





ABSTRACT
We utilize mock catalogues from high-accuracy cosmological N-body simulations to quantify shifts in the recovery of the acoustic scale that could potentially result from galaxy clustering bias. The relationship between galaxies and dark matter haloes presents a complicated source of systematic errors in modern redshift surveys, particularly when aiming to make cosmological measurements to sub-per cent precision. Apart from a scalar, linear bias parameter accounting for the density contrast ratio between matter tracers and the true matter distribution, other types of galaxy bias, such as assembly and velocity biases, may also significantly alter clustering signals from small to large scales. We create mocks based on generalized halo occupation populations of 36 periodic boxes from the abacus cosmosrelease, and test various biased models along with an unbiased base case in a total volume of |$48 \, h^{-3} \, {\rm Gpc}^{3}$|. Two reconstruction methods are applied to galaxy samples and the apparent acoustic scale is derived by fitting the two-point correlation function multipoles. With respect to the baseline, we find a 0.3 per cent shift in the line-of-sight acoustic scale for one variation in the satellite galaxy population, and we find a 0.7 per cent shift for an extreme level of velocity bias of the central galaxies. All other bias models are consistent with zero shift at the 0.2 per cent level after reconstruction. We note that the bias models explored are relatively large variations, producing sizeable and likely distinguishable changes in small-scale clustering, the modelling of which would further calibrate the baryon acoustic oscillations standard ruler.
1 INTRODUCTION
The standard ruler provided by baryon acoustic oscillations (BAO) has become a powerful probe in the past decade for studying the large-scale structure of the Universe and constraining properties of dark energy. The next generation of dark energy experiments, such as the Dark Energy Spectroscopic Instrument (DESI; DESI Collaboration 2016), Euclid (Laureijs et al. 2011), and WFIRST (Spergel et al. 2015), are designed and built with BAO as a primary method to measure the expansion history of the Universe to unprecedented precision. The acoustic scale around 100 h−1 Mpc is much larger than the scales relevant for non-linear gravitational evolution, and galaxy formation and remains in the linear regime today. However, non-linear effects still have small but important consequences, despite the acoustic scale being a robust standard ruler for measuring cosmological distances. Systematic errors on the distance scales inferred from BAO measurements are indeed dominated by non-linear structure growth as well as redshift-space distortions. As reconstruction has been shown to substantially reduce these major contributors to systematics if not reverse them entirely (Sherwin & Zaldarriaga 2012), the next subleading source of systematics, galaxy bias, is increasingly relevant with the precision of BAO measurements reaching the |$0.1{{\ \rm per\ cent}}$| level in future surveys (Mehta et al. 2011).
Density field reconstruction uses Lagrangian perturbation theory to reduce anisotropies in the clustering and reverse the large-scale gravitational bulk flows in the observed galaxy sample (Eisenstein et al. 2007). This procedure is very effective in undoing the smoothing of the BAO feature and the shift of the BAO scale due to non-linear structure growth, thereby improving the precision of BAO measurements. The one-step version, known as standard reconstruction, has been field tested extensively with on-sky data (Anderson et al. 2012, 2014a,b; Padmanabhan et al. 2012; Kazin et al. 2014; Ross et al. 2017) and become part of the standard analysis procedure in modern galaxy redshift surveys. There has been much recent development in reconstruction (Schmittfull, Baldauf & Zaldarriaga 2017; Seljak et al. 2017; Hada & Eisenstein 2018; Shi, Cautun & Li 2018; Zhu, Yu & Pen 2018; Wang & Pen 2019). While standard reconstruction has worked well to restore and enhance the BAO signature, whether newer algorithms can perform better is a question. To find out, we employ one of the new methods, the iterative reconstruction in particular (Hada & Eisenstein 2018), which provides better correlation to the matter density field and closer-to-truth statistics than standard reconstruction when applied to galaxy mocks (Hada & Eisenstein 2019).
Galaxies as tracers of the underlying matter density field are far from perfect and tend to overweigh overdense regions. It is well known that galaxy bias can be scale-dependent and, even with a linear bias correction, shift the acoustic scale measurement (Padmanabhan & White 2009; Mehta et al. 2011), increasing systematic errors in cosmic distances and cosmological parameters. Mehta et al. (2011) showed that the one-step reconstruction (Eisenstein et al. 2007) reduces the BAO shifts due to linear bias b ≤ 3.29 and results in no significant shift of the BAO scale in a volume of |$44 \, h^{-3}\, {\rm Gpc}^{3}$|. Yet, many mechanisms in the halo model can give rise to galaxy bias that may not be well approximated as a linear parameter, and can induce sub-per cent level shifts of the acoustic scale. For example, galaxy or halo assembly bias is a significant source of systematic error in the galaxy–halo relationship at small scales (Zentner, Hearin & van den Bosch 2014). The CMASS Baryon Oscillations Spectroscopic Survey (BOSS) galaxy sample was found to have significant velocity bias for the central galaxies, and between velocity and spatial distributions of satellites, at least one is biased (Guo et al. 2015a). Wu & Huterer (2013) found significant changes of the power spectrum caused by non-Poisson distribution and velocity bias of satellite galaxies.
This study seeks to assess the sensitivity of the acoustic scale in the two-point correlation functions (2PCF) to the effects of galaxy bias. Our analysis packages together a number of improvements over existing literature. The anisotropic acoustic scale is measured in both radial and transverse directions. Several types of galaxy bias are considered, including satellite distribution bias, assembly bias for central and satellite galaxies, velocity bias for centrals and satellites, and more subhalo-scale effects. The cosmological N-body simulations are generated by the high-accuracy abacus code (Garrison et al. 2016; Garrison, Eisenstein & Pinto 2019), and the total simulation volume of |$48 \, h^{-3}\, {\rm Gpc}^{3}$| is the largest as of the writing of this paper. A newer iterative reconstruction method is applied in addition to standard reconstruction (Hada & Eisenstein 2018). Halo catalogues are populated with mock galaxies in a generalized halo occupation distribution (HOD) model akin to Yuan, Eisenstein & Garrison (2018), which can be implemented in a deterministic way such that clustering statistics are differentiable with respect to variations of the input HOD model parameters.
The layout of this paper is as follows. In Section 2 methods, Section 2.1 describes the N-body simulations and halo catalogues, Section 2.2 covers generation of mock galaxy catalogues with biased HOD models and reconstruction parameters, Sections 2.3 and 2.4 goes through the correlation and covariance calculation, and Section 2.5 motivates the BAO fitting test for iterative reconstruction with alternative models. In Section 3, we examine the differential change in 2PCF resulting from all bias models in Section 3.1, and then presents the shift of the BAO scale measurement for each type of bias in Section 3.2. Finally, the conclusions section, Section 4 highlights the findings.
2 SIMULATIONS, CATALOGUES, AND METHODS
2.1 Simulations and halo catalogues
Our study uses cosmological N-body simulations produced by the abacus code (Garrison et al. 2019). Specifically, 36 simulation boxes assuming the Planck cosmology (Planck Collaboration XIII 2016) are used. They all have particle mass about |$4\times 10^{10} \, h^{-1}\,\mathrm{ M}_\odot$|, particle count 14403, box size 1100 h−1 Mpc , periodic boundary conditions, and initial conditions created with the same input linear power spectrum and independent initial phases (Garrison et al. 2016). The total volume adds up to |$48 \, h^{-3}\, {\rm Gpc}^{3}$|. The only difference among the 36 boxes is that 16 were run with Plummer force softening and the other 20 with spline softening. Detailed descriptions of the force softening can be found in the abacus cosmos public data release paper (Garrison et al. 2018). These two sets are first analysed separately from applying halo mass cuts all the way through to the BAO scale measurements, where we find all clustering statistics within 1σ range of each other when analysing matter density field and galaxy samples created by any given HOD model. There is no difference between two simulations at any confidence level, despite their slightly different halo mass functions. With fixed halo finder and HOD parameters, spline softening typically results in more massive and large haloes, meaning more haloes pass the mass cut and more galaxies are generated. But as we have found, the BAO scale evolves slowly with respect to the halo mass function, and it is safe to combined two simulations for a larger total volume. All results hereafter have two sets combined and treated as one simulation of 36 boxes.
