





ABSTRACT
As we observe a rapidly growing number of astrophysical transients, we learn more about the diverse host galaxy environments in which they occur. Host galaxy information can be used to purify samples of cosmological Type Ia supernovae, uncover the progenitor systems of individual classes, and facilitate low-latency follow-up of rare and peculiar explosions. In this work, we develop a novel data-driven methodology to simulate the time-domain sky that includes detailed modelling of the probability density function for multiple transient classes conditioned on host galaxy magnitudes, colours, star formation rates, and masses. We have designed these simulations to optimize photometric classification and analysis in upcoming large synoptic surveys. We integrate host galaxy information into the snana simulation framework to construct the simulated catalogue of optical transients and correlated hosts (SCOTCH, a publicly available catalogue of 5-million idealized transient light curves in LSST passbands and their host galaxy properties over the redshift range 0 < z < 3. This catalogue includes supernovae, tidal disruption events, kilonovae, and active galactic nuclei. Each light curve consists of true top-of-the-galaxy magnitudes sampled with high (≲2 d) cadence. In conjunction with SCOTCH, we also release an associated set of tutorials and transient-specific libraries to enable simulations of arbitrary space- and ground-based surveys. Our methodology is being used to test critical science infrastructure in advance of surveys by the Vera C. Rubin Observatory and the Nancy G. Roman Space Telescope.
1 INTRODUCTION
An era of rapid and large-scale astronomical data collection is underway. Surveys are now detecting transient events across large swaths of the sky, e.g. the Zwicky Transient Facility (ZTF; Bellm et al. 2019), ASAS-SN (Shappee et al. 2014), Gaia (Gaia Collaboration 2016), and MeerKAT (Jonas 2009). Entirely novel classes of events, including those at higher redshifts, will soon be revealed as telescopes such as the Vera C. Rubin Observatory (Ivezić et al. 2019), the Nancy Grace Roman Space Telescope (Spergel et al. 2015), and the JWST (Gardner et al. 2006) begin collecting data. Notable among these, the Rubin Observatory (set to begin science operations in Chile in 2024) will undertake the Legacy Survey of Space and Time (LSST), expected to observe millions of transients out to and beyond z ∼ 1 as it repeatedly scans 18 000 deg2 of the sky over 10 yr.
The science goals of these large-scale transient surveys are manifold, but include measuring the expansion history of the Universe, improving our understanding of progenitor physics, and discovering faster and fainter transients that have eluded prior searches. Accurate classification will be paramount for each of these goals. In the majority of cases, transients discovered in upcoming surveys must be classified without spectroscopic information. Algorithms that classify transients based on photometry alone have proliferated in recent years, some based on traditional template-matching methods and others employing novel machine learning algorithms (e.g. Möller & de Boissière 2020; Villar et al. 2020; Qu et al. 2021; Alves et al. 2022).
Multiple studies have demonstrated correlations between the class of a transient and the properties of the galaxy where it occurs (deemed its ‘host galaxy’). Where light curve sampling is sparse, host galaxy data can be used to more easily distinguish transients of different classes. The occurrence rate of Type Ia supernovae (SNe Ia) is directly proportional to both the stellar mass and the star formation rate of its host galaxy, although a non-negligible subset has also been discovered in passive galaxies (Sullivan et al. 2006). As the end-states of short-lived (∼50 Myr) massive stars, core-collapse SNe (CCSNe) are most likely to occur in spiral galaxies undergoing periods of significant star formation (Svensson et al. 2010). Variations also arise in the host populations of stripped-envelope SNe, events characterized by a dearth of hydrogen (SNe Ib) and helium (SNe Ic) in spectral observations. Broad-lined SNe Ic (SNe Ic-BL), the only supernovae to be unambiguously associated with long-duration Gamma Ray Bursts (LGRBs; Japelj et al. 2016), have host galaxies with lower average metallicity than their lower energy counterparts (SNe Ic; Modjaz et al. 2020). This suggests a potential relationship between progenitor metallicity and the formation of jets in the tumult of stellar death (Graham & Fruchter 2013). Further, SED fits to multiband photometry of Type-I (Hydrogen-poor) Super-Luminous SN (SLSN-I) hosts have revealed that these events occur almost exclusively in metal-poor, low-mass, star-forming host galaxies (Leloudas et al. 2015; Angus et al. 2016; Perley et al. 2016). In the pursuit of optimally standardized light curves for cosmology, subtler correlations have also been identified between SN Ia photometry and both host galaxy mass and star formation rate (Lampeitl et al. 2010; Sullivan et al. 2010; Barkhudaryan et al. 2019; Rose, Garnavich & Berg 2019; Brout & Scolnic 2021).
At low redshifts, spatially resolved studies enabled by multiwavelength photometry and Integral Field Unit spectroscopy have revealed local-scale correlations. From a sample of 519 host galaxies selected in the Sloan Digital Sky Survey (SDSS; Blanton et al. 2017), Kelly & Kirshner (2012) found that SNe Ic-BL and SNe IIb occurred in extremely blue locations. Local correlations are weak for SNe Ia (Anderson et al. 2015): due to the advanced ages of their white-dwarf progenitors (∼Gyr), these systems can migrate substantially from formation to explosion. Nevertheless, the environment may alter the evolution of an event for the same progenitor: the observational properties of SNe Ia are correlated with local dust extinction, although this is itself linked to the global properties of the host galaxy (Holwerda et al. 2015; Popovic et al. 2021). Spatially resolved host galaxy information can also be used to distinguish between SN explosion models in the absence of direct detections of a progenitor (Fruchter et al. 2006; Raskin et al. 2008)
Preliminary correlations have been identified in recent years for rare classes of events, including a preference of rapidly evolving transients (RETs; Drout et al. 2014; Pursiainen et al. 2018) for hosts of intermediate mass between high-mass SN Ia hosts and low-mass SLSN hosts (Wiseman et al. 2020). For observationally rare events (e.g. kilonovae, KNe; Smartt et al. 2017), correlations remain as yet unconstrained, but may play a decisive role in maximizing the yield of future targeted searches. Upcoming surveys are well-poised to further extend our understanding of these class-specific correlations towards higher redshifts and rare subtypes. However, only a few transient classifiers to date (Foley & Mandel 2013; Gagliano et al. 2021; Kisley et al. 2023) have incorporated host galaxy information. Efforts are stymied by the limited observational data available for training these algorithms; perhaps worse, extant samples are frequently biased towards low-redshift, bright host galaxies, uncharacteristic of the galaxies anticipated from upcoming surveys.
In this transitional period when observed transient samples are limited to the local Universe, simulations are vital for developing and testing classification algorithms that incorporate host galaxy information. Such algorithms will need to perform reasonably well on new faint and high-redshift data in the early days of LSST, until they can be iteratively tested and updated using the incoming data and the corresponding advancements in time-domain theory. This interim period requires high-redshift simulations that extrapolate bright, low-redshift existing measurements (such as transient rates and host correlations) to fainter magnitudes and into the Universe’s past. High-redshift simulations necessarily require assuming untested theoretical models for evolution, or assuming that trends at low redshift extend to high redshift.
We follow the latter assumption, and present the first large-scale simulation of optical transients and their host galaxies that extrapolates existing data to high redshifts (z ∼ 3). This work extends the simulations generated for the Photometric LSST Astronomical Time-Series Classification Challenge (PLAsTiCC; Kessler et al. 2019a). PLAsTiCC data were generated by simulation code in the SuperNova ANAlysis package (snana; Kessler et al. 2009), and the challenge represented the first large-scale effort to realistically simulate a broad diversity of transient phenomena. Simulated host-galaxy information, however, was limited: the data set only includes the photometric redshifts of host galaxies assigned near the redshift of the transient. This work extends the PLAsTiCC framework with the inclusion of empirical and theoretical host-galaxy correlations for both common and rare transient classes. We embed these correlations using a series of host galaxy libraries (called HOSTLIBs within snana) and weight maps (WGTMAPs) that describe the likelihood of a given galaxy to host a transient of a certain class within the simulation.
Our work is enabled by multiple previous efforts to consolidate the properties of transient host galaxy populations. The Gamma Ray Burst (GRB) Host Studies catalogue1 (GHOstS; Savaglio, Glazebrook & Le Borgne 2006) consolidates derived host galaxy information (including star formation rate, stellar mass, and redshift) for ∼100 GRBs, finding that these bursts occur preferentially in star-forming, low-mass galaxies. Gagliano et al. (2021) constructed the Galaxies Hosting Supernovae and other Transients (GHOST) Catalogue, which contains the optical photometric properties of ∼16 500 galaxies that have hosted observed SNe of all classes. At the time of writing, Qin et al. (2022) has released the Transient Host Exchange (THEx), a catalogue containing >36 000 host galaxies of many transient types and the photometric properties of their hosts spanning infrared to ultraviolet wavelengths.
There is precedent to the use of host galaxy libraries in supernova simulations. In snana, HOSTLIBs were first used to model Poisson noise in simulated bias corrections for SN Ia distances for the Joint Lightcurve Analysis (Kessler et al. 2013; Betoule et al. 2014). HOSTLIBs were similarly used to forecast constraints for the Nancy Grace Roman Space Telescope (Hounsell et al. 2018). The Pantheon (Scolnic et al. 2018) and DES 3-yr (Abbott et al. 2019; Brout et al. 2019) SN Ia-cosmology analyses further extended the scope of these files to account for correlations between SN properties and host galaxy stellar mass. An alternative machine learning-based simulation, EmpiriciSN (Holoien, Marshall & Wechsler 2017), employed a library of photometric host galaxy data in SDSS to generate synthetic light curves of SNe Ia.
As part of the recent Dark Energy Survey (DES) cosmology analysis using photometrically identified SNe Ia, Vincenzi et al. (2021) expanded the snana-specific HOSTLIB framework to realistically simulate SN host galaxies by class using a set of physically motivated WGTMAP files. To account for contamination from non-Ia classes, their simulation includes CCSNe (including SNe II and Ib/c) and considers the dependence on host galaxy mass and star formation rate for each SN type. The resulting SN Ia + CC SN simulation of host properties and SN-host correlations shows excellent agreement with DES data, and this simulation is now in use as a training set for photometric classifiers (Möller et al., in preparation).
In this work, we extend the results of Vincenzi et al. (2021) by simulating additional classes of supernovae and other non-SN transients, incorporating correlations across a wider range of host galaxy properties, and separately validating hosts of different classes across these properties. We extrapolate information from archival events, mostly at low-redshift, to a high-redshift simulated sample of galaxies via associations in intrinsic – rather than observed – properties. In doing so, we encode correlations for each transient class to significantly higher redshifts (z ∼ 3) than the ranges spanned by current observations. Due to a lack of high-z evidence, the most practical option is to assume no redshift evolution of the observed transient–host relationships in the local Universe and smoothly extrapolate transient rate models measured at low redshifts. Therefore, the simulation is likely to become increasingly inaccurate at higher redshifts, and SCOTCH (https://zenodo.org/record/7563623#.Y8_2my9h2yA) by itself should not be used for precision cosmological forecasts or high-redshift transient analyses. However, the catalogue can be used to test classifier algorithms and alert broker systems, examine the effects of contamination on cosmological constraints, and model selection biases in the current and upcoming transient/host galaxy surveys.
Our paper is organized as follows. We outline the overall methodology in Section 2. We introduce the archival catalogues used to construct our host galaxy sample in Section 3. We describe the snana simulation code that we use to generate our transient events and summarize the models underlying each event in Section 4. We present our methods in Section 5 for combining observed and simulated catalogues into a library containing millions of host galaxies. We then describe our process for incorporating additional class-specific transient correlations using WGTMAPs in Section 6. We comment briefly on the inclusion of class-specific radial offsets in Section 7. We validate our results in Section 8 and present the schema of our final catalogue in Section 9. We then conclude with a discussion of the limitations of our sample and areas for future research in Section 10.
2 METHODOLOGY OVERVIEW
Because the methods we use to simulate the transients themselves are nearly identical to those described in Kessler et al. (2019a), this paper focuses on our methodology for constructing a set of HOSTLIBs and WGTMAPs for the snana simulation code. This allows us to realistically associate a simulated host galaxy with each transient, given its class. We provide a flowchart of this pipeline in Fig. 1. The initial input is the CosmoDC2 synthetic galaxy catalogue (Korytov et al. 2019, described in Section 3.1) with slight modifications made via the PZFlow algorithm (Crenshaw, Connolly & Kalmbach 2021, described in Section 5.2). First, we create four large galaxy libraries: for SNe, by selecting synthetic galaxies matching the rest-frame colour and absolute magnitude distributions of three broad categories of transient hosts in observational data; and for non-SNe, by generating a generic catalogue of galaxies which will be tailored to match observations at a later stage. For SNe, we utilize the observational data in GHOST (Gagliano et al. 2021), a catalogue of supernova host galaxy properties described in additional detail in Section 3.2. Our process for selecting synthetic galaxies matching the statistical properties of the observational data, including the use of the ANNOY2 algorithm, is described in detail in Section 5.3. The resulting three galaxy libraries include: Type Ia hosts (I); Type II, IIn, IIp hosts (II); and Type Ib, Ic, IIb hosts (III). We construct a fourth library of randomly selected CosmoDC2 galaxies to serve as the hosts of transients from classes that have little observational data, and for which the correlation between explosion and environment is unconstrained by GHOST. Next, for nine different transient classes including SN and non-SN, we encode the probability that an event of that class will occur in a host galaxy given its mass and star formation rate. These probabilities are motivated by observations and are described in Section 6. Finally, the snana simulation (Section 4) is used to generate transient light curves and place each in a realistically associated host galaxy, with host galaxies selected from one of the four libraries depending on the transient class and the probability of selection given by the class-specific functions described in Section 6.
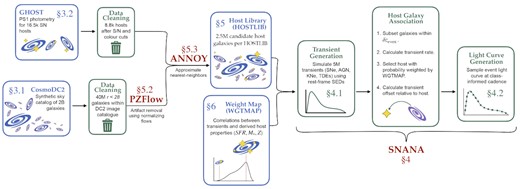
Analysis flowchart with section labels. Intermediate catalogues and data products are given in blue text, major software packages in red text, and methodology in green text.
3 GALAXY DATA
3.1 The DC2 simulations
Our work aims to simulate transient-host associations to higher redshifts and fainter magnitudes than have been previously observed. We also wish to produce a catalogue containing valuable derived properties of transient hosts, including morphology, star formation rates, and stellar masses. Observed galaxy catalogues are limited in these respects, so we make use of synthetic galaxy data from the LSST Dark Energy Science Collaboration (DESC).
DESC is in the midst of a series of data challenges in preparation for the Rubin Observatory. The goal of the data challenges is to produce realistic end-to-end simulations of LSST survey operations, data reduction, and analysis. For data challenge 2 (DC2), DESC produced a suite of simulated LSST-like data sets, including an extragalactic source catalogue and co-added images (LSST Dark Energy Science Collaboration 2021). We make use of the extragalactic catalogue, named the CosmoDC2 Synthetic Sky catalogue (Korytov et al. 2019), and its associated DC2 image data.
