





Abstract
We introduce a new methodology to robustly determine the mass profile, as well as the overall distribution, of Local Group satellite galaxies. Specifically, we employ a statistical multilevel modelling technique, Bayesian hierarchical modelling, to simultaneously constrain the properties of individual Local Group Milky Way satellite galaxies and the characteristics of the Milky Way satellite population. We show that this methodology reduces the uncertainty in individual dwarf galaxy mass measurements up to a factor of a few for the faintest galaxies. We find that the distribution of Milky Way satellites inferred by this analysis, with the exception of the apparent lack of high-mass haloes, is consistent with the Λ cold dark matter (ΛCDM) paradigm. In particular, we find that both the measured relationship between the maximum circular velocity and the radius at this velocity, as well as the inferred relationship between the mass within 300 pc and luminosity, match the values predicted by ΛCDM simulations for haloes with maximum circular velocities below 20 km s−1. Perhaps more striking is that this analysis seems to suggest a more cusped ‘average’ halo shape that is shared by these galaxies. While this study reconciles many of the observed properties of the Milky Way satellite distribution with that of ΛCDM simulations, we find that there is still a deficit of satellites with maximum circular velocities of 20–40 km s−1.
1 INTRODUCTION
The Λ cold dark matter (ΛCDM) paradigm makes far-reaching predictions about galaxy formation and cosmology. Observations of the CMB and large-scale structure have confirmed many of these predictions (Efstathiou, Bond & White 1992; Riess et al. 1998; Komatsu et al. 2011) making this paradigm the favoured cosmological model. Although ΛCDM has enjoyed much success at large scales, there are some indications of discrepancies at smaller scales. These discrepancies can be categorized in two ways: individual halo density profiles and overall distributions of sub-structure. Particularly, it has been suggested that the Milky Way Local Group dwarf spheroidal (dSph) galaxies have a much flatter mass–luminosity relation and possess much shallower inner density profiles than those predicted by ΛCDM (Goerdt et al. 2006; Gilmore et al. 2007; Evans, An & Walker 2009; Walker & Peñarrubia 2011; Agnello & Evans 2012). This has motivated development of alternative hypotheses such as warm and self-interacting dark matter (Bond, Efstathiou & Silk 1980; Carlson, Machacek & Hall 1992; Burkert 2000; Spergel & Steinhardt 2000; Dalcanton & Hogan 2001; Colín et al. 2002; Ahn & Shapiro 2005; Strigari et al. 2006; Boyarsky et al. 2009; Loeb & Weiner 2011; Macciò et al. 2012; Rocha et al. 2013). Many of these models give flatter inner density profiles at dSph scales while retaining CDM's successful large-scale predictions. However, recent studies have suggested that shallow inner density profiles may be a consequence of the flattening of inner cusps from baryonic effects (Mashchenko, Couchman & Wadsley 2006; Mashchenko, Wadsley & Couchman 2008; Governato et al. 2012; Parry et al. 2012; Pontzen & Governato 2012; Zolotov et al. 2012; Brooks et al. 2013; Arraki et al. 2014).
Perhaps just as troubling is the apparent disagreement between the sub-structure distributions observed locally and those predicted by ΛCDM simulations. One of the best studied discrepancies is the apparent lack of numerous low-mass sub-structures predicted by the ΛCDM paradigm (Kauffmann, White & Guiderdoni 1993; Klypin et al. 1999; Moore et al. 1999; Bullock 2010). This so-called Missing Satellites Problem persisted even after the discovery of several additional ultrafaint satellite galaxies (Grebel 2000; Willman et al. 2005; Irwin et al. 2007; Simon & Geha 2007; Belokurov et al. 2008; Liu et al. 2008; Martin, de Jong & Rix 2008; Watkins et al. 2009; Belokurov et al. 2010; Martinez et al. 2011; Simon et al. 2011). This problem is further complicated by the fact that these galaxies may share a common mass scale over several orders of magnitude in luminosity (Strigari et al. 2007a, 2008). Many of these discrepancies have been addressed by including astrophysical and observational effects, such as suppression of star formation due to reionization and feedback (Quinn, Katz & Efstathiou 1996; Thoul & Weinberg 1996; Navarro & Steinmetz 1997; Barkana & Loeb 1999; Klypin et al. 1999; Bullock, Kravtsov & Weinberg 2000; Gnedin 2000; Benson et al. 2002; Hoeft et al. 2006; Madau, Diemand & Kuhlen 2008; Alvarez et al. 2009), and selection biases (Willman et al. 2004; Simon & Geha 2007; Tollerud et al. 2008; Koposov et al. 2009; Walsh, Willman & Jerjen 2009; Rashkov et al. 2012). However, a slight correlation between the mass and luminosity is still common in these improved dark matter analyses (Ricotti & Gnedin 2005; Koposov et al. 2009; Macciò, Kang & Moore 2009; Okamoto & Frenk 2009; Busha et al. 2010; Font et al. 2011; Rashkov et al. 2012). To make matters worse, there is also a deficit of observed satellites at the high-mass end of the dwarf satellite mass spectrum. Dubbed the ‘Too Big to Fail’ problem, Boylan-Kolchin, Bullock & Kaplinghat (2011, also see Vera-Ciro et al. 2013) noted that the Aquarius simulations predict at least 10 sub-haloes with a maximum circular velocity greater than 25 km s−1. Attempts to place the most luminous known satellites into haloes of this size result in halo densities inconsistent with CDM simulations (Boylan-Kolchin, Bullock & Kaplinghat 2012). One possible solution to this discrepancy may originate in the same baryonic processes used to explain the cusp/core problem – in that core-like central regions created by supernova feedback and tidal stripping make these galaxies more susceptible to disruption by the Milky Way disc (Peñarrubia et al. 2010, 2012; di Cintio et al. 2011; Zolotov et al. 2012; Brooks et al. 2013). On the other hand, if the mass of the Milky Way halo has been overestimated, this apparent lack of high-mass sub-haloes may be due to a statistical anomaly (Wang et al. 2012). However, the efficacy of these solutions has been disputed by various authors (Boylan-Kolchin et al. 2012; Strigari & Wechsler 2012; Garrison-Kimmel et al. 2013). For a general review of these issues, see Strigari (2012).
While much effort has been focused on reconciling CDM predictions with various dwarf galaxy observations, little attention has been paid to the statistical consistency of the measurements themselves. Current Jeans modelling methods used to constrain dSph halo properties are dominated by assumed prior probabilities (Martinez et al. 2009; Walker et al. 2009b; Wolf et al. 2010; Walker 2013). This can potentially be overcome by using more advanced methods such as phase space, Schwarzschild or higher order Jeans modelling (Łokas, Mamon & Prada 2005; Wu 2007; Amorisco & Evans 2012; Jardel & Gebhardt 2012; Breddels et al. 2013; Jardel et al. 2013; Richardson & Fairbairn 2013). However, these methodologies introduce systematics such as binary contributions and membership effects that, to date, have not been included in such analyses (Walker et al. 2009a; Minor et al. 2010; Martinez et al. 2011). Therefore, prior dominance is crucial to this discussion as it not only affects the characterization of individual dSphs, but has an unknown effect on the inferred parameters of the population. In this paper, we aim to address this issue through the powerful statistical technique of multilevel modelling (MLM; Mandel et al. 2009; Loredo & Hendry 2010; Mandel, Narayan & Kirshner 2011; Soiaporn et al. 2012). This broad class of modelling techniques base prior probabilities on the actual model parameter distribution implied between data sets. MLM constrains the actual prior distribution by requiring that the distribution derived from the individual measurements match the prior distribution assumed.
In the next section, we will introduce the MLM methodology and outline the specific technique used here: Bayesian Hierarchical Modelling. In Section 3, we specify our model assumptions. Finally, we present our results and discuss their implications for characterizing Local Group dSphs.
2 MULTILEVEL MODELLING
Constraining dark matter halo properties from individual stellar line-of-sight velocity measurements in Local Group dSph galaxies is a difficult problem. Mass constraints from dispersion measurements are riddled with unconstrained degeneracies that affect mass measurements far from the stellar half-light radius (Walker et al. 2009b; Wolf et al. 2010). This causes inferred mass probabilities to be dominated by prior probabilities. In Bayesian analysis, this is problematic because of the ‘degree of belief’ probabilistic interpretation that is usually assigned to the prior and posterior probabilities (Cox 1946). In other words, the mass posterior beyond the half-light radius is dominated by the observer's (sometimes arbitrary) prior belief rather than being dominated by data. One solution is to apply the strict frequentist interpretation of probability to the prior – e.g. restrict the interpretation of the prior probability density function (PDF) to represent the frequency of observing a halo property given a sufficiently large galaxy sample. Within this interpretation, the choice of prior is constrained to match that of the overall galaxy sample. This causes resultant mass posteriors to be much more stringent. However, the accuracy of these posteriors is highly dependent on the agreement between the assumed prior probability and the actual galaxy sample distribution. For the Local Group dSphs, the properties of the source galaxy sample is usually inferred from numerical simulations. Unfortunately, even if these simulations are an adequate description of the underlying distribution, the actual observable distribution will only be a sub-set of this sample. Because the sub-set is determined by astrophysical interactions that currently are not well understood, it is very likely that strict application of numerical simulations, in this regard, will lead to erroneous results.
In this paper, we address the issue of prior dominance by applying a multilevel statistical modelling technique to directly constrain the prior probabilities. MLM divides the parameters of the dSph galaxies into various ‘levels’, each with its own set of observables. Starting with the most basic ‘lowest’ level, the posteriors on the observables at each level are used as input into subsequent levels.
Regardless of the number of levels applied, the prior introduced at the top-level is still completely unconstrained. Thus, to utilize the complete posterior distribution in a statistically consistent manner, either the top-level prior must be inferred from external information or the interpretation of probability must be expanded to include the Bayesian ‘degree of belief’ probabilistic interpretation. Although logically consistent, the ‘degree of belief’ interpretation introduces subjectivity that is unsettling to some scientists. And, the applicability or accessibility of prior information can make the former methodology difficult to implement. However, the subjectivity of the top-level prior has only an indirect, and thus mitigated, effect on lower level posteriors. This is because this prior affects lower-level posteriors only indirectly through lower-level priors. The strict frequentist interpretation applied to the likelihoods at various levels and their associated lower-level priors ensure that these lower-level priors are constrained by the intrinsic distribution of the data. This, thereby, mitigates the effect of the top-level prior assumptions.
