





Abstract
We present EasyCritics, an algorithm to detect strongly lensing groups and clusters in wide-field surveys without relying on a direct recognition of arcs. EasyCritics assumes that light traces mass in order to predict the most likely locations of critical curves from the observed fluxes of luminous red early-type galaxies in the line of sight. The positions, redshifts, and fluxes of these galaxies constrain the idealized gravitational lensing potential as a function of source redshift up to five free parameters, which are calibrated on few known lenses. From the lensing potential, EasyCritics derives the critical curves for a given, representative source redshift. The code is highly parallelized, uses fast Fourier methods and, optionally, GPU acceleration in order to process large data sets efficiently. The search of a |$\smash{1 \, \mathrm{deg}^2}$| field of view requires less than 1 min on a modern quad-core CPU, when using a pixel resolution of 0.25 arcsec px−1. In this first part of a paper series on EasyCritics, we describe the main underlying concepts and present a first demonstration on data from the Canada–France–Hawaii-Telescope Lensing Survey. We show that EasyCritics is able to identify known group- and cluster-scale lenses, including a cluster with two giant arc candidates that were previously missed by automated arc detectors.
1 INTRODUCTION
Gravitational lensing by galaxy clusters has become a powerful tool for studying the dark Universe. Strong and weak lensing signatures provide the most robust observational constraints on the projected mass distribution in clusters (e.g. Cacciato et al. 2006; Limousin et al. 2007; Merten et al. 2009). The cluster mass function and profiles are sensitive to the late time evolution of cosmic structures and thus offer insights into fundamental questions of cosmology, such as the origin of the cosmic acceleration (Voit 2005; Allen, Evrard & Mantz 2011).
In the dense core regions of massive groups and clusters, lensing unfolds its strong regime, where multiple images of a background source can be formed. For extended sources, these images are highly distorted and magnified, which causes them to appear in the form of luminous arcs. The analysis of arcs and multiple images allows us to probe the inner cluster structure with minimal biases (e.g. Meneghetti et al. 2013), to measure the Hubble constant (e.g. Grillo et al. 2018; Vega-Ferrero et al. 2018) and to test cosmological models with giant arc statistics (e.g. Bartelmann et al. 1998).
Intriguingly, the statistics of giant arcs are observed to be in conflict with theoretical expectations. For nearly two decades, ΛCDM cosmological simulations have underestimated both the abundance (Bartelmann et al. 1998; Gladders et al. 2003; Li et al. 2006; Fedeli et al. 2008; Horesh et al. 2011; Bayliss 2012) and the mean radii (e.g. Broadhurst & Barkana 2008; Zitrin et al. 2012a) of giant arcs by differing amounts. Although considerable progress has been made in refining simulations with improved lens and source models, the precise levels and origins of these discrepancies are still not well understood (Meneghetti et al. 2013; Boldrin et al. 2016). One of the major reasons for this uncertain picture is the limited sizes of available data sets, which so far appear insufficient for a solid comparison of theory with observations.
At present, the largest homogeneous samples of giant arcs comprise a few hundred exemplars only. A significant rise in the rate of detections, however, is expected with the next generation of wide-field surveys, carried out with the ESA Euclid space mission (Laureijs et al. 2011) and the Large Synoptic Survey Telescope (LSST Science Collaboration 2009). The latter promises order-of-magnitude increases in the number of observed arcs (Boldrin et al. 2012), opening exciting prospects for the use of giant arcs as a competitive cosmological probe.
However, the reliable identification of strong lensing events within large image material remains a significant challenge. Recent blind searches have focused on crowdsourced visual inspection (e.g. Marshall et al. 2016) and automated arc-finding algorithms (e.g. Lenzen, Schindler & Scherzer 2004; Horesh et al. 2005; Alard 2006; Seidel & Bartelmann 2007; More et al. 2012; Xu et al. 2016). Although many new arc candidates were discovered, especially around single galaxies, both approaches face some limitations. Visual inspection generally lacks an objective definition of arcs. Moreover, it does not allow for a straightforward repetition of the analysis with new selection criteria; and, in addition, it is highly time consuming. In order to remain feasible, the efforts of increasingly large communities of trained volunteers are required (e.g. Marshall et al. 2016; More et al. 2016). Automated arc detectors, on the other hand, mostly suffer from a high contamination with spurious detections – at least in the case of searches on group and cluster scales, where the features of interest can have complex morphologies. As a result, a manual validation of up to thousands of candidates per square degree is required none the less (Maturi, Mizera & Seidel 2014).
In order to alleviate the human bottleneck in lens detection, increasing interest has lately been devoted to machine learning methods (e.g. Bom et al. 2017; Jacobs et al. 2017). None the less, there are good reasons to investigate alternative strategies for lens detection, as well. Arc-based searches are naturally affected by ambiguities due to the inherent similarity of arcs with several other, commonly observed features.1 The secure identification of arcs thus requires a subsequent spectroscopic redshift measurement. For this, the candidate samples need to be sufficiently pure to optimize the follow-up efficiency. An effective decontamination of candidate samples can only be achieved at high costs, involving the use of increasingly complex – and less physically understood – search patterns or the exhaustion of time and human resources. Complementary to the existing approaches, however, a pre-selection of targets for arc searches, based on additional, independent indicators of the presence of strongly lensing structures, may have the potential to remove a significant part of the aforementioned ambiguities with minimal effort and based on simple physical arguments.
Here, we present a method that identifies group- and cluster-scale strong lenses by their own optical characteristics rather than by their effect on background images. We introduce the EasyCritics algorithm, which predicts the locations of critical curves based on the spatial distribution of early-type luminous red galaxies (LRGs) observed in the line of sight. Under the assumption that this distribution follows the underlying matter field, EasyCritics develops an idealized model of the line-of-sight mass density distribution, which requires only five free parameters and is used to predict the lensing potential. For a given source redshift, EasyCritics then produces maps and catalogues of the resulting critical curves, which can be used to pre-select targets for a subsequent inspection with conventional methods. The pre-selection with EasyCritics promises (1) a significant increase in efficiency compared to visual inspection methods; (2) a significant increase in purity compared to existing automated methods; (3) a quantitative criterion for rating the likelihood of detections; and (4) a first estimate of the strong lensing properties, such as the sizes and orientations of the critical curves.
The underlying assumption that light traces mass (LTM) is well tested over a wide range of scales (e.g. Bahcall & Kulier 2014; Zitrin et al. 2015). Early-type LRGs, in particular, have been recognized as distinguished probes of the underlying density field (e.g. Gavazzi et al. 2004; Zheng et al. 2009; Zitrin et al. 2012b; Wong et al. 2013). In the context of lens modelling, the LTM assumption is routinely used for the reconstruction and prediction of multiple images in massive clusters (e.g. Limousin et al.2007,2012; Zitrin et al. 2009, 2011b; Richard et al. 2014; Ishigaki et al. 2015; Jauzac et al. 2015; Kawamata et al. 2016; Caminha et al. 2017). So far, however, the LTM-based analysis of lensing has primarily focused on fitting the properties of individual, known lenses. In contrast, EasyCritics blindly models the foreground structures over an entire line of sight and throughout large celestial regions – not only for predefined, isolated galaxy clusters. The galaxies to be used are determined automatically according to their luminosity function and for different redshift bins. In doing so, EasyCritics combines the lens modelling approach described by Zitrin et al. (2009) and the arc-free analysis by Zitrin et al. (2012b) with the LRG-based lens detection by Wong et al. (2013) and Ammons et al. (2014). Due to the much larger data sets at hand, the mathematical approach and numerical implementation were changed in order to achieve higher computational performances.
This is the first of a series of papers devoted to EasyCritics. In this work, we describe the underlying concepts and methods, and demonstrate their feasibility by showing a few preliminary examples of the application of EasyCritics to data from the Canada–France–Hawaii-Telescope Lensing survey (CFHTLenS; Heymans et al. 2012; Erben et al. 2013). In two forthcoming papers, we will furthermore provide a full statistical description of the purity and completeness, the positive detections, and their lensing properties; and a comparison of the latter with other studies – using both observational (Carrasco et al. 2018, in preparation) and simulated data.
The paper is organized as follows. Section 2 summarizes the input observables and pre-processing steps. Section 3 gives an outline of the LTM model, as we propose it, and Section 4 proceeds with our description of lensing. In Section 5, we then discuss details of the numerical implementation, before we conclude this work with the application examples in Section 6.
2 OBSERVABLES AND GALAXY SELECTION
EasyCritics takes as input a galaxy catalogue, containing the coordinates |$\boldsymbol{\theta }$|, photometric or spectroscopic redshifts |$z$| and red2-band fluxes F of all early-type3 (E/S0) galaxies observed. The fluxes are converted to intrinsic luminosities L using the redshift information and the luminosity distance for a given background cosmological model.
The galaxy redshifts are binned, with the size of each bin set to twice the median photometric measurement uncertainty Δ|$z$| of the given input data. The position of each bin is then set to the average redshift of the galaxies it contains. For a future implementation, we intend to take into account the whole redshift probability density distribution by accordingly distributing the contribution of each galaxy over multiple bins.
