





ABSTRACT
We study the effect of magnification in the Dark Energy Survey Year 3 analysis of galaxy clustering and galaxy–galaxy lensing, using two different lens samples: a sample of luminous red galaxies, redMaGiC, and a sample with a redshift-dependent magnitude limit, MagLim. We account for the effect of magnification on both the flux and size selection of galaxies, accounting for systematic effects using the Balrog image simulations. We estimate the impact of magnification on the galaxy clustering and galaxy–galaxy lensing cosmology analysis, finding it to be a significant systematic for the MagLim sample. We show cosmological constraints from the galaxy clustering autocorrelation and galaxy–galaxy lensing signal with different magnifications priors, finding broad consistency in cosmological parameters in ΛCDM and wCDM. However, when magnification bias amplitude is allowed to be free, we find the two-point correlation functions prefer a different amplitude to the fiducial input derived from the image simulations. We validate the magnification analysis by comparing the cross-clustering between lens bins with the prediction from the baseline analysis, which uses only the autocorrelation of the lens bins, indicating that systematics other than magnification may be the cause of the discrepancy. We show that adding the cross-clustering between lens redshift bins to the fit significantly improves the constraints on lens magnification parameters and allows uninformative priors to be used on magnification coefficients, without any loss of constraining power or prior volume concerns.
1 INTRODUCTION
Although astronomers have a long history of mapping out the projected distribution of galaxies on the sky, cosmological models make the cleanest predictions about the three-dimensional distribution of mass in the universe, i.e. the dark-matter-dominated, total matter distribution. The relation between galaxy and matter density, known as the galaxy bias, is difficult to predict theoretically; hence, it is difficult to extract cosmological information from maps of projected galaxy density alone. Gravitational lensing provides a relatively direct way to probe the total mass distribution that galaxies sit within. In particular, the mass associated with foreground, lens, galaxies distorts the observed shapes of background, source, allowing inference of the mass distribution around the foreground lenses, a phenomenon known as galaxy–galaxy lensing. Galaxy–galaxy lensing then can be used to break the degeneracy between the galaxy bias and the amplitude of total matter clustering, which is present in galaxy clustering measurements, and thus infer useful cosmological constraints (see e.g. Hu & Jain 2004; Bernstein 2009; Joachimi & Bridle 2010; Yoo & Seljak 2012; Mandelbaum et al. 2013).
The Dark Energy Survey (DES) is one of several galaxy imaging surveys aiming to exploit the combination of clustering and lensing information, with large sky area and deep imaging now returning high signal-to-noise measurements of the angular correlation function of galaxies, w(θ), and the mean tangential shear induced in the background galaxies by the foreground lenses, γt(θ). As statistical power continues to increase, more subtle effects need to be included in the modelling of the signal. Here we focus on gravitational lensing magnification, which impacts the number of galaxies observed in a given area of sky, leading to observable effects on the galaxy clustering and galaxy–galaxy lensing statistics. Therefore, they need to be accounted for and the data from DES Year 3 data (Y3, from the first 3 years of DES observations) afford an excellent opportunity to detect this effect. Needless to say, as surveys get wider and deeper, this effect will become more and more important, so we view this paper as one in a series of communal attempts to incorporate magnification into cosmological analyses. Lensing magnification has been investigated in the context of the weak lensing cosmology analyses, most recently in Lorenz, Alonso & Ferreira (2018), Deshpande & Kitching (2020), Thiele, Duncan & Alonso (2020), von Wietersheim-Kramsta et al. (2021), Duncan et al. (2022), and Mahony et al. (2022), and has been detected in a number of different ways dating back to at least Scranton et al. (2005) (and see references therein for even earlier detections).
We begin by overviewing the relevant theory in Section 2 and we describe the data and simulations used in Sections 3 and 4. In Section 5, we estimate the amplitudes of the magnification contributions to our theory predictions, for both lens samples using several methods and then in Section 6 propagate that to a projection of what should be expected in DES Y3. In Section 7, we validate our modelling framework on cosmological simulations, and then present our results for the DES Y3 data in Section 8.
This paper is one of three from the DES Y3 analysis presenting cosmology results from the combination of galaxy clustering and galaxy–galaxy lensing, which we will refer to as ‘2 × 2 pt’. The other two are Porredon et al. (2021a), which presents results from the MagLim lens sample, and Pandey et al. (2022), which presents results from the redMaGiC lens sample. These results are combined with the lensing shear autocorrelation (known as cosmic shear, see Amon et al. 2022; Secco et al. 2022) in the the 3 × 2 pt paper (Abbott et al. 2022).
2 THEORY
In photometric surveys, such as DES, we use photometric redshift estimates to place galaxies into redshift bins, for which we have estimates of the ensemble redshift distribution. In the absence of magnification, the intrinsic projected galaxy density contrast in redshift bin i, |$\delta ^i_{g,\mathrm{int}} (\boldsymbol{\hat{{\bf n}}})$|, is given by the line-of-sight integral of the three-dimensional galaxy density contrast
with χ the comoving distance and |$W_{g}^i = n_g^i(z)\, d z/d\chi$| the normalized selection function of galaxies in redshift bin i. The approximate equality acknowledges that this neglects redshift space distortions (RSD, Kaiser 1987). These are included in our modelling but suppressed here for simplicity. In this section, we derive the modulation of the observed projected galaxy density by magnification and calculate the magnification contribution to angular two-point statistics.
2.1 Magnification
We can express magnification in terms of the convergence κ and the shear γ (e.g. Bartelmann & Schneider 2001):
in the limit of weak lensing when κ ≪ 1 and γ ≪ 1.
Magnification alters the trajectory of photons such that in regions of positive (negative) convergence (i) the apparent distance between any two points on a source plane is increased (decreased) and (ii) the telescope captures a greater (smaller) fraction of the solid angle of light emitted from an object. Magnification then impacts both the apparent position of galaxies and the distribution of light received from an individual galaxy image. In large-scale structure surveys, where we are interested specifically in the observed number density of objects, the impact of magnification can be separated into the following two effects:
Change in observed area element: Since the distance between the centroids of galaxy images will increase with positive convergence, this will appear to an observer as a given area element ΔΩ on the unlensed sky being mapped to an area element of area μΔΩ in the presence of magnification μ. Hence the observed area number density of galaxies decreases by a factor μ.
Change in selection probability of individual galaxies: A lensing magnification μ increases the apparent distance between points within the image of the galaxy, enlarging the apparent image size, while the increased solid angle captured by the telescope increases the total flux received (such that galaxy surface brightness is conserved). To first order, this increases the total observed flux by a factor μ. Galaxies entering a given photometric sample are selected based on their measured (i.e. observed) properties, for example their flux or size. We note that in real data, galaxy selection can be complex in detail (i.e. not simply a threshold in total galaxy flux), and so accurately predicting the response of the number density to a change in magnification requires simulations of the selection function.
The overdensity due to convergence κ at position |$\boldsymbol{\hat{{\bf n}}}$| on the sky, can be written in terms of the observed galaxy number densities, |$n^{\textrm {sel}}(\boldsymbol{\hat{{\bf n}}},\kappa)$|, and the same quantity at κ = 0 (e.g. Bernstein 2009; Joachimi & Bridle 2010),
Here the superscript ‘sel’ indicates that a selection has been applied using thresholds on various observed (i.e. lensed) properties of the galaxies, which we will denote by a vector |$\vec{F}^{\prime }$|. The observed number density at position |$\boldsymbol{\hat{{\bf n}}}$| can be written as an integral over |$N(\vec{F},\boldsymbol{\hat{{\bf n}}})$|, the absolute number of galaxies in direction |$\boldsymbol{\hat{{\bf n}}}$| with unlensed properties |$\vec{F}$|, divided by the area element ΔΩ(κ) (on the lensed sky)
where |$S(\vec{F}^{\prime })$| is the sample selection function, which operates on lensed properties |$\vec{F}^{\prime }$|. For small convergence κ, we can make the substitution ΔΩ(κ) = ΔΩ(0)/(1 − 2κ), such that
We can then Taylor expand |$S(\vec{F}^{\prime })$| around κ = 0
and drop terms involving κ2, leading to
Substituting this into equation (3), we have
where
In equation (8), we can identify the first term as being the number density in the unlensed case, |$n^{\mathrm{sel}}(\boldsymbol{\hat{{\bf n}}},0)$|, modulated by (1 − 2κ) due to the change in area element. The second term is proportional to κ, with constant of proportionality given by the response of the number of selected objects per (unlensed) area element, to a change in κ. We can thus summarize the effect on the projected number density contrast as,
with Carea = −2, and the total magnification contribution described by a single constant |$C^i=C_{\text{area}} + C_{\rm sample} ^i$|.
Where the galaxy selection function is simply made via a cut in magnitude, mcut, this expression becomes (Joachimi & Bridle 2010; Garcia-Fernandez et al. 2016)
where
and Nμ(m) is the (lensed) cumulative number of galaxies as a function of maximum magnitude m.
In this case, whether an excess magnification increases or decreases the observed number density, i.e. whether the increase in observed flux wins over the dilution due to change in area element, depends on the intrinsic slope of the cumulative flux distribution. The larger the ratio of faint to bright objects in the sample, the more dominant the former effect is.
Since real galaxy samples are a complex selection of flux, colour, position, and shape, we estimate the response constant Csample in DES Y3 using the image simulation Balrog (Everett et al. 2022), as described in Section 5.1.
2.2 Lens magnification
The primary effect we will study is magnification of the lens sample1 by structure that is between the lenses and the observer,
Following Section 2.1, we can write the change in number density produced by magnification as proportional to the convergence, and we define Ci as follows:
where κ here denotes the convergence experienced by the lens galaxies in redshift bin i, and note we are now working with harmonic transform of the density contrast, |$\delta ^i_{g,\text{mag}} (\vec{l})$|. Recall that these are the galaxies whose clustering we are measuring, but we will also be cross-correlating this sample with the background source sample in the galaxy–galaxy lensing probe. The galaxies in the source sample also experience magnification, which we can ignore here since it impacts the two-point functions at higher order. See Appendix B for more details on source magnification in this sample and Prat et al. (2022) and Duncan et al. (2022) for further studies justifying the exclusion of source magnification from 2 × 2 pt analyses.
Then, this change in the density contrast affects the galaxy overdensity angular power spectrum, Cgg(l) as follows:
where angle brackets <> denote an angular power spectrum and we have dropped the |$(\vec{l})$| arguments for brevity.
Lens magnification also impacts galaxy–galaxy lensing since the convergence experienced by the lens galaxies is correlated with that causing the shear of the source galaxies (denoted here as γG), as well as their intrinsic alignment (denoted here as γIA). The angular cross-correlation power spectrum between lens galaxy overdensity of redshift bin i and shape of galaxies in redshift bin j is then
2.3 Modeling the correlation functions
The modeling of the two point functions is described in detail in Krause et al. (2021); here we summarize the basic structure of this computation.
