





ABSTRACT
We introduce a method to infer the vertical distribution of stars in the Milky Way using a Poisson likelihood function, with a view to applying our method to the Gaia catalogue. We show how to account for the sample selection function and for parallax measurement uncertainties. Our method is validated against a simulated sample drawn from a model with two exponential discs and a power-law halo profile. A mock Gaia sample is generated using the Gaia astrometry selection function, whilst realistic parallax uncertainties are drawn from the Gaia Astrometric Spread Function. The model is fit to the mock in order to rediscover the input parameters used to generate the sample. We recover posterior distributions that accurately fit the input parameters within statistical uncertainties, demonstrating the efficacy of our method. Using the GUMS synthetic Milky Way catalogue, we find that our halo parameter fits can be heavily biased by our overly simplistic model; however, the fits to the thin and thick discs are not significantly impacted. We apply this method to Gaia Early Data Release 3 in a companion paper where we also quantify the systematic uncertainties introduced by oversimplifications in our model.
1 INTRODUCTION
Models for the distribution of stars in the Milky Way are key to stellar physics, Galactic archaeology (study of the formation history of the Galaxy) and understanding observations of external galaxies.
A core scientific aim of the Gaia mission is to map the 3D distribution of sources throughout the Milky Way (Perryman et al. 2001). To achieve this, Gaia has measured parallaxes for 1467 744 818 sources (Gaia Collaboration et al. 2016, 2021a) providing geometric distance estimates with no assumptions about source intrinsic brightness (Lindegren et al. 2021). However, we cannot straightforwardly use these billions of distances to construct a map of stars throughout the Galaxy for two key reasons.
Until recently, the completeness limits of the Gaia catalogues were largely unknown. The observation strategy of the mission results in a completeness that varies significantly across the sky on sub-degree scales. Traditional methods of evaluating selection functions rely on the existence of a more complete source catalogue against which the sample can be compared; however, there is no such catalogue to compare against, due to the incredible depth and resolution of Gaia across the entire sky. Without a selection function, it is impossible to generate an unbiased map of the Milky Way using the full power of the Gaia data. We refer the interested reader to Rix et al. (2021) for a detailed discussion on evaluating and using selection functions.
Furthermore, parallax-based distances are statistically awkward to work with. Much of our statistical methodology is constructed around the assumption of Gaussian measurement uncertainties, motivated by the central limit theorem. Parallax uncertainties are Gaussian distributed, which means that distances are reciprocal Gaussian distributed. This is a highly asymmetric distribution that, under an improper uniform prior, cannot be normalized. As such, the distribution does not have a finite mean. Detailed discussions on how to use Gaia parallaxes for distance inference on individual stars are given in Bailer-Jones (2015) and Luri et al. (2018).
In spite of these hurdles, the structure of the Milky Way has been studied in detail by many authors. A work-around to the challenges of parallax uncertainties is to focus on particular stellar populations for which the intrinsic brightness can be modelled. The distance can then be inferred from the measured apparent brightness. In some cases, simple stellar colour–absolute magnitude relations are used for either a large population of sources across the CMD (e.g. Bilir et al. 2006; Dobbie & Warren 2020) or a small subset (e.g. horizontal branch stars; Fukushima et al. 2019). This approach has been taken further by using full stellar evolution models to infer intrinsic source brightness (de Jong et al. 2010). Period–luminosity relations for certain variable sources are also incredibly valuable distance indicators. Ak et al. (2008) used cataclysmic variables to estimate the vertical profile of the Milky Way disc, whilst Mateu & Vivas (2018) used RR Lyrae to determine the structure of the old thick disc and radial profile of the halo.
Some of these approaches apply uncertain colour–magnitude relations to large populations across the CMD, leaving the results susceptible to systematic biases. Other approaches use more carefully chosen sub-samples of specific stellar types such that only a small fraction of the data are used.
In this paper, we develop a method to overcome the challenges of directly using Gaia parallaxes and applying the selection functions for the Gaia source catalogue and astrometry subset from Everall & Boubert (2021). We demonstrate its feasibility on a Gaia-like mock sample with a known ground-truth. We limit the scope of this work to a high latitude region of the sky for statistical and computational reasons, and due to the challenge of dust extinction that we do not attempt to solve here.
This paper is arranged as follows. In Section 2, we introduce the likelihood optimization method used for this work, followed by a full description of the model in Section 3. The Gaia-like mock sample is explained in Section 4 and we demonstrate the application of the method in Section 5. The method is tested on a more realistic mock catalogue in Section 6. In a companion paper (Everall et al. 2021a, henceforth Paper II), we apply this method to high latitude regions of the Gaia EDR3 catalogue to estimate the vertical stellar profile of the Milky Way at the Solar radius and quantify the systematic uncertainties introduced by the simplifications and assumptions used in our model.
2 METHOD
Mateu & Vivas (2018) use this method on a sample of RR Lyrae to constrain the structure of the thick disc and halo considering only spatial dimensions, while Bovy et al. (2012b) apply a more complex model to a population of G-dwarfs to fit the Milky Way disc using measured apparent magnitude, colour, and metallicity. The aim of this work is to model the purely spatial distribution of sources, however the selection function, which will be introduced in more detail in Section 3.3, is a function of position on the sky and apparent magnitude. Therefore, we must also consider the intrinsic brightness of a source, so our source properties are |$\boldsymbol {x} = (l, b, s, M_{\rm G})$|.
2.1 Parallax error integration
We numerically evaluate the integral of each section using the following five-step recipe:
- Transform into logit-parallax space using the substitutionThis gives(13)$$\begin{eqnarray} x^{\prime } = \log \left(\frac{\varpi - \varpi _j}{\varpi _{j+1}-\varpi }\right). \end{eqnarray}$$where the Jacobian is(14)$$\begin{eqnarray} \int _{\varpi _j}^{\varpi _{j+1}} \, \mathrm{d}\varpi I(\varpi) = \int _{-\infty }^{\infty } \mathrm{d}x^{\prime } \frac{I}{J}, \end{eqnarray}$$(15)$$\begin{eqnarray} J = \left|\frac{\partial x^{\prime }}{\partial \varpi }\right| = \frac{\varpi _{j+1}-\varpi _j}{(\varpi -\varpi _j)(\varpi _{j+1}-\varpi)}. \end{eqnarray}$$
- Find the peak of the logit-transformed integrand by solvingusing the bisection algorithm with respect to ϖ initializing at the integration boundaries, ϖj, ϖj + 1. Transform the parallax of the peak into logit space giving us the mode, |$x_0^{\prime }$|.(16)$$\begin{eqnarray} \frac{\partial }{\partial x^{\prime }}\left(\frac{I}{J}\right) = 0 \end{eqnarray}$$
- Estimate the width of the peak from the curvature around |$x^{\prime }_0$|,(17)$$\begin{eqnarray} \sigma _{x^{\prime }} = \left(\frac{\partial ^2I/J}{\partial x^{\prime 2}}\right)^{-{1}/{2}}\bigg \vert _{x^{\prime }=x_0^{\prime }} . \end{eqnarray}$$
- Recentre and rescale viasuch that the integrand is approximately I ∼ exp (− x2) around the peak.(18)$$\begin{eqnarray} x = \frac{x^{\prime } - x_0^{\prime }}{\sqrt{2}\sigma _{x^{\prime }}}, \end{eqnarray}$$
- Apply the Gauss–Hermite quadrature in x-space, which gives(19)$$\begin{eqnarray} \int _{\varpi _j}^{\varpi _{j+1}} \mathrm{d}\varpi \, I = \sum _k w_k \frac{\sqrt{2}\sigma _{x^{\prime }}\, I(\varpi (x_k))}{J(\varpi (x_k))} \exp \left(x_k^2\right). \end{eqnarray}$$
In our application of the method, we use the Gauss–Hermite quadrature with 11 sample points. Increasing the number of sampling points has no appreciable effect on our inferred likelihood.
