






Abstract
This article proposes that Resource Description Framework (RDF) technology is well suited for representing and storing inherently connected epistolary data. We justify this proposition by creating an RDF-based digital edition of the correspondence of members of the Bernoulli dynasty and Leonhard Euler and depicting the benefits this type of edition provides, which are hardly achievable otherwise. We describe the ontologies defined to fully represent letters and illustrate how we formulated letters’ historical, scientific content, rich with mathematical formulae, markups, figures, and references, as RDF statements to facilitate complex queries common in the humanities field. Next, we outline the tools we developed for presenting these editions in an efficient and user-friendly form, hiding the complexity of the data structure from non-technical users while offering sophisticated analysis features to explore atoms of knowledge and their relations. Additionally, since the citability and durability of the studied digital sources play a crucial role for scholars who publish research on the editions, we explain the steps we undertook to ensure the sustainability of the RDF-based editions and to offer persistent citation possibility.
1. Introduction
In the field of digital humanities, scholarly digital editions have revolutionized how researchers and historians engage with historical correspondence. The editions built on the Resource Description Framework (RDF) principles offer a robust framework for organizing, annotating, and disseminating vast collections of letters and correspondences from the past. By leveraging the semantic web technologies and the Linked Open Data (LOD) principles, RDF-based scholarly digital editions enable scholars to navigate, analyze, and interpret historical documents with unprecedented depth and efficiency. RDF, a standard developed by the World Wide Web Consortium, provides a flexible and extensible framework for representing knowledge on the web. It allows for the creation of structured data by expressing relationships between resources using subject–predicate–object triples (Allemang and Hendler 2012: 6–8). This data model aligns perfectly with the complex network of relationships found within the historical correspondence, making RDF an ideal foundation for creating digital editions that capture the intricacies of these rich historical artifacts. Scholarly digital editions based on RDF empower researchers to move beyond the traditional boundaries of linear texts. By encoding the content, context, and metadata of historical letters in RDF, scholars can unlock a wealth of information that would otherwise remain hidden in the vast ocean of archival material. The RDF-based approach enables the creation of comprehensive knowledge graphs that interconnect various aspects of the correspondence, including authors, recipients, dates, locations, and even the relationships between letters.
Moreover, RDF-based scholarly digital editions facilitate collaboration and knowledge sharing among scholars. These editions ensure interoperability and enable researchers to connect and integrate digital resources across different projects, web platforms, and institutions by employing standard vocabularies and ontologies. This interconnectedness leads to a broader and more holistic understanding of historical correspondence, as scholars can combine their efforts and insights to explore cross-references, analyze patterns, and gain new perspectives on the past. In this digital transformation era, RDF-based scholarly digital editions have emerged as a vital tool for preserving, studying, and disseminating historical correspondence. They bridge the gap between traditional archival research and digital methodologies, offering a flexible and dynamic approach to engage with the complexities of historical documents. RDF-based scholarly digital editions provide a solid foundation for exploring the interconnected web of historical correspondences, fostering discoveries, and advancing our knowledge of the past.
Creating RDF-based digital editions of historical epistolary data and developing tools to facilitate studying the resulting knowledge graph necessitates a practical knowledge of the data complexity. In this article, we present how we approached defining ontologies to represent the correspondence data and tools to present and analyze epistolary data practically through examples from two prototype editions: the correspondence of members of the Bernoulli dynasty and their disciples, as well as the correspondence of Leonhard Euler (1707–83), all of whom were natural philosophers from Basel, Switzerland. The resulting RDF-based editions are integrated into the Bernoulli–Euler Online (BEOL) platform,1 a virtual research environment (VRE) for studying early modern mathematics and science influenced by the Bernoulli dynasty and Leonhard Euler. The BEOL project team consisted of the authors of this article together with Dr Tobias Schweizer,2 a postdoctoral researcher at the time, and Martin Mattmüller, the project’s editor. The project was successfully finalized in January 2020, presenting three prototype LOD-based digital editions on the BEOL platform, two of which were correspondence editions. Still, the ongoing editions of works and correspondence of members of the Bernoulli dynasty, their disciples, Leonhard Euler, and his son continue to be integrated into the BEOL platform based on the approaches described in this article and using the developed infrastructure. Through the BEOL platform, researchers can access, query, and annotate the graph data. BEOL is based on DSP-API (previously known as Knora API),3 an open-source RESTful API that relies on semantic web technologies such as RDF and OWL ontologies and is well-suited to represent complex structured qualitative knowledge. The BEOL project team contributed to developing this API to add the features needed for the BEOL editions in a generic way so that other projects can utilize them.
In this article, we first introduce the prototype correspondence data used in this article to explain the methodology; then, we describe the ontologies developed for modeling correspondence data, their textual content, and embedded references as RDF. Next, we describe the process of storing the correspondence data as an RDF graph and the analysis tools we developed to facilitate the study of the graph with examples. Lastly, we discuss the approaches we undertook to ensure the persistence and citability of the resources and the corresponding challenges.
2. BEOL correspondence data
BEOL presents the digital edition of the correspondence of members of the Bernoulli dynasty and Leonhard Euler as a network of interconnected resources. The following epistolary data (a total of 1,946 letters) were primarily chosen to be converted to RDF-based editions:
Basler Edition der Bernoulli Briefwechsel (BEBB) is an ongoing online edition of the correspondence of the members of the Bernoulli dynasty and Jacob Hermann (1678–1733), Jacob Bernoulli’s disciple.4 More than 1,500 letters of this edition (mainly in German and French) are currently integrated into the BEOL platform. This correspondence series was previously edited using MediaWiki.5
Leonhard Euler’s Correspondence: The edition of the works of Leonhard Euler, entitled Leonhardi Euleri Opera Omnia (LEOO), is a monument of scholarship known to most historians of science. Leonhard Euler’s Opera Omnia consists of eighty-one volumes, the edition of which started a century ago and concluded in 2021. The fourth series of Euler’s Opera Omnia (series IVA) is devoted to his correspondence and contains approximately 3,200 letters, 1,000 of them written by Euler himself. From this extensive set of correspondence, we have currently integrated the following two into the BEOL platform:
LEOO IVA/IV, volume IV of the IVA series, published in 2015, contains the 35 years of correspondence between Leonhard Euler and the Prussian mathematician Christian Goldbach (1690–1764), encompassing almost 200 letters.6 This volume also contains three letters exchanged between Christian Goldbach and Euler’s oldest son, Johann Albrecht Euler (1734–1800).7 The letters are mainly in German and their English translations were published in the second book of the LEOO IVA/IV volume. This correspondence series and translations were transcribed in LATEX.8
Leonhardi Euleri Commercium Epistolicum (LECE) is a small collection of letters, mostly in French, exchanged between Euler and diverse figures of that time that were excluded from the LEOO IVA series due to editorial decisions. This edition currently contains Euler’s correspondence with the Marquis de Condorcet (1743–94), seven letters, and Anne Robert Jacques Turgot (1727–81), two letters. The LECE edition currently also contains letters Condorcet exchanged with others about the content of his correspondence with Euler. He exchanged five letters with Johann Albrecht Euler, three letters with Nicolaus (I) Fuss (1755–1826), and one letter with Andres Johann Lexell (1740–84).
These epistolary data contain a rich set of metadata information such as dates, locations, authors and recipients of letters, the topic of the correspondence, and information about editors of historical manuscripts and the archive where the original manuscript is kept. The body of the scientific letters contains text with markup, mathematical equations, figures, and references to persons, locations, and bibliographical items such as journal articles and books. To create a knowledge graph representing these correspondence data and making every piece of information in them machine-readable, ontologies must be defined to model the atoms of knowledge as RDF statements.
