friedrich et al. (2016), and Favole et al. (2021). One fundamental deficiency of all internal covariance estimators is the large-scale bias coming from a lack of a proper estimation of the supersample covariance (Lacasa, Fabien & Kunz, Martin 2017), which is due to the lack of modes larger than the survey size. Recently, a correction to the standard jackknife resampling method was proposed in Mohammad & Percival (2022) which consists in introducing a different weighting scheme for the cross-pairs than for the auto-pairs, where the auto-pairs are made up of objects that lie in the same subsample and cross-pairs of two objects that reside in two distinct subsamples. Indeed, the choice of assigning weights to pairs of objects is arbitrary and Mohammad & Percival (2022) tested different prescriptions. They found that by adjusting the weighting of the pairs that compose the estimates of the two-point correlation function, they were able to provide more accurate estimates of the variance than the standard jackknife. However, it remains an internal estimator, with the associated characteristic fundamental problems such as supersample covariance.
In this work, we follow a similar methodology but propose to go beyond that work by (i) considering some cross-pairs that were neglected in both the standard jackknife and the jackknife method with Mohammad–Percival correction, (ii) fitting the appropriate weighting scheme to a mock-based covariance built from a smaller number of mocks than for traditional mock-based approach. The paper’s outline is as follows: in Section 2, we review the formalism associated with the standard jackknife resampling method and the correction proposed in Mohammad & Percival (2022). We introduce the formalism of our proposed hybrid approach. Its performance on mocks is presented in Section 3 and compared with the original correction for jackknife and with mock-based method for estimating the covariance matrix. We conclude and discuss further prospects in Section 4.
2 COVARIANCE ESTIMATORS
In this paper, we work in configuration space. We use the Landy–Szalay estimator with double-counting assumed, (Landy & Szalay 1993), which can be written as:
where s is the redshift space separation of a pair of galaxies, μ is the cosine of the angle between the separation vector and the line of sight, ξ(s, μ) is the two-point correlation function in redshift space, DD(s, μ) are the binned auto-pair counts of the data catalogue, RR(s, μ) are the binned pair counts computed from a matching random catalogue, and DR(s, μ) are the binned cross-pair counts between the random and the data catalogue. All pair counts are assumed to be suitably normalized in equation (1).
The two-point correlation function can be decomposed into Legendre multipoles defined as:
where ℓ is the order of the multipole, and Lℓ(μ) are the Legendre polynomials.
2.1 Covariance from data or data-like mocks
Cosmological simulations can be divided into two categories: (i) precise and expensive computationally N-body simulations, which are known to treat properly non-linear gravitational evolution; (ii) less accurate approximate mock methods, such as Bias Assignment Method, (Balaguera-Antolínez et al. 2018), COmoving Lagrangian Acceleration (Tassev, Zaldarriaga & Eisenstein 2013), Effective Zeldovich mock (Chuang et al. 2014), (Zhao et al. 2021), Fast Particle Mesh (Feng et al. 2016), GLAM, (Klypin & Prada 2018), lognormal, PATCHY (Kitaura et al. 2016), etc. They can provide a good covariance for scales >10 h−1 Mpc, but small-scale clustering is not properly resolved.
Assuming a survey with Nm mocks, the covariance matrix of the two-point correlation function is defined as:
where |$\xi ^{[k]}_i$| is the ith bin of correlation function of the kth mock, and 〈ξi〉 is the mean over the Nm mocks of the ith bin of the correlation function.
However, for some subsets of modern surveys, like the DESI Bright Galaxy Survey, the number of galaxies and their number density sometimes becomes so large, that even these approximate methods become expensive computationally, posing a problem.
2.2 Jackknife covariance
Jackknife is a data resampling approach that involves creating multiple subsamples of the same data set by systematically excluding regions of the data. When applied to the cosmological surveys, the footprint is divided into regions of similar area and it is these that are systematically excluded to make the multiple subsamples.
This approach has the advantage of making no assumptions regarding non-linear evolution and non-standard physics, and at the same time is extremely cheap from the computational perspective, as it does not require expensive production of thousands of mocks. Assuming we have cut our data set into Njk pieces, the covariance matrix is:
where |$\xi ^{[k]}_i$| is the ith bin of the correlation function of the kth jackknife region, and 〈ξi〉 is its mean over all the Njk jackknife regions. The coefficient on the right-hand side is larger than the corresponding factor in equation (3) as it compensates for the reduction in the covariance due to the overlap between the subsamples.
In practice, we consider the galaxy two-point correlation function and the DD, DR , and RR pair counts mentioned in the Landy–Szalay estimator defined in equation (1).
2.2.1 Standard approach
We will assume the number of subsamples is Njk and work in terms of pair counts rather than correlation functions. For simplicity, we will denote as AAk the auto-counts that are contributed by pairs of galaxies that both reside in the kth area of the survey (the areas that are systematically excluded to form the jackknife subsamples) and CCk the cross-counts between galaxies in this kth area and those in the jackknife subsample that is made by excluding this area. The counts in the jackknife subsample TTk are related to the overall number of counts in the full survey TTtot and the above quantities by
where in defining each of these pair counts we count each unique pair only once. The total number of auto- and cross-pairs can be related to their means over the jackknife samples by
and, as we account for double counting with the cross-pairs only while looking at the full sample, we need to divide the obtained estimate by 2 to be consistent with the auto-pairs:
where |$\overline{\mathrm{ \mathit{ AA}}} = \frac{1}{N_{\rm jk}}\sum _{k=1}^{N_{\rm jk}} \mathrm{ \mathit{ AA}}_k$| and |$\overline{\mathrm{ \mathit{ CC}}} = \frac{2}{N_{\rm jk}}\sum _{k=1}^{N_{\rm jk}} \mathrm{ \mathit{ CC}}_k$|.
Following (Mohammad & Percival 2022), we choose to define an estimator of the normalized auto-pairs θa,k in a specific realization, such that |$\overline{\theta }_{\rm a}=\overline{AA}$| by
and the estimator of the normalized cross-pairs θc, k such that |$\overline{\theta }_{\rm c}=\overline{CC}$| by
where it was taken into account that the cross-pairs contribute to the total estimate twice, while the auto-pairs only once.
We can then further compute for each jackknife realization the deviation from the mean value of the auto paircounts
and cross paircounts
We can now express how the covariance of each type of pair count can be represented in terms of the estimators above, if we assume the following definition for the covariance, where DDt are just some pair counts of type t:
By replacing (DD1, DD2) by (AA, AA) or (CC, CC) or (CC, AA) in equation (12) and using equations (10) and (11), one obtains:
This gives all the components needed to compute the covariance of TT, using its definition in equation (5):
Note how the terms scale differently with the number of the jackknife regions. Mohammad & Percival (2022) argue that this inconsistent scaling is the source of the bias that arises with the standard jackknife approach. In the next sections, we will see how adjusting this scaling can enable one to recover an unbiased covariance estimator and demonstrate the need for going beyond the Mohammad–Percival correction to get unbiased covariance estimators in all regimes of galaxy number density.
