





Abstract
This study aims to explore the ability of GPT-4o to imitate the literary style of renowned authors. Ernest Hemingway and Mary Shelley were selected due to their contrasting literary styles and their overall impact on world literature. Using three distinct prompting strategies—zero-shot generation, zero-shot imitation, and in-context learning—we generated forty-five stylistic imitations and analyzed them alongside the authors’ original texts. To ensure thematic consistency, we constrained the generated texts to shared narrative themes derived from the authors’ works. We used a distance-based approach to authorship attribution using the 1,000 most frequent words and cosine distance to explore how the large language model’s imitations were positioned in the multidimensional authorship space. Moreover, we exploited a random forest classifier and repeated the authorship attribution task to analyze the authorship distinctiveness of the GPT imitations further. We used a combination of Textual Complexity and Readability, Author Multilevel N-gram Profiles, Word Embeddings, and Linguistic Inquiry and Word Count features. t-SNE visualizations further evaluated the stylistic alignment between original and GPT-generated texts. The findings reveal that while GPT-4o captures some surface-level stylistic elements of the authors, it struggles to fully replicate the depth and uniqueness of their stylometric signatures. Imitations generated via in-context learning showed improved alignment with the original authors but still exhibited significant overlap with generic GPT outputs.
1. Introduction
The advent of large language models (LLMs), such as the Generative Pre-trained Transformer 4 Omni (GPT-4o), a multimodal LLM developed by OpenAI, has transformed natural language processing, enabling the generation of text with remarkable fluency and coherence. Among the many capabilities of LLMs, stylistic imitation, the ability to replicate a target author’s distinct linguistic, structural, and tonal features, has garnered increasing attention. This capability holds promise for applications ranging from literary analysis and personalized communication to pedagogical tools and creative writing. However, it also raises ethical concerns, including intellectual property violations, misinformation, and impersonation risks.
Stylistic imitation requires an LLM to go beyond generating coherent text and align its output with a given author’s specific stylistic and linguistic features. While LLMs excel at mimicking surface-level attributes, such as vocabulary and sentence structure, replicating deeper stylistic elements, including an author’s unique narrative voice and emotional spectrum, remains a significant challenge. This study seeks to evaluate how well GPT-4o can replicate the distinct stylistic profiles of two renowned authors, Ernest Hemingway and Mary Shelley, whose contrasting literary styles provide an ideal testbed for examining the effectiveness of stylistic imitation. These distinct styles offer a robust framework for testing GPT-4o’s ability to adapt its tone, structure, and narrative elements to emulate diverse authorial voices faithfully.
The remainder of this paper is organized as follows: Section 2 reviews related work on LLMs’ stylistic imitation, highlighting key methodologies and challenges in the field. Section 3 outlines the study’s methodology, including the author selection process, thematic control, prompt design, and generation procedures. Section 4 presents the results of stylometric analyses, including distance-based authorship attribution, machine learning classification, and visualization methods. Finally, Section 5 concludes the paper by summarizing the findings, discussing the limitations of the research, and offering directions for future work.
2. Related work
Stylistic imitation broadly entails aligning an LLM’s output with particular linguistic, structural, or tonal features characteristic of a chosen target, such as a renowned author, a fictional character, or a particular role. This capacity not only holds promise for personalized communication (Wang et al. 2024), literary analysis, and pedagogical tools (Kostopolus 2025), but also poses critical ethical and intellectual property concerns (Lee, Hilty, and Liu 2021; Yan et al. 2024).
Recent research has tackled stylistic imitation through various methodologies—ranging from fine-tuning and prompt engineering to few-shot prompting, style embeddings, and role-specific benchmarks. While LLMs have demonstrated remarkable proficiency in mimicking surface-level stylistic attributes, challenges remain in capturing subtler qualities of human writing, including innovation, deep causal reasoning, and authentic authorial voice (Chakrabarty et al. 2024; Riemer and Peter 2024; Si, Yang, and Hashimoto 2024).
Fine-tuning a pre-trained LLM on a corpus of a specific author’s work can yield highly accurate stylistic imitation, capturing subtle details such as unique vocabulary choices, syntactic tendencies, and tonal qualities (Hicke and Mimno 2023; Guo, Xu, and Ritter 2024). Studies have shown that even seemingly trivial elements—like stop words—can be critical to maintaining an author’s stylistic fingerprint (Eder 2011; Mikros and Perifanos 2011). Fine-tuning, however, requires substantial data from the target author and can be computationally expensive, risking overfitting, and limited generalization.
Additionally, a substantial body of work focuses on enabling LLMs to imitate the language and persona of defined characters. Wang et al. (2024) introduced RoleLLM, a framework that fine-tunes models to adopt role-specific behaviors by leveraging role profiles and context-based instructions. By providing custom role prompts and creating a benchmark dataset, RoleBench, this approach yields LLM responses that align with predefined personalities, making them valuable for dialogue systems, gaming, and immersive narrative experiences. Similar endeavors using prompt-based role specification have shown that models can mimic the language styles of fictional characters, celebrities, or historical figures (Jiang et al. 2022; Mou et al. 2024). Such techniques offer potential for entertainment, education, and creative exploration while also opening paths to more personalized interaction with virtual agents (S. Chen et al. 2024).
Beyond literary or conversational style, LLMs have been adapted for imitation learning in task-specific domains, such as robotics and control tasks. Liu et al. (2023) developed TAIL (Task-specific Adapters for Imitation Learning), which uses parameter-efficient fine-tuning techniques like Bottleneck Adapters and Low-Rank Adaptation (LoRA). TAIL allows LLMs to learn new tasks from limited demonstrations and mimic domain-specific behaviors without catastrophic forgetting, enabling refined task performance and role adaptation. Such work gives a useful framework on how imitation learning can bridge the gap between linguistic style imitation and practical decision-making tasks.
Another approach to steering the stylistic output of LLMs is text style transfer and adaptation. Xu et al. (2023) demonstrate that smaller models with latent attribute pre-training can efficiently perform style transfer while retaining key stylistic elements, highlighting that smaller, specialized architectures can rival massive models in handling complex stylistic constraints with minimal computational resources. Similarly, Shao et al. (2024) address the limitations of LLMs in authorship style transfer, particularly when in-context demonstrations for less frequent styles are scarce. To overcome these challenges, they propose an inverse transfer data augmentation (ITDA) method, which utilizes LLMs to generate neutral-stylized text pairs by removing style attributes from existing texts. By exploiting the abundance of neutral texts from pre-training corpora, this method enables the creation of robust datasets for training compact models that are both efficient for deployment and adept at replicating targeted styles. Experimental results across multiple authorship style datasets confirmed that ITDA outperforms traditional style transfer approaches and forward transfer methods using GPT-3.5, further underscoring the potential of efficient, smaller-scale models in achieving high-quality stylistic adaptation.