3. Ontology definition and data modeling
While there are many conventional tools for dealing with data and, more specifically, dealing with the relationships between data (i.e. the embedded semantics), RDF is the most accessible and most potent standard designed until now.9 In a graphical representation of an RDF statement, a triple, the source of the relationship is called the subject, the relationship represented is the predicate (also called property), and the relationship’s destination is the object.10 With the representation in RDF, the relations are made explicit and can be queried and processed by machines. The subject of a statement is always an RDF resource (a describable entity), while the object can be a resource or an RDF literal (a simple value of type string, integer, double, date, etc.). A set of interconnected RDF statements comprise an RDF graph. In RDF diagrams, resources are always drawn as ovals, literals as boxes, and the predicates are represented as labeled arrows. Resources and predicates have unique, URL-like identifiers called an Internationalized Resource Identifier (IRI) that enables internal and external linkage to the resources and use of classes and predicates defined in one ontology in other repositories.
An ontology typically contains a hierarchy of concepts within a domain and describes the fundamental properties of each concept through an attribute-value mechanism. Further relations between concepts might be expressed through additional logical statements.11 RDF and RDF Schema (RDFS) offer some basic concepts for modeling, and the Web Ontology Language (OWL) provides the means for building ontologies of high complexity. Ontologies formalize semantic concepts and can be read by machines. Based on the ontologies, data can be structured as RDF triples and verified to ensure the consistency of the data and the ontology. The verified RDF data can be stored as a graph in an RDF triplestore such as GraphDB12 or Apache Jena Fuseki.13 Then, the RDF graph stored in a triplestore can be easily queried using query languages such as SPARQL. Thus, to make every piece of information given in editions machine-readable, we defined OWL-based ontologies and modeled the epistolary data as RDF triples while utilizing the existing ontologies. In this way, we ensure interoperability between the BEOL repository and other LOD repositories.
To comprehensively represent the correspondence as a digital edition, the metadata of the letters and the text body of the letters with all embedded references must be modeled as RDF statements. This would allow scholars studying the digital editions of correspondences to query for texts that contain a specific reference, for example, to find all letter resources in which a journal article by Leibniz was cited or a particular person or location was mentioned. These queries, however, would only be possible if the referenced entities were correctly identified and added to the RDF graph and occurrences of the textual references were replaced with links to the corresponding RDF resources. Traditionally, through a research-based analysis of texts, editors identify the references in historical texts and list them with additional information in the editions; for example, LEOO IVA/IV includes a name index14 and a bibliography.15 Recently, automatic approaches have been proposed to recognize references given in texts; for example, named entities mentioned in the texts, such as persons and locations, can be identified through natural language processing pipelines (Alassi 2023). Pertsas and Constantopoulos (2018) suggest an ontology-driven approach to extract information about bibliographical items from research publications. These promising approaches face challenges regarding historical texts; nonetheless, they can immensely reduce manual editorial efforts in creating comprehensive digital editions. Since the prototype correspondence editions (BEBB and LEOO IVA/IV) already contain carefully designed lists of mentioned persons and bibliographical items in the letters, we did not need to explore the mentioned automatic approaches to identify the references. The information could be parsed from these lists and added to the RDF graph. We will discuss how we created ontologies to add these references to the knowledge graph and replace the pure textual references with machine-readable typed links to resources to allow sophisticated queries of text with respect to an embedded reference in the upcoming sections.
Moreover, some advanced scholarly editions contain a list of the main topics discussed in the texts, allowing researchers to find the sources related to their research topic. Traditionally, expert editors carefully create a systematic subject index listing topics discussed in editions, and for each topic, they list the sources in the edition by closely studying the texts; for example, LEOO IVA/IV editors expertly generated a generic and hierarchical subject index for this edition.16 Creating this kind of subject index requires knowledge of the field to identify the topics of a text accurately; for example, categorizing letters to generic topics such as mathematics would not be helpful for a researcher who studies a specific topic in this field, like Fermat Numbers. This researcher would want to easily find all letters in the digital edition about this particular sub-category of algebraic equations in mathematics. Even though textual corpus can be, to some extent, automatically classified using topic modeling algorithms, acquiring a hierarchical classification of the corpus as given for the LEOO IVA/IV edition would need extensive work on classification algorithms, which was out of the scope of our project. Thus, as described in Section 3.3, we focused on undertaking an optimized approach to preserve the hierarchical structure of the subject index as intended by the editor while keeping the RDF construct representing these topics generic enough to be extended in the future and used by other editions to add topics to their resources.
Next, we will discuss how we have defined classes and properties within our ontologies to represent information about the references (persons and bibliographical items) and topics as RDF triples. We will then illustrate how these ontological constructs can convert the information in the two correspondence editions to RDF statements. Having nodes added to the RDF graph to represent referenced items, we can then describe the letters fully as RDF resources. The last step in defining the ontology is thus modeling the letters with metadata and rich text bodies containing figures, text formatting, mathematical formulas, links to referenced internal resources, etc. By representing persons, bibliographical items, and letters as RDF resources using ontologies built upon shared vocabularies, we render all information about them machine-readable. This approach allows machines to infer information about these items through the semantics defined in the ontologies. RDF representations also facilitate sophisticated data queries that are not feasible in relational and XML databases; see examples in Section 5.1.1. Furthermore, the IRIs of resources serve to interlink related resources within the data graph, embed typed links in the texts instead of plain text references, and allow incoming links to the resources from external repositories. This interconnectedness enhances the discoverability of the data and streamlines the retrieval of information from open repositories.
We first start with explaining how persons can be represented in correspondence graphs since names of persons appear in different contexts in correspondence editions: author or recipient of a letter, a person mentioned in a letter, an author or editor of a referenced bibliographical resource, etc. Thus, persons are the initial building blocks of epistolary knowledge graphs; other graph nodes are then connected to person resources through various properties.
3.1 Persons
We have defined the class beol:person in our ontology (with prefix beol and namespace http://www.knora.org/ontology/0801/beol#) to represent the persons that appear in correspondence editions. To enable interoperability with other LOD-based repositories, we have used existing shared vocabularies through sub-classes and sub-properties—for example, the class beol:person is a subclass of foaf:person, where foaf is the prefix of the Friend of a Friend ontology.17 Every person in our dataset is described then as a resource of type beol:person and has a unique IRI. Other resources can be linked to a resource representing a person using its IRI. This IRI is also used to create a direct link to the resource in the precise place in the text where a person is referenced so that users can instantly access all available information about the mentioned person. Figure 1 shows biographical information about Nicolaus I Bernoulli as RDF triples.18

An RDF resource representing Nicolaus I Bernoulli.
This figure shows some of the many object and datatype properties defined in the beol ontology to describe a person, with different constraints on each property specified in the ontology for verifying the consistency of the data with the ontology. For example, properties with date values as their objects, such as beol:hasBirthDate, a sub-property of schema:birthdate, have the RDFS range knora-base:DateValue. This data type is defined within DSP-API to allow calendar specification for each date value with year, month, day precision, and optional specification of the era (BC and CE). This data type also allows the specification of a date interval. This is particularly useful when dealing with historical datasets that continue dates in different calendars. When storing the data, the API converts the date values to Julian day numbers and stores the dates in numerical form to facilitate the comparison of dates for queries and the conversion of numeric date values to any calendar specified by the user during data retrieval. Another essential property describing a beol:person resource is beol:hasIAFIdentifier, which ensures the uniqueness of each resource of type beol:person in the database. The literal object value of this property is an Integrated Authority File (IAF or GND) number maintained by the German National Library, DNB.19 In the cases where no GND number is available for a person, its corresponding Virtual International Authority File identifier (VIAF)20 is used, or new GND numbers are created through a collaboration with DNB. The GND and VIAF identifiers facilitate the collaborative use and administration of authority data representing persons. This way, each resource representing a person in the BEOL database is connected to the person’s representation in other databases.
To create resources of type beol:person, we took an ontology-driven information extraction approach to parse information from the name indexes, that is, lists of persons available for both correspondence editions. Further information about persons, such as GND numbers, could be retrieved from open repositories like Wikidata.21 We implemented an automatic workflow to extract information, create RDF resources for persons based on the defined ontology, and store the person records in the triplestore through the DSP-API. Using the beol:person class, we also represent authors and editors of bibliographical items.
