





Abstract
Study of brain images of rodent animals is the most straightforward way to understand brain functions and neural basis of physiological functions. An important step in brain image analysis is to precisely assign signal labels to specified brain regions through matching brain images to standardized brain reference atlases. However, no significant effort has been made to match different types of brain images to atlas images due to influence of artifact operation during slice preparation, relatively low resolution of images and large structural variations in individual brains.
In this study, we develop a novel image sequence matching procedure, termed accurate and robust matching brain image sequences (ARMBIS), to match brain image sequences to established atlas image sequences. First, for a given query image sequence a scaling factor is estimated to match a reference image sequence by a curve fitting algorithm based on geometric features. Then, the texture features as well as the scale and rotation invariant shape features are extracted, and a dynamic programming-based procedure is designed to select optimal image subsequences. Finally, a hierarchical decision approach is employed to find the best matched subsequence using regional textures. Our simulation studies show that ARMBIS is effective and robust to image deformations such as linear or non-linear scaling, 2D or 3D rotations, tissue tear and tissue loss. We demonstrate the superior performance of ARMBIS on three types of brain images including magnetic resonance imaging, mCherry with 4′,6-diamidino-2-phenylindole (DAPI) staining and green fluorescent protein without DAPI staining images.
The R software package is freely available at https://www.synapse.org/#!Synapse:syn18638510/wiki/591054 for Not-For-Profit Institutions. If you are a For-Profit Institution, please contact the corresponding author.
Supplementary data are available at Bioinformatics online.
1 Introduction
Brain research has been significantly facilitated in the past several years due to the launch of several brain projects in Europe, USA, Japan and Korea (Poo et al., 2016). For these brain projects, rodent animals play a very important role for a large number of shared genes with human and easy operation of genome editing. Brain images are important for studying the brain functions or the neural basis of physiological functions (Toga, 2015).
Brain imaging can be done invasively or non-invasively. Non-invasive in vivo methods include positron emission tomography (PET) and magnetic resonance imaging (MRI) while brain slices imaging with histology or other technologies obtained with various microscopes are typical invasive approaches. For those brain images, it is important to visualize and explore them against standardized brain reference atlases and the very first step is to find the best matched atlas image for a query brain image (Ng et al., 2012). However, due to influence of artifact operation during slice preparation (e.g. tissue folds, tears, regions missing, tissue stretch or compress), variations in sample structures or damaged regions, precise matching is usually very difficult and thus the matching procedure is usually performed manually in most neuroanatomical laboratories, and (Agarwal et al., 2016; Yushkevich et al., 2006). Recently, Agarwal (Agarwal et al., 2017) and Midroit (Midroit et al., 2018) developed two methods to align histological sections and achieved some promising results. However, these methods do not have the function for matching brain slices.
To our knowledge, no method has been developed to match different kinds of brain images (e.g. matching MRI images to the atlas images) due to several challenges. First, query images and atlas images cannot be directly compared as they are likely to have different scales (sizes). Different scales between query images and atlas images are one key factor affecting the matching performance especially when image textures are used. Second, the relative low spatial resolution and image contrast as well as large structural variations pose a great challenge for feature-based image matching. Even some scale invariant features such as SIFT (Scale Invariant Feature Transform) (Lowe, 2004) cannot work well under such situations (Wu et al., 2009). Third, image sequence matching has to take into account large variations, due to different resolutions or artifacts during sample slicing, between query images and atlas images which may lead to unevenly spaced atlas images.
In this study, we developed a novel effective image-sequence matching framework, termed accurate and robust matching of brain image sequences (ARMBIS), to match query image sequences to reference brain image atlases (Fig. 1). To take advantage of the spatial relationship among 3D image slices in both test and atlas image sequences, the change rates of the geometric features extracted from image sequences are used to first estimate a scaling factor and then roughly locate the query image sequence in the atlas image sequence. Then the query images are rescaled by the estimated scaling factor so that the two image sequences are comparable in size and suitable for exact matching based on texture and shape features. The global texture similarity is measured by mutual information of the overall local binary pattern (LBP) while the local similarity is measured by the intersection distance of the corresponding regional LBP histograms. In addition to these texture features, scale and rotation invariant shape features are extracted as well. Then, a mathematical induction-based optimization under the constraints of order and distance for the best matched indices is implemented to the grouped global texture and shape features to identify several optimal subsequences. Finally, the best matched subsequence in the atlas images is determined by a hierarchical decision approach using local texture features.
