





Abstract
We investigate the shape of the extinction law in two 1° square fields of the Perseus molecular cloud complex. We combine deep red-optical (r, i and z band) observations obtained using Megacam on the MMT with UKIRT (United Kingdom Infrared Telescope) Infrared Deep Sky Survey near-infrared (J, H and K band) data to measure the colours of background stars. We develop a new hierarchical Bayesian statistical model, including measurement error, intrinsic colour variation, spectral type and dust reddening, to simultaneously infer parameters for individual stars and characteristics of the population. We implement an efficient Markov chain Monte Carlo algorithm utilizing generalized Gibbs sampling to compute coherent probabilistic inferences. We find a strong correlation between the extinction (AV) and the slope of the extinction law (parametrized by RV). Because the majority of the extinction towards our stars comes from the Perseus molecular cloud, we interpret this correlation as evidence of grain growth at moderate optical depths. The extinction law changes from the ‘diffuse’ value of RV ∼ 3 to the ‘dense cloud’ value of RV ∼ 5 as the column density rises from AV = 2 to 10 mag. This relationship is similar for the two regions in our study, despite their different physical conditions, suggesting that dust grain growth is a fairly universal process.
1 INTRODUCTION
Interstellar dust affects virtually all astronomical observations, yet remains poorly understood. A full prescriptive theory which quantitatively explains the production, destruction and steady-state conditions of interstellar dust does not exist, although various simple models (e.g. Inoue 2011) have been proposed. In particular, the specific minerals, the shape (or structure), mass/size distribution and total amount of interstellar dust cannot generally be produced from first principles. Much progress, though, has been made towards a descriptive theory. A basic model with separate power-law size distributions of bare graphite and silicate grains was shown to adequately reproduce most of the observational evidence by Draine & Lee (1984). Weingartner & Draine (2001) updated the model to include very small grains – polycyclic aromatic hydrocarbons (PAHs) – which are necessary both to reproduce observed mid-infrared spectral features and to explain the transiently heated grains identified by Sellgren (1984). Although the Weingartner & Draine (2001) model is relatively simplistic (the model uses spheroidal grains although grains are probably ‘fluffy’ and fractal) and slightly ad hoc (the silicate is ‘astronomical amorphous silicate’ with a few lab-measured spectral features modified to accommodate the observations), this model has proven to be quite robust and is still widely used to interpret the extinction and emission features of dust from the X-ray through the mid-infrared (see Draine 2003, for a review of this model's successes and shortcomings).
Inside dense clouds, dust undergoes significant processing. The two most important processes are coagulation (grains sticking together and growing) and mantle accretion of volatile elements. Some accretion of a volatile mantle on to refractory dust grains is presumed to occur in cold dense regions because observations of gas in molecular cores show severe depletion of several important molecules at high densities. This is particularly true for carbon-bearing species (see Bergin & Tafalla 2007, and references therein). Indeed, a theory of grains where bare silicate cores are covered by carbon-rich mantles can do a fair job of explaining the ISM dust more generally (Greenberg & Li 1999). Additionally, the mid-infrared spectra of dense regions often show features which are interpreted as ice mantles of volatiles. At the same time, coagulation must be important, because the extinction per hydrogen atom [AV/N(H)] is observed to decrease in dense regions. This is interpreted by Mathis (1990) as requiring the coagulation of grains, which can be thought of as preventing the interiors of grains from effectively participating in extinction. Adding more material to the extinguishing dust via depletion without also coagulating would generally tend to increase the total amount of extinction per hydrogen atom simply because there is more material blocking radiation.
Observations of background stars behind a column of dust provide the best way to directly measure the shape of the extinction law but the wavelength range must be chosen with care. Dust exhibits rich spectral features in the mid-infrared which are normally ascribed to PAHs. The strength of these features is expected to be a function of the precise chemical history of a population of dust grains and the particular radiation environment to which the dust is currently exposed. These features can also produce emission which contributes to the mid-infrared fluxes of background stars observed through a dust cloud, complicating the use of these wavebands and presumably explaining the disparate attempts to nail down this portion of the extinction curve (compare Indebetouw et al. 2005; Flaherty et al. 2007; Chapman et al. 2009). Wavelengths in the blue-optical or ultraviolet are quite sensitive probes of the extinction law, but it is prohibitively expensive to obtain observations of highly reddened stars at these wavelengths. The red-optical and NIR are thus the best place to study the question.
A single molecular cloud is a complex hierarchical structure, with a dense filamentary web and a vast range of physical environments. The cores that eventually form stars are often well modelled as simple Bonner–Ebert spheres (e.g. Alves, Lada & Lada 2001; Schnee & Goodman 2005). Within such a centrally condensed spherical object the observed quantity – the total column density, which we shall call AV for conventional reasons – can be loosely related to the underlying physical driver of dust grain growth – the volume density – in the sense that increasing column density implies increasing volume density. Our chain of inference is thus RV ∝ 〈a〉 ∝ n ∝ AV, where n is the volume density and 〈a〉 represents the average size of dust grains. Outside of a single centrally condensed object, the connection between column and volume density will break down. Nonetheless, because structures in molecular clouds tend to be centrally condensed this chain of inference may hold, at least for the portions of the cloud where we are predominantly seeing through a single structure.
Previous studies of changes in extinction law in molecular clouds have mostly been at large AV (AV > 10 mag). Cambrésy et al. (2011) report a transition in the extinction law at AV = 20 mag in Spitzer Infrared Array Camera (IRAC) bands (3.6, 4.5 and 5.8 μm). Román-Zúñiga et al. (2007) measured the extinction law at large optical depths (up to AV of 60 mag) in B59 and found no evidence for variation in the extinction law at these depths; the favoured extinction law through the entire cloud was the Weingartner & Draine (2001) model with RV = 5.5. Cambrésy, Jarrett & Beichman (2005) report a change in the extinction properties around AV = 1 mag averaged over the Galactic anticentre hemisphere. This analysis is based on a comparison against the Schlegel, Finkbeiner & Davis (1998) dust emission maps, so this could also correspond to the regime where the Schlegel et al. (1998) dust temperature correction is uncertain (Arce & Goodman 1999). Studies using other methods have also inferred changes in dust properties as a function of increasing depth inside a cloud using, for example, scattered light (e.g. Steinacker et al. 2010) or changes in the dust emissivity at submillimetre wavelengths (e.g. Stepnik et al. 2003).
In this study, we combine deep multiwavelength data in the red-optical (r, i, z) with NIR (J, H, K) data from the UKIRT Infrared Deep Sky Survey (UKIDSS) for large sections of the Perseus molecular cloud in order to test the relationship between RV and AV over the range of column densities where the diffuse ISM-like matter of the molecular cloud transitions into the dense-core regime. We employ a novel hierarchical Bayesian approach to statistically model multiple sources of uncertainty and coherently estimate the parameters for individual stars and the population. We find strong evidence that there is a global correlation in the sense that the extinction law becomes steeper (RV becomes larger which corresponds to larger dust grains in the model of Weingartner & Draine 2001) as AV increases from around 2 mag to about 10 mag of extinction.
In Section 2 we describe the acquisition, reduction and calibration of our photometric data. In Section 3 we describe our model to fit the photometric data using an empirical colour locus and a parametrized extinction law. We describe a traditional least-squares approach (Section 3.1) as well as a hierarchical Bayesian model (Section 3.2) to overcome some of the problems in the least-squares approach. We present the results from this hierarchical Bayesian model in Section 4, and we conclude in Section 5. We describe the mathematical details of our statistical model in Appendix A. In Appendix A, we present details of our Markov chain Monte Carlo (MCMC) algorithm for computing statistical inferences.
2 DATA
2.1 Megacam data acquisition
Our red-optical data were taken during the second halves of the night on 2007 November 2 and 3 using Megacam at the 6.5-m MMT on Mt Hopkins.1 We observed two fields within the Perseus molecular cloud complex; one field was centred on B5 (RA, Dec. = 56| ${.\!\!\!\!\!\!^{\circ}}$|96, +32| ${.\!\!\!\!\!\!^{\circ}}$|84; Fig. 1) and the other field was centred on the ‘West-End’ of Perseus (see Pineda, Caselli & Goodman 2008, for the definition of this region), containing L1448, L1451 and L1455 (RA, Dec. = 51| ${.\!\!\!\!\!\!^{\circ}}$|58, +30| ${.\!\!\!\!\!\!^{\circ}}$|50; Fig. 2). Individual exposures were 80 s in r, 60 s in i and 50 s in z. The general pattern was to observe all of one field each night, so the West-End (WE) was observed on 2007 November 2, while B5 was observed on 2007 November 3. However, a few additional WE images were obtained on 2007 November 3 at the end of the night.

