





Abstract
We exploit a suite of large N-body simulations (up to N = 40963) performed with abacus, of scale-free models with a range of spectral indices n, to better understand and quantify convergence of the matter power spectrum. Using self-similarity to identify converged regions, we show that the maximal wavenumber resolved at a given level of accuracy increases monotonically as a function of time. At 1 per cent level it starts at early times from a fraction of |$k_\Lambda$|, the Nyquist wavenumber of the initial grid, and reaches at most, if the force softening is sufficiently small, |${\sim}2{-}3 k_\Lambda$| at the very latest times we evolve to. At the |$5{{\ \rm per\ cent}}$| level, accuracy extends up to wavenumbers of order |$5k_\Lambda$| at late times. Expressed as a suitable function of the scale-factor, accuracy shows a very simple n-dependence, allowing a extrapolation to place conservative bounds on the accuracy of N-body simulations of non-scale-free models like LCDM. We note that deviations due to discretization in the converged range are not well modelled by shot noise, and subtracting it in fact degrades accuracy. Quantitatively our findings are broadly in line with the conservative assumptions about resolution adopted by recent studies using large cosmological simulations (e.g. Euclid Flagship) aiming to constrain the mildly non-linear regime. On the other hand, we remark that conclusions about small-scale clustering (e.g. concerning the validity of stable clustering) obtained using PS data at wavenumbers larger than a few |$k_\Lambda$| may need revision in light of our convergence analysis.
1 INTRODUCTION
The power spectrum (PS), together with its Fourier transform, the two-point correlation function (2PCF), are the most basic statistical tools employed to characterize clustering at large scales in cosmology. Building a precise theoretical framework for their calculation is crucial in order to fully exploit observational data coming from the next generation surveys, such as DESI (DESI Collaboration 2016), Vera C. Rubin Observatory LSST (Ivezić et al. 2019), or Euclid (Laureijs et al. 2011), that will open a new window in the era of ‘precision cosmology’. In this context the non-linear regime of gravitational evolution is of particular importance, as it will be a key to distinguishing among the plethora of exotic dark energy and modified gravity models (Casas et al. 2017), as well as tightly constraining the LCDM scenario. Studies have estimated that to fully exploit the observed data, the matter PS in the range of scale (0.1 ≲ k/hMpc−1 ≲ 10) needs to be determined to |$1{-}2{{\ \rm per\ cent}}$| accuracy, depending on the specifications of the survey (Huterer & Takada 2005; Kitching & Taylor 2011; Hearin, Zentner & Ma 2012). In the context of the preparation for the Euclid mission, a new study has been carried out with the goal of achieving |$1{{\ \rm per\ cent}}$| precision at non-linear scales (Knabenhans et al. 2019), which adds to the efforts of other large-volume simulations (Angulo et al. 2021; Heitmann et al. 2021; Ishiyama et al. 2021), the amendments to the widely used HaloFit Model in Takahashi et al. (2012), or the most recent updated version of HMcode (Mead et al. 2021).
In practice, calculation of predictions at these scales rely entirely on numerical simulations that use the N-body method. One important and unresolved issue in this context is the accuracy limitations on such simulations arising from the fact that they approximate the evolution of the dark matter phase space distribution using a finite particle sampling, as well as a regularization at small scales of the gravitational force. Despite the extensive use and spectacular development of N-body cosmological simulations over the last several decades, no clear consensus exists in the literature about how achieved accuracy, even for the PS, depends on the relevant parameters in an N-body simulation. Various studies have led to different conclusions [see e.g. Splinter et al. (1998), Knebe et al. (2000), Romeo et al. (2008), Joyce, Marcos & Baertschiger (2009)], and in practice very different assumptions are made by different simulators about the range of resolved wavenumbers. A crucial difficulty is that, strictly, attaining the physical limit requires extrapolating the number of particles to be so large that there are many particles inside the gravitational softening length. Such a regime is unattainable in practice as the softening itself is small in simulations resolving small scales. Alternatively convergence may be probed also by comparing between two or more codes to assess the accuracy of their results [see e.g. Schneider et al. (2016), Garrison, Eisenstein & Pinto (2019)], but this establishes only a relative convergence that can give confidence in the accuracy of the clustering calculation but does not take into account the effects of discretization and dependence on the N-body parameters.
In this article we study the small-scale resolution limits on the PS arising from finite particle density and gravitational softening. To do so we use and extend a methodology detailed in Joyce, Garrison & Eisenstein (2020; hereafter P1), which uses the property of self-similarity of ‘scale-free’ cosmological models, with an input power-law spectrum of fluctuations P(k) ∝ kn and an Einstein de Sitter expansion law, to derive resolution limits for the 2PCF. In Garrison, Joyce & Eisenstein (2021a; hereafter P2), this analysis has been extended to determine how resolution depends in detail on the gravitational softening, and in particular on whether such softening is held constant in comoving or proper coordinates. In Leroy et al. (2020), the method has been shown to be a powerful tool also to infer the accuracy of measurements of the halo mass function and halo 2PCFs. In our analysis, here we change focus to the PS, determining small-scale resolution limits for it and examine how they compare with the limits for the 2PCF. While these previous articles based their analysis on a suite of simulations of a single scale-free model, with n = −2, we extend to simulations of a range of indices. This allows us to address more precisely the question of extrapolation to non-scale-free cosmologies like the standard LCDM model. Furthermore, we are able to exploit a new set of much larger scale-free simulations (N = 40963 rather than N = 10243) that were produced on the Summit supercomputer based on the methodology of the AbacusSummit suite (Maksimova et al. 2021). These allow us, in particular, to identify more precisely the finite box size effects that are an important limiting factor for analysis of scale-free models with redder spectra. Our analysis shows that we can indeed obtain precise information about convergence and spatial resolution cut-offs for the PS as a function of time, and that a level of precision in line with the requirements of forthcoming observational programs may be achieved.
The article is structured as follows. In the next section we recall briefly what scale-free cosmologies are and explain how their self-similar evolution is able to provide a method for determining the precision with which statistical quantities are measured in N-body simulations. In Section 3, we describe our numerical simulations and then detail our calculation of the PS. In Section 4, we present and analyse our results, detailing the criteria used to identify converged values of the PS and temporal regions within which a given accuracy is attained, and using them to infer limits on resolution at small scales in the different models. Section 5 describes how the results can be extrapolated to infer conservative resolution limits in non-scale-free (LCDM type) cosmologies. In the final section, we summarize our results and discuss them in relation to both the related works P1 and P2, and more broadly to the literature on numerical study of the dark matter PS in cosmology.
2 SCALE-FREE COSMOLOGIES AND SELF-SIMILARITY
One of the limitations of using N-body simulations for the study of cosmological systems comes from its inherent discreteness, as the continuous phase space density describing dark matter is sampled using a finite number N of objects. Such simulations thus introduce a set of unphysical parameters that necessarily limit the range of time and length scales which they resolve. These parameters can be divided into the numerical parameters controlling the approximations made in the integration of the N-body dynamics and forces, and the parameters introduced in passing from the physical model to the N-body system: the mean interparticle spacing Λ, the force softening scale ϵ and the size of the periodic box L, and a starting redshift |$z$|i that can be parametrized by the value of σi(Λ, zi), the square root of the variance of normalized linear mass fluctuations in a top-hat sphere of radius Λ. We will refer to the latter as the discretization parameters.