![The architecture of ARMBIS for matching image sequences. ARMBIS takes a query image sequence and an atlas image sequence as inputs and outputs the best matched image sequence in the atlas. (A) Extraction of shape features. (B) Break point detection and curve fitting. Left: the original feature curve of the atlas image sequence (blue line) represented by piecewise linear (black dotted line) divided by several break points (red triangle). Middle: The original feature curve of the query image sequence (orange line) represented piecewise linear (black dotted line) divided by several break points (purple triangle). Right: Matching the two curves by matching two slope sequences. (C) Extraction of texture features. (D) Feature fusion and feature enhancement for fused similarity curve (Simifeature) of each query image. First all the spikes are identified as dSimifeature<0 and then the spikes greater than the mean of Simifeature (gray dotted line) and their eight nearest neighbors are selected as candidate peaks. Finally the values on the candidate peaks are scaled up by a constant c (c>1). (E) The optimization procedure based on the fused similarity matrix Sim. The orange squares indicate the selected indices in each row which leads to maximal ∑j=1NSimj,mj. The intervals between adjacent indices of m are within the range of [c-g,c+g]. (F) A hierarchical decision procedure identifies the final best matched atlas images by local texture features. The ranking of each optimal matching patch is obtained by Equation (9). (G) Output of the best matched image sequence in atlas](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/bioinformatics/35/24/10.1093_bioinformatics_btz404/2/m_bioinformatics_35_24_5281_f1.jpeg?Expires=1750242776&Signature=FQsjrSQiA9HEoEshgv6mjWk2iQ~99G2w46HzwwlLsOvBGJimn~iU89R4kcEvnW0Jj~WK-LN7FHqxl9AAD9VPTv6bIeI8aU6EMkO9GJ~Aqfd17LD2H5R5IfTc0FoquWWJVim1FoM4-5fkIs1LNzQv96V-owThP19gw~qtfxPfw3jsjya73C7WiQbQXG9c-LIJuKWLY9Qf-3SFxZNzxpZ2NFzr-XN0CgEsCVQ6sLDCsLgxoU6F4U3uTRkmRHznuVE69Eg5QTRShcpU5198dwwIxY-Jz~ZaD65vI04JFh7Tsz7i0kg4Vcp5J5OhBVCh6eperq6rqQk0TXXqHCR7uHvm0A__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
The architecture of ARMBIS for matching image sequences. ARMBIS takes a query image sequence and an atlas image sequence as inputs and outputs the best matched image sequence in the atlas. (A) Extraction of shape features. (B) Break point detection and curve fitting. Left: the original feature curve of the atlas image sequence (blue line) represented by piecewise linear (black dotted line) divided by several break points (red triangle). Middle: The original feature curve of the query image sequence (orange line) represented piecewise linear (black dotted line) divided by several break points (purple triangle). Right: Matching the two curves by matching two slope sequences. (C) Extraction of texture features. (D) Feature fusion and feature enhancement for fused similarity curve () of each query image. First all the spikes are identified as and then the spikes greater than the mean of (gray dotted line) and their eight nearest neighbors are selected as candidate peaks. Finally the values on the candidate peaks are scaled up by a constant (c. (E) The optimization procedure based on the fused similarity matrix . The orange squares indicate the selected indices in each row which leads to maximal . The intervals between adjacent indices of are within the range of . (F) A hierarchical decision procedure identifies the final best matched atlas images by local texture features. The ranking of each optimal matching patch is obtained by Equation (9). (G) Output of the best matched image sequence in atlas
The rest of the paper is organized as follows. Section 2 introduces ARMBIS in detail. Section 3 evaluates the performance of our proposed method using simulation data and real brain MRI data. Section 4 concludes the article.
2 Methods
Given a sequence of query images and a sequence of atlas images, the goal is to match each individual query image () to an atlas image ), where is the index of the best matched atlas image for a query image , and the best matched indices are under the constraint of or .
2.1 Feature extraction
Feature extraction is the most important step in pattern matching. In the proposed method, texture and shape features are extracted, as described in Figure 1A–C, and the flowchart of the detailed feature extraction procedure is given in Supplementary Figure S1.