2.2.2 Mohammad–Percival correction
Mohammad & Percival (2022) proposed to weight the cross-pairs CC in order to fix the mismatch in the scaling, as seen in equation (16). With this weight α multiplying all the CC pair counts, the expression for TTk becomes
The definition of θc,k is then generalized to:
which also changes slightly the mean of this quantity as |$\overline{\theta }_{c}(\alpha)= \alpha \overline{CC}$|.
Following the steps from equations (9), (11), and (14), the modified expression for the covariance of the CC paircounts weighted by α is
We see that for α = 1 we recover the ordinary jackknife, as it will remove the cross-pairs in the same way as it removes the auto-pairs. Alternatively, by choosing |$\alpha = N_{\rm jk}/\left[2+\sqrt{2}(N_{\rm jk}-1)\right]$| we can achieve equal scaling for the first two terms. Therefore, under the assumption of cov(CC, AA) = 0 we indeed have all the terms scaling with Njk in same manner, which can be seen by rewriting the expression for cov(TT(α), TT(α)) as
In order to illustrate the effect of introducing the α weighting of Mohammad & Percival (2022), we create 1000 Poisson random catalogues in a box with a size of 1 Gpc h−1, divide them into 125 cubic regions and then compute the covariance matrices of the real-space correlation function. We do this for both the standard jackknife and jackknife with the Mohammad–Percival correction. The results are presented in Fig. 1. We show the ratio of the mean of the diagonal elements, σ2 ≡ Cii, of the covariance matrix between jackknife-based σjk and mock-based σ (estimated directly using equation 3), where the blue curve uses the standard jackknife and the orange one includes the Mohammad–Percival correction. The standard jackknife is over-estimating the covariance with respect to that from the mocks, while introducing the α weighting of Mohammad & Percival (2022) for the cross-pairs removes this bias.
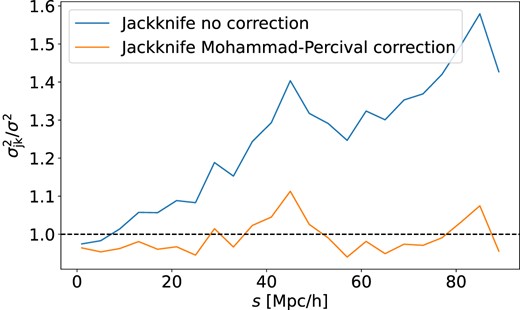
Comparison of the accuracy in the estimate of the diagonal elements of the covariance matrix for the real-space correlation functions as a function of scale obtained from 1000 cubic box independent mock catalogues. The ratio is the mean of the diagonal elements obtained using different jackknife approaches to those obtained directly from the ensemble of mocks. The noticeable scale-dependent bias that is visible for the standard jackknife estimate is absent when the Mohammad–Percival correction is employed.
2.3 Hybrid approach
The real galaxy density has physical correlations and so galaxy distributions are not Poisson distributions. Therefore, the assumption of cov(CC, AA) = 0 is not valid. With the α weighting of the cross-pairs that was introduced in Section 2.2.2, equation (15) becomes
We can see that adopting any general fixed value of α unfortunately leaves the scaling of cov(CC, AA) different from those of cov(AA, AA) and cov(CC, CC), so, in order to try to recover the benefits of the Mohammad–Percival approach, we are treating α as a free parameter. We propose therefore to augment the jackknife method with α weighting where the value of α is tuned by fitting the covariance estimate from a limited number of mocks. A scheme that represents the approach is shown in Fig. 2. First, let us assume we have a set of Nm mocks |$S = \lbrace S_1... S_{N_\mathrm{ m}} \rbrace$|. Then, S/Sk denotes the set of mocks with the kth mock removed. Then, we refer to the mock covariance from such a set S/Sk as Cij[S/Sk]. We also introduce the α-dependent jackknife covariance obtained from a mock Sk with a chosen α weighting as Cij[Sk](α), from correlation functions constructed with counts following equation (17).

Having that in our possession, we are able to estimate the uncertainty on the diagonal elements of the covariance Ξij(diag(C)). First, we resample the given set of mocks and produce Nm covariances Cij[S/Sk]. Then we compute the covariance matrix of the diagonals Ξij(diag(C)), where we limit ourselves to the diagonal elements as there are not enough degrees of freedom to build a covariance of matrices (Wishart 1928):
In general Nm should be greater than the number of elements in the fitted part of the covariance. However, in the case of a small Nm, one can restrict this to just the diagonal elements of Ξij, to ensure that covariance matrix stays non-singular. The next step consists of finding which specific α is needed to obtain a realisation of the covariance matrix to describe Cij[S]. First, we can write the α dependent estimator of the covariance Cij(α) based on the mean of Nm α dependent jackknife covariances:
Then, the χ2 of the Cii(α) describing the Cii[S] can be written as:
Following that, we minimize |$\chi ^2_C$| by varying α, such that we obtain |$\chi ^2_{C}(\alpha _{\rm min}) = {\rm min} (\chi ^2_C(\alpha))$|. To justify using the Gaussian likelihood in this procedure, we first notice that we are using only the diagonals of the covariance matrix. That allows us, with sufficiently large Nm, to approximate the distribution of the separate bins of the diagonals Cii with a Gaussian.
Therefore, our proposed estimator of the α dependent covariance matrix |$C^{(\rm fit)}_{ij}$| can be defined as:
While only the diagonal of |$C^{(\rm fit)}_{ij}$| are used when fitting for α, all the elements of |$C^{(\rm fit)}_{ij}$| are consistently adjusted with the value of α that is found. In the original Mohammad–Percival approach, the contribution of the cross-pairs to the covariance is adjusted to match that of the auto-pairs. Our hybrid approach allows us to adjust the cross-pair contribution on the α weighted covariance so that the covariance matches the one obtained from the limited set of mocks. We will show in the next section that by doing so, we can greatly reduce the bias that can appear for dense samples when using the fixed α weighting of Mohammad & Percival (2022). However, the hybrid approach does require more than a single mock to create a covariance estimate, but in the next section we will also show that the number of mocks needed is significantly reduced compared to a purely mock-based approach.
3 TESTS ON MOCKS
We test the performance of the fitted jackknife method with respect to other covariance matrix estimation methods on different sets of mocks that include RSD (Redshift Space Distortions) and some geometrical effects that we will describe in subsequent sections. For each specific set of mocks we also generate a set of matching random synthetic catalogues.