The CosmoDC2 catalogue was constructed from a dark matter only N-body simulation in a 4.225 Gpc3 volume. This volume is insufficient to probe to z ∼ 3 as needed for LSST, so to create lightcones, the volume was replicated once per axis. After the lightcone generation, realistic galaxies with Sersic profiles and SEDs were associated with dark matter halos. The resultant galaxy catalogue, which is delivered in HEALPix3 (Hierarchical Equal Area iso-Latitude Pixelization) format (Górski et al. 2005), spans 440 deg2 of the sky and cosmological distances (z ≃ 3). The CosmoDC2 data has also undergone rigorous validation to ensure that it matches observed galaxy properties (Kovacs et al. 2021). However, due to necessary compromises made to accommodate the needs of the diverse DESC working groups, the CosmoDC2 distributions of galaxy colours are far from perfect, particularly at higher redshifts (z > 0.5). We discuss how these colour limitations affect the final SCOTCH catalogue in Section 8.
We use the GCRCatalogs4 analysis tool (Mao et al. 2018) to select CosmoDC2 galaxies within 31 neighbouring HEALPixels from an Nside = 32 pixelization, corresponding to 104 deg2 of total area. The selected HEALPixels are chosen to completely overlap with the DC2 image catalogues [LSST Dark Energy Science Collaboration (LSST DESC) 2021], which contain image properties for CosmoDC2 galaxies as LSST would observe them over 5 yr, corresponding to a co-add depth of r = 28 (where r is the apparent AB magnitude in the LSST filter). The overlap in coverage between these HEALPixels and the image catalogue is shown in Fig. 2. To ensure the generality of our final catalogue, the sky coverage displayed in the figure is not maintained in SCOTCH (we discuss this in additional detail in Section 4.1).
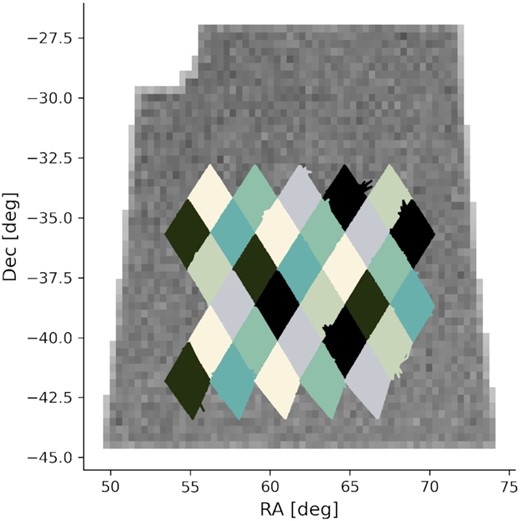
Selected HEALPixels from CosmoDC2 (diamonds) overlaid on the greyscale footprint of the DC2 image catalogues. We cross-match CosmoDC2 and the DC2 image catalogues for the image properties of extragalactic objects.
Within these HEALPixels, we select CosmoDC2 galaxies with r < 28, which removes the majority of galaxies that were not detected within the DC2 5-yr image co-add catalogues. We further refine this sample by removing objects with unreported image properties. After this cut, |$\sim 98{{\ \rm per\ cent}}$| of galaxies have an average r-band surface brightness within the half-light radius of less than 26 mag arcsec–2. This selection yields a sample of ∼40-million galaxies, which represent a realistic magnitude-limited galaxy sample. In Section 5.3, we describe the process of selecting galaxies that match observed properties of transient hosts; this further reduces the sample to ∼10-million galaxies.
3.2 The GHOST catalogue of transient-host galaxies
The GHOST catalogue (Gagliano et al. 2021) consists of ∼16 500 archival SNe consolidated from the Transient Name Server (TNS) and the Open SN Catalogue (OSC), as well as the observed properties of their host-galaxies from the first data release of Pan-STARRS (PS1; Chambers et al. 2016). Host galaxies within the catalogue were identified and validated through a combination of the established Directional-Light Radius method (DLR; Gupta et al. 2016) and the Gradient Ascent method (Gagliano et al. 2021). Although this GHOST sample contains realistic statistical correlations between transients and their host galaxies, it does not contain a representative sample of events anticipated from upcoming surveys. First, the catalogue comprises a small number of low-redshift (z < 0.2) explosions. LSST will dramatically enhance our current discovery rate for luminous SNe, motivating the need to scale the sample sizes in the GHOST catalogue for every class. Further, GHOST does not include non-SN transients such as Tidal Disruption Events (TDEs) and Active Galactic Nuclei (AGN), classes whose discovery and characterization are key science drivers for LSST. Finally, because the catalogue contains only the photometric properties of SN host galaxies, it lacks an explicit correlation between a transient and the stellar-mass and star formation rate of its host galaxy.
The CosmoDC2 catalogue provides photometry in LSST (ugrizY) and SDSS (griz) filters, while GHOST galaxy photometry is provided only in the PS1 (grizy) filter system. To accurately match galaxy photometry between these catalogues, we convert the GHOST photometry from the PS1 to the SDSS system. We use the approximate quadratic conversions defined in Tonry et al. (2012) and k-correct the apparent magnitude in each band using the analytic approximations5 described in Chilingarian, Melchior & Zolotukhin (2010) and Chilingarian & Zolotukhin (2012), which were computed according to the SEDs of simple stellar populations ranging from 25 Myr to 16.5 Gyr and −2.5 < [Fe/H] < +1.0 dex fit to 170 533 galaxies within SDSS Data Release 7. This transformation allows us to accurately match GHOST galaxies to those in CosmoDC2. Next, we use the spectroscopic redshift of each galaxy’s associated transient (or the spectroscopic redshift of the host, if the former was unreported on TNS) to calculate the absolute rest-frame brightness of each galaxy in SDSS pass-bands. We use these to compute rest-frame g − r, r − i, and i − z colours. To ensure that only galaxies with high-SNR photometry are considered, we apply stringent quality cuts to the galaxies in the GHOST sample based on the values of the PS1 primaryDetection and objInfoFlag flags, as well as the InfoFlag1, InfoFlag2, and InfoFlag3 values in each band.6 While this may limit our observed sample to only low-redshift events, it ensures that the photometric correlations we encode from this regime are accurate. Our final sample after these cuts consists of 8800 SN host galaxies.
4 GENERATING TRANSIENTS WITH THE snana SIMULATION
4.1 The snana framework for generating transients
Our methodology is shaped by the existing framework of the snana simulation code (Kessler et al. 2009). Therefore, although the use of snana constitutes the final stage of our pipeline as displayed in Fig. 1, we first describe the snana simulation and introduce the simulation-specific terminology before detailing our methods for host galaxy association. This simulation reads user-defined transient model SEDs (rest-frame), redshift-dependent rates, and realistic observing conditions, and outputs transient events with realistic light curves and spatial distributions as a function of redshift. The snana simulation was used to generate nine distinct classes of extragalactic transients for PLAsTiCC; fig. 1 from Kessler et al. (2019a) shows example output light curves in ugrizY bands from each model. In this paper, we distinguish SNe Ib from SNe Ic and SNe IIn from SNe II to simulate 11 classes: AGN, KN, TDE, SLSN-I, SN Ib, SN Ic, SN II, SN IIn, SN Iax, SN Ia-91bg, and SN Ia, with the addition of SN IIb and SN Ic-BL and with some updates to the PLAsTiCC models as described in Section 4.2. We implement a cosmology of ΩM = 0.3, |$\Omega _\Lambda =0.7$|, w0 = −1, and H0 = 70 km s−1Mpc−1. We note that, while these values are slightly different from the Planck (Planck Collaboration VI 2020) parameters used in the Outer Rim simulation to generate the CosmoDC2 catalogue, the small inconsistencies that this difference introduces are far sub-dominant to the shifts that we apply to galaxy redshifts in Section 5.2. The transient models differ in the distributions of emission across bands, the shape of the light curves, and the peak brightness. For example, most of the SN Ib/c model flux is emitted at redder wavelengths; the KN model exhibits a characteristic time-scale shorter than most other transients in our sample; and simulated SLSNe-I emit significantly higher flux than the other models.
The snana simulation includes the option of associating each simulated transient to a host galaxy from a user-input catalogue (the host library or ‘HOSTLIB’) that includes redshift and other galaxy properties (Section 5). After each transient is simulated, the algorithm selects a HOSTLIB galaxy that lies within δz of the transient. We set δz to correspond approximately to 100 comoving Mpc, which ranges from 0.02 at z ∼ 0 to 0.1 at z = 3 given the 2018 cosmological parameters from the Planck satellite (Planck Collaboration VI 2020). Host galaxy selection is further influenced by a user-input weight map (WGTMAP) that defines the probability of selecting a galaxy as a function of its properties (Section 6). The WGTMAP framework is flexible, such that the probability can depend on different galaxy properties for different classes – in other words, the parameter space over which the WGTMAP probabilities are defined is not fixed but rather user-defined.
Following Fig. 1, the simulation begins by generating a transient SED and drawing a redshift according to the class-specific rate model. The rate models are detailed in Section 4.2 and are entirely responsible for the redshift distributions of events in the final catalogue. This may be counterintuitive, as one might expect that the features of the synthetic host galaxy population should determine the transient event rates; however, myriad uncertainties in the transient-host connections make such an approach far more challenging to match observed event rates at low redshifts.
Next, the transient is matched to a host galaxy. The surface brightness profile of each galaxy in cosmoDC2 is a weighted combination of two Sersic profiles: that of an exponential disc (n0), and that of a deVaucouleurs bulge (n1). For each galaxy associated with a supernova, one of these profiles is selected using their relative weights. Next, a radius and azimuthal angle are selected (where the radius selection is weighted by the Sersic profile), and this determines the position of the transient with respect to the host centre. We further encode simple models for the radial offsets of TDEs, AGN, and KNe as described in Section 7.
After the transient offset is computed, the host galaxy redshift is set to the redshift of the transient and the host’s apparent magnitudes are updated to reflect the small change in distance (100 comoving Mpc or less). With this framework, one host galaxy from the HOSTLIB can be used multiple times, which is often necessary given the desired number of transients (5M) that we aim to simulate, the similar size of the HOSTLIBs, and the different redshift distributions for the transient model and the HOSTLIBs. In such a case, the single input galaxy is mapped to multiple host galaxies with slightly different redshifts and apparent magnitudes in the final catalogue. Due to this duplication, it is necessary to remove on-sky position information from the galaxies such that duplicated galaxies do not appear at the same sky location. Unfortunately, this loses the initial positioning within realistic large-scale structure from CosmoDC2. We leave an accurate embedding of transients within the cosmic web to future work. In our simulation, the host centres are arbitrarily set to be simulated at (RA, Dec.) = (0,0) and positions are not reported in the final catalogue.
The transient SED is modified for cosmic expansion, weak lensing magnification, redshift, and host galaxy extinction. The weak lensing model aims to statistically match the average magnification effects as a function of redshift; Kessler et al. (2019b) describes the model in further detail. We do not explicitly model host extinction from each galaxy’s morphology; rather, we follow the statistical treatment in PLAsTiCC (Kessler et al. 2019a). For the theoretical models (MOSFIT and KNe), extinction is parametrized by AV. For most models, this parameter is drawn from a Galactic Line-of-Sight distribution with a Gaussian core of σ = 0.1 and an exponential tail parametrized by τ = 0.4 (Sako et al. 2008; Bernstein et al. 2012). Dimming is then computed assuming the Milky Way colour law from Fitzpatrick (1999). For TDEs, only the exponential is included in order to simulate significantly higher extinction near the host galaxy centres where these transients occur. For KNe experiencing less host extinction at large offsets (see Section 7), the exponential tail is reduced by a factor of two. The other transient models have been constructed from observed photometry, which implicitly includes the effects of host-galaxy extinction. This formalism assumes no evolution in dust properties with redshift.
The final SED corresponds to what an observation would look like from a vantage point just outside the Milky Way, without Galactic extinction, because we have not simulated transient locations on the sky. This leaves flexibility for the user to place events within the sky footprint of a preferred survey and apply the corresponding line-of-sight extinction and noise models. Next, the SED is converted to an apparent magnitude in the LSST photometric system (ugrizY). We configure snana to report all light curves in true LSST magnitudes without applying any threshold for detection. Therefore, very faint magnitudes are included in the transient light curves. Because hosts are restricted to r < 28, catalogue users are encouraged to apply a limiting magnitude equal to or brighter than r = 28 to the full catalogue to create consistency before use.
We sample most of our simulated light curves from 100 d preceding peak light to 100 d after peak. Due to the rapid rise and decline of KN photometry, we sample the light curve for only 10 d pre-peak and 60 d after-peak. For each transient class, we implement one of three cadence strategies. For SNe Ia, CCSNe (II, IIn, IIP, and IIL), and H-poor SNe (Ib/c, Ic-BL, IIb, SLSN-I), we adopt a sampling of δt = 2.0 d (so that each light curve has 100 observations each in ugrizY). Because of the rarity of high-cadence KN and TDE observations, we aim to preserve as much physical information about these light curves as possible while keeping file sizes manageable. For these events, we adopt a logarithmic sampling scheme, with δt = 0.1d at peak and increasing towards δt = 2.0 d in either temporal direction. Because the rise of many transient light curves occurs on significantly shorter time-scales than a decline powered by emission from radioactive decay, our cadence increases more slowly from peak light to late times than from peak light to pre-explosion epochs (Fig. 3). This sampling scheme generates ∼260 observations per pass-band. The rapidly evolving stochasticity of AGN light curves cannot be accurately characterized by either of these cadences. For the AGN in our catalogue, we provide light curves at cadences of both δt = 0.1 d (250 events) and δt = 2.0 d (2250 events). The choice in light curve can be made by the user, depending on their science goals. We show the cumulative number of observations for our three light-curve cadences, along with sample light curves, in Fig. 3.
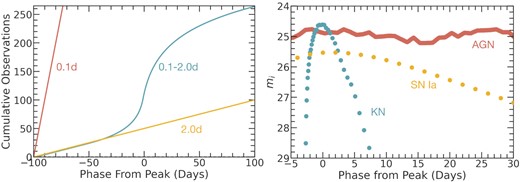
Left-hand panel: Number of cumulative observations for the variable-cadence (0.1 d ≤ δt ≤ 2.0 d) light-curve sampling method for KNe (turquoise), shown alongside the δt = 0.1 d (red) and the δt = 2.0 d (yellow) cadences. The function describing the variable-cadence sampling rate is asymmetric in time to mimic the rapid rise and slow decay of transient phenomena. Right-hand panel: Sample light curves for events using these cadences. Colours indicate the sampling method used.
In summary, the key features of the catalogue are as follows: top-of-the-galaxy observing conditions, near-perfect transient observing efficiency, host galaxies as faint as r = 28 associated in a class-dependent manner, and physically motivated transient-host separations. We provide an overview of the classes of transients generated in this work, the HOSTLIBs and WGTMAPs used to associate them with hosts, and the sampling method for each class, in Table 1.
