





Abstract
We introduce a high-performance simulation framework that permits the semi-independent, task-based solution of sets of partial differential equations, typically manifesting as updates to a collection of ‘patches’ in space–time. A hybrid MPI/OpenMP execution model is adopted, where work tasks are controlled by a rank-local ‘dispatcher’ which selects, from a set of tasks generally much larger than the number of physical cores (or hardware threads), tasks that are ready for updating. The definition of a task can vary, for example, with some solving the equations of ideal magnetohydrodynamics (MHD), others non-ideal MHD, radiative transfer, or particle motion, and yet others applying particle-in-cell (PIC) methods. Tasks do not have to be grid based, while tasks that are, may use either Cartesian or orthogonal curvilinear meshes. Patches may be stationary or moving. Mesh refinement can be static or dynamic. A feature of decisive importance for the overall performance of the framework is that time-steps are determined and applied locally; this allows potentially large reductions in the total number of updates required in cases when the signal speed varies greatly across the computational domain, and therefore a corresponding reduction in computing time. Another feature is a load balancing algorithm that operates ‘locally’ and aims to simultaneously minimize load and communication imbalance. The framework generally relies on already existing solvers, whose performance is augmented when run under the framework, due to more efficient cache usage, vectorization, local time-stepping, plus near-linear and, in principle, unlimited OpenMP and MPI scaling.
1 INTRODUCTION
Numerical simulations of astrophysical phenomena are indispensable in furthering our understanding of the Universe. A particularly successful example is the many applications of the equations of magnetohydrodynamics (MHD) in the contexts of cosmology, galaxy evolution, star formation, stellar evolution, solar and stellar activity, and planet formation. As the available computer power has increased over time, so too has the fidelity and complexity of astrophysical fluid simulations; more precisely, one could say these simulations have consistently been at the limit of what is computationally possible. The algorithms and techniques used to exploit the available resources have also increased in ingenuity and complexity over the years; from block-based adaptive mesh refinement (AMR; Berger & Oliger 1984; Berger & Colella 1989) to space-filling curves (e.g. Peano-Hilbert) to non-blocking distributed communication (e.g. Message Passing Interface version 3; MPI). The next evolution in high-performance computing (HPC), ‘exa-scale’,1 is approaching and, as currently available tools are quickly reaching their limits (see e.g. Dubey et al. 2014), new paradigms and techniques must be developed to fully exploit the upcoming generation of supercomputers.
However, since exa-scale supercomputers do not yet exist, we instead choose to limit our definition of ‘exa-scale ready’ to software that has intra- and inter-node scaling expected to continue to the number of cores required to reach exa-scales. Here, we present an intra-node task scheduling algorithm that has no practical limit, and we demonstrate that MPI-communications are only needed between a limited number of ‘nearby’ nodes. The first property guarantees that we will always be able to utilize the full capacity inside nodes, limited mainly by the memory bandwidth. The second property means that, as long as cluster network capacity continues to grow in proportion to compute capacity, inter-node communication will never become a bottleneck. Load and communication balancing is only indirectly involved, in the sense that, for problems where static load balancing is sufficient, the scaling properties can be measured for arbitrary size problems. In what follows, we point out that balancing the compute load is essentially trivial when tasks can be freely traded between compute nodes, and that the most important aspect of load balancing then shifts to minimizing inter-node communications. We indicate how this can be accomplished using only communications with nearest neighbour nodes, leaving the details to a forthcoming paper.
There are many astrophysical fluid simulation codes currently available within the scientific community. The most commonly used techniques include single grids (e.g. zeus; Stone & Norman 1992; Clarke 1996, fargo|$\scriptstyle{3}$|d; Benítez-Llambay & Masset 2016, pluto; Mignone et al. 2007, athena; Stone et al. 2008, pencil; Brandenburg & Dobler 2002, stagger; Nordlund, Galsgaard & Stein 1994; Kritsuk et al. 2011, bifrost; Gudiksen et al. 2011), adaptively refined grids (e.g. art; Kravtsov, Klypin & Khokhlov 1997, nirvana; Ziegler 1998, orion; Klein 1999, flash; Fryxell et al. 2000, ramses; Teyssier 2002; Fromang, Hennebelle & Teyssier 2006, astrobear; Cunningham et al. 2009, castro; Almgren et al. 2010, crash; van der Holst et al. 2011, azeus; Ramsey, Clarke & Men'shchikov 2012, enzo; Bryan et al. 2014, amrvac; Porth et al. 2014), and smoothed particle hydrodynamics (e.g. gadget; Springel 2005, phantom; Lodato & Price 2010). More recently, moving mesh and mesh-less methods have begun to emerge (e.g. arepo; Springel 2010, tess; Duffell & MacFadyen 2011, gizmo; Hopkins 2015, gandalf; Hubber, Rosotti & Booth 2018). The range of physics available from one code to the next is very broad, and includes (but is not limited to) radiative transport, heating and cooling, conduction, non-ideal MHD, cosmological expansion, special and general relativity, multiple fluids, and self-gravity.
There also exists a growing collection of frameworks which are solver- and physics-agnostic, but instead manage the parallelism, communication, scheduling, input/output (I/O) and even resolution of a simulation (e.g. boxlib,2charm++; Kale et al. 2008, chombo; Adams et al. 2015, overture; Brown, Henshaw & Quinlan 1997, Uintah; Berzins et al. 2010, patchwork; Shiokawa et al. 2017). Indeed, a few of these frameworks already couple to some of the aforementioned simulation codes (e.g. pluto+chombo, castro+boxlib, enzo-p/cello+charm++).
Nearly all of the codes and frameworks mentioned above have fundamental weaknesses which limit their ability to scale indefinitely. In the survey of block-based AMR codes and frameworks by Dubey et al. (2014), the authors conclude that ‘future architectures dictate the need to eliminate the bulk synchronous model that most codes currently employ’. Traditional grid-based codes must advance using time-steps that obey the worst possible condition throughout the simulation volume, advancing at some fraction of a time-step Δt = min (Δx/vsignal). The time-step may be determined locally, but it is applied globally. For AMR codes with sub-cycling, where larger meshes can take longer time-steps, these must generally be a multiple of the finer mesh time-steps, resulting again in a global coupling of time-steps. A global time-step which is controlled by the globally worst single cell is problematic, and the problem unavoidably becomes exasperated as supercomputers grow larger and the physical complexity of models correspondingly increases. Dubey et al. (2014) also discuss challenges related to both static load balancing, where difficulties arise when multiphysics simulations employ physics modules with very different update costs, and dynamic load balancing, wherein the load per MPI process needs to be adjusted, for example, because of time-dependent AMR.
Parallelism in both specific codes and frameworks is almost always implemented using (distributed-memory) MPI, shared-memory thread-based parallelism (e.g. OpenMP, pthreads), or a combination of the two. Although MPI has its limitations (e.g. fault tolerance support), and new approaches are beginning to emerge (e.g. partitioned global address space), it is the de facto standard for distributed-computing and will likely remain so leading up to the exa-scale era. Therefore, efficient and clever use of MPI is necessary to ensure that performance and scaling do not degrade as we attempt to use the ever-growing resources enabled by ever-larger supercomputers (e.g. Mendygral et al. 2017). An important aspect of this is efficient load balancing, whereby a simulation redistributes the work dynamically in an attempt to maintain an even workload across resources.
Herein, we put forward and explore novel techniques that not only enable better utilization and scaling for the forthcoming exa-scale era, but immediately offer distinct advantages for existing tools. Key to this, among other features, are the concept of locally determined time-steps, which, in realistic situations, can lead to dramatic savings of computing time. Next, the closely related concept of task-based execution, wherein each task depends on only a finite number of ‘neighbouring’ tasks. These tasks are often, but not necessarily, geometrically close. For example, sets of neighbouring tasks which solve a system of partial differential equations in space and time (which we denote as patches) need to supply guard zone values of density, momentum, etc., to one another, but neighbouring tasks can also encompass radiative transfer tasks with rays passing through the patch, or particle-based tasks, where particles travel through and interact with gas in a grid-based task. The neighbour concept can thus be described as a ‘dependence’ concept. By relying on this concept, we can ensure that MPI processes only need to communicate with a finite number of other MPI processes and, thus, we can, to a large (and often complete) extent, avoid the use of MPI global communications. In this regard, the neighbour concept provides the potential for essentially unlimited MPI scalability. The avoidance of global operations and the neighbour concept also applies to intra-node shared-memory parallelism: First, we keep the number of OpenMP ‘critical regions’ to an absolute minimum and instead rely on ‘atomic’ constructs. Secondly, we employ many more tasks per MPI rank than there are hardware threads, ensuring there are many more executable tasks than neighbour dependencies. Intra-node scalability is therefore, in general, limited only by memory bandwidth and cache usage.