Several time slices of the simulations after z = 1 are saved on disc with data products available. We take the z = 0.5 snapshot to mimic luminous red galaxy (LRG) samples and to stay close to the galaxy redshifts in the BOSS DR12 data set (Alam et al. 2015) as well as the mocks used to analyse it (Alam et al. 2017). The halo catalogues are created by the rockstar halo finder (Behroozi, Wechsler & Wu 2013). To incorporate galaxy assembly bias later in the HOD, the halo NFW concentration, defined as cNFW ≡ Rvirial/Rs,Klypin, is added to the halo properties, where the virial radius of the halo is chosen as rvirial = r200 and the scale radius is given by Klypin, Trujillo-Gomez & Primack (2011), which is more stable than the traditional scale radius for small haloes (Behroozi et al. 2013).
A mass cut at 70 dark matter (DM) particles, or approximately Mhalo = 4 × 1012 M⊙, was applied, as small haloes have essentially zero chance of hosting galaxies and slow down the computation. Subhaloes are not reliable indicators of in-halo galaxy distribution and are removed as well. Instead, we use the position and velocity of DM particles to generate satellite galaxies. Each halo catalogue is accompanied by a DM particle catalogue, which is a 10 per cent subsample of the particles enclosed by halo boundaries. Particles within subhaloes are associated only to their host subhaloes in rockstarcatalogues, not the higher level host haloes. This becomes a problem after subhaloes are removed, and the particle associations have to be rebuilt before satellite generation to ensure that all particles are associated with their highest level host haloes. In addition, a |$10{{\ \rm per\ cent}}$| uniform subsample of all 14403 particles in any given simulation box was also used to validate our BAO fitter, as well as to quantify how much cosmic variance there exists in the BAO measurements and are cancelled out when the difference is taken.
2.2 Galaxy and random catalogues
2.2.1 Halo occupation distribution
The HOD model used for populating haloes with galaxies is based on the classic 5-parameter model by Zheng, Coil & Zehavi (2007) with decorations accounting for assembly bias, velocity bias, satellite distribution bias, and perihelion distance bias (Yuan et al. 2018). abacus provides direct access to DM particles from which haloes have been found in the simulation. Although halo finders only produce spherical halo boundaries and therefore spherical DM particle distributions, the matter distribution is still a much better representation of the actual density profile within a halo than NFW profiles. Satellite galaxies generated with DM particles more realistically trace the matter distribution of the halo.
A key feature of this HOD model is the deterministically seeded random numbers used for populating each simulation box. The seed is chosen such that all haloes and DM particles always receive the same random number assignment completely irrespective of the HOD parameters specified. This means any infinitesimal change in the input HOD parameters would correspond to an infinitesimal change in the clustering results.
Assembly bias is implemented as comparing the halo concentration to the median concentration of all haloes of that mass. The more concentrated halo may have a more favourable assembly history and a higher probability of hosting central or satellite galaxies, or vice versa. The median halo concentration as a function of halo mass cmed(M) is obtained by putting all haloes into mass bins and fitting a polynomial to cmed(M). Instead of taking the haloes from a single simulation box as the sample and repeating the fit for all boxes, we take the entire halo population from all boxes in a given simulation and perform the fitting once for all. This has a better theoretical motivation because the function cmed(M), in principle, is independent from the phase of initial conditions and does not vary across boxes. Even though the entire halo population is now an order of magnitude larger than that of a single box, if a smooth fit is desired and the bin specification is fine, there are still some mass bins with few haloes and thereby, small variances in halo concentration. The usual weight definition for all mass bins is |$w=1/\sigma _c = \sqrt{(N-1)/\Sigma _i (c_i-\mu _c)}$| up to a normalization constant, where N is the number of haloes in the mass bin, ci is the concentration of each halo in the bin, and μc is the mean concentration of the bin. With |$\sqrt{N}$| in the numerator, this gives disproportionally large weights for those least populated bins, resulting in poor fits. We corrected for this pathology by adjusting the bin weight definition, multiplying the canonical weight by (N − 1) in powers of 1/2 in an attempt to increase the weight for the more populated bins. Both |$w=\sqrt{N-1}/\sigma _c$| and w = (N − 1)/σc produced quality fits that were almost identical. We chose |$w \equiv \sqrt{N-1}/\sigma _c = (N-1)/\sqrt{\Sigma _i (c_i-\mu _c)}$| as the weight definition.
To optimize I/O performance and the size of data products, abacus saves each halo catalogue for a single box into many HDF5 files, each being a subset of the halo catalogue. When populating haloes, GRAND-HOD proceeds on a subset-by-subset basis as it goes through the HDF5 files sequentially. As a result, all halo ranking operations involved in the decorations, e.g. pseudo-mass calculations, are limited to the current HDF5 subset of haloes only. Our code utilizes the halo reader built-in to abacusand loads the complete halo catalogue at once in the standard Halotools (Hearin et al. 2017) format together with the DM particle subsample with corrected host IDs as part of the mock. The new code fully conforms to the astropy (Astropy Collaboration 2018) and Halotools standards, supports the Halotools prebuilt HOD models, and is compatible with both the latest python 3 and 2 builds. It provides flexibility in customizing HOD parameters and preset models, and boosts performance with parallelism.
2.2.2 Biased HOD models
The generalized HOD framework easily allows any aforementioned source of bias, or combination of sources, to be introduced into the model with flexibility. The biased HOD models tested in this paper are summarized in Table 1. All models, except the baseline (denoted Base 1), have only a single mechanism of galaxy bias applied in order to explore the ‘unit vector’ directions in the space of variations. Although this HOD parametrization does not exactly preserve the number density of galaxies, the resulting number density of all biased models only differ from the baseline by about |$0.1{{\ \rm per\ cent}}$|, which is negligible. By default, central galaxies inherit the velocity of the host haloes, and satellite galaxies generated with DM particles assume the DM particle velocities, unless velocity bias is applied. To understand how each bias mechanism changes clustering statistics and the acoustic scale, we first establish a base case, free of any decoration for reference. The baseline is a simple 5-parameter model; its parameters are unimportant as we are only interested in the differential change with respect to the baseline. We reiterate that our HOD implementation is differentiable, which is precisely what enables us to set up a baseline and subtract it from the bias model results. For each simulation box, the random numbers are strictly model-independent with both the order and quantity being fixed.
Parameters of the biased HOD models that are tested. The first five columns are input for the classic 5-parameter vanilla HOD model as defined in equations (1) and (2). The last six decorations parameters are briefly reviewed in Section 2.2.2. All model parameters are given relatively extreme values intentionally. Dash line means no change from the baseline model. The satellite parameters in Base 2 and Base 3 models are tuned to maintain a constant galaxy number density in the simulation box with respect to the baseline.
| Biased HOD models | log10Mcut | σ′ | κ | log10M1 | α | Acen | Asat | αcen | s | sv | sp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 1 (baseline) | 13.35 | 0.85 | 1.0 | 13.800 | 1.00 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base 2 | – | – | – | 13.770 | 0.75 | – | – | – | – | – | – |
| Base 3 | – | – | – | 13.848 | 1.25 | – | – | – | – | – | – |
| Assembly bias (centrals +) | – | – | – | – | – | 1.0 | – | – | – | – | – |
| Assembly bias (centrals −) | – | – | – | – | – | −1.0 | – | – | – | – | – |
| Assembly bias (satellites +) | – | – | – | – | – | – | 1.0 | – | – | – | – |
| Assembly bias (satellites −) | – | – | – | – | – | – | −1.0 | – | – | – | – |
| Velocity bias (centrals 20 per cent) | – | – | – | – | – | – | – | 0.2 | – | – | – |
| Velocity bias (centrals 100 per cent) | – | – | – | – | – | – | – | 1.0 | – | – | – |
| Halo centric distance bias (satellites +) | – | – | – | – | – | – | – | – | 0.9 | – | – |
| Halo centric distance bias (satellites −) | – | – | – | – | – | – | – | – | −0.9 | – | – |
| Velocity bias (satellites +) | – | – | – | – | – | – | – | – | – | 0.9 | – |
| Velocity bias (satellites −) | – | – | – | – | – | – | – | – | – | −0.9 | – |
| Perihelion distance bias (satellites +) | – | – | – | – | – | – | – | – | – | – | 0.9 |
| Perihelion distance bias (satellites −) | – | – | – | – | – | – | – | – | – | – | −0.9 |
| Biased HOD models | log10Mcut | σ′ | κ | log10M1 | α | Acen | Asat | αcen | s | sv | sp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 1 (baseline) | 13.35 | 0.85 | 1.0 | 13.800 | 1.00 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base 2 | – | – | – | 13.770 | 0.75 | – | – | – | – | – | – |
| Base 3 | – | – | – | 13.848 | 1.25 | – | – | – | – | – | – |
| Assembly bias (centrals +) | – | – | – | – | – | 1.0 | – | – | – | – | – |
| Assembly bias (centrals −) | – | – | – | – | – | −1.0 | – | – | – | – | – |
| Assembly bias (satellites +) | – | – | – | – | – | – | 1.0 | – | – | – | – |
| Assembly bias (satellites −) | – | – | – | – | – | – | −1.0 | – | – | – | – |
| Velocity bias (centrals 20 per cent) | – | – | – | – | – | – | – | 0.2 | – | – | – |
| Velocity bias (centrals 100 per cent) | – | – | – | – | – | – | – | 1.0 | – | – | – |
| Halo centric distance bias (satellites +) | – | – | – | – | – | – | – | – | 0.9 | – | – |
| Halo centric distance bias (satellites −) | – | – | – | – | – | – | – | – | −0.9 | – | – |
| Velocity bias (satellites +) | – | – | – | – | – | – | – | – | – | 0.9 | – |
| Velocity bias (satellites −) | – | – | – | – | – | – | – | – | – | −0.9 | – |
| Perihelion distance bias (satellites +) | – | – | – | – | – | – | – | – | – | – | 0.9 |
| Perihelion distance bias (satellites −) | – | – | – | – | – | – | – | – | – | – | −0.9 |
Parameters of the biased HOD models that are tested. The first five columns are input for the classic 5-parameter vanilla HOD model as defined in equations (1) and (2). The last six decorations parameters are briefly reviewed in Section 2.2.2. All model parameters are given relatively extreme values intentionally. Dash line means no change from the baseline model. The satellite parameters in Base 2 and Base 3 models are tuned to maintain a constant galaxy number density in the simulation box with respect to the baseline.
