





ABSTRACT
The 1D Ly α forest flux power spectrum P1D is sensitive to scales smaller than a typical galaxy survey, and hence ties to the intergalactic medium’s thermal state, suppression from neutrino masses, and new dark matter models. It has emerged as a competitive framework to study new physics, but also has come with various challenges and systematic errors in analysis. In this work, we revisit the optimal quadratic estimator for P1D, which is robust against the relevant problems such as pixel masking, time evolution within spectrum, and quasar continuum errors. We further improve the estimator by introducing a fiducial power spectrum, which enables us to extract more information by alleviating the discreteness of band powers. We meticulously apply our method to synthetic Dark Energy Spectroscopic Instrument (DESI) spectra and demonstrate how the estimator overcomes each challenge. We further apply an optimization scheme that approximates the Fisher matrix to three elements per row and reduces computation time by 60 per cent. We show that we can achieve per cent precision in P1D with 5-yr DESI data in the absence of systematics and provide forecasts for different spectral qualities.
1 INTRODUCTION
Through absorption lines in quasar spectra, the Ly α forest technique can probe matter in vast volumes far into the past and at smaller scales than galaxy surveys, that are shaped by the thermal state of the gas and reionization history of the universe (Hui & Gnedin 1997; Gnedin & Hui 1998). Connecting flux fluctuations in quasar spectra to physical parameters relies on multiple demanding steps in a typical analysis. The first step is to summarize the statistical information contained in millions of pixels across thousands of spectra using the correlation function or the power spectrum. Second, one relies on numerical simulations to relate the matter fluctuations to the neutral hydrogen that reionizes until z ∼ 6 to obtain mock quasar spectra. The physical parameters are then mapped to the statistics using large numbers of these mocks with different parameters. The final step constrains physical parameters by performing a likelihood analysis on the observed statistics using this mapping and a prior.
The Ly α forest technique already proved to be fruitful. The Extended Baryon Oscillation Spectroscopic Survey (eBOSS) (Dawson et al. 2016) and its predecessors successfully measured baryon acoustic oscillations in large-scale 3D correlations of the Ly α forest (Slosar et al. 2011, 2013; Busca et al. 2013; Font-Ribera et al. 2014; Delubac et al. 2015; Bautista et al. 2017; du Mas des Bourboux et al. 2017; Blomqvist et al. 2019; de Sainte Agathe et al. 2019). It has also emerged as a promising tool to investigate intergalactic medium (IGM) thermal evolution (Boera et al. 2019; Walther et al. 2019), to constrain neutrino masses (Croft, Hu & Dave’ 1999; Seljak et al. 2006; Palanque-Delabrouille et al. 2015a, b; Yeche et al. 2017) and to probe the nature of dark matter (Boyarsky et al. 2009; Viel et al. 2013; Baur et al. 2016; Iršič et al. 2017a; Garzilli et al. 2019).
The line-of-sight flux power spectrum of the Ly α forest has been at the frontier in new physics by being sensitive to medium to small scales. McDonald et al. (2006), Palanque-Delabrouille et al. (2013), and Chabanier et al. (2019) measured this 1D power spectrum at large to medium scales (0.001 s km−1 ≤ k ≤ 0.02 s km−1) using thousands of quasar spectra, whereas Viel et al. (2013), Iršič et al. (2017b), Walther et al. (2017), Boera et al. (2019), and Day, Tytler & Kambalur (2019) pushed the measurement to smaller scales (k ≤ 0.1 s km−1) using few but high-resolution spectra.
These recent works utilize three different methods in power spectrum estimation. Palanque-Delabrouille et al. and Chabanier et al. applies fast Fourier transforms (FFT), which require all pixels to be present, equally spaced, and have uniform noise and resolution. These conditions are rarely met in real spectra due to masking of sky emission lines, high column density absorbers (HCD), bad pixels, and sometimes metal contamination. As a result, Chabanier et al. apply up to 20 per cent corrections to their power spectrum estimates. In their small-scale measurement, Walther et al. and Day et al. use Lomb–Scargle periodogram (Lomb 1976; Scargle 1982) as this method allows for masking. However, neither method is able to weight pixels with respective noise estimates and cannot account for the time evolution within a spectrum without splitting the spectrum into multiple chunks; and both are limited by S/N and resolution in their quasar samples. Third method is the likelihood maximization. Palanque-Delabrouille et al. also implemented a direct maximization of the likelihood function, which they found sensitive to the implementation details and noise in spectra. Our focus in this paper is the faster and more stable quadratic maximum likelihood estimator (QMLE), which McDonald et al. applied while splitting the spectra into two chunks because of computational limitations. However, with recent developments in computing, QMLE promises its full strength by careful application to 1D power spectrum.
Our work focuses on developing and applying an improved QMLE to measure the 1D power spectrum. We meticulously apply the formalism to maximize the information extraction. Our method readily handles the redshift evolution by interpolating pixel pairs to two redshift bins. This enables us to keep the full forest and all pixel pairs. We also introduce a baseline estimate that improves the accuracy by alleviating discrete band powers. As The Dark Energy Spectroscopic Instrument (DESI; Levi et al. 2013; DESI Collaboration 2016) comes online to find abundance of quasar spectra, our improved QMLE can exploit the most information and make the best measurement.
This paper is organized under six sections. We summarize relevant general and specific formula for QMLE in Section 2. This section also briefly discusses a continuum limit to clarify what QMLE actually yields. Section 3 outlines the algorithm and further provides details on our implementation, including validation with synthetic spectra. We then move to applying our method to simulated simple DESI data in Section 4. In this section, we examine the effects of gaps and continuum errors, the advantage of fiducial power, Fisher matrix approximation, and 5-yr forecasts for DESI with different spectral qualities. Section 5 discusses the finer details of our method, such as interpretation of QMLE results, its advantages and possible problems. Finally, we summarize this work in Section 6.
2 METHOD
2.1 Ly α forest specifics
Finally, we assume that the noise of every pixel is independent. This results in a diagonal noise matrix with |$N_{ii}=\sigma _i^2$|, where σi is the pipeline noise divided by the continuum and the mean normalized flux |$\bar{F}(z)$|.
2.2 Continuum limit
3 IMPLEMENTATION
QMLE implementation presents challenges in memory, CPU time, numerical stability, and confident validation of the results. In this section, we clarify our implementation decisions in order to overcome such challenges.
We will refer Palanque-Delabrouille et al. (2013) as PD13, Walther et al. (2017) as W17, and McDonald et al. (2006) as M06 from now on.
3.1 Algorithm
At every iteration, the algorithm for each spectrum is as follows:
Compute the covariance matrix using the previous iteration’s |$\hat{\boldsymbol {\theta }}$| estimates, then invert the covariance matrix. Note that the fiducial signal matrix stays fixed.
Compute weighted data vector |$\boldsymbol {y} = \mathbf {C}^{-1} \boldsymbol {\delta }_F$|, then |$d_{\alpha } = \boldsymbol {y}^\mathrm{T} \mathbf {Q}_{\alpha } \boldsymbol {y}$|.
Compute |$\mathbf {C}^{-1}\mathbf {Q}_{\alpha } \mathbf {C}^{-1}$|, then bα and tα using equations (5) and (6).