3 MASS MODEL
EasyCritics uses the distribution of light from LRGs for a blind, automated identification and modelling of strongly lensing structures. These structures are distributed over a wide range in redshift and their strong lensing signatures may be perturbed significantly by the foreground interlopers present within the line of sight (e.g. Wambsganss, Bode & Ostriker 2005; King & Corless 2007; Puchwein & Hilbert 2009; Wong et al. 2013; Bayliss et al. 2014). For this reason, we include all galaxies, selected as discussed in Section 2, within the considered light cone. In this section, we discuss our mass model based on the LTM approach.
3.1 Stacked mass sheets
We introduce mass sheets |$\smash{\Sigma ^{(k)}}$||$(k \in \mathbb{N})$| at all redshift bins |$\smash{z^{(k)}}$| (cf. Fig. 1, left). The surface density distribution on each sheet is modelled based on the LRGs belonging to the respective bin. In our derivation, we assume that there is only one dominant group- or cluster-scale lens within the line of sight, while the remaining structures add weak and uncorrelated local perturbations only. The angular separation of the lenses at different redshifts is assumed to be large enough for their deflections to be effectively independent. This assumption allows us to neglect the lens–lens coupling between the sheets and is justified by the low probability of having chance alignments of large objects, such as the groups and clusters we are interested in (e.g. Schneider 2014, and references therein). However, in the rare situation that such alignments are encountered, EasyCritics would detect the lenses anyway unless their ability to form a critical curve depends on the higher order interactions.
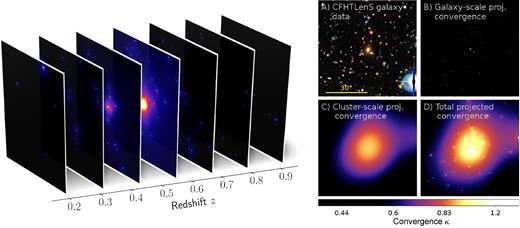
Blind identification and modelling of overdense line-of-sight structures based on LRGs, illustrated for a region centred on a cluster-scale detection. Left: Surface density distributions |$\smash{\Sigma ^{(k)}}$| of the various sheets distributed along the line of sight, in arbitrary units. Right: CFHTLenS i′r′g′-composite image (A) and line-of-sight projected maps of the predicted convergence at different levels of the modelling procedure (B–D). Shown are (B) the projected convergence |$\smash{\bar{\kappa }_{\mathrm{gal}}}$| of the galaxies only, (C) the resulting projected convergence |$\smash{\bar{\kappa }_{\mathrm{clus}}}$| of cluster-scale matter, and (D) the total projected convergence |$\smash{\bar{\kappa }= \bar{\kappa }_{\mathrm{clus}} + \bar{\kappa }_{\mathrm{gal}}}$|.
3.2 Surface density estimation
This two-component modelling approach is motivated by a number of previous strong-lensing analyses of massive clusters, where its accuracy and efficiency has been shown (e.g. Smith et al. 2001; Broadhurst et al. 2005; Zitrin et al. 2009). The modelling of mass down to galaxy scales allows us to resolve smaller granularity in the lens matter. Although most member galaxies in groups and clusters are expected to have only little influence on the formation of arcs (Kassiola, Kovner & Fort 1992; Kneib et al. 1996; Meneghetti et al. 2000), tidal field contributions by individual bright members, such as cD-galaxies, can perturb the strong lensing cross-section significantly (Meneghetti, Bartelmann & Moscardini 2003).
The components |$\smash{\Sigma ^{(k)}_{\mathrm{clus}}}$| and |$\smash{\Sigma ^{(k)}_{\mathrm{gal}}}$| are related to the LRG observables via the blind LTM modelling approach described and explained in detail throughout Subsections 3.3 and 3.4. The LTM modelling approach is ideally suited for the purpose of a first estimation of strong lensing properties, since it provides a highly flexible mass model at a minimum number of required model parameters – allowing to recover the often important asymmetries and substructures in the cluster matter distribution (e.g. Bartelmann, Steinmetz & Weiss 1995; Meneghetti et al. 2007b). In particular, the LTM model introduced here has only five free parameters, which are calibrated by fitting critical curves to the locations of the arcs of few known lenses.
3.3 Galaxy-scale subhaloes
Galaxy-scale subhaloes are assigned to all LRGs that are selected from the line of sight according to the criteria outlined in Section 2, including the majority of galaxies that may not be bound to a strongly lensing group or cluster. Each galaxy-scale subhalo is modelled as an axially symmetric density contribution, since the influence of intrinsic ellipticities on the tidal shear perturbations is negligible.
3.4 Cluster-scale component
According to the LTM assumption, high concentrations of LRGs trace the peaks of the underlying density field, such as cluster-scale4 haloes. Within these haloes, the density distribution of matter can be approximated by the smoothed distribution of LRGs (Zitrin et al. 2015). Of course, not all galaxies are associated with a cluster environment. Isolated field galaxies, for instance, need to be excluded from the |$\smash{\Sigma ^{(k)}_{\mathrm{clus}}}$| component. We distinguish between cluster and field regions by introducing a weight |$\smash{w^{(k)}}$|, defined to be |$\smash{w^{(k)} = 1}$| in supercritical cluster environments and |$\smash{w^{(k)} = 0}$| in voids.
All free parameters introduced in the previous two subsections are summarized in Table 1.
Summary of LTM model parameters.
| Symbol | Description |
|---|---|
| q | Power-law index |
| Kgal | Σ/L conversion constant for LRGs |
| Kclus | Σ/L conversion constant for galaxy clusters |
| σ | Standard deviation for the Gaussian smoothing |
| nc | Critical number density |
| Symbol | Description |
|---|---|
| q | Power-law index |
| Kgal | Σ/L conversion constant for LRGs |
| Kclus | Σ/L conversion constant for galaxy clusters |
| σ | Standard deviation for the Gaussian smoothing |
| nc | Critical number density |
Summary of LTM model parameters.
| Symbol | Description |
|---|---|
| q | Power-law index |
| Kgal | Σ/L conversion constant for LRGs |
| Kclus | Σ/L conversion constant for galaxy clusters |
| σ | Standard deviation for the Gaussian smoothing |
| nc | Critical number density |
| Symbol | Description |
|---|---|
| q | Power-law index |
| Kgal | Σ/L conversion constant for LRGs |
| Kclus | Σ/L conversion constant for galaxy clusters |
| σ | Standard deviation for the Gaussian smoothing |
| nc | Critical number density |
4 STRONG LENSING PRESCRIPTION
4.1 General assumptions
For our physical description of lensing, we adopt an idealized version of the multiple lens-plane framework, in which we introduce multiple geometrically thin mass sheets |$\smash{\Sigma ^{(k)}}$| under the assumption that these sheets are uncorrelated and contain a dominant strongly lensing object embedded in weakly lensing structures, as stated before in Section 3.1. The lens equation and its Jacobian are expanded to first order in the lensing potential, thus neglecting corrections due to Born’s approximation or lens–lens coupling, as described in Section 4.2.
Throughout all calculations, we assume a fixed source plane that can be defined by the user. Our default choice is |$z$|s = 2, a value representative for the typical giant arc population according to broad-band photometric (e.g. Bayliss 2012) and spectroscopic studies (e.g. Bayliss et al. 2011b; Carrasco et al. 2017). For sources at |$z$|s = 2, lenses are expected to be most efficient at |$\smash{z^{(k)} \sim 0.5}$| (cf. Fig. A1), which is consistent with our choice equation (1) for the bounds on the lens redshifts |$\smash{z^{(k)}}$|. However, it is worth to point out that the results predicted by EasyCritics are not very sensitive to this number, as we demonstrate in Section 6.
4.2 Effective lens equation
4.3 The lensing potential
In order to maximize the numerical efficiency, we derive all lensing properties starting from the lensing potential instead of the deflection angle, in contrast to previous studies. This has the advantage of capturing all physical properties of lensing in a scalar instead of a vector field, thus (1) enabling an efficient handling of memory; (2) providing a significant reduction of the runtime by reducing the number of convolutions necessary for deriving the Jacobian; and (3) avoiding possible artefacts that may arise from the convolutions because of border effects and the cuspy profiles of galaxies. In the particular case of the power-law halo density profiles equation (7), an additional benefit of deriving all quantities from the lensing potential instead of the deflection angle is the finiteness of |$\bar{\psi }$| at the galaxy centres, where the deflections become singular for q > 1. We now discuss in detail the analytic and numerical steps in computing the gravitational lensing potential for our LTM model.
4.4 Galaxy-scale subhalo lensing potential
Despite the generally divergent Fourier transform of G for q ∈ [0, 2), its fast Fourier transform, after discretizing its spatial representation over the pixel coordinates, is well defined everywhere and enables a very efficient evaluation of equation (23). The convolution technique of equation (24) for lens modelling in Fourier space has been applied earlier by Bartelmann & Weiss (1994) and Puchwein et al. (2005), who gave a detailed discussion on the limits of its accuracy.
