





ABSTRACT
The existence of globular clusters (GCs) in a few satellite galaxies, and their absence in majority of dwarf galaxies, present a challenge for models attempting to understand the origins of GCs. In addition to GC presence appearing stochastic and difficult to describe with average trends, in the smallest satellite galaxies GCs contribute a substantial fraction of total stellar mass. We investigate the stochasticity and number of GCs in dwarf galaxies using an updated version of our model that links the formation of GCs to the growth of the host galaxy mass. We find that more than 50 per cent of dwarf galaxies with stellar mass |$M_{\star }\lesssim 2\times 10^7\, \mathrm{M}_\odot$| do not host GCs, whereas dwarfs with |$M_{\star }\sim 10^8\, \mathrm{M}_\odot$| almost always contain some GCs, with a median number ∼10 at z = 0. These predictions are in agreement with the observations of the Local Volume dwarfs. We also confirm the near-linear GC system mass–halo mass relation down to |$M_{\mathrm{h}}\simeq 10^8\, \mathrm{M}_\odot$| under the assumption that GC formation and evolution in galaxies of all mass can be described by the same physical model. A detailed case study of two model dwarfs that resemble the Fornax dwarf spheroidal galaxy shows that observational samples can be notably biased by incompleteness below detection limit and at large radii.
1 INTRODUCTION
Observations show a tight near-linear relation between the mass of a globular cluster (GC) system and the total mass of the host halo (Spitler & Forbes 2009; Georgiev et al. 2010; Hudson, Harris & Harris 2014; Harris, Harris & Hudson 2015; Forbes et al. 2018). For example, Harris et al. (2015) find MGC = 3.4 × 10−5Mh for galaxies with halo mass between 1010 and |$10^{14}\, \mathrm{M}_\odot$|, with a total scatter of 0.35 dex most of which can be contributed by measurement uncertainties. Considering the complicated interplay of various non-linear baryonic processes involved in the formation of GCs, such a simple relation is quite remarkable.
At a host mass |$M_{\mathrm{h}}\sim 10^{9}\, \mathrm{M}_\odot$| the expected number of GCs is 1 or 0. In such a regime the cluster formation must become very stochastic. Therefore, it is particularly interesting to investigate how far the near-linear MGC–Mh relation holds. The main uncertainty is not the number of GCs but the measurement of the total halo mass of dwarf galaxies. Forbes et al. (2018) used stellar and |$\rm HI$| gas kinematics to derive dynamical mass measurements for dwarf galaxies in the Local Group (LG) and isolated late-type dwarfs with detected GC systems. They concluded that the number of GCs still correlates almost linearly with the halo mass down to |$M_{\rm h}\lesssim 10^9\, \mathrm{M}_\odot$|, although their derived halo masses fall systematically lower than those predicted by empirical stellar mass-halo mass (SMHM) relations such as those found by Behroozi, Wechsler & Conroy (2013c) and Danieli et al. (2022, who investigated this relation in nearby dwarf galaxies).
Another challenge to study the MGC–Mh relation is small number of GCs in dwarf galaxies. Therefore, measuring the number of GCs can be heavily affected by incompleteness and contamination in surveys of dwarf galaxies. Fortunately, the Exploration of Local VolumE Satellites Survey (ELVES, Carlsten et al. 2022a, b) has extended the census of GC systems in a sample of 140 confirmed early-type dwarf satellite galaxies with stellar mass between 105.5 and |$10^{8.5}\, \mathrm{M}_\odot$|. These authors parameterized and optimized the number of GCs as a function of stellar mass of the host galaxies M⋆. For the low-mass regime where a significant fraction of galaxies do not host GCs, they calculated the occupation fraction (the fraction of galaxies hosting at least one GC) as a function of M⋆. They found that the number of GCs increases monotonically with galaxy stellar mass, and the occupation fraction rises rapidly from 0 to 1 for galaxies with M⋆ growing from 106 to |$10^8\, \mathrm{M}_\odot$|.
The ELVES survey does not provide direct measurement of host halo mass. Only a limited number of nearby dwarf galaxies have independent measurements of both halo mass and GC mass/number. This motivates the use of numerical methods to understand the formation of GCs, such as applying a model of GC formation and evolution to galaxy formation simulations such as the E-MOSAICS project (Pfeffer et al. 2018; Kruijssen et al. 2019), EMP-Pathfinder (Reina-Campos et al. 2022), the model presented by Doppel et al. (2022), and our previous models (Muratov & Gnedin 2010; Li & Gnedin 2014; Choksi, Gnedin & Li 2018; Chen & Gnedin 2022). These works have successfully reproduced the near-linear MGC–Mh relation in the mass range between Mh ∼ 1012 and |$10^{14}\, \mathrm{M}_\odot$|, without explicitly linking GC formation to the halo mass of host galaxies. However, Choksi et al. (2018) noticed a departure from linearity at the low-mass end of |$M_{\rm h}\sim 10^{11}\, \mathrm{M}_\odot$|. Bastian et al. (2020) further extended the MGC–Mh relation relation down to |$M_{\rm h}\sim 10^{10}\, \mathrm{M}_\odot$| and found this relation to deviate downwards significantly below |$M_{\rm h}\sim 5\times 10^{11}\, \mathrm{M}_\odot$|, in contrast to Forbes et al. (2018) who found the near-linear correlation to be valid down to |$M_{\rm h}\sim 10^8\, \mathrm{M}_\odot$|. The causes of the deviation in numerical works are still unclear. Bastian et al. (2020) argued that this is because of the highly non-linear and uncertain SMHM relation at the low-mass end. Purely numerical limitations, such as inadequate mass resolution for dwarf galaxies, may also play a role.
Another caveat of numerical modelling is that most models cannot correctly reproduce the present-day cluster mass function from the assumed initial mass function, mainly because the treatment of tidal disruption is problematic. Due to the limited mass resolution in galaxy formation simulations, tidal disruption is normally modeled via subgrid prescriptions, which are unavoidably over-simplified. Moreover, the inadequate spatial resolution in simulations makes it challenging to explicitly calculate the tidal field on a scale of the tidal radius of GCs, 20–50 pc.
In this work, we apply our latest GC formation model presented in Chen & Gnedin (2022) to a suite of higher resolution collisionless simulations, which are specifically tuned to the LG environment. The simulations have mass resolution of |$2\times 10^{5}\, \mathrm{M}_\odot$|, enabling robust modelling of even the smallest dwarf galaxies down to |$M_{\rm h}\sim 10^8\, \mathrm{M}_\odot$|. We modify the cluster sampling process in the model to make it work with dark matter (DM) particles. Also, we update the prescription for tidal disruption based on the most recent results of direct N-body simulations. We find our results consistent with the ELVES survey of the Local Volume (LV) GCs. We also investigate which aspects of the model can be constrained by the observational data.
The paper is organized as follows. First, we recap the GC formation model in Chen & Gnedin (2022) and introduce the modifications that we make to the model in Section 2. Next, we present our main results in Sections 3, 4, and 5. In Section 3, we analyse the GC occupation fraction and the number/mass of GCs in the model galaxies with different stellar/halo mass. Next, we perform a detailed case study of the GC systems in two model galaxies that resemble the Fornax dwarf spheroidal galaxy (Fornax dSph) in Section 4. In Section 5, we investigate how different model settings influence the GC occupation fraction and the number of GCs and constraint the models with observational data. We summarize our key findings in Section 6.
2 MODEL SETUP
To investigate the formation of GCs in the LG dwarf galaxies, we apply our model of GC formation on a suite of cosmological simulations that resemble present-day properties of the LG environment. In this section, we describe the simulations and the GC model.
2.1 Simulations of the LG
We use a suite of collisionless (‘DM only’) zoom-in simulations with initial conditions (ICs) chosen to match the present-day LG. Full galaxy formation runs with these ICs are presented in Brown & Gnedin (2022). The simulations are performed with the Adaptive Refinement Tree (ART) code (Kravtsov, Klypin & Khokhlov 1997). The ICs are Thelma & Louise (in short, T&L) and Romeo & Juliet (R&J). The modifications from the original version of Garrison-Kimmel et al. (2014) include reducing the simulation box sizes to ∼35 comoving Mpc and improving the root grid resolution (Brown & Gnedin 2021). The zoom-in region is around 10 comoving Mpc across, and the particle mass in the zoom-in region is smaller than |$2\times 10^5\, \mathrm{M}_\odot$|. We summarize the key parameters for the two ICs in Table 1.
Important simulation parameters of the ICs employed in this work.
| IC | Box size | Root cell size | # of particles | Particle mass | Ωm | Mh, 1 | Mh, 2 | Ωb | h |
|---|---|---|---|---|---|---|---|---|---|
| T&L | 35.2 Mpc | 138 kpc | 65,589,112 | |$1.89\times 10^5\, \mathrm{M}_\odot$| | 0.266 | |$1.09\times 10^{12}\, \mathrm{M}_\odot$| (T) | |$0.94\times 10^{12}\, \mathrm{M}_\odot$| (L) | 0.0449 | 0.71 |
| R&J | 34.0 Mpc | 133 kpc | 56,765,377 | |$1.82\times 10^5\, \mathrm{M}_\odot$| | 0.31 | |$1.28\times 10^{12}\, \mathrm{M}_\odot$| (R) | |$0.97\times 10^{12}\, \mathrm{M}_\odot$| (J) | 0.048 | 0.68 |
| IC | Box size | Root cell size | # of particles | Particle mass | Ωm | Mh, 1 | Mh, 2 | Ωb | h |
|---|---|---|---|---|---|---|---|---|---|
| T&L | 35.2 Mpc | 138 kpc | 65,589,112 | |$1.89\times 10^5\, \mathrm{M}_\odot$| | 0.266 | |$1.09\times 10^{12}\, \mathrm{M}_\odot$| (T) | |$0.94\times 10^{12}\, \mathrm{M}_\odot$| (L) | 0.0449 | 0.71 |
| R&J | 34.0 Mpc | 133 kpc | 56,765,377 | |$1.82\times 10^5\, \mathrm{M}_\odot$| | 0.31 | |$1.28\times 10^{12}\, \mathrm{M}_\odot$| (R) | |$0.97\times 10^{12}\, \mathrm{M}_\odot$| (J) | 0.048 | 0.68 |
The lengths are given in comoving units and the particles mass refers to the particles in the zoom-in region. The z = 0 halo mass of the two main galaxies in each IC are also given.
Important simulation parameters of the ICs employed in this work.
| IC | Box size | Root cell size | # of particles | Particle mass | Ωm | Mh, 1 | Mh, 2 | Ωb | h |
|---|---|---|---|---|---|---|---|---|---|
| T&L | 35.2 Mpc | 138 kpc | 65,589,112 | |$1.89\times 10^5\, \mathrm{M}_\odot$| | 0.266 | |$1.09\times 10^{12}\, \mathrm{M}_\odot$| (T) | |$0.94\times 10^{12}\, \mathrm{M}_\odot$| (L) | 0.0449 | 0.71 |
| R&J | 34.0 Mpc | 133 kpc | 56,765,377 | |$1.82\times 10^5\, \mathrm{M}_\odot$| | 0.31 | |$1.28\times 10^{12}\, \mathrm{M}_\odot$| (R) | |$0.97\times 10^{12}\, \mathrm{M}_\odot$| (J) | 0.048 | 0.68 |
| IC | Box size | Root cell size | # of particles | Particle mass | Ωm | Mh, 1 | Mh, 2 | Ωb | h |
|---|---|---|---|---|---|---|---|---|---|
| T&L | 35.2 Mpc | 138 kpc | 65,589,112 | |$1.89\times 10^5\, \mathrm{M}_\odot$| | 0.266 | |$1.09\times 10^{12}\, \mathrm{M}_\odot$| (T) | |$0.94\times 10^{12}\, \mathrm{M}_\odot$| (L) | 0.0449 | 0.71 |
| R&J | 34.0 Mpc | 133 kpc | 56,765,377 | |$1.82\times 10^5\, \mathrm{M}_\odot$| | 0.31 | |$1.28\times 10^{12}\, \mathrm{M}_\odot$| (R) | |$0.97\times 10^{12}\, \mathrm{M}_\odot$| (J) | 0.048 | 0.68 |
The lengths are given in comoving units and the particles mass refers to the particles in the zoom-in region. The z = 0 halo mass of the two main galaxies in each IC are also given.