Compute Fisher matrix using equation (7). Note that this needs to consider all redshift bins that the spectrum spans.
We then sum dα, bα, tα, and |$F_{{\alpha }{\alpha }^{\prime }}$| of every quasar. Finally, we invert |$\mathbf {F}$| and find |$\hat{\boldsymbol {\theta }}$| estimates using equation (3). We check for convergence by comparing these results to the previous iteration using the expressions in Section 3.3.
One can bootstrap QMLE results easily by saving |$F_{{\alpha }{\alpha }^{\prime }}$| and (dα − bα − tα) of each spectrum to a file. Since each spectrum is treated independently, there is no need to recompute these for every realization. One can generate as many bootstrap realizations as needed on spectrum level, and then simply add these saved quantities with repetition to find a bootstrapped estimate. This treatment is exact at the first iteration, and should be a good approximation at convergence.
We find that using a smooth weighted spline in step (i) makes the algorithm numerically stable. This smoothing spline is performed on (k, P = Pfid + θ), and it can be more reliable if performed on (ln k, ln P) while non-positive values are removed.
This algorithm can be implemented using only three matrices for each quasar: One holds the covariance matrix and its inverse, and the other two temporarily hold the derivative and fiducial signal matrices. Holding all matrices in memory for a quasar at a time can improve computation time when memory is the lesser concern, which we find possible in our tests.
This method demands substantial CPU time, and therefore some optimization mechanisms are noteworthy. First, instead of integrating |$\mathbf {S}_{\mathrm{fid}}$| and |$\mathbf {Q}_{\alpha }$| when needed, we create lookup tables once and interpolate. Moreover, every spectrum can be computed in parallel as they are assumed independent. Each CPU should have near-equal workload for efficient parallelization. Matrix operations scale as |$\mathcal {O}(N_D^3)$|, where ND is the number of pixels in a spectrum. Let us define NB as the number of total bins to which a spectrum contributes. Then, the Fisher matrix calculation will require NB(NB + 1)/2 matrix multiplications for that spectrum. Hence, we use |$T_{\mathrm{cpu}}=N_D^3 N_B(N_B+1)$| as an estimate for computation time, and distribute spectra accordingly.
We use gsl3 for interpolation, integration, matrix inversion; Intel’s mkl library4 for matrix multiplication; and we compile with open-mpi5 for parallelization. Smooth weighted spline is constructed using scipy.6
3.2 Fiducial power spectrum
Our implementation is also equipped with taking a tabulated fiducial power as input. This feature gives greater freedom in the choice of fiducial. We use this to eliminate any discord between synthetic data and the estimator; and to investigate different choices as fiducial.
3.3 Convergence
3.4 Validation
We use lognormal mocks for validation. These semirealistic spectra are crucial to examine the accuracy, precision, and efficiency of our method.
We generate lognormal mocks by using a modified version of M06. These realizations approximately produce theoretically expected mean flux redshift evolution (Faucher-Giguére et al. 2008; Becker et al. 2013) and power spectra similar to PD13 and W17.
Generate a long high-resolution Gaussian random grid with equal spacing in velocity v, zero mean, and unit variance.
- FFT this grid and multiply with |$\sqrt{P(k)/\mathrm{ d}v}$| to obtain |$\tilde{\delta }_{b}(k)$|, where dv is the grid spacing in velocity units and the power spectrum iswhere k0 = 0.001 s km−1, k1 = 0.04 s km−1, n = 0.5, α = 0.26, and γ = 1.8. Inverse FFT and save the variance of this grid σ2. This is a crude Gaussian base for baryon fluctuations δb(v) with defined power spectrum at z0 = 3.(20)$$\begin{eqnarray*} P(k) = \frac{(k/k_0)^{n-\alpha \ln (k/k_0)}}{1 + (k/k_1)^\gamma }, \end{eqnarray*}$$
- Multiply with a redshift evolution factor a(z). Such that δb(z) = a(z)δb and σ2(z) = a2(z)σ2.(21)$$\begin{eqnarray*} a^2(z) = 58.6 \left(\frac{1+z}{1+z_0}\right)^{-2.82} \end{eqnarray*}$$
- Apply a squared lognormal transformation to approximate the non-linear and non-Gaussian H i column density field.(22)$$\begin{eqnarray*} n(z) = \mathrm{ e}^{2\delta _b(z) - \sigma ^2(z)} \end{eqnarray*}$$
- Transform this to optical depth τ by multiplying with another redshift-dependent function.(23)$$\begin{eqnarray*} \tau (z) = 0.55\left(\frac{1+z}{1+z_0}\right)^{5.1} n(z) \end{eqnarray*}$$
Finally, the flux is F(z) = e−τ(z).
Smoothing F(z) with a Gaussian kernel and resampling it on to the observed wavelength grid will result in a spectrograph function in equation (12).
We perform an initial test in the absence of redshift distribution and resolution effects. We start with a long fine grid (|$\mathrm{ d}v=0.4\bar{3}$| km s−1, N = 220), and generate mocks that are discretely distributed in redshift. For validation, we pick four redshifts (2.2, 2.4, 2.6, 2.8), and simulate 100 catalogues where each catalogue has 1000 spectra in every redshift bin. These spectra are exactly centred at these redshifts. We set the spectrograph resolution R = 71 600 to diminish its effect, limit the spectral length to half of the bin size Δz = 0.1, and finally resample to pixel size of Δv = 20.8 km s−1. Fig. 1 shows our results. Our method reaches sub per cent level accuracy in the absence of any systematic.
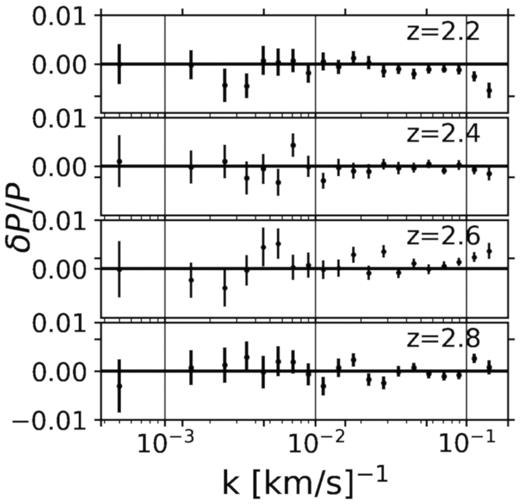
The relative error in our measurements from 100 lognormal catalogues where each has 1000 spectra in every redshift bin. Our method reaches sub per cent level precision in the absence of any systematic. Bins go up to the Nyquist frequency.
4 DESI-LITE SPECTRA
To test the feasibility of our method for future DESI spectra, we generate semirealistic data set using the following simplifying assumptions:
We set the observed wavelength grid between 3600 and 9800 Å. This means the closest forest pixel is at z = 1.96.
We create a logarithmically spaced wavelength grid with Δv = 30 km s−1.7 Our grid spacing corresponds to a Nyquist frequency of 0.1 s km−1.
We assume a constant resolution power of R = 3200 (≈94 km s−1 FWHM in velocity units) for all spectra at all wavelengths.
We add Gaussian random errors with σ = 0.7 to F, which is approximately S/N = 2 Å−1.