We use the Limber approximation to calculate each term contributing to the galaxy–galaxy lensing power spectrum. For two general fields, this is simply
where the window functions for galaxy density and shear are defined in Krause et al. (2021). However, when computing the angular clustering power spectrum (equation 17), the Limber approximation is insufficient, and we follow Fang et al. (2020b). For example, the exact expression for the galaxy angular power spectrum (ignoring magnification and RSD) is
and the full expressions including magnification and RSD are given in Fang et al. (2020b). Schematically, the integrand in equation (20) is split into the contribution from non-linear evolution, for which unequal time contributions are negligible so that the Limber approximation is sufficient, and the linear-evolution power spectrum, for which time evolution factorizes.
We relate the power spectra to the angular correction functions via (e.g. Stebbins 1996; Kamionkowski, Kosowsky & Stebbins 1997)
where Pℓ and |$P_\ell ^2$| are the Legendre polynomials.
3 DATA
DES collected imaging data for 6 years, from 2013 to 2019, using the Dark Energy Camera (DECam) (DECam; Flaugher et al. 2015) mounted on the Blanco 4m telescope at the Cerro Tololo Inter-American Observatory (CTIO) in Chile. The observed sky area covers |$\sim 5000 \deg ^2$| in five broadband filters, grizY, covering near-infrared and visible wavelengths. This work uses data from the the first 3 years (from August 2013 to February 2016), with approximately four overlapping exposures over the full wide-field area, reaching a limiting magnitude of i ∼ 23.3 for S/N = 10 point sources.
The data were processed by the DES Data Management system (Morganson et al. 2018) and, after a complex reduction and vetting procedure, compiled into object catalogues, using the SExtractor (Bertin & Arnouts 1996) software for detection on coadded images. For ease of management when performing this detection, the sky is divided into chunks 0.7306 square degrees across, which we call tiles. This catalogue includes several photometric measurements for galaxies of which the Single Object Flux (SOF) is the most accurate available. We calculate additional metadata in the form of quality flags, survey flags, survey property maps, object classifiers, and photometric redshifts to build the Y3 Gold data set (Sevilla-Noarbe et al. 2021).
3.1 Lens samples
This paper uses two different samples of lens galaxies: redMaGiC, a sample of luminous red galaxies (LRGs) selected from the redMaPPer galaxy cluster calibration, and MagLim, a sample with a redshift-dependent magnitude limit optimized for combinations of clustering and galaxy–galaxy lensing.
3.1.1 MagLim
Our fiducial sample, MagLim, is defined with a magnitude cut in the i band that depends linearly with photometric redshift, i < 4zphot + 18, where zphot is the photometric redshift estimate from DNF (De Vicente, Sánchez & Sevilla-Noarbe 2016). This selection has been optimized in Porredon et al. (2021b) in terms of the wCDM cosmological constraints from the 2 × 2 pt data vector, resulting in a sample with 3.5 times more galaxies than redMaGic and 30 per cent wider redshift distributions. The sample is divided in six tomographic bins using the the |$\mathrm{DNF\_ZMEAN\_SOF}$| quantity with bin edges z = [0.20, 0.40, 0.55, 0.70, 0.85, 0.95, 1.05]. The MagLim sample shows variations in number density correlated with observing properties that are corrected for with weights applied to each galaxy, described in Rodríguez-Monroy et al. (2022).
The final MagLim selection can be summarized by the following cuts on quantities from the gold catalogue:
Removed objects with FLAGS_GOLD in 2|4|8|16|32|64
Star galaxy separation with EXTENDED_CLASS = 3
SOF_CM_MAG_CORRECTED_I |$\lt 4 \ z_{DNF\_ZMEAN\_SOF} + 18$|
SOF_CM_MAG_CORRECTED_I >17.5
|$0.2 \lt z_{\mathrm{DNF\_ZMEAN\_SOF}} \lt 1.05$|.
See Sevilla-Noarbe et al. (2021) for further details on these quantities.
3.1.2 redMaGiC
We also use the DES Year 3 redMaGiC sample. redMaGiC selects LRGs using the sequence model calibrated from bright red galaxy spectra, using the redmapper calibration (Rykoff et al. 2014, 2016). The redMaGiC sample is produced by applying a redshift-dependent threshold luminosity Lmin that selects for constant co-moving density. The full redMaGiC algorithm is described in Rozo et al. (2016).
We divide the Y3 redMaGiC sample into five photometric redshift bins, selected on the redMaGiC redshift point estimate ZREDMAGIC. The bin edges used are z = 0.15, 0.35, 0.50, 0.65, 0.80, and 0.90. The first three bins use a luminosity threshold of Lmin > 0.5L* and are known as the high density sample. The last two redshift bins use a luminosity threshold of Lmin > 1.0L* and are known as the high luminosity sample.
The redshift distributions are computed by stacking samples from the redshift PDF of each individual redMaGiC galaxy, allowing for the non-Gaussianity of the PDF. From the variance of these samples, we find an average individual redshift uncertainty of σz/(1 + z) = 0.0126 in the redshift range used.
In Rodríguez-Monroy et al. (2022), it was found that the redMaGiC number density correlates with a number of observational properties of the survey. This imprints a non-cosmological bias into the galaxy clustering. To account for this, we assign a weight to each galaxy, which corresponds to the inverse of the angular selection function at that galaxy's location. The computation and validation of these weights is described in Rodríguez-Monroy et al. (2022).
The final redMaGiC selection can be summarized by the following cuts on quantities from the gold catalogue and redMaGiC calibration,
Removed objects with FLAGS_GOLD in 8|16|32|64
Star galaxy separation with EXTENDED_CLASS > = 2
Cut on the red-sequence goodness of fit |$\chi ^{2} \lt \chi ^{2}_{\rm max}(z)$|
0.15 < ZREDMAGIC < 0.9
The star galaxy separator EXTENDED_CLASS is defined as the sum of three integer conditions, T + 5Terr > 0.1, T + Terr > 0.05, and T − Terr > 0.02, where T is the galaxy size squared, as determined by the SOF composite model described in Sevilla-Noarbe et al. (2021) measured in arcmin2.
3.2 Mask
The lens samples are selected from within the DES Year 3 3 × 2 pt footprint, defined on a pixelated healpix map (Górski et al. 2005) with Nside = 4096. This angular mask only includes pixels with photometry deep enough that both lens samples are expected to have a uniform selection function in all redshift bins. We also remove pixels close to foreground objects, with photometric anomalies, or with a fractional coverage less than 80 per cent, resulting in a total area of 4143 deg2. The GOLD catalogue quantities we select on are summarized by,
footprint > = 1
foreground = = 0
badregions < = 1
fracdet > 0.8
depth_i > = 22.2
ZMAX_highdens > 0.65
ZMAX_highlum > 0.95
See Sevilla-Noarbe et al. (2021) for further details on these quantities.
3.3 Source sample
The source sample is another subset of the DES Year 3 Gold catalogue (Sevilla-Noarbe et al. 2021). It consists of 100 208 944 galaxies with measured photometry and shapes after imposing the following cuts in r, i, and z bands, as motivated in Gatti et al. (2021):
18 < mi < 23.5
15 < mr < 26
15 < mz < 26
−1.5 < mr − mi < 4
−4 < mz − mi < 1.5
The shapes of these galaxies, determined in Gatti et al. (2021) and calibrated for use in weak lensing shear statistics in MacCrann et al. (2022), are used for the galaxy–galaxy lensing measurement. This measurement also requires the redshift distribution of the source galaxies. Just as the lens galaxies are divided into distinct redshifts bins, the source galaxies are divided into four redshift bins, with mean redshifts ranging from 0.34 to 0.96. Myles et al. (2021) describe how these bins are populated and the inference of the redshift distributions and uncertainties for each bin.
4 SIMULATIONS
A number of simulations are used in this analysis. The details of these simulations are described here.
4.1 Balrog
The Balrog image simulations are created by injecting ‘fake’ galaxy images into real DES single-epoch wide-field images. The complete DES photometric pipeline is run on the images, resulting in object catalogues. The objects in the output catalogues can be matched to the Balrog injections to investigate the survey transfer function. The injected galaxies are model fits to the DES deep-field observations that are typically 3–4 magnitudes deeper than the wide field data (Hartley et al. 2022). Further details of the Year 3 Balrog simulations are described in Everett et al. (2022).
A number of Balrog catalogues were produced for the DES Year 3 analysis. In this analysis, we use Balrog run2a and run2a-mag. These runs both cover the same 500 random DES tiles, with approximately 4 million detected objects in each. The injections were randomly selected from objects in the DES deep fields down to a magnitude limit of 24.5.2 In run2a-mag, the exact same deep-field objects are injected at the same coordinates as in run2a but with a 2 per cent magnification applied to each galaxy image.3 This magnification increases the size of the image by 2 per cent while preserving surface brightness such that, in the absence of systematics and selection effects, the flux is also expected to increase by 2 per cent.
All Sextractor and SOF quantities used in the lens sample selection are computed on the matched objects in both run2a and run2a-mag. The difference in g-band fluxes for the same objects is shown in Fig. 1. The scatter in the flux difference is dominated by noise in the photometric fitting.
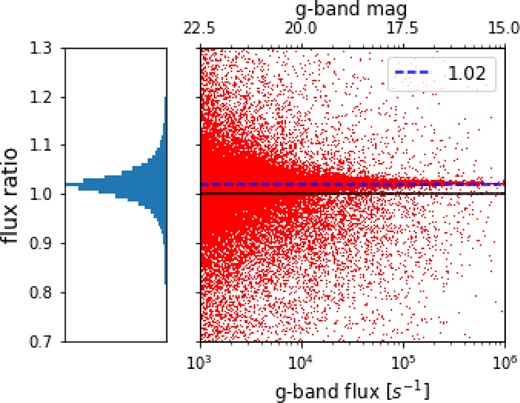
Ratio of Balrog fluxes, measured in counts per second, in the magnified and unmagnified Balrog runs. The average flux difference is consistent with the input 2 per cent magnification. The large scatter at low flux is dominated by noise in the SOF photometric fitting. The left panel is a histogram of the flux ratio, showing the tails are small and the distribution is centred on 1.02.
We show in Appendix A that the Balrog method produces a realistic simulation of the DES-Y3 data, with good agreement in distributions of measured quantities such as magnitudes, sizes, and photometric redshifts.