3.2 Bibliographical items
In addition to mentions of persons, letters might also contain citations of bibliographic items such as books, articles, etc. Editors also add citations to correspondence editions to lead readers to relevant secondary literature. Our two prototype correspondence editions include a long list of bibliographical items cited by the editor in a commentary or by the original letters’ author in the letters’ textual body. Commonly in digital editions, a description of this bibliographical information is added to transcriptions as plain texts, which are not fully machine-readable. To represent all information available in the bibliographical lists of the two editions as RDF, we have defined a second ontology, the biblio ontology (with namespace http://www.knora.org/ontology/0801/biblio#), to define classes and properties representing bibliographical items such as books, journals, journal articles, web articles, proceedings, etc. In this ontology, we employ existing vocabularies like bibo (Di Iorio et al. 2014)22 and extend its classes and properties to capture some project-specific features; for example, a journal article might also be reprinted in an edited collection of works of a natural philosopher. This relation is modeled through the biblio:isReprinted property. The pre-defined beol:person class represents editors and authors of the bibliographic items.
Based on the biblio ontology, we parsed the information from the listed bibliographical items of the prototype editions with an automatic workflow. The ISBN of books and DOI identifiers of articles are retrieved from publication portals and added to the resources where applicable. Lastly, as part of the workflow, RDF resources are created correspondingly for the bibliographical items and stored in the triplestore through the API, which validates the consistency of the generated RDF data with the ontology. The IRIs of the new person and bibliography resources are used to connect the related resources and replace the mentions of persons and citations in the editions with links to the corresponding resources.23 The biblio ontology also defines nested classes of resources: a collection article is part of an edited book that can belong to a series, see Fig. 2. In this excerpt of the RDF graph, we see that a journal article by Jacob Bernoulli is represented as a resource of type biblio:JournalArticle that is connected to the resource of type beol:person representing the author. This journal article was edited in 1744 by Gabriel Cramer (1704–52) and reprinted in Jacob Bernoulli’s Opera Omnia, an edited volume of Bernoulli’s works.
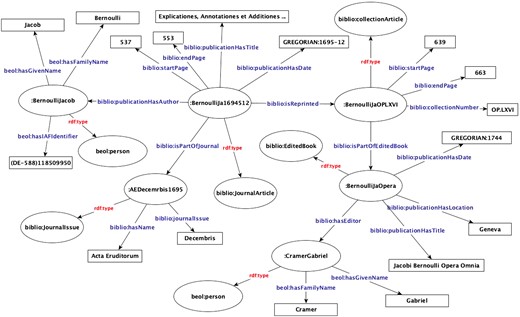
Representation of Jacob Bernoulli’s Explicationes article as RDF.
Having represented the bibliographical items as nodes of the RDF graph allows users to perform sophisticated queries on the RDF graph; for example, to query for all journal articles by Jacob Bernoulli published between 1st of December 1695 and 15th of December 1696 in the journal Acta Eruditorum which contain the word “Explicationes” in the title. The SPARQL endpoint of BEOL will list all journal articles matching these criteria. Furthermore, replacing the references to bibliographical items in the text of letters with corresponding links using resource IRIs enables the query of the information concerning the embedded references. For example, a historian of science studying the influence of Bernoulli’s idea given in this journal article might be interested in finding all written sources whose text contains a reference to Bernoulli’s article. Structuring the data as an RDF graph using the explained ontologies makes this query possible; see the query in Table 1. For another slightly more complex query based on the subgraph depicted in Fig. 2, suppose a historian does not remember the title of Bernoulli’s article but knows its famous identifier in Opera Omnia, namely OP.LXVI, she can query for all letters whose text contains a reference to a resource that is a reprint of a collection article with biblio:collectionNumber that is OP.LXVI. In response to this query, the API would return all correspondences in the repository whose text contains a citation of Bernoulli’s famous Explicantiones article.
A query for sources with text that contains a bibliographical reference to Jacob Bernoulli’s Explicationes article.
|
|
A query for sources with text that contains a bibliographical reference to Jacob Bernoulli’s Explicationes article.
|
|
These queries illustrate a few examples of how researchers can create their research inventory through data queries. Most of the time, however, historians are interested in collecting all sources about a specific topic. Some of the editions categorize correspondence based on the topic of the content. For example, the LEOO IVA/IV edition contains a hierarchical subject index to facilitate identifying letters about a particular topic. Next, we will discuss how such a subject index or any topical categories of correspondence editions can be represented as RDF.
3.3 Topics
Online versions of articles are often published with keywords to facilitate searches. Most authors and editors define the keywords identifying a subject matter to increase the findability of their contributions. Similarly, in printed volumes, authors or editors often classify the content of a book based on the topics in a list generally appended to the end of the book: the subject index. This list helps researchers interested in a particular topic to retrieve the relevant materials by pointing them to the specific sections or pages of the book. However, most digital or printed editions do not include a subject index; thus, topics must be automatically discovered using topic modeling algorithms or manually added to textual entities. Discussing how to detect the categories of topics addressed in correspondence data and structure the categories is not our objective here. Here, we discuss, once such structured topical categories are available for correspondence editions, how to include them in RDF databases and assign topics to RDF resources representing letters.
As mentioned earlier, the LEOO IVA/IV edition includes a systematic hierarchical subject index that lists the topics discussed in the Euler–Goldbach correspondence and letters about each topic listed by their numbers.24 This subject index is an ordered hierarchical collection of topics carefully designed by experts in the field; thus, to preserve this structure, we model it as a hierarchical RDF list, see Fig 3. This nested list can be extended easily to be used by other projects.
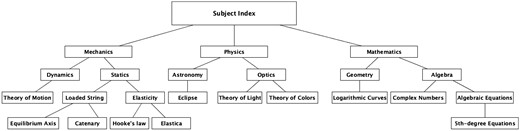
An example of a hierarchical topics list.
Each topic, a list node, has a unique IRI that we use to assign the topic to different written resources through the beol:hasSubject property. Every written source, an entry in a manuscript, or a letter can have multiple topics. We have parsed out the information available in the subject index of LEOO IVA/IV edition to create the hierarchical RDF list for topics, and the letter numbers for each topic are then used to add the topics of a letter to the resource representing it. Figure 4 shows that letters 51 and 52 of LEOO IVA/IV edition and entry CXXII of Jacob Bernoulli’s scientific diary Meditations have a topic in common, namely Algebraic Equations.
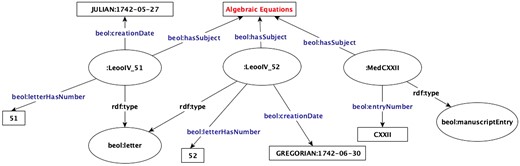
RDF resources with a subject in common.
Researchers can then query for and obtain all records in the BEOL database about a particular topic. This would help researchers easily create their research inventory through such queries. Next, having defined RDF constructs in the ontology to represent persons, bibliographical items, and topics, we can define an RDF class to represent letters.
3.4 Letters
Linked data structures such as correspondence networks can best be represented as RDF graphs. To create an RDF model that represents the complexity of the epistolary data, we first have to understand what a letter is. There are many definitions for a letter, each highlighting some characteristics. Creating a comprehensive data model to represent all sorts of documents considered a letter due to one definition or another is not our goal here. We focus on defining a data model to represent BEOL letters and their characteristics, yet generic enough to be utilized for other correspondence editions and extensible to suit different definitions of a letter. So, what is the primary meaning of a letter? In his Opus de conscribendis epistolis, Erasmus defines a letter as a conversation between two absent persons (Erasmus 1985). A text, furthermore, is considered a letter if it contains the name of the sender, the name of the intended recipient, the place name of the letter’s origin, the place name of the letter’s destination, and the date the letter was written. A letter also contains a salute, which usually includes the addressee’s name, the message narrating the letter’s subject, any request or argument, and a farewell (Boran and Matthews-Schlinzig 2019: 65–66). So, a letter is a physical object intended by one party to convey a message to another party primarily in textual form. While transmission is the crucial event that defines a letter, this must refer to any version so that drafts and literary copies are covered even though they are not sent themselves (Jeffries et al. 2019: 172). BEOL correspondence editions contain original letters and a few surviving drafts. We now look into defining an RDF class to represent letters and their most essential characteristics. Furthermore, the surviving manuscripts of letters are kept in archives and, thus, have a catalog entry and physical artifact. The intent of the letter’s creator is to transmit the message in a written version to another specified party or parties.