4.5 Cluster-scale halo lensing potential
An alternative way to arrive at the solution would be to evaluate the convolution (S*G) in Fourier space using the discrete Fourier transforms of S and G. However, this does not improve the accuracy or the computational performance on the set-up tested here and would be less elegant.
4.6 Total lensing potential
5 NUMERICAL IMPLEMENTATION
After having introduced the mathematical formalism adopted in this work, we now briefly summarize the most important details of the numerical implementation.
5.1 Parallel computation on mesh grids
The EasyCritics code is highly optimized both for a sequential and a parallel processing on the most common CPUs. An efficient memory management ensures that EasyCritics is optimized for large field of views covered by the current and upcoming wide-field surveys.
The total search area on the sky is divided into an array of tiles, which are processed independently and parallelly by multiple threads. The number and size of these tiles, as well as the number of threads, are defined by the user. During the computations, each tile is temporarily extended by a buffer area necessary to account for the most important gravitational contributions by adjacent matter, as illustrated in Fig. 2. Without such an extended area, the prediction would become increasingly inaccurate towards the tile boundaries and could lead to the loss of critical curves extending over neighbouring tiles. In addition, the temporary buffer alleviates numerical artefacts introduced by the discrete Fourier transform used to solve equations (24) and (30). The relative increase in the area of the tiles is specified by the user. A typical example setting would be an effective area of 5 arcmin × 5 arcmin, temporarily extended on each side by up to a factor of 3 to ensure continuity in the lensing potential at the tile boundaries.
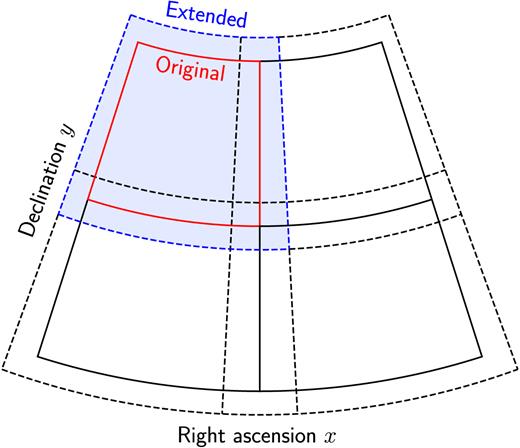
Illustration of the tiled geometry in the gnomonic projection. Solid boxes: Original tiles. Dashed boxes: Temporarily extended tiles. For a better distinction, the first tile is coloured.
The computations are performed on regular mesh grids with default resolutions of 0.25 arcsec/px. Celestial coordinates are locally mapped to the tangent plane by a gnomonic projection (e.g. Calabretta & Greisen 2002). A vector-valued grid is defined for the weighted effective luminosity maps |$\smash{\tilde{K}^{(l)}_{\mathrm{gal}} L^{(l)}}$| and |$\smash{\tilde{K}^{(l)}_{\mathrm{clus}} L^{(l)}}$|, from which scalar-valued grids are derived via line-of-sight projection and convolved with the kernels G and C according to equation (37). The confluent hypergeometric function 1F1 is evaluated using common approximation schemes (e.g. Muller 2001; Pearson, Olver & Porter 2017).
For the numerical solution of the convolutions, we use discrete Fast Fourier methods (Cooley & Tukey 1965) and exploit the discrete convolution theorem (Cochran et al. 1967), which allows us to substitute the Fourier transform of a convolution by a product of Fourier transforms. For the subsequent differentiation of the lensing potential, we apply suitable definitions of forward, backward, and central finite differences. The angular finite differences are locally approximated by Cartesian finite differences.
5.2 Critical curve recognition
For each contour, the centroid |$(\bar{\theta }_1, \bar{\theta }_2)$|, the orientation ϕ, and the principal axis lengths a, b are determined by an analysis of second-order image moments (Hu 1962; Stobie 1986), as defined in Appendix C. The geometrical parameters determined in this way enable a selection of targets for subsequent searches based on position and size. In order to avoid pixel artefacts due to the central cusp in our power-law description of the galaxy-scale subhaloes, EasyCritics discards all detections with an effective Einstein radius below a certain threshold, defined as the equivalent circle radius, |$\theta _{\mathrm{E,eff}} \equiv \sqrt{A/{\pi} }$| (Puchwein & Hilbert 2009; Zitrin et al. 2011a). In this study, we apply the empirically motivated value θE, eff ∼ 1.5 arcsec.
The different steps of the recognition algorithm are illustrated for an example cluster-scale detection in Fig. 3. For each set of critical pixels, the pixel coordinates are stored in critical curve catalogues together with the geometrical parameters |$\bar{\theta }_1$|, |$\bar{\theta }_2$|, ϕ, a, b and the effective Einstein radius θE, eff.
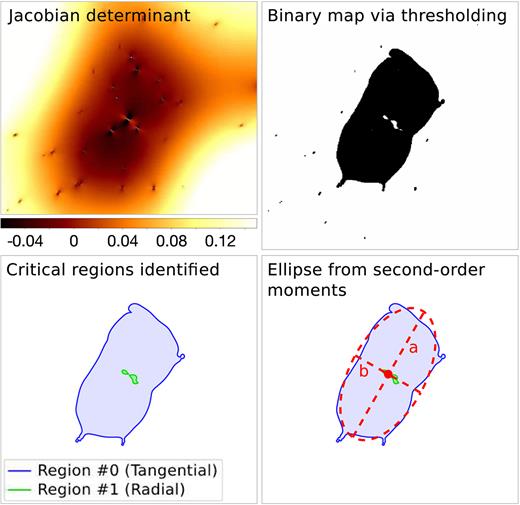
Illustration of the critical curve recognition for a region centred on a cluster-scale detection. Top left: Jacobian determinant. Top right: Binary map |$B(\boldsymbol{\theta })$| from thresholding. Bottom left: Detected regions and their contours, displayed as filled polygons. Bottom right: Ellipse from the moment calculation for the tangential critical curve.
5.3 Parameter calibration
For an efficient minimization procedure, we have developed a parallelized generalization of the Metropolis–Hastings algorithm (Metropolis et al. 1953; Hastings 1970), which is able to perform up to 10 |$\smash{\chi ^2}$|-evaluations per second by combining Markov Chain Monte Carlo (MCMC) sampling with an innovative use of adaptive grid methods. In particular, the randomly drawn variates for q and σ characterizing the shapes of the kernels G and C are binned on a regular grid (cf. Fig. 4) in order to reuse intermediate results between the sampling steps, while retaining the Gaussian distribution of the priors. The parameter space is explored by multiple threads in parallel, which update the mean values of their prior distributions periodically according to the global χ2 minimum. Around this minimum, the grid can be iteratively refined to achieve a higher accuracy and precision. With this scheme, the runtime is reduced by orders of magnitude when compared with a standard MCMC approach (see Section 5.4 for runtime measurements). The MCMC approach is optimally suited for our purpose, because it enables to deal with non-convex objective functions as well. Moreover, it requires no additional parameters to tune the algorithm.
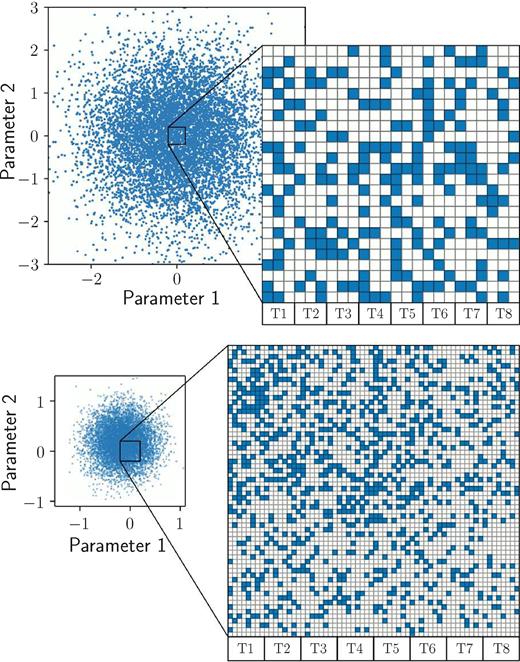
Illustration of the adaptive grid-based MCMC method for a two-dimensional parameter space: Gaussian random variates are sampled on a fine regular grid (top), which is iteratively refined in size and resolution (bottom) according to the previous optimum. The computation is performed column-wise, distributed on a given number of threads, in this example eight (T1–T8).
In contrast to the other parameters, the critical number density nc is defined based on the number of LRGs used. In the current implementation, we keep nc constant at an empirically determined value of nc ≈ 65/(15 arcmin × 15 arcmin) per sheet.
Currently, the calibration can be performed on individual known lenses to obtain independent sets of parameters, which then need to be combined appropriately. In an upcoming implementation, we are going to introduce a multilens calibration, in which all parameters are fitted to a larger set of known lenses simultaneously, optimizing the detection rate and the number of predictions to obtain the most efficient set of parameters, which is able to provide the best description for a broad range of lensing mass distributions.