In Section 3.1, we present the methodology of the tests that we perform on our mocks. In Section 3.2, a set of tests is performed on lognormal mocks produced by the mockfactory code1 with three number densities to explore shot noise-dominated and sample variance-dominated regimes, but also to mimic the DESI LRG (Luminous Red Galaxies) and ELG (Emission Line Galaxies) samples. In Section 3.3, approximate EZmocks mimicking the DESI LRG and ELG samples are used to provide a mock-based covariance matrix which has the level of statistical precision of expected from the DESI Year-5 data. The corresponding number densities can be seen in Fig. 3 for LRG EZmocks in red, ELG EZmocks in purple, and the different lognormal mocks at |$\bar{n}=(2,~5,~15)~\times ~10^{-4}$| [Mpc h−1]−3 in blue, orange, and green, respectively. We use 1500 lognormal mocks for each space density, and 1000 ELG and LRG EZ mocks, respectively.
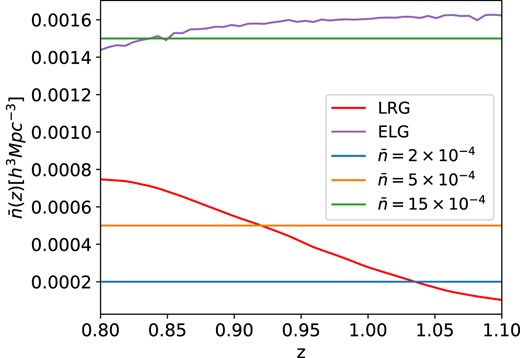
Number density dependence on redshift for different data sets used. The lognormal mock samples were chosen to have a constant density selection function, to simplify the matters, while LRG and ELG mock samples follow the expected values from the corresponding DESI survey subsets.
3.1 Methodology
Both the random and data samples are divided into Njk = 196 jackknife regions (the results shown in Section 3.2 are not sensitive to Njk) and FKP (Feldman, Kaiser & Peacock 1994) weights wi for each point i in the data set are assigned as follows:
where P0 = 104 h3 Mpc−3 is the power spectrum estimate at the given redshift. The FKP weights minimize the variance of the power spectrum estimate for samples that have a number density that varies with redshift. Then, the correlation functions are computed using pycorr2 for both the samples and the jackknife realizations, which allows us to obtain Cij, Cij(α), and |$C^{(\rm fit)}_{ij}$|, defined in equations (3), (23), and (25).
In order to test the robustness and precision of different covariance estimators using our set of lognormal mocks we have used the procedure described in Fig. 4. There we have created a set of 30 fitted and jackknife covariances and inferred cosmological parameters from 50 randomly selected mocks. In total we have 1500 pairs of covariances and mocks, which give us a set of 1500 fits for both the jackknife and fitted covariance approaches. As the mocks have the same cosmological parameters, and the covariances are considered estimators of the same underlying ‘true’ covariance matrix, we then compared the spread of parameter values and their uncertainties to the one obtained from fitting separately each of the 1500 mocks to the conventional mock-based covariance matrix. The same is then repeated for the approximate mocks, with the difference that this time we have only 1000 mocks, bringing us to the sets of 20 fitted and jackknife covariances.
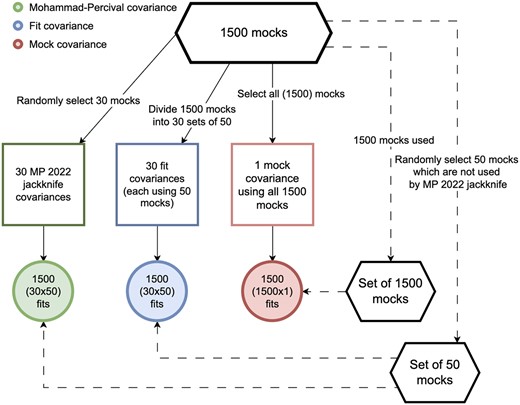
Schematic view of the procedure to test different covariance matrix estimators, as described in Section 3.1.
3.2 Lognormal mocks
In order to quickly test our approach with different parameters, such as number density, we produce a set of lognormal mocks which are often used as a simple approximation to the non-linear density field that evolves from Gaussian initial conditions. The lognormal distributed density contrast |$\delta (\vec{x})$| is related to a Gaussian field |$G(\vec{x})= \ln [1+\delta (\vec{x})] - \langle \ln [1+\delta (\vec{x})]\rangle$| as:
The two-point correlation function ξ(r) is related to the correlation function of the Gaussian field ξG(r) as:
So, a fiducial power spectrum P(k) can be transformed into the correlation function ξ(r), which is then converted to the correlation function of the Gaussian field using equation (28). We Fourier transform it to the power spectrum PG(k) and eventually generate the Fourier space Gaussian field G(k) as:
where θr, θi are Gaussian random variables with unit variance and zero mean, and V is the volume of the simulation. After simulating the Fourier Gaussian field G(k) on the grid, we then use Fast Fourier Transform to transform it and obtain the regular configuration space Gaussian field G(x). This is then transformed into the over-density field using equation (27). The expectation value for the number of galaxies in a particular cell is computed given a fixed mean number density |$\bar{n}$|, and galaxies are then drawn using the Poisson distribution and placed randomly the cell. Velocities are then assigned using the linearized continuity equation:
where a(t) is a scale factor, and which is solved using Zeldovich approximation (Zel’dovich 1970).
Eventually, the RSD effect is modelled at a chosen redshift using the velocity information by affecting the coordinates of the galaxy xi as:
where |$x^i_{\rm rsd}$| are the redshift-distorted coordinates, f is the linear growth rate of structure, |$\vec{v}$| is the velocity of the galaxy, and ni is the line of sight.
3.2.1 Dependence on number density
We create three sets of lognormal mocks, each set containing 1500 realizations, for number densities |$\bar{n} = 2\times 10^{-4}$|, 5 × 10−4, and 15 × 10−4 h3 Mpc−3 at z = 1. Each of the realizations is made from a cubic box with a volume of (2 Gpc h−1)3 with grid of size 3843 and fiducial cosmology with h = 0.674, σ8 = 0.816, and |$\Omega _{\rm m}^{(0)} = 0.31$|. The class code (Blas, Lesgourgues & Tram 2011) is used to generate the initial power spectrum. Redshift space distortions are then added, and each box is cut to have a footprint that covers |$15~{{\ \rm per\ cent}}$| of the full sky. Each mock is then analysed in the redshift range from 0.8 to 1.2, and the corresponding randoms are generated, which are about four times denser than the data mocks. The procedure to obtain the fitted jackknife covariance is summarized in Fig. 2 and explained in the previous section. Here, we use Nm = 50 mocks. We measure correlation functions from the mocks in bins of 5 h−1 Mpc. Fig. 5 presents the α parameter value distribution, obtained from the fits of the covariances.