3 MODEL ASSUMPTIONS
4 RESULTS
The previously mentioned anisotropy-mass degeneracy that is intrinsic in Jeans modelling makes mass modelling inherently dominated by prior assumptions. Because MLM constrains the overall distribution (and thus the lower-level priors), this approach can significantly reduce the effect of this degeneracy. Fig. 1 (left-hand panel) illustrates the advantage of this methodology in limiting prior dominance on lower-level posteriors. This figure shows the impact of varying prior assumptions on the astrophysical contribution of the dark matter annihilation flux, the J factor (Strigari et al. 2007a; Martinez et al. 2009; Abdo et al. 2010; Ackermann et al. 2011; Charbonnier et al. 2011; Llena Garde et al. 2011). Shown is one of the most prior dominated galaxies: Segue 1. Compared are the solutions of assuming two priors, one non-informative and the other biasing the solution to low masses, with and without the use of hierarchical modelling. Varying prior assumptions without the use of hierarchical priors can alter the J factor posteriors by more than an order of magnitude. However, this effect is minimized when hierarchical priors are used.
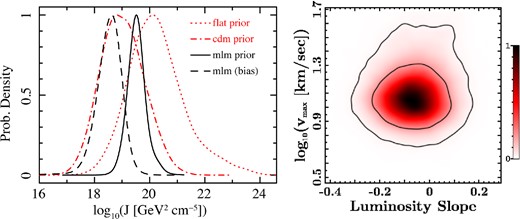
Left: this figure illustrates the ability of this methodology to limit prior dominance on lower-level posteriors. Compared are the J factors posteriors using MLM to that using assumed lower-level priors. Plotted are the J factor assuming a prior that resembles the distribution predicted by CDM simulations (CDM prior, dotted red line), priors uniform in log (rmax and log (vmax) (dash–dotted red line) and two posteriors that employ the MLM methodology presented in this paper. Because simulations predict a large amount of low-mass sub-haloes, the CDM prior assumptions bias the J posterior artificially to lower values. The result is a posterior that is significantly lower than if uniform priors where assumed. For comparison, the posteriors of two MLM runs are also plotted: one result assumes the usual non-informative priors (black solid line) and the other result drastically biases our posterior results to artificially low concentrations. Not only are these two posteriors more robust to top-level assumptions, but the resulting posteriors are better constrained. Right: shown is the joint posterior of the maximum circular velocity (vmax) and the slope of the luminosity function. Unsurprisingly, there is no apparent correlation between the shape of the luminosity function (e.g. the slope) and lower-level posteriors. This is because, to the lower-level posteriors, the effective prior that influences the result is the prior integrated over all possible luminosities (see Section 4, especially equation 19) .
In Fig. 4, we plot the relevant parameter constraints for each galaxy: log (vmax) versus log (L), log (rmax) versus log (vmax) and log (M(300)) versus log (L). Overlaid is the median fit prior distribution. These plots show that individual posterior constraints for each galaxy agree well with the inferred overall galaxy distribution. The log (rmax) versus log (vmax) plots show the net effect of the ‘αlv – |$v_{\beta _{lv}}$| degeneracy’ in the extreme values of log (vmax). This effect is most prominent at low vmax values where the posteriors widths are the largest. This is due to the scale radii being far from the stellar half-light radius – an unfortunate byproduct of the approximate common scale shared by the Milky Way dSph galaxies. The effect of this degeneracy also manifests at the low-luminosity end of the log (vmax)–log (L) relation. But this effect is minimal compared to the overall effect on the log (rmax)–log (vmax) relation. Most notable, though, is the implied log (M(300))–log (L) relation. While this relation is fairly constant, there is a definite implied small positive slope consistent with the value of 0.088 ± 0.024 from simulations (Rashkov et al. 2012, compare to Table 3 of this paper). Whereas, the implied intrinsic dispersion of ∼−0.7 (Springel et al. 2008, in log) is consistent with the value derived here (see Table 3). The median and 68 per cent credible levels for the individual galaxies parameters log (rmax) and log (vmax), as well as the overall distribution parameters, are summarized in Tables 2 and 3. It is important to note that these bottom-level posteriors contain information of both the individual galaxy fit as well as the fit of the full data set to the lower-level prior. Thus, the width of the posteriors reflect both the uncertainty of the individual galaxy parameters as well as the quality of fit of the lower-level prior. Models that produce distributions that fit the lower-level prior well allow for a larger range in the lower-level parameters since these models naturally produce more solutions that are a good overall fit to the data. Conversely, models that produce distributions that poorly fit the lower-level prior allow a shorter range in the lower-level posteriors for the same reason. Since the posteriors contain information about the full parameter space, the posterior width is the result of both the individual galaxy distribution as well as the allowed range due to the fit of the prior distribution. Thus, a narrower posterior width is not necessarily indicating a better overall fit. This is indeed the case with the Einasto profile that even with narrower posteriors, the Bayes factor (see Table 1) indicates that this profile is disfavoured relative to the other, more cuspy, profiles. Also, from Fig. 2, we see that the constraints on the common halo shape parameters for the cored NFW and Einasto models indicated a more cuspy common halo shape as well. However, this study does not allow for different density profile shapes among the galaxies, but rather imposes a common shape among the full sample. Nevertheless, this result may have interesting implications on galaxy formation as discussed in the next section.
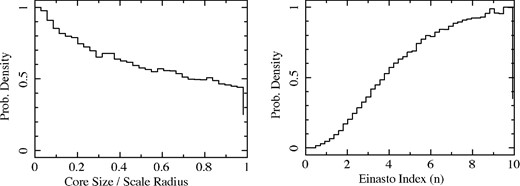
These figures plot the posteriors for the scaled core radius of the cored NFW model (rc/rS) and the Einasto index of the Einasto model (n). Interestingly, the constraints on the common halo shape parameters for the cored NFW and Einasto models indicate a more cuspy common halo shape. However, this study does not allow for different halo profile shapes among the galaxies, but rather imposes a common shape among the full sample. Thus, these results should be viewed as the aggregate solution to the full sample rather than a statement about any individual halo shape. Even so, this is an interesting result given recent literature (see Section 5).
5 DISCUSSION
Our result of a more cuspy halo, as compared to very core-like (such as the Einasto or profiles with a very shallow slope), has interesting implications given recent literature (Evans, An & Walker 2009; Strigari, Frenk & White 2010; Walker & Peñarrubia 2011; Agnello & Evans 2012; Breddels & Helmi 2013). First, it is important to note that these results should be viewed as the aggregate solution to the full sample rather than a statement about any individual halo shape. It is entirely possible that, while taken as a whole, these galaxies prefer a cuspy dark matter profile, an individual galaxy's profile may indeed exhibit more core-like behaviour. This is especially true for the more extended (and luminous) galaxies whose half-light radii do not probe the very inner portions of their dark matter distributions. If this hypothesis is correct, it may suggest that these haloes’ once cuspy inner regions were softened due to subsequent astrophysical interactions. Another possibility is that these recent slope measurements suffer from a constant systematic bias due to asphericity in the shape of the stellar and dark matter density profiles. A stellar profile of high asphericity can shift the measured mass at the half-light radius and implied slope by a factor of a few (Kowalczyk et al. 2013). However, it is expected that reliable lower limits to the inner slope can be achieved regardless of dark matter halo triaxiality (Laporte, Walker & Peñarrubia 2013). Because these haloes would be randomly originated within the sample, the bias due to triaxiality is not expected to sensitively affect central prior measurements. Thus, the expected net effect on hierarchical modelling is an increase in the dispersion of the priors.
This work utilizes only the line-of-sight second order velocity moments (dispersion) of a single population. With only line-of-sight dispersions of a single population, it is not possible to uniquely determine the full mass profile (Walker et al. 2009b; Wolf et al. 2010). So in this sense, when analysing a single galaxy, this data cannot distinguish between different mass profile models. This work attempts to alleviate this by including information of the full galaxy sample. But, if more information beyond the line-of-sight velocity dispersions were included, such as higher order velocity moments or multiple populations, it may be possible to individually constrain the inner slope solely by analysing a single galaxy (Walker & Peñarrubia 2011). Specifically, incorporating multiple population into this analysis would likely increase the ‘average’ profile constraint and is subject of future work. Other authors have obtained mass profile constraints from the use of higher order moments [for example, using methods such as phase space, Schwarzschild or higher-order Jeans modelling (Łokas et al. 2005; Wu 2007; Amorisco & Evans 2012; Jardel & Gebhardt 2012; Breddels et al. 2013; Jardel et al. 2013; Richardson & Fairbairn 2013)]. But these methods are more sensitive to membership issues due to foreground contamination and any physical process that would affect higher order moments (e.g. unresolved binaries; Minor et al. 2010). Thus, in ordered to avoid these systematics, we avoid such methodologies in this study.
Finally, we should mention that, while our results are consistent with a shared cuspy halo profile, there is a small preference for shallow core-like properties towards the centre. With the exception of the Einasto profile, the Bayes factor (Table 1) between the various models indicate that, while not definitively preferring one model, models with core-like behaviour (especially, the cored NFW) have a small preference over the NFW model. However, even if these galaxies’ inner regions truly are shallow, their outer regions are very NFW-like.
Summary of the Bayes factors.
| Model | loge(Bayes factora) |
|---|---|
| NFW | 0 |
| Burkert | 1.03 ± 0.36 |
| Cored NFW | 2.19 ± 0.34 |
| Einasto | −16.42 ± 0.35 |
| Model | loge(Bayes factora) |
|---|---|
| NFW | 0 |
| Burkert | 1.03 ± 0.36 |
| Cored NFW | 2.19 ± 0.34 |
| Einasto | −16.42 ± 0.35 |
aHere the Bayes factor is the ratio of the evidences (|$\scr {E}$|) relative to the evidence of the NFW model (|$\scr {E}_{ {\rm model}}/\scr {E}_{ {\rm NFW}}$|).
Summary of the Bayes factors.
| Model | loge(Bayes factora) |
|---|---|
| NFW | 0 |
| Burkert | 1.03 ± 0.36 |
| Cored NFW | 2.19 ± 0.34 |
| Einasto | −16.42 ± 0.35 |
| Model | loge(Bayes factora) |
|---|---|
| NFW | 0 |
| Burkert | 1.03 ± 0.36 |
| Cored NFW | 2.19 ± 0.34 |
| Einasto | −16.42 ± 0.35 |
aHere the Bayes factor is the ratio of the evidences (|$\scr {E}$|) relative to the evidence of the NFW model (|$\scr {E}_{ {\rm model}}/\scr {E}_{ {\rm NFW}}$|).