5.4 Performance
Due to the large area that needs to be explored with the calibrated parameter sets, as well as the large number of MCMC sampling steps to be evaluated during the calibration itself, an optimization of the code design for cost-efficiency, i.e. for a low consumption of time and memory, is of critical importance. For the cost-efficiency to scale well with both the number of parallel processes and the problem size, we aim at a maximal parallel portion6 (Amdahl 1967) and weak scalability. In our implementation, we apply these criteria by using discrete fast Fourier methods for the convolutions and by parallelizing the computation of lensing quantities using the OpenMP7 interface. As an option, specific instructions can be accelerated on a CUDA8-capable GPU, if available.
In Appendix D, we present runtime measurements for the calibration and application phases on a recent 64-bit consumer PC9 when EasyCritics is applied to a realistic scenario and using different numbers of CPU cores. We compare and discuss these results in the context of strong and weak scalability. The typical runtime for a single calibration step remains below a second even in single-thread mode, demonstrating the advantages of the adaptive, grid-based MCMC method. The application to a |$\smash{1 \, \mathrm{deg^2}}$| region takes less than a minute on a commercial CPU. In comparison with crowdsourced visual inspection, these time-scales represent a significant improvement. The visual inspection of a |$\smash{154 \, \mathrm{deg^2}}$| region by 37 000 volunteers can require up to eight months (Marshall et al. 2016). For upcoming |$\smash{\gtrsim 10^4 \, \mathrm{deg^2}}$| surveys, such an analysis would require the same number of people to inspect the images for half a lifetime, highlighting the high costs and low efficiency of visual inspection. In contrast, EasyCritics is able to analyse |$\smash{10^4 \, \mathrm{deg^2}}$| on time-scales of days or weeks10 on a consumer PC, once calibrated.
6 APPLICATION EXAMPLES
As a first test to investigate and demonstrate the concepts discussed in this work, we apply EasyCritics to the CFHTLenS data set (Heymans et al. 2012; Erben et al. 2013; Miller et al. 2013). CFHTLenS is a wide-field photometric survey that covers |$\smash{154 \, \mathrm{deg}^2}$| and provides optical images in the five broad-band filters u*, g′, r′, i′, |$z$|′. With a depth of mlim = 25.5 in the i′-band, sub-arcsecond seeing conditions and accurate photometric redshifts, the CFHTLenS imaging data and object catalogues are well suited for gravitational lensing studies (Hildebrandt et al. 2012; Erben et al. 2013).
For the use with EasyCritics, we filter the object catalogues for early-type galaxies by removing all stellar sources and objects with a spectral type11TB > 1.7 according to the classification by Coleman, Wu & Weedman (1980). We apply a k-correction to the fluxes and magnitudes of the galaxies using the template spectra described by Capak (2004) and the final transmittance curves of the MegaCam filters.12 However, the k-correction does not have a strong impact on the results because it is to a large part degenerate with the free model parameter K and, over small redshift ranges, could be absorbed into the calibration. For the computation of cosmological distances, we use a ΛCDM model with Planck 2015 parameter values (Planck Collaboration XIII 2016).
We apply EasyCritics to a subset of four individual lenses, selecting well-studied objects that cover small and large structures. We start by calibrating the parameters on two known lenses, a small group (‘A’) and a rich cluster (‘B’). This yields the two independent parameter sets PA and PB. Applying both sets one after each other, we then test whether EasyCritics is able to predict critical curves around two further known lenses ‘C’ and ‘D’. As a consistency check, we perform also a reverse test by calibrating the model parameters against the lenses C and D and applying them to the lenses A and B. Moreover, we apply EasyCritics to a |$\smash{1 \, \mathrm{deg}^2}$| field in which no group- and cluster-scale lens candidates have been reported yet. The four calibrations are summarized in Section 6.2 and the resulting predictions are presented and discussed in Section 6.3. In Section 6.4, we estimate how the results are affected by uncertainties with regard to the lens and source redshifts .
Note that a full assessment of the detection efficiency, using the entire survey area and simulations, is beyond the scope of this work and will be presented in our upcoming papers (Carrasco et al. 2018; Stapelberg et al. , in preparation).
6.1 Selection of known lenses
The lenses A–D are representative for the group- and cluster-scale lenses reported in CFHTLens. Three of the lenses (A, B, C) are extracted from the CFHTLS Strong Lensing Legacy Survey (SL2S; Cabanac et al. 2007; More et al. 2012) and one (D) from the newly reported lenses by SpaceWarps (SW; Marshall et al. 2016; More et al. 2016) that has so far been missed by automated methods. The four examples are chosen to ‘challenge’ EasyCritics by including lenses with very different properties: (1) The lenses are located in areas with different depths and environmental properties; (2) The lenses represent different regimes in Einstein radii, masses, and redshifts; (3) The lenses have different numbers of arcs, ranging from 1 to 3 arcs/images. Below, we briefly introduce all four objects and describe their main characteristics:
Lens A: The first object is a compact group of galaxies, SL2S J021408-053532 or SA22,13 located at |$z$|phot = 0.48 ± 0.02 (More et al. 2012). It shows a fold configuration of two arcs (A1, cf. Fig. 5) at |$z$|spec = 1.628 ± 0.001 and a possible third feature (A2, cf. Fig. 5) observed at |$z$|spec = 1.017 ± 0.001 (Verdugo et al. 2011, 2016). The apparent Einstein radius amounts to θE ∼ 7.1 arcsec. A combined dynamical and parametric lensing mass reconstruction carried out by Verdugo et al. (2016) suggests that the centres and orientations of the main dark matter halo, the intracluster gas halo, and the luminosity contours are in good agreement if fitting a NFW profile for the main group halo and pseudo-isothermal ellipses to the central galaxy haloes.
Lens B: The second object is the galaxy cluster SL2S J141447 + 544703 or SA100 (Cabanac et al. 2007) at |$z$|phot = 0.63 ± 0.02 (More et al. 2012), which is known to be a Sunyaev-Zel’dovich bright cluster (PSZ1 G099.84 + 58.45; Planck Collaboration XXIX 2014; Gruen et al. 2014). It shows a tangential giant arc (B1, cf. Fig. 5), whose redshift, however, has not yet been measured spectroscopically. With an apparent Einstein radius of θE ∼ 14.7 arcsec, the cluster belongs to the largest strong lenses imaged by CFHTLenS.
Lens C: The third object is the galaxy group SL2S J08544-0121 or SA66 at |$z$|spec = 0.351 (Limousin et al. 2009), which stands out by a bimodal light distribution with luminosity peaks separated by |$\smash{\gtrsim 50\rm{\,arcsec}}$|. One of these peaks is associated with a bright, double-cored galaxy, near which a typical cusp configuration at |$z$|spec = 1.2680 ± 0.0003 (Limousin et al. 2010) is observed. The latter shows three images merging into a giant arc and a bright counter image (cf. Fig. 6). The lens has an Einstein radius of 4.8 arcsec and appears to be dominated by a single massive galaxy, which makes this candidate an ideal application target for testing the limits of EasyCritics towards smaller scales.
Lens D: The fourth object is the small cluster J220257 + 023432 or SW7 at redshift14|$z$|phot ∼ 0.51, which shows two very promising, although partially faint and overblended giant arc candidates (cf. Fig. 6) at a radius θE ∼ 6.8 arcsec. These have been newly reported as secure detections by SW (More et al. 2016) after they were missed by various automated algorithms applied within the region (e.g. More et al. 2012). The strongly lensing system is an interesting case to test the potential of the arc-free search approach underlying EasyCritics, since a successful detection and identification of this object as a strong lens would be the first achieved with a fully automated method.
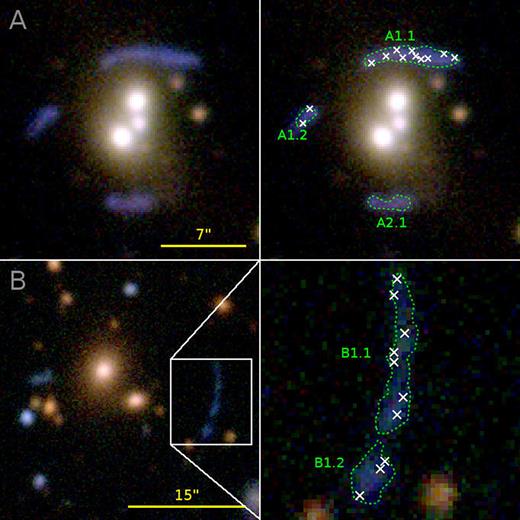
Illustration of the calibration for lenses A and B. The figure shows CFHTLenS i′r′g′-composite images with the arc regions (green contours) and the random χ2-minimization pixels Θcrit (white crosses) used in Section 6.2.