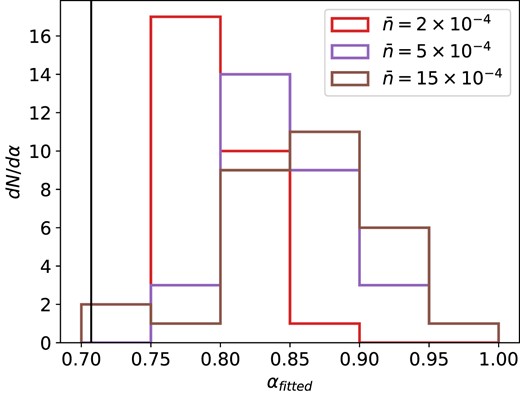
Histogram of the α parameter fitted from 50 mocks for lognormal mocks with |$\overline{n} = 2\times 10^{-4}, 5\times 10^{-4}$|, and |$15\times 10^{-4} \, h^3 {\rm Mpc}^{-3}$|. The vertical black line shows the value of |$\alpha = N_{\rm jk} /(2+\sqrt{2}(N_{\rm jk}-1))$|.
Fig. 6 shows a measure of the relative bias |$\Delta \sigma ^2(\xi _{\ell })/\sigma (\sigma ^2_{\rm Mock})$| between a jackknife-based covariance matrix and the mock-based covariance as a function of pair separation s. For simplicity we only consider the diagonal elements of each covariance matrix estimate. This relative bias is defined as
where σ(ξℓ) is the variance on a given multipole l obtained from the jackknife method, σMock(ξℓ) is the variance on the same multipole obtained from the 1500 lognormal mocks and |$\sigma (\sigma ^2_{\rm Mock})$| is the uncertainty on the mock-based error bar, determined by applying the classical jackknife delete-one mock estimator to the set of mocks from which the covariance is estimated.
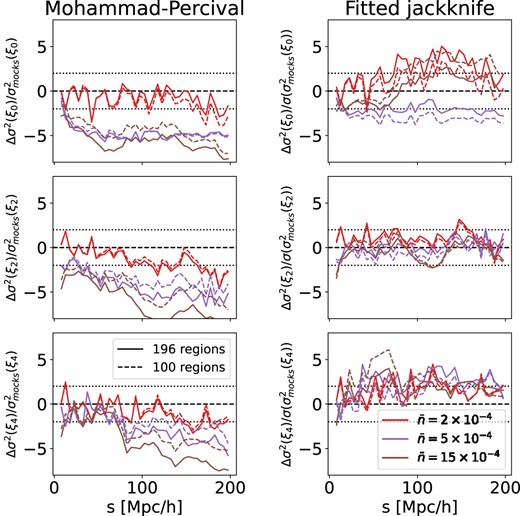
The average of the quantity defined in equation (32) representing the bias of the specific covariance estimation approach plotted as a function of separation, s, for various number densities.
The left panel of Fig. 6 shows this relative bias of the jackknife method with the Mohammad–Percival correction while the right panel shows the result for our fitted jackknife method. In both cases, the monopole, ξ0, is displayed in the top panel, the quadrupole, ξ2, in the middle, and the hexadecapole, ξ4, in the bottom. The coloured lines show different number densities and the solid lines are the baseline configuration of 196 jackknife regions while the dashed lines show the test of using 100 jackknife regions instead. As expected, the underestimation slightly worsens with the increase in the number of jackknife regions, as predicted by equation (15).
However, as the number density |$\bar{n}$| increases, the underestimation of the jackknife method with the Mohammad–Percival correction becomes more and more significant, especially for |$\bar{n} = 15\times 10^{-4}\, h^3{\rm Mpc}^{-3}$|. This underestimation is not visible on the jackknife covariance matrix estimates produced from the random catalogues as shown in Fig. 1. As explained in the previous section, the clustering of the data leads to higher covariance due to additional covariance coming from cross-correlations between CC and AA pair counts.
Additionally, there is no strong dependence on the number density for the fitted jackknife method which makes it more robust whatever the density regime of the galaxy sample of interest. It should be noted that for low-density regimes optimal α seems to be closer to the default value of Mohammad–Percival approach, and its fitted estimation in our method introduces additional uncertainty, which makes our method more imprecise as |$\overline{n}(z)$| decreases.
3.2.2 Effect on the cosmological parameters
To test the performance of different covariance estimation techniques we infer fσ8, α∥, and α⊥ by fitting the theoretical predictions for the multipoles to the ones from the mocks using covariances from estimators reviewed earlier. The fit is performed using a 5-parameter model, which is based on Lagrangian Perturbation Theory and includes the linear growth rate fσ8, Alcock–Paczynski parameters (Alcock & Paczynski 1979) α∥ and α⊥, first- and second-order biases b1, b2, and the effective Fingers Of God parameter (FOG) σFOG. The theoretical power spectrum PFOG is obtained using the MomentumExpansion module of the velocileptors package (for more details, see Chen, Vlah & White 2020; Chen et al. 2021). The Fingers-Of-God effect is modelled following Taruya, Nishimichi & Saito (2010), as
where |$P(\boldsymbol{k})$| is the power spectrum without the FOG effect obtained with velocileptors, σFOG is the one-dimensional velocity dispersion, and |$\hat{\boldsymbol{n}}$| is the LOS (line of sight) direction unit vector. The power spectrum |$P_\mathrm{FOG}(\boldsymbol{k})$| is then transformed into the two-point correlation function ξth(s, μ) using a Fast-Fourier-Transform and from that we compute the theoretical correlation function multipoles |$\xi ^{th}_{\ell }(s,\mu)$|.
Once we have the correlation function multipoles ξℓ(si), and covariance matrix |$\Sigma ^{\ell _1 \ell _2}_{ij} = C_{ij}$|, |$C^k_{ij}(\alpha)$| or |$C^{(\rm fit)}_{ij}$|, we can obtain the likelihood L(p1,..., pn):
where |$\xi ^{(th)}_{\ell }(s)$| is the theoretical prediction of the multipole for the set of k parameters {a1,.., ak} and we apply the Hartlap correction (Hartlap, Simon & Schneider, 2007) on the inverse of the covariance matrix such that the original uncorrected covariance matrix denoted as |$C^{(\rm orig)}_{ij}$| and the corrected inverse covariance matrix |$\Sigma ^{-1}_{ij}$| are related by:
where n is the number of discrete samples, and p is the number of entries in the data vector (number of bins used). We use a likelihood maximization method to find the χ2 minima using iminuit (Dembinski et al. 2020). Errors are estimated from the region of Δχ2 = 1 of the marginalized χ2 distribution, and they are allowed to be asymmetric. The choice of a frequentist method of analysis is motivated by its low computational cost.