Summary of unrestrained top-level model parameters and results.
| Prior | Prior | Derived value | Derived value | Derived value | Derived value | |
|---|---|---|---|---|---|---|
| parameters | range | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description |
| log10(σrv) | [−10, 3] | |$-1.00_{-0.37}^{+0.36}$| | |$-1.01_{-0.44}^{+0.37}$| | |$-1.44_{-0.38}^{+0.54}$| | |$-1.03_{-0.61}^{+0.40}$| | (log) dispersion of the log (rmax)–log (vmax) relation |
| αrv | [−30, 30] | |$2.44_{-1.20}^{+1.30}$| | |$2.59_{-1.10}^{+1.43}$| | |$2.43_{-0.95}^{+0.97}$| | |$1.89_{-1.23}^{+1.57}$| | Slope of the log (rmax)–log (vmax) relation |
| βrv | [−30, 30] | |$-3.10_{-1.58}^{+1.46}$| | |$-3.41_{-1.74}^{+1.27}$| | |$-3.32_{-1.13}^{+1.07}$| | |$-2.31_{-1.84}^{+1.47}$| | Intercept of the log (rmax)–log (vmax) relation |
| log10(σvl) | [−4, 3] | |$-1.10_{-0.16}^{+0.16}$| | |$-1.15_{-0.15}^{+0.15}$| | |$-1.20_{-0.13}^{+0.12}$| | |$-1.14_{-0.16}^{+0.16}$| | (log) dispersion of the log (vmax)–log (L) relation |
| αvl | [−10, 10] | |$0.05_{-0.04}^{+0.03}$| | |$0.05_{-0.03}^{+0.03}$| | |$0.06_{-0.02}^{+0.02}$| | |$0.05_{-0.03}^{+0.03}$| | Slope of the log (vmax)–log (L) relation |
| βvl | [−10, 10] | |$0.93_{-0.18}^{+0.24}$| | |$0.89_{-0.16}^{+0.16}$| | |$0.87_{-0.13}^{+0.14}$| | |$0.91_{-0.18}^{+0.20}$| | Intercept of the log (vmax)–log (L) relation |
| αl | [−3, 3] | |$-0.07_{-0.09}^{+0.08}$| | |$-0.07_{-0.08}^{+0.08}$| | |$-0.06_{-0.08}^{+0.08}$| | |$0.00_{-0.06}^{+0.06}$| | Slope of the luminosity function |
| rc/rS | [0, 1] | – | |$0.40_{-0.30}^{+0.39}$| | – | – | Scaled core radius |
| n | [0.5, 10] | – | – | – | |$6.87_{-2.72}^{+2.18}$| | Einasto index |
| Derived prior | Derived value | Derived value | Derived value | Derived value | ||
| parameters | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description | |
| log10(σml) | |$-0.88_{-0.13}^{+0.14}$| | |$-0.86_{-0.13}^{+0.15}$| | |$-0.88_{-0.12}^{+0.12}$| | |$-0.90_{-0.11}^{+0.13}$| | (log) dispersion of the log (M300)–log (L) relation | |
| αml | |$0.07_{-0.06}^{+0.07}$| | |$0.08_{-0.05}^{+0.06}$| | |$0.10_{-0.05}^{+0.06}$| | |$0.07_{-0.05}^{+0.06}$| | Slope of log (M300)–log (L) relation | |
| βml | |$6.76_{-0.38}^{+0.32}$| | |$6.67_{-0.35}^{+0.31}$| | |$6.57_{-0.32}^{+0.32}$| | |$6.71_{-0.32}^{+0.28}$| | Intercept of log (M300)–log (L) relation |
| Prior | Prior | Derived value | Derived value | Derived value | Derived value | |
|---|---|---|---|---|---|---|
| parameters | range | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description |
| log10(σrv) | [−10, 3] | |$-1.00_{-0.37}^{+0.36}$| | |$-1.01_{-0.44}^{+0.37}$| | |$-1.44_{-0.38}^{+0.54}$| | |$-1.03_{-0.61}^{+0.40}$| | (log) dispersion of the log (rmax)–log (vmax) relation |
| αrv | [−30, 30] | |$2.44_{-1.20}^{+1.30}$| | |$2.59_{-1.10}^{+1.43}$| | |$2.43_{-0.95}^{+0.97}$| | |$1.89_{-1.23}^{+1.57}$| | Slope of the log (rmax)–log (vmax) relation |
| βrv | [−30, 30] | |$-3.10_{-1.58}^{+1.46}$| | |$-3.41_{-1.74}^{+1.27}$| | |$-3.32_{-1.13}^{+1.07}$| | |$-2.31_{-1.84}^{+1.47}$| | Intercept of the log (rmax)–log (vmax) relation |
| log10(σvl) | [−4, 3] | |$-1.10_{-0.16}^{+0.16}$| | |$-1.15_{-0.15}^{+0.15}$| | |$-1.20_{-0.13}^{+0.12}$| | |$-1.14_{-0.16}^{+0.16}$| | (log) dispersion of the log (vmax)–log (L) relation |
| αvl | [−10, 10] | |$0.05_{-0.04}^{+0.03}$| | |$0.05_{-0.03}^{+0.03}$| | |$0.06_{-0.02}^{+0.02}$| | |$0.05_{-0.03}^{+0.03}$| | Slope of the log (vmax)–log (L) relation |
| βvl | [−10, 10] | |$0.93_{-0.18}^{+0.24}$| | |$0.89_{-0.16}^{+0.16}$| | |$0.87_{-0.13}^{+0.14}$| | |$0.91_{-0.18}^{+0.20}$| | Intercept of the log (vmax)–log (L) relation |
| αl | [−3, 3] | |$-0.07_{-0.09}^{+0.08}$| | |$-0.07_{-0.08}^{+0.08}$| | |$-0.06_{-0.08}^{+0.08}$| | |$0.00_{-0.06}^{+0.06}$| | Slope of the luminosity function |
| rc/rS | [0, 1] | – | |$0.40_{-0.30}^{+0.39}$| | – | – | Scaled core radius |
| n | [0.5, 10] | – | – | – | |$6.87_{-2.72}^{+2.18}$| | Einasto index |
| Derived prior | Derived value | Derived value | Derived value | Derived value | ||
| parameters | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description | |
| log10(σml) | |$-0.88_{-0.13}^{+0.14}$| | |$-0.86_{-0.13}^{+0.15}$| | |$-0.88_{-0.12}^{+0.12}$| | |$-0.90_{-0.11}^{+0.13}$| | (log) dispersion of the log (M300)–log (L) relation | |
| αml | |$0.07_{-0.06}^{+0.07}$| | |$0.08_{-0.05}^{+0.06}$| | |$0.10_{-0.05}^{+0.06}$| | |$0.07_{-0.05}^{+0.06}$| | Slope of log (M300)–log (L) relation | |
| βml | |$6.76_{-0.38}^{+0.32}$| | |$6.67_{-0.35}^{+0.31}$| | |$6.57_{-0.32}^{+0.32}$| | |$6.71_{-0.32}^{+0.28}$| | Intercept of log (M300)–log (L) relation |
Note. All vmax in km s−1. All rmax and r1/2 in kpc. All Masses in M⊙. All Luminosities in L⊙. All log to the base of 10.
Summary of unrestrained top-level model parameters and results.
