





Abstract
We present the angular correlation function measured from photometric samples comprising 1562 800 luminous red galaxies (LRGs). Three LRG samples were extracted from the Sloan Digital Sky Survey (SDSS) imaging data, based on colour-cut selections at redshifts, z≈ 0.35, 0.55 and 0.7 as calibrated by the spectroscopic surveys, SDSS-LRG, 2dF-SDSS LRG and QSO (quasi-stellar object) (2SLAQ) and the AAΩ-LRG survey. The galaxy samples cover ≈7600 deg2 of sky, probing a total cosmic volume of ≈5.5 h−3 Gpc3.
The small- and intermediate-scale correlation functions generally show significant deviations from a single power-law fit with a well-detected break at ≈1 h−1 Mpc, consistent with the transition scale between the one- and two-halo terms in halo occupation models. For galaxy separations 1–20 h−1 Mpc and at fixed luminosity, we see virtually no evolution of the clustering with redshift and the data are consistent with a simple high peaks biasing model where the comoving LRG space density is constant with z. At fixed z, the LRG clustering amplitude increases with luminosity in accordance with the simple high peaks model, with a typical LRG dark matter halo mass 1013–1014h−1 M⊙. For r < 1 h−1 Mpc, the evolution is slightly faster and the clustering decreases towards high redshift consistent with a virialized clustering model. However, assuming the halo occupation distribution (HOD) and Λ cold dark matter (ΛCDM) halo merger frameworks, ∼2–3 per cent/Gyr of the LRGs are required to merge in order to explain the small scales clustering evolution, consistent with previous results.
At large scales, our result shows good agreement with the SDSS-LRG result of Eisenstein et al. but we find an apparent excess clustering signal beyond the baryon acoustic oscillations (BAO) scale. Angular power spectrum analyses of similar LRG samples also detect a similar apparent large-scale clustering excess but more data are required to check for this feature in independent galaxy data sets. Certainly, if the ΛCDM model were correct then we would have to conclude that this excess was caused by systematics at the level of Δw≈ 0.001–0.0015 in the photometric AAΩ-LRG sample.
1 INTRODUCTION
The galaxy two-point function whether in its correlation function or power spectrum form has long been recognized as a powerful statistical tool for studying large-scale structure (LSS) of the Universe (Peebles 1980). In an isotropic and homogeneous Universe, if the density fluctuation arises from a Gaussian random process, the two-point correlation function, ξ(r), and its Fourier transform, P(k), contain a complete description of such fluctuations. It has been used to measure the clustering strength of galaxies in numerous galaxy surveys (see e.g. Groth & Peebles 1977; Shanks et al. 1989; Baugh & Efstathiou 1993; Ratcliffe et al. 1998) and the observed ξ(r) is reasonably well represented by a power law of the form ξ(r) = (r/r0)−1.8 over a large range of scales, ≈100 h−1 kpc–10 h−1 Mpc, where r0 is approximately 5 h−1 Mpc.
More recently, large galaxy redshift surveys have become available [Sloan Digital Sky Survey (SDSS): York et al. 2000, Two-degree-Field Galaxy Redshift Survey (2dFGRS): Colless et al. 2001] and these surveys provide a perfect opportunity to exploit the two-point function as a tool to constrain cosmological parameters (Hawkins et al. 2003; Cole et al. 2005; Eisenstein et al. 2005; Tegmark et al. 2006; Percival et al. 2007) which in turn provides an excellent test for our current understanding of the Universe and the processes by which the LSS were formed.
In the past, when galaxy redshift surveys were less available, the angular correlation function, w(θ), was heavily utilized in the analysis of imaging galaxy samples. The spatial correlation function, ξ(r), can be related to w(θ) via Limber’s equation (Limber 1953), alternatively w(θ) can be inverted to ξ(r) using Lucy’s iterative technique (Lucy 1974), both approaches providing a means to recover the 3D clustering information numerically. Even today, galaxy imaging surveys still tend to cover a bigger area of the sky and occupy a larger volume than redshift surveys and therefore could offer a route to a more accurate estimation of the correlation function and power spectrum (see e.g. Baugh & Efstathiou 1993). One of the disadvantages of using w(θ) is the dilution of the clustering signal from projection and hence any small-scale/sharp feature which might exist in the 3D clustering may not be observable in w(θ).
As mentioned above, the correlation function at small to intermediate scales can be approximately described by a single power law which also results in a power-law w(θ) but with a slope of 1 −γ. However with larger sample sizes, recent analyses of galaxy distributions start to show a deviation from a simple power law (Zehavi et al. 2005b; Phleps et al. 2006; Ross et al. 2007; Blake, Collister & Lahav 2008, see also Shanks et al. 1983). This poses a challenge for a physical explanation and understanding of non-linear evolution of structure formation. Several authors attempted to fit such correlation function using a description of halo model framework (e.g. Cooray & Sheth 2002) invoking a transition between one- and two-halo terms which occurs at ≈1 h−1 Mpc where the feature is observed. This distance scale could potentially be used as a ‘standard ruler’ in tracking the expansion history of the Universe, provided that its physical origin is well understood and the scale can be accurately calibrated.
Another feature in the correlation function predicted by the standard Λcold dark matter (ΛCDM) model is the ‘baryon acoustic oscillations’ (BAO). BAO arise from sound waves that propagated in the hot plasma of tightly coupled photons and baryons in the early Universe. As the Universe expands and temperature drops below 3000 K, and photons decouple from the baryons at the so-called ‘epoch of recombination’. The sound speed drops dramatically and oscillatory pattern imprinted on the baryon distribution as well as the temperature distribution of the photons which approximately 13 billions years after the big bang revealed as the acoustic oscillations in the temperature anisotropies of the cosmic microwave background. The equivalent but attenuated feature exists in the clustering of matter, as baryons fall into dark matter potential wells after the recombination. In recent years, the acoustic peak scale in the LSS has been proposed as a potential ‘standard ruler’ (e.g. Blake & Glazebrook 2003; Glazebrook et al. 2007; McDonald & Eisenstein 2007) for constraining the dark energy equation of state (w=p/ρc2) and its evolution.
For the BAO approach to the study of dark energy to yield a competitive result, a large survey of several million galaxies is generally required (Blake & Glazebrook 2003; Seo & Eisenstein 2003; Parkinson et al. 2007; Angulo et al. 2008). A galaxy spectroscopic redshift survey would require a substantial amount of time and resources. An alternative route which will enable a quicker and larger area covered is through the use of photometric redshift (hereafter photo-z) at the expense of the ability to probe the radial component directly. The photo-z errors are usually worse than spectroscopic redshift errors, but this can be compensated by a larger survey and deeper imaging.
The potential of the distribution of luminous red galaxies (LRGs) as a powerful cosmological probe has long been appreciated (Gladders & Yee 2000; Eisenstein et al. 2001, hereafter E01). Their intrinsically high luminosities provide us with at least two advantages, one being the ability to observe such a population out to a greater distance whilst the other is the possibility of detecting the small overdensity of the BAO in matter distribution at ≈100 h−1 Mpc owing to their high linear bias.1 In addition, their typically uniform spectral energy distributions (SEDs) allow a homogeneous sample to be selected over the volume of interest. Moreover, the strong 4000 Å break in their SEDs makes them an ideal candidate for the photometric redshift route or even a colour–magnitude cut as demonstrated by the success of the target selection algorithm of three LRG spectroscopic follow-ups using SDSS imaging. In fact, the first clear detection of the BAO in the galaxy distribution came from the analysis of LRG clustering at low redshift (Eisenstein et al. 2005).
Here, we shall present new measurements of the angular correlation functions determined from colour-selected LRG samples. We shall show that this route provides redshift distribution, n(z), widths that are close to the current photo-z accuracy, with none of the associated systematic problems. Indeed, one of our aims is to assess the efficiency of this route to BAO measurement compared to a full 3D redshift correlation function. This possibility arises because the n(z) width that we obtain is comparable to the ≈100 h−1 Mpc scale of the expected acoustic peak.
A similar clustering analysis measuring w(θ) of LRGs with photo-zs has been carried out by Blake et al. (2008). Equipped with a higher-redshift LRG selection algorithm whose effectiveness has been tested with the new LRG spectroscopic redshift survey, the VST-AAΩATLAS pilot run (Ross et al. 2008a), our approach is an improvement over Blake et al. (2008) as it probes an almost four times larger cosmic volume and we extend the analysis to large scales to search for the BAO peak.
The layout of this paper is as follows. An overview of the galaxy samples used here is given in Section 2. Section 3 describes the techniques for estimating the angular correlation functions and their statistical uncertainties. We then present the correlation results in Section 4. In Section 5, the clustering evolution of these LRGs are discussed. We then investigate a possibility of the acoustic peak detection in the w(θ) from the combined sample in Section 6. Finally, the summary and conclusions of our study are presented in Section 7.
2 DATA
The galaxy samples used in this study were selected photometrically from SDSS DR5 (Adelman-McCarthy et al. 2007) imaging data based on three LRG spectroscopic redshift surveys with  , 0.55 and 0.7 (E01; Cannon et al. 2006, hereafter C06; Ross et al. 2008a). In summary, these surveys utilized a crude but effective determination of photometric redshift as the strong 4000 Å feature of a typical LRG SED moves through SDSS g, r, i and z bandpasses (Fukugita et al. 1996; Smith et al. 2002). In each survey, a two-colour system (either g−r versus r−i or r−i versus i−z) suitable for the desired redshift range was used in conjunction with r- or i-band magnitude to select luminous intrinsically red galaxies. The method employed by these surveys has been proven to be highly effective in selecting LRGs in the target redshift range. The full selection criteria will not be repeated here but a summary of the algorithms and any additional criteria will be highlighted below (see E01; C06; Ross et al. 2008a for further details). Redshift distributions, n(z), of the LRGs from the spectroscopic surveys utilized in this work are shown in Fig. 1. The LRG samples corresponding to the above n(z) have been carefully selected to match our selection criteria hence these n(z) will be assumed in determining the 3D correlation functions, ξ(r), from their projected counterparts, w(θ), via the Limber (1953) equation.
, 0.55 and 0.7 (E01; Cannon et al. 2006, hereafter C06; Ross et al. 2008a). In summary, these surveys utilized a crude but effective determination of photometric redshift as the strong 4000 Å feature of a typical LRG SED moves through SDSS g, r, i and z bandpasses (Fukugita et al. 1996; Smith et al. 2002). In each survey, a two-colour system (either g−r versus r−i or r−i versus i−z) suitable for the desired redshift range was used in conjunction with r- or i-band magnitude to select luminous intrinsically red galaxies. The method employed by these surveys has been proven to be highly effective in selecting LRGs in the target redshift range. The full selection criteria will not be repeated here but a summary of the algorithms and any additional criteria will be highlighted below (see E01; C06; Ross et al. 2008a for further details). Redshift distributions, n(z), of the LRGs from the spectroscopic surveys utilized in this work are shown in Fig. 1. The LRG samples corresponding to the above n(z) have been carefully selected to match our selection criteria hence these n(z) will be assumed in determining the 3D correlation functions, ξ(r), from their projected counterparts, w(θ), via the Limber (1953) equation.
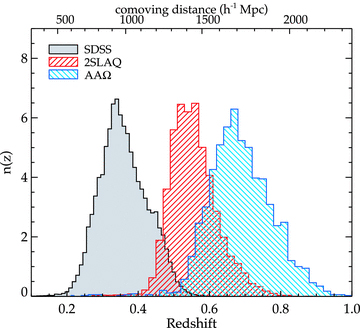
Normalized redshift distributions, n(z), of the three LRG spectroscopic surveys used as the basis for selection criteria in this study.
All magnitudes and colours are given in SDSS AB system and are corrected for extinction using the Galactic dust map of Schlegel, Finkbeiner & Davis (1998). In this analysis, we only used the galaxy samples in the most contiguous part of the survey, i.e. the northern Galactic cap (NGC). All colours described below refer to the differences in ‘model’ magnitudes (see Lupton et al. 2001, for a review on model magnitudes) unless otherwise stated.
Hereafter, we shall refer to the photometrically selected sample (not to be confused with the spectroscopic sample from which they are associated) at average redshift of 0.35, 0.55 and 0.7 as the ‘SDSS LRG’, ‘2SLAQ LRG’ and ‘AAΩ LRG’, respectively.
2.1 SDSS LRG
The sample used here is similar to the target sample of the recently completed SDSS-LRG spectroscopic survey which contains ≈100 000 spectra and cover over 1 h−3 Gpc3. These objects are classified as LRGs on the basis of their colours and magnitudes following E01. The sample is approximately volume-limited up to z≈ 0.38 and spans out to z≈ 0.5. The selection is done using (g−r) and (r−i) colours coupled with r-band (Petrosian 1976) magnitude system. The algorithm is designed to extract LRGs in two different (but slightly overlapped) regions of the gri colour space and hence using two selection criteria (Cut I and Cut II in E01) as naturally suggested by the locus of early-type galaxy on this colour plane (see Fig. 2). The tracks shown in Fig. 2 were constructed using a spectral evolution model of stellar populations (Bruzual & Charlot 2003) with output spectra mimicking a typical SED of the LRGs. The stellar populations were formed at z≈ 10 and then evolve with two different scenarios, namely (i) passive evolution of an instantaneous star formation (single burst), and (ii) exponentially decayed star formation rate (SFR) with e-folding time of 1 Gyr. Solar metallicity and Salpeter (1955) initial mass function (IMF) were assumed in both evolutionary models.
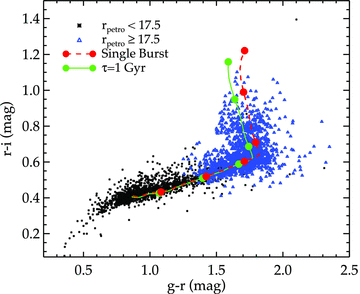
The colour–colour plot of SDSS LRG Cut I and II showing their positions on the gri colour plane compared to the predicted colour–colour locus (observer frame) of typical early-type galaxies as a function of redshift (see text for more details). Each solid circle denotes the redshift evolution of the colour–colour tracks at the interval of 0.1 beginning with z = 0.1 (bottom left).
We used the same colour–magnitude selection as that described by E01 but with additional restriction on the r-band apparent magnitudes of the objects, i.e. rpetro≥ 17.5. This is due mainly to two reasons, (i) to separate out the objects with z < 0.2 because Cut I is too permissive and allows under-luminous objects to enter the sample below redshift 0.2 as also emphasized by E01, and (ii) to tighten the redshift distribution of our sample while maintaining the number of objects and its average redshift (see Fig. 3).
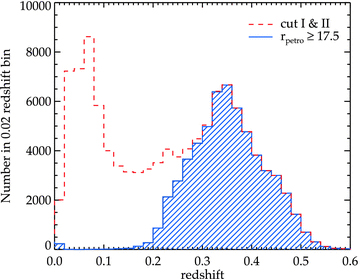
The number of objects as a function of redshift from SDSS-LRG spectroscopic redshift survey, also shown is the subset of Cut I and II with additional magnitude cut, rpetro≥ 17.5, applied.
The selection criteria mentioned above also have another star–galaxy separation algorithm apart from the pipeline PHOTO classification (Lupton et al. 2001). This was done by setting a lower limit on the differences in r-band point spread function (PSF) magnitudes and model magnitudes as most galaxies populate the upper part of rPSF−rmodel space compare to the foreground star of similar apparent magnitude. The algorithm has been proven to be quite effective (less than 1 per cent stellar contamination) for this range of redshift and magnitude although Cut II needs a more restrictive threshold, rPSF−rmodel > 0.5 as compared to 0.3 for Cut I.
In practice, the LRG sample described here can be extracted from the SDSS DR5 imaging data base using the Structured Query Language (SQL) query by setting the flag PRIMTARGET to GALAXY_RED. This yields a catalogue of approximately 200 000 objects which after applying the additional magnitude cut mentioned above becomes 106 699 objects and results in the sky surface density of about 13 objects per square degree.
