





ABSTRACT
We look at the distribution of the Bayesian evidence for mock realizations of supernova and baryon acoustic oscillation data. The ratios of Bayesian evidence of different models are often used to perform model selection. The significance of these Bayes factors is then interpreted using scales such as the Jeffreys or Kass & Raftery scale. First, we demonstrate how to use the evidence itself to validate the model, that is to say how well a model fits the data, regardless of how well other models perform. The basic idea is that if, for some real data set, a model’s evidence lies outside the distribution of evidence that result when the same fiducial model that generates the data sets is used for the analysis, then the model in question is robustly ruled out. Further, we show how to assess the significance of a hypothetically computed Bayes factor. We show that the range of the distribution of Bayes factors can greatly depend on the models in question and also the number of data points in the data set. Thus, we have demonstrated that the significance of Bayes factors needs to be calculated for each unique data set.
1 INTRODUCTION
Modern cosmology, in its current ‘precision era’, requires a thorough understanding of the employed statistical methodology in order to make robust inferences from the data. This is especially important with regards to understanding the plethora of statistical ‘tensions’ that have cropped up in the past years, which have the potential to challenge the current concordance model of cosmology ΛCDM (cosmological constant dark energy; cold dark matter). The most notorious tension is the ‘H0 tension’ that is the disagreement between the local expansion rate inferred by Planck’s measurement of the cosmic microwave background (CMB; Planck Collaboration VI 2020) and that value directly measured by observations of Cepheids by the SH0ES collaboration (Riess et al. 2019). These tensions are often investigated in terms of a model selection question where the ΛCDM model is compared to some new model (Joachimi et al. 2021; Tröster et al. 2021). The comparison is typically performed by computing the Bayes factor Bij = log Zi/Zj, where Z is the evidence, P(D|Mi, j), the probability of the data, D, given model Mi, j. If Bij > 0, the model i is favoured over model j and vice versa. This quantity is useful since using Bayes’ theorem P(Mi|D) = P(D|Mi)P(Mi)/P(D), and using equal prior probabilities for the models, implies that Bij = log P(Mi|D)/P(Mj|D). Thus, the Bayes factor corresponds to the relative probability of one model over another.
Seminal works that have laid the ground work for the adoption of Bayesian statistics in cosmology include Trotta (2007, 2008) and Liddle (2007). In particular, Trotta (2007) introduces the Savage–Dickey ratio that is an efficient way to calculate the Bayes factor for the case where the two models in question are nested.
There are a few drawbacks to this inference procedure. The first problem is that this procedure is inherently a comparison; it can only determine which model is better or worse, not whether either model is a good fit to the data in an absolute sense. In other words, it is useful only for model selection, not for model validation. This is an important point to keep in mind since there is no reason to believe that the true model of the Universe, whatever it may be, could be guessed at and so included as a discrete choice in this model selection procedure.
The second drawback is a question of significance. The mathematics of the procedure returns a number. It is a further step of human interpretation to decide what that number means in terms of whether we should believe one model is true and the other is false. This interpretation is done with one of the two commonly used scales, the Jeffreys scale (Jeffreys 1961) and the Kass & Raftery scale (Kass & Raftery 1995, see Table 1). However, these scales are not a one size fits all solution. Of course, determining a criteria for mapping the value of a statistic and significance is arbitrary and so either of these scales could serve as the mapping between the statistic and significance. However, physics already employs a criteria to determine whether a signal is significant, the oft-quoted ‘5σ’ p-value. A p-value is the probability of observing a signal given that a null hypothesis is true. This p-value is a frequentist statistic so, at first, it may seem counter intuitive to use a frequentist criteria for a Bayesian calculation. However, it is a meaningful question to ask what is the distribution of any statistic over different realizations of the data, even the Bayesian evidence.