| Biased HOD models | log10Mcut | σ′ | κ | log10M1 | α | Acen | Asat | αcen | s | sv | sp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 1 (baseline) | 13.35 | 0.85 | 1.0 | 13.800 | 1.00 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base 2 | – | – | – | 13.770 | 0.75 | – | – | – | – | – | – |
| Base 3 | – | – | – | 13.848 | 1.25 | – | – | – | – | – | – |
| Assembly bias (centrals +) | – | – | – | – | – | 1.0 | – | – | – | – | – |
| Assembly bias (centrals −) | – | – | – | – | – | −1.0 | – | – | – | – | – |
| Assembly bias (satellites +) | – | – | – | – | – | – | 1.0 | – | – | – | – |
| Assembly bias (satellites −) | – | – | – | – | – | – | −1.0 | – | – | – | – |
| Velocity bias (centrals 20 per cent) | – | – | – | – | – | – | – | 0.2 | – | – | – |
| Velocity bias (centrals 100 per cent) | – | – | – | – | – | – | – | 1.0 | – | – | – |
| Halo centric distance bias (satellites +) | – | – | – | – | – | – | – | – | 0.9 | – | – |
| Halo centric distance bias (satellites −) | – | – | – | – | – | – | – | – | −0.9 | – | – |
| Velocity bias (satellites +) | – | – | – | – | – | – | – | – | – | 0.9 | – |
| Velocity bias (satellites −) | – | – | – | – | – | – | – | – | – | −0.9 | – |
| Perihelion distance bias (satellites +) | – | – | – | – | – | – | – | – | – | – | 0.9 |
| Perihelion distance bias (satellites −) | – | – | – | – | – | – | – | – | – | – | −0.9 |
| Biased HOD models | log10Mcut | σ′ | κ | log10M1 | α | Acen | Asat | αcen | s | sv | sp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 1 (baseline) | 13.35 | 0.85 | 1.0 | 13.800 | 1.00 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base 2 | – | – | – | 13.770 | 0.75 | – | – | – | – | – | – |
| Base 3 | – | – | – | 13.848 | 1.25 | – | – | – | – | – | – |
| Assembly bias (centrals +) | – | – | – | – | – | 1.0 | – | – | – | – | – |
| Assembly bias (centrals −) | – | – | – | – | – | −1.0 | – | – | – | – | – |
| Assembly bias (satellites +) | – | – | – | – | – | – | 1.0 | – | – | – | – |
| Assembly bias (satellites −) | – | – | – | – | – | – | −1.0 | – | – | – | – |
| Velocity bias (centrals 20 per cent) | – | – | – | – | – | – | – | 0.2 | – | – | – |
| Velocity bias (centrals 100 per cent) | – | – | – | – | – | – | – | 1.0 | – | – | – |
| Halo centric distance bias (satellites +) | – | – | – | – | – | – | – | – | 0.9 | – | – |
| Halo centric distance bias (satellites −) | – | – | – | – | – | – | – | – | −0.9 | – | – |
| Velocity bias (satellites +) | – | – | – | – | – | – | – | – | – | 0.9 | – |
| Velocity bias (satellites −) | – | – | – | – | – | – | – | – | – | −0.9 | – |
| Perihelion distance bias (satellites +) | – | – | – | – | – | – | – | – | – | – | 0.9 |
| Perihelion distance bias (satellites −) | – | – | – | – | – | – | – | – | – | – | −0.9 |
Besides the baseline two more undecorated models are defined, which vary only the vanilla HOD parameters. The models named Base 2 and 3 differ from the baseline only in the satellite parameters in equation (2): the exponent α is changed by |$\pm 25{{\ \rm per\ cent}}$|, and the denominator in the power-law term, M1, is tuned accordingly. The specific combinations of M1 and α values are chosen to match the number density in the baseline model, |$4\times 10^{-4} h^{3}\, {\rm Mpc}^{-3}$|, which agrees with realistic LRG sample densities.
Next, there are a number of single-decoration models that come in pairs. Single-decoration means that each model has only one origin of bias present with respect to the baseline model. And each pair of models have opposite changes in the parameter(s) of interest. Two models have assembly bias only for central galaxies with opposite assembly bias parameter Acen, and similarly two assembly bias models for satellites only. Then there are two central velocity bias models, one assumes a more realistic, |$20\, {\rm per\, cent} \cdot v_\text{rms}$| velocity dispersion for the central galaxy relative to the DM halo, and the other assuming a more extreme, |$100\, {\rm per\, cent} \cdot v_\text{rms}$| dispersion. The last six models investigate three bias effects arising from subhalo-scale astrophysics, by giving preferential treatment to DM particles based on the particle’s speed, halo centric distance, or total mechanical energy (quantified by perihelion distance) when assigning satellite galaxies. Below is a brief review of the definitions of the parameters, and readers are referred to Yuan et al. (2018) for a more detailed discussion.
We stress that the parameters for the bias models listed in Table 1 are intentionally chosen to be quite extreme. For a common 20-particle halo and s = 0.9, for example, the innermost particle (rank r = 0) has 19 times the probability of the outermost particle (r = 19) to match to a satellite galaxy. The purpose is to increase the chance of detecting a shift in the acoustic peak location and to explore the worse-case scenarios.
2.2.3 Redshift-space distortion and reconstruction
By adding decorations to the base HOD class, we are modifying the line-of-sight velocity of galaxies and assuming an alternative truth velocity. As apparent RSD depends on the true peculiar velocity in addition to the Hubble flow, we artificially apply RSD to the line-of-sight coordinate as the last step of mock galaxy generation by modifying |$x^\prime _{/\!/} = x_{/\!/} + v_{/\!/} / \left[a H(a) \right]$| in the line-of-sight direction, after all decorations are completed. In practice, this is implemented as |$x^\prime _{/\!/} = x_{/\!/} + v_{/\!/} / \left[a H_0 E(z) \right]$| where E(z) is the astropy efunc defined as H(z) ≡ H0E(z).
Now the complete mock galaxy catalogue is ready to be treated as observed data. Two reconstruction methods are applied and compared side by side: the standard reconstruction (Eisenstein et al. 2007) and a recent iterative reconstruction method (Hada & Eisenstein 2018). For both reconstruction methods, the optimal smoothing scale |$\Sigma = 15\,h^{-1}\,\mathrm{Mpc}$| is used. Additional parameters for iterative reconstruction used are grid size Ngrid = 4803, galaxy bias b = 2.23, initial smoothing scale |$\Sigma _\text{ini} = 15\,h^{-1}\,\mathrm{Mpc}\,$|, annealing parameter |$\mathcal {D} = 1.2$|, weight w = 0.7, and number of iterations niter = 6. These parameters are chosen based on Hada & Eisenstein (2018, 2019) where variations in the input galaxy bias b up to |$20\, {\rm per\, cent}$| was found to hardly impact the iterative reconstruction result.