4.2 N-body simulations
4.2.1 B uzzard v2.0
The Buzzard v2.0 simulations are a suite of 18 synthetic DES Y3 galaxy catalogues constructed from N-body lightcone simulations (DeRose et al. 2022). Each pair of two synthetic DES Y3 catalogues is generated from a set of three independent lightcones with mass resolutions |$[0.33,\, 1.6, \, 5.9] \, \times 10^{11}\, h^{-1}{\rm M}_{\odot }$|, box sizes of |$[1.05,\, 2.6,\, 4.0]\, (h^{-3}\, \rm Gpc^3)$|, spanning redshift ranges in the intervals |$[0.0,\, 0.32,\, 0.84, \, 2.35]$|, respectively. Each lightcone is run with L-Gadget2, a version of Gadget2 (Springel 2005) optimized for memory efficiency when running dark-matter-only configurations. The simulations were initialized at z = 50 with initial conditions generated by 2LPTIC (Crocce, Pueblas & Scoccimarro 2006) from linear matter power spectra produced by camb (Code for Anisotropies in the Microwave Background) (Lewis, Challinor & Lasenby 2000) at the Buzzard cosmology.
Galaxies are added to the N-body outputs using the Addgals algorithm (DeRose et al. 2022; Wechsler et al. 2022), which imbues each galaxy with a position, velocity, absolute magnitude, SED, half-light radius, and ellipticity. The Calclens raytracing code (Becker 2013), which employs a spherical harmonic transform Poisson solver on an Nside = 8192 HEALPix grid (Górski et al. 2005), is used to compute lensing quantities, including convergence and shear, at each galaxy position. These quantities are then used to magnify galaxy magnitudes and sizes, and shear ellipticities. The catalogues are cut to the DES Y3 footprint and photometric errors are applied to the magnitudes using error distributions derived from Balrog (Everett et al. 2022).
The redMaGiC sample is selected from each synthetic galaxy catalogue using the same algorithm that is employed on the DES Y3 data. This is possible given the close match between red-sequence galaxy colours in Buzzard and the DES Y3 data. A source galaxy sample is selected to match the effective number density and shape noise of the DES Y3 Metacalibration source sample (Gatti et al. 2021), and photometric redshifts are estimated with the sompz algorithm (Myles et al. 2021). For a comprehensive overview of these simulations, see DeRose et al. (2022).
4.2.2 MICE
The MICE Grand Challenge (MICE-GC) simulation is a large N-body run, which evolved 40963 particles in a volume of |$(3072 \, {\rm Mpc} \, h^{-1})^3$| using the gadget-2 code (Springel 2005; Fosalba et al. 2015b). It assumes a flat ΛCDM cosmology with Ωm = 0.25, ΩΛ = 0.75, Ωb = 0.044, ns = 0.95, σ8 = 0.8, and h = 0.7. This results in a particle mass of |$2.93 \times 10^{10} \, h^{-1}{\rm M}_{\odot }$| (Fosalba et al. 2015b). The run produced, on-the-fly, a light-cone output of dark-matter particles up to z = 1.4 in one octant of the sky without repetition (Crocce et al. 2015). A set of 256 maps of the projected mass density field in narrow redshift shells, with angular Healpix resolution Nside = 8184, were measured. These were used to derive the convergence field κ in the Born approximation by integrating them along the line-of-sight weighted by the appropriate lensing kernel. These κ maps are then used to implement the magnification in the magnitudes and positions of mock galaxies due to weak lensing, as detailed in Fosalba et al. (2015a).
Haloes in the light-cone were populated with galaxies as detailed in Carretero et al. (2015), assigning positions, velocities, luminosities, and colours to reproduce the luminosity function, (g-r) colour distribution and clustering as a function of colour and luminosity in SDSS (Blanton et al. 2003; Zehavi et al. 2011). Spectral energy distributions (SEDs) are then assigned to the galaxy resampling from the COSMOS catalogue of Ilbert et al. (2009) galaxies with compatible luminosity and (g-r) colour at the given redshift. Once with the SED, any desired magnitude can be computed. In particular, DES magnitudes are generated by convolving the SEDs with the DES pass bands, including the expected photometric noise per band given the depth of DES Y3. Finally, in order to reproduce with high fidelity, the distribution of colours and magnitudes of the observational data,we map data photometry into the MICE one using an N-dimensional PDF transfer function, which also preserves the correlation among colours.
Once provided with this catalogue, we run both the Redmagic and DNF algorithms to determine photometric redshifts, starting from magnitudes with and without the contribution from magnification. We then selected the redMaGiC and MagLim samples. The abundance, clustering, and photometric redshift errors of the real and simulated data resemble each other very well for both samples.
5 ESTIMATING MAGNIFICATION COEFFICIENTS
As described in Section 2.1, the constant C in equation (16), which is the response of the galaxy number density to κ, can be split into C = Csample + Carea. The Carea from the area change is equal to −2. The Csample from the flux and galaxy size change can be estimated from our simulations separately, as the fractional change in the number of selected galaxies in response to a small convergence, δκ, applied to the simulated, input galaxy properties (i.e. flux and size) only – note the galaxy positions are not altered and so the change in area effect is not included. Csample can then be estimated simply via a numerical derivative
where N(0) and N(δκ) are the absolute number of galaxies selected from the κ = 0 and κ = δκ simulations, respectively. Then
This is the basic equation we will use to estimate Csample, but using a variety of input data, as described in Sections 5.1–5.3.
5.1 Estimate from BALROG simulations
The Balrog magnification run described in Section 4.1 uses the same input galaxy models in the same positions as the unmagnified run, but with a constant magnification δμ = 1.02 (i.e. δκ ∼ 0.01) applied to each input galaxy. We find δκ ∼ 0.01 is large enough that we can get a sufficiently precise estimate of Csample (i.e. a sufficient number of objects are magnified across the detection threshold), but small enough to ensure that the quadratic κ2 contributions to the change in number density are small (∼10−4). We apply the MagLim and redMaGiC lens sample selection on the galaxy catalogues from both the κ = 0 run and the κ = δκ run. We then estimate Csample via equation (24).
This estimate should capture the impact of magnification on the specific colour and magnitude selection of the redMaGiC and MagLim samples, plus any size selections such as the star–galaxy separation cuts.
The estimates of Csample in each of the tomographic bins for the two lens samples using Balrog are shown in Fig. 2, labelled ‘Balrog full’. These estimates are subject to shot-noise due to the finite volume of the Balrog simulation, which we calculate as follows:
where N(0 only) is the number of objects selected from the κ = 0 simulation and not selected from the κ = δκ simulation, and N(δκ only) is the number of objects selected from the κ = δκ simulation and not selected from the κ = 0 simulation. This is the statistical contribution to the error bars shown in Fig. 2. A derivation of this uncertainty can be found in Appendix Section D.
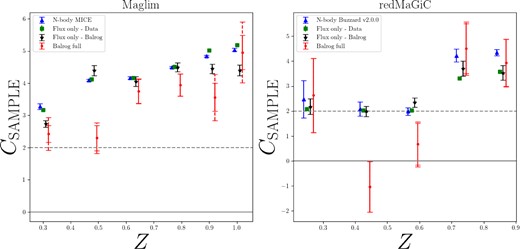
Magnification coefficient estimates for the two lens samples. Each panel shows multiple estimates for the magnification coefficients from the different methods outlined in Section 5. Our primary method of estimating these coefficients, shown as red circles, uses the Balrog simulations (with and without a small magnification applied to the injected galaxy properties) to accurately quantify galaxy selection effects and systematic effects (as described in Section 5.1). The blue triangles show an estimate from N-body simulations, containing flux magnification only (see Section 5.3). The green squares are estimates from perturbing the measured fluxes in the data (see Section 5.2). The black stars are from perturbing the measured fluxes in the baseline simulated BALROG sample. If the Balrog sample was truly representative of the real data, we would expect the green and black points to be the same. We therefore use the difference between the green and black points is used as a source of systematic error on the red Balrog estimates. We show both the statistical errors and the total (stat + sys) error from Balrog. The solid line corresponds to zero magnification bias from the sample selection, while the dashed line corresponds to zero magnification bias when also including the change in area element.
5.2 Estimate from perturbing measured fluxes
For this method, we add a constant offset Δm directly to the Y3 real data magnitudes used in the sample selection.
where δκ = 0.01.
We then re-select the sample using these perturbed magnitude and can compute the |$C^{\rm Data}_{\rm sample}$| value directly from equation (24). Note that we do not re-run the photometric redshifts, so these are computed using quantities derived from the true magnitudes. This method provides a simplistic estimate of the effect of magnification on the fluxes only and ignores the effects of photometric noise, selection on photometric redshift, size selection, observational systematics, and more generally the survey transfer function.
Since there is no additional photometric noise introduced between the original and perturbed fluxes in this method, we can use a simplified version of equation (25) to estimate the statistical uncertainty,
We also apply this ‘flux-only’ method to the BALROG catalogues; by comparing to the ‘flux-only’ results on the real data, this tests how representative the BALROG sample is of the real data.
5.3 N-body simulations
The third method used in this analysis is performed on the MICE and Buzzard N-body simulations described in Sections 4.2.1 and 4.2.2. This method takes advantage of of the fact that we know the true convergence, κ, at each simulated galaxy location. The N-body simulations used here include magnification effects on the galaxy positions and fluxes, but do not realistically simulate the full impact of lensing on observed galaxy images, and our estimate of the selection response from them includes only that due to change in flux.
We select the lens samples with and without magnification applied to the fluxes and compute fractional change in number of selected objects, in 10 equally spaced κ bins. From equation (24), one can see that the gradient of this relation is equal to Csample. We estimate this gradient with a least square fit and use this as |$C^{\rm N-body}_{\rm sample}$|.
As with our estimate from perturbing measured fluxes in the data Section 5.2, this method only captures the effect of magnification on galaxy fluxes, and not any size-selection effects. We also find agreement with the colour-magnitude distribution in the N-body simulations and the data and therefore this would also be a reasonable estimate of the data coefficients if other selection effects are small.
We note that we initially used only the Buzzard simulations for both the MagLim and redMaGiC samples, but based on evidence that the MagLim sample was not sufficiently representative of the real data (due to a decrement of galaxies at high redshift in Buzzard, see DeRose et al. ), we instead used the MICE simulations for MagLim only.
5.4 Comparison of magnification coefficient estimates
Tables 1 and 2 show the relevant number counts and Csample estimates from the three different methods. The Csample estimates are also compared in Fig. 2. The |$C^{\tt {Balrog}}_{\rm sample}$| estimates include a systematic error that accounts for any differences in the colour–magnitude–size selection in Balrog compared to the real data. We compute this by running the flux-only estimate described in Section 5.2 on the unmagnified Balrog sample and take the difference between this estimate and the flux-only estimate from the data to be a systematic error in the |$C^{\tt {Balrog}}_{\rm sample}$| estimates. This difference captures only differences in the flux-size distribution, not the effects from our magnified Balrog method. In general, the distribution of Balrog magnitudes and sizes agrees well with the data, as can be seen in Appendix A, but there are some small differences at the size-selection cut. The flux-only Csample estimates on Balrog are shown in Fig. 2 and agree well with the flux-only data estimates for the redMaGiC sample. The systematic error is largest for the MagLim sample in bins 1, 5, and 6, potentially indicating that the BalrogMagLim sample is less representative of the real data at these redshifts.