The Jeffreys and Kass–Raftery scales.
| Jeffreys scale Zi/Zj | Kass–Rafferty scale Zi/Zj | Interpretation |
|---|---|---|
| 1–3.2 | 1–3 | Not worth mentioning |
| 3.2–10 | 3–20 | Positive |
| 10–100 | 20–150 | Strong |
| > 100 | >150 | Very strong |
| Jeffreys scale Zi/Zj | Kass–Rafferty scale Zi/Zj | Interpretation |
|---|---|---|
| 1–3.2 | 1–3 | Not worth mentioning |
| 3.2–10 | 3–20 | Positive |
| 10–100 | 20–150 | Strong |
| > 100 | >150 | Very strong |
The Jeffreys and Kass–Raftery scales.
| Jeffreys scale Zi/Zj | Kass–Rafferty scale Zi/Zj | Interpretation |
|---|---|---|
| 1–3.2 | 1–3 | Not worth mentioning |
| 3.2–10 | 3–20 | Positive |
| 10–100 | 20–150 | Strong |
| > 100 | >150 | Very strong |
| Jeffreys scale Zi/Zj | Kass–Rafferty scale Zi/Zj | Interpretation |
|---|---|---|
| 1–3.2 | 1–3 | Not worth mentioning |
| 3.2–10 | 3–20 | Positive |
| 10–100 | 20–150 | Strong |
| > 100 | >150 | Very strong |
A third drawback is that Bayesian evidence generally depend on the subjective choice of a prior. Common choices of such a prior includes the flat prior, where the prior probability of a value of a parameter being true is uniform over some domain. This is often a good choice since such a flat prior reflects a maximum amount of agnosticism about the value of a parameter. However, flat priors are not invariant under changes in parametrization, e.g. flat in P(θ) is not flat in P(log θ). Further, any uniform distribution is only well defined if the domain is finite, e.g. we might say Ωm is free to vary in the range [0,1]. However, since the Bayesian evidence is the average of the likelihood over the prior volume, if the volume were expanded to include regions of low likelihood, then the evidence will decrease.
Previous studies have investigated the utility of Bayes factors and the Jeffreys scale for performing model selection (Starkman, Trotta & Vaudrevange 2008; Jenkins & Peacock 2011; Raveri & Hu 2019; Joachimi et al. 2021). For instance, Jenkins & Peacock (2011) treat the evidence ratio as a statistic and point out that it is noisy (see also Joachimi et al. (2021)) and thus selecting models based solely on that number may be insufficient. Both Jenkins & Peacock (2011), Joachimi et al. (2021) find that the log of the evidence should have a variance that scales with the number of data points. Furthermore, Nesseris & García-Bellido (2013) calculate false-positive and false-negative rates when using the Jeffreys scale to select a particular class of models. Specifically, the models they consider have predictions that are linear in their parameters. The different models considered in that paper are all nested with different numbers of parameters. That is, model M2 has one extra parameter compared to M1 and for a certain value for that extra parameter, reduces to M1. The authors show that the Jeffreys scale can fail to penalize extra degrees of freedom when mock data was generated from the simpler model. They show that the frequency of this failure is influenced by the choice of prior. The authors conclude that the Bayes factor should not be the only tool used for model selection.
Another recent, companion paper points out related short comings of using the Bayes factor. Specifically, Koo et al. (2021a) demonstrate that, if the true model is not an option when calculating Bayes factors, such a scheme will still pick some false model as being best and thus not rule it out. They go on to show that the distribution of likelihoods from the iterative smoothing method (Shafieloo 2007; Shafieloo et al. 2006) can rule out all false models (Koo et al. (2021b). The current work takes inspiration from the methodology of that paper and shows how to use a models’ evidence alone, not the Bayes factors, to determine if a model is a good fit to the data regardless of how well other models perform.
In contrast to questions of model selection, which are often answered by computing Bayes factors, there are questions of model validation that are answered with other statistical tools. Such ‘goodness-of-fit’ tests can come in frequentist forms, such as the χ2 test, or Bayesian forms, such as the posterior predictive distribution (Doux et al. 2021).
In this paper, we seek to develop a methodology to address these three drawbacks of using Bayes factors for model comparison. We first calculate the distribution of the Bayesian evidence, for data sets commonly used in cosmology, and show how to use this distribution to answer the question of whether a model is a good fit to the data, irrespective of other models. Further, for these same data sets, we show how to assign a frequentist p-value to the Bayes factor to characterize significance when used for model comparison.
2 MOCK DATA
The approach to calculating the distribution of the Bayesian evidence is to generate a hundred mock realizations of the data and then calculate the Bayesian evidence for each one. The data sets that we use for this calculation are mock future supernova (SN) data sets as might be expected from the WFIRST telescope (Green et al. 2012; Spergel et al. 2015) and future baryon acoustic oscillation (BAO) data sets as might be expected from DESI (DESI Collaboration et al. 2016a,b).