| Prior | Prior | Derived value | Derived value | Derived value | Derived value | |
|---|---|---|---|---|---|---|
| parameters | range | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description |
| log10(σrv) | [−10, 3] | |$-1.00_{-0.37}^{+0.36}$| | |$-1.01_{-0.44}^{+0.37}$| | |$-1.44_{-0.38}^{+0.54}$| | |$-1.03_{-0.61}^{+0.40}$| | (log) dispersion of the log (rmax)–log (vmax) relation |
| αrv | [−30, 30] | |$2.44_{-1.20}^{+1.30}$| | |$2.59_{-1.10}^{+1.43}$| | |$2.43_{-0.95}^{+0.97}$| | |$1.89_{-1.23}^{+1.57}$| | Slope of the log (rmax)–log (vmax) relation |
| βrv | [−30, 30] | |$-3.10_{-1.58}^{+1.46}$| | |$-3.41_{-1.74}^{+1.27}$| | |$-3.32_{-1.13}^{+1.07}$| | |$-2.31_{-1.84}^{+1.47}$| | Intercept of the log (rmax)–log (vmax) relation |
| log10(σvl) | [−4, 3] | |$-1.10_{-0.16}^{+0.16}$| | |$-1.15_{-0.15}^{+0.15}$| | |$-1.20_{-0.13}^{+0.12}$| | |$-1.14_{-0.16}^{+0.16}$| | (log) dispersion of the log (vmax)–log (L) relation |
| αvl | [−10, 10] | |$0.05_{-0.04}^{+0.03}$| | |$0.05_{-0.03}^{+0.03}$| | |$0.06_{-0.02}^{+0.02}$| | |$0.05_{-0.03}^{+0.03}$| | Slope of the log (vmax)–log (L) relation |
| βvl | [−10, 10] | |$0.93_{-0.18}^{+0.24}$| | |$0.89_{-0.16}^{+0.16}$| | |$0.87_{-0.13}^{+0.14}$| | |$0.91_{-0.18}^{+0.20}$| | Intercept of the log (vmax)–log (L) relation |
| αl | [−3, 3] | |$-0.07_{-0.09}^{+0.08}$| | |$-0.07_{-0.08}^{+0.08}$| | |$-0.06_{-0.08}^{+0.08}$| | |$0.00_{-0.06}^{+0.06}$| | Slope of the luminosity function |
| rc/rS | [0, 1] | – | |$0.40_{-0.30}^{+0.39}$| | – | – | Scaled core radius |
| n | [0.5, 10] | – | – | – | |$6.87_{-2.72}^{+2.18}$| | Einasto index |
| Derived prior | Derived value | Derived value | Derived value | Derived value | ||
| parameters | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description | |
| log10(σml) | |$-0.88_{-0.13}^{+0.14}$| | |$-0.86_{-0.13}^{+0.15}$| | |$-0.88_{-0.12}^{+0.12}$| | |$-0.90_{-0.11}^{+0.13}$| | (log) dispersion of the log (M300)–log (L) relation | |
| αml | |$0.07_{-0.06}^{+0.07}$| | |$0.08_{-0.05}^{+0.06}$| | |$0.10_{-0.05}^{+0.06}$| | |$0.07_{-0.05}^{+0.06}$| | Slope of log (M300)–log (L) relation | |
| βml | |$6.76_{-0.38}^{+0.32}$| | |$6.67_{-0.35}^{+0.31}$| | |$6.57_{-0.32}^{+0.32}$| | |$6.71_{-0.32}^{+0.28}$| | Intercept of log (M300)–log (L) relation |
| Prior | Prior | Derived value | Derived value | Derived value | Derived value | |
|---|---|---|---|---|---|---|
| parameters | range | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description |
| log10(σrv) | [−10, 3] | |$-1.00_{-0.37}^{+0.36}$| | |$-1.01_{-0.44}^{+0.37}$| | |$-1.44_{-0.38}^{+0.54}$| | |$-1.03_{-0.61}^{+0.40}$| | (log) dispersion of the log (rmax)–log (vmax) relation |
| αrv | [−30, 30] | |$2.44_{-1.20}^{+1.30}$| | |$2.59_{-1.10}^{+1.43}$| | |$2.43_{-0.95}^{+0.97}$| | |$1.89_{-1.23}^{+1.57}$| | Slope of the log (rmax)–log (vmax) relation |
| βrv | [−30, 30] | |$-3.10_{-1.58}^{+1.46}$| | |$-3.41_{-1.74}^{+1.27}$| | |$-3.32_{-1.13}^{+1.07}$| | |$-2.31_{-1.84}^{+1.47}$| | Intercept of the log (rmax)–log (vmax) relation |
| log10(σvl) | [−4, 3] | |$-1.10_{-0.16}^{+0.16}$| | |$-1.15_{-0.15}^{+0.15}$| | |$-1.20_{-0.13}^{+0.12}$| | |$-1.14_{-0.16}^{+0.16}$| | (log) dispersion of the log (vmax)–log (L) relation |
| αvl | [−10, 10] | |$0.05_{-0.04}^{+0.03}$| | |$0.05_{-0.03}^{+0.03}$| | |$0.06_{-0.02}^{+0.02}$| | |$0.05_{-0.03}^{+0.03}$| | Slope of the log (vmax)–log (L) relation |
| βvl | [−10, 10] | |$0.93_{-0.18}^{+0.24}$| | |$0.89_{-0.16}^{+0.16}$| | |$0.87_{-0.13}^{+0.14}$| | |$0.91_{-0.18}^{+0.20}$| | Intercept of the log (vmax)–log (L) relation |
| αl | [−3, 3] | |$-0.07_{-0.09}^{+0.08}$| | |$-0.07_{-0.08}^{+0.08}$| | |$-0.06_{-0.08}^{+0.08}$| | |$0.00_{-0.06}^{+0.06}$| | Slope of the luminosity function |
| rc/rS | [0, 1] | – | |$0.40_{-0.30}^{+0.39}$| | – | – | Scaled core radius |
| n | [0.5, 10] | – | – | – | |$6.87_{-2.72}^{+2.18}$| | Einasto index |
| Derived prior | Derived value | Derived value | Derived value | Derived value | ||
| parameters | (NFW) | (Cored NFW) | (Burkert) | (Einasto) | Description | |
| log10(σml) | |$-0.88_{-0.13}^{+0.14}$| | |$-0.86_{-0.13}^{+0.15}$| | |$-0.88_{-0.12}^{+0.12}$| | |$-0.90_{-0.11}^{+0.13}$| | (log) dispersion of the log (M300)–log (L) relation | |
| αml | |$0.07_{-0.06}^{+0.07}$| | |$0.08_{-0.05}^{+0.06}$| | |$0.10_{-0.05}^{+0.06}$| | |$0.07_{-0.05}^{+0.06}$| | Slope of log (M300)–log (L) relation | |
| βml | |$6.76_{-0.38}^{+0.32}$| | |$6.67_{-0.35}^{+0.31}$| | |$6.57_{-0.32}^{+0.32}$| | |$6.71_{-0.32}^{+0.28}$| | Intercept of log (M300)–log (L) relation |
Note. All vmax in km s−1. All rmax and r1/2 in kpc. All Masses in M⊙. All Luminosities in L⊙. All log to the base of 10.
Summary of galaxy model parameters and results.
| NFW | Cored NFW | Burkert | Einasto | |||||
|---|---|---|---|---|---|---|---|---|
| Galaxy | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b |
| Carina | |$1.09_{-0.04}^{+0.14}$| | |$-0.35_{-0.33}^{+0.72}$| | |$1.09_{-0.03}^{+0.09}$| | |$-0.58_{-0.26}^{+0.58}$| | |$1.09_{-0.03}^{+0.04}$| | |$-0.69_{-0.15}^{+0.25}$| | |$1.10_{-0.04}^{+0.10}$| | |$-0.18_{-0.39}^{+0.61}$| |
| Draco | |$1.26_{-0.04}^{+0.07}$| | |$-0.12_{-0.24}^{+0.28}$| | |$1.24_{-0.04}^{+0.04}$| | |$-0.28_{-0.19}^{+0.19}$| | |$1.23_{-0.03}^{+0.04}$| | |$-0.36_{-0.17}^{+0.16}$| | |$1.26_{-0.05}^{+0.08}$| | |$-0.01_{-0.30}^{+0.42}$| |
| Fornax | |$1.27_{-0.02}^{+0.03}$| | |$0.01_{-0.21}^{+0.31}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.11_{-0.18}^{+0.32}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.22_{-0.16}^{+0.17}$| | |$1.28_{-0.02}^{+0.06}$| | |$0.11_{-0.30}^{+0.56}$| |
| Leo I | |$1.24_{-0.05}^{+0.09}$| | |$-0.06_{-0.28}^{+0.40}$| | |$1.23_{-0.05}^{+0.07}$| | |$-0.24_{-0.24}^{+0.35}$| | |$1.22_{-0.04}^{+0.05}$| | |$-0.37_{-0.19}^{+0.27}$| | |$1.24_{-0.05}^{+0.09}$| | |$0.02_{-0.33}^{+0.52}$| |
| Leo II | |$1.15_{-0.07}^{+0.15}$| | |$-0.18_{-0.40}^{+0.54}$| | |$1.13_{-0.06}^{+0.12}$| | |$-0.38_{-0.33}^{+0.46}$| | |$1.12_{-0.04}^{+0.11}$| | |$-0.57_{-0.21}^{+0.48}$| | |$1.15_{-0.06}^{+0.11}$| | |$-0.08_{-0.37}^{+0.57}$| |
| Sculptor | |$1.24_{-0.05}^{+0.08}$| | |$-0.07_{-0.27}^{+0.35}$| | |$1.23_{-0.04}^{+0.06}$| | |$-0.24_{-0.22}^{+0.31}$| | |$1.23_{-0.03}^{+0.05}$| | |$-0.36_{-0.18}^{+0.24}$| | |$1.24_{-0.05}^{+0.08}$| | |$0.02_{-0.32}^{+0.49}$| |
| Sextans | |$1.13_{-0.03}^{+0.04}$| | |$-0.36_{-0.19}^{+0.28}$| | |$1.15_{-0.03}^{+0.04}$| | |$-0.48_{-0.15}^{+0.16}$| | |$1.16_{-0.03}^{+0.03}$| | |$-0.51_{-0.11}^{+0.10}$| | |$1.13_{-0.04}^{+0.05}$| | |$-0.22_{-0.25}^{+0.44}$| |
| Ursa Minor | |$1.29_{-0.04}^{+0.05}$| | |$0.01_{-0.24}^{+0.27}$| | |$1.28_{-0.04}^{+0.04}$| | |$-0.13_{-0.19}^{+0.22}$| | |$1.28_{-0.03}^{+0.04}$| | |$-0.24_{-0.17}^{+0.17}$| | |$1.29_{-0.04}^{+0.06}$| | |$0.08_{-0.29}^{+0.43}$| |
| Bootes | |$1.18_{-0.08}^{+0.10}$| | |$-0.23_{-0.30}^{+0.36}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.43_{-0.24}^{+0.25}$| | |$1.15_{-0.06}^{+0.06}$| | |$-0.53_{-0.18}^{+0.20}$| | |$1.17_{-0.07}^{+0.10}$| | |$-0.12_{-0.33}^{+0.44}$| |
| Canes Venatici I | |$1.15_{-0.05}^{+0.05}$| | |$-0.32_{-0.22}^{+0.32}$| | |$1.15_{-0.04}^{+0.04}$| | |$-0.46_{-0.18}^{+0.20}$| | |$1.16_{-0.03}^{+0.04}$| | |$-0.52_{-0.13}^{+0.14}$| | |$1.15_{-0.05}^{+0.06}$| | |$-0.16_{-0.29}^{+0.47}$| |