These features are the foundation of the dispatch simulation framework. In what follows, we first describe the overall structure of the framework, outlining its constituent components and their interaction (Section 2). In Section 3, we then review the code structure in the context of execution of an experiment. In Section 4, we describe the major code components of the dispatch framework in detail. In Section 5, we validate the concepts and components by using four different numerical experiments to demonstrate the advantages of the dispatch framework and confirm that the solvers employed produce the same results as when used separately. To emphasize the framework aspect, each of the experiments uses a different solver; two internal solvers (a hydrodynamical Riemann solver and a staggered-mesh RMHD solver) and one external solver (zeus-|$\scriptstyle{3}$|d, implemented as an external library). Finally, in Section 6, we summarize the properties and advantages of the dispatch framework, relative to using conventional codes such as ramses, stagger, and azeus. In follow-up work (Popovas et al. in preparation; Ramsey et al. in preparation), we will extend our description of the dispatch framework to include dynamic refinement, moving patches, and patches of mixed coordinate types.
2 OBJECT HIERARCHY
dispatch is written in object-oriented fortran and relies heavily on the concept of inheritance.3 Certainly, the ideas and concepts within dispatch could easily be carried over to another object-oriented language, such as c++, but conversely, fortran does not impose any serious language-related limitations on their implementation.
The framework is built on two main classes of objects: tasks and task lists.
2.1 Tasks
The task class hierarchy has, as its defining member, a
task data type, which carries fundamental state information such as task position, times, time-steps, the number of time slices stored, status flags, rank, and so on. The task data type also includes methods4 for acquiring a task ID, setting and inquiring about status flags, plus ‘deferred methods’ that extending objects must implement. All mesh-based tasks extend the task data type to a
patch data type, which adds spatial properties, such as size, resolution, number of guard zones, coordinate system (Cartesian or curvilinear), number of physical variables, etc. Patches also contain methods for measuring intersections between different patches in space and time, as well as for writing and reading snapshots. These are generic properties and methods, and are shared by all mesh based
solver data types, which specify the physical variables to be advanced, adds methods to initialize and advance the patch data forward in time, plus any parameters that are specific to the solver in question. The specific solver data type is then extended to an
experiment data type, which adds experiment-specific functionality, such as initial and boundary conditions, in addition to the specific update procedure for the experiment. The experiment data type also serves as a generic wrapper that is accessed from the task list class hierarchy, effectively hiding the choice of solver, thus making it possible to execute the same experiment with different solvers.
2.2 Task lists
The task list class hierarchy has as its base member a
node data type, which defines a single node in a doubly linked list that points to, and carries information about, individual tasks. In addition to pointers to the previous and next nodes, nodes have a pointer to the head of a linked list of nbors, a concept that generalizes neighbours beyond spatial proximity to include tasks that in one way or another depend on the current task, or because the current task depends on them. The node data type also includes methods to initialize and maintain its own neighbour list. Individual nodes are used by the
list data type, which defines a doubly-linked list of nodes and keeps track of its properties. The list data type also contains the generic methods necessary to manipulate linked lists, such as appending, removing and sorting of nodes. It is, however, the
task list data type that extends the list data type with methods that are specific to the execution of tasks and the handling of task relations. In particular, the task list data type contains the update method, which is a key procedure in dispatch and responsible for selecting a task for updating. The complete execution of a dispatch experiment essentially consists of calling the task list execute procedure, which calls the task list update procedure repeatedly until all tasks are finished; this is typically defined as having advanced to a task's final time.
2.3 Components
The primary means of generating task lists in dispatch is via a set of components, each of which produces a subset of tasks, organized in some systematic fashion. For example, one of the most frequently used components is the Cartesian component, which generates and organizes tasks in a non-overlapping, regular and Cartesian-like spatial decomposition; in this case, each task initially has, in general, 33 − 1 = 26 spatial nbors. The corresponding mesh-based tasks/patches may, in turn, use Cartesian or orthogonal curvilinear coordinates; in the latter case, the Cartesian-like partitioning of tasks is performed in curvilinear space.
Another commonly used component creates nested sets of ‘Rubik's Cube’ (3 × 3 × 3) or ‘Rubik's Revenge’ (4 × 4 × 4) patches. For example, one can arrange 27 patches into a 3 × 3 × 3 cube, and then repeat the arrangement recursively by splitting the central patch into 3 × 3 × 3 child patches, each with a cell size that is three times smaller than its parent patch. A ‘Rubik's Revenge’ setup is analogous, except that it uses 4 × 4 × 4 patches and the central 2 × 2 × 2 patches are each split into a new 2 × 2 × 2 arrangement, leading to a resolution hierarchy with a factor of 2 decrease in patch and cell size with each additional level. The nested set can furthermore be complemented by repeating the coarsest level configuration in one or more directions.
The Rubik's-type component is useful, for example, to represent the environment near a planetary embryo embedded in an accretion disc, making it possible to cover the dynamic range from a small fraction of the planet radius to the scale height of the accretion disc with a relatively limited number of patches (e.g. [no. levels + no. extra sets]× 27). The set of patches produced by a Rubik's component can then be placed in the reference frame comoving with the planetary embryo, with corresponding Coriolis and net inertial (centrifugal) forces added to the solver, thus gaining a time-step advantage relative to the stationary lab frame.
Another kind of component available in dispatch, exemplified by sets of tasks that solve radiative transfer (Section 4.2), may overlap spatially with patches, but there is additionally an important causal dependence present. For example, patches which solve the equations of MHD provide densities and temperatures to sets of radiative transfer tasks in order to calculate the radiation field. In return, the radiative transfer tasks provide heating or cooling rates to be applied to the MHD patches prior to the next update. This kind of ‘causally linked’ component can operate either as an extension on top of another task, or as a semi-independent set of tasks coupled only by pointers. In the former, the task presents as only a single task and is therefore updated in step with its causal nbor. In the latter, there is substantial freedom in choosing when to update the component. A good example of this in practice in bifrost (Gudiksen et al. 2011) solar simulations, where the radiative transfer problem is solved with a slower cadence than the one used to evolve the MHD (Hayek et al. 2010).
2.4 Scenes
Components, such as those described in the previous subsection, are used as building blocks to create a scene hierarchy, where one could have, for example, a top level that is a galaxy model, which, in its spiral arms, contain a number of instances of giant molecular cloud components, each of which contains any number of protostellar system components, where a protostellar system component contains an accretion disc component, with a collection of moving patches representing the gas in the accretion disc. These patches would be orbiting a central star, whose evolution could be followed by, for example, a mesa (Paxton et al. 2010) model, which takes the accretion rate directly from a sink particle component that represents the star. In addition, the protostellar system component could contain Rubik's Cube components, comoving with planetary embryos, which could, in turn, be coupled to particle transport tasks representing dust in the accretion disc. Indeed, scenes are the way to build up simulations, complex or otherwise, from one or more individual components in dispatch; in the end, a scene need only provide a task list that is ready for execution, i.e. with the nbor relations already determined.
3 CODE FUNCTIONALITY
The overall structure and functionality of the code framework is best understood by combining several possible perspectives on the activities that take place as an experiment is executed. Below we adopt, one-by-one, perspectives that take (A) the point of view of a single task, and the steps it goes through cyclically, (B) the point of view of the task scheduler/dispatcher, as it first selects tasks for execution/updating and then later checks on these tasks to evaluate the consequences of the updates. Then (C) we take the point of view of the ensemble of MPI processes, and their means of communicating. Next, (D) we take the point of view of the load balancer, and look at how, in addition to keeping the load balanced between the MPI processes, it tries to minimize the actual need to communicate. Finally, (E) we take the point of view of the I/O sub-system, and examine how, within the ensemble of MPI processes, snapshots can be written to disc for post-processing and/or experiment continuation.
3.1 (A) Single task view
For simplicity, we consider the phases that a mesh-based experiment task goes through; the sequence that a different type of task experiences does not differ substantially. An experiment task, an extension of a solver task, itself an extension of a patch task, relies on having guard zone values that are up-to-date before it can be advanced to the next time-step. In general, guard zone values have to be interpolated in time and space, since patches use local time-stepping (and are therefore generally not synchronized in time) and can have differing resolutions. To enable interpolation in time, values of the field variables (e.g. density, momentum, etc.) in each patch are saved in a number of time slices (typically 5–7) using a circular buffer. Interpolation in space, prolongation, and its inverse process, restriction, are meanwhile accomplished using conservative interpolation and averaging operators.
The ‘dispatcher’ (see below) checks if neighbouring patches have advanced sufficiently enough in time to supply guard zone values to the current patch before moving it to a (time-sorted) ‘ready queue’. After having been selected by the dispatcher for update, patches are then switched to a ‘busy’ state, in which both the internal state variables (e.g. the MHD variables) and the patch time is updated. The new state overwrites the oldest state in the circular buffer, and since guard zone values corresponding to the next time-step are not yet available, the task is put back in to the ‘not ready’ state. Occasionally, when the patch time exceeds its next scheduled output time, an output method (which can be generic to the patch data type or overloaded by a solver or experiment-specific method) is called (see below).
3.2 (B) Task scheduler view
In the series of states and events discussed above, the selection and preparation of the task for update is the responsibility of the task scheduler update method, which is a central functionality (in practice, spread over several methods) in the dispatch code – this is essentially the dispatcher functionality that has given the code framework one of the inspirations for its name (the other one derived from its use of partially DISconnected PATCHes).