We generate 100 realizations of the combined data sets for each of the three models in question (see Section 3) for a total of 300 mock data sets. The seed is fixed for the different models so the residuals are the same. As in, there are only 100 unique realizations of the residuals.
3 MODELS
The evidence are calculated using multinest (Feroz & Hobson 2008; Feroz, Hobson & Bridges 2009; Feroz et al. 2019), specifically the importance nested sampling algorithm, with 400 live points, a sampling efficiency of 0.3, and an evidence tolerance of 0.1.
We also investigate the case where the models in question have different degrees of freedom. Specifically, we look at the cases where we allow the curvature to vary in our models, though the data is still generated from the case where the curvature is fixed to be 0. We call these models where the curvature (Ωk) is allowed to vary, kTDE, kPEDE, and kΛCDM.
4 RESULTS
In Fig. 2, we see the distributions of the log evidence for nine different cases (three models were used to generate the data and three models were used for inference). Of particular note are the cases where the model being used to infer the evidence is the one used to generate the data. The distributions for these cases are exactly the same and lie on top of each other in the figure. This is expected since generating these mock data sets is essentially generating random residuals and these random residuals are the same between the different models. Additionally, the fact that the models have the same parameters that are allowed to vary is also necessary for the distributions to be identical. This distribution of the evidence can be used as a robust test of validation, to see if a model is a good fit to the data. To perform this test, we take the evidence calculated with real data and some model to be validated and compare it to the distribution calculated with that same model. If the evidence calculated with real data lies outside this distribution, then we can robustly say that model is ruled out or invalidated, regardless of how well other models perform.

One example mock data set (generated from the fiducial ΛCDM model) along with the predictions of our three considered models, ΛCDM, TDE, and PEDE, that are best fit to the data.
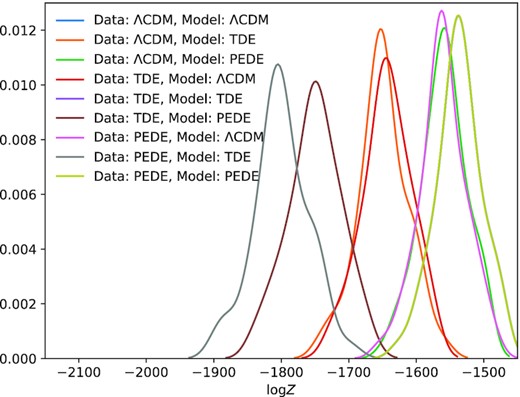
Distribution of the log evidence for mock data sets generated from the model labelled on the left, inferred using the model labelled on the top. Of particular note is that the distributions for the cases that the model used for the inference is the same as the one used for the data generation are all exactly the same.
In Fig. 3, we see the distributions of the differences in the log evidence for each of the three pairwise combination of models for each of the three models used to generate the data sets. To explain the figure’s labels, the difference is such that Δlog Z = log ZL − log ZR so positive values represent a preference for the model on the left. Basic expectations are borne out by this figure. The model used to generate the data always performs better than a false model. Further, since the TDE model is a quintessent dark energy model in the regime where there is the most data, and since the PEDE model is always phantom, ΛCDM is preferred over the TDE model when the PEDE model is true, and ΛCDM is also preferred over the PEDE model when the TDE model is true. Further, PEDE is closer to ΛCDM and thus it is preferred over TDE when ΛCDM is the true model. That Δlog Z = 0 is outside the distribution in all these cases indicates that, for this optimistic forecast for DESI BAO data and WFIRST SN data, these dark energy models should be imminently distinguishable. One point that is worth bringing up is that the range of these distributions is noticeably different. For different model comparisons, the scatter in the Δlog Z values will be different. This goes to show that using a fixed scale like the Jeffreys or the Kass & Rafferty scale cannot serve as one size fits all solutions to the interpretation of Bayes factors. Indeed, for different data sets and models, one would need to calculate these kinds of distributions to make robust inferences about Bayes factors.
