





Abstract
Genomic data for priapulans are limited to a single species, restricting broad comparative analyses and thorough interrogation of questions spanning phylogenomics, ecdysozoan physiology, and development. To help fill this void, we present here a high-quality priapulan genome for the meiofaunal species Tubiluchus corallicola. Our assembly combines Nanopore and Illumina sequencing technologies and makes use of a whole-genome amplification, to generate enough DNA to sequence this small meiofaunal species. We generated a moderately contiguous assembly (2,547 scaffolds), with a high level of completeness (metazoan BUSCOs n = 954, single-copy complete = 89.6%, duplicated = 3.9%, fragmented = 3.5%, and missing = 3.0%). We then screened the genome for homologs of the Halloween genes, key genes implicated in the ecdysis (molting) pathway of arthropods, recovering a putative homolog of shadow. The presence of a shadow ortholog in two priapulan genomes suggests that the Halloween genes may not have evolved in a stepwise manner in Panarthropoda, as previously thought, but may have a deeper origin at the base of Ecdysozoa.
Priapulans, or “penis worms,” are the putative sister group to the rest of Ecdysozoa. Due to this phylogenetic position, genomic data from species in this group can help us to better understand the evolution of key gene families associated with the ecdysozoan success, often attributed to their ability to molt. Presently, only one species in the phylum Priapulida has a sequenced genome, the macrofaunal species Priapulus caudatus. We have sequenced the genome of a meiofaunal priapulan, Tubiluchus corallicola, a species that reaches a mature adult body size of only 1–2 mm in length. Screening our genome assembly for molting-related Halloween genes has revealed a putative ortholog of shadow, implying an older origin for this gene family than previously thought.
Introduction
Priapulida constitutes an exclusively marine phylum also known as “penis worms.” Together, body and trace fossil evidence suggests that priapulan-like animals were a dominant group in mid-Cambrian seas (Vannier et al. 2010), but today, the group consists of only 22 species across 2 families (Vannier et al. 2010; Schmidt-Rhaesa et al. 2017). Despite their Cambrian origins and evolutionary importance, priapulans remain poorly studied at the genomic level. Currently, there are only a handful of published transcriptomes (Borner et al. 2014; Laumer et al. 2015) and one unpublished genome for Priapulida available. With the exception of one transcriptome, all these resources have focused on larger macrofaunal species. The currently available genome is that of macrofaunal species Priapulus caudatus collected from Gullmarsfjorden, Sweden. This assembly does not have an associated paper, but statistics on the NCBI genome hub indicate a genome size of 511.7 Mb. The assembly is composed of 59,586 scaffolds, with a scaffold N50 of 209,727 bp, and has a high level of completeness (metazoan BUSCOs n = 954, single-copy complete = 88.4%, duplicated = 0.9%, fragmented = 5.0%, and missing = 5.7%) (fig. 1A and 1B).
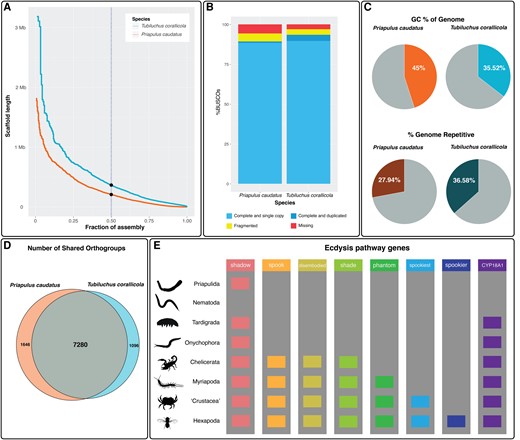
(A) N50 graph, illustrating proportion of genome that each scaffold, arranged from largest to smallest, contributes to size. Dashed line and dots indicate N50 for P. caudatus (lower) and T. corallicola (higher). Scaffold length at 50% total assembly length. (B) BUSCO percentage graph for P. caudatus and T. corallicola assemblies. (C) GC% and % repetitive for P. caudatus and T. corallicola assemblies. (D) Number of orthogroups in OrthoFinder analysis shared between P. caudatus and T. corallicola. (E) Presence and absence of ecdysis pathway genes, Cyp18a1 and the Halloween genes, across ecdysozoan phyla.
Morphological and molecular evidence support the position of Priapulida within the clade Ecdysozoa (Giribet and Edgecombe 2020). Although further genomic data from these groups are necessary to robustly test their relationships, recent phylogenomic analyses have placed priapulans as the putative sister group to all other ecdysozoans (Laumer et al. 2019; Marlétaz et al. 2019). Due to this phylogenetic position, increasing the genomic data available for priapulans can help us to better understand the evolution of key gene families associated with the ecdysozoan success, often attributed to their ability to molt.