A major limitation of this method is that it cannot accurately integrate multimodal integrands. The integrand must be unimodal such that we can integrate around the single peak. We will discuss the implications of this in Section 3 when introducing our model. However, since this is purely a numerical rather than conceptual challenge, we hope future work can improve on our method to allow for more general models to be evaluated and with greater computational efficiency.
3 MODEL
For this work, we only consider high latitudes, |b| > 80°. There are several reasons for this:
Dust extinction is negligible at high latitudes. Modelling the 3D distribution of dust throughout the Milky Way is a complicated problem on its own (Marshall et al. 2006; Green et al. 2014). We quantify the impact of dust extinction on our results in Paper II.
The in-plane structure of the Milky Way disc is complex with waves, spiral arms, and the bar that add vast numbers of free parameters to any spatial model.
Parallax integration is computationally expensive and scales linearly with the number of sources. By focusing on a subset of Gaia data, we are left with a computationally tractable problem.
The aim of this work is to demonstrate how Gaia parallax information can be used to obtain an unbiased model of the Milky Way’s stellar content. The vertical distribution at the Solar neighbourhood is a tractable first step in this direction.
The vertical distribution of sources is assumed to be a mixture of three distinct components: thin disc, thick disc, and halo. This canonical model has been used for decades since the addition of the second disc component by Gilmore & Reid (1983). More recent work has shown that – rather than a dichotomy into thin and thick discs – there may be a continuous evolution of disc height with stellar metallicity (Bovy, Rix & Hogg 2012a; Bovy et al. 2016). However, since metallicity is not an observable in our sample, we keep to the canonical distinct thin and thick disc model.
We have deliberately chosen to assume a separable thin disc – thick disc – halo Milky Way as this provides a simple and tractable application of our method that we introduced in Section 2 whilst still returning physically informative parameters. It will be worthwhile applying our method to Gaia data with more detailed model parametrizations. It is beyond the scope of this work because the exact choice of model will depend on the scientific interests of the researcher so we wish to leave this open.
Note that wc is a free parameter of the model for each component and gives the total number of stars for that component within the given region of the sky and absolute magnitude range.
3.1 Spatial distributions
We consider the thin and thick discs to have exponential profiles vertically |$\nu _{\rm c}\propto \exp \left(-{|z|}/{h_{\rm c}}\right)$| similar to previous work (e.g. Jurić et al. 2008; Bovy et al. 2012b, 2016). Other possibilities include sech or sech2 profiles, but there is a moderate preference in the data for an exponential profile (Dobbie & Warren 2020).
Since we are only considering high latitudes, we neglect any radial dependence of the vertical density profile. This makes the numerical integral described in Section 2.1 significantly more tractable. The complexity introduced by adding radial dependence is explained in more detail in Appendix A. The impact of this simplification on the results is tested and quantified in Paper II.
For the spatial distribution of the halo, we use a spherically symmetric single power-law profile centred on the Galactic Centre, |$\nu _\mathrm{H}(r)\mathrm{d}V \propto r^{-n_\mathrm{H}}$|. Many other works also include a free parameter for the halo axial ratio (Jurić et al. 2008; Mateu & Vivas 2018); however, as we are only using a narrow window on the sky, there will be limited information to independently constrain the profile and axial ratio of the halo. Furthermore, previous works have either implicitly or explicitly truncated the halo or included a broken power-law profile. The halo profile used in this work is assumed to extend infinitely and as such a normalization constraint is placed such that nH > 3. This will be in tension with Deason et al. (2014) and Fukushima et al. (2019), who find a steeper halo profile beyond r ∼ 50 and 160 kpc, respectively. This corresponds to a parallax ϖ < 0.02 mas, which is pushing the precision limit of Gaia parallaxes even for bright sources (see fig. 7 of Lindegren et al. 2021). Therefore, our model should not be significantly sensitive to this shift.
3.2 Luminosity functions
The luminosity distribution function of stars in the Milky Way is an intricate function of the star formation history, accretion history, and dynamical evolution of the Galaxy. The aim of this work is to derive the spatial distribution of sources in the Galaxy – independent of stellar populations – and so the magnitude distribution is only included in order to formally account for the survey selection function. In this section, we will explain how to derive an adequate parametrization for the luminosity function for each Milky Way component.
Each of the three Milky Way components is assumed to be a single mono-age, mono-abundance stellar population. Using the results of Kilic et al. (2017) from white dwarf populations, the ages used for the thin disc, thick disc, and halo are 6.9, 7.8, and 12.5 Gyr, respectively. Using SDSS spectroscopy, Ivezić et al. (2008) derived halo and thick disc metallicities of [Fe/H] = −1.5 and −0.7, respectively, whilst Recio-Blanco et al. (2014) used the Gaia-ESO survey (Gilmore et al. 2012) to find the thin disc metallicity fell in the range [ − 0.8, 0.2] and the thick disc in the range [ − 1.0, −0.25]. Combining these results, we assume the thin disc, thick disc, and halo have metallicities of −0.3, −0.7, and −1.5. The HR diagram in Fig. 1 shows the three isochrones that are taken from parsec v1.2s (Bressan et al. 2012; Tang et al. 2014; Chen et al. 2014, 2015).
![HR diagram showing the isochrones used for our mock model of Milky Way sources, with ages τ = 6.9, 7.8, and 12.5 Gyr and metallicities [Fe/H] = −0.3, −0.7, and −1.5 for the thin disc, thick disc, and halo, respectively (orange, green, and purple). The grey dashed line shows the minimum absolute magnitude of our model – MG = 12.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/mnras/511/2/10.1093_mnras_stab3325/2/m_stab3325fig1.jpeg?Expires=1750059249&Signature=pxb5V5dWv0ZjMbV3H4yI6CsdJqH7Go9IXPkCEuEghpk6FGg~SsQg4hNudQSygM9YjynPlhV02l43~cLetYwdn5HPD-JLIQFGF7wiBSinKrrgjyDIdwRMd95SeDV8Pu~Sj8JHCWcQD3CGi2RRre6eTYXCh8NFe2T1F~HWcSn5Cy5597V2X1TmEQfnMO9JshSPA5usAEsNIKr6akvrr6mHgUKvYSO5MhJ-PSwsYyBYy0zHQttH11JkraNngcNyBIudkeQJnXB~56X42-qNM52~VW0yj5FWjUONoOnpxXI4n8yEcRoejTL0cQoOwlJYJep9nqslikKBs0G1uzXjHRRCWQ__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
HR diagram showing the isochrones used for our mock model of Milky Way sources, with ages τ = 6.9, 7.8, and 12.5 Gyr and metallicities [Fe/H] = −0.3, −0.7, and −1.5 for the thin disc, thick disc, and halo, respectively (orange, green, and purple). The grey dashed line shows the minimum absolute magnitude of our model – MG = 12.
We then draw a random sample from the broken power law initial mass function (IMF) of Kroupa (2001) for initial masses greater than 0.09 M⊙ with |${\mathcal {M}_\mathrm{ini}\sim \mathcal {M}_\mathrm{ini}^{-1.3}}$| for |${\mathcal {M}_\mathrm{ini}\lt 0.5\, \mathrm{M}_\odot }$| and |${\mathcal {M}_\mathrm{ini}\sim \mathcal {M}_\mathrm{ini}^{-2.3}}$| otherwise. This is shown in the top panel of Fig. 2. The individual component isochrones, shown in the middle panel, are then used to transform the IMF into an absolute magnitude distribution that is shown in the right hand panel. This sample is not used as our mock catalogue, it is only for deriving our model absolute magnitude distribution.