Prompt engineering can also produce carefully crafted instructions to guide an LLM’s output toward a desired style. By conditioning the model’s responses on specific cues, users can produce text closely aligned with a chosen stylistic framework, including the language style of fictional characters or domain experts (Berryman and Ziegler 2024; Marvin et al. 2024). This technique offers flexibility and resource efficiency compared to large-scale fine-tuning. However, its success depends heavily on prompt quality and specificity, and the approach may struggle to capture the full complexity of a target author’s style consistently. The presence of instructive tokens or specific instruction-tuned training procedures may limit style fidelity. Recent research has integrated prompt engineering with role-specific cues, showing that models trained for role-play respond more accurately to persona descriptions and detailed prompts (N. Chen et al. 2024; Li et al. 2024; Tang et al. 2024; Wang et al. 2024). While promising, prompt engineering remains sensitive to prompt design and may require extensive experimentation to achieve consistent stylistic fidelity.
One very successful variation of prompting is in-context learning. It enables LLMs to achieve stylistic imitation by utilizing examples provided within a prompt, allowing for on-the-fly adaptation to specific writing styles without requiring additional fine-tuning. LLMs can infer stylistic patterns and replicate them in generated outputs by including a carefully curated example that showcases desired stylistic features—such as tone, sentence complexity, and lexical choices. Chen and Moscholios (2024), based on this idea, developed a Complex Emulation Protocol (CEP) where the LLM is provided with additional author data and/or guided instructions in the form of a few key linguistic features that potentially demonstrate the author’s unique linguistic preferences.
Another alternative under the broader framework of prompt engineering is few-shot prompting. It provides the model with a handful of examples illustrating the target style. Even with limited data, the LLM can learn essential stylistic patterns and apply them to new text generations (Li et al. 2024; Liu, Diddee, and Ippolito 2024; Soto et al. 2024). This method reduces the need for extensive datasets and computational costs, but its effectiveness heavily depends on the quality and diversity of the examples provided. This limitation may restrict the model’s ability to generalize across diverse topics or sustain a high-fidelity style over more extended outputs.
Complementing few-shot prompting is the use of author style as vector embeddings, which provide a compact and flexible mechanism for guiding text generation. Style embeddings can capture a wide range of stylistic features, making it possible to compare and cluster different authors or to retrieve relevant text samples for context (Wegmann, Schraagen, and Nguyen 2022; Terreau, Gourru, and Velcin 2024). By combining embeddings with Retrieval-Augmented Generation (RAG), LLMs can adapt their output to a particular style more dynamically (Luo et al. 2024; Neelakanteswara, Chaudhari, and Zamani 2024). However, generating effective style embeddings can be challenging, and their interpretation may not always be straightforward.
Researchers have also explored ways to align generation with an LLM’s “native” style, thereby enhancing the model’s reasoning performance. Yang et al. (2024) introduced AlignCoT, a method for integrating in-context examples that match the LLM’s inherent linguistic characteristics. By aligning output style with the model’s natural tendencies, LLMs can achieve more accurate and natural reasoning behaviors.
Building on the impact of stylistic alignment, recent studies have examined how humans perceive AI-generated texts across different genres, often revealing a surprising inability to distinguish them from human-authored content. In some cases, readers even prefer AI-generated texts, attributing higher value to them. Porter and Machery (2024) recruited 1,000 participants to evaluate 100 poems—half by humans and half by AI. The findings revealed that participants often rated AI-generated poems higher than those by renowned poets like Sylvia Plath and T.S. Eliot, indicating a challenge in distinguishing between the two and a tendency to value AI-generated poetry more. Similarly, Amirjalili, Neysani, and Nikbakht (2024) compared AI-generated essays to those written by students and found that AI-produced texts were perceived as coherent and contextually relevant. However, they lacked the depth and specificity characteristic of human authorship. Despite these shortcomings, the AI-generated content was often rated favorably, highlighting the persuasive nature of LLM outputs in academic contexts. Moreover, in the domain of news articles, Zhang et al. (2024) have shown that LLMs can produce content with linguistic patterns closely mirroring human writing. This similarity makes it challenging for readers to differentiate between human and AI-generated news texts, potentially leading to equal or greater trust in AI-produced journalism. Furthermore, research into social media (Radivojevic et al. 2024) has demonstrated that humans often struggle to identify AI-generated posts. In experiments where participants attempted to distinguish between human and AI-authored social media entries, accuracy was low, suggesting that AI-generated content is perceived as authentically human across this genre as well.
While LLMs excel at replicating surface-level patterns, studies have shown that they lag behind human children in cognitive tasks requiring creative problem-solving or deep causal reasoning (Yiu, Kosoy, and Gopnik 2024). Despite impressive linguistic mimicry, current LLMs struggle with capturing the full richness and innovation inherent in human writing. Bhandarkar et al. (2024) found that LLMs often fail to achieve effective author-style emulation, and human evaluators can frequently distinguish LLM-generated text from genuinely human-authored text. These limitations underscore the critical role of human perception in evaluating stylistic imitation. Readers may recognize when style is only superficially imitated—lacking depth, originality, or authentic creative flair. Understanding which linguistic cues and contextual factors influence human judgments of authenticity remains an open research challenge. Systematic user studies are needed to identify how humans perceive and evaluate stylistic imitation, informing more nuanced approaches to LLM training and evaluation.
However, the ability of LLMs to replicate writing styles also raises significant ethical concerns. The technology risks being misused for generating disinformation, impersonation, or deceptive content, with intellectual property disputes arising when LLMs produce text closely mirroring the style of a copyrighted author. Intellectual property concerns emerge when LLMs produce text that closely mirrors the style of a copyrighted author. The “Matthew effect” (Rigney 2010), whereby the styles of well-known authors are more easily replicated, may worsen existing disparities in visibility and influence. Furthermore, the creation of persuasive bots that mimic specific personalities for marketing or political purposes raises critical questions about authenticity, consent, and trust (Simchon, Edwards, and Lewandowsky 2024). As LLMs are being further developed and their reasoning and writing skills increase, it is important to research how to balance their potential benefits with mitigating risks, ensuring that ethical considerations, transparency, and safeguards against misuse guide advancements in AI technology.
3. Methodology
3.1 LLMs and prompting
LLMs like OpenAI’s GPT-4o are AI systems trained on extensive text data to generate human-like language. These systems, commonly known as chatbots, can create coherent text following specific instructions called “prompts.” Prompts range from simple questions to detailed stylistic guidelines that direct the model’s output. The effectiveness of generated text depends significantly on prompt design, a practice termed “prompt engineering.” In our research, we implemented three distinct prompting strategies (zero-shot generation, zero-shot imitation, and in-context learning) to evaluate how different instructional approaches affect GPT-4o’s literary style imitation capabilities, providing a systematic assessment under varying levels of contextual guidance.