Following this distinction, we can divide the consideration of limitations on N-body simulations into two main parts: the issue of convergence of the numerical solution of a specific configuration (fixed Λ, ϵ, L, and σi), and the convergence towards the continuum cosmological model (extrapolated by taking the appropriate limit of the discretization parameters). The former can be treated by studying stability under variations of numerical parameters such as time-stepping or force accuracy. We will discuss this point only briefly here as it has already been treated extensively in P1 and P2. The latter is more challenging and, as we have discussed in the introduction, lacks a consensus in the literature. We will be focusing primarily on it here, considering convergence to the physical limit of the matter PS.
3 NUMERICAL SIMULATIONS
3.1 Abacus code and simulation parameters
We have performed simulations using the Abacus N-body code (Garrison et al. 2021b). Abacus is designed for high-accuracy, high-performance cosmological N-body simulations, exploiting a high-order multipole method for the far-field force evaluation and GPU-accelerated pairwise evaluation for the near-field. The larger, N = 40963 simulations in this work were run as a part of the AbacusSummit project (Maksimova et al. 2021) using the Summit supercomputer of the Oak Ridge Leadership Computing Facility.
We report results here based on the simulations listed in Table 1. We have simulated three different exponents for the PS (n = −1.5, −2.0, −2.25) in order to probe the range of exponents relevant to structure formation in a LCDM cosmology. Ideally we would extend this range further towards n = −3, but as we will discuss below, n = −2.25 represents in practice the accessible limit below which even our largest simulations would be swamped by finite box size effects. Indeed our simulations include for each n, a pair of simulations with N = 10243 and N = 40963 for which parameters are otherwise identical.
Summary of the N-body simulations used for the analysis in this paper. The first column shows the name of the simulation, n is the spectral index of the initial PS, and N the number of particles. The fourth column gives the ratio of the effective Plummer force smoothing length ϵ to mean inter-particle separation (equal to the initial grid spacing Λ), for a < a0 (as defined by equation (6), the time of our first output). For the cases without an asterisk this is its value at all times (i.e. the smoothing is fixed in comoving coordinates) while for the cases with an asterisk the smoothing for a > a0 is fixed in proper coordinates. The last two columns give, respectively, the value of the time parameter S at the last snapshot and the final scale factor relative to that at first output. Note that given that the first output is at S = 0, the number of outputs for each simulation is Sf + 1.
| Name | n | N | ϵ/Λ | Sf | log2(af/a0) |
|---|---|---|---|---|---|
| N4096_n1.5_eps0.3phy | −1.5 | 40963 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.3phy | −1.5 | 10243 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.03com | −1.5 | 10243 | 1/30 | 29 | 3.625 |
| N4096_n2.0_eps0.3phy | −2.0 | 40963 | 0.3* | 35 | 2.917 |
| N1024_n2.0_eps0.3phy | −2.0 | 10243 | 0.3* | 37 | 3.083 |
| N1024_n2.0_eps0.03com | −2.0 | 10243 | 1/30 | 37 | 3.083 |
| N1024_n2.0_eps0.02com | −2.0 | 10243 | 1/60 | 37 | 3.083 |
| N1024_n2.0_eps0.07com | −2.0 | 10243 | 1/15 | 37 | 3.083 |
| N4096_n2.25_eps0.3phy | -2.25 | 40963 | 0.3* | 35 | 2.1875 |
| N1024_n2.25_eps0.3phy | -2.25 | 10243 | 0.3* | 37 | 2.3125 |
| N1024_n2.25_eps0.03com | -2.25 | 10243 | 1/30 | 37 | 2.3125 |
| Name | n | N | ϵ/Λ | Sf | log2(af/a0) |
|---|---|---|---|---|---|
| N4096_n1.5_eps0.3phy | −1.5 | 40963 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.3phy | −1.5 | 10243 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.03com | −1.5 | 10243 | 1/30 | 29 | 3.625 |
| N4096_n2.0_eps0.3phy | −2.0 | 40963 | 0.3* | 35 | 2.917 |
| N1024_n2.0_eps0.3phy | −2.0 | 10243 | 0.3* | 37 | 3.083 |
| N1024_n2.0_eps0.03com | −2.0 | 10243 | 1/30 | 37 | 3.083 |
| N1024_n2.0_eps0.02com | −2.0 | 10243 | 1/60 | 37 | 3.083 |
| N1024_n2.0_eps0.07com | −2.0 | 10243 | 1/15 | 37 | 3.083 |
| N4096_n2.25_eps0.3phy | -2.25 | 40963 | 0.3* | 35 | 2.1875 |
| N1024_n2.25_eps0.3phy | -2.25 | 10243 | 0.3* | 37 | 2.3125 |
| N1024_n2.25_eps0.03com | -2.25 | 10243 | 1/30 | 37 | 2.3125 |
Summary of the N-body simulations used for the analysis in this paper. The first column shows the name of the simulation, n is the spectral index of the initial PS, and N the number of particles. The fourth column gives the ratio of the effective Plummer force smoothing length ϵ to mean inter-particle separation (equal to the initial grid spacing Λ), for a < a0 (as defined by equation (6), the time of our first output). For the cases without an asterisk this is its value at all times (i.e. the smoothing is fixed in comoving coordinates) while for the cases with an asterisk the smoothing for a > a0 is fixed in proper coordinates. The last two columns give, respectively, the value of the time parameter S at the last snapshot and the final scale factor relative to that at first output. Note that given that the first output is at S = 0, the number of outputs for each simulation is Sf + 1.
| Name | n | N | ϵ/Λ | Sf | log2(af/a0) |
|---|---|---|---|---|---|
| N4096_n1.5_eps0.3phy | −1.5 | 40963 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.3phy | −1.5 | 10243 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.03com | −1.5 | 10243 | 1/30 | 29 | 3.625 |
| N4096_n2.0_eps0.3phy | −2.0 | 40963 | 0.3* | 35 | 2.917 |
| N1024_n2.0_eps0.3phy | −2.0 | 10243 | 0.3* | 37 | 3.083 |
| N1024_n2.0_eps0.03com | −2.0 | 10243 | 1/30 | 37 | 3.083 |
| N1024_n2.0_eps0.02com | −2.0 | 10243 | 1/60 | 37 | 3.083 |
| N1024_n2.0_eps0.07com | −2.0 | 10243 | 1/15 | 37 | 3.083 |
| N4096_n2.25_eps0.3phy | -2.25 | 40963 | 0.3* | 35 | 2.1875 |
| N1024_n2.25_eps0.3phy | -2.25 | 10243 | 0.3* | 37 | 2.3125 |
| N1024_n2.25_eps0.03com | -2.25 | 10243 | 1/30 | 37 | 2.3125 |
| Name | n | N | ϵ/Λ | Sf | log2(af/a0) |
|---|---|---|---|---|---|
| N4096_n1.5_eps0.3phy | −1.5 | 40963 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.3phy | −1.5 | 10243 | 0.3* | 29 | 3.625 |
| N1024_n1.5_eps0.03com | −1.5 | 10243 | 1/30 | 29 | 3.625 |
| N4096_n2.0_eps0.3phy | −2.0 | 40963 | 0.3* | 35 | 2.917 |
| N1024_n2.0_eps0.3phy | −2.0 | 10243 | 0.3* | 37 | 3.083 |
| N1024_n2.0_eps0.03com | −2.0 | 10243 | 1/30 | 37 | 3.083 |
| N1024_n2.0_eps0.02com | −2.0 | 10243 | 1/60 | 37 | 3.083 |
| N1024_n2.0_eps0.07com | −2.0 | 10243 | 1/15 | 37 | 3.083 |
| N4096_n2.25_eps0.3phy | -2.25 | 40963 | 0.3* | 35 | 2.1875 |
| N1024_n2.25_eps0.3phy | -2.25 | 10243 | 0.3* | 37 | 2.3125 |
| N1024_n2.25_eps0.03com | -2.25 | 10243 | 1/30 | 37 | 2.3125 |
The remaining crucial parameter for our simulations is the softening length. Again the simulations in Table 1 have been chosen to include for each n a least one pair of simulations (with N = 10243) which differ only in this parameter (and for n = −2.0 a range of different softenings). In Abacus, the gravitational force is softened (see P2 for the explicit functional form and a more detailed discussion) from its Newtonian form using a compact spline which reverts to the exact Newtonian force at 2.16ϵ, where ϵ is defined for convenience as an ‘effective Plummer smoothing’ i.e. the softening of a Plummer model (with two body force F(r) ∝ (r2 + ϵ2)−3/2) with the same minimal pairwise dynamical time. The values of ϵ in our simulations are given in Table 1 as a ratio to the mean inter-particle spacing Λ. For the values given without an asterisk, this value is fixed throughout the simulation i.e. the smoothing length is fixed in comoving units. For the values with an asterisk, the value given is that at the time of our first output, at the scale-factor a = a0 defined below. For a < a0, the smoothing is again fixed in comoving coordinate, while for a > a0 it is kept fixed in physical coordinates i.e. ϵ/Λ ∝ 1/a. Our choices for the simulations with n ≠ −2 have been guided by the detailed study in P2 of the effect of softening on resolution, based on the study of the 2PCF in a very large suite of n = −2 simulations (including the subset of four 10243 simulations of n = −2.0 we report here). We will see below that the qualitative and quantitative conclusions of P2 found using the 2PCF extend also to the PS.