Csample estimates for the MagLim sample, for the three different methods described in Section 5. The Balrog estimate include a systematic uncertainty derived from the difference between the perturbation of measured fluxes method applied to the data and Balrog samples.
| MagLim | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.2 < z < 0.4 | 2.43 ± 0.26 ± 0.44(sys) | 3.18 ± 0.012 | 3.28 ± 0.091 |
| 0.4 < z < 0.55 | 2.30 ± 0.39 ± 0.27(sys) | 4.13 ± 0.016 | 4.09 ± 0.034 |
| 0.55 < z < 0.7 | 3.75 ± 0.38 ± 0.11(sys) | 4.17 ± 0.016 | 4.17 ± 0.04 |
| 0.7 < z < 0.85 | 3.94 ± 0.35 ± 0.01(sys) | 4.52 ± 0.015 | 4.5 ± 0.03 |
| 0.85 < z < 0.95 | 3.56 ± 0.44 ± 0.57(sys) | 5.02 ± 0.018 | 4.84 ± 0.023 |
| 0.95 < z < 1.05 | 4.96 ± 0.53 ± 0.79(sys) | 5.19 ± 0.019 | 5.04 ± 0.054 |
| MagLim | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.2 < z < 0.4 | 2.43 ± 0.26 ± 0.44(sys) | 3.18 ± 0.012 | 3.28 ± 0.091 |
| 0.4 < z < 0.55 | 2.30 ± 0.39 ± 0.27(sys) | 4.13 ± 0.016 | 4.09 ± 0.034 |
| 0.55 < z < 0.7 | 3.75 ± 0.38 ± 0.11(sys) | 4.17 ± 0.016 | 4.17 ± 0.04 |
| 0.7 < z < 0.85 | 3.94 ± 0.35 ± 0.01(sys) | 4.52 ± 0.015 | 4.5 ± 0.03 |
| 0.85 < z < 0.95 | 3.56 ± 0.44 ± 0.57(sys) | 5.02 ± 0.018 | 4.84 ± 0.023 |
| 0.95 < z < 1.05 | 4.96 ± 0.53 ± 0.79(sys) | 5.19 ± 0.019 | 5.04 ± 0.054 |
Csample estimates for the MagLim sample, for the three different methods described in Section 5. The Balrog estimate include a systematic uncertainty derived from the difference between the perturbation of measured fluxes method applied to the data and Balrog samples.
| MagLim | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.2 < z < 0.4 | 2.43 ± 0.26 ± 0.44(sys) | 3.18 ± 0.012 | 3.28 ± 0.091 |
| 0.4 < z < 0.55 | 2.30 ± 0.39 ± 0.27(sys) | 4.13 ± 0.016 | 4.09 ± 0.034 |
| 0.55 < z < 0.7 | 3.75 ± 0.38 ± 0.11(sys) | 4.17 ± 0.016 | 4.17 ± 0.04 |
| 0.7 < z < 0.85 | 3.94 ± 0.35 ± 0.01(sys) | 4.52 ± 0.015 | 4.5 ± 0.03 |
| 0.85 < z < 0.95 | 3.56 ± 0.44 ± 0.57(sys) | 5.02 ± 0.018 | 4.84 ± 0.023 |
| 0.95 < z < 1.05 | 4.96 ± 0.53 ± 0.79(sys) | 5.19 ± 0.019 | 5.04 ± 0.054 |
| MagLim | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.2 < z < 0.4 | 2.43 ± 0.26 ± 0.44(sys) | 3.18 ± 0.012 | 3.28 ± 0.091 |
| 0.4 < z < 0.55 | 2.30 ± 0.39 ± 0.27(sys) | 4.13 ± 0.016 | 4.09 ± 0.034 |
| 0.55 < z < 0.7 | 3.75 ± 0.38 ± 0.11(sys) | 4.17 ± 0.016 | 4.17 ± 0.04 |
| 0.7 < z < 0.85 | 3.94 ± 0.35 ± 0.01(sys) | 4.52 ± 0.015 | 4.5 ± 0.03 |
| 0.85 < z < 0.95 | 3.56 ± 0.44 ± 0.57(sys) | 5.02 ± 0.018 | 4.84 ± 0.023 |
| 0.95 < z < 1.05 | 4.96 ± 0.53 ± 0.79(sys) | 5.19 ± 0.019 | 5.04 ± 0.054 |
Csample estimates for the redMaGiC sample for the three different methods described in Section 5. The Balrog estimate include a systematic uncertainty derived from the difference between the perturbation of measured fluxes method applied to the data and Balrog samples.
| redMaGiC | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.15 < z < 0.35 | 2.63 ± 1.50 ± 0.093(sys) | 2.08 ± 0.025 | 2.47 ± 0.753 |
| 0.35 < z < 0.5 | −1.04 ± 1.01 ± 0.32(sys) | 2.02 ± 0.019 | 2.08 ± 0.287 |
| 0.5 < z < 0.65 | 0.67 ± 0.90 ± 0.32(sys) | 2.03 ± 0.015 | 1.99 ± 0.157 |
| 0.65 < z < 0.8 | 4.50 ± 1.07 ± 0.39(sys) | 3.32 ± 0.027 | 4.22 ± 0.259 |
| 0.8 < z < 0.9 | 3.93 ± 0.95 ± 0.043(sys) | 3.58 ± 0.031 | 4.35 ± 0.122 |
| redMaGiC | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.15 < z < 0.35 | 2.63 ± 1.50 ± 0.093(sys) | 2.08 ± 0.025 | 2.47 ± 0.753 |
| 0.35 < z < 0.5 | −1.04 ± 1.01 ± 0.32(sys) | 2.02 ± 0.019 | 2.08 ± 0.287 |
| 0.5 < z < 0.65 | 0.67 ± 0.90 ± 0.32(sys) | 2.03 ± 0.015 | 1.99 ± 0.157 |
| 0.65 < z < 0.8 | 4.50 ± 1.07 ± 0.39(sys) | 3.32 ± 0.027 | 4.22 ± 0.259 |
| 0.8 < z < 0.9 | 3.93 ± 0.95 ± 0.043(sys) | 3.58 ± 0.031 | 4.35 ± 0.122 |
Csample estimates for the redMaGiC sample for the three different methods described in Section 5. The Balrog estimate include a systematic uncertainty derived from the difference between the perturbation of measured fluxes method applied to the data and Balrog samples.
| redMaGiC | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.15 < z < 0.35 | 2.63 ± 1.50 ± 0.093(sys) | 2.08 ± 0.025 | 2.47 ± 0.753 |
| 0.35 < z < 0.5 | −1.04 ± 1.01 ± 0.32(sys) | 2.02 ± 0.019 | 2.08 ± 0.287 |
| 0.5 < z < 0.65 | 0.67 ± 0.90 ± 0.32(sys) | 2.03 ± 0.015 | 1.99 ± 0.157 |
| 0.65 < z < 0.8 | 4.50 ± 1.07 ± 0.39(sys) | 3.32 ± 0.027 | 4.22 ± 0.259 |
| 0.8 < z < 0.9 | 3.93 ± 0.95 ± 0.043(sys) | 3.58 ± 0.031 | 4.35 ± 0.122 |
| redMaGiC | |||
|---|---|---|---|
| redshift | |$C^{\tt {Balrog}}_{\rm sample}$| | |$C^{\rm Data}_{\rm sample}$| | |$C^{\rm \mathit{ N}-body}_{\rm sample}$| |
| 0.15 < z < 0.35 | 2.63 ± 1.50 ± 0.093(sys) | 2.08 ± 0.025 | 2.47 ± 0.753 |
| 0.35 < z < 0.5 | −1.04 ± 1.01 ± 0.32(sys) | 2.02 ± 0.019 | 2.08 ± 0.287 |
| 0.5 < z < 0.65 | 0.67 ± 0.90 ± 0.32(sys) | 2.03 ± 0.015 | 1.99 ± 0.157 |
| 0.65 < z < 0.8 | 4.50 ± 1.07 ± 0.39(sys) | 3.32 ± 0.027 | 4.22 ± 0.259 |
| 0.8 < z < 0.9 | 3.93 ± 0.95 ± 0.043(sys) | 3.58 ± 0.031 | 4.35 ± 0.122 |
The Csample estimates from the magnified Balrog sample (our fiducial measurement) tend to be smaller than the flux-only methods. This is particularly apparent in redshift bins between ∼0.3 and ∼0.6. This difference could be caused by the dependence on quantities other than flux inherent in the sample selection, for example size (used in star–galaxy separation), or systematics in the photometric pipeline. We note that the agreement is better for simple flux-limited samples without tomographic binning, as shown in Everett et al. (2022).
The redMaGiC coefficients tend to have smaller magnification bias than MagLim, and when including the Carea contribution, the low-redshift redMaGiC total magnification bias contributions are small.
We believe Balrog, which include a wide range of observational effects and account for selection on quantities beyond only flux, is our most accurate method for estimating the magnification coefficients, so use the Balrog estimates as fiducial hereafter.
6 EXPECTED IMPACT ON DES Y3 ANALYSES
In this section, we estimate the impact of magnification in the DES Year 3 galaxy clustering + galaxy–galaxy lensing (2 × 2 pt) analysis, using a noiseless datavector generated from our theoretical model (we use the same fiducial model and parameter values as Krause et al. 2021). For these tests, we use the default |$C_{\rm sample} = C^{\tt {Balrog}}_{\rm sample}$| values estimated with the Balrog simulations.
To guide intuition for the subsequent analysis of parameter biases, we show in Fig. 3 the impact of lens magnification on the different parts of the DES Year 3 data vector (for the MagLim sample). It shows magnification has the largest impact on the galaxy–galaxy lensing of high redshift source bins around high redshift lens bins. This is expected since only high redshift lens galaxies will experience large magnification. In relative terms, the clustering autocorrelations have a small contribution due to magnification, while for widely separated redshift bins [e.g. the (1,6) pairing] magnification is the dominant contribution to the signal. Despite this impact, we note that we might still expect little impact from lens magnification on the cosmological parameter constraints for the fiducial DES Y3 cosmology analysis in Abbott et al. (2022) because (i) most of signal-to-noise in the galaxy–galaxy lensing datavector is contributed by the lowest three lens redshift bins where biases are small and (ii) the cross-correlation clustering signal between different lens redshift bins is not used in the fiducial 3 × 2 pt analysis in Abbott et al. (2022) (though we note Thiele et al. (2020) find magnification bias can still be significant in the absence of cross-redshift bin clustering due to the cosmological bias from the cross-correlations acting in the opposite direction to the galaxy–galaxy lensing). We do consider this cross-correlation signal in this work, given its constraining power on the magnification signal.