3.2 Author selection and rationale
We used GPT-4o (model gpt-4o-2024-05-13) accessed through the OpenAI API to create texts that imitate the literary style of two well-known authors, Ernest Hemingway and Mary Shelley. These two authors were chosen as stylistic targets due to their well-documented, distinct literary voices. Hemingway’s style is characterized by economical prose, short sentences, sparse description, and emphasis on dialogue, reflecting themes of stoicism, existential struggle, and the human condition. In contrast, Mary Shelley’s style, exemplified by works such as Frankenstein, is more elaborate and descriptive, featuring emotionally charged narrative passages, gothic and romantic elements, and an exploration of scientific ambition and isolation. This deliberate contrast provides a robust testing ground for the GPT-4o’s ability to convincingly shift its tone, narrative structure, and thematic focus in response to stylistic prompts.
To ensure that stylistic differences were not conflated with thematic disparities between the authors’ source texts, an additional layer of thematic control was integrated into the methodology. The goal was to identify narrative themes that were inherently present in both Hemingway’s The Old Man and the Sea and Shelley’s Frankenstein, allowing for the generation of text samples that explored shared conceptual ground. By constraining the thematic space, we aimed to ensure that subsequent stylistic analyses would not be skewed by differences in topic selection. Moreover, using this approach, we were able to direct the GPT-4o model to produce new text that was thematically related to the author but without forcing it to recreate passages from the source text.
3.3 Topic modeling procedure
The first step involved performing topic modeling on both novels. Latent Dirichlet Allocation (LDA), a widely recognized algorithm for extracting latent thematic structures from textual data, was employed for this. Each text underwent preprocessing, which included tokenization, lowercasing, and removal of stopwords.
For preprocessing, we implemented a comprehensive protocol to ensure consistency and reliability. Tokenization was performed using the NLTK word_tokenize function, which segments text based on whitespace and punctuation while preserving linguistically meaningful units. For stopword removal, we utilized the standard English stopword list from NLTK, consisting of 179 common function words that typically do not contribute to thematic content. Normalization was not limited to lowercase conversion; we also standardized contractions, removed non-alphabetic characters except for relevant punctuation marks needed for sentence boundary detection, and eliminated extraneous whitespace. Additionally, we applied lemmatization using NLTK’s WordNet lemmatizer to reduce inflectional word forms to their base forms, which helps consolidate related terms for more coherent topic extraction.
After these linguistic normalizations, each novel was analyzed separately to extract the underlying topics. For each novel, we identified twenty topics, each represented by its twenty most significant keywords. This figure was chosen to capture a sufficiently granular thematic representation, ensuring that even subtle thematic patterns could surface. Once the LDA modeling was complete, the resulting topics were examined. Topic interpretation involved reviewing each topic’s twenty top-ranking keywords and representative segments. With two sets of topics, twenty from Hemingway’s text and twenty from Shelley’s—we proceeded to cross-reference them in search of conceptual overlaps. The aim was to find thematic domains that both texts addressed, albeit in their distinct narrative styles. By reviewing the descriptive keywords and sample passages, we identified points of resonance between the two corpora. For example, The Old Man and the Sea and Frankenstein both explore the individual’s struggle against the natural environment, though they do so in stylistically distinct ways. Similarly, both works refer to themes of ambition, identity, isolation, and moral responsibility, each through their unique narrative voices and fictional constructs.
This cross-referencing stage resulted in the selection of nine central themes that consistently emerged across both books and are the following: (1) Nature’s Dual Role as Friend and Foe, (2) Isolation, (3) The Price of Ambition, (4) Man Versus Nature, (5) The Search for Identity, (6) Love and Loss, (7) The Weight of Guilt, these results demonstrate, (8) Mortality, and (9) Knowledge as Power and Peril. The most prominent topic words associated with the above themes can be found in Table 1.
Key topic words associated with common themes in Shelley’s “Frankenstein” and Hemingway’s “The Old Man and the Sea.”
| Common themes | Shelley | Hemingway |
|---|---|---|
| Nature’s Dual Role as Friend and Foe | sea, ocean, snow, whale, wild | shark, fish, wind, turtle, breeze |
| Isolation | unvisited, fearful, secret, silent, far | shack, lost, fear, gone, deep |
| The Price of Ambition | glory, prize, success, enterprise, perseverance | yankees, league, dimaggio, team, big |
| Man Versus Nature | voyage, discovery, pole, dangerous, kill | harpoon, caught, boat, skiff, fishermen |
| The Search for Identity | mind, know, brother, sister, understand | boy, man, remember, i’m, thought |
| Love and Loss | love, loved, dear, friend, heart | wife, sad, remembered, home, share |
| The Weight of Guilt | evil, brutality, woeful, soul, dreadfully | bad, truly, scars, took, black |
| Mortality | life, fate, days, winter, men | old, winter, eighty, time, passed |
| Knowledge as Power and Peril | study, read, explore, modern, projects | think, newspaper, faith, means, league |
| Common themes | Shelley | Hemingway |
|---|---|---|
| Nature’s Dual Role as Friend and Foe | sea, ocean, snow, whale, wild | shark, fish, wind, turtle, breeze |
| Isolation | unvisited, fearful, secret, silent, far | shack, lost, fear, gone, deep |
| The Price of Ambition | glory, prize, success, enterprise, perseverance | yankees, league, dimaggio, team, big |
| Man Versus Nature | voyage, discovery, pole, dangerous, kill | harpoon, caught, boat, skiff, fishermen |
| The Search for Identity | mind, know, brother, sister, understand | boy, man, remember, i’m, thought |
| Love and Loss | love, loved, dear, friend, heart | wife, sad, remembered, home, share |
| The Weight of Guilt | evil, brutality, woeful, soul, dreadfully | bad, truly, scars, took, black |
| Mortality | life, fate, days, winter, men | old, winter, eighty, time, passed |
| Knowledge as Power and Peril | study, read, explore, modern, projects | think, newspaper, faith, means, league |
Key topic words associated with common themes in Shelley’s “Frankenstein” and Hemingway’s “The Old Man and the Sea.”