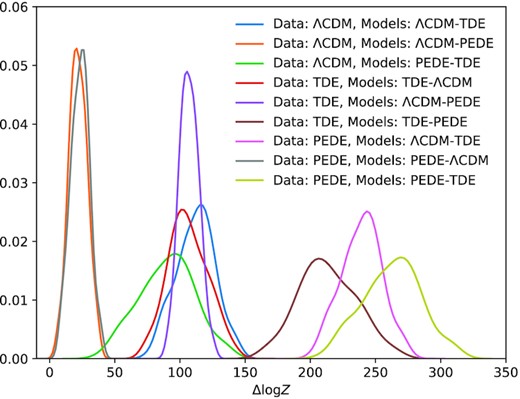
Distribution of the difference in the log evidence for mock data sets generated from the model labelled on the left, inferred using the models labelled on the top. The labels on the top refer the log evidence of the first model minus the log evidence of the second model.
In Fig. 4, we see the distribution of evidence for the specific case of when the data is generated from the TDE model. This figure is useful to make an easy comparison to Koo et al. (2021b). This figure also highlights one potential advantage or drawback of Bayesian methods over the distribution of likelihoods from the iterated smoothing method. The Bayesian evidence explicitly uses models and so are more interpretive and thus can say things specifically about model quantities such as curvature. However, because Bayesian methods are more interpretive, they can arrive at wrong conclusions. As is the case in this figure, when the wrong dark energy model is used in the inference, Bayesian methods can come to the wrong conclusion about the existence of curvature.
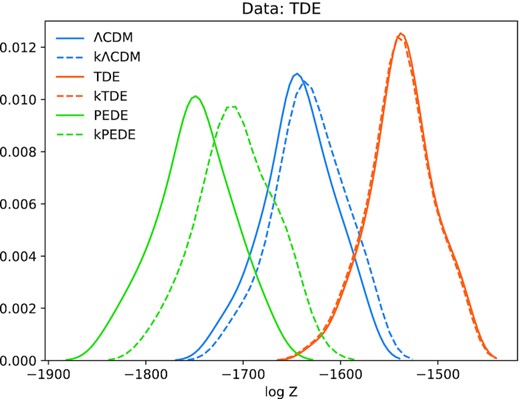
Distribution of the log evidence for mock realizations from the TDE model inferred using different models when curvature is and is not allowed to vary.
In Fig. 5, we see the distribution of the differences in the log evidence for each of the models when curvature is and is not allowed to vary. This is an example of an additional degree of freedom. In all of these cases, the data were generated from models with no amount of curvature. To explain the figure’s labels, the difference is such that Δlog Z = log Zflat − log Zcurved and so positive values in the distribution indicate that the flat model is preferred and allowing for this extra degree of freedom is disfavoured. Further, focusing on the curves where the models in question are different than the ones used to generate the data, using the wrong dark energy model can, in turn, cause wrong conclusions about whether the Universe is curved. There can either be some amount of confusion between the mismatch in the dark energy models and the curvature (cases where the distribution spans Δlog Z = 0) or there can be a significant preference for curvature when none was included in the mock data sets, as in the cases where the data was generated with the TDE model but PEDE or ΛCDM were assumed. Further, in the cases where the model used to generate the data is the same as the model used for inference, along with its extension that includes curvature, the distributions of the evidence are roughly equivalent (they each span Δlog Z ∈ [ − 1.0, 3]). In this specific case of using a known model of dark energy and inferring whether curvature is preferred, one could set the criteria for a |$\gt 99{{\ \rm per\ cent}}$| detection of curvature at Δlog Z < −1.0. Of course, we would not a priori know that we have correctly identified the true model of dark energy. Further, this calculation does not generalize to arbitrary data sets or nested models. For instance, if one were to include different data sets such as weak lensing or the CMB, or were to investigate different models, one would need to recalculate the significance of the Bayes factor value.

Distribution of the difference in the log evidence for mock data sets generated from the model labelled on the left, inferred using the models labelled on the top. The difference in the models as labelled on the top is whether curvature is allowed to vary. The difference in the log evidence is the difference between the flat version of the model minus the version where curvature is free to vary. The right-hand panel is the same as the left-hand panel but zoomed in on the region −1.0 < Δlog Z < 3.5.