The accuracy of the numerical integration of the initialized N-body system in Abacus is determined in practice essentially by a single parameter, the time-step parameter η. For all simulations here, we have used η = 0.15, on the basis of the extensive tests of the convergence of the 2PCF reported in P1 and P2. We do not explore here further the sensitivity of results to the choices of σi and aPLT, based also on tests which have been performed in the context of the studies of P1 and P2. In practice, our σi is sufficiently small so that reducing it further leads to no significant change to the initial conditions, because of the application of the PLT corrections. The effects of the choice of the value of aPLT is a subject we will explore in future work.
3.2 Power spectrum calculation
In this section, we describe the method we have used to measure the matter PS of our particle data sets.
Equation (12) tells us how the use of the FFT grid limits the accuracy of our measurement of the PS, due to ‘aliasing’ which becomes important for wavenumbers of modulus k approaching kg. As detailed further in Appendix A, we apply a commonly used correction that reduces these effects dividing Pf by |$\sum _n W^2(\mathbf {k}+2k_g\mathbf {n})$| and cutting the results at kg/2, where the correction is no longer valid [see Angulo et al. (2007), Sato & Matsubara (2011), Takahashi et al. (2012)].
We need for our study to obtain highly accurate PS measurements at scales well below the Nyquist frequency of the initial particle grid, |$k_\Lambda = \pi N^{1/3}/L$|. Our analysis establishes a posteriori what the maximal required wavenumber is, and what level of accuracy we need. In practice, the calculation times for the PS of the full particle loads of even our smaller 10243 simulations becomes excessive for Ng ∼ 30003, which does not give sufficient resolution for our requirements. To overcome this limitation we employ the widely used technique of ‘folding’ [see e.g. Jenkins et al. (1998)]: the PS is calculated (using the FFT method) on a new particle configuration obtained by superimposing sub-cubes of the initial configuration i.e. the particle positions are modified by taking |$\mathbf {x}\rightarrow \mathbf {x}{{\ \rm per\ cent}}\left(L/2^m\right)$|, where the operation |$a{{\ \rm per\ cent}}b$| stands for the reminder of the division of a by b and m is a positive integer. It can be shown easily that the PS of the two configurations are identical for the modes which are common to them. If one uses the same FFT grid, for each folding we can access accurately a maximal wavenumber which is multiplied by two, at the cost of losing half the wave-vectors (as they are integer multiples of 2m + 1π/L).
For the results reported here, we have used a grid with Ng = 10243. For the 10243 simulations, we have calculated the PS using the full particle loads for foldings m = 0, 1, 2, 3, 4, and 6; for the 40963 simulations, we have used the available random down-sampling to |$10{{\ \rm per\ cent}}$| of the full particle loads, and have included an additional folding with m = 8 (in order to reach the same maximal wavenumber in units of |$k_\Lambda$|).
The shot noise subtraction in equation (13) accounts for (random) down-sampling, and vanishes when f = 1 (as in all of our 10243 simulations). We note that this formula does not include subtraction of the shot noise term characteristic of the PS (of any stochastic point process) at asymptotically large k (here P(k → ∞) = L3/N = Λ3). Some authors advocate making such a subtraction to correct for discreteness effects, while others argue against doing so (see e.g. Heitmann et al. (2010)). Our method here is precisely designed to detect how N-body discretization modifies the continuum PS, and so we do not wish to make any a priori assumption about how to model such effects. It is nevertheless an interesting question to assess specifically whether shot noise subtraction can be effectively used to correct for discreteness effects. We return to a discussion of this issue therefore after our main analysis, in Section 4.4. As detailed there, it turns out that shot noise is not a good model in the range of wave-number where we can establish accurate convergence to the physical limit.
Finally, we combine, for each snapshot, the measurements with different foldings to obtain a single estimate for each bin. Since the ratio of a given wavenumber k to the Nyquist wavenumber of the grid scales as 1/2m, comparison of the different measurements of P(k; Δk) in a given simulation allows us to assess the magnitude of the (systematic) inaccuracies arising from the FFT grid. Doing so we have concluded that, for k < kg/2, the accuracy of our PS measurement is always better than |$0.2{{\ \rm per\ cent}}$|. As this level of accuracy is sufficient for our purposes here, we construct a single measurement of P(k; Δk) for each snapshot taking for each bin the measurement from the available folding with the lowest value of m.
For economy of notation we will omit everywhere the bin width and label bins by a k corresponding to their geometric centre. Likewise, we calculate Δ2(k) using equation (4) at this same value for k.
4 RESULTS
4.1 Self-similarity of the dimensionless power spectrum
As we have discussed, in scale-free cosmologies independence of the discretization parameters in an N-body simulation should correspond to a self-similar evolution for the PS, which is conveniently characterized in terms of the dimensionless Δ2 as given in equation (5). Fig. 1 shows the evolution of Δ2 as a function of time (parametrized by the variable log2(a/a0)) for each of the three different spectral indices we have simulated, in all cases for the largest simulation (with N = 40963) in Table 1. For each index there are two panels: the left-hand panel gives Δ2(k) as a function of |$k/k_\Lambda$| (where |$k_\Lambda$| is the Nyquist wavenumber of the initial particle grid), while the right-hand panels give the same rescaled quantity as a function of the variable kRNL. Thus self-similar evolution corresponds to the superposition in this latter plot of the data at different times. In the right-hand panel, vertical dotted lines are plotted of the rescaled |$k_\Lambda R_{NL}$| for each epoch, while dotted-point lines in both panels represent the shot-noise L3/N.