The rest of the procedures including 2PCF, covariance, and fitting is performed on all three types of galaxy catalogues: pre-reconstruction, post-reconstruction (standard), and post-reconstruction (iterative).
2.3 Noise suppression in two-point correlation functions
To suppress the shot noise in galaxy generation, for the same simulation box and same biased HOD model, 12 realizations of the galaxy catalogue are generated repeatedly with varied initial seed. The initial condition phase for a box p is an integer index labelling the simulation box. The realization index r is an integer from 0 to 11. The random number generator seed is reset as s = 100p + r before every galaxy generation, which guarantees that the random numbers are always deterministic and model-independent, as long as we never exceed 100 realizations. In the beginning of each galaxy catalogue generation, a fixed quantity of random numbers (Nhaloes + Nparticles) are thrown for centrals and satellites before any other operation takes place that may involve throwing more random numbers (e.g. central velocity bias that draws randomly from a Gaussian distribution). As Nhaloes and Nparticles are both constant for a given simulation box, this ensures that the same random numbers are always generated, regardless of the HOD model imposed, and assigned to every halo or DM particle in a fixed order.
For each realization of the galaxy sample, the 2PCF and their Legendre multipole decompositions are calculated using a Fast Fourier Transform algorithm on the k-grid (Slepian & Eisenstein 2016), as well as using the pair-counting method for cross-checking when applicable. All pair-counting is done in fine (s, μ) and (rp, π) bins using a highly efficient pair-counting code corrfunc (Sinha & Garrison 2017; Sinha & Garrison 2019): s bin edges from 0 to 150 h−1 Mpc at 1 h−1 Mpc steps and μ bin edges from 0 to 1 at 0.01 steps. The pair-counts are re-binned with optimal bin size |$\Delta s = 5\,h^{-1}\,\mathrm{Mpc}\,$| found in Ross et al. (2017).
The multipoles from all realizations are co-added into one correlation sample for a given simulation box. To further increase signal-to-noise ratio in the clustering statistics, we take the delete-1 jackknife samples of the multipoles by ignoring one box and co-adding all the other boxes at a time. A comparison between individual box samples and jackknife samples is shown in Fig. 1. There are large enough fluctuations across different boxes that jackknife re-sampling is a necessary step before BAO fitting and significantly reduces sample variance. The Nbox = 36 jackknife samples are then passed on to the fitter.
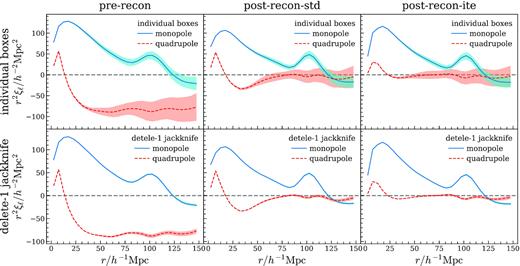
The first two multipoles of the galaxy 2PCF for the baseline HOD model showing fluctuations among simulation boxes. The first row shows Nbox = 36 multipole samples derived from co-adding 12 realizations of each box; the curves are the mean monopole or quadrupole, and the shaded regions are ±1σ intervals around the mean. The second row shows the re-sampled, delete-1 jackknife multipoles derived from co-adding Nbox − 1 boxes at a time; the shaded ±1σ regions are in fact the standard deviation rescaled by |$\sqrt{N_\text{box}-1}=\sqrt{35}$| to account for the jackknife re-sampling, though difficult to see. Three columns are pre-reconstruction, post-reconstruction (standard), and post-reconstruction (iterative). From left to right, the monopole BAO peak is sharpened and the quadrupole getting closer to zero, indicating less anisotropy and better restored spherical BAO shell. Although different boxes in a given simulation only differ by the initial condition phase and over 10 realizations are generated and co-added, there are still considerable fluctuations in the 2PCF among boxes. Jackknife re-sampling yields much smoother and stabler samples, and greatly reduces the uncertainty in the mean correlations.
2.4 Covariance estimation
The covariance between all multipoles and (s, μ) bins in the 2PCF must be estimated before fitting for any physical parameter. Since we are interested in the acoustic scale around 100 h−1 Mpc , an order of magnitude smaller than the simulation box size 1100 h−1 Mpc , we opt to divide the box into subvolumes, increasing the number of correlation samples while still retaining the BAO signal, and bootstrap the covariance. We choose Nsub = 3 along each dimension, so that each subvolume has a side length of over three times the BAO scale of interest. For each realization, the full box galaxy sample is divided into |$N_\text{sub}^3 = 27$| subvolumes. The galaxies in each subvolume are cross-correlated with the full box volume using equation (7), with index 1 being the full box and index 2 being the subvolume. Every subvolume is treated independently, and all its realizations are co-added to prevent shot noise from entering the covariance matrix.
By taking cross-correlations between the full box and the subvolume, we obtain |$N_\text{sub}^3=27$| times the number of autocorrelation samples in |$1/N_\text{sub}^3=1/27$| of the box volume. In the end, the joint monopole-quadrupole covariance matrix is derived from |$N_\text{box}N_\text{sub}^3=36\times 3^3=972$| correlation samples. As covariance scales inversely with the spatial volume in which it is calculated, and the autocorrelations used in the fitting are for the full box, this covariance matrix is re-scaled by a factor of |$1/N_\text{sub}^3$| to account for the subvolume division. An additional factor of 1/(Nbox − 1) is needed if fitting to jackknife multipoles averaged over Nbox − 1 samples.
It is worth noting that for every bias model and every type of correlation there is a different covariance matrix. Pre-reconstruction galaxy samples are given uniform, analytic randoms to calculate the correlations and covariance. Standard reconstruction produces a shifted galaxy catalogue as well as shifted numerical randoms, which can then be both subdivided to estimate the covariance. Our standard reconstruction implementation produces a shifted random set 200 times the size of the data set. For the purpose of estimating covariance, it is computationally expensive and unnecessary to use all of it. We opt to speed up the pair-counting by randomly downsampling the random set to a level of 10 times the data. To further balance the pair-counting workload between the DR and RR terms in the correlation estimator for covariance bootstrap, while D1R2 and R1D2 are counted using the 10 × subsample of shifted randoms, for R1R2 the 10 × subsample is split into 10 copies, each of size 1 × the galaxy sample, and R1R2 is counted 10 times using the 1 × split samples and then the pair-counts averaged. Iterative reconstruction does not provide any shifted sample after it completes, only the autocorrelations. We assume it shares the same covariance matrix as standard reconstruction, given how similar their post-reconstruction correlations are.
For BAO fitting, which involves about 10 degree of freedoms, this estimate of the covariance matrix is acceptable but of course not perfect (Percival et al. 2014). We emphasize that the purpose is to determine the shifts in the acoustic scale, not the confidence level of the chi-square fit in the (α⊥, α|$_{/\!/}$|) space. The covariance matrices only weight the fit overall and still give the correct acoustic scale.
2.5 Fitting 2PCF for the BAO scale
Following the tried-and-true fitting methods described in previous BAO analyses of galaxy redshift surveys (Anderson et al. 2014a,b; Ross et al. 2017), we fit to the monopole and quadrupole jackknife samples and determine the anisotropic acoustic scale. This is done by performing a χ2 grid scan in the radial and transverse acoustic scale plane (α|$_{/\!/}$|, α⊥), marginalizing over all polynomial nuisance parameters in the monopole and quadrupole templates. The fiducial fitting model assumes fitting range |$r \in (50\,h^{-1}\,\mathrm{Mpc}, 150\,h^{-1}\,\mathrm{Mpc})$|, bin size 5 h−1 Mpc , and the poly3 nuisance form (third-order inverse polynomial in power k), Aℓ(r) = A2/r2 + A1/r + A0.
As a validation of the fitter, we fit to a |$0.2{{\ \rm per\ cent}}$| uniform subsample of the matter field (6 × 106 of 14403 DM particles in a box) without RSD applied in addition to mock galaxy samples. We find the fitted matter field acoustic scale in excellent agreement with the theoretical template at the |$0.3{{\ \rm per\ cent}}$| level up to non-linear corrections after standard reconstruction (middle panel of Fig. 2). This level of shift is expected due to non-linear evolutions when fitting with a linear power spectrum as input (Seo et al. 2008), and is observed in the first two panels of Fig. 2: the baseline galaxy and uniform matter field fits have mean BAO shifts of |$0.3{{\ \rm per\ cent}}$| to |$0.4{{\ \rm per\ cent}}$|.