In Fig. 6, we can more clearly see cases where the Jeffreys scale would return wrong conclusions. The mock data used in this analysis is the same as above except now the errors are 10 times larger. To elaborate, the data are generated with uncertainties that are 10 times larger than the normal case, and the likelihood in the analysis for this case uses the same expanded uncertainties. We will focus on the gold curve corresponding to the case where the PEDE model was used to generate the data and the two models being compared are the PEDE and TDE models. In that case in particular, 15 per cent of the time Δlog Z is above log (100) and 3 per cent of the time Δlog Z is below −log (100). Thus there is a non-negligible chance that this analysis would return ‘very strong’ conclusions when a more indeterminate conclusion be returned. It is additionally important to emphasize the pink curve, which corresponds to the case where the PEDE model was used to generate the data and the two models being compared are the ΛCDM and TDE models. In this case, 10 per cent of the time Δlog Z is above log (100) and 3 per cent of the time Δlog Z is below −log (10). Any strong conclusion is inaccurate in this case since the true model is not included in the inference. Similarly, we see for the for all of these cases, the scatter in Δlog Z is large compared the scale the different levels of the Jeffreys scale thus making it an unreliable tool for interpreting Bayes factors. The specific values for the frequencies of these confidently wrong conclusions is not of primary concern, but instead the concern arises from the fact these frequencies are non-negligible.
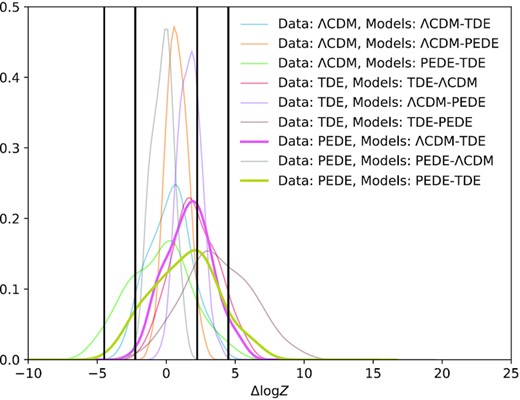
Same as Fig. 3 except now the errors on the data are 10 times larger. Since the distribution of Δlog Z spans a wide range on either side of 0, there is no insignificant chance of returning a ‘very strong’ conclusion that either model is true. The pink and gold curves are highlighted as discussion will focus on them. The gold curve illustrates this well where there is a non-negligible chance of returning very strong conclusions for both the correct and incorrect model, when a more indeterminate conclusion would be appropriate. Similarly, the case for the pink curve returns very strong or strong conclusions for two wrong models, since of course, as the true model is not included in the inference. The black vertical lines denote the ‘strong’ and ‘very strong’ regions of the Jeffreys scale.
5 DISCUSSION AND CONCLUSIONS
The first takeaway from this paper is that the models presented here should be distinguishable with future WFIRST and DESI data sets.
Secondly, is that we have shown how to use the evidence itself as a criterion for model validation, to judge if a model is a good fit to the data at all, independently of any other model. Using a distribution of the evidence for mock data generated from a model and inferred using the same model, one can see if the evidence calculated from the real data lies outside that distribution. Should the evidence computed with real data for a given model fall outside that range, then that model would be invalidated. The distribution of the evidence can be used to calculate the mapping between the Bayesian evidence and a p-value and determine a model-independent criteria to answer the question: ‘Below what value would the Bayesian evidence have to be to conclude a model is not a good fit to the data?’
A third takeaway is that we have demonstrated interpreting Bayes factors using fixed scales, like the Jeffreys or Kass & Rafferty scales, can yield incorrect conclusions. This is seen in the fact that the distributions of Δlog Z span hundreds of values. Even in the case where the uncertainties in the data is 10 times larger than normal, such that the models should be indistinguishable, the scatter in the Bayes factors is large compared to the range of the Jeffreys scale and will come to correct and incorrect ‘very strong’ conclusions. Thus, blindly using a fixed scale such as the Jeffreys scale can be misleading. To accurately assess the significance of a computed Bayes factor, one should perform these kinds of calculations, generate a sample of mock data sets and calculate the Bayes factors in those cases, and then see where the Bayes factor for the real data set lies in that distribution.
Finally, we point out that the distributions of both log Z and Δlog Z depend greatly on the specifics of the data set, both the size of the covariance matrix and the nature of the data sets (e.g. BAO and SN).