In Fig. 7, the first row shows the distributions of reduced χ2 for different choices of |$\bar{n}$|, and the other rows show the marginalized 2D-distributions of parameters and their uncertainties for respectively, fσ8, α∥, and α⊥. The distributions of reduced χ2 show the goodness of the individual fits for the three methods. The contours in the bottom panel show how, for all the parameters, the spread from the Mohammad–Percival jackknife in green is in general much wider than the one from the mock covariance in red both in terms of uncertainty and parameter values. While in case of the fitted jackknife covariance, the blue contours are very similar to the mock covariance ones. Presumably, this improvement comes from using 50 realizations rather than one. In Fig. 8, we also show in the same form the performance from the standard jackknife in comparison with the Mohammad–Percival corrected jackknife and mock-based covariance. As expected, the standard jackknife produces slightly larger contours, which are noticeably shifted with respect to the mock covariance, especially for fσ8.
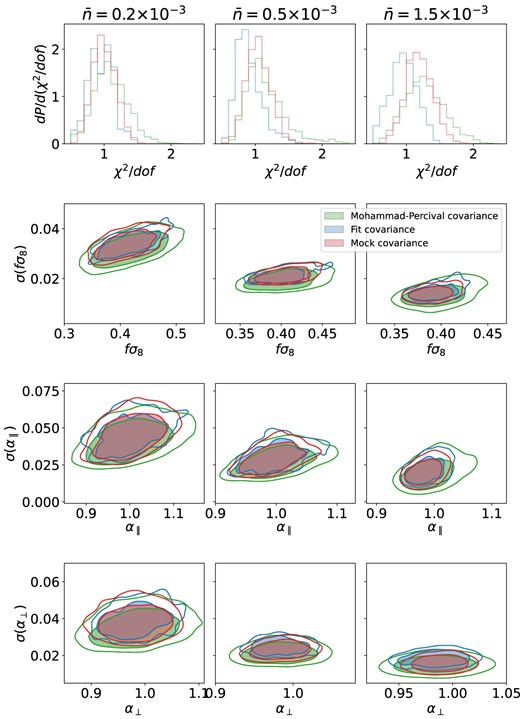
The summary of the results from the cosmological fits from the lognormal mocks with varying density (one for each column and with density in (Mpc h−1)3 indicated at the top) for the three covariance matrix estimation methods: jackknife covariance with Mohammad–Percival correction in green, fitted jackknife covariance in blue, and mock covariance in red. The top panels shows the histograms of the reduced χ2, while the three bottom ones show the marginalized 2D-distributions of parameters and their uncertainties for fσ8, α∥, and α⊥, obtained from the set of fits described in the Section 3.1.
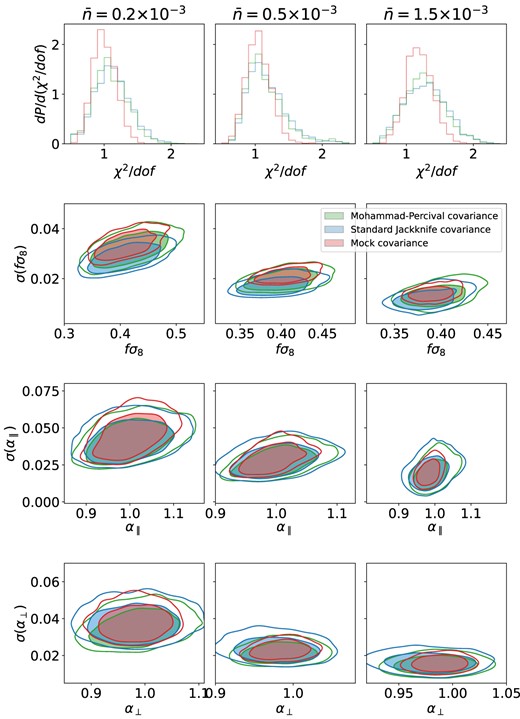
The summary of the cosmological fits from the lognormal mocks with a varying density. Similar to Fig. 7 but for a slightly different set of covariance matrix methods: jackknife covariance with the Mohammad–Percival correction in green, mock covariance in red (the same contours as on Fig. 7), and standard jackknife covariance in blue.
To additionally test the validity of our inference approaches, we will define the quantity
where η is an inferred parameter from a specific fit, |$\bar{\eta }$| is the mean from all the fits, and σ(η) is the error estimation from a specific fit. The distribution of quantity x is called a pull distribution. If η follows a Gaussian distribution, the distribution of x will form a normal distribution with |$\bar{x}=0$| and σ(x) = 1.
For the mock covariance, we fit the 1500 available samples, while for the Mohammad–Percival jackknife and for the fitted jackknife 50 random mocks are fitted using 30 realizations of the covariance, under the assumption that all of the covariance estimators are probing the same underlying likelihood.
Pull distributions for fσ8, α∥, and α⊥ are presented in Fig. 9 for each number density of the lognormal mocks. The fitted jackknife and mock covariance pull distributions have Gaussian-shape with σ = 1 normal distributions as expected, while the pull distributions obtained when using Mohammad–Percival jackknife are slightly wider, which is due the covariance being less precise. We can see it quantitatively in the Table 1, where the standard deviations of the distributions from Fig. 9 are presented. That is due to various shifts of the distributions obtained from fitting to different jackknife covariances. This is not the case for the fitted approach, however.
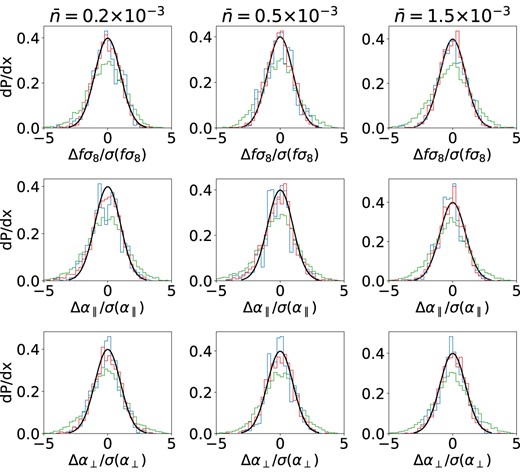
Pull distributions for different covariance estimation techniques with results from fits on various lognormal mocks, shown for 3 different number densities indicated at the top in (Mpc h−1)3. Line colours follow those in Fig. 7.