We start the simulation at z ≃ 100 and run it until the present. We output simulation snapshots at approximately every 0.01 increment of the scale factor a. Next, we generate halo catalogues at each snapshot with the rockstar halo finder (Behroozi, Wechsler & Wu 2013a). The halo catalogues and simulation snapshots are then passed to the consistent tree code (Behroozi et al. 2013b) to generate merger trees.
The mass assembly of the four main galaxies in the two ICs can be split into two categories (see fig. 3 in Brown & Gnedin 2022 for the mass growth histories). Louise, Romeo, and Juliet have no major merger with a mass ratio less than 4:1 after z ≃ 5, which resembles the formation history of the Milky Way (MW; Hammer et al. 2007). We therefore refer to the three galaxies as ‘MW-like’. In contrast, the Thelma galaxy encounters more major mergers at later times.
2.2 Modelling the formation and evolution of globular clusters
We apply a GC formation model on the simulation outputs to study GC systems of the LG galaxies. Based on Chen & Gnedin (2022), we describe GC formation and evolution via four steps: (1) cluster formation, (2) cluster sampling, (3) particle assignment, and (4) cluster evolution. In this section, we recap the GC model and describe several modifications required to study dwarf galaxies.
2.2.1 Cluster formation
In the cluster formation step, we trigger a GC formation event when the specific mass accretion rate of the host galaxy exceeds a threshold value, p3, which is an adjustable model parameter. The specific mass accretion rate, Rm, is defined as the fractional change of galaxy mass between two adjacent simulation snapshots,
where tnow and tprog stand for the cosmic times of the current snapshot and the progenitor snapshot, respectively. Similarly, the masses of the current galaxy and the main progenitor galaxy are represented by Mnow and Mprog. Since the mass of DM particles in zoom-in regions is around |$2\times 10^5\, \mathrm{M}_\odot$| we only take into account halos with |$M_{\rm h}\gt 10^8\, \mathrm{M}_\odot$| to ensure that each halo contains at least 500 particles. Halos smaller than that may be numerically under-resolved, but they are very unlikely to host any massive star clusters.
When a cluster formation event is triggered, we analytically calculate the stellar mass of a galaxy from its halo mass using the SMHM relation proposed by Behroozi et al. (2013c), with a redshift-dependent scatter ξ(z) = 0.218 + 0.0203z/(1 + z). We then follow Choksi et al. (2018) to evolve the stellar mass self-consistently. First, we assign an initial stellar mass to the first progenitor along each branch, |$M_{\star }^0$|, sampled from a Gaussian distribution, |${\cal N}(\overline{M_{\star }^0},\xi (z_0))$|. The average value |$\overline{M_{\star }^0}$| refers to the raw stellar mass from SMHM without scatter. Next, we evolve the stellar mass as
This method preserves some memory of the historical stellar mass, so that a galaxy deviating from the mean SMHM at the beginning tends to continue the trend.
Using the stellar mass, we calculate the cold gas mass via the gas mass–stellar mass relation by Choksi et al. (2018),
based on the observations of Lilly et al. (2013), Genzel et al. (2015), Tacconi et al. (2018), and Wang et al. (2022). Here nM(M⋆) = 0.33 for |$M_{\star }\gt 10^9 \, \mathrm{M}_\odot$| and nM(M⋆) = 0.19 for |$M_{\star }\lt 10^9 \, \mathrm{M}_\odot$|. The redshift dependency is characterized by nz(z) = 1.4 for z > 2 and nz(z) = 2.7 otherwise. When z > 3, following Li & Gnedin (2014) we adopt a fixed upper limit: η(M⋆, z > 3) = η(M⋆, z = 3). An intrinsic scatter of 0.3 dex is also added to this relation.
Another constraint on the gas mass of the host galaxy is that sum of the gas fraction fg = Mg/Mh and the stellar fraction f* = M⋆/Mh cannot exceed the total accreted baryon fraction fin, which is limited by extragalactic UV background after reionization. Since this condition is particularly important for dwarf galaxies, here we update the expression for fin used in our previous models since Muratov & Gnedin (2010). The new expression from Kravtsov & Manwadkar (2022) takes the form
where fb = Ωb/Ωm is the universal baryon fraction, s(x, y) = [1 + (2y/3 − 1)xy]−3/y is a soft step-function, and Mch is the characteristic mass scale at which fin = 0.5fb,
where
We adopt the reionization epoch at zrei = 6 and γ = 15 as in Kravtsov & Manwadkar (2022). If fg + f* > fin, we set fg = fin − f*. The new expression of fin is similar to the one in our previous models at z ≲ 4, but gives significantly larger values at higher redshift. Such a constraint is important for halos with |$M_{\rm h} \lesssim 10^9\, \mathrm{M}_\odot$| at z ≃ 2 when the formation of GCs is active.
The linear cluster mass–gas mass relation obtained from a simulation by Kravtsov & Gnedin (2005) is employed to calculate the total mass of a newly formed GC population,
where Mg is the cold gas mass of the host galaxy, and p2 is another adjustable parameter.1 This linear relation intuitively links the intensity of cluster formation to the total gas mass of the host galaxy, reflecting the fact that star clusters are formed in gas clouds (Shu, Adams & Lizano 1987; Scoville & Good 1989; McKee & Ostriker 2007; Krumholz, McKee & Bland-Hawthorn 2019). Similar relation is also observed in elliptical galaxies by McLaughlin (1999), who found that the ratio between cluster mass and baryon mass is roughly a constant.
The metallicity of the newly formed cluster population is directly drawn from the metallicity of the interstellar medium of the host galaxy, which is given by
We follow Ma et al. (2016) to employ 0.35 slope for the stellar mass dependency. The 0.9 slope of the redshift dependency is calculated based on the observations of Lyman-break galaxies by Mannucci et al. (2009), who found a 0.6 dex drop of [Fe/H] from z = 0 to ∼4. In addition, we apply a 0.3 dex intrinsic scatter to [Fe/H].
2.2.2 Cluster sampling
The next step is GC sampling, where we compute an initial mass of each individual cluster. For each GC formation event with total mass Mtot, we sample the masses of individual clusters from a Schechter (1976) initial cluster mass function (ICMF) with a power-law slope of −2,
Following Choksi & Gnedin (2019a), we set |$M_{\rm c}=10^7\, \mathrm{M}_\odot$|. To numerically draw clusters from the ICMF, we first calculate the cumulative distribution function
where Mmin/max are the minimum/maximum cluster mass. We will specify the selection of Mmin/max later. The variable r(M) ∈ [0, 1) is a monotonic function for any M ∈ [Mmin, Mmax), and thus r(M) is invertible. Then, we draw a random number x ∈ [0, 1) and convert x to a cluster mass via M = r−1(x). We repeat the process until the total mass of newly formed clusters, MGC, just exceeds Mtot. We drop the last cluster (with mass M) with a probability P = (MGC − Mtot)/M. Therefore, the expected value of MGC is E(MGC) = MGC(1 − P) + (MGC − M)P = Mtot.
In a rare case of Mtot < Mmin, we still randomly draw a cluster from the ICMF with the above method. However, since the mass of such a cluster, M, is greater than Mmin (and thus greater than Mtot), we must stochastically determine whether to keep it to ensure that the expected value of MGC is still Mtot. Therefore, we keep this cluster with a probability P = Mtot/M, so that the expected value of MGC is E(MGC) = MP = Mtot. By employing these techniques, we can guarantee that the expected value of MGC is always Mtot.
While in previous versions of our model we used the minimum cluster mass of |$10^5\, \mathrm{M}_\odot$|; here, we set |$M_{\rm min} = 10^4\, \mathrm{M}_\odot$| so that we can correctly model the masses of GCs even in the smallest halos with |$M_{\rm h}\gtrsim 10^8\, \mathrm{M}_\odot$|. We show our motivation with an order-of-magnitude calculation: plugging |$M_{\rm g}\sim f_{\rm b}M_{\rm h} \gtrsim 10^7\, \mathrm{M}_\odot$| and p2 ∼ 10 into equation (6), we get |$M_{\mathrm{tot}}\gtrsim 10^4\, \mathrm{M}_\odot$|. Therefore, we expect |$M_{\rm min}\ge 10^4\, \mathrm{M}_\odot$| to avoid the abnormal case of Mtot < Mmin. However, clusters with |$M\lt 10^4\, \mathrm{M}_\odot$| will be disrupted relatively quickly by the tidal field: the estimated lifetime of |$10^4\, \mathrm{M}_\odot$| cluster at 3 kpc from the galactic centre of a MW-mass galaxy is less than 1 Gyr. Moreover, since we will mainly compare our results with the ELVES survey (Carlsten et al. 2022a), which is magnitude-limited to Mg < −5.5, corresponding to |$M\gt 3\times 10^4\, \mathrm{M}_\odot$|, it is unnecessary to model clusters less massive than |$10^4\, \mathrm{M}_\odot$|. We thus set |$M_{\rm min}=10^4\, \mathrm{M}_\odot$|. Note that we adopted |$M_{\rm min}=10^5\, \mathrm{M}_\odot$| in Chen & Gnedin (2022) due to the limited mass resolution in that work. Therefore, the p2 values in the two works are not directly comparable as a larger p2 is needed to maintain the same ICMF at the high-mass end if we reduce Mmin from |$10^5\, \mathrm{M}_\odot$| to |$10^4\, \mathrm{M}_\odot$|.
In Choksi & Gnedin (2019a) and Chen & Gnedin (2022), Mmax is set to match the deterministic constraint
In other words, there is only one cluster with M = Mmax in each GC formation event. Such cluster is drawn first in the list of newly formed GCs. An alternative method is to set Mmax → ∞ and allow more massive clusters to form with a small but non-zero probability. Numerically, we can set Mmax to be a large enough number |$\gtrsim 10^7\, \mathrm{M}_\odot$|. These two methods produce similar results for galaxies with |$M_{\rm h}\gg 10^9\, \mathrm{M}_\odot$|. However, for galaxies with |$M_{\rm h}\sim 10^9\, \mathrm{M}_\odot$|, the former method prevents the formation of massive clusters (|$M\sim 10^5\, \mathrm{M}_\odot$|) as Mmax is too small, whereas the latter method can still form massive clusters with nonzero probability. This may lead to noticeable difference in the final GC abundances in dwarf galaxies. In the rest of the work, we investigate both methods but treat Mmax → ∞ as the default.