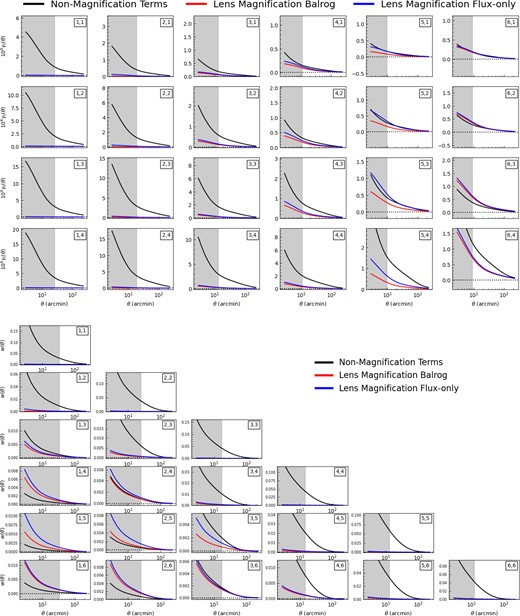
The impact of magnification on the galaxy–galaxy lensing (γt(θ)) (top panel) and galaxy clustering (w(θ)) (bottom panel) model prediction, for all redshift bin combinations, for the MagLim sample. In each panel, the black line (labelled ‘Non-Magnification Terms’) is the model prediction when ignoring lens magnification terms. The red and blue lines are the additional contributions to the model prediction from lens magnification, for magnification coefficient values estimated using Balrog (red lines, see Section 5.1 for details), and the perturbing flux method (blue lines, see Section 5.2 for details).
Having generated a noiseless datavector from our fiducial theoretical model, we perform cosmological parameter inference following the DES Year 3 analysis choices outlined in Krause et al. (2021). We test this within a ΛCDM model. This analysis is designed to estimate the impact of magnification analysis choices in an idealized case, where we can identify the expected size of the magnification signal and the expected projection effects from new parameters. We later explore magnification choices on N-body simulations and the real data.
We show in Fig. 4 the recovered constraints on |$S_8=\sigma _8\sqrt{\Omega _m/0.3}$| with four choices of prior on the magnification coefficients |$C_{\rm sample} ^i$|:
|$C_{\rm sample} ^i$| fixed to their true (i.e. used to generate the datavector) values (labelled ‘2 × 2 pt Fiducial’).
|$C_{\rm sample} ^i=2$|, such that there is no magnification contribution to the datavector (since Ctotal = 0, labelled ‘no mag’).
Gaussian priors on |$C_{\rm sample} ^i$| centred on their true values and with widths equal to the statistical uncertainties in the Balrog measurements, listed in Tables 2 and 1 (labelled ‘2 × 2 pt Gaussian prior’).
Uniform priors on the |$C_{\rm sample} ^i$| in the range of −4 to 12 (labelled ‘2 × 2 pt Free mag’).
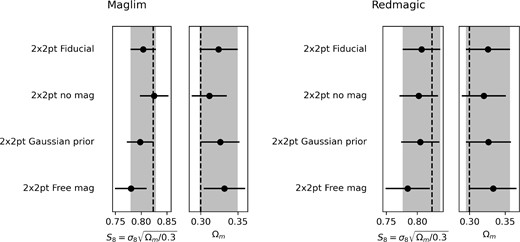
ΛCDM parameter constraints from a simulated, noiseless, galaxy clustering + galaxy–galaxy lensing data vector closely following the DES Year 3 methodology with both the MagLim lens sample (left) and the redMaGiC lens sample (right). Three different priors on the magnification bias Csample are shown; a delta function at the true values used in the simulated vector (labelled ‘Fiducial’), a flat prior with width (green), a Gaussian prior with width equal to the Balrog errors in Table 2, and wide, uniform priors −4 < Csample < 12 (labelled ‘Free mag’). The input magnification coefficients are the Balrog values. The dashed vertical line indicates true input values to the datavector, and shaded band the 1σ uncertainty region for the Fiducial analysis.
We first note that even for a noiseless datavector generated from the theoretical model, the mean of the marginalized posterior does not perfectly recover the input parameter values. For the redMaGiC sample with fixed magnification coefficients, the mean of the S8 posterior is biased (with respect to the input value) by −0.55σ and the mean of the Ωm posterior is biased by 0.84σ. For MagLim, the corresponding biases are −0.79 and 0.93σ. We have verified that the maximum posterior parameter values match the input cosmological parameters to high precision, implying that the biases seen in the first row of Fig. 4 are due to ‘prior volume’ of ‘projection effects’. Put broadly, these can occur when the data are not powerful enough to make the prior choice on marginalized parameters irrelevant, and their presence here means marginalized parameter constraints should be interpreted with caution (especially when comparing to other cosmological data sets). In this case, the bias is at least partially caused by the degeneracy between S8 and the sum of the neutrino masses ∑mν, for which the input value ∑mν = 0.06 eV is at the lower edges of a flat prior.
Beyond the biases from prior volume effects, there is a small additional −0.13σ bias in S8 for the case where magnification is not included in the datavector for the redMaGiC sample, while for MagLim the additional bias is larger, at 0.85σ with respect to the case where the correct magnification coefficients are assumed in the datavector. This implies that especially for the MagLim sample, it is important to include magnification contributions in the theoretical model for our analysis.
When marginalizing over the magnification coefficients with Gaussian priors, the recovered constraints are very similar to the case where they are fixed to their true values (with a 0.06σ and 0.19σ change in S8 for redMaGiC and MagLim, respectively, compared to the fixed magnification coefficient case).
We find that using a flat prior on Csample somewhat degrades the constraining power of the analysis (the 1σ uncertainty in S8 is 18 per cent and 24 per cent larger for redMaGiC and MagLim, respectively), and there is a corresponding increase in the prior volume bias in the marginalized S8, which in this case is −1.1σ (−1.4σ) for redMaGiC (MagLim).
We consider the Balrog estimates with Gaussian priors to be the most complete way to model magnification as these consider the widest range of magnification effects and their uncertainties, as shown in Section 5. We consider the flat prior to be the case most insensitive to the measurement of the coefficients, and the fixed case to be most convenient for running the inference pipeline. Because the flat prior induces additional prior volume effects, and the difference between Gaussian and fixed priors is negligible, these results justify the decision to keep the magnification coefficients fixed in the fiducial DES Y3 3 × 2 pt cosmology analysis (Abbott et al. 2022).
These results show that the impact of magnification in DES Year 3 is a significant systematic that must be accounted for in the modelling of the two-point functions in order to avoid cosmological bias. This supports similar conclusions in recent magnification studies for other survey specifications (Duncan et al. 2022; Mahony et al. 2022).
7 VALIDATION USING BUZZARD SIMULATIONS
In this section, we validate our theoretical predictions and parameter inference using the DES Year 3 Buzzard simulations, which are described in detail in Section 4.2.1. We measure a DES Y3-like datavector, consisting of tomographic galaxy clustering (w(θ)), galaxy–galaxy lensing (γt(θ)), and shear (ξ±(θ)) two-point correlation functions. We test our modeling of these signals in the Buzzard simulations by analysing the mean datavector across all realizations of the Y3 Buzzard simulations, while assuming a covariance on that datavector appropriate for one realization i.e. a level of uncertainty close to that for DES Y3. While the baseline DES Y3 3 × 2 pt analysis is validated in DeRose et al. (2022), here we aim to test the extended analysis explored here, as well as provide further confidence that the magnification components of the signal in the baseline analysis are being modelled accurately. In particular, we test:
whether at fixed cosmology, the values of the magnification coefficients estimated in Section 5.3 are recovered accurately
whether the true Y3 Buzzard cosmology is recovered accurately for different choices of prior on the magnification coefficients.
whether the true cosmology is recovered accurately, and with what extra precision, when including cross-correlations between different redshift bins in w(θ).
The right-hand panel of Fig. 5 compares the recovered magnification coefficients from the Buzzard analysis at fixed cosmology, with and without including w(θ) cross-correlations in the datavector. These constraints are compared to the values directly measured in the simulations as described in Section 5.3. We see that the coefficients are well recovered (for the uniform prior case as well as the more trivial Gaussian prior case), with better constraining power when w(θ) cross-correlations are included. We are confident therefore that our modeling of the lens magnification signal in the two-point functions matches our estimates in Section 5.3 for the Buzzard simulations.
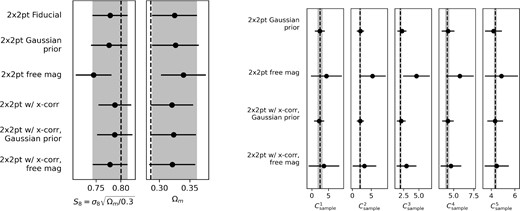
Constraints from running our parameter inference pipeline on the Buzzard simulations (using the redMaGiC sample). Left: Posterior mean and 1σ uncertainties on the recovered S8 and Ωm with the true (i.e. input to the simulations) values indicated by the black dashed line). Right: Constraints on the magnification coefficients Csample, for each lens redshift bin. In both, we show constraints from various different analysis variations with respect to our fiducial set-up, which did not vary the magnification coefficients (see Section 7 for further discussion).
We further test recovery of the true cosmology for the same three choices of prior on the magnification coefficients used in Section 6: a wide flat prior, a Gaussian prior from the statistical Balrog uncertainties on the data and fixed to their true values. We use the Balrog uncertainties for the Gaussian prior to mimic the prior size in the real data analysis. We find consistent recovery of cosmological constraints, as for the theory model datavector case in Section 6, i.e. offsets with the true cosmology, appear consistent with being due to prior volume/projection effects. When a wide, uniform prior is used on the magnification coefficients Csample, these volume effects appear to increase (see third line of Fig. 5 left panel).
The inclusion of cross-correlations in w(θ) appears to reduce these volume effects, producing with S8 and Ωm constraints almost identical to those from the fiducial analysis (see sixth line of Fig. 5 left panel).
8 DES YEAR 3 RESULTS
In this section, we present cosmology constraints from the DES Y3 2 × 2 pt data, investigating the impact of magnification-related analysis choices on cosmological constraints, and test the internal consistency of the magnification modelling.
8.1 Impact of magnification priors
In Fig. 6, we show the impact of allowing Csample to vary with the same three sets of priors used in Sections 6 and 7: fixed to their fiducial values, Gaussian priors with widths based on the Balrog uncertainties (including the systematic uncertainties we assigned as described in Section 5.4), and uniform priors. We show results for ΛCDM and wCDM models for the MagLim sample, and for ΛCDM only in the redMaGiC sample (as MagLim is the default sample in the 3 × 2 pt analysis (Abbott et al. 2022), who suggested the potential presence of observational systematics in the redMaGiC measurements). The cosmological constraints are broadly robust to changing the priors on the magnification coefficients.