| Common themes | Shelley | Hemingway |
|---|---|---|
| Nature’s Dual Role as Friend and Foe | sea, ocean, snow, whale, wild | shark, fish, wind, turtle, breeze |
| Isolation | unvisited, fearful, secret, silent, far | shack, lost, fear, gone, deep |
| The Price of Ambition | glory, prize, success, enterprise, perseverance | yankees, league, dimaggio, team, big |
| Man Versus Nature | voyage, discovery, pole, dangerous, kill | harpoon, caught, boat, skiff, fishermen |
| The Search for Identity | mind, know, brother, sister, understand | boy, man, remember, i’m, thought |
| Love and Loss | love, loved, dear, friend, heart | wife, sad, remembered, home, share |
| The Weight of Guilt | evil, brutality, woeful, soul, dreadfully | bad, truly, scars, took, black |
| Mortality | life, fate, days, winter, men | old, winter, eighty, time, passed |
| Knowledge as Power and Peril | study, read, explore, modern, projects | think, newspaper, faith, means, league |
| Common themes | Shelley | Hemingway |
|---|---|---|
| Nature’s Dual Role as Friend and Foe | sea, ocean, snow, whale, wild | shark, fish, wind, turtle, breeze |
| Isolation | unvisited, fearful, secret, silent, far | shack, lost, fear, gone, deep |
| The Price of Ambition | glory, prize, success, enterprise, perseverance | yankees, league, dimaggio, team, big |
| Man Versus Nature | voyage, discovery, pole, dangerous, kill | harpoon, caught, boat, skiff, fishermen |
| The Search for Identity | mind, know, brother, sister, understand | boy, man, remember, i’m, thought |
| Love and Loss | love, loved, dear, friend, heart | wife, sad, remembered, home, share |
| The Weight of Guilt | evil, brutality, woeful, soul, dreadfully | bad, truly, scars, took, black |
| Mortality | life, fate, days, winter, men | old, winter, eighty, time, passed |
| Knowledge as Power and Peril | study, read, explore, modern, projects | think, newspaper, faith, means, league |
These nine themes represent the common thematic ground that both Hemingway and Shelley engage with, enabling the creation of prompts and generation tasks that do not favor one author’s narrative concerns over the other’s.
3.4 Prompt design and text generation
Three prompts were developed to elicit stylistically imitative texts from the GPT-4o model and are described below:
Zero-shot: We asked GPT-4o to produce short novels on the nine specific topics outlined above using its native style. This would produce a baseline of the model’s stylistic signature. The generated texts were assigned the prefix “GPT” in their filenames. The prompts used are the following:
Write a 2,000-word short novel on the topic “[Topic Name]”.
Zero-shot (imitation): In this prompt, we specifically asked for the imitation of the authors’ styles. Imitation will be achieved by exploiting the overall model’s knowledge about these authors and the stylistic characteristics of their works. The generated texts were assigned the prefixes “GPT_Hemingway” and “GPT_Shelley,” respectively, in their filenames. The prompt used is the following:
Write a 2,000-word short novel on the topic “[Topic Name],” imitating the literary style of Ernest Hemingway.
Write a 2,000-word short novel on the topic “[Topic Name],” imitating the literary style of Mary Shelley.
In-context learning: For this prompt, we used a 15,000-word excerpt from Hemingway’s “The Old Man and the Sea” and Shelley’s “Frankenstein.” This excerpt was taken from the middle of each source book and was used as a reference to the original authors’ style. The generated texts were assigned the prefixes “EnhGPT_Hemingway” and “EnhGPT_Shelley,” respectively, in their filenames. The prompt used is the following:
You are tasked with reading a given text, imitating its style, and then writing a 2,000-word short novel using the learned style with the topic “[Topic Name].” Follow these instructions carefully:
First, carefully read the following text: <text_to_imitate> </text_to_imitate>
Analyze the text thoroughly, paying close attention to:
Sentence structure and length
Vocabulary choices
Tone and mood
Narrative voice (first person, third person, etc)
Use of literary devices (metaphors, similes, alliteration, etc)
Pacing and rhythm
Dialogue style (if present)
Descriptive techniques
Now, write a 2,000-word short novel that imitates the style of the given text. Your novel should:
Have a clear beginning, middle, and end
Include well-developed characters
Have a coherent plot or central theme
Maintain the identified stylistic elements throughout
Remember, your goal is to create a new, original story that feels as if it could have been written by the author of the text you are imitating. Focus on capturing the essence of their style rather than copying specific plot elements or characters.
The linguistic measurements reported in Table 2 represent corpus-level calculations for each author category rather than averages of individual texts. To provide additional insight into the variation within each category, Table 2 presents the mean and standard deviation of the following key linguistic measure calculated at the individual text level:
Mean and standard deviation of linguistic measures for individual texts by author category.
| Author | N | Tokens | Types | stTTR | Mean word length (in characters) | Mean sentence length (in words) |
|---|---|---|---|---|---|---|
| Overall mean | 47 | 3,710.17 ± 393.83 | 756.91 ± 979.03 | 43.77 ± 3.42 | 4.53 ± 0.24 | 15.83 ± 3.29 |
| EnhGPT.Hemingway | 9 | 1,587.78 ± 393.83 | 537.78 ± 74.93 | 42.70 ± 0.48 | 4.29 ± 0.17 | 12.95 ± 2.29 |
| EnhGPT.Shelley | 9 | 1,993.78 ± 651.67 | 662.89 ± 147.07 | 38.57 ± 3.48 | 4.53 ± 0.17 | 19.75 ± 2.85 |
| GPT.Hemingway | 9 | 1,499 ± 219.27 | 541.56 ± 57.30 | 47.79 ± 0.95 | 4.49 ± 0.18 | 13.47 ± 1.44 |
| GPT.Shelley | 9 | 1,577.22 ± 163.46 | 599.56 ± 68.53 | 45.57 ± 0.53 | 4.71 ± 0.13 | 17.70 ± 1.94 |
| GPT | 9 | 1,399.22 ± 115.71 | 550.22 ± 50.76 | 44.01 ± 0.29 | 4.72 ± 0.17 | 15.01 ± 1.07 |
| Hemingway_The Old Man and The Sea | 1 | 26,663 | 2,539 | 34.62 | 3.84 | 14.15 |
| Shelley_Frankenstein | 1 | 75,143 | 7,008 | 44.33 | 4.42 | 41.51 |
| Author | N | Tokens | Types | stTTR | Mean word length (in characters) | Mean sentence length (in words) |
|---|---|---|---|---|---|---|
| Overall mean | 47 | 3,710.17 ± 393.83 | 756.91 ± 979.03 | 43.77 ± 3.42 | 4.53 ± 0.24 | 15.83 ± 3.29 |
| EnhGPT.Hemingway | 9 | 1,587.78 ± 393.83 | 537.78 ± 74.93 | 42.70 ± 0.48 | 4.29 ± 0.17 | 12.95 ± 2.29 |
| EnhGPT.Shelley | 9 | 1,993.78 ± 651.67 | 662.89 ± 147.07 | 38.57 ± 3.48 | 4.53 ± 0.17 | 19.75 ± 2.85 |
| GPT.Hemingway | 9 | 1,499 ± 219.27 | 541.56 ± 57.30 | 47.79 ± 0.95 | 4.49 ± 0.18 | 13.47 ± 1.44 |
| GPT.Shelley | 9 | 1,577.22 ± 163.46 | 599.56 ± 68.53 | 45.57 ± 0.53 | 4.71 ± 0.13 | 17.70 ± 1.94 |
| GPT | 9 | 1,399.22 ± 115.71 | 550.22 ± 50.76 | 44.01 ± 0.29 | 4.72 ± 0.17 | 15.01 ± 1.07 |
| Hemingway_The Old Man and The Sea | 1 | 26,663 | 2,539 | 34.62 | 3.84 | 14.15 |
| Shelley_Frankenstein | 1 | 75,143 | 7,008 | 44.33 | 4.42 | 41.51 |
Mean and standard deviation of linguistic measures for individual texts by author category.