2.2.3 Particle assignment
After determining the masses of individual GCs, we link the newly formed clusters to collisionless particles in the simulation snapshots. This step is different from our previous work (Chen & Gnedin 2022), where we applied the model mostly on stellar particles in the Illustris TNG50 simulation. There we chose particles representing young stellar populations, with age typically less than 10 Myr, that indicate likely formation sites of giant molecular clouds within the galaxy. In this work we have only DM particles from our new LG simulations, and therefore we need to assign GCs to DM particles near possible locations of giant molecular clouds. To try to find reasonable proxies for the cloud location, we search for peaks of matter density. These peaks may correspond to surviving dense cores of satellite galaxies or other galactic structure with deep potential wells. Giant gas clouds are more likely to be formed around such peaks than elsewhere, and we therefore adopt these local density peaks to mimic the location of giant clouds. We then identify local density peaks within rs of the galaxy centre, where rs is the scale radius of the best-fit Navarro–Frenk–White (NFW) halo profile.We require the peak density to be higher than the mass density of the 16 closest grid cells and 30 times the mean density enclosed within the rs sphere. The first criterion ensures that the peak is located at a local maximum, while the second criterion excludes low-density peaks that are unlikely to host massive star clusters. The factor 30 is chosen such that the resulting radial number density profiles of model GCs can match the observed profiles of both the MW and satellites.
To find all such density peaks, we start with the central peak and search for the next highest density peak outside 1 kpc of the first peak. We repeat the process to search for the remaining peaks outside 1 kpc of all existing peaks. Every time we find a peak, we assign one GC to the DM particle located near the centre of the peak until we find all peaks satisfying the criteria or we have assigned all GCs to peaks. If there are more GCs than the number of peaks, we loop through the peaks again: first assign one GC to a random DM particle within 500 pc of the first peak, then another GC to the second peak, and so on. We repeat the process until we have assigned all GCs to the peaks. This guarantees that each peak has approximately equal number of GCs. Benefited by the high mass resolution of the simulations, we can always find sufficient number of DM particles satisfying the above criteria even during the early epochs of galaxy formation.
This particle assignment ensures that the GC profiles of the three MW-like galaxies are consistent with the observed GC profile of the MW. After calibration (described in Section 2.3), our model gives the GC half number radius for Louise, Romeo, and Juliet to be 5.8, 4.1, and 4.3 kpc, respectively, in agreement with the observed half number radius around 4.8 kpc. We also notice that the projected GC profiles of the three MW-like galaxies have a flat core within the central 1 kpc and follow a power-law function at R = 1–100 kpc, with slopes varying from −2.3 to −2.5, being consistent with the −2.4 slope of the MW. In addition, the new assignment method allows GCs to form farther away from the galactic centre. This assignment typically selects DM particles 200–5000 kpc from the galactic centre for |$M_{\mathrm{h}}\sim 10^{10}\, \mathrm{M}_\odot$|, in agreement with Sameie et al. (2023), who employed hydrodynamic simulations and suggested that clusters are formed ∼1000 pc to the galactic centre for |$M_{\mathrm{h}}\sim 10^{10}\, \mathrm{M}_\odot$|.
2.2.4 Cluster evolution
The final step is to follow the trajectories of GC particles and model the evolution of GC mass until the present. We take into account two main processes of mass evolution: tidal disruption and stellar evolution. The tidal disruption rate of a cluster with mass M can be expressed as
where ttid is the tidal disruption time-scale. As suggested by Gieles & Baumgardt (2008), the disruption time depends significantly on the local tidal field strength, parametrized by the effective angular frequency Ωtid. In the previous versions of this model (Choksi et al. 2018; Chen & Gnedin 2022) we used the expression
with y = 2/3 and the tidal frequency estimated as |$\tilde{\Omega }_{\rm tid}^2 \simeq \max (|\lambda _1|,|\lambda _2|,|\lambda _3|)/3$|, where (λ1, λ2, λ3) are the three eigenvalues of tidal tensor |${\bf T}(\boldsymbol {x}_0,t)$| sorted in descending order. This mass loss rate can be rewritten as
In this work, we apply a modified expression for the cluster mass loss, motivated by a re-evaluation of direct N-body models of cluster disruption by Gieles & Gnedin (2023),
with potentially different scalings x and y. The main change here is separating the overall normalization of the mass loss rate as a function of initial cluster mass Mi (via x) and the dependence on current cluster mass M(t) (via y). We obtain the previous prescription if x = y and Mi cancels out. However, recent N-body models indicate that the evolution slope y may deviate from the initial x depending on cluster density and even exceed the value of 1.
To explore systematic variation of our results on the modeling of tidal disruption, we consider three alternative models. The first is the old version, x = y = 2/3. The second is a modified version with x = y = 1, which should produce stronger disruption of low-mass clusters. The third model has x = 2/3 but y = 4/3, which is preferred by the new N-body models. This parametrization should also reduce the fraction of low-mass clusters.
The present-day GC mass function depends noticeably on the disruption models. In Fig. 1, we compare the average mass functions of GCs in the three MW-like galaxies produced by the three models of tidal disruption. The model parameters are calibrated as we describe in Section 2.3. The mass function of the x = 2/3, y = 4/3 model lies between the two other models for |$M\gt 3\times 10^4\, \mathrm{M}_\odot$| and predicts lower abundance of clusters below this mass, better matching the observed mass function of the MW GCs. Therefore, we treat the x = 2/3, y = 4/3 prescription as the default, and the other versions as alternates unless mentioned specifically.
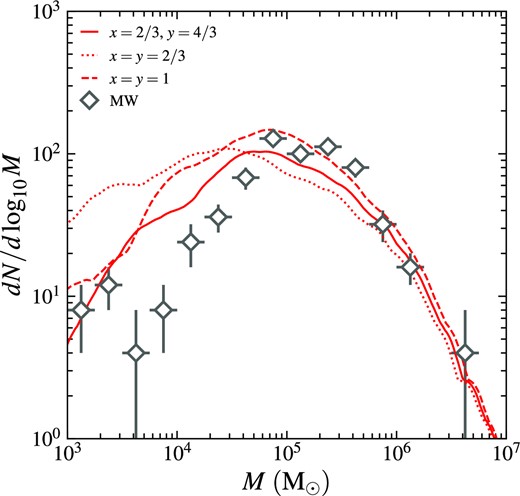
Average GC mass functions of the three MW-like galaxies with different prescriptions for tidal disruption, given by equation (14). Solid line is for x = 2/3, y = 4/3, dotted line is for x = y = 2/3, and dashed line is for x = y = 1. For comparison, the mass function of the MW GC system is overplotted as diamonds with errorbars: vertical errorbars show the interquartile ranges computed via bootstrap resampling, and horizontal errorbars correspond to the bin width. We repeat bootstrap resampling until the estimated interquartile ranges converge.
We also use an updated expression for the tidal frequency Ωtid via the effective eigenvalue λ1, e that takes into account the centrifugal, Euler, and Coriolis forces (Renaud, Gieles & Boily 2011),
Typically, λ1 > 0 and λ3 < 0. This expression reflects the mass loss more accurately than |$\tilde{\Omega }_{\rm tid}$|. The resulting values of Ωtid are systematically higher by a factor 1.2–2.1 at z = 2–5 when GC formation is the most active, so that we updated the normalization factor from 100 to 150 Gyr−1 to maintain consistency with the previous versions of the model.
The tidal tensor is defined as
where i and j are the orthogonal directions in the Cartesian coordinate system, and |$\boldsymbol {x}_0$| stands for the location of the cluster. Based on numerical experiments, Pfeffer et al. (2018) suggested to use λ1, e ≃ λ1 − 0.5(λ2 + λ3). In spherical symmetry we have λ2 = λ3, which leads to the second equality in equation (15).
We numerically calculate the tidal tensor by placing a 3 × 3 × 3 cell cube centred on the GC particle, where the side length of the cell is d. We approximate the diagonal terms of the tidal tensor via
where |$\hat{\boldsymbol {e}}_i$| is the unit vector along the i direction. Similarly, the non-diagonal terms are given by
As in Chen & Gnedin (2022), we set d = 300 pc for best accuracy in the regions containing most GCs. Although this value is still too large compared to the tidal radius of GCs (|$20-50\,$| pc) we cannot adopt a lower d as we are limited by the spatial resolution of the simulation. In addition, since we apply the model on collisionless simulations, we cannot directly model the gravitational potential of baryons, which may be different from that of DM. Ignoring baryonic structure typically tends to underestimate the tidal force. However, this effect is not obvious for dwarf galaxies |$M_{\star }\lt 10^8\, \mathrm{M}_\odot$|, which are dominated by DM. To correct the underestimate of the tidal field strength Ωtid due to both aforementioned effects, we boost it by the third adjustable model parameter κ,
The notation |$\hat{\lambda }_i$| stands for the i-th eigenvalue of the tidal tensor calculated by the finite differences in equations (17) and (18).
Using equation (14) we calculate the current mass of a GC at time t after formation due to tidal disruption as M′(t). Assuming the time-scale of stellar evolution is much shorter than ttid, the final mass of the GC is given by
where νse is the mass loss rate due to stellar evolution by Prieto & Gnedin (2008).
2.3 Selecting model parameters
The model has three adjustable parameters (p2, p3, κ) controlling the formation rate, formation timing, and disruption rate of GCs. To obtain the values of these parameters that match best the three MW-like galaxies (Louise, Romeo, and Juliet), we compare several key properties of surviving clusters with the observational data of MW GC system, including the number of clusters, mass function, metallicity distribution, and radial profile. We calibrate the model specifically for the MW because the observations of the MW GC system are the most complete among all GC systems. This allows comparison of the model GC systems with observations in many different aspects, as we introduce below. Also, the mass assembly history of the MW is understood better than any other galaxy of similar masses, such as M31. Since the mass assembly history is one of the key inputs of the model, we are more confident that the three MW-like galaxies should produce GC systems similar to the MW GC system with the calibrated model parameters. The calibration is done by minimizing the following merit function:
The first term is the reduced χ2 of the number of surviving clusters,
where Nh = 3 is the number of MW-like galaxies in our simulations, Ni is the number of surviving clusters in the i-th simulated galaxy, and NMW = 150 in the observed number of GCs in the MW. We adopt Poisson’s error of σlog N = 0.04.
Similarly, the second term is the reduced χ2 of the velocity dispersion of surviving clusters. Here the velocity dispersion is defined as the 3D dispersion, |$\sigma ^2 \equiv \sigma _R^2 + \sigma _\phi ^2 + \sigma _z^2$|, for the MW and its simulated analogues.
The remaining three terms in equation (21) are the ‘goodness’ of the mass function, metallicity distribution, and radial profile, respectively. For example, GM stands for the inverse of the fraction of MW-like galaxies that can match the observed mass function of surviving GCs. By performing the Kolmogorov–Smirnov (KS) test on the model galaxies with observations, we define a galaxy to match observation if the p-value of KS test exceeds 0.01. Similarly, GZ is the inverse of the fraction of MW-like galaxies that can match the observed distribution of [Fe/H], and GR is the inverse of the fraction of MW-like galaxies that can match the observed radial profile, i.e. the distribution of face-on projected distance between GCs and the galaxy centre.
By minimizing the merit function, we find the best parameters to be (p2, p3, κ) = (14, 0.7 Gyr−1, 1.5) both for the default prescription of tidal disruption, x = 2/3, y = 4/3, and for the case of x = y = 1. For the old model with x = y = 2/3, the best parameters are (p2, p3, κ) = (14, 0.7 Gyr−1, 2.5). It is worth emphasizing that these parameter sets are calibrated specifically for the MW system. The results for satellite galaxies are true predictions of the model.