Each written source, a letter or a manuscript, consists of metadata and a text body. Thus, we can define an RDF class beol:writtenSource with properties representing a written document with its metadata (such as author, creation date, topics, and title) and text body. A letter has some additional characteristics, such as metadata containing information about correspondents, place and date of writing, catalog entries for the letter (e.g. in catalog portals like Early Modern Letters Online, EMLO),25 archival information of the physical artifact, as well as connections to the replies to the letter and existing translations and drafts. Thus, we define a new class beol:letter as a subclass of beol:writtenSource with properties to represent these data unique to letters. For interoperability with other RDF-based correspondence repositories, we use existing vocabularies; for example, beol:letter is a subclass of schema: Message.26 The connection between the transcription of a letter, its translation, and replies creates a network of interconnected letter resources that enables users to browse the data and study any resource together with those related to it. Figure 5 shows an excerpt of the RDF graph representing Euler–Goldbach correspondence containing letters 5127 and 52.
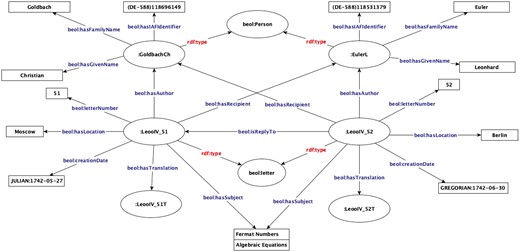
Euler–Goldbach letters 51 and 52 as RDF graph.
Furthermore, scientific correspondence, such as Euler’s letters, contains mathematical diagrams that must be stored and included in the edition. Similarly, if available, the facsimile of letters should also be stored and presented with the transcription. Digital editions mostly present transcriptions of a written source separate from its facsimile. However, researchers need to consider the digital copy of the manuscript to examine the features that cannot be presented in transcriptions, such as ink color, text orientation, style of writing, etc. Some of these non-transcribable features are essential for historical research; for example, from this information, historians can estimate the date of the writing and the author of a marginal text. Editions, however, seldom contain information about these features visible in the original documents. Therefore, the text in a scholarly edition is always distinctly different from any contingently historical manifestation of the text or work it represents. Being distinctly different, the edition text in a scholarly edition is always the editor’s text. It might also be the case that researchers doubt an editor’s representation of a part of the text; thus, they must be able to directly retrieve the region of interest in the facsimile representation to study the original text and compare it to the editor’s version.
Since RDF is not a suitable storage medium for binary data such as images, the API stores them outside the triplestore in ordinary files using a media server called Sipi.28 Sipi is an IIIF29 server which interacts with DSP-API which manages the RDF triplestore where the metadata of images is stored. Sipi also provides a high-performance transformation of the images, including rotation and format conversions, while preserving all the metadata embedded in the images (Rosenthaler, Andrea, and Peter 2017: 566). The beol:figure resource class represents any existing facsimile of letters and mathematical diagrams with their associated caption. The metadata of the digital object is stored in the triplestore as a knora-base:FileValue. Users would only need to specify the file path; then, during the resource import, the API will store the image’s metadata in the triplestore, and Sipi will store the image itself. The facsimiles of letters and mathematical diagrams are stored in this way. Figure 6 depicts the connection of the letter 51 to its facsimile.30

Representation of the facsimile of letters 51.
The IRI of a resource representing a mathematical diagram is then used to insert the graphics into the text. Therefore, the text body of a scientific letter is often rich with formatted text, mathematical expressions and diagrams, references to persons, bibliographical items, etc. Next, we will look into how rich texts can best be represented in RDF, allowing users to query the text for the embedded structures.
3.4.1 Text Representation as RDF
Most online digital editions are encoded in TEI/XML,31 pure HTML, or Wiki markup. TEI/XML has become the standard way to encode texts in humanities research. It defines markup for metadata descriptions and renditions of the text. However, TEI has a few drawbacks: it cannot directly deal with the overlapping markup, and one cannot easily query the TEI/XML content based on its renditions. To overcome overlapping markup problems and to be able to search for text based on markup, annotations must be stored separately from the content. For that, using DSP-API,32 we have stored the annotated texts as standoff markup; that means the annotation content is stored as a simple Unicode string, and the markup with its position in the text is represented independently as RDF data. For example, consider the following text exempt from letter 52 of the Euler–Goldbach edition,
“Hochedelgebohrner Herr
Hochgeehrtester Herr Etats-Rath
Eur. Hochedelgeb. neues Engagement bey dem ReichsCollegio hat mir der H. Rath Schumacher so gleich zu wissen gethan und sogar eine Copie von der deswegen ergangenen Ukase zugeschickt [1]. … Ingleichen habe auch noch keine von meinen in Paris gedruckten Dissertationen bekommen…”
This text contains terms in italics, references to persons (Schumacher), bibliographical items such as Euler’s dissertation, and an editorial comment in note [1]. Figure 7 shows the representation of some of the annotations and references embedded in this text as RDF with standoff markup.
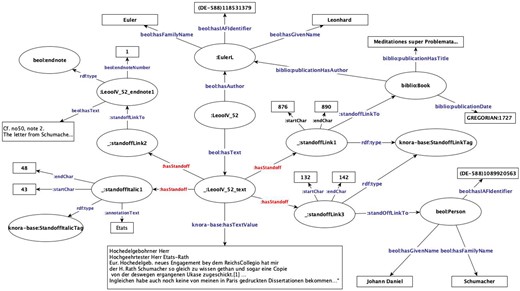
Standoff markup representation.
Figure 7 shows that the links to other internal resources of the repository given within texts, such as references to persons or bibliographic items, are stored as blank nodes of knora-base:StandoffLinkTag type with the target resource of the link given as the object of knora-base:standoffLinkTo property. The start and end character numbers are stored with the standoff markup to indicate the link’s location in the text. For example, between characters 876 and 890 in the text, there is a reference to Euler’s dissertation; that means a link to a resource of type biblio:Book. From characters 132 to 142, there is a reference to Schumacher in the text that is a standoff link to a resource of type beol:person representing Johann Daniel Schumacher. The editorial commentary given in the original edition of the letter as endnote number 1 is stored as a resource of type beol:endnote with its text. The text of this endnote or any other resource containing annotations can be similarly stored as texts with standoff markups. Having stored the references given in the text as explained, a user can query for all resources in the BEOL repository whose text contains a reference to Schumacher, see Table 2. Similarly, stylistic annotations, like italics, bold, underline, etc. are stored as standoff markup. For example, the phrase Etats is given in the text as italics and is stored plainly within the text content, and the markup is stored separately as a blank node with type knora-base:standoffItalicTag with text location indices. This allows the user to query the resulting RDF graph for all letters containing the term “Etats” in italics.