| Author | N | Tokens | Types | stTTR | Mean word length (in characters) | Mean sentence length (in words) |
|---|---|---|---|---|---|---|
| Overall mean | 47 | 3,710.17 ± 393.83 | 756.91 ± 979.03 | 43.77 ± 3.42 | 4.53 ± 0.24 | 15.83 ± 3.29 |
| EnhGPT.Hemingway | 9 | 1,587.78 ± 393.83 | 537.78 ± 74.93 | 42.70 ± 0.48 | 4.29 ± 0.17 | 12.95 ± 2.29 |
| EnhGPT.Shelley | 9 | 1,993.78 ± 651.67 | 662.89 ± 147.07 | 38.57 ± 3.48 | 4.53 ± 0.17 | 19.75 ± 2.85 |
| GPT.Hemingway | 9 | 1,499 ± 219.27 | 541.56 ± 57.30 | 47.79 ± 0.95 | 4.49 ± 0.18 | 13.47 ± 1.44 |
| GPT.Shelley | 9 | 1,577.22 ± 163.46 | 599.56 ± 68.53 | 45.57 ± 0.53 | 4.71 ± 0.13 | 17.70 ± 1.94 |
| GPT | 9 | 1,399.22 ± 115.71 | 550.22 ± 50.76 | 44.01 ± 0.29 | 4.72 ± 0.17 | 15.01 ± 1.07 |
| Hemingway_The Old Man and The Sea | 1 | 26,663 | 2,539 | 34.62 | 3.84 | 14.15 |
| Shelley_Frankenstein | 1 | 75,143 | 7,008 | 44.33 | 4.42 | 41.51 |
| Author | N | Tokens | Types | stTTR | Mean word length (in characters) | Mean sentence length (in words) |
|---|---|---|---|---|---|---|
| Overall mean | 47 | 3,710.17 ± 393.83 | 756.91 ± 979.03 | 43.77 ± 3.42 | 4.53 ± 0.24 | 15.83 ± 3.29 |
| EnhGPT.Hemingway | 9 | 1,587.78 ± 393.83 | 537.78 ± 74.93 | 42.70 ± 0.48 | 4.29 ± 0.17 | 12.95 ± 2.29 |
| EnhGPT.Shelley | 9 | 1,993.78 ± 651.67 | 662.89 ± 147.07 | 38.57 ± 3.48 | 4.53 ± 0.17 | 19.75 ± 2.85 |
| GPT.Hemingway | 9 | 1,499 ± 219.27 | 541.56 ± 57.30 | 47.79 ± 0.95 | 4.49 ± 0.18 | 13.47 ± 1.44 |
| GPT.Shelley | 9 | 1,577.22 ± 163.46 | 599.56 ± 68.53 | 45.57 ± 0.53 | 4.71 ± 0.13 | 17.70 ± 1.94 |
| GPT | 9 | 1,399.22 ± 115.71 | 550.22 ± 50.76 | 44.01 ± 0.29 | 4.72 ± 0.17 | 15.01 ± 1.07 |
| Hemingway_The Old Man and The Sea | 1 | 26,663 | 2,539 | 34.62 | 3.84 | 14.15 |
| Shelley_Frankenstein | 1 | 75,143 | 7,008 | 44.33 | 4.42 | 41.51 |
Tokens: The total count of individual word occurrences in the text, including repeated words.
Types: The count of unique words in the text, with each distinct word included in the count.
stTTR (standardized Type-Token Ratio): A measure of lexical diversity calculated as (Types ÷ Tokens) × 100, standardized across fixed-length text segments (1,000 words) to control for text length effects. Higher values indicate greater lexical diversity.
Mean Word Length: The average number of characters per word, which can indicate complexity of vocabulary or writing style.
Mean Sentence Length: The average number of words per sentence, which often correlates with syntactic complexity and writing style. Shorter sentences are typically associated with Hemingway’s style, while longer, more complex sentences align with Shelley’s gothic prose.
The linguistic measurements outlined in the report reflect corpus-level calculations for each author category, derived from the average of the nine text segments. To enhance our understanding of the variation within each category, we also included the standard deviation:
It is important to note that although we requested 2,000-word texts in our prompts to GPT-4o, the actual output varied. The nine texts in each generated category collectively range from 12,593 words (GPT) to 17,917 words (EnhGPT.Shelley), averaging approximately 1,399 to 1,991 words per text—slightly below the requested 2,000 words per text. This variation occurred because GPT-4o occasionally terminated text generation before reaching the exact word count specified in the prompt, particularly when reaching narrative closure points. We chose to preserve these natural termination points rather than forcing additional content, as this approach better maintained the narrative integrity of the generated texts.
Moreover, Table 2 reveals distinctive linguistic patterns across author categories. EnhGPT.Shelley texts show the highest token count (1,993.78 ± 651.67), approaching our 2,000-word target, while generic GPT outputs contain the fewest (1,399.22 ± 115.71). Stylistic patterns align with expectations: Hemingway imitations feature shorter sentences (12.95-13.47 words) and words (4.29-4.49 characters) compared to Shelley imitations (17.70-19.75 words, 4.53-4.71 characters). However, lexical diversity results are unexpected, with GPT.Hemingway showing the highest diversity (47.79 ± 0.95) and EnhGPT.Shelley the lowest (38.57 ± 3.48), contrary to the original authors’ patterns (Hemingway: 34.62, Shelley: 44.33). This suggests GPT-4o successfully captures sentence-level stylistic traits but struggles with vocabulary richness imitation.
4. Stylometric analysis
4.1 Profile-based authorship attribution
Our analysis aims to systematically examine whether LLMs (specifically GPT-4o) can accurately replicate an author’s stylometric profile. More specifically, we seek to determine whether it is possible to distinguish between a text written by GPT-4o imitating an author and one authored by the original writer. To achieve this, we treated each generated subcorpus as a distinct author, resulting in five artificial authors (GPT, GPT_Hemingway, GPT_Shelley, EnhGPT_Hemingway, EnhGPT_Shelley) alongside two human authors (Hemingway and Shelley).