The task list update procedure can operate in two modes. It can either
let threads pick the oldest task from a linked list of tasks (the ready queue) that have been cleared for update. This linked list is sorted by time (oldest first), so a thread only has to pick off the head from the queue and execute its update method. In this scheme, after updating the task, the thread immediately checks the neighbours of the updated task to see if perhaps one of those tasks became ‘ready’, e.g. because the newly updated task is able to provide the last piece of missing guard zone data. If any ‘ready’ tasks are found, they are inserted into the ‘ready queue’ in ascending time order. Alternatively,
the task list update procedure runs on a single OpenMP thread, picks off the oldest task from the ready queue and subsequently spawns a thread to update it. As before, it then searches the neighbour list for tasks that possibly became executable, and adds these tasks to the ready queue.
Note that, regardless of the operational mode, the task scheduler is rank-local.
The first operational mode is the simpler one; indeed, thread-parallelism in this mode is implemented using a single $omp parallel construct placed around the task list update method. This mode, however, has the drawback that two of the linked list operations – picking off the head and adding new tasks to the ready queue – are continuously being performed by a large number of threads in parallel. These two operations must therefore be protected with OpenMP critical regions to ensure that only one thread at a time is allowed to manipulate the ready queue. This is not a problem as long as the number of threads per MPI process is limited; even on a 68-core Intel Xeon Phi processor, there is hardly any measurable impact.
However, in order to obtain truly unlimited OpenMP scalability, it is necessary to operate entirely without OpenMP critical regions, which is possible with the second mode of operation. In this mode, a single (master) thread is responsible for both removing tasks from the ready queue, as well as adding new tasks to it. In this mode, the actual task updates are performed by OpenMP threads initiated by $omp task constructs, with the task list update method running on the master thread being responsible (only) for spawning tasks and handling linked list operations. Therefore, no critical regions are needed, and one can reach much larger numbers of threads per MPI process. The load on the master thread is expected to be ignorable, and if it ever tended to become noticeable, it can easily spawn sub-tasks that would take care of most of the actual work. Note also, that the default behaviour of OpenMP task constructs is that the spawning task can also participate in the actual work (possibly encouraged to do so by suitably placed $omp taskyield constructs).
3.2.1 Defining task ‘readiness’
The is_ahead_of function may be overloaded at any level of the task hierarchy. This may be used, e.g. where the tasks of a particular experiment are defined. One might decide, as is done routinely in the bifrost code, that the radiative transfer solution should be calculated less frequently than the dynamics, and thus is_ahead_of should be overloaded to return true when the causal neighbours of self satisfy an appropriate criterion.
When extrapolation in time is actually used, as well as when interpolating in time to fill guard zone values, the default action is to use linear inter- and extrapolation in time. However, since several time slices are available, one may choose to use higher order time inter- and extrapolation. Second-order extrapolation in time has, e.g. turned out to be optimal for the gravitational potential when solving the Poisson equation under certain circumstances (Ramsey, Haugbølle & Nordlund submitted).
3.3 (C) MPI process view
In dispatch, there is typically one MPI process per compute node or per physical CPU (central processing unit) ‘socket’. Each MPI process also typically engages a number of OpenMP threads that matches or exceeds (if ‘hyper-threading’ is supported and favourable) the number of physical cores. Since the number of tasks that are executable at any given time may be a small fraction of the total number of tasks, each MPI process typically ‘owns’ a number of tasks that significantly exceeds the number of available OpenMP threads. Some of these tasks are naturally located near the geometrical edge of a rank (henceforth ‘boundary tasks’), and they therefore could have neighbour tasks that belong to a different MPI process (henceforth ‘virtual tasks’); the remaining ‘internal’ tasks have, by definition, neighbours that are entirely owned by the same MPI process.
As soon as a task marked as a boundary task has been updated by an OpenMP thread, the thread prepares an MPI package and sends it to all MPI processes that need information from that task (i.e. its ‘nbors’). Conversely, each time a thread receives a package from a nbor, it immediately issues a new MPI_IRECV to initiate receipt of the next package. Threads that become available for new work start by checking a share of the outstanding message requests using a thread private list, which eliminates the need for OpenMP critical regions when receiving and unpacking MPI packages.
The MPI packages are typically used for supplying guard zone values. By sending this information pro-actively (using MPI_ISEND), rather than having other MPI processes ask for it, the latency can be greatly reduced, and chances improve that the boundary patches of other processes will have up-to-date data available in their virtual neighbours to supply guard zone data when their neighbour lists are checked.
The MPI packaging for patches contains both a copy of the most relevant task parameters and the state variables in the interior of the patch. There are essentially two reasons to ship data for all interior zones, rather than limiting the package content only to layers that will be needed for guard zone data. First, this simplifies package creation and handling, and network capacity is generally large enough to allow this for moderately sized patches without any noticeable slowdown. Second, this simplifies load balancing (see below), since it allows changing the owner of a patch by simply ‘giving’ a patch to a neighbour MPI process. The patch then needs only change its status, from ‘virtual’ to ‘boundary’ on the receiver side, and from ‘boundary’ to ‘virtual’ on the sender side.
Should memory bandwidth actually become a problem one can reduce the network traffic significantly by only sending guard zone values, at the cost of added complexity in the package pack and unpack methods and in the load balancing methods.
3.4 (D) Load balancer view
Given the ownership swap protocol outlined above, the actual balancing of workload is a nearly trivial task, since any MPI process that finds itself with a surplus of work, relative to a neighbouring MPI process, can easily ‘sell’ some of its boundary tasks to its less-loaded neighbour MPI processes. However, doing so indiscriminately risks creating ragged geometric boundaries between neighbouring MPI processes. In this sense, the load balancer should also function as a ‘communication balancer’ which attempts to keep the number of MPI communications per rank and per unit simulation time near some minimum value.
Load balancing follows each task update, and can be performed after every update, after a given number of updates of each task, or after a given wall clock time has passed since the previous load balance. Load balancing is entirely local, with each task evaluating (in an OpenMP critical region) if the number of communications, or the load imbalance, can be reduced by passing ownership of the task to one of its rank neighbours. A minimum threshold for imbalance is implemented to prevent frequent passing of tasks that only marginally improves the imbalance. Only boundary tasks, i.e. tasks that have neighbours on other ranks are candidates for ownership transfer. If the transfer is beneficial, the task indicates to the rank neighbour that ownership should be changed. The rank that takes over ownership then changes the task status from ‘virtual’ to ‘boundary’, while the previous owner changes the status from ‘boundary’ to ‘virtual’. All affected tasks then refresh their neighbour lists to reflect the new situation.
By using emulation of an initially and severely fragmented patch distribution via software prototyping, we find that it is more efficient to address the load imbalance and the communication reduction in two separate steps while, within each step, the other aspect of the balancing is more or less ignored.
The procedure is essentially as follows:
Count the number of MPI neighbours for each rank by enumerating the number of different ranks recorded in the neighbour lists of a rank's boundary tasks.
Evaluate, for each boundary task, if the total number of MPI neighbours on the involved ranks would be reduced if ownership of a task is swapped. In this step, one carries out the most advantageous swaps, even if a swap would tend to introduce a load imbalance.
In a separate step, evaluate if any task swaps can be made that restore load balance, without increasing the number of MPI neighbours.
The reason this two-step procedure is advantageous, relative to trying to reduce communications under the simultaneous constraint to avoid causing imbalance, is that it is relatively difficult to find good swaps in step (ii), and the process is made easier if load (im)balance is temporarily ignored. It is, meanwhile, relatively easy in step (iii) to find swaps that improve load balance without changing the total number of MPI neighbours.
3.5 (E) Input/output view
After a task has been updated, its current time in code units is compared to the task per centout_next parameter and, upon passage of that out_next, the task output method is called and a snapshot is written. The actual method invoked depends on where in the task hierarchy the generic output method has been overridden. For example, if an experiment-specific method has not been implemented, then a solver-specific method will be invoked if implemented, otherwise a generic patch output method is used. Currently, dispatch snapshots use one of two output formats: One that writes patch data as raw binary data to one file, and patch information as text to another file. An alternative output format uses the packing procedure used to communicate task data between MPI ranks, and collects the data for all tasks on a MPI rank into a single file. In either case, these snapshots are suitable not only for visualization but also for restarting a simulation. Finally, for reasons of portability and performance, parallel HDF5 support is currently being explored.
4 CURRENT CODE COMPONENTS
4.1 Internal and external HD, MHD, and PIC solvers
The solvers from a few well-used and well-documented astrophysical fluid codes have been ported to the dispatch framework and validated using experiments carried out with both the original code and the dispatch implementation. As a first representative of Godunov-type Riemann solvers, the HLLC solver from the public domain ramses code (Teyssier 2002) has been incorporated. To take advantage of the dispatch speed advantages in stellar atmosphere and similar work (e.g. Baumann, Haugbølle & Nordlund 2013), several versions of the stagger code (Nordlund et al. 1994; Kritsuk et al. 2011) class of solvers have also been ported. As an example of connecting to an external solver, the zeus-|$\scriptstyle{3}$|d solver (Clarke 1996, 2010) used in the azeus AMR code (Ramsey et al. 2012) is available; the zeus-|$\scriptstyle{3}$|d solver is also the only currently-included solver that can leverage the advantage of orthogonal, curvilinear coordinate systems (e.g. cylindrical, spherical).