Summary of the HOSTLIB, WGTMAP, and cadence used for each transient class in our simulation. The first three HOSTLIBs contain CosmoDC2 galaxies that extrapolate distributions of observed hosts in GHOST; the fourth is a representative sample from CosmoDC2. Pclass refers to the probability of each transient class occurring given the properties of a galaxy; these functions are defined in Section 6 and implemented via the WGTMAPs. The cadence refers to the time interval between light-curve samples in the simulation.
| HOSTLIB | WGTMAP | Class | Cadence (day) |
|---|---|---|---|
| SN Ia Hosts | PIa | SN Ia | 2.0 |
| SN II Hosts | PII | SN II/IIn/IIP/IIL | 2.0 |
| H-Poor SN Hosts | PIbc | SN Ib/Ic | 2.0 |
| RIc-BL | SN Ic-BL | 2.0 | |
| PSLSNI | SLSN-I | 2.0 | |
| PII | SN IIb | 2.0 | |
| Rand. DC2 Subset | PAGN | AGN | 0.1, 2.0 |
| RKN | KN | 0.1–2.0 | |
| PTDE | TDE | 0.1–2.0 |
| HOSTLIB | WGTMAP | Class | Cadence (day) |
|---|---|---|---|
| SN Ia Hosts | PIa | SN Ia | 2.0 |
| SN II Hosts | PII | SN II/IIn/IIP/IIL | 2.0 |
| H-Poor SN Hosts | PIbc | SN Ib/Ic | 2.0 |
| RIc-BL | SN Ic-BL | 2.0 | |
| PSLSNI | SLSN-I | 2.0 | |
| PII | SN IIb | 2.0 | |
| Rand. DC2 Subset | PAGN | AGN | 0.1, 2.0 |
| RKN | KN | 0.1–2.0 | |
| PTDE | TDE | 0.1–2.0 |
Summary of the HOSTLIB, WGTMAP, and cadence used for each transient class in our simulation. The first three HOSTLIBs contain CosmoDC2 galaxies that extrapolate distributions of observed hosts in GHOST; the fourth is a representative sample from CosmoDC2. Pclass refers to the probability of each transient class occurring given the properties of a galaxy; these functions are defined in Section 6 and implemented via the WGTMAPs. The cadence refers to the time interval between light-curve samples in the simulation.
| HOSTLIB | WGTMAP | Class | Cadence (day) |
|---|---|---|---|
| SN Ia Hosts | PIa | SN Ia | 2.0 |
| SN II Hosts | PII | SN II/IIn/IIP/IIL | 2.0 |
| H-Poor SN Hosts | PIbc | SN Ib/Ic | 2.0 |
| RIc-BL | SN Ic-BL | 2.0 | |
| PSLSNI | SLSN-I | 2.0 | |
| PII | SN IIb | 2.0 | |
| Rand. DC2 Subset | PAGN | AGN | 0.1, 2.0 |
| RKN | KN | 0.1–2.0 | |
| PTDE | TDE | 0.1–2.0 |
| HOSTLIB | WGTMAP | Class | Cadence (day) |
|---|---|---|---|
| SN Ia Hosts | PIa | SN Ia | 2.0 |
| SN II Hosts | PII | SN II/IIn/IIP/IIL | 2.0 |
| H-Poor SN Hosts | PIbc | SN Ib/Ic | 2.0 |
| RIc-BL | SN Ic-BL | 2.0 | |
| PSLSNI | SLSN-I | 2.0 | |
| PII | SN IIb | 2.0 | |
| Rand. DC2 Subset | PAGN | AGN | 0.1, 2.0 |
| RKN | KN | 0.1–2.0 | |
| PTDE | TDE | 0.1–2.0 |
For completeness, we also summarize here the list of major assumptions and approximations used to construct the SCOTCH catalogue:
Representative correlations from observed samples: Limited observational data exists for many of the transient classes we simulate. Nevertheless, we assume that each data set presents a representative sample of that class’s host population. With small sample sizes, this may cause host-transient correlations to be overconfidently inferred.
sGRBs and KNe occur in the same host galaxies: Given the extremely low number of KNe detected to date, and the intense interest from the community in detecting additional events, we choose to include KNe in our simulation framework with host-galaxy properties determined by a sample of well-localized sGRBs (Section 6.6).
Galaxy populations have been shifted in redshift space: We introduce redshift adjustments to host galaxies in several stages of the pipeline: when smoothing over unphysical tracks in colour-redshift space in CosmoDC2 (see Section 5.2) and when adjusting the host redshift to the transient redshift in snana. Thus, while the final host galaxy properties depend on redshift in a broadly similar way as in CosmoDC2, any realistic tight redshift dependencies that were encoded into the original simulation may be lost in SCOTCH.
No on-sky positions: The hosts and their transients are not placed realistically on the sky, and thus the catalogue lacks realistic large-scale structure.
Similar host-galaxy extinction parameters across cosmic time: Dust parameters were determined from transient studies at low-z (primarily SNe Ia), and this work extends these properties to z < 3. Deep host-galaxy studies will further clarify the dust properties of host galaxies at higher redshifts, which can be used to simulate an evolution in dust properties in future work.
k-corrections linked to Simple Stellar Populations: The k-correction equations used to calculate the rest-frame properties of host galaxies in GHOST (Gagliano et al. 2021) were computed by SED fits to SDSS galaxies assuming simple stellar populations. This is done to obviate the need for detailed SED fitting, which would be a valuable independent study but is outside the scope of this work.
No evolution in host-galaxy correlations: We did not attempt to model any evolution of host-transient correlations with redshift, and therefore host populations at high-z in the catalogue have similar distributions in intrinsic properties to hosts at low-z. Upcoming high-z surveys will shed more light on any potential evolution in host galaxy populations.
Malmquist-like bias: The necessary r < 28 cut on synthetic galaxies causes the hosts at higher redshift to be drawn from an intrinsically brighter population.
4.2 Transient models
We simulate each transient class with a similar setup as that of the PLAsTiCC challenge (see Kessler et al. 2019a, hereafter K19, and references therein). Unless otherwise noted, the event rate of each class follows the same redshift dependency as in PLAsTiCC. As detailed in K19, the redshift-dependent rates have been measured from existing observations, and thus become increasingly uncertain with redshift. We extrapolate the rates to z = 3 for SCOTCH, but caution that the rate functions are unlikely to be trustworthy at high redshifts. We are unable to simulate realistic volumetric rates with the framework described, as our ideal ‘observing’ conditions and wide redshift range would generate a prohibitively large catalogue. Instead, we choose to simulate 5-million events and divide the sample by class based on anticipated interest to users. Table 2 displays the number of light curves and model used per class. The sky density of events at any given redshift, and the relative rates of different classes, are therefore inaccurate. Nevertheless, the volumetric rates predicted for each class by the respective rate model in K19 can be calculated using information in the supplementary material, Appendix B, and the corresponding functions provided in the GitHub repository for this work. This information can also be used to over or undersample the catalogue as needed to generate realistic mock observations.
Simulated transients in the SCOTCH catalogue organized by class and model name. N, the number of transients simulated per class, sums to 5 million.
| Class | Model name | N |
|---|---|---|
| Ia (2.2M total) | SALT2-Ia | 2M |
| Iax | 100 000 | |
| 91bg-like | 100 000 | |
| H-Rich Core-Collapse (1999 000 total) | ||
| SN II (1.9M total) | SNII-Templates | 633 000 |
| SNII-NMF | 633 000 | |
| SNII + HostXT_V19 | 633 000 | |
| SN IIn (100 000 total) | SNIIn-MOSFiT | 50 000 |
| SNIIn + HostXT_V19 | 50 000 | |
| Stripped Envelope / H-Poor Core-Collapse (500 000 total) | ||
| Ib (100 000 total) | SNIb-Templates | 50 000 |
| SNIb + HostXT_V19 | 50 000 | |
| Ic (100 000 total) | SNIc-Templates | 50 000 |
| SNIc + HostXT_V19 | 50 000 | |
| IcBL | SNIcBL + HostXT_V19 | 100 000 |
| IIb | SNIIb + HostXT_V19 | 100 000 |
| SLSN-I | SLSN-I-MOSFiT | 100 000 |
| Non-SN transients (301 000 total) | ||
| KN (100 000 total) | Kasen 2017 | 50 000 |
| Bulla 2019 | 50 000 | |
| TDE | TDE_MOSFiT | 101 000 |
| AGN | AGN-LSST | 100 000 |
| Class | Model name | N |
|---|---|---|
| Ia (2.2M total) | SALT2-Ia | 2M |
| Iax | 100 000 | |
| 91bg-like | 100 000 | |
| H-Rich Core-Collapse (1999 000 total) | ||
| SN II (1.9M total) | SNII-Templates | 633 000 |
| SNII-NMF | 633 000 | |
| SNII + HostXT_V19 | 633 000 | |
| SN IIn (100 000 total) | SNIIn-MOSFiT | 50 000 |
| SNIIn + HostXT_V19 | 50 000 | |
| Stripped Envelope / H-Poor Core-Collapse (500 000 total) | ||
| Ib (100 000 total) | SNIb-Templates | 50 000 |
| SNIb + HostXT_V19 | 50 000 | |
| Ic (100 000 total) | SNIc-Templates | 50 000 |
| SNIc + HostXT_V19 | 50 000 | |
| IcBL | SNIcBL + HostXT_V19 | 100 000 |
| IIb | SNIIb + HostXT_V19 | 100 000 |
| SLSN-I | SLSN-I-MOSFiT | 100 000 |
| Non-SN transients (301 000 total) | ||
| KN (100 000 total) | Kasen 2017 | 50 000 |
| Bulla 2019 | 50 000 | |
| TDE | TDE_MOSFiT | 101 000 |
| AGN | AGN-LSST | 100 000 |
Simulated transients in the SCOTCH catalogue organized by class and model name. N, the number of transients simulated per class, sums to 5 million.
| Class | Model name | N |
|---|---|---|
| Ia (2.2M total) | SALT2-Ia | 2M |
| Iax | 100 000 | |
| 91bg-like | 100 000 | |
| H-Rich Core-Collapse (1999 000 total) | ||
| SN II (1.9M total) | SNII-Templates | 633 000 |
| SNII-NMF | 633 000 | |
| SNII + HostXT_V19 | 633 000 | |
| SN IIn (100 000 total) | SNIIn-MOSFiT | 50 000 |
| SNIIn + HostXT_V19 | 50 000 | |
| Stripped Envelope / H-Poor Core-Collapse (500 000 total) | ||
| Ib (100 000 total) | SNIb-Templates | 50 000 |
| SNIb + HostXT_V19 | 50 000 | |
| Ic (100 000 total) | SNIc-Templates | 50 000 |
| SNIc + HostXT_V19 | 50 000 | |
| IcBL | SNIcBL + HostXT_V19 | 100 000 |
| IIb | SNIIb + HostXT_V19 | 100 000 |
| SLSN-I | SLSN-I-MOSFiT | 100 000 |
| Non-SN transients (301 000 total) | ||
| KN (100 000 total) | Kasen 2017 | 50 000 |
| Bulla 2019 | 50 000 | |
| TDE | TDE_MOSFiT | 101 000 |
| AGN | AGN-LSST | 100 000 |
| Class | Model name | N |
|---|---|---|
| Ia (2.2M total) | SALT2-Ia | 2M |
| Iax | 100 000 | |
| 91bg-like | 100 000 | |
| H-Rich Core-Collapse (1999 000 total) | ||
| SN II (1.9M total) | SNII-Templates | 633 000 |
| SNII-NMF | 633 000 | |
| SNII + HostXT_V19 | 633 000 | |
| SN IIn (100 000 total) | SNIIn-MOSFiT | 50 000 |
| SNIIn + HostXT_V19 | 50 000 | |
| Stripped Envelope / H-Poor Core-Collapse (500 000 total) | ||
| Ib (100 000 total) | SNIb-Templates | 50 000 |
| SNIb + HostXT_V19 | 50 000 | |
| Ic (100 000 total) | SNIc-Templates | 50 000 |
| SNIc + HostXT_V19 | 50 000 | |
| IcBL | SNIcBL + HostXT_V19 | 100 000 |
| IIb | SNIIb + HostXT_V19 | 100 000 |
| SLSN-I | SLSN-I-MOSFiT | 100 000 |
| Non-SN transients (301 000 total) | ||
| KN (100 000 total) | Kasen 2017 | 50 000 |
| Bulla 2019 | 50 000 | |
| TDE | TDE_MOSFiT | 101 000 |
| AGN | AGN-LSST | 100 000 |
We simulate normal and peculiar SNe Ia using the same models used in K19. Additionally, the core-collapse SN models suffixed with NMF, Templates, and MOSFIT in Table 2 are identical to those detailed in K19. However, several features of our simulation are different from PLAsTiCC. We do not include the parametric SN Ibc MOSFiT model, which was part of PLAsTiCC, because its parameters were drawn from unrealistic flat distributions and the models produce unphysical light curves. We also add the recent core-collapse spectrophotometric templates from Vincenzi et al. (2019), which are suffixed by HostXT_V19 in Table 2. The V19 models add realistic diversity to our core-collapse sample. The V19 models include templates for SNe IIb and SNe Ic-BL, which are both new since PLAsTiCC. SNe Ic-BL are energetic Ic events observed with broad lines in their spectra, indicating enhanced absorption velocities of ∼15 000–30 000 km s−1 (Modjaz et al. 2016). Thus, the Ic-BL templates are distinguishable from the typical Ic model primarily through spectroscopy. As we only simulate photometric light curves for SCOTCH, the only relevant difference from SNe Ic is that SN Ic-BL light curves are brighter.
The SLSN I, TDE, and AGN models are similar to those in K19, the only difference being that we impose an upper redshift limit of z = 3 to match the limit of CosmoDC2 galaxies within the HOSTLIBs.
PLAsTiCC included a set of kilonova SED models from Kasen et al. (2017). In this work, we incorporate the Kasen model as well as an SED model by Bulla (2019). Both approaches parametrize the rapidly decompressing ejecta from the merger of two neutron stars that are heated by radioactivity from r-process nucleosynthesis. The Bulla (2019) model7 is parametrized by the mass of the ejecta, the half-opening angle of its lanthanide-rich component, and the angle between the line of sight and the plane of merger. The Kasen et al. (2017) models consider the SED parametrized by the ejecta mass, the lanthanide fraction, and the ejecta velocity, without an observing angle dependence. In general, larger values of the ejecta mass lead to brighter events, while increasing the lanthanide fraction leads to redder, longer lived kilonovae. Both models are grid-based, i.e. an SED given on a grid of discrete model parameters. Recently, Chatterjee et al. (2021) incorporated the Bulla model into snana, and used both these kilonova models to create a classifier to filter kilonovae from other astrophysical transients using photometric and contextual information available from gravitational wave data products. The SED data for both the models are publicly available as part of the snana package.8
We present the distribution of light curves for a representative sample of each simulated transient class in Fig. 4. We further present the volumetric rate evolution of transients within the catalogue, re-scaled to the match the model predictions using the values in Table B1, in Fig. 5. The re-scaling is necessary because the total event numbers in SCOTCH (Table 2) are arbitrary. For comparison, we show the observed volumetric rates for SNe Ia from Rodney et al. (2014) and CCSNe from Strolger et al. (2015). We find agreement with the observed volumetric rates, with the deviations dominated by the theoretical fits to the data and not limitations in the simulation pipeline.
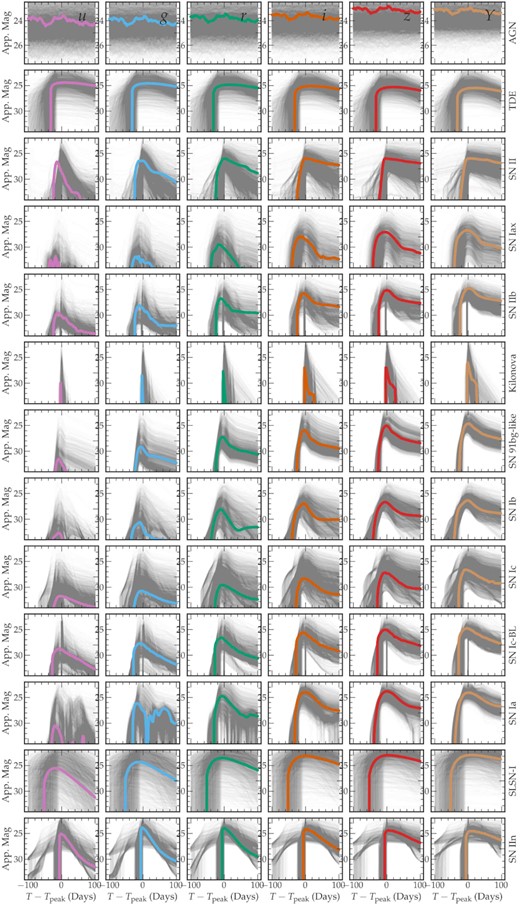
Light curves for the transient classes simulated in this work. Gray curves show a representative sample of events, and coloured curves show one example event for each class. Due to the rapid rise of the kilonova model, few KN light curves feature emission at epochs prior to peak light.