2.4 Selecting dwarf galaxies
The main goal of this work is to investigate the formation of GCs in dwarf galaxies, especially the satellite galaxies that are associated with MW and M31. To achieve this, we select 10 satellite galaxies with the highest maximum halo mass for either T&L and R&J, yielding 20 satellite galaxies in total. We define satellite galaxy as the galaxy located inside the virial radius of any of the main galaxies at z = 0. The ‘highest maximum halo mass’ refers to the mass of the historically most massive progenitor galaxy in the merger tree. We apply the model on this halo sample and analyse the GC systems in these galaxies throughout the paper.
Since most dwarf galaxies have only a few or even no GCs, the model randomness can play an important role in shaping the GC systems. The randomness includes the scatter in galactic scaling relations and the stochasticity when sampling clusters from the ICMF and when assigning clusters to simulation particles. To study how much the resulting GC systems are influenced by the model randomness, we rerun the model 25 times on each dwarf galaxy with different random seeds. This allows us to present most results in terms of the median values and interquartile (25 per cent–75 per cent) ranges.
3 GLOBULAR CLUSTER SYSTEMS OF DWARF GALAXIES
One of the most fundamental properties of observed GC systems in dwarf galaxies is the number of GCs. Since a large fraction of dwarf galaxies do not presently host any GCs, we divide the sample into two categories: galaxies with GCs and without GCs, and analyse them separately. We compare the model results with observations including the ELVES survey of LV GCs, the GC systems in the MW and MW/M31 satellites, and the catalogues of GC systems from Harris, Harris & Alessi (2013), Harris, Blakeslee & Harris (2017), and Forbes et al. (2018).
3.1 Observational data in the LV
We compare the predictions of our model with the observational data from Carlsten et al. (2022a). These authors analysed GC systems in the LV galaxies from the ELVES survey. This survey reviews satellite galaxies inside 300 projected kpc of luminous host galaxies (MV < −22.1) out to 12 Mpc of Earth. They investigated GC systems in a sample of 140 confirmed early-type dwarf satellite galaxies with stellar mass between 105.5 and |$10^{8.5}\, \mathrm{M}_\odot$| associated with 23 LV hosts.
Carlsten et al. (2022a) obtained GC catalogues by identifying point sources in the surroundings of each dwarf galaxy. To exclude red sources that are unlikely to be GCs, they applied a colour selection g–r ∈ [0.1, 0.9] for dwarfs with |$\rm g/r$| imaging or g–i ∈ [0.2, 1.1] for dwarfs with |$\rm g/i$| imaging. Additionally, they also applied a magnitude cut Mg ∈ (− 9.5, −5.5). They determined the total number of GCs by counting GCs within twice of the dwarf’s effective radius (2re) and corrected the value for the incompleteness of faint GCs, GCs outside 2re, and the subtraction of background sources. They also applied an alternate likelihood method taking into account the magnitude and spatial distribution of candidate GCs. The magnitude distribution is modeled by a two-parameter Gaussian distribution, and the spatial distribution by a Plummer profile with a single parameter: re. This method models the dwarf galaxies as a mixture of systems without GCs and with non-zero GCs. They parameterize the number of GCs as a two-parameter power-law function of the stellar mass of host galaxy, and the fraction of dwarfs with non-zero GCs as a monotonically increasing function of stellar mass characterized by values at five reference stellar masses. These accumulate to a total of 10 free parameters. The posterior distributions of the 10 parameters are obtained via Markov chain Monte Carlo.
3.2 Occupation fraction
A measure of stellar mass of dwarf satellite galaxies can be more easily obtained from observations than the total dynamical mass, and therefore it is beneficial to investigate how the properties of their GC systems scale with the stellar mass. On the other hand, our model is based on the halo mass, and the information about stellar mass comes only from applying the SMHM relation (Behroozi et al. 2013c). Note that this relation is poorly constrained at the low-mass end, where the observed scatter is large and many physical processes that can introduce additional systematic bias are not considered. For example, applying this relation at z = 0 may underestimate the actual stellar mass for satellite galaxies because of tidal truncation by the host galaxy. This truncation is likely to strip a higher fraction of halo mass than stellar mass, because stars are more compactly distributed even in satellite galaxies. Therefore, |$M_{\star }^{\rm z=0}$| is likely a lower limit on the actual stellar mass of the satellite. An opposite limit can be obtained by assuming that no stellar mass is stripped from the satellite. Then we could use the historical maximum value |$M_{\star }^{\rm max}$|, which is the stellar mass resulting from applying the SMHM relation at the time of its peak value (typically, around the time of accretion onto the host). The true value of the satellite’s stellar mass must lie between these two limits. Therefore, we treat the stellar mass of a model galaxy i as obeying a continuous distribution between |$M_{\star ,i}^{\rm z=0}$| and |$M_{\star ,i}^{\rm max}$|.
We employ two distribution functions for M⋆. The first option is a simple flat function in the base-10 logarithmic space, i.e.
For visual clarity, with drop the 10 subscript in log10M⋆ for this expression and hereafter. This function assumes that the probability density for log M⋆ being any value within that range is the same.
Alternatively, we may expect that the actual stellar mass is closer to |$M_{\star }^{\rm max}$|, since stars are more concentrated towards the satellite centre and less likely to be tidally stripped than the dark matter. To account for this, we introduce an alternate distribution which is a linear function in the logarithmic space,
This function places more emphasis near |$M_{\star }^{\rm max}$|. We will use both priors to investigate how GC numbers depend on stellar mass, and treat the difference in the results as systematic uncertainty associated with measuring M⋆.
For example, when calculating the fraction of galaxies hosting at least one GC (‘GC occupation fraction’ focc) as a function of M⋆, we take the weighted average value in bins using a kernel smoothing method,
The summation in the denominator is over all galaxies, while the summation in the numerator is over galaxies with non-zero GCs. We define the term ‘non-zero GCs’ as galaxies that contain at least one cluster above a certain lower mass limit Mlow. We set a default value |$M_{\rm low}=3\times 10^4\, \mathrm{M}_\odot$| to mimic the Mg < −5.5 magnitude cut employed in the LV observations. Since focc can depend significantly on Mlow, we compare the results for different choices of Mlow in Section 5.
We also require the GCs to be located inside a certain radius from the galaxy centre. Here, we set this radius to be an estimate of the tidal radius in an isothermal density potential, rtid = dhost(Msat/2Mhost)1/3. Even though the actual tidal radius may not be used when identifying satellite GCs in observations, it is a physically meaningful proxy to use in the model.
The kernel function pi(log M⋆) in equation (25) is either pflat or plin: the distribution function of stellar mass for the i-th galaxy. We obtain 25 values for j-th mass bin from the 25 random model realizations. We present the final result as the median of the 25 values, as well as the scatter represented by the interquartile range of the 25 values.
In Fig. 2, we show the occupation fraction as a function of stellar mass of the satellite galaxy. We note that pflat and plin produce similar focc–M⋆ relations, although the relation from plin is shifted slightly to the high-mass end. For both distribution functions, the occupation fraction is almost 1 for |$M_{\star }\gtrsim 5\times 10^7\, \mathrm{M}_\odot$| but drops to less than 0.2 for |$M_{\star }\lesssim 10^6\, \mathrm{M}_\odot$|. At |$M_{\star }\simeq 2\times 10^7\, \mathrm{M}_\odot$|, the occupation fraction is approximately 0.5.
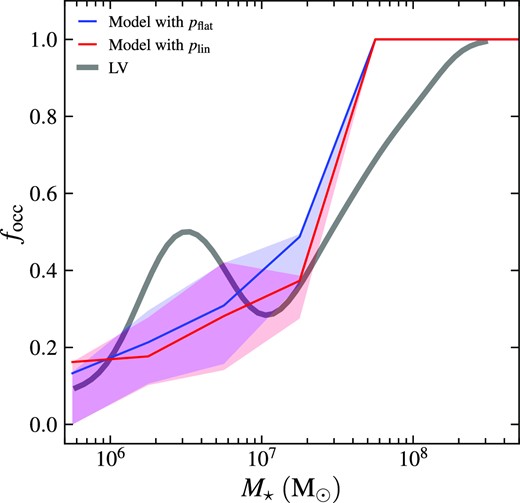
GC occupation fraction focc relation as a function of stellar mass of host galaxy M⋆. The focc–M⋆ relations of model galaxies are shown as the cyan and magenta curves, employing the flat and linear distribution functions of M⋆, respectively. The grey curve represents observed relation from the LV (Carlsten et al. 2022a) with Gaussian kernel smoothing. See the main text for a detailed description of how we obtain these curves.
The observational focc–M⋆ relation is also shown in Fig. 2 for comparison. The observed relation is computed via the kernel smoothing method with a Gaussian kernel. The expression for the Gaussian kernel smoothing method is also given by equation (25), but replacing pi with a Gaussian function. Since the uncertainty of stellar mass in the ELVES data is ≳ 0.1 dex (Carlsten et al. 2021), we set the standard deviation of the Gaussian function to be σlog M = 0.2 dex. The number of GCs provided by the ELVES data (Nobs) is not necessarily an integer (or even positive) due to background subtraction. Therefore, we round Nobs to the nearest integer and define focc as the fraction of galaxies hosting at least one GC (which can be equivalently defined as the fraction of galaxies with Nobs > 0.5).
This method is different from the likelihood method employed in Carlsten et al. (2022a), who enforced focc to be a monotonically increasing function of M⋆. In contrast, we find the observational relation to be non-monotonic as focc has a spike at |$M_{\star }\simeq 3\times 10^6\, \mathrm{M}_\odot$|. We do not investigate the origin of this spike in depth, as it is not the main focus of this work. Despite the spike, the observed occupation fraction is around 1 for |$M_{\star }\gtrsim 3\times 10^8\, \mathrm{M}_\odot$| and also drops to less than 0.2 for |$M_{\star }\lesssim 10^6\, \mathrm{M}_\odot$|. At |$M_{\star }\simeq 3\times 10^7\, \mathrm{M}_\odot$|, the occupation fraction is about 0.5. The model relation generally agrees with the observations except that the transition from focc = 1 to 0 is steeper than the observed relation. It is surprising that our model shows good agreement with the observed satellite galaxies even if the model parameters are only calibrated for the three MW-like central galaxies with the MW GCs, suggesting that GC formation and evolution in satellite galaxies can be described by the same physical processes as the central galaxy.
3.3 Number of globular clusters
For the dwarf galaxies with non-zero GCs, we further investigate the relation between NGC and stellar mass of the galaxy. We calculate this relation in a similar fashion to the occupation fraction. After splitting M⋆ into bins, we compute the weighted average of the j-th bin using a kernel smoothing method,
where NGC, i stands for the number of clusters of the i-th galaxy. Again, we define NGC to be the number of clusters with mass above Mlow, which is set by default to |$3\times 10^4\, \mathrm{M}_\odot$| to mimic the observed magnitude cut. Here, both summations are over galaxies with non-zero GCs.
In Fig. 3, we show the NGC–M⋆ relation for model galaxies and compare it with the observed relation for the LV dwarf galaxies with Gaussian kernel smoothing similar to the calculation of the occupation fraction. In addition to the LV dwarf galaxies, we also compare our results with several satellites of the MW and M31 systems, including the Sagittarius dwarf spheroidal galaxy (Sgr dSph; Law & Majewski 2010), Fornax dSph galaxy (Pace et al. 2021), NGC 205 (Da Costa & Mould 1988), NGC 185 (Veljanoski et al. 2013), and NGC 147 (Veljanoski et al. 2013). The observed number of GCs is very uncertain for some satellites. For example, Law & Majewski (2010) suggested that Sgr dSph hosts eight GCs, whereas Minniti et al. (2021) almost tripled this number to 23. However, this does not affect qualitatively the comparison with observations since we are interested in a general trend of the NGC–M⋆ relation rather than reproducing the exact number of GCs in a particular observed galaxy.