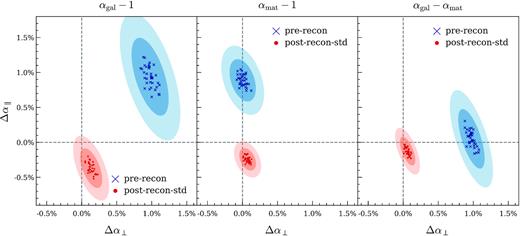
BAO fitting results for uniform matter density filed and the mock galaxy sample in the baseline HOD model. From left to right, the first panel shows baseline mock galaxy BAO scale deviation from 1 in the transverse and radial directions, the second panel shows the same for matter density field, and the third panel shows their difference αgal − αmat. In each panel, the data points are derived from fitting Nbox = 36 jackknife samples, and the shaded 1σ, 2σ confidence regions are scaled accordingly to reflect the true uncertainty. Comparing panels 1 and 3, the variance visibly decreases when subtracting out the matter field result from the galaxy result, and the mean residue is close to the origin post-reconstruction, indicating galaxy bias in the base model has introduced no statistically significant shift relative to the matter.
We also find that Nbox = 36 jackknife fitting results in the (α|$_{/\!/}$|, α⊥) plane are distributed like an ellipse, indicating that the errors are Gaussian and we may estimate the confidence region using the elliptical distribution of points. Ultimately we are concerned with the differential change in the acoustic scale α when a certain source of galaxy bias is introduced, and the sample variance in the fitted α values should largely cancel out. In the last panel of Fig. 2 showing the αgal − αmat subtraction, the uncertainty regions indeed shrink and the data points are much more tightly bound together compared to the first panel without subtraction. For a given simulation box, this subtraction does cancel out a significant amount of sample variance. The post-reconstruction point being at the origin also indicates that galaxy bias in the base model has introduced no statistically significant shift relative to the matter.
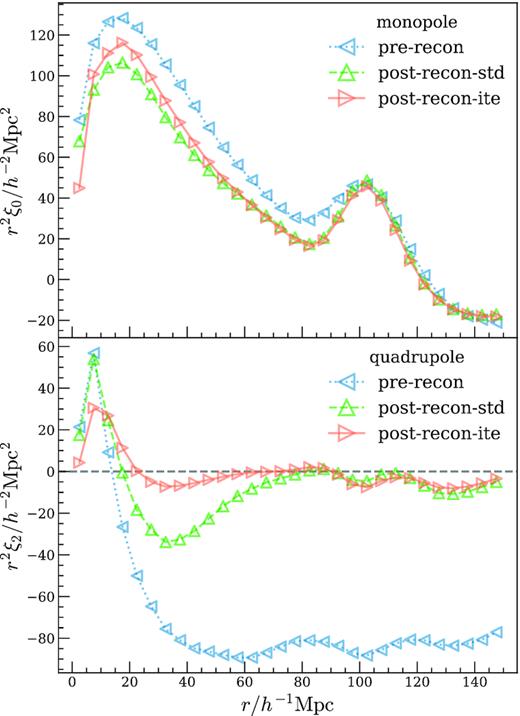
An overplotted comparison between pre- and post-reconstruction multipoles for the baseline HOD model, averaged over all simulation boxes. In the top monopole panel, two reconstruction methods both sharpen and narrow the BAO peak, and essentially overlap with each other from 60 to 150 h−1 Mpc , only differing on small scales. In the bottom quadrupole plot, iterative reconstruction does a significantly better job reducing anisotropy and appears nearly flat down to 20 h−1 Mpc , whereas standard reconstruction has large residual anisotropies below 80 h−1 Mpc . Two reconstruction methods also produce slightly different monopole on small scales below 50 h−1 Mpc , with iterative reconstruction supposedly be more accurate, but this range is usually discarded in BAO fitting to better isolate the BAO signal.
3 RESULTS
3.1 Two-point correlation functions of bias models
Before presenting BAO fitting results, we first examine the 2PCF resulting from different biased HOD models and reconstruction methods. Fig. 4 shows the ξ(rp, π) 2PCF for the baseline model before and after standard reconstruction, averaged over all boxes up to 120 h−1Mpc (heatmap colour is rescaled by |$r^2 = r_p^2 + \pi ^2$| or |$r^2 = r_\perp ^2 + r_{/\!/}^2$|). Standard reconstruction does a fine job restoring the isotropy of the spherical BAO shell in the redshift-space 2PCF around |$r = 100\,h^{-1}\,\mathrm{Mpc}$|. On intermediate to large scales, all bias models look very similar in this ξ(rp, π) plot, with differences being obvious only on the small scales.
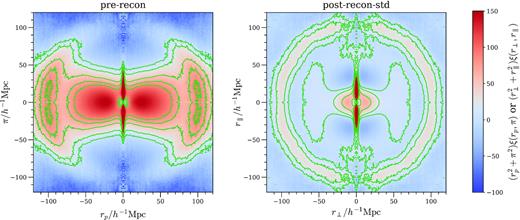
Comparison between pre- and post-reconstruction 2D 2PCF for the baseline HOD model, averaged over all boxes, normalized by r2. The left-hand panel is pre-reconstruction, and the right-hand panel is after standard reconstruction is applied. Iso-correlation contours are drawn in green. The 1-step standard reconstruction works well in restoring the spherical BAO shell around 100 h−1Mpc . Other bias models are visually the same in this plot, and there are interesting differences on small scales around the origin that are shown in Fig. 5.
Zooming in to the small-scale correlations around the origin in Fig. 4, we take a closer look at the effects of galaxy bias on clustering in Fig. 5 by plotting the correlation difference with respect to the baseline model, Δξ = ξmodel − ξbase, again rescaled by |$r^2 = r_p^2 + \pi ^2$| or |$r^2 = r_\perp ^2 + r_{/\!/}^2$|. Each row is a side-by-side comparison between two HOD models with symmetric changes in the bias parameter, as defined in Table. 1. There are substantial changes on small scales in many cases, and the finger-of-god effect is especially exacerbated.
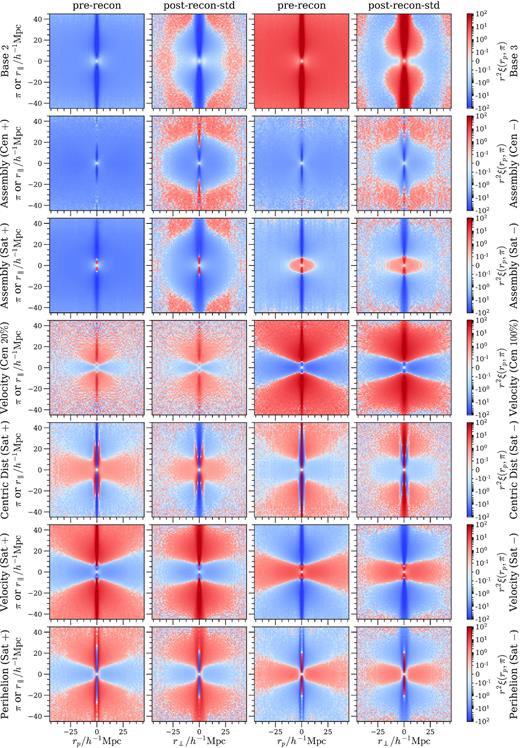
Changes in 2D 2PCF of each biased HOD model with respect to the baseline model, averaged over all boxes. Each row contains a pair of two comparable models; each model has a pre-reconstruction panel and a post-reconstruction (standard) one. Symmetrical positive and negative changes in the HOD parameters in all pairs of models but assembly bias ones induce symmetrical change in the correlation Δξ in rows 1, 5, 6, and 7.
For assembly bias in rows 2 and 3, because re-assigning halo masses in our implementation essentially changes the mass distribution of galaxies, reversing the sign of the assembly bias parameter does not simply result in the opposite change in the correlation. With the exception of assembly bias models, symmetrical positive and negative changes in the HOD parameters in all the other bias models induce symmetrical Δξ when comparing columns 1 to 3, or columns 2 to 4. All single-variation models tested produce distinct Δξ patterns (up to normalization by r2) on small scales and can be easily distinguishable from each other. When more than source of galaxy bias is present, the resulting 2D correlation will be a combination of all the contributions, making the pattern difficult to parse and likely creating degeneracies. Comparing the pre- and post-reconstruction columns, we see that the peripheral regions become noisy after reconstruction. This means that although the decorations imposed may cause non-trivial changes in 2PCF on intermediate scales around 40, these changes are largely removed by reconstruction.