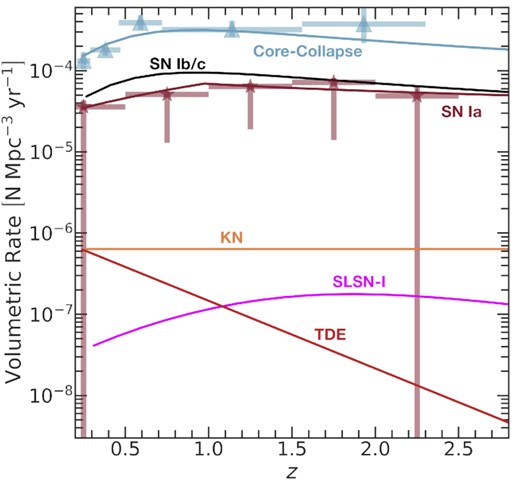
Re-scaled volumetric rates in the SCOTCH catalogue as a function of redshift for multiple transient classes. The true catalogue rates (with the same redshift evolution but arbitrary total event numbers) have been re-scaled to match the predicted volumetric rates given the input model. Stars correspond to observed volumetric rates for SNe Ia and core-collapse SNe, with statistical and systematic uncertainties plotted.
5 HOST LIBRARY CREATION (HOSTLIB)
5.1 Overview
Our first step to realistically associate transients with hosts is to create HOSTLIBs from CosmoDC2 galaxies. In the previous work, including Vincenzi et al. (2021), HOSTLIBs were constructed of representative field galaxies and correlations with transient class were implemented solely via the WGTMAP schema. However, WGTMAPs that depend on more than a few host properties N are prohibitively memory-intensive and computationally slow, as the snana code requires weights to be defined over an evenly spaced grid across the full N-dimensional parameter space. To incorporate additional galaxy properties in our transient-host association, we generate tailoredHOSTLIBs for different transient categories containing correlations in host galaxy colour and magnitude.
5.2 Accounting for CosmoDC2 artefacts with pzflow
The distribution of CosmoDC2 galaxies in colour-redshift space contains non-physical structure that worsens at higher redshifts. The problem is caused by a mismatch between the colour ranges in different components of the hybrid catalogue production pipeline for CosmoDC2 (Korytov et al. 2019), and manifests as discrete ‘tracks’ in colour-redshift space across the full redshift range (upper panel of Fig. 6). These artefacts limit our ability to test upcoming machine-learning based photometric redshift estimators. Along each track, the dispersion about the colour–redshift relation is unrealistically low. Photometric redshift and classification algorithms trained using these data are likely to achieve unrealistically accurate results. As photo-z estimation is an important component of upcoming large-sky transient and galaxy surveys, we mitigate this effect by smearing the streaky colour–redshift relationship for selected CosmoDC2 galaxies.
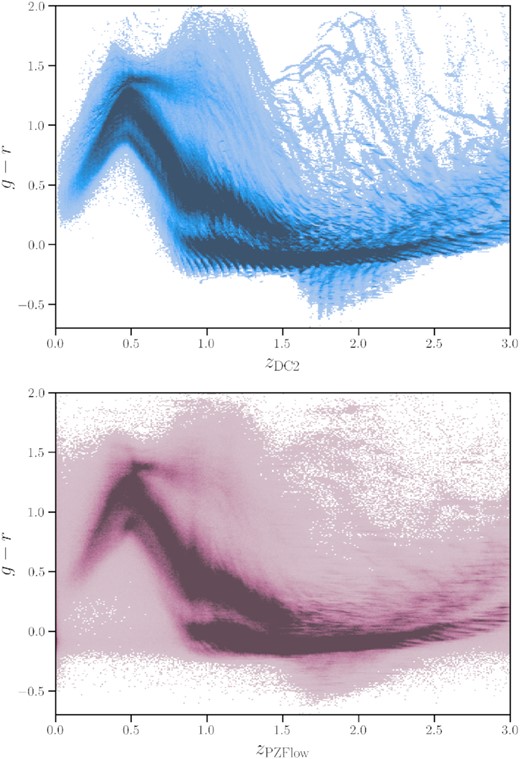
Top panel: Observed g − r colour versus redshift for galaxies within the CosmoDC2 synthetic sky catalogue (Korytov et al. 2019). Discrete tracks visible in this space are an artefact of the limited number of SED models used to generate the derived properties of these galaxies. Bottom panel: The same g − r values plotted against redshifts drawn from a probability density function estimated using a normalizing flow (Crenshaw et al. 2021). There is a one-to-one mapping between the galaxies in the top and bottom image; each galaxy’s redshift is slightly shifted, which smears out many of the non-physical tracks.
We use the code pzflow9 (Crenshaw et al. 2021) to realistically shift galaxy redshifts and smear the colour-redshift tracks. pzflow uses normalizing flows (Jimenez Rezende & Mohamed 2015) to efficiently model a multidimensional probability density function (PDF). The normalizing flow learns a bijection, a function which maps the PDF to a tractable latent distribution (such as a uniform distribution) in which we can easily sample points and calculate densities. We train a normalizing flow to model the conditional PDF |$p(z|\mathbf {m}, M_*, \text{SFR})$|, where |$\mathbf {m}$| is a vector of LSST ugrizY apparent magnitudes. The latent distribution for the flow is uniform over the range [−5, 5]. The bijection consists of two layers: the first layer shifts the redshift range [0, 3] into the range of the latent uniform distribution, [−5, 5]; the second layer is a Rational-Quadratic Neural Spline Coupling layer (RQ-NSC; Durkan et al. 2019), which transforms the redshift distribution into a uniform distribution. The RQ-NSC performs this transformation using splines parametrized by a set of knots. The number of spline knots, K, can be chosen to increase or decrease the resolution of information captured by the flow. We choose a low value of K = 2 so that the flow does not learn the discrete tracks in the CosmoDC2 colour-redshift space, and instead smooths over them.
We train the normalizing flow on the 40M r < 28 CosmoDC2 galaxies for 30 epochs using maximum likelihood estimation. Then, for each galaxy, we sample a new redshift zpzflow from the normalizing flow. These new redshifts are consistent with the galaxies’ photometry, stellar masses, and star formation rates, but are slightly perturbed from their original values (see left-hand and middle panels of Fig. 7). For |$92{{\ \rm per\ cent}}$| of the galaxies, the change in redshift is δz < 0.1. While |$8{{\ \rm per\ cent}}$| of redshifts have more substantial perturbations, we stress that each perturbed redshift is consistent with that galaxy’s observed and derived properties. It should not be surprising that, for some galaxies, a substantially different redshift remains consistent with its other properties (Salvato, Ilbert & Hoyle 2019), particularly if the original distribution contained discrete artefacts.
![Left-hand panel: Difference between pzflow-sampled redshift and original CosmoDC2 redshift as a function of CosmoDC2 redshift for each galaxy in the sample. Shifts are minimal, and the discrete paths at top left- and bottom right-hand reflect the bounds of [0, 3] imposed in generating pzflow samples. Middle panel: Histogram of fractional differences in galaxy redshift before and after the pzflow-oversampling stage. Right-hand panel: Histogram of fractional differences in absolute magnitude propagated from the pzflow-shifted redshifts.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/mnras/520/2/10.1093_mnras_stad302/1/m_stad302fig7.jpeg?Expires=1750182028&Signature=4bh0hkDLP424jV92mzDpFOXh5ozel6xwKk17CpynhJE4rxkP8KIxkk5Fa6K8MKmp6WyIU4xmprJ~p~xNEy0CuvVVjRG-~ozivrilmzTPk4ydgB0PClVVw0yvzOogDddpCJW67VFiFNU7erqeodW0fKraJqyIYOJ9EdUH2pSAV2ngxtQKIkGekor5w9~CeeqPavvqCoFwkLG5fzxd-M-bJe-AleyV-~dYoT7ZQRPIZyLiCJK6RbMvPZaaqUXowzT4U4mZYpB3HDZKPYAQ0FzLSABNfQy0zJH-S3~Qj8lIpRXKGT3F84GYS60rAMg1MSPwwUzx7Mj9MZcTd9lVZvsFzA__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
Left-hand panel: Difference between pzflow-sampled redshift and original CosmoDC2 redshift as a function of CosmoDC2 redshift for each galaxy in the sample. Shifts are minimal, and the discrete paths at top left- and bottom right-hand reflect the bounds of [0, 3] imposed in generating pzflow samples. Middle panel: Histogram of fractional differences in galaxy redshift before and after the pzflow-oversampling stage. Right-hand panel: Histogram of fractional differences in absolute magnitude propagated from the pzflow-shifted redshifts.
We next adjust each galaxy’s absolute magnitude to retain the same apparent magnitude given its shifted luminosity distance. The right-hand panel of Fig. 7 shows the size of these adjustments. For |$93{{\ \rm per\ cent}}$| of galaxies, the absolute magnitude change is δM < 0.2. We expect the small magnitude perturbations to lie within the realistic scatter of galaxy properties.
We have perturbed the galaxy redshifts with the goal of removing the discrete tracks in colour-redshift space that would lead to overly optimistic photo-z estimates. We present the original and re-sampled redshift distributions in the upper and lower panels of Fig. 6, respectively, in which only a fraction of the tracks remain (and these are primarily at very high redshift).
After applying pzflow, we perform an additional cut to clean the CosmoDC2 rest-frame colour distribution. We limit our sample to galaxies with −0.18 < i − z < 0.5, which maintains the vast majority of the CosmoDC2 colour distribution but removes two unrealistic clumps that were visible on the red and blue extremes after re-sampling.
5.3 Selecting a CosmoDC2 subsample
Ideally, we would sample directly from the CosmoDC2 galaxies, with our selection informed by real data, to populate a catalogue of synthetic host galaxies for each transient class. Although the GHOST data set includes many SN classes, for most classes (e.g. SNe IIn, Ic-BL, and IIb) the sample size is too small to contain representative information. To combat this issue, before matching we group the hosts of archival GHOST SNe into three broader categories:
6284 hosts of Type Ia SNe.
1973 hosts of core-collapse SNe with hydrogen lines in their spectra, including those classified as Type II, IIn, and IIP.
443 hosts of hydrogen-poor SNe, including stripped-envelope core-collapse SNe and hydrogen-poor superluminous SNe (SLSNe-I).
For each group, we select a many-times larger sample of synthetic CosmoDC2 galaxies that approximates the distribution in GHOST galaxy properties while extending to higher redshifts. We construct a HOSTLIB for each of these in three broad categories.
With insufficient high-z data to model any cosmic evolution of transient-host correlations, a reasonable approach to high-redshift HOSTLIB sampling is to find high-z CosmoDC2 galaxies with similar intrinsic properties as low-z galaxies; e.g. rest-frame absolute magnitudes, rest-frame colours, and morphology. This approach ignores the possible evolution of transient-host correlations over cosmic time.
We employ a nearest-neighbour (NN) technique, illustrated in Fig. 8, to achieve this matching. NN algorithms deteriorate in high-dimensional space due to decreased data density (the so-called ‘curse of dimensionality’), so we select a small number of galaxy properties that most strongly correlate with transient properties. We train our NN matching on absolute rest-frame r- and i-band magnitudes, rest-frame g − r and i − z colours, and the pzflow-shifted redshifts. This combination of properties incorporates information from all griz bands (u and y being unavailable after converting GHOST data to SDSS filters) without redundancy. Although a similar matching could be achieved by simply using the griz magnitudes and allowing colour to be implicitly included, doing so would down-weight the importance of colour. We choose to explicitly make two of the four dimensions colours, with an even weighting as the magnitudes, because colour correlates strongly with a galaxy’s star formation rate, and consequently the rate of core-collapse SNe; while brightness correlates strongly with stellar mass, and consequently the rate of SNe Ia and SNe II (see Section 6). We manually down-weight redshift with respect to the colours and magnitudes to allow for neighbour matching across a wide range of redshifts. We considered also matching on morphological information such as galaxy radius and ellipticity, but found the difference between observational and simulated estimates to be prohibitive given the necessary corrections to systematics in the GHOST data (e.g. deconvolving the PSF from ellipticity and radius measurements) and the strong redshift-dependent observational bias towards intrinsically large and face-on galaxies in targeted surveys.

Illustration of CosmoDC2 sampling for HOSTLIB generation. Left-hand panel: We identify GHOST galaxies which hosted transients belonging to a particular category (the three categories are defined in the text). The GHOST sample is observationally biased towards low-redshift, but we assume the rest-frame properties (like colour, shown on the y-axis) are representative of the true full sample of hosts. Right-hand panel: For every GHOST galaxy, we select k synthetic galaxies from CosmoDC2 nearby in rest-frame colour, brightness, and redshift (with small dANNOY values; see Appendix A from the supplementary materials for details) but extending to z = 3. For simplicity, the diagram shows k = 2 and a 2-dimensional parameter space; in practice, however, k = 800−18 000 and five parameters are used for matching.
Although exact NN algorithms (e.g. scikit-learn’s KNeighbours) are sufficient for samples of N ∼ 105, they become increasingly slow when scaling up to ∼107 galaxies. Instead, we make use of a rapid approximate NN method called ANNOY, which leverages Locality-Sensitive Hashing (LSH; Datar et al. 2004), to rapidly cross-match data sets in parallel. We provide additional information on our use of this method in Appendix A in the Supplementary Materials accompanying this paper, available online. We select k neighbours in CosmoDC2 with low Euclidean distance (dANNOY) to each GHOST galaxy. Rather than impose a limit on dANNOY, we set k to a value that produces several million matched CosmoDC2 galaxies. We then remove synthetic galaxies that were matched to multiple GHOST galaxies, creating HOSTLIBs with ∼3-million objects each. This requires k to range from 800 to 18 000 across the three host categories.
Using this pipeline, we generate HOSTLIBs of CosmoDC2 galaxies matching the host-galaxy distributions in GHOST for the three groups of transient classes described above. We show the distribution of observed GHOST galaxies, a random subset of CosmoDC2 galaxies, and the final matched sample for the Hydrogen-poor host group in Fig. 9. In addition to the three HOSTLIBs described above, we create a HOSTLIB consisting of galaxies randomly sampled from CosmoDC2 for transient classes not in the GHOST catalogue. The host correlations for events using this unmatched HOSTLIB originate entirely from the transient-specific WGTMAP.