![Dimensionless PS Δ2 as a function of wavenumber (left-most panels) and of rescaled wavenumber (second column) of our largest simulations (N = 40963), for which self-similar evolution corresponds to a Δ2 which is invariant in time. The times shown correspond to every fourth snapshot S = 0, 3, 7⋅⋅⋅ [where S is as defined in equation (8)] over the total time-span of the simulations. The vertical dotted lines in the right-hand panels correspond to the rescaled Nyquist wavenumbers for each displayed epoch. The shot noise limit, $\Delta ^2_{\text{shot}}=(\pi /2)(k/k_{\Lambda })^3$, is represented with dash–dotted lines. The right-hand panels show the appropriately shifted line for each displayed epoch.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/mnras/512/2/10.1093_mnras_stac578/1/m_stac578fig1.jpeg?Expires=1750275778&Signature=zp4C4UQl2QqqYSiQuXrZdBHLXLj7ySMyB7oJeZyDAuJ2Pj60d-4fTQIY45zBSZXJ-hSKrjFL~HaJ57YypeEFKrkTsyxLn8SCd4-KaaRQD80fTs~3Lhja-TqzknwEeeRHPN9RMPOLOYPEb-xsiQ6EMjkAy5TpwC24O8coS8uqao~uraC-yGRYOaZ6rzvutaSixXYefCKqXuThR7c26D1U485Ce3pyGQwgYRUV9JEbwoZL6tC7DKeI0GiJejPiNkb5IpuxDmUb6G-dI8~phTDsG-p72VZ9wTAv6NApQBBlndNKDBpwCxOdNCrz-XjfKCivOx0HvlHSHysVtVNj-mtXQQ__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
Dimensionless PS Δ2 as a function of wavenumber (left-most panels) and of rescaled wavenumber (second column) of our largest simulations (N = 40963), for which self-similar evolution corresponds to a Δ2 which is invariant in time. The times shown correspond to every fourth snapshot S = 0, 3, 7⋅⋅⋅ [where S is as defined in equation (8)] over the total time-span of the simulations. The vertical dotted lines in the right-hand panels correspond to the rescaled Nyquist wavenumbers for each displayed epoch. The shot noise limit, |$\Delta ^2_{\text{shot}}=(\pi /2)(k/k_{\Lambda })^3$|, is represented with dash–dotted lines. The right-hand panels show the appropriately shifted line for each displayed epoch.
These plots illustrate qualitatively the crucial features we will analyse more quantitatively below. For all spectral indices, we can see the same basic trends: self-similarity – identified as proximity to the common locus traced by the different curves – propagates monotonically to larger kRNL (and thus larger Δ2) as a function of time. At early times the self-similar range is restricted to linear scales (Δ2 ≪ 1), but it develops progressively in the non-linear regime (Δ2 ≫ 1). At each time we can identify an apparent upper cut-off (in k-space) to self-similarity where it branches off from the common locus. As a function of time, this cut-off starts very close to |$k_\Lambda$|, this corresponds to the imprint of the initial lattice, as in the initial conditions the input PS is represented only up to this wavenumber. As non-linear structure develops at smaller scales, this cut-off appears to progressively overtake the wavenumber |$k_\Lambda$| and at the final time appears to be significantly larger. Regarding the shot noise, we can see two main behaviours: at early times evolution is still self-similar for values of the PS larger than a rescaled L3/N term, while for later times self-similarity is broken at a smaller k and it is only at large k when Δ2 is completely dominated by it.
Differences between the evolution for the three cases, which we will see in greater detail below, are also evident on visual inspection. Firstly the range of scale, and the maximal value of Δ2, for which there is self-similarity decreases markedly from n = −1.5 to n = −2.25. This is just a reflection of the smaller range of scale-factor which is accessible in simulations of a fixed size. Furthermore, we can detect that the quality of the superposition is significantly poorer for n = −2.25. This is the result of the very much more significant finite size effects present for this very red index: in fact, as we will see below, the quality of the self-similarity is so much less good in this case that we can exploit these simulations to obtain information about the propagation of resolution at the |$1{{\ \rm per\ cent}}$| level only in a very limited range.
4.2 Convergence to self-similarity
The accuracy and extent of self-similarity, and how it is limited by the different unphysical simulation parameters, can be better visualized by plotting the data in the right-hand panels of Fig. 1 at chosen fixed values of kRNL as a function of time, and for the different simulations in Table 1. Figs 2–4 show such plots for, respectively, n = −1.5, n = −2.0, and n = −2.25, for the indicated values of kRNL. For convenience, we also plot on the upper x-axis the corresponding value of |$k/k_\Lambda$|, and a sub-plot of the ratio of shot noise over Δ2. As RNL is a monotonically growing function of time, |$k/k_\Lambda$|increases from right to left in each plot: indeed |$k/k_\Lambda$| can simply be considered as the inverse of the spatial resolution relative to the grid which increases as a function of time. Likewise the consecutive plots, at increasing kRNL, correspond to smaller scales (i.e. larger |$k/k_\Lambda$|) at any given time. The first plot in the first two figures (not plotted for n = −2.25) corresponds to the highly linear regime, and a comoving k which is at the first output more than a decade below |$k_\Lambda$|, while the last plot for all figures corresponds to the highly non-linear amplitude and a comoving k which is larger than |$k_\Lambda$| until close to the last output.
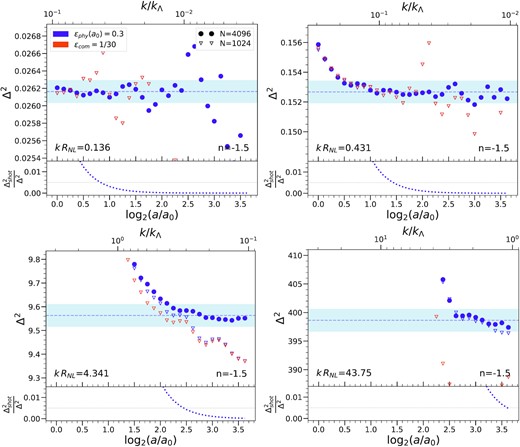
Evolution of the dimensionless PS as a function of logarithmic scale factor log2(a/a0) (lower x-axis) and as a function of |$k/k_\Lambda$| (upper x-axis) for a set of given rescaled bins labelled by their bin value kRNL, in each of the indicated n = −1.5 simulations (cf. Table 1). Circles correspond to the largest (N = 40963) simulations and triangles to the N = 10243 simulations. The simulations using physical softening are plotted in purple and those with comoving softening in orange. The horizontal dashed line marks our estimated converged value (|$\Delta ^2_{\text{conv}}$|) in each bin, determined in the largest simulation as described in the text. The blue shaded region indicates that within |$\pm 0.5{{\ \rm per\ cent}}$| of this value. These plots show in particular that the convergence of the PS depends on box-size for larger scales (i.e. small k) and on the force smoothing for smaller scales. The lower panel of each plot shows, for the larger simulation, the fraction of Δ2 represented by a shot-noise term (|$\Delta ^2_{\text{shot}}=(\pi /2)(k/k_{\Lambda })^3$|), and the dotted horizontal line marks |$0.5{{\ \rm per\ cent}}$|. We note that the observed deviations from the estimated converged value are not well approximated by such a term.
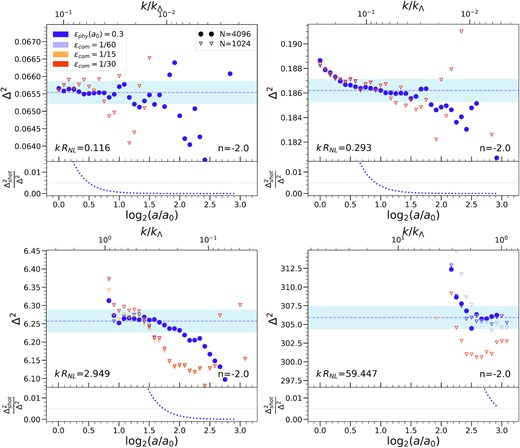
Same as in Fig. 2 but for the five indicated simulations with n = −2.0. Circles again correspond to the N = 40963 simulation and triangles to those with N = 10243. Purple corresponds again to physical softening, while the different choices of comoving softening (1/60, 1/15, and 1/30) correspond respectively to lilac, yellow, and orange. The additional simulations with different softenings allow us to see more clearly its effect on convergence at smaller scales. In particular, we note that the chosen physical softening converges, as well as the smallest comoving softening, as found in P2 for the 2PCF.