Previous studies that have screened the genomes of ecdysozoan taxa for genes involved in the molting pathway have revealed homologs of Ecdysone receptor (EcR), ultraspiracle, and the early genes in Priapulida, Nematoda, Tardigrada, Onychophora, and Arthropoda (Schumann et al. 2018). This suggests that these ecdysozoan phyla contain a common genomic repertoire for key components of the ecdysis pathway. In contrast, cytochrome P450 genes known from arthropods and involved in ecdysone biosynthesis (Halloween genes) and ecdysone degradation (cytochrome P450 18a1 or Cyp18a1) are thought to have evolved in a stepwise fashion in Panarthropoda. Among the set of seven Halloween genes, Tardigrada and Onychophora possess homologs of only one of them (shadow), Chelicerata has homologs of four (shadow, spook, disembodied, and shade), and Hexapoda possesses all seven (shadow, spook, disembodied, shade, phantom, spookiest, and spookier) (Schumann et al. 2018). Cyp18a1 homologs have been found in Tardigrada, Onychophora, and Arthropoda (Schumann et al. 2018). So far, no Halloween gene or Cyp18a1 homologs have been recovered from genome assembly of P. caudatus.
Results and Discussion
Sequencing and Assembly
Total yield from Nanopore sequencing was 10.68 Gb, with a read N50 of 7,420 bp, resulting in ∼33X coverage of the estimated genome size (320 Mb). The final assembly was moderately contiguous, yielding 2,547 scaffolds, scaffold N50 of 363,593 bp, and a final assembly size of 345 Mb (table 1). An assembly larger than the expected size can occur when there are several uncollapsed haplotype variants. In the GenomeScope profile of the Tubiluchus genome, there are two distinct peaks (supplementary fig. S1, Supplementary Material online). The first peak is located at coverage of around 90X, whereas a second peak is located at a coverage of around 180X. Heterozygosity rate was estimated to be between 0.981284% and 1.00537% and could be contributing to the discrepancy between estimated and final assembly sizes.
Summary Statistics for T. corallicola Genome Assembly Versus the Unpublished Genome of P. caudatus
| T. corallicola | P. caudatus | |
|---|---|---|
| Source | This study | GCF_000485595.1 |
| Assembly size | 345.4 Mb | 511.7 Mb |
| Scaffolds | 2,547 | 59,586 |
| N50 | 363,593 bp | 209,727 bp |
| Largest scaffold | 3,186,305 | — |
| GC | 35% | 45% |
| Predicted genes | 27,681 | 17,138 |
| Fully or partially supported genes | 15,629 | — |
| BUSCO metazoa_odb10 database (n = 954) | C: 93.5%(S: 89.6%, D: 3.9%), F: 3.5%, M: 3.0% | C: 89.3%(S: 88.4%, D: 0.9%), F: 5.0%, M: 5.7% |
| Repeats masked | 36.58% | 27.94% |
| T. corallicola | P. caudatus | |
|---|---|---|
| Source | This study | GCF_000485595.1 |
| Assembly size | 345.4 Mb | 511.7 Mb |
| Scaffolds | 2,547 | 59,586 |
| N50 | 363,593 bp | 209,727 bp |
| Largest scaffold | 3,186,305 | — |
| GC | 35% | 45% |
| Predicted genes | 27,681 | 17,138 |
| Fully or partially supported genes | 15,629 | — |
| BUSCO metazoa_odb10 database (n = 954) | C: 93.5%(S: 89.6%, D: 3.9%), F: 3.5%, M: 3.0% | C: 89.3%(S: 88.4%, D: 0.9%), F: 5.0%, M: 5.7% |
| Repeats masked | 36.58% | 27.94% |
Summary Statistics for T. corallicola Genome Assembly Versus the Unpublished Genome of P. caudatus
| T. corallicola | P. caudatus | |
|---|---|---|
| Source | This study | GCF_000485595.1 |
| Assembly size | 345.4 Mb | 511.7 Mb |
| Scaffolds | 2,547 | 59,586 |
| N50 | 363,593 bp | 209,727 bp |
| Largest scaffold | 3,186,305 | — |
| GC | 35% | 45% |
| Predicted genes | 27,681 | 17,138 |
| Fully or partially supported genes | 15,629 | — |
| BUSCO metazoa_odb10 database (n = 954) | C: 93.5%(S: 89.6%, D: 3.9%), F: 3.5%, M: 3.0% | C: 89.3%(S: 88.4%, D: 0.9%), F: 5.0%, M: 5.7% |
| Repeats masked | 36.58% | 27.94% |
| T. corallicola | P. caudatus | |
|---|---|---|
| Source | This study | GCF_000485595.1 |
| Assembly size | 345.4 Mb | 511.7 Mb |
| Scaffolds | 2,547 | 59,586 |
| N50 | 363,593 bp | 209,727 bp |
| Largest scaffold | 3,186,305 | — |
| GC | 35% | 45% |
| Predicted genes | 27,681 | 17,138 |
| Fully or partially supported genes | 15,629 | — |
| BUSCO metazoa_odb10 database (n = 954) | C: 93.5%(S: 89.6%, D: 3.9%), F: 3.5%, M: 3.0% | C: 89.3%(S: 88.4%, D: 0.9%), F: 5.0%, M: 5.7% |
| Repeats masked | 36.58% | 27.94% |
The final Tubiluchus corallicola assembly has a high level of complete BUSCOs based on the metazoa_odb10 data set which is comprised of 954 metazoan single-copy orthologs (single-copy complete = 89.6%, duplicated = 3.9%, fragmented = 3.5%, and missing = 3.0%).