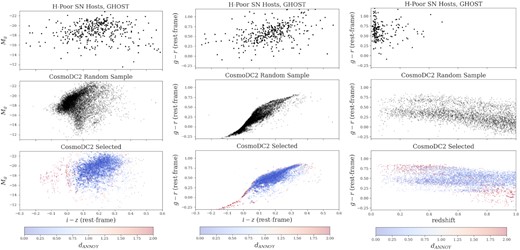
A representation of how the GHOST-CosmoDC2 matching process produces a larger sample of GHOST-like galaxies from CosmoDC2. Each set of three panels (stacked vertically) show the same steps of the process which creates the H-poor host library. The three left-hand plots show a magnitude–colour distribution, the middle show colour–colour space, while the right show colour vs. redshift. Top panel: the GHOST H-poor event host galaxies. Center panel: a random subset of CosmoDC2 galaxies. Bottom panel: nearest-neighbour galaxies selected from CosmoDC2 to match each GHOST galaxy in a multidimensional parameter space. The colour bar, applying only to the bottom three plots, signifies the nearest-neighbour Euclidean distance and is truncated at 2 for visual purposes. Red points are CosmoDC2 galaxies that are far from their nearest GHOST neighbour. From the left-hand and centre plots, it is apparent that the limited colour ranges in CosmoDC2 also limit the effectiveness of matching, as some GHOST galaxies lie beyond the available DC2 colour extent. The right plots demonstrates how down-weighting redshift as a matched property allows us to select CosmoDC2 galaxies across a wide range (extending to z = 3, but only shown up to z = 1).
The CosmoDC2 simulation contains many ultra-faint galaxies that were injected into the simulation to account for its finite mass resolution (Korytov et al. 2019). These galaxies were not assigned properties as rigorously as the normal galaxies in the simulation; as a result, we exclude them from our HOSTLIBs. Our initial r < 28 cut on CosmoDC2, as well as the matching to GHOST galaxies (which are generally bright), remove many of these galaxies from our sample. We identify any remaining ultra-faint galaxies by their negative halo_id after HOSTLIB creation and cut them from the samples.
6 TRANSIENT-HOST GALAXY CORRELATIONS (WGTMAP)
The GHOST data base contains only basic photometric properties for SN host galaxies. Additional properties like masses and star formation rates, which can be estimated from galaxy imaging and/or spectra, are not reported in GHOST due to the lack of availability. Thus, the HOSTLIBs of CosmoDC2 galaxies matched to GHOST are realistically distributed in colour and brightness, but only contain an implicit dependence on derived properties. There is motivation to fold in explicit dependence on mass and star formation rate: many studies have empirically verified this dependence for multiple transient classes (using smaller samples than GHOST) and found statistically significant differences between classes. To more precisely simulate these correlations, we construct a series of WGTMAPs that explicitly encode the class-specific dependence of host-transient association on a galaxy’s derived properties. These WGTMAPs enable us to fine-tune the host populations of the three matched HOSTLIBs and add in class-specific correlations for events whose hosts will be drawn from the unmatched, randomly sampled HOSTLIB.
Each WGTMAP consists of a multidimensional grid of host properties, where values in the grid correspond to the probability of a galaxy with those properties being selected to host a given transient event in snana. The weightmap values can be scaled arbitrarily, so long as the relative weights between galaxies of different properties are preserved. When the snana simulation generates a transient at z, a sample of candidate host galaxies within δz are retrieved from the HOSTLIB. snana then assigns a corresponding weight to each potential host using the WGTMAP. The simulation creates a cumulative distribution function (CDF) for all galaxies, where the horizontal axis orders the galaxies arbitrarily, and the function is augmented by each galaxy’s weight. The CDF is normalized to have a maximum value of one. The simulation selects a random number for the CDF vertical axis, and picks the corresponding galaxy along the horizontal axis, such that highly weighted galaxies have a higher CDF slope and are therefore more likely to be selected. Because the normalization is computed internally within SNANA, only the proportionality linking the probability P to the host galaxy parameters must be defined for the WGTMAPs.
We emphasize that the transient rate models, described in Section 4.2 and extensively detailed in K19, are entered into the snana simulation independently of host properties. In other words, the final transient event rate in the simulation is not affected by the associated host galaxies. Transients are generated according to the rate function and the total number desired (Table 2), and only then assigned a host. The WGTMAP plays a role only in determining the relative likelihood of one host being selected over another.
The following subsections review the observations that motivate the WGTMAPs of each class. We caution that for several classes (TDEs, KNe, SNe Ic-BL, and SLSNe-I), the data statistics remain limited, and thus the resulting simulations may not capture the full diversity of host galaxies. Fig. 10 provides some intuition for the probability equations that follow by showing the SFR-mass distribution of hosts selected by snana from these equations for six classes.
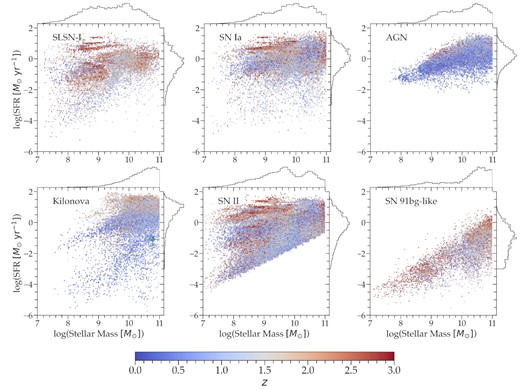
Distribution of derived host-galaxy properties for six simulated classes of transients. Galaxies are coloured by redshift (with red points for high-redshift galaxies). Marginal distributions are given at the top and right of each sub-plot. NGC 4993, the host of GW170817, is shown as the green diamond.
6.1 SNe Ia
SN Ia explosions are thought to occur when a white dwarf accretes material from a companion star (which may also be degenerate) in a binary system, approaches the Chandrasekhar mass, and ignites in a runaway chain reaction of carbon fusion. SNe Ia occur more frequently in high-mass and highly star-forming galaxies (Sullivan et al. 2006; Smith et al. 2012; Wiseman et al. 2021). Their light curves are parametrized in the snana simulation using the Spectral Adaptive Lightcurve Template (SALT2/SALT3) frameworks (Guy et al. 2007; Kenworthy et al. 2021).
The first component of the probability, |$P^{\mathrm{KDE}}_{\mathrm{Ia}}$|, encodes a dependence on galaxy stellar mass and star formation rate. It has been constructed to replicate the distribution of 200 SN Ia host galaxies from the Dark Energy Survey Supernovae Program (Smith et al. 2020). Using the statsmodelpython package, we perform kernel density estimation on the DES log (M*) and log (SFR) values to estimate a smooth probability density function in log (M*) versus log (SFR) space. We use a Gaussian kernel for both parameters and determine the best-fitting bandwidths from the KDE fit, finding 0.49 and 0.47 for log (M*) and log (SFR), respectively. Because |$P_{\mathrm{Ia}}^{\mathrm{KDE}}$| is a non-parametric estimate for the probability density of observed events, it has no closed form.
6.2 Peculiar SNe Ia
In addition to ‘normal’ SNe Ia, our simulated sample includes two classes of peculiar transients: SN2002cx-like SNe (SNe Iax; Foley et al. 2013), which are underluminous and red at peak light relative to their Branch-normal counterparts; and SN1991bg-like SNe Ia, which are more rapidly evolving (Filippenko et al. 1992). Although observed samples are small, there are indications that SNe Iax occur almost exclusively in late-type, star forming galaxies (Jha 2017; Takaro et al. 2020) and SNe 91bg-like preferentially occur in early-type, passive galaxies (van den Bergh, Li & Filippenko 2005; H20). Accordingly, Vincenzi et al. (2021) set the SN Iax probability to the SN Ia probability in active hosts and 0 in passive hosts; conversely, they define the SN 91bg-like probability as equal to the SN Ia probability in passive hosts and 0 in active hosts. We adopt a similar approach, and assume that the peculiar SNe Ia originate from similar progenitors as normal SNe Ia, but that their hosts represent opposite ends of a continuum in galaxy age and morphology. However, we exponentially taper the probability of SNe Iax in passive galaxies and 91bg-like events in star-forming galaxies. This is done in order to avoid encoding an unrealistically discrete boundary in our catalogue, and to account for the possibility that a sub-population of these events does occur in hosts distinct from those previously discovered.
Because PIa is not symmetric about xs (it increases with galaxy mass and star formation), we note that this formalism results in a higher probability for 91bg-like events to occur in star-forming host galaxies than SNe Iax to occur in passive host galaxies. SCOTCH contains ∼0.1 per cent of SNe Iax in passive hosts and >25 per cent of SNe 91bg-like in active hosts. This implementation is motivated by previous work (e.g. H20) showing a larger tail of 91bg-like hosts towards spiral-type morphologies than of SNe Iax towards elliptical galaxies.
6.3 Types II, Ib, and Ic Supernovae (SNe II, SNe Ib/c)
Type II, Type Ib, and Type Ic are three subclasses of core-collapse SNe. Type II events are characterized by strong Hydrogen emission lines, indicating that an outer Hydrogen shell was present in the progenitor star. Types Ib and Ic lack Hydrogen features, indicating that their outer shell was stripped from the progenitor star prior to explosion. Type Ic also lacks Helium features, indicating that the Helium envelope was also lost. Although SNe IIb are typically grouped with these ‘stripped-envelope’ events, they exhibit weak hydrogen features at early times. As the explosion progresses, the hydrogen emission quickly fades and the light curves begin to resemble those of SNe Ib. Because of their short-lived progenitor systems (typically <50 Myr), core-collapse explosions are predominantly observed in galaxies that are actively forming massive stars. The probability of these events occurring in passive galaxies, in contrast, is suppressed. Active and passive galaxies can be distinguished by their sSFR, defined as the star formation rate of the galaxy per unit of stellar mass.
6.4 Type Ic-BL supernovae (SNe Ic-BL)
We note that the SN Ic and Ic-BL light-curve models are photometrically similar, and therefore these classes provide a unique opportunity to test the value of host galaxy information in classification.
6.5 Type I superluminous supernovae (SLSNe-I)
Superluminous SNe (SLSNe) are unusually bright explosions potentially powered by exotic engines (e.g. pair instability or magnetar spin-down; Kozyreva & Blinnikov 2015; Nicholl, Guillochon & Berger 2017). Type-I SLSNe are hydrogen-poor and have been found to occur predominantly in low-mass, metal-poor, and highly star-forming galaxies (Lunnan et al. 2014; Perley et al. 2016; Schulze et al. 2018). We model their rate based on the observations of ∼50 SLSN-I hosts from Lunnan et al. (2014), Perley et al. (2016), and Schulze et al. (2018). All studies report SLSN-I hosts with specific star formation rates greater than 10−10 yr−1; thus, we model the SLSN-I probability to be exponentially suppressed below this threshold.
6.6 Using short-duration gamma-ray bursts as a proxy for kilonova correlations
The discovery of gravitational-wave event GW170817 by the LIGO and Virgo collaborations, followed by short-duration (≲2 s) Gamma-Ray Burst (sGRB) GRB170817A a few seconds later and the optical kilonova (KN) AT2017gfo several hours later, confirmed the association of these signals during a likely neutron star–neutron star merger (Abbott et al. 2017a,b; Goldstein et al. 2017). The multiband photometry of AT2017gfo, an event which took place in the nearby (z ≈ 0.00972) galaxy NGC 4993, provided direct evidence for compact mergers as a site where r-process elements are forged (Drout et al. 2017). Nevertheless, many questions remain. Although the colour of the emission reveals information on the fraction of lanthanides and actinides produced from the neutron-rich ejecta, more events are needed to understand the relationship between an event’s emission and its precise nucleosynthetic yield. Further, the differences between KNe generated from the merging of a neutron star–black hole system and those originating in a neutron star–neutron star collision remain unknown. Though there have been no observations of KNe from a neutron star–black hole system yet, numerical simulations show differences between these types of KNe (Tanaka et al. 2014; Kawaguchi et al. 2016; Shibata & Hotokezaka 2019; Bulla et al. 2021). The strength of the subsequent electromagnetic signal also encodes information regarding the neutron–star equation of state (Bauswein et al. 2017; Li et al. 2021; Raaijmakers et al. 2021). Because our knowledge of these systems starts and ends at this prototypical event, owing to the large sky localization area of gravitational wave observations – especially when events are observed only in some of the existing detectors – and the low intrinsic event rate, additional KN discoveries in upcoming surveys would vastly improve our understanding of these systems.
Because our aim is to improve the ability to accurately identify a diversity of KN events in upcoming survey streams, we do not want to limit our KN host-galaxy model solely to galaxies matching the properties of NGC 4993 (the host of AT2017gfo). Indeed, whereas NGC 4993 is a quiescent galaxy (Levan et al. 2017), sGRBs have been discovered in a variety of both star-forming and quiescent systems (Prochaska et al. 2006; Berger 2009). Based on recent evidence that these signatures share a common astrophysical site (Abbott et al. 2017a), for this work, we assume that sGRBs and KNe inhabit host galaxies with similar properties. This assumption has the added benefit that GRBs are regularly observed across the full sky (D’Avanzo 2015), and as a result we have amassed hundreds of GRB detections to date.
We begin constructing the KN WGTMAP by retrieving the positions of reasonably well-localized sGRBs (uncertainty radius re < 0.01° and t90 ≲ 2 s) from the NASA Fermi GBM Burst catalogue (Gruber et al. 2014; von Kienlin et al. 2014; Narayana Bhat et al. 2016; von Kienlin et al. 2020) and from the GRB Host Studies catalogue (Savaglio, Glazebrook & Le Borgne 2006). Next, we use the astro_ghost10 software to identify the most-likely host galaxy associated with these events and retrieve photometric data from these galaxies. Whereas the original implementation of the package considered only Northern-hemisphere galaxies within the Pan-STARRs source catalogue (Flewelling et al. 2020), for this work, we have extended the code to query the SkyMapper catalogue (Onken et al. 2019) for Southern-hemisphere sources as well. After visually verifying each association, we arrive at a sample of 11 sGRB-hosts, one of which is NGC 4993. Apparent gri-band magnitudes are reported for all hosts except two, which lack high-SNR brightness estimates in the r band. We then convert apparent magnitudes to absolute magnitudes. We adopt the galaxies’ spectroscopic redshifts as reported in the NASA/IPAC Extragalactic Database11 where possible, and use a photo-z estimator12 for the galaxies without a reported redshift. We generate a kernel density estimate (KDE) to approximate the joint distribution of absolute magnitudes in gri for these hosts using the available data. From this KDE and using a Gaussian kernel, we determine best-fitting bandwidths of 0.93, 0.62, and 0.57 for gri-band absolute magnitudes, respectively.
We then sample from this KDE along a uniformly spaced grid spanning the apparent magnitudes of a random sample of CosmoDC2 galaxies. This sampling forms the basis of our KN WGTMAP.
To select hosts for our KN simulations, we initially applied this WGTMAP to the HOSTLIB of randomly sampled cosmoDC2 galaxies. The resulting simulations exhibited an unrealistically small scatter in the host r − i vs. g − r colours. We identified this as a result of tight colour correlations in the HOSTLIB coming from the cosmoDC2 colour assignment, unrelated to the WGTMAP construction. To correct for this artefact, we shift the apparent magnitudes of cosmoDC2 galaxies in each LSST band by a random number less than or equal to the observational uncertainty in that band. This sample of magnitude-shifted cosmoDC2 galaxies is stored as a distinct HOSTLIB and used only for the KN class. The shifts are effective at smearing the tight colour relationship. The KN WGTMAP is unchanged.
6.7 Active galactic nuclei
The emission from active galactic nuclei (AGN) originates from black holes at the centres of host galaxies in one of various states of active accretion (Lynden-Bell 1969). Multiple theoretical and observational studies have lent support for the co-evolution of supermassive black holes and the galaxies they inhabit (Ellison et al. 2011; Rosario et al. 2015), making these bright transients powerful probes both for galaxy formation and black hole evolution across cosmic time (Alonso et al. 2007). Kauffmann et al. (2003) found by analyzing a sample of 22 623 AGN within z < 0.3 that these transients occur predominantly in massive (>1010 M⊙) galaxies. The properties of an AGN, including its overall luminosity and the characteristic time-scale of its optical variability, have also been linked to the luminosity and stellar mass of its host, respectively (Heckman 1980; Ho, Filippenko & Sargent 1997; Burke et al. 2021).