A three-colour (r, i, z) image of B5 with contours at 3 and 5 mag of AV from a 2MASS-based extinction map (Ridge et al. 2006). Also shown are the four quadrants used in observing. The most energetic young star, B5-IRS1 is visible at the centre with a small reflection nebula around it. Processing artefacts include the ‘donut’ shaped ghosts around bright stars and streaks from satellites. In the top left of the image, green lines show areas not covered by r band due to a mistaken alignment. The bright star in this corner caused problems for the defringing algorithm, resulting in a corrupt image here.
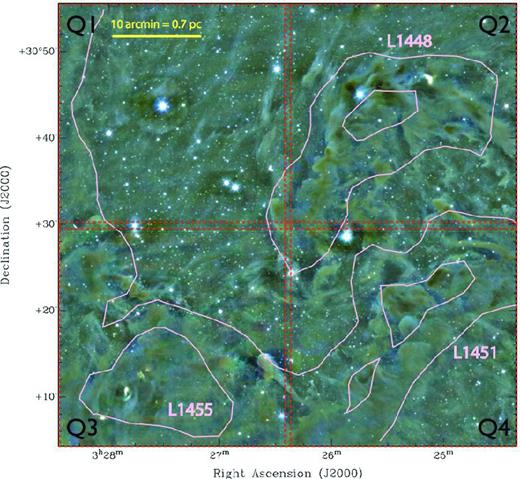
A three-colour (r, i, z) image of our data from the West-End of Perseus with pink contours at 3 and 5 mag of AV from a 2MASS-based extinction map (Ridge et al. 2006). Also shown are the four quadrants used in observing. The three main clouds, L1448, L1451 and L1455, are labelled. L1448 and L1455 contain young stars. Visible remaining artefacts include the faint ‘donut’ shaped ghosts around bright stars, streaks from some satellites or asteroids and some residual fringing around the ‘comet’ in the lower centre of the image where the scaling algorithm failed.
Science observations were interlaced with images of our calibration field in order to provide airmass solutions. Our calibration field was Per-Cal, a portion of the Perseus supercluster of galaxies included in the Sloan Digital Sky Survey Extension for Galactic Understanding and Exploration (SDSS-SEGUE; Aihara et al. 2011) and centred at RA, Dec. = (54| ${.\!\!\!\!\!\!^{\circ}}$|9755, +41| ${.\!\!\!\!\!\!^{\circ}}$|1533). All r-band science images and calibration images were taken first during the night, and were thus taken between an airmass of 1.0 and 1.06, providing insufficient lever arm to fit for an airmass correction term. Total exposure times were 800 s in r, 600 s in i and 500 s in z. For i and z, data were typically taken between 1.1 and 2.0 airmass and the observations were interleaved with five repetitions of the following pattern: i, z, z and i. Each field was observed as four different quadrants, with some overlap between quadrants (see Figs 1 and 2) and each quadrant was observed contiguously in i and z. Thus, for an individual quadrant, the r-band images were taken near zenith and then the i and z observations were taken in an interleaved fashion later in the night.
The weather was generally good but not perfectly photometric. On 2007 November 2 the seeing was excellent with typical values of 0.6 arcsec, sometimes improving to 0.4 arcsec. Some cirrus clouds were observed during the first half of the night (before our data were collected) and were occasionally observed during the early part of our observing (mostly during calibration images of Per-Cal). On 2007 November 3 the seeing was relatively poor (0.7–1 arcsec). Again, a few clouds were observed earlier in the night, but then cleared. In B5, the r-band images for the first quadrant were taken at 45° with respect to north, causing us to have some gaps in our final images and catalogue (see Fig. 1).
2.2 Megacam data reduction
Data reduction of the Megacam data followed a largely standard set of procedures in Image Reduction and Analysis Facility (iraf; Tody 1993). Bias and flat frames were made and used to process the images. Bad pixels were identified and cosmic rays removed. Significant interference fringing (where unabsorbed light reflects off the bottom of the CCD and interferes with incoming radiation) is present in the i and z images, and the de-fringe program by B. McLeod was used to remove it. Megacam is made up of 36 individual CCDs. Because the defringing algorithm scales the intensity of the fringe pattern before subtracting it from an individual CCD, in places where individual bright stars or strong surface brightness features dominate the background for an entire individual CCD the fringes are poorly subtracted. Bright stars also cause some ‘ghosts’ or haloes on the final images, where light scatters internally in the telescope optics, and these increased surface brightnesses cause additional problems for the defringing scaling. Defects from bright stars and other features can be seen in both Figs 1 and 2.
An illumination correction was also applied, although this correction was only significant at r. This correction removes most large variations in zero-point from one CCD chip to the next, but in practice this correction was not sufficient, and we applied a different zero-point for each CCD in the calibration.
We used swarp (Bertin et al. 2002) to co-add individual images (weighting was based on measured noise within the images) to produce Figs 1 and 2, and source detection was performed on these deep co-added images to use in cross-referencing the catalogues. Calibrated photometry was performed on each frame individually (so that the airmass and zero-point corrections discussed in the following section could be applied) and final source magnitudes were the noise-weighted average of the magnitudes measured in each frame.
2.3 Megacam data calibration
Because we wish to fit a parametrized main sequence in SDSS colours, it is necessary to place our Megacam photometry on to the SDSS (r, i, z) system. This process accounts for variations in filter and atmospheric transmission at different sites, as well as any other optical features of the telescope which may change the efficiency with which a flux at a given wavelength is measured. Literature colour corrections of this type are often based on only a small number of comparison standard stars, and are thus rather perilous. For example, Carpenter (2001) uses roughly 50 stars to derive the widely used transformation equations between Two Micron All Sky Survey (2MASS; Skrutskie et al. 2006) and other NIR photometric systems. Our calibration fields contain thousands of stars in the SDSS catalogue and were taken concurrently with our data, reducing the influence of variable atmospheric transparency. This provides us with a robust way to calculate these transformations.
| Filter (x) | Zero-points (ZPx, j) | Airmass (cx) | Colour (dx) |
|---|---|---|---|
| WE | |||
| r | −1.01 to −1.08 | N/A | −0.127 |
| i | −0.28 to −0.32 | 0.0104 | −0.153 |
| z | 0.8 to 0.9 | 0.073 | −0.0089 |
| B5 | |||
| r | −1.0 to −1.1 | N/A | −0.133 |
| i | −0.21 to −0.30 | 0.033 | −0.156 |
| z | 0.9 to 1.0 | 0.093 | −0.0067 |
| Filter (x) | Zero-points (ZPx, j) | Airmass (cx) | Colour (dx) |
|---|---|---|---|
| WE | |||
| r | −1.01 to −1.08 | N/A | −0.127 |
| i | −0.28 to −0.32 | 0.0104 | −0.153 |
| z | 0.8 to 0.9 | 0.073 | −0.0089 |
| B5 | |||
| r | −1.0 to −1.1 | N/A | −0.133 |
| i | −0.21 to −0.30 | 0.033 | −0.156 |
| z | 0.9 to 1.0 | 0.093 | −0.0067 |
| Filter (x) | Zero-points (ZPx, j) | Airmass (cx) | Colour (dx) |
|---|---|---|---|
| WE | |||
| r | −1.01 to −1.08 | N/A | −0.127 |
| i | −0.28 to −0.32 | 0.0104 | −0.153 |
| z | 0.8 to 0.9 | 0.073 | −0.0089 |
| B5 | |||
| r | −1.0 to −1.1 | N/A | −0.133 |
| i | −0.21 to −0.30 | 0.033 | −0.156 |
| z | 0.9 to 1.0 | 0.093 | −0.0067 |
| Filter (x) | Zero-points (ZPx, j) | Airmass (cx) | Colour (dx) |
|---|---|---|---|
| WE | |||
| r | −1.01 to −1.08 | N/A | −0.127 |
| i | −0.28 to −0.32 | 0.0104 | −0.153 |
| z | 0.8 to 0.9 | 0.073 | −0.0089 |
| B5 | |||
| r | −1.0 to −1.1 | N/A | −0.133 |
| i | −0.21 to −0.30 | 0.033 | −0.156 |
| z | 0.9 to 1.0 | 0.093 | −0.0067 |
The colour terms (dx) proved to be quite significant for the r and i bands but insignificant for z. We show the results of applying this calibration to the control field stars for the second night in Figs 3– 5 for r, i and z, respectively. Figures for the first night of data are similar. We experimented with expanding the colour correction to include a term proportional to SDSSi − SDSSz but found that this additional complexity did not significantly reduce the observed scatter around the calibration relation. Plots similar to Figs 3–5 but versus i − z showed that applying the r − i colour correction corrected this colour as well.