Annotation
The genome of T. corallicola is 36.58% repetitive; in comparison, the P. caudatus genome is 27.94% repetitive (fig. 1C). Interspersed repeats make up the majority of repetitive regions in the T. corallicola genome. A high proportion, 23.22% of total sequence length, is unclassified repeats. Because repeat annotation relies on reference databases (such as Repbase or Dfam), the lack of closely related species in these databases can impact the ability to generate annotations for repeats in novel genomes.
Our initial BRAKER2 annotation predicted a total of 27,681 genes; running BUSCO on this protein set indicates that 87.7% of BUSCO orthologs are present and single copy, 5.1% are duplicated, 2.7% are fragmented, and 4.5% are missing. The higher number of duplicated BUSCOs in the annotation versus the assembly (5.1% vs. 3.9%) is likely due to the prediction of multiple isoforms for the same gene. In this initial annotation, 15,629 genes had either full or partial support from external evidence (reference proteins from the metazoan OrthoDB v.10 database). We filtered the initial annotation on the basis of this external support to get a more conservative set of predicted genes which were used in following analyses. OrthoFinder analysis revealed that genes from T. corallicola and P. caudatus were both present in a total of 7,280 orthogroups (fig. 1D). Only 13.7% of T. corallicola genes and 12.6% of P. caudatus genes belonged to species-specific orthogroups; meanwhile in other taxa in the analysis, the percentage of genes in species-specific orthogroups ranged from 28.9% (Drosophila melanogaster) to 36.6% (Pristionchus pacificus). The priapulan genomes may not have experienced unique expansions in their respective lineages to the same degree of which other taxa in the analysis may have.
P450 Family Proteins and Halloween Genes across Representative Ecdysozoans
We screened the T. corallicola genome for putative Cyp18a1 and Halloween gene homologs and generated a gene phylogeny (supplementary fig. S2, Supplementary Material online). The phylogenetic tree shows the two clusters, the CYP2 clan (spook, phantom, and Cyp18A1) and the mitochondrial clan (disembodied, shadow, and shade), with individual subclusters for each gene. Our results reveal a putative ortholog for the Halloween gene shadow (Cyp315a1) in both T. corallicola and P. caudatus (fig. 1E and green box in supplementary fig. S2, Supplementary Material online). This forms a clade together with corresponding sequences from Tardigrada, Onychophora, and Arthropoda. We searched for and confirmed that all five conserved insect P450 motifs were present in the putative shadow gene from the T. corallicola genome. Previous analyses such as Schumann et al. (2018) did not recover any shadow ortholog for P. caudatus. However, the methodology used for generating these gene trees relies upon sequence similarity; therefore, stringent Blast search cut-offs, sequencing error in the raw reads, or misassemblies by the genome assembler could have meant that the P. caudatus protein identified as a putative shadow ortholog here lacked sufficient similarity to the panarthropod proteins to be recovered in previous studies. The T. corallicola protein included in our analysis must have sufficient similarity to both panarthropod shadow proteins and this P. caudatus protein, so that they now cluster together in the gene tree. The presence of a shadow ortholog in two priapulan genomes suggests that the Halloween genes may not have evolved in a stepwise manner in Panarthropoda, as previously thought, but may have a deeper origin at the base of Ecdysozoa.