2.2 2SLAQ LRG

A sample of 655 775 photometrically selected LRG candidates (≈5 per cent stellar contamination) is returned by the SDSS DR5 ‘Best Imaging’ data base when the Sample 8 selection criteria are used in the SQL query from table GALAXY. Objects with BRIGHT or SATURATED or BLENDED but not DEBLENDED flags are not included in our sample.
2.3 AAΩ LRG
The AAΩ-AAT LRG Pilot observing run was carried out in 2006 March by Ross et al. (2008a, and references therein) as a ‘Proof of Concept’ for a large spectroscopic redshift survey, VST-AAΩATLAS, using the new AAΩ instrument on the AAT. The survey was designed to target photometrically selected LRGs out to z≈ 1.0 with the average redshift of 0.7. The target sample was observed in three 2dF including the COSMOS field (Scoville et al. 2007), the COMBO-17 S11 field (Wolf et al. 2001), and 2SLAQ d05 field (C06).
We follow the survey main selection criteria, 19.8 < ideV≤ 20.5, together with the riz colour cuts as described by Ross et al. (2008a). In summary, the cut utilizes the upturn of the early-type galaxy colour–colour locus similar to that used by 2SLAQ and SDSS-LRG surveys. The turning point of the track on the riz colour plane occurs at z = 0.6–0.7 as the 4000 Å feature moves from the SDSS r to i band whilst this happens at z≈ 0.4 in the gri case. The selection technique has been proven to work reasonably well by the observed redshift distribution. This is further confirmed by the ongoing AAT-AAΩ LRG project, the down-sized version of the VST-AAΩATLAS survey, designed to observe several thousands of LRG redshifts for photo-z calibration and a clustering evolution study. The n(z) (Fig. 1) used in inferring the 3D clustering information also includes ≈2000 AAΩ LRG redshifts taken during the run in June 2008.
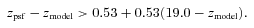
Applying the above selection rules on the ‘Best Imaging’ data of the SDSS DR5 yields a photometric sample of 800 346 high-redshift LRG candidates with the sky surface density of approximately 110 objects per square degree. As with the 2SLAQ-LRG sample, objects with BRIGHT or SATURATED or BLENDED but not DEBLENDED flags are discarded from our sample.
3 ESTIMATING w(θ) AND ITS ERROR
3.1 Optimal estimator and techniques
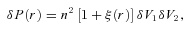
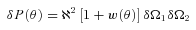
Two possible routes for estimating w(θ) are the pixelization of galaxy number overdensity,  and pair counting. The pixelization approach usually requires less computation time but its smallest scale probed is limited by the pixel size. We choose to follow the latter. To calculate w(θ) using the pair counting method, one usually generates a random catalogue whose angular selection function is described by the survey. The number of random points are generally required to be 10 times the number of objects or more. This is necessary to reduce the shot noise. Our random catalogue for each sample has ≈20 times the number of LRGs in SDSS and 10 times for 2SLAQ and AAΩ-pilot (see the next section for details on how this was achieved).
and pair counting. The pixelization approach usually requires less computation time but its smallest scale probed is limited by the pixel size. We choose to follow the latter. To calculate w(θ) using the pair counting method, one usually generates a random catalogue whose angular selection function is described by the survey. The number of random points are generally required to be 10 times the number of objects or more. This is necessary to reduce the shot noise. Our random catalogue for each sample has ≈20 times the number of LRGs in SDSS and 10 times for 2SLAQ and AAΩ-pilot (see the next section for details on how this was achieved).
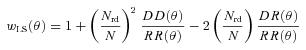
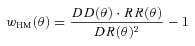
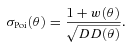

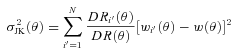
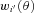 is now an angular correlation function estimated using the whole sample except the ith subfield and
is now an angular correlation function estimated using the whole sample except the ith subfield and 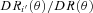 is approximately 23/24 with slight variation depending on the size of the resampling field.
is approximately 23/24 with slight variation depending on the size of the resampling field.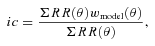
It is well known that the correlation function bins are correlated which could affect the confidence limit on the parameter estimation performed under the assumption that each data point is independent. Comparison of the estimated error using the field-to-field and JK techniques to the simple Poisson error can give a rough estimate of the deviation from the independent point assumption. This is plotted in Fig. 4 which shows that the assumption is valid on small scales where Poisson error is a fair estimate of the statistical uncertainty. However the same cannot be said on large scales where the data points are correlated and the independent point assumption no longer holds. At these scales, such statistical uncertainty is likely to be dominated by edge-effects and cosmic variance.
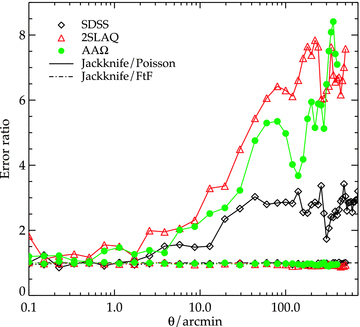
The ratio of JK to Poisson and field-to-field errors on the measurements of w(θ). The open diamonds, triangles and solid circles give the error ratios of w(θ) estimated from SDSS, 2SLAQ and AAΩ LRG, respectively.
Fig. 4 also shows that the errors estimated using field-to-field and JK methods are in good agreement at all angular scales except for 2SLAQ and AAΩ samples where the JK errors are slightly smaller towards the large scales but still agree within 10 per cent. The errors quoted in later sections are estimated using the JK resampling method.
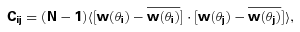
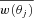 is the mean angular correlation function of all the JK subsamples in the jth bin. Note that the difference between
is the mean angular correlation function of all the JK subsamples in the jth bin. Note that the difference between 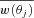 and w(θ) estimated using the whole sample is negligible. We then proceed to compute the ‘correlation coefficient’,
and w(θ) estimated using the whole sample is negligible. We then proceed to compute the ‘correlation coefficient’, 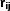 , defined by
, defined by 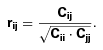
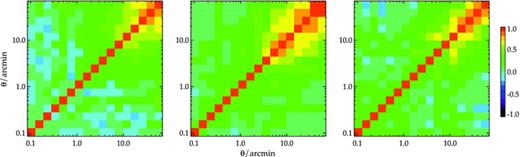
The correlation coefficients,  , showing the level of correlation between each angular separation bin for SDSS, 2SLAQ and AAΩ LRG (left to right). Note that for each sample we only show
, showing the level of correlation between each angular separation bin for SDSS, 2SLAQ and AAΩ LRG (left to right). Note that for each sample we only show  up to the angular separation which corresponds to ≈20 h−1 Mpc where later we shall attempt to fit power-law forms to the measured w(θ)s.
up to the angular separation which corresponds to ≈20 h−1 Mpc where later we shall attempt to fit power-law forms to the measured w(θ)s.
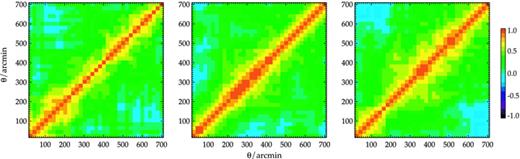
The correlation coefficients,  , out to very large angular separations. These are derived from the covariance matrices (equation 13) via 96 JK re-sampling fields. Three panels show
, out to very large angular separations. These are derived from the covariance matrices (equation 13) via 96 JK re-sampling fields. Three panels show  for SDSS, 2SLAQ and AAΩ-LRG samples from left to right.
for SDSS, 2SLAQ and AAΩ-LRG samples from left to right.
We use the kd-trees code (Moore et al. 2001) to minimize the computation time required in the pair counting procedure. The angular correlation function is estimated using the method described above and then corrected for stellar contamination which reduce the amplitude by a factor (1 −f)2, where f is the contamination fraction for each sample given in Section 2.
3.2 Constructing random catalogues
In order to calculate the angular correlation function accurately, a random catalogue is required. This catalogue consists of randomly distributed points with the total number at least 10 times that of the data. Each random point is assigned a position in Right Ascension (RA) and Declination (DEC). Since our sample spans a wide range in DEC (see Fig. 6 for the SDSS DR5 sky coverage), care must be taken to keep the surface number density constant assuming the survey completeness is constant and uniform throughout. Only the random points that satisfy the angular selection function of the survey as defined by the mask are selected.

An equal area Aitoff projection of a random catalogue described in Section 3.2. The red/grey highlighted regions indicate the areas where adjacent stripes are overlapped. Note that the shading is purely diagrammatic to show the overlap regions and is unrelated to galaxy density.
The mask is constructed from ‘BEST’ DR5 imaging sky coverage given2 in the survey coordinate (λ, η) and stripe number. The sky is drift scanned in a strip parallel to η and two strips are required to fill a stripe (York et al. 2000). Each stripe is  wide and their centres are separated by
wide and their centres are separated by  . In addition to the ‘BEST’ sky coverage mask, we also exclude regions in the quality ‘holes’ and regions defined as ‘BLEEDING’, ‘BRIGHT_STAR’, ‘TRAIL’ and ‘HOLE’ in the ‘mask’ table given by the SDSS data base. The final mask is applied to both our data and random catalogues.
. In addition to the ‘BEST’ sky coverage mask, we also exclude regions in the quality ‘holes’ and regions defined as ‘BLEEDING’, ‘BRIGHT_STAR’, ‘TRAIL’ and ‘HOLE’ in the ‘mask’ table given by the SDSS data base. The final mask is applied to both our data and random catalogues.
Note that further away from the survey equator (RA2000 = 185°), the adjacent stripes become overlapped which account for almost 20 per cent of the sky coverage. The ‘BEST’ imaging data base only keep the best photometry of the objects which have been detected more than once in the overlap regions. At the faint magnitude limit of our sample, this could lead to a higher completeness in the overlap region and introduces bias in the estimated correlation function. This issue has also been addressed by Blake et al. (2007). They compared the measurement from the sample which omits the overlap region against their best estimate and found no significant difference. We follow their approach by excluding the overlap regions and re-calculating the angular correlation function of our faintest apparent magnitude sample, AAΩ-LRG, where the issue is expected to be the most severe. We found no significant change compared to our best estimate using the whole sample.
3.3 Inferring 3D clustering
The angular correlation function estimated from the same population with the same clustering strength will have a different amplitude at a given angular scale if they are at different depths (redshifts) or have different redshift selection functions, ϕ(z). Therefore in order to accurately compare the clustering strengths of different samples inferred from w(θ), one needs to know the sample ϕ(z). Even if the redshifts of individual galaxies are not available, their 3D clustering information can be recovered if the sample redshift distribution, n(z), is known. The equation that relates the spatial coherence length, r0, to the amplitude of w(θ) is usually referred to as Limber’s equation.
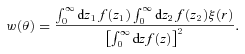
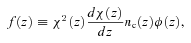
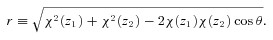
The angular correlation function computed using the full (dashed-lines) and approximate (solid-lines) Limber equation, derived using a power law, ξ(r) = (r/r0)−γ where r0 = 10 h−1 Mpc and γ = 1.8 with the SDSS LRG n(z) for the thin lines and much narrower n(z) (±0.01 centred at z = 0.35) for the thick lines.
Fig. 7 shows w(θ) computed using equation (14) (dashed lines) compared to the conventional Limber’s approximation (solid lines) for a power-law ξ(r) with clustering length 10 h−1 Mpc and γ = 1.8. The effect of a much narrower redshift distribution (thick lines) is also shown where the break scale becomes smaller and the power-law slope of w(θ) asymptotically approaches that of ξ(r), agreeing with the finding of Simon (2007). We shall use equation (14) together with the known n(z) to infer the 3D spatial clustering of the LRGs.
4 RESULTS
4.1 Power-law fits
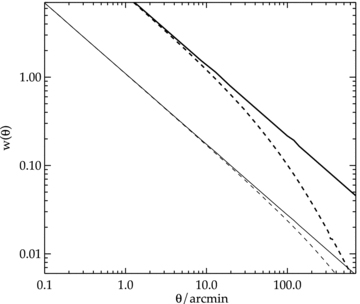
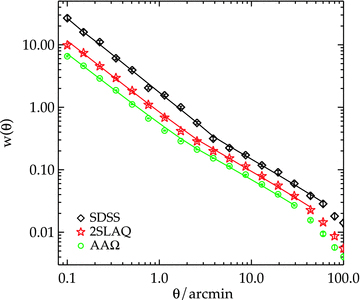
We first look at the angular correlation function measured from the LRG sample at scales less than 1° corresponding to approximately 20 h−1 Mpc where previous studies suggested that the spatial 2PCF can be described by a single power law of the form ξ(r) = (r/r0)−γ (typically γ = 1.8) and a single power-law w(θ) with slope 1 −γ is expected (see Fig. 7). However in this study, we find a deviation from a single power law with a break in the slope at ≈1 h−1 Mpc in all three samples (less significant for the SDSS LRG). The measurement has a steeper slope at small scales (<1 h−1 Mpc) and is slightly flatter on scales up to ≈20 h−1 Mpc where it begins to drop sharply (see Figs 8 and 9). The inflexion feature at ≈1 h−1 Mpc has also been reported in the spatial and semi-projected, wp(σ), correlation function by many authors (e.g. Zehavi et al. 2005a; Phleps et al. 2006; Ross et al. 2007; Blake et al. 2008) and detections go back as far as Shanks et al. (1983). We shall return to discuss these features in the halo model framework (Section 4.3).
The angular correlation function measured from the three LRG samples. The solid lines are the projection of best-fitting double power-law ξ(r) with r0 and γ given in Table 2 for each sample. The break scales occur at approximately a few arcmin depending on the average redshift of the sample. This corresponds to a comoving separation of ≈1 h−1 Mpc (see Fig. 9).
The angular correlation function with the best-fitting single (red dashed line) and double (blue solid line) power law for the SDSS, 2SLAQ and AAΩ LRGs. Lower panels show the fitting residuals for the single (circles) and double (triangles) power law.
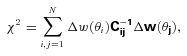
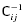 is the inverse of covariance matrix.
is the inverse of covariance matrix.The single power-law fit is of the form w(θ) = (θ/θ0)(1 −γ). We also recover the spatial clustering length, r0, and its slope through the fitting via equation (14). For a double power law, the fitting procedure is performed separately at the scales smaller and larger than θb, corresponding to ≈1 h−1 Mpc for all three samples (see Fig. 9). The largest scale considered in the fitting for all cases is ≈20 h−1 Mpc where a steeper drop-off of w(θ) is observed.
In Fig. 9, the best-fitting power laws for all three samples are shown. The summary of the best-fitting parameters is given in Table 2. Equations (14) and (17) are then used to find the spatial clustering lengths and slopes that best describe our w(θ) results. The best-fitting clustering slopes from r0−γ analysis using Limber’s equation are in good agreement with that from θ0−γ and hence we only report the latter in Table 2. If we require continuity in the double power-law ξ(r) at the break scale, such a scale can be constrained by the pair of best-fitting r0-γ for each sample. From Table 2, the double power-law break for the SDSS, 2SLAQ and AAΩ samples is then at 2.2, 1.9 and 1.3 h−1 Mpc, respectively [see Section 5.2 for further discussion of the possible small-scale evolution of ξ(r)]. By assuming the 1 h−1 Mpc break instead of aforementioned values, the w(θ) is underestimated by ≈10 per cent for the SDSS case (less for the other two samples) which is only localized to around θb. The clustering length (single power law), r0, ranges from 7.5 to 8.7 h−1 Mpc, consistent with highly biased luminous galaxies. Single power-law fits to the data can be ruled out at high statistical significance. While the double power law gives better fits to the data than the single power law, their χ2red values indicate that such a model is still not a good fit to the data, given the small statistical errors. Nevertheless, to the first order, the double power-law fits provide a good way of quantifying the spatial clustering strength of the samples via the use of Limber’s equation.