For each of the estimation methods we tabulate the standard deviation σ of |$(f\sigma _{8i}-\overline{f\sigma _8})/\sigma _i(f\sigma _8)$|, over independent fits, i. For the mock covariance method σ ≈ 1 (as expected when all the fits are performed consistently with the same covariance), for the fitted covariance method it is also quite close to unity, but for the jackknife method σ > 1.4, which shows a much higher degree of deviation from the truth.
| |$\bar{n}(z) (h^3 {\rm Mpc}^{-3})$| | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| 2 × 10−4 | 1.03 | 1.40 | 1.05 |
| 5 × 10−4 | 0.99 | 1.42 | 1.05 |
| 15 × 10−4 | 1.00 | 1.56 | 1.08 |
| |$\bar{n}(z) (h^3 {\rm Mpc}^{-3})$| | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| 2 × 10−4 | 1.03 | 1.40 | 1.05 |
| 5 × 10−4 | 0.99 | 1.42 | 1.05 |
| 15 × 10−4 | 1.00 | 1.56 | 1.08 |
For each of the estimation methods we tabulate the standard deviation σ of |$(f\sigma _{8i}-\overline{f\sigma _8})/\sigma _i(f\sigma _8)$|, over independent fits, i. For the mock covariance method σ ≈ 1 (as expected when all the fits are performed consistently with the same covariance), for the fitted covariance method it is also quite close to unity, but for the jackknife method σ > 1.4, which shows a much higher degree of deviation from the truth.
| |$\bar{n}(z) (h^3 {\rm Mpc}^{-3})$| | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| 2 × 10−4 | 1.03 | 1.40 | 1.05 |
| 5 × 10−4 | 0.99 | 1.42 | 1.05 |
| 15 × 10−4 | 1.00 | 1.56 | 1.08 |
| |$\bar{n}(z) (h^3 {\rm Mpc}^{-3})$| | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| 2 × 10−4 | 1.03 | 1.40 | 1.05 |
| 5 × 10−4 | 0.99 | 1.42 | 1.05 |
| 15 × 10−4 | 1.00 | 1.56 | 1.08 |
Overall, for all the number densities, the performance of the fitted jackknife method using 50 mocks is much better than that of the standard jackknife with the Mohammad–Percival correction, and, most importantly, it gives similar performance as the covariance matrix created from 1500 mocks.
We also test the performance of the approach when varying the number of mocks used for producing the fitted covariance. We test using 10, 25, and 50 mocks and report the results on the cosmological fits in Fig. 10, following the same methodology as explained before for 50 mocks. The precision on the marginalized 2D contours of the cosmological parameters of interest starts to drop noticeably when 10 mocks are used, while it remains stable between 25 and 50 mocks.
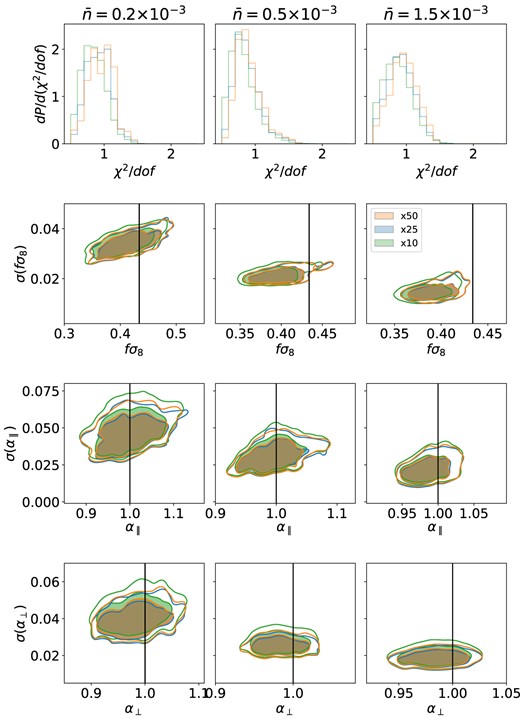
The summary of the cosmological fits when using different numbers of mocks to obtain the fitted jackknife covariance: the default number of 50 mocks in red, 25 mocks in blue, and 10 mocks in green. The figure is organized like Fig. 7.
3.3 Approximate mocks
Approximate mocks based on the extended Zeldovich approximation described in Zhao et al. (2021) are used to mimic the DESI LRG and ELG samples. These mocks are expected also to reproduce the clustering in the quasi-linear regime, although they are less accurate than N-body simulations. They provide a better representation of the real survey and better reproduce the non-Gaussian effects, which are not present in the lognormal mocks. The EZmocks used here are built using a 4-parameter model that is calibrated to match the clustering of N-body simulations, the 25 AbacusSummit simulations designed to meet the DESI requirements (Maksimova et al. 2021). The four model parameters are: (1) ρc - critical density required to overcome the background expansion; (2) ρexp - responsible for the exponential cut-off of the halo bias relation; (3) b - argument in the power-law probability distribution function P(n) = const × bn of having n galaxies in the limited volume; (4) ν is the standard deviation for the distribution modelling peculiar velocities.
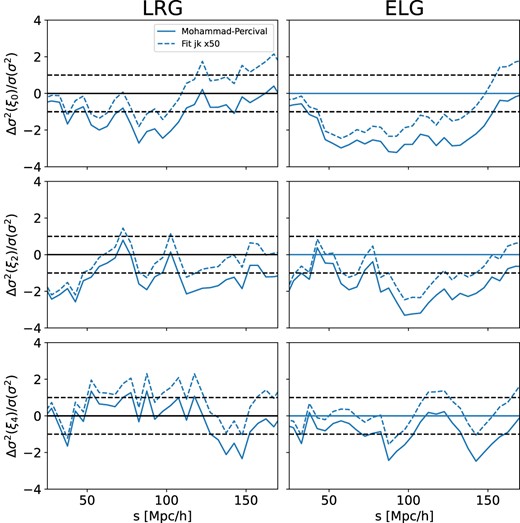
In this work, we use a set of 1000 EZmocks generated from N-body simulations with 6 Gpc h−1 box size. The fiducial cosmology employed is Planck 2018 (Aghanim et al. 2020), and the boxes are generated at z = 0.8 for the LRGs and z = 1.1 for the ELGs. We use the redshift range of z = [0.8, 1.1] and the mocks are cut to a footprint that reproduces that planned for the 5-year DESI data in order to match the expected final precision of the mock-based covariance matrix. The comparison of the difference with the mock covariance for the single realisation of the jackknife covariance and the fitted covariance is presented in Fig. 11.

Comparison of the deviation of jackknife and fit covariances from the mock covariance multiplied by a square of separation for multipoles ℓ = 0, 2, 4 for the EZ LRG mocks.
On Fig. 12, the relative bias of the diagonals of jackknife-based versus mock-based covariances as defined by equation (32) are shown for the LRG sample on the left and for the ELG sample on the right, in a similar way to Fig. 6. First, The same trend is seen for the Mohammad–Percival jackknife as we found with the lognormal mocks: the bias of the jackknife method with the Mohammad–Percival correction tends to increase with number density, so from LRG to ELG, and the fitted jackknife is still able to mitigate it. However, we can also notice that the differences are less pronounced in the case of the EZmocks which is due to a bigger volume being probed by the same number density. In Appendix A, we test the impact of the size of the footprint on the diagonal elements of the covariance matrices by considering the North Galactic Cap, South Galactic Cap, and full footprint separately.