Conclusion
We present here our assembly for the meiofaunal priapulan T. corallicola, the second genome assembly for the phylum and the first for a meiofaunal priapulan species. When compared with the P. caudatus genome, our assembly is more contiguous and has less missing BUSCO orthologs. Screening our genome for molting-related Halloween genes has revealed a putative ortholog of shadow, implying an older origin for this gene family than previously thought. This new result illustrates how increased sampling of underrepresented groups can shed new light on the evolution of gene families and their contributions to evolutionary success.
Materials and Methods
Tissue Collection
Mud sediment was collected on SCUBA in Castle Harbor, Bermuda. Specimens were collected under Special Permit no. SP190701 from the Department of Environment and Natural Resources of the Government of Bermuda. Individual T. corallicola specimens were kept in petri dishes and starved for 3 days. Specimens were then preserved in RNAlater, 96% EtOH, or flash-frozen.
DNA Extraction and Sequencing
Specimens of T. corallicola are ∼1 mm in size, excluding the tail. Genomic DNA (gDNA) was extracted from a single whole flash-frozen individual (MCZ IZ-153158; https://mczbase.mcz.harvard.edu/guid/MCZ:IZ:153158) using a high-salt protocol from the University of Liverpool (Donnan Laboratories 2001), scaled down to smaller volumes due to the small body size of the organism. Extraction was followed by DNA repair with the PreCR Repair Mix (New England Biolabs) and a chloroform clean-up.
For short-read sequencing, a whole-genome shotgun library was prepared using the Kapa Hyper-Plus library preparation kit (Roche) starting with about 90 ng of input DNA. The library was dual-indexed and sequenced for paired ends of 150 bp in an Illumina NovaSeq S4 flow cell, pooled with unrelated libraries at the Bauer Core Facility at Harvard University.
For long-read sequencing, whole-genome amplification was first used to increase the amount of available DNA, following Oxford Nanopore protocols. We used the Repli-G Midi kit (Qiagen) starting with ∼250 ng of input DNA and scaling all reactions in the original Nanopore protocol for this input amount. A bead clean-up was performed, followed by an Oxford Nanopore protocol with the T7 Endonuclease I (New England Biolabs) to resolve the hyperbranched structure of the amplified DNA. The quality, quantity, and size distribution of extracted and amplified DNA was assessed with a NanoDrop spectrophotometer (Thermo Fisher Scientific), Qubit fluorometer (Thermo Fisher Scientific), and TapeStation Genomic DNA screen tape (Agilent), respectively. Size selection was performed on the DNA with the Short Read Eliminator Kit (Circulomics). A library was prepared with the SQK-LSK109 kit (Oxford Nanopore Technologies) according to the manufacturer's protocol, with modifications, including two rounds of T7 Endonuclease I and SRE treatment, before library preparation and loading (further details described in Supplementary material).
Tubiluchus Genome Assembly
Genome size was estimated from raw Illumina reads using Jellyfish and GenomeScope 2.0 and a kmer length of 21 (Marçais and Kingsford 2011; Vurture et al. 2017). Nanopore data were basecalled using Guppy v.4.4.1 (Oxford Nanopore Technologies 2021). The long Nanopore reads and short Illumina reads were assembled using the hybrid MaSuRCA assembler v3.4.2 (Zimin et al. 2013). Illumina short reads were trimmed and quality filtered using TrimGalore (https://github.com/FelixKrueger/TrimGalore); this resulted in 327,099,875 paired reads, which equates to around 306x coverage for this genome. These reads were mapped to the initial assembly using Minimap2, and one round of HyPo was used to polish (Li 2018; Kundu et al. 2019). The assembly was screened for contaminants using BlobTools (v1.1) (Laetsch and Blaxter 2017). Contigs flagged as coming from an exogenous source were manually checked using a Blast search prior to being removed (Altschul et al. 1990). Purge Haplotigs was run on the assembly to remove any duplicated contigs (Roach et al. 2018). The remaining contigs were scaffolded with LRScaf (Qin et al. 2019); this consolidated the 3547 contigs into 2761 scaffolds. Purge Haplotigs was then run a second time as the number of duplicated BUSCOs in the assembly increased after scaffolding (see supplementary table S5, Supplementary Material online) . The final assembly was checked once more for any contaminants or duplicate scaffolds and then assessed for completeness using BUSCO v.5 (Simão et al. 2015) and the metazoan OrthoDB v10 (Kriventseva et al. 2019).