In our study, we evaluate imitation success using authorship attribution results in the above-mentioned corpus. By assigning each imitation sample a virtual author label, we assess the model’s ability to mimic distinct stylistic features by comparing the classification accuracy of the imitation samples against those of the original human authors.
In our stylometric analysis, we employed the Cosine Delta distance measure using the 1,000 most frequent words as features. This approach offers substantial robustness against text length variations, as it measures the angular similarity between feature vectors rather than their magnitudes. The frequency vectors are normalized during calculation, which further mitigates potential biases from unequal text lengths (Evert et al. 2017). While dividing texts into equal-sized chunks can be valuable in certain stylometric contexts, our use of normalized frequency vectors with Cosine Delta distance provides reliable comparative analysis despite the modest variations in text length across our corpus. This methodological decision is further supported by previous research demonstrating the Cosine Delta distance’s effectiveness with frequency-based stylometric features in comparative analyses of texts with varying lengths (Eder, Rybicki, and Kestemont 2016; Evert et al. 2017).
For visualization, we employed hierarchical cluster analysis (HCA) and principal component analysis (PCA) based on matrix correlations. These methods will allow us to visually represent the cosine distances, where texts with similar styles are positioned closer under the same branch, and those with distinct styles are farther apart. The results of both analyses can be seen in Fig. 1.

HCA and PCA graphs of the 1,000 most frequent words using the cosine distance.
HCA reveals that while GPT-4o can approximate an author’s stylistic profile, it does not fully replicate the nuanced stylometric signatures of human-authored texts. The original works by Hemingway and Shelley form a distinct cluster, indicating that their unique styles are preserved. Generated texts imitating Hemingway (GPT_Hemingway and EnhGPT_Hemingway) and Shelley (GPT_Shelley and EnhGPT_Shelley) show consistency within their respective groups but remain separate from the originals, suggesting partial replication of their styles. Generic GPT outputs (GPT) are the most distinct, lacking the stylistic features of both the original and imitated texts. Enhanced imitations (EnhGPT) show some improvement in stylistic alignment but do not bridge the gap to the original authors. Overall, these results demonstrate the LLM’s capability to imitate stylistic elements but highlight its limitations in fully capturing the complexity of human-authored texts.
The PCA analysis replicates the HCA findings. Hemingway’s The Old Man and the Sea and Shelley’s Frankenstein occupy distinct positions on the plot, highlighting their unique stylistic signatures. The imitations of Shelley (GPT_Shelley and EnhGPT_Shelley) cluster closer to Frankenstein, indicating some degree of alignment with Shelley’s style, though differences remain evident. Similarly, the imitations of Hemingway (GPT_Hemingway and EnhGPT_Hemingway) group together but are positioned away from The Old Man and the Sea, suggesting partial but incomplete stylistic replication. The generic GPT output (GPT) is located between the imitations, demonstrating its lack of alignment with either author’s stylistic features. The PCA plot further underscores the limitations of LLMs in fully capturing the detailed stylometric profiles of human-authored texts while showing some capability for stylistic approximation.
4.2 Instance-based authorship attribution
We repeated the authorship attribution experiment using an instance-based approach. We trained a Random Forest algorithm using the same authors set as the previous profile-based analysis. To enhance the dataset and improve the robustness of the analysis, the original texts were segmented into 500-word chunks, resulting in a total sample of 372 texts. Each task employed a distinct group of stylometric features to capture the broadest possible range of stylistic variations in the texts. The specific feature groups utilized in the analysis are as follows:
TCR features: We calculated seventy-four stylometric features organized in the following wider thematic areas:
Word and Sentence Lengths and standard deviations (measured in characters, words, and syllables)
Word Frequency distribution indices such as hapax legomena and dis legomena
Quantitative aspects of text, such as entropy, perplexity, and the corresponding standard deviations
Lexical diversity indices:
○ Text size neutralized TTR measures: log-transformed TTR, root-transformed TTR, Mass TTR, Mean Segmental TTR, Moving Average TTR
○ Measure of Textual Lexical Diversity (MTLD)
○ Hypergeometric Distribution D measure
○ Functional diversity (the ratio of content to functional words)
Readability indices:
○ Flesch- Kincaid reading ease and grade level
○ SMOG
○ Automated Readability Index
○ Dale-Chall
○ Linsear Write formula
○ Gunning-Fog score
○ Coleman-Liau index
Metrics related to coherence, text quality, syntactic complexity, and Part-of-Speech (PoS) tags frequencies
Author Multilevel N-gram Profiles (AMNP): Mikros and Perifanos (2013) introduced the AMNP approach, which has demonstrated significant effectiveness in authorship attribution and author profiling research (Mikros 2013a, 2013b; Mikros and Perifanos 2015; Mikros 2018). AMNP provides a comprehensive document representation framework that incorporates progressively larger n-gram units at both character and word levels.
This dual-dimension approach ensures coverage across multiple linguistic strata. The methodology draws its theoretical foundation from the Prague School of Linguistics and specifically the concept of “double articulation” (Nöth 1995: 238). According to this principle, language operates on two distinct structural layers: the first containing meaningful units (morphemes) that form grammatical patterns, and the second comprising minimal functional units (phonemes) that lack independent meaning. The integration of elements from both layers produces grammatically sound linguistic output.
Stylistic analysis can be approached through a similar framework. To effectively capture the multidimensional nature of stylistic features, researchers must identify and systematically integrate characteristics across diverse linguistic levels to accurately represent an author’s distinctive style.
For our current research, we constructed a feature vector of 900 elements by extracting the 300 most frequent character bigrams (n = 2), character trigrams (n = 3), and word unigrams. This comprehensive vector constitutes the Author’s Multilevel N-gram Profile (AMNP), providing a document representation that simultaneously encapsulates both character and word sequence patterns. To eliminate potential text-length biases in our subsequent analyses, we normalized the frequency calculations across all features.
Word Embeddings (WE): Word Embeddings are a popular representation of a text’s vocabulary. Words or phrases from the lexicon are translated into vectors of real numbers and can subsequently be used in language modeling and feature-learning approaches. These numerical vectors can capture text representations in an n-dimensional space, where words with the same meaning are represented similarly. This indicates that two comparable words are located extremely closely together in vector space and have almost identical vector representations. Therefore, the objective of creating a word embedding space is to record some form of relationship in that space, be it based on meaning, morphology, context, or another type of link. Our study utilized OpenAI’s pre-trained text-embedding-3-small model to generate word embeddings for each text. By averaging these embeddings, we represented each document with a single vector that encapsulates the mean of its word embeddings.