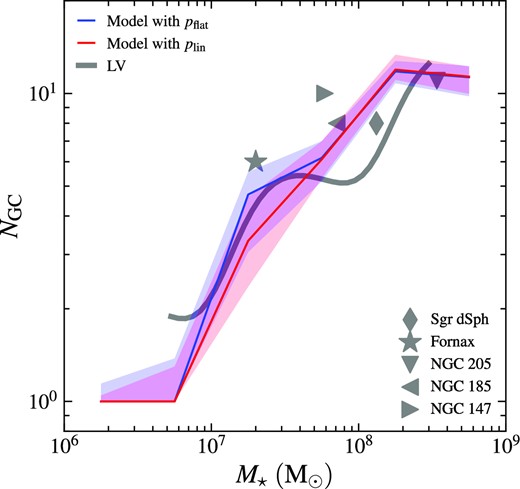
Number of GCs NGC as a function of stellar mass of host galaxy M⋆. We plot the NGC–M⋆ relation from Gaussian kernel smoothing for the LV dwarf galaxies (Carlsten et al. 2022a) as the grey curve. Satellites of the MW and M31 are shown as grey symbols.
We find that the NGC–M⋆ relations obtained with pflat and plin are consistent with each other. Both relations show that the number of GCs is around 10 at |$M_{\star }=10^8\, \mathrm{M}_\odot$| and decreases monotonically to less than 2 at |$M_{\star }\lesssim 10^7\, \mathrm{M}_\odot$| (note that NGC is always greater than 0 since we only analyse here galaxies with non-zero GCs). The modeled NGC continue to drop to around 1 at |$M_{\star }\lesssim 5\times 10^6\, \mathrm{M}_\odot$|. We do not plot the observed relation below |$M_{\star }=5\times 10^6\, \mathrm{M}_\odot$| because NGC from the ELVES survey may be influenced by numerical bias at small M⋆: the numbers of GCs in LV dwarf galaxies provided by Carlsten et al. (2022a) are corrected for GCs outside 2re annulus by dividing the GC counts by a factor of 0.646. Additionally, they apply a small factor to correct for GCs below the detection limit. Such corrections boost GC counts by a factor of around 1.6, leading to numerical bias in the low-mass end where the lowest non-zero GC count is 1. Therefore, NGC of LV galaxies drops to a minimum value ≳ 1.6 instead of 1 at |$M_{\star }\lesssim 5\times 10^6\, \mathrm{M}_\odot$|. It is meaningless to compare the model and observed relations in this regime. Despite this region, our model predicts the NGC–M⋆ relation in consistency with observations from 5 × 106 to |$3\times 10^9\, \mathrm{M}_\odot$|. We emphasize that the model is only calibrated for the MW-like galaxies with |$M_{\star }\gt 10^{10}\, \mathrm{M}_\odot$|, the good agreement at such a low-mass range is not a trivial outcome of tuning the model parameters. Instead, it implies that physical processes controlling GC formation and evolution may be universal for both central and satellite galaxies. We also note that the model relations have significant scatter at all masses, which increases the uncertainty when trying to apply the NGC–M⋆ relation to estimate the stellar mass and number of GCs of a dwarf galaxy.
3.4 Scaling with stellar mass
In this section, we extend our comparison with observations to a broader stellar mass range. In Fig. 4, we show the NGC/MGC–M⋆ relations, where MGC stands for the total mass of the GC system. For clarity we show only relations using the plin distribution function, since the two distribution functions pflat and plin give consistent results. Different from the above analysis, we also include dwarfs with zero GCs in the calculation of NGC. That is, the summations in equation (26) are over all galaxies instead of galaxies with non-zero GCs only. This setting allows NGC to drop below 1 for the lowest-mass galaxies. The model NGC behaves similarly to Fig. 3 for |$M_{\star }\gt 10^7\, \mathrm{M}_\odot$|, where most galaxies have at least one GC, and continues to drop to ∼0.1 at |$M_{\star }=10^6\, \mathrm{M}_\odot$| since a large fraction of dwarf galaxies do not actually host any cluster (see, Carlsten et al. 2022a, and relevant discussion in Section 3.2). We notice that NGC drops significantly at |$M_{\star }=(1-3)\times 10^7\, \mathrm{M}_\odot$|. However, we have no evidence that such an abrupt decline is physically real since only two galaxies lie in this range. The poor statistics in this narrow range is unreliable. Therefore, we only focus on the scaling relations across a wider mass range (≳1 order of magnitude) which includes more galaxies (∼10). The MGC–M⋆ relation has a similar trend. Starting from |$M_{\mathrm{GC}}\simeq 10^6\, \mathrm{M}_\odot$| at |$M_{\star }=10^8\, \mathrm{M}_\odot$|, MGC drops to |$\sim 10^4\, \mathrm{M}_\odot$| at |$M_{\star }=10^6\, \mathrm{M}_\odot$|, i.e. |$\sim 1~{{\ \rm per\ cent}}$| of the total stellar mass resides in surviving GCs. For comparison, |$5-40~{{\ \rm per\, cent}}$| of total stellar mass was originally formed in GCs (with initial mass |$\gt 10^4\, \mathrm{M}_\odot$|). At z ≳ 5, this fraction approaches (even slightly exceeds) 100 per cent, indicating that star formation is dominated by cluster formation at early epochs. The slight excess of cluster formation rate may be due to the potentially underestimated star formation rate by the Behroozi et al. (2013c) SMHM, which is poorly constrained at the low mass end and at high redshift. The subsequent tidal disruption significantly reduces the fraction of stars in clusters to its present-day value |$\sim 1~{{\ \rm per\, cent}}$|.
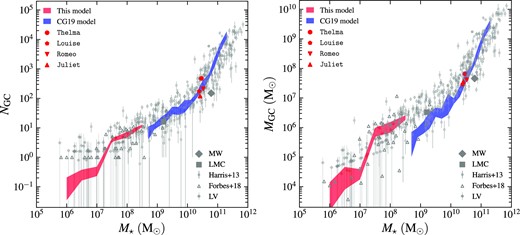
Number of GCs (left-hand panel) and total mass of GCs (right-hand panel) vs the stellar mass of host galaxy. Red shaded region shows the interquartile range of the present model, blue shaded region shows the interquartile range of the model from Choksi & Gnedin (2019b). We plot the observational data from (Harris et al. 2013) as grey circles with errorbars, the data from Forbes et al. (2018) as open triangles, and the data from the LV (Carlsten et al. 2022a) as diamonds with errorbars. We also plot the four main galaxies in the simulations as the red symbols, with the MW and LMC shown as the grey diamond and square for comparison.
For comparison, we plot the observed GC systems in the MW (stellar mass from Licquia & Newman 2015) and Large Magellanic Cloud (LMC) as well as the catalogues of GC systems from the LV survey, the catalogues by Harris et al. (2013) and Forbes et al. (2018). The latter catalogue focuses on GC systems in the LG dwarf galaxies down to stellar mass |$\lesssim 10^6\, \mathrm{M}_\odot$|. Note that the Harris et al. (2013) catalogue does not list M⋆ directly. Instead, it provides K-band magnitude MK. We convert MK to M⋆ using a fixed stellar mass-to-light ratio log (M⋆/LK) = −0.3 (estimated from fig. 20 in Bell et al. 2003). Moreover, the LV data do not provide the total mass of GC systems. To estimate MGC from NGC, we fit the mean GC mass in Forbes et al. (2018) as a power-law function of M⋆: |$\log \overline{M}=2.3+0.35\log M_{\star }$|, and compute the total GC mass as |$M_{\mathrm{GC}}=N_{\mathrm{GC}}\overline{M}$|.
We also overplot in Fig. 3 the NGC/MGC–M⋆ relations from a previous version of our model (Choksi & Gnedin 2019a), which successfully matches the observational trend for |$10^{9.5}\lt M_{\star }\lt 10^{11}\, \mathrm{M}_\odot$|. However, that model deviates from observations at |$M_{\star }\lesssim 10^{9.5}\, \mathrm{M}_\odot$|. Compared to the scaling of NGC, the deviation is more significant for MGC. This is partly because the previous model has inefficient disruption of low-mass clusters (the y = 2/3 case in Section 2.2.4). Therefore, such a prescription predicts a GC mass function peaked at lower mass, and thus tends to underestimate the mean mass of surviving clusters, as shown in Fig. 1. Our updated model attempts to solve the deviation by following the formation of less massive clusters (down to |$10^4\, \mathrm{M}_\odot$|) in low-mass galaxies (down to |$M_{\mathrm{h}}=10^8\, \mathrm{M}_\odot$|). In addition, the current model applies a more realistic tidal disruption prescription taking into account the local environment of clusters. The resulting NGC/MGC of the new model can match the observed relations at a mass range where most galaxies have non-zero GCs, |$M_{\star }\gtrsim 3\times 10^7\, \mathrm{M}_\odot$|. Below this mass, the model NGC continues to drop below 1, while the observational data on dwarfs from Forbes et al. (2018) only consider galaxies with non-zero clusters, leading to the observed NGC–Mh relation bending upwards at the low-mass end. It is therefore meaningless to compare the NGC/MGC–M⋆ relations at |$M_{\star }\lesssim 3\times 10^7\, \mathrm{M}_\odot$|. We still need better observations of dwarf galaxies to further test the validity of our model.
3.5 Scaling with halo mass
After investigating the dependence of NGC/MGC on stellar mass and showing that it is consistent with observations, we can turn to the dependence on the satellite halo mass. In the left-hand panel of Fig. 5, we present the model NGC–Mh relation via the kernel smoothing method with an Epanechnikov (1969) kernel: K(u) = 0.75(1 − u2) for |u| ≤ 1 and K(u) = 0 otherwise. The bandwidth is set to 0.5 dex. We find that different bandwidths from 0.4 to 1 dex do not alter the relation significantly (however, a bandwidth < 0.4 dex is insufficient to cover all gaps between neighbouring data points).
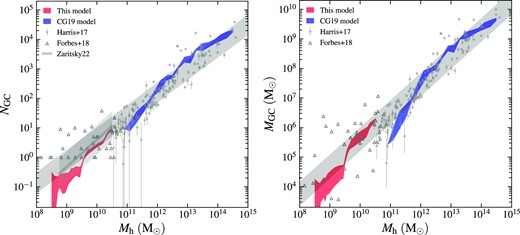
Number of GCs (left-hand panel) and total mass of GCs (right-hand panel) vs the total mass of host galaxy. Red shaded region shows the interquartile range of the present model, blue shaded region shows the interquartile range of the model from Choksi & Gnedin (2019b). We plot the observational data from (Harris et al. 2017) as grey circles with errorbars, and data from Forbes et al. (2018) as open triangles. The long grey region shows the jointly fitted power-law relation of the two observational data sets with intrinsic scatter. The power-law dependence from Zaritsky (2022, |$N_{\mathrm{GC}}\propto M_{\mathrm{h}}^{0.92}$|) is shown as the grey line in the left-hand panel, with the estimated scatter 0.5 dex plotted as the short grey region. The grey shaded region shows the power-law fit of the observational data, see the main text for more details.