Parameters for the power-law fits to the angular correlation function derived from three LRG samples. The best-fitting parameters given are defined such that w(θ) = (θ/θ0)1 −γ and ξ(r) = (r/r0)−γ. The parameters for the best-fitting double power law are given in two rows whereas the θ < θb result is given in the top row. Also given are the corresponding 1σ error for each parameter.
| Sample |  | ng (h3 Mpc−3) | Single power law | Double power law | χ2red | |||||
| θ0(arcmin) | γ | r0(h−1 Mpc) | χ2red | θ0(arcmin) | γ | r0(h−1 Mpc) | ||||
| SDSS | 0.35 | 1.1 × 10−4 | 1.69 ± 0.03 | 2.07 ± 0.01 | 8.70 ± 0.09 | 16.2 | 1.57 ± 0.05 | 2.19 ± 0.03 | 7.35 ± 0.08 | 2.2 |
| 1.05 ± 0.09 | 1.85 ± 0.04 | 9.15 ± 0.16 | ||||||||
| 2SLAQ | 0.55 | 3.2 × 10−4 | 0.87 ± 0.01 | 2.01 ± 0.01 | 7.50 ± 0.04 | 57.5 | 0.83 ± 0.01 | 2.16 ± 0.01 | 6.32 ± 0.03 | 3.9 |
| 0.60 ± 0.03 | 1.84 ± 0.02 | 7.78 ± 0.05 | ||||||||
| AAΩ | 0.68 | 2.7 × 10−4 | 0.57 ± 0.01 | 1.96 ± 0.01 | 7.56 ± 0.03 | 42.8 | 0.56 ± 0.01 | 2.14 ± 0.01 | 5.96 ± 0.03 | 3.4 |
| 0.38 ± 0.02 | 1.81 ± 0.02 | 7.84 ± 0.04 | ||||||||
| Sample | | ng (h3 Mpc−3) | Single power law | Double power law | χ2red | |||||
| θ0(arcmin) | γ | r0(h−1 Mpc) | χ2red | θ0(arcmin) | γ | r0(h−1 Mpc) | ||||
| SDSS | 0.35 | 1.1 × 10−4 | 1.69 ± 0.03 | 2.07 ± 0.01 | 8.70 ± 0.09 | 16.2 | 1.57 ± 0.05 | 2.19 ± 0.03 | 7.35 ± 0.08 | 2.2 |
| 1.05 ± 0.09 | 1.85 ± 0.04 | 9.15 ± 0.16 | ||||||||
| 2SLAQ | 0.55 | 3.2 × 10−4 | 0.87 ± 0.01 | 2.01 ± 0.01 | 7.50 ± 0.04 | 57.5 | 0.83 ± 0.01 | 2.16 ± 0.01 | 6.32 ± 0.03 | 3.9 |
| 0.60 ± 0.03 | 1.84 ± 0.02 | 7.78 ± 0.05 | ||||||||
| AAΩ | 0.68 | 2.7 × 10−4 | 0.57 ± 0.01 | 1.96 ± 0.01 | 7.56 ± 0.03 | 42.8 | 0.56 ± 0.01 | 2.14 ± 0.01 | 5.96 ± 0.03 | 3.4 |
| 0.38 ± 0.02 | 1.81 ± 0.02 | 7.84 ± 0.04 | ||||||||
Parameters for the power-law fits to the angular correlation function derived from three LRG samples. The best-fitting parameters given are defined such that w(θ) = (θ/θ0)1 −γ and ξ(r) = (r/r0)−γ. The parameters for the best-fitting double power law are given in two rows whereas the θ < θb result is given in the top row. Also given are the corresponding 1σ error for each parameter.
| Sample | | ng (h3 Mpc−3) | Single power law | Double power law | χ2red | |||||
| θ0(arcmin) | γ | r0(h−1 Mpc) | χ2red | θ0(arcmin) | γ | r0(h−1 Mpc) | ||||
| SDSS | 0.35 | 1.1 × 10−4 | 1.69 ± 0.03 | 2.07 ± 0.01 | 8.70 ± 0.09 | 16.2 | 1.57 ± 0.05 | 2.19 ± 0.03 | 7.35 ± 0.08 | 2.2 |
| 1.05 ± 0.09 | 1.85 ± 0.04 | 9.15 ± 0.16 | ||||||||
| 2SLAQ | 0.55 | 3.2 × 10−4 | 0.87 ± 0.01 | 2.01 ± 0.01 | 7.50 ± 0.04 | 57.5 | 0.83 ± 0.01 | 2.16 ± 0.01 | 6.32 ± 0.03 | 3.9 |
| 0.60 ± 0.03 | 1.84 ± 0.02 | 7.78 ± 0.05 | ||||||||
| AAΩ | 0.68 | 2.7 × 10−4 | 0.57 ± 0.01 | 1.96 ± 0.01 | 7.56 ± 0.03 | 42.8 | 0.56 ± 0.01 | 2.14 ± 0.01 | 5.96 ± 0.03 | 3.4 |
| 0.38 ± 0.02 | 1.81 ± 0.02 | 7.84 ± 0.04 | ||||||||
| Sample | | ng (h3 Mpc−3) | Single power law | Double power law | χ2red | |||||
| θ0(arcmin) | γ | r0(h−1 Mpc) | χ2red | θ0(arcmin) | γ | r0(h−1 Mpc) | ||||
| SDSS | 0.35 | 1.1 × 10−4 | 1.69 ± 0.03 | 2.07 ± 0.01 | 8.70 ± 0.09 | 16.2 | 1.57 ± 0.05 | 2.19 ± 0.03 | 7.35 ± 0.08 | 2.2 |
| 1.05 ± 0.09 | 1.85 ± 0.04 | 9.15 ± 0.16 | ||||||||
| 2SLAQ | 0.55 | 3.2 × 10−4 | 0.87 ± 0.01 | 2.01 ± 0.01 | 7.50 ± 0.04 | 57.5 | 0.83 ± 0.01 | 2.16 ± 0.01 | 6.32 ± 0.03 | 3.9 |
| 0.60 ± 0.03 | 1.84 ± 0.02 | 7.78 ± 0.05 | ||||||||
| AAΩ | 0.68 | 2.7 × 10−4 | 0.57 ± 0.01 | 1.96 ± 0.01 | 7.56 ± 0.03 | 42.8 | 0.56 ± 0.01 | 2.14 ± 0.01 | 5.96 ± 0.03 | 3.4 |
| 0.38 ± 0.02 | 1.81 ± 0.02 | 7.84 ± 0.04 | ||||||||
The best-fitting slopes at small scales show a slight decrease with increasing redshift, similar to that found by Wake et al. (2008). The SDSS-LRG sample is more strongly clustered than the rest as expected. This is simply because the SDSS-LRG sample is intrinsically more luminous than the 2SLAQ and AAΩ-LRG samples, and is not an indication of evolution.
To this end, we cut back the faint magnitude limit of 2SLAQ and AAΩ LRGs to ideV < 19.32 and 20.25, respectively. These cuts are imposed in order to select the samples of galaxies whose comoving number densities are approximately matched to that of the SDSS LRG. The K+e corrected i-band absolute magnitudes of these samples are presented in Fig. 10. We see that their absolute magnitudes are also approximately matched. We note that we do not attempt to match the LRGs’ colour of different samples here. This would then allow us to roughly constrain the evolution of LRG clustering up to z≈ 0.68 (see Section 5). A summary of the properties of these samples and the best-fitting parameters is given in Table 3. The measured w(θ)s are shown in Fig. 11(a).
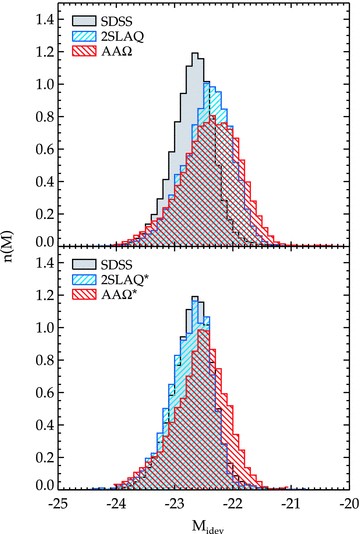
Top: the i-band absolute magnitude distribution of the spectroscopic LRG catalogues. All photometry is galactic-extinction corrected using dust map of Schlegel et al. (1998) and K+e corrected to z = 0 using the early-type galaxy templates from Bruzual & Charlot (2003). Bottom: the distribution of the absolute magnitude after applying a faint limit cut to 2SLAQ and AAΩ LRG in order to match the comoving number density of the SDSS LRG.
Properties and the best-fitting parameters for double power law of w(θ) measured from the SDSS-density matched samples.
| Sample | Number | Magnitude |  | ng (h3 Mpc−3) | Double power law | ||
| γ | r0(h−1 Mpc) | χ2red | |||||
| 2SLAQ* | 182 841 | 17.5 < ideV < 19.32 | 0.53 | 1.2 × 10−4 | 2.25 ± 0.02 | 6.33 ± 0.04 | 2.1 |
| 1.80 ± 0.02 | 8.88 ± 0.08 | ||||||
| AAΩ* | 374 198 | 19.8 < ideV < 20.25 | 0.67 | 1.1 × 10−4 | 2.20 ± 0.02 | 6.25 ± 0.03 | 1.7 |
| 1.76 ± 0.03 | 9.08 ± 0.06 | ||||||
| Sample | Number | Magnitude | | ng (h3 Mpc−3) | Double power law | ||
| γ | r0(h−1 Mpc) | χ2red | |||||
| 2SLAQ* | 182 841 | 17.5 < ideV < 19.32 | 0.53 | 1.2 × 10−4 | 2.25 ± 0.02 | 6.33 ± 0.04 | 2.1 |
| 1.80 ± 0.02 | 8.88 ± 0.08 | ||||||
| AAΩ* | 374 198 | 19.8 < ideV < 20.25 | 0.67 | 1.1 × 10−4 | 2.20 ± 0.02 | 6.25 ± 0.03 | 1.7 |
| 1.76 ± 0.03 | 9.08 ± 0.06 | ||||||
Properties and the best-fitting parameters for double power law of w(θ) measured from the SDSS-density matched samples.
| Sample | Number | Magnitude | | ng (h3 Mpc−3) | Double power law | ||
| γ | r0(h−1 Mpc) | χ2red | |||||
| 2SLAQ* | 182 841 | 17.5 < ideV < 19.32 | 0.53 | 1.2 × 10−4 | 2.25 ± 0.02 | 6.33 ± 0.04 | 2.1 |
| 1.80 ± 0.02 | 8.88 ± 0.08 | ||||||
| AAΩ* | 374 198 | 19.8 < ideV < 20.25 | 0.67 | 1.1 × 10−4 | 2.20 ± 0.02 | 6.25 ± 0.03 | 1.7 |
| 1.76 ± 0.03 | 9.08 ± 0.06 | ||||||
| Sample | Number | Magnitude | | ng (h3 Mpc−3) | Double power law | ||
| γ | r0(h−1 Mpc) | χ2red | |||||
| 2SLAQ* | 182 841 | 17.5 < ideV < 19.32 | 0.53 | 1.2 × 10−4 | 2.25 ± 0.02 | 6.33 ± 0.04 | 2.1 |
| 1.80 ± 0.02 | 8.88 ± 0.08 | ||||||
| AAΩ* | 374 198 | 19.8 < ideV < 20.25 | 0.67 | 1.1 × 10−4 | 2.20 ± 0.02 | 6.25 ± 0.03 | 1.7 |
| 1.76 ± 0.03 | 9.08 ± 0.06 | ||||||
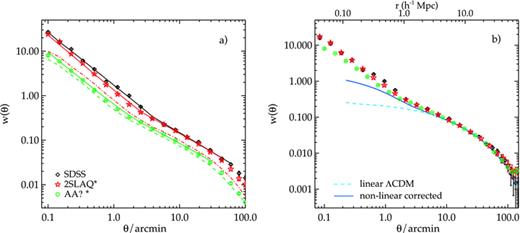
(a) The angular correlation function measured from the SDSS LRG and the brighter magnitude limit samples drawn from 2SLAQ and AAΩ sample (symbols). The solid lines are the projection of the best-fitting double power-law ξ(r) with the parameters shown in Table 3. For comparison, the dot–dashed and dashed lines are w(θ) measured from the whole 2SLAQ and AAΩ samples, respectively. (b) Same as (a) but now scaled to AAΩ depth and taking into account the relative amplitude due to the different n(z) widths (see text for more details).
As expected, the amplitudes of the brighter cut 2SLAQ and AAΩ samples (denoted by 2SLAQ* and AAΩ* hereafter) are higher than the original sample. In its raw form, w(θ) measured from 2SLAQ* increases relative to 2SLAQ more than AAΩ relative to AAΩ*, due to the narrower redshift distribution of the 2SLAQ* sample. However, if we perform a double power-law fit to these results, the large-scale, ≳1 h−1 Mpc, clustering lengths are very similar and agree within ≈1σ statistical error. To the first order these large-scale clustering lengths are also consistent with that of the SDSS LRGs. We shall investigate the clustering evolution of these LRG samples further in Section 5.
4.2 Comparison of the clustering form to the standard ΛCDM model
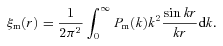
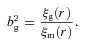
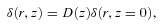
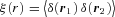 , where r = |r1−r2 |, then
, where r = |r1−r2 |, then 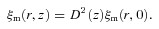
The linear growth factor is unity at the present epoch, by definition, and decreases as a function of redshift. The ξm(r, z) therefore decreases as the redshift increases hence given that the number-density/luminosity-matched samples have similar ξg(r) amplitudes suggests that the bias increases as a function of redshift.
We proceed by projecting the predicted ξm(r) using equation (14). Our fiducial models assume a ΛCDM Universe with ΩΛ = 0.73, Ωm = 0.27, fbaryon = 0.167, σ8 = 0.8, h = 0.7 and ns = 0.95. The linear bias factor is then estimated by fitting the matter w(θ) to our measurements for the comoving separation of ≈ 6–60 h−1 Mpc, using the full covariance matrices. The best-fitting linear bias (χ2red) for SDSS, 2SLAQ*, AAΩ*, 2SLAQ and AAΩ samples are 2.09 ± 0.05(1.2), 2.20 ± 0.04(0.65), 2.33 ± 0.03(0.66), 1.98 ± 0.03(0.53) and 2.07 ± 0.02(1.2), respectively. The measured biases are consistent with the results from other authors. For example, Tegmark et al. (2006) analysed P(k) of SDSS LRG and found b(z = 0.35) = 2.25 ± 0.08 for the best-fitting σ8 = 0.756 ± 0.035 and for our fiducial σ8 this becomes b = 2.12 ± 0.12. Ross et al. (2007) found 2SLAQ LRG b = 1.66 ± 0.35 using the redshift-space distortion analysis. Padmanabhan et al. (2007), using C(l) of SDSS+2SLAQ photo-z sample, found that b(z = 0.376) = 1.94 ± 0.06 and b(z = 0.55) = 1.8 ± 0.04 (assumed σ8 = 0.9), for our fiducial σ8 these are b = 2.18 ± 0.07 and b = 2.02 ± 0.05, respectively.
Fig. 11(b) shows the full scaling of the w(θ)s, accounting for their survey differences. First, the w(θ) of the SDSS, and 2SLAQ* samples scaled in the angular direction according to their average redshifts and relative to the AAΩ* sample. The amplitudes are then scaled to obtain a fair comparison for samples with different redshift distributions. This is done by taking the relative amplitudes of the projections of a power-law ξ(r) of the same clustering strength but projected through different n(z) widths. Since the observed large-scale clustering lengths are very similar, ≈9 h−1 Mpc, the scaled w(θ)s in these ranges agree reasonably well. The figure also shows the best-fitting biased non-linear model for the AAΩ* sample. Our w(θ) shapes in the ranges 6 ≲r≲ 60 h−1 Mpc can be described very well by the perturbation theory in the standard flat ΛCDM Universe (see the χ2red for the best-fitting bias factor given above). However, at smaller scales the theory underestimates the clustering amplitude, as expected for early-type galaxies. As we shall see in Section 4.3, the reason for this may lie in the details of how the LRGs populate their dark matter halo hosts.
4.3 Halo model fits
We fit a halo model (e.g. Peacock & Smith 2000; Berlind & Weinberg 2002; Cooray & Sheth 2002) to our angular correlation function results. One of the key ingredients of the halo model is the halo occupation distribution (HOD) which tells us how the galaxies populate dark matter haloes as a function of halo mass. Recently, the model has been used to fit various data sets as a means to physically interpret the galaxy correlation function and gain insight into their evolution (e.g. White et al. 2007; Blake et al. 2008; Brown et al. 2008; Wake et al. 2008; Ross & Brunner 2009; Zheng et al. 2009).