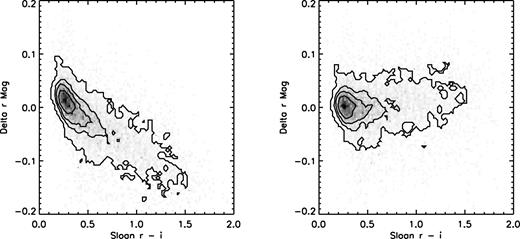
The effect of colour correction in r band. Left-hand panel shows (MMT–SDSS) r-band magnitude after solving for zero-point but before correcting for the colour term. Right-hand panel shows the same difference after applying our colour term.
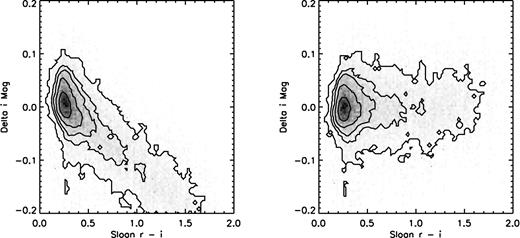
The effect of colour correction in i band. Left-hand panel shows (MMT–SDSS) i-band magnitude after solving for zero-point but before correcting for the colour term. Right-hand panel shows the same difference after applying our colour term.
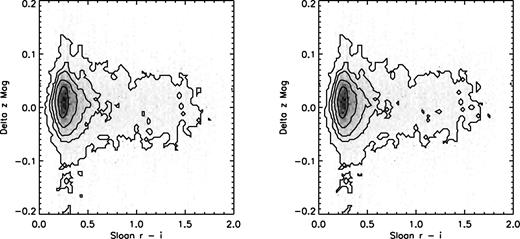
The effect of colour correction in z band. Left-hand panel shows (MMT–SDSS) z-band magnitude after solving for zero-point but before correcting for the colour term. Right-hand panel shows the same difference after applying our colour term. Note that the correction was insignificant for this band.
Preliminary results of this analysis were presented by Foster et al. (2008), combining these Megacam observations with 2MASS data to infer a relationship between AV and RV similar to what we report here. The photometric uncertainties of the 2MASS data, however, dominated the error budget of this prior analysis and motivated us to modify our analysis to incorporate higher quality NIR photometry from the UKIDSS survey (see Section 2.4). The subsequent improvement in our error budget also revealed the presence of a photometric offset in the fourth quadrant of the B5 Megacam photometry.
Because the four quadrants for each field overlapped slightly, we were able to check the reliability of our calibration by comparing the calibrated magnitudes for stars appearing in multiple quadrants. The spread in magnitude was typically consistent with our estimated measurement and calibration uncertainty. The only exception was the fourth quadrant in B5. For this quadrant, magnitudes were not consistent with the other three quadrants (the other three were all consistent). We found the median offset in the overlapping stars and offset the magnitudes in the fourth quadrant by these amounts (Δr = 0.01 mag, Δi = 0.23 mag and Δz = 0.13 mag). Since the i and z magnitudes (which were observed interleaved together) are most significantly discrepant, it is likely that some of the cirrus observed earlier in the night was in front of our field during these observations. We used these offsets with overlapping stars to correct the magnitudes in this quadrant.
2.4 UKIDSS data
We obtained UKIDSS data for our two regions from the WFCAM Science Archive.2 B5 is covered in the Galactic Clusters Survey (GCS) while most of the WE is covered in the Galactic Plane Survey (GPS; Lucas et al. 2008). We used the following quality cuts in the SQL query as recommended by Lucas et al. (2008) for high-reliability photometry:
jAperMag3 > −10 and hAperMag3 > −10 and
k_1AperMag3 > −10 and jAperMag3Err < 0.03
and hAperMag3Err < 0.03 and k_1AperMag3Err < 0.03
and jEll < 0.2 and hEll < 0.2 and k_1Ell < 0.2
and jpperrbits < 256 and hpperrbits < 256 and
k_1pperrbits < 256 and pstar > 0.99 and
sqrt(hXi*hXi + hEta*hEta) < 0.3 and
sqrt(k_1Xi*k_1Xi + k_1Eta*k_1Eta) < 0.3
and mergedClass !=0 and
(PriOrSec=0 or PriOrSec=framesetID)
and cross-matched the Megacam data with the UKIDSS data for stars within 0.6 arcsec. The UKIDSS survey data are approximately on the 2MASS colour system, although the filters and system responses are slightly different. We discuss the influence this may have on our results in Section 3.4. The UKIDSS data are preferable to the 2MASS data because the uncertainties on 2MASS colours for our stellar sample are many times larger than the uncertainties on our Megacam data and so 2MASS errors would dominate the errors in our analysis.
3 FITTING PROCEDURES
3.1 Least-squares-fitting approach
The traditional least-squares method for determining correlation between AV and RV involves first deriving best-fitting estimates for each star's AV and RV and then testing these best-fitting values for correlation with another least-squares procedure.
This stellar locus has finite (observed) width, which is due to both intrinsic and measurement dispersion. This width is different for each colour, n, and varies along the sequence (i.e. is a function of intrinsic stellar type, x). We average this dispersion along x to produce a single number characterizing the width of the observed stellar locus, |$\sigma _{C_{n}}$|, and we assume that the intrinsic width of this distribution is one-half the reported width, to crudely account for the difficult-to-assess influence of measurement error.
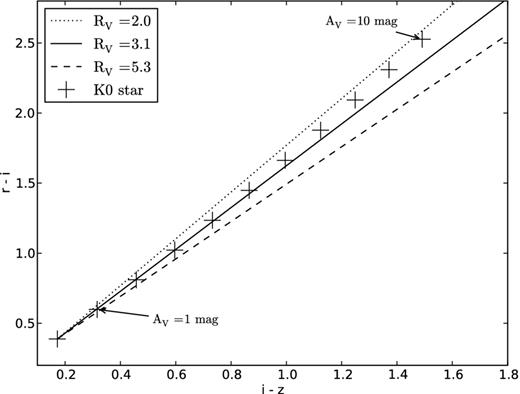
Red-optical (r − i versus i − z) colours of a Castelli & Kurucz (2004) model K0V star produced in synphot by convolving the stellar spectrum with the filter response curves for the MMT. The stellar spectrum is reddened with a CCM RV = 3.1 reddening law in steps of AV = 1 mag (plus symbols). The change in the effective wavelength of the reddened spectrum causes the colours to trace out a curved line in colour–colour space, rather than the straight vectors assumed in our model (straight lines). This effect makes it look as if a star behind more extinction is being reddened by an extinction law with a smaller RV.
Fig. 6 shows the worst case in our study, since it considers the r − i and i − z colours which are most sensitive to reddening and includes up to 10 mag of visual extinction, which is the maximum value we infer for any stars in this study. Most stars are behind only a few magnitudes of AV or less, and the longer wavelength colours are less influenced. Including this effect would increase the complexity of the model significantly since we would have to iteratively compute the reddening. Therefore, we do not include it for this study (but see Section 3.4 for a discussion of systematic biases and other possible errors), where the column of dust is relatively small (<10 mag of extinction in AV), but it should not be ignored when considering the extinction law in denser regions.
CCM coefficients.
| Filter | λeff (Å) | aλ | bλ |
|---|---|---|---|
| r | 6374 | 0.930 | −0.240 |
| i | 7797 | 0.799 | −0.533 |
| z | 9052 | 0.675 | −0.619 |
| J | 12 554 | 0.414 | −0.380 |
| H | 16 358 | 0.260 | −0.239 |
| K | 22 002 | 0.162 | −0.149 |
| Filter | λeff (Å) | aλ | bλ |
|---|---|---|---|
| r | 6374 | 0.930 | −0.240 |
| i | 7797 | 0.799 | −0.533 |
| z | 9052 | 0.675 | −0.619 |
| J | 12 554 | 0.414 | −0.380 |
| H | 16 358 | 0.260 | −0.239 |
| K | 22 002 | 0.162 | −0.149 |
CCM coefficients.
| Filter | λeff (Å) | aλ | bλ |
|---|---|---|---|
| r | 6374 | 0.930 | −0.240 |
| i | 7797 | 0.799 | −0.533 |
| z | 9052 | 0.675 | −0.619 |
| J | 12 554 | 0.414 | −0.380 |
| H | 16 358 | 0.260 | −0.239 |
| K | 22 002 | 0.162 | −0.149 |
| Filter | λeff (Å) | aλ | bλ |
|---|---|---|---|
| r | 6374 | 0.930 | −0.240 |
| i | 7797 | 0.799 | −0.533 |
| z | 9052 | 0.675 | −0.619 |
| J | 12 554 | 0.414 | −0.380 |
| H | 16 358 | 0.260 | −0.239 |
| K | 22 002 | 0.162 | −0.149 |
The problem with this approach is that we often run into limits on RV. Relaxing the RV limits does not help; there is no local minimum in χ2-space along this dimension. In particular, in the case of low AV, we have very little handle on RV, and not a great deal on AV (the intrinsic spectral type, x, is normally fitted robustly in such a case). The large number of points which hit our limits on RV makes it hard to test the hypothesis that Cov(AV, RV) ≠ 0 for confidence. Another statistical drawback of this approach is that applying standard statistical estimators to a sample of estimates in the presence of error results in biased estimates of the population variance and correlation (e.g. Kelly 2007; Loredo & Hendry 2010). That is, when each individual star's (AV, RV) parameters are fitted separately, the resulting ensemble of estimates will be wider than the intrinsic variance, and the apparent correlation of the ensemble will be diminished relative to the true intrinsic correlation.