To simulate the properties of AGN host galaxies, we model the properties of 2204 AGN hosts from Stemo et al. (2020). While not a volume-limited sample, the catalogue provides publicly available stellar masses and star-formation rates for AGN hosts from SEDs derived using HST, Spitzer, and Chandra data and spans 0.2 < z < 2.5, nearly the same redshift range considered in this work.
As was done for SNe Ia, we model the joint probability distribution PAGN(M*, SFR) by performing kernel density estimation on the observed sample, using a Gaussian kernel for both parameters and the best-fitting bandwidth of 0.18 for both parameters.
6.8 Tidal disruption events
7 OFFSETS FROM THE HOST CENTRE
7.1 Transient offset model and validation
Within the snana simulation, we select the position of a transient relative to its host galaxy centre by randomly sampling from a probability distribution defined by the galaxy’s surface brightness profile. This is motivated by prior studies that, averaging over class, SN surface density profiles roughly trace the surface brightness distribution of the spiral disks that host them (Hakobyan et al. 2009). Nevertheless, differences exist between the observed distributions of radial offsets for multiple transient classes. While we have aimed primarily at reproducing global transient-host galaxy correlations in this work, we also integrate a basic local model for three classes of transients: AGN, KNe, and TDEs. When post-processing SCOTCH to place events within a survey footprint, care should be taken to preserve the listed offsets.
Because AGN are nuclear transients by definition, we place them closer to their host centres than any other class. AGN are placed within a radius that encompasses 10 per cent of the total galaxy flux; within this radius, their distribution traces the surface brightness profile. We caution that AGN have been detected that are more offset relative to their galaxy centres, but these are rare (<5 per cent; Comerford & Greene 2014) and may be traced back to specific merger events, which is challenging to model with our existing framework.
TDEs, typically discovered as the optical signal from the tidal interaction between a star and a central supermassive black hole, are placed at small offsets in our simulations. However, the recent discovery of a TDE from a candidate intermediate-mass black hole (IMBH) in the nucleus of a dwarf galaxy (Angus et al. 2022) suggests that future observations may reveal TDEs from IMBHs offset from the nucleus of massive hosts (see Bellovary et al. 2019, for a discussion of wandering IMBHs). To allow for this possibility, we model the TDE offsets slightly more broadly than AGN, with probability profiles truncated beyond the radius that encompasses 30 per cent of the host galaxy flux.
Conversely to TDE and AGN, we place KNe at broad offsets: their positions are sampled from distributions in which the innermost 20 per cent of a host galaxy is truncated. This is done to encode the prediction that natal kicks prior to explosion eject KNe from the inner regions of their host galaxies (Gompertz, Levan & Tanvir 2020).
We present the offsets for AGN, KNe, TDEs, and SNe Ia in our catalogue in Fig. 11, and compare the SNe Ia and TDE offsets to observed SNe from the Young Supernova Experiment (YSE) Data Release 1 (Aleo et al. 2022) and the KN offsets to Swift satellite sGRB data (Gehrels et al. 2004) that was previously collected and analysed in Fong et al. (2013) and Pan et al. (2017). The qualitative differences in our simulation clearly follow our model prescription: AGN lie closest to their host nucleus, TDE are slightly more offset, KN are evacuated from the central region of the host, and SNe Ia (representative of the treatment for all SN classes) appear throughout the host galaxy with most within the inner few kpc. The observational data shows reasonable agreement to the simulations, despite the fact that our approach for offset prescriptions was approximate, and we did not explicitly aim to replicate observations. We leave a more detailed prescription for individual SN classes to future work.
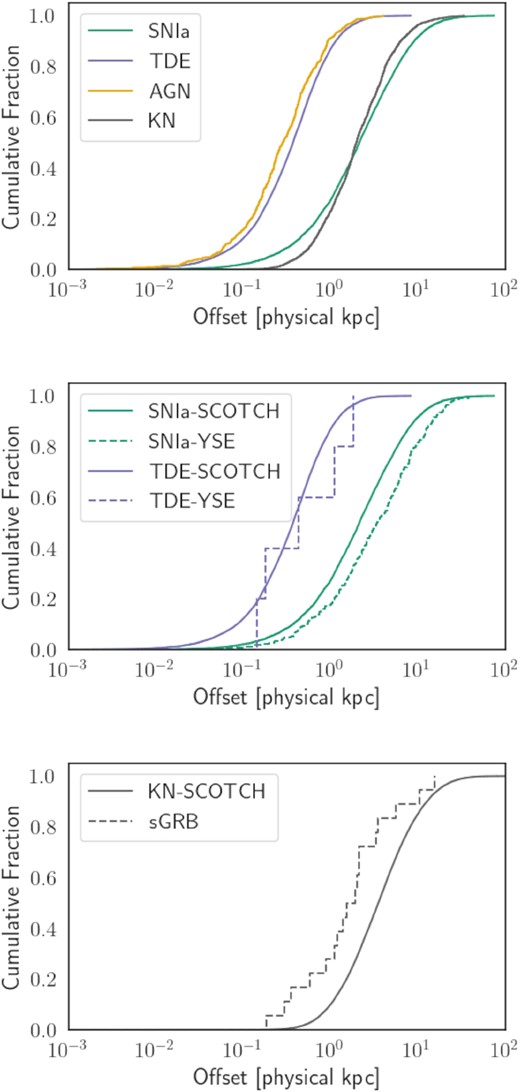
The CDF for transient-nucleus offsets for several classes in SCOTCH only (top) and a SCOTCH comparison to observational data from YSE (middle panel) and Swift data (bottom panel). Top panel: qualitative differences in our treatment of several classes are visible; AGN and TDE are closest to the centre of galaxies while SN Ia and KN are distributed further out. KN are not allowed to exist within the centres of galaxies to simulate the kick effect. Here, SCOTCH data is limited to the range z < 0.25, where most YSE data lies, to facilitate a comparison in the middle plot. Middle panel: SCOTCH TDE and SNIa CDFs are duplicated and YSE data is added. The simulated TDE fit the YSE data well; the simulated SNIa are distributed closer to the centre than in YSE. Bottom panel: SCOTCH KN data is shown for z < 1 and are distributed somewhat further than the distribution of sGRBs from Swift data, which also extend to z ∼ 1 (Fong et al. 2013).
7.2 Hostless events
Some transient events are reported without a host in SCOTCH. This occurs when the distance of the transient from its host exceeds a particular threshold. After generating the position as described above, snana calculates the dDLR, the angular separation from the transient and nucleus (in arcseconds) normalized by the DLR, which is a measure of the galaxy radius in the direction of the transient. If dDLR > 4, the host is rejected to simulate the fact that a realistic survey would be unlikely to match that transient with its host (specifically, the rate of mismatch within dDLR < 4 is expected to be small, |$\sim 4{{\ \rm per\ cent}}$| according to Gupta et al. 2016). Hostless events due to dDLR rejection do not occur for TDE or AGN due to their inner-galaxy placement; for all other classes, the rate of hostless events is at the few-per cent level (|$\sim 3-8{{\ \rm per\ cent}}$|).
In SCOTCH, these transients appear without host association in the final catalogue. A more realistic treatment would be to provide an incorrect host when another galaxy lies closer to the transient than the true host. However, because SCOTCH removes all on-sky position information for hosts, including galaxy neighbours as false hosts in this manner is infeasible.
8 VALIDATION OF HOST GALAXY CORRELATIONS
To validate the SCOTCH catalogue, we first confirm that the correlations described in Section 6 appear in the final sample as expected. Fig. 10 displays the SFR versus M* relationships for a representative sample of hosts associated with six transient classes. Each matches qualitative trends in host types: SN Ia hosts are massive and highly star-forming, SLSNe-I occur mainly in galaxies with high specific star formation rates (and trace the cosmic star formation rate), and SNe 91bg-like occur in passive, massive galaxies. The generated samples, which used WGTMAP probabilities from Vincenzi et al. (2021), match the correlations therein, but extend to lower masses and star formation rates due to our use of CosmoDC2 versus their use of observed DES galaxies. To more directly compare the host-galaxy derived properties for each class, we plot the CDFs for M* and SFR in Fig. 12.
CDFs in host galaxy stellar mass (left-hand panel), star formation rate (middle panel), and specific star formation rate (right-hand panel) for a representative sample of transient classes in the catalogue. Differences between transient classes reflect a combination of WGTMAP and HOSTLIB effects.
The CDFs show that, of all transients simulated in SCOTCH TDEs are simulated in the lowest-mass host galaxies, followed by SLSNe-I. Simulated KNe are hosted by the highest-mass galaxies, followed by the host galaxies of stripped-envelope systems (particularly SNe Ic). The star formation rate CDFs indicate an overabundance of TDEs in galaxies of low star formation rate, which is consistent with observations of them in post-starburst galaxies. SNe 91bg-like events in our simulation occur on average in the galaxies with the lowest star formation rates, a feature of our exponential suppression in active galaxies for this class. Simulated SNe Iax and KNe occur in galaxies with the highest average star formation rate. For SNe Iax, this reflects the exponential suppression of these events in passive hosts.
Consistent with the fact that we simulated nearly all core-collapse supernovae (besides SNe Ic-BL) with the same WGTMAP and HOSTLIB, the CDFs do not show any clear differences between the host galaxy SFR of different core-collapse subclasses. The exception is the Ic-BL class, which appears more often in the simulation in galaxies of low mean SFR due to the different implemented WGTMAP. We note that, in our models, we can distinguish between statistical samples of SNe Ic and SNe Ic-BL by the mass of their host galaxy, as SNe Ic-BL occur in lower metallicity host galaxies (Modjaz et al. 2020) and therefore in lower mass hosts on average. A detailed analysis of the typical observational uncertainties associated with these derived properties and how they might obfuscate these differences in observed data is beyond the scope of this work.
Fig. 13 shows the distributions of host colours within each class. Redder galaxies appear to the upper right-hand panel and bluer to the lower left-hand panel. We did not directly encode colour correlations into the WGTMAPS for any of these classes; therefore, the differences between distributions stem from the initial GHOST matching in conjunction with the WGTMAPs in which transient probabilities are dependent on galaxy mass and star formation rate. We caution that we have not converted galaxy colours to the rest-frame for Fig. 13, and so the redshift-dependent rates for each class affect this comparison.
Density distribution of observed colours for simulated transient classes (combining WGTMAP and HOSTLIB contributions). Marginal histograms are shown at top and at right of each sub-panel. The green diamond indicates NGC 4993, the host of the single kilonova observed. Overdensities near g − r = 0 reflect remaining discrete tracks in CosmoDC2 galaxy distribution.
Qualitatively, the observed colour plots display many of the intended comparative attributes. Simulated SLSN-I host galaxies are bluer than other SN hosts, reproducing observations that show that these events occur in highly star-forming galaxies (Schulze et al. 2018). SN 91bg-like host galaxies are redder than normal SN Ia, as intended. The KN hosts are surprisingly blue; given the broad redshift distribution of simulated events (Fig. 13), this may reflect the preference of observed sGRBs for late-type hosts (Fong et al. 2013). As GW170817 (diamond in Fig. 13) occurred in a lenticular galaxy, its host galaxy is redder than the majority of the simulated sample. The simulated g − r distribution for TDE host galaxies is broader than all others, which is consistent with observations (French et al. 2020); however, the i − z span may be unrealistically restricted.
Next, we quantitatively compare the colours of SNe Ia (including peculiar) hosts with the observed distributions reported in H20. H20 examined u − r colours (SDSS photometry) for a low-redshift sample and found statistically significant differences between the <u − r > of ‘normal’ SNe Ia, 91bg-type, and Iax-type host galaxies. The authors reported that galaxies hosting SNe Iax are bluer than normal, while SNe 91bg are redder than normal, with Δ < u − r > ∼ 0.4 in each case. To investigate this trend in our own data, we calculate the average u − r SDSS rest-frame colour among 10 000 random members of the SCOTCH host sample for the same three classes. Although H20 examined hosts with z < 0.04, for the comparison, we draw the SCOTCH host sample from the entire z < 3 redshift range because our simulation methodology treats high-z host selection equivalently to low-z. The results are shown in Table 3. Our average mean simulated host colour values are significantly bluer than those of the H20 sample for two of the three classes. Our mean SN Iax host colour is also bluer, but consistent within 2σ with the H20 observations. The blue trend may be a consequence of unrealistic galaxy colours in CosmoDC2, as demonstrated in fig. 3 of Kovacs et al. (2021): the CosmoDC2 u − g distribution is significantly bluer than observational data while g − r is consistent with observations, suggesting that u − r tends to be non-physically blue. The colour differences between the Ia classes in SCOTCH are in the same direction as the observed differences and are statistically significant. The magnitudes of the differences are somewhat mismatched from observations. Although qualitatively imperfect, the fact that SCOTCH reproduces the general trend in colour differences between the SN Ia subtypes should enable catalogue users to test algorithms which include host information for classification.
A comparison of the mean rest-frame u − r colour of observed SN Ia host galaxies (all z < 0.04) in H20 with the simulated catalogue (spanning all redshifts) presented in this work. Each reported uncertainty is the standard error of the mean. Δ-norm is the difference between < u − r > of the peculiar SN Ia sample and the normal sample. All simulated hosts are bluer than the observed hosts; SN Ia and SN Ia-91bg-like hosts are significantly bluer, while SN Iax are consistent within 2σ. The qualitative relationship between the classes (SN Iax hosts are bluer, SN 91bg-like hosts are redder) is similar.
| H20 | This work | |||
|---|---|---|---|---|
| <u − r > | Δ-norm | < u − r > | Δ-norm | |
| SN Ia (normal) | 1.86 ± 0.03 | 1.372 ± 0.005 | ||
| SN Iax | 1.47 ± 0.10 | −0.39 ± 0.10 | 1.255 ± 0.006 | −0.117 ± 0.008 |
| SN Ia-91bg | 2.23 ± 0.05 | 0.37 ± 0.06 | 1.908 ± 0.003 | 0.536 ± 0.007 |
| H20 | This work | |||
|---|---|---|---|---|
| <u − r > | Δ-norm | < u − r > | Δ-norm | |
| SN Ia (normal) | 1.86 ± 0.03 | 1.372 ± 0.005 | ||
| SN Iax | 1.47 ± 0.10 | −0.39 ± 0.10 | 1.255 ± 0.006 | −0.117 ± 0.008 |
| SN Ia-91bg | 2.23 ± 0.05 | 0.37 ± 0.06 | 1.908 ± 0.003 | 0.536 ± 0.007 |
A comparison of the mean rest-frame u − r colour of observed SN Ia host galaxies (all z < 0.04) in H20 with the simulated catalogue (spanning all redshifts) presented in this work. Each reported uncertainty is the standard error of the mean. Δ-norm is the difference between < u − r > of the peculiar SN Ia sample and the normal sample. All simulated hosts are bluer than the observed hosts; SN Ia and SN Ia-91bg-like hosts are significantly bluer, while SN Iax are consistent within 2σ. The qualitative relationship between the classes (SN Iax hosts are bluer, SN 91bg-like hosts are redder) is similar.
| H20 | This work | |||
|---|---|---|---|---|
| <u − r > | Δ-norm | < u − r > | Δ-norm | |
| SN Ia (normal) | 1.86 ± 0.03 | 1.372 ± 0.005 | ||
| SN Iax | 1.47 ± 0.10 | −0.39 ± 0.10 | 1.255 ± 0.006 | −0.117 ± 0.008 |
| SN Ia-91bg | 2.23 ± 0.05 | 0.37 ± 0.06 | 1.908 ± 0.003 | 0.536 ± 0.007 |
| H20 | This work | |||
|---|---|---|---|---|
| <u − r > | Δ-norm | < u − r > | Δ-norm | |
| SN Ia (normal) | 1.86 ± 0.03 | 1.372 ± 0.005 | ||
| SN Iax | 1.47 ± 0.10 | −0.39 ± 0.10 | 1.255 ± 0.006 | −0.117 ± 0.008 |
| SN Ia-91bg | 2.23 ± 0.05 | 0.37 ± 0.06 | 1.908 ± 0.003 | 0.536 ± 0.007 |
We also aim to reproduce observed correlations between the photometric light curves of SNe Ia and their host galaxies. These have been extensively studied in the literature due to the use of these events as cosmological distance indicators. We present the SALT2 (Guy et al. 2007) fitted parameters x1 and c (describing the stretch and colour of an SN Ia light curve, respectively) as a function of the intrinsic properties of our associated hosts in Fig. 14. We find similar distributions to those presented in Childress et al. (2013), including a mass-step at 1010 M⊙ (this has been explicitly encoded in our simulations, so its presence is not surprising), and weak anticorrelations between x1 and both host galaxy M* and sSFR. We observe a few SALT2 c values above c = 0.2, and multiple are identified in Childress et al. (2013); although these are anomalous, our model their presence indicates that our correlation model is able to reproduce both the central distribution and the tails of the observed data.