| Canes Venatii II | |$1.09_{-0.10}^{+0.13}$| | |$-0.39_{-0.48}^{+0.46}$| | |$1.09_{-0.09}^{+0.10}$| | |$-0.56_{-0.41}^{+0.33}$| | |$1.08_{-0.08}^{+0.09}$| | |$-0.68_{-0.27}^{+0.26}$| | |$1.10_{-0.10}^{+0.11}$| | |$-0.23_{-0.43}^{+0.49}$| |
| Coma Berentices | |$1.09_{-0.09}^{+0.13}$| | |$-0.40_{-0.46}^{+0.46}$| | |$1.07_{-0.08}^{+0.10}$| | |$-0.63_{-0.39}^{+0.32}$| | |$1.05_{-0.07}^{+0.09}$| | |$-0.75_{-0.27}^{+0.26}$| | |$1.08_{-0.09}^{+0.12}$| | |$-0.26_{-0.44}^{+0.48}$| |
| Hercules | |$1.11_{-0.08}^{+0.11}$| | |$-0.37_{-0.36}^{+0.42}$| | |$1.09_{-0.07}^{+0.07}$| | |$-0.61_{-0.29}^{+0.30}$| | |$1.08_{-0.06}^{+0.06}$| | |$-0.71_{-0.20}^{+0.21}$| | |$1.10_{-0.08}^{+0.10}$| | |$-0.24_{-0.40}^{+0.49}$| |
| Leo IV | |$1.11_{-0.10}^{+0.12}$| | |$-0.37_{-0.44}^{+0.44}$| | |$1.09_{-0.09}^{+0.09}$| | |$-0.58_{-0.37}^{+0.32}$| | |$1.09_{-0.08}^{+0.08}$| | |$-0.68_{-0.24}^{+0.24}$| | |$1.11_{-0.10}^{+0.11}$| | |$-0.22_{-0.43}^{+0.49}$| |
| Leo T | |$1.19_{-0.08}^{+0.10}$| | |$-0.21_{-0.30}^{+0.34}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.44_{-0.25}^{+0.23}$| | |$1.16_{-0.06}^{+0.06}$| | |$-0.53_{-0.19}^{+0.19}$| | |$1.19_{-0.07}^{+0.09}$| | |$-0.12_{-0.33}^{+0.45}$| |
| Segue I | |$1.07_{-0.12}^{+0.15}$| | |$-0.50_{-0.51}^{+0.46}$| | |$1.04_{-0.10}^{+0.11}$| | |$-0.74_{-0.43}^{+0.32}$| | |$1.02_{-0.08}^{+0.09}$| | |$-0.84_{-0.28}^{+0.24}$| | |$1.05_{-0.12}^{+0.14}$| | |$-0.35_{-0.52}^{+0.49}$| |
| Ursa Major I | |$1.12_{-0.07}^{+0.09}$| | |$-0.38_{-0.33}^{+0.41}$| | |$1.10_{-0.06}^{+0.06}$| | |$-0.56_{-0.26}^{+0.26}$| | |$1.09_{-0.05}^{+0.05}$| | |$-0.68_{-0.17}^{+0.18}$| | |$1.11_{-0.07}^{+0.09}$| | |$-0.22_{-0.36}^{+0.47}$| |
| Ursa Major II | |$1.12_{-0.08}^{+0.11}$| | |$-0.39_{-0.35}^{+0.39}$| | |$1.10_{-0.07}^{+0.08}$| | |$-0.58_{-0.29}^{+0.28}$| | |$1.09_{-0.06}^{+0.07}$| | |$-0.68_{-0.20}^{+0.20}$| | |$1.12_{-0.08}^{+0.11}$| | |$-0.22_{-0.38}^{+0.45}$| |
| Willman 1 | |$1.08_{-0.12}^{+0.15}$| | |$-0.45_{-0.49}^{+0.46}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.71_{-0.39}^{+0.30}$| | |$1.04_{-0.09}^{+0.09}$| | |$-0.80_{-0.27}^{+0.23}$| | |$1.06_{-0.11}^{+0.13}$| | |$-0.31_{-0.49}^{+0.47}$| |
| Segue 2 | |$1.07_{-0.12}^{+0.15}$| | |$-0.45_{-0.52}^{+0.48}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.69_{-0.41}^{+0.31}$| | |$1.03_{-0.09}^{+0.09}$| | |$-0.81_{-0.27}^{+0.24}$| | |$1.05_{-0.11}^{+0.13}$| | |$-0.31_{-0.50}^{+0.50}$| |
| NFW | Cored NFW | Burkert | Einasto | |||||
|---|---|---|---|---|---|---|---|---|
| Galaxy | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b |
| Carina | |$1.09_{-0.04}^{+0.14}$| | |$-0.35_{-0.33}^{+0.72}$| | |$1.09_{-0.03}^{+0.09}$| | |$-0.58_{-0.26}^{+0.58}$| | |$1.09_{-0.03}^{+0.04}$| | |$-0.69_{-0.15}^{+0.25}$| | |$1.10_{-0.04}^{+0.10}$| | |$-0.18_{-0.39}^{+0.61}$| |
| Draco | |$1.26_{-0.04}^{+0.07}$| | |$-0.12_{-0.24}^{+0.28}$| | |$1.24_{-0.04}^{+0.04}$| | |$-0.28_{-0.19}^{+0.19}$| | |$1.23_{-0.03}^{+0.04}$| | |$-0.36_{-0.17}^{+0.16}$| | |$1.26_{-0.05}^{+0.08}$| | |$-0.01_{-0.30}^{+0.42}$| |
| Fornax | |$1.27_{-0.02}^{+0.03}$| | |$0.01_{-0.21}^{+0.31}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.11_{-0.18}^{+0.32}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.22_{-0.16}^{+0.17}$| | |$1.28_{-0.02}^{+0.06}$| | |$0.11_{-0.30}^{+0.56}$| |
| Leo I | |$1.24_{-0.05}^{+0.09}$| | |$-0.06_{-0.28}^{+0.40}$| | |$1.23_{-0.05}^{+0.07}$| | |$-0.24_{-0.24}^{+0.35}$| | |$1.22_{-0.04}^{+0.05}$| | |$-0.37_{-0.19}^{+0.27}$| | |$1.24_{-0.05}^{+0.09}$| | |$0.02_{-0.33}^{+0.52}$| |
| Leo II | |$1.15_{-0.07}^{+0.15}$| | |$-0.18_{-0.40}^{+0.54}$| | |$1.13_{-0.06}^{+0.12}$| | |$-0.38_{-0.33}^{+0.46}$| | |$1.12_{-0.04}^{+0.11}$| | |$-0.57_{-0.21}^{+0.48}$| | |$1.15_{-0.06}^{+0.11}$| | |$-0.08_{-0.37}^{+0.57}$| |
| Sculptor | |$1.24_{-0.05}^{+0.08}$| | |$-0.07_{-0.27}^{+0.35}$| | |$1.23_{-0.04}^{+0.06}$| | |$-0.24_{-0.22}^{+0.31}$| | |$1.23_{-0.03}^{+0.05}$| | |$-0.36_{-0.18}^{+0.24}$| | |$1.24_{-0.05}^{+0.08}$| | |$0.02_{-0.32}^{+0.49}$| |
| Sextans | |$1.13_{-0.03}^{+0.04}$| | |$-0.36_{-0.19}^{+0.28}$| | |$1.15_{-0.03}^{+0.04}$| | |$-0.48_{-0.15}^{+0.16}$| | |$1.16_{-0.03}^{+0.03}$| | |$-0.51_{-0.11}^{+0.10}$| | |$1.13_{-0.04}^{+0.05}$| | |$-0.22_{-0.25}^{+0.44}$| |
| Ursa Minor | |$1.29_{-0.04}^{+0.05}$| | |$0.01_{-0.24}^{+0.27}$| | |$1.28_{-0.04}^{+0.04}$| | |$-0.13_{-0.19}^{+0.22}$| | |$1.28_{-0.03}^{+0.04}$| | |$-0.24_{-0.17}^{+0.17}$| | |$1.29_{-0.04}^{+0.06}$| | |$0.08_{-0.29}^{+0.43}$| |
| Bootes | |$1.18_{-0.08}^{+0.10}$| | |$-0.23_{-0.30}^{+0.36}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.43_{-0.24}^{+0.25}$| | |$1.15_{-0.06}^{+0.06}$| | |$-0.53_{-0.18}^{+0.20}$| | |$1.17_{-0.07}^{+0.10}$| | |$-0.12_{-0.33}^{+0.44}$| |
| Canes Venatici I | |$1.15_{-0.05}^{+0.05}$| | |$-0.32_{-0.22}^{+0.32}$| | |$1.15_{-0.04}^{+0.04}$| | |$-0.46_{-0.18}^{+0.20}$| | |$1.16_{-0.03}^{+0.04}$| | |$-0.52_{-0.13}^{+0.14}$| | |$1.15_{-0.05}^{+0.06}$| | |$-0.16_{-0.29}^{+0.47}$| |
| Canes Venatii II | |$1.09_{-0.10}^{+0.13}$| | |$-0.39_{-0.48}^{+0.46}$| | |$1.09_{-0.09}^{+0.10}$| | |$-0.56_{-0.41}^{+0.33}$| | |$1.08_{-0.08}^{+0.09}$| | |$-0.68_{-0.27}^{+0.26}$| | |$1.10_{-0.10}^{+0.11}$| | |$-0.23_{-0.43}^{+0.49}$| |
| Coma Berentices | |$1.09_{-0.09}^{+0.13}$| | |$-0.40_{-0.46}^{+0.46}$| | |$1.07_{-0.08}^{+0.10}$| | |$-0.63_{-0.39}^{+0.32}$| | |$1.05_{-0.07}^{+0.09}$| | |$-0.75_{-0.27}^{+0.26}$| | |$1.08_{-0.09}^{+0.12}$| | |$-0.26_{-0.44}^{+0.48}$| |
| Hercules | |$1.11_{-0.08}^{+0.11}$| | |$-0.37_{-0.36}^{+0.42}$| | |$1.09_{-0.07}^{+0.07}$| | |$-0.61_{-0.29}^{+0.30}$| | |$1.08_{-0.06}^{+0.06}$| | |$-0.71_{-0.20}^{+0.21}$| | |$1.10_{-0.08}^{+0.10}$| | |$-0.24_{-0.40}^{+0.49}$| |
| Leo IV | |$1.11_{-0.10}^{+0.12}$| | |$-0.37_{-0.44}^{+0.44}$| | |$1.09_{-0.09}^{+0.09}$| | |$-0.58_{-0.37}^{+0.32}$| | |$1.09_{-0.08}^{+0.08}$| | |$-0.68_{-0.24}^{+0.24}$| | |$1.11_{-0.10}^{+0.11}$| | |$-0.22_{-0.43}^{+0.49}$| |
| Leo T | |$1.19_{-0.08}^{+0.10}$| | |$-0.21_{-0.30}^{+0.34}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.44_{-0.25}^{+0.23}$| | |$1.16_{-0.06}^{+0.06}$| | |$-0.53_{-0.19}^{+0.19}$| | |$1.19_{-0.07}^{+0.09}$| | |$-0.12_{-0.33}^{+0.45}$| |
| Segue I | |$1.07_{-0.12}^{+0.15}$| | |$-0.50_{-0.51}^{+0.46}$| | |$1.04_{-0.10}^{+0.11}$| | |$-0.74_{-0.43}^{+0.32}$| | |$1.02_{-0.08}^{+0.09}$| | |$-0.84_{-0.28}^{+0.24}$| | |$1.05_{-0.12}^{+0.14}$| | |$-0.35_{-0.52}^{+0.49}$| |
| Ursa Major I | |$1.12_{-0.07}^{+0.09}$| | |$-0.38_{-0.33}^{+0.41}$| | |$1.10_{-0.06}^{+0.06}$| | |$-0.56_{-0.26}^{+0.26}$| | |$1.09_{-0.05}^{+0.05}$| | |$-0.68_{-0.17}^{+0.18}$| | |$1.11_{-0.07}^{+0.09}$| | |$-0.22_{-0.36}^{+0.47}$| |
| Ursa Major II | |$1.12_{-0.08}^{+0.11}$| | |$-0.39_{-0.35}^{+0.39}$| | |$1.10_{-0.07}^{+0.08}$| | |$-0.58_{-0.29}^{+0.28}$| | |$1.09_{-0.06}^{+0.07}$| | |$-0.68_{-0.20}^{+0.20}$| | |$1.12_{-0.08}^{+0.11}$| | |$-0.22_{-0.38}^{+0.45}$| |
| Willman 1 | |$1.08_{-0.12}^{+0.15}$| | |$-0.45_{-0.49}^{+0.46}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.71_{-0.39}^{+0.30}$| | |$1.04_{-0.09}^{+0.09}$| | |$-0.80_{-0.27}^{+0.23}$| | |$1.06_{-0.11}^{+0.13}$| | |$-0.31_{-0.49}^{+0.47}$| |
| Segue 2 | |$1.07_{-0.12}^{+0.15}$| | |$-0.45_{-0.52}^{+0.48}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.69_{-0.41}^{+0.31}$| | |$1.03_{-0.09}^{+0.09}$| | |$-0.81_{-0.27}^{+0.24}$| | |$1.05_{-0.11}^{+0.13}$| | |$-0.31_{-0.50}^{+0.50}$| |
aAll vmax in km s−1.
bAll rmax in kpc.