A query for BEOL letters referencing Johann Daniel Schumacher.
|
|
A query for BEOL letters referencing Johann Daniel Schumacher.
|
|
Pure text transcriptions of epistolary text can then be stored as a plain text literal in the triplestore connected to the letter resources via properties such as beol:hasText. The standoff markup of the text can be added to the text upon representation on the web application hosting the digital edition as HTML tags inserted in the exact positions in texts through the stored index locations for markups. Moreover, scholarly correspondence editions can contain complex scientific texts with mathematical formulas that should be stored in the triplestore and correctly rendered in the BEOL web applications. Wenzel and Reinhardt (2012) suggest using OpenMath to represent the mathematical expressions as RDF statements.33 This way, the mathematical expressions could be evaluated and embedded in SPARQL queries. This approach is practical for scientific data, where evaluating the expressions is essential, especially for querying for the resources based on the numerical calculation of mathematical expressions. In digital editions of historical mathematical sources, on the other hand, storing the expressions as mathematical annotations and representing them to readers with correct rendering on the web is sufficient. Furthermore, the stylistic annotations the author has added to the mathematical expressions, such as underlining or striking-through (deletion) of a phrase or formulae in the original document, must be preserved in the digital edition. Thus, to correctly represent the mathematical expressions with overlapping stylistic markup, we store them as an RDF resource of type beol:standoffMathTag class. This standoff annotation adds semantic information to the entity by indicating that the part of the text inside the markup is a mathematical expression. The mathematical expressions given in LATEX notation are stored in this notation to be rendered on the web using MathJax.34 DSP-API requires all project-specific standoff tags, such as beol:standoffMathTag to be defined within the project ontology. In its knora-base ontology, the API offers classes for standard annotation markups. Table 3 shows the RDF beol:standoffMathTag class definition in the beol ontology:
RDF class representing the StandoffMathTag.
|
|
RDF class representing the StandoffMathTag.
|
|
The ontologies described in this section are generic and openly accessible and, thus, can be used for creating other RDF-based correspondence editions. Having the ontologies in place to fully represent letters, their texts, and all related entities, we can store the epistolary data as an RDF graph. If transcriptions exist for correspondence data, these can be converted to RDF, as explained next for the two prototype editions. Before storing the transcriptions of the textual body of the letters, we first import all person and bibliography resources into the triplestore through the DSP-API to generate unique IRIs for them, which are then used to replace the references in the text body of letters as we describe next.
4. Conversion of rich texts to RDF
This section will describe how rich texts containing references, markups, and math formulae can be stored as RDF using examples from the BEBB and LEOO editions. These editions are transcribed in different formats: BEBB was encoded in MediaWiki format, and LEOO IVA/IV edition was transcribed in LATEX. These transcriptions needed to be homogenized into a single format; we chose XML. We transformed the BEBB Wiki markup to XML using the MediaWiki parser.35 Wikitags and structures were converted to XML tags, including references to figures, persons, and bibliographical items (Schweizer et al. 2017). The LEOO IVA/IV transcriptions were converted to XML using the LaTeXML software,36 a powerful tool for converting LATEX to XML. With the default setup, however, this software cannot convert all mathematical LATEX commands imported from all diverse mathematical LATEX libraries. Thus, we extended the LaTeXML software through Perl scripts (Alassi et al. 2018). LaTeXML converts the mathematical expressions to MathML and includes the LATEX notations of formulae in the tex attribute of <math> elements, which we preserve in the XML transcriptions. We then validate these automatically created XMLs with our pre-defined schematics (XSDs). Furthermore, the\index commands used in LATEX transcriptions to create a link to a name index or bibliography items are then converted to <entity> elements in XML transcriptions with the IRI of the referenced resource given in the ref attribute, as shown in Table 4.
Representation of entities in XML.
|
|
Representation of entities in XML.
|
|
The next step is to import the XML transcriptions of BEOL editions into the RDF triplestore through the DSP-API. All XML elements within texts must be mapped to the corresponding standoff tags to guide the API in storing the annotations in the text correctly based on the standoff classes defined in the ontology. Thus, if XMLs contain project-specific annotations when submitting a text encoded in XML to the API for storage, one should define the mapping rules that must be used to store the XML markups as corresponding Standoff/RDF resources.37 Otherwise, DSP-API will use its default rules to map standard markups to corresponding standoff tags, such as bold and italic renditions. The project-specific mapping rules can be given in XML formats; for example, a rule to map <math> elements in BEOL editions to beol:StandoffMathTag is shown inTable 5.
Mapping rule for conversion of XML <math> Elements to StandoffMathTags.
|
|
Mapping rule for conversion of XML <math> Elements to StandoffMathTags.
|
|
The custom mapping rule set of the BEOL project contains several rules for project-specific elements in the transcription XMLs. For example, Jacob Bernoulli, Euler, and others invented and used some specific characters in the text and math formulas with no equivalent Unicode character. To represent these characters on the web, we developed customized fonts. The characters are drawn and saved as scalable vector graphics (SVG files), for which we created web fonts using the icomoon application.38 In the transcription XMLs, an <font> element specifies a web font that must be embedded in the text, which is then mapped to beol:standoffFontTag defined in the beol ontology.
Another example of widely used mapping in BEOL editions is for <entity> elements (as shown in Table 4), which define links to referenced resources. This type of element is mapped to the standard knora-base:hasStandOffLinkTo, and the API ensures that the target of a link exists when the connection is created. Furthermore, to optimize the speed of queries that look for texts based on embedded references, in addition to linking the text content to the target resource, the letter resource itself is also connected to the target resource through the knora-base:hasStandOffLinkTo property. We use the type attribute of the <entity> elements to add different icons to these links in the web-based application, clicking on which directs the users to the underlying resources, see Fig. 8.

An example of links added to index resources within text.
Similarly, the mathematical diagrams or references to facsimiles given in XML transcription as <figure> or <facsimile> elements with the src attribute indicating the IRI of the stored image resource are mapped to beol:StandoffFigureTag. Moreover, scholarly editions are enriched with editorial comments added to the transcriptions of epistolary data as footnotes or endnotes. LEOO editions are rich in endnotes referenced from transcriptions and translations. Each endnote contains text offering additional information about a concept and can contain citations, mentions of persons, as well as mathematical formulae and figures. The text body of the editorial notes can also contain links to the other letters or endnotes. We have defined the beol:endnote class in our ontology to represent the editorial notes as RDF resources, and we substitute the links given in LaTeX notation to <a href=targetResourceIRI> elements in the XML transcriptions with IRI of the target resource representing the editorial note which is then mapped to the standard knora-base:standoffLinkTag.
Once all custom rules necessary to map XML elements to their corresponding standoff tags are defined, the API can use it to create standoff resources for XML elements and replace the elements in transcription XMLs with links to the corresponding standoff resources, see Fig. 7. Thus, the custom mapping rules must be first stored in the database. The DSP-API provides an endpoint for importing the mapping rule sets and a schema to validate the project-specific mappings.39 After successfully validating the mapping rule set, the API stores it in the triplestore as an RDF resource and assigns it an IRI. Next, the transcription XMLs are imported through the DSP-API, specifying the mappings that must be used for the standoff conversion using the IRI of the pre-stored mapping ruleset. Using this IRI, the API will retrieve the mapping ruleset from the database and use its rules to create standoff representations for constructs given in XMLs. This way, the rich text content of epistolary data can be stored as RDF data in the triplestore.
In the next step, we needed to develop an inverse mechanism to convert standoff annotations to HTML elements to represent the editions on the web. For this purpose, the DSP-API again uses the mapping rules to convert standoff/RDF data to XML elements. Then, using XSLT rules, it converts XML tags to HTML tags. The API offers a default XSLT ruleset corresponding to its default mapping rules for standard XML elements, yet it accepts custom XSLT rulesets corresponding to project-specific custom mappings. Thus, the corresponding XSLT rules must also be provided with the custom mapping rules. The API stores a custom XSLT file in Sipi and its metadata in the triplestore and will assign a unique IRI to it. The IRI of the XSLT ruleset can then already be specified in the mapping XML file. Whenever the API receives an HTTP GET request for a text resource, it retrieves the standoff/RDF resource representing the text content and the corresponding mapping IRI to covert standoff markup back to XML elements. From the mapping rule set, it gets the IRI of the corresponding XSLT resource and retrieves the XSLT file from the database. It then applies the XSLT rules to XML content and returns the XML with the resulting HTML representation of the rich text to the client. Figure 9 shows the workflow to store and represent a text with bold markup, namely Tensiones.
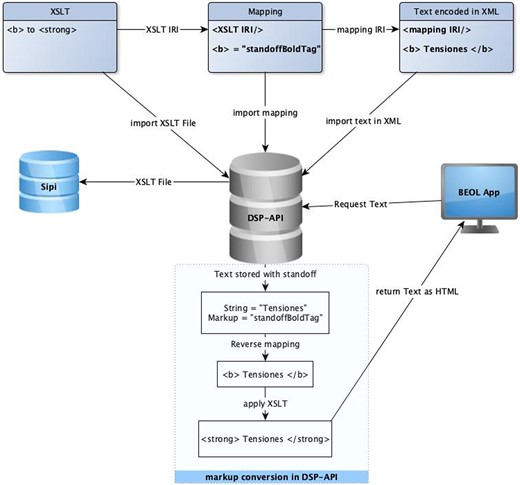
Text markup conversion workflow.