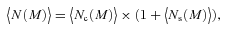
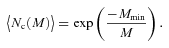
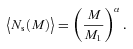
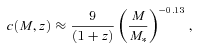
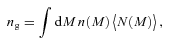
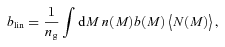
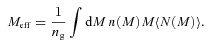
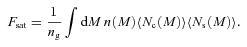
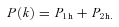
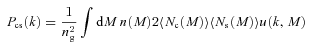
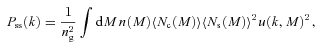

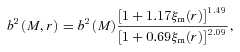

We then project the predicted galaxy correlation function to w(θ) using equation (14) for a range of HOD parameters. The best-fitting model for each of our sample is then determined from chi-square minimization using the full covariance matrix. Note that we exclude angular bins corresponding to scales smaller than 0.1 h−1 Mpc because any uncertainty in the ξ(r) model at very small scales, r≲ 0.01 h−1 Mpc, can have a strong effect on w(θ) even at these scales due to the projection. The best-fitting Mmin, M1 and α and the associated values for ng, Meff, Fsat and blin are given in Table 4. The 1σ uncertainties on the best-fitting Mmin, M1 and α are determined from the parameter space where Δχ2≤ 1. For ng, Meff, Fsat and blin which depend on the three main HOD parameters, this becomes Δχ2≤ 3.53. Fig. 12 shows the best-fitting HOD for each sample; the coloured solid lines are the mean number of LRGs per halo with the central and satellite contributions shown separately as the dashed and dotted lines, respectively.
Best-fitting HOD parameters.
| Sample |  | Mmin (1013h−1 M⊙) | M1 (1013h−1 M⊙) | α | ng (10−4h3 Mpc−3) | Meff (1013h−1 M⊙) | Fsat (per cent) | blin | χ2red |
| SDSS | 0.35 | 2.5 ± 0.2 | 29.5 ± 2.5 | 1.58 ± 0.04 | 1.3 ± 0.4 | 6.4 ± 0.5 | 8.1 ± 1.8 | 2.08 ± 0.05 | 3.1 |
| 2SLAQ* | 0.53 | 2.2 ± 0.1 | 27.3 ± 2.0 | 1.49 ± 0.03 | 1.3 ± 0.3 | 4.7 ± 0.2 | 7.0 ± 0.8 | 2.21 ± 0.04 | 7.7 |
| AAΩ* | 0.67 | 2.1 ± 0.1 | 23.8 ± 2.0 | 1.76 ± 0.04 | 1.2 ± 0.2 | 4.3 ± 0.2 | 5.7 ± 0.7 | 2.36 ± 0.04 | 10.1 |
| 2SLAQ | 0.55 | 1.10 ± 0.07 | 13.6 ± 1.1 | 1.42 ± 0.02 | 3.2 ± 0.5 | 3.4 ± 0.2 | 10.0 ± 1.1 | 1.97 ± 0.03 | 14.2 |
| AAΩ | 0.68 | 1.02 ± 0.03 | 12.6 ± 1.0 | 1.50 ± 0.03 | 3.1 ± 0.4 | 3.0 ± 0.1 | 9.0 ± 0.09 | 2.08 ± 0.03 | 13.6 |
| Sample | | Mmin (1013h−1 M⊙) | M1 (1013h−1 M⊙) | α | ng (10−4h3 Mpc−3) | Meff (1013h−1 M⊙) | Fsat (per cent) | blin | χ2red |
| SDSS | 0.35 | 2.5 ± 0.2 | 29.5 ± 2.5 | 1.58 ± 0.04 | 1.3 ± 0.4 | 6.4 ± 0.5 | 8.1 ± 1.8 | 2.08 ± 0.05 | 3.1 |
| 2SLAQ* | 0.53 | 2.2 ± 0.1 | 27.3 ± 2.0 | 1.49 ± 0.03 | 1.3 ± 0.3 | 4.7 ± 0.2 | 7.0 ± 0.8 | 2.21 ± 0.04 | 7.7 |
| AAΩ* | 0.67 | 2.1 ± 0.1 | 23.8 ± 2.0 | 1.76 ± 0.04 | 1.2 ± 0.2 | 4.3 ± 0.2 | 5.7 ± 0.7 | 2.36 ± 0.04 | 10.1 |
| 2SLAQ | 0.55 | 1.10 ± 0.07 | 13.6 ± 1.1 | 1.42 ± 0.02 | 3.2 ± 0.5 | 3.4 ± 0.2 | 10.0 ± 1.1 | 1.97 ± 0.03 | 14.2 |
| AAΩ | 0.68 | 1.02 ± 0.03 | 12.6 ± 1.0 | 1.50 ± 0.03 | 3.1 ± 0.4 | 3.0 ± 0.1 | 9.0 ± 0.09 | 2.08 ± 0.03 | 13.6 |
Best-fitting HOD parameters.
| Sample | | Mmin (1013h−1 M⊙) | M1 (1013h−1 M⊙) | α | ng (10−4h3 Mpc−3) | Meff (1013h−1 M⊙) | Fsat (per cent) | blin | χ2red |
| SDSS | 0.35 | 2.5 ± 0.2 | 29.5 ± 2.5 | 1.58 ± 0.04 | 1.3 ± 0.4 | 6.4 ± 0.5 | 8.1 ± 1.8 | 2.08 ± 0.05 | 3.1 |
| 2SLAQ* | 0.53 | 2.2 ± 0.1 | 27.3 ± 2.0 | 1.49 ± 0.03 | 1.3 ± 0.3 | 4.7 ± 0.2 | 7.0 ± 0.8 | 2.21 ± 0.04 | 7.7 |
| AAΩ* | 0.67 | 2.1 ± 0.1 | 23.8 ± 2.0 | 1.76 ± 0.04 | 1.2 ± 0.2 | 4.3 ± 0.2 | 5.7 ± 0.7 | 2.36 ± 0.04 | 10.1 |
| 2SLAQ | 0.55 | 1.10 ± 0.07 | 13.6 ± 1.1 | 1.42 ± 0.02 | 3.2 ± 0.5 | 3.4 ± 0.2 | 10.0 ± 1.1 | 1.97 ± 0.03 | 14.2 |
| AAΩ | 0.68 | 1.02 ± 0.03 | 12.6 ± 1.0 | 1.50 ± 0.03 | 3.1 ± 0.4 | 3.0 ± 0.1 | 9.0 ± 0.09 | 2.08 ± 0.03 | 13.6 |
| Sample | | Mmin (1013h−1 M⊙) | M1 (1013h−1 M⊙) | α | ng (10−4h3 Mpc−3) | Meff (1013h−1 M⊙) | Fsat (per cent) | blin | χ2red |
| SDSS | 0.35 | 2.5 ± 0.2 | 29.5 ± 2.5 | 1.58 ± 0.04 | 1.3 ± 0.4 | 6.4 ± 0.5 | 8.1 ± 1.8 | 2.08 ± 0.05 | 3.1 |
| 2SLAQ* | 0.53 | 2.2 ± 0.1 | 27.3 ± 2.0 | 1.49 ± 0.03 | 1.3 ± 0.3 | 4.7 ± 0.2 | 7.0 ± 0.8 | 2.21 ± 0.04 | 7.7 |
| AAΩ* | 0.67 | 2.1 ± 0.1 | 23.8 ± 2.0 | 1.76 ± 0.04 | 1.2 ± 0.2 | 4.3 ± 0.2 | 5.7 ± 0.7 | 2.36 ± 0.04 | 10.1 |
| 2SLAQ | 0.55 | 1.10 ± 0.07 | 13.6 ± 1.1 | 1.42 ± 0.02 | 3.2 ± 0.5 | 3.4 ± 0.2 | 10.0 ± 1.1 | 1.97 ± 0.03 | 14.2 |
| AAΩ | 0.68 | 1.02 ± 0.03 | 12.6 ± 1.0 | 1.50 ± 0.03 | 3.1 ± 0.4 | 3.0 ± 0.1 | 9.0 ± 0.09 | 2.08 ± 0.03 | 13.6 |
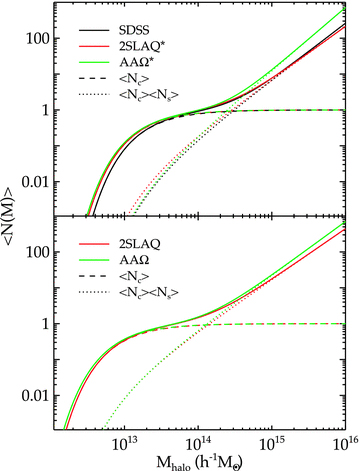
The mean number of LRGs per halo as a function of mass (solid lines) from the best-fitting HOD for the SDSS, 2SLAQ*, AAΩ* samples (top) and 2SLAQ, AAΩ samples (bottom). The central and satellite contributions for each sample are shown as the dashed and dotted lines.
As expected, the LRGs populate rather massive dark matter haloes with the masses ≈1013–1014h−1 M⊙. At approximately the same redshift, the more luminous samples, 2SLAQ* and AAΩ*, are hosted by more massive haloes than fainter samples. Most of the LRGs, >90 per cent, are central galaxies in their dark matter haloes; the satellite fraction is only 10 per cent or less with the increasing trend towards low redshift. This can be explained in the framework of halo mergers at lower redshift (see Section 5.2.2). The best-fitting linear bias factors for all samples are in excellent agreement with the values derived in Section 4.2. Also the galaxy number density from the best-fitting halo model is consistent with that derived from equation (18) (see Tables 2 and 3).
Note that, to the first order, our best-fitting HODs are compatible with the measurements from other authors although a direct comparison with samples selected differently may not be simple. For example, our SDSS sample has similar space density (although at higher redshift, z = 0.35 versus 0.3) as the sample studied by Seo et al. (2008). Our M1/Mmin and satellite fraction are in excellent agreement with their model 11 (their best-fitting N-body evolved HOD). But their α is somewhat lower which is caused by the higher σ8 = 0.9 value (Wake et al. 2008) and the lower average redshift. Their M1 and Mmin are also somewhat higher than our best-fitting values for the same reason as for α. Another example, our best-fitting M1, Mmin, blin and Fsat for 2SLAQ* sample are in good agreement with Wake et al. (2008)z = 0.55 2SLAQ selection, although our values are somewhat higher which may be due to our lower galaxy number density, implying that our sample contains rarer and more biased objects.
The best-fitting models for w(θ) are shown in Fig. 13, comparing to the data. Both the models and data are scaled to account for the projection effect (see Section 4.2) and are plotted at the depth of AAΩ*/AAΩ sample. We immediately see that while the fits at the large scales (r≳ 3 h−1 Mpc) are good, the fits at the small scales and at r≈ 1 − 2 h−1 Mpc are rather poor especially for the higher redshift samples. This is evident in the high best-fitting reduced chi-square values in Table 4. Given our small error bars, this may indicate that a more complicated halo model may be needed, e.g. five/six parameters HOD, an improved halo-exclusion model (see fig. 11 of Tinker et al. 2005), or different halo concentration parametrization. Another important point to note is that the HOD formalism assumes a volume-limited sample, which we do not have here. This means that our observed galaxy number density corresponds to a cut-off which evolves with redshift rather than a cut-off in halo mass or LRG luminosity. Nevertheless, to the first order the HOD fits generally describe the shape and amplitude of our measured w(θ), and we believe that the derived blin and Meff are reasonably robust despite the statistically poor fits.
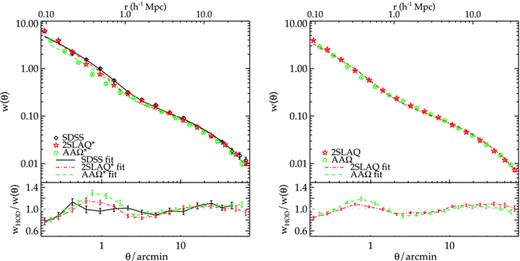
The best-fitting HOD models for the SDSS, 2SLAQ*, AAΩ* samples (left) and 2SLAQ, AAΩ samples (right). These are scaled to the AAΩ*/AAΩ depth similar to that shown in Fig. 11(b). The bottom panels show the ratios between the best-fitting HOD models and the measured correlation functions.
5 EVOLUTION OF LRG CLUSTERING AND DARK MATTER HALO MASSES
5.1 Intermediate scales
We study the LRGs clustering and dark matter halo mass evolution by employing the methods used by Croom et al. (2005) and da Ângela et al. (2008) to analyse their quasi-stellar object (QSO) samples. We then proceed by considering the small-scale clustering evolution in the framework of the halo model.
5.1.1 Clustering evolution
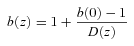
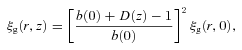
We shall also compare the data directly to the linear theory prediction for dark matter evolution in the ΛCDM model, ξ(r, z) ∝D2(z). In addition, we shall also check the stable clustering and no-evolution (comoving) clustering models of Phillipps et al. (1978). The stable model refers to clustering that is virialized and therefore stable in proper coordinates. For a ξ(r) with r measured in comoving coordinates, the stable model has evolution ξ(r) ∝ (1 +z)γ− 3 and the no-evolution model has ξ(r) independent of redshift. At these intermediate scales, the clustering is unlikely to be virialized so the stable model is shown mainly as a reference point. From equation (38), the no-evolution model represents the high bias limit of the long-lived model of Fry (1996). The stable and comoving models are similar to the long-lived model in that they both assume that the comoving galaxy density remains constant with redshift.
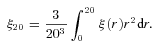
The 20 h−1 Mpc radius is chosen to ensure a large enough scale for linear theory to be valid and in our case the power law with γ≈ 1.8 remains a good approximation up to ≈20 h−1 Mpc. Furthermore, the non-linearity at small scales does not significantly affect the clustering measurements, when averaged over this range of scales.
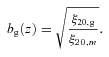
The mass-integrated correlation functions are again computed assuming our fiducial cosmological model using the matter power spectra output from camb. The values for ξ20, m used here are 0.153, 0.126 and 0.112 for z = 0.35, 0.55 and 0.68, respectively.
The ξ20, g is calculated using the best-fitting double power-law parameters for each sample. The results are plotted in Fig. 14(a) along with the best-fitting linear theory evolution (long-dashed line), stable clustering (dotted line), long-lived (dashed line) and no-evolution models (dot-dot–dashed line). The linear bias factors measured using the ξ20 approach are given in Table 5 and are also presented in Fig. 14(b). The bias factors determined here are in good agreement with the large-scale ΛCDM (Section 4.2) and HOD (Section 4.3) best-fitting models.
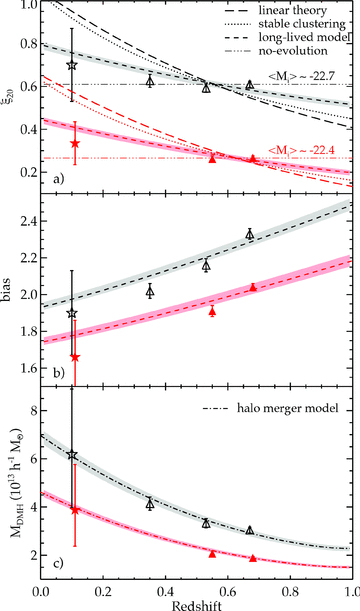
(a): The LRG ξ20 measurements as a function of redshift and luminosity. The data at z≈ 0.1 (stars) are taken from the correlation functions of early-type galaxies in 2dFGRS (Norberg et al. 2002). Open and solid symbols correspond to the samples with median absolute magnitude, Mi− 5log10h=−22.7 (SDSS/2SLAQ*/AAΩ*) and −22.4 (2SLAQ/AAΩ). The best fits for various models are also shown (see text for more details). The lower luminosity data have been lowered by 0.2 for clarity. (b) The LRG linear biases as a function of redshift and luminosity, comparing to the best-fitting long-lived model. (c) The typical mass of dark matter haloes occupied by the LRGs as estimated from the halo bias function. The dot–dashed lines are the best-fitting evolution model of dark matter halo mass via the merger framework (Lacey & Cole 1993).