Summary of galaxy model parameters and results.
| NFW | Cored NFW | Burkert | Einasto | |||||
|---|---|---|---|---|---|---|---|---|
| Galaxy | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b |
| Carina | |$1.09_{-0.04}^{+0.14}$| | |$-0.35_{-0.33}^{+0.72}$| | |$1.09_{-0.03}^{+0.09}$| | |$-0.58_{-0.26}^{+0.58}$| | |$1.09_{-0.03}^{+0.04}$| | |$-0.69_{-0.15}^{+0.25}$| | |$1.10_{-0.04}^{+0.10}$| | |$-0.18_{-0.39}^{+0.61}$| |
| Draco | |$1.26_{-0.04}^{+0.07}$| | |$-0.12_{-0.24}^{+0.28}$| | |$1.24_{-0.04}^{+0.04}$| | |$-0.28_{-0.19}^{+0.19}$| | |$1.23_{-0.03}^{+0.04}$| | |$-0.36_{-0.17}^{+0.16}$| | |$1.26_{-0.05}^{+0.08}$| | |$-0.01_{-0.30}^{+0.42}$| |
| Fornax | |$1.27_{-0.02}^{+0.03}$| | |$0.01_{-0.21}^{+0.31}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.11_{-0.18}^{+0.32}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.22_{-0.16}^{+0.17}$| | |$1.28_{-0.02}^{+0.06}$| | |$0.11_{-0.30}^{+0.56}$| |
| Leo I | |$1.24_{-0.05}^{+0.09}$| | |$-0.06_{-0.28}^{+0.40}$| | |$1.23_{-0.05}^{+0.07}$| | |$-0.24_{-0.24}^{+0.35}$| | |$1.22_{-0.04}^{+0.05}$| | |$-0.37_{-0.19}^{+0.27}$| | |$1.24_{-0.05}^{+0.09}$| | |$0.02_{-0.33}^{+0.52}$| |
| Leo II | |$1.15_{-0.07}^{+0.15}$| | |$-0.18_{-0.40}^{+0.54}$| | |$1.13_{-0.06}^{+0.12}$| | |$-0.38_{-0.33}^{+0.46}$| | |$1.12_{-0.04}^{+0.11}$| | |$-0.57_{-0.21}^{+0.48}$| | |$1.15_{-0.06}^{+0.11}$| | |$-0.08_{-0.37}^{+0.57}$| |
| Sculptor | |$1.24_{-0.05}^{+0.08}$| | |$-0.07_{-0.27}^{+0.35}$| | |$1.23_{-0.04}^{+0.06}$| | |$-0.24_{-0.22}^{+0.31}$| | |$1.23_{-0.03}^{+0.05}$| | |$-0.36_{-0.18}^{+0.24}$| | |$1.24_{-0.05}^{+0.08}$| | |$0.02_{-0.32}^{+0.49}$| |
| Sextans | |$1.13_{-0.03}^{+0.04}$| | |$-0.36_{-0.19}^{+0.28}$| | |$1.15_{-0.03}^{+0.04}$| | |$-0.48_{-0.15}^{+0.16}$| | |$1.16_{-0.03}^{+0.03}$| | |$-0.51_{-0.11}^{+0.10}$| | |$1.13_{-0.04}^{+0.05}$| | |$-0.22_{-0.25}^{+0.44}$| |
| Ursa Minor | |$1.29_{-0.04}^{+0.05}$| | |$0.01_{-0.24}^{+0.27}$| | |$1.28_{-0.04}^{+0.04}$| | |$-0.13_{-0.19}^{+0.22}$| | |$1.28_{-0.03}^{+0.04}$| | |$-0.24_{-0.17}^{+0.17}$| | |$1.29_{-0.04}^{+0.06}$| | |$0.08_{-0.29}^{+0.43}$| |
| Bootes | |$1.18_{-0.08}^{+0.10}$| | |$-0.23_{-0.30}^{+0.36}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.43_{-0.24}^{+0.25}$| | |$1.15_{-0.06}^{+0.06}$| | |$-0.53_{-0.18}^{+0.20}$| | |$1.17_{-0.07}^{+0.10}$| | |$-0.12_{-0.33}^{+0.44}$| |
| Canes Venatici I | |$1.15_{-0.05}^{+0.05}$| | |$-0.32_{-0.22}^{+0.32}$| | |$1.15_{-0.04}^{+0.04}$| | |$-0.46_{-0.18}^{+0.20}$| | |$1.16_{-0.03}^{+0.04}$| | |$-0.52_{-0.13}^{+0.14}$| | |$1.15_{-0.05}^{+0.06}$| | |$-0.16_{-0.29}^{+0.47}$| |
| Canes Venatii II | |$1.09_{-0.10}^{+0.13}$| | |$-0.39_{-0.48}^{+0.46}$| | |$1.09_{-0.09}^{+0.10}$| | |$-0.56_{-0.41}^{+0.33}$| | |$1.08_{-0.08}^{+0.09}$| | |$-0.68_{-0.27}^{+0.26}$| | |$1.10_{-0.10}^{+0.11}$| | |$-0.23_{-0.43}^{+0.49}$| |
| Coma Berentices | |$1.09_{-0.09}^{+0.13}$| | |$-0.40_{-0.46}^{+0.46}$| | |$1.07_{-0.08}^{+0.10}$| | |$-0.63_{-0.39}^{+0.32}$| | |$1.05_{-0.07}^{+0.09}$| | |$-0.75_{-0.27}^{+0.26}$| | |$1.08_{-0.09}^{+0.12}$| | |$-0.26_{-0.44}^{+0.48}$| |
| Hercules | |$1.11_{-0.08}^{+0.11}$| | |$-0.37_{-0.36}^{+0.42}$| | |$1.09_{-0.07}^{+0.07}$| | |$-0.61_{-0.29}^{+0.30}$| | |$1.08_{-0.06}^{+0.06}$| | |$-0.71_{-0.20}^{+0.21}$| | |$1.10_{-0.08}^{+0.10}$| | |$-0.24_{-0.40}^{+0.49}$| |
| Leo IV | |$1.11_{-0.10}^{+0.12}$| | |$-0.37_{-0.44}^{+0.44}$| | |$1.09_{-0.09}^{+0.09}$| | |$-0.58_{-0.37}^{+0.32}$| | |$1.09_{-0.08}^{+0.08}$| | |$-0.68_{-0.24}^{+0.24}$| | |$1.11_{-0.10}^{+0.11}$| | |$-0.22_{-0.43}^{+0.49}$| |
| Leo T | |$1.19_{-0.08}^{+0.10}$| | |$-0.21_{-0.30}^{+0.34}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.44_{-0.25}^{+0.23}$| | |$1.16_{-0.06}^{+0.06}$| | |$-0.53_{-0.19}^{+0.19}$| | |$1.19_{-0.07}^{+0.09}$| | |$-0.12_{-0.33}^{+0.45}$| |
| Segue I | |$1.07_{-0.12}^{+0.15}$| | |$-0.50_{-0.51}^{+0.46}$| | |$1.04_{-0.10}^{+0.11}$| | |$-0.74_{-0.43}^{+0.32}$| | |$1.02_{-0.08}^{+0.09}$| | |$-0.84_{-0.28}^{+0.24}$| | |$1.05_{-0.12}^{+0.14}$| | |$-0.35_{-0.52}^{+0.49}$| |
| Ursa Major I | |$1.12_{-0.07}^{+0.09}$| | |$-0.38_{-0.33}^{+0.41}$| | |$1.10_{-0.06}^{+0.06}$| | |$-0.56_{-0.26}^{+0.26}$| | |$1.09_{-0.05}^{+0.05}$| | |$-0.68_{-0.17}^{+0.18}$| | |$1.11_{-0.07}^{+0.09}$| | |$-0.22_{-0.36}^{+0.47}$| |
| Ursa Major II | |$1.12_{-0.08}^{+0.11}$| | |$-0.39_{-0.35}^{+0.39}$| | |$1.10_{-0.07}^{+0.08}$| | |$-0.58_{-0.29}^{+0.28}$| | |$1.09_{-0.06}^{+0.07}$| | |$-0.68_{-0.20}^{+0.20}$| | |$1.12_{-0.08}^{+0.11}$| | |$-0.22_{-0.38}^{+0.45}$| |
| Willman 1 | |$1.08_{-0.12}^{+0.15}$| | |$-0.45_{-0.49}^{+0.46}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.71_{-0.39}^{+0.30}$| | |$1.04_{-0.09}^{+0.09}$| | |$-0.80_{-0.27}^{+0.23}$| | |$1.06_{-0.11}^{+0.13}$| | |$-0.31_{-0.49}^{+0.47}$| |
| Segue 2 | |$1.07_{-0.12}^{+0.15}$| | |$-0.45_{-0.52}^{+0.48}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.69_{-0.41}^{+0.31}$| | |$1.03_{-0.09}^{+0.09}$| | |$-0.81_{-0.27}^{+0.24}$| | |$1.05_{-0.11}^{+0.13}$| | |$-0.31_{-0.50}^{+0.50}$| |
| NFW | Cored NFW | Burkert | Einasto | |||||
|---|---|---|---|---|---|---|---|---|
| Galaxy | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b | log10(vmax)a | log10(rmax)b |
| Carina | |$1.09_{-0.04}^{+0.14}$| | |$-0.35_{-0.33}^{+0.72}$| | |$1.09_{-0.03}^{+0.09}$| | |$-0.58_{-0.26}^{+0.58}$| | |$1.09_{-0.03}^{+0.04}$| | |$-0.69_{-0.15}^{+0.25}$| | |$1.10_{-0.04}^{+0.10}$| | |$-0.18_{-0.39}^{+0.61}$| |
| Draco | |$1.26_{-0.04}^{+0.07}$| | |$-0.12_{-0.24}^{+0.28}$| | |$1.24_{-0.04}^{+0.04}$| | |$-0.28_{-0.19}^{+0.19}$| | |$1.23_{-0.03}^{+0.04}$| | |$-0.36_{-0.17}^{+0.16}$| | |$1.26_{-0.05}^{+0.08}$| | |$-0.01_{-0.30}^{+0.42}$| |
| Fornax | |$1.27_{-0.02}^{+0.03}$| | |$0.01_{-0.21}^{+0.31}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.11_{-0.18}^{+0.32}$| | |$1.28_{-0.02}^{+0.03}$| | |$-0.22_{-0.16}^{+0.17}$| | |$1.28_{-0.02}^{+0.06}$| | |$0.11_{-0.30}^{+0.56}$| |