2.1.1 Extraction of scale and rotation invariant shape features
2.1.2 Scaling factor estimation by robust curve fitting of the feature series
It is difficult to compare two images directly if they are at different scales. However, for a sequence of spatially related images, more features can be obtained by taking advantage of the image sequence from the geometric feature space. Geometric features including width, height, area and perimeter are extracted from the contour in each test or atlas image, which is identified in the previous section. Extraction of scale and rotation invariant shape features, to estimate the scale of the query image sequence with respect to an atlas sequence (termed scaling factor).
Suppose that the geometric feature matrices for a query image sequence and an atlas image sequence are and , respectively. First, we define as a subset of the vector , where is a subset of the set of the indices of X. Let be a vector of the first-order differences for a given window of , defined as | Thus a break point is defined as }, indicating a ‘true’ sign change on the curve. Since the feature curves of the query image and atlas image sequences have different resolution scales, different smoothing stratagems are used for the two curves, respectively. For the atlas image feature series, the smooth stratagem should maintain the main peak pattern. Here we use the double-exponential moving average (Mulloy, 1994) to preserve the changes in the curve and remove the unexpected noise. As in general the resolution of query images, is lower than that of the atlas images, the dimension of the features from query images is much smaller than that of atlas image. To maintain the shape of the feature curve, we first fit the points on the curve using a loess regression model (Cleveland and Devlin, 1988) and define the points beyond the upper and lower bounds (1.5 and 0.5 times the smoothed y-value) as noise points then replace them by the average of their respective two neighboring points. Finally, a break point vectors for the atlas and query image sequences are denoted as and , respectively (Fig. 1B).
To have a robust estimation, four features including width, height, area and perimeter from the identified contours are used in this curve fitting procedure. The overall scaling factor can be obtained by a majority voting.
Then, all the query images are scaled in size by the estimated scaling factor so that they are at the same scale as the corresponding atlas images.
2.1.3 Extraction of texture features
To assess texture similarities between a query image and those in an atlas, we resize all the atlas images to the size of the query image. Specifically, we first crop the query image and all the atlas images according to their regions of interest (ROIs) and then perform zero-padding or cropping on the atlas images.
The original LBPs are used as texture features (Ojala et al., 2002). LBP is a popular texture descriptor for its simplicity and ability to capture image micro-structures and local geometric information and the robustness to illumination variations. LBP codes represent fundamental characteristics of texture features.
To eliminate the effect of structure variations, each image is divided into non-overlapping patches for extraction of the LBP features.
The similarity between two LBP texture descriptors is computed by the intersection distance between the two corresponding histograms of the LBP codes (Swain and Ballard, 1991). The similarities from both global and regional LBP texture features are used for image matching (Fig. 1C).
2.2 Image matching
After the shape and texture similarities are calculated, we develop a two-step procedure to identify the best matched atlas images for each image in the query sequence. Each feature matrix, , can be considered as one particular perspective of the overall similarity between two image sequences under investigation. We group the shape similarity and the global texture similarity into a fused overall similarity matrix on which an optimization procedure is developed to find candidate subsequences of the atlas images under the constraints of the sequential order and the maximal distance between adjacent images in the query sequence. Then, the best matched subsequence is determined by the precise image matching using the regional LBP distances which are robust to structure variations or image defections. The matching procedure is illustrated in Figure 1D–F, and the detailed diagram is given in Supplementary Figure S2.
Let ) be the similarity scores between the ith query image and all the images in an atlas. Then an optimization is designed to find candidate atlas images for the query images, i.e. to identify a subsequence of atlas images most similar to the query image sequence. Since each atlas image is spatially related to its adjacent images, we give more weight to the identified peaks so that the images at the peaks can be more likely to be selected (Fig. 1D). The global texture and shape similarities are then combined into a fused similarity, , via the z-score transformation (Jain et al., 2005).
Then, finding the optimal atlas image subsequences for the query image sequence becomes a global optimization problem based on the fused similarity matrix , i.e. to find an index from each row that maximize the sum of the similarities, under the constraints of the order and the roughly even space between adjacent images. The latter constraint can be expressed as , where is the estimated interval between two adjacent matched indices obtained previously and is the maximal deviation allowed (Fig. 1E).
If there are multiple atlases, the results from the matchings of one query image sequence to all these atlases can be used to verify each other.