We present SDSS-griz histograms of the absolute magnitudes of host galaxies associated with each transient in Fig. 15. GHOST data with z > 0.05 are shown for several classes with black histograms; the cut is motivated by the fact that SCOTCH has very few events below this redshift. The data reasonably fit the simulation. The impact of our encoded correlations is readily apparent by the variation in median and skew between distributions. However, we caution that the host magnitude differences between classes are not only due to encoded correlations, but also due to two important redshift-dependent effects within SCOTCH the intrinsic rate of different transients across cosmological distances and the r < 28 magnitude cut imposed prior to matching in order to cross-match with the 5-yr DC2 image catalogue. The confluence of these effects results in a Malmquist-like bias in the sample, with the distribution of host galaxies for a given class tending towards intrinsically brighter galaxies with increasing redshift (fainter hosts being unavailable to draw from the HOSTLIBs at those redshifts). For events occurring in galaxies ranging in brightness and observed only at low and intermediate redshifts (e.g. TDEs), we observe a realistic skew towards fainter galaxies that dominate the HOSTLIBs at these redshifts. For bright classes (e.g. SLSNe-I) and common ones spanning the full simulated redshift range (SNe II), the majority of events will be simulated at high-redshift where this bias is the strongest. As a result, the histograms in Fig. 15 reveal a distribution for SNe Ia, SNe II, and SLSNe-I skewed towards bright hosts. This effect is especially visible when examining absolute magnitude as a function of redshift for both GHOST data and SCOTCH results (not shown): the distributions match well across the overlapping redshift range, but both the simulated and observed hosts taper rapidly from including a broad range of magnitudes at low-z to a tighter, brighter range of hosts as z increases.
Distribution of host-galaxy absolute magnitudes for a representative sample of SCOTCH transients using both HOSTLIBs and WGTMAPs. Host galaxy photometry from the GHOST catalogue for classes with statistical samples is shown as a black outline. Photometry is presented in the SDSS filter system.
We next compare the distributions of various properties of our final sample to GHOST to examine the combined effects of our two-step host selection process. Fig. 16 shows the galaxy colour distribution for the hydrogen-poor event HOSTLIB (consisting of SN Ib, Ic, IIb, and SLSN host matches to GHOST) and the distribution of hosts selected by SNANA after WGTMAPS are applied. The WGTMAPS cause the overall g − r distribution to become slightly bluer and more peaked than the GHOST data. Examining the colours for individual host classes reveals how the different WGTMAPs cause the distributions to stratify. The final SLSN-I host sample is bluer than the others, as encoded via SFR. The Ic hosts separate from the Ic-BL hosts in colour space due to the implemented metallicity dependence. Overall, the final combined host grouping remains similar to observed data, but the individual host classes within that group are subtly different, demonstrating the combined power of the HOSTLIB + WGTMAP formalism.
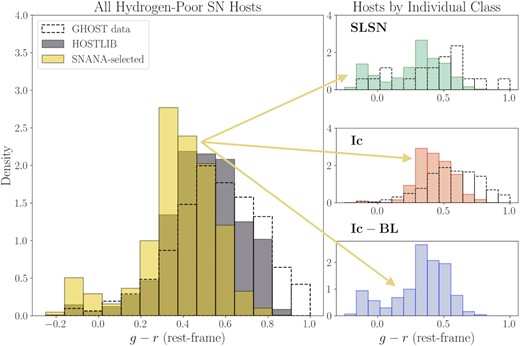
Histogram of g − r colour for synthetic Hydrogen-poor SN hosts before and after running the SNANA simulation. Left-hand panel: The HOSTLIB of all H-poor (Ib/c, SLSN, IIb) hosts (gray), which was tailored to match the GHOST data (dashed line). The hosts selected after running the SNANA simulation for all H-poor classes with their respective WGTMAPs are shown in yellow. Right-hand panel: SNANA-selected hosts of SLSN, Ic, and Ic-BL events. SLSN hosts are bluest, and Ic-BL hosts are bluer than the rest of the Ic class due to SFR and metallicity correlations. GHOST data are shown with a dashed outline, and we avoid plotting SNe Ic-BL hosts in GHOST due to the small sample size.
To further demonstrate the utility of including both a HOSTLIB and WGTMAP in our simulation, we compare our final results for SN Ia host galaxies with (1) a sample simulated only using the GHOST-matched HOSTLIB and no WGTMAP, and (2) a sample simulated using a randomly selected (unmatched) CosmoDC2 HOSTLIB and the SN Ia WGTMAP. Fig. 17 demonstrates how the implementation of either a HOSTLIB or a WGTMAP results in reasonable distributions for some, but not other, host properties. Implementing both the HOSTLIB and WGTMAP leads to an improved match with data from both DES (Smith et al. 2020) and GHOST in multidimensional parameter space.
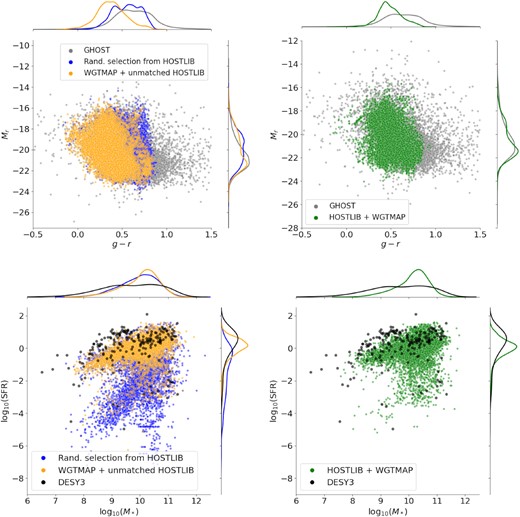
Simulated SN Ia hosts compared to observational data for simulations using either a HOSTLIB or a WGTMAP (left-hand panel), and simulations using both (right-hand panel). Marginal kernel density estimates are shown at top and at right-hand side in each panel. In the upper left panel, the HOSTLIB-only simulation (blue) decently reproduces the colour–magnitude spread of SN Ia hosts in GHOST (grey), although it is worse in g − r than in Mr due to the CosmoDC2 colour limitations. The blue points, however, are a poor match to DES data from Smith et al. (2020) (black) in SFR–stellar mass (SFR-M*) space (lower left-hand panel), especially in the SFR distribution. A random sampling of CosmoDC2 galaxies which is associated with snana transients via a realistic WGTMAP (yellow) yields more realistic SFR–M* results but does worse in colour–magnitude space. Notably, the yellow distribution in g − r is in strong disagreement with GHOST. Simulations using both HOSTLIB and WGTMAP (green at right) result in decent matches to both data sets in both parameter spaces. In all plots, the redshift range is limited to z < 0.85 to enable fairer comparison with observational data. In the lower plots, the simulations are further limited to r < 23.8, the 10σ magnitude limit for the DES3YR sample, for optimal comparison.
9 CATALOGUE ACCESS AND INTENDED USE
The SCOTCH catalogues are presented in HDF5 format and can be accessed on Zenodo at https://zenodo.org/record/7563623#.Y8_2my9h2yA. There are two separate catalogues, one for transients and one for hosts, which can be cross-matched to access the complete associated host-transient information. The properties of the transient and host catalogue are listed in Tables 4 and 5, respectively. Each transient in the catalogue is assigned a unique transient ID (TID) and each host a unique galaxy ID (GID), which are reported in both catalogues to enable cross-matching. If an event is considered hostless using our pipeline, we include an associated entry in the host catalogue with a unique GID, but populate the host properties with filler values (999).
Summary of the transient information in the SCOTCH catalogue.
| Variable | Summary |
|---|---|
| TID | Transient ID |
| z | True Redshift (of host and transient) |
| GID | Host-galaxy ID |
| MJD | Array of Modified Julian Dates of light curve observations (only spacing is meaningful) |
| m<band > | Apparent brightness in LSST ugrizY bands (AB magnitudes) |
| Class | Transient class |
| Model | Simulation model from Table 2 |
| Cadence | Time-spacing of light curve samples (days) |
| |$\rm RA_{\rm off}$| | Transient offset from host nucleus in RA (arcsec) |
| |$\rm \delta {\rm off}$| | Transient offset from host nucleus in Dec. (arcsec) |
| Sep | Total great-circle distance between transient and host nucleus (arcsec) |
| Variable | Summary |
|---|---|
| TID | Transient ID |
| z | True Redshift (of host and transient) |
| GID | Host-galaxy ID |
| MJD | Array of Modified Julian Dates of light curve observations (only spacing is meaningful) |
| m<band > | Apparent brightness in LSST ugrizY bands (AB magnitudes) |
| Class | Transient class |
| Model | Simulation model from Table 2 |
| Cadence | Time-spacing of light curve samples (days) |
| |$\rm RA_{\rm off}$| | Transient offset from host nucleus in RA (arcsec) |
| |$\rm \delta {\rm off}$| | Transient offset from host nucleus in Dec. (arcsec) |
| Sep | Total great-circle distance between transient and host nucleus (arcsec) |
Summary of the transient information in the SCOTCH catalogue.
| Variable | Summary |
|---|---|
| TID | Transient ID |
| z | True Redshift (of host and transient) |
| GID | Host-galaxy ID |
| MJD | Array of Modified Julian Dates of light curve observations (only spacing is meaningful) |
| m<band > | Apparent brightness in LSST ugrizY bands (AB magnitudes) |
| Class | Transient class |
| Model | Simulation model from Table 2 |
| Cadence | Time-spacing of light curve samples (days) |
| |$\rm RA_{\rm off}$| | Transient offset from host nucleus in RA (arcsec) |
| |$\rm \delta {\rm off}$| | Transient offset from host nucleus in Dec. (arcsec) |
| Sep | Total great-circle distance between transient and host nucleus (arcsec) |
| Variable | Summary |
|---|---|
| TID | Transient ID |
| z | True Redshift (of host and transient) |
| GID | Host-galaxy ID |
| MJD | Array of Modified Julian Dates of light curve observations (only spacing is meaningful) |
| m<band > | Apparent brightness in LSST ugrizY bands (AB magnitudes) |
| Class | Transient class |
| Model | Simulation model from Table 2 |
| Cadence | Time-spacing of light curve samples (days) |
| |$\rm RA_{\rm off}$| | Transient offset from host nucleus in RA (arcsec) |
| |$\rm \delta {\rm off}$| | Transient offset from host nucleus in Dec. (arcsec) |
| Sep | Total great-circle distance between transient and host nucleus (arcsec) |
Summary of the host galaxy information in the SCOTCH catalogue. We note that the original CosmoDC2 catalogue contains inaccurate ellipticities due to a bug; in SCOTCH, we report the corrected ellipticity and minor axis values following the corrections from https://github.com/LSSTDESC/gcr-catalogs/blob/ellipticity_bug_fix/GCRCatalogs/cosmodc2.py.
| Variable | Summary |
|---|---|
| GID | Host-galaxy ID |
| TID | Transient ID |
| dc2ID | ID of corresponding CosmoDC2 galaxy |
| m<band > | Apparent AB magnitudes in LSST ugrizY bands |
| σm, <band > | 10-yr estimated apparent AB magnitude errors for LSST |
| e | Shear ellipticity (1 − q)/(1 + q), where q is the axis ratio |
| Rd | Disc half-light radius in physical kpc |
| Rs | Spheroid half-light radius in physical kpc |
| log (M*) | Log stellar mass (M⊙) |
| log (SFR) | Log star formation rate (M⊙ yr–1) |
| ni | Sersic index for i = [0, 1]; n0 = 1 (exponential disc) and n1 = 4 (deVaucouleurs bulge) |
| wi | Weight of i = [0, 1] Sersic components (bulge and disc) |
| ai | Major-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| bi | Minor-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| ei | Ellipticity of i = [0, 1] Sersic components |
| etot | Luminosity-weighted sum of bulge and disc ellipticities |
| arot | Rotation angle of major axis with respect to the +RA coordinate (°) |
| Variable | Summary |
|---|---|
| GID | Host-galaxy ID |
| TID | Transient ID |
| dc2ID | ID of corresponding CosmoDC2 galaxy |
| m<band > | Apparent AB magnitudes in LSST ugrizY bands |
| σm, <band > | 10-yr estimated apparent AB magnitude errors for LSST |
| e | Shear ellipticity (1 − q)/(1 + q), where q is the axis ratio |
| Rd | Disc half-light radius in physical kpc |
| Rs | Spheroid half-light radius in physical kpc |
| log (M*) | Log stellar mass (M⊙) |
| log (SFR) | Log star formation rate (M⊙ yr–1) |
| ni | Sersic index for i = [0, 1]; n0 = 1 (exponential disc) and n1 = 4 (deVaucouleurs bulge) |
| wi | Weight of i = [0, 1] Sersic components (bulge and disc) |
| ai | Major-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| bi | Minor-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| ei | Ellipticity of i = [0, 1] Sersic components |
| etot | Luminosity-weighted sum of bulge and disc ellipticities |
| arot | Rotation angle of major axis with respect to the +RA coordinate (°) |
Summary of the host galaxy information in the SCOTCH catalogue. We note that the original CosmoDC2 catalogue contains inaccurate ellipticities due to a bug; in SCOTCH, we report the corrected ellipticity and minor axis values following the corrections from https://github.com/LSSTDESC/gcr-catalogs/blob/ellipticity_bug_fix/GCRCatalogs/cosmodc2.py.