Fig. 6 shows the phase-matched differences of the first two jackknife multipoles for each biased HOD model with respect to the baseline model, i.e. Δξℓ = ξℓ, model − ξℓ, base rescaled by r2. The sample variance across simulation boxes is already very small after jackknife resampling, and the 1σ errors are too small when plotted, so the error regions in Fig. 6 are artificially enlarged 10 times to improve visibility and demonstrate the reduction of sample variance by two reconstruction methods.
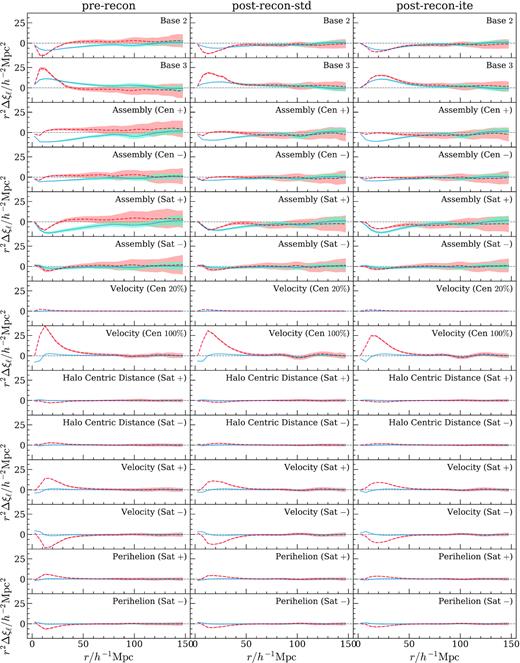
Phase-matched difference of jackknife multipoles for each biased HOD model with respect to the baseline; monopole in blue solid line, quadrupole in red dashed line. Every row is a biased HOD model with and without reconstruction applied. The shaded regions are 10 times the size of the actual 1σ error bands, which would have been hardly visible. All axes share the same scaling.
The correlation multipoles show the same trend as does the 2D redshift-space correlation function. Satellite variations in the first two rows change small-scale clustering significantly, indicating the re-distribution of satellite galaxies mostly changing the 1-halo term; on larger scales the changes get noisier but one can barely see that there exist rises and drops around the BAO scale, and monopole and quadrupoles change in opposite directions. The assembly bias models in rows 3–6 re-assign halo masses by ranking halo pseudo-masses, and the mass distribution of haloes selected with the mass cut varies across simulation boxes, so these plots are the noisiest ones; the changes in 2PCF are not symmetrical as the assembly bias parameters flips signs. From the first six rows, one notices that reconstruction shrinks the error bands considerably, reducing the sample variance. It also reduces the net change, bringing the multipoles closer to the unbiased zero-point.
As velocity dispersion of central galaxies is increased from 20 per cent to 100 per cent, the multipole differences grow drastically, and a decrease in BAO peak amplitude is seen on large scales after reconstruction right around 100 h−1 Mpc , as central velocity bias smears the central–central contribution in the 2-halo term. Models in the last six rows incorporate subhalo-scale physics and only significantly affect small-scale clustering up to about 50 h−1 Mpc as expected. These models are extremely stable across random realizations, with very small scatter in spite of highly exaggerated error ranges. One can see that for each pair of models with symmetric changes in the HOD parameters, the Δξℓ plots are essentially symmetric in the same way as in the redshift-space 2PCF (Fig. 5). Again, the difference between standard and iterative reconstruction mostly lies in small to intermediate scales, and on large scales they are visually the same.
3.2 Effects of galaxy bias on the acoustic scale measurement
Having computed the correlation functions of our various models, we fit the acoustic signal to yield transverse and radial scale measurements. Then the α values are subtracted by the baseline model value for each simulation box in a phased-matched manner. The subtraction yields the differential change in BAO α for each biased model relative to the baseline. Phase-matching is critical when taking the difference, because every box has its own sample variance shared by the realizations of all models and this sample variance can be cancelled out effectively as demonstrated in Section 2.5. Table 2 summarizes the shifts of the acoustic scale for all biased HOD models with respect to the baseline model. Two reconstruction methods are listed separately. The same numerical results are plotted in Fig. 7, where each row shows a pair of comparable models and each column is a pre- or post-reconstruction sample type.
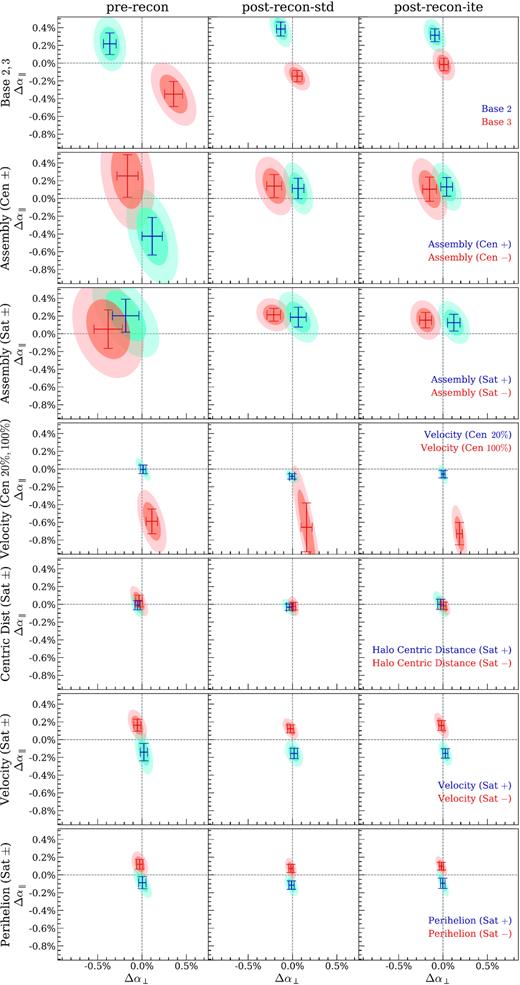
Phase-matched difference between the BAO scales found in biased HOD models and the baseline model, Δα = αmodel − α⊥baseline in both directions. Every pair of comparable models are plotted in the same row. Each mean and uncertainty patch is derived from Nbos = 36 fitting results.
BAO fitting results for all biased HOD models, subtracted by the corresponding α of the baseline case. Values are the mean and jackknife-corrected 1σ uncertainty of all simulation boxes. The two post-recon columns in the first header row represent standard and iterative reconstructions, respectively.