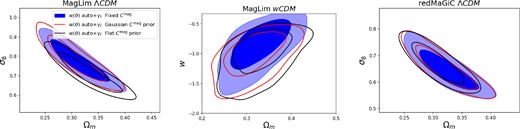
Unblind cosmology constraints on data with different magnification priors. Each panel shows cosmology constraints with the magnification coefficients Ctotal, fixed at the best-fitting value from Balrog, with a Gaussian prior from Balrog, and with a wide flat prior. left: ΛCDM MagLim 2 × 2 pt constraints, centre: wCDM MagLim 2 × 2 pt constraints, right: ΛCDM redMaGiC 2 × 2 pt constraints.
We find that allowing the magnification parameters to vary within the Gaussian prior set by the Balrog simulations does not notably change the cosmological constraints. However, when allowing Csample to vary with a wide uninformative prior, the MagLim ΛCDM S8 constraint is lower than the fixed case by ∼1.2σ. This behaviour is consistent with that seen when analysing the simulated datavectors in Sections 6 and 7, where projection/volume effects resulted in a low S8 constraint (−1.4σ for a noiseless MagLim data vector) when the magnification parameters were varied freely. The improvement in goodness-of-fit indicated by the posterior predictive distribution (PPD) is only modest (0.014 to 0.046) and therefore does not allow us to make definitive statements about whether free magnification coefficients are required by the data. While there may be other unmodelled systematic effects that complicate the picture in the case of the real data analysis (we discuss this further in Section 8.3), we believe the similar size and direction of these shifts means it is reasonable to ascribe it to projection/volume effects. Thus we should be careful in interpreting these constraints; these projection/volume effects imply that when allowing the magnification coefficients to vary, without supplying any extra data, we enter a regime where we are in some sense trying to fit too many parameters to our data.
We discuss the degeneracy of Csample with other parameters, including intrinsic alignment amplitude, in Appendix C.
We discuss the Csample posteriors from these runs later in Section 8.3.
8.2 Clustering cross-correlations
We now explore the addition of the clustering cross-correlation measurements between lens redshift bins, with the intention of better constraining the magnification signal.
In Fig. 7, we show the w(θ) cross-correlations (between redshift bins) measured on the real data compared to the best-fitting 2 × 2 pt from the fiducial analysis that only uses autocorrelations in the fit. The covariance matrix was computed using the Cosmolike package (Krause & Eifler 2017; Fang, Eifler & Krause 2020a) following the procedure in Krause et al. (2021). The inclusion of the cross-correlations is sensitive to both the magnification bias and the accuracy of the tails of the lens sample redshift distributions. Note that unless stated otherwise, we follow the main 3 × 2 pt analysis and exclude the two highest redshift MagLim bins.
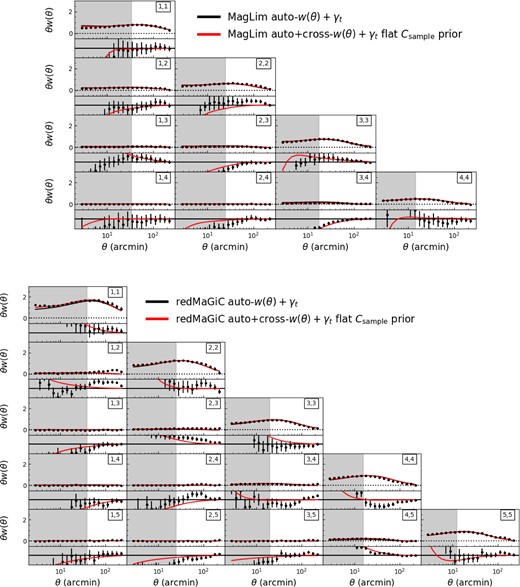
The measured clustering signal, w(θ) for the MagLim sample (top) and redMaGiC sample (bottom), including cross-correlations between redshift bins. The lower panels in each block show the difference between the data and the best-fitting theory from the fiducial ΛCDM analysis (which fixed magnification coefficients, and used only the autocorrelations of w(θ)). Also shown in red is the prediction based on the best-fitting parameters when including the cross-correlations between redshift bins in the fit, and allowing the magnification coefficients to vary. For MagLim, the prediction based on the best-fitting from the fiducial analysis is a poor fit to the cross-correlation measurements, with a χ2 of 130.7 for the 59 cross-correlation datapoints. The red line shows significant improvement, with a χ2 of 63.7. Note that we still exclude redshift bins 5 and 6 for MagLim, consistent with the fiducial 3 × 2 pt analysis. For redMaGiC, the χ2 of the w(θ) cross-correlations improves from 167.6 to 144.7 (for 96 data points) when the cross-correlations are included in the fit and magnification coefficients allowed to vary. So while there is significant improvement in the fit, it remains quite poor, probably suggesting the presence of further unaccounted-for systematics.
The measured MagLim cross correlations are systematically lower than the expectation from the fiducial analysis, which has fixed magnification coefficients; the 59 cross-correlation datapoints have a χ2 of 130.7. This indicates that either the magnification coefficients estimated using Balrog are inaccurate or some other systematic is present, for example, these cross-correlations are likely to be more sensitive to the tails of the lens redshift distributions than when using only autocorrelations. When the cross-correlations are included in the fit and the magnification coefficients are allowed to vary, this χ2 reduces to 63.7.
For redMaGiC, we also see significant deviations of the measured cross-correlations from the prediction based on the fiducial analysis, with a χ2 of the cross-correlation data of 167.6 for 96 data points, reducing to 144.7 when cross-correlations are included in the fit and magnification is allowed to vary. So while there is significant improvement in the fit, it remains quite poor, probably suggesting the presence of further unaccounted-for systematics.
We then investigate whether including w(θ) cross-correlations and allowing the magnification coefficients to vary (i) affects the cosmological parameter inference and (ii) improves the model fit to the w(θ) cross-correlations. Fig. 8 demonstrates that the cosmological constraints are robust to the inclusion of w(θ). Allowing the Csample values to vary in the analysis naturally loses some constraining power (although perhaps due to the presence of projection/volume effects, this is not apparent in the width of the resulting S8 constraint, and may manifest instead as a shift in the S8 constraint). Adding the clustering between bins allows us to regain some of the lost information. Including the clustering between bins gives cosmology constraints quite consistent with the fiducial analysis, with the mean of the S8 posterior increasing by 0.2σ (0.9σ) for MagLim (redMaGiC).
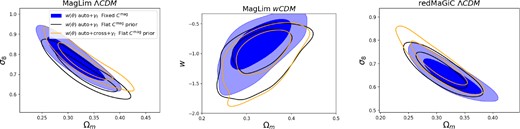
Cosmology constraints on data with and without including w(θ) cross-correlations. Each panel shows cosmology constraints with auto-only fixed magnification coefficients, auto-only free magnification coefficients, and auto + cross-free magnification coefficients. left: ΛCDM MagLim 2 × 2 pt constraints, centre: wCDM MagLim 2 × 2 pt constraints, right: ΛCDM redMaGiC 2 × 2 pt constraints.
In Table 3, we show the p-value for the PPD for each cosmology MCMC chain (see Doux et al. 2021 for details). These values can be interpreted as a goodness-of-fit metric, indicating how likely the particular realization of the Y3 data (for the full 2 × 2 pt data vector as well as γt(θ) and w(θ) separately) is, given the assumed cosmological model. When allowing magnification coefficients to vary, we see a moderate improvement in the PPD values for both lens galaxy samples. When additionally including w(θ) cross-correlations, we see no significant change in the p-value, suggesting at least that our modelling framework can be applied to the w(θ) cross-correlation reasonably successfully.
The p-value for the PPD for each cosmology MCMC chain (see Doux et al. 2021 for details). These values indicate how likely the particular realization of the Y3 data (for the full 2 × 2 pt data vector as well as γt(θ) and w(θ) separately) is, given the assumed cosmological model. The p-value is therefore a measure of the goodness of fit. For both lens samples, there is a moderate improvement in p-value when allowing magnification parameters to vary. There is no significant change to the p-value when cross-correlations are added.
| MagLim | |||||
|---|---|---|---|---|---|
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.014 | 0.015 | 0.182 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.038 | 0.047 | 0.340 |
| 2 × 2 pt | ΛCDM | flat | 0.046 | 0.056 | 0.311 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.052 | 0.063 | 0.345 |
| 2 × 2 pt | wCDM | fixed | 0.024 | 0.029 | 0.208 |
| 2 × 2 pt | wCDM | Gaussian | 0.054 | 0.048 | 0.366 |
| 2 × 2 pt | wCDM | flat | 0.053 | 0.050 | 0.346 |
| 2 × 2 pt + cross | wCDM | Flat | 0.040 | 0.038 | 0.211 |
| 2 × 2 pt (six bins) | ΛCDM | Flat | 0.046 | 0.042 | 0.231 |
| redMaGiC | |||||
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.025 | 0.028 | 0.171 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.056 | 0.107 | 0.098 |
| 2 × 2 pt | ΛCDM | flat | 0.095 | 0.150 | 0.127 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.093 | 0.134 | 0.126 |
| MagLim | |||||
|---|---|---|---|---|---|
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.014 | 0.015 | 0.182 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.038 | 0.047 | 0.340 |
| 2 × 2 pt | ΛCDM | flat | 0.046 | 0.056 | 0.311 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.052 | 0.063 | 0.345 |
| 2 × 2 pt | wCDM | fixed | 0.024 | 0.029 | 0.208 |
| 2 × 2 pt | wCDM | Gaussian | 0.054 | 0.048 | 0.366 |
| 2 × 2 pt | wCDM | flat | 0.053 | 0.050 | 0.346 |
| 2 × 2 pt + cross | wCDM | Flat | 0.040 | 0.038 | 0.211 |
| 2 × 2 pt (six bins) | ΛCDM | Flat | 0.046 | 0.042 | 0.231 |
| redMaGiC | |||||
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.025 | 0.028 | 0.171 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.056 | 0.107 | 0.098 |
| 2 × 2 pt | ΛCDM | flat | 0.095 | 0.150 | 0.127 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.093 | 0.134 | 0.126 |
The p-value for the PPD for each cosmology MCMC chain (see Doux et al. 2021 for details). These values indicate how likely the particular realization of the Y3 data (for the full 2 × 2 pt data vector as well as γt(θ) and w(θ) separately) is, given the assumed cosmological model. The p-value is therefore a measure of the goodness of fit. For both lens samples, there is a moderate improvement in p-value when allowing magnification parameters to vary. There is no significant change to the p-value when cross-correlations are added.