Search for the optimal matching paths between two image sequences
| Inputs: The fused similarity matrix , the estimated interval between two adjacent images in a given atlas, the maximum deviation of intervals from the estimated one (i.e. c ) . |
| Output: The top optimal matching paths, and their corresponding total similarity scores , and . |
|
| Inputs: The fused similarity matrix , the estimated interval between two adjacent images in a given atlas, the maximum deviation of intervals from the estimated one (i.e. c ) . |
| Output: The top optimal matching paths, and their corresponding total similarity scores , and . |
|
Search for the optimal matching paths between two image sequences
| Inputs: The fused similarity matrix , the estimated interval between two adjacent images in a given atlas, the maximum deviation of intervals from the estimated one (i.e. c ) . |
| Output: The top optimal matching paths, and their corresponding total similarity scores , and . |
|
| Inputs: The fused similarity matrix , the estimated interval between two adjacent images in a given atlas, the maximum deviation of intervals from the estimated one (i.e. c ) . |
| Output: The top optimal matching paths, and their corresponding total similarity scores , and . |
|
Given atlases and the best matched index for the th query image and atlas set identified from our algorithm is, we will further identify the best matched atlas image for each query image . A simple solution is to use the median of as the best match since both atlas and query images are spatially related to their adjacent images. In practice, in order to get a more robust estimation, we count the overlap around the central index and its corresponding two neighbors at. Then, the best matched location is the one that occurs most frequently in the best matched adjacent indices in all the atlases. If multiple locations have the same frequency, then the median site of these locations is selected (see Supplementary Methods 1.2).
2.3 Robust matching for single query image
For single query image or a set of un-ordered query images, we provide an alternative solution. For a single image the scaling factor cannot be estimated by the current approach. It will not affect the estimation of shape distances but the texture feature will not be precise if two images are not scaled to the same size. Under this condition, to obtain an unbiased estimation of the texture similarity, we first crop a test image and all the atlas images according to their ROIs, and then perform pair-wised comparisons after scaling the ROIs to the same size. Detailed description for single image matching is provided in Supplementary Methods 1.3.
3 Results
Atlas database: There are two main multi-subject in-vivo T2-MRI mouse atlases available: MRM NeAt (Neurological Atlas) Mouse Brain Database http://brainatlas.mbi.ufl.edu (Ma et al., 2005) and NUS mouse atlas http://www.bioeng.nus.edu.sg/cfa/mouse_atlas.html (Bai et al., 2012). In this study, we use the MRM NeAt database comprised of 10 individual atlases. For more details about the data preparation, please refer to http://brainatlas.mbi.ufl.edu/Atlas_creation.php.
Baseline: To our knowledge, no method has been developed to match two brain image sequences. For comparison purpose, we consider a baseline method which uses image intensity based features and mutual information-based similarity measurement. Note that all the images under test are cropped by their ROIs.
Evaluation: In our simulation study, the ground truth of the best matched images is known, while in the real applications, the ground truth is derived by the manual examination of experts. The distances between the best matched images and their ground truth are used to evaluate the performance of our proposed method and the baseline method.
3.1 Simulation studies
In a simulation study, we evaluate the performance of the baseline approach, the full and partial models of ARMBIS (partial models without estimation of scaling factor, texture or shape features. A total of 12 images from the atlas image set are randomly selected, the spatial distance between the each pair of the adjacent images is selected randomly from to . We considered six types of image deformations including linear and non-linear scaling, 2D and 3D rotation as well as tissue tears and tissue loss to mimic the slice artifacts. More details about the simulation design are provided in Supplementary Results 2.1.1.
The matching accuracy is defined as the distance between the index of the best matched image and that of the associated ground truth image. In order to demonstrate the effectiveness and robustness of our proposed full model, ARMBIS, based on all the features (shape, scaling factor, global texture and local texture), we also consider a baseline matching method which uses only the global image intensity similarity without any order constraint and eight additional partial models with order constraints.