We show the observational data from Harris et al. (2017) and Forbes et al. (2018) for comparison. The first catalogue covers galaxies with halo mass between |$10^{9.5}-10^{14.5}\, \mathrm{M}_\odot$|, and the second catalogue focuses on LG dwarf galaxies with |$M_{\mathrm{h}}=10^8-10^{11}\, \mathrm{M}_\odot$|. We fit the two data sets jointly with a power-law,
where Mh12 is the halo mass Mh in unit of |$10^{12}\, \mathrm{M}_\odot$|. The intrinsic scatter is represented by a random variable ϵ following a Gaussian distribution |${\cal N}(0, \sigma _{\rm int})$|. We perform the fit by maximizing the likelihood,
where δi = log NGC, i − a − blog Mh12, i is the vertical deviation, with the subscript i denoting the i-th data point. In addition, σlog N, i is set to the observed uncertainty of log NGC, i if provided or 0.3 dex otherwise. We apply bootstrap resampling 1000 times until all fitting parameters converge to estimate the mean values and standard deviations of a, b, and σint. Maximizing the likelihood |${\cal L}$| yields
with an intrinsic scatter σint = (0.34 ± 0.03) dex.
Again, we show in Fig. 5 the NGC–Mh relation from Choksi & Gnedin (2019a). This model successfully matches the observational trend for |$10^{12}\lt M_{\rm h}\lt 10^{14}\, \mathrm{M}_\odot$|. Like the NGC–M⋆ relation, this model underestimates NGC at the low-mass end |$M_{\mathrm{h}}\sim 10^{11}\, \mathrm{M}_\odot$|. In the contrast, although the new model still falls systematically below the observed NGC in the dwarf galaxy range we study here, it is within a factor of ∼2 of the average trend. Moreover, the observational trend may be biased upwards as the data of dwarfs from Forbes et al. (2018) only consider galaxies with non-zero clusters, and they measured halo mass systematically below the derived values from the majority of SMHM relations. A more appropriate comparison in the lowest-mass end is with Zaritsky (2022), who revisited the observational data by Forbes et al. (2020) and Carlsten et al. (2022a). These two data sets both provide information about galaxies hosting zero GCs. Forbes et al. (2020) studied the GC systems in the Coma cluster ultra-diffuse galaxies (UDGs). Zaritsky (2022) reconciled the number of GCs in Forbes et al. (2020) by multiplying a factor of 0.27, taking into account a more precise constraints on GC luminosity function and radial distribution (Saifollahi et al. 2022). Zaritsky (2022) also derived total mass of galaxies from the two existing catalogues using an extension of the fundamental plane formalism. This method uses empirically calibrated relations to estimate the mass-to-light ratio within the half-light radius and the enclosed mass. The author then fit an NFW profile to the DM components inside the half-light radius to obtain the total mass of the galaxy. The author discovered a near-linear NGC–Mh relation for both Forbes et al. (2020) and Carlsten et al. (2022a) samples: |$N_{\mathrm{GC}}\propto M_{\mathrm{h}}^{0.92\pm 0.08}$|. By plotting this relation in Fig. 5, we find that it is consistent with the observed power-law relation from Harris et al. (2017) and Forbes et al. (2018). The model relation shows a similar slope but lies ∼0.3 dex below. Considering the large scatter of the NGC–Mh relation found by Zaritsky (2022), at least ∼0.5 dex, our model still makes predictions consistent with observations.
However, it is worth noting that Forbes et al. (2020) studied GCs in UDGs instead of satellite galaxies as analysed in this work and in Carlsten et al. (2022a). These UDGs normally have more GCs than the dwarfs of the same stellar mass, indicating that these galaxies have greater total mass than the predictions from typical SMHM. Although Zaritsky (2022) suggested that the NGC–Mh relation from UDGs is consistent with the relation from the LV satellites, the two categories of galaxies may follow different formation scenarios and are not directly comparable.
In addition to the NGC–Mh relation, we also investigate the MGC–Mh relation from the model. This relation follows an interesting near-linear scaling across a broad mass range (Spitler & Forbes 2009; Georgiev et al. 2010; Hudson et al. 2014; Harris et al. 2015; Forbes et al. 2018). However, this scaling is only confirmed for galaxies with |$M_{\rm h}\gt 10^{10}\, \mathrm{M}_\odot$| since it is challenging to determine the halo mass of dwarf galaxies directly. With the observational data from Forbes et al. (2018), we attempt to extend the relation to low-mass galaxies. Similarly to the NGC–Mh relation, we fit the observational data from Harris et al. (2017) and Forbes et al. (2018) jointly and obtain a power-law relation,
with an intrinsic scatter σint = (0.39 ± 0.04) dex. The slope of 0.93 ± 0.03 is very close to unity, meaning that we can extend the near-linear relation down to |$M_{\mathrm{h}}\sim 10^8\, \mathrm{M}_\odot$|. In the right-hand panel of Fig. 5, we compare the model MGC–Mh relation with this observational relation. Compared to the NGC–Mh relation, MGC from the Choksi & Gnedin (2019a) model deviates even more from the observations at |$M_{\mathrm{h}}\sim 10^{11}\, \mathrm{M}_\odot$| because it underestimates the mean mass of surviving clusters (see the discussion in Section 3.4). In contrast, the new model is in good agreement with observations as the model relation mostly overlaps the observed MGC in dwarfs. It is remarkable that our model can match the observational relation down to |$M_{\mathrm{h}}\sim 10^8\, \mathrm{M}_\odot$|, extending this near-linear correlation to ∼6 orders of magnitude of halo mass even considering the complicated interplay of multiple non-linear processes in GC formation.
However, we emphasize that the SMHM relation, which is widely used to convert observed stellar mass to halo mass, and simulated halo mass to stellar mass, is not well constrained at the low-mass end. This is due to the scarcity of independent measurements of halo mass for dwarf galaxies. Also, the scatter of SMHM may be underestimated in the Behroozi et al. (2013c) relation, which assumes a constant scatter for all masses. More detailed observations are needed to better constrain the SMHM in the dwarf range and that may change our current knowledge of the NGC/MGC–M⋆ relation.
4 DETAILED EXAMPLE: ANALOGUE OF FORNAX DSPH GALAXY
In this section we show a detailed example of how GC systems in satellite galaxies evolve over cosmic time. We focus on the most massive satellite of the Romeo (or R2) and Juliet (or J2) galaxies in the R&J simulation. These two satellites resemble the Fornax dSph galaxy in many aspects. In Fig. 6 we show the time evolution of the halo mass Mh, stellar mass M⋆, number of clusters NGC, and the distance to the host galaxy dhost. J2 is 140 kpc away from the host galaxy at present, in close agreement with the Fornax dSph which is also about 140 kpc away from the MW centre. We compute the tidal radius of J2 to be 24 kpc. The other satellite (R2) is closer (∼70 kpc) to the host galaxy as it is near the pericentre. However, the properties of this satellite agree better with those of Fornax dSph if we look back for 1 Gyr, when this satellite is near its apocentre about 110 kpc away from the host galaxy, with a corresponding tidal radius being 17 kpc. Therefore, we consider tlookback = 1 Gyr as the ‘present-day’ for R2 and only focus on the properties at/before this epoch when referring to this galaxy. In addition, we find that the two satellites have present-day stellar mass (1–2) × 107, consistent with the observed stellar mass of Fornax dSph, |$2\times 10^7\, \mathrm{M}_\odot$|. Our model predicts the median of seven and six GCs with |$M\gt 3\times 10^4\, \mathrm{M}_\odot$|, with the interquartile ranges spanning NGC = 5–9 and 4–8 for R2 and J2, respectively. These values match the observations of six GCs in Fornax dSph (Pace et al. 2021).
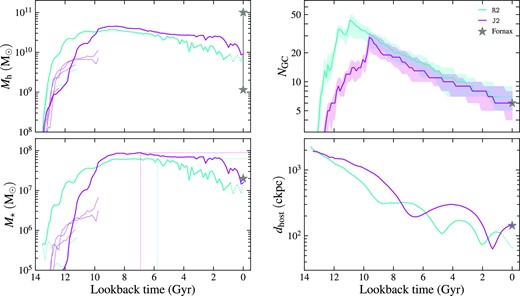
Time evolution of halo mass Mh (upper left), stellar mass M⋆ (lower left), number of GCs NGC (upper right), and the distance to the host galaxy dhost (in comoving kpc, lower right) of the two Fornax-like dwarf galaxies in the R&J run. We plot them as solid curves until the epoch when we consider these two galaxies to be the most similar to the Fornax dSph. After that, we plot the curves in dotted style. We also plot with thin lines the mass histories of their own satellites that contribute at least one surviving cluster to the present-day GC population. We mark the historical maximum of M⋆ as intersections of the vertical and horizontal lines in the lower left-hand panel. In the upper right-hand panel, The time evolution of NGC is shown as solid curves with shaded regions, representing the median value and the interquartile range from the 25 random realizations. The Fornax dSph galaxy is represented by grey stars in each panel. Since different works predict vastly different halo masses for Fornax, ranging from |$M_{\rm h}\sim 10^9\, \mathrm{M}_\odot$| (Forbes et al. 2018) to |$M_{\rm h}\sim 10^{11}\, \mathrm{M}_\odot$| (obtained from the SMHM relation by Danieli et al. 2022), we show the two extreme halo masses in the upper left-hand panel for completeness.
The masses (both halo and stellar) of the two satellite galaxies grow rapidly over the first 3 Gyr. During this period, the R2 galaxy has a smoother mass growth history compared to J2, which has more discrete jumps indicating more frequent major mergers. To show this, we plot in Fig. 6 the mass growth histories of their own satellites2 that contribute at least one surviving cluster to the present-day GC population. The R2 galaxy has encountered two major mergers both with peak mass |$M_{\mathrm{h}}\lt 10^{10}\, \mathrm{M}_\odot$|, whereas J2 galaxy has four major mergers, and one of them has peak mass greater than |$10^{10}\, \mathrm{M}_\odot$|. Around 5 per cent and 20 per cent of surviving GCs are accreted onto R2 and J2 via mergers, respectively. Although this ratio is small compared to that of MW-size galaxies (Chen & Gnedin 2022), different merger histories can significantly alter the radial distribution of GCs as we show later.
The two satellite galaxies stop growing mass at a lookback time around 10 Gyr when they accrete onto the central galaxy. The formation of GCs in the two satellites is also quenched at this epoch. After that, the satellite galaxies lose a significant fraction of their halo mass until the present-day. The number of GCs also drops by a factor around 5 compared to the peak value as a result of tidal disruption.
We show the GC number density profiles of the two satellites in Fig. 7. The profiles are obtained via kernel density estimation with the Epanechnikov (1969) kernel. The bandwidth of the kernel is 0.3 dex; varying the bandwidth between 0.2 and 0.5 dex does not change the profiles significantly. We also take the observed coordinates of the six Fornax GCs from Mackey & Gilmore (2003; Fornax 1–5) and Pace et al. (2021; Fornax 6) to compute the projected distances from the centre of the Fornax dSph. The R2 galaxy can match the observed profile in the radius range where the Fornax GCs are present, R ≲ 1.6 kpc. Different from the centrally concentrated GC system of Fornax, R2 still hosts GCs out to R ≳ 5 kpc. These GCs raise the half-number radius of R2, 1.3 kpc, to be greater than that of the Fornax dSph, 0.8 kpc. Note that the half-light radius of Fornax is only ∼0.8 kpc (Wang et al. 2019), and a cluster at R ≳ 5 kpc may not be identified as a member of the galaxy in observations. If we take this selection effect into account and apply a smaller search radius for R2, we can obtain a radial distribution more similar to the Fornax system.