The quantity defined in equation (32) representing the bias of the specific covariance estimation approach plotted for three multipoles of LRG and ELG EZmocks (left and right panels, respectively). Solid lines are with Mohammad–Percival correction and dashed lines for the fitted jackknife.
As in the previous section, we also infer the values of the cosmological parameters fσ8, α∥, and α⊥, using the same methodology as for the lognormal mocks. The results of the fits are shown in Fig. 13 where the first row shows the χ2/dof distribution and the other rows show the marginalized 2D contours for best-fitting values and uncertainties on the cosmological parameters. We confirm the findings with the lognormal mocks that the fitted jackknife method provides results which are in much better agreement with the mock-based method while the jackknife method with the Mohammad–Percival correction over-estimates clearly the uncertainties on all the cosmological parameters. The effect is also stronger as the number density of the galaxy sample increases. Moreover, as we have fewer mocks than for the tests with the lognormal mocks, we can notice that the fitted covariance based on 50 mocks actually produces smaller contours overall than the mock covariance which uses 1000 EZmocks.
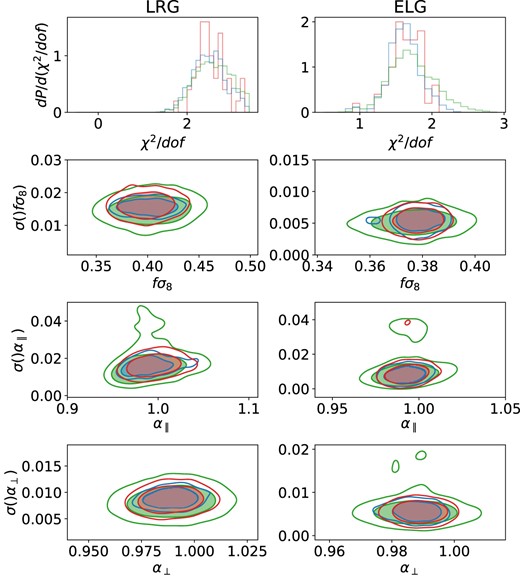
The summary of the cosmological fits for the EZ mocks for LRGs and ELGs (left and right column, respectively), similar to Fig. 7 layout.
In Fig. 14, we show the pull distribution as defined by equation (36) for the cosmological parameters and the standard deviations of the fσ8 distribution, which is taken as an example, are presented on Table 2. The results are also similar to the ones obtained with the lognormal mocks: both the fitted jackknife and mock covariances produce a Gaussian shape with σ = 1, while the standard deviation of the pull distribution obtained using the Mohammad–Percival correction for the jackknife method is larger (σ = 1.5, 1.8 for LRG and ELG, respectively). This quantitative test thus demonstrates that the fitted jackknife method performs better in estimating an unbiased and accurate covariance matrix for the two-point correlation function.
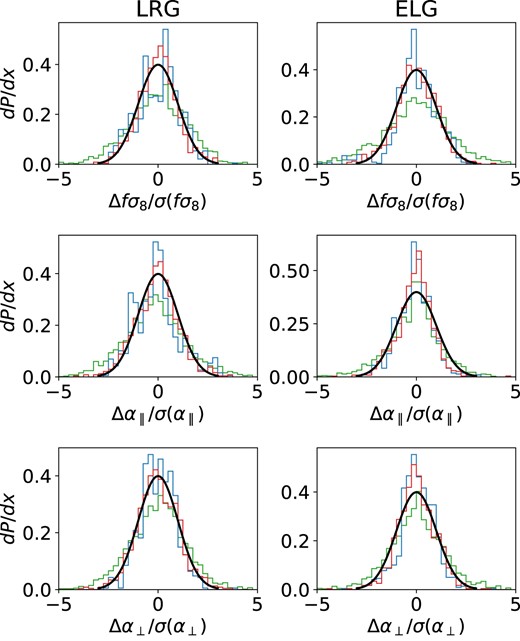
Pull distributions for different covariance estimation techniques with results from fits on LRG and ELG mocks with line colours as in Fig. 9.
Standard deviation σ of |$(f\sigma _{8,i}-\overline{f\sigma _8})/\sigma _i(f\sigma _8)$|, where i is a separate fit for each of the methods. We can see, that for the mock covariance, it is close to 1 (as it is supposed to be when all of the fits share the same covariance.), for fitted covariance it is closing on it, and for jackknife usually takes values >1.4, which shows a much higher degree of deviation from what we assumed to be the truth.
| Survey | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| LRG | 1.04 | 1.49 | 1.07 |
| ELG | 1.08 | 1.80 | 1.07 |
| Survey | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| LRG | 1.04 | 1.49 | 1.07 |
| ELG | 1.08 | 1.80 | 1.07 |
Standard deviation σ of |$(f\sigma _{8,i}-\overline{f\sigma _8})/\sigma _i(f\sigma _8)$|, where i is a separate fit for each of the methods. We can see, that for the mock covariance, it is close to 1 (as it is supposed to be when all of the fits share the same covariance.), for fitted covariance it is closing on it, and for jackknife usually takes values >1.4, which shows a much higher degree of deviation from what we assumed to be the truth.
| Survey | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| LRG | 1.04 | 1.49 | 1.07 |
| ELG | 1.08 | 1.80 | 1.07 |
| Survey | Mock | Mohammad–Percival | Fit |
|---|---|---|---|
| LRG | 1.04 | 1.49 | 1.07 |
| ELG | 1.08 | 1.80 | 1.07 |
Overall, throughout all of the tests for varying number densities, different types of mocks, and number of fitted mocks, the fitted jackknife approach shows a considerable improvement over the correction for standard jackknife proposed by Mohammad & Percival (2022). The fitted jackknife approach can achieve an unbiased estimate of the covariance matrix with similar precision to a mock-based covariance but with the major advantage of requiring a much smaller number of mocks.
4 CONCLUSIONS
Obtaining an accurate covariance matrix is a key ingredient for any cosmological analysis, and raises a significant challenge due to the limitations in computing power for mock-based methods or in the assumptions used in the analytical approaches. Additionally, as was shown in a series of reviews comparing different approximate methods, they still have problems reproducing exactly the results of more computationally intensive codes, especially in the non-linear regime (Colavincenzo et al. 2018; Lippich et al. 2018; Blot et al. 2019). Some works also focused on decreasing the number of simulations needed to obtain a precise covariance matrix (Chartier et al. 2021), for example combining the results from N-body and approximate simulations.