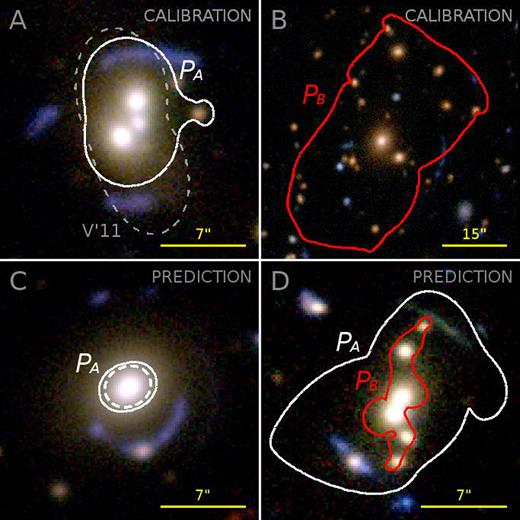
Calibrated and predicted tangential critical curves for the first test scenario, shown on CFHTLenS i′r′g′-composite images. Top row: Calibrations PA and PB on the two lenses A and B (solid lines) and literature comparison showing the model of Verdugo et al. (2011, V’11). Bottom row: Predictions for lenses C and D using PA and PB and assuming |$z$|s = 2 (solid lines) and for lens C the known value |$z$|s = 1.268 (dashed line).
6.2 Calibrations
In the following, we describe the four independent calibrations on lenses A–D and discuss their results. For each lens, the model parameters are estimated via the MCMC-based critical curve fitting method described in Section 5.3. In case that there is more than one configuration of known arcs, we select that covering the largest area. Where available, we use spectroscopic information on the source redshift. For the initial parameter values and ranges, we apply empirically motivated values, which are specified in Table 2. The MCMC sampler is initialized with a Gaussian random distribution that has a width σr = 0.4Δr, with Δr denoting the interval considered for the respective parameter.
Initial parameter values and ranges considered for the calibration, where K is given in arbitrary units.
| q | K | μclus | σ (arcsec) | |
|---|---|---|---|---|
| Lower limit: | 1.10 | |$\hphantom{10}5$| | 0.70 | |$\hphantom{1}3$| |
| Initial value: | 1.25 | |$\hphantom{1}47$| | 0.85 | 10 |
| Upper limit: | 1.40 | 100 | 0.95 | 20 |
| q | K | μclus | σ (arcsec) | |
|---|---|---|---|---|
| Lower limit: | 1.10 | |$\hphantom{10}5$| | 0.70 | |$\hphantom{1}3$| |
| Initial value: | 1.25 | |$\hphantom{1}47$| | 0.85 | 10 |
| Upper limit: | 1.40 | 100 | 0.95 | 20 |
Initial parameter values and ranges considered for the calibration, where K is given in arbitrary units.
| q | K | μclus | σ (arcsec) | |
|---|---|---|---|---|
| Lower limit: | 1.10 | |$\hphantom{10}5$| | 0.70 | |$\hphantom{1}3$| |
| Initial value: | 1.25 | |$\hphantom{1}47$| | 0.85 | 10 |
| Upper limit: | 1.40 | 100 | 0.95 | 20 |
| q | K | μclus | σ (arcsec) | |
|---|---|---|---|---|
| Lower limit: | 1.10 | |$\hphantom{10}5$| | 0.70 | |$\hphantom{1}3$| |
| Initial value: | 1.25 | |$\hphantom{1}47$| | 0.85 | 10 |
| Upper limit: | 1.40 | 100 | 0.95 | 20 |
The positions of the pixels Θcrit to be used for the eigenvalue minimization are sampled randomly over the areas covered by the arcs, as illustrated in Fig. 5. These areas are defined by a visual selection of suitable g′-band contours. As discussed in Section 5.3, the true path of the critical curve is in principle unknown, but it can be approximated to good accuracy by the positions of the arcs for an estimation of the LTM model parameters. The uncertainty Δχ2 is estimated based on the largest difference in the squared Jacobian eigenvalues within the selection area. The final outcome of the calibration is given by the set sitting in the global minimum within Δχ2. The uncertainties of the individual parameters are estimated by computing the second moments among all MCMC samples within a separation of Δχ2 from the optimum. These are used to compare different calibrations in order to test for compatibility between data sets and to probe the influence of other uncertainties, as it will be addressed in Section 6.4.
We present the four results PA to PD together with their 1σ uncertainties due to Δχ2 in Table 3 and show the associated best-fitting critical curves in Figs 6 and 7. The fits converged within |$\smash{N \lesssim \mathcal {O}(10^5)}$| sampling steps, resulting in final least-square deviations between |$\smash{\chi ^2 \sim \mathcal {O}(10^{-3})}$| and |$\smash{\chi ^2 \sim \mathcal {O}(10^{-2}})$|. The calibrated critical curves qualitatively match our expectation. For instance, the result for lens A resembles the lens modelling reconstruction of Verdugo et al. (2011) well. In Fig. 6, we compare the critical curve obtained with our approach (solid line) and the result of Verdugo et al. (dashed line). A slight deviation can be noted in the bottom image region, but this is well explained by a slight misalignment between the smoothed r′-band luminosity isocontours and the total mass. For lens D, the shape of the predicted critical curve might have been affected slightly too much by local galaxies in the proximity of the northern giant arc candidate. However, its location and size match the arcs well.

Calibrated and predicted tangential critical curves for the second test scenario. Top row: Calibrations PC and PD on the lenses C and D. Bottom row: Tangential critical curves predicted for lenses A and C by PC and PD, assuming |$z$|s = 2 where the source redshift is not known.
Calibration results for all four lenses A–D. The parameter K is given in arbitrary units.
| Lens | q | K | μclus | σ (arcsec) |
|---|---|---|---|---|
| A | 1.24 ± 0.02 | 37 ± 7 | 0.84 ± 0.01 | 10 ± 1 |
| B | 1.22 ± 0.02 | 35 ± 7 | 0.93 ± 0.01 | 18 ± 1 |
| C | 1.28 ± 0.01 | 68 ± 6 | 0.81 ± 0.01 | 5 ± 1 |
| D | 1.26 ± 0.02 | 40 ± 7 | 0.81 ± 0.02 | 10 ± 1 |
| Lens | q | K | μclus | σ (arcsec) |
|---|---|---|---|---|
| A | 1.24 ± 0.02 | 37 ± 7 | 0.84 ± 0.01 | 10 ± 1 |
| B | 1.22 ± 0.02 | 35 ± 7 | 0.93 ± 0.01 | 18 ± 1 |
| C | 1.28 ± 0.01 | 68 ± 6 | 0.81 ± 0.01 | 5 ± 1 |
| D | 1.26 ± 0.02 | 40 ± 7 | 0.81 ± 0.02 | 10 ± 1 |
Calibration results for all four lenses A–D. The parameter K is given in arbitrary units.
| Lens | q | K | μclus | σ (arcsec) |
|---|---|---|---|---|
| A | 1.24 ± 0.02 | 37 ± 7 | 0.84 ± 0.01 | 10 ± 1 |
| B | 1.22 ± 0.02 | 35 ± 7 | 0.93 ± 0.01 | 18 ± 1 |
| C | 1.28 ± 0.01 | 68 ± 6 | 0.81 ± 0.01 | 5 ± 1 |
| D | 1.26 ± 0.02 | 40 ± 7 | 0.81 ± 0.02 | 10 ± 1 |
| Lens | q | K | μclus | σ (arcsec) |
|---|---|---|---|---|
| A | 1.24 ± 0.02 | 37 ± 7 | 0.84 ± 0.01 | 10 ± 1 |
| B | 1.22 ± 0.02 | 35 ± 7 | 0.93 ± 0.01 | 18 ± 1 |
| C | 1.28 ± 0.01 | 68 ± 6 | 0.81 ± 0.01 | 5 ± 1 |
| D | 1.26 ± 0.02 | 40 ± 7 | 0.81 ± 0.02 | 10 ± 1 |
| Lens | Right ascension | Declination δ | Lens | Detected? | Arc radius | Calibrated eff. Einstein | Predicted eff. Einstein | |
|---|---|---|---|---|---|---|---|---|
| α (J2000) (deg) | (J2000) (deg) | redshift |$z$|l | (No. of curves) | θE (arcsec) | radius θE, eff (arcsec) | radii θE, eff (arcsec) | ||
| A | 33.5336 | −5.5922 | 0.48 | Yes (2) | 7.1 | 5 | PC: 15; | PD: 4 |
| B | 213.6965 | +54.7842 | 0.63 | Yes (2) | 14.7 | 21 | PC: 29; | PD: 12 |
| C | 133.6940 | −1.3603 | 0.351 | Yes (1) | 4.8 | 5 | PA: 2 | – |
| D | 330.7372 | +2.5760 | 0.51 | Yes (2) | 6.8 | 6 | PA: 8; | PB: 3 |
| |$1 \, \mathrm{deg}^2$| field | 215.3273 | +55.2480 | 0.3...0.4 | – | – | – | PC: 3 | – |
| Lens | Right ascension | Declination δ | Lens | Detected? | Arc radius | Calibrated eff. Einstein | Predicted eff. Einstein | |
|---|---|---|---|---|---|---|---|---|
| α (J2000) (deg) | (J2000) (deg) | redshift |$z$|l | (No. of curves) | θE (arcsec) | radius θE, eff (arcsec) | radii θE, eff (arcsec) | ||
| A | 33.5336 | −5.5922 | 0.48 | Yes (2) | 7.1 | 5 | PC: 15; | PD: 4 |
| B | 213.6965 | +54.7842 | 0.63 | Yes (2) | 14.7 | 21 | PC: 29; | PD: 12 |
| C | 133.6940 | −1.3603 | 0.351 | Yes (1) | 4.8 | 5 | PA: 2 | – |
| D | 330.7372 | +2.5760 | 0.51 | Yes (2) | 6.8 | 6 | PA: 8; | PB: 3 |
| |$1 \, \mathrm{deg}^2$| field | 215.3273 | +55.2480 | 0.3...0.4 | – | – | – | PC: 3 | – |
| Lens | Right ascension | Declination δ | Lens | Detected? | Arc radius | Calibrated eff. Einstein | Predicted eff. Einstein | |
|---|---|---|---|---|---|---|---|---|
| α (J2000) (deg) | (J2000) (deg) | redshift |$z$|l | (No. of curves) | θE (arcsec) | radius θE, eff (arcsec) | radii θE, eff (arcsec) | ||
| A | 33.5336 | −5.5922 | 0.48 | Yes (2) | 7.1 | 5 | PC: 15; | PD: 4 |