The conversion of transcriptions of editions to RDF and generation of RDF representations of letters, including metadata and resulting rich texts based on the defined ontologies, is done automatically for the BOEL project. The corresponding scripts are collected into a package that can be used to convert and model similar editions, such as eighty other volumes of Euler’s correspondence. Additionally, we developed a generic framework through which future correspondence editions can be directly transcribed as XMLs reflecting the defined data model. This framework also allows for handling the references and links and can be verified with schemas driven from the ontologies using DSP-API.40 The resulting XML files contain the definitions of all resources, their properties, and the relations between the resources. These XML files can be directly imported into triplestore through the API and integrated into the BEOL platform without conversion.41 RDF-based LECE edition was created by editors using this framework. Figure 10 shows the workflow to import the facsimiles and figures of the editions and the generated RDF data with the related ontologies and their storage in the triplestore.
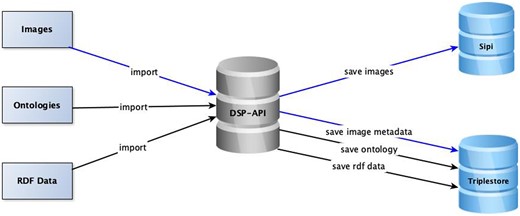
Data import workflow.
Using the abovementioned ontologies and the workflows from the BEBB and LEOO IVA/IV and LECE editions, a network is created consisting of 1,946 letter resources with text bodies that include thousands of links. Together with nearly 2,000 bibliography items and almost 3,000 person resources, all these resources are imported using a bulk import routine in less than 8 min; in total, around eight million RDF triples were created from the two correspondence editions. Once epistolary data are stored in RDF-triplestore, one can access and query the information.
5. Infrastructure and analysis tools
The primary expectations from a digital edition platform are that it provides an accurate representation of the editions, stable access to the data, powerful search tools, and a practical user interface. BEOL provides an application layer to interact with the RDF data without dealing with the complexity of the internal representation of the data in the RDF-triplestore. BEOL platform uses DSP-API to access and query the RDF graph in the triplestore. The DSP-API makes RDF data available in different serialization formats; our preferred format is JSON-LD, but the API also supports RDF/XML and Turtle serializations. The resource representing a letter, person, bibliographical item, etc. can be obtained through an HTTP GET request to the resources route of the API (Schweizer and Alassi 2018). The text of the resource is returned directly to the client as HTML so it can be displayed in web applications without further processing. We have developed an Angular-based web application for the BEOL platform that allows easy access to the BEOL editions and faithful representation of the correspondence resources and their texts on the web. It prevents users of the platform from dealing with the complexity of JSON-LD data structures and facilitates access to the content of editions through a user-friendly interface. It represents the correspondence data with tools that allow one to navigate the correspondence resources and access metadata of the letters, their figures, and texts with embedded mathematical formulas, index references, and editorial commentaries. Furthermore, the platform offers powerful analysis tools to query the data. Figure 11 shows the workflow of the access and query of the data through the BEOL application.
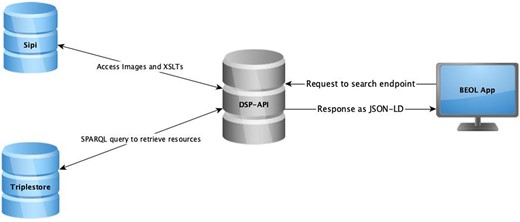
Workflow to access and query data through the BEOL application.
5.1 Query tools
Humanities researchers spend tremendous time searching for sources relevant to their research topic. Advanced search functionality can reduce the time spent looking for material and reveal sources previously unknown to researchers. On the web platform of editions, researchers mostly use two types of search routines: search for a specific term such as Velaria in the databases (full-text search) or query for sources that comply with particular criteria (advanced search). For example, a user might be interested in letters written in a certain period by a specific author. The BEOL platform offers both of these search functionalities.
5.1.1 Advanced search
SPARQL is the query language for RDF data.42 Every triplestore offers a SPARQL endpoint to process queries on the RDF graph. However, SPARQL is not well suited for the humanities data and is cumbersome for non-experts. DSP-API uses the Virtual Graph Search (Gravsearch),43 a query language based on SPARQL, to support complex searches that are relevant to humanities data. In a Gravsearch query, the client can ask about one or more relations between the RDF resources and specify which information should be returned. More generally, a Gravsearch query can use data structures that are simpler than the ones used in the triplestore, thus increasing ease of use. It can better support humanities-focused data structures, such as text markup and calendar-independent historical dates. It also offers features commonly found in web-based APIs, such as access control, filtering search results, and enforcing pagination on search results to improve scalability (Geer and Schweizer 2021).
Through the BEOL platform’s advanced search tools, users can enter their query, for example, to search for all letters Euler sent to Goldbach between 1730.01.01 and 1735.06.15, see Fig. 12. Here, we specify that the results should be sorted by date.
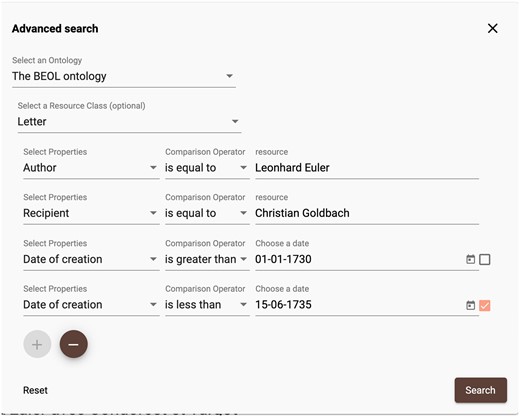
Search for correspondence with date interval.
In the background, this query is converted to the Gravsearch query statement in Table 6 and sent to the search endpoint of the API (https://api.dasch.swiss/v2/searchextended) as an HTTP post request; see Fig. 11.44
A query for letters Euler sent to Goldbach between 1 January 1730 and 15 June 1735.
|
|
A query for letters Euler sent to Goldbach between 1 January 1730 and 15 June 1735.
|
|
The twenty-four letters that match the search criteria are then retrieved from the API and listed to the user. Similarly, users can query resources by topic; Fig. 11 illustrates a query for all resources about Fermat Numbers. All the available subjects stored as a hierarchical RDF list are displayed to the user in the BEOL platform’s search tool as a hierarchical menu, see Fig. 13. The client can choose the topic from this menu; the application constructs the Grvasearch query shown in Table 7 and sends it to the API.
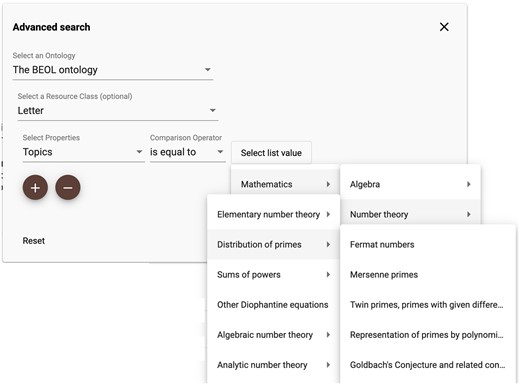
Search with the topic.
A query for letters with a particular subject.
|
|
A query for letters with a particular subject.
|
|
The API will retrieve all letters with Fermat Numbers listed as their topic and return them to the client. This query can be extended to look for all types of resources (letters or manuscript entries) containing this topic.
Furthermore, one can perform advanced Gravsearch queries on the text using standoff annotations. For example, one can query for all records in the BEOL database whose text contains a particular reference or a phrase with a specific rendition, such as italics. It is also possible to query for the written resources whose text has a specific mathematical formula. Table 1 illustrates a Gravsearch query for all resources whose text references a journal article by Jacob I Bernoulli between 1 December 1684 and 15 December 1695 with “Explicationes” in the title.