We set the minimum redshift of an Ly α quasar to 2.1 and the maximum to 4.4, and pick random redshifts from a distribution n(z) (DESI Collaboration 2016; Palanque-Delabrouille et al. 2016). We always limit the forest to [1050 Å, 1180 Å] range in quasar’s rest frame.
Finally, we assume DESI will observe 800 000 quasar spectra.
We choose 12 redshift bins between 2.0 and 4.2 with Δz = 0.2. First 5 k bins are linearly spaced with Δklin = 0.001 s km−1, and the following 14 bins are logarithmically spaced with Δklog = 0.1. Hence, 0.0005 s km−1 ≤ k ≤ 0.112 s km−1.
Fig. 2 shows power spectrum estimates for each redshift bin with error bars from the diagonal elements of the inverse Fisher matrix. The chi-square using the full Fisher matrix is χ2/ν = 248/228,8 which implies a valid agreement with the truth. We measure the power spectrum to sub per cent accuracy at lower redshifts, but the accuracy and precision get progressively worse towards high redshifts due to declining quasar numbers. We also expected noise and window function corrections to dominate at high k as the noise power crosses the signal at kN ≈ 0.025 s km−1.9 This constitutes our foundation as validation of our method.
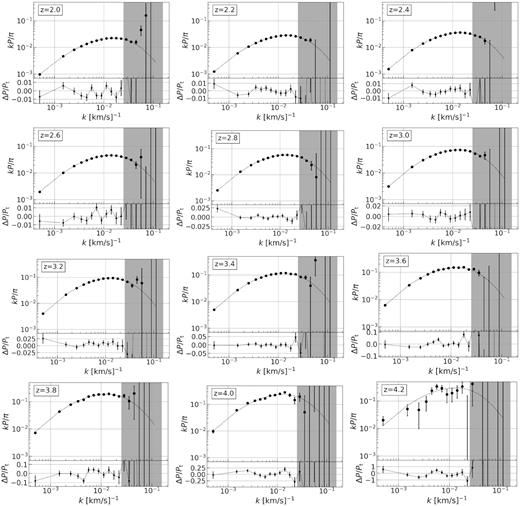
Power spectrum estimates from 800 000 DESI-lite spectra. Error bars from the diagonal of the inverse Fisher matrix. Dotted line in each upper panel is the true power. Noise begins to dominate in grey shaded area, k > kN = 0.025 s km−1. The estimates reach per cent-level accuracy in lower redshift bins. However, last redshift bins are poorly estimated due to significant decline in statistics. The χ2 calculated from diagonal (all) elements is 240 (248) for 228 degrees of freedom.
We would like to stress a subtle point here. First of all, the estimator constructs correct covariance matrices in the first iteration by using the true power as fiducial input. This means we also have the correct Fisher matrix and expect θ ≈ 0 after the iteration. However, the convergence criteria in equation (18) will still yield nearly 1 due to the statistical fluctuations of the power spectrum (note |$\mathrm{Var}[\theta _{\alpha }] \sim F^{-1}_{\alpha \alpha }$|). Therefore, when the estimator goes into the second iteration, it misidentifies these intrinsic fluctuations as corrections to the covariance matrices and readjusts the Fisher matrix. The smoothing spline ameliorates this digression, though imperfectly.
Fisher matrix calculation consumes the most time as it requires calculating |$\mathbf {Q}_{\alpha }$| matrices and multiplying them |$\mathcal {O}(N^2)$| many times. We identified that at least 46 per cent of the total time goes into the Fisher matrix (see Fig. 3). Moreover, we also found that the Fisher matrix is a band matrix that is prominently tridiagonal for individual k and z bins. We normalize the Fisher matrix with respect to its diagonal elements for a clear representation in Fig. 4, which is for k = 0.0071 s km−1 bin, but represents a typical redshift dependence.10 This tridiagonal shape is due to keeping the full forest and distributing pixel pairs into two redshift bins. This structure weakly persists between k bins for a given z bin as well. Given Fisher matrix is the longest step, limiting its calculation to only these terms will speed up the estimation significantly by decreasing the number of matrix multiplications to |$\mathcal {O}(N)$|. We consider this optimization scheme and how well it performs in Section 4.4. It is also worth pointing out that the Fisher matrix does not depend on the data, but only on the input power spectrum. Therefore, one could also choose a common Fisher matrix for analysis with many simulations.
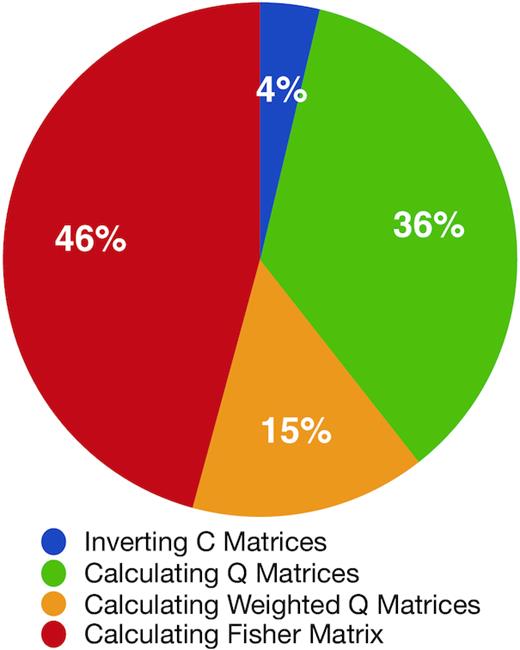
Percentage of time spent in different steps for 800 000 DESI-lite spectra. The weighted Q matrices are |$\mathbf {C}^{-1}\mathbf {Q}_{\alpha }\mathbf {C}^{-1}$|. Fisher matrix calculation consumes the most time, which also requires calculating |$\mathbf {Q}_{\alpha }$| matrices as prerequisite. The time for remaining steps is insignificant.
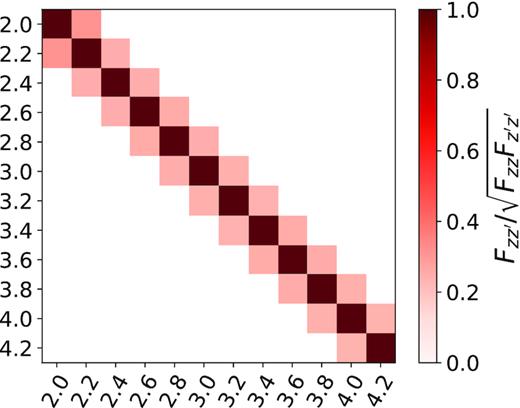
The normalized Fisher matrix between redshift bins for k = 0.0071 s km−1 bin. The off-diagonal terms are approximately |$40{{\ \rm per\ cent}}$|. Only neighbouring redshift bins dominate the Fisher matrix, since a pixel pair is split into two bins.
We also computed the power spectrum covariance matrix with 5000 bootstrap realizations using the results of the first iteration as discussed in Section 3.1. We found that the diagonals of the covariance matrix estimated from this bootstrap procedure agreed within per cent level with the formal estimates from the Fisher matrix except for the high-redshift bin where we do not have enough quasars to compute robust bootstrap errors. This bootstrapping procedure therefore provides a straightforward test of the assumptions underlying the error estimates from the Fisher matrix.