| B | 213.6965 | +54.7842 | 0.63 | Yes (2) | 14.7 | 21 | PC: 29; | PD: 12 |
| C | 133.6940 | −1.3603 | 0.351 | Yes (1) | 4.8 | 5 | PA: 2 | – |
| D | 330.7372 | +2.5760 | 0.51 | Yes (2) | 6.8 | 6 | PA: 8; | PB: 3 |
| |$1 \, \mathrm{deg}^2$| field | 215.3273 | +55.2480 | 0.3...0.4 | – | – | – | PC: 3 | – |
| Lens | Right ascension | Declination δ | Lens | Detected? | Arc radius | Calibrated eff. Einstein | Predicted eff. Einstein | |
|---|---|---|---|---|---|---|---|---|
| α (J2000) (deg) | (J2000) (deg) | redshift |$z$|l | (No. of curves) | θE (arcsec) | radius θE, eff (arcsec) | radii θE, eff (arcsec) | ||
| A | 33.5336 | −5.5922 | 0.48 | Yes (2) | 7.1 | 5 | PC: 15; | PD: 4 |
| B | 213.6965 | +54.7842 | 0.63 | Yes (2) | 14.7 | 21 | PC: 29; | PD: 12 |
| C | 133.6940 | −1.3603 | 0.351 | Yes (1) | 4.8 | 5 | PA: 2 | – |
| D | 330.7372 | +2.5760 | 0.51 | Yes (2) | 6.8 | 6 | PA: 8; | PB: 3 |
| |$1 \, \mathrm{deg}^2$| field | 215.3273 | +55.2480 | 0.3...0.4 | – | – | – | PC: 3 | – |
A quantitative comparison of the best-fitting parameter values for the lenses PA to PD listed in Table 3 shows that the scatter in q and K between the lenses within the estimated uncertainties is low despite the large difference in the redshift and Einstein radii of the lenses. As expected, the largest differences between all four parameter sets are found between lenses B and C. Despite a possible impact of the low number of satellites on the M/L estimate in the case of lens C (Lu, Yang & Shen 2015), the different values obtained for K are consistent with the expected scatter in the M/L ratios of groups and clusters (e.g. Lin et al. 2004; Tinker et al. 2005; Bahcall & Kulier 2014; Lu et al. 2015; Viola et al. 2015; Mulroy et al. 2017).
6.3 Identification of known lenses
For each of the four lenses, we apply EasyCritics to a 5 arcmin × 5 arcmin (extended: 15 arcmin × 15 arcmin) region around the cD galaxies. The precise centre of the region is not relevant because in a general application, the algorithm is run over the entire data set. For a positive detection, we require that at least one of the parameter sets produces a critical curve with a centroid separated by less than 40 arcsec from the expected lens centre.15 The choice of this maximum distance accounts for intrinsic offsets between the dark and luminous matter components. In addition, we investigate the agreement of the predicted critical curves with those obtained from the calibrations, which represent the best fit of our LTM model. This allows us to study the impact of the intrinsic variation of lens parameters on the model predictions.
In general, the variation of parameters from lens to lens is expected to yield slight deviations of the predicted Einstein radii from the true ones. These, however, are well within the aims of lens detection. In fact, the goal is not a precise reconstruction of the mass, which can be achieved only via a subsequent fit, but to find the regions in which strong lensing features are produced. Thus, the sensitivity of the predicted critical curves to variations in the model parameters should become relevant only to the extent to which it may affect the detection rate or the area for follow-up inspection. An extensive analysis of the detection efficiency of EasyCritics for different settings will be the subject of upcoming papers (Carrasco et al. 2018). Here, we focus on the individual performance of the parameter sets PA to PD.
The tests yield positive outcomes for all four lenses. Each lens is identified by each parameter set, except for lens C, for which a critical curve is produced only by the group-scale set PA. This, however, is not surprising given the very low richness of lens C, for which PA may provide a better description than PB. A more remarkable result is the successful identification of the SW lens candidate D, as it had been missed by several automated methods before (More et al. 2012). This demonstrates the importance and benefits of using foreground search criteria complementary to arc data, thus avoids problems due to low signal-to-noise ratios, complex morphologies, or overblending.
A comparison of all four predicted critical curves is shown in Figs 6 and 7. Not surprisingly, the parameters obtained from small/large lenses perform best when applied to the other small/large lenses. At the same time, the smallest scale calibrations PC and PD show an overall better performance than the cluster-scale calibration PB by predicting critical curves with either large or compatible Einstein radii for all mass regimes, while PB strongly underestimates the surface density on group scales. This is because a small Gaussian width σ (resulting from the calibration on a small lens) applied to large lenses is still going to result in cluster-scale haloes concentrated enough to produce critical curves close to the Einstein radii, which is no longer the case when applying a large σ to small lenses. In this case, the predicted cluster-scale component is spread over a large area producing an excessive dilution that can prevent the appearance of critical regions. This effect is illustrated in Fig. 8 for the example of lens B, where it gets further enhanced by the fact that multiple haloes are superposed. In contrast, the remaining parameters q, K, μclus have a much smaller influence on the model. This would allow to fix fiducial values for these parameters and to perform an optimization on the parameter σ in order to reduce the degrees of freedom of the model, at least for the sample of lenses studied here.
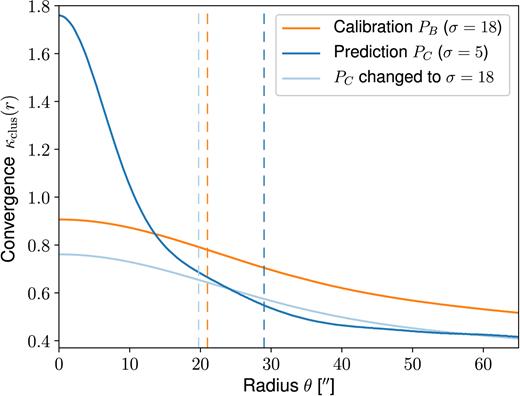
Comparison of the convergence profile |$\bar{\kappa }_{\mathrm{clus}}(r)$| for the smooth cluster-scale component of lens B, illustrating the behaviour of different sizes σ for the Gaussian smoothing kernel. The curves show the profiles computed for PB, PC and when using PC with the value σ from PB. The dashed lines mark the predicted effective Einstein radii θE, eff.
In the remaining part of our tests, we apply EasyCritics to a |$\smash{1 \, \mathrm{deg}^2}$| field for which no group- or cluster-scale strong lens candidates have been reported by the SL2S (Cabanac et al. 2007; More et al. 2012), by SW16 (More et al. 2016), or in NED17 (Helou et al. 1995). In contrast to the previous examples, we display a case for a low-density region in which we expect to find either new or no critical regions. In this field, EasyCritics produces only a single critical curve on group or cluster scales with θE, eff ≈ 3 arcsec, found by the set PC and centred around what appears to be an elongated small cluster (‘E’). The latter can be estimated to be at |$z$| ∼ 0.3…0.4 based on the photometric redshifts of the elliptical galaxies in the region. In addition, very few critical curves are produced around single isolated field galaxies, all having Einstein radii θE, eff < 2.75 arcsec. These features are mostly artificial detections due to the central cusp in our description of galaxies, which can give rise to few pixels with supercritical surface densities. They can be avoided easily by increasing the critical curve size threshold or by a slight modification of the parameter values. For instance, in configuration PB, only one of these objects is created. A map of the convergence for the entire region and a zoom-in on the central region of candidate E is presented in Fig. 9.
An overview of the calibration and detection results is presented in Table 4.
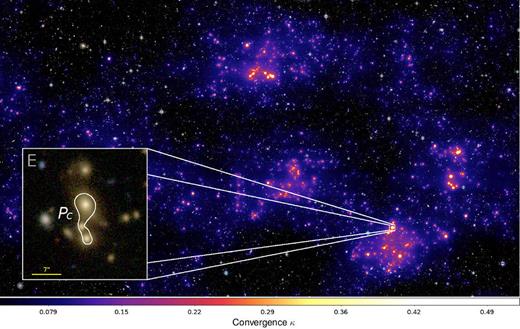
Cluster-scale convergence predicted with parameter set PC for the candidate-free |$1 \, \mathrm{deg}^2$| region, superimposed on a CFHTLenS i′r′g′-composite image. The box on the left shows a zoom-in on the critical curve of the only group-scale critical curve detection.