The matching accuracy of these models is shown in Figure 2 and Supplementary Table S1. The performance of the full model ARMBIS is quite stable under all the simulated situations of image deformations, with a minimal distance of 0.83 for linear scaling and 2D rotation and a maximal distance of 3.29 for non-linear scaling and 3D rotation. As the proposed shape features is scale and rotation invariant, deformations such as linear, non-linear scaling, 2D or 3 D rotation and tissue loss in ROIs have no impact on image shape estimation and thus the matchings are very precise (with a minimum distance of 0.63) by using only the shape features. In fact, for such scenarios the shape based features are even better than the full model because the matchings are not affected by the variations from texture features. However, when images have tissue loss on the boundary, shape features has poor performance with the matching distances ranging from 73 to 73.67. Tissue tears can also affect the shape estimation when a sunken region is detected by the edge detection algorithm, thus the performance for the shaped-based features is not stable with the mean distances of 1.68 and 5.48 for the linear scaling and non-linear scaling scenarios, respectively. On the other hand, the global texture features without any scaling factor estimation has the worst performance with the matching distances ranging from 26 to 74.17. Use of local texture features can improve performance with a minimal distance of 11.67. However, the scaled global texture features have much better performance with the matching distances ranging from 1.45 to 5.25 while the scaled global and local texture features have significantly improved performance especially for the scenarios of tissue tears and tissue loss (the matching distances range from 0.58 to 3.33). These results indicate that the scaling factor is an important feature for comparing the texture features (the full results are provided in Supplementary Results 2.1.2). The maximal mean absolute error of the scaling factor estimations under all the simulated cases is less than 0.025, suggesting that the proposed approach to estimate scaling factors is fairly accurate and robust. Note that when image rotations exist, the proposed texture features will fail for the scenarios of rotation deformation since they are not rotation invariant, as reflected the matching distances ranging from 18.67 to 31.16.
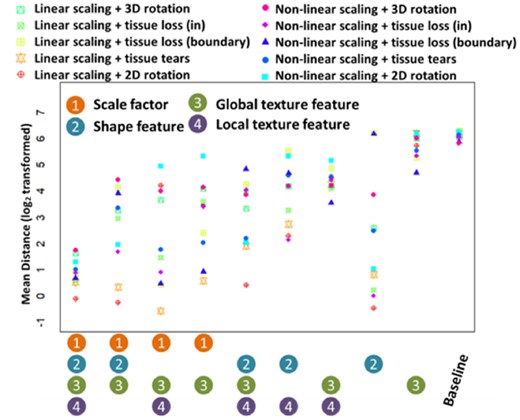
Matching performance on the simulated data. Matching performance of 10 methods (baseline method, the proposed ARMBIS method and eight partial ARMBIS without some of the grouped features, including scaling factor, global texture, shape feature or local texture features) under 10 different simulation settings. The matching accuracy is measured by the mean distance between the matched index of the image and the ground truth
Correction for rotation angles estimated by the shape feature leads to better matching performance. The model without scaling factor estimation can be taken as a special case of ARMBIS for single image matching. However, such image matching highly depends on the shape features and is accurate only when the shape features have strong discriminative ability under the scenarios of linear and non-linear scaling with 2D rotations (the matching distances range from 1.68 to 4.00). Supplementary Table S2 summarizes the performance of different types of features in the simulated studies.
3.2 Real applications
The performance of ARMBIS is tested on MRI, DAPI and GFP images.
MRI images: We used 13 MRI image sets to test the performance of our propose matching method. The MRI experiments were performed by the BrukerBiospec 70/20USR small animal MR system (BrukerBioSpin MRI, Ettlingen, Germany) operating at 300 MHz (7.0 T). The experiment process is described in detail in Supplementary Methods 1.4. These MRI images went through BET (Brain Extraction Tool) (Smith, 2002) for extraction of mouse brains. BET removes non-brain tissue (e.g. brain skull) from an image of the whole head. It uses a deformable model that evolves to fit the brain's surface with the aid from a set of locally adaptive model forces. After BET, some manual refinement was performed to remove some obvious errors so as to derive clean and accurate mouse brain regions.
DAPI and GFP images: We randomly chose nine DAPI and nine GFP images to test the performance of the proposed ARMBIS. The coronal brain sections with red or green fluorescence signal came from C57 mice with anterograde or retrograde transsynaptic virus tracers (Beier et al., 2011; Smith et al., 2000). PRV531 (3.7 × 109 PFU/ml) and VSV-mCherry (5.0 × 107genomix copies/ml) were provided by Brain VTA (BrainVTA Co., Ltd., Wuhan, China). PRV531 or VSV-mCherry was injected into the unilateral olfactory bulb in C57 mice. After three days, the mice were euthanized by cardiac perfusion, and the brain was removed and post-fixed for further histological studies. Then 40 μm coronal frozen slices were acquired. The upper whole steps were detailed described in our previous study (Zhang et al., 2017). For VSV tracing samples, one out of six consecutive slices was stained with DAPI. Selection of PRV tracing samples was similar with VSV group, but they were not treated by DAPI. The fluorescent images of brain slices were obtained from Olympus VS120 microscope (Olympus, Japan).