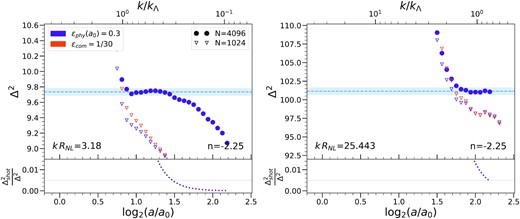
Same as in Figs 2 and 3 but for the three indicated simulations with n = −2.25. Circles correspond to the N = 40963 simulation and triangles to N = 10243; physical softening is plotted in purple and orange is used for comoving softening. The light blue region corresponds again to |$\pm 0.5{{\ \rm per\ cent}}$| of |$\Delta ^2_{\text{conv}}$|, but it appears smaller than on the previous plots because the range on the y-axis has been increased to fit the data in the smaller simulations. Compared to the plots in the previous two figures, we see clearly how convergence can be obtained only with much larger simulations as n decreases towards n = −3.
These selected plots illustrate that, in the large range of rescaled wavenumbers and clustering amplitudes shown, we can clearly identify, for each of these three values of n, converged values of the PS at the sub percent level. The temporal extent and the degree of the convergence vary, but the converged values are indeed independent of the (unphysical) parameters of the different simulations. Examining the deviations from the self-similar behaviour, we can clearly identify the signatures of the three crucial unphysical scales: the initial grid spacing Λ (parametrized by |$k_\Lambda$|), the force softening ϵ, and the box size. In the first three panels of Figs 2 and 3, which show data for wavenumbers |$k \in [0.005,1] k_\Lambda$|, we can see that the results obtained are insensitive to the gravitational softening (with only some marginally significant differences in the third panel). This is as expected given that the smoothing in all simulations is always much smaller than Λ. In these same three panels, on the other hand, the imprint of the two other scales are clearly visible. Comparing the simulations of the two different box sizes (10243 and 40963). we can see that the larger box improves the self-similarity at larger scales (and later times). While in the first panel this improvement appears just to be due to the reduced noise in the PS estimator (because of the finer sampling in reciprocal space), in the other two bins we observe that the cut-off to the self-similar plateau extends to smaller |$k/k_\Lambda$|. This effect is particularly important in the first panel of Fig. 4, where the smaller simulations (N = 10243) are highly affected by the size of the box and do not reach a converged value. Finally the cut-off (at small scales) to self-similarity clearly depends significantly only on k/kΛ, and is set by it alone. It is crucial for our extrapolation of our results to non-scale-free models that we can thus separate the effects of resolution due to the grid from the effects of finite box size.
We note that the quality of the convergence to self-similar behaviour is much better for n = −1.5 (it is achieved through a larger number of snapshots), because of the finite size effects which become more marked as the spectrum reddens. In particular, this effect is crucial in the intermediate scales (typified by the third panel in the first two figures and the first one in Fig. 4) where we observe that, for n = −2.0, the converged window is still quite small even in the largest N = 40963 simulation.
The last panel in these figures, for all three n, corresponds to considerably smaller scales and is close to the larger kRNL for which we can identify robustly a converged value (using criteria described in detail below). At these smaller scales, the results are now insensitive to the box size, but do show dependence on the softening (except for n = −2.25 where box-size effects wipe out this behaviour). The simulations with proper softening and those with the smaller comoving softening show the widest and most coincident regions of self-similarity, while the simulations with larger comoving softening show a suppression of power relative to the self-similar value which decreases as |$k/k_\Lambda$| does so. Further the same ϵ = Λ/30 comoving smoothing shows just marginal (|${\sim}1{{\ \rm per\ cent}}$|) deviation in the n = −2.0 simulation, but more significant (|${\sim}3{{\ \rm per\ cent}}$|) deviation for n = −1.5. These behaviours are very similar to those which have been analysed and discussed for the 2PCF in P2 for n = −2.0. They provide clear evidence that the analogous conclusion may be drawn for the PS as was drawn in P1 and P2 for the 2PCF: the limit on resolution at small scales at any time, corresponding to the largest k at which self-similarity may be attained, is determined by |$k_\Lambda$| alone (i.e. by the initial grid spacing, or mass resolution) provided the smoothing is chosen sufficiently small. As can be seen already by comparing the panels of Figs 2–4, and will be quantified more precisely below, this intrinsic limit on the resolved |$k/k_\Lambda$| increases with time (i.e. as a function of log2(a/a0)). Thus there is an upper limit on the required comoving smoothing to attain this intrinsic resolution limit, which depends on the range of scale-factor over which the simulation is run. Our results for n = −2.0 indicate, in line with the conclusion of P2 based on the 2PCF, that for a comoving smoothing below approximately Λ/30 there is no significant gain in resolution for a typical large LCDM simulation (which has a comparable range of scale-factor, log2(a/a0) ∼ 2.5). For the n = −1.5 simulation which runs over a slightly larger range of scale-factor (or a LCDM simulation with a correspondingly higher mass resolution), the limiting comoving smoothing required will be a little smaller. Likewise for the n = −2.25 simulations, which span a much lesser range of scale factor, a larger comoving smoothing is sufficient. In all cases, on the other hand, as was also observed in P2 for the 2PCF, we see that the chosen proper smoothing – despite being significantly larger at early times than the comoving smoothing, and thus providing significant numerical economy – appears to be quite adequate to attain the intrinsic resolution limit.
4.3 Evolution of small-scale resolution as a function of time
We turn now to a more precise quantitative analysis. We focus on the intrinsic upper cut-off (in wavenumber) to resolution determined by |$k_\Lambda$|, using our data to estimate how it evolves with a/a0. To do so, we first detail the procedure we use to estimate a converged value of Δ2 in each rescaled bin with an associated error bar (relative to the true physical value). Using these we can then determine, for each comoving k, its precision relative to this estimated converged value as a function of time. For any fixed level of precision significantly larger than our intrinsic error on the converged value, we can thus obtain an accurate estimate of the maximal resolved wavenumber at each time.
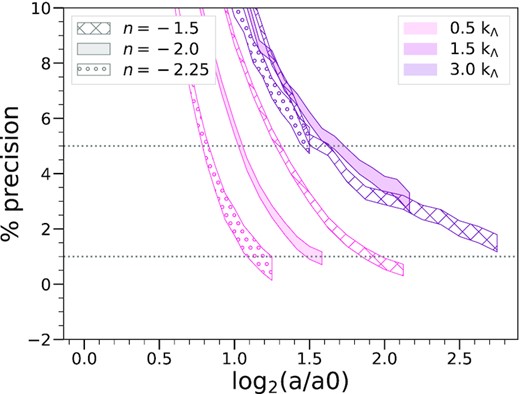
We can now determine the estimated precision of the PS measured at any scale and time, i.e. the difference between its measured value in a given simulation and the true physical value. Fig. 5 displays the result for five different comoving scales specified in units of |$k_\Lambda$|, |$(0.5, 1.5, 3)k_\Lambda$|, for the 40963 simulations with n = −1.5 (hashed), n = −2.0 (filled), and n = −2.25 (circles). The horizontal grey dotted lines mark the |$5{{\ \rm per\ cent}}$| and |$1{{\ \rm per\ cent}}$| precision levels.