We plot these results for both B5 and the WE in Fig. 7. Despite the large number of points which hit the limit, there is a suggestion of a correlation in the remaining points for values of AV above 1 mag. This correlation is in the direction expected – larger values of RV at higher column density.
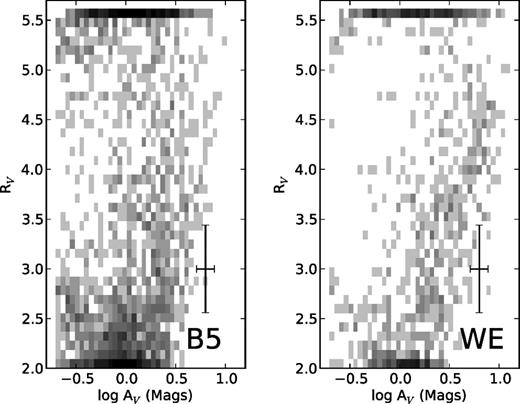
Least-squares fits for AV and RV for the stars in our data samples for B5 (left-hand panel) and the West-End (right-hand panel). The shades of grey show the density of points at a particular location in the diagram. A representative error bar is shown, which displays the median uncertainty on AV and RV for a single star (rather than for one of the bins displayed in this figure). Stars for which no local χ2-minimum exists between RV = 2 and 5.5 ‘pin’ at these extreme values. These points are therefore unreliable.
3.2 A hierarchical Bayesian approach
We developed a hierarchical Bayesian model to address some of the problems present in the least-squares-fitting approach. This model allows us to constrain the properties of the dust towards, and the intrinsic colours of, individual stars by simultaneously modelling the populations of dust properties and stellar colours. These parameters of the full population are called hyper-parameters, and describe the shape of the distributions of AV and RV. An advantage to this approach is that we can include the correlation of AV and RV explicitly in our model as a hyper-parameter, and then examine its marginal posterior probability distribution conditional on our full data set in order to make probabilistic inferences about the dust population. Furthermore, by taking a fully Bayesian approach, we can coherently compute the joint uncertainties in the estimates of both the hyper-parameters governing the population and the dust and colour parameters of individual stars. By modelling the intrinsic population distribution directly, the hierarchical approach coherently accounts for the relevant estimation errors when inferring the intrinsic population covariances, thus correcting the biases that plague standard estimators in the presence of error. The mathematical details of the statistical model are given in Appendix A. All other aspects of the dust model are as described in Section 3.1. The statistical and numerical methods used here are similar in principle to those introduced by Mandel et al. (2009) and Mandel, Narayan & Kirshner (2011) for estimating dust extinction to Type Ia supernovae using optical and NIR photometry.
![The global posterior density of the unknowns given the full data set of apparent stellar colours is represented by a directed acyclic graph. Unknown parameters are represented by open nodes. Observed data (measured colours $\boldsymbol {O}$) and knowns are represented by shaded nodes. The directed arrows between the nodes indicate relations of conditional probability. The hierarchical model coherently incorporates randomness and uncertainties due to measurement error (purple arrows), spectral class (x = g − i) and the intrinsic stellar locus [$\boldsymbol {\mu }_C(x), \boldsymbol {\Sigma }_C(x)$] (blue arrows), and dust extinction and reddening (AV, RV), and its population ($\boldsymbol {\alpha }, \sigma ^2, \mu _r, \sigma _r^2$) (red arrows) into inferences about individual stars and the population. The probabilistic graphical model describes a conceptual mechanism for generating the observed data.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/mnras/428/2/10.1093/mnras/sts144/2/m_sts144fig8.jpeg?Expires=1750078580&Signature=aCZxhGH-UGfIullAKN90BAlR0EnSh8sRK0SaMIOnaUFRRVCoLMxlmMuSd~9bs3ajXYG5cgONdg-u9wJNj9OsKc-V4oCBsK7PQHUkrcSGVB7S-MNlD5ubdRvXe6CiiUmfa2fQDUwfLLfTz6xMl~yIsSxEmZH~uyfagrtEBb-dfNfxTqBpwBG-0922A2KFNUEoCSyY65ky6e6wBirpcWdjMSspnOphC8qfdgz5zfV~5MB3IGD89GWPIRTQAo~oHxcKHnNWcNHJzIRfKc~XQNtMv17k3PxPa-xPKZx6ObbzAftUF9-zTV1-JXQC1sqoIcMQ9bKdCqx0KB7G6mguFRt0Pw__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
The global posterior density of the unknowns given the full data set of apparent stellar colours is represented by a directed acyclic graph. Unknown parameters are represented by open nodes. Observed data (measured colours |$\boldsymbol {O}$|) and knowns are represented by shaded nodes. The directed arrows between the nodes indicate relations of conditional probability. The hierarchical model coherently incorporates randomness and uncertainties due to measurement error (purple arrows), spectral class (x = g − i) and the intrinsic stellar locus [|$\boldsymbol {\mu }_C(x), \boldsymbol {\Sigma }_C(x)$|] (blue arrows), and dust extinction and reddening (AV, RV), and its population (|$\boldsymbol {\alpha }, \sigma ^2, \mu _r, \sigma _r^2$|) (red arrows) into inferences about individual stars and the population. The probabilistic graphical model describes a conceptual mechanism for generating the observed data.
Because we are considering several thousand stars at once, there are a large number of parameters and hyper-parameters to be estimated jointly (3N + 5). Details of an efficient algorithm for solving this problem are presented in Appendix B. An MCMC algorithm with generalized Gibbs sampling was used to efficiently explore the probability distribution of the model parameters. This algorithm was designed to avoid getting stuck at spurious local maxima with extreme RV (the problem plaguing the least-squares-fitting approach), and to negotiate multiple possible solutions in the global posterior distribution. At each step we draw a new value of a given parameter by sampling from the probability distribution of this parameter, conditioned on the current value of all the other parameters at this step. In each full cycle we sample the intrinsic colour (x), AV and rV for each star, and then sample the hyper-parameters which describe the whole population. After a full cycle, the current value of all parameters is recorded as the position of the Markov chain. After a sufficient number of iterations the Gibbs sampler converges to a stationary solution and maps out the full posterior probability distribution of parameters and hyper-parameters conditioned on the full data set of observed colours.
We used least-squares fitting (equation 16) to estimate initial values for each parameter for each stars. To each value we added some random noise to generate different starting positions for each individual Markov chain. We remove the first 10 per cent of each chain as ‘burn-in’, during which time the chain is still seeking the equilibrium distribution of the parameters. We sample 2500 times with four parallel, independent chains, but record only every 10th sample to reduce the autocorrelation within each chain. We measure the convergence of the model using the Gelman–Rubin (Gelman & Rubin 1992) statistic. This compares the variance between chains and within chains to estimate the mixing of the chains and diagnose their convergence to the equilibrium posterior distribution. We consider a chain to have converged if the maximum Gelman–Rubin ratio is less than 1.1.
This general approach in which we use population information to infer properties of individual stars in a Bayesian context is similar to the work reported in Bailer-Jones (2011). Unlike that work, our model does not include parallax information. We make no attempt to solve for distance, considering only colours rather than magnitudes. In addition, our model does not consider prior information about the expected density of stars of different spectral types; we consider all spectral types (g − i) to be equally probable. Our study incorporates a more detailed model for the dust extinction as that is the focus of this work.
In some respects this work is similar to Kelly et al. (2012). Kelly et al. (2012) use a hierarchical Bayesian approach to infer changes in dust grain properties as a function of dust temperature and column density in the Bok globule CB244. Kelly et al. (2012) examined the dust emissivity spectral index (β) in the far-infrared and millimetre and found, in contrast to many prior studies, no anticorrelation between β and temperature, but a strong correlation between β and column density. In that work, each independent pixel in an emission map was fitted individually, and the overall population modelled with hyper-parameters. In our work, each individual star is fitted individually, and the overall population is modelled with hyper-parameters. Future work could combine the information about dust emission in Kelly et al. (2012) with the information in this study about dust extinction to more tightly constrain models of dust growth.