4.1 Gaps in spectra
An advantage of our estimator is that it works in pixel space and can therefore robustly handle missing data in the spectrum. In order to test how masking affects our results, we remove continuous regions from some spectra. We assign 15 per cent probability of having a high HCD in a spectrum, matching Noterdaeme et al. (2012). If a spectrum has an HCD, we randomly pick a central wavelength and mask 12.5 A° on each side by setting the flux to the mean value (δF = 0). We apply this random masking procedure to 100 000 spectra. We perform a run where masked pixels are removed by assigning large errors, and another run without removing these pixels for comparison.
Fig. 5 shows our results in two redshift bins. The masking suppresses power at small scales, but propagates to all scales. The run without any correction yields extremely poor results with χ2 ∼ 4000. When we correct for these pixels by assigning large errors, the power spectrum estimates yield χ2 = 234, close to the original case. This confirms our method is robust against gaps in spectra.
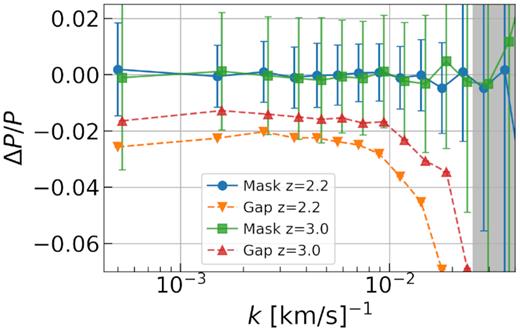
The effect of gaps in P1D for two redshift bins z = 2.2 and z = 3.0. Points labelled ‘Mask’ are corrected measurements by large pixel errors, whereas ‘Gap’ points have unchanged errors. For clarity, we slightly shift z = 3.0 points and omit error bars from uncorrected results. The masking error propagates to all scales.
4.2 Continuum marginalization
In a typical pipeline, the real observable flux f(λ) is divided by the quasar continuum C(λ) to obtain the normalized flux F(λ) for each spectrum. Furthermore, flux fluctuations are obtained by diving this with the mean normalized flux |$\bar{F}(\lambda)$|. The errors in this process propagate to mostly large scales and are called the continuum errors in Ly α nomenclature.
Our quadratic estimator is armed with marginalization capability to suppress these offsets (appendix B, Slosar et al. 2013). By modifying the covariance matrix to |$\mathbf {C}^{\prime } = \mathbf {C} + N \boldsymbol t \boldsymbol t^{\mathrm{T}}$|, where N is large and |$\boldsymbol t$| is the mode we want to marginalize out, one can show that |$\mathbf {C}^{\prime -1}(\boldsymbol {\delta }_F^{\prime } + \alpha \boldsymbol t) \approx \mathbf {C}^{-1} \boldsymbol {\delta }_F^{\prime }$|, where the new data vector |$\boldsymbol {\delta }_F^{\prime }$| is orthogonal to |$\boldsymbol t$|. This effectively removes any information from data that is in mode |$\boldsymbol t$|.
To replicate these continuum errors, we add an error η(λ) to each quasar’s flux fluctuations δF(λ). We limit the form of η(λ) to the equation above in order to perform a controlled test. We randomly generate the two parameters from a Gaussian distribution with σ = 0.1. We run eight independent sets of 100 000 spectra.
We add a large constant N0 to all elements of the covariance matrix to marginalize the amplitude, and |$N_1 \boldsymbol t \boldsymbol t^{\mathrm{T}}$| to marginalize the slope, where t = ln (λ/λLy α).
Fig. 6 presents the average of eight runs. The continuum errors mostly contaminate large scales. The largest scale k = 5 × 10−4 s km−1 bins show big offsets, whereas the following k bin is less affected. When we marginalize these two continuum terms with N0 = N1 = 1000, results go back to the expected values. As a side effect, marginalization increases the error in the first bin by 25–45 per cent.
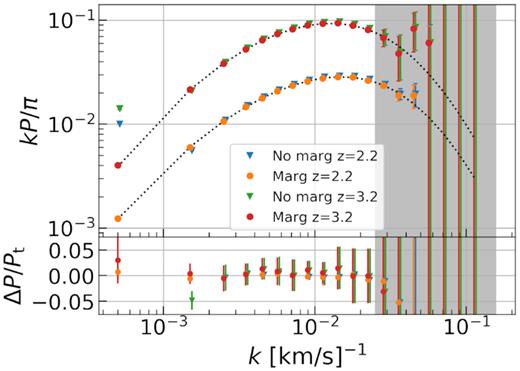
Average power spectra of eight runs at z = 2.2 and z = 3.2 with and without marginalizing continuum errors. The continuum errors highly contaminate the first two k bins at k = 5 × 10−4 s km−1 and k = 1.5 × 10−3 s km−1. The remaining scales are less affected. By marginalizing two continuum modes, we are able to correctly estimate the power at these scales. Average errors of eight runs at k = 5 × 10−4 s km−1 bin increase by 25–45 per cent. The change in the second bin is insignificant.
4.3 Choice of fiducial
We already established in the previous sections that using the true power as fiducial yields correct results. In this section, we investigate how different fiducial power influences results by considering two additional cases. First, we run the estimator without any fiducial power. Second, imagining a realistic pipeline, we fit equation (17) to these no fiducial results, and employ this best-fitting function as fiducial. In order to run multiple independent realizations, we use eight subsamples of 100 000 spectra.
We compare χ2 for every case using respective Fisher matrices, which can be seen in Fig. 7. True fiducial yields the correct answer in one iteration and is the best estimate as expected. Not using any prior naturally starts away from the truth, but converges to the correct power immediately while being relatively a poor fit. Using the results from no prior to construct a better fiducial decisively outperforms no fiducial case, which we found to hold for all eight runs.
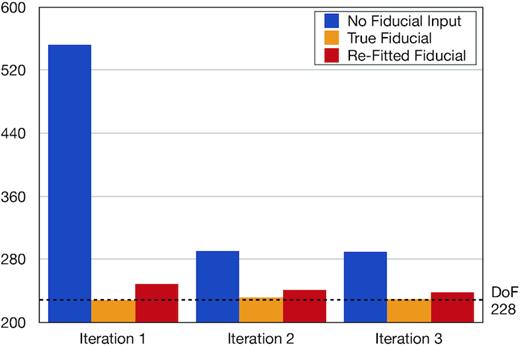
Comparing average χ2 of eight runs for three different fiducials using respective Fisher matrices. True fiducial yields the correct answer in one iteration and outperforms other cases as expected. Not using any prior naturally starts away from the truth, but converges to the correct power immediately. Using the results from no prior to construct a better fiducial (re-fitted fiducial) decisively surpasses no fiducial case. Repeating this analysis with true Fisher matrix yields the same conclusion. In that case, χ2 stays constant over three iterations with values close iteration two and three of this figure. This implies that the first iteration yields good P1D and subsequent iterations correct the error estimates.