ACKNOWLEDGEMENTS
We would like to thank Benjamin L’Huillier and Hanwool Koo for useful comments on the draft. This work was supported by the high performance computing cluster Seondeok at the Korea Astronomy and Space Science Institute. AS would like to acknowledge the support by National Research Foundation of Korea NRF-2021M3F7A1082053 and Korea Institute for Advanced Study (KIAS) grant funded by the Government of Korea.
DATA AVAILABILITY
The data used in this work are mocks generated by the authors, as described in the text. They are available upon request.
REFERENCES
APPENDIX A: SCALINGS WITH SIZE AND TYPES OF DATA SETS
In this Appendix, we will seek to understand the dependence of the mode and variance of the distributions of log Z on the size and kind of the data set. We will focus discussion primarily on the distributions where the models used to generate the data and make inferences from the data are the same since they should be the most generalizable case.
In Fig. A1, we can begin to see the dependence of the kind and size of data sets on the distribution of evidence. We lay out three cases where we have calculated evidence for subsets of the full data set, namely an ‘SN only’ case, a ‘BAO only’ case, and a case where we use every other data point for both kinds of data sets, which we will refer to as the ‘half’ case. To elaborate about the ‘half’ case, we include both SN and BAO information but half of the total data points of each. For the SN part of the ‘half’ case, we include the distance moduli information of the lowest redshift SN, but skip the next lowest, include the third lowest, and so on. The BAO part is similar where we include the measurement of H(z) and DM(z) for the lowest redshift bin, skip the next bin, include the third bin, and so on. This case is the simplest comparison with the full case, since both the BAO and SN data sets are included and since both span similar redshift ranges. In other words, this case should be most similar to a case with half the information and the transformation N → N/2. The point the ‘SN only’ and ‘BAO only’ cases is to demonstrate that the distributions of evidence become more distinguishable than would be expected from just increasing the number of data points. This would have to arise from the fact that degeneracies in model parameters are being broken by the different kinds of data sets.
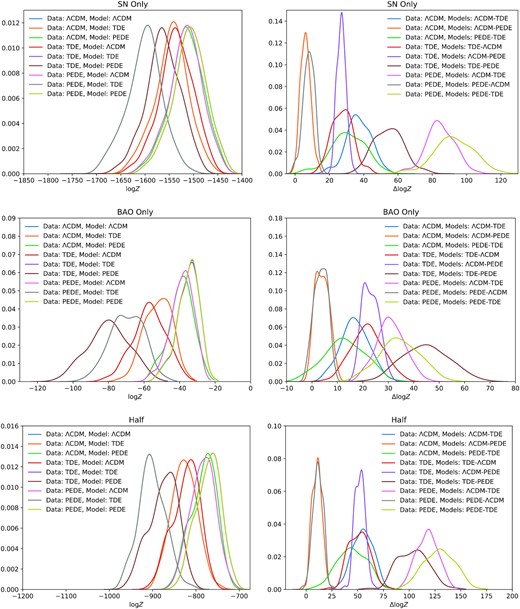
Distributions of log Z (left-hand panel) and Δlog Z (right-hand panel) for different partitions of our full data set. On the top is the distributions of evidence for only the SN data set, on the middle is the distribution of evidence for only the BAO data set, and on the bottom is the distribution of evidence for half of the full data set such that every other data point is used. The difference in scale corresponds to the difference in the number of data points in the different partitions.
For the full data set, the mode of the in-kind distributions are −1537 and they have a variance of 1107. For the ‘half’ data set, the mode of the in-kind distributions are −760 and they have a variance of 758. For the ‘BAO only’ and ‘SN only cases, we see the mode of the in-kind distributions are −33 and −1506, respectively, and their variances are 36 and 1109, respectively. From this, we see that the difference in the modes of the various cases scales as half the number of data points N/2. This result is similar to the familiar statistics of measurements of multiple Gaussian random variables, with the familiar expectations that the χ2 value of the true value scales as N/2.
Further, the difference between the left-hand panels of Figs A1 and A2, in particular that the distributions are more distinguishable in Fig. 2, arises from the fact that, more than just adding more data, the fact the BAO also constrains H(z) allows it to break degeneracies that is essential for making these distributions distinguishable. In particular, the ‘SN only’ panel of Fig. A1 has essentially the same number of data points as the full case (3000 versus 3058) but the full case is far less distinguishable. Indeed, the ‘SN only’ has a similar distinguishability as the ‘half’ case (see Table A2). Counter-intuitively, the ‘BAO only’ case is more distinguishable than the ‘half’ case and is similar to the full case. Simply adding more of the same kind of data points increases the variance of these distributions more than they separate the modes of the distributions.