Incorporating an external solver as a library call in dispatch is straightforward, but requires some modification of the external code. An explicit interface must be defined by the external solver. One must also ensure that the external solver is ‘thread-safe’, i.e. it can safely be invoked by many threads at once. Initialization and updating procedures are meanwhile defined in the dispatchsolver module; these procedures exist for all solvers in dispatch, external or otherwise. As part of the update procedure, conversion procedures may be required to ensure the physical variables are in a format suitable for the solver. For example, in zeus-|$\scriptstyle{3}$|d, velocity is a primary variable while, in dispatch, we store the momentum. After the external solver is called, the data must be converted back to dispatch variables. At this point, the developer decides whether dispatch or the external solver determines the next time-step. In the case of zeus-|$\scriptstyle{3}$|d, it determines the next Courant-limited time-step internally and returns the value to dispatch. Calling an external solver occurs at the same point in dispatch as any other solver, as part of a task update procedure. Memory management within the external solver is, meanwhile, not controlled by dispatch.
In ongoing work, we are also incorporating the public domain version of the photon-plasma particle-in-cell code, ppcode5 (Haugbølle, Frederiksen & Nordlund 2013), and the bifrost MHD code (Gudiksen et al. 2011), including its modules related to chromospheric and coronal physics. We intend to use these solvers for multiple-domain-multiple-physics experiments in the context of modelling solar and stellar atmospheric dynamics driven by sub-surface magneto-convection, expanding on the type of work exemplified in Baumann et al. (2013).
4.2 Radiative transfer
Radiative processes are undeniably important in most astrophysical applications (e.g. planetary atmospheres, protoplanetary disc structure, H ii regions, and solar physics, to name a few). Being a 7D problem (three space + time + wavelength + unit position vector), it can be a daunting physical process to solve. A number of approaches have been developed over the last several decades in an attempt to tackle the problem, including flux-limited diffusion (Levermore & Pomraning 1981, Fourier transforms (e.g. Cen 2002), Monte Carlo techniques (e.g. Robitaille 2011), variable tensor Eddington factors (Dullemond & Turolla 2000), short (e.g. Stone, Mihalas & Norman 1992), long (e.g. Nordlund 1982; Heinemann et al. 2006), and hybrid (Rijkhorst et al. 2006) characteristics ray-tracing.
dispatch currently implements a hybrid-characteristics ray-tracing radiative transfer (RT) scheme: long rays inside patches and short rays in-between, albeit with a few exceptions as described below. The RT module consists of a ray-geometry (RG) component, an initialization component, and run time schemes; each component needs to know very little about how the others work, even though they rely heavily on each other. In addition, since the RT module depends on the values of, for example, density and temperature, it also relies on the co-existence of instances of a solver data type that can provide these quantities. Below, we briefly explain the purpose of each of the RT components; a detailed description of the RT module, together with implementation details for refined meshes and additional validation tests, will appear in a subsequent paper of this series (Popovas et al. in preparation).
Current solver implementations include Feautrier and integral method formal solvers (e.g. Nordlund 1984), multifrequency bin opacities, and source function formulations with either pure thermal emission, or with a scattering component.6 Scattering is handled in a similar way as in the bifrost code (Hayek et al. 2010). For cases with low to moderate albedos, the method is essentially lambda-iteration. The specific intensities from previous time-steps are stored in dispatch time slices and are used as starting values for the next time-steps, which makes this approach effective. Extreme scattering cases could be handled by implementing more sophisticated methods, such as accelerated lambda iteration (Hubeny 2003).
4.2.1 Ray geometry
When the RT module is initialized, it first creates a RG for existing patches. The only information the RG component needs is the simulation geometry type (Cartesian/cylindrical/spherical), dimensions of a patch (number of cells per direction), the desired number of ray directions, and their angular separation. The RG component then proceeds to spawn rays: Each ray starts at one patch boundary and ends at another boundary (face, edge, or corner) of the same patch. Spacing of rays is set to the patch cell size along the direction that forms the largest angle with the ray. The ray points are, ideally, co-centred with patch cell centres along the direction of the ray. In this case, the required hydrodynamic quantities (e.g. density and internal energy) do not need to be interpolated to the RG, and neither do the resulting intensities need to be interpolated back to the mesh; this saves a significant amount of computational time. If angular resolution surpassing that provided by rays along axes, face diagonals, and space diagonals is required, this can be accomplished via rays in arbitrary directions but with an extra cost resulting from interpolating temperature and density to ray points and then interpolating the resulting net heating or cooling back to the patch mesh. In this case, as with the MHD variables, interpolation to ray points and of the subsequent heating rate back to the mesh are done using conservative operators.
Once all rays have been created, they are organized into a fast look-up tree hierarchy. The primary access to this tree is through the RG type. Within a RG object, the rays are further sub-divided into
ray directions – in principle, as long as scattering is not considered, rays in one direction do not care about rays with another direction, so they can be separated and updated as independent tasks by different threads. To solve for RT inside a patch, boundary conditions from the patch walls (i.e. boundary face) that the rays originate from are required. Not all slanted rays with one direction originate and terminate at the same wall (see Fig. 1). To avoid waiting time originating from sets of ray directions that end on more than one patch wall, the complete set is further sub-divided into
ray bundles – these are defined as sets of rays that originate and terminate on the same pair of patch walls. RT is a highly repetitive task, where a large numbers of rays is typically considered. It is thus highly advantageous to use schemes that maximize hardware vectorization in order to reduce the computation time. Therefore, all rays should, preferably, be of the same length. This is a natural feature of rays that are parallel to a patch coordinate axis; slanted ones, meanwhile, are further rearranged into
ray packets – these are the sets of rays in one ray bundle that have the same length. To promote faster data lookup (e.g. interpolating ray coordinates to patch coordinates, origin/termination points, etc.), they are organized as data arrays.

Ray-geometry representation in 2D. (M)HD grid cells are represented by grey squares, coloured lines represent rays. Different line styles represent different directions. Different colours represent different bundles.
Note that axis-oriented rays, as well as rays with specific spatial angles (e.g. 45°), will generally terminate at locations that coincide with the origins of rays in a ‘downstream’ (with respect to RT) patch. This is exploited in the current implementation by introducing the concept of ray bundle chains.
4.2.2 Ray bundle chains
To obtain the correct heating/cooling rates inside a patch, one needs boundary values/incoming intensities from ‘upstream’ patches. By reorganizing rays into bundles (see above), one minimizes the number of walls needed per particular bundle down to a single pair: one at the origin and one at the termination. Such an arrangement allows the connection of one ray bundle to a similar ray bundle in a neighbour patch, resulting in a bundle chain. If we continue the analogy with actual chains, then the first, or master, chain ‘link’ is connected to an outer boundary, and all the other links, by virtue of the chain, obtain their boundary values from their upstream link immediately after the RT is solved on the upstream link. If the upstream surface of a link is a physical boundary or a change in spatial resolution, this particular link is defined as being the first link in the chain, i.e. the one from which execution of the chain starts. Bundle chains effectively transform the short-characteristic ray scheme inside patches into long-characteristic rays over many patches along the ray bundle direction.
4.2.3 RT initialization and execution
After the RG has been generated, the RT initialization component steps through all of the patches in the task list and creates an overlapping RT patch. The RT patch keeps track of all the ray directions and sets up bundle chains by searching for upstream patches in a patch's neighbour list.
When an (M)HD patch, and subsequently the internal state variables, is updated, a corresponding RT patch is ready to be executed. Initially, it may not have wall/boundary data available, but it can still prepare the internal part by evaluating the source function and opacities for the internal cells. The RT patch then steps through its list of bundles and ‘nudges’ the master links of any bundle chains. The master link could belong to this patch, or it could belong to a very distant patch along a particular ray direction. In most cases, chain links along an arbitrary ray direction are not yet ready for execution (e.g. the internal data for an RT patch is not prepared yet), so the master link simply records which links in the chain are ready. As soon as a last nudge indicates that all links are ready, the chain can be executed recursively, as follows:
The first bundle in the chain gets boundary values either from physical boundary conditions, or retrieves them from an upstream patch; in the latter case, the upstream source is either a virtual patch on another MPI rank or has a different spatial resolution (and therefore requires interpolation).
Simultaneously, the source function and opacities are mapped from internal patch data on to the ray bundle coordinates.
The boundary values and mapped internal data are sent to an RT solver. The solver returns the heating/cooling rates for internal cells in addition to wall intensities, which, in turn, are sent to the next, downstream link in the bundle chain.
Once a bundle chain has executed, the chain and its individual links are placed in a ‘not ready’ state while the chain waits for the corresponding MHD patches to be updated again. In practice, it may not be necessary (or practical) to solve RT after every MHD update. Thus, one can instead specify the number of MHD updates or time interval after which the next RT update will be scheduled.