3.3 Testing the Gibbs sampler
To test our hierarchical model for sensitivity to factors which could lead to spurious correlations, we constructed fake data sets and assessed our ability to recover input parameters. Unreddened stars were drawn from the empirical distribution of Covey et al. (2007) using the observed distribution of intrinsic g − i colours as the underlying probability distribution. This basic g − i colour was used to generate the other five colours (r − i, i − z, z − J, J − H and H − K) by drawing from Gaussian distributions with means and standard deviations determined by the stellar colour loci and standard deviations tabulated in Covey et al. (2007). Values of log (AV) and rV were drawn from specified distributions with known hyper-parameters and used to redden stellar colours according to our CCM parameters. Gaussian errors of a specified magnitude were then added to simulate the observed colours.
Our primary goal is to constrain ρ, the correlation between log (AV) and rV. To test this, we generated test data sets, each with 2000 stars. Values of log (AV) and rV were drawn from joint normal populations in order to produce data with a particular correlation. Because of finite sampling, these simulations did not produce a population with exactly the specified correlation, so we measured the sample correlation in these parameters after generation and use that value for comparison. The marginal posterior distributions on most hyper-parameters were approximately normal, with mean values close to (well within the 95 per cent interval) the input values. As would be expected, the posterior distributions for the parameters of individual stars covered the input values – we had to recover the input values of individual stars reasonably well in order to get the population parameters correct. Many stars had very broad posterior distributions on RV, as we expected.
As a basic test of our sensitivity to the mathematical form of our prior distributions, we conducted another series of tests in which log (AV) and rV were drawn from a bivariate uniform distribution with a linear correlation over a sensible range (AV from 0.1 to 10 mag, RV from 2.0 to 5.5 mag). Again, ρ was recovered accurately.
3.4 Potential biases
We know that our model contains some important simplifications which may bias our result. In addition, our catalogue of stellar colours has been produced using some simplifying assumptions that could, since we are considering small colour shifts, bias our result. We discuss what we believe are the most important assumptions and sources of bias here.
For each filter (r, i, z, J, H, K) we assume a single effective wavelength for all stars when calculating the parameters in Table 2, but this assumption is not precisely true. However, the spread in effective wavelengths for the stellar population we study (which is dominated by late-type stars) is small. The spread in effective wavelength is largest in z, where Δλeff = 15 Å between an F0 and K0 star.
A more significant shift in the effective wavelength is produced by reddening itself. As seen in Fig. 6, when extinction reaches many magnitudes of visual extinction, the extinction tracks are actually curves rather than straight vectors (as we assume). This introduces a bias in our work, but crucially it is the opposite direction of the effect we infer in Section 4. That is, if we were to calculate RV from Fig. 6 at the point where AV = 10 mag, we would infer a value of RV < 3.1, closer to RV = 2. Since all stellar spectra behave in qualitatively the same way under extinction (effective wavelengths become longer in each band, but more quickly in blue bands), this effect would tend to bias us towards inferring that RV decreases with AV, the opposite of what we actually infer. The effect is small for the low extinction we study here, and thus probably has only a small impact biasing our results towards finding less of a correlation between RV and AV.
Naoi et al. (2007) point out the dangers of photometric transformations in studies which attempt to study the extinction law (they also find a change in the extinction law as a function of increasing optical depth). A similar conclusion is reached by Gosling, Bandyopadhyay & Blundell (2009) in their study of NIR extinction towards the nuclear bulge and Kenyon, Lada & Barsony (1998) in their study of Taurus – their results are only properly valid in their own photometric system. We have attempted to transform our Megacam data on to the SDSS system and the UKIDSS data are calibrated on to the 2MASS system. These transformations are necessary, since we use an observed stellar colour locus in SDSS and 2MASS colours. Despite the large number of stars we are able to use for these transformations, this transformation probably remains our largest source of systematic uncertainty.
Our prior on intrinsic spectral type (parametrized by x ≡ g − i) is relatively uninformative. That is, we use a uniform prior between a range of intrinsic g − i colours. The true distribution of intrinsic spectral types is probably not uniform, but we do not have a good estimate for this distribution a priori. In Section 3.3 we use the observed g − i colour distribution from Covey et al. (2007) when testing the Gibbs sampler, but this distribution is for the portion of the Galaxy sampled by the low-extinction SDSS footprint; it is not necessarily appropriate for the particular portion of the Galactic stellar population sampled in this study. Even with our uninformative prior, the median posterior uncertainty on the intrinsic g − i colour is only 0.24, significantly smaller than the width of allowed colours in our prior (0.2 < g − i < 4.2). We choose to leave the prior relatively uninformative, rather than use a potentially incorrect prior.
We also do not assume that there is an a priori correlation between intrinsic stellar type and AV. This correlation may be present at large column densities where only the brightest background stars and foreground stars are detected. In extinction studies, methods such as NICEST improve on the NIR colour excess method (nice) to account for the bias that this correlation produces in extinction maps (Lombardi 2009). As noted in Lombardi (2009), the bias in extinction maps only becomes significant at column densities where AV > 10 mag, which is the maximum extinction we probe. For this reason, we do not attempt to model this correlation.
Additional possible systematic effects include calibration problems with our Megacam data as we saw in the fourth quadrant of B5 and correlations in the underlying population not represented in our model. Our study fits slope of the extinction law under the parametrization of the CCM model. If the extinction in these portions of Perseus is not well described by the CCM model then our fits to the CCM model may not be particularly enlightening. A number of objects in our survey may not have intrinsic colours lying on the Covey et al. (2007) tracks. These include unresolved background galaxies or quasars, embedded young stars and brown dwarfs. These objects probably constitute a small fractional contamination (∼10 per cent) at the depths studied in this work (see the estimates in Foster et al. 2008).
4 RESULTS
We ran our two regions separately, but the results are similar. In each case, a few objects failed to converge, producing large maximum values of the Gelman–Rubin statistic. Other than that, the chains behaved well, with Gelman–Rubin less than 1.1 for 99.9 per cent of the objects in both regions. We identified the objects which failed to converge, removed them from the catalogue, and reran the model. Doing this verified that the inferences on the hyper-parameters were unaffected by these objects.
The inferences on RV and AV are shown in Fig. 9. These plots show the same basic behaviour in both samples, with RV rising with AV. The points at low AV are poorly constrained by the data from the individual stars, and the posterior estimates of RV and AV in this regime are strongly informed by the population hyper-parameters.
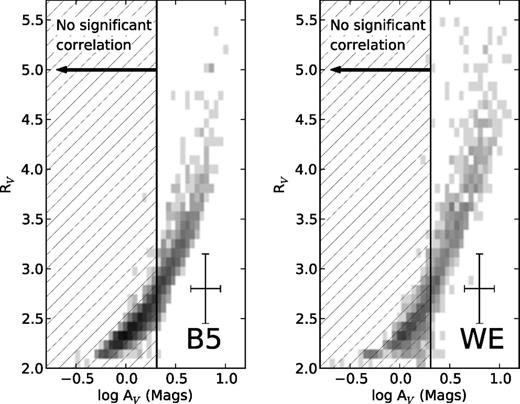
The mean and standard deviations of the marginal posterior distributions on AV and RV for all the stars in our data samples for B5 (left-hand panel) and the West-End (right-hand panel) from our hierarchical Bayesian model. The shade of grey shows the density of points at a position within the diagram. A representative error bar is shown, which displays the median width of the posterior probability distribution for AV and RV for a single star (rather than for one of the bins displayed in this figure). Note that the widths of the posterior probability distributions for AV and RV vary greatly among individual stars. When we include only sources with AV < 2 mag the correlation between AV and RV is no longer distinguishable from zero. For these points we are unable to infer any underlying correlation and the tight relationship seen in this diagram is due to the strong correlation inferred for stars with AV > 2 mag.
To assess the reliability of inferences at low AV we performed a series of tests in which we progressively removed stars with large inferred values of AV. We used our initial catalogue of inferred values for AV to remove the most highly extinguished stars and reran the analysis with these subsets of low-extinction stars. The posterior probability distribution on ρ becomes broader until, when considering only stars with AV < 2 mag, the inference on ρ no longer is inconsistent with zero. That is, if we consider only stars with AV < 2 mag, we are not able to claim that a significant correlation exists between RV and AV. The inference on RV is very weak for these stars because there is not a significant amount of reddening. Ultimately, therefore, the RV and AV inferences for these stars are strongly determined by the (linear) relationship we assume between rV and log (AV) and the hyper-parameters which describe this relationship. Without the stars at high extinction we would have very little information about the relationship between RV and AV. One should therefore not pay too much attention to the relationship below AV of 2 mag. This result gives us some confidence that subtle errors in catalogue colours (due to errors in calibration or photometric transformations as discussed in Section 3.4) are not producing a spurious relationship; the lack of strong correlation at low AV makes it more likely that the strong correlation we infer at high AV is genuine.
An alternative approach would be to expand our model to allow for a non-linear population relation between log AV and rV, with which the strength of the correlation could change as a function of log AV. This would require building a more advance statistical model and significant changes to the sampling algorithm, which we leave for future work.