6.4 Impact of redshift uncertainties
Apart from the intrinsic variation in the best-fitting parameters, some impacts on the models may arise due to the photometric redshift measurement uncertainty, Δ|$z$|phot, and the intrinsic scatter of the source redshifts, Δ|$z$|s. Both could mildly affect the detection statistics by altering the calibration and the predicted sizes of critical curves. In order to estimate at least the order of magnitude of these effects, we study how the critical curves are affected by small displacements in the lens and source redshifts and compare this to the previously discussed sources of uncertainty. The results obtained in this way are very similar for all four lenses and in the following discussed in detail for the example of the cluster-scale lens B, which is farthest away in redshift and thus may be affected the most by the photometric uncertainties.
We first investigate the sensitivity of predicted critical curve sizes to the average photometric measurement uncertainty Δ|$z$|phot = 0.04(1 + |$z$|) of the CFHTLenS data (cf. Hildebrandt et al. 2012). We displace all redshift bins by Gaussian random variates with a mean μr = |$z$|(k) and a standard deviation σr = Δ|$z$|phot, while keeping the parameters fixed at the calibration set PB. The procedure is performed 200 times, yielding the critical curves shown in the left-hand panel of Fig. 10. The mean Einstein radius is θE, eff = 21 arcsec with a standard deviation of 2.6 arcsec. The results confirm our expectation that the photometric measurement uncertainties influence the sizes of the critical curves mildly, although leaving the overall outcome unchanged. We repeat the calibration for the random displacements that yielded critical curve sizes closest to the 1σ neighbourhood around the mean to estimate the impact of Δ|$z$|phot on the parameter values. The results are shown in Table 5.
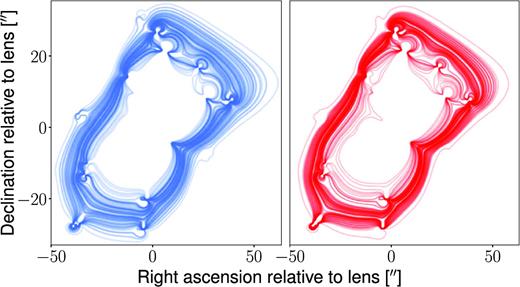
Impact of the mean photo-|$z$| uncertainties (left/blue) and the source redshift uncertainties (right/red). Shown are in both cases the tangential critical curves of lens B produced with PB for different random displacements of the redshifts, as described in Section 6.4. For a clearer presentation, we only show every second of the 200 lines.
Comparison of absolute uncertainties in the calibrated parameter values due to (1) redshift misestimations, (2) the degeneracy between optimization points, and (3) the intrinsic deviation of PB from PA.
| Parameter | Dev. due | Dev. due | Dev. due | Dev. |
|---|---|---|---|---|
| to Δ|$z$|phot | to Δ|$z$|s | to Δχ2 | from PA | |
| q | 0.05 | 0.01 | 0.02 | 0.02 |
| K | 16 | 4.5 | 7 | 2 |
| μclus | 0.04 | 0.01 | 0.01 | 0.09 |
| σ | 2 | 2 | 1 | 8 |
| Parameter | Dev. due | Dev. due | Dev. due | Dev. |
|---|---|---|---|---|
| to Δ|$z$|phot | to Δ|$z$|s | to Δχ2 | from PA | |
| q | 0.05 | 0.01 | 0.02 | 0.02 |
| K | 16 | 4.5 | 7 | 2 |
| μclus | 0.04 | 0.01 | 0.01 | 0.09 |
| σ | 2 | 2 | 1 | 8 |
Comparison of absolute uncertainties in the calibrated parameter values due to (1) redshift misestimations, (2) the degeneracy between optimization points, and (3) the intrinsic deviation of PB from PA.
| Parameter | Dev. due | Dev. due | Dev. due | Dev. |
|---|---|---|---|---|
| to Δ|$z$|phot | to Δ|$z$|s | to Δχ2 | from PA | |
| q | 0.05 | 0.01 | 0.02 | 0.02 |
| K | 16 | 4.5 | 7 | 2 |
| μclus | 0.04 | 0.01 | 0.01 | 0.09 |
| σ | 2 | 2 | 1 | 8 |
| Parameter | Dev. due | Dev. due | Dev. due | Dev. |
|---|---|---|---|---|
| to Δ|$z$|phot | to Δ|$z$|s | to Δχ2 | from PA | |
| q | 0.05 | 0.01 | 0.02 | 0.02 |
| K | 16 | 4.5 | 7 | 2 |
| μclus | 0.04 | 0.01 | 0.01 | 0.09 |
| σ | 2 | 2 | 1 | 8 |
In a second test, we investigate the change in the calibrated and predicted critical curves when the source redshift differs from our default expectation value |$z$|s = 2. This does not represent a test of the lens model itself, but of its dependence on the source redshift only. We first study the change in predicted critical curves by re-applying the parameter values PB calibrated under the assumption |$z$|s = 2 to lens B, using 200 random redshift displacements within the empirically motivated range of bright giant arcs, |$z$|s = 2.0 ± 0.1 (Bayliss 2012). The critical curves predicted for these different source redshifts are visualized in the right-hand panel of Fig. 10. The effective Einstein radii are distributed with a mean of θE, eff = 21 arcsec and a standard deviation of 2 arcsec. As before, we also study the impact on the calibration by repeating the calibration for the various source redshifts, which yields the maximum differences Δ|$z$|s in the final best-fitting parameters PB listed in Table 5.
The tests show that the detection of the critical curve itself is stable with respect to the redshift uncertainties Δ|$z$|phot and Δ|$z$|s, although the critical curve may vary in size. In extreme cases, this might affect the completeness of predictions due to underestimating the size of critical curves.
7 SUMMARY AND CONCLUSIONS
We have developed an algorithm to detect group- and cluster-scale strong lenses in wide-field surveys, based on the distribution of fluxes from LRGs as a tracer for dense structures. EasyCritics models these structures in a blind and automated way to identify the most likely strongly lensing groups and clusters of galaxies. This promises to avoid a large number of spurious detections and to decrease the required amount of post-processing, as it significantly reduces and restricts the area that needs to be validated or inspected by a follow-up study. The main advantage of EasyCritics is that it enables a simple, physically motivated selection criterion based on few model assumptions and without relying on the identification of arcs. In addition, EasyCritics provides a first characterization of the properties of lens candidates, such as their positions, surface densities, Einstein radii, and orientations of the critical curves.
In this work, we presented a modified and numerically improved version of the LTM modelling approach, based on the brightest early-type galaxies distributed along the line of sight. In particular, EasyCritics blindly models the lensing distortion produced within the entire line of sight (not only pre-selected, isolated structures) and derives lensing quantities from a potential instead of working with the deflection angle. In combination with the use of parallelization and fast Fourier and matrix calculation routines, this allows us to obtain a substantial speed-up in the identification and modelling of strongly lensing structures. The optimization of time and memory resources is important to enable the analysis of very large portions of the sky and to automate the estimation of the model parameters based on the adaptive MCMC methods we introduced in this work.
We applied EasyCritics to regions centred on known lens candidates to provide a detailed description of actual cases. In an analysis of the primary uncertainties, we showed that the accuracy of the predicted critical curves returns stable results. In one of the presented examples, the lens candidate detected by EasyCritics had previously been missed by automated searches and was eventually discovered through crowdsourced visual inspection. Its successful identification by EasyCritics is very encouraging, considering that it required no community efforts and that the overall area of CFHTLenS can be processed with two parameter sets in a few hours to days. The result demonstrates the power of combining lens detection with LTM modelling for an improved automated search based on foreground observables. A full assessment of the purity and completeness of the catalogue of strong lensing features is going to be presented in the two forthcoming papers, in which EasyCritics will be applied to the entire CFHTLenS survey and tested against simulations. For the near future, we furthermore prepare a release of the EasyCritics code, which is going to be made available on request at a suitable time.
EasyCritics enables a reliable, fast, and automated detection and characterization of strongly lensing galaxy groups and galaxy clusters in wide-field optical surveys. It will thus be able to contribute to various near-future studies exploring the dark Universe.
ACKNOWLEDGEMENTS
We gratefully acknowledge valuable discussions and comments from Matthias Bartelmann, Jenny Wagner, Thomas Erben, Gregor Seidel, and Lars Henkelmann. We thank the anonymous referee for constructive criticisms, suggestions, and comments that helped to improve the manuscript. This work was supported by the Transregional Collaborative Research CenterTRR33‘The Dark Universe’ (MC, MM).
Footnotes
Especially in the case of arcs with small length-to-width ratios and images blurred by atmospheric turbulence.
E.g. the CFHTLenS – r′ or CFHTLenS – i′ band.
Selected, for example according to their spectral energy distribution.
In order to simplify the nomenclature, we will use the term ‘cluster’ to refer to groups as well unless an explicit distinction is made.
The method is, however, not limited to tangential eigenvalues. Radial arc data could be included as well, with each of the two eigenvalues minimized at the respective arc locations.