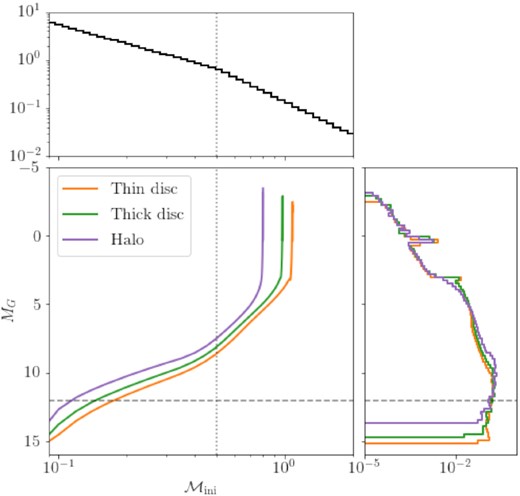
The thin disc, thick disc, and halo isochrones (orange, green, and purple) are used to transform a mock sample of stars from initial mass (|$\mathcal {M}_\mathrm{ini}$|) to absolute magnitude (MG). The initial mass (top panel) is drawn from a Kroupa IMF (Kroupa 2001) with |$\mathcal {M}_\mathrm{ini}\gt 0.09\mathrm{M}_\odot$| where the vertical grey dotted line is the break mass |$0.5\, \mathrm{M}_\odot$|. This produces the absolute magnitude distribution shown in the right-hand panel. The horizontal grey-dashed line shows the maximum absolute magnitude as our model only includes sources with MG < 12.
The absolute magnitude distributions of the three components from the right-hand panel of Fig. 2 are shown as shaded histograms in Fig. 3. They are made up of four regimes. At the bright end (MG ≲ 3), sources evolve much faster along the giant branch than the main sequence (MS), generating a sharp drop at the turn-off above which the number density of sources falls quickly aside from a spike at the red clump (MG ∼ 0). The MS has three components, a relatively shallow upper sequence for MG ∼ [3, 7], a steeper section for MG ∼ [7, 9] where the slope of the MS in Fig. 1 shifts, which is also around the power-law break of the IMF (we will refer to this section as the ‘gap’), and a very flat lower MS for MG ≳ 9. Sources continue fainter to the brown dwarf regime; however, stellar models in these regions of parameter space are poorly constrained by observations as there are few stars this dim yet bright enough for current observatories. For this reason, we only consider sources with MG > 12 in this work. This will be especially beneficial when we model the Gaia data in Paper II as the majority of sources with spurious astrometric solutions as classified by Rybizki et al. (2021) and Gaia Collaboration et al. (2021b) have absolute magnitudes fainter than MG = 12.
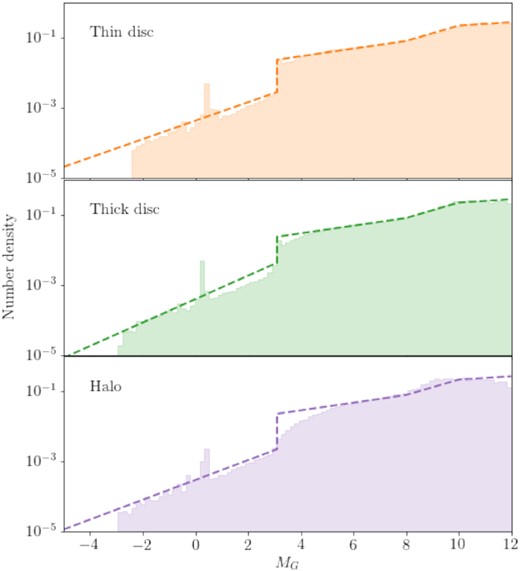
The mock distributions produced by transforming the Kroupa IMF through isochrones from Fig. 1 (shaded histograms) are fit with the approximate absolute magnitude distribution used for the model (dashed lines).
The distribution is continuous everywhere except from at the turnoff where the discontinuous change in the gradient of the magnitude–initial mass relation leads to a discontinuity in the magnitude distribution. Continuity conditions at MG = 7 and 9 constrain the exponential profile αg and the normalization Ag of the gap profile.
The magnitude distribution introduces five parameters: α1, α2, MTO, αG, and fG, the fraction of the population that are giants, which constrains the size of the discontinuity at the turn-off. We could fix all parameters using the IMF-isochrone sample just constructed. However, this is only an approximate representation of the magnitude distribution that may introduce large systematics. To avoid this problem, we free up α1, α2, and fG to be constrained by the real data. α1 and α2 are assumed to be the same for all populations as the MS is dominated by older stars that show a similar distribution independent of population parameters.
The position of the turn-off, MTO, defines a discontinuity for the model. Depending on the location of individual sources in relation to the turnoff, this can generate sample-dependent local optima in the likelihood space that is challenging for optimization. For this reason, we fix MTO = 3.1 for all models and address the implications of this in Paper II. αG has a strong degeneracy with fG as both control the number of sources at bright magnitudes. We also fix αG in all optimizations to avoid this degeneracy to values that are discussed in Section 4. All free parameters are listed in Table 1 with their respective components.
The 11 free parameters used to model the spatial and absolute magnitude distributions of sources along with their priors.
| Component | Parameter | Prior | Transformation | Bounds |
|---|---|---|---|---|
| Thin disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTn | U[0.1, 0.6] | |$\mathrm{logit}\left(({h-0.1})/({0.6-0.1})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Thick disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTk | U[0.6, 3.0] | |$\mathrm{logit}\left(({h-0.6})/({3.0-0.6})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Halo | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| nH | U[3, 7.3] | |$\mathrm{logit}\left(({h-3})/({7.3-3})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Shared | α1 | −α1 ∼ log U[e−5, e3] | log (− α1) | [−5,3] |
| α2 | −α2 ∼ log U[e−5, e3] | log (− α2) | [−5,3] |
| Component | Parameter | Prior | Transformation | Bounds |
|---|---|---|---|---|
| Thin disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTn | U[0.1, 0.6] | |$\mathrm{logit}\left(({h-0.1})/({0.6-0.1})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Thick disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTk | U[0.6, 3.0] | |$\mathrm{logit}\left(({h-0.6})/({3.0-0.6})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Halo | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| nH | U[3, 7.3] | |$\mathrm{logit}\left(({h-3})/({7.3-3})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Shared | α1 | −α1 ∼ log U[e−5, e3] | log (− α1) | [−5,3] |
| α2 | −α2 ∼ log U[e−5, e3] | log (− α2) | [−5,3] |
Notes. The method fits directly to the parameters under the given transformations where logistic priors are also included to correct for the logit transform. The bounds are applied to the transformed parameters for numerical stability of the optimization.
The 11 free parameters used to model the spatial and absolute magnitude distributions of sources along with their priors.
| Component | Parameter | Prior | Transformation | Bounds |
|---|---|---|---|---|
| Thin disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTn | U[0.1, 0.6] | |$\mathrm{logit}\left(({h-0.1})/({0.6-0.1})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Thick disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTk | U[0.6, 3.0] | |$\mathrm{logit}\left(({h-0.6})/({3.0-0.6})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Halo | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| nH | U[3, 7.3] | |$\mathrm{logit}\left(({h-3})/({7.3-3})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Shared | α1 | −α1 ∼ log U[e−5, e3] | log (− α1) | [−5,3] |
| α2 | −α2 ∼ log U[e−5, e3] | log (− α2) | [−5,3] |
| Component | Parameter | Prior | Transformation | Bounds |
|---|---|---|---|---|
| Thin disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTn | U[0.1, 0.6] | |$\mathrm{logit}\left(({h-0.1})/({0.6-0.1})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Thick disc | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| hTk | U[0.6, 3.0] | |$\mathrm{logit}\left(({h-0.6})/({3.0-0.6})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Halo | w | Dirichlet(a = 2) | log (w) | [−10,50] |
| nH | U[3, 7.3] | |$\mathrm{logit}\left(({h-3})/({7.3-3})\right)$| | [−10,10] | |
| fD | U[0, 1] | logit(fD) | [−10,10] | |
| Shared | α1 | −α1 ∼ log U[e−5, e3] | log (− α1) | [−5,3] |
| α2 | −α2 ∼ log U[e−5, e3] | log (− α2) | [−5,3] |
Notes. The method fits directly to the parameters under the given transformations where logistic priors are also included to correct for the logit transform. The bounds are applied to the transformed parameters for numerical stability of the optimization.