We compute the posterior distributions of individual hyper-parameters marginalized over all the other parameters. These posterior distributions are all roughly normal so we summarize them with the median values and standard deviations in Table 3. In particular, the two regions are found to have relatively similar distributions in rV but the WE has a larger average AV as well as a larger range in this parameter. Translating the median values in Table 3 into the conventional units, B5 has a median RV of 2.6 and a median AV of 2.2 mag, while the WE has a median RV of 2.8 and a median AV of 4.3 mag. The low median in B5 is easily seen in Fig. 10, which shows the spatial distribution of inferred AV values for both regions. Our solutions for AV exhibit spatial structure which is consistent with known cloud features, as seen in Fig. 10.
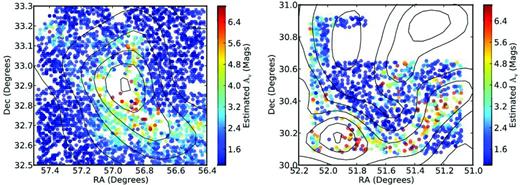
Spatial distribution of inferred AV in B5 (left-hand panel) and the West-End (right-hand panel) using our hierarchical model with extinction coded in colour. Overlain are AV contours from the COMPLETE (COordinated Molecular Probe Line Extinction Thermal Emission) NICER (Near-Infrared Colour Excess method Revisited) map (Ridge et al. 2006) with contour levels at 1.6, 2.4, 3.2, 4.0, 4.8, 5.6 and 6.4 mag of AV. The spatial distribution of stars with high extinction from our Bayesian analysis conforms to known cloud structures. The lower density of points in West-End is principally because the UKIDSS/GPS data available for this region is less deep than the UKIDSS/GCS data for B5. Gaps at the edges can be due to non-uniform coverage either in our Megacam observations (e.g. B5) or in the UKIDSS data (e.g. West-End). Gaps in the stellar distribution in regions of high extinction are areas where the extinction is too high for background stars to be seen in our Megacam observations.
Median marginal posteriors of hyper-parameters. μr and σr are the hyper-parameters describing the normal distribution of rV, which is R− 1V; μA and σA describe the normal distribution of log (AV). α0 and α1 describe the linear relationship between rV and log (AV) as defined in equation (20). ρ is the correlation between rV and log (AV).
| # Stars | μr | σr | μA | σA | α0 | α1 | ρ | |
|---|---|---|---|---|---|---|---|---|
| B5 | ||||||||
| 3144 | 0.391 ± 0.002 | 0.062 ± 0.001 | 0.34 ± 0.01 | 0.31 ± 0.01 | 0.95 ± 0.02 | −0.338 ± 0.008 | −0.86 ± 0.01 | |
| West-End | ||||||||
| 1278 | 0.363 ± 0.003 | 0.082 ± 0.002 | 0.63 ± 0.02 | 0.38 ± 0.01 | 0.94 ± 0.02 | −0.287 ± 0.008 | −0.84 ± 0.01 |
| # Stars | μr | σr | μA | σA | α0 | α1 | ρ | |
|---|---|---|---|---|---|---|---|---|
| B5 | ||||||||
| 3144 | 0.391 ± 0.002 | 0.062 ± 0.001 | 0.34 ± 0.01 | 0.31 ± 0.01 | 0.95 ± 0.02 | −0.338 ± 0.008 | −0.86 ± 0.01 | |
| West-End | ||||||||
| 1278 | 0.363 ± 0.003 | 0.082 ± 0.002 | 0.63 ± 0.02 | 0.38 ± 0.01 | 0.94 ± 0.02 | −0.287 ± 0.008 | −0.84 ± 0.01 |
Median marginal posteriors of hyper-parameters. μr and σr are the hyper-parameters describing the normal distribution of rV, which is R− 1V; μA and σA describe the normal distribution of log (AV). α0 and α1 describe the linear relationship between rV and log (AV) as defined in equation (20). ρ is the correlation between rV and log (AV).
| # Stars | μr | σr | μA | σA | α0 | α1 | ρ | |
|---|---|---|---|---|---|---|---|---|
| B5 | ||||||||
| 3144 | 0.391 ± 0.002 | 0.062 ± 0.001 | 0.34 ± 0.01 | 0.31 ± 0.01 | 0.95 ± 0.02 | −0.338 ± 0.008 | −0.86 ± 0.01 | |
| West-End | ||||||||
| 1278 | 0.363 ± 0.003 | 0.082 ± 0.002 | 0.63 ± 0.02 | 0.38 ± 0.01 | 0.94 ± 0.02 | −0.287 ± 0.008 | −0.84 ± 0.01 |
| # Stars | μr | σr | μA | σA | α0 | α1 | ρ | |
|---|---|---|---|---|---|---|---|---|
| B5 | ||||||||
| 3144 | 0.391 ± 0.002 | 0.062 ± 0.001 | 0.34 ± 0.01 | 0.31 ± 0.01 | 0.95 ± 0.02 | −0.338 ± 0.008 | −0.86 ± 0.01 | |
| West-End | ||||||||
| 1278 | 0.363 ± 0.003 | 0.082 ± 0.002 | 0.63 ± 0.02 | 0.38 ± 0.01 | 0.94 ± 0.02 | −0.287 ± 0.008 | −0.84 ± 0.01 |
Consistent with the appearance of Fig. 9, the posterior distribution of ρ is negative and inconsistent with zero. Remember that ρ is the correlation between rV and log (AV), and so a negative ρ implies a positive correlation between AV and RV. The posterior distributions of ρ are shown in Fig. 11 and the results from the two regions are consistent with each other.
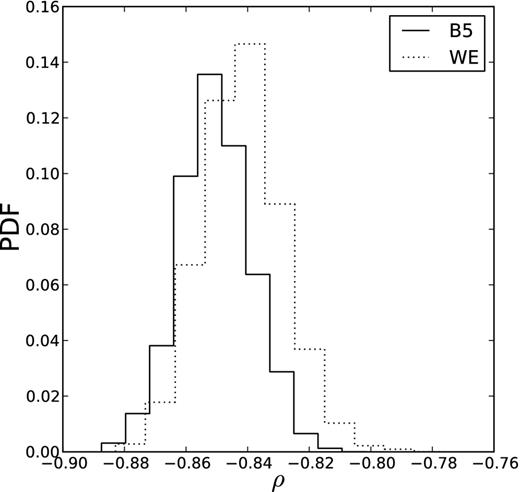
The marginal posterior distributions for the hyper-parameter ρ, which describes the correlation between rV and log (AV), for both B5 (solid) and the West-End (dashed). The two distributions are consistent with each other and inconsistent with ρ = 0. The sense of the correlation is that RV increases with increasing AV.
The consistency in posterior distributions exists despite the differences between the two regions. In their consideration of subregions within Perseus, Pineda et al. (2008) found that B5 was the most quiescent region with a simple density structure and a simple relationship between column density and CO intensity, while the WE had a more complicated relationship between column density and CO intensity, suggesting significant clumping within the region. Later studies have found that the quiescent core within B5 (Pineda et al. 2010) is dominated by a very narrow (5000 au wide) filament (Pineda et al. 2011).
Chapman & Mundy (2009) proposed that outflows within two isolated molecular cores may be the cause of regions where the mid-infrared extinction law is inconsistent with dust models as the outflows impact the dust population. As shown in Fig. 1, B5 is dominated by a single dense structure, at the heart of which lies B5-IRS1, which drives a powerful multiparsec molecular outflow (Bally, Devine & Alten 1996; Yu, Billawala & Bally 1999; Arce et al. 2010). Most of the high-extinction stars in the B5 data set come from areas near this outflow. The WE hosts a few impressive outflows in L1448, but also a large number of isolated, dense, cores with little or no star formation (see Fig. 2). L1448 is mostly outside the UKIDSS coverage of this region. Thus, the majority of the WE stars at high extinction are found in cores without strong outflows.
Geometrical differences between the two regions could also be expected to produce different correlations between AV and RV. Recall our basic assumption that RV ∝ 〈a〉 ∝ n ∝ AV, where n is the volume density and 〈a〉 is the average size of dust grains. Increasing the scatter in the connection between n and AV would tend to increase the scatter between RV and AV and thus decrease any measured correlation. As described above, B5 is a relatively simple large single structure. Velocity information from the COordinated Molecular Probe Line Extinction Thermal Emission COMPLETE CO survey (Ridge et al. 2006) and an exhaustive search for outflows and shells throughout Perseus by Arce et al. (2010, 2011) suggest that the region is simple in velocity space too. Here, the assumption that column density is simply related to volume density is probably reasonably robust. In the WE the story is quite different. A large shell appears to be disturbing the entire region, and there are multiple velocity components towards some positions – and therefore likely multiple independent clouds along some lines of sight. These additional velocity components have relatively low antenna temperatures and so do not contribute much to the measured column density along the line of sight, maintaining the connection between column density and volume density. The consistency of our results for these two regions suggests that geometrical effects are not a significant problem.