Annotation
Repeat content in the assembled genome was modeled and identified using RepeatModeler2 (Flynn et al. 2020). Repeats were masked using RepeatMasker v.4.1.2 (Smit et al. 2021). We annotated the masked assembly using BRAKER2 (Stanke et al. 2006; Stanke et al. 2008; Hoff et al. 2016; Hoff et al. 2019; Brůna et al. 2021) using reference proteins from the metazoan OrthoDB v10 database (Kriventseva et al. 2019). We used the BRAKER2 “selectSupportedSubsets.py” script to filter the initial annotation to get a more conservative set of predicted genes which were used in all subsequent analyses. Functional and Pfam domain annotations were added to the final protein predictions using eggNOG-mapper v.2.1.7 (Huerta-Cepas et al. 2019; Cantalapiedra et al. 2021). This was run using settings to report only alignments equal or above an identity threshold of 40% percent and query and subject coverage fraction thresholds of 20%.
An OrthoFinder analysis (Emms and Kelly 2019) was run on the T. corallicola, P. caudatus, P. pacificus, Caenorhabditis elegans, D. melanogaster, and Homarus americanus genomes using default settings (see supplementary table S1, Supplementary Material online, for GenBank accession numbers).
P450 Family Exploration
Putative Halloween genes were identified in the T. corallicola genome using methodology based on Schumann et al. (2018). A fasta file containing representative Cytochrome P450 family proteins was downloaded from GenBank to use as “baits.” These baits were blasted for in a custom T. corallicola proteome Blast database, using a cut off of 1e−6, to generate a list of unique T. corallicola proteins. Putative T. corallicola proteins were removed from the candidate set if they did not contain the Pfam P450 domain (as per NCBI conserved domain search). Remaining proteins were used as queries for reciprocal Blast searches against the NCBI nr database (Sayers et al. 2011) using BlastP v2.12.0 and a cut off of 1e−10 (Altschul et al. 1990). The Blast NCBI nr database output, putative T. corallicola proteins, and bait sequences were combined and filtered for redundancies. The putative “Cyp315a1” and “Cyp18a1” genes identified by Schumann et al. (2018) for both Euperipatoides rowelli and Hypsibius exemplaris were manually added to our data set for the sake of comparison. This final data set was then aligned with MAFFT using the L-INS-I strategy (Katoh and Standley 2013), and a phylogenetic tree of this final matrix was generated using IQ-TREE; nodal support was calculated using ultrafast bootstrap algorithm and 1,000 bootstrap replicates (Nguyen et al. 2015; Kalyaanamoorthy et al. 2017; Hoang et al. 2018). The putative Tubiluchus shadow homolog was queried in the NCBI conserved domain database, and an amino acid alignment of representative shadow homologs was generated using MUSCLE (Edgar 2004), and conserved regions were highlighted using BOXSHADE (https://github.com/mdbaron42/pyBoxshade). Five conserved insect P450 motifs, Helix C, Helix I, Helix K, PERF motif, and Haem-binding domain (Wan et al. 2015), were manually searched for in an amino acid sequence alignment of shadow proteins recovered in our gene tree (see supplementary fig. S3, Supplementary Material online).).
Supplementary Material
Supplementary data are available at Genome Biology and Evolution online (http://www.gbe.oxfordjournals.org/).
Acknowledgments
We would like to acknowledge Richard K. Wilson, Director, and the McDonnell Genome Institute, Washington University School of Medicine, for making the P. caudatus 5.0 sequence assembly available on GenBank (GCF_000485595.1). We would also like to acknowledge Christopher Laumer who provided his modified salting protocol for DNA extraction. We would finally like to acknowledge GBE Associate Editor Christopher Wheat for feedback on an earlier version of this manuscript. This work was published by a grant from the Wetmore Colles fund.
Data Availability
New sequences and the assembled genome are deposited in Sequence Read Archive (SRA) and GenBank: BioProject PRJNA901945, BioSample SAMN31742125, and SRA accession numbers SRR22984503, SRR22964790, and SRR22964791. The assembly has been deposited in GenBank under the accession JAQGDQ000000000. Annotation peptide fastas, eggNOG-mapper annotations, OrthoFinder output, the protein alignment for Halloween gene analysis, gene phylogeny, and shadow gene conserved motifs alignment are deposited in figshare: https://figshare.com/projects/Expanding_on_our_knowledge_of_ecdysozoan_genomes_a_contiguous_assembly_of_the_meiofaunal_priapulan_Tubiluchus_corallicola_/165529.

{kind=link}