| Leo I | |$1.24_{-0.05}^{+0.09}$| | |$-0.06_{-0.28}^{+0.40}$| | |$1.23_{-0.05}^{+0.07}$| | |$-0.24_{-0.24}^{+0.35}$| | |$1.22_{-0.04}^{+0.05}$| | |$-0.37_{-0.19}^{+0.27}$| | |$1.24_{-0.05}^{+0.09}$| | |$0.02_{-0.33}^{+0.52}$| |
| Leo II | |$1.15_{-0.07}^{+0.15}$| | |$-0.18_{-0.40}^{+0.54}$| | |$1.13_{-0.06}^{+0.12}$| | |$-0.38_{-0.33}^{+0.46}$| | |$1.12_{-0.04}^{+0.11}$| | |$-0.57_{-0.21}^{+0.48}$| | |$1.15_{-0.06}^{+0.11}$| | |$-0.08_{-0.37}^{+0.57}$| |
| Sculptor | |$1.24_{-0.05}^{+0.08}$| | |$-0.07_{-0.27}^{+0.35}$| | |$1.23_{-0.04}^{+0.06}$| | |$-0.24_{-0.22}^{+0.31}$| | |$1.23_{-0.03}^{+0.05}$| | |$-0.36_{-0.18}^{+0.24}$| | |$1.24_{-0.05}^{+0.08}$| | |$0.02_{-0.32}^{+0.49}$| |
| Sextans | |$1.13_{-0.03}^{+0.04}$| | |$-0.36_{-0.19}^{+0.28}$| | |$1.15_{-0.03}^{+0.04}$| | |$-0.48_{-0.15}^{+0.16}$| | |$1.16_{-0.03}^{+0.03}$| | |$-0.51_{-0.11}^{+0.10}$| | |$1.13_{-0.04}^{+0.05}$| | |$-0.22_{-0.25}^{+0.44}$| |
| Ursa Minor | |$1.29_{-0.04}^{+0.05}$| | |$0.01_{-0.24}^{+0.27}$| | |$1.28_{-0.04}^{+0.04}$| | |$-0.13_{-0.19}^{+0.22}$| | |$1.28_{-0.03}^{+0.04}$| | |$-0.24_{-0.17}^{+0.17}$| | |$1.29_{-0.04}^{+0.06}$| | |$0.08_{-0.29}^{+0.43}$| |
| Bootes | |$1.18_{-0.08}^{+0.10}$| | |$-0.23_{-0.30}^{+0.36}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.43_{-0.24}^{+0.25}$| | |$1.15_{-0.06}^{+0.06}$| | |$-0.53_{-0.18}^{+0.20}$| | |$1.17_{-0.07}^{+0.10}$| | |$-0.12_{-0.33}^{+0.44}$| |
| Canes Venatici I | |$1.15_{-0.05}^{+0.05}$| | |$-0.32_{-0.22}^{+0.32}$| | |$1.15_{-0.04}^{+0.04}$| | |$-0.46_{-0.18}^{+0.20}$| | |$1.16_{-0.03}^{+0.04}$| | |$-0.52_{-0.13}^{+0.14}$| | |$1.15_{-0.05}^{+0.06}$| | |$-0.16_{-0.29}^{+0.47}$| |
| Canes Venatii II | |$1.09_{-0.10}^{+0.13}$| | |$-0.39_{-0.48}^{+0.46}$| | |$1.09_{-0.09}^{+0.10}$| | |$-0.56_{-0.41}^{+0.33}$| | |$1.08_{-0.08}^{+0.09}$| | |$-0.68_{-0.27}^{+0.26}$| | |$1.10_{-0.10}^{+0.11}$| | |$-0.23_{-0.43}^{+0.49}$| |
| Coma Berentices | |$1.09_{-0.09}^{+0.13}$| | |$-0.40_{-0.46}^{+0.46}$| | |$1.07_{-0.08}^{+0.10}$| | |$-0.63_{-0.39}^{+0.32}$| | |$1.05_{-0.07}^{+0.09}$| | |$-0.75_{-0.27}^{+0.26}$| | |$1.08_{-0.09}^{+0.12}$| | |$-0.26_{-0.44}^{+0.48}$| |
| Hercules | |$1.11_{-0.08}^{+0.11}$| | |$-0.37_{-0.36}^{+0.42}$| | |$1.09_{-0.07}^{+0.07}$| | |$-0.61_{-0.29}^{+0.30}$| | |$1.08_{-0.06}^{+0.06}$| | |$-0.71_{-0.20}^{+0.21}$| | |$1.10_{-0.08}^{+0.10}$| | |$-0.24_{-0.40}^{+0.49}$| |
| Leo IV | |$1.11_{-0.10}^{+0.12}$| | |$-0.37_{-0.44}^{+0.44}$| | |$1.09_{-0.09}^{+0.09}$| | |$-0.58_{-0.37}^{+0.32}$| | |$1.09_{-0.08}^{+0.08}$| | |$-0.68_{-0.24}^{+0.24}$| | |$1.11_{-0.10}^{+0.11}$| | |$-0.22_{-0.43}^{+0.49}$| |
| Leo T | |$1.19_{-0.08}^{+0.10}$| | |$-0.21_{-0.30}^{+0.34}$| | |$1.16_{-0.06}^{+0.07}$| | |$-0.44_{-0.25}^{+0.23}$| | |$1.16_{-0.06}^{+0.06}$| | |$-0.53_{-0.19}^{+0.19}$| | |$1.19_{-0.07}^{+0.09}$| | |$-0.12_{-0.33}^{+0.45}$| |
| Segue I | |$1.07_{-0.12}^{+0.15}$| | |$-0.50_{-0.51}^{+0.46}$| | |$1.04_{-0.10}^{+0.11}$| | |$-0.74_{-0.43}^{+0.32}$| | |$1.02_{-0.08}^{+0.09}$| | |$-0.84_{-0.28}^{+0.24}$| | |$1.05_{-0.12}^{+0.14}$| | |$-0.35_{-0.52}^{+0.49}$| |
| Ursa Major I | |$1.12_{-0.07}^{+0.09}$| | |$-0.38_{-0.33}^{+0.41}$| | |$1.10_{-0.06}^{+0.06}$| | |$-0.56_{-0.26}^{+0.26}$| | |$1.09_{-0.05}^{+0.05}$| | |$-0.68_{-0.17}^{+0.18}$| | |$1.11_{-0.07}^{+0.09}$| | |$-0.22_{-0.36}^{+0.47}$| |
| Ursa Major II | |$1.12_{-0.08}^{+0.11}$| | |$-0.39_{-0.35}^{+0.39}$| | |$1.10_{-0.07}^{+0.08}$| | |$-0.58_{-0.29}^{+0.28}$| | |$1.09_{-0.06}^{+0.07}$| | |$-0.68_{-0.20}^{+0.20}$| | |$1.12_{-0.08}^{+0.11}$| | |$-0.22_{-0.38}^{+0.45}$| |
| Willman 1 | |$1.08_{-0.12}^{+0.15}$| | |$-0.45_{-0.49}^{+0.46}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.71_{-0.39}^{+0.30}$| | |$1.04_{-0.09}^{+0.09}$| | |$-0.80_{-0.27}^{+0.23}$| | |$1.06_{-0.11}^{+0.13}$| | |$-0.31_{-0.49}^{+0.47}$| |
| Segue 2 | |$1.07_{-0.12}^{+0.15}$| | |$-0.45_{-0.52}^{+0.48}$| | |$1.05_{-0.11}^{+0.10}$| | |$-0.69_{-0.41}^{+0.31}$| | |$1.03_{-0.09}^{+0.09}$| | |$-0.81_{-0.27}^{+0.24}$| | |$1.05_{-0.11}^{+0.13}$| | |$-0.31_{-0.50}^{+0.50}$| |
aAll vmax in km s−1.
bAll rmax in kpc.
The primary benefit of hierarchical modelling to dynamical mass modelling is the inclusion of relevant galaxy population distribution information. This is particularly true in prior dominated systems in which exclusion of such information will lead to posteriors dominated by prior assumptions rather than by data. This is the origin in the apparent difference between the results presented here and those presented in Strigari et al. (2007a). Because some of the galaxies are prior dominated, use of an arbitrary (non-hierarchical) prior can drastically shift the results. In some instances, especially with the prior-dominated ultrafaint galaxies, the differences in these posteriors differ by more than two standard deviations. This is a typical consequence of applying an arbitrary prior instead of constraining these priors from the complete data set. Specifically this can be seen at the high and low ends of the luminosity function. With the use of the data-driven priors used here, we generally find lower rmax and vmax values at low luminosities whereas these values were a bit higher at high luminosities (when compared to Strigari et al. 2007a).
While hierarchical modelling has done quite a lot reconciling the Local Group dwarf spheriodal distribution with that predicted by CDM at the lower end of the mass function, it has only exacerbated the Too-Big-To-Fail problem. Here we have shown that, not only would the local dwarfs have concentrations inconsistent with CDM if they were hosted by haloes with a vmax of 20–40 km s−1, but that it is statistically inconsistent for them to be hosted by haloes of a vmax this size. In other words, the improved results from this analysis undoubtedly shows that there is a deficit of Milky Way haloes with a vmax of 20–40 km s−1.