The χ2 analysis above weights absolute errors with respective Fisher matrices. The differences in these matrices partially source the χ2 trend in Fig. 7. In order to decouple error accuracy from P1D accuracy, we also calculate all χ2s using the true Fisher matrix. We find this quantity still distinguishes different fiducials as before with values close to the last two iterations of the initial analysis, and stays approximately flat over three iterations. This indicates that QMLE yields good P1D at the first iteration even for no fiducial case, but it does not improve at subsequent iterations. Evidently, these iterations mostly correct the error estimates. This behaviour is reasonable given the weights in equation (15) stay approximately constant across bins, and therefore are unaffected by band power corrections. The only way to overcome the band power discretization is through integrating a fiducial power.
To summarize, the key points are as follows: (1) even with no fiducial, the power spectrum is correctly recovered, (2) a simple iteration quickly gets the correct Fisher matrix, and (3) a good fiducial yields better power spectrum and error estimates.
4.4 Fisher matrix approximation
Each quasar’s Fisher matrix requires NB(NB + 1)/2 matrix multiplications, where NB is the number of total bins to which this spectrum contributes. However, Fig. 4 tells us that only few elements are dominant in the Fisher matrix. Moreover, we see this structure in all cases, i.e. different fiducial powers, masking, and continuum marginalization.
While the sparsity structure of the Fisher matrix appears to be quite generic, the exact details (as to the number of non-zero elements) do appear to depend on the total signal to noise of the sample. For the DESI-like data considered in this work, we find that including a single off-diagonal element in the k − and z − directions works very well. Specifically, for every (kn, zm) pair we calculate (kn + 1, zm) and (kn, zm + 1) elements besides the diagonal. That reduces the number of matrix multiplications to 3NB, which will boost the speed. Note that this should also be taken into account in load balancing.
We test this optimization scheme on 800 000 spectra. We find that the resulting χ2 is not changed while the average time per iteration decreases by 64 per cent and the time spent in Fisher matrix calculation per iteration drops by 95 per cent.
Even though we do not have an exact prescription for computing the number of non-zero elements, the above discussion suggests a procedure by which one starts to fill in the Fisher matrix from the diagonals outwards and stops when the overall relative contribution is below a chosen threshold.
4.5 5-yr forecasts
We would like to make simple predictions for future DESI performance using our simple spectra. We run two additional cases where S/N = 1 Å−1 and S/N = 4 Å−1 on 800 000 spectra. In order to speed up our analysis, we turn on the Fisher optimization scheme. We perform only one iteration with true power as fiducial.
We compare P1D estimates for different redshifts at a fixed wavenumber kf = 2.5 × 10−3 s km−1. Our results are summarized in Table 2. This prediction is under ideal circumstances, hence further complications should be added for accuracy. For example, metal contamination constitutes 5–15 per cent of the Ly α forest power (Day et al. 2019).
Our model power spectrum and precision forecasts for 5-yr DESI survey for fixed kf = 2.5 × 10−3 s km−1. The precision is defined as error divided by signal: e/P1D. For reference, metal contamination constitutes 5–15 per cent of the Ly α power in reality.
| z | P1D(kf) | Precision | Precision | Precision |
|---|---|---|---|---|
| (km s−1) | S/N = 1 Å−1 | S/N = 2 Å−1 | S/N = 4 Å−1 | |
| 2.0 | 10.2 | 1.31 per cent | 0.44 per cent | 0.22 per cent |
| 2.2 | 13.4 | 1.08 per cent | 0.37 per cent | 0.20 per cent |
| 2.4 | 17.5 | 1.12 per cent | 0.40 per cent | 0.23 per cent |
| 2.6 | 22.8 | 1.24 per cent | 0.46 per cent | 0.27 per cent |
| 2.8 | 29.5 | 1.46 per cent | 0.56 per cent | 0.34 per cent |
| 3.0 | 37.8 | 1.87 per cent | 0.74 per cent | 0.45 per cent |
| 3.2 | 48.3 | 2.50 per cent | 0.99 per cent | 0.62 per cent |
| 3.4 | 61.4 | 3.34 per cent | 1.32 per cent | 0.82 per cent |
| 3.6 | 77.6 | 4.82 per cent | 1.89 per cent | 1.15 per cent |
| 3.8 | 97.7 | 8.67 per cent | 3.32 per cent | 1.98 per cent |
| 4.0 | 123.0 | 22.00 per cent | 8.14 per cent | 4.63 per cent |
| 4.2 | 153.0 | 95.30 per cent | 33.30 per cent | 18.10 per cent |
| z | P1D(kf) | Precision | Precision | Precision |
|---|---|---|---|---|
| (km s−1) | S/N = 1 Å−1 | S/N = 2 Å−1 | S/N = 4 Å−1 | |
| 2.0 | 10.2 | 1.31 per cent | 0.44 per cent | 0.22 per cent |
| 2.2 | 13.4 | 1.08 per cent | 0.37 per cent | 0.20 per cent |
| 2.4 | 17.5 | 1.12 per cent | 0.40 per cent | 0.23 per cent |
| 2.6 | 22.8 | 1.24 per cent | 0.46 per cent | 0.27 per cent |
| 2.8 | 29.5 | 1.46 per cent | 0.56 per cent | 0.34 per cent |
| 3.0 | 37.8 | 1.87 per cent | 0.74 per cent | 0.45 per cent |
| 3.2 | 48.3 | 2.50 per cent | 0.99 per cent | 0.62 per cent |
| 3.4 | 61.4 | 3.34 per cent | 1.32 per cent | 0.82 per cent |
| 3.6 | 77.6 | 4.82 per cent | 1.89 per cent | 1.15 per cent |
| 3.8 | 97.7 | 8.67 per cent | 3.32 per cent | 1.98 per cent |
| 4.0 | 123.0 | 22.00 per cent | 8.14 per cent | 4.63 per cent |
| 4.2 | 153.0 | 95.30 per cent | 33.30 per cent | 18.10 per cent |
Our model power spectrum and precision forecasts for 5-yr DESI survey for fixed kf = 2.5 × 10−3 s km−1. The precision is defined as error divided by signal: e/P1D. For reference, metal contamination constitutes 5–15 per cent of the Ly α power in reality.