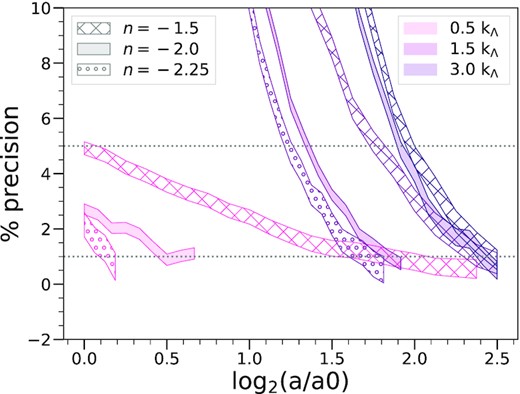
Estimated precision, in percentage, of the PS relative to its true physical value as a function of time, for different selected comoving scales. The indicated confidence intervals correspond to the estimated error δ in the converged value. The plots in each case are for the largest simulations (N = 40963) for the three spectral indices: n = −1.5 (hashed), n = −2.0 (filled), and n = −2.25 (circles). The horizontal dotted lines correspond to |$1{{\ \rm per\ cent}}$| and |$5{{\ \rm per\ cent}}$|.
This plot shows that the precision of the PS measured at any giving comoving k improves monotonically in time (at least starting from the time a = a0 at which the first non-linear structures start to form). This is a reflection of the fact that the physical origin of the imprecision probed in this plot is the discretization on the lattice: our plot is restricted to values of k/kΛ and time-scales where the finite box size effects are negligible, and the data are for the largest simulations (with proper softening) in which the convergence is insensitive to softening. The monotonic improvement of precision is then simply a result of the non-linear gravitational dynamics which efficiently ‘transfers power’ from large to small scales i.e. the power at fixed comoving k is determined by power initially at progressively larger scales less affected by the lattice discretization. Correspondingly in a given simulation the maximal wavenumber resolved at any given precision (e.g. |$1{{\ \rm per\ cent}}$| or |$5{{\ \rm per\ cent}}$|) increases monotonically as a function of time.
Fig. 5 also clearly illustrates the qualitative difference between the modes |$k\lt k_\Lambda$| and |$k\gt k_\Lambda$|: the former are wavenumbers for which the PS is already resolved well in the initial conditions, while for the latter the physical PS can only be first resolved when the fluctuations at these sub-grid scales are created by non-linear evolution at a level sufficient to dominate over the initial discreteness fluctuations. For the smallest k, the precision of the n = −2.25 and n = −2.0 simulations, at a given time, are markedly better than for n = −1.5, but this difference in precision appears to systematically decrease as k increases, becoming almost negligible for |$k=3k_\Lambda$|. The source of the difference for the smaller k arises from the method used to set up initial conditions: as they are defined by a fixed amplitude of σlin at the starting redshift (and thus also at a = a0), a redder spectrum – for which the mass variance decreases more slowly with scale – dominates more over the corrections to power from discreteness above |$k_\Lambda$|. On the other hand, as we are comparing the simulations starting from a0 – approximately the epoch at which non-linear structure formation first develops in them – it is not surprising to see that the propagation of the resolution at non-linear scales may be approximately model independent when plotted as a function of a/a0: it is the evolution of the comoving size of the first virialized structures which might be expected to determine the propagation of resolution, and this can be expected to be primarily determined by a/a0.
To probe further this apparent model independence of the resolution as a function of a/a0, we show in Fig. 6 the evolution of the maximal resolved wavenumber (left-hand panel) and maximal resolved Δ2 (right-hand panel) as a function of time. The criterion for resolution is set at a precision of |$5{{\ \rm per\ cent}}$| (i.e. the parameter α = 0.05), which allows us to extend both the temporal range probed and obtain also more constraints from the n = −2.25 simulation. We see that indeed, once the non-linear evolution develops sufficiently, starting from approximately a ∼ 4a0, the resolution is approximately the same irrespective of n. Further the resolution appears to be correlated with the maximal resolved Δ2, consistent with the hypothesis that it can essentially be determined in a model-independent manner.
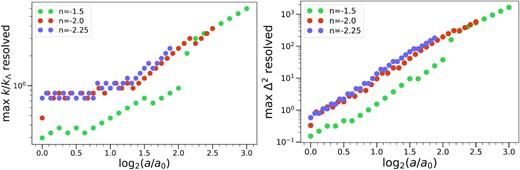
Maximum resolved wavenumber (in units of the Nyquist frequency of the grid) at |$5{{\ \rm per\ cent}}$| precision as a function of time (left-hand panel), and the corresponding maximum resolved dimensionless PS as a function of time (right-hand panel). Results are given for our three different spectral indices (n = −1.5, −2.0, and −2.25) for the 40963 simulation of each case. We note an approximately n-independent resolution in the non-linear regime.
4.4 Shot noise and discreteness effects
As discussed in Section 3.2, it is interesting to consider whether shot noise can be used to model deviations from the physical PS due to N-body discretization. In our analysis above, we did not subtract a Poisson noise term from the calculated PS other than to account for that induced by random down-sampling of our larger samples. Indeed our method is designed to pick up any dependence on any unphysical scale (and Λ in particular) as a break from self-similarity. It does not require that we make any assumption on the functional form of such modifications or the range of applicable scales. We now consider what our results above tell us specifically about this question.
First from Fig. 1 we see that the PS does approach the shot noise level at asymptotically large k (as it must, by definition). However, it can be seen that it only attains this behaviour at scales k ≫ kΛ, significantly larger than those where we have seen the simulations to be converged (as shown in Fig. 5). At early times, in particular, it can be seen that the measured PS is in fact below the shot noise level. Subtracting such a term clearly cannot then give an approximation for the (positive) physical PS, and it would evidently spoil the apparent self-similarity of our data (seen in the right-hand panels) in a range of scale. At intermediate times, especially for the smaller n = −2.25 index, we can observe that the simulations depart from self-similarity at k smaller than those where the shot noise dominates the PS, indicating that the reason for this self-similarity breaking is not due to a shot noise of this form. Only in the latest snapshot of our simulations can we see that this term dominates at the scales close to those where there are deviations from self-similarity.
These conclusions can be seen more fully and further quantified from the lower sub-plots of Figs 2–4. We can compare directly the deviation of the PS actually observed in the simulations from its converged value, with the fraction represented by a shot noise term (shown in the lower sub-panels). In all cases we see that, in some part of the range where the PS falls within |$0.5{{\ \rm per\ cent}}$| of its estimated converged value, the shot noise represents a significantly larger fraction. Shot noise thus overestimates the deviations of the PS. This makes it clear that if such a term is subtracted, it will in fact degrade the convergence in some range i.e. the PS with subtracted shot noise will approximate the physical PS with a reduced range of scale and/or time.
To see how significant this undesired effect of shot noise subtraction may be, we have performed an identical analysis as the one described in the sections above, but now subtracting a Poisson noise term. Fig. 7 is the equivalent of Fig. 5 with the subtraction. We see clearly that the convergence is indeed destroyed at early times, as anticipated above. We also see that convergence for larger k is affected, and |$1{{\ \rm per\ cent}}$| precision for k > kΛ is never really achieved, and we do not resolve k ∼ kΛ even at |$5{{\ \rm per\ cent}}$| and later times.
Equivalent analysis to Fig. 5 where a shot noise term (P(k) = Λ3) has been subtracted from the computed PS. It shows the estimated precision, in percentage, of the PS relative to its true physical value as a function of time, for different selected comoving scales. The indicated confidence intervals correspond to the estimated error δ in the converged value. The plots in each case are for the largest simulations (N = 40963) for the three spectral indices: n = −1.5 (hashed), n = −2.0 (filled), and n = −2.25 (circles). The horizontal dotted lines correspond to |$1{{\ \rm per\ cent}}$| and |$5{{\ \rm per\ cent}}$|.