| MagLim | |||||
|---|---|---|---|---|---|
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.014 | 0.015 | 0.182 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.038 | 0.047 | 0.340 |
| 2 × 2 pt | ΛCDM | flat | 0.046 | 0.056 | 0.311 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.052 | 0.063 | 0.345 |
| 2 × 2 pt | wCDM | fixed | 0.024 | 0.029 | 0.208 |
| 2 × 2 pt | wCDM | Gaussian | 0.054 | 0.048 | 0.366 |
| 2 × 2 pt | wCDM | flat | 0.053 | 0.050 | 0.346 |
| 2 × 2 pt + cross | wCDM | Flat | 0.040 | 0.038 | 0.211 |
| 2 × 2 pt (six bins) | ΛCDM | Flat | 0.046 | 0.042 | 0.231 |
| redMaGiC | |||||
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.025 | 0.028 | 0.171 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.056 | 0.107 | 0.098 |
| 2 × 2 pt | ΛCDM | flat | 0.095 | 0.150 | 0.127 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.093 | 0.134 | 0.126 |
| MagLim | |||||
|---|---|---|---|---|---|
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.014 | 0.015 | 0.182 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.038 | 0.047 | 0.340 |
| 2 × 2 pt | ΛCDM | flat | 0.046 | 0.056 | 0.311 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.052 | 0.063 | 0.345 |
| 2 × 2 pt | wCDM | fixed | 0.024 | 0.029 | 0.208 |
| 2 × 2 pt | wCDM | Gaussian | 0.054 | 0.048 | 0.366 |
| 2 × 2 pt | wCDM | flat | 0.053 | 0.050 | 0.346 |
| 2 × 2 pt + cross | wCDM | Flat | 0.040 | 0.038 | 0.211 |
| 2 × 2 pt (six bins) | ΛCDM | Flat | 0.046 | 0.042 | 0.231 |
| redMaGiC | |||||
| Data | Model | Mag prior | PPD 2 × 2 pt | PPD γt | PPD w(θ) |
| 2 × 2 pt | ΛCDM | fixed | 0.025 | 0.028 | 0.171 |
| 2 × 2 pt | ΛCDM | Gaussian | 0.056 | 0.107 | 0.098 |
| 2 × 2 pt | ΛCDM | flat | 0.095 | 0.150 | 0.127 |
| 2 × 2 pt + cross | ΛCDM | flat | 0.093 | 0.134 | 0.126 |
8.3 Magnification coefficient (Csample) constraints
In Fig. 9, we show the posterior distribution of the Csample in each redshift bin compared to the estimates from Balrog i.e. those that we fixed Csample to in the fiducial analysis. The Csample posterior in the third redshift bin of the MagLim sample is significantly larger than any of the estimates from Balrog, N-body simulations, or the flux perturbations. When adding the cross-correlations between lens bins, this constraint moves closer to the estimated values, though remains significantly higher. Given the good agreement between the prior estimates in this redshift bin, it is likely that the magnification parameters are capturing some other systematic in the DES data that bias the clustering measurements.
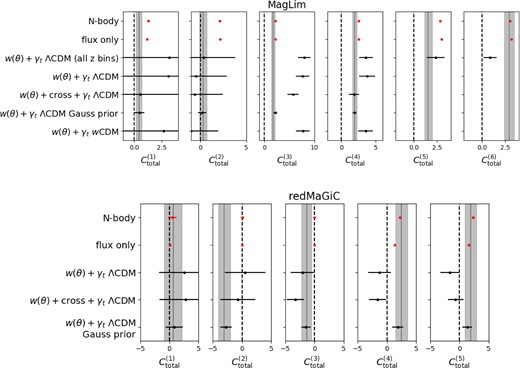
Unblinded posterior constraints on magnification coefficients Ctotal in the MagLim sample (top) and redMaGiC sample (bottom). The vertical grey band is the estimate from the Balrog image simulations. The red points were estimated on the data prior to the cosmology analysis. The black points are 68 per cent posterior bounds from the analysis of galaxy clustering and galaxy–galaxy lensing.
The fourth MagLim redshift bin posteriors are in good agreement with the prior estimates, especially when w(θ) cross-correlations are included. Given their low redshift and therefore weak magnification signal, the constraining power on the magnification coefficients for the lowest two redshift bins is too weak to make a useful comparison.
We also analyse a 2 × 2 pt data vector using all six MagLim redshift bins, keeping all other analysis choices the same as in the fiducial analysis. We find the posteriors on the first four Csample parameters are consistent with the four bin run. The fifth bin is consistent with expectation from Balrog. However, the sixth bin is around 3σ lower than expectation. Given that these redshift bins were excluded from the fiducial analysis due to the likely presence of (not-well-understood) measurement systematics, we cannot ascribe a specific cause to this discrepancy.
For the redMaGiC sample, we find good agreement between the posteriors and prior estimates in the first three redshift bins (although again the constraining power for the first two bins is weak). For the two highest redshift bins, the 2 × 2 pt posteriors favour lower Csample values at 2–3σ. Again, this may be an indication of the magnification coefficients’ sensitivity to other observational systematics (see discussion in Abbott et al. 2022; Pandey et al. 2022; Rodríguez-Monroy et al. 2022).
In general, when allowing the magnification coefficients to vary freely in the analysis, we do not always recover values expected from the prior estimates described in Section 5. This could be due to missing effects in the image simulations used to estimate the magnification coefficients that were not captured by any of the methods in Section 5. It could also be driven by observational systematics in the data vector that are degenerate with the magnification signal. These potential systematics are further explored in Porredon et al. (2021a), Abbott et al. (2022), Pandey et al. (2022), and Rodríguez-Monroy et al. (2022).
9 CONCLUSIONS
This analysis has studied the impact of lensing magnification of the lens sample in the DES Year 3 cosmological analysis, which combines galaxy clustering with galaxy weak lensing (Abbott et al. 2022). We estimate the amplitude of the magnification coefficients via several methods prior to analysis of the measured datavector, test the model assumptions of the fiducial analysis, and infer cosmological parameter constraints with different modelling choices related to lens magnification.
We estimate the amplitude of the magnification coefficients from the realistic Balrog image simulations (Everett et al. 2022), by injecting fake objects into real DES images and testing the response of the number density of selected objects to magnifying the input objects. We compare these estimates with simplified estimates from directly perturbing fluxes in the real data, and from mock catalogue simulations, and find some deviations, especially at intermediate redshifts. These differences may be driven by the additional effects included in the Balrog image simulations, such as the impact on galaxy size and photometric redshift estimates.
By running variants on the fiducial DES Y3 analysis, on both simulated and real data, we demonstrate that the fiducial analysis choice, where magnification coefficients were fixed at the best-fitting estimates from the image simulations, does not bias the cosmological inference relative to imposing an informative prior that accounts for uncertainty in those estimates. We constrain cosmological parameters in ΛCDM and wCDM with different sets of priors on magnification coefficients and find the cosmology constraints on the data to behave as expected from the simulation, where changes in the S8 constraint less than 1σ can be induced by incorrect magnification modelling or projection effects from a model that is too flexible.
We demonstrate the usefulness of including the clustering cross-correlations between lens redshift bins to better constrain the magnification coefficients, and therefore also the cosmological parameters. In our simulated analyses in Section 6, we show that on the Buzzard simulation measurement, including the w(θ) cross-correlations allows one to vary freely the magnification coefficients, without incurring a cost in constraining power on S8 with respect to the fiducial analysis (which fixed the magnification coefficients and did not include w(θ) cross-correlations). This opens up the possibility of a more conservative analysis with minimal assumptions on the magnification coefficient values. It also points to the potential for extracting significant cosmological information from the w(θ) cross-correlations if the magnification coefficient values can be calibrated from simulations, as we have attempted here.
We constrain the magnification coefficients Csample from the two-point functions themselves and find some of the coefficients to be inconsistent with their prior estimates from both the Balrog image simulations and the alternative methods. While this could be caused by incorrect input coefficients, we believe the extreme values are more likely to be induced by other unmodelled systematics in the DES 2 × 2 pt data. Despite this preference for unexpected values of the magnification coefficients, when freeing the magnification parameters we observe shifts in cosmological parameters that are very similar to those biases expected from projection/prior volume effects, as observed on simulated where the modelling is perfect and no systematics are present. It is therefore unlikely that the fiducial DES Year 3 approach is incurring large (∼>1σ) biases in cosmological parameters due to degeneracies with magnification parameters that have been fixed to incorrect values, since in this case we would see cosmological parameter shift when freeing magnification coefficients that are inconsistent across data and simulations. Rather, it is likely that (i) there are projection/prior volume effects that are introduced by freeing the magnification coefficients and (ii) the extreme and unexpected inferred values of magnification parameters are due to unmodelled systematics in the data. In addition, the same systematic effects could also be biasing the cosmological parameters in both the fixed and free magnification coefficients cases, and require further investigation before we can claim the DES Year 3 constraints are fully robust. One unmodelled systematic that could be degenerate with magnification is the impact of dust extinction from galaxies that trace structures between us and the lens galaxies. This extinction could also produce changes in the observed number density of galaxies that is correlated with foreground large-scale structure, although, unlike lensing, its impact on galaxy fluxes is chromatic (Ménard et al. 2010). The Csample inconsistency is interesting in the context of the much studied high-redshift inconsistency between clustering and galaxy–galaxy lensing in DES Year 3 (Porredon et al. 2021a; Abbott et al. 2022; Pandey et al. 2022). However, because some of the Csample posteriors are significantly discrepant with all of the methods explored in this paper, we also consider the possibility that the magnification signal is partially degenerate with this inconsistency, rather than the cause.
The results in this paper demonstrate the DES 2 × 2pt cosmology results are broadly robust to the pre-unblinding choices of magnification prior, and changes in cosmological parameters follow the expected small shifts seen on simulations. The magnification signal itself is detectable in the 2 × 2 pt data vector, but can be sensitive to systematics.
ACKNOWLEDGEMENTS
Funding for the DES Projects has been provided by the DOE and NSF (USA), MEC/MICINN/MINECO (Spain), STFC (UK), HEFCE (UK). NCSA (UIUC), KICP (U. Chicago), CCAPP (Ohio State), MIFPA (Texas A&M), CNPQ, FAPERJ, FINEP (Brazil), DFG (Germany) and the Collaborating Institutions in the Dark Energy Survey.
The Collaborating Institutions are Argonne Lab, UC Santa Cruz, University of Cambridge, CIEMAT-Madrid, University of Chicago, University College London, DES-Brazil Consortium, University of Edinburgh, ETH Zürich, Fermilab, University of Illinois, ICE (IEEC-CSIC), IFAE Barcelona, Lawrence Berkeley Lab, LMU München and the associated Excellence Cluster Universe, University of Michigan, NFS’s NOIRLab, University of Nottingham, Ohio State University, University of Pennsylvania, University of Portsmouth, SLAC National Lab, Stanford University, University of Sussex, Texas A&M University, and the OzDES Membership Consortium.