| z | P1D(kf) | Precision | Precision | Precision |
|---|---|---|---|---|
| (km s−1) | S/N = 1 Å−1 | S/N = 2 Å−1 | S/N = 4 Å−1 | |
| 2.0 | 10.2 | 1.31 per cent | 0.44 per cent | 0.22 per cent |
| 2.2 | 13.4 | 1.08 per cent | 0.37 per cent | 0.20 per cent |
| 2.4 | 17.5 | 1.12 per cent | 0.40 per cent | 0.23 per cent |
| 2.6 | 22.8 | 1.24 per cent | 0.46 per cent | 0.27 per cent |
| 2.8 | 29.5 | 1.46 per cent | 0.56 per cent | 0.34 per cent |
| 3.0 | 37.8 | 1.87 per cent | 0.74 per cent | 0.45 per cent |
| 3.2 | 48.3 | 2.50 per cent | 0.99 per cent | 0.62 per cent |
| 3.4 | 61.4 | 3.34 per cent | 1.32 per cent | 0.82 per cent |
| 3.6 | 77.6 | 4.82 per cent | 1.89 per cent | 1.15 per cent |
| 3.8 | 97.7 | 8.67 per cent | 3.32 per cent | 1.98 per cent |
| 4.0 | 123.0 | 22.00 per cent | 8.14 per cent | 4.63 per cent |
| 4.2 | 153.0 | 95.30 per cent | 33.30 per cent | 18.10 per cent |
| z | P1D(kf) | Precision | Precision | Precision |
|---|---|---|---|---|
| (km s−1) | S/N = 1 Å−1 | S/N = 2 Å−1 | S/N = 4 Å−1 | |
| 2.0 | 10.2 | 1.31 per cent | 0.44 per cent | 0.22 per cent |
| 2.2 | 13.4 | 1.08 per cent | 0.37 per cent | 0.20 per cent |
| 2.4 | 17.5 | 1.12 per cent | 0.40 per cent | 0.23 per cent |
| 2.6 | 22.8 | 1.24 per cent | 0.46 per cent | 0.27 per cent |
| 2.8 | 29.5 | 1.46 per cent | 0.56 per cent | 0.34 per cent |
| 3.0 | 37.8 | 1.87 per cent | 0.74 per cent | 0.45 per cent |
| 3.2 | 48.3 | 2.50 per cent | 0.99 per cent | 0.62 per cent |
| 3.4 | 61.4 | 3.34 per cent | 1.32 per cent | 0.82 per cent |
| 3.6 | 77.6 | 4.82 per cent | 1.89 per cent | 1.15 per cent |
| 3.8 | 97.7 | 8.67 per cent | 3.32 per cent | 1.98 per cent |
| 4.0 | 123.0 | 22.00 per cent | 8.14 per cent | 4.63 per cent |
| 4.2 | 153.0 | 95.30 per cent | 33.30 per cent | 18.10 per cent |
We provide the model power spectrum and the full Fisher matrices in the electronic form. A summary of the Fisher matrices is in Table 3.
Our Fisher matrix forecasts for 5-yr DESI survey for different spectral qualities. The subscript in F refers to the S/N value. The full table and model power spectrum can be found in the electronic submission of this article.
| (zi, ki) | (zj, kj) | F1 | F2 | F4 |
|---|---|---|---|---|
| [, (s km−1)] | [, (s km−1)] | (s2 km−2) | (s2 km−2) | (s2 km−2) |
| (2.0, 5.00 × 10−4) | (2.0, 5.00 × 10−4) | 6.02867 × 101 | 6.51197 × 102 | 3.66215 × 103 |
| (2.0, 5.00 × 10−4) | (2.0, 1.50 × 10−3) | 6.63624 × 100 | 6.52238 × 101 | 3.02865 × 102 |
| (2.0, 5.00 × 10−4) | (2.2, 5.00 × 10−4) | 2.12509 × 101 | 2.30833 × 102 | 1.33759 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 1.50 × 10−3) | 6.54364 × 101 | 6.00179 × 102 | 2.47973 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 2.50 × 10−3) | 5.99838 × 100 | 5.43360 × 101 | 2.19731 × 102 |
| (2.0, 1.50 × 10−3) | (2.2, 1.50 × 10−3) | 1.97400 × 101 | 1.75264 × 102 | 6.90261 × 102 |
| (2.0, 2.50 × 10−3) | (2.0, 2.50 × 10−3) | 6.38029 × 101 | 5.69068 × 102 | 2.25086 × 103 |
| (2.0, 2.50 × 10−3) | (2.0, 3.50 × 10−3) | 5.83666 × 100 | 5.28085 × 101 | 2.13079 × 102 |
| (2.0, 2.50 × 10−3) | (2.2, 2.50 × 10−3) | 1.92028 × 101 | 1.65626 × 102 | 6.24662 × 102 |
| (2.0, 3.50 × 10−3) | (2.0, 3.50 × 10−3) | 6.29898 × 101 | 5.69389 × 102 | 2.29742 × 103 |
| (2.0, 3.50 × 10−3) | (2.0, 4.50 × 10−3) | 5.74635 × 100 | 5.31461 × 101 | 2.21748 × 102 |
| (2.0, 3.50 × 10−3) | (2.2, 3.50 × 10−3) | 1.89681 × 101 | 1.66002 × 102 | 6.39374 × 102 |
| (2.0, 4.50 × 10−3) | (2.0, 4.50 × 10−3) | 6.21816 × 101 | 5.77621 × 102 | 2.43005 × 103 |
| (2.0, 4.50 × 10−3) | (2.0, 5.65 × 10−3) | 5.85085 × 100 | 5.58077 × 101 | 2.44502 × 102 |
| (2.0, 4.50 × 10−3) | (2.2, 4.50 × 10−3) | 1.87450 × 101 | 1.68881 × 102 | 6.78999 × 102 |
| (2.0, 5.65 × 10−3) | (2.0, 5.65 × 10−3) | 8.19711 × 101 | 7.90781 × 102 | 3.53432 × 103 |
| (2.0, 5.65 × 10−3) | (2.0, 7.11 × 10−3) | 6.07740 × 100 | 6.05452 × 101 | 2.85148 × 102 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| (zi, ki) | (zj, kj) | F1 | F2 | F4 |
|---|---|---|---|---|
| [, (s km−1)] | [, (s km−1)] | (s2 km−2) | (s2 km−2) | (s2 km−2) |
| (2.0, 5.00 × 10−4) | (2.0, 5.00 × 10−4) | 6.02867 × 101 | 6.51197 × 102 | 3.66215 × 103 |
| (2.0, 5.00 × 10−4) | (2.0, 1.50 × 10−3) | 6.63624 × 100 | 6.52238 × 101 | 3.02865 × 102 |
| (2.0, 5.00 × 10−4) | (2.2, 5.00 × 10−4) | 2.12509 × 101 | 2.30833 × 102 | 1.33759 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 1.50 × 10−3) | 6.54364 × 101 | 6.00179 × 102 | 2.47973 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 2.50 × 10−3) | 5.99838 × 100 | 5.43360 × 101 | 2.19731 × 102 |
| (2.0, 1.50 × 10−3) | (2.2, 1.50 × 10−3) | 1.97400 × 101 | 1.75264 × 102 | 6.90261 × 102 |
| (2.0, 2.50 × 10−3) | (2.0, 2.50 × 10−3) | 6.38029 × 101 | 5.69068 × 102 | 2.25086 × 103 |
| (2.0, 2.50 × 10−3) | (2.0, 3.50 × 10−3) | 5.83666 × 100 | 5.28085 × 101 | 2.13079 × 102 |
| (2.0, 2.50 × 10−3) | (2.2, 2.50 × 10−3) | 1.92028 × 101 | 1.65626 × 102 | 6.24662 × 102 |
| (2.0, 3.50 × 10−3) | (2.0, 3.50 × 10−3) | 6.29898 × 101 | 5.69389 × 102 | 2.29742 × 103 |
| (2.0, 3.50 × 10−3) | (2.0, 4.50 × 10−3) | 5.74635 × 100 | 5.31461 × 101 | 2.21748 × 102 |
| (2.0, 3.50 × 10−3) | (2.2, 3.50 × 10−3) | 1.89681 × 101 | 1.66002 × 102 | 6.39374 × 102 |
| (2.0, 4.50 × 10−3) | (2.0, 4.50 × 10−3) | 6.21816 × 101 | 5.77621 × 102 | 2.43005 × 103 |
| (2.0, 4.50 × 10−3) | (2.0, 5.65 × 10−3) | 5.85085 × 100 | 5.58077 × 101 | 2.44502 × 102 |
| (2.0, 4.50 × 10−3) | (2.2, 4.50 × 10−3) | 1.87450 × 101 | 1.68881 × 102 | 6.78999 × 102 |
| (2.0, 5.65 × 10−3) | (2.0, 5.65 × 10−3) | 8.19711 × 101 | 7.90781 × 102 | 3.53432 × 103 |
| (2.0, 5.65 × 10−3) | (2.0, 7.11 × 10−3) | 6.07740 × 100 | 6.05452 × 101 | 2.85148 × 102 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
Our Fisher matrix forecasts for 5-yr DESI survey for different spectral qualities. The subscript in F refers to the S/N value. The full table and model power spectrum can be found in the electronic submission of this article.