The search results would contain a list of all resources (manuscripts, editorial comments, or letters) with citations to this article within the text. Similarly, one can query for all resources whose text references Johann Daniel Schumacher, as shown in Table 2. This query returns all letters with links to the resource representing Johann Daniel Schumacher.
5.1.2 Full-text search
Most of the time, researchers are interested in finding text sources containing one specific term or phrase. For example, a historian of science might be interested in finding all resources such as Jacob Bernoulli’s notes, his correspondence, correspondence of those after him, journal articles, etc. where the term Elastica is mentioned. Using the API’s Full-Text search functionality, BEOL can retrieve all resources with this term in their text bodies. A BEOL user only needs to enter the phrase to be queried in the text search field of the BEOL application and hit the return button. BEOL then submits this phrase to the full-text query route of the API. The API searches for the phrase in all text literals in the BEOL graph. This search routine is helpful for cases where the term is specific. Otherwise, a query for a frequent word such as Sir would be slow and yield many results.
A full-text search for phrases would return only some relevant results due to word conjugation differences. For example, if a researcher is interested in finding sources about a sail or velum, she must search for all possible conjugations, such as veli or velis. The user must be able to obtain the results for all variations of the word with one query without having to repeat it for every conjugation. A full-text search for a compound phrase would help in these cases. While storing the text in the triplestore, it is indexed. The API uses the Lucene full-text index provided by the triplestore to perform full-text queries, thus supporting the Lucene parser syntax. Hence, the search phrase can either be a single word or consist of multiple terms combined with Boolean operators. Therefore, the user can search for all variations simultaneously with a compound phrase such as veli OR velis OR velum OR velaria. This would return all resources where any of these words appear.
Through the BEOL application or directly using the DSP-API, researchers can enter even more complicated full-text queries as compound phrases. For example, in his writing, Jacob Bernoulli alternatively used one of the following terms: line of mean direction, line of mean impulsion, or equilibrium axis, all meaning the same thing. A historian of science studying this topic would want to obtain all resources in which at least one of these terms is mentioned. The researcher can enter a compound phrase as (medi AND (directio OR impuls)) OR (axis AND aequalibr). The core parts of the words are only used to catch all possible conjugations of the terms. This full-text search will return all resources that include any of the three phrases.
So far, we have described our approach to creating LOD-based digital editions of correspondence data and the presentation of these editions in a web-based application in practical form to allow for efficient and comprehensive analysis of the content. Nevertheless, further steps need to be taken to make digital editions a reliable research source. We will discuss our approach to ensure the sustainability and citability of digital resources.
6. Data sustainability
Research data must be sustainable, and access to digital resources must be possible over a long period. In addition, reliability is a fundamental requirement so that digital sources can be cited, reused, and quoted (Rosenthaler, Fornaro, and Clivaz 2015). Researchers would need to rely on the availability of digital editions over a long period. Generally, at the end of a project funding, employees and postdoctoral fellows move on to the next project; Ph.D. students graduate and leave behind a considerable amount of data. The platforms and tools developed during the project are usually not maintained and consequently not updated to new technologies; they become obsolete over time. For a scholar to be able to start research on digital editions and reliably use and cite its content beyond the project’s life span, the digital editions must be preserved and accessible for an extended period. Researchers must not fear losing access to their research data from one day to the next.
Furthermore, to ensure transparency, the source material the research is based on should be available for critical review. Some HTML-based edition projects tend to publish their editions in article format, with the concern that “no one knows how long in the future the current HTML technologies will function.” Indeed, the best method for maintaining the sustainability, functionality, and usability of structured data is to migrate data repositories and their software environments (user interfaces, analytic tools, and so forth) to new technologies, thus ensuring their ongoing functional accessibility (Rosenthaler, Rudolf, and Frey 1999). However, tackling such an issue requires technical knowledge out of the scope of editorial work. Moreover, updating the software infrastructure is a constant and labor-intensive process that requires continuous financial support that is unavailable to most humanities projects. An infrastructure should be in place with technical competence to ensure the preservation and availability of digital sources for an extended period.
Over the last years, national research infrastructures have been established to manage humanities research data; for example, CLARIAH in the Netherlands, Huma-Num in France, and NFDI4Culture in Germany. In Switzerland, the Data and Service Center for the Humanities (DaSCH),45 an institution funded by the Swiss National Science Foundation, manages open humanities research data and guarantees the preservation of the data for decades. BEOL data are integrated into the DaSCH infrastructure, which uses the DSP-API. The BEOL data graph can be accessed, modified, and queried through the web application of DaSCH infrastructure.46 This application is used continuously by project editors to extend the BEOL data graph. Following the open research data principles, it is possible to download the BEOL data graph in TriG format or retrieve the resources through the DSP-API in one of the following RDF serialization formats: Turtle, JSON-LD, or RDF/XML.47 Through the DSP-API, it is also possible to export a resource (e.g. a letter) as a TEI document by converting the standoff markup to TEI/XML.48 We extended the DSP-API and implemented all the features necessary for the BEOL project in a generic form so that other DaSCH projects could benefit from these functionalities (Schweizer and Alassi 2018). Since BEOL data will be available for a long time, its resources can be faithfully cited.
6.1 Citation
Web users know the irritation of broken URLs. Returning to a web address only to find the desired object missing is more than an irritation for scholars and catalogers, whose trades rely on persistent reference. The URLs break because objects are moved, removed, or replaced. The conventional approach to solving such a problem is to use indirect names that resolve to URLs at the moment of access (Kunze 2003: 1–2). Initially, we used this kind of directive to allow other projects, such as EMLO, to integrate BEOL material into other platforms.49 EMLO is an ongoing project that offers a catalog of early modern correspondence, including catalog entries for Euler’s correspondence. Each of Euler’s letters has a unique identifier called the Repertorium number. We have created a particular route to resolve this identifier to the IRI of the corresponding resource in the BEOL database.50 In this way, EMLO users are directed to the BEOL platform to access the complete representation of a letter, including metadata and text. This allows third-party repositories like EMLO to refer to resources on the BEOL platform without knowing the underlying IRI.
Even though this approach offers a reliable solution to retrieve a specific resource type using a unique identifier instead of IRI, it is not feasible to define a directive per resource type because not all resource types have an exclusive property like Repertorium Number. Thus, we needed to consider another approach to provide reliable, persistent access to any resource through durable links. Currently, the DSP-API and, respectively, the BEOL application offer a permanent, citable URL for each resource. These URLs use Archival Resource Key (ARK) Identifiers51 and are designed to remain valid even if the underlying resource is moved from one repository to another.52 The founding principle of the ARK is that persistence is purely a matter of service and is neither inherent in an object nor conferred on it by a particular naming syntax (Kunze 2019). An ARK is a special kind of URL; its general form is “http://NMAH/ark:/NAAN/Name” (Kunze 2003: 6). The ARK URLs of BEOL resources contain the project shortcode 0801 on the DASCH database and the resource UUID. When a client requires access to a resource using this URL type, the ARK Resolver resolves it to the IRI of the corresponding resource and directs the request to the BEOL application, which can present the resource with this IRI.53 Furthermore, the DSP-API has a version control; it versions resources during the import and modifications with time stamps. Thus, if a resource is cited, its version information is contained in the citation, so the resource can be retrieved precisely in the state it was in when the quote was created, even if it has changed since the time of access.54
Even though the data can be preserved for decades through national associations like DaSCH, long-time maintenance of project-specific web applications is a resource-intensive and challenging task that DaSCH or any similar institution cannot overtake. Thus, maintenance of the web application would remain a burden on the shoulders of the project team that often moves on to the next project; therefore, over time, these applications would decay. ARK-resolvers require a web application to display the cited resources. As a possible solution to this issue, DaSCH provides and maintains a generic application to represent the data of all projects integrated into its infrastructure.55 Even though this would help with persistent accessibility of the data and retrieval and display of the cited resources, the data are displayed generically, and the labor and financial resources invested in developing the project-specific web applications will be wasted.