3.2.1 Performance of curve fitting
In well-ordered MRI image sequences, the images on both ends of each sequence are much smaller than those in the middle, suggesting a single peak in the extracted geometric feature sequence which should be considered in pattern matching. Curve fitting is used to estimate a scaling factor between a query image sequence and a reference image sequence. The curve fitting results for the MRI query image sets are shown in Supplementary Figures S7–S19. Due to large variations and intrinsic noises in imaging, feature curves, especially feature curves of query images have low resolution and are not smooth. This makes it difficult to represent these curves by piecewise line segments. However, the proposed curve smoothing and matching approach is robust to such noises, and scaling factors estimated by the four geometric features are very consistent with a mean absolute difference of 8%.
3.2.2 Discriminative power of the proposed features
In our proposed method, the texture and contour shape features can provide an additional verification to each other when one category of the features does not have much discriminative ability for some image deformations. In Figure 3A, the seventh query image has some distinct texture features and thus its similarities to the reference images have an anticipated major peak located at #124. But the shape similarity curve has several points with similar similarities around the best matched index, leading to ambiguous estimations. Figure 3B shows an example query image whose shape features are more informative than its texture features. In both (A) and (B), the discriminative power of the unscaled texture feature is much lower than the scaled global texture feature.
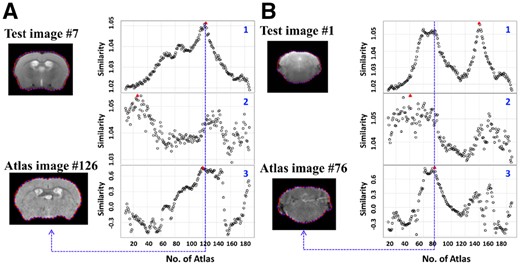
Examples of texture and shape feature curves. (A) (1) The scaled global texture similarities, (2) The unscaled global texture similarities, (3). The shape similarities between the seventh image (up) in the query sequence and all the images in the atlas image set 1. The red triangle indicates the location of the maximum on each curve. Atlas #126 (bottom) is the best matched image in the atlas image set. (B) (1) The scaled global texture similarities, (2) The unscaled global texture similarities, (3) The shape similarities between the first image (up) in the query sequence and all the images in the atlas image set 1. Atlas #76 (bottom) is the best matched image in the atlas image set
3.2.3 Image sequence matching accuracy
The most important criterion for evaluating image matching is matching accuracy. Figure 4 shows examples of matching a query image sequence 1 to three brain atlas image sets. The images at the beginning and the end of the query image sequence do not have distinct texture characteristics while the query images #5, #6, #7, #8 and #9 have rich texture features. All these matching results are consistent with the best matched indices provided by the experts. It is worth noting that the final best matched image indices are given by the aforementioned decision scheme for multiple atlases. Similar to the simulation study, we compare the performance of the full and partial ARMBIS models as well as the baseline method using the MRI dataset 1. As shown in Supplementary Figure S20, the integration of all the features gives rise to robust results in the real situation. More results from the MRI image sequences are shown in Supplementary Figures S21–S33.
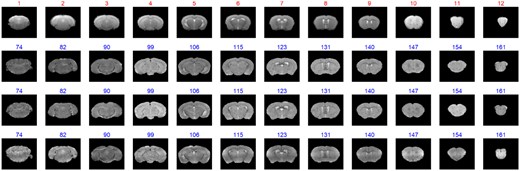
The matching result of the MRI images. The red numbers are the indices of the test image, and the blue numbers are the indices of the best matched indices from atlas image sequence (The whole matching results for the 10 atlas image sets are shown in Supplementary Fig. S21)
3.2.4 Single image matching accuracy
Figure 5 shows the results for a single DAPI image and a single GFP image. The fluorescent images with detailed structures and textures have much higher resolution than the MRI images. Some regions of the fluorescent images have extremely high intensity due to fluorescence staining and this may be a challenge for comparison based on global features. The regional texture features can be taken as an additional verification of the final matching results. In this example, not all the orders of the image patches are summed up in Equation (9). For an image , we select patches with the smallest instead of all the patches to avoid the influence of non-informative patches due to large individual variations in the patches compared to the atlas images. More results of single DAPI and GFP image matching results are shown in Supplementary Figures S34–S51. All of the matching results are consistent with the best matched images provided by the experts.