4.3 Non-ideal MHD
The importance of magnetic fields in astrophysics is well established, as is the application of MHD to problems involving magnetized fluids. However, non-ideal MHD effects (Ohmic dissipation, ambipolar diffusion, and the Hall effect) can be important in various astrophysical contexts, for instance, in protoplanetary discs and the interstellar medium. Here, we account for the additional physical effects of Ohmic dissipation and ambipolar diffusion in dispatch by extending the already implemented MHD solvers. We illustrate the process using the staggered-mesh solvers based on the stagger code (Nordlund et al. 1994; Kritsuk et al. 2011); the implementation in other solvers would differs mainly in details related to the centring of variables. In the stagger and zeus-|$\scriptstyle{3}$|d solvers, for example, components of momentum are face-centred, while in the ramses MHD solver, momentum is cell-centred. In all of the currently implemented MHD solvers, electric currents and electric fields are edge-centred, following the constrained transport method (Evans & Hawley 1988) to conserve |$\nabla \cdot \boldsymbol B = 0$|.
4.3.1 Ohmic dissipation
4.3.2 Ambipolar diffusion
In the case of a gas that is only partially ionized, magnetic fields directly affect the ionized gas but not the neutral gas; the neutral gas is instead coupled to the ions via an ion-neutral drag term. In general, therefore, the ionized gas moves with a different speed than the neutral gas. If the speed difference is small enough to neglect inertial effects, the drag term can be represented by estimating the speed difference (i.e. the ‘drift speed’) between the ionized and neutral gas. We implement this so-called single-fluid approach along the lines of previous works (cf. Mac Low et al. 1995; Padoan, Zweibel & Nordlund 2000; Duffin & Pudritz 2008; Masson et al. 2012).
4.4 Particle trajectory integration
Particles in dispatch can be treated as both massive and massless. Massless particles may be used for diagnostic tracing of Lagrangian evolution histories, while particles with mass may be used to model the interaction of gas and dust, which is an important process, particularly in protoplanetary discs.
To be able to represent a wide distribution of dust particle sizes without major impact on the cost the particle solver must be fast, and the particle integration methods have been chosen with that in mind. Trajectories are integrated using a symplectic, kick-drift-kick leap-frog integrator, similar to the one in gadget|$\scriptstyle{2}$| (Springel 2005). In the case of massive particles we use forward-time-centring of the drag force, which maintains stability in the stiff limit when drag dominates in the equation of motion. Back-reaction of the drag force on the gas is currently neglected – this will be included in a future version.
4.5 Equation-of-state and opacity tables
dispatch is designed from the ground up to include several options and look-up tables for both idealized and realistic equation of state (EOS) and opacities. To look-up tables as efficient as possible, binary data files with fine grained tables are generated ahead of time using utilities written in python and included with the code. These utilities read data from various sources and convert it to look-up tables in the logarithm of density and an energy variable; which type energy is used depends on the solver. For example, the HLLC and zeus-|$\scriptstyle{3}$|d solvers use thermal energy in the EOS, as do most of the stagger code solvers, while one version of the stagger code instead uses entropy as the ‘energy’ variable. Naturally, for simple EOSs such as constant gamma ideal gas, a look-up table is not necessary and calls to the EOS component instead end in a function appropriate for the current solver.
The look-up table is heavily optimized, first by using spline interpolations in the python utilities to produce tables with sufficient resolution to enable bi-linear interpolation in log-space in dispatch. The table address calculations and interpolations are vectorized, while a small fraction of the procedure (data access) remains non-vectorized because of indirect addressing.
5 VALIDATION
Since the solver components of dispatch are taken from existing, well-documented codes, validation in the current context requires only verification that the dispatch results agree with those from the standalone codes and, furthermore, verification that the partitioning into patches with independent time-steps does not significantly affect the results. In this section, we document validation tests for the main HD and MHD solvers, for the non-ideal MHD extension to these solvers, and for the radiative transfer code component. We concentrate on the validation aspect, mentioning performance and scaling only in passing; more details on these aspects will appear in a subsequent paper (Ramsey et al. in preparation).
For any particular experiment, all solvers use the same ‘generator’ to set the initial conditions, which makes it easy to validate the solvers against each other, and to check functionality and reproducibility after changes to the code. A simple regression testing mechanism has been implemented in the form of a shell script, permitting each experiment to be validated against previous or fiducial results. By also making use of the ‘pipelines’ feature on bitbucket.org, selected validations are automatically triggered whenever an update is pushed to the code's git repository.
5.1 Supersonic turbulence
For the first demonstration that the solvers implemented in the dispatch framework reproduce results from the stand-alone versions of existing codes, we use the decaying turbulence experiment from the kitp code comparison (Kritsuk et al. 2011). The experiment follows the decay of supersonic turbulence, starting from an archived snapshot with 2563 cells at time t = 0.02, until time t = 0.2.
In Fig. 2, we display the projected mass density at the end of the experiment, carried out using the HLLC solver from ramses. On the one hand, a single patch (left-hand panel) reproduces results obtained with ramses, while, on the other hand, using 512 (right-hand panel) patches with 323 cells each, evolving with local time-steps determined by the same Courant conditions as in the ramses code (but locally, for each patch), still demonstrates good agreement with the ramses results. The solutions are visually nearly indistinguishable, even after roughly two dynamical times. The root-mean-square velocities are practically identical, with a relative difference of only 6 × 10−4 at the end of the experiments.
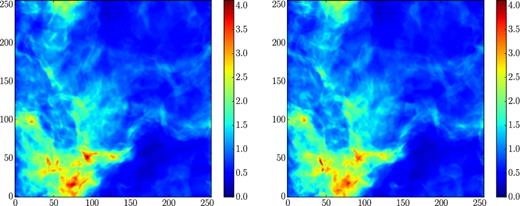
Left: Projected density in code units at time t = 0.2 for the kitp decaying turbulence experiment when using a single patch with 2563 cells. Right: The same, but using 512 patches, each with 323 cells. Note that the density has been raised to a power of 0.5 to enhance the contrast. The cell indices are denoted on the axes.
Fig. 3 shows two difference images, displaying the absolute value of the differences in the projected density (raised to the power of 0.5 to enhance visibility). The left-hand panel shows the difference between the runs with 1 and 512 patches, while the right-hand panel shows the difference between two otherwise identical cases with 512 patches, but with slightly different Courant numbers (0.6 and 0.8). This illustrates that a turbulence experiment can never be reproduced identically, except when all conditions are exactly the same; small differences due to truncation errors grow with time, according to some Lyapunov exponent.
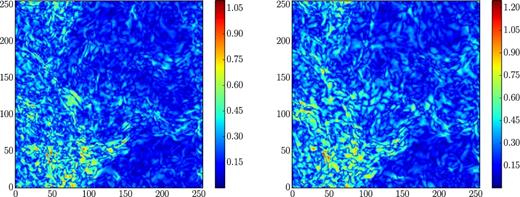
Left: The absolute difference between the left-hand and right-hand panels of Fig. 2 (i.e. in projected density). Right: The difference between two runs, obtained with Courant numbers 0.6 and 0.8, respectively.
Figs 2 and 3 validate the use of our patch-based local time-stepping in two different ways: First, through the absence of any trace of patch boundaries in the difference image and, secondly, by demonstrating that the differences are consistent with differences expected simply from the use of different Courant numbers. In the single-patch case (as well as in ramses and other traditional codes), local regions with relatively low flow speeds are effectively evolved with very low local Courant numbers (i.e. time-steps are locally much smaller than that permitted by the local Courant condition), while the patch-based evolution takes advantage of the lower speeds by using locally larger time-steps.
The local time-step advantage can be quantified by the number of cell-updates needed. The single-patch case needs about 2 × 1010 cell updates (as does ramses), while the experiment using 512 patches with local time-steps needs only about 1.4 × 1010 cell-updates. Using 20-core Intel Xeon Ivy Bridge CPUs, the 512 patch experiment takes only 6.5 min when run on 30 hardware threads (and 7.0 min with 20 threads). The cost per cell update is 0.61 core-|$\mu$|s in the single-patch case, 0.56 core-|$\mu$|s in the 20 thread case, and 0.53 core-|$\mu$|s in the 30 thread case. The superlinear scaling from 1 to 20 cores is mainly due to better cache utilization when using 323 cells per patch, while the additional improvement when using 30 hardware threads on 20 cores illustrates a hyper-threading advantage; with more hardware threads than cores, the CPU has a better chance to find executable threads.
5.2 The local time-step advantage
In this benchmark, where the initially highly supersonic turbulence rapidly decays, and a uniform resolution is used, the local time-step advantage is only of the order of 30 per cent. However, the advantage grows with the complexity of the simulation and, in particular, with the dynamic range of signal speeds present. Two examples, using snapshots from published works may be used to illustrate this point: In zoom-in simulations with ramses, such as Kuffmeier et al. (2016), Kuffmeier, Haugbølle & Nordlund (2017), time-steps are a factor of two smaller in octs with half the cell size. This is already a significant improvement relative to using the same time-step at all AMR resolution levels. However, the global time-step is still set by the highest signal speed that occurs in the domain. In this particular case, this is typically – often not even at the highest resolution level – where the density is very low, but the magnetic field is not. By analysing snapshots from such simulations we find that the update cost per unit time can be reduced by factors of order 10–30 if time-steps are determined locally in patches with dimensions of the order of 323 cells.