This fully defines the model that we fit to the Gaia data. In total, there are 11 free parameters of the model.
3.3 Selection function
A major obstacle to using a catalogue of sources to fit a distribution is the selection function. Many surveys have complex and unknown observation limitations that are a strong function of observatory properties and observing conditions. Gaia is no exception due in part to the complexity of the scanning law (Boubert, Everall & Holl 2020; Boubert et al. 2021).
In most previous works, the sample is either assumed to be magnitude complete to some limit (e.g. Jurić et al. 2008; Bilir et al. 2006; Ak et al. 2008), or the sample is bright and nearby for which there are larger, complete catalogues against which the selection function has been estimated (e.g. Bovy 2017; Mateu & Vivas 2018; Bennett & Bovy 2019). Gaia is neither complete in position on the sky or apparent magnitude, nor is there a larger, more complete sample against which to compare the Gaia catalogue.
Fortunately, a solution for the Gaia source catalogue selection function has been developed and applied to Gaia DR2 (Boubert & Everall 2020). Appendix A of Everall & Boubert (2021) provides a simple extension to model the selection function of the Gaia EDR3 source catalogue using the nominal EDR3 scanning law. This may have some limitations in crowded regions due to changes in Gaia’s data processing pipeline. However, since we are only considering high latitude fields, it should be sufficient for our purposes. The selection probability as a function of apparent magnitude for b = 90° is given by the green dashed line in Fig. 4, showing that the source catalogue is nearly complete for 3 < G < 21.
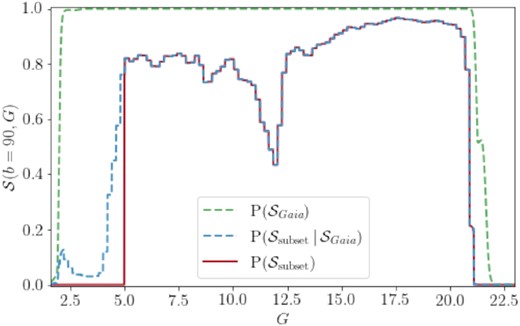
The selection function probability at b = 90° for the Gaia EDR3 source catalogue (green dashed) drops off at bright magnitudes (G < 2, due to CCD oversaturation) and faint magnitudes (G ≳ 21); however, it remains high across the rest of apparent magnitude space. The Gaia EDR3 astrometry with RUWE < 1.4 relative selection function (blue dashed) is more restrictive over the entire magnitude range and dominates the total selection function (red solid). The cut-off at G < 5 is deliberately imposed to remove regions of apparent magnitude with poor astrometry calibration.
The results are applied in 0.2-mag bins in G in |${\small NSIDE}=64$|healpix pixels (Górski et al. 2005) across the sky. The selection probability for b = 90° is given by the red line in Fig. 4. Due to the challenges of modelling sources that saturate the Gaia CCDs at the bright end of the magnitude distribution, we use a selection function that truncates at G = 5. Our sample will also only include those sources with G > 5.
4 MOCK
To test and demonstrate the efficacy of the method, we generate a mock catalogue from our model with realistic parameters. Information on the true parameters is then removed, the Gaia selection function and Gaia-like parallax uncertainties are applied, and we attempt to infer the input parameters from the mock sample. We note that this only tests the method. Because the data are drawn from the same model that is being refit, any inconsistencies between the model and true Milky Way distribution of stars do not show up here. These inconsistencies are discussed, tested and quantified in Paper II.
4.1 Input parameters
Parameters for the scaleheights and power-law indices of the discs and halo respectively are taken from the literature. For the thin disc, hTn = 300pc, and for the thick disc, hTk = 900pc (Jurić et al. 2008). The power-law index used is nH = 3.74 from Fukushima et al. (2019).
The relative stellar mass density of the discs is ρTk/ρTn = 0.12 and ρH/ρTn = 0.005 (Jurić et al. 2008). Instead of local mass density, our model fits the total number of sources in each component with |b| > 80°. To convert mass density into number density in the Solar neighbourhood, we divide by the mean mass of a star. The mean mass is estimated using the IMF-isochrone sample in Section 3.2 as |$\mathcal {M} \sim 0.413,0.369,0.308\, \mathrm{M}_\odot$| for the thin disc, thick disc, and halo, respectively. We then divide the number density by the value of the normalized component at s = 0 to get the total number of sources in each component. The result is that wTn/wTk = 0.275 and wTn/wH = 0.0127. The halo dominates the total counts because our observing volume is a cone with |b| > 80°. This significantly reduces the relative contribution from the disc to the sample.
The absolute magnitude distributions for each Milky Way component are shown by the shaded histograms in Fig 3. To estimate magnitude parameters for the luminosity function described in Section 3.2, we directly fit the parameters to the magnitude distributions. For each component, the turn-off magnitude is at MG ∼ 3.1. fG is approximated from the ratio of sources with G < 3.1 to those with G > 3.1. For G < 3.1, we fit a power-law profile to each component independently using the Poisson likelihood function from equation (1). This gives α3 = −0.60, −0.77, and −0.64 and fG = 0.0045, 0.0054, and 0.0035 for the thin disc, thick disc, and halo, respectively.
The lower MS is dominated by old, long-lived stars that evolve slowly on the HR diagram. Therefore, we assume that the MS profiles are similar between different Milky Way components such that the values of α1, α2 are shared between profiles. We draw a sample of sources from each of the components according to the component’s respective weight and fit the MS profiles to the sources with G > 3.1, which gives α1 = −0.12, α2 = −0.26. The dashed lines in Fig. 3 give the absolute magnitude distributions implied by the parameters we have just derived.
All selected and evaluated parameter values are listed as ‘Input’ in Table 2.
The input parameters for the mock sample catalogue generation and the results of the fit to the data are shown when using the full sample with no observational errors (‘Full’), the selection function with no observational errors (‘SF’), and the sample with both the selection function and the added parallax errors (‘SF and |$\sigma _\varpi$|’).