Summary of the estimated LRG and 2dFGRS early-type galaxy bias factor and MDMH as a function of redshift and luminosity.
| Sample |  |  −5log10h −5log10h | b | MDMH (1013h−1 M⊙) |
| SDSS | 0.35 | −22.67 | 2.02 ± 0.04 | 4.1 ± 0.3 |
| 2SLAQ* | 0.53 | −22.69 | 2.16 ± 0.04 | 3.3 ± 0.2 |
| AAΩ* | 0.67 | −22.60 | 2.33 ± 0.03 | 3.1 ± 0.1 |
| 2SLAQ | 0.55 | −22.40 | 1.91 ± 0.03 | 2.1 ± 0.1 |
| AAΩ | 0.68 | −22.37 | 2.04 ± 0.02 | 1.9 ± 0.1 |
| N02E1 | ≈0.1 | −22.68 | 1.90 ± 0.23 | 6.2 ± 2.2 |
| N02E2 | ≈0.1 | −22.40 | 1.66 ± 0.20 | 3.9 ± 1.5 |
| Sample | | −5log10h | b | MDMH (1013h−1 M⊙) |
| SDSS | 0.35 | −22.67 | 2.02 ± 0.04 | 4.1 ± 0.3 |
| 2SLAQ* | 0.53 | −22.69 | 2.16 ± 0.04 | 3.3 ± 0.2 |
| AAΩ* | 0.67 | −22.60 | 2.33 ± 0.03 | 3.1 ± 0.1 |
| 2SLAQ | 0.55 | −22.40 | 1.91 ± 0.03 | 2.1 ± 0.1 |
| AAΩ | 0.68 | −22.37 | 2.04 ± 0.02 | 1.9 ± 0.1 |
| N02E1 | ≈0.1 | −22.68 | 1.90 ± 0.23 | 6.2 ± 2.2 |
| N02E2 | ≈0.1 | −22.40 | 1.66 ± 0.20 | 3.9 ± 1.5 |
Summary of the estimated LRG and 2dFGRS early-type galaxy bias factor and MDMH as a function of redshift and luminosity.
| Sample | | −5log10h | b | MDMH (1013h−1 M⊙) |
| SDSS | 0.35 | −22.67 | 2.02 ± 0.04 | 4.1 ± 0.3 |
| 2SLAQ* | 0.53 | −22.69 | 2.16 ± 0.04 | 3.3 ± 0.2 |
| AAΩ* | 0.67 | −22.60 | 2.33 ± 0.03 | 3.1 ± 0.1 |
| 2SLAQ | 0.55 | −22.40 | 1.91 ± 0.03 | 2.1 ± 0.1 |
| AAΩ | 0.68 | −22.37 | 2.04 ± 0.02 | 1.9 ± 0.1 |
| N02E1 | ≈0.1 | −22.68 | 1.90 ± 0.23 | 6.2 ± 2.2 |
| N02E2 | ≈0.1 | −22.40 | 1.66 ± 0.20 | 3.9 ± 1.5 |
| Sample | | −5log10h | b | MDMH (1013h−1 M⊙) |
| SDSS | 0.35 | −22.67 | 2.02 ± 0.04 | 4.1 ± 0.3 |
| 2SLAQ* | 0.53 | −22.69 | 2.16 ± 0.04 | 3.3 ± 0.2 |
| AAΩ* | 0.67 | −22.60 | 2.33 ± 0.03 | 3.1 ± 0.1 |
| 2SLAQ | 0.55 | −22.40 | 1.91 ± 0.03 | 2.1 ± 0.1 |
| AAΩ | 0.68 | −22.37 | 2.04 ± 0.02 | 1.9 ± 0.1 |
| N02E1 | ≈0.1 | −22.68 | 1.90 ± 0.23 | 6.2 ± 2.2 |
| N02E2 | ≈0.1 | −22.40 | 1.66 ± 0.20 | 3.9 ± 1.5 |
To extend the redshift range, we shall compare our results to the clustering of early-type galaxies in 2dFGRS studied by Norberg et al. (2002) that roughly match the absolute magnitude of our samples after the K+e-correction. These are the samples with  and
and  , being compared to the SDSS/2SLAQ*/AAΩ* and 2SLAQ/AAΩ data and denoted as N02E1 and N02E2 in Table 5, respectively. We proceed in a similar fashion to the procedure described above and use the author’s best-fitting power law to estimate the ξ20, gs and hence the bias values (see Table 5).
, being compared to the SDSS/2SLAQ*/AAΩ* and 2SLAQ/AAΩ data and denoted as N02E1 and N02E2 in Table 5, respectively. We proceed in a similar fashion to the procedure described above and use the author’s best-fitting power law to estimate the ξ20, gs and hence the bias values (see Table 5).
Both luminosity bins can be reasonably fitted by the long-lived model. The best-fitting models for the Mi− 5log10h=−22.7 and −22.4 samples have b(0) = 1.93 ± 0.02 and 1.74 ± 0.02 with χ2 = 7.34 [3 degrees of freedom (d.o.f.)] and 4.11 (2 d.o.f.), respectively, i.e. 1.5 − 1.9σ deviation. This is interesting given the lack of number density evolution seen in the LRG luminosity function by Wake et al. (2006). Nevertheless, it is intriguing that such a simple model gets so close to fitting data over the wide redshift range analysed here.
The stable model and the linear theory (with constant bias) model rise too quickly as the redshift decreases, excluded at >99.99 per cent confidence. However, the comoving model also gives a good fit to the SDSS/2SLAQ*/AAΩ* data in Fig. 14(a), as expected from the lack of evolution shown in Fig. 11(b). For this model to be exactly correct it would suggest that there was an inconsistency in these results with the underlying ΛCDM halo mass function. More certainly, we conclude that the evolution of the LRG clustering seems very slow. This general conclusion agrees with previous work (White et al. 2007; Wake et al. 2008). The latter author also only found a marginal rejection of the long-lived model from the large-scale clustering signal (1.8σ) compared to 1.9σ here. They found a much stronger rejection of a ‘passive’ evolution model from the small-scale LRG clustering and we shall return to this issue in Section 5.2.
5.1.2 LRG dark matter halo masses
The large-scale galaxy bias is roughly the same as that of the dark matter haloes which is a known function of mass threshold. Thus by measuring the clustering of the LRGs one can infer the typical mass of the haloes they reside in. The procedure employed here is similar to that used by Croom et al. (2005) and da Ângela et al. (2008) to estimate the dark matter halo masses of QSOs.
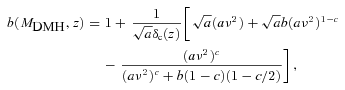
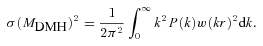
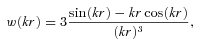
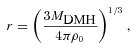
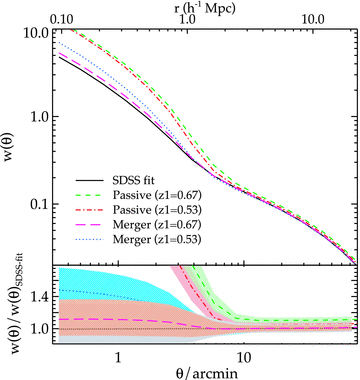
The estimated dark matter halo masses of the LRG samples are given in Table 5 and plotted in Fig. 14(c). Note that the formalism of estimating dark matter halo masses from the galaxy biases used here assumes one galaxy per halo and can overestimate the threshold mass for a given value of bias (Zheng, Coil & Zehavi 2007). This is particularly true when we consider the mass estimated from equation (41) as the threshold mass, minimum mass required for a halo to host at least one galaxy and compare the results derived here to Mmin from the best-fitting HOD (Section 4.3). However, if it is used as an estimate for the average mass of the host halo then it is underestimated by ≈40 per cent compared to the value given by the HOD due to the one galaxy per halo assumption.
Next, we attempt to fit the derived dark matter halo masses of these LRGs to the halo merger framework in hierarchical models of galaxy formation. We use the formalism discussed by Lacey & Cole (1993) to predict the median MDMH of the descendants of virialized haloes at z = 1 for a given halo mass and fit this to our data. In essence, the model gives the probability distribution of the haloes with mass M1 at time t1 evolving into a halo of mass M2 at time t2 via merging. Fig. 14(c) shows the best-fitting models for the MDMH evolution estimated in this way. These models appear to be good fits to both luminosity bins with the best-fitting MDMH(z = 1) = 2.32 ± 0.07 × 1013h−1 M⊙ and 1.47 ± 0.05 × 1013h−1 M⊙ for the L≳ 3L* and ≳ 2L* samples, respectively.
The most massive haloes hosting these luminous early-type galaxies appear to have tripled their masses over the past 7 Gyr (i.e. half cosmic time) in stark contrast to the little evolution observed in the LRG stellar masses over the same period (see e.g. Wake et al. 2006; Cool et al. 2008). This lack of evolution contradicts the predictions in the standard hierarchical models of galaxy formation where one expects the most massive galaxies to form late via ‘dry’ merging of many less massive galaxies. However, this comes with a caveat that the MDMH at z∼ 0 is an extrapolation [assuming Lacey & Cole (1993) halo merging model] of the z = 0.35–0.7 measurements and the constraint on the MDMH(z = 0.1) is much weaker than the higher redshift results.
5.2 Small-scale clustering evolution
Finally, we discuss the evolution of the correlation function at scales corresponding to r < 1 h−1 Mpc. We concentrate on comparing the number density matched AAΩ* and 2SLAQ* samples to the SDSS sample. As can be seen in Fig. 11(b), while at larger scales the w(θ) show amplitudes that are remarkably independent of redshift, at smaller scales the high redshift AAΩ* sample appears to have a lower amplitude than the lower redshift surveys. Here, we compare the clustering in non-linear regime to two clustering evolution models, namely stable clustering and HOD evolution models.
5.2.1 Stable clustering model
The stable model describes the clustering in the virialized regime and hence stable (unchanged) in proper coordinates (e.g. Phillipps et al. 1978). Therefore, assuming this model one expect the spatial correlation function to evolve as ξ(r)∝(1 +z)γ− 3, where r is measured in comoving coordinates and γ is the power-law slope of the correlation function. Fig. 15 shows the small-scale, r≲ 1 h−1 Mpc, w(θ) of the SDSS sample plus its best-fitting double power-law model, comparing to the evolved w(θ) from the z1 = 0.53 and 0.67 best-fitting models. Their ratios to the z = 0.35 best-fitting model are shown in the bottom panel with the shaded regions representing 1σ uncertainties in the best-fitting models. We see that the evolved z1 = 0.67 stable model underpredicts the z = 0.35 w(θ) somewhat but otherwise is within the 1σ regions of each other with the probability of acceptance P(<χ2) = 0.827. The agreement between the evolved z1 = 0.53 and the z = 0.35 is better, P(<χ2) = 0.999, given that the redshift difference is smaller. Note that the stable clustering model overpredicts the clustering amplitude at r≳ 1 h−1 Mpc which is also observed in Fig. 14(a) as expected.
The small-scale w(θ) at z = 0.35 evolved from the best-fitting double power law of AAΩ* (green dashed line) and 2SLAQ* (red dot–dashed line) samples, assuming stable clustering model. The ratios of the evolved w(θ)s to the best-fitting double power law of SDSS sample are shown in the bottom panel. The shaded regions signify 1σ uncertainties in the best-fitting models.
The physical picture that is suggested is that the inflexion in the correlation function may represent the boundary between a virialized regime at small scales and a comoving or passively evolving biased regime at larger scales. As noted by Hamilton et al. (1991) and Peacock & Dodds (1996), the small-scale, non-linear, DM clustering is clearly expected from N-body simulations to follow the evolution of the virialized clustering model. However, for galaxies in a ΛCDM context, the picture may be more complicated.
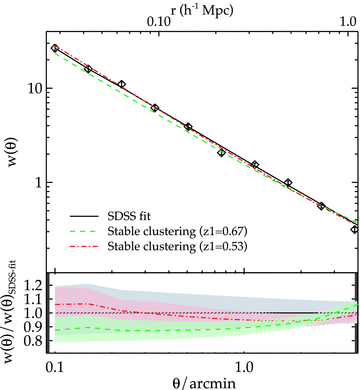
For example, by comparing the 2SLAQ and SDSS-LRG redshift surveys using the semi-projected correlation function, Wake et al. (2008) have suggested that a passively evolving model is rejected, weakly from the large-scale evolution but more strongly from the evolution at small scales. Wake et al. (2008) interpret the clustering evolution using an HOD description based on the ΛCDM halo mass function. Their ‘passive’ model predicts a far faster evolution at small scales than is given by our stable clustering (see Fig. 16). Our stable model is certainly passive in that it is based on the idea that the comoving number density of galaxies is independent of redshift. However, the passive HOD model of Wake et al. (2008) requires only 7.5 per cent of LRGs to merge between z = 0.55 and 0.19 to reconcile the slow LRG density and clustering evolution in the ΛCDM model. We shall see in the next section if this model can also accommodate our z = 0.68 clustering result while maintaining such a low merger rate.
The predicted SDSS LRG w(θ) from passively (fno-merge = 1) evolving the best-fitting HODs of 2SLAQ* (z1 = 0.53, red dot–dashed line) and AAΩ* (z1 = 0.67, green dashed line) samples. The results when central galaxies from high-redshift samples are allowed to merge (see text for more detail) are also shown, blue dotted and magenta long-dashed lines. The bottom panel shows the ratios of the evolved w(θ)s to the SDSS best fit, and the shaded regions signify the 1σ uncertainties.
5.2.2 HOD evolution
In Section 5.1.1, we found using the large-scale linear bias that the long-lived model (Fry 1996) is only marginally rejected at 1.5–1.9σ. This is in good agreement with the similar analysis of Wake et al. (2008). However, they argued that if the small-scale clustering signal was also taken into consideration, the long-lived model can be ruled out at much higher significance (>99.9 per cent).
Recall that our goodness of fit (based on the minimum χ2) for the halo models is rather poor (see Table 4). This may be an indication that a more complicated model may be needed, e.g. five-parameters HOD and/or a better two-halo-exclusion prescription, etc., given our small error bars. Nevertheless, the HOD fit generally describes the shape and amplitude of our measured w(θ) between 0.1 and 40 h−1 Mpc. Therefore, at the risk of overinterpreting these HOD fits, we make a further test of the long-lived model by evolving the best-fitting HODs of the higher redshift samples to the SDSS-LRG average redshift.
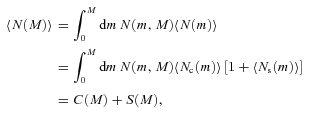
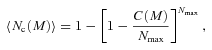
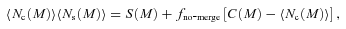
For the long-lived model, we set fno-merge = 1. The results of passively evolving the best-fitting HODs from z1 = 0.67 (AAΩ*) and z1 = 0.53 (2SLAQ*) to z0 = 0.35 are shown in Fig. 16 along with the SDSS best-fitting model. At large scales (r≥ 5 h−1 Mpc), the long-lived model can only be marginally rejected at no more than 2σ for the AAΩ* case and is consistent within 1σ in the case of 2SLAQ*. However, if we now consider the small-scale, r < 1 h−1 Mpc, clustering signal we see from the bottom panel of Fig. 16 that the long-lived model becomes increasingly inconsistent with the best-fitting model at z = 0.35. For r≥ 0.5 h−1 Mpc, the long-lived model can be rejected at 99.88 and >99.99 per cent significance using the evolved 2SLAQ* and AAΩ* HODs, respectively. The much higher clustering signal at small scales is caused by far too many satellite galaxies in the low-redshift haloes being predicted by the long-lived model. This also results in the higher satellite fractions than observed; both evolved 2SLAQ* and AAΩ* give Fsat = 18 ± 1 per cent at z = 0.35 compared to 8.1 ± 1.8 seen in the SDSS best fit.