In conclusion, and under our self-similar analysis of our simulations, we understand that a term of such form does not appropriately describe the shape of PS. While the smallest scales per snapshots are indeed well dominated by L3/N, we argue that subtracting a term of this form at all times and scales is not justified, and does indeed degrade the PS resolution. The region where this procedure would be reasonable (k ≫ kΛ) is not accessible at a |$1{{\ \rm per\ cent}}$| precision for comparable simulations, and thus the procedure becomes redundant.
5 RESOLUTION LIMITS FOR NON-SCALE-FREE COSMOLOGIES
While our method, by construction, is limited strictly to scale-free cosmologies, our underlying motivation is of course to quantify the resolution in simulations of non-scale-free cosmologies such as LCDM or variants of it. Such cosmologies are not really so very different from scale-free cosmologies for what concerns their non-linear evolution: for this purpose their PS can be considered to be an adiabatic interpolation of power-law spectra, with the modified expansion rate due to dark energy only coming into play at very low redshift.
We have anticipated this extrapolation of our results above by choosing to simulate, as far as practicable, scale-free models with n in the range relevant to LCDM, and focusing on the dependence of our results on these exponents. Further we have characterized how resolution depends on time in terms of a scale factor relative to a0 which can be defined, as given in equation (6), for any cosmology, and has the simple physical meaning as the time when non-linear structures start to develop. Fig. 8 illustrates how the parameter log2(a/a0) maps to the redshift in a simulation of a standard LCDM model (‘Planck 2013’; Planck Collaboration (2014)). The mapping is just a function of the mean interparticle spacing Λ (and the linear PS of the model) as these allow the determination of a0. This means that, given a simulation of a determined grid spacing Λ, one can always find a one-to-one relation between the desired evolved redshift of the LCDM and our time variable log2(a/a0). As discussed in P1, non-EdS expansion at low redshift introduces the possibility of mapping the time rather than the scale-factor, but the difference in the effective log2(a/a0) is in practice very small, and we will neglect it here.
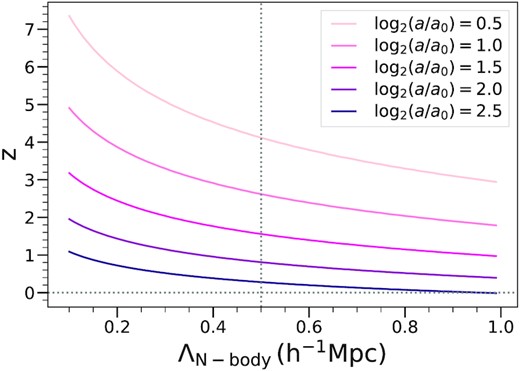
Redshift |$z$| corresponding to different fixed values of log2(a/a0) as a function of mean interparticle spacing Λ, using a standard LCDM cosmology (‘Planck 2013’, Planck Collaboration (2014)). As discussed in the text, combining this plot with the curves for in Figs 5 and 6 we can infer a conservative bound on attainable precision as a function of redshift in an LCDM simulation.
Our analysis above shows that we have two quite different regimes for the evolution of small-scale resolution. For the modes |$k \gt k_\Lambda$|, which are not modelled in the initial conditions and which always describe the strongly non-linear regime, resolution is approximately n independent as a function of log2(a/a0). For these modes it seems very reasonable that we can carry over straightforwardly our results from the scale-free case to the general case (modulo small possible corrections due to non-EdS evolution). That is, given the grid spacing of the simulation, the results in Fig. 5 (or Fig. 6) can simply be converted to resolution as a function of redshift using Fig. 8. As an example, Fig. 9 shows, for a model Λ = 0.5 h−1 Mpc simulation, the smallest scale which we will have access to as a function of redshift at |$1{{\ \rm per\ cent}}$| and |$5{{\ \rm per\ cent}}$| precision.
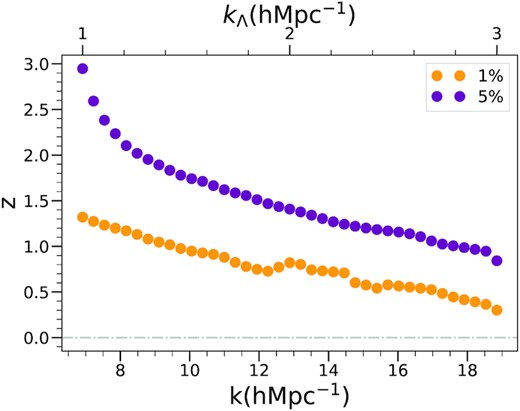
Resolved k as a function of redshift for a fixed value of the mean interparticle spacing Λ = 0.5 h−1 Mpc, using a standard LCDM cosmology (‘Planck 2013’, Planck Collaboration (2014)). Orange points correspond to |$1{{\ \rm per\ cent}}$| precision, α = 0.01, while purple points represent |$5{{\ \rm per\ cent}}$| precision, α = 0.05. We have added an axis for the kΛ of the hypothetical LCDM simulation for an easier extrapolation with Figs 8 and 5.
Taking the aforementioned LCDM model (‘Planck 2013’), its estimated neff is situated typically around or below our smallest simulated exponent, at least for Λs of typical (current) N-body simulations, n ∼ (− 2.5, −2) for Λ ∈ [0.1, 1]. The resolution of n = −2.25 shows the same tendency as n = −2.0, inferred from Fig. 5. We thus conclude that we can use our results for n = −2.0 to obtain conservative bounds on precision for numerical simulations of such models.
These statements assume of course implicitly that the method of setting up initial conditions is like that used in our simulations, that convergence has been established with respect to time-stepping and any all other numerical parameters, and that the box size is sufficiently large so that finite box effects are negligible at these scales considered.
6 DISCUSSION AND CONCLUSIONS
We conclude by discussing our results first in relation to the closely related recent studies in P1 and P2, and then in relation to the broader literature on the PS of dark matter in the non-linear regime.
Our analysis here is a development of that already presented in P1 and P2, which focused on the self-similarity of the 2PCF, and also in Leroy et al. (2020), which explored the self-similarity of halo mass and 2PCF functions. It further confirms that the study of self-similarity in scale-free cosmologies, using the methods introduced in P1, is a very powerful tool to quantify resolution of cosmological N-body simulations. We have performed a complementary analysis to the real-space analysis of the 2PCF in P1, giving a precise quantitative characterization of the evolution of resolution of the PS in k-space. Doing so we have tested even further the accuracy of the Abacus code by demonstrating that it can measure this essential cosmological statistic to an accuracy well below percent level in a wide range of scales. While these previous studies used suites of simulations for a single power-law (n = −2.0) and a single box size (N = 10243), we have considered a suite for both different power laws and also a much larger box (N = 40963). This has allowed us to identify the effects of finite box size, and separate them clearly – over a range which depends strongly on the exponent n – from the resolution limits due to the finite particle density and gravitational smoothing. This is essential for robustly extrapolating these results on small-scale resolution limits to non-scale-free models.