We have shown here that MLM may drastically improve results and can be applied to any problem that involves an ensemble of data sets – given that this ensemble originate from the same underlying distribution. Problems that meet this criterion, such as determining the mass and period distribution of planets (Howard et al. 2012) or the stellar initial mass function of star clusters (Bastian, Covey & Meyer 2010) stand to benefit from this type of analysis. In particular, Milky Way dSph measurements stand to benefit from this analysis because they not only meet this criterion, but previous analyses suggest that these galaxies truly follow an underlying distribution (Diemand et al. 2007; Neto et al. 2007; Strigari et al. 2007a; Springel et al. 2008). Most notable, the galaxies at ultrafaint luminosities have benefited the most from this analysis. This is entirely due to the fact that the uncertainty is simply an representation of our total ‘degree of belief’. Here, it is important to realize that this belief is based on all available information: information contained in the individual data set and information contained in the underlying distribution. Since these galaxies’ constraints on their mass profiles are dominated by the lack of knowledge of the underlying distribution, it is these constraints that have the most to gain from this methodology. These galaxies will also be affected most if our knowledge of the underlying distribution changes. Indications that some of the ultrafaint satellites may have dispersion lower than previously measured (e.g. Kirby et al. 2013) would not only affect the mass measurements of those individual galaxies, but also all the ultrafaint galaxies as a whole. However, such indications would only serve to exclude solutions with high concentrations (e.g. large log (rmax)–log (rmax) slopes, see Fig. 3) that are inconsistent with CDM simulations. Therefore, if this were indeed the case, we suspect that this would only strengthen our main conclusion that the Milky Way dSph's distribution is consistent within the ΛCDM paradigm for haloes with vmax < 20 km s−1.
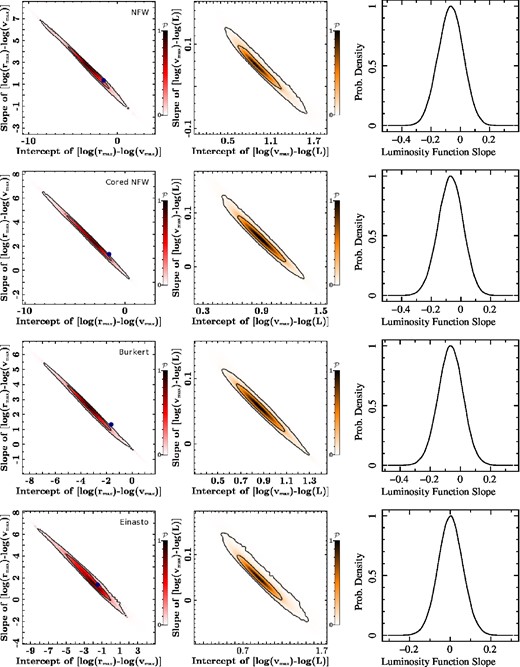
This figure shows the unrestrained top-level parameter posteriors (|$\mathcal {P}$|). Shown in each column, from left to right, are the joint posteriors αrv–βrv and αlv–βlv, as well as the posterior for αl. From top to bottom, each row contains the posteriors assuming the NFW, cored NFW, Burkert and Einasto models. The blue dot represents the αrv and βrv values predicted by simulations (Diemand et al. 2007; Strigari et al. 2007b; Springel et al. 2008). The solid lines represent the 68 and 95 per cent credible levels (all log s are base 10).
We reiterate that these conclusions are based on data constraints rather than prior assumptions. Although it may seem that the subjectivity increased with the inclusion of seven new top-level priors, this is indeed not the case because the 20 lower-level priors are being interpreted as actual physical distributions. As a matter of fact, the only assumption MLM requires is that the total galaxy set samples an overall distribution described by the prior probability. But this is equivalent to assuming that each individual data set samples a larger distribution of data described by the likelihood – an assumption that is necessary to perform any likelihood analysis. Furthermore, the issues that plague a normal likelihood analysis also hold for the complete set of lower-level posteriors. One example that is often overlooked is the effect of the choice of parametrization of the likelihood. If a likelihood is parametrized with too few parameters, relevant detail may be lost or misinterpreted, whereas too many parameters may cause overfitting. Likewise, prior parametrization (e.g. equation 12) is also an issue for MLM for the same reasons. An interesting direction of this work is to explore varying forms of |$\mathcal {P}(v_{ {\rm max}}|L)$| (e.g. |$\mathcal {P}(M(300)|L)$|). Our main motivation in the selection of a lognormal form of |$\mathcal {P}(v_{ {\rm max}}|L)$| was the apparent flat M(300)–L relation claimed by Strigari et al. (2007b). Specifically, we questioned whether posteriors derived using this prior information would yield the same results. Of course, we found that they did not. But, from Fig. 4 it is conceivable that the high luminosity galaxies follow a different M(300)–L relationship than low-luminosity galaxies. If so, this may have profound consequences on our conclusions considering that the main reason for our improved constraints is the addition of luminosity information. While it is hard to surmise what effect, if any, these issues have on the allowed density profiles and the subsequently constrained rmax–vmax distribution, study of alternative prior forms may give insights to the consistency of alternative dark matter theories. Because of the large dimensional parameter space that is usually involved in Bayesian hierarchical modelling we have taken advantage here of every technical simplification available. Specifically, we have integrated over the luminosities of each individual galaxy to reduce the parameter space by a third. But if more complicated luminosity mass relations were considered, then the integral over luminosity would not be analytic. For this reason, these technical difficulties preclude us from including these issues in this current study. Thus, we leave this analysis to future work.

This figure shows the various bottom-level posteriors for rmax, vmax and M(300). Shown in each column, from left to right, are the individual galaxies posteriors of log (rmax) verses log (vmax), log (vmax) verses log (L) and log (M(300)) verses log (L). From top to bottom, each row contains the posteriors assuming the NFW, cored NFW, Burkert and Einasto models. Overlaid is the median fit prior distribution showing the distribution peak (solid line) and intrinsic one sigma variance (dashed line). These plots show that individual posterior constraints for each galaxy agrees well with the inferred overall galaxy distribution. The log (rmax) versus log (vmax) plots show the net effect of the ‘αlv – |$v_{\beta _{lv}}$| degeneracy’ in the extreme values of log (vmax). This effect is most prominent at low vmax values where the posteriors widths increase the at more extreme vmax values. This is due to the scale radii being far from the stellar half-light radius – an unfortunate byproduct of the approximate common scale shared by the Milky Way dSph galaxies. The effect of this degeneracy also manifests at the low-luminosity end of the log (vmax) versus log (L) relation. But this effect is minimal compared to the overall effect on the log (rmax) versus log (vmax) relation. Most notably though is the implied log (M(300)) versus log (L) relation. While this relation is fairly constant, there is a definite implied small positive slope consistent with simulated value of 0.088 ± 0.024 (Rashkov et al. 2012). Note that these bottom-level posteriors contain information of both the individual galaxy fit as well as the fit of the full data set to the lower-level prior. Thus, the width of the posteriors reflect both the uncertainty of the individual galaxy parameters as well as the quality of fit of the lower-level prior. Models that produce distributions that fit the lower-prior well allow for a larger range in the lower-level parameters since these models naturally produce more solutions that are a good overall fit to the data. Conversely, models that produce distributions that poorly fit the lower-level prior allow a shorter range in the lower-level posteriors for the same reason. Since the posteriors contain information about the full parameter space, the posterior width is the result of both the individual galaxy distribution as well as the allowed range due to the fit of the prior distribution. Thus, a narrower posterior width is not necessarily indicate a better overall fit.
6 CONCLUSION
In this work, we introduced a new methodology to derive mass profiles for the Milky Way Local Group dSphs. This new methodology, based on MLM, exploits the fact that these individual galaxies sample an underlying distribution. By simultaneously constraining both the individual galaxy and the overall galaxy distribution parameters, not only do individual galaxies’ posteriors become more robust, but the overall distribution properties may also be inferred. This is done by interpreting the individual galaxy prior probabilities as the probability of observing a particular galaxy from this overall distribution. In other words, we interpret the prior probability as a frequentist probability sampling from an actual physical galaxy distribution. Thus, in much the same way that single data point probabilities can be combined to form a ‘lower-level’ likelihood that can be used to constrain individual galaxy parameters, the posteriors from the full galaxy sample can be combined to form a ‘upper-level’ likelihood that can be used to constrain both the overall galaxy distribution and the individual galaxy parameters. This interpretation of the individual prior distributions then becomes beneficial for the following reasons. First, it removes the subjectivity normally associated with the Bayesian ‘degree of belief’ interpretation of probability on the lower-level priors. And secondly, it allows us to use of the combined data set to directly constrain the prior probabilities via this newly defined ‘higher-level’ likelihood. Because the Bayesian interpretation of probability has not been used in the formation of this likelihood, multilevel analysis can be done in both the frequentist and Bayesian frameworks. For this analysis, we utilized the Bayesian multilevel methodology, Bayesian hierarchical modelling.
Application of this methodology resulted not only in more robust individual galaxy mass profile constraints, but also in fairly robust constraints on the overall distribution. The galaxies that benefited the most from this analysis were the ultrafaint dwarf satellite galaxies. These galaxies, because of their extreme prior dominance, had the most to gain from the extra information gained from constraining the prior PDF. Although the anisotropy-mass degeneracy was greatly minimized, we found that this indirectly caused a somewhat constrained degeneracy between the slope and intercept of the overall distribution's rmax–vmax relation. Even so, the overall inferred relationship between rmax and vmax as well as the inferred relationship between the mass within 300 pc and luminosity are in excellent agreement with CDM simulations. Also, we found that a cuspy halo is a good ‘average’ fit to the Milky Way satellites density profiles. Although this does not exclude the possibility that individual galaxies (especially extended high-luminosity satellites) from having cored dark matter profiles, it may suggest that these galaxies’ central regions were once cusped but may have ‘softened’ due to astrophysical interactions.
GDM is very appreciative to Alex Drlica-Wagner, Jan Conrad, Louie Strigari, Annika Peter, Tuan Do, Manoj Kaplinghat and Christian Farnier for useful comments and discussions. GDM also acknowledges support from the Wennergren foundation.
REFERENCES

{kind=link}
{kind=link}
{kind=link}
{kind=link}