| Component | Parameter | Input | Full | SF | SF and σϖ |
|---|---|---|---|---|---|
| Thin disc | log10(w) | 4.0792 | |${4.0700} _{-0.0191} ^{+0.0194}$| | |${4.0637} _{-0.0359} ^{+0.0331}$| | |${3.9816} _{-0.0657} ^{+0.0586}$| |
| hTn | 0.300 | |${0.301} _{-0.006} ^{+0.007}$| | |${0.301} _{-0.010} ^{+0.010}$| | |${0.281} _{-0.015} ^{+0.015}$| | |
| fG | 4.50 × 10−3 | |${3.73} _{-0.99} ^{+1.00}\times 10^{-3}$| | |${3.91} _{-1.22} ^{+1.23}\times 10^{-3}$| | |${3.76} _{-1.30} ^{+1.43}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.6 | ||||
| Thick disc | log10(w) | 4.6335 | |${4.6249} _{-0.0050} ^{+0.0051}$| | |${4.6253} _{-0.0093} ^{+0.0092}$| | |${4.6221} _{-0.0198} ^{+0.0200}$| |
| hTk | 0.900 | |${0.891} _{-0.011} ^{+0.012}$| | |${0.884} _{-0.028} ^{+0.029}$| | |${0.812} _{-0.045} ^{+0.052}$| | |
| fG | 5.40 × 10−3 | |${5.76} _{-0.52} ^{+0.54}\times 10^{-3}$| | |${5.80} _{-0.60} ^{+0.64}\times 10^{-3}$| | |${5.83} _{-0.66} ^{+0.69}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.77 | ||||
| Halo | log10(w) | 5.9754 | |${5.9759} _{-0.0005} ^{+0.0005}$| | |${5.9662} _{-0.0105} ^{+0.0106}$| | |${5.9450} _{-0.0229} ^{+0.0247}$| |
| nH | 3.740 | |${3.745} _{-0.001} ^{+0.001}$| | |${3.753} _{-0.020} ^{+0.020}$| | |${3.812} _{-0.066} ^{+0.068}$| | |
| fG | 3.50 × 10−3 | |${3.47} _{-0.06} ^{+0.06}\times 10^{-3}$| | |${3.49} _{-0.09} ^{+0.10}\times 10^{-3}$| | |${3.48} _{-0.15} ^{+0.15}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.64 | ||||
| Shared | α1 | −0.1100 | |${-0.1109} _{-0.0004} ^{+0.0003}$| | |${-0.1094} _{-0.0015} ^{+0.0014}$| | |${-0.1098} _{-0.0020} ^{+0.0020}$| |
| α2 | −0.2500 | |${-0.2524} _{-0.0019} ^{+0.0020}$| | |${-0.2534} _{-0.0046} ^{+0.0045}$| | |${-0.2521} _{-0.0084} ^{+0.0089}$| |
| Component | Parameter | Input | Full | SF | SF and σϖ |
|---|---|---|---|---|---|
| Thin disc | log10(w) | 4.0792 | |${4.0700} _{-0.0191} ^{+0.0194}$| | |${4.0637} _{-0.0359} ^{+0.0331}$| | |${3.9816} _{-0.0657} ^{+0.0586}$| |
| hTn | 0.300 | |${0.301} _{-0.006} ^{+0.007}$| | |${0.301} _{-0.010} ^{+0.010}$| | |${0.281} _{-0.015} ^{+0.015}$| | |
| fG | 4.50 × 10−3 | |${3.73} _{-0.99} ^{+1.00}\times 10^{-3}$| | |${3.91} _{-1.22} ^{+1.23}\times 10^{-3}$| | |${3.76} _{-1.30} ^{+1.43}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.6 | ||||
| Thick disc | log10(w) | 4.6335 | |${4.6249} _{-0.0050} ^{+0.0051}$| | |${4.6253} _{-0.0093} ^{+0.0092}$| | |${4.6221} _{-0.0198} ^{+0.0200}$| |
| hTk | 0.900 | |${0.891} _{-0.011} ^{+0.012}$| | |${0.884} _{-0.028} ^{+0.029}$| | |${0.812} _{-0.045} ^{+0.052}$| | |
| fG | 5.40 × 10−3 | |${5.76} _{-0.52} ^{+0.54}\times 10^{-3}$| | |${5.80} _{-0.60} ^{+0.64}\times 10^{-3}$| | |${5.83} _{-0.66} ^{+0.69}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.77 | ||||
| Halo | log10(w) | 5.9754 | |${5.9759} _{-0.0005} ^{+0.0005}$| | |${5.9662} _{-0.0105} ^{+0.0106}$| | |${5.9450} _{-0.0229} ^{+0.0247}$| |
| nH | 3.740 | |${3.745} _{-0.001} ^{+0.001}$| | |${3.753} _{-0.020} ^{+0.020}$| | |${3.812} _{-0.066} ^{+0.068}$| | |
| fG | 3.50 × 10−3 | |${3.47} _{-0.06} ^{+0.06}\times 10^{-3}$| | |${3.49} _{-0.09} ^{+0.10}\times 10^{-3}$| | |${3.48} _{-0.15} ^{+0.15}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.64 | ||||
| Shared | α1 | −0.1100 | |${-0.1109} _{-0.0004} ^{+0.0003}$| | |${-0.1094} _{-0.0015} ^{+0.0014}$| | |${-0.1098} _{-0.0020} ^{+0.0020}$| |
| α2 | −0.2500 | |${-0.2524} _{-0.0019} ^{+0.0020}$| | |${-0.2534} _{-0.0046} ^{+0.0045}$| | |${-0.2521} _{-0.0084} ^{+0.0089}$| |
Note. For all parameters, we provide the median and 16th and 84th percentile uncertainties.
The input parameters for the mock sample catalogue generation and the results of the fit to the data are shown when using the full sample with no observational errors (‘Full’), the selection function with no observational errors (‘SF’), and the sample with both the selection function and the added parallax errors (‘SF and |$\sigma _\varpi$|’).
| Component | Parameter | Input | Full | SF | SF and σϖ |
|---|---|---|---|---|---|
| Thin disc | log10(w) | 4.0792 | |${4.0700} _{-0.0191} ^{+0.0194}$| | |${4.0637} _{-0.0359} ^{+0.0331}$| | |${3.9816} _{-0.0657} ^{+0.0586}$| |
| hTn | 0.300 | |${0.301} _{-0.006} ^{+0.007}$| | |${0.301} _{-0.010} ^{+0.010}$| | |${0.281} _{-0.015} ^{+0.015}$| | |
| fG | 4.50 × 10−3 | |${3.73} _{-0.99} ^{+1.00}\times 10^{-3}$| | |${3.91} _{-1.22} ^{+1.23}\times 10^{-3}$| | |${3.76} _{-1.30} ^{+1.43}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.6 | ||||
| Thick disc | log10(w) | 4.6335 | |${4.6249} _{-0.0050} ^{+0.0051}$| | |${4.6253} _{-0.0093} ^{+0.0092}$| | |${4.6221} _{-0.0198} ^{+0.0200}$| |
| hTk | 0.900 | |${0.891} _{-0.011} ^{+0.012}$| | |${0.884} _{-0.028} ^{+0.029}$| | |${0.812} _{-0.045} ^{+0.052}$| | |
| fG | 5.40 × 10−3 | |${5.76} _{-0.52} ^{+0.54}\times 10^{-3}$| | |${5.80} _{-0.60} ^{+0.64}\times 10^{-3}$| | |${5.83} _{-0.66} ^{+0.69}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.77 | ||||
| Halo | log10(w) | 5.9754 | |${5.9759} _{-0.0005} ^{+0.0005}$| | |${5.9662} _{-0.0105} ^{+0.0106}$| | |${5.9450} _{-0.0229} ^{+0.0247}$| |
| nH | 3.740 | |${3.745} _{-0.001} ^{+0.001}$| | |${3.753} _{-0.020} ^{+0.020}$| | |${3.812} _{-0.066} ^{+0.068}$| | |
| fG | 3.50 × 10−3 | |${3.47} _{-0.06} ^{+0.06}\times 10^{-3}$| | |${3.49} _{-0.09} ^{+0.10}\times 10^{-3}$| | |${3.48} _{-0.15} ^{+0.15}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.64 | ||||
| Shared | α1 | −0.1100 | |${-0.1109} _{-0.0004} ^{+0.0003}$| | |${-0.1094} _{-0.0015} ^{+0.0014}$| | |${-0.1098} _{-0.0020} ^{+0.0020}$| |
| α2 | −0.2500 | |${-0.2524} _{-0.0019} ^{+0.0020}$| | |${-0.2534} _{-0.0046} ^{+0.0045}$| | |${-0.2521} _{-0.0084} ^{+0.0089}$| |
| Component | Parameter | Input | Full | SF | SF and σϖ |
|---|---|---|---|---|---|
| Thin disc | log10(w) | 4.0792 | |${4.0700} _{-0.0191} ^{+0.0194}$| | |${4.0637} _{-0.0359} ^{+0.0331}$| | |${3.9816} _{-0.0657} ^{+0.0586}$| |
| hTn | 0.300 | |${0.301} _{-0.006} ^{+0.007}$| | |${0.301} _{-0.010} ^{+0.010}$| | |${0.281} _{-0.015} ^{+0.015}$| | |
| fG | 4.50 × 10−3 | |${3.73} _{-0.99} ^{+1.00}\times 10^{-3}$| | |${3.91} _{-1.22} ^{+1.23}\times 10^{-3}$| | |${3.76} _{-1.30} ^{+1.43}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.6 | ||||
| Thick disc | log10(w) | 4.6335 | |${4.6249} _{-0.0050} ^{+0.0051}$| | |${4.6253} _{-0.0093} ^{+0.0092}$| | |${4.6221} _{-0.0198} ^{+0.0200}$| |
| hTk | 0.900 | |${0.891} _{-0.011} ^{+0.012}$| | |${0.884} _{-0.028} ^{+0.029}$| | |${0.812} _{-0.045} ^{+0.052}$| | |
| fG | 5.40 × 10−3 | |${5.76} _{-0.52} ^{+0.54}\times 10^{-3}$| | |${5.80} _{-0.60} ^{+0.64}\times 10^{-3}$| | |${5.83} _{-0.66} ^{+0.69}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.77 | ||||
| Halo | log10(w) | 5.9754 | |${5.9759} _{-0.0005} ^{+0.0005}$| | |${5.9662} _{-0.0105} ^{+0.0106}$| | |${5.9450} _{-0.0229} ^{+0.0247}$| |
| nH | 3.740 | |${3.745} _{-0.001} ^{+0.001}$| | |${3.753} _{-0.020} ^{+0.020}$| | |${3.812} _{-0.066} ^{+0.068}$| | |
| fG | 3.50 × 10−3 | |${3.47} _{-0.06} ^{+0.06}\times 10^{-3}$| | |${3.49} _{-0.09} ^{+0.10}\times 10^{-3}$| | |${3.48} _{-0.15} ^{+0.15}\times 10^{-3}$| | |
| MTO | 3.1 | ||||
| α3 | −0.64 | ||||
| Shared | α1 | −0.1100 | |${-0.1109} _{-0.0004} ^{+0.0003}$| | |${-0.1094} _{-0.0015} ^{+0.0014}$| | |${-0.1098} _{-0.0020} ^{+0.0020}$| |
| α2 | −0.2500 | |${-0.2524} _{-0.0019} ^{+0.0020}$| | |${-0.2534} _{-0.0046} ^{+0.0045}$| | |${-0.2521} _{-0.0084} ^{+0.0089}$| |
Note. For all parameters, we provide the median and 16th and 84th percentile uncertainties.