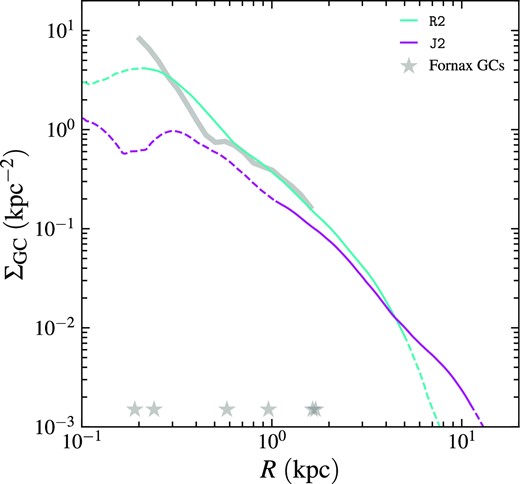
GC number density profiles of the two Fornax-like dwarf galaxies in the R&J run. The projected radii of the six Fornax GCs (Fornax 1–6) to the centre of the Fornax dSph are shown as stars. We also show the number density profile of Fornax GCs as the grey curve. The portions with number density below one GC per bandwidth are shown as dashed curves.
The GC distribution in the more merger-dominated J2 galaxy is even more extended, with the half-number radius of 3.2 kpc. J2 has lower GC number density than R2 for R ≲ 5 kpc, but higher in the outside. The J2 galaxy has GC number density lower than the statistical significance level (one GC per bandwidth) within the central 1 kpc, whereas it can host GCs out to R ≳ 10 kpc. The GC system in J2 is extended likely because major mergers can add kinetic energy to GCs and bring them outwards. It is notable that although R2 and J2 have similar properties in many aspects, such as the halo mass, stellar mass, and distance to the central galaxies, the GC number density profiles of the two galaxies still differ significantly. If we apply a smaller search radius, the distinct GC distributions in the two galaxies can lead to a notable difference in NGC. For example, a smaller search radius of 5 kpc does not change NGC for R2 (recall that the default search radius is the tidal radius ∼20 kpc), but reduces that for J2 to NGC = 2–5.
As mentioned before, both observations and the model show large scatter in NGC when scaled with M⋆ or Mh. Here, we suggest that ‘hidden variables’ like the merger history can also alter the observed number of GCs. Although different merger histories do not directly change the number of GCs as mergers only contribute |$5-20~{{\ \rm per\ cent}}$| of surviving GCs to the two model galaxies, in agreement with the findings that the formation of dwarf galaxies is not dominated by hierarchical assembly (Fitts et al. 2018; Martin et al. 2020), a more merger-rich assembly history may lead to a more extended GC spatial distribution and hence a smaller NGC within a fixed search radius.
5 CONSTRAINING MODEL VARIANTS
In this section, we compare three alternate model variants to investigate their influences on the focc–M⋆ and NGC–M⋆ relations. The first alternate model setting employs different lower mass limits Mlow when counting GCs. By default, we set |$M_{\rm low}=3\times 10^4\, \mathrm{M}_\odot$| to mimic the Mg < −5.5 magnitude cut employed in the observations of LV dwarf galaxies (Carlsten et al. 2022a). Here, we introduce a lower mass limit of |$M_{\rm low}=10^4\, \mathrm{M}_\odot$| and a higher mass limit of |$M_{\rm low}=10^5\, \mathrm{M}_\odot$| to study selection effects due to the cut in GC mass.
Next, we employ an alternate method when sampling cluster mass from the ICMF. As mentioned in Section 2.2.2, by default we sample GC mass from |$M_{\rm min}=10^4\, \mathrm{M}_\odot$| to Mmax → ∞, i.e. there is no higher mass constraint when forming GCs. We thus refer to this setting as ‘without Mmax’ in the subsequent text. In contrast, the previous versions of the model (Choksi & Gnedin 2019a; Chen & Gnedin 2022) set Mmax to be a finite value, which is selected to match the deterministic constraint in equation (10). In this setting, a galaxy with mass |$M_{\rm h}\sim 10^9\, \mathrm{M}_\odot$| has |$M_{\rm max}\sim 10^5\, \mathrm{M}_\odot$|. Therefore, the formation of high mass clusters with |$M \gt 10^5\, \mathrm{M}_\odot$| is strictly prohibited in low-mass galaxies. We refer to such a setting as ‘with Mmax’ in the following description.
The third variant explores dependence of the tidal disruption rate on cluster mass, which still remains uncertain. This motivates us to examine the performance of different prescriptions of tidal disruption during GC evolution. The default prescription, as mentioned in Section 2.2.4 and equation (14), sets x = 2/3 and y = 4/3. Additionally, this prescription approximates the angular frequency Ωtid in equation (12) by |$\Omega _{\rm tid}^2\simeq \lambda _{\rm 1,e}\simeq \lambda _1-\lambda _3$|, where λ1, e is the effective tidal strength. We also employ a boost parameter κ to account for numerical bias when estimating the tidal tensor: we multiply the derived |$\Omega _{\rm tid}^2$| by κ. By comparing the three MW-like galaxies in the simulations with the observed MW GC system, in Section 2.3 we calibrate κ as well as two other model parameters to be (p2, p3, κ) = (14, 0.7 Gyr−1, 1.5). Here, we test two additional prescriptions with x = y = 2/3 and x = y = 1. The first of them was applied in our previous work (Chen & Gnedin 2022). In order to properly compare the three prescriptions, we re-calibrate the model parameters for the alternative prescriptions as in Section 2.3. After re-calibration, we find (p2, p3, κ) = (14, 0.7 Gyr−1, 2.5) for the x = y = 2/3 prescription and (p2, p3, κ) = (14, 0.7 Gyr−1, 1.5) for x = y = 1. The latter parameter set is the same as our fiducial.
In Fig. 8, we compare the occupation fraction predicted by the different model variants. We use the same kernel smoothing method as in Section 3 to make the focc–M⋆ curves. For clarity we show only the focc–M⋆ relations using the plin distribution function, since the two distribution functions pflat and plin give consistent results.
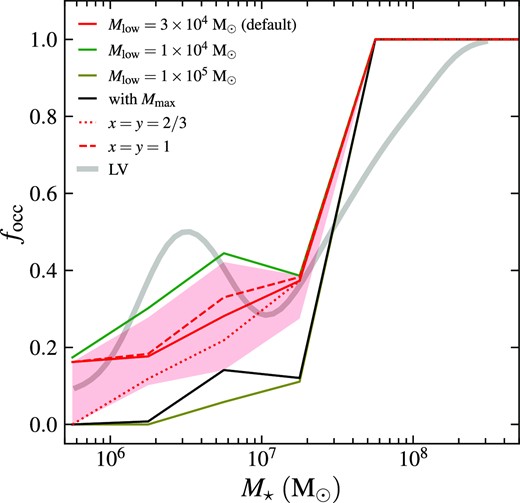
GC occupation fraction focc as a function of stellar mass of host galaxy M⋆ for different model settings. We show the default model (Mlow = 3 × 104 M⊙, without Mmax, x = 2/3, y = 4/3) as red solid curve with the shaded region representing the interquartile range, in consistency with Fig. 2. Other models are shown in curves with different styles and colours as described in the legend. The NGC–M⋆ relation for the LV dwarf galaxies is over-plotted as the grey curve as in Fig. 2.
We find that focc varies significantly with the lower mass cut Mlow. Greater Mlow can significantly reduce focc in a broad mass range of satellite galaxies from M⋆ = 5 × 105 to |$5\times 10^7\, \mathrm{M}_\odot$|. The occupation fractions from the |$M_{\rm low}=10^4\, \mathrm{M}_\odot$| and |$10^5\, \mathrm{M}_\odot$| cases differ by around 0.3 at |$M_{\star }=10^7\, \mathrm{M}_\odot$|. We would expect focc to be invariant of Mlow if the galaxies host at least one cluster that is more massive than any of the Mlow employed here. In contrast, such a strong variation suggests that a large fraction of dwarf galaxies can only host GCs less massive than |$\lesssim 10^5\, \mathrm{M}_\odot$|. In fact, among the 20 × 25 = 500 model satellites (satellites from different realizations are treated as independent galaxies), only 25 per cent can host GCs more massive than |$10^5\, \mathrm{M}_\odot$|, 38 per cent can host GCs more massive than |$3\times 10^4\, \mathrm{M}_\odot$|, and 50 per cent can host GCs more massive than |$10^4\, \mathrm{M}_\odot$|.
We also find that the occupation fraction in the model with Mmax is significantly lower than that in the model without Mmax, for galaxies with |$M_{\star }\lesssim 5\times 10^7\, \mathrm{M}_\odot$|. This is because the model with Mmax strictly prevents the formation of massive clusters with |$M\gtrsim 10^5\, \mathrm{M}_\odot$| in dwarf galaxies with |$M_{\rm h}\lesssim 10^9\, \mathrm{M}_\odot$|. Clusters initially less massive than |$10^5\, \mathrm{M}_\odot$| are unlikely to survive tidal disruption to the present-day. However, the model without Mmax has a small but non-zero probability of forming such massive clusters. In our cluster formation scenario, a galaxy may experience multiple cluster formation events. The cumulative probability of forming at least one massive cluster becomes significant for the model without Mmax and thus leads to the noticeable difference between the two models. This effect is less important for galaxies with |$M_{\star }\gt 5\times 10^7\, \mathrm{M}_\odot$| as Mmax becomes large enough to enable the formation of massive clusters. The model with Mmax predicts the occupation fraction very similar to that in the model with a higher minimum cluster mass |$M_{\rm low}=10^5\, \mathrm{M}_\odot$|.
Finally, the alternate prescriptions of tidal disruption do not change the focc–M⋆ relation noticeably. The occupation fractions from the two alternate prescriptions are always within the interquartile range of the default model.
To quantitatively evaluate which model agrees better with the observations, we compute the rms difference between the model and LV satellite galaxies,
where index j stands for the j-th mass bin, and Nj is the number of bins. The mass bins are equally spaced in the log M⋆ space from M⋆ = 105.5 to |$10^{8.5}\, \mathrm{M}_\odot$|. We take the bin width to be 0.5 dex, in consistency with the focc–M⋆ curves for model galaxies in Fig. 2. The occupation fraction within a bin is calculated with the kernel smoothing method given by equation (25). For the default model setting (Mlow = 3 × 104 M⊙, without Mmax, x = 2/3, y = 4/3), the rms deviation is 0.164. For the alternate settings, we find the rms deviation to be 0.139 for |$M_{\rm low}=10^4\, \mathrm{M}_\odot$|, 0.268 for |$M_{\rm low}=10^5\, \mathrm{M}_\odot$|, 0.249 for the sampling method with finite Mmax, 0.187 for the disruption method of x = y = 2/3, and 0.157 for x = y = 1, suggesting that the lower mass limit model with |$M_{\rm low}=10^4\, \mathrm{M}_\odot$| and the disruption model with x = y = 1 can match the observed focc–M⋆ relation slightly better than the default model. However, as we show later, the two models perform worse than the default model in matching the NGC–M⋆ relation.
Next, we show in Fig. 9 the number of GCs as a function of M⋆ for different model variants. Before going deep into the analysis, we emphasize that it is meaningless to look at the NGC–M⋆ relation below |$M_{\star }\simeq 5\times 10^6\, \mathrm{M}_\odot$| because these low-mass galaxies normally host at most 1 GC, and usually none. Since we analyse here galaxies with non-zero GCs, the NGC value is almost always 1 regardless of model settings. It is therefore more meaningful to look at the occupation fraction mentioned before for galaxies below |$M_{\star }\simeq 5\times 10^6\, \mathrm{M}_\odot$|.