Similar situations arise when modelling solar active regions (Stein & Nordlund 2012). The Alfvén speed can become extremely large (of the order of 30 per cent the speed of light) at some height above sunspots where the temperature is low and the density drops much more rapidly with height than the magnetic field. The fractional volume where this happens is very small, but in current simulations the time-step is imposed on the entire computational volume when, in fact, signal speeds are typically only 10–30 km s−1. Analysis of such snapshots shows cost reductions of the order of 30 from using local time-steps. Clearly, the larger the computational volume, the larger the chance to encounter ‘hotspots’ with locally very high signal speeds, and hence the time-step advantage may be expected to become even larger in the future, particularly as models become more realistic and highly resolved.
5.3 Weak and strong scaling
We now switch to driven isothermal turbulence experiments to explore the weak and strong scaling properties of dispatch; the decaying turbulence experiment relies on the 2563 code comparison snapshot, and is therefore not suitable for weak scaling tests. In brief, we drive purely solenoidal, supersonic turbulence in a box with wavenumbers kL/2π ≤ 3.2, where L = 1 is the box size, until t = 0.2. The density is initially uniform and equal to 1.0, while the velocities are initially zero. There are nominally 512 patches per MPI rank, each with 323–643 cells per patch. The optimal number of cells per patch is problem and hardware dependent; a substantially reduced number of cells per patch results in a degradation in performance (cf. Mendygral et al. 2017), but also allows a potentially larger local time-step advantage.
On Intel Xeon (Haswell) CPUs, we find that, as in the decaying turbulence case, the typical cell-update cost on a single node is of the order of 0.5–0.6 core-|$\mu$|s, while on the somewhat slower Intel Xeon Phi (Knights Landing; KNL) cores, the update cost is approximately 0.8–1.1 core-|$\mu$|s. As with traditional Xeon CPUs, we find that using 2 × hyper-threading on Xeon Phi CPUs reduces the run time by |${\sim } 20\hbox{ per cent}$|. Fig. 4 demonstrates that dispatch has excellent strong scaling properties, subject to the conditions that there needs to be enough work to keep the threads busy, and sufficient memory to hold the time slices. Fig. 4 also demonstrates that, even with MPI overhead (visible at higher core counts), dispatch weak scaling on Intel Xeon and Xeon Phi CPUs is virtually flat up to 1024 (corresponding to 24 576 cores) and 3000 MPI ranks (corresponding to 204 000 cores), respectively. For comparison, we also include performance measurements for ramses (using the HLLD solver) operating in uniform resolution mode for the same driven turbulence experiment. After adjusting for the cost difference between HLLD and HLLC solvers (the former is ∼5 × more expensive than the latter), evidently, HLLD in dispatch is up to 16× faster than in ramses at large core counts. In the ramses simulations in, e.g. Padoan et al. (2016, 2017), the combined effects of HLLD speed, AMR overhead, and non-ideal OpenMP and MPI scaling result in an update cost often exceeding 100 core-|$\mu$|s per cell update, indicating that, when combined with expected gains from the local time-step advantage, accrued gain factors of the order of 1000 are possible with dispatch in extreme settings.
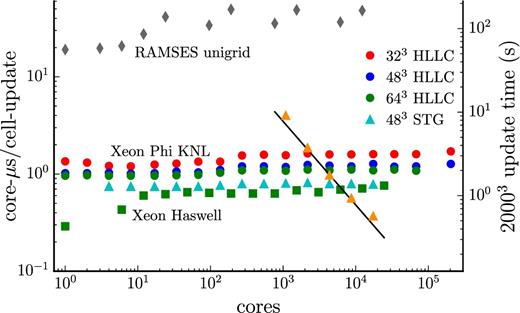
Strong and weak scaling for dispatch with the ramses HLLC and stagger (STG) code solvers, as applied to a driven turbulence experiment. The performance of the framework is demonstrated using the cost to update one cell as a function of the number of cores. The bottom set of squares denote scaling on Intel Xeon Haswell nodes at HLRS Stuttgart/HazelHen, while the top set of circles (HLLC) and triangles (stagger) denote scaling on Intel Xeon Phi Knights Landing (KNL) nodes at CINECA/Marconi (in both cases, with generally two MPI ranks per node). The grey diamonds denote the performance of ramses (HLLD) in uniform resolution mode on Intel Xeon Haswell nodes for the same driven turbulence setup. The orange triangles shows strong scaling with 16, 32, 64, 128, and 256 KNL nodes on a 20483 fixed size case, using the stagger solver with 323 patches; the straight line indicates ideal strong scaling.
Fig. 5 presents another metric of the performance of the dispatch framework and integrated solvers: the gigaflops per second (GFlop s−1) as a function of the number of cores for the driven turbulence experiment. The theoretical single precision peak performance of one Intel Xeon Phi 7250 (KNL) CPU (i.e. the ones that constitute CINECA/Marconi-KNL) is ∼78 GFlop s−1 per core. The solvers currently implemented in dispatch only reach |${\sim } 2{\rm -}3\hbox{ per cent}$| of this theoretical peak. This is not uncommon for astrophysical fluid codes, which are typically memory bandwidth limited. Note that these values characterize the solvers even in single core execution; the dispatch framework controls the scaling of the performance, while the performance per core is determined by the particular solver.
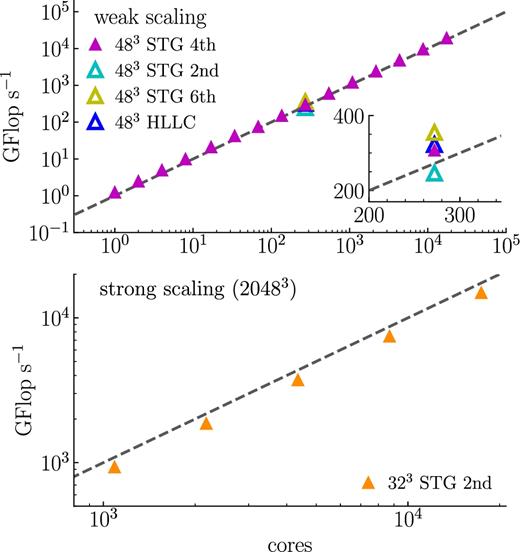
Weak (top) and strong (bottom) scaling for the driven turbulence experiment expressed in units of GFlop s−1 as a function of the number of cores. Dashed lines indicate ideal scaling. The inset zooms in on the differences in GFlop s−1 between solvers. All data was collected on CINECA/Marconi. Weak scaling tests were conducted with 483 cells per patch. The strong scaling was conducted with a fixed total 20483 cells and 323 cells per patch.
However, while the time per cell update and its scalings (Fig. 4) are the main factors determining the ‘time-to-solution’ for a simulation, the number of Flops used per second remains an important complementary indicator; not only is it the measure that defines exa-scale, its consideration is also important when trying to minimizing the time-to-solution. Modern CPUs can do many Flops per memory load/store, and for essentially all (M)HD solvers, the Flop s−1 is limited by memory bandwidth rather than by theoretical peak performance. Added complexity per update step thus potentially carries very low extra cost, especially if it does not incur any extra loads/stores. We illustrate this in Fig. 5 by showing the number of GFlop s−1 when employing second-, fourth-, and sixth-order operators in the stagger solver. Although the fourth-order operators use five Flops per point, vis-a-vis two Flops per point for the second-order operators, the total number of Flops per cell update increases only by a factor of ∼1.3 (due to Flops not related to differential operators). Meanwhile, the time per cell update/number of cell updates per core-second remains essentially unchanged, consistent with memory bandwidth being the bottleneck. Since higher order operators reduce the numerical dispersion of the scheme, they potentially allow for a reduction in the number of cells at constant solution quality, and since, in 3D, the time-to-solution generally scales as the fourth power of the number of cells per dimension, using fourth-order operators is a virtually certain advantage. Using sixth-order operators further increases the number of Flops per core-second while affecting the time per cell update only marginally, potentially offering yet more advantage. However, the increased number of guard zones necessary for higher order operators is another factor that enters the cost balance analysis, and the most optimal choice is thus problem dependent. In current (and future) applications of the framework, we (will) base the choice of solver and order of operators on the quality of the, and the time to, solution using pilot simulations to compare outcomes and to choose measures of ‘quality’ most relevant for each application.
5.4 Non-ideal MHD: C-shock
To validate the non-ideal MHD extensions, we carry out C-shock experiments following Masson et al. (2012) for both Ohmic dissipation and ambipolar diffusion. Table 1 shows the initial (left and right) states. In the isothermal case, we set the adiabatic index γ = 1 + 10−7, while we use γ = 5/3 for the non-isothermal and Ohmic dissipation runs. In the ambipolar diffusion runs, we set γAD = 75, and in the Ohmic dissipation run we use ηOhm = 0.1, where we assumed an ion density of ρi = 1 in all three cases. We test the implementations using five patches, each with dimensions 30 × 1 × 1, and plot the results in Fig. 6. Our results are in good agreement with Masson et al. (2012). Like Masson et al. (2012) and Duffin & Pudritz (2008), we find that the shock undergoes a brief period of adjustment before reaching a steady-state solution in all cases. We have confirmed that, for a moving C-shock, the solution quality is not affected by crossing patch boundaries.