4.2 Parallax error
To generate a realistic mock, we also need to sample measurement uncertainties. Since the Gaia astrometry was fit using an iterative linear regression process, the covariance may be estimated from information theory (neglecting excess noise) using only the scanning law and individual observation centroid uncertainties. This process is performed in Everall et al. (2021b) for Gaia DR2 and we use the Gaia EDR3 nominal scanning law to extend this to the EDR3 baseline.
The covariance estimates break down for sources with significant excess noise, such as in heavily crowded regions and for sources with intrinsic astrometric variability like binaries. Since we will only consider sources with |b| > 80°, crowding is negligible. By focusing on the sample with RUWE < 1.4, we expect to have removed sources with observable binary motion.
4.3 Mock samples
A sample of one million sources with distance, latitude and absolute magnitude is drawn from the model using MCMC sampling (Foreman-Mackey et al. 2013). Since all sources are assumed to be at the projected distance from the Galactic Centre of the Sun, the full model is Galactic longitude-independent so the longitude is drawn from a uniform distribution l ∼ U[0, 2π]. The distribution of drawn sources as a function of distance from the Galactic disc and absolute magnitude is given by the blue histograms in the top panels of Fig. 5.
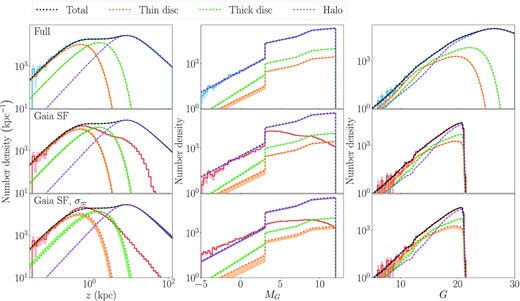
The posterior distribution of fits to the mock sample are shown by the shaded regions for the thin disc (orange), thick disc (green), halo (purple), and the sum total (black) as a function of vertical height (z, left-hand panel), absolute magnitude (MG, middle panel), and apparent magnitude (G, right-hand panel). Blue histograms in the top row show the full sample that the model fit perfectly cut through. The red histograms in the middle and bottom rows show the distribution of SF selected samples with the bottom row showing the distribution of z = sin (b)/ϖ and MG = G + 5log10(ϖ) − 10, demonstrating the impact of parallax uncertainties on measured quantities. The posteriors agree extremely well with the ground truth shown by the dotted lines in all panels. This is true when fitting to the full sample (top panel), the SF-limited sample (middle panel), and the SF-limited sample with measured parallaxes sampled from their error distributions (bottom panel). The posterior distributions are evaluated by randomly selecting 100 samples from the MCMC posteriors and taking the 16th–84th percentile range. In several cases, particularly for the ‘Full’ fits in the top row, the posterior is so tight that the distribution appears as a line in the figure.
The selection function probability is evaluated for all sources, given their position on the sky and apparent magnitude as described in Section 3.3. To generate the mock Gaia astrometry with RUWE < 1.4 sample, the event of a source being included is drawn from a Bernoulli distribution with the given selection probability |${\mathrm{\it S}_i \sim \mathrm{Bernoulli}(\mathcal {S}(l_i, b_i, G_i))}$|, where Si = 0, 1. Of the |$1000\,000$| source in the full sample, 73 132 survive the selection cuts, shown by the red histograms in the middle and bottom panels of Fig. 5.
Parallax error is evaluated from the Astrometric Spread Function described in Section 4.2. The observed parallax is drawn from a Gaussian distribution with the given error for each source |$\varpi \sim \mathcal {N}(1/s, \sigma _\varpi)$|. The red histograms in the bottom panels of Fig. 5 show the distribution of measured z = sin (b)/ϖ, MG = G − 10 + 5log10(ϖ/mas) after sampling ϖ from the parallax error. This significantly affects the distributions, demonstrating the importance of properly accounting for parallax uncertainty when modelling the structure of the Milky Way from Gaia data.
This produces three samples that can each be used to independently fit the model parameters demonstrating each stage of the method:
Full sample fit with equation (1): |$l^i, b^i, si, G^i \, \forall \, i$|,
SF sample fit with equation (3): |$l^i, b^i, s^i, G^i \, \forall \, i$|, where Si = 1,
SF and σϖ fit with equation (9): |$l^i, b^i, \varpi ^i, G^i \, \forall \, i$|, where Si = 1.
To be clear, in sample (iii), the selection function is not dependent on measured parallax or parallax error as discussed in Section 2. We simply mean that the selection function is applied and parallax error on sources is also included. Samples (ii) and (iii) contain the exact same subset of sources from the mock catalogue. Sample (ii) has no parallax error, whilst measured parallaxes in (iii) have been drawn from the parallax uncertainties.
5 PARAMETER INFERENCE
In this section, we will use the method introduced in Section 2 to fit the model parameters to the three mock samples described in Section 4.
5.1 Priors
Priors for all free parameters of the fits are given in Table 1. As is common with mixture model fits to density distributions, the likelihood space is strongly multimodal. For the thin and thick discs, there is of course a complete degeneracy where the components can be switched, but there are also problematic modes where, for example, a single component is expanded to fit the full data set, whilst remaining components are suppressed.
Priors are chosen specifically to avoid local optima in the model. All weights are assumed to be drawn from a Dirichlet distribution with a = 2 to remove modes where any component is completely suppressed relative to the others. To avoid the disc degeneracy, the possible disc scaleheights are limited to non-overlapping ranges with hTn ∼ U[0.1kpc, 0.6kpc] and hTk ∼ U[0.6kpc, 3.0kpc]. The power-law index of the halo is also limited to nH ∼ U[3.0, 7.3] as nH < 3.0 would produce an unnormalized halo and nH > 7.3 produces an incredibly steep halo profile that can mimic the exponential discs (for nH = 7.3, the mean halo source distance is the same as an exponential profile with h = 3.0 kpc).
For numerical stability, the fits are made on the transformed parameters where transformations are given in Table 1. The transformations scale parameters to the range [ − ∞, ∞] in all cases. For logit transformed parameters, we include a logistic prior in logit space that is equivalent to a uniform prior in untransformed space. Therefore the logit transformation has no effect on the prior.