| Reconstruction type | Pre-recon | Post-recon-std | Post-recon-ite | |||
|---|---|---|---|---|---|---|
| BAO direction | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| |
| Base 2 | −0.36 (07) | 0.22 (12) | −0.13 (05) | 0.38 (08) | −0.09 (05) | 0.31 (07) |
| Base 3 | 0.36 (10) | −0.35 (14) | 0.05 (06) | −0.15 (06) | 0.01 (05) | −0.02 (07) |
| Assembly bias (centrals +) | 0.12 (11) | −0.43 (21) | 0.06 (07) | 0.11 (11) | 0.04 (07) | 0.13 (11) |
| Assembly bias (centrals −) | −0.16 (12) | 0.25 (24) | −0.21 (08) | 0.14 (13) | −0.15 (08) | 0.10 (14) |
| Assembly bias (satellites +) | −0.18 (15) | 0.20 (19) | 0.07 (09) | 0.19 (11) | 0.12 (07) | 0.12 (09) |
| Assembly bias (satellites −) | −0.38 (16) | 0.05 (22) | −0.21 (08) | 0.21 (07) | −0.20 (07) | 0.15 (09) |
| Velocity bias (centrals 20 per cent) | 0.01 (03) | −0.00 (05) | −0.00 (03) | −0.08 (03) | 0.00 (02) | −0.06 (04) |
| Velocity bias (centrals 100 per cent) | 0.11 (06) | −0.59 (14) | 0.16 (06) | −0.66 (28) | 0.18 (03) | −0.73 (13) |
| Halo centric distance bias (satellites +) | −0.05 (03) | −0.01 (05) | −0.04 (03) | −0.03 (04) | −0.03 (03) | 0.00 (06) |
| Halo centric distance bias (satellites −) | −0.03 (04) | 0.04 (07) | 0.01 (02) | −0.02 (04) | 0.01 (03) | −0.02 (04) |
| Velocity bias (satellites +) | 0.02 (04) | −0.14 (10) | 0.02 (04) | −0.16 (06) | 0.03 (03) | −0.15 (05) |
| Velocity bias (satellites −) | −0.05 (04) | 0.16 (07) | −0.02 (03) | 0.12 (05) | −0.02 (03) | 0.16 (06) |
| Perihelion distance bias (satellites +) | 0.00 (04) | −0.09 (07) | −0.01 (03) | −0.11 (05) | −0.00 (03) | −0.09 (06) |
| Perihelion distance bias (satellites −) | −0.02 (04) | 0.12 (06) | −0.02 (02) | 0.07 (05) | −0.02 (02) | 0.10 (04) |
| Reconstruction type | Pre-recon | Post-recon-std | Post-recon-ite | |||
|---|---|---|---|---|---|---|
| BAO direction | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| |
| Base 2 | −0.36 (07) | 0.22 (12) | −0.13 (05) | 0.38 (08) | −0.09 (05) | 0.31 (07) |
| Base 3 | 0.36 (10) | −0.35 (14) | 0.05 (06) | −0.15 (06) | 0.01 (05) | −0.02 (07) |
| Assembly bias (centrals +) | 0.12 (11) | −0.43 (21) | 0.06 (07) | 0.11 (11) | 0.04 (07) | 0.13 (11) |
| Assembly bias (centrals −) | −0.16 (12) | 0.25 (24) | −0.21 (08) | 0.14 (13) | −0.15 (08) | 0.10 (14) |
| Assembly bias (satellites +) | −0.18 (15) | 0.20 (19) | 0.07 (09) | 0.19 (11) | 0.12 (07) | 0.12 (09) |
| Assembly bias (satellites −) | −0.38 (16) | 0.05 (22) | −0.21 (08) | 0.21 (07) | −0.20 (07) | 0.15 (09) |
| Velocity bias (centrals 20 per cent) | 0.01 (03) | −0.00 (05) | −0.00 (03) | −0.08 (03) | 0.00 (02) | −0.06 (04) |
| Velocity bias (centrals 100 per cent) | 0.11 (06) | −0.59 (14) | 0.16 (06) | −0.66 (28) | 0.18 (03) | −0.73 (13) |
| Halo centric distance bias (satellites +) | −0.05 (03) | −0.01 (05) | −0.04 (03) | −0.03 (04) | −0.03 (03) | 0.00 (06) |
| Halo centric distance bias (satellites −) | −0.03 (04) | 0.04 (07) | 0.01 (02) | −0.02 (04) | 0.01 (03) | −0.02 (04) |
| Velocity bias (satellites +) | 0.02 (04) | −0.14 (10) | 0.02 (04) | −0.16 (06) | 0.03 (03) | −0.15 (05) |
| Velocity bias (satellites −) | −0.05 (04) | 0.16 (07) | −0.02 (03) | 0.12 (05) | −0.02 (03) | 0.16 (06) |
| Perihelion distance bias (satellites +) | 0.00 (04) | −0.09 (07) | −0.01 (03) | −0.11 (05) | −0.00 (03) | −0.09 (06) |
| Perihelion distance bias (satellites −) | −0.02 (04) | 0.12 (06) | −0.02 (02) | 0.07 (05) | −0.02 (02) | 0.10 (04) |
BAO fitting results for all biased HOD models, subtracted by the corresponding α of the baseline case. Values are the mean and jackknife-corrected 1σ uncertainty of all simulation boxes. The two post-recon columns in the first header row represent standard and iterative reconstructions, respectively.
| Reconstruction type | Pre-recon | Post-recon-std | Post-recon-ite | |||
|---|---|---|---|---|---|---|
| BAO direction | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| |
| Base 2 | −0.36 (07) | 0.22 (12) | −0.13 (05) | 0.38 (08) | −0.09 (05) | 0.31 (07) |
| Base 3 | 0.36 (10) | −0.35 (14) | 0.05 (06) | −0.15 (06) | 0.01 (05) | −0.02 (07) |
| Assembly bias (centrals +) | 0.12 (11) | −0.43 (21) | 0.06 (07) | 0.11 (11) | 0.04 (07) | 0.13 (11) |
| Assembly bias (centrals −) | −0.16 (12) | 0.25 (24) | −0.21 (08) | 0.14 (13) | −0.15 (08) | 0.10 (14) |
| Assembly bias (satellites +) | −0.18 (15) | 0.20 (19) | 0.07 (09) | 0.19 (11) | 0.12 (07) | 0.12 (09) |
| Assembly bias (satellites −) | −0.38 (16) | 0.05 (22) | −0.21 (08) | 0.21 (07) | −0.20 (07) | 0.15 (09) |
| Velocity bias (centrals 20 per cent) | 0.01 (03) | −0.00 (05) | −0.00 (03) | −0.08 (03) | 0.00 (02) | −0.06 (04) |
| Velocity bias (centrals 100 per cent) | 0.11 (06) | −0.59 (14) | 0.16 (06) | −0.66 (28) | 0.18 (03) | −0.73 (13) |
| Halo centric distance bias (satellites +) | −0.05 (03) | −0.01 (05) | −0.04 (03) | −0.03 (04) | −0.03 (03) | 0.00 (06) |
| Halo centric distance bias (satellites −) | −0.03 (04) | 0.04 (07) | 0.01 (02) | −0.02 (04) | 0.01 (03) | −0.02 (04) |
| Velocity bias (satellites +) | 0.02 (04) | −0.14 (10) | 0.02 (04) | −0.16 (06) | 0.03 (03) | −0.15 (05) |
| Velocity bias (satellites −) | −0.05 (04) | 0.16 (07) | −0.02 (03) | 0.12 (05) | −0.02 (03) | 0.16 (06) |
| Perihelion distance bias (satellites +) | 0.00 (04) | −0.09 (07) | −0.01 (03) | −0.11 (05) | −0.00 (03) | −0.09 (06) |
| Perihelion distance bias (satellites −) | −0.02 (04) | 0.12 (06) | −0.02 (02) | 0.07 (05) | −0.02 (02) | 0.10 (04) |
| Reconstruction type | Pre-recon | Post-recon-std | Post-recon-ite | |||
|---|---|---|---|---|---|---|
| BAO direction | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| | |$\Delta \alpha _\perp /{\rm per\,cent}$| | |$\Delta \alpha _{/\!/}/{\rm per\,cent}$| |
| Base 2 | −0.36 (07) | 0.22 (12) | −0.13 (05) | 0.38 (08) | −0.09 (05) | 0.31 (07) |
| Base 3 | 0.36 (10) | −0.35 (14) | 0.05 (06) | −0.15 (06) | 0.01 (05) | −0.02 (07) |
| Assembly bias (centrals +) | 0.12 (11) | −0.43 (21) | 0.06 (07) | 0.11 (11) | 0.04 (07) | 0.13 (11) |
| Assembly bias (centrals −) | −0.16 (12) | 0.25 (24) | −0.21 (08) | 0.14 (13) | −0.15 (08) | 0.10 (14) |
| Assembly bias (satellites +) | −0.18 (15) | 0.20 (19) | 0.07 (09) | 0.19 (11) | 0.12 (07) | 0.12 (09) |
| Assembly bias (satellites −) | −0.38 (16) | 0.05 (22) | −0.21 (08) | 0.21 (07) | −0.20 (07) | 0.15 (09) |
| Velocity bias (centrals 20 per cent) | 0.01 (03) | −0.00 (05) | −0.00 (03) | −0.08 (03) | 0.00 (02) | −0.06 (04) |
| Velocity bias (centrals 100 per cent) | 0.11 (06) | −0.59 (14) | 0.16 (06) | −0.66 (28) | 0.18 (03) | −0.73 (13) |
| Halo centric distance bias (satellites +) | −0.05 (03) | −0.01 (05) | −0.04 (03) | −0.03 (04) | −0.03 (03) | 0.00 (06) |
| Halo centric distance bias (satellites −) | −0.03 (04) | 0.04 (07) | 0.01 (02) | −0.02 (04) | 0.01 (03) | −0.02 (04) |
| Velocity bias (satellites +) | 0.02 (04) | −0.14 (10) | 0.02 (04) | −0.16 (06) | 0.03 (03) | −0.15 (05) |
| Velocity bias (satellites −) | −0.05 (04) | 0.16 (07) | −0.02 (03) | 0.12 (05) | −0.02 (03) | 0.16 (06) |
| Perihelion distance bias (satellites +) | 0.00 (04) | −0.09 (07) | −0.01 (03) | −0.11 (05) | −0.00 (03) | −0.09 (06) |
| Perihelion distance bias (satellites −) | −0.02 (04) | 0.12 (06) | −0.02 (02) | 0.07 (05) | −0.02 (02) | 0.10 (04) |
The first two models in the first row with opposite variations in satellite mass cut-off and power-law exponent see asymmetric shifts. It is encouraging to see that iterative reconstruction manages to completely eliminate the bias of the Base 3 model (higher M1 and α), bringing the red cross back right on to the origin, and slightly reduces the bias of the Base 2 model (lower M1 and α). This is one of the only two cases where iterative reconstruction noticeably performs better than standard reconstruction at restoring the unbiased BAO scale. By lowering M1 and α, Base 2 effectively moves satellite galaxies from high-mass haloes to lower mass haloes. There are many more possible locations to put them at a lower mass cut, and low-mass haloes do not mark the highest initial overdensities as much as high-mass haloes do, so correcting for the bias for Base 2 is naturally more difficult than for Base 3, resulting in a residual shift of 0.3 per cent post-reconstruction primarily in the radial direction.