| (zi, ki) | (zj, kj) | F1 | F2 | F4 |
|---|---|---|---|---|
| [, (s km−1)] | [, (s km−1)] | (s2 km−2) | (s2 km−2) | (s2 km−2) |
| (2.0, 5.00 × 10−4) | (2.0, 5.00 × 10−4) | 6.02867 × 101 | 6.51197 × 102 | 3.66215 × 103 |
| (2.0, 5.00 × 10−4) | (2.0, 1.50 × 10−3) | 6.63624 × 100 | 6.52238 × 101 | 3.02865 × 102 |
| (2.0, 5.00 × 10−4) | (2.2, 5.00 × 10−4) | 2.12509 × 101 | 2.30833 × 102 | 1.33759 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 1.50 × 10−3) | 6.54364 × 101 | 6.00179 × 102 | 2.47973 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 2.50 × 10−3) | 5.99838 × 100 | 5.43360 × 101 | 2.19731 × 102 |
| (2.0, 1.50 × 10−3) | (2.2, 1.50 × 10−3) | 1.97400 × 101 | 1.75264 × 102 | 6.90261 × 102 |
| (2.0, 2.50 × 10−3) | (2.0, 2.50 × 10−3) | 6.38029 × 101 | 5.69068 × 102 | 2.25086 × 103 |
| (2.0, 2.50 × 10−3) | (2.0, 3.50 × 10−3) | 5.83666 × 100 | 5.28085 × 101 | 2.13079 × 102 |
| (2.0, 2.50 × 10−3) | (2.2, 2.50 × 10−3) | 1.92028 × 101 | 1.65626 × 102 | 6.24662 × 102 |
| (2.0, 3.50 × 10−3) | (2.0, 3.50 × 10−3) | 6.29898 × 101 | 5.69389 × 102 | 2.29742 × 103 |
| (2.0, 3.50 × 10−3) | (2.0, 4.50 × 10−3) | 5.74635 × 100 | 5.31461 × 101 | 2.21748 × 102 |
| (2.0, 3.50 × 10−3) | (2.2, 3.50 × 10−3) | 1.89681 × 101 | 1.66002 × 102 | 6.39374 × 102 |
| (2.0, 4.50 × 10−3) | (2.0, 4.50 × 10−3) | 6.21816 × 101 | 5.77621 × 102 | 2.43005 × 103 |
| (2.0, 4.50 × 10−3) | (2.0, 5.65 × 10−3) | 5.85085 × 100 | 5.58077 × 101 | 2.44502 × 102 |
| (2.0, 4.50 × 10−3) | (2.2, 4.50 × 10−3) | 1.87450 × 101 | 1.68881 × 102 | 6.78999 × 102 |
| (2.0, 5.65 × 10−3) | (2.0, 5.65 × 10−3) | 8.19711 × 101 | 7.90781 × 102 | 3.53432 × 103 |
| (2.0, 5.65 × 10−3) | (2.0, 7.11 × 10−3) | 6.07740 × 100 | 6.05452 × 101 | 2.85148 × 102 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| (zi, ki) | (zj, kj) | F1 | F2 | F4 |
|---|---|---|---|---|
| [, (s km−1)] | [, (s km−1)] | (s2 km−2) | (s2 km−2) | (s2 km−2) |
| (2.0, 5.00 × 10−4) | (2.0, 5.00 × 10−4) | 6.02867 × 101 | 6.51197 × 102 | 3.66215 × 103 |
| (2.0, 5.00 × 10−4) | (2.0, 1.50 × 10−3) | 6.63624 × 100 | 6.52238 × 101 | 3.02865 × 102 |
| (2.0, 5.00 × 10−4) | (2.2, 5.00 × 10−4) | 2.12509 × 101 | 2.30833 × 102 | 1.33759 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 1.50 × 10−3) | 6.54364 × 101 | 6.00179 × 102 | 2.47973 × 103 |
| (2.0, 1.50 × 10−3) | (2.0, 2.50 × 10−3) | 5.99838 × 100 | 5.43360 × 101 | 2.19731 × 102 |
| (2.0, 1.50 × 10−3) | (2.2, 1.50 × 10−3) | 1.97400 × 101 | 1.75264 × 102 | 6.90261 × 102 |
| (2.0, 2.50 × 10−3) | (2.0, 2.50 × 10−3) | 6.38029 × 101 | 5.69068 × 102 | 2.25086 × 103 |
| (2.0, 2.50 × 10−3) | (2.0, 3.50 × 10−3) | 5.83666 × 100 | 5.28085 × 101 | 2.13079 × 102 |
| (2.0, 2.50 × 10−3) | (2.2, 2.50 × 10−3) | 1.92028 × 101 | 1.65626 × 102 | 6.24662 × 102 |
| (2.0, 3.50 × 10−3) | (2.0, 3.50 × 10−3) | 6.29898 × 101 | 5.69389 × 102 | 2.29742 × 103 |
| (2.0, 3.50 × 10−3) | (2.0, 4.50 × 10−3) | 5.74635 × 100 | 5.31461 × 101 | 2.21748 × 102 |
| (2.0, 3.50 × 10−3) | (2.2, 3.50 × 10−3) | 1.89681 × 101 | 1.66002 × 102 | 6.39374 × 102 |
| (2.0, 4.50 × 10−3) | (2.0, 4.50 × 10−3) | 6.21816 × 101 | 5.77621 × 102 | 2.43005 × 103 |
| (2.0, 4.50 × 10−3) | (2.0, 5.65 × 10−3) | 5.85085 × 100 | 5.58077 × 101 | 2.44502 × 102 |
| (2.0, 4.50 × 10−3) | (2.2, 4.50 × 10−3) | 1.87450 × 101 | 1.68881 × 102 | 6.78999 × 102 |
| (2.0, 5.65 × 10−3) | (2.0, 5.65 × 10−3) | 8.19711 × 101 | 7.90781 × 102 | 3.53432 × 103 |
| (2.0, 5.65 × 10−3) | (2.0, 7.11 × 10−3) | 6.07740 × 100 | 6.05452 × 101 | 2.85148 × 102 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
In the noise dominated limit, the covariance matrix is |$\mathbf {C} \approx \mathbf {N}$|, and so the Fisher matrix scales as |$\mathbf {N}^{-2}$|. Assuming the noise is uncorrelated and Gaussian with standard deviation σ, this means that the Fisher matrix is proportional to |$\mathbf {F} \propto \sigma ^{-4} = \mathrm{(S/N)}^4$| (or the precision scales as (S/N)2), where we substituted the definition S/N≡ 1/σ. We confirmed that this scaling holds true for high k values in the Fisher matrix.