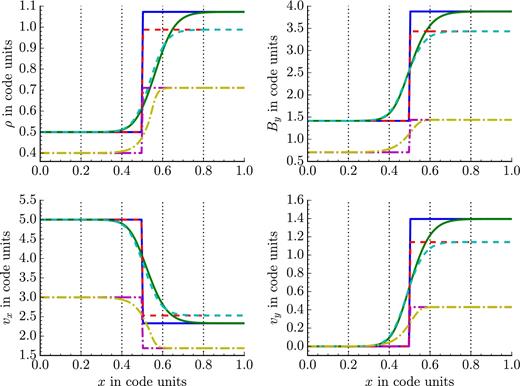
Density (upper left), By (upper right), vx (lower left), and vy (lower right) for the C-shock experiments. The solid lines correspond to the initial (blue) and evolved (green) states of the isothermal run with AD, the dashed lines correspond to the initial (red) and evolved (cyan) states of the non-isothermal run with AD, the dash–dotted lines correspond to the initial (magenta) and evolved (yellow) states of the non-isothermal run with Ohmic dissipation. Vertical dotted lines denote patch boundaries.
Initial conditions for the non-ideal C-shock experiments. Pre-shock (upstream) values refer to the left-hand side of panels in Fig. 6.
| Variable | ρ | vx | vy | Bx | By | P |
|---|---|---|---|---|---|---|
| Pre-shock (AD) | 0.5 | 5 | 0 | |$\sqrt{2}$| | |$\sqrt{2}$| | 0.125 |
| Post-shock (AD; isothermal) | 1.0727 | 2.3305 | 1.3953 | |$\sqrt{2}$| | 3.8809 | 0.2681 |
| Post-shock (AD; non-isothermal) | 0.9880 | 2.5303 | 1.1415 | |$\sqrt{2}$| | 3.4327 | 1.4075 |
| Pre-shock (Ohm) | 0.4 | 3 | 0 | |$\frac{1}{\sqrt{2}}$| | |$\frac{1}{\sqrt{2}}$| | 0.4 |
| Post-shock (Ohm) | 0.710 84 | 1.688 14 | 0.4299 | |$\frac{1}{\sqrt{2}}$| | 1.436 67 | 1.192 22 |
| Variable | ρ | vx | vy | Bx | By | P |
|---|---|---|---|---|---|---|
| Pre-shock (AD) | 0.5 | 5 | 0 | |$\sqrt{2}$| | |$\sqrt{2}$| | 0.125 |
| Post-shock (AD; isothermal) | 1.0727 | 2.3305 | 1.3953 | |$\sqrt{2}$| | 3.8809 | 0.2681 |
| Post-shock (AD; non-isothermal) | 0.9880 | 2.5303 | 1.1415 | |$\sqrt{2}$| | 3.4327 | 1.4075 |
| Pre-shock (Ohm) | 0.4 | 3 | 0 | |$\frac{1}{\sqrt{2}}$| | |$\frac{1}{\sqrt{2}}$| | 0.4 |
| Post-shock (Ohm) | 0.710 84 | 1.688 14 | 0.4299 | |$\frac{1}{\sqrt{2}}$| | 1.436 67 | 1.192 22 |
Initial conditions for the non-ideal C-shock experiments. Pre-shock (upstream) values refer to the left-hand side of panels in Fig. 6.
| Variable | ρ | vx | vy | Bx | By | P |
|---|---|---|---|---|---|---|
| Pre-shock (AD) | 0.5 | 5 | 0 | |$\sqrt{2}$| | |$\sqrt{2}$| | 0.125 |
| Post-shock (AD; isothermal) | 1.0727 | 2.3305 | 1.3953 | |$\sqrt{2}$| | 3.8809 | 0.2681 |
| Post-shock (AD; non-isothermal) | 0.9880 | 2.5303 | 1.1415 | |$\sqrt{2}$| | 3.4327 | 1.4075 |
| Pre-shock (Ohm) | 0.4 | 3 | 0 | |$\frac{1}{\sqrt{2}}$| | |$\frac{1}{\sqrt{2}}$| | 0.4 |
| Post-shock (Ohm) | 0.710 84 | 1.688 14 | 0.4299 | |$\frac{1}{\sqrt{2}}$| | 1.436 67 | 1.192 22 |
| Variable | ρ | vx | vy | Bx | By | P |
|---|---|---|---|---|---|---|
| Pre-shock (AD) | 0.5 | 5 | 0 | |$\sqrt{2}$| | |$\sqrt{2}$| | 0.125 |
| Post-shock (AD; isothermal) | 1.0727 | 2.3305 | 1.3953 | |$\sqrt{2}$| | 3.8809 | 0.2681 |
| Post-shock (AD; non-isothermal) | 0.9880 | 2.5303 | 1.1415 | |$\sqrt{2}$| | 3.4327 | 1.4075 |
| Pre-shock (Ohm) | 0.4 | 3 | 0 | |$\frac{1}{\sqrt{2}}$| | |$\frac{1}{\sqrt{2}}$| | 0.4 |
| Post-shock (Ohm) | 0.710 84 | 1.688 14 | 0.4299 | |$\frac{1}{\sqrt{2}}$| | 1.436 67 | 1.192 22 |
Even for a simple benchmark like the non-ideal C-shock, the dispatch local time-stepping advantage is already beginning to show: In the ambipolar diffusion experiments, there is a factor of ∼2 difference in the time-steps between patches.7 As the complexity of the problem and the number of patches increases, the advantage for non-ideal MHD experiments is expected to increase. Indeed, we are currently exploring if dispatch can compete with super-timestepping algorithms (e.g. Alexiades, Amiez & Gremaud 1996; Meyer, Balsara & Aslam 2014) for ambipolar diffusion, or even if there is a greater benefit by combining them.
5.5 Radiative transfer: shadow casting benchmark
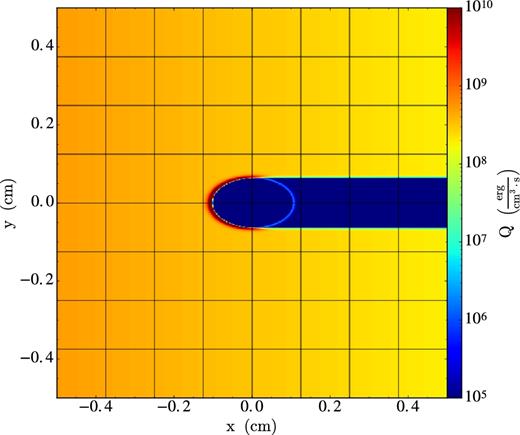
Results for the shadow casting benchmark. The irradiation source is located at the left boundary. The heating rate per unit volume, Q (equation 11), is shown, with levels indicated by the colour bar to the right.
For this experiment, the update cost is ∼0.6 core-|$\mu$|s per cell on Intel Xeon Ivy Bridge CPUs, including RT. Running the same experiment with RT disabled instead results in a cost of ∼0.5 core-|$\mu$|s per cell. Thus, even with 13 spatial directions, and even with solving for RT after every MHD update, the RT algorithm only adds approximately 20 per cent to the experiment cost. Although using a more realistic EOS (i.e. look-up table) will increase the cost slightly, clearly, the dispatch RT algorithm can provide accurate RT solutions at a very low cost. In a subsequent paper of this series (Popovas et al. in preparation), additional details and benchmarks, including further documentation on the accuracy and speed of RT in dispatch, will be provided.
5.6 de Val-Borro disc benchmark
One of the current and primary science goals of dispatch is to model planet formation processes in global and realistic settings. As such, we now apply dispatch to the global disc benchmark of de Val-Borro et al. (2006). More specifically, we embed a Jupiter-like planet in an initially uniform surface density protoplanetary accretion disc and then allow the disc to evolve for 100 orbits at the semimajor axis of the planet. Following de Val-Borro et al. (2006), we initialize a 2D, geometrically thin disc with a constant surface density given by Σ0 = 0.002M*/πa2, where M* is the mass of the central star and a is the semimajor axis of the planet. We use an aspect ratio of H/R = 0.05, where H is the canonical disc scale height, an effectively isothermal EOS (γ = 1.0001), and an initially Keplerian orbital velocity.
The computational domain has dimensions [0.4a, 2.5a] in radius and [−π, π] in azimuth; we use polar cylindrical coordinates and the zeus-|$\scriptstyle{3}$|d solver. When using curvilinear coordinates with zeus-|$\scriptstyle{3}$|d, it is the angular rather than the linear momentum that is solved, thus guaranteeing the conservation of angular momentum (Kley 1998). Code parameters of note are the Courant factor, which is set to 0.5, and the artificial viscosity parameters (Clarke 2010), qcon and qlin, are set to 2.0 and 0.1, respectively. In the results presented below, a kinematic viscosity of 10−5 (in units where GM* = 1 and a = 1) is used.
We adopt periodic boundary conditions in the azimuthal direction, and the ‘wave-killing’ conditions of de Val-Borro et al. (2006) in the radial direction, with damping activated in the ranges [0.4a, 0.5a] and [2.1a, 2.5a]. It is worth noting that we do not gradually grow the planet mass over the first few orbits (cf. de Val-Borro et al. 2006; section 3.1), but instead begin with the full planetary mass in place.