Linguistic Inquiry and Word Count (LIWC) features: LIWC is a text analysis tool that quantifies linguistic and psychological attributes by categorizing words into predefined groups. It assesses dimensions such as emotional tone, cognitive processes, social concerns, and perceptual processes. In this study, we utilized LIWC-22 (Boyd et al. 2022) to extract 115 features related to affective processes (e.g., positive and negative emotions), cognitive processes (e.g., insight, causation), social processes (e.g., family, friends), and perceptual processes (e.g., see, hear, feel). These features provide insights into the psychological and emotional aspects of the texts, complementing the other stylometric analyses.
For our random forest classification evaluation, we employed a rigorous fivefold cross-validation approach rather than relying solely on training performance metrics. The corpus was randomly partitioned into five equal subsets, with four subsets (80 per cent of data) used for training and one subset (20 per cent) reserved for testing in each fold. This process was repeated five times, with each subset serving once as the test data. The performance metrics reported in Table 3 represent the averages across all five folds, thus providing a more reliable estimate of the model’s generalization capabilities. This cross-validation strategy helps mitigate concerns about overfitting and ensures that our evaluation reflects the model’s ability to accurately classify unseen texts. All classifications were performed independently for each feature group (TCR, AMNP, WE, and LIWC) to assess their individual discriminative power. The results of the authorship attribution tasks can be found in Table 3.
Classification metrics in authorship attribution using RF.
| Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|
| TCR | 0.7984 | 0.7984 | 0.8037 | 0.7896 |
| AMNP | 0.8329 | 0.8329 | 0.8447 | 0.8213 |
| WE | 0.8364 | 0.8364 | 0.8637 | 0.8201 |
| LIWC | 0.8403 | 0.8403 | 0.8474 | 0.8282 |
| Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|
| TCR | 0.7984 | 0.7984 | 0.8037 | 0.7896 |
| AMNP | 0.8329 | 0.8329 | 0.8447 | 0.8213 |
| WE | 0.8364 | 0.8364 | 0.8637 | 0.8201 |
| LIWC | 0.8403 | 0.8403 | 0.8474 | 0.8282 |
Classification metrics in authorship attribution using RF.
| Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|
| TCR | 0.7984 | 0.7984 | 0.8037 | 0.7896 |
| AMNP | 0.8329 | 0.8329 | 0.8447 | 0.8213 |
| WE | 0.8364 | 0.8364 | 0.8637 | 0.8201 |
| LIWC | 0.8403 | 0.8403 | 0.8474 | 0.8282 |
| Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|
| TCR | 0.7984 | 0.7984 | 0.8037 | 0.7896 |
| AMNP | 0.8329 | 0.8329 | 0.8447 | 0.8213 |
| WE | 0.8364 | 0.8364 | 0.8637 | 0.8201 |
| LIWC | 0.8403 | 0.8403 | 0.8474 | 0.8282 |
To thoroughly examine the classification results for each category, we generated a detailed classification report for each class (author) across the different feature groups. The results are presented in Fig. 2.
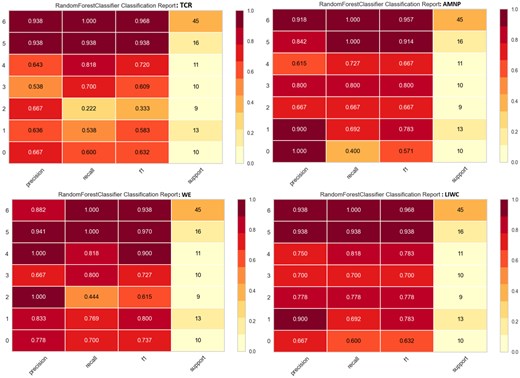
Detailed classification report for each class in each feature group. Class labels: EnhGPTHemingway: 0, EnhGPTShelley: 1, GPT: 2, GPTHemingway: 3, GPTShelley: 4, Hemingway: 5, Shelley: 6.
From the detailed analysis of the classification metrics for each author, we can explore whether these imitations successfully capture the unique stylistic characteristics of the original authors. More specifically, the original works by Shelley and Hemingway are consistently well-identified across all feature groups, with high precision and perfect or near-perfect recall. However, GPT-generated imitations, especially those using in-context learning, show varied performance. In-context learning imitations of Hemingway (EnhGPTHemingway) are particularly difficult to classify, with low recall in AMNP and WE features, indicating significant overlap with both original texts and other imitative categories. Shelley’s in-context learning imitations (EnhGPTShelley) perform slightly better but still demonstrate inconsistencies in recall and precision, suggesting only partial replication of her stylistic features.
Generic GPT outputs perform moderately, particularly in TCR and WE, where they show noticeable overlap with other categories, indicating that they lack clear stylistic alignment with either original or imitative profiles. LIWC features capture some psychological and emotional details but are less effective for distinguishing complex stylistic patterns in imitative texts.
Overall, the analysis reveals that GPT-generated texts approximate the original authors’ styles to some degree but cannot fully replicate their unique stylometric profiles. This highlights the current limitations of GPT in accurately imitating the depth and complexity of human-authored stylistic patterns, particularly for enhanced imitations. While GPT can mimic surface-level stylistic elements, it struggles to capture the full richness of an author’s stylometric signature, making it distinguishable from the originals.
4.3 t-SNE analysis
As a final step, we visualized the author discrimination results by applying dimensionality reduction using the t-SNE (t-distributed Stochastic Neighbor Embedding) method for each feature group analyzed. t-SNE is a non-linear dimensionality reduction technique particularly effective for visualizing high-dimensional data by preserving the local structure of the data points in a lower-dimensional space, making it well-suited for identifying patterns and clusters within the stylometric features of the texts (Van der Maaten and Hinton 2008). The results of the analysis can be found in Fig. 3.
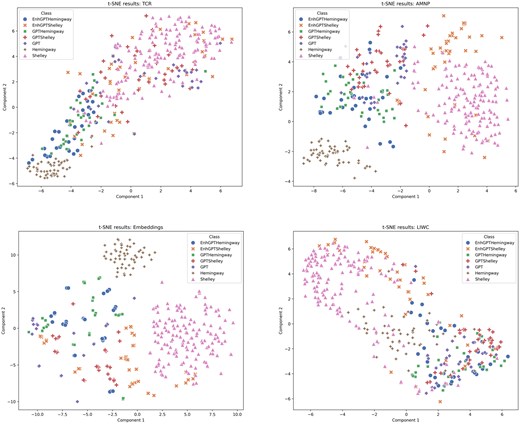
t-SNE plots for each feature group.