We compute a simple estimate of the volume density at which we are seeing significant changes in the extinction law. By a column density of AV = 10 mag we have typical RV values of 4–5. Arce et al. (2011) estimate the width of B5 to be no more than 0.5 pc. 10 mag of visual extinction corresponds to roughly 1022 cm−2 H2 atoms (Bohlin, Savage & Drake 1978). If we simply assume a constant volume density we can calculate that a typical volume density at 10 mag of AV inside B5 is 6.6 × 103 cm−3. Because of the density substructure within B5 (Pineda et al. 2011), this estimate represents a lower limit on the volume density by which point we are seeing clear evidence of grain growth.
5 CONCLUSION
We have used r, i, z deep data from Megacam on the MMT combined with UKIDSS J, H, K to probe the extinction law in the column density range 0.1 < AV < 10 mag using a hierarchical Bayesian model. The Bayesian model allows us to place a well motivated prior on AV (log-normality), and work in a consistent framework with the correlation between AV and RV treated as just another parameter for which we compute the posterior distribution. This model is implemented using a generalized Gibbs sampler to generate Monte Carlo Markov chains which explore the full joint parameter space. The implementation has undergone a series of tests using synthetic data similar to our study data, and performs well.
We find evidence that the extinction law changes over a relatively narrow range of column densities, rising from an RV ∼ 3 at 2 mag of AV to an RV ∼ 5 by 10 mag of AV. Below 2 mag of AV we have insufficient sensitivity to infer a relationship between RV and AV. The two regions in our study, B5 and the WE, lie at opposite ends of Perseus and have different physical conditions, yet both show a strong correlations between RV and AV, suggesting that the steepening of the extinction curve (most likely via grain growth) is a fairly universal process.
We deliberately do not provide an explicit relation predicting the value of RV for a given value of AV. These relations are slightly different for the two different regions and are effectively determined only over a narrow range of AV. In addition, we expect the underlying predictor of RV to be the volume density, n, not AV, and the relation between n and any observed AV is likely to be highly variable in different regions. This is particularly the case for observations of more distant objects, when substantial column density can be the result of a long path through diffuse matter.
Several recent studies have used SDSS data to study dust reddening and extinction (e.g. Schlafly et al. 2010; Jones, West & Foster 2011; Schlafly & Finkbeiner 2011). SDSS data are typically not of sufficient quality in high-extinction regions (we examined the portion of Taurus covered in SDSS-SEGUE) to be useful in constraining the extinction law. Future surveys with deeper coverage in the red-optical [Pan-STARRS (Panoramic Survey Telescope & Rapid Response System) and LSST (Large Synoptic Survey Telescope)] and broader sky coverage will provide the necessary depth to apply this technique to a large number of molecular clouds without the need for dedicated deep observations.
This material is based upon work supported by the National Science Foundation under Grant No. AST-0908159, AST-0407172 and AST-0907903. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation and the US Department of Energy Office of Science. The SDSS-III website is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration. This publication makes use of data products from the 2MASS, which is a joint project of the University of Massachusetts and the Infrared Processing and Analysis Center/California Institute of Technology, funded by the National Aeronautics and Space Administration and the National Science Foundation.
Present address: Department of Astronomy Yale University, PO Box 208101 New Haven, CT 06520-8101, USA.
Present address: ESO, Karl Schwarzschild Str. 2, 85748 Garching bei Munchen, Germany.
Megacam has since moved to the Magellan Clay telescope at Las Campanas Observatory.
REFERENCES
APPENDIX A: HIERARCHICAL BAYESIAN MODEL FOR STELLAR COLOURS AND DUST
Hierarchical Bayesian analysis is a framework for probabilistically modelling multiple sources of randomness and uncertainty underlying observed data and unifies inference for both populations and individuals of those populations. Statistical inference with hierarchical models provides a principled method of probabilistic deconvolution of physically distinct and random effects that are combined in the observed data. Probabilistic inference allows for not only the estimation of each separate effect, but also the exploration of the joint uncertainties and trade-offs between the multiple effects. It enables the estimation of the statistical characteristics of an underlying intrinsic population distribution while accounting for the distortions in the observed distribution caused by estimation error. This correction is called shrinkage. This is accomplished by hierarchical models via partial pooling, which combines the individual estimates with population information. Similar issues regarding inferring the intrinsic distributions of inferred quantities in the presence of random error have been discussed and specific Bayesian techniques have been applied by Kelly (2007), Kelly & Bechtold (2007), Hogg, Myers & Bovy (2010), Loredo & Hendry (2010) and Mandel et al. (2009, 2011), among others, in other astrophysical contexts. An excellent statistical reference for hierarchical Bayesian modelling is Gelman et al. (2003).
Our statistical model includes a population distribution that models the intrinsic stellar locus of colours, a population distribution for the dust extinction and reddening to each star, and incorporates the measurement error for the observed colours for each star. Using Bayes’ theorem, probabilistic estimates for the unknown parameters of individual stars, as well as the hyper-parameters of the populations, are coherently derived. In the following sections, we build the components of our statistical model and then derive the global posterior density of the unknown parameters conditional on the data.
A1 The observed colour likelihood function
A2 The intrinsic colour population model
A3 Dust population model with correlations
A4 The hierarchical posterior probability density
To complete the full probability model we must specify the hyper-prior density on the hyper-parameters |$\boldsymbol {\alpha }, \sigma ^2, \mu _r$| and σ2r. We choose standard diffuse non-informative distributions: uniform distributions on μr, |$\boldsymbol {\alpha }$|, log σ2r and log σ2.
APPENDIX B: MCMC SIMULATION OF THE POSTERIOR PROBABILITY DENSITY WITH GIBBS SAMPLING
For a data set with N ∼ 2000 stars, there are 3N + 5 parameters and hyper-parameters to be estimated jointly from the hierarchical posterior distribution, after analytically marginalizing out the intrinsic colours |$\lbrace \boldsymbol {C}_s \rbrace$|. To do this efficiently, we have developed an MCMC algorithm based on Gibbs sampling.
MCMC is a class of algorithms that generate random draws from an arbitrary probability distribution by simulating a stochastic process or random walk through parameter space. Gibbs sampling is a particular MCMC strategy that uses the information in the set of conditional distributions to make the random moves in the stochastic process. One parameter at a time is updated from its conditional probability density, holding the other parameters fixed at their current values. Cycling this process through all the parameters repeatedly generates a Markov chain that explores parameter space and converges to the joint posterior probability density. Once the random samples are generated, inferences can be computed using these samples. Further theory and techniques of MCMC can be found in various textbooks, e.g. Liu (2002), Gelman et al. (2003) and Robert & Casella (2004).
An advantage of using a Gibbs sampling approach by sequential sampling of the conditional densities compared to a standard Metropolis strategy is that the Gibbs sampling approach does not require tuning the jump size of the proposal distribution. This is important when probing a high-dimensional parameter space as we do here; it is practically infeasible to optimize the jump size for thousands of parameters.
A disadvantage of traditional Gibbs sampling is that it allows only for orthogonal moves in the parameter space, as one parameter is sampled conditional on the fixed current values of the other parameters. This problem can be acute if there are strong posterior degeneracies or correlations between parameters. For example, in this work, we expect there to be trade-offs between the intrinsic colours and dust reddening in the fit for a single star's observed colours. This trade-off will depend upon the shape of the intrinsic stellar locus as well as the current estimate of the reddening law parameter RV for the dust to the star. If there exist multiple local posterior maxima in parameter space separated along a directions oblique to the parameter axes, the orthogonal nature of the Gibbs sampling moves could cause the Markov chain to get stuck at a suboptimal solution.
To alleviate these problems, we have included generalized conditional sampling steps to our MCMC algorithm. These steps enable the chain to move along expected degeneracies between parameters that may be oblique with respect to the natural coordinate system defined by the chosen parameters (Liu & Sabatti 2000; Liu 2002). This strategy allows for non-orthogonal moves through parameter space that change several parameters at once. For example, we found it advantageous when fitting for each star to simultaneously reduce dust extinction and increase the intrinsic colour while adjusting the reddening law. This corresponds to an oblique translation through parameter space described by AV → AV + γ, x → x + cxγ and rV → rV + crγ. The coefficients (cr, cx), determining the direction of the translation, are randomly chosen according to pre-determined probability distributions, and the magnitude of the translation γ is sampled from the posterior density, such that the stationary distribution of the chain is left invariant. These generalized conditional sampling steps are described in step 4. Note that the Gibbs sampler without these steps (i.e. using only steps 1–3 and 5–7) generates a valid Markov chain. The additional step 4 is added to speed convergence of the chain and help it escape local maxima.