| Variable | Summary |
|---|---|
| GID | Host-galaxy ID |
| TID | Transient ID |
| dc2ID | ID of corresponding CosmoDC2 galaxy |
| m<band > | Apparent AB magnitudes in LSST ugrizY bands |
| σm, <band > | 10-yr estimated apparent AB magnitude errors for LSST |
| e | Shear ellipticity (1 − q)/(1 + q), where q is the axis ratio |
| Rd | Disc half-light radius in physical kpc |
| Rs | Spheroid half-light radius in physical kpc |
| log (M*) | Log stellar mass (M⊙) |
| log (SFR) | Log star formation rate (M⊙ yr–1) |
| ni | Sersic index for i = [0, 1]; n0 = 1 (exponential disc) and n1 = 4 (deVaucouleurs bulge) |
| wi | Weight of i = [0, 1] Sersic components (bulge and disc) |
| ai | Major-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| bi | Minor-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| ei | Ellipticity of i = [0, 1] Sersic components |
| etot | Luminosity-weighted sum of bulge and disc ellipticities |
| arot | Rotation angle of major axis with respect to the +RA coordinate (°) |
| Variable | Summary |
|---|---|
| GID | Host-galaxy ID |
| TID | Transient ID |
| dc2ID | ID of corresponding CosmoDC2 galaxy |
| m<band > | Apparent AB magnitudes in LSST ugrizY bands |
| σm, <band > | 10-yr estimated apparent AB magnitude errors for LSST |
| e | Shear ellipticity (1 − q)/(1 + q), where q is the axis ratio |
| Rd | Disc half-light radius in physical kpc |
| Rs | Spheroid half-light radius in physical kpc |
| log (M*) | Log stellar mass (M⊙) |
| log (SFR) | Log star formation rate (M⊙ yr–1) |
| ni | Sersic index for i = [0, 1]; n0 = 1 (exponential disc) and n1 = 4 (deVaucouleurs bulge) |
| wi | Weight of i = [0, 1] Sersic components (bulge and disc) |
| ai | Major-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| bi | Minor-axis half-light size (arcsec) for i = [0, 1] Sersic components |
| ei | Ellipticity of i = [0, 1] Sersic components |
| etot | Luminosity-weighted sum of bulge and disc ellipticities |
| arot | Rotation angle of major axis with respect to the +RA coordinate (°) |
We additionally provide dc2ID, the original ID of each galaxy within the CosmoDC2 catalogue, so that users can query the CosmoDC2 image simulations13 for additional properties. For example, although SCOTCH erases the realistic position information of host galaxies due to the necessary repeat use of HOSTLIB galaxies (see Section 4), if a user is interested in the original position and large-scale environment of a galaxy, e.g. to check whether the galaxy was a cluster member, they may retrieve the relevant information from CosmoDC2. A user in need of host galaxy SED information may access the original CosmoDC2 SED, find the amount that the galaxy’s redshift has changed from CosmoDC2 to SCOTCH, and red- or blue-shift the SED accordingly. However, we warn that for kilonova hosts in particular, the magnitude and colours of SCOTCH hosts are not directly traceable to the CosmoDC2 native values, as the kilonova host galaxy magnitudes in SCOTCH have been shifted (Section 6.6). In the case of hostless events, the dc2ID of the galaxy which was rejected by the dDLR threshold is included in order to enable fetching information about the rejected host.
With top-of-the-galaxy observing conditions, users aiming to simulate optical surveys with similar passbands to LSST have a straightforward path to forecasting survey data. The path would include converting the magnitudes accordingly, subselecting events according to expected survey densities, updating transient and host positions to span the survey footprint, and implementing Galactic extinction and atmospheric noise. The ideally sampled light curves can be degraded by adding noise and by sub-sampling as needed. We provide a series of basic tutorials for querying the catalogue and post-processing the data in Appendix B, available in the online Supplementary Materials.
Due to the increased volumes at higher redshifts in the Universe and the fact that we simulate a fixed number of transient events per class, the full z < 3 catalogue is sparsely populated at very low redshifts. Users wishing to access a larger amount of low-z data may alternatively make use of an additional z-limited catalogue that we release. In this catalogue, we restrict the maximum z to 0.8 for each transient class so that the same number of events N as the full catalogue, as given in Table 2, are generated at lower redshifts. The z < 3 catalogue is named SCOTCH_Z3 and the additional catalogue is named SCOTCH_ZLIM.
For users wishing to simulate significantly different surveys, we also provide the HOSTLIBs and WGTMAPs in the Zenodo release for re-running the snana simulation code.
10 CONCLUSIONS AND DISCUSSION
We have presented our methodology for constructing the SCOTCH catalogue, a data set consisting of multiple classes of simulated transients and their host galaxies. The final catalogue includes 5-million light curves for 10 distinct classes of supernovae and 3 additional transient classes, as well as the observed and derived properties of their host galaxies and physically motivated offsets between the galaxy and transient positions. The cadence of these simulated light curves is class-specific in order to resolve rapidly evolving features while limiting total data volumes. This catalogue significantly advances the framework for simulating the time-domain sky initially constructed for PLAsTiCC, which included minimal host-galaxy information.
This catalogue can be used for a broad range of scientific studies. First, teams developing transient classification algorithms for upcoming surveys can test the value of large samples of realistic host information. This added contextual information may help classify transients earlier in their light curves, facilitating rapid follow-up of interesting objects. Host information can also increase the precision of classifications, of particular value for collecting large uncontaminated samples of Type Ia supernovae for precision dark energy measurements. However, users should take caution when training classifiers on this catalogue, as overconfidence in the correlations represented therein could limit classifiers from finding transients in hosts not described by extant samples. We have not attempted to include any anomalies in the catalogue to mitigate this problem. Additionally, this catalogue is missing some known transient classes, and does not include any mock new classes of transients. Classifier trained for anomaly detection should be able to flag a totally unknown class of event in an upcoming survey, and this will be an important aspect of upcoming surveys.
Beyond classification, this catalogue can be used to forecast future population-level studies of transients – e.g. for progenitor studies or cosmological applications – using upcoming survey data. Besides the LSST-specific passbands, the catalogue is not tailored to fit the observational limitations of any particular survey. With empirically derived transient rates extrapolated to z = 3 and host galaxy magnitudes as faint as r = 28, users can post-process the catalogue to reflect the expected footprint, depth, and observational biases of planned surveys. The catalogue can then be used to generate a proof-of-concept for science ideas, forecast results, estimate expected biases, and test new methods to mitigate them.
Although not the focus of this work, the validated correlations between simulated SNe Ia and their host galaxies are encouraging. Because we have linked the properties of observed SN Ia host galaxies to synthetic galaxies in CosmoDC2, myriad intrinsic host properties are available. The authors encourage future catalogue users to evaluate the use of synthetic SNe Ia for cosmological analyses, and explore additional correlations between Hubble Residuals and the CosmoDC2 properties of host galaxies.
The realism of this simulated catalogue is limited by approximations made during the simulation pipeline and the limitations of pre-existing transient-host galaxy catalogues. Here, we re-emphasize several points and discuss opportunities for future improvements.
Generally, we allow the catalogue to reflect the trends seen in the existing data, so that developers of classification algorithms can better incorporate host galaxy information where available. The classes with the sparsest currently available data will have the least accurate host property distributions. Thus the transient-host correlations learned by a classifier trained on SCOTCH may be revealed to be too strong, or even fully inaccurate, with future data influxes.
Future updates to the catalogue should seek to augment the small samples with recent data. For example, the Transient Host Exchange (Qin et al. 2022) could be ingested into our simulation framework to incorporate additional data into the existing SCOTCH classes as well as expand to more classes. During the writing of this work, the first long-duration GRB (lGRB) was discovered with evidence for coincident kilonova emission (Rastinejad et al. 2022). This result underscores our limited understanding of these events. Should additional future events be discovered with joint lGRB-KN emission, upcoming iterations of host galaxy simulations should include the properties of lGRB host galaxies as possible KN sites. The authors will consider incorporating this in future SCOTCH releases given sufficient demand. Finally, while preparing this manuscript, O’Connor et al. (2022) also investigated a series of high-redshift (z < 2) sGRB host galaxies and found a potential increase in the number of hostless events with redshift. Given the small number of observed sGRBs considered in this study, additional work should be devoted to identifying and integrating correlations among high-z samples.
In addition, a major approximation in SCOTCH is that the hosts and transients are not distributed in a realistic large-scale-structure. Although the relative offsets between transients and their host galaxies are physically motivated, we have avoided placing these systems on the sky so that the catalogue may be of general use for generating synthetic transient catalogues for both Northern and Southern hemispheres surveys by the user. Therefore, the SCOTCH catalogue cannot be used to forecast cosmological applications of surveys that rely on realistic positions or velocities within the large-scale structure. Previous studies have found SNe to be highly clustered within the large-scale structure of the Universe (Tsaprazi et al. 2022), so at the very least, retaining the locations of the synthetic SNe hosts within their simulated cosmic web environment would be a major improvement in realism. To retain large-scale structure information while matching empirically determined transient rates, it is necessary to have very large HOSTLIBs. The current computational time required to read the large files into memory many times during the simulation is a bottleneck. In addition, retaining realistic position information would limit the sky area to the 440 deg2 currently simulated in CosmoDC2, which is less helpful for creating survey mocks. The future release of 5000 deg2 of CosmoDC2 will present an opportunity for expansion, while other larger volume synthetic galaxy catalogues could also be explored (e.g. Buzzard et al. 2019).
Another possible extension of this work is to implement correlations between a transient and its location within a galaxy, as multiple studies have revealed local transient correlations (for example, with the amount of host-galaxy extinction for SNe Ia; see Holwerda 2008; Holwerda et al. 2015; Popovic et al. 2021). For some classes (e.g. TDEs), this local information may be more valuable in early classification than global host galaxy information (Gomez et al. 2022).
In addition to these catalogue-level corrections, our methods could be expanded to produce simulated images. This is a non-trivial issue because the transient image must be overlaid on the host galaxy image as well as surrounded by a realistic background which accurately reflects the galaxy density at the location in the simulation (which would require the preservation of large-scale structure information). Machine learning-based algorithms such as Generative Adversarial Networks (GAN) have shown significant promise in generating galaxy images that are both survey-specific and realistic (Fussell & Moews 2019; Dia et al. 2020; Buncher, Sharma & Carrasco Kind 2021, among others), and conditional networks allow for the encoding of model-specific parameters in generated images (Ravanbakhsh et al. 2016). A generative model conditioned on transient and host galaxy correlations, along with local galaxy density, could be used to rapidly generate realistic images for the systems in the SCOTCH sample. This framework would represent a significant milestone towards complete end-to-end validation of survey infrastructure.
SUPPORTING INFORMATION
Appendix A. Approximate nearest-neighbours matching of GHOST and CosmoDC2 galaxies with ANNOY.
Appendix B. Using the SCOTCH catalogue.
Please note: Oxford University Press is not responsible for the content or functionality of any supporting materials supplied by the authors. Any queries (other than missing material) should be directed to the corresponding author for the article.
ACKNOWLEDGEMENTS
We thank the referee for their invaluable comments, which improved the clarity of the manuscript and quality of the simulations.
This paper has undergone internal review in the LSST Dark Energy Science Collaboration. The internal reviewers were Eve Kovacs, Christopher Frohmaier, Benjamin Rose, and Douglas Clowe. The authors thank the internal reviewers for their thorough reviews of this work, which have improved both its content and presentation.
The DESC acknowledges ongoing support from the Institut National de Physique Nucléaire et de Physique des Particules in France; the Science and Technology Facilities Council in the United Kingdom; and the Department of Energy, the National Science Foundation, and the LSST Corporation in the United States. DESC uses resources of the IN2P3 Computing Center (CC-IN2P3–Lyon/Villeurbanne - France) funded by the Centre National de la Recherche Scientifique; the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility supported by the Office of Science of the U.S. Department of Energy under contract No. DE-AC02-05CH11231; STFC DiRAC HPC Facilities, funded by UK BEIS National E-infrastructure capital grants; and the UK particle physics grid, supported by the GridPP Collaboration. This work was performed in part under DOE Contract DE-AC02-76SF00515.
ML acknowledges the support of the Natural Sciences and Engineering Research Council of Canada (NSERC) [PGSD3 - 559296 - 2021]. ML also partially conducted this research while supported by the Queen Elizabeth II/Graduate Scholarships in Science and Technology (QEII-GSST).
AG is supported by the National Science Foundation Graduate Research Fellowship Program under grant no. DGE-1746047. AG further acknowledges funding from the Center for Astrophysical Surveys Fellowship at UIUC/NCSA and the Illinois Distinguished Fellowship.
The Pan-STARRS1 Surveys (PS1) and the PS1 public science archive have been made possible through contributions by the Institute for Astronomy, the University of Hawaii, the Pan-STARRS Project Office, the Max-Planck Society and its participating institutes, the Max Planck Institute for Astronomy, Heidelberg and the Max Planck Institute for Extraterrestrial Physics, Garching, The Johns Hopkins University, Durham University, the University of Edinburgh, the Queen’s University Belfast, the Harvard-Smithsonian Center for Astrophysics, the Las Cumbres Observatory Global Telescope Network Incorporated, the National Central University of Taiwan, the Space Telescope Science Institute, the National Aeronautics and Space Administration under grant no. NNX08AR22G issued through the Planetary Science Division of the NASA Science Mission Directorate, the National Science Foundation Grant No. AST-1238877, the University of Maryland, Eotvos Lorand University (ELTE), the Los Alamos National Laboratory, and the Gordon and Betty Moore Foundation.
The Dunlap Institute is funded through an endowment established by the David Dunlap family and the University of Toronto. The authors at the University of Toronto acknowledge that the land on which the University of Toronto is built is the traditional territory of the Haudenosaunee, and most recently, the territory of the Mississaugas of the New Credit First Nation. R.H is a CIFAR Azrieli Global Scholar in the Gravity and the Extreme Universe Program, and acknowledges funding from the Alfred P. Sloan Foundation, the National Science and Engineering Research Council of Canada and the Connaught Fund.
This research made use of the ‘K-corrections calculator’ service available at http://kcor.sai.msu.ru/.
This work was partially enabled by funding from the UCL Cosmoparticle Initiative.
LS is supported by the Data Science in MultiMessenger Astrophysics program at the University of Minnesota.
JFC is supported by the U.S. Department of Energy, Office of Science, under Award DE-SC0011665.
AIM acknowledges support from the Max Planck Society and the Alexander von Humboldt Foundation in the framework of the Max Planck-Humboldt Research Award endowed by the Federal Ministry of Education and Research.
This project uses models developed for the Photometric LSST Astronomical Time-series Classification Challenge. PLAsTiCC was a joint project between the Dark Energy Science Collaboration and Transient and Variable Stars Science Collaboration, and was supported by a LSST Enabling Science Grant, as well as funding from Kaggle, a subsidiary of Google.
This research has made use of the GHostS data base (www.grbhosts.org), which is partly funded by Spitzer/NASA grant RSA Agreement No. 1287913.
DATA AVAILABILITY
The simulated data are available at https://zenodo.org/record/7563623#.Y8_2my9h2yA (Lokken et al. 2022). Any updates after the publication of this manuscript will be given a unique Zenodo identifier and link, and accompanied by text describing the changes. The most up-to-date version can always be accessed using https://doi.org/10.5281/zenodo.6601210. All code used for this project is publicly visible at https://github.com/LSSTDESC/transient-host-sims. Users are encouraged to report any catalogue problems or bugs in the code via GitHub Issues or by e-mail to the authors. The Supplementary Materials to this paper, available online, include a description of the nearest-neighbours matching from Section 5.3 (Appendix A) and a description of the catalogue walk-through tutorials (Appendix B).
Footnotes
A full list of the imposed quality cuts can be found at the GitHub repository for this work.
We consider the two-component model here; ‘BULLA-BNS-M2-2COMP’ in the snana package data.
CosmoDC2_v1.1.4_image at https://data.lsstdesc.org/doc/cosmodc2.
REFERENCES
Author notes
National Science Foundation Graduate Research Fellow.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}