Next, we assume the central–central mergers model (Wake et al. 2008) and attempt to match the large-scale clustering signal of the evolved HOD from high-z to the z = 0.35 best-fitting model. As argued by Wake et al. (2008) and here, this is more likely to happen than the satellite–satellite merging case. The fno-merge parameters in equation (47) required to give the best matches to the large-scale clustering amplitude of the SDSS best fit are 0.2 and 0.1 for the 2SLAQ* and AAΩ* case, respectively. The new w(θ)s determined from these models are plotted in Fig. 16 as the blue dotted and magenta long-dashed lines. We can see that the z1 = 0.67 evolved w(θ) at small scales is in excellent agreement with the SDSS best-fitting model. The predicted satellite fraction, Fsat = 7.8 ± 0.9, is also consistent with the SDSS best-fitting value. For the z1 = 0.53 case, the small-scale clustering signal is still somewhat stronger than the SDSS best-fitting model but otherwise are within 1σ confidence regions of each other, and the predicted Fsat = 10.5 ± 1.3 is also somewhat higher than the best-fitting value. The galaxy number density is reduced due to these central–central merger by ≈6 and 11 per cent for the z1 = 0.53 and 0.67, respectively. However, note that this is two to three times smaller than the fractional errors of our best-fitting ng, ≈20 per cent.
In order to get a handle on the merger rates which can then be compared to the previous results of White et al. (2007) and Wake et al. (2008), we follow their method of adjusting the galaxy number density. This is because for this type of analysis the galaxy samples at different redshifts are usually designed to have the same space density. Merging means that the space density of the low-z sample must be reduced unless there are new galaxies created via merging of the fainter objects which fail to be in the high-z sample but become bright enough to be in the low-z sample. To account for such an effect by physically removing galaxies in a sample is rather difficult to do in practice as argued by Wake et al. (2008). White et al. (2007) and Wake et al. (2008) adjusted the mass-scale of the low-z HOD fit by several per cent which reduce the space density and increase the clustering signal and hence require lower amount of merging of the high-z population needed to match the low-z measurement. Increasing the fno-merge factor in equation (47) results in a higher galaxy number density and clustering signal. Therefore, there is only one unique solution of mass-scaling and merging fraction that will simultaneously match the galaxy number density and the clustering signal (at large scales) of the evolved and best-fitting HODs at low z.
We increase the mass-scale of z = 0.35 HOD fit by 12 (7) per cent and allow 60 (50) per cent of the z1 = 0.67 (0.53) central galaxies to merge in order to get the matched large-scale bias of 2.12 (2.10) and ng = 1.12(1.19) × 10−4h3 Mpc−3. This yields the merger rate between z = 0.67 (0.53) and z = 0.35 of ≈6.6 (5) per cent, i.e. ≈2.8 (3.4) per cent Gyr−1. The evolved w(θ) divided by the model at z = 0.35 with increased mass-scaled HOD fit is shown in Fig. 17. As noted earlier, the reduction in the galaxy number density is small compared to its best-fitting fractional error which means that our constraints on these merger rates are rather weak. However, to the first order the merger rates derived here appear to be consistent with the value of 2.4 ± 0.7 and 3.4 per cent Gyr−1 found by Wake et al. (2008) and White et al. (2007), respectively.
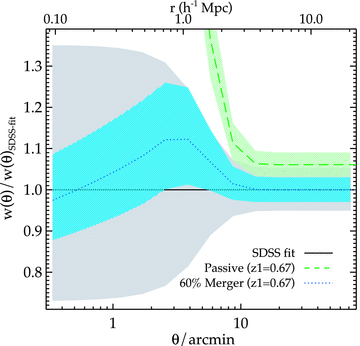
The ratio of the evolved w(θ) to the SDSS best-fitting model with the HOD mass-scale increased by 12 per cent.
In summary, the combination of the stable clustering and passive evolution model is remarkably close to explaining the clustering evolution of the LRGs at small and large scales. These models are much simpler than the HOD framework which require an understanding of how galaxies populate dark matter haloes and how they and their host haloes merge. The galaxy long-lived model in the context of halo framework is significantly incompatible with the small-scale clustering data and requires that ≈2–3 per cent/Gyr LRGs to merge in order to explain their slow clustering evolution. In contrast, the stable model requires the comoving number density to be constant with redshift. This may suggest that the simple virialized model may only provide a phenomenological fit to the small-scale clustering evolution in the context of the ΛCDM model.
6 SEARCHING FOR THE BAO PEAK
Next, we inspect the correlation functions at larger scales to make a search for the BAO feature. We first present the raw correlation functions in Fig. 18(a). Note that the integral constraints (see Section 3.1) are subdominant compared to w(θ)’s amplitudes at these scales. Each correlation function shows a feature at large scales, the most significant detection comes from the AAΩ sample where the clustering signal at 120 < θ < 500 arcmin is detected (above zero) at more than 4σ significance, P(<χ2) = 1 × 10−6 (with covariance matrix) and 3.5σ significance for 200 < θ < 500 arcmin.
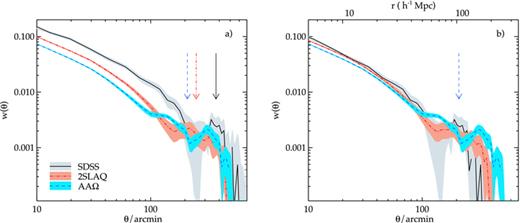
(a) The angular correlation function of the three LRG samples at large scales. The shaded regions are 1σ JK errors. The arrow indicates the expected BAO angular separation in each sample, assuming our fiducial cosmology. (b) Same as (a) but now scaled in the angular direction to the depth of the AAΩ-LRG sample.
The question is that are these features real or simply due to systematic error (see Section 6.1 for a series of systematic tests)? Here, we perform a classic scaling test to see if any feature is reproduced at the different depths of the three LRG samples. Given that the samples have intrinsically different r0 (see Table 2), we choose simply to scale in the angular direction only. The SDSS and 2SLAQ LRG correlation functions are scaled in the angular direction to the AAΩ’s depth using the average radial comoving distance of each sample.
In Fig. 18(b), we see that the scaling agreement of the large-scale, θ≈ 300 arcmin, features is poor. Although SDSS shows a moderately strong peak feature, this is not reproduced at the same comoving physical scale in the other two data sets.
Despite this failure of the scaling test, we now attempt to increase the signal-to-noise ratio by combining the measurements from the three samples using inverse quadrature error weighting. First, the SDSS and 2SLAQ w(θ)s are scaled in the angular direction to the depth of the AAΩ LRGs (radial comoving distance, χ≈ 1737 h−1 Mpc as opposed to ≈1451 h−1 Mpc for 2SLAQ and ≈970 h−1 Mpc for SDSS) where their amplitudes and errors are then interpolated to the AAΩ’s angular bins (i.e. Fig. 18b). The amplitudes of the scaled SDSS and 2SLAQ w(θ)s are then normalized to that of the AAΩ sample’s at 10 arcmin. This involves lowering SDSS and 2SLAQ amplitudes by 25 and 15 per cent, respectively. The resulting correlation function is presented in Fig. 19 with the arrow showing the expected position of the BAO peak. Note that due to the relatively small statistical errors of the AAΩ LRG compared to other samples, the w(θ) result is dominated by the AAΩ sample; therefore the possible SDSS peak at ≈100 h−1 Mpc is not evident in the combined sample. There also seems to be an indication of an excess out to possibly 200 h−1 Mpc (see Section 6.1 for a robustness test of this excess clustering signal).
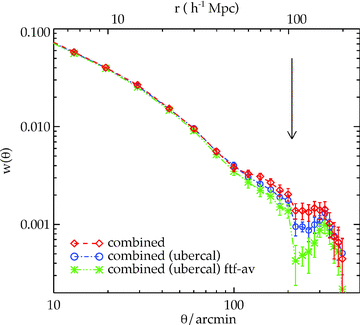
The combined angular correlation function of the three LRG samples scaled to the AAΩ depth, comparing the results when the SDSS standard (diamonds) and uber (circles) calibration are used. Also shown is the average field-to-field w(θ) (asterisks) which represents an attempt to filter out any large-scale gradients in the SDSS data.
Using the uber-calibration (Padmanabhan et al. 2008) instead of the standard calibration, we find similar results at small and intermediate scales but somewhat lower amplitude at ≈100 h−1 Mpc although the results agree within the 1σ error (see Fig. 19). This means the correlation functions at small and intermediate scales including the parameters derived (e.g. power-law fits, linear biases, dark matter halo masses) in the earlier parts are not affected by which calibration we use. The biggest difference, although less than 1.5σ, is observed at scales larger than 120 h−1 Mpc and up to 150 h−1 Mpc where the correlation signal is small and hence more prone to possible systematics. The weak dependence of w(θ) at very large scales on the different calibrations may be an indication that this apparent extra peak at θ≈ 300 arcmin could indeed be a systematics effect. We shall return to this in Section 6.1.
We also tested whether the 200 h−1 Mpc excess can be eliminated by taking the average w(θ) from 15 × 20 deg2 subfields. The result, after integral constraint correction, is shown in Fig. 19. The 200 h−1 Mpc excess persists even though there is some change at smaller scales. Given the model dependence introduced by the integral constraint correction (equation 11), hereafter we shall use the correlation function of the uber-cal sample measured using our normal method.
6.1 Testing for systematic effects
We have performed a series of tests to check our results against possible systematic effects. The tests include exclusions of high dust extinction and ‘poor’ astronomical seeing regions, an improved star–galaxy separation for the AAΩ sample and effects of possible contamination by clustered stars.
First, we exclude the regions where the i-band extinction is greater than 0.1 mag which discards ≈20 per cent of the data. The results are shown in the top row of Fig. 20. For 2SLAQ and AAΩ samples, the results appear to be lower than the main measurements but otherwise remain within 1σ statistical errors of each other. Although the amplitudes at θ≥ 220 arcmin are somewhat lower than the default AAΩ result, the excess at θ≳ 300 arcmin still persists. We then investigate the effect of excluding the regions with ‘poor’ astronomical seeing; the limit of 1.7 arcsec is used following the SDSS ‘poor’ seeing definition which discards ≈30 per cent of the data. The results here are in good agreement with the main results with the exception of a few angular bins around 320 arcmin of the 2SLAQ sample where they are somewhat (non-significantly) lower than the default measurements.
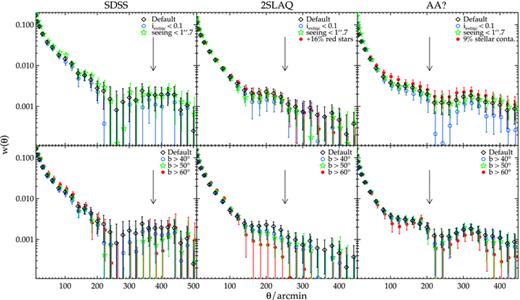
The angular correlation functions for SDSS, 2SLAQ and AAΩ samples (left to right), measured with varying dust extinction limit, astronomical seeing and different star–galaxy separation (top row), compared to our ‘Default’ results. Also shown is the effect of low galactic latitude region exclusion for each sample (bottom row). Note that for the b > 60°, the sample size is reduced by 60 per cent. In each case, an arrow indicates the expected position of the BAO peak assuming our fiducial cosmology.
Next, we attempt to reduce the stellar contamination fraction in the AAΩ sample. As a reminder, our default (optimized) star–galaxy separation algorithm (see Section 2) leaves ≈16 per cent stellar contamination in the sample while losing genuine LRGs only at a sub-per-cent level. Here, we impose a more aggressive star–galaxy separation cut which reduces the contamination level to ≈9 per cent at the expense of nearly halving the number of genuine AAΩ LRGs. The cut is a combination of the fitted ‘de Vaucouleurs’ radius as a function of zdeV magnitude and the correlation between the ‘de Vaucouleurs’ and fibre magnitudes in z band. The w(θ) measurement for this new AAΩ sample after correction by a factor of 1/(1 −f)2, where f = 0.09, is shown in the top-right panel of Fig. 20. This is in good agreement with the main results.
We test our earlier assumption (Section 3; see also Blake et al. 2008) that the effect of the stellar contamination is simply a dilution of δg by (1 −f) and hence the amplitude of galaxy–galaxy correlation function by (1 −f)2, where f is the contamination fraction. We add a sample of red stars to the 2SLAQ sample at the 16 per cent level, similar to what we expect in the AAΩ sample. The stars are selected from SDSS photometric objects which are classified as ‘star’. The colour selections have been matched to that of the AAΩ-LRG sample. The sample is then randomly selected to have the number of objects at 16 per cent of the 2SLAQ sample. They therefore follow the stellar distribution with galactic latitude. The w(θ) result after correction by 1/(1 −f)2 is shown in the top-middle panel of Fig. 20 and is found to be in excellent agreement with the main 2SLAQ result. We do not see any evidence of a slope change which may arise from a possible clustering of the stellar contaminants at large scales, at least for the contamination level expected in our sample.
We apply various minimum galactic latitude cuts on the data in order to test for any systematic error. Such systematics (if they exist) could be due to the gradient caused by galactic dust extinction and/or different stellar contamination fractions which one might expect to be worse in the lower galactic latitude regions. Note that in our default data sets ≈95 per cent of the data are at b≥ 30°. The results of applying the galactic latitude cuts of b≥ 40°, 50° and 60° are shown in the bottom row of Fig. 20. Note that with the b≥ 60° limit, ≈60 per cent of the data are discarded. The 2SLAQ results appear to be marginally dependent on the galactic latitude limits. In the AAΩ sample the results are in good agreement with the main measurement although the b≥ 60° limit appears to be ≈1σ lower in some angular bins.
Finally, we cross-correlate the SDSS and AAΩ samples. The redshift distributions of the two samples are well separated with only slight overlap (see Fig. 1). Therefore, any residual signal in their cross-correlation function (CCF) at large scales can be used as evidence for systematic errors. The CCF is shown in Fig. 21, comparing to the auto-correlation functions of the SDSS and AAΩ samples in the top and bottom panels, respectively. The CCF has much lower signal than the auto-correlation function at θ < 120 arcmin and is consistent with zero, P(<χ2) = 0.997, between 120 < θ < 500 arcmin whereas the AAΩw(θ) signal is detected at more than 4σ significance (see above) in the same angular ranges.
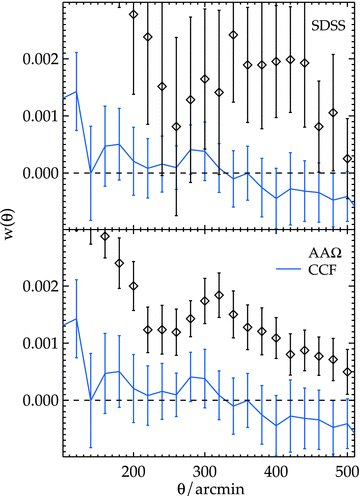
The auto-correlation functions for SDSS (top panel) and AAΩ (bottom panel) samples, comparing to the CCF between the two samples (blue solid lines).
We note that Ross et al. (2011) have suggested that there is a systematic effect associated with the area effectively masked by foreground stars which may be important in terms of a systematic that may produce excess clustering at large scales. However, such an effect would predict a decrease in galaxy density at low galactic latitudes and this is not seen in our samples (see fig. 9 of Sawangwit et al. 2010). If anything, the opposite effect is seen in our data with an increase in density towards lower galactic latitude which may be caused by stellar contamination. Here, we have tested our w(θ) measurements by successively cutting out data at low galactic latitudes. Although the 2SLAQ results may show some marginal dependence on the galactic latitude cut, the AAΩ results seem reasonably unaffected (see Fig. 20f). This may be due to the higher stellar contamination fraction in AAΩ sample which means that the effect seen by Ross et al. (2011) may not be directly applicable to the AAΩ sample.
We conclude that the apparent clustering excess at ≈300 arcmin in the AAΩ sample appears to be reasonably robust against most of the systematic tests we performed here. However, one might argue that the weakening of the excess signal when iextinc > 0.1 regions (≈20 per cent) is excluded and the marginal dependence on the galactic latitude cuts of the 2SLAQ results may be taken as some evidence for systematic effects. On the other hand, the SDSS–AAΩ cross-correlation test also tends to limit the size of possible systematic errors.