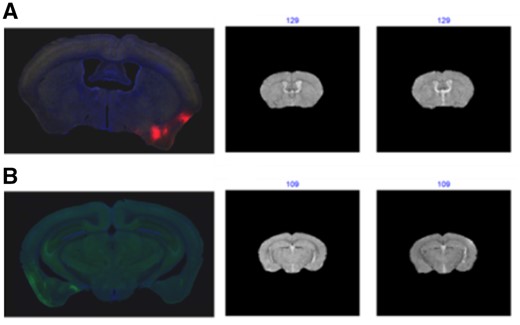
(A) The matching results of DAPI images. (B) The matching result of the GFP. The blue numbers are the indices of the best matched indices from 2 atlas image series (The whole matching results for the 10 atlas image sets are shown in Supplementary Figs S34 and S43)
4 Discussion
In this study, we develop a novel algorithm, ARMBIS, for matching brain image sequences to established atlas image sequences. Image sequence matching here can be considered as a classification task in which each class has only one training sample but training samples are spatially related. Unlike traditional intensity-based image matching approaches, ARMBIS utilizes both texture features of image contents and shape features of image contours. The two types of features are complementary to each other and are mechanistically integrated to make a final decision. Applications of ARMBIS to the simulated and real data show outstanding performance. The main contributions of this study are summarized as follows: (i) ARMBIS can be applied to multiple types of brain images if query images are properly processed into gray-scale images. (ii) ARMBIS takes advantage of continuity in the geometric feature space from 3D brain images to overcome the problem of different scales in query image and atlas sequences. If an image sequence is not incomplete, ARMBIS provides an alternative solution based on a hierarchical decision approach using both global and local features of the original images. (iii) ARMBIS utilizes a piecewise linear approximation for the representation of functional imaging data. Images are represented as feature curves which are further partitioned into segments by detecting important sign change points as break points. An optimization function is implemented to identify the best matched region and an optimal scaling factor for a query image sequence and an atlas one. (iv) ARMBIS can handle large variations in query images and reference atlas images that may lead to evenly spaced best matched atlas images through a dynamic programming-based procedure with the constraints on the order and maximal distance.
After several best matched candidate images are determined by the global features, regional features are used for precise image matching to eliminate the effect of image defections or individual structure variations. The similarities between the patches of a query image and those of the atlas images can be taken as additional verification of the matching results given by the global features. In Equation (9), if all the patches are considered, may be affected by the patches which have large variations compared with the atlas image, and the matching results are more likely to be same as the results from the global features. However, if only a few most informative patches are considered, the model is more robust to noises. As shown in Supplementary Figure S3, the orders of the most similar atlas images for the patches #1 and #2 are much larger than the other patches and this may be caused by image defections or individual variations at the upper left region of the image. Therefore, if we discard these two patches in the calculation by Equation (9), will be 10, leading to the best matched index of 126, a more accurate matching. In general, selecting the optimal number of patches highly depends on image quality. In all our experiments, is chosen as 6 and 4 patches are used in the sum of the orders.
In the simulation study, we perform 3D rotations by rotating the original image along its Z-axis and then find the most similar image in the atlas space. The results show that our model can handle well such image deformations. In real data, sometimes slicing direction or interslice distance between query images is too different from that in an atlas to find any matched images. Such cases can be determined by a pre-defined similarity threshold and will be matched against new atlases that can be generated through 3D reconstruction based on the original atlas until the overall similarities are acceptable. Matching brain image sequences to reference atlases is the very first step to understand the function of the brain. Here we do not consider the problem of image registration. Another limitation with the current study is that only different types of coronal brain slices are tested. The future work will be focused on (i) evaluating ARMBIS by horizontal or sagittal images, extending ARMBIS to different mouse atlases, and integrating ARMBIS and 3D brain image registration.
Funding
This work was supported, in part, a Seed Fund from the Icahn School of Medicine at Mount Sinai (to B.Z.), a grant from the National Institutes of Health [U01AG046170] (to B.Z.) and a grant from the Youth Innovation Promotion Association of Chinese Academy of Sciences [Y6Y0021004] (to J.W.).
Conflict of Interest: none declared.
References


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}