The results reveal that GPT-generated imitations capture some stylistic elements of the original texts, but their fidelity varies significantly depending on the feature group analyzed. AMNP features were the most effective at differentiating between original and imitation texts. Hemingway’s and Shelley’s original texts formed distinct and well-defined clusters, indicating that their multilevel stylistic traits, including n-grams and word patterns, were difficult for GPT-generated texts to replicate fully. Enhanced in-context learning models (EnhGPTHemingway and EnhGPTShelley) showed moderate success in aligning with the original styles but still exhibited noticeable overlap with other categories, particularly for Hemingway.
The LIWC features demonstrated that GPT imitations could capture some emotional and cognitive processes but struggled with more intricate stylistic nuances. Shelley’s original texts showed greater dispersion, and the enhanced GPT-generated texts only partially overlapped with her cluster. Hemingway’s texts, on the other hand, were more distinct but still showed some alignment with enhanced GPT outputs, suggesting that certain psychological aspects of his style are easier for GPT to emulate.
The TCR features highlighted the complexity and readability aspects of the texts. Hemingway’s texts were more distinctly clustered, reflecting his characteristic readability and sentence-level simplicity, which the GPT models approximated to a moderate degree. In contrast, Shelley’s stylistic complexity resulted in more dispersed clustering, with her texts overlapping with both generic GPT and in-context learning imitations, suggesting challenges in replicating her unique structural and lexical richness.
The WE features offered insights into the semantic alignment of the texts. Hemingway’s cluster was tightly grouped and minimally overlapped with GPT outputs, indicating his lexical and semantic style was challenging for GPT to replicate fully. Shelley’s texts exhibited slightly more dispersion, with enhanced imitative outputs clustering closer to her original works than generic GPT outputs. However, overlap across categories persisted, particularly with generic GPT outputs, reflecting limitations in achieving high semantic fidelity.
Overall, the effectiveness of GPT-generated texts in producing stylometrically similar outputs to the originals was moderate but incomplete. Across all feature groups, the original texts by Hemingway and Shelley consistently formed distinct clusters, confirming the uniqueness and coherence of their stylometric profiles. In-context learning outputs demonstrated closer alignment to the originals compared to generic GPT outputs, highlighting the value of contextual guidance in improving stylistic fidelity. However, significant dispersion and overlap across categories underscore the ongoing limitations of GPT models in fully replicating the intricacies of human-authored styles.
GPT-generated imitations better approximated Hemingway’s style, characterized by simplicity and structural consistency. Shelley’s more intricate and complex style posed more significant challenges, as evidenced by more dispersed clustering and higher overlap with GPT-generated texts. This suggests that the effectiveness of GPT-generated imitations varies depending on the stylistic complexity and distinctiveness of the original author.
The findings demonstrate that while GPT-generated texts can approximate surface-level stylistic features, they struggle to replicate the depth, detail, and coherence of human-authored writing. In-context learning improves stylistic alignment but cannot fully emulate the unique stylometric profiles of authors like Shelley and Hemingway. These limitations are particularly evident in the more complex and semantically rich features, such as AMNP and WE, which require capturing subtler patterns of linguistic expression.
5. Conclusions
This study examined the extent to which GPT-4o can produce stylometrically similar texts to the original works of Ernest Hemingway and Mary Shelley. Using various prompting strategies, zero-shot generation, zero-shot imitation, and in-context learning, we generated stylistic imitations and analyzed them through multiple stylometric methodologies, including profile-based and instance-based authorship attribution and t-SNE visualization across four feature groups. The findings reveal that while GPT-4o demonstrates the ability to approximate surface-level stylistic features, it falls short of fully replicating the unique stylometric profiles of the human authors. Across all analyses, original texts by Hemingway and Shelley consistently formed distinct and well-defined clusters, emphasizing the coherence and distinctiveness of their stylistic signatures. In contrast, GPT-generated imitations, particularly those using in-context learning, showed moderate improvement in stylistic alignment but still exhibited significant overlap with generic GPT outputs, underscoring their limitations.
Hemingway’s concise and structurally consistent style proved somewhat easier for GPT to emulate, as reflected in the tighter clustering and greater alignment of imitative outputs in TCR and WE analyses. However, Shelley’s complex, richly descriptive style posed more significant challenges, with her imitative outputs showing more dispersion and overlap with generic GPT outputs. These findings suggest that the effectiveness of GPT-generated imitations depends heavily on the stylistic complexity and distinctiveness of the original author.
The t-SNE analyses demonstrate that the fidelity of GPT’s stylistic imitation is closely tied to the discriminative power of the feature group. AMNP and WE features, which were the most effective at distinguishing between original texts and imitations, also captured the most complex and multilevel stylistic traits, making them the hardest for GPT-generated texts to replicate. In contrast, LIWC and TCR features, while offering complementary insights, were less effective in differentiating original and imitative texts, suggesting that the stylistic elements they capture are more easily mimicked by GPT.
Overall, GPT-4o demonstrates a promising but incomplete ability to imitate human literary styles. Enhanced prompting strategies, such as in-context learning, show potential for improving stylistic fidelity but remain insufficient for fully capturing the depth, coherence, and innovation of human-authored writing. These limitations highlight the ongoing challenges in developing LLMs capable of high-fidelity stylistic replication.
This research underscores the need for further exploration into advanced modeling techniques, such as integrating richer contextual frameworks, improving feature representations, and leveraging more sophisticated learning paradigms. Additionally, the ethical implications of stylistic imitation, including concerns over intellectual property, authenticity, and trust, warrant careful consideration as LLMs continue to advance. Future studies should aim to refine both the technical and ethical dimensions of AI-driven stylistic imitation, bridging the gap between human creativity and machine-generated text.
This research has several limitations. First, the study focused on only two authors with highly distinct styles, limiting the generalizability of the findings to other authors or genres with more subtle stylistic differences. Second, the thematic control imposed on the text generation process may have influenced the stylistic outputs, potentially constraining the model’s natural stylistic adaptation. Third, the study employed a single LLM (GPT-4o) and specific analytical methods, which may not fully capture the potential of other LLMs or alternative approaches to stylistic imitation.
Future research should explore broader authorial datasets, incorporating a wider variety of styles and genres to evaluate the generalizability of these findings. Additionally, future studies could examine the effect of thematic constraints on stylistic outputs and explore the potential of advanced fine-tuning or retrieval-augmented techniques for improving imitation fidelity. Finally, conducting systematic user evaluations to assess human perceptions of GPT-generated stylistic imitations could provide valuable insights into the authenticity and acceptability of these texts.
Overall, while GPT-4o demonstrates the ability to approximate certain stylistic traits, this study highlights the challenges in replicating the full depth and richness of human writing, paving the way for future advancements in stylistic imitation research.
Acknowledgments
Open Access funding provided by the Qatar National Library.
Author contributions
George Mikros (Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing—original draft, Writing—review and editing).
Data availability
The data underlying this article will be shared on reasonable request to the corresponding author.

{kind=link}
{kind=link}
{kind=link}