For the assembly bias models in rows 2 and 3 of Fig. 7, the shifts induced by opposite bias parameters are almost symmetrical in the horizontal, or traverse, direction, but in the radial direction all models are slightly biased towards a higher α|$_{/\!/}$| regardless of the sign of the bias parameter. The previous plots (Figs 5 and 6) do not clearly separate the two directions and show this difference. The second and third rows have similar mean values for the same coloured models post-reconstruction, only the uncertainty is smaller for satellite assembly bias. This resemblance implies that, whether assembly bias is present in the central or satellite galaxies, the end effect on the acoustic scale is virtually the same if reconstruction is applied. In other words, assembly bias does not distinguish between centrals and satellites. Comparing the models with negative signs only (red markers and orange ellipses), however, one sees that the satellite assembly bias results are better constrained than central assembly bias ones, making the same 0.2 per cent shift more significant for the satellite negative model. But it is only about 2σ, and at the 0.2 per cent level all four models are consistent with zero shift.
For the velocity bias models in the fourth row, a realistic dispersion at the 20 per cent level hardly causes any shift, whereas the more extreme 100 per cent case resulted in large shifts of 0.7 per cent. This is the other one of the two cases where iterative reconstruction performs noticeably better than standard reconstruction. In fact, there is even a qualitative difference here – the orange error region of standard reconstruction seems to be consistent with zero shift at the 2σ level, but the iterative reconstruction uncertainty is much more confined and certainly rules out the no shift possibility.
The last three rows are six models with subhalo-scale astrophysics. Galaxy bias originating from halo centric distances of DM particles clearly does not impact the BAO measurement. On the other hand, satellite velocity bias and perihelion bias (or dependence on the total mechanical energy of DM particle) do make small differences of 0.1–0.2 per cent. Satellite velocity bias results in almost |$0.2{{\ \rm per\ cent}}$| shifts with just above 2σ significance. The perihelion bias models have smaller shifts of 0.1 per cent, which are insignificant. The symmetric pattern of shifts can again be seen in the last two rows for models of opposite signs. Again, at the 0.2 per cent level all six models are consistent with zero shift.
Iterative reconstruction offers better BAO fitting results than standard reconstruction in general. In rows 1 and 4 of Fig. 7, it made a real difference by significantly reducing the bias and uncertainty in the acoustic scale measurement, as mentioned above. For other models, it is not drastically better and the mean α values are extremely close to the standard reconstruction ones, but still it yields slightly less bias in the acoustic scale and tighter constraints.
Lastly, we also notice a reliable inverse correlation between the sign of Δα|$_{/\!/}$| and the sign of Δξ2, when comparing Fig. 7 with Fig. 6. This is obeyed by every model tested, even if the changes in 2PCF and acoustic scale are not very significant. A positive Δξ2 relative to the baseline corresponds to a negative Δα|$_{/\!/}$|, and vice versa. While we used the fiducial BAO fitting model with a fitting range of |$r \in (50\,h^{-1}\mathrm{Mpc}, 150\,h^{-1}\mathrm{Mpc}\,)$| and the poly3′ nuisance form, improved fitting methods may exploit this inverse correlation by extending the range to smaller scales.
4 CONCLUSIONS
In this work, we test the effect of galaxy bias on the acoustic scale by considering several bias mechanisms to their extremes. With accurate N-body simulations in a total volume of |$48 \, h^{-3}\, {\rm Gpc}^{3}$| and a generalized HOD approach, every biased model can be compared to the baseline to derive the differential shift in the acoustic scale measurement that precisely corresponds to the change in the input HOD parameters.
We find a 0.3 per cent shift in the line-of-sight acoustic scale for one variation in the satellite galaxy population, the Base 2 model. The model with an extreme level of velocity bias of the central galaxies produces the largest shift in the BAO measurement, |$0.7{{\ \rm per\ cent}}$| relative to the unbiased scale. All the other bias models result in either small (|$0.2{{\ \rm per\ cent}}$| or less) or statistically insignificant (2σ or less) shifts. Except for the highly unlikely event that the central galaxies have very large velocity dispersions relative to the halo bulk (close to the typical speed of DM particles), we find the shifts caused by single-variation models to be below 0.3 per cent. However, this is by no means a claim that the theoretical systematic error in the acoustic scale measurement due to galaxy bias originating from the halo–galaxy connection in the halo model is only|$0.3{{\ \rm per\ cent}}$|. Observed galaxy samples from redshift surveys may well be subject to not one, but many processes that can introduce galaxy bias. Combinations of bias mechanisms at play may potentially compound the uncertainties we found and push the BAO shift above 0.3 per cent.
That said, the biggest shift of the acoustic scale at 0.7 per cent comes from increased velocity bias for central galaxies, which seems readily detectable – there would be sizeable changes in the velocity dispersion of clusters compared to their weak lensing masses. In addition, these bias models also create substantial changes on small scales, which may in fact allow one to detect these effects and thereby improve the modelling of the acoustic scale. In Fig. 5, many bias models have greatly increased finger-of-god effect in the correlation function, both pre- and post-reconstruction. Given the inverse correlation we found between the sign of Δα|$_{/\!/}$| and the sign of Δξ2, small-scale clustering data offer a promising opportunity to correct for galaxy bias and further calibrate the acoustic peak ruler with future development in the 2PCF fitting formalism.
In regards to reconstruction, both standard and iterative reconstruction methods show similar efficacy in reducing the imposed bias and recovering the unbiased 2PCF and acoustic scale. In terms of the performance for BAO fitting, iterative reconstruction is more robust against galaxy bias, bringing the BAO measurements closer to the true, unbiased acoustic scale; it is also more precise, being less prone to sample variance and producing less uncertainty. It is a promising new method with the potential to benefit from further development and optimization in the future. Although it currently requires an order of magnitude more resources in CPU time and memory allocation than standard reconstruction does, reconstruction and BAO fitting comprise a minor fraction of the computation time in comparison to the time needed for genuine N-body simulations. The extra time needed for iterative reconstruction is worthwhile If one is concerned with minimizing the bias and uncertainty in the BAO analysis.
While current galaxy surveys, such as the Sloan Digital Sky Survey III BOSS, measure the acoustic scale to about 1 per cent precision and are insensitive to the galaxy bias effects shown, upcoming dark energy experiments, including DESI, Euclid, and WFIRST, will make use of the BAO standard ruler to sub-per cent level precision and these effects can no longer be overlooked. Our ability to account for or even correct for galaxy bias in the modelling of the acoustic scale directly impacts the measurement precision of the BAO ruler and the success of upcoming surveys. Having shown that the systematic effects of galaxy bias alone could amount to 0.3 per cent, we find the majority of the shifts values in Table 2 encouraging and note that these bias effects may be detected. Accurate modelling of the galaxy–halo connection, in conjunction with the bias that comes with it, is a need of growing urgency as the statistical uncertainties of larger surveys approach the level of cosmic variance limit and theoretical systematics. Future analysis of the BAO signal may benefit from the inclusion of velocity dispersion and small-scale clustering to mitigate the non-negligible systematic effects of galaxy bias.
ACKNOWLEDGEMENTS
The authors would like to thank Lehman Garrison for producing the abacus simulation products and managing the computing cluster. DYT thanks Lehman Garrison for helpful discussions on Corrfunc and rockstar halo and particle catalogue products, Ryuichiro Hada for providing the reconstruction code, Ashley Ross for sharing his BAO fitter used in BOSS DR12, and Prof. Steve Ahlen for his continued support and mentorship. DE is supported by U.S. Department of Energy grant DE-SC0013718 and as a Simons Foundation Investigator. DYT is supported by U.S. Department of Energy grant DE-SC0015628.
Footnotes
Publicly available at https://github.com/duanyutong/abacus_baofit. This repository also includes our new BAO fitter described in Section 2.5.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}