The left-hand panel of Fig. 8 shows the benchmark results for a single patch at a resolution of |$n_R \times n_\Phi = 160 \times 450$| cells after 100 orbits. These results can be directly and favourably compared with fig. 10 of de Val-Borro et al. (2006). The middle panel, meanwhile, shows the results from sub-dividing the domain into 45 equally sized patches. As can be seen, the model with 45 individual patches is nearly identical to the model with a single patch. Finally, the right-hand panel illustrates the time-step in each patch after 100 orbits; there is a factor of ∼8.2 difference between the largest and smallest time-steps. This local time-stepping advantage, over the course of 100 orbits, reduces the CPU time required by the multiple-patch version by a factor of roughly two relative to the single-patch version (∼6 h versus ∼12 h).
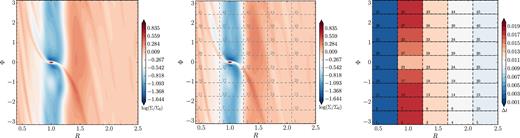
Left: A 1MJ planet simulated for 100 orbits using a single patch with |$n_R \times n_\Phi = 160 \times 450$| uniformly spaced zones. Middle: The same but subdividing the domain into 45 equally sized patches. Right: The time-step in each patch after 100 orbits.
6 SUMMARY AND OUTLOOK
We have introduced a hybrid MPI/OpenMP code framework that permits semi-independent task-based execution of code, e.g. for the purpose of updating a collection of semi-independent patches in space–time. OpenMP parallelism is handled entirely by the code framework – already existing code need not (and should not) contain OpenMP parallel constructs beyond declaring appropriate variables as threadprivate. OpenMP tasks are generated by a rank-local dispatcher, which also selects the tasks that are ready for (and most in need of) updating. This typically implies having valid guard zone data imported from neighbours, but can take the form of any type of inter-task dependence. The type of tasks can vary, with HD, ideal MHD, radiative transfer and non-ideal MHD demonstrated here; particle-in-cell (PIC) methods coupled to MHD methods on neighbouring patches are currently in development. Tasks do not necessarily have to be grid based (allowing, e.g. particle-based tasks), while tasks that are may use either Cartesian or curvilinear meshes. The code framework supports both stationary and moving patches, as well as both static and dynamic mesh refinement; the implementation details for moving patches and dynamic refinement will be featured in a forthcoming paper (Ramsey et al. in preparation).
As dispatch is targeting exa-scale computing, a feature of great importance for the performance of the framework is that time-steps are determined by local conditions (e.g. the Courant condition in the case of mesh-based tasks/patches); this can lead to potentially significant reductions in computing time in cases where the signal speed varies greatly within the computational domain. Patches, in particular, are surrounded by a sufficient number of guard zones to allow interior cells to be updated independently of other patches within a single time-step; the guard zone data is retrieved or interpolated from neighbouring patches. Since patches evolve with different time-steps, it is necessary to save a number of time slices for interpolation (and possibly extrapolation) to the time whence guard zone values are required. Performance, even for existing codes, improves when running under the dispatch framework for several reasons: First, patches are small enough to utilize cache memory efficiently, while simultaneously being large enough to obtain good vectorization efficiency. Secondly, task overloading ensures all OpenMP threads remain constantly busy, which results in nearly linear OpenMP speed-up, even for a very large numbers of cores (e.g. Intel Xeon Phi). Third, load imbalance caused by multiphysics modules with significantly different update costs per unit time is automatically compensated for, since the task scheduling automatically favours tasks that tend to lag behind. Fourth, each MPI process (typically one per socket per node) only communicates with its nearest neighbours – here interpreted broadly as those MPI processes that are either geometrically close, or else causally coupled via, for example, radiative transfer. Finally, load balancing is designed to minimize work imbalance while simultaneously keeping the number of communications links near a minimum. As demonstrated in Figs 4 and 5, these features result in a code framework with excellent OpenMP and MPI scaling properties.
In protoplanetary discs, for example, the advantages of dispatch relative to a conventional AMR code such as ramses are, first of all, a gain from comoving patches and, second, an additional advantage due to local time-stepping. Indeed, analysis of snapshots from recent zoom-in simulations performed with ramses (Nordlund et al. 2014; Kuffmeier et al. 2016, 2017) demonstrate that the cost reduction from local time-stepping and comoving patches can be of the order of 10–30 in such simulations. Beyond that, the implementation of the HLLD solver in dispatch exhibits a substantial raw speed improvement per cell update by a factor of about 16 relative to the implementation in ramses – in large part due to the much smaller guard zone overhead (the 2 × 2 × 2 octs used in ramses need 6 × 6 × 6 cells for updates), but also due to contributions from better vectorization and cache utilization. In extreme cases, the accrued reductions in raw update cost and AMR overhead, improved OpenMP and MPI scaling, plus comoving patches and local time-steps, can result in cost reductions that reach factors of the order of 1000. Meanwhile, under simpler conditions where the resolution is constant, and the dynamic range of signal speeds is small, the cost reduction will be limited to mainly the difference in raw cell update cost. Relative to AMR codes that work with blocks of dimensions similar to dispatch, the advantages lie mainly in the gains from minimal AMR overhead, local time-stepping, and comoving patches.
In dispatch, the number of tasks per MPI rank (typically one per compute node or CPU socket) is kept sufficiently high to ensure all of the cores within a rank stay busy at all times. As the capacity (i.e. the number of cores) of compute nodes is growing with time, in the future, each rank will be able to handle more tasks, and hence an increasing fraction of tasks will be ‘internal’, i.e. their neighbour tasks will reside on the same MPI rank, and thus will not require communication with neighbouring ranks. By construction then, as the capacity grows, each node remains fully occupied, and inter-node communication needs decrease rather than increase with growing problem size. Combined with the fact that, in dispatch, each rank only communicates with its nearest neighbours, the OpenMP and MPI scaling characteristics of dispatch therefore satisfy our definition of being exa-scale ready.
Planned and ongoing applications of the dispatch code framework include pebble accretion via hierarchically resolved Hill spheres around planetary embryos (Popovas et al. submitted), solar and stellar magneto-convection with chromospheric and coronal activity, with further extensions applying a combined MHD–PIC multiple-domain-multiple-physics method to particle acceleration in model coronae. Solar and stellar magneto-convection is a context where the local time-step advantage can become very large. Analysis of snapshots from Stein & Nordlund (2012) shows a gain of a factor ∼30, caused by the contrast between the extremely short time-steps required in the low-density atmosphere above sunspots, and the generally much longer time-steps allowed at most other locations. In both this context and the star formation context, the local time-step advantage is expected to become even more significant in the future as models grow in physical size and complexity.
Part of the motivation for developing dispatch was to create a framework that is suitable for studying planet formation. Recall, for example, the scene including a protostellar system modelled by using a sink particle component plus mesa stellar evolution model for the central star, plus a collection of moving, orbiting patches to represent the gas in the protostellar accretion disc (Section 2.4). Likewise, particle tasks could be operating to represent the dust, either as sub-tasks inside other tasks, or as semi-independent separate tasks. These would then be able to use data on gas and dust properties from accretion disc patches to estimate the production rate of thermally processed components – representing, for example, chondrules and high-temperature condensates (calcium–aluminium inclusions, amoeboid olivine aggregates, hibonites, etc.; cf. Haugboelle et al. 2017), and would be able to model the subsequent transport of thermally processed components by disc winds and jet outflows (e.g. Bizzarro et al. 2017).
The dispatch framework will be made open-source and publicly available in a not too distant future.
ACKNOWLEDGEMENTS
The work of ÅN, MK, and AP was supported by a grant from the Danish Council for Independent Research (DFF grant 1323-00199B). The Centre for Star and Planet Formation is funded by the Danish National Research Foundation (DNRF97). Storage and computing resources at the University of Copenhagen HPC centre, funded in part by Villum Fonden (VKR023406), were used to carry out some of the simulations presented here. We also acknowledge Partnership for Advance Computing in Europe (PRACE) for awarding us preparatory access (2010PA3402) to Hazel Hen at Höchstleistungsrechenzentrum Stuttgart (HLRS) Stuttgart to obtain scaling data. We further acknowledge Klaus Galsgaard for allowing us to obtain KNL scaling data on CINECA/Marconi under his PRACE grant 2016143286 and CINECA support staff for helping us obtain scaling measurements at 204 000 cores.
Footnotes
Exa-scale computing is defined as the use of computer systems capable of 1018 floating point operations (FLOPs) per second.
In fortran, ‘objects’ are called ‘derived types’, and inheritance is implemented by ‘extending’ a derived type.
‘Type-bound procedures’ in fortran speak.
While the second-order Feautrier method conserves energy by construction, the more accurate integral method does not. As such, the choice of RT solver should be made with this in mind.
In the Ohmic dissipation experiment, since the Ohmic time-step depends only on (a constant) ηOhm and the grid spacing, the time-step is the same in every patch.
REFERENCES

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}