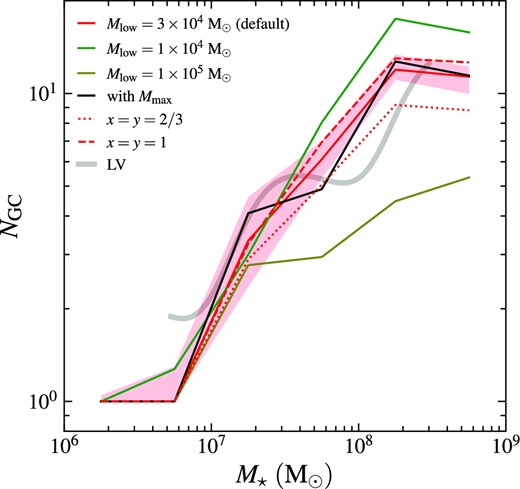
Number of GCs NGC as a function of stellar mass of host galaxy M⋆ for different model settings. We show the default model (Mlow = 3 × 104 M⊙, without Mmax, x = 2/3, y = 4/3) as red solid curve with the shaded region representing the interquartile range, in consistency with Fig. 3. Other models are shown in curves with different styles and colours as described in the legend. The NGC–M⋆ relation for the LV dwarf galaxies is over-plotted as the grey curve as in Fig. 3.
We note that NGC is sensitive to Mlow. As Mlow increases from 104 to |$10^5\, \mathrm{M}_\odot$|, the number of GCs in a galaxy can drop by a factor of 3 at |$M_{\star }\simeq 10^8\, \mathrm{M}_\odot$|. In contrast, NGC is not greatly affected by the alternate sampling model with Mmax, except for a more wiggled NGC–M⋆ relation, although this model predicts significantly lower focc at |$M_{\star }=5\times 10^5-5\times 10^7\, \mathrm{M}_\odot$|. This is because the ‘without Mmax’ and ‘with Mmax’ models become equivalent when the galaxy is massive enough to host at least one massive cluster that can survive to the present-day. Finally, the NGC–M⋆ relation is almost unchanged with the alternate disruption prescriptions.
Again, we quantitatively evaluate model agreement with observations by computing the rms deviation between the model and LV NGC,
Here we include the denominator σN to account for the uncertainties in the number of GCs. We set |$\sigma _{N,j}=\sqrt{N_{{\rm GC},j}^{\rm obs}}$| as the Poisson’s error when counting GCs. The mass bins are equally spaced in the log M⋆ space from M⋆ = 106.5 to |$10^{8.5}\, \mathrm{M}_\odot$|. For the default model setting the rms deviation is 0.725. For the alternate settings, we find the rms deviation to be 1.702 for |$M_{\rm low}=10^4\, \mathrm{M}_\odot$|, 0.955 for |$M_{\rm low}=10^5\, \mathrm{M}_\odot$|, 0.806 for the sampling method with finite Mmax, 0.434 for the disruption method of x = y = 2/3, and 0.940 for x = y = 1. Only the x = y = 2/3 model performs better than our default model in matching the occupation fraction. Although the Mlow = 104 M⊙ case can match the occupation fraction slightly better, it significantly overestimates the number of GCs. The alternate disruption prescriptions have similar performance to the default model: the x = y = 2/3 model gives a better match for NGC but a worse match for focc, while the x = y = 1 model gives a better match for focc but a worse match for NGC. Since the default setting x = 2/3, y = 4/3 can better match the observed GC mass function of the MW (see Fig. 1), we favour the default setting over the alternate disruption models.
6 SUMMARY AND DISCUSSION
In this work, we tested the performance of the GC formation and evolution model in the dwarf galaxy regime (|$M_{\mathrm{h}}\lt 10^{11}\, \mathrm{M}_\odot$|) resembling the LG environment. The model is based on our previous work (Chen & Gnedin 2022) with four stages: cluster formation, cluster sampling, particle assignment, and cluster evolution. We use empirical scaling relations to calculate the total mass of GCs from the halo merger history, and stochastically sample the mass of individual clusters. We have removed the deterministic setting of maximum GC mass in the previous sampling method to allow the formation of massive clusters (|$M\gtrsim 10^5\, \mathrm{M}_\odot$|) in low-mass galaxies (|$M_{\mathrm{h}}\lesssim 10^9\, \mathrm{M}_\odot$|) with a small but non-zero probability. Such stochasticity is important for correctly reproducing the observed GC occupation fraction in dwarf galaxies. Different from our previous work, where we preferentially assign GCs to stellar particles, here we assign GCs to DM particles restricted to local density peaks because we use collisionless simulations of the LG environment with sufficiently high mass resolution to capture all relevant dwarfs. We additionally require all GCs to form within the scale radius of the host galaxy. These settings ensure resulting radial number density profiles of model GCs can match the observed profiles of both the MW and satellites. We also employ a new prescription of tidal disruption that produces stronger disruption of low-mass clusters and can better match the observed GC mass function.
Despite these minor adjustments, the overall structure of the model remain unchanged: the model still has three adjustable parameters that control the formation rate, formation timing, and disruption rate of GCs. It is worth noting that although the main focus of this work is the LG dwarf satellites, we only calibrate the model parameters by comparing key properties of the GC systems in the three central MW-like galaxies from the simulations to the observed properties of the MW GC system. Therefore, any consistency with observations of dwarf GC systems is a true prediction of the model rather than an outcome of fitting the data.
We run the calibrated model on 20 satellite galaxies in the simulated LG systems and repeat 25 times with different random seeds to study how much the resulting GC systems are influenced by the model randomness. Since the central galaxy may tidally strip GCs from the host satellite if the GCs are too distant from the satellite, we only count GCs within the tidal radius of the satellite galaxy. Our model performs surprisingly well in matching the occupation fraction and number of GCs in the dwarf regime with the LV observations by Carlsten et al. (2022a); see Figs 2, 3, and 4. This consistency implies that the physics of GC formation and evolution may be universal for both central and satellite galaxies.
Dwarf galaxies in this study can only host a few or even no GCs. Small number statistics becomes important as a minor change in any physical process that is relevant to GC formation or evolution may introduce significant variance in the number of GCs. In an even lower-mass regime |$M_{\star }\lesssim 10^7\, \mathrm{M}_\odot$|, most galaxies host less than 2 GCs, with cluster mass |$\lesssim 10^5\, \mathrm{M}_\odot$|. The ability to match the observed number of GCs and the occupation fraction in such a regime is a very strict test of the model implementation of cluster formation and disruption mechanisms.
We also test different model settings to study their influence on the observable results. We find that the occupation fraction statistic primarily constrains the low-mass cut when counting GCs, Mlow, and the potential existence of maximum GC mass, Mmax (Fig. 8). Since most dwarf galaxies in this study can only host clusters with mass |$\lesssim 10^5\, \mathrm{M}_\odot$|, Mlow varying from 104 to |$10^5\, \mathrm{M}_\odot$| can cause the occupation fraction to differ by ∼0.3. In addition, the ‘with Mmax’ model strictly prevents the formation of massive clusters (|$M\gtrsim 10^5\, \mathrm{M}_\odot$|) in low-mass galaxies (|$M_{\mathrm{h}}\lesssim 10^9\, \mathrm{M}_\odot$|) by setting a deterministic upper mass limit. Although this setting is not very different from the default ‘without Mmax’ model in massive galaxies (|$M_{\mathrm{h}}\gt 10^9\, \mathrm{M}_\odot$|), it predicts a much lower occupation fraction in the low-mass end where majority of clusters are tidally disrupted.
On the other hand, the GC number statistic sets strong constraints on Mlow but is not sensitive to Mmax (Fig. 9). As Mlow increases from 104 to |$10^5\, \mathrm{M}_\odot$|, NGC drops by a factor of ∼3 at |$M_{\star }\simeq 10^8\, \mathrm{M}_\odot$|. Since the average GC mass in low-mass galaxies is typically lower than in the MW-size galaxies, it is important to correct for the observational incompleteness below the detection limit in dwarf GC systems. In contrast, the ‘with Mmax’ model predicts a similar NGC–M⋆ relation compared to the default ‘without Mmax’ model since the two models become equivalent when the galaxy is massive enough to host massive clusters that can survive to the present-day.
We also investigate the near-linear MGC–Mh relation in a wide mass range across six orders of magnitude (Fig. 5). By jointly fitting the observational data from Harris et al. (2017) and Forbes et al. (2018) we obtain |$N_{\mathrm{GC}}\propto M_{\mathrm{h}}^{0.77\pm 0.03}$| and |$M_{\mathrm{GC}}\propto M_{\mathrm{h}}^{0.93\pm 0.03}$| with a significant intrinsic scatter of 0.3 − 0.4 dex. The latter relation is very close to linearity, and has been reliably confirmed for |$M_{\mathrm{h}}=10^{10}-10^{15}\, \mathrm{M}_\odot$|. Since independently measuring the halo mass is challenging below |$M_{\mathrm{h}}\simeq 10^{10}\, \mathrm{M}_\odot$|, only a limited number of works attempted to study the relation in the low-mass end. Our model predicts an MGC–Mh relation in agreement with the observational relation in the low-mass end down to |$M_{\mathrm{h}}\simeq 10^8\, \mathrm{M}_\odot$|. We emphasize that since our model is only calibrated for the central galaxies, such an agreement indicates that the near-linear MGC–Mh relation is an evidence for universal physical processes governing GC formation and evolution in galaxies of all size, from dwarfs to giants.
We discuss a specific example of two satellite GC systems similar to that of Fornax dSph, which previously remained unexplained. We find the systems could have contained up to 30–50 GCs in the past but have stopped GC formation after accretion onto the central galaxies ∼10 Gyr ago (Fig. 6). There are two mechanisms that reduce the number of satellite GCs: tidal disruption and tidal stripping by the central galaxy. We find that our two example galaxies have already had peri-galactic encounters prior to the present. Only 4–9 GCs in the two galaxies can survive and remain inside the tidal radius.
We note that GCs in the two Fornax-like galaxies are located out to 5–10 kpc (Fig. 7), which is much larger than the effective radius of Fornax dSph, 0.8 kpc. Observationally, these GCs are unlikely to be identified as members of the galaxy since they are too distant. To avoid the biased measurement of NGC observations must employ a large enough search radius (≳ rtid). However, this is challenging as the background GCs may be indistinguishable from the GCs belonging to the satellite at such a large radius.
Moreover, different merger history can also alter the radial distribution of GCs: the more merger-dominated satellite has an even more extended GC system. The satellite with fewer major mergers better matches the GC number density profile in the Fornax dSph. Although different merger histories may not directly change the number of GCs, a more merger-rich assembly history leads to a more extended GC spatial distribution and hence a smaller NGC within a fixed search radius. This is one of the ‘hidden variables’ that contributes to the scatter in the NGC–M⋆ and NGC–Mh relations.
ACKNOWLEDGEMENTS
We thank Gillen Brown, Eric Bell, Mark Gieles, Xi Meng, Leandro Beraldo e Silva, and Monica Valluri for insightful discussions. This research was mainly conducted with the python programming language, employing the following packages: numpy (Harris et al. 2020), matplotlib (Hunter 2007), yt (Turk et al. 2011), scipy (Virtanen et al. 2020), and astropy (The Astropy Collaboration 2018). OG and YC were supported in part by the U.S. National Science Foundation through grant AST-1909063 and by National Aeronautics and Space Administration through contract NAS5-26555 for Space Telescope Science Institute program HST-AR-16614.
DATA AVAILABILITY
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Footnotes
For consistency with previous work, we keep the notation of p2 and p3 as in Li & Gnedin (2014).
Since R2 and J2 are satellites of the main galaxies, these satellite galaxies are satellites of satellites.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}