The L-BFGS-B algorithm requires boundaries on all parameters that are given in the final column of Table 1. The boundaries are chosen to avoid regions of parameter space that suffer from numerical precision issues. None of the parameter posterior distributions push up against the boundaries.
5.2 Optimization
The likelihood optimization is performed in three stages. All MCMC processes used emcee (Foreman-Mackey et al. 2013). First, a set of samples is drawn from the parameter priors using MCMC with 44 walkers (this is four times the number of free parameters in our model), with 100 step burn-in and 100 steps of sampling. Secondly, 10 samples are randomly selected from the prior samples as initialization for gradient descent using L-BFGS-B (Zhu et al. 1997) as implemented in scipy. Finally, the maximum likelihood estimate with the highest likelihood is taken as the best fit solution. A secondary MCMC process is initialized with 44 walkers drawn from a Gaussian ball around the maximum likelihood estimate with variance of 10−10 times the boundary width. These walkers were run with the likelihood × prior for 5000 steps. The latter 2500 steps are used at five-step intervals as the posterior samples. This process is used for fitting all mock samples and the real Gaia data in Paper II.
5.3 Results
The ‘Full’ sample posteriors, given by the blue contours in Fig. 6, provide tight solutions around the input parameter values that are shown by the black dot. A more quantitative comparison can be made from Table 2 that shows that the majority of input parameters fall within the 16th–84th percentile range of the posterior distribution. The top panels of Fig. 5 compare the ground truth input model, shown with dotted lines, to the refit model, shown by the narrow shaded regions. To produce the shaded posteriors in Fig. 5, we draw 100 samples from the posterior parameter distributions and plot the 16th–84th percentile range as a function of z, MG, and G. The posteriors are so tight in most cases that the shaded regions appear as lines perfectly tracking the input model and the total of the components in black sits exactly on top of the blue histograms that show the distribution of the data in the sample.

The posterior distributions for all mock samples are shown as a function of transformed parameters that are fit to the data. The Full sample fits (blue), SF sample (red), and SF with parallax error (purple) all show strong agreement with one another and the input parameters (black lines). The enhancement of the statistical uncertainty by introducing parallax error can clearly be seen by the increased spread of the posterior for the purple contours.
The ‘SF’ sample, fit to only 73 132 of the initial one million mock sources, has a significantly less tight constraint around the true parameters, shown by the red contours in Fig 6, but the parameters show no significant bias. The fits to the halo parameters are slightly shifted from the true values but all parameters are well within 2σ of the input so this can be well explained by correlated noise, particularly considering the negative correlation between the halo weight and power-law index, nH. The red histograms in the middle panels of Fig. 5 show the selection-limited sample that drops significantly at large vertical heights and faint apparent magnitudes demonstrating how much the model has to extrapolate using the selection function. Again, the model posteriors sit perfectly on the input model shown by the dotted lines.
For the apparent magnitude distribution in the middle right-hand panel of Fig. 5, we show the model multiplied by the selection function probability. The total model (black) sits perfectly on top of the red sample histograms demonstrating how successfully the model is fit to the data. This distribution will be especially important when analysing fits to the real Gaia data when we cannot directly infer the distance of stars from the Galactic plane or their absolute magnitudes due to significant parallax uncertainties.
The ‘SF and σϖ’ posterior, given by the purple contours in Fig. 6, has significantly enhanced uncertainty compared with the solely SF limited data. This demonstrates how much information is held in the parallax and how information is lost when realistic Gaia parallax uncertainties are included. In spite of this, the input parameters are still recovered with reasonable precision and good accuracy. In the bottom panels of Fig. 5, we can see the posterior samples produce a clearer spread around the input distribution. This time the thin and thick discs have not been perfectly fit within the posteriors however the difference is still small enough to be well explained by statistical noise.
These results have demonstrated that the Poisson-likelihood method accounting for the Gaia selection function and parallax error is a powerful tool for recovering the spatial distribution of sources in the Milky Way. However, this only tests the self-consistency of the method; the results may still be susceptible to systematic uncertainties if the model does not represent the real Milky Way.
6 GUMS
So far, we have only tested the method on data drawn from the fitted model. But what happens when we attempt to fit our model to a more general and realistic catalogue? To test this we use the Gaia Universe Model Snapshot (GUMS; Robin et al. 2012), a synthetic Milky Way based on the Besançon Galaxy Model (Robin et al. 2003) that was developed to test the Gaia data processing pipeline with a realistic population of sources.
The latest GUMS sample is provided with Gaia EDR3 and described in the Gaia documentation.1 We will provide a very brief overview of the key components.
The thin disc is composed of seven mono-age populations each contributing a sum of square-exponential radial and vertical profiles to the Milky Way disc. The scaleheights of the profiles increase with age, with ages ranging from 0 to 10 Gyr. The thick disc is based on the results of Robin et al. (2014) and consists of a sum of two components that are exponentially distributed in Galactocentric radius and reciprocal-cosh -square distributed in vertical height above the mid-plane with ages 10 and 12 Gyr, and scaleheights 400 and 795 pc, respectively. Flaring is also applied to the disc profiles; however, this only takes effect for R > 10 kpc so should not affect our analysis. The spheroidal halo is power law distributed with nH ∼ 3.77 for Galactocentric distances of r > >2.2 kpc and is slightly oblate with q = 0.77.
The absolute magnitudes of the populations are determined by sampling from an IMF and star formation history and using stellar evolution tracks. The thin discs use a constant star formation history whilst instantaneous bursts of star formation at 10 and 12 Gyr are used for the thick disc and 14 Gyr for the halo.
The sample provided through the Gaia archive includes binary and higher order systems for a significant fraction of stars. For the purposes of this study, we treat all systems as unresolvable with Gaia, i.e. we only include them as a single point source with flux given by the sum of all stars in the system.
We select sources with b > 80° in the north and b < −80° in the south from the GUMS catalogue. Due to computational limitations, we work only with a randomly-drawn |$10{{\ \rm per\ cent}}$| subsample when testing our method on GUMS. The GUMS sample was cut internally to only include sources with G < 21, where G was estimated from simple colour relations. The published apparent G-band magnitude is computed from the GUMS synthetic spectra such that the originally sharp cut becomes a smooth drop off at G ∼ 21 (Robin, private communication). To avoid this, we cut the sample at G = 20.5 and set the selection function to |$\mathcal {S}=0$| for G > 20.5. We then produce a Gaia-like mock catalogue by resampling the data from the selection function introduced in Section 3.3. This produces 47 027 sources in the north and 49 508 in the south. The distributions of the north sample as a function of height above the mid-plane, absolute magnitude, and apparent magnitude are shown by the red histograms in the lower panels of Fig. 7.
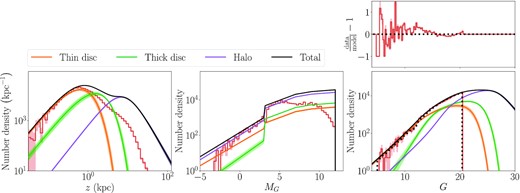
Bottom row: number density of sources in sample (red histograms) and predicted by the model in the thin disc (orange), thick disc (green), halo (purple), and sum total (black). Model shaded regions show the 1st–99th percentiles of posterior parameter fits to the data. Top right-hand panel: relative residual of the data from the median model fit showing that the model produces a small but significant underestimate of the data at bright magnitudes and overestimate at fainter magnitudes. The shaded red regions show the 1 standard deviation Poisson uncertainties of the bin counts.
As we did for the mock in Section 4.2, we also resample a realistic observed parallax measurement for each source from the Astrometric Spread Function (Everall et al. 2021b). We then run two fits for each of the north and south samples, one fit to the sample with no parallax error applied and the other with parallax error applied. These are equivalent to fits (ii) and (iii) in Section 4.