It is interesting to compare our conclusions concerning the resolution of the PS to those obtained for the 2PCF in P1 and P2. Qualitatively, our analysis simply confirms that the main conclusions in these works map into reciprocal space just as one would naively expect. In particular, P1 and P2 concluded that the lower cut-off scale to resolution for the 2PCF is, provided gravitational force smoothing is sufficiently small, fixed by the initial grid spacing. Further this scale is found, starting from a certain time, to be a monotonically decreasing function of time. We have drawn here identical conclusions about the PS in k-space. Looked at in more detail qualitatively, and quantitatively, the results in the two spaces are not, however, related in the simple manner one might expect. For example, the lower cut-off to resolution in real space was found, at the few percent level, to decrease in proportion to a−1/2 starting from 0.2Λ. Mapped into reciprocal space this would give a resolved k very considerably larger than what we have found (and with a very different a dependence). Comparing any of our various measurements confirms the conclusion that the resolution in reciprocal space is much poorer than in direct space, in the simple sense that inverse wavenumber characterizing it is much smaller than π divided by the spatial resolution. Thus, in reciprocal space, discreteness effects are ‘smeared’ out over a larger range of scale than in direct space, where they are more localized. The same is true also of the effects of gravitational smoothing: indeed we have found here that for the n = −2.0 simulation, a comoving smoothing of Λ/30 produces few percent (|$1{{\ \rm per\ cent}}$|) deviations from self-similarity at |$k \sim 2 k_\Lambda$| (i.e. k ∼ π/(15ϵ)) while in real space similar deviations are seen at only ∼Λ/10 (i.e. r ∼ 3ϵ).
As we have discussed in the introduction the question of resolution of different statistics, and in particular the 2PCF or PS, as measured in N-body simulations, has long been a subject of discussion in the literature. In the light of new and more accurate surveys, it has become an even more important practical issue. Most current studies are based on the comparison of results from simulations at different mass resolution, where the highest available resolution is considered as the ‘true’ converged value relative to which precision is measured. Our analysis here is based on the much more robust identification of converged values possible in scale-free simulations. As we have discussed in the last section, these results can be extrapolated in a simple manner to obtain robust conservative resolution limits in LCDM models.
Laying aside the numerous caveats that we have underlined should be born in mind when extrapolating to any other set of simulations (and notably different codes), it is interesting to compare our conclusions with typical assumptions about resolution of PS measurements in the literature. In the recent literature on simulations of LCDM cosmologies focused on extracting very accurate measurements at intermediate scales, such assumptions are generally quite consistent with, and indeed often somewhat more conservative than the limits we have found. For example, Ishiyama et al. (2021) assume that |$2{{\ \rm per\ cent}}$| accuracy is attained for |$k \lt k_\Lambda /2$| at |$z$| = 0, Heitmann et al. (2021) assume |$5{{\ \rm per\ cent}}$| accuracy at the same range up to |$z$| < 1, or Angulo et al. (2021) assume a |$1{{\ \rm per\ cent}}$| accuracy up to the same scale. In studies which extend their analysis of the PS to the strongly non-linear regime, on the other hand, it is commonplace to include wavenumbers k approaching k ∼ π/ϵ, for ϵ ≪ Λ (e.g. Smith et al. (2003), Springel et al. (2018)). Indeed strong clustering develops down to these small scales, and it may be that it provides a reasonable approximation to the true physical limit, allowing at the very least qualitative conclusions that are correct. Nevertheless our analysis indicates that resolution in fact appears to degrade very rapidly for k significantly larger than a few |$k_\Lambda$|. This suggests (as argued previously in e.g. Splinter et al. (1998), Romeo et al. (2008), and Joyce et al. (2009) that caution should be exercised in making use of simulation data in the range of k ≫ kΛ.
An illustration of this conclusion is given by considering what has been inferred from N-body simulations about the behaviour of the PS at asymptotically large k. In early work, Peebles (Peebles 1974) envisaged the possibility that the non-linear structures would decouple as they shrink in comoving coordinates, the so-called ‘stable clustering’ hypothesis. Simulations of scale-free models have been an ideal testing ground for it, as Peebles derived in this case a simple analytical prediction for a power-law behaviour corresponding to Δ2(k) ∼ kγ where γ = 3(3 + n)/(5 + n). While early simulation studies (Efstathiou et al. 1988; Colombi, Bouchet & Hernquist 1996; Bertschinger 1998; Jain & Bertschinger 1998; Valageas, Lacey & Schaeffer 2000) showed evidence for its validity – at least for the shallower indices in which the finite box effects were not overwhelming for smaller simulations – studies by Smith et al. (2003) and Widrow et al. (2009) concluded that it breaks down, and further that the PS’s behaviour at small scales can be characterized by a single, but significantly smaller, n-dependent exponent. The robustness of these conclusions have been questioned in Benhaiem, Joyce & Marcos (2013) and Benhaiem, Joyce & Sylos Labini (2017), using a new analysis of simulations of the same size (N = 2563) as those of Smith et al. (2003). Shown in Fig. 10 are the estimated converged values of the logarithmic slope of Δ2, from our 40963 simulation of each of the three exponents. These have been estimated by applying to the logarithmic slope the same method described in detail in Section 3 for the PS, with parameter α = 0.05. This corresponds to an estimated precision of at most |$\pm 2.5{{\ \rm per\ cent}}$|, i.e. about twice the diameter of the plotted points. The error bars shown in the plot correspond to ± the absolute value of the biggest difference in the converged values obtained in our different simulations (using identical convergence criteria), and indicate a significantly larger systematic error (towards an underestimate of the exponent) due to smoothing in the last few bins. These results show measured exponents remarkably close to the predicted stable clustering values, with at most marginal evidence for a deviation from stable clustering. The considerably smaller exponents derived in the studies of Smith et al. (2003) and Widrow et al. (2009) are clearly due to the extrapolation to poorly resolved scales [Smith et al. (2003) used ϵ = Λ/15 and N = 2563]. We will present elsewhere further detailed study of this issue, including also in particular the corresponding real space analysis of the 2PCF that can provide a consistency check on any possible detection of an asymptotic exponent.
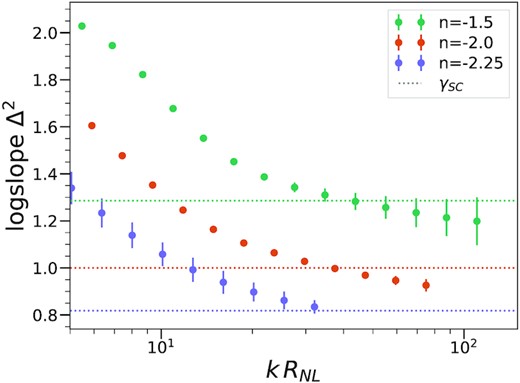
Estimated converged logarithmic slopes of the PS for each of the three simulated values of n in our biggest 40963 simulations. The dashed horizontal lines indicate the exponent corresponding to stable clustering, γ = 3(3 + n)/(5 + n). The estimated precision of these measurements and the derivation of the error bars are detailed in the text. The curves are remarkably close to consistency with the hypothesis of asymptotic stable clustering, with at most, given our indicated error bars, marginal evidence for slightly lower values. We note that the studies by Smith et al. (2003) and Widrow et al. (2009) estimate asymptotic converged slopes equal to 0.91 for n = −1.5 and 0.77 for n = −2.0 and 0.7 for n = −2.25.
ACKNOWLEDGEMENTS
SM thanks the Institute for Theory and Computation (ITC) for hosting her in early 2020 and acknowledges the Fondation CFM pour la Recherche for financial support. DJE is supported by the U.S. Department of Energy grant DE-SC0013178 and as a Simons Foundation Investigator. LHG is also supported by the Simons Foundation. This research used resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725. The AbacusSummit simulations have been supported by OLCF projects AST135 and AST145, the latter through the Department of Energy ALCC program.
DATA AVAILABILITY
The data reported in the article are provided in csv format in the online supplementary material.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}