The number of data points for each of the data cases, along with the mode of the in-kind distributions.
| Case | Number of data points | Mode of log Z distribution |
|---|---|---|
| Full | 3058 | −1537 |
| Half | 1530 | −760 |
| SN only | 3000 | −1506 |
| BAO only | 58 | −33 |
| Case | Number of data points | Mode of log Z distribution |
|---|---|---|
| Full | 3058 | −1537 |
| Half | 1530 | −760 |
| SN only | 3000 | −1506 |
| BAO only | 58 | −33 |
The number of data points for each of the data cases, along with the mode of the in-kind distributions.
| Case | Number of data points | Mode of log Z distribution |
|---|---|---|
| Full | 3058 | −1537 |
| Half | 1530 | −760 |
| SN only | 3000 | −1506 |
| BAO only | 58 | −33 |
| Case | Number of data points | Mode of log Z distribution |
|---|---|---|
| Full | 3058 | −1537 |
| Half | 1530 | −760 |
| SN only | 3000 | −1506 |
| BAO only | 58 | −33 |
The frequency that the not in-kind distributions are beyond the 95 per cent level of the in-kind distributions.
| Data: Model: | Full | Half | SN only | BAO only |
|---|---|---|---|---|
| (per cent) | (per cent) | (per cent) | (per cent) | |
| D:ΛCDM M:TDE | 91 | 57 | 19 | 69 |
| D:ΛCDM M:PEDE | 11 | 14 | 4 | 11 |
| D:TDE M:ΛCDM | 85 | 48 | 11 | 83 |
| D:TDE M:PEDE | 100 | 98 | 34 | 100 |
| D:PEDE M:ΛCDM | 12 | 11 | 5 | 8 |
| D:PEDE M:TDE | 100 | 99 | 80 | 100 |
| Data: Model: | Full | Half | SN only | BAO only |
|---|---|---|---|---|
| (per cent) | (per cent) | (per cent) | (per cent) | |
| D:ΛCDM M:TDE | 91 | 57 | 19 | 69 |
| D:ΛCDM M:PEDE | 11 | 14 | 4 | 11 |
| D:TDE M:ΛCDM | 85 | 48 | 11 | 83 |
| D:TDE M:PEDE | 100 | 98 | 34 | 100 |
| D:PEDE M:ΛCDM | 12 | 11 | 5 | 8 |
| D:PEDE M:TDE | 100 | 99 | 80 | 100 |
The frequency that the not in-kind distributions are beyond the 95 per cent level of the in-kind distributions.
| Data: Model: | Full | Half | SN only | BAO only |
|---|---|---|---|---|
| (per cent) | (per cent) | (per cent) | (per cent) | |
| D:ΛCDM M:TDE | 91 | 57 | 19 | 69 |
| D:ΛCDM M:PEDE | 11 | 14 | 4 | 11 |
| D:TDE M:ΛCDM | 85 | 48 | 11 | 83 |
| D:TDE M:PEDE | 100 | 98 | 34 | 100 |
| D:PEDE M:ΛCDM | 12 | 11 | 5 | 8 |
| D:PEDE M:TDE | 100 | 99 | 80 | 100 |
| Data: Model: | Full | Half | SN only | BAO only |
|---|---|---|---|---|
| (per cent) | (per cent) | (per cent) | (per cent) | |
| D:ΛCDM M:TDE | 91 | 57 | 19 | 69 |
| D:ΛCDM M:PEDE | 11 | 14 | 4 | 11 |
| D:TDE M:ΛCDM | 85 | 48 | 11 | 83 |
| D:TDE M:PEDE | 100 | 98 | 34 | 100 |
| D:PEDE M:ΛCDM | 12 | 11 | 5 | 8 |
| D:PEDE M:TDE | 100 | 99 | 80 | 100 |
For completeness, we include the distributions of Δlog Z but we will limit discussion of their scalings because these distributions will naturally depend on not just the number of data points but the differences in what the models predict and thus are not generalizable. We will point out that the variance of these distributions is large, as in the full case, and, for some cases, will occasionally come to strong incorrect conclusions, as in the case with expanded errors.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}