The results of the fits to the north sample with parallax error are shown in Fig. 7. The model is only slightly above the data at small z and bright absolute magnitudes, which is unsurprising as few sources will have been removed by the selection function in these regions of parameter space. For the apparent magnitude distribution, we also apply the selection function to the total model that produces the black dotted line. The top right-hand panel of the figure shows the relative residuals of the data from the model. At bright magnitudes, the residuals are very large but decline to approximately a few per cent for G ≳ 15. This demonstrates that our model is not flexible enough to accurately reproduce the data; however, at the fainter magnitudes, this inaccuracy is small relative to the scale of the model.
The parameter posteriors for all four fits are shown in Fig. 8. The first thing to note is that the north and south posteriors, shown by blue and red contours respectively, are consistent with one another for all parameters whether parallax error is applied or not. This demonstrates that we are correctly finding no asymmetry north or south of the Milky Way disc. The glaring problem with our results is that the halo fits are significantly different when exact distances are used (solid contours) and when parallaxes are drawn from uncertainties (dashed contours). The halo distribution peaks at z ∼ 10 kpc corresponding to a parallax of ∼0.1 mas, which is smaller than the parallax uncertainty for sources fainter than G ∼ 18. Many faint sources will have low parallax signal-to-noise ratio and so will only have weakly constrained distances. At these large distances, we expect that the method is using the absolute magnitude distribution combined with the measured apparent magnitude of sources to estimate the distance distribution. Oversimplifications in our absolute magnitude model therefore significantly bias the inferred halo profile. In spite of this, the thin and thick disc profiles are remarkably resilient to the halo systematics with no parameters producing significant offsets between the two fits.
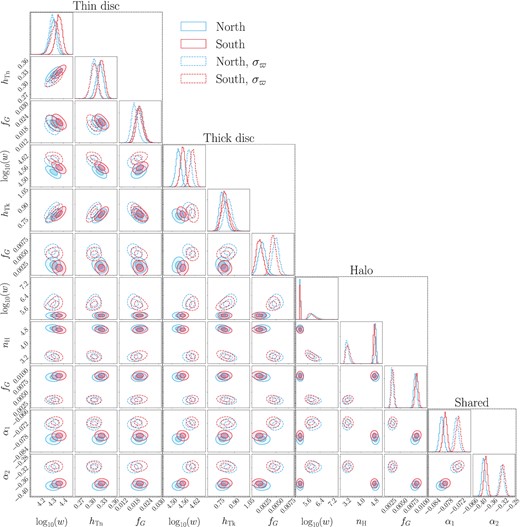
Posterior distribution of fits to GUMS data for the north (blue) and south (red) samples show reasonable agreement across all parameters. The fits with precise distances (solid) and parallaxes drawn from uncertainty distributions (dashed) are consistent for disc parameters but significantly disagree for the halo, likely related to a overly simplistic magnitude model.
As the model parametrization used for GUMS is significantly different to our own, we cannot make direct comparisons between our parameter values and a ‘ground truth’ input. The thick disc scaleheight of 670–780 pc is broadly consistent with the scaleheights used to generate the population however the GUMS sample has two profiles for different age populations that bracket our inferred value.
We conclude from this that the inferred halo profile parameters are susceptible to significant systematic uncertainties when applying our method to realistic Gaia samples likely due to an oversimplified absolute magnitude model. However, the disc parameters are more reliable and we can draw information about the structure of the Milky Way disc profiles from our results when applying to the real Gaia data in Paper II.
Even given the consistency of our disc parameter results, we cannot guarantee that we have managed to separate out the two components. Since our model is different to the one used to generate GUMS, it is likely that some thin disc stars will be contributing to the thick disc and vice versa. This will happen to some extent with the real Gaia data too assuming that the Galactic disc can even be decomposed into discrete components, which is contested (e.g. Bovy et al. 2012a). In the scenario that the Milky Way disc does not decompose well into exponential thin and thick discs, the sum total of our disc models that describes the total tracer density may be of greater interest to the community than the individual components that contribute to it.
In Paper II, we quantify the systematic uncertainty introduced by some of the assumptions we have applied. We test the impact of Solar position offset from the Galactic mid-plane, dust extinction, magnitude uncertainty, parallax zero-point offset, shifting the turn-off absolute magnitude, Galactocentric-radius-dependent disc and halo distributions, and an oblate stellar halo. This provides a comprehensive overview of the systematic uncertainties introduced to parameter estimates by oversimplifications in our model of stars in the Galaxy.
7 CONCLUSIONS
We have developed a method to fit the distribution of stars in the Milky Way using the Poisson likelihood function. Our method correctly accounts for the sample selection function and parallax measurement uncertainty.
The method is used to fit the vertical distribution of stars with |b| > 80°. For the model, we use two exponential disc components and a power-law halo. The data are also simultaneously fit with a four-piece exponential absolute-magnitude distribution.
The efficacy of our method is demonstrated against a mock sample. By refitting the model parameters, we demonstrate that the method produces results that are accurate to within the statistical uncertainties of the parameter posteriors.
We apply our method to the GUMS mock sample to infer the parameters of a population that are drawn from a far more complex Milky Way model. We obtain consistent fits when applying our model with and without parallax error for disc parameters but not for halo parameters. This suggests that our results for disc parameters are reliable when fit to data that does not exactly represent our model but that our disc parameters should be viewed with caution.
In Paper II, we set the machinery working on Gaia EDR3. We undertake a set of strenuous tests to quantify the systematic uncertainties in our parameter estimates due to oversimplifications in the model.
ACKNOWLEDGEMENTS
AE thanks the Science and Technology Facilities Council of the United Kingdom for financial support. DB thanks Magdalen College for his fellowship and the Rudolf Peierls Centre for Theoretical Physics for providing office space and travel funds. RG acknowledges financial support from the Spanish Ministry of Science and Innovation (MICINN) through the Spanish State Research Agency, under the Severo Ochoa Program 2020-2023 (CEX2019-000920-S).
This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC; https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
This paper made use of the Whole Sky Database (wsdb) created by Sergey Koposov and maintained at the Institute of Astronomy, Cambridge by Sergey Koposov, Vasily Belokurov and Wyn Evans with financial support from the Science /& Technology Facilities Council (STFC) and the European Research Council (ERC). This software made use of the Q3C software Koposov & Bartunov (2006).
AE is very grateful to Eugene Vasiliev who provided valuable assistance on numerical integration methods. His comments on this paper content led to many significant improvements.
Whilst not detailed in this paper, the authors made use of the AuriGaia mock catalogues (Grand et al. 2018) that helped to motivate the model and approach taken.
The authors are grateful to the anonymous referee who suggested the use of GUMS to test our model and to Annie Robin for providing insight into the GUMS sample selection.
DATA AVAILABILITY
The data underlying this paper are publicly available from the European Space Agency’s Gaia archive (https://gea.esac.esa.int/archive/). The EDR3 nominal scanning law is also available from the Gaia archive (http://cdn.gea.esac.esa.int/Gaia/gedr3/auxiliary/commanded_scan_law/).
The selection function implementations used in this work are described in Boubert & Everall (2020) and Everall & Boubert (2021), and made publicly accessible through the python package selectionfunctions (https://github.com/gaiaverse/selectionfunctions). The Astrometric Spread Function used to generate realistic uncertainties can be accessed through the python package scanninglaw (https://github.com/gaiaverse/scanninglaw).
The code used to fit the model and produce all figures is made publicly available as a GitHub repository (https://github.com/aeverall/mwtrace.git).
Footnotes
REFERENCES
APPENDIX A: INTEGRAND LIMITATIONS
In Section 2.1, we stated that the integral over parallax uncertainty becomes intractable for more complex models, we will briefly justify that statement here where we will use the example of the exponential disc model to demonstrate.
APPENDIX B: MAGNITUDE DISTRIBUTION
where |$\mathcal {N}_{\rm D}$| is the normalization of the full MS. In order to make this well normalized, an upper absolute magnitude limit, MX, has been placed on the lower MS. This also cuts the distribution off before it reaches the end of the information from isochrones. At these magnitudes, there are very few visible stars and those that are in the Gaia data set will be nearby with well constrained parallaxes enabling them to be easily removed from the sample as contamination.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}