6.2 Model comparisons
6.2.1 Standard ΛCDM model
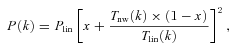

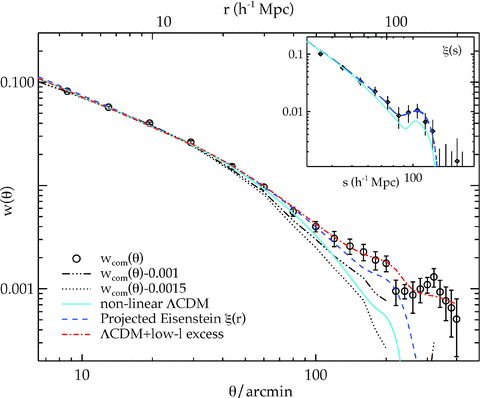
The combined w(θ) (open circles) compared to the projections of non-linear ΛCDM model plus mode coupling, scale-dependent redshift-space distortion and halo bias correction (cyan solid line) and the Eisenstein et al. (2005)ξ(s) (blue dashed line). The red dot–dashed line is the ΛCDM model plus low-l power excess (Section 6.2.2). The dash-dot–dotted and dotted lines show the effect of subtracting the data by 0.001 and 0.0015, respectively. The ξ(r) models used in the w(θ) projection are given as an inset together with the Eisenstein et al. (2005) measurement (diamonds). Here, the same symbols are used for the Eisenstein et al. (2005) and non-linear ΛCDM ξ(s) models as for the w(θ) models above.
Next, we compare our w(θ) to the best estimate of ξ(s) at the BAO scale as measured by Eisenstein et al. (2005). Although these measurements may have been superseded by DR7 spectroscopic LRG clustering analyses based on larger samples, these more recent estimates are usually in reasonable agreement with the results of Eisenstein et al. (2005), whether they are in correlation function (Martínez et al. 2009; Kazin et al. 2010) or power spectrum (Percival et al. 2010) form. For our comparison, we thus simply make a polynomial fit to the best estimate ξ(s) of Eisenstein et al. (2005) (blue dashed line in the inset of Fig. 22). The polynomial-fit ξ(s) is Kaiser de-boosted (equation 49) to give ξ(r) by assuming β = 0.45. The ξ(r) is then corrected for the linear growth between z = 0.35 and z = 0.68 which reduces the amplitude by ≈30 per cent. The resulting model has similar amplitude with the expected AAΩ-LRG ξ(r) because the SDSS and AAΩ-LRG linear biases are coincidentally the same (see Section 4.2). The model is then projected to w(θ) using equation (14) and is shown as a blue dashed line in Fig. 22. Our result appears to be in good agreement with the model up to ≈120 h−1 Mpc given statistical uncertainties in our measurement and the ξ(s) data. Beyond ≈120 h−1 Mpc, our w(θ) shows a higher clustering amplitude as noted above.
Summarizing, the wcom result appears consistent with the w(θ) prediction based on the Eisenstein et al. (2005) best estimate of ξ(s) (at least out to ≈120 h−1 Mpc) but not with the prediction based on the flat ΛCDM model due to the apparent large-scale clustering excess in the w(θ). This means that given the size of error bars of the Eisenstein et al. (2005) result, the ΛCDM model is quite compatible with the ξ(s) data but given the much smaller statistical error on w(θ), in this case our measurements are inconsistent with the ΛCDM model. While the feature observed at ≈300 arcmin persists in most of the systematic tests we performed on the AAΩ samples (Section 6.1), a few of these tests, e.g. dust extinction, indicate there is still the possibility that systematic errors are affecting the w(θ). Therefore, if we now assume that the excess signal at ≈150 h−1 Mpc is an indication of a systematic and subtract 0.001 to 0.0015, the level of the excess amplitude at this point in wcom (see Fig. 22), we obtain the w(θ) results as shown by the dash–dot-dotted and dotted lines. These two lines now bracket the flat ΛCDM result. Thus, the issue of the disagreement between the w(θ) result and the ΛCDM model seems to rest on the reality of the apparent clustering excess at large scales.
6.2.2 low-ℓ power excess?
Recently, Thomas, Abdalla & Lahav (2011a) (see also Padmanabhan et al. 2007; Blake et al. 2007; Thomas, Abdalla & Lahav 2011b) have also found a significant excess in their angular power spectrum, Cℓ, at the low multipoles relative to the best-fitting ΛCDM models. They used photometric-redshift catalogues of the LRGs at z≈ 0.5 similar to our 2SLAQ sample. The most significant (≈4σ) low-ℓ power excess is observed in the highest redshift bin. The author carried out various systematic checks and found no indication of such an effect.
While the clustering excess only affects Cℓ at multipoles smaller than the acoustic oscillations in Fourier space, unfortunately in configuration space the effect is expected on a wider range of scales and could affect our w(θ) BAO measurement.
Fig. 23 shows the Thomas et al. (2011a),Cℓ and the excess power model used to predict the AAΩw(θ). For further detail of the low-ℓ power excess model, see Sawangwit (in preparation). The resulting w(θ) model with the amplitude normalized to fit the data at θ = 40–400 arcmin is shown as the red dot–dashed line in Fig. 22. The model appears to be consistent with our wcom (13 per cent confidence level, χ2 = 23.6 over 18 − 1 d.o.f.) at r≈ 20–200 h−1 Mpc. Therefore we note that the excess clustering signal in our w(θ) is in good agreement with that observed in the Cℓ by Thomas et al. (2011a). The fact that the excess power in the Cℓ has the form of an ℓ≈ 10 spike, suggests that this excess in w(θ) is due to something other than acoustic oscillations in the power spectrum.
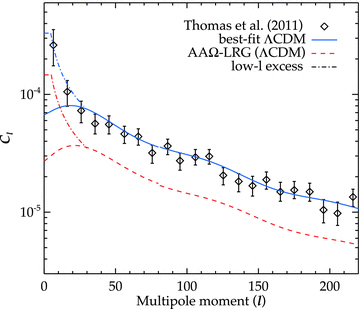
The angular power spectrum of the 0.6 < z < 0.65 MegaZ-DR7 LRG (Thomas et al. 2011b) with significant power excess at low multipoles (diamonds). The low-ℓ power excess plus the best-fitting ΛCDM model of the 0.6 < z < 0.65 Cℓ (blue dot–dashed and solid lines) is extrapolated to the AAΩ redshift range (red dot–dashed and dashed lines).
We note that evidence for a large-scale (>150 h−1 Mpc) correlation function excess has also been detected in the NRAO VLA Sky Survey (NVSS) radio source survey by Blake & Wall (2002) and Xia et al. (2010). We have compared our results with theirs and find that our correlation function shows a similar shape but a factor of 2–3 times lower amplitude. If the excess clustering signal observed here is real, then it could be evidence for non-Gaussianity (Xia et al. 2010) or for the gauge dependence of the matter power spectrum on the largest scales (Lin 2001; Yoo, Fitzpatrick & Zaldarriaga 2009). But until this feature is detected in an independent galaxy data set, there will always be the possibility that it is caused by some unknown systematics. Certainly, if the ΛCDM model were correct then we would have to conclude that this excess was caused by systematics at the level of Δw≈ 0.001–0.0015 in the photometric AAΩ-LRG sample.
7 SUMMARY AND CONCLUSIONS
We have presented here a new and detailed analysis of the angular correlation function of the LRGs extracted from the SDSS DR5 photometric catalogue. All the necessary information for inferring the spatial clustering is obtained and calibrated through redshift surveys of sample subsets. Our conclusions are as follows.
We measured the angular correlation function of the LRGs at three different redshifts, namely 0.35, 0.55 and 0.68, and found the results to be well approximated by power laws at small and intermediate scales.
With the large samples in terms of the numbers of objects and volume cover by the data, we see the deviation from the canonical single power law at high significance.
The data are better fitted by a double power law where the large-scale (≳1–2 h−1 Mpc) slope is equal to that of the conventional single power law, i.e. γ≈ 1.8.
The form of the angular correlation functions at large scales is consistent with the expectation of the linear perturbation theory in the flat standard ΛCDM Universe.
The LRG linear bias is high, bg≈ 2.0, as expected for massive luminous early-type galaxies, and the clustering strength is found to be strongly linked to the sample intrinsic brightness.
The best-fitting HOD models suggest that these LRGs reside in the massive dark matter haloes, 1013–1014h−1 M⊙, and are typically central galaxies in their dark matter halo hosts, with the satellite fraction no more than 10 per cent.
The clustering evolution at intermediate scales (1 < r < 20 h−1 Mpc) is remarkably slow and may be approximately explained by a long-lived model or even a no-evolution model. The long-lived model may be in line with the observed passive evolution of the LRG luminosity function, consistent with a constant comoving LRG space density in this redshift range. This latter conclusion would also apply in the case that the no-evolution (comoving) model were found to fit better but in this case the observations may require a significantly higher bias.
Using the Lacey & Cole (1993) framework, our MDMH(z) measurements are well fitted by the model where halo mass is grown via merging of progenitors with masses of ≈1.4 × 1013h−1 M⊙ and ≈2.3 × 1013h−1 M⊙ from z = 1, for haloes that typically host L≥ 2L* and ≥3L* galaxies, respectively. We found that these dark matter haloes have tripled their masses over the last half of cosmic time (although see the caveat given at the end of Section 5.1.2) whereas it has been claimed that the LRG stellar masses have grown by less than 50 per cent (Cool et al. 2008).
At small scales (r < 1 h−1 Mpc) the clustering evolution appears slightly faster at fixed luminosity and the clustering increases towards lower redshift, consistent with a virialized clustering model. Since our virialized model assumes a constant comoving LRG space density, a combination of this stable clustering model at small scales and the long-lived model at intermediate scales could be consistent with the idea that merging of LRGs may not change the LRG space density significantly out to z≈ 0.7.
However, the evolution based on HOD and the ΛCDM halo merging framework requires that ∼ 2–3 per cent/Gyr of the LRGs merge with each other in order to explain the small-scale clustering evolution, consistent with the results of White et al. (2007) and Wake et al. (2008).
In our AAΩ-LRG result we find a BAO peak at a level consistent with the best estimate of ξ(s) obtained by Eisenstein et al (2005). But, given the small size of our statistical errors, these results deviate significantly, ≈4σ, from the standard ΛCDM prediction because of an apparent large-scale clustering excess.
The excess clustering signal generally persists after a series of systematic tests we performed. However, a few of these tests did change the feature somewhat, suggesting that it could still be caused by some unknown systematic effects.
If the ΛCDM model were correct then we would have to conclude that this excess was caused by systematics at the level of Δw≈ 0.001–0.0015 in the photometric AAΩ-LRG sample.
Otherwise, the excess signal in our w(θ) relative to the standard ΛCDM model appears to be in good agreement with the Cℓ power excess at low l observed by other authors who used photo-z LRG samples at z≈ 0.5.
If real, the large-scale clustering excess may be interpreted as evidence for a non-standard cosmological model, e.g. primordial non-Gaussianity or general relativistic effects. However, more, independent, data are required to check the reality of this clustering excess.
This is the well-known luminosity-dependent bias as shown observationally by e.g. Norberg et al. (2002) and Zehavi et al. (2005b) and is expected in hierarchical clustering CDM universe (Benson et al. 2001).
US acknowledges financial support from the Institute for the Promotion of Teaching Science and Technology (IPST) of The Royal Thai Government. We thank Michael J. I. Brown for useful comments. We thank the referee for useful comments which have improved the quality of the paper. We also thank all the present and former staff of the Anglo-Australian Observatory for their work in building and operating the 2dF and AAΩ facility.
Funding for the SDSS and SDSS-II has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, the US Department of Energy, the National Aeronautics and Space Administration, the Japanese Monbukagakusho, the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web Site is http://www.sdss.org/.
The SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions. The Participating Institutions are the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, Cambridge University, Case Western Reserve University, University of Chicago, Drexel University, Fermilab, the Institute for Advanced Study, the Japan Participation Group, Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Chinese Academy of Sciences (LAMOST), Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, Ohio State University, University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory, and the University of Washington.
REFERENCES
Appendix
APPENDIX A: ANGULAR CORRELATION FUNCTIONS AND COVARIANCE MATRICES
At the referee’s request, we tabulate the angular correlation functions (Table A1) measured from the three photometric LRG samples studied in this paper. The full covariance matrices in the form of correlation coefficients are also shown in Fig. A1.
The measured angular correlation functions for the SDSS, 2SLAQ and AAΩ-LRG and their 1σ JK errors.