In this work we have attempted to tackle this challenge with the use of internal resampling methods. In Section 2, we review the basics of the jackknife formalism for two-point correlation function covariance estimation and perform a test on a toy model which confirms the improvement brought by a correction to the standard jackknife approach proposed by Mohammad & Percival (2022). Instead of using an analytically fixed correction to some terms that enter the jackknife covariance matrix, we propose to fit the correction to a mock-based covariance obtained from a small number of mocks. Moreover, we also noticed an unconstrained term in the different pairs that comprise the jackknife estimate of the covariance matrix, which we propose to account for by the same fitted jackknife procedure. In Section 3, we have tested this fitted jackknife covariance method and compared its performance with respect to the jackknife method with Mohammad–Percival correction and to a mock-based approach using lognormal mocks and approximate EZ mocks. We showed that the underestimation of the covariance obtained when using the Mohammad–Percival correction increases with galaxy number density while the fitted jackknife covariance remains unbiased. Performing the cosmological inference showed that the fitted jackknife covariance based on 50 mocks performs with the same accuracy as the covariance created from 1000–1500 mocks, both in terms of precision (unbiased constraints) and accuracy (similar uncertainties). There is also a significant decrease in computational power needed and we also stress that the method is simple to implement on top of the standard jackknife covariance computation. We provide a Python package that contains the implementation of the fitted jackknife method: https://github.com/theonefromnowhere/FitCov
Future work may include further tests of such a fitted jackknife covariance estimation technique when applied to scales smaller than ∼20 h−1 Mpc. We plan to investigate the small scales in another work that aims at fitting the clustering of DESI Early Data with this method and mock-based covariances in order to estimate the galaxy–halo connection for different galaxy samples. A similar technique could also be developed in Fourier space, however, it would require a proper treatment of the window function effects when splitting the footprint into subsamples, together with a significant computational effort. We leave for future work the application of such techniques to other statistics, such as three-point correlation function. Such a fitted jackknife covariance method can also be beneficial for multi-tracer analysis where it could accommodate all the degrees of freedom needed without requiring too many additional mocks. We plan to continue this work and apply the multi-tracer technique on the upcoming DESI Bright Galaxy Survey (Zarrouk et al. 2021; Hahn et al. 2022) whose high-density sampling make it a challenging test of the performance of the fitted jackknife covariance method.
ACKNOWLEDGEMENTS
The authors acknowledge and are highly grateful for the fruitful discussions with Will Percival, Arnaud de Mattia, and Michael Rashkovetskyi. ST and PZ acknowledge the Fondation CFM pour la Recherche for their financial support. PN and SC acknowledge STFC funding ST/T000244/1 and ST/X001075/1.
This work used the DiRAC@Durham facility managed by the Institute for Computational Cosmology on behalf of the STFC DiRAC HPC Facility (www.dirac.ac.uk). The equipment was funded by BEIS capital funding via STFC capital grants ST/K00042X/1, ST/P002293/1, ST/R002371/1, and ST/S002502/1, Durham University and STFC operations grant ST/R000832/1. DiRAC is part of the National e-Infrastructure.
This research was supported by the Director, Office of Science, Office of High Energy Physics of the U.S. Department of Energy under Contract No. DE–AC02–05CH11231, and by the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility under the same contract; additional support for DESI was provided by the U.S. National Science Foundation, Division of Astronomical Sciences under Contract No. AST-0950945 to the NSF’s National Optical-Infrared Astronomy Research Laboratory; the Science and Technologies Facilities Council of the United Kingdom; the Gordon and Betty Moore Foundation; the Heising-Simons Foundation; the French Alternative Energies and Atomic Energy Commission (CEA); the National Council of Science and Technology of Mexico (CONACYT); the Ministry of Science and Innovation of Spain (MICINN), and by the DESI Member Institutions: https://www.desi.lbl.gov/collaborating-institutions.
The authors are honoured to be permitted to conduct scientific research on Iolkam Du’ag (Kitt Peak), a mountain with particular significance to the Tohono O’odham Nation.
DATA AVAILABILITY
The lognormal mocks can be easily reproduced using the public mockfactory code at https://github.com/cosmodesi/mockfactory. The approximate EZmocks will be made public with upcoming DESI data releases. Data enabling the reproduction of the plots in this paper are published at https://zenodo.org/record/7635683.
Footnotes
References
APPENDIX A: IMPACT OF THE SIZE OF THE FOOTPRINT
The lognormal and approximate EZmocks used in this work for testing the different covariance matrix estimates do not use the same size survey footprint. Given that for the same number density we see a bigger discrepancy between the jackknife method with Mohammad–Percival correction and the mock-based covariance matrix in the case of the lognormal mocks than with the approximate mocks, we also explore the effect of varying the size of the footprint. We consider the LRG EZmocks and compute the covariance matrix for the three methods (jackknife with Mohammad–Percival, fitted jackknife and mock-based) for the Southern Galactic Cap separately and compare the results with the ones for the full Y5 footprint. We keep the same number of jackknife regions in all cases.
The results are displayed in Fig. A1 where we plot the relative bias as defined by equation (32) between a jackknife method and the mock-based covariance as a function of pair separation for the monopole (top), quadrupole (middle), and hexadecapole (bottom). The results for the SGC are shown in orange and the ones for the full footprint in blue. Indeed, we see that the bias associated with the Mohammad–Percival approach is higher when a smaller footprint is used. We also confirm the same effect for the ELG data set. Therefore, it makes the fitted jackknife covariance method even more useful when the footprint considered is relatively small. We believe that this effect might be related to supersampling covariance, and if it is indeed the case, it would mean that our approach can successfully take it into account.
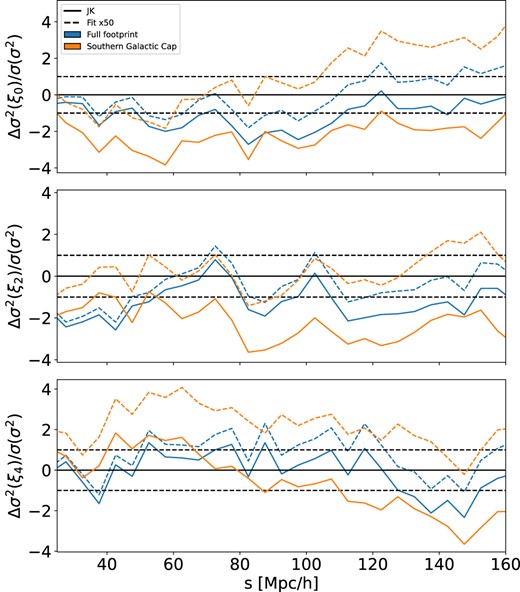
Relative bias as defined in equation (32) for the fitted jackknife method (dashed) and for the Mohammad–Percival approach (solid) as a function of pair separation for LRG EZ mocks. The orange curves are the results for the SGC while the blue curves are for the larger full footprint.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}