We start with initial guesses of the unknown parameters and hyper-parameters. The current position of the Markov chain is |$\mathcal {S} = (\lbrace A_V^s, r_V^s, x_s\rbrace ; \boldsymbol {\alpha }, \sigma ^2, \mu _r, \sigma _r^2)$|. Our Gibbs sampling strategy proceeds as follows. At each step we sample a new value of a parameter conditional on all the others, and replace the new value in the state vector |$\mathcal {S}$|. The first four steps are repeated for all stars, conditional on the current values of the population hyper-parameters.
Draw a new xs from the conditional posterior density |$P( x_s | \cdot , \lbrace \boldsymbol {O}_s\rbrace ) \propto P( \boldsymbol {O}_s | \, x_s, A_V^s, r_V^s) \times P(x_s)$|. [We use ( · ) to denote all other parameters and hyper-parameters not written explicitly]. This is done by evaluating equation (A3) on a fine grid in xs and using the inverse-cdf (inverse cumulative distribution function) sampling method.
- Draw a new AsV from the conditional posteriorwhere |$\hat{A} = \hat{V}_A \boldsymbol {\beta }^T \boldsymbol {\Sigma }(x)^{-1} [\boldsymbol {O}_s -\boldsymbol {\mu }_C(x_s)]$| is the least-squares estimate of AV with variance |$\hat{V}_A = [\boldsymbol {\beta }^T \boldsymbol {\Sigma }(x)^{-1} \boldsymbol {\beta }]^{-1}$|, and |$\boldsymbol {\beta } = \Delta \boldsymbol {a} + \Delta \boldsymbol {b} \, r_V$| and |$\boldsymbol {\Sigma }(x) = \boldsymbol {\Sigma }_O^s + \boldsymbol {\Sigma }_C(x_s)$|. The last term is given by equation (A6). Since this is non-Gaussian, we obtain a draw by evaluating this on a fine grid in AsV and using the inverse-cdf sampling method.(B1)\begin{eqnarray} P(A_V^s \big| \cdot , \lbrace \boldsymbol {O}_s\rbrace ) &=& P\big(A_V^s \big| x_s, r_V^s, \boldsymbol {\alpha }, \sigma ^2; \boldsymbol {O}_s\big) \nonumber\\ &&\propto N\big(A_V^s \big| \hat{A}, \hat{V}_A\big) \times P\big(A_V^s \big| r_V^s, \boldsymbol {\alpha }, \sigma ^2\big), \end{eqnarray}
- Sample a new rsV from the conditional posteriorwhere |$\hat{r}_V = \hat{\sigma }_r^2 A_V^s \Delta \boldsymbol {b}^T \boldsymbol {\Sigma }_O^{-1}[\boldsymbol {O}_s -\boldsymbol {\mu }_C(x_s) -A_V^s \Delta \boldsymbol {a}]$| is the least-squares estimate of rV and |$\hat{\sigma }_r^2 = [\Delta \boldsymbol {b}^T \Sigma _O^{-1} \Delta \boldsymbol {b} (A_V^s)^2]^{-1}$| is its variance. A new rsV is generated by evaluating this on a fine grid in rsV between 0.18 and 0.50 and using the inverse-cdf sampling method.(B2)\begin{eqnarray} P(r_V^s \big| \cdot , \lbrace \boldsymbol {O}_s\rbrace ) &=& P(r_V^s \big| x_s, A_V^s, \boldsymbol {\alpha }, \sigma ^2, \mu _r, \sigma _r^2, \boldsymbol {O}_s) \nonumber\\ &&\propto N(r_V^s \big| \hat{r}_V, \hat{\sigma }_r^2) \times N( r_V^s \big| \mu _r, \sigma _r^2) \nonumber\\ &&\times P( A_V^s \big| r_V^s, \boldsymbol {\alpha }, \sigma ^2), \end{eqnarray}
- Generalized Gibbs sampling. We translate along directions involving changes in the three parameters:The direction is randomly chosen each time from the following distributions:(B3)\begin{eqnarray} A^s_V \rightarrow A^s_V + \gamma , & x_s \rightarrow x_s + c_x \gamma \hbox{ and } & r^s_V \rightarrow r^s_V + c_r \gamma . \end{eqnarray}(B4)\begin{eqnarray} c_x &\sim& \frac{1}{3} N(-0.60, 0.05^2) + \frac{1}{3} N(-0.55, 0.02^2)\nonumber\\ && + \frac{1}{3} N(-0.50, 0.05^2), \end{eqnarray}and the sign of cr is flipped with 50 per cent probability. These distributions were chosen via experimentation and were found to significantly help the mixing of the chains. The shift γ is sampled from(B5)\begin{eqnarray} c_r \sim \frac{1}{3} N(0.03, 0.02^2) + \frac{1}{3} N(0.05, 0.02^2)+ \frac{1}{3} N(0.08, 0.02^2), \nonumber\\ \end{eqnarray}by evaluating this density on a fine grid in γ and using the inverse-cdf method. Then with γ, cx and cr chosen, the translation equations (B3) is performed.(B6)\begin{eqnarray} P(\gamma ) \propto P( A^s_V + \gamma , r^s_V + c_r \gamma , x_s + c_x \gamma | \, \boldsymbol {\alpha }, \sigma ^2, \mu _r, \sigma _r^2; \boldsymbol {O}_s) \end{eqnarray}
- Steps 1–4 are repeated for all stars. Once all individual parameters have been updated, we update the hyper-parameters. First, we sample from the joint conditional posterior density |$P(\mu _r, \sigma _r^2 | \cdot , \lbrace \boldsymbol {O}_s\rbrace ) = P(\mu _r | \bar{r}_V, \sigma _r^2) P(\sigma _r^2 | s_r^2)$|, where |$\bar{r}_V$| is the sample mean of the current rsV of all stars and s2r is the sample variance. This is done by drawing σ2r from a scaled inverse chi-squared distribution and, conditional on that, drawing μr from a normal:(B7)\begin{eqnarray} \sigma _r^2 \big| \, s^2_r\sim {\rm Inv-}\chi ^2\big(N -1, s_r^2\big), \end{eqnarray}(B8)\begin{eqnarray} \mu _r | \, \bar{r}_V, \sigma ^2_r \sim N\big(\bar{r}_V, \sigma _r^2 /N\big). \end{eqnarray}
- Next we sample from the joint conditional posterior |$P( \boldsymbol {\alpha }, \sigma ^2 | \cdot , \lbrace \boldsymbol {O}_s\rbrace ) = P( \boldsymbol {\alpha }, \sigma ^2 | \lbrace \log A_V^s, r_V^s\rbrace )$|. This is equivalent to the Bayesian ordinary linear regression problem. If we let |$\boldsymbol {Y}$| be vector with elements log AsV, then we have |$\boldsymbol {Y} | \boldsymbol {\alpha }, \sigma ^2, \lbrace r_V^s\rbrace \sim N( \boldsymbol {D} \boldsymbol {\alpha }, \boldsymbol {I} \sigma ^2)$|. The design matrix |$\boldsymbol {D}$| has rows |$\boldsymbol {D}_s = [1, (r_V^s-0.32)/0.04]$|. Compute |$\hat{\boldsymbol {V}}_\alpha = (\boldsymbol {D}^T \boldsymbol {D})^{-1}$|, |$\hat{\boldsymbol {\alpha }} = \hat{\boldsymbol {V}}_\alpha \boldsymbol {D}^T \boldsymbol {Y}$| andGibbs sampling proceeds by drawing a new σ2 from a scaled inverse chi-squared distribution, and then, conditional on that, sampling new |$\boldsymbol {\alpha }$| from a multivariate normal:(B9)\begin{eqnarray} S^2_Y = \frac{1}{ (N-2)} (\boldsymbol {Y} - \boldsymbol {D} \hat{\boldsymbol {\alpha }})^T (\boldsymbol {Y} - \boldsymbol {D} \hat{\boldsymbol {\alpha }}). \end{eqnarray}(B10)\begin{eqnarray} \sigma ^2 \big| \, S^2_Y \sim {\rm Inv-}\chi ^2(N-2 |\, S^2_Y), \end{eqnarray}(B11)\begin{eqnarray} \boldsymbol {\alpha } | \, \boldsymbol {Y}, \boldsymbol {D}, \sigma ^2 \sim N( \hat{\boldsymbol {\alpha }}, \hat{\boldsymbol {V}}_\alpha \sigma ^2). \end{eqnarray}
At this point, we have updated every parameter and hyper-parameter, and we record the state of the chain |$\mathcal {S}$|. We return to step 1 and iterate the Gibbs sampler with the current parameter values many times until convergence.
We typically run multiple independent chains in parallel starting from randomized positions and monitor convergence using the Gelman–Rubin ratio (Gelman & Rubin 1992).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}