5 DISCUSSION
We would like to start our discussion by highlighting the differences between QMLE and FFT. As we have shown in Section 2.2, QMLE finds inverse variance weighted averages across bins. Measuring deviations from a baseline power further lessens the averaging, so that QMLE yields near exact P1D(k). On the other hand, FFT estimator computes simple averages. For wide enough bins, this does not equal to P1D(k). Therefore, it is important to note that these two methods will not fully agree unless special circumstances are met, because they compute mathematically different quantities.
Systematic errors are the significant uncertainty source in P1D analysis. We have considered three such error sources: (1) HCD absorbers, (2) metal contamination, and (3) continuum fitting. Using our method, we showed that HCDs can be masked without further complications. Modelling their contribution can now be solely a theoretical question as they are biased tracers in reality. However, metal contamination is more complicated as they are not easily separable from data like HCDs. Metal contamination estimates will inevitably bring statistical errors; and these errors can be fairly higher than our simple forecasts. Nevertheless, all methods face this challenge. Third, continuum errors can be more complicated than our simple model, but we believe these errors can still be marginalized with careful investigation. Even though marginalization washes out some information, it still enables us to keep the largest scales in P1D. Furthermore, DESI will supply plenty of spectra to study and better understand these errors in the future.
Two additional error sources not considered here are uncertainties in the estimates of the resolution and the noise. Although, we used a simple Gaussian form of the spectrograph resolution and a diagonal noise matrix, the QMLE formalism allows us trivially extend this to more complicated forms, such as described in Bolton & Schlegel (2010). We defer a complete analysis, including a sensitivity analysis to resolution and noise misestimations to future work.
A disadvantage of our method over a direct FFT method is the additional computational time. However, we demonstrated that these calculations are now practical even for surveys of the scope of DESI, as we were able to perform multiple runs of full DESI-like data in a small cluster of 30 nodes with 24 cores each. We also introduced an optimization scheme that brings down the CPU time significantly. We think this cost is reasonable given QMLE’s capacity to overcome Ly α forest specific challenges. Further computational speedups such as using GPUs are likely possible; we defer these to later work.
6 SUMMARY
The Ly α forest has emerged as a unique and competitive tool to investigate the large-scale structure of the universe. This technique can probe cosmological parameters on large scales, while being sensitive to the thermal state of the IGM, neutrino masses, and new dark matter models on small scales. This small-scale physics enriches the 1D and 3D power spectrum of the Ly α forest.
In this work, we studied the optimal quadratic estimator (QMLE) for P1D by first formulating its generic and Ly α specific expressions, offered an analytic continuum limit formula to depict what QMLE calculates and a straightforward way to bootstrap its results. Under the simplest terms, QMLE finds an inverse variance weighted average power for each bin. We then outlined the implementation in detail by providing our step-by-step algorithm. We here underline two of our decisions that mitigates the systematics and numerical instabilities: (1) we fed smoothed estimates to the covariance matrix, and (2) we picked a convergence criteria that weights changes between iterations by the error estimates. Then, we described our synthetic spectra and provided analytic expressions for what they construct. These analytic expressions were crucial to ascertain the performance of QMLE.
We generated DESI-oriented synthetic spectra in order to perform comprehensive tests. These mocks assumed constant resolution (R = 3200) and noise at all wavelengths, and limited the quasar redshift range to zqso ∈ [2.1, 4.4] with pixel width cΔln λ = 30 km s−1. A summary of our findings is as follows:
Using 800 000 of these spectra with S/N = 2 Å−1, we first showed that the power spectrum could be accurately measured with 1 per cent precision. This number declined towards higher redshifts due to diminishing statistics. This proved the absence of biases in our algorithm.
We randomly masked Δλ = 25 Å region of 15 per cent of spectra, and showed that this masking badly affected the measurement when untreated, and proved QMLE was robust against its effects on 100 000 mocks. As real analyses would mask bad pixels and high-density absorbers, this strength is invaluable to P1D analysis.
We introduced continuum errors by adding wavelength-dependent error |$\eta (\lambda) \sim 10{{\ \rm per\ cent}}$| to flux fluctuations δF. This error function η(λ) had two independent parameters for each quasar: amplitude and slope. Using eight independent runs with 100 000 spectra each, we demonstrated that these continuum errors contaminate first two k bins, but QMLE could marginalize out the noisiest modes, and recover these scales.
We presented, both analytically and by using 100 000 spectra, how a baseline model improved the accuracy. This fiducial power enables us to integrate over bins and to lessen the discretization of band powers. Our proposed unbiased procedure to find this fiducial power is to first measure the power spectrum without any input, then find the best-fitting analytic function on these results. We showed this feature significantly boosted our measurements.
Finally, we found that computation was mostly spent on Fisher matrix calculation. We also found that Fisher matrix had a simple structure, which allowed us to come up with an optimization scheme that reduced the computation time by 60 per cent.
This work represents an initial step towards analysing the upcoming Lyman α data sets with surveys like DESI. The quadratic estimator formalism allows us to optimally use all the available data (even with varying S/N) and to effectively mitigate systematic errors like those arising from an imperfect continuum estimate. We address several practical issues with implementing a QMLE power spectrum code for the Lyman α forest. Future work will use these results and the codes described here to analyse both existing high-resolution data as well as upcoming DESI data.
SUPPORTING INFORMATION
fiducial_p1d.txt
fisher_matrix_table.txt
Please note: Oxford University Press is not responsible for the content or functionality of any supporting materials supplied by the authors. Any queries (other than missing material) should be directed to the corresponding author for the article.
ACKNOWLEDGEMENTS
We thank Michael Walther, Nathalie Palanque-Delabrouille, Christophe Yèche, Vid Iršič, and DESI Lyman α working group for useful discussions. We also thank the referee for their detailed comments and suggestions.
NGK and NP are supported by DOE, reference number DE-SC0017660. AFR acknowledges support by an STFC Ernest Rutherford Fellowship, grant reference ST/N003853/1, and by FSE funds through the program Ramon y Cajal (RYC-2018-025210) of the Spanish Ministry of Science and Innovation.
DATA AVAILABILITY
The data underlying this article are available in the article and in its online supplementary material.
Footnotes
The 3D analysis inherently needs these correlations between spectra, so this would not hold true.
The pivot point does not matter as long as v = cln λ, and therefore the Ly α rest-frame wavelength can also be used instead of the median wavelength of the spectrum.
DESI will use linear wavelength spacing in its pipeline, but QMLE does not require equal velocity spacing.
We performed nine independent runs and found χ2 fluctuating around 228 as expected. The value 248 is from our first run, and not a special case.
This kN roughly corresponds to |$P_N/\sqrt{N_{\mathrm{qso}}}=P_{\mathrm{1D}}$|, where the noise power is |$P_N=\left(\sigma \Delta v/\bar{F}(z)\right)^2$| with Nqso = 100 000 for all redshift bins and P1D is obtained analytically.
The lowest k bin is weakly coupled |$(\sim 1{{\ \rm per\ cent}})$| to an additional redshift bin.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}