Defined as the proportion of parallelizable workload.
Open Multi-Processing (http://openmp.org/).
The test machine runs on a |$4.20 \, \mathrm{GHz}$|Core i7-7700K quad-core processor with |$32 \, \mathrm{GB}$| RAM (|$2400 \, \mathrm{MHz}$|DDR4).
Depending on the details of the set-up
Where TB = 1 corresponds to E/S0 galaxies, TB = 2 to SBc barred spirals, and TB ≥ 2 to spiral and irregular galaxies.
Estimated by the mean photometric redshift of the central galaxies according to the CFHTLenS catalogues.
Defined as the predicted maximum |$\boldsymbol{\theta }_{\mathrm{c}}$| of the convergence within the region enclosed by the visible arcs.
As of 2015 November 10.
NASA/IPAC Extragalactic Database, https://ned.ipac.caltech.edu/.
Here, we refer to physical, not logical, cores.
If ignoring a variety of additional factors, such as communication overheads, load imbalance, or superlinear speed-up.
REFERENCES
APPENDIX A: REDSHIFT DEPENDENCE OF THE CRITICAL SURFACE DENSITY
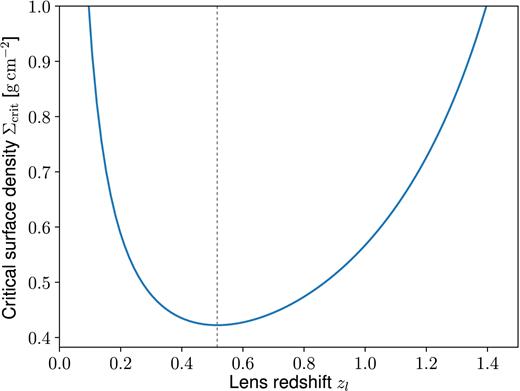
Dependence of the critical surface density for lensing on the lens redshift, computed for a source redshift of |$z$|s = 2 and cosmological parameters from the Planck 2015 results (Planck Collaboration XIII 2016). The dotted grey line marks the minimum at |$z$| ∼ 0.5.
APPENDIX B: SMOOTHED CLUSTER KERNEL
APPENDIX C: CRITICAL CURVE SHAPE PARAMETERS
APPENDIX D: PERFORMANCE AND SCALABILITY
For the calibration mode, we measured the average durations of single iterations when using the CPU only and when using GPU acceleration. The average is performed over all sampling iterations (=106) by measuring the total calibration runtime in seconds and dividing by the number of iteration steps. Note that the speed-up of the iterations due to a usage of multiple CPU cores18 depends on a variety of parameters related to the MCMC sampling procedure. Thus, the values in Table D1 are presented only to give an impression of the order of the involved time-scales; and error bars have been omitted. The duration of a single iteration needs to be kept as short as possible because a large number of MCMC steps are necessary for a reliable estimation of the model parameters. Most of the acceleration is achieved by the reuse of resources in the adaptive MCMC method (cf. Section 5.3), which enables a speed-up by a factor of 10 compared to conventional MCMC methods. The remaining gain from the GPU acceleration contributes only a small part of the speed-up for our set-up due to the unavoidable bottleneck arising from the data transfer between host and GPU device.
Average duration (in milliseconds) of a single MCMC sampling step for a region of |$\smash{15\,\rm{arcmin} \times 15\,\rm{arcmin}}$| as a function of used CPU cores on our test system.
| Number of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time in CPU-only mode (ms): | 360 | 240 | 170 | 130 |
| Time in GPU-accelerated mode (ms): | 280 | 190 | 140 | 110 |
| Number of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time in CPU-only mode (ms): | 360 | 240 | 170 | 130 |
| Time in GPU-accelerated mode (ms): | 280 | 190 | 140 | 110 |
Average duration (in milliseconds) of a single MCMC sampling step for a region of |$\smash{15\,\rm{arcmin} \times 15\,\rm{arcmin}}$| as a function of used CPU cores on our test system.
| Number of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time in CPU-only mode (ms): | 360 | 240 | 170 | 130 |
| Time in GPU-accelerated mode (ms): | 280 | 190 | 140 | 110 |
| Number of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time in CPU-only mode (ms): | 360 | 240 | 170 | 130 |
| Time in GPU-accelerated mode (ms): | 280 | 190 | 140 | 110 |
Average runtimes (in seconds) and their statistical uncertainties for application runs on our test system for different region sizes as a function of used CPU cores.
| No. of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time for |$\smash{15\rm{\,arcmin} \times 15\rm{\,arcmin}}$| (4 tiles, not extended) (s): | 5.81 ± 0.18 | 3.69 ± 0.13 | 2.84 ± 0.01 | 2.596 ± 0.003 |
| Time for |$\smash{\, 1 \, \mathrm{deg}^2}$| (16 tiles, not extended) (s): | 73.35 ± 0.47 | 39.92 ± 0.35 | 29.24 ± 0.37 | 24.65 ± 0.42 |
| Time for |$\smash{1 \, \mathrm{deg}^2 }$| (16 tiles, sides extended by 1.5) (s): | 160.9 ± 3.9 | 83.71 ± 0.49 | 57.40 ± 0.48 | 41.16 ± 0.35 |
| No. of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time for |$\smash{15\rm{\,arcmin} \times 15\rm{\,arcmin}}$| (4 tiles, not extended) (s): | 5.81 ± 0.18 | 3.69 ± 0.13 | 2.84 ± 0.01 | 2.596 ± 0.003 |
| Time for |$\smash{\, 1 \, \mathrm{deg}^2}$| (16 tiles, not extended) (s): | 73.35 ± 0.47 | 39.92 ± 0.35 | 29.24 ± 0.37 | 24.65 ± 0.42 |
| Time for |$\smash{1 \, \mathrm{deg}^2 }$| (16 tiles, sides extended by 1.5) (s): | 160.9 ± 3.9 | 83.71 ± 0.49 | 57.40 ± 0.48 | 41.16 ± 0.35 |
Average runtimes (in seconds) and their statistical uncertainties for application runs on our test system for different region sizes as a function of used CPU cores.
| No. of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time for |$\smash{15\rm{\,arcmin} \times 15\rm{\,arcmin}}$| (4 tiles, not extended) (s): | 5.81 ± 0.18 | 3.69 ± 0.13 | 2.84 ± 0.01 | 2.596 ± 0.003 |
| Time for |$\smash{\, 1 \, \mathrm{deg}^2}$| (16 tiles, not extended) (s): | 73.35 ± 0.47 | 39.92 ± 0.35 | 29.24 ± 0.37 | 24.65 ± 0.42 |
| Time for |$\smash{1 \, \mathrm{deg}^2 }$| (16 tiles, sides extended by 1.5) (s): | 160.9 ± 3.9 | 83.71 ± 0.49 | 57.40 ± 0.48 | 41.16 ± 0.35 |
| No. of CPU cores: | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Time for |$\smash{15\rm{\,arcmin} \times 15\rm{\,arcmin}}$| (4 tiles, not extended) (s): | 5.81 ± 0.18 | 3.69 ± 0.13 | 2.84 ± 0.01 | 2.596 ± 0.003 |
| Time for |$\smash{\, 1 \, \mathrm{deg}^2}$| (16 tiles, not extended) (s): | 73.35 ± 0.47 | 39.92 ± 0.35 | 29.24 ± 0.37 | 24.65 ± 0.42 |
| Time for |$\smash{1 \, \mathrm{deg}^2 }$| (16 tiles, sides extended by 1.5) (s): | 160.9 ± 3.9 | 83.71 ± 0.49 | 57.40 ± 0.48 | 41.16 ± 0.35 |
The measured speed-ups are shown together with the ideal Amdahl speed-ups in Fig. D1. The error bars presented label the statistical errors. Note that the systematic uncertainties due to factors such as the number or luminosity density of galaxies in the volume or due to numerical settings can be larger. The data suggest a good qualitative agreement with the expectation, although small systematic deviations can be observed, which are most likely due to parallel overheads. As expected, the speed-up improves for a larger area due to the increased parallel portion, indicating a partial weak performance scalability as well. The latter is of interest since EasyCritics is intended for the application to very large data sets.
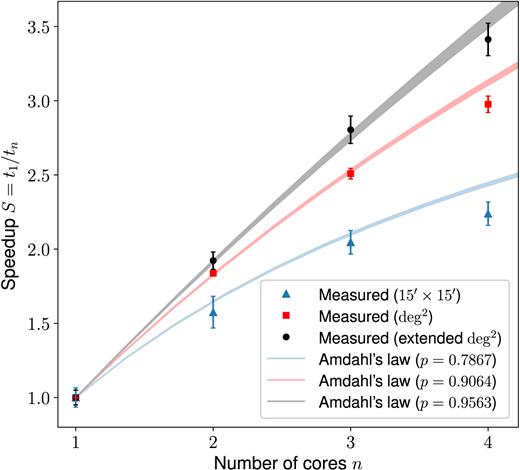
Measured versus ideal speed-up of the computation time for the application mode as a function of CPU cores. The expected ideal speed-up is derived from Amdahl’s law for parallel portions p determined by direct time measurements.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}