Furthermore, project teams attempt to enhance user’s experience of the web application and analysis of data by acknowledging potential users’ needs and facilitating the data analysis with GUI widgets and tools. If project applications are not maintained and decay over time, the researchers would need to switch to generic applications offered by data archiving institutions such as DaSCH and explore possibilities to navigate the data graphs optimally without edition-specific tools. Hence, ensuring the long-term availability of web applications presenting humanities scholarly data remains a challenging task that requires the immediate attention of the DH community.
7. Conclusion
This article presents a systematic approach to creating LOD-based digital editions of epistolary data, including metadata, text, markups, and references, resulting in a fully machine-readable and thoroughly analyzable correspondence graph. We explored the potential and significance of RDF-based digital editions in humanities and digital scholarship. Through an in-depth analysis of RDF as a data modeling technology and its application to correspondence editions, we highlighted its transformative capabilities. We applied our approach to create RDF-based editions of the correspondence of Bernoulli mathematicians and Leonhard Euler. In this way, we showed the stages of application of our approach, the reasons behind each step, and the benefits of the approach with multiple examples. Thus, we provided yet another example to illustrate that RDF technology offers a structured and flexible framework for representing complex and interlinked resources, highlighting rich semantic relationships in epistolary data and enhancing the interoperability of correspondence-related repositories. The meticulous construction of RDF-based digital editions offers a profound means of delving into the intricate layers of historical correspondence with unparalleled semantic accuracy.
We know that RDF-based digital editions present challenges related to data modeling and graph queries for non-expert users. However, the benefits of enhanced discoverability, semantic richness, and long-term preservation of these digital editions outweigh the challenges. The generic ontologies we developed for the BEOL correspondence editions represent all aspects of epistolary data and can be used by other similar edition projects. Furthermore, user-friendly applications can facilitate these RDF graphs’ creation, access, and querying. Through a web application such as BEOL, researchers can access and study the epistolary data graph and recognize the relations between the textual sources. Through this kind of infrastructure, historians can explore the epistolary network using graph analysis tools, access the transcriptions and translations of every letter and its connections to other resources, and simultaneously access the digitized source material. Through the edition’s platform, researchers could gather all sources mentioning a particular topic of interest, person, publication, etc, by querying for items based on references they contain. Based on these functionalities, historians can access textual objects with all related sources and study them as a data network. Applications can make the links between network nodes even more evident and easy to access for non-technical users unable to write sophisticated queries by illustrating all the linkages within the text of a letter and by listing all resources linked to the letter. In this way, users can traverse the graph through the provided links.
This representation of epistolary data enables a new research methodology, the network method. Instead of spending a tremendous amount of time reading texts to find the connections, with this methodology, users first study the linkage of resources and the network as a whole, gather the resources related to their research question through graph queries, and then dive into a close study of correspondence. Furthermore, studying the network as a whole would allow researchers to study the distribution of data and the degrees of interconnectedness of resources. This might raise new research questions that are not evident through a close study of correspondence data. For example, by studying the network resulting from BEBB correspondence, we came across eight letters Jacob Hermann, Jacob Bernoulli’s disciple, sent to Johann Bernoulli, Jacob Bernoulli’s brother and rival, before his master’s death. The fact that these letters were sent before Jacob Bernoulli’s death is unexpected. It raises questions about the nature of the relationship between Hermann and Johann Bernoulli—a question yet to be studied.
Hence, the continued exploration and adoption of RDF-based digital editions have the potential to reshape the landscape of digital humanities and open up new avenues for scholarly research in humanities. We discussed the necessity of ensuring the sustainability of digital data and its long-term preservation, which is essential for faithful citation of the content of digital editions in scholarly publications. We also presented our approach to ensure the sustainability and durable citability of BEOL resources and discussed the remaining challenge regarding the long-term maintenance of project-specific web applications of digital editions. Furthermore, it is to be noted that the persistence of the BEOL repository containing data and ontologies facilitates interoperability with other LOD repositories. We explored a new approach to connect the BEOL repository to other non-LOD repositories of historical scientific correspondence editions without centralizing data silos in an attempt to create an e-version of the Republic of Letters (see Alassi et al. 2019; Alassi and Rosenthaler 2020, and more detailed in Alassi 2020, chapter 7). As a next step, we envision developing an infrastructure to extend the network resulting from the remote connection of repositories and offer tools to access and query the metadata and texts of all epistolary items in the network. Currently, the functioning proof of concept is integrated into the BEOL platform, which hosts the network generated from the connection of BEOL correspondence editions to the scientific correspondence of Isaac Newton (1643–1727) presented in The Newton Project platform56 and correspondence of Gottfried Wilhelm Leibniz (1646–1716) presented in the Briefportal Leibniz platform.57
Lastly, the network method mentioned above can best be utilized by studying the RDF graphs visually. The picture of data graphs promotes relational thinking and helps researchers understand the nature of relations between written sources and any irregularities in the data distribution. Through interaction with the visualized model, researchers can access the underlying resources and immerse themselves in a detailed analysis. Visualizations bring researchers’ attention to hidden facts, such as unexpected communications between natural philosophers and the correspondence density or type. Although experts might already know the information data graphs offer, younger researchers often do not. Thus, we have generated 3D web-based interactive visualizations of the correspondence network and integrated them into the BEOL platform (see Alassi, Iliffe, and Rosenthaler 2020, and more detailed in Alassi 2020, chapter 8).58 These visualizations can help researchers understand the connection between written sources, create their research inventory, and acquire the sources relevant to their topic of interest. The correspondence graphs are visualized as 3D force-directed graphs to avoid overlapping nodes and edges and for accurate and spatially intuitive data representation. As a next step, we intend to develop a generic tool to retrieve sub-graphs from RDF triplestores based on user-specific criteria and visualize them as interactive 3D force-directed graphs that can be embedded into web applications.
Author contributions
Sepideh Alassi (Conceptualization, Methodology, Software, Validation, Writing—original draft) and Lukas Rosenthaler (Funding acquisition, Investigation, Project administration, Supervision).
Funding
This work was supported by the Swiss National Science Foundation (SNSF) [166072] (https://data.snf.ch/grants/grant/166072) from 1 July 2016 to 31 January 2020.
Footnotes
https://beol.dasch.swiss/. A new and more user-friendly version of the application is available at https://bernoulli-euler.dhlab.unibas.ch/
See Alassi et al. (2018).
Decker et al. (2000b: 68).
For a list of persons referenced in LEOO IVA/IV edition letters, see https://edoc.unibas.ch/58842/2/IVA4_PDFA.pdf#page=1227.
List of bibliographical items referenced in LEOO IVA/IV edition letters: https://edoc.unibas.ch/58842/2/IVA4_PDFA.pdf#page=1179.
In all graphs in this article, customized labels are given for resources like BernoulliNI instead of the actual IRI for simplicity.
Gemeinsame Norm-Datei https://www.dnb.de/DE/Professionell/Standardisierung/GND/gnd.html.
Representation of Nicolaus I Bernoulli on wikidata https://www.wikidata.org/wiki/Q123992.
Further project-specific resource classes are defined to model bibliographical items of the BEOL project, see Alassi (2020:172–173).
https://ark.dasch.swiss/ark:/72163/1/0801/RBP1iFCpTqeqsF9uBfMn8gT.20191028T09322842Z.
The International Image Interoperability Framework (IIIF) defines a URL-based syntax for digital images, allowing for interoperability among image repositories. https://iiif.io/api/image/2.1/.
https://ark.dasch.swiss/ark:/72163/1/0801/pOH=921VSN691ZG3=B6amQ1.20191028T09322842Z
The Text Encoding Initiative (TEI) is a consortium that collectively develops and maintains a standard for text representation in digital format. https://tei-c.org/.
IRIs in the Gravsearch queries are given in a reader-friendly style.
See note 26.
Citation URL of the first letter in Euler–Goldbach correspondence: https://ark.dasch.swiss/ark:/72163/1/0801/gqo1mCmjQuK7LYhz5tP9TwT.20191028T092858112Z

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}