| θ (arcmin) | SDSS | 2SLAQ | AAΩ |
| 0.100 | 26.78 ± 2.37 | 9.85 ± 0.39 | 6.27 ± 0.24 |
| 0.150 | 15.96 ± 1.47 | 7.40 ± 0.14 | 4.65 ± 0.10 |
| 0.225 | 11.09 ± 0.56 | 4.54 ± 0.085 | 2.95 ± 0.057 |
| 0.337 | 6.10 ± 0.33 | 2.95 ± 0.050 | 1.86 ± 0.033 |
| 0.506 | 3.93 ± 0.19 | 1.83 ± 0.026 | 1.11 ± 0.016 |
| 0.759 | 2.04 ± 0.090 | 1.09 ± 0.020 | 0.65 ± 0.014 |
| 1.139 | 1.55 ± 0.061 | 0.68 ± 0.011 | 0.419 ± 0.0095 |
| 1.708 | 1.00 ± 0.038 | 0.416 ± 0.0057 | 0.282 ± 0.0059 |
| 2.562 | 0.56 ± 0.025 | 0.285 ± 0.0061 | 0.213 ± 0.0036 |
| 3.844 | 0.31 ± 0.019 | 0.199 ± 0.0038 | 0.151 ± 0.0023 |
| 5.766 | 0.22 ± 0.012 | 0.152 ± 0.0026 | 0.112 ± 0.0020 |
| 8.649 | 0.171 ± 0.0081 | 0.113 ± 0.0019 | 0.083 ± 0.0013 |
| 12.97 | 0.118 ± 0.0053 | 0.078 ± 0.0018 | 0.057 ± 0.0011 |
| 19.46 | 0.091 ± 0.0055 | 0.055 ± 0.0012 | 0.0405 ± 0.00077 |
| 29.19 | 0.060 ± 0.0041 | 0.038 ± 0.0011 | 0.0264 ± 0.00062 |
| 43.78 | 0.038 ± 0.0031 | 0.0226 ± 0.0009 | 0.0157 ± 0.00060 |
| 60.00 | 0.028 ± 0.0023 | 0.0144 ± 0.0008 | 0.0093 ± 0.00053 |
| 80.00 | 0.018 ± 0.0020 | 0.0086 ± 0.00076 | 0.0056 ± 0.00051 |
| 100.0 | 0.014 ± 0.0019 | 0.0054 ± 0.00067 | 0.0040 ± 0.00045 |
| 120.0 | 0.011 ± 0.0017 | 0.0034 ± 0.00060 | 0.0039 ± 0.00036 |
| 140.0 | 0.0071 ± 0.0018 | 0.0024 ± 0.00061 | 0.0035 ± 0.00027 |
| 160.0 | 0.0063 ± 0.0014 | 0.0019 ± 0.00064 | 0.0029 ± 0.00032 |
| 180.0 | 0.0045 ± 0.0013 | 0.0021 ± 0.00065 | 0.0024 ± 0.00039 |
| 200.0 | 0.0026 ± 0.0014 | 0.0020 ± 0.00060 | 0.0020 ± 0.00039 |
| 220.0 | 0.0020 ± 0.0014 | 0.0022 ± 0.00062 | 0.0011 ± 0.00035 |
| 240.0 | 0.0014 ± 0.0013 | 0.0019 ± 0.00058 | 0.0014 ± 0.00039 |
| 260.0 | 0.0014 ± 0.0015 | 0.0015 ± 0.00045 | 0.0015 ± 0.00040 |
| 280.0 | 0.0017 ± 0.0011 | 0.0013 ± 0.00044 | 0.0018 ± 0.00032 |
| 300.0 | 0.0020 ± 0.00077 | 0.0013 ± 0.00045 | 0.0021 ± 0.00038 |
| 320.0 | 0.0016 ± 0.00091 | 0.0015 ± 0.00045 | 0.0021 ± 0.00043 |
| 340.0 | 0.0032 ± 0.0010 | 0.0013 ± 0.00053 | 0.0019 ± 0.00048 |
| 360.0 | 0.0025 ± 0.0010 | 0.0011 ± 0.00047 | 0.0016 ± 0.00048 |
| 380.0 | 0.0023 ± 0.0011 | 0.0012 ± 0.00045 | 0.0016 ± 0.00045 |
| 400.0 | 0.0025 ± 0.0010 | 0.0010 ± 0.00045 | 0.0013 ± 0.00041 |
| 420.0 | 0.0017 ± 0.0011 | 0.00054 ± 0.00045 | 0.0007 ± 0.00041 |
| 440.0 | 0.0020 ± 0.0012 | 0.00064 ± 0.00042 | 0.0006 ± 0.00038 |
| 460.0 | 0.0003 ± 0.0012 | 0.00017 ± 0.00045 | 0.0008 ± 0.00038 |
| 480.0 | 0.0006 ± 0.0014 | 0.00002 ± 0.00047 | 0.0005 ± 0.00039 |
| 500.0 | −0.0001 ± 0.0012 | 0.00018 ± 0.00051 | 0.0005 ± 0.00044 |
| θ (arcmin) | SDSS | 2SLAQ | AAΩ |
| 0.100 | 26.78 ± 2.37 | 9.85 ± 0.39 | 6.27 ± 0.24 |
| 0.150 | 15.96 ± 1.47 | 7.40 ± 0.14 | 4.65 ± 0.10 |
| 0.225 | 11.09 ± 0.56 | 4.54 ± 0.085 | 2.95 ± 0.057 |
| 0.337 | 6.10 ± 0.33 | 2.95 ± 0.050 | 1.86 ± 0.033 |
| 0.506 | 3.93 ± 0.19 | 1.83 ± 0.026 | 1.11 ± 0.016 |
| 0.759 | 2.04 ± 0.090 | 1.09 ± 0.020 | 0.65 ± 0.014 |
| 1.139 | 1.55 ± 0.061 | 0.68 ± 0.011 | 0.419 ± 0.0095 |
| 1.708 | 1.00 ± 0.038 | 0.416 ± 0.0057 | 0.282 ± 0.0059 |
| 2.562 | 0.56 ± 0.025 | 0.285 ± 0.0061 | 0.213 ± 0.0036 |
| 3.844 | 0.31 ± 0.019 | 0.199 ± 0.0038 | 0.151 ± 0.0023 |
| 5.766 | 0.22 ± 0.012 | 0.152 ± 0.0026 | 0.112 ± 0.0020 |
| 8.649 | 0.171 ± 0.0081 | 0.113 ± 0.0019 | 0.083 ± 0.0013 |
| 12.97 | 0.118 ± 0.0053 | 0.078 ± 0.0018 | 0.057 ± 0.0011 |
| 19.46 | 0.091 ± 0.0055 | 0.055 ± 0.0012 | 0.0405 ± 0.00077 |
| 29.19 | 0.060 ± 0.0041 | 0.038 ± 0.0011 | 0.0264 ± 0.00062 |
| 43.78 | 0.038 ± 0.0031 | 0.0226 ± 0.0009 | 0.0157 ± 0.00060 |
| 60.00 | 0.028 ± 0.0023 | 0.0144 ± 0.0008 | 0.0093 ± 0.00053 |
| 80.00 | 0.018 ± 0.0020 | 0.0086 ± 0.00076 | 0.0056 ± 0.00051 |
| 100.0 | 0.014 ± 0.0019 | 0.0054 ± 0.00067 | 0.0040 ± 0.00045 |
| 120.0 | 0.011 ± 0.0017 | 0.0034 ± 0.00060 | 0.0039 ± 0.00036 |
| 140.0 | 0.0071 ± 0.0018 | 0.0024 ± 0.00061 | 0.0035 ± 0.00027 |
| 160.0 | 0.0063 ± 0.0014 | 0.0019 ± 0.00064 | 0.0029 ± 0.00032 |
| 180.0 | 0.0045 ± 0.0013 | 0.0021 ± 0.00065 | 0.0024 ± 0.00039 |
| 200.0 | 0.0026 ± 0.0014 | 0.0020 ± 0.00060 | 0.0020 ± 0.00039 |
| 220.0 | 0.0020 ± 0.0014 | 0.0022 ± 0.00062 | 0.0011 ± 0.00035 |
| 240.0 | 0.0014 ± 0.0013 | 0.0019 ± 0.00058 | 0.0014 ± 0.00039 |
| 260.0 | 0.0014 ± 0.0015 | 0.0015 ± 0.00045 | 0.0015 ± 0.00040 |
| 280.0 | 0.0017 ± 0.0011 | 0.0013 ± 0.00044 | 0.0018 ± 0.00032 |
| 300.0 | 0.0020 ± 0.00077 | 0.0013 ± 0.00045 | 0.0021 ± 0.00038 |
| 320.0 | 0.0016 ± 0.00091 | 0.0015 ± 0.00045 | 0.0021 ± 0.00043 |
| 340.0 | 0.0032 ± 0.0010 | 0.0013 ± 0.00053 | 0.0019 ± 0.00048 |
| 360.0 | 0.0025 ± 0.0010 | 0.0011 ± 0.00047 | 0.0016 ± 0.00048 |
| 380.0 | 0.0023 ± 0.0011 | 0.0012 ± 0.00045 | 0.0016 ± 0.00045 |
| 400.0 | 0.0025 ± 0.0010 | 0.0010 ± 0.00045 | 0.0013 ± 0.00041 |
| 420.0 | 0.0017 ± 0.0011 | 0.00054 ± 0.00045 | 0.0007 ± 0.00041 |
| 440.0 | 0.0020 ± 0.0012 | 0.00064 ± 0.00042 | 0.0006 ± 0.00038 |
| 460.0 | 0.0003 ± 0.0012 | 0.00017 ± 0.00045 | 0.0008 ± 0.00038 |
| 480.0 | 0.0006 ± 0.0014 | 0.00002 ± 0.00047 | 0.0005 ± 0.00039 |
| 500.0 | −0.0001 ± 0.0012 | 0.00018 ± 0.00051 | 0.0005 ± 0.00044 |
The measured angular correlation functions for the SDSS, 2SLAQ and AAΩ-LRG and their 1σ JK errors.
| θ (arcmin) | SDSS | 2SLAQ | AAΩ |
| 0.100 | 26.78 ± 2.37 | 9.85 ± 0.39 | 6.27 ± 0.24 |
| 0.150 | 15.96 ± 1.47 | 7.40 ± 0.14 | 4.65 ± 0.10 |
| 0.225 | 11.09 ± 0.56 | 4.54 ± 0.085 | 2.95 ± 0.057 |
| 0.337 | 6.10 ± 0.33 | 2.95 ± 0.050 | 1.86 ± 0.033 |
| 0.506 | 3.93 ± 0.19 | 1.83 ± 0.026 | 1.11 ± 0.016 |
| 0.759 | 2.04 ± 0.090 | 1.09 ± 0.020 | 0.65 ± 0.014 |
| 1.139 | 1.55 ± 0.061 | 0.68 ± 0.011 | 0.419 ± 0.0095 |
| 1.708 | 1.00 ± 0.038 | 0.416 ± 0.0057 | 0.282 ± 0.0059 |
| 2.562 | 0.56 ± 0.025 | 0.285 ± 0.0061 | 0.213 ± 0.0036 |
| 3.844 | 0.31 ± 0.019 | 0.199 ± 0.0038 | 0.151 ± 0.0023 |
| 5.766 | 0.22 ± 0.012 | 0.152 ± 0.0026 | 0.112 ± 0.0020 |
| 8.649 | 0.171 ± 0.0081 | 0.113 ± 0.0019 | 0.083 ± 0.0013 |
| 12.97 | 0.118 ± 0.0053 | 0.078 ± 0.0018 | 0.057 ± 0.0011 |
| 19.46 | 0.091 ± 0.0055 | 0.055 ± 0.0012 | 0.0405 ± 0.00077 |
| 29.19 | 0.060 ± 0.0041 | 0.038 ± 0.0011 | 0.0264 ± 0.00062 |
| 43.78 | 0.038 ± 0.0031 | 0.0226 ± 0.0009 | 0.0157 ± 0.00060 |
| 60.00 | 0.028 ± 0.0023 | 0.0144 ± 0.0008 | 0.0093 ± 0.00053 |
| 80.00 | 0.018 ± 0.0020 | 0.0086 ± 0.00076 | 0.0056 ± 0.00051 |
| 100.0 | 0.014 ± 0.0019 | 0.0054 ± 0.00067 | 0.0040 ± 0.00045 |
| 120.0 | 0.011 ± 0.0017 | 0.0034 ± 0.00060 | 0.0039 ± 0.00036 |
| 140.0 | 0.0071 ± 0.0018 | 0.0024 ± 0.00061 | 0.0035 ± 0.00027 |
| 160.0 | 0.0063 ± 0.0014 | 0.0019 ± 0.00064 | 0.0029 ± 0.00032 |
| 180.0 | 0.0045 ± 0.0013 | 0.0021 ± 0.00065 | 0.0024 ± 0.00039 |
| 200.0 | 0.0026 ± 0.0014 | 0.0020 ± 0.00060 | 0.0020 ± 0.00039 |
| 220.0 | 0.0020 ± 0.0014 | 0.0022 ± 0.00062 | 0.0011 ± 0.00035 |
| 240.0 | 0.0014 ± 0.0013 | 0.0019 ± 0.00058 | 0.0014 ± 0.00039 |
| 260.0 | 0.0014 ± 0.0015 | 0.0015 ± 0.00045 | 0.0015 ± 0.00040 |
| 280.0 | 0.0017 ± 0.0011 | 0.0013 ± 0.00044 | 0.0018 ± 0.00032 |
| 300.0 | 0.0020 ± 0.00077 | 0.0013 ± 0.00045 | 0.0021 ± 0.00038 |
| 320.0 | 0.0016 ± 0.00091 | 0.0015 ± 0.00045 | 0.0021 ± 0.00043 |
| 340.0 | 0.0032 ± 0.0010 | 0.0013 ± 0.00053 | 0.0019 ± 0.00048 |
| 360.0 | 0.0025 ± 0.0010 | 0.0011 ± 0.00047 | 0.0016 ± 0.00048 |
| 380.0 | 0.0023 ± 0.0011 | 0.0012 ± 0.00045 | 0.0016 ± 0.00045 |
| 400.0 | 0.0025 ± 0.0010 | 0.0010 ± 0.00045 | 0.0013 ± 0.00041 |
| 420.0 | 0.0017 ± 0.0011 | 0.00054 ± 0.00045 | 0.0007 ± 0.00041 |
| 440.0 | 0.0020 ± 0.0012 | 0.00064 ± 0.00042 | 0.0006 ± 0.00038 |
| 460.0 | 0.0003 ± 0.0012 | 0.00017 ± 0.00045 | 0.0008 ± 0.00038 |
| 480.0 | 0.0006 ± 0.0014 | 0.00002 ± 0.00047 | 0.0005 ± 0.00039 |
| 500.0 | −0.0001 ± 0.0012 | 0.00018 ± 0.00051 | 0.0005 ± 0.00044 |
| θ (arcmin) | SDSS | 2SLAQ | AAΩ |
| 0.100 | 26.78 ± 2.37 | 9.85 ± 0.39 | 6.27 ± 0.24 |
| 0.150 | 15.96 ± 1.47 | 7.40 ± 0.14 | 4.65 ± 0.10 |
| 0.225 | 11.09 ± 0.56 | 4.54 ± 0.085 | 2.95 ± 0.057 |
| 0.337 | 6.10 ± 0.33 | 2.95 ± 0.050 | 1.86 ± 0.033 |
| 0.506 | 3.93 ± 0.19 | 1.83 ± 0.026 | 1.11 ± 0.016 |
| 0.759 | 2.04 ± 0.090 | 1.09 ± 0.020 | 0.65 ± 0.014 |
| 1.139 | 1.55 ± 0.061 | 0.68 ± 0.011 | 0.419 ± 0.0095 |
| 1.708 | 1.00 ± 0.038 | 0.416 ± 0.0057 | 0.282 ± 0.0059 |
| 2.562 | 0.56 ± 0.025 | 0.285 ± 0.0061 | 0.213 ± 0.0036 |
| 3.844 | 0.31 ± 0.019 | 0.199 ± 0.0038 | 0.151 ± 0.0023 |
| 5.766 | 0.22 ± 0.012 | 0.152 ± 0.0026 | 0.112 ± 0.0020 |
| 8.649 | 0.171 ± 0.0081 | 0.113 ± 0.0019 | 0.083 ± 0.0013 |
| 12.97 | 0.118 ± 0.0053 | 0.078 ± 0.0018 | 0.057 ± 0.0011 |
| 19.46 | 0.091 ± 0.0055 | 0.055 ± 0.0012 | 0.0405 ± 0.00077 |
| 29.19 | 0.060 ± 0.0041 | 0.038 ± 0.0011 | 0.0264 ± 0.00062 |
| 43.78 | 0.038 ± 0.0031 | 0.0226 ± 0.0009 | 0.0157 ± 0.00060 |
| 60.00 | 0.028 ± 0.0023 | 0.0144 ± 0.0008 | 0.0093 ± 0.00053 |
| 80.00 | 0.018 ± 0.0020 | 0.0086 ± 0.00076 | 0.0056 ± 0.00051 |
| 100.0 | 0.014 ± 0.0019 | 0.0054 ± 0.00067 | 0.0040 ± 0.00045 |
| 120.0 | 0.011 ± 0.0017 | 0.0034 ± 0.00060 | 0.0039 ± 0.00036 |
| 140.0 | 0.0071 ± 0.0018 | 0.0024 ± 0.00061 | 0.0035 ± 0.00027 |
| 160.0 | 0.0063 ± 0.0014 | 0.0019 ± 0.00064 | 0.0029 ± 0.00032 |
| 180.0 | 0.0045 ± 0.0013 | 0.0021 ± 0.00065 | 0.0024 ± 0.00039 |
| 200.0 | 0.0026 ± 0.0014 | 0.0020 ± 0.00060 | 0.0020 ± 0.00039 |
| 220.0 | 0.0020 ± 0.0014 | 0.0022 ± 0.00062 | 0.0011 ± 0.00035 |
| 240.0 | 0.0014 ± 0.0013 | 0.0019 ± 0.00058 | 0.0014 ± 0.00039 |
| 260.0 | 0.0014 ± 0.0015 | 0.0015 ± 0.00045 | 0.0015 ± 0.00040 |
| 280.0 | 0.0017 ± 0.0011 | 0.0013 ± 0.00044 | 0.0018 ± 0.00032 |
| 300.0 | 0.0020 ± 0.00077 | 0.0013 ± 0.00045 | 0.0021 ± 0.00038 |
| 320.0 | 0.0016 ± 0.00091 | 0.0015 ± 0.00045 | 0.0021 ± 0.00043 |
| 340.0 | 0.0032 ± 0.0010 | 0.0013 ± 0.00053 | 0.0019 ± 0.00048 |
| 360.0 | 0.0025 ± 0.0010 | 0.0011 ± 0.00047 | 0.0016 ± 0.00048 |
| 380.0 | 0.0023 ± 0.0011 | 0.0012 ± 0.00045 | 0.0016 ± 0.00045 |
| 400.0 | 0.0025 ± 0.0010 | 0.0010 ± 0.00045 | 0.0013 ± 0.00041 |
| 420.0 | 0.0017 ± 0.0011 | 0.00054 ± 0.00045 | 0.0007 ± 0.00041 |
| 440.0 | 0.0020 ± 0.0012 | 0.00064 ± 0.00042 | 0.0006 ± 0.00038 |
| 460.0 | 0.0003 ± 0.0012 | 0.00017 ± 0.00045 | 0.0008 ± 0.00038 |
| 480.0 | 0.0006 ± 0.0014 | 0.00002 ± 0.00047 | 0.0005 ± 0.00039 |
| 500.0 | −0.0001 ± 0.0012 | 0.00018 ± 0.00051 | 0.0005 ± 0.00044 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}