Based in part on observations at CTIO at NSF’s NOIRLab (NOIRLab Prop. ID 2012B-0001; PI: J. Frieman), which is managed by the Association of Universities for Research in Astronomy (AURA) under a cooperative agreement with the National Science Foundation.
The DES Data Management System is supported by the NSF under grant numbers AST-1138766 and AST-1536171. The DES participants from Spanish institutions are partially supported by MICINN under grants ESP2017-89838, PGC2018-094773, PGC2018-102021, SEV-2016-0588, SEV-2016-0597, and MDM-2015-0509, some of which include ERDF funds from the European Union. IFAE is partially funded by the CERCA program of the Generalitat de Catalunya. Research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Program (FP7/2007-2013) including ERC grant agreements 240672, 291329, and 306478. We acknowledge support from the Brazilian Instituto Nacional de Ciência e Tecnologia (INCT) do e-Universo (CNPq grant 465376/2014-2).
This manuscript has been authored by Fermi Research Alliance, LLC under Contract No. DE-AC02-07CH11359 with the U.S. Department of Energy, Office of Science, Office of High Energy Physics.
DATA AVAILABILITY
All Dark Energy Survey data used in this work is available through the cosmological data release on the Dark Energy Survey Data Management (DESDM) system https://des.ncsa.illinois.edu/releases/y3a2.
Footnotes
See Appendix B for discussion of the magnification of the source sample.
This was in fact a magnitude based on the total flux in the riz-bands – see Everett et al. (2022) for details.
Magnification is applied to the injected images using the GalSim (Rowe et al. 2015) magnify method.
References
APPENDIX A: Balrog SAMPLES
In this appendix, we present a comparison between the real data and the Balrog lens samples used in this analysis. Histograms of the measured magnitude, colour, photo-z, and galaxy size are shown in Fig. A1 for the MagLim sample and in Fig. A2 for redMaGiC. We find good agreement between the colour, magnitude, and photometric redshift distributions between the two samples. There are some small differences in the distributions of galaxy size T and size uncertainty Terr. These quantities are used in the star galaxy separation cuts. In the Balrog sample, the photometric pipeline appears to generally find a slightly smaller size uncertainty than on the real data. Any differences between these two samples are accounted for by including a systematic error on Csample equal to the difference between the flux only measurements in Balrog and the real data.
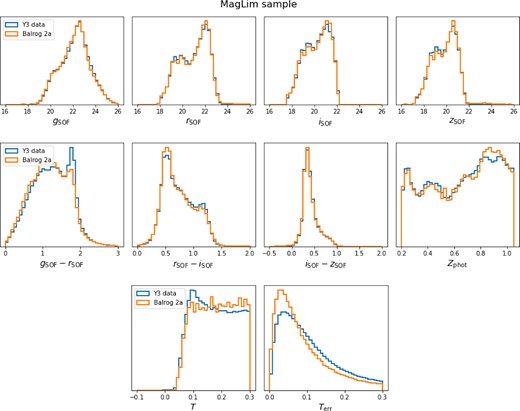
Histograms comparing quantities of the MagLim lens sample between the real data and Balrog. The quantities shown are SOF (single-object fitting) magnitudes and colours using bands g, r, i, and z, photometric redshift point estimate from the DNF algorithm used for selecting and binning the MagLim galaxies, and size estimates T and Terr that were used for star–galaxy separation. The distribution of magnitude and colour agree well between the samples, but the Balrog pipeline appears to underestimate the uncertainty on galaxy sizes Terr. This difference is accounted for in the systematic uncertainty applied to Csample.
Same as Fig. A1 but for the redMaGiC sample. The photometric redshift shown is the ZredMaGiC estimate calibrated from the same red sequence training as the data.
APPENDIX B: SOURCE MAGNIFICATION
As well as impacting the lens galaxies, magnification can also have an impact on the source sample by increasing the sampling of the shear field behind overdense structures. This effect generally has a smaller impact on the 3 × 2 pt data vector than lens magnification as demonstrated for the DES year 3 analysis in Prat et al. (2022). Source magnification also has a small impact estimations of source redshift uncertainties using the clustering redshift method as demonstrated for DES Year 3 in Gatti et al. (2020). In this appendix, we show the results of applying the Balrog method to the source selection to obtain approximate Csample values for source galaxies. Since source magnification is not included in the baseline analysis modelling Krause et al. (2021) for 3 × 2 pt, we present only the best-fitting Csample values output from the Balrog method and do not perform the full error analysis. These values were used only to demonstrate insensitivity to source magnification. The source sample was selected by running the metacalibration (Huff & Mandelbaum 2017) shape measurement pipeline on the balrog sample as described in Everett et al. (2022) to produce a sample equivalent to the shape catalog described in Gatti et al. (2021). In order to estimate the redshift dependence of the source magnification signal, we split the source sample into tomographic bins using the photometric redshift estimate of the deep field object associated with each balrog injection. This photometric redshift point estimate came from the EAzY template fitting photo-z code (Brammer, van Dokkum & Coppi 2008). The performance of this photo-z code on the DES deep fields is described in Hartley et al. (2022). While these tomographic bins should not be considered the same as the photo-z binning of the wide field objects, it does demonstrate the redshift dependence of the Csample quantity in the redshift ranges relevant to the tomographic bins used in the main 3 × 2 pt analysis. The final SOMPZ redshift binning used in the final analysis Myles et al. (2021) was not available at the time these validation tests were performed for the Y3 analysis. The Csample value obtained for the non-tomographic source sample is |$C_{\rm sample}^{\rm source \ notomo} = 1.90$|. When split into tomographic bins using the deep field photo-z, we obtain |$C_{\rm sample} ^{\rm source} = [0.67 , 1.37 , 1.986, 2.916]$|.
APPENDIX C: PARAMETER DEGENERACY IN THE FREE MAGNIFICATION ANALYSIS
In this appendix, we further detail the parameter degeneracies in the 2 × 2 pt analysis when the magnification parameters Csample are allowed to be free. We aim to describe the features in the data that cause some Csample posteriors to disagree the Balrog estimates in Fig. 9 and to describe the reasons for the small shifts in σ8 in Fig. 6.
In Fig. C1, we show the 2D parameter constraints of the intrinsic alignment parameters (using the TATT model (Blazek et al. 2019), which was the fiducial IA model in the DES year 3 analysis) and the Csample parameters from the lowest and highest MagLim redshift bins. We see some mild correlation between the IA amplitude parameter |$A^{(IA)}_1$| and the constrained |$C_{\rm sample} ^4$|. The other constrained Csample parameters show similar behaviour. This leads to a positive shift in the |$A^{(IA)}_1$| posterior when magnification is freed. A higher |$A^{(IA)}_1$| results in a lower σ8, explaining the shift in Fig. 6.
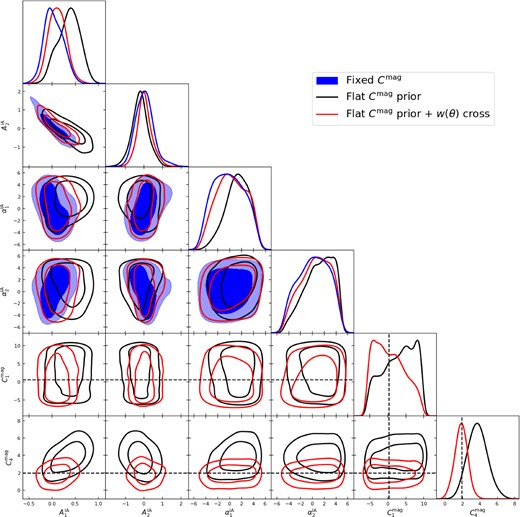
2 × 2 pt MagLim constraints on magnification coefficients and intrinsic alignment (IA) parameters in the TATT model. Results are shown for two magnification priors; a delta function at the Balrog best fits (dashed line) and the wide flat prior. Results are shown only for Csample in MagLim bins 1 and 4 for conciseness. We see a mild positive degeneracy between the IA amplitude and the constrained (higher-redshift) Csample. Freeing the magnification coefficients shifts the |$A^{(IA)}_1$| posterior higher. We also show the posterior for the case with cross-correlations between lens bins included in the fit, using a flat magnification prior (red). The cross-correlations constrain the high redshift Csample and shift the IA posteriors back towards the fixed case. Posteriors on Csample in the other tomographic bins were shown in Fig. 9.
Also in Fig. C1, we show the posteriors from a data vector including cross-correlations between lens bins, with a flat prior on magnification parameters. One can see the cross-correlations move the magnification and IA posteriors towards the fixed magnification case, and break the degeneracy between magnification and IA.
We also show the residual MagLim galaxy–galaxy lensing γt signal for the best-fitting model from the fiducial fixed magnification chain in Fig. C2. It is of particular interest to look at the γt signal for MagLim bin 3 as we find a |$C_{\rm sample} ^{3}$| posterior much higher than the fiducial Balrog value when using a flat magnification prior (as seen in Fig. 9). We find this signal decreases when magnification is freed, relative to the fixed case, due to the lower σ8, despite the increase in the |$C_{\rm sample} ^{3}$| posterior. When the cross-lens bin clustering is added to the inference, the model best fit returns closer to the fixed case.
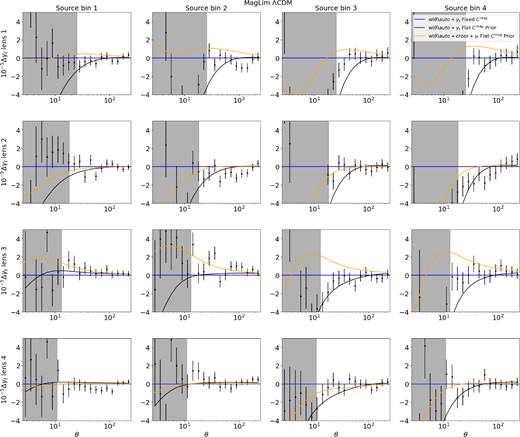
Residual γt signal for the best fit of different magnification set-ups.
APPENDIX D: STATISTICAL UNCERTAINTY IN Balrog
In this appendix, we derive the statistical uncertainty on the Balrog estimates in equation (25).
The magnified and unmagnified Balrog samples contain a number of objects that are common between the two samples; we will call this N(δκ + 0) and a number of objects that are unique to each sample N(δκonly) and N(0only). We assume that these are three, independent Poisson-distributed quantities with uncertainties
We can write the total number of objects in the two samples as follows:
Starting with equation (24), we can write |$C^{\tt {Balrog}}_{\rm sample}$| as follows:
and the uncertainty on this quantity as follows:
We can then derive equation (25) by substituting in the following relations